VideoPipe
VideoPipe 是一个用 C++ 编写的跨平台视频结构化与分析框架,旨在帮助开发者像搭积木一样灵活构建视频处理应用。它通过“管道”机制将视频读取、解码、算法推理、目标跟踪及行为分析等环节串联起来,每个环节都是独立的插件节点,可按需自由组合。
在视频智能分析领域,现有的高性能方案往往依赖特定硬件厂商(如 NVIDIA 或华为)且不开源,学习门槛较高。VideoPipe 的出现解决了这一痛点,它以极少的依赖和较低的学习曲线,实现了在任意平台上的便捷部署,让视频分析不再受限于特定生态。
这款工具非常适合需要开发定制化视频应用的工程师和研究人员,尤其适用于交通监控、安防预警、图像检索及行为分析等场景。无论是检测车辆违章、识别特定人脸,还是集成最新的多模态大语言模型(mLLM),VideoPipe 都能提供强力支持。
其核心技术亮点在于高度的灵活性与兼容性:支持 RTSP、RTMP 等多种流媒体协议及硬件加速解码;推理后端可自由选择 OpenCV::DNN、TensorRT、ONNXRuntime 等;同时允许用户轻松嵌入自定义业务逻辑或将结构化数据推送至云端。如果你希望快速原型验证或构建轻量级视频分析系统,VideoPipe 是一个值得尝试的开源选择。
使用场景
某智慧交通团队正在构建一套跨城市的违章行为检测系统,需同时兼容老旧服务器与新型边缘设备,实时分析多路 RTSP 监控流中的车辆越线与违停行为。
没有 VideoPipe 时
- 开发周期漫长:团队需手动编写大量 C++ 代码来串联视频解码、模型推理(如 YOLO)和轨迹跟踪模块,每增加一个新算法都要重构底层逻辑。
- 硬件绑定严重:原有方案深度依赖特定厂商的私有框架(如仅限 NVIDIA 或华为芯片),导致无法在普通 x86 服务器上部署,扩容成本极高。
- 业务逻辑耦合:具体的违章判断规则(如越线检测)硬编码在推理流程中,一旦交通法规调整或需要新增“逆行”检测,修改代码极易引发系统崩溃。
