threestudio
threestudio 是一个专为 3D 内容创作打造的统一开源框架。它巧妙地将成熟的 2D 文本生成图像模型“升维”应用,让用户能够仅通过文字描述、单张图片或少量参考图,即可高效生成高质量的 3D 资产。
在 threestudio 出现之前,3D 生成领域算法众多但实现分散,研究人员复现和对比不同方法(如 DreamFusion、Magic3D、ProlificDreamer 等)往往面临极高的环境配置与代码整合门槛。threestudio 通过模块化设计解决了这一痛点,将多种前沿算法整合在同一套代码库中,极大地降低了实验难度,促进了技术社区的交流与迭代。
这款工具主要面向 AI 研究人员、3D 开发者以及希望探索生成式 3D 技术的设计师。对于研究者而言,它提供了便捷的基准测试平台;对于开发者,其清晰的架构便于二次开发和功能扩展;即使是具备一定编程基础的高级用户,也能利用其提供的 Colab 笔记本和 Gradio 演示快速上手体验。
threestudio 的核心亮点在于其卓越的兼容性与扩展性。它不仅原生支持十多种主流 3D 生成算法,还推出了专门的扩展仓库(threestudio-extensions),允许社区轻松贡献新模型。这种“统一框架 + 灵活扩展”的模式,使其成为当前 3D 生成领域不可或缺的基础设施之一。
使用场景
一家独立游戏工作室的美术团队正急需为即将上线的奇幻 RPG 项目批量制作高质量的 3D 道具资产,但团队中缺乏专业的 3D 建模师。
没有 threestudio 时
- 人力成本高昂:必须外包或招聘昂贵的 3D 建模师,每个道具从概念图到完成模型需耗时数天,严重拖慢开发进度。
- 创意落地困难:策划人员脑海中独特的“火焰纹章盾牌”或“水晶法杖”难以通过文字准确传达给建模师,反复修改沟通成本极高。
- 技术门槛壁垒:团队成员虽擅长使用 Stable Diffusion 生成 2D 概念图,但完全不懂 NeRF、网格提取等复杂的 3D 生成算法,无法自行尝试。
- 风格统一性差:不同外包人员制作的资产风格割裂,难以保证与游戏整体美术风格的高度一致。
使用 threestudio 后
- 自动化快速生产:美术人员直接输入文本提示词或上传单张概念图,threestudio 即可自动调用底层模型生成完整的 3D 几何与纹理,将制作周期缩短至小时级。
- 所见即所得的创意验证:策划人员可即时将文字描述转化为 3D 原型进行预览,快速迭代设计方案,无需依赖中间人翻译需求。
- 统一框架降低门槛:threestudio 集成了 DreamFusion、Magic3D 等多种前沿算法于统一框架下,用户无需深究数学原理,通过配置文件即可轻松切换不同生成策略。
- 高质量且风格可控:利用强大的 2D 先验知识提升 3D 细节,生成的资产拓扑结构更合理,且能严格遵循输入的图像风格,确保游戏资产的一致性。
threestudio 成功打破了 2D 创意与 3D 资产之间的技术鸿沟,让小型团队也能以极低成本实现高质量的 3D 内容自由创作。
运行环境要求
- Linux
必需,NVIDIA GPU,显存至少 6GB,需安装 CUDA
未说明
快速开始

threestudio 是一个统一的框架,通过迁移 2D 文本到图像生成模型,实现从文本提示、单张图像以及少量示例图像进行 3D 内容创作。









👆 由 threestudio 实现的方法所得到的结果 👆
| ProlificDreamer | DreamFusion | Magic3D | SJC | Latent-NeRF | Fantasia3D | TextMesh |
| Zero-1-to-3 | Magic123 | HiFA | SDI |
| InstructNeRF2NeRF | Control4D |
![]()
没有找到您想要的内容?请查看 threestudio 扩展 或在此处提交功能请求 这里!










| Animate-124 | 4D-fy | GeoDream | DreamCraft3D | Dreamwaltz | 3DFuse | Progressive3D | GaussianDreamer | 高斯泼溅 | MVDream | 网格拟合 |
新闻
- 2024年11月8日:感谢Artem Lukoianov实现了通过重参数化DDIM进行分数蒸馏!Threestudio中新增了文本到3D模块,并附带了一个包含2D分数蒸馏实验的Notebook。
- 2024年10月21日:感谢Amir Barda实现了MagicClay!请按照其官网上的说明尝试使用。
- 2024年3月12日:感谢Matthew Kwak和Inès Hyeonsu Kim实现了3DFuse!请按照其官网上的说明尝试使用。
- 2024年3月8日:感谢Xinhua Cheng实现了GaussianDreamer!请按照其官网上的说明尝试使用。
- 2024年3月1日:感谢Xinhua Cheng实现了Progressive3D!请按照其官网上的说明尝试使用。
- 2024年1月9日:感谢Zehuan Huang实现了3D人体虚拟形象生成Dreamwaltz!请按照其官网上的说明尝试使用。
- 2024年1月6日:感谢Baorui Ma实现了GeoGream扩展!请按照其官网上的说明尝试使用。
- 2024年1月5日:实现了HiFA。请按照这里的说明尝试所有三种变体。
- 2023年12月23日:感谢Yuyang Zhao实现了图像到4D生成扩展Animate-124!请按照扩展官网上的说明尝试使用。
- 2023年12月18日:作为自定义扩展,实现了用于4D生成的4D-fy以及用于高质量图像到3D生成的DreamCraft3D!请按照扩展官网上的说明尝试使用。
- 2023年12月13日:实现了对Stable Zero123的支持,可用于从单张图片生成3D模型!请按照这里的说明尝试使用。
- 2023年11月30日:实现了MVDream和Gaussian Splatting作为自定义扩展。您还可以使用神经表示通过Mesh-Fitting来拟合网格。
- 2023年11月30日:实现了自定义扩展系统,您可以在这个项目中添加自己的扩展。
- 2023年6月25日:实现了Magic123!请按照这里的说明尝试使用。
- 2023年7月6日:加入我们的Discord服务器,参与热烈讨论!
