DSOD
DSOD 是一款专注于目标检测任务的开源深度学习框架,其核心理念是“从零开始训练深度监督的目标检测器”。传统检测模型通常依赖在 ImageNet 等大型数据集上预训练的权重来初始化,而 DSOD 成功打破了这一惯例,无需任何预训练模型即可直接训练出高性能的检测器。
这一技术主要解决了两个关键问题:一是降低了对大规模标注预训练数据的依赖,使得在特定领域或数据稀缺场景下训练模型变得更加可行;二是简化了训练流程,避免了迁移学习中可能产生的域偏差问题。DSOD 基于经典的 SSD 架构,通过引入密集预测结构和深度监督机制,有效提升了特征提取能力和梯度传播效率。此外,后续更新还发现,适当增大批量大小(Batch Size)能显著提升其检测精度。
DSOD 特别适合计算机视觉领域的研究人员、算法工程师以及希望深入理解目标检测底层原理的开发者使用。对于想要尝试不依赖预训练权重进行模型探索,或需要在自定义数据集上从头构建检测系统的团队,DSOD 提供了一个高效且极具参考价值的基准方案。虽然普通用户难以直接调用,但其思想对推动轻量化和定制化 AI 应用具有重要启发意义。
使用场景
某医疗影像初创团队需要在缺乏公开预训练模型的情况下,从零开始训练一个能精准识别罕见皮肤病变的检测系统。
没有 DSOD 时
- 依赖外部数据风险高:必须寻找与医疗场景高度匹配的大规模预训练模型,但通用数据集(如 ImageNet)的特征与皮肤纹理差异巨大,导致迁移效果差。
- 训练收敛困难:直接从随机初始化权重开始训练深层网络时,梯度容易消失或爆炸,模型难以收敛,甚至无法学到有效特征。
- 算力资源浪费:为了稳定训练,往往需要尝试各种复杂的预热策略或大幅降低学习率,导致实验周期漫长,GPU 空转率高。
- 精度遭遇瓶颈:即便勉强收敛,由于缺乏深层监督信号,模型对微小病灶的定位能力弱,漏检率居高不下。
使用 DSOD 后
- 彻底摆脱预训练依赖:DSOD 通过深度监督机制,让网络能够直接从随机初始化状态高效学习,无需任何外部预训练权重即可在医疗专有数据上启动训练。
- 加速模型收敛:利用中间层的辅助损失函数引导梯度流动,显著缓解了深层网络的训练难度,使模型在更少迭代次数内达到稳定状态。
- 提升小目标检测率:深层监督增强了特征金字塔的表达能力,显著提升了对微小皮肤病变区域的定位精度,mAP 值从早期的不稳定状态提升至可用水平。
- 简化调参流程:不再需要设计复杂的预训练加载逻辑或特殊的初始化技巧,标准训练流程即可复现论文中提到的优异性能(如在 VOC 数据集上验证的鲁棒性)。
DSOD 的核心价值在于打破了目标检测对大规模预训练模型的强依赖,让垂直领域的开发者能用有限的数据和算力,从零构建出高精度的专用检测器。
运行环境要求
- Linux
需要 NVIDIA GPU (文中提及 Titan X, P40),基于 Caffe 框架,需支持 CUDA (具体版本未说明)
未说明

快速开始
DSOD:从头开始学习深度监督目标检测器
更新(2019年2月26日)
我们观察到,如果在训练BN层时,将每张GPU上的批量大小(bs)从4(Titan X)简单地增加到12(P40),我们的DSOD300无需任何其他修改就能获得更好的性能(见下文对比)。我们认为,如果能有更好的方法来调整BN层的参数,例如在有限批量大小下从头训练检测器时使用同步BN [1]或组归一化 [2],那么精度可能会更高。这一点也与文献[3]一致。