- 数据对接困难:结构化结果(如车牌、时间、违章类型)格式不统一,需额外开发中间件才能推送到云端数据库,延迟高且易丢包。
使用 VideoPipe 后
- 搭建效率倍增:利用 VideoPipe 的插件化节点机制,开发者只需像搭积木一样配置“拉流 - 解码 - 推理 - 跟踪 - 行为分析”流水线,无需重复造轮子,原型验证从数周缩短至数天。
- 真正跨平台部署:凭借极少的第三方依赖,同一套配置文件可直接运行在 NVIDIA GPU 服务器、普通 Linux 工控机甚至树莓派上,完美利旧现有硬件资源。
- 灵活定制业务:通过独立的行为分析节点,团队可轻松插入自定义的越线或违停逻辑,甚至集成最新的多模态大模型(mLLM)进行复杂场景理解,升级无需改动核心框架。
- 标准化数据输出:内置的数据代理节点自动将分析结果封装为标准 JSON 格式,并稳定推送至云端或本地文件,实现了从视频流到结构化数据的端到端闭环。
VideoPipe 通过低代码的流水线架构,让复杂的视频结构化应用变得像组装乐高一样简单高效,彻底打破了算法落地中的平台壁垒与开发瓶颈。
运行环境要求
- Linux (Ubuntu 18.04
- Ubuntu 22.04)
- 非必需(支持纯 CPU 运行)
- 若需加速,支持 NVIDIA RTX/Tesla 系列、Jetson 系列、寒武纪 MLU 系列、昇腾 Ascend 310/910 系列及瑞芯微 RK3588
- CUDA 为可选依赖,具体版本未说明
未说明
快速开始

中文README | VideoPipe 官网 | VideoPipe 教程(视频教程)
🚀one-yolo,让 YOLO 集成一步到位。所有任务、所有版本、所有运行时环境,一应俱全。🚀
简介
VideoPipe 是一个用 C++ 编写的视频分析与结构化框架,依赖极少且易于使用。它采用流水线式架构,每个节点相互独立,可以灵活组合。VideoPipe 可用于构建各类视频分析应用,适用于视频结构化、图像搜索、人脸识别以及交通/安防领域的行为分析(如交通事件检测)等场景。