- 2023年7月3日:您可以在HuggingFace Spaces上在线体验文本到3D功能,或使用我们的自托管服务(腾讯提供GPU支持)。如需在本地部署Web界面,请参阅这里。
- 2023年6月20日:实现了Instruct-NeRF2NeRF和Control4D,用于高保真度的3D编辑!请按照Control4D和Instruct-NeRF2NeRF的说明尝试使用。
- 2023年6月14日:实现了TextMesh!请按照这里的说明尝试使用。
- 2023年6月14日:实现了提示去偏见和Perp-Neg!请按照这里的说明尝试使用。
- 2023年5月29日:实验性地实现了使用Zero-1-to-3从单张图片生成3D模型!请按照这里的说明尝试使用。
- 2023年5月26日:实现了ProlificDreamer!请按照这里的说明尝试使用。
- 2023年5月14日:您可以通过我们的2dplayground在2D图像上试验SDS损失。
- 2023年5月13日:现在您可以在Google Colab上试用Threestudio!
- 2023年5月11日:我们现在支持导出带有纹理的网格!有关说明,请参阅这里。
安装
更多信息请参阅installation.md,包括通过Docker安装的方法。
以下步骤已在Ubuntu 20.04上测试通过。
- 您必须拥有至少6GB显存的NVIDIA显卡,并已安装CUDA。
- 安装
Python >= 3.8。 - (可选,推荐)创建虚拟环境:
python3 -m virtualenv venv
. venv/bin/activate
# 较新的pip版本,例如pip-23.x,通常比旧版本(如pip-20.x)快得多。
# 例如,它会缓存Git包的轮子文件,以避免后续不必要的重新构建。
python3 -m pip install --upgrade pip
- 安装
PyTorch >= 1.12。我们已在torch1.12.1+cu113和torch2.0.0+cu118上进行了测试,但其他版本也应该可以正常工作。
# torch1.12.1+cu113
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
# 或者 torch2.0.0+cu118
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu118
- (可选,推荐)安装 ninja 以加快 CUDA 扩展的编译速度:
pip install ninja
- 安装依赖项:
pip install -r requirements.txt
(可选)
tiny-cuda-nn的安装可能需要将 pip 降级到 23.0.1。(可选,推荐)threestudio 中性能最佳的模型使用了新发布的 T2I 模型 DeepFloyd IF,该模型目前需要签署许可协议。如果您希望使用这些模型,您需要在 DeepFloyd IF 的模型卡片上接受许可协议,并在终端中通过
huggingface-cli login登录 Hugging Face Hub。对于贡献者,请参阅 这里。
快速入门
下面我们展示 threestudio 的一些基本用法。首先让我们训练一个 DreamFusion 模型来创建一只经典的煎饼兔子。
如果您在与 Hugging Face 的连接中遇到不稳定的情况,我们建议您:(1) 在首次运行成功获取所有所需文件后,在运行命令之前设置环境变量 TRANSFORMERS_OFFLINE=1 DIFFUSERS_OFFLINE=1 HF_HUB_OFFLINE=1,以避免每次运行时都尝试连接 Hugging Face;或者 (2) 按照 这里 和 这里 将您使用的指导模型下载到本地文件夹,并将指导模型和提示处理器的 pretrained_model_name_or_path 设置为本地路径。
# 如果您已同意 DeepFloyd IF 的许可协议且显存大于 20GB
# 请尝试此配置以获得更高质量的效果
python launch.py --config configs/dreamfusion-if.yaml --train --gpu 0 system.prompt_processor.prompt="一张从远处拍摄的婴儿兔子坐在一摞煎饼上的单反照片"
# 否则,您可以尝试使用 Stable Diffusion 模型,该模型只需 6GB 显存即可运行
python launch.py --config configs/dreamfusion-sd.yaml --train --gpu 0 system.prompt_processor.prompt="一张从远处拍摄的婴儿兔子坐在一摞煎饼上的单反照片"
threestudio 使用 OmegaConf 实现灵活的配置。您可以通过指定不带 -- 的参数轻松更改 YAML 文件中的任何配置,例如上述示例中的指定提示。有关所有支持的配置,请参阅我们的 文档。
训练将持续 10,000 次迭代。您可以在默认为 [exp_root_dir]/[name]/[tag]@[timestamp] 的试验目录中找到当前状态的可视化结果,其中 exp_root_dir(默认为 outputs/)、name 和 tag 可以在配置文件中设置。训练完成后将生成一段 360 度视频。在训练过程中,按一次 ctrl+c 将停止训练并直接进入生成视频的测试阶段。再次按下 ctrl+c 则会完全退出程序。
多 GPU 训练
多 GPU 训练已被支持,但仍可能存在 bug。请注意,data.batch_size 是 每个进程(设备) 的批次大小。此外,请务必:
- 将
data.n_val_views设置为 GPU 数量的倍数。 - 设置唯一的
tag,因为在多 GPU 训练中时间戳功能已被禁用,不会附加在标签之后。如果您使用与先前试验相同的标签,保存的配置文件、代码和可视化结果将会被覆盖。
# 这将导致有效的批次大小为 4(GPU 数量)* 2(data.batch_size)= 8
python launch.py --config configs/dreamfusion-if.yaml --train --gpu 0,1,2,3 system.prompt_processor.prompt="一张从远处拍摄的婴儿兔子坐在一摞煎饼上的单反照片" data.batch_size=2 data.n_val_views=4
如果您在调用 launch.py 之前定义了 CUDA_VISIBLE_DEVICES 环境变量,则无需指定 --gpu——这将使用 CUDA_VISIBLE_DEVICES 中的所有可用 GPU。例如,以下命令将自动使用 GPU 3 和 4:
CUDA_VISIBLE_DEVICES=3,4 python launch.py --config configs/dreamfusion-if.yaml --train system.prompt_processor.prompt="一张从远处拍摄的婴儿兔子坐在一摞煎饼上的单反照片"
这在您通过集群运行 launch.py 并使用自动选择 GPU 并通过 CUDA_VISIBLE_DEVICES 导出其 ID 的命令时特别有用,例如通过 SLURM:
cd git/threestudio
. venv/bin/activate
srun --account mod3d --partition=g40 --gpus=1 --job-name=3s_bunny python launch.py --config configs/dreamfusion-if.yaml --train system.prompt_processor.prompt="一张从远处拍摄的婴儿兔子坐在一摞煎饼上的单反照片"
从检查点恢复
如果您想从检查点恢复训练,可以执行以下操作:
# 从最后一个检查点恢复训练,您可以将 last.ckpt 替换为其他检查点
python launch.py --config path/to/trial/dir/configs/parsed.yaml --train --gpu 0 resume=path/to/trial/dir/ckpts/last.ckpt