我们还在扩展版论文(v2)[4]中提供了一些初步结果,探讨了从头训练两阶段检测器的影响因素。
PASCAL VOC测试集上的新结果:
| 方法 | VOC 2007测试集 mAP | 参数量 | 模型 |
|---|---|---|---|
| DSOD300 (07+12) 每张GPU上bs=4 | 77.7 | 14.8M | 下载(59.2M) |
| DSOD300 (07+12) 每张GPU上bs=12 | 78.9 | 14.8M | 下载(59.2M) |
[1] Chao Peng, Tete Xiao, Zeming Li, Yuning Jiang, Xiangyu Zhang, Kai Jia, Gang Yu, and Jian Sun. “Megdet:一种大规模小批量目标检测器。”载于IEEE计算机视觉与模式识别会议论文集,第6181–6189页,2018年。
[2] Yuxin Wu 和 Kaiming He. “组归一化。”载于欧洲计算机视觉会议(ECCV)论文集,第3–19页,2018年。
[3] Kaiming He、Ross Girshick 和 Piotr Dollár. “重新思考ImageNet预训练。”载于IEEE国际计算机视觉会议论文集,第4918–4927页,2019年。
[4] Zhiqiang Shen、Zhuang Liu、Jianguo Li、Yu-Gang Jiang、Yurong Chen 和 Xiangyang Xue. “基于深度监督的从零开始目标检测。”IEEE模式分析与机器智能汇刊(2019年)。
本仓库包含以下论文的代码:
DSOD:从头开始学习深度监督目标检测器(ICCV 2017)。
Zhiqiang Shen*, Zhuang Liu*, Jianguo Li、Yu-Gang Jiang、Yurong Chen、Xiangyang Xue。(*同等贡献)
代码基于SSD框架。
其他实现: [Pytorch]由Yun Chen实现,[Pytorch]由uoip实现,[Pytorch]由qqadssp实现,[Pytorch]由Ellinier实现,[Mxnet]由Leo Cheng实现,[Mxnet]由eureka7mt实现,[Tensorflow]由Windaway实现。
如果您觉得这有助于您的研究,请引用:
@inproceedings{Shen2017DSOD,
title = {DSOD:从头开始学习深度监督目标检测器},
author = {Shen, Zhiqiang 和 Liu, Zhuang 以及 Li, Jianguo 和 Jiang, Yu-Gang 和 Chen, Yurong 和 Xue, Xiangyang},
booktitle = {ICCV},
year = {2017}
}
@article{shen2018object,
title={基于深度监督的从零开始目标检测},
author={Shen, Zhiqiang 和 Liu, Zhuang 以及 Li, Jianguo 和 Jiang, Yu-Gang 和 Chen, Yurong 和 Xue, Xiangyang},