优势与特性
VideoPipe 类似于 NVIDIA 的 DeepStream 和华为的 mxVision 框架,但使用起来更加简单,移植性也更强。
以下是对比表格:
| 名称 | 开源 | 学习曲线 | 支持平台 | 性能 | 第三方依赖 |
|---|---|---|---|---|---|
| DeepStream | 否 | 高 | 仅 NVIDIA | 高 | 多 |
| mxVision | 否 | 高 | 仅华为 | 高 | 多 |
| VideoPipe | 是 | 低 | 任意平台 | 中 | 少 |
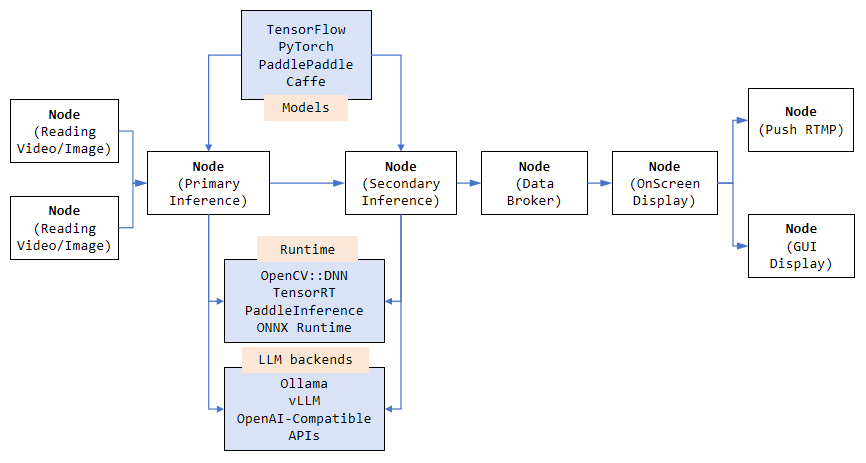
VideoPipe 采用插件化的编程风格,可根据不同需求灵活配置。我们可以通过独立的插件(在框架中称为“Node”类型)来构建各种类型的视频分析应用。用户只需准备好模型并了解其输出解析方式即可。推理部分可使用不同的后端实现,例如 OpenCV::DNN(默认)、TensorRT、PaddleInference、ONNXRuntime,或任何其他您偏好的后端。
演示
https://github.com/sherlockchou86/video_pipe_c/assets/13251045/b1289faa-e2c7-4d38-871e-879ae36f6d50
全屏观看请使用播放器右下角的按钮,更多视频演示
功能
VideoPipe 是一个简化计算机视觉算法模型集成的框架。需要注意的是,它并非像 TensorFlow 或 TensorRT 那样的深度学习框架。VideoPipe 的主要功能如下:
- 流读取:支持主流视频流协议,如 UDP、RTSP、RTMP、文件和应用程序;同时也支持图像读取。
- 视频解码:基于 OpenCV/GStreamer 支持视频和图像解码,并具备硬件加速功能。