# 如果训练已完成,您仍然可以通过设置 trainer.max_steps 来继续训练更长时间
python launch.py --config path/to/trial/dir/configs/parsed.yaml --train --gpu 0 resume=path/to/trial/dir/ckpts/last.ckpt trainer.max_steps=20000
# 您也可以使用恢复的检查点进行测试
python launch.py --config path/to/trial/dir/configs/parsed.yaml --test --gpu 0 resume=path/to/trial/dir/ckpts/last.ckpt
# 请注意,上述命令使用的是先前试验的解析配置文件
# 这些命令将继续使用相同的试验目录
# 如果您想保存到新的试验目录,请在命令中将 parsed.yaml 替换为 raw.yaml
# 仅加载保存的检查点中的权重,但不恢复训练(即不加载优化器状态):
python launch.py --config path/to/trial/dir/configs/parsed.yaml --train --gpu 0 system.weights=path/to/trial/dir/ckpts/last.ckpt
导出网格
要将场景导出为带有纹理的网格,请使用 --export 选项。我们目前支持导出为 obj+mtl 格式,或带有顶点颜色的 obj 格式。
# 这将使用默认的网格导出配置,导出 obj+mtl 格式
python launch.py --config path/to/trial/dir/configs/parsed.yaml --export --gpu 0 resume=path/to/trial/dir/ckpts/last.ckpt system.exporter_type=mesh-exporter
# 指定 system.exporter.fmt=obj 即可获得带有顶点颜色的 obj 格式
# 你也可以添加 system.exporter.save_uv=false 来加速导出过程,适合快速预览结果
python launch.py --config path/to/trial/dir/configs/parsed.yaml --export --gpu 0 resume=path/to/trial/dir/ckpts/last.ckpt system.exporter_type=mesh-exporter system.exporter.fmt=obj
# 对于基于 NeRF 的方法(DreamFusion、Magic3D coarse、Latent-NeRF、SJC)
# 你可能需要调整等值面阈值(默认为 25),以获得满意的效果
# 如果提取的模型不完整,可以降低阈值;如果模型过度膨胀,则提高阈值
python launch.py --config path/to/trial/dir/configs/parsed.yaml --export --gpu 0 resume=path/to/trial/dir/ckpts/last.ckpt system.exporter_type=mesh-exporter system.geometry.isosurface_threshold=10.
# 使用更高分辨率的 marching cubes 算法来获取更精细的模型
python launch.py --config path/to/trial/dir/configs/parsed.yaml --export --gpu 0 resume=path/to/trial/dir/ckpts/last.ckpt system.exporter_type=mesh-exporter system.geometry.isosurface_method=mc-cpu system.geometry.isosurface_resolution=256
有关导出时可指定的所有选项,请参阅 文档。
关于我们所有支持模型的示例运行命令,请参阅 此处。如需获取更高质量的结果,请参考 此处,而要减少显存占用,请参阅 此处。
Gradio Web 界面
通过以下命令启动 Gradio Web 界面:
python gradio_app.py launch
参数说明:
--listen:在启动 Gradio 应用时将server_name="0.0.0.0"设置为监听所有地址。--self-deploy:允许直接从网页更改任意配置。--save:启用检查点保存功能。
如需功能请求、错误报告或技术问题讨论,请 提交 issue。如果您想讨论生成质量或展示您的生成成果,欢迎参与 讨论区。
支持的模型
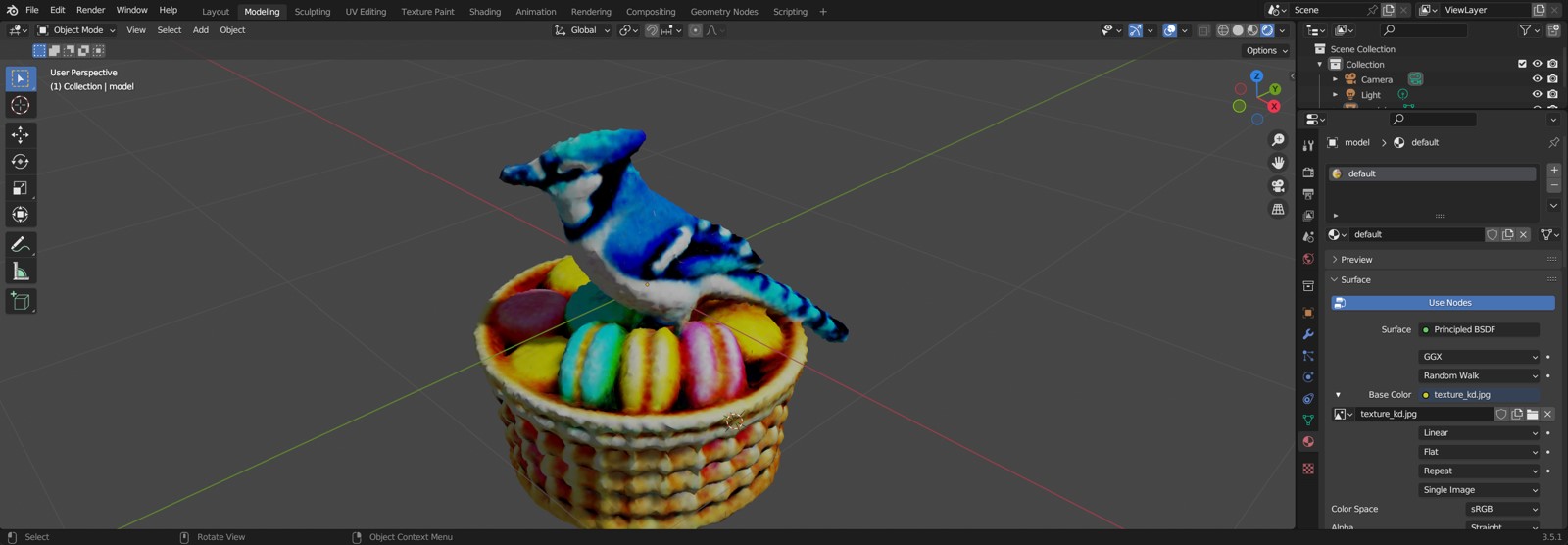
基于重参数化 DDIM 的分数蒸馏(SDI)
SDI 提议重新思考 Dreamfusion 中噪声项采样的方法。论文表明,分数蒸馏过程可以被视为对二维图像采样算法的重新参数化。在这种情况下,分数蒸馏每一步添加的噪声应具有非常特定的形式。然而,在 Dreamfusion(SDS)中,噪声是随机采样的,这会导致过度模糊。SDI 通过反向 DDIM 过程来近似正确的噪声项。
与原论文相比的显著差异:无。
优点:
- 纹理质量高
- 几何细节清晰
缺点:
- 由于额外的反向过程,速度比 SDS 慢 1.5 倍。不过,由于步骤较少,仍比 Prolific Dreamer 快。
- 由于渲染分辨率较高,所需显存比 SDS 更多。若使用显存较小的 GPU,可适当降低分辨率。
在 threestudio 中使用 Stable Diffusion (512x512) 获得的结果


示例运行命令
python launch.py --config configs/sdi.yaml --train --gpu 0 system.prompt_processor.prompt="南瓜头僵尸,瘦削,高度细节,照片级真实感"
python launch.py --config configs/sdi.yaml --train --gpu 1 system.prompt_processor.prompt="忍者的照片"
python launch.py --config configs/sdi.yaml --train --gpu 2 system.prompt_processor.prompt="汉堡的广角 DSLR 照片"
python launch.py --config configs/sdi.yaml --train --gpu 3 system.prompt_processor.prompt="夹有奶油芝士和熏鲑鱼的贝果"
ProlificDreamer 
这是一个非官方的实验性实现!请参阅 https://github.com/thu-ml/prolificdreamer 获取官方代码发布。
threestudio 使用 Stable Diffusion (256x256 Stage1) 获得的结果
threestudio 使用 Stable Diffusion (256x256 Stage1, 512x512 Stage2+3) 获得的结果
与原论文相比的显著差异:
- ProlificDreamer 采用两阶段采样策略,即先进行 64 次粗略采样,再进行 32 次精细采样,而我们仅使用 512 次粗略采样。
- 在第一阶段,我们只在前 5000 次迭代中渲染 64x64 的图像。之后,由于空余空间已被有效裁剪,渲染 512x512 的图像并不会消耗太多显存。
- 目前我们还不支持多粒子模式。
# --------- 第一阶段(NeRF)--------- #
# 物体生成,采用 512x512 NeRF 渲染,约需 30GB 显存
python launch.py --config configs/prolificdreamer.yaml --train --gpu 0 system.prompt_processor.prompt="一个菠萝"
# 如果显存不足,可以尝试使用 64x64 NeRF 渲染,约需 15GB 显存
python launch.py --config configs/prolificdreamer.yaml --train --gpu 0 system.prompt_processor.prompt="一个菠萝" data.width=64 data.height=64 data.batch_size=1