journal={arXiv预印本 arXiv:1809.09294},
year={2018}
}
引言
DSOD专注于从头训练目标检测器的问题(即不使用ImageNet上的预训练模型)。据我们所知,这是首篇以最先进水平从头训练神经网络目标检测器的工作。在这项工作中,我们提出了一套为此目的设计的原则。其中一个关键发现是,通过密集层间连接实现的深度监督结构,在学习良好的检测模型方面起着至关重要的作用。更多细节请参阅我们的论文。
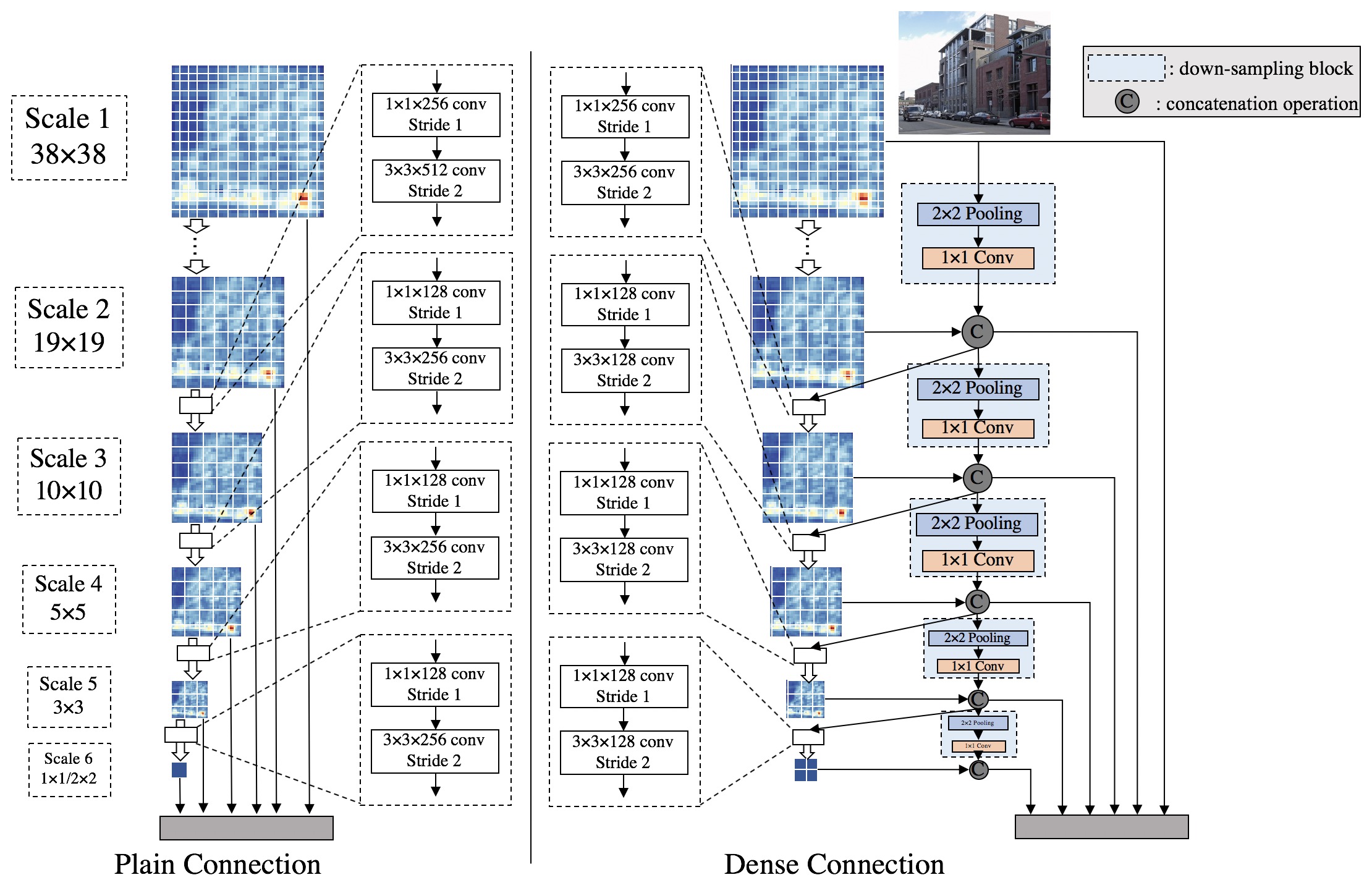
可视化
- 网络结构可视化(工具来自ethereon,请忽略警告信息):
结果与模型
下表展示了在PASCAL VOC 2007、2012以及MS COCO数据集上的结果。
PASCAL VOC测试结果:
| 方法 | VOC 2007测试集 mAP | 帧率(Titan X) | 参数量 | 模型 |
|---|---|---|---|---|
| DSOD300_smallest (07+12) | 73.6 | - | 5.9M | 下载(23.5M) |
| DSOD300_lite (07+12) | 76.7 | 25.8 | 10.4M | 下载(41.8M) |
| DSOD300 (07+12) | 77.7 | 17.4 | 14.8M | 下载(59.2M) |
| DSOD300 (07+12+COCO) | 81.7 | 17.4 | 14.8M | 下载(59.2M) |
| 方法 | VOC 2012测试集 mAP | 帧率 | 参数量 | 模型 |
|---|---|---|---|---|
| DSOD300 (07++12) | 76.3 | 17.4 | 14.8M | 下载(59.2M) |
| DSOD300 (07++12+COCO) | 79.3 | 17.4 | 14.8M | 下载(59.2M) |
COCO test-dev 2015结果(COCO的数据类别比VOC多,因此模型规模略大):
| 方法 | COCO test-dev 2015 mAP(IoU 0.5–0.95) | 模型 |
|---|---|---|
| DSOD300 (COCO trainval) | 29.3 | 下载(87.2M) |
准备工作
- 按照 SSD 的官方文档(https://github.com/weiliu89/caffe/tree/ssd)中的说明安装 SSD,包括:(1) 安装 SSD 版本的 Caffe;(2) 下载 PASCAL VOC 2007 和 2012 数据集;以及 (3) 创建 LMDB 文件。请确保安装完成后能够正常运行且无任何错误。
我们的 PASCAL VOC LMDB 文件:
| 方法 | LMDB 文件 |
|---|---|
| 在 VOC07+12 上训练,在 VOC07 上测试 | 下载 |
| 在 VOC07++12 上训练,在 VOC12(Comp4)上测试 | 下载 |
| 在 VOC12 上训练,在 VOC12(Comp3)上测试 | 下载 |
- 在