- 算法推理:支持多层级的深度学习推理,如目标检测、图像分类、特征提取和图像生成;同时支持传统图像算法的集成。现已支持多模态大语言模型(mLLM)集成(更新于 2025 年 8 月 12 日)
- 目标跟踪:支持目标跟踪,例如 IOU 和 SORT 跟踪算法。
- 行为分析(BA):基于跟踪结果进行行为分析,例如交通行为检测,如越线、停车和违规行为。
- 业务逻辑:允许集成任何自定义业务逻辑,以紧密贴合具体业务需求。
- 数据代理:支持将结构化数据(JSON、XML 或自定义格式)通过 Kafka、Socket 等方式推送到云端、文件或其他第三方平台。
- 录制:支持特定时间段的视频录制及特定帧的截图,并可保存为文件。
- 屏幕显示(OSD):支持在帧上叠加结构化数据及业务逻辑处理结果。
- 视频编码:基于 OpenCV/GStreamer 支持视频和图像编码,并具备硬件加速功能。
- 流推送:支持主流视频流协议,如 UDP、RTSP、RTMP、文件和应用程序;同时也支持图像流传输。
快速入门
依赖项
平台
- Ubuntu 18.04 x86_64,配备 NVIDIA RTX/Tesla 显卡
- Ubuntu 18.04 aarch64,NVIDIA Jetson 系列设备,已测试 TX2 型号
- Ubuntu 22.04 x86_64,基于 Windows 10 的 VMware 虚拟机,纯 CPU 环境
- Ubuntu 18.04 x86_64,Cambrian MLU 系列设备,已测试 MLU 370 型号(未提供代码)
- Ubuntu 18.04 aarch64,Rockchip RK35** 系列设备,已测试 RK3588 型号(未提供代码)
- Ubuntu 22.04 aarch64,Ascend 310/910 系列设备,已测试 Atlas 300I-Pro 型号(未提供代码)
- 欢迎您的测试
基础
- C++ 17
- OpenCV >= 4.6