# 使用同一模型进行预训练和 LoRA 训练,可以在 <10GB 显存下进行 64x64 训练
# 但质量会稍差,因为 LoRA 训练使用的是 epsilon 预测模型
python launch.py --config configs/prolificdreamer.yaml --train --gpu 0 system.prompt_processor.prompt="一个菠萝" data.width=64 data.height=64 data.batch_size=1 system.guidance.pretrained_model_name_or_path_lora="stabilityai/stable-diffusion-2-1-base"
# 使用基于补丁的渲染器以减少内存消耗,分辨率为 512x512,约需 20GB 显存
python launch.py --config configs/prolificdreamer-patch.yaml --train --gpu 0 system.prompt_processor.prompt="一个菠萝"
# 场景生成,采用 512x512 NeRF 渲染,约需 30GB 显存
python launch.py --config configs/prolificdreamer-scene.yaml --train --gpu 0 system.prompt_processor.prompt="智能家居内部,写实细腻的照片,4k"
# --------- 第二阶段(几何精修)--------- #
# 使用512×512光栅化细化几何体,结合Stable Diffusion SDS指导
python launch.py --config configs/prolificdreamer-geometry.yaml --train --gpu 0 system.prompt_processor.prompt="一个菠萝" system.geometry_convert_from=路径/到/阶段1/试验/目录/检查点/last.ckpt
# --------- 阶段3(纹理化) --------- #
# 使用512×512光栅化进行纹理化,结合Stable Diffusion VSD指导
python launch.py --config configs/prolificdreamer-texture.yaml --train --gpu 0 system.prompt_processor.prompt="一个菠萝" system.geometry_convert_from=路径/到/阶段2/试验/目录/检查点/last.ckpt
HiFA 
这是一个重新实现的版本,缺少了原论文中的一些改进(从粗到精的NeRF采样、核平滑)。如需原始结果,请参考https://github.com/JunzheJosephZhu/HiFA
HiFA更像是一套改进方案,包括图像空间SDS、z方差损失和噪声强度退火等。它兼容大多数基于优化的方法。因此,我们提供了基于DreamFusion、ProlificDreamer和Magic123的三种变体。我们还提供了一个统一的指导配置以及针对DreamFusion和ProlificDreamer变体的SDS/VSD指导配置,这两种配置应该能达到相同的效果。此外,我们也使HiFA与ProlificDreamer-scene兼容。
由threestudio获得的结果(Dreamfusion-HiFA,512×512)
由threestudio获得的结果(ProlificDreamer-HiFA,512×512)
由threestudio获得的结果(Magic123-HiFA,512×512)
示例运行命令
# ------ DreamFusion-HiFA ------- # (类似于原论文)
python launch.py --config configs/hifa.yaml --train --gpu 0 system.prompt_processor.prompt="一盘美味的塔可"
python launch.py --config configs/experimental/unified-guidance/hifa.yaml --train --gpu 0 system.prompt_processor.prompt="一盘美味的塔可"
# ------ ProlificDreamer-HiFA ------- #
python launch.py --config configs/prolificdreamer-hifa.yaml --train --gpu 0 system.prompt_processor.prompt="一盘美味的塔可"
python launch.py --config configs/experimental/unified-guidance/prolificdreamer-hifa.yaml --train --gpu 0 system.prompt_processor.prompt="一盘美味的塔可"
# ------ ProlificDreamer-scene-HiFA ------- #
python launch.py --config configs/prolificdreamer-scene-hifa.yaml --train --gpu 0 system.prompt_processor.prompt="餐厅内的一张单反相机拍摄的汉堡照片"
# ------ Magic123-HiFA ------ #
python launch.py --config configs/magic123-hifa-coarse-sd.yaml --train --gpu 0 data.image_path=加载/图片/firekeeper_rgba.png system.prompt_processor.prompt="黑暗之魂中的守火者玩具人偶"
# 我们为magic123的细化阶段提供了一个配置,但并未真正运行,因为粗略阶段的结果已经相当不错。
提示
- 如果生成物体的颜色显得过于饱和,可以降低lambda_sds_img(或使用统一指导时的lambda_sd_img)。
- 如果生成物体看起来模糊不清,可以增加lamda_z_variance;如果形状变得扭曲,则应降低lambda_z_variance。
- 如果生成物体整体亮度较高,可以提高min_step_percent。
- 确保sqrt_anneal和use_img_loss都设置为True。
- 请查看原仓库!那里的效果更好。
- 如果您使用sqrt_anneal,请确保system.guidance.trainer_max_steps等于trainer.max_steps,以便噪声强度退火能够正常工作。
DreamFusion
由threestudio获得的结果(DeepFloyd IF,批次大小8)
与论文相比的显著差异
- 我们使用开源的T2I模型(StableDiffusion、DeepFloyd IF),而论文中使用的是Imagen。
- 对于DeepFloyd IF,我们采用20的指导尺度,而论文中对Imagen使用的是100。
- 我们没有使用sigmoid函数来归一化反照率颜色,而是直接将颜色从
[-1,1]缩放到[0,1],因为我们发现这样有助于收敛。 - 我们使用HashGrid编码,并沿光线均匀采样点,而论文中则采用了集成位置编码和来自MipNeRF360的采样策略。
- 我们借鉴了Magic3D的相机设置和密度初始化策略,这与DreamFusion论文中的做法略有不同。
- 一些超参数也有所不同,例如损失项的权重。
示例运行命令
# 使用DeepFloyd IF,提取文本嵌入需要约15GB显存,训练时约需10GB显存
# 在这里,我们采用了随机背景增强来提升几何质量
python launch.py --config configs/dreamfusion-if.yaml --train --gpu 0 system.prompt_processor.prompt="一个美味的汉堡" system.background.random_aug=true
# 使用StableDiffusion,训练时约需6GB显存
python launch.py --config configs/dreamfusion-sd.yaml --train --gpu 0 system.prompt_processor.prompt="一个美味的汉堡"