example/目录下创建子文件夹dsod,并将文件DSOD300_pascal.py、DSOD300_pascal++.py、DSOD300_coco.py、score_DSOD300_pascal.py和DSOD300_detection_demo.py添加到example/dsod/文件夹中。 - 在
example/目录下创建子文件夹grp_dsod,并将文件GRP_DSOD320_pascal.py和score_GRP_DSOD320_pascal.py添加到example/grp_dsod/文件夹中。 - 将
python/caffe/文件夹中的model_libs.py文件替换为我们的版本。
训练与测试
在 VOC 07+12 数据集上训练 DSOD 模型:
python examples/dsod/DSOD300_pascal.py在 VOC 07++12 数据集上训练 DSOD 模型:
python examples/dsod/DSOD300_pascal++.py在 COCO trainval 数据集上训练 DSOD 模型:
python examples/dsod/DSOD300_coco.py评估 DSOD 模型:
python examples/dsod/score_DSOD300_pascal.py运行 DSOD 模型的演示:
python examples/dsod/DSOD300_detection_demo.py在 VOC 07+12 数据集上训练 GRP_DSOD 模型:
python examples/grp_dsod/GRP_DSOD320_pascal.py评估 GRP_DSOD 模型:
python examples/dsod/score_GRP_DSOD320_pascal.py
注意:您可以修改 model_lib.py 文件,根据自己的需求设计网络结构。
示例

联系方式
沈志强(zhiqiangshen0214 at gmail.com)
刘壮(liuzhuangthu at gmail.com)
欢迎提出任何意见或建议!
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
AutoGPT
AutoGPT 是一个旨在让每个人都能轻松使用和构建 AI 的强大平台,核心功能是帮助用户创建、部署和管理能够自动执行复杂任务的连续型 AI 智能体。它解决了传统 AI 应用中需要频繁人工干预、难以自动化长流程工作的痛点,让用户只需设定目标,AI 即可自主规划步骤、调用工具并持续运行直至完成任务。 无论是开发者、研究人员,还是希望提升工作效率的普通用户,都能从 AutoGPT 中受益。开发者可利用其低代码界面快速定制专属智能体;研究人员能基于开源架构探索多智能体协作机制;而非技术背景用户也可直接选用预置的智能体模板,立即投入实际工作场景。 AutoGPT 的技术亮点在于其模块化“积木式”工作流设计——用户通过连接功能块即可构建复杂逻辑,每个块负责单一动作,灵活且易于调试。同时,平台支持本地自托管与云端部署两种模式,兼顾数据隐私与使用便捷性。配合完善的文档和一键安装脚本,即使是初次接触的用户也能在几分钟内启动自己的第一个 AI 智能体。AutoGPT 正致力于降低 AI 应用门槛,让人人都能成为 AI 的创造者与受益者。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。