- GStreamer 1.14.5(OpenCV 所需)
- GCC >= 7.5
可选,如果您需要实现自定义推理后端,或使用除 opencv::dnn 之外的其他后端:
- CUDA
- TensorRT
- Paddle Inference
- ONNX Runtime
- mLLM(Ollama/vLLM/OpenAI 兼容 API 服务)
- 您喜欢的任何工具
编译与调试
- 运行
git clone https://github.com/sherlockchou86/VideoPipe.git - 运行
cd VideoPipe - 运行
mkdir build && cd build - 运行
cmake .. - 运行
make -j8
编译完成后,所有库文件将存储在 build/libs 目录下,所有示例可执行文件则位于 build/bin 目录。在第4步中,您可以添加一些编译选项:
-DVP_WITH_CUDA=ON(编译 CUDA 相关功能;默认为 OFF)-DVP_WITH_TRT=ON(编译 TensorRT 相关功能及示例;默认为 OFF)-DVP_WITH_PADDLE=ON(编译 PaddlePaddle 相关功能及示例;默认为 OFF)-DVP_WITH_KAFKA=ON(编译 Kafka 相关功能及示例;默认为 OFF)-DVP_WITH_LLM=ON(编译 LLM 相关功能及示例;默认为 OFF)-DVP_BUILD_COMPLEX_SAMPLES=ON(编译高级示例;默认为 OFF)
例如,要启用 CUDA 和 TensorRT 模块,可以运行:
cmake -DVP_WITH_CUDA=ON -DVP_WITH_TRT=ON ..
如果您只运行:
cmake ..
则所有代码将在 CPU 上执行。
要运行编译好的示例,首先需要下载模型文件和测试数据:
将下载的目录(命名为 vp_data)放置在任意位置(例如 /root/abc)。然后,在 vp_data 所在的目录下运行示例。例如,在 /root/abc 中执行以下命令:
[path to VideoPipe]/build/bin/1-1-1_sample
注意:./third_party/ 目录包含独立的项目。其中一些是仅含头文件的库,直接由 VideoPipe 引用;另一些则包含 CPP 文件,可以单独编译或运行。VideoPipe 依赖这些库,并且它们会在 VideoPipe 的构建过程中自动编译。这些库也包含各自的示例;具体使用方法请参考相应子目录中的 README 文件。
使用方法
以下是使用 VideoPipe 构建并运行示例管道的指南。您可以将 VideoPipe 编译为库并进行链接,也可以直接包含源代码并编译整个应用程序。
下面是一个示例代码,演示如何构建管道并运行它。请务必根据实际情况更新代码中的文件路径:
#include "../nodes/vp_file_src_node.h"
#include "../nodes/infers/vp_yunet_face_detector_node.h"
#include "../nodes/infers/vp_sface_feature_encoder_node.h"
#include "../nodes/osd/vp_face_osd_node_v2.h"
#include "../nodes/vp_screen_des_node.h"
#include "../nodes/vp_rtmp_des_node.h"
#include "../utils/analysis_board/vp_analysis_board.h"
/*
* 名称:1-1-N 示例
* 完整代码位于:samples/1-1-N_sample.cpp
* 功能:1 路视频输入,1 项视频分析任务(人脸检测与识别),2 路输出(屏幕显示/RTMP 流)
*/
int main() {