提示
- DeepFloyd IF的表现远远优于StableDiffusion。
- 测试显示,在
system.material.ambient_only_steps之前是反照率颜色,之后则是着色后的颜色。 - 如果场景中漂浮物过多或变得空洞,可以尝试调整
system.loss.lambda_sparsity的值。 - 如果物体显得模糊或过度平滑,可以调整
system.loss.lambda_orient。 - 如果发现模型错误地将背景视为物体的一部分,可以尝试将背景替换为随机颜色,概率设为0.5,即设置
system.background.random_aug=true。 - DeepFloyd IF使用T5-XXL作为文本编码器,即使采用8位量化,也会消耗约15GB显存。目前这是在显存较少的情况下训练的瓶颈。如果有人知道如何用更少的显存运行文本编码器,请提交问题。我们也在尝试将文本编码器部署到Replicate上,以便通过API提取文本嵌入,但遇到了一些网络连接问题。如果您愿意帮忙,请联系bennyguo。
Magic3D 
由 threestudio 获得的结果(DeepFloyd IF,批量大小 8;第一行:粗略阶段,第二行:细化阶段)
与论文相比的显著差异
- 我们在粗略阶段使用开源的 T2I 模型(StableDiffusion、DeepFloyd IF),而论文中使用的是 eDiff-I。
- 在粗略阶段,我们为 DeepFloyd IF 使用 20 的指导尺度,而论文中 eDiff-I 使用的是 100。
- 在粗略阶段,我们使用解析法计算的法线,而论文中使用的是预测的法线。
- 在粗略阶段,我们采用了 DreamFusion 中的方向损失,而论文中没有使用。
- 论文中省略了许多内容,例如损失项的权重以及 DMTet 网格分辨率等,这些可能有所不同。
示例运行命令
首先训练粗略阶段的 NeRF:
# 使用 DeepFloyd IF,提取文本嵌入需要约 15GB 显存,训练时约需 10GB 显存
python launch.py --config configs/magic3d-coarse-if.yaml --train --gpu 0 system.prompt_processor.prompt="一个美味的汉堡"
# 使用 StableDiffusion,训练时约需 6GB 显存
python launch.py --config configs/magic3d-coarse-sd.yaml --train --gpu 0 system.prompt_processor.prompt="一个美味的汉堡"
然后将粗略阶段的 NeRF 转换为 DMTet,并使用可微光栅化进行训练:
# 细化阶段使用 StableDiffusion,训练时约需 5GB 显存
python launch.py --config configs/magic3d-refine-sd.yaml --train --gpu 0 system.prompt_processor.prompt="一个美味的汉堡" system.geometry_convert_from=粗略阶段试验目录/检查点/last.ckpt
# 如果对默认阈值(25)提取的表面不满意,
# 可以通过 `system.geometry_convert_override` 指定阈值:
# 表面不完整时降低阈值,过度膨胀时则提高。
python launch.py --config configs/magic3d-refine-sd.yaml --train --gpu 0 system.prompt_processor.prompt="一个美味的汉堡" system.geometry_convert_from=粗略阶段试验目录/检查点/last.ckpt system.geometry_convert_override.isosurface_threshold=10.
提示
- 对于粗略阶段,DeepFloyd IF 的表现 远优于 StableDiffusion。
- Magic3D 使用神经网络预测表面法线,这可能与真实的几何法线不符,从而降低几何质量,因此我们改用解析法计算的法线。
- 如果场景中漂浮物过多或过于空洞,可以尝试调整
system.loss.lambda_sparsity的值。 - 如果物体显得模糊或过度平滑,可以尝试调整
system.loss.lambda_orient。 - 如果发现模型错误地将背景视为物体的一部分,可以通过设置
system.background.random_aug=true,以 50% 的概率用随机颜色替换背景。
Score Jacobian Chaining 
由 threestudio 获得的结果(Stable Diffusion)
与论文相比的显著差异:无。
示例运行命令
# 在潜在空间中使用 SJC 引导进行训练
python launch.py --config configs/sjc.yaml --train --gpu 0 system.prompt_processor.prompt="一张高质量的美味汉堡照片"
# 在潜在空间中使用 SJC 引导进行训练,特朗普人偶
python launch.py --config configs/sjc.yaml --train --gpu 0 system.prompt_processor.prompt="特朗普人偶" trainer.max_steps=30000 system.loss.lambda_emptiness="[15000,10000.0,200000.0,15001]" system.optimizer.params.background.lr=0.05 seed=42
提示
- SJC 使用亚像素渲染技术,解码一个
128x128的潜在特征图,以获得更好的可视化效果。如果在验证或测试时希望节省显存,可以关闭此功能,设置为system.subpixel_rendering=false。
Latent-NeRF 
由 threestudio 获得的结果(Stable Diffusion)
与论文相比的显著差异:无。
目前我们仅实现了用于文本引导的 Latent-NeRF,以及用于(文本、形状)引导的 Sketch-Shape 三维生成。Latent-Paint 尚未实现。
示例运行命令
# 在 Stable Diffusion 潜在空间中训练 Latent-NeRF
python launch.py --config configs/latentnerf.yaml --train --gpu 0 system.prompt_processor.prompt="一个美味的汉堡"
# 在 RGB 空间中细化 Latent-NeRF
python launch.py --config configs/latentnerf-refine.yaml --train --gpu 0 system.prompt_processor.prompt="一个美味的汉堡" system.weights=潜阶段试验目录/检查点/last.ckpt
# 在 Stable Diffusion 潜在空间中训练 Sketch-Shape
python launch.py --config configs/sketchshape.yaml --train --gpu 0 system.guide_shape=加载/形状/泰迪熊.obj system.prompt_processor.prompt="穿着燕尾服的泰迪熊"
# 在 RGB 空间中细化 Sketch-Shape
python launch.py --config configs/sketchshape-refine.yaml --train --gpu 0 system.guide_shape=加载/形状/泰迪熊.obj system.prompt_processor.prompt="穿着燕尾服的泰迪熊" system.weights=潜阶段试验目录/检查点/last.ckpt
Fantasia3D 
由 threestudio 获得的结果(Stable Diffusion)
由 threestudio 获得的结果(Stable Diffusion,网格初始化)

与论文相比的显著差异:
- 我们默认启用了切线空间法线扰动,可通过添加
system.material.use_bump=false来关闭。
示例运行命令
# --------- 几何部分 --------- #
python launch.py --config configs/fantasia3d.yaml --train --gpu 0 system.prompt_processor.prompt="一张单反相机拍摄的冰淇淋圣代照片"
# Fantasia3D 非常依赖于初始化的 SDF 形状
# 默认形状是一个半径为 0.5 的球体
# 可以根据输入提示更改形状初始化
python launch.py --config configs/fantasia3d.yaml --train --gpu 0 system.prompt_processor.prompt="比萨斜塔" system.geometry.shape_init=椭球 system.geometry.shape_init_params="[0.3,0.3,0.8]"
# 或者也可以从网格文件初始化
# 这里 shape_init_params 是形状的缩放比例
# 同时请确保输入正确的上方向和前方向轴(取值为 +x、+y、+z、-x、-y、-z)
python launch.py --config configs/fantasia3d.yaml --train --gpu 0 system.prompt_processor.prompt="hulk" system.geometry.shape_init=mesh:load/shapes/human.obj system.geometry.shape_init_params=0.9 system.geometry.shape_init_mesh_up=+y system.geometry.shape_init_mesh_front=+z
# --------- 纹理 --------- #
# 从几何检查点继续训练 PBR 纹理:
python launch.py --config configs/fantasia3d-texture.yaml --train --gpu 0 system.prompt_processor.prompt="一张冰淇淋圣代的单反照片" system.geometry_convert_from=path/to/geometry/stage/trial/dir/ckpts/last.ckpt
提示
- 如果在训练初期发现形状容易发散,可以降低指导尺度,将
system.guidance.guidance_scale设置为30。
TextMesh 
由 threestudio(DeepFloyd IF,批量大小 4)获得的结果
与论文相比的显著差异
- 大多数设置与 DreamFusion 模型相同。请参考 DreamFusion 模型的显著差异。
- 我们使用 NeuS 作为几何表示,而原论文使用 VolSDF。
- 我们采用了来自 Neuralangelo 的技术,以在使用哈希网格时稳定法线计算。
- 目前我们仅实现了 TextMesh 的粗略阶段。
示例运行命令
# 使用 DeepFloyd IF,需要约 15GB 显存
python launch.py --config configs/textmesh-if.yaml --train --gpu 0 system.prompt_processor.prompt="lib:cowboy_boots"
提示
- TextMesh 使用基于表面的几何表示,因此在导出网格时无需手动调整等值面阈值!
Control4D 
这是使用 threestudio 对 Control4D 的实验性实现!Control4D 将在论文被接受后发布包含静态和动态编辑的完整代码。
由 threestudio 获得的结果(512×512)
我们目前不支持动态编辑。
请使用此链接下载 Control4D 的数据样本:link。
示例运行命令
# --------- Control4D --------- #
# 静态编辑,采用 128×128 NeRF + 512×512 GAN 渲染,约 20GB 显存
python launch.py --config configs/control4d-static.yaml --train --gpu 0 data.dataroot="YOUR_DATAROOT/twindom" system.prompt_processor.prompt="埃隆·马斯克穿着红衬衫,RAW 照片,(高细节皮肤:1.2),8k 超高清,单反相机,柔和光线,高质量,胶片颗粒感,富士 XT3"
InstructNeRF2NeRF 
由 threestudio 获得的结果
请使用此链接下载 InstructNeRF2NeRF 的数据样本:link。
示例运行命令
# --------- InstructNeRF2NeRF --------- #
# 基于 NeRF 片段渲染的 3D 编辑,约 20GB 显存
python launch.py --config configs/instructnerf2nerf.yaml --train --gpu 0 data.dataroot="YOUR_DATAROOT/face" data.camera_layout="front" data.camera_distance=1 data.eval_interpolation=[1,3,50] system.prompt_processor.prompt="把他变成爱因斯坦"
Magic123 
由 threestudio 获得的结果(Zero123 + Stable Diffusion)
与论文相比的显著差异
- 这是一个非官方的重新实现,其总体思路与 官方实现 相同,但在一些方面有所不同,例如超参数。
- 不支持文本反转,这意味着训练时需要提供文本提示。
示例运行命令
首先训练粗略阶段的 NeRF:
# Zero123 + Stable Diffusion,约 12GB 显存
# data.image_path 必须指向一张 4 通道 RGBA 图像
# 必须指定 system.prompt_proessor.prompt
python launch.py --config configs/magic123-coarse-sd.yaml --train --gpu 0 data.image_path=load/images/hamburger_rgba.png system.prompt_processor.prompt="一个美味的汉堡"
然后将粗略阶段的 NeRF 转换为 DMTet,并使用可微分光栅化进行训练:
# Zero123 + Stable Diffusion,约 10GB 显存
# data.image_path 必须指向一张 4 通道 RGBA 图像
# 必须指定 system.prompt_proessor.prompt
python launch.py --config configs/magic123-refine-sd.yaml --train --gpu 0 data.image_path=load/images/hamburger_rgba.png system.prompt_processor.prompt="一个美味的汉堡" system.geometry_convert_from=path/to/coarse/stage/trial/dir/ckpts/last.ckpt
# 如果对使用默认阈值(25)提取的表面不满意
# 可以通过 `system.geometry_convert_override` 指定阈值
# 如果提取的表面不完整,则降低该值;如果过度膨胀,则提高该值
python launch.py --config configs/magic123-refine-sd.yaml --train --gpu 0 data.image_path=load/images/hamburger_rgba.png system.prompt_processor.prompt="一个美味的汉堡" system.geometry_convert_from=path/to/coarse/stage/trial/dir/ckpts/last.ckpt system.geometry_convert_override.isosurface_threshold=10.