VP_SET_LOG_INCLUDE_CODE_LOCATION(false);
VP_SET_LOG_INCLUDE_THREAD_ID(false);
VP_LOGGER_INIT();
// 1. 创建节点
// 视频源节点
auto file_src_0 = std::make_shared<vp_nodes::vp_file_src_node>("file_src_0", 0, "./test_video/10.mp4", 0.6);
// 2. 模型推理节点
// 第一层推理:人脸检测
auto yunet_face_detector_0 = std::make_shared<vp_nodes::vp_yunet_face_detector_node>("yunet_face_detector_0", "./models/face/face_detection_yunet_2022mar.onnx");
// 第二层推理:人脸识别
auto sface_face_encoder_0 = std::make_shared<vp_nodes::vp_sface_feature_encoder_node>("sface_face_encoder_0", "./models/face/face_recognition_sface_2021dec.onnx");
// 3. OSD 节点
// 在帧上绘制结果
auto osd_0 = std::make_shared<vp_nodes::vp_face_osd_node_v2>("osd_0");
// 屏幕显示节点
auto screen_des_0 = std::make_shared<vp_nodes::vp_screen_des_node>("screen_des_0", 0);
// RTMP 流节点
auto rtmp_des_0 = std::make_shared<vp_nodes::vp_rtmp_des_node>("rtmp_des_0", 0, "rtmp://192.168.77.60/live/10000");