提示
- 如果图像中包含非正面朝向的物体,通过设置
data.default_elevation_deg和data.default_azimuth_deg来指定近似的仰角和方位角可能会有所帮助。在 threestudio 中,顶部为仰角 +90 度,底部为仰角 -90 度;左侧为方位角 -90 度,右侧为方位角 +90 度。
Stable Zero123
安装
从 https://huggingface.co/stabilityai/stable-zero123 下载预训练的 Stable Zero123 检查点 stable-zero123.ckpt,并将其放置在 load/zero123 目录下。
由 threestudio 获得的结果(Stable Zero123 与 Zero123-XL 对比)

直接生成多视角图像 如果您只想生成多视角图像,请参考 threestudio-mvimg-gen。该扩展可以使用 Stable Zero123 直接从多视角生成图像。
示例运行命令
- 选择一张您喜欢的图片,或者使用您喜爱的 AI 图像生成器(如 SDXL Turbo,https://clipdrop.co/stable-diffusion-turbo)根据文本生成一张图片,例如:“一只友好的狗的简单 3D 渲染”。
- 使用 Clipdrop(https://clipdrop.co/remove-background)去除其背景。
- 将图片保存到
load/images/目录下,最好以_rgba.png作为后缀。 - 使用 Stable Zero123 检查点运行 Zero-1-to-3:
python launch.py --config configs/stable-zero123.yaml --train --gpu 0 data.image_path=./load/images/hamburger_rgba.png
重要提示:这是一个实验性实现,我们正在不断改进其质量。
重要提示:该实现扩展了下方的 Zero-1-to-3 实现,并深受 https://github.com/ashawkey/stable-dreamfusion 中 Zero-1-to-3 实现的启发!extern/ldm_zero123 借鉴自 stable-dreamfusion/ldm。
Zero-1-to-3 
安装
将预训练的 Zero123XL 权重下载到 load/zero123 目录:
cd load/zero123
wget https://zero123.cs.columbia.edu/assets/zero123-xl.ckpt
由 threestudio 获得的结果(Zero-1-to-3)
重要提示:这是一个实验性实现,我们正在不断改进其质量。
重要提示:该实现深受 https://github.com/ashawkey/stable-dreamfusion 中 Zero-1-to-3 实现的启发!extern/ldm_zero123 借鉴自 stable-dreamfusion/ldm。
示例运行命令
- 选择一张您喜欢的图片,或者使用您喜爱的 AI 图像生成器(如 Stable Diffusion XL,https://clipdrop.co/stable-diffusion)根据文本生成一张图片,例如:“一只友好的狗的简单 3D 渲染”。
- 使用 Clipdrop(https://clipdrop.co/remove-background)去除其背景。
- 将图片保存到
load/images/目录下,最好以_rgba.png作为后缀。 - 运行 Zero-1-to-3:
python launch.py --config configs/zero123.yaml --train --gpu 0 data.image_path=./load/images/dog1_rgba.png
更多 Zero-1-to-3 的脚本,请查看 threestudio/scripts/run_zero123.sh。
之前的 Zero-1-to-3 权重可在 https://huggingface.co/cvlab/zero123-weights/ 获取。您可以按照上述方法将其下载到 load/zero123 目录,并替换 system.guidance.pretrained_model_name_or_path 中的路径。
指导评估
还包括训练过程中的指导评估。如果将 system.freq.guidance_eval 设置为大于 0 的值,系统会保存渲染后的图像、添加噪声的图像(左上角所示)、单步去噪后的图像、对原始图像的单步预测以及完全去噪后的图像。例如:

更多内容敬请期待。
如果您希望为 threestudio 贡献新的方法,请参阅 此处。
提示词库
为了便于比较,我们将 DreamFusion 网站上的 397 条预设提示词收集到了 此文件 中。您可以通过设置 system.prompt_processor.prompt=lib:keyword1_keyword2_..._keywordN 来使用这些提示词。请注意,提示词必须以 lib: 开头,且所有关键词之间用 _ 分隔。提示词处理器会将这些关键词与库中的所有提示词进行匹配,只有当恰好匹配一条时才会成功。所使用的提示词将会打印到控制台。另外请注意,您不能使用这种语法指向库中的每一条提示词,因为有些提示词是其他提示词的子集,哈哈。我们将进一步完善这一功能的使用。
提升质量的技巧
需要注意的是,现有的将2D到3D图像生成模型提升至3D的技术,并不能始终如一地产生令人满意的结果。像DreamFusion和Magic3D这样优秀论文中的结果,在某种程度上是经过精心挑选的,因此如果你在第一次尝试时没有得到预期的效果,也不必感到沮丧。以下是一些可能帮助你提高生成质量的技巧:
增加批量大小。较大的批量有助于收敛,并提高几何体的一致性。当前最先进的方法都声称使用了较大的批量:DreamFusion使用4的批量大小;Magic3D使用32的批量大小;Fantasia3D使用24的批量大小;上述展示的一些结果则使用8的批量大小。你可以通过设置
data.batch_size=N轻松更改批量大小。增加批量大小需要更多的显存。如果你显存有限,但仍希望获得大批次的好处,可以使用PyTorch Lightning提供的梯度累积功能,通过设置trainer.accumulate_grad_batches=N来实现。这会累积多个批次的梯度,从而达到较大的有效批量。请注意,如果使用梯度累积,你可能需要在配置中将所有步数相关的值(例如带有X_steps名称的值以及trainer.val_check_interval)乘以N倍,因为现在N个批次等同于一个大批次。延长训练时间。如果你已经能够获得合理的结果,并希望进一步提升细节,那么延长训练时间会有帮助。但如果经过数千步后结果仍然一团糟,继续训练通常不会带来改善。你可以通过设置
trainer.max_steps=N来指定总的训练迭代次数。尝试不同的随机种子。如果你的结果整体几何形状正确,但存在多面Janus问题,这是一个简单的解决方案。你可以通过设置
seed=N来改变随机种子。祝你好运!调整正则化权重。一些方法包含正则化项,这些正则化对于获得良好的几何形状至关重要。你可以通过设置
system.loss.lambda_X=value来尝试调整这些正则化项的权重。具体的数值取决于你的实际情况,更多详细说明请参考每个支持模型的提示。尝试去偏方法。当传统的SDS技术,如DreamFusion、Magic3D、SJC等无法生成理想的3D结果时,去偏分数蒸馏采样(D-SDS)可能是一个解决方案。D-SDS旨在解决诸如伪影或Janus问题等挑战,采用了两种策略:分数去偏和提示去偏。你只需通过设置
system.guidance.grad_clip=[0,0.5,2.0,10000]即可激活分数去偏,其中顺序为开始步数、开始值、结束值、结束步数。要启用提示去偏,可以设置system.prompt_processor.use_prompt_debiasing=true。使用提示去偏时,建议通过system.prompt_processor.prompt_debiasing_mask_ids=[i1,i2,...]设置一个可能需要被移除的词索引列表。例如,如果提示是一只微笑的狗,而你只想针对某些视角移除“微笑”这个词,那么就应设置为[1]。你还可以通过设置system.prompt_processor.prompt_side、system.prompt_processor.prompt_back和system.prompt_processor.prompt_overhead来手动指定每个视角的提示。有关这些技术的详细解释,请参阅D-SDS论文或访问项目页面。尝试Perp-Neg。Perp-Neg算法有可能缓解多面Janus问题。我们现在支持在
stable-diffusion-guidance和deep-floyd-guidance中使用Perp-Neg,只需设置system.prompt_processor.use_perp_neg=true即可。
显存优化
如果你遇到CUDA OOM错误,可以按照以下顺序(大致按推荐程度排序)尝试操作,以满足你的显存需求。
如果你只在验证/测试时遇到OOM,可以设置
system.cleanup_after_validation_step=true和system.cleanup_after_test_step=true,以便在每次验证/测试步骤后释放内存。这样做会降低验证/测试的速度。使用较小的批量大小,或者如此处所示使用梯度累积。
如果你使用的是PyTorch 1.x版本,可以通过设置
system.guidance.enable_memory_efficient_attention=true来启用高效注意力机制。PyTorch 2.0已内置对此优化的支持,默认情况下已启用。通过设置
system.guidance.enable_attention_slicing=true来启用注意力切片。这会使训练速度减慢约20%。如果你使用StableDiffusionGuidance,可以利用Token Merging来大幅加快计算速度并节省显存。只需设置
system.guidance.token_merging=true即可轻松启用Token Merging。你还可以通过设置此处的参数来自定义Token Merging的行为,即system.guidance.token_merging_params。请注意,Token Merging可能会降低生成质量。通过设置
system.guidance.enable_sequential_cpu_offload=true来启用顺序CPU卸载。这可以节省大量显存,但会使训练过程变得极其缓慢。
文档
threestudio使用OmegaConf来管理配置。你可以直接修改yaml配置文件中的任何内容,也可以通过添加不带--的命令行参数来进行更改。我们在文档中列出了所有可以在配置中更改的参数。祝你实验愉快!
wandb(Weights & Biases)日志记录
要启用(实验性)wandb支持,需设置system.loggers.wandb.enable=true,例如:
python launch.py --config configs/zero123.yaml --train --gpu 0 system.loggers.wandb.enable=true`
如果你使用的是企业版wandb服务器,可能需要先登录你的wandb实例,例如:
wandb login --host=https://COMPANY_XYZ.wandb.io --relogin
默认情况下,运行会有一个随机名称,并记录在threestudio项目中。你可以覆盖这些名称,为其赋予更具描述性的名字,例如:
python launch.py --config configs/zero123.yaml --train --gpu 0 system.loggers.wandb.enable=true system.loggers.wandb.name="zero123xl_accum;bs=4;lr=0.05"`
参与 threestudio 的开发
- 克隆仓库并基于
main分支创建你的分支。 - 安装开发依赖:
pip install -r requirements-dev.txt
如果你使用 VSCode 作为编辑器:(1) 安装
editorconfig插件。(2) 将默认的 linter 设置为 mypy,以启用静态类型检查。(3) 将默认格式化工具设置为 black。你可以手动格式化文档,也可以通过设置"editor.formatOnSave": true让编辑器在每次保存时自动格式化。运行
pre-commit install来安装 pre-commit 钩子,这些钩子会在提交前自动格式化文件。对代码进行修改,必要时更新 README 和 DOCUMENTATION,然后发起 Pull Request。
代码结构
这里我们简要介绍该项目的代码结构。未来我们将提供更详细的文档。
- 所有方法都实现为
BaseSystem的子类(位于systems/base.py)。一个系统通常包含六个模块:geometry、material、background、renderer、guidance 和 prompt_processor。除 guidance 和 prompt_processor 外,所有模块都是BaseModule的子类(位于utils/base.py),而 guidance 和 prompt_processor 则是BaseObject的子类,这样可以避免它们被视为模型参数,并更好地控制其在多 GPU 环境下的行为。 - 所有系统、模块和数据模块都有各自的数据类配置。
- 整个项目的基础配置可以在
utils/config.py中找到。在ExperimentConfig数据类中,data、system以及system下的模块配置会被解析为上述各类的配置。这些配置具有严格的类型约束,这意味着你只能使用数据类中定义的属性,并且必须遵守每个属性的类型。这种配置方式 (1) 自然支持属性的默认值;(2) 有效防止了属性的错误赋值(例如 YAML 文件中的拼写错误)或运行时的不当使用。 - 该项目同时使用静态和运行时类型检查。更多细节请参阅
utils/typing.py。 - 若要在每个训练步骤中更新模块的任何内容,只需让该模块继承
Updateable类(见utils/base.py)。在每次迭代开始时,Updateable实例会自行更新,并递归更新其所有也是Updateable的属性。需要注意的是,BaseSystem、BaseModule和BaseObject的子类默认都继承了Updateable。
已知问题
- 在 AMP 模式下,Vanilla MLP 参数的梯度为空(暂时通过禁用 autocast 解决)。
- FullyFused MLP 在 32 位精度下可能导致 NaN 值。
致谢
threestudio 基于以下优秀的开源项目构建:
以下仓库极大地启发了 threestudio:
感谢这些项目的维护者们对社区的贡献!
引用 threestudio
如果你觉得 threestudio 有所帮助,请考虑引用以下文献:
@Misc{threestudio2023,
author = {Yuan-Chen Guo and Ying-Tian Liu and Ruizhi Shao and Christian Laforte and Vikram Voleti and Guan Luo and Chia-Hao Chen and Zi-Xin Zou and Chen Wang and Yan-Pei Cao and Song-Hai Zhang},
title = {threestudio: A unified framework for 3D content generation},
howpublished = {\url{https://github.com/threestudio-project/threestudio}},
year = {2023}
}
版本历史
v0.1.02023/05/11常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。