// 通过连接节点构建管道
yunet_face_detector_0->attach_to({file_src_0});
sface_face_encoder_0->attach_to({yunet_face_detector_0});
osd_0->attach_to({sface_face_encoder_0});
// 自动拆分管道,分别用于屏幕显示和 RTMP 流传输
screen_des_0->attach_to({osd_0});
rtmp_des_0->attach_to({osd_0});
// 启动管道
file_src_0->start();
// 可视化管道
vp_utils::vp_analysis_board board({file_src_0});
board.display();
}
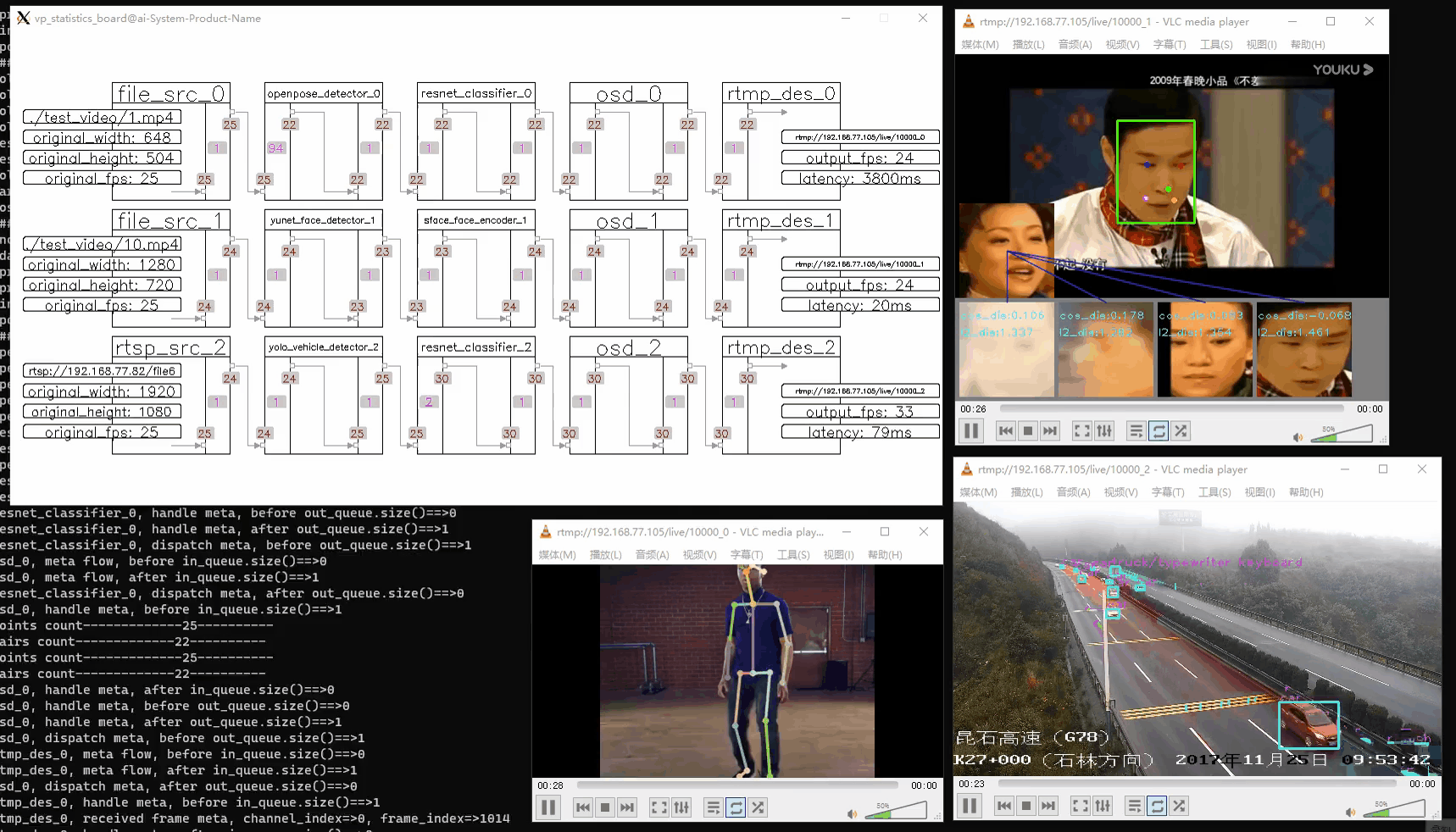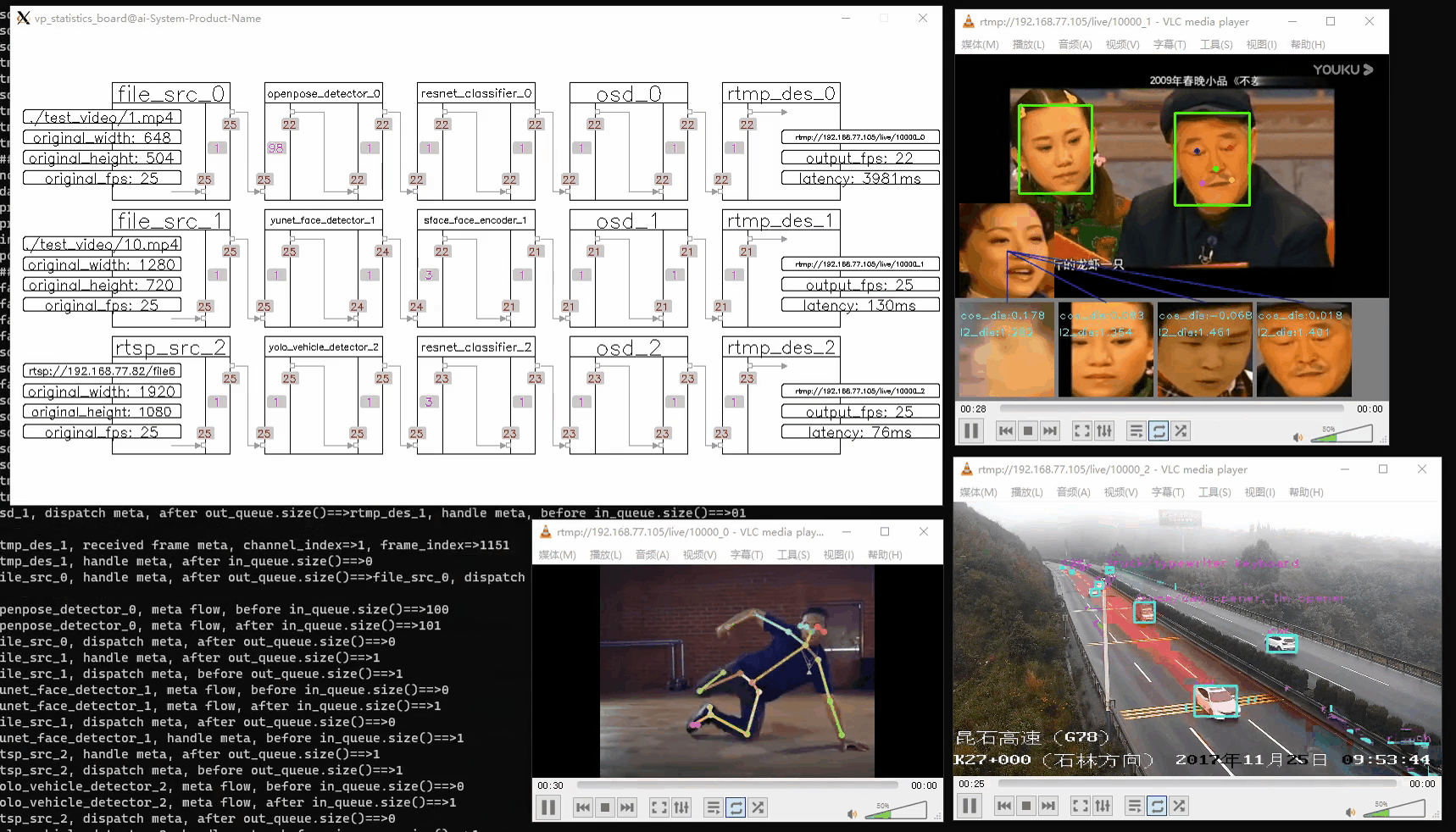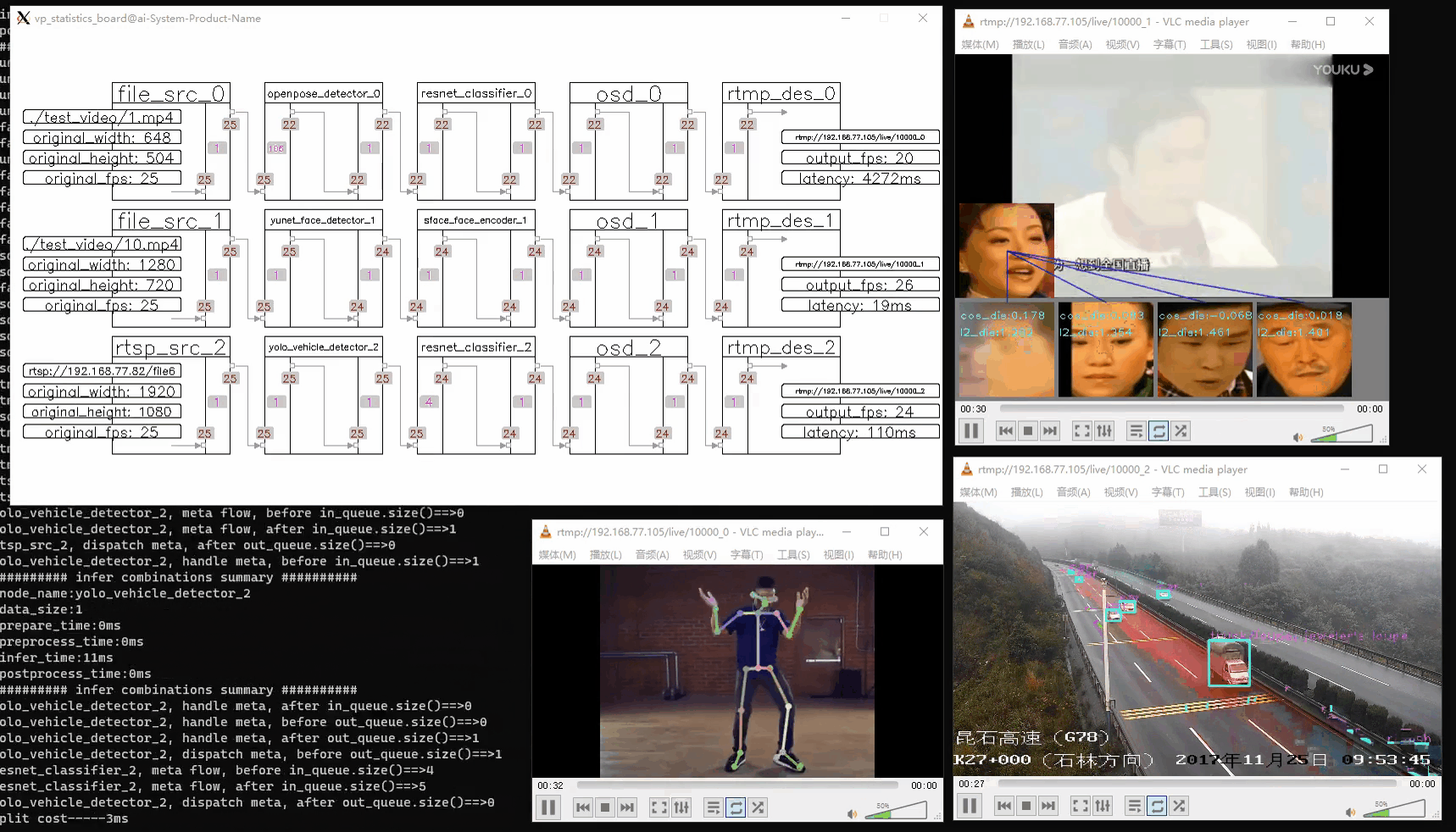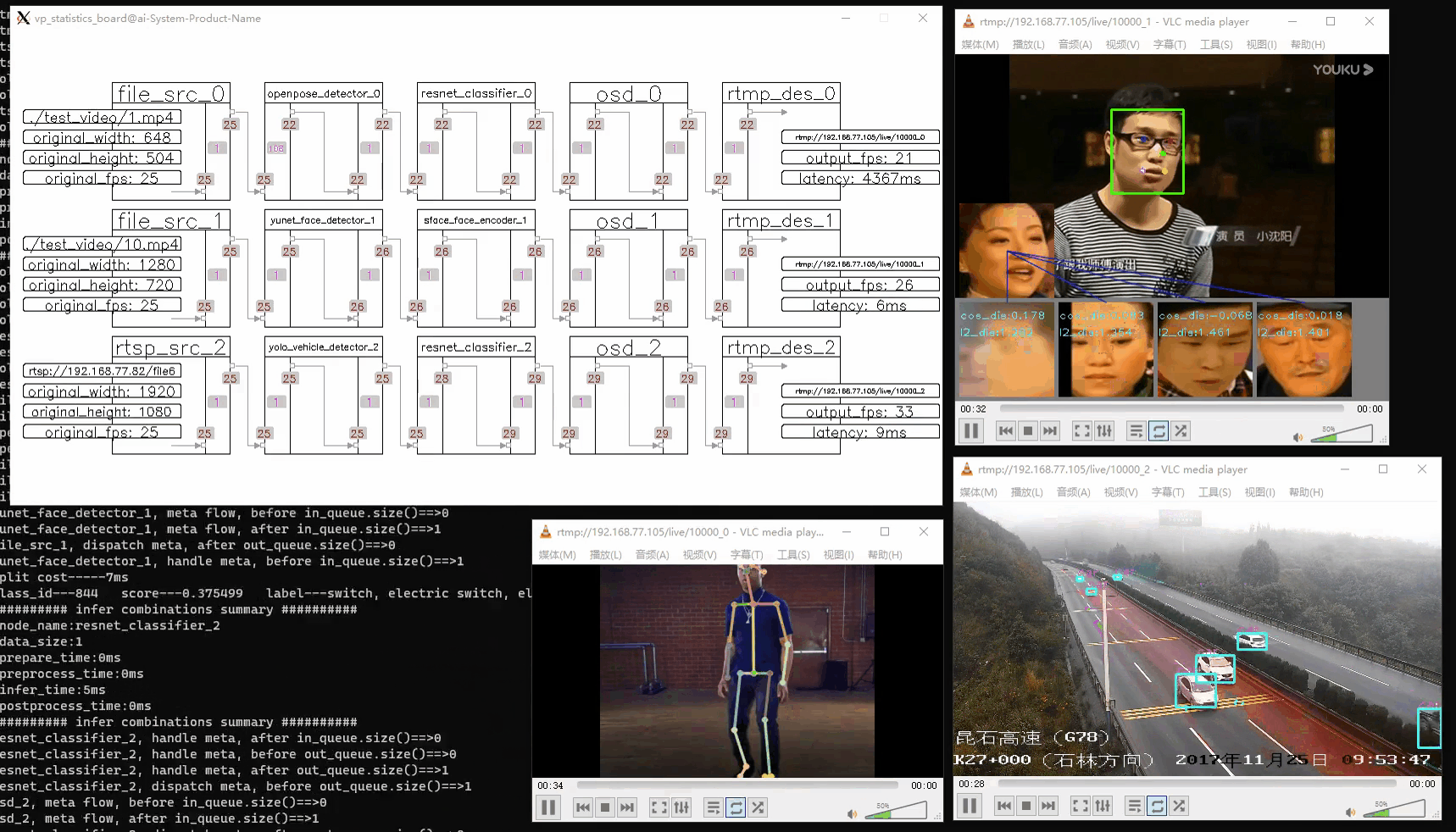
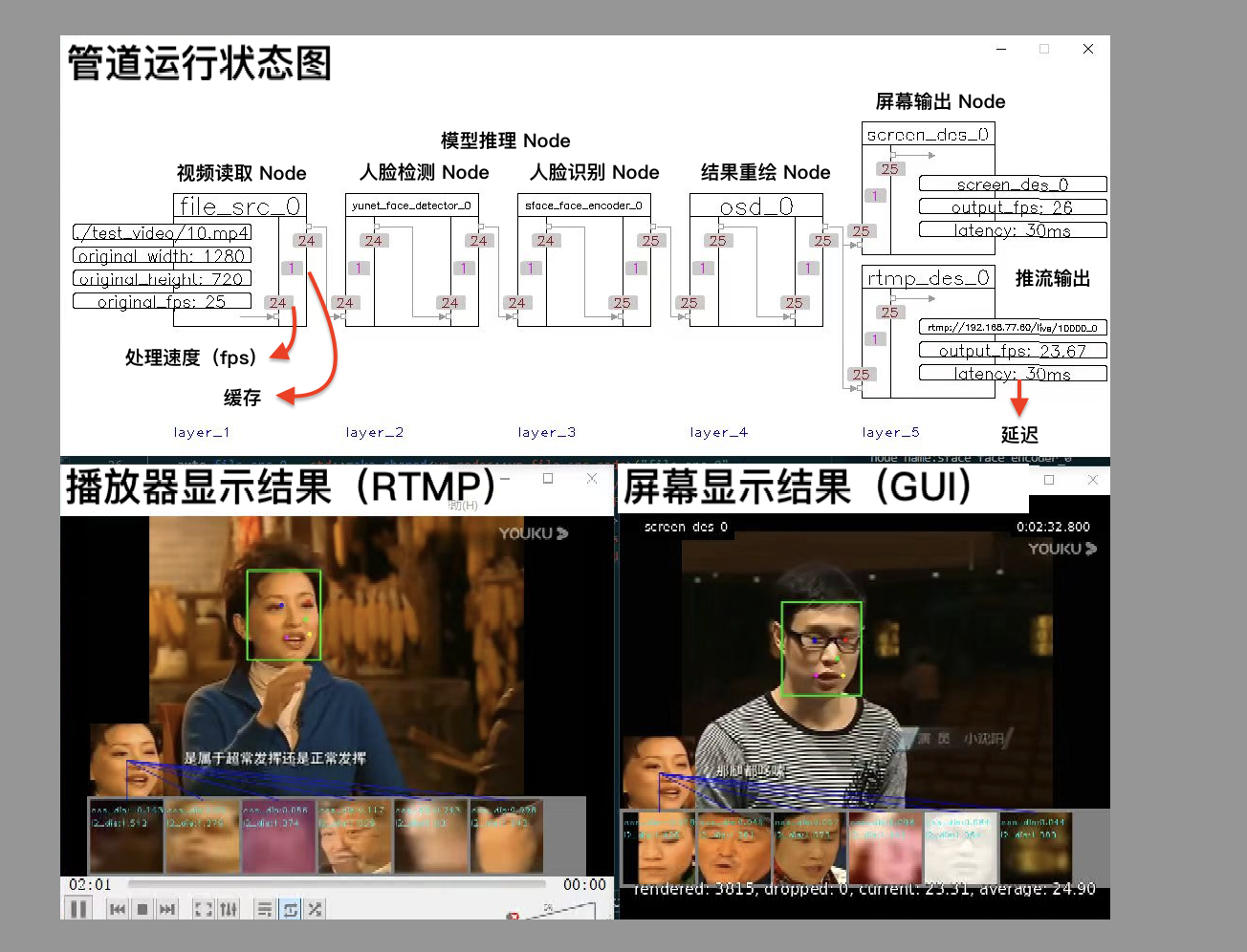
注意:运行此代码将显示三个画面:
- 管道状态:实时更新的管道运行状态。
- 屏幕输出:GUI 界面显示的结果。
- RTMP 输出:可在指定 RTMP URL 上观看的流媒体输出。
原型示例
| 编号 | 示例 | 截图 |
|---|---|---|
| 1 | face_tracking_sample | 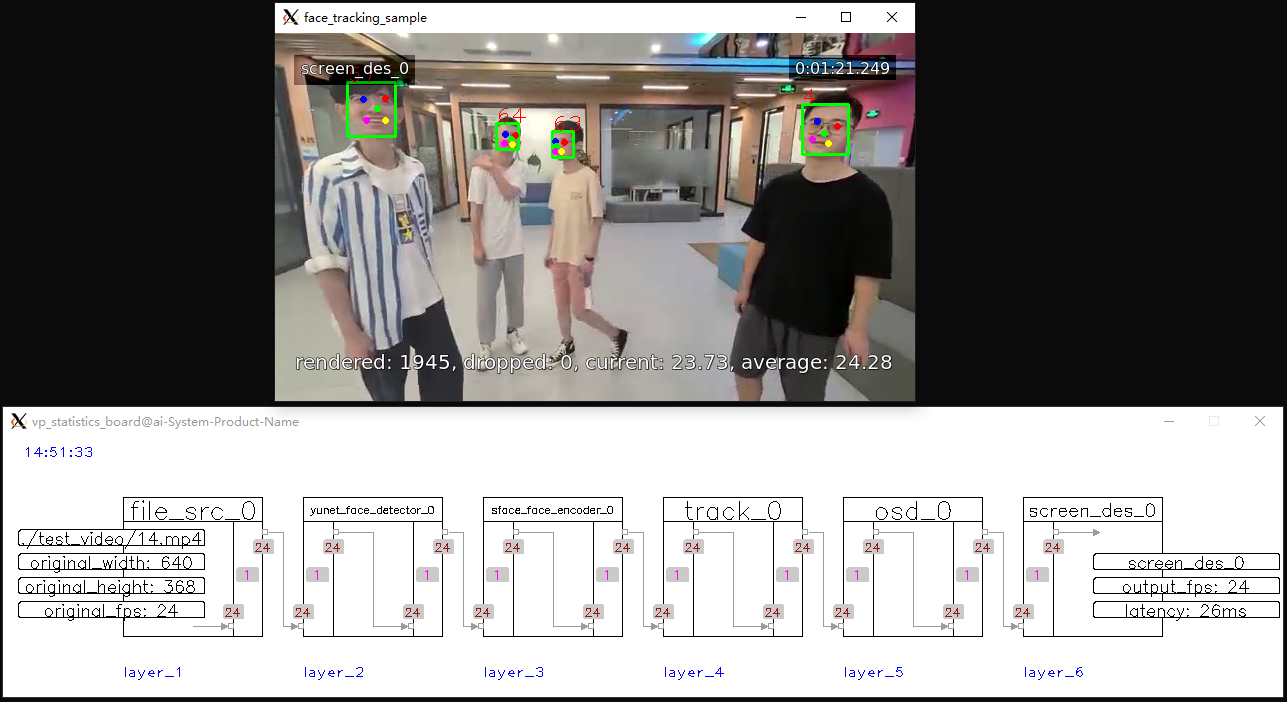 |
| 2 | vehicle_tracking_sample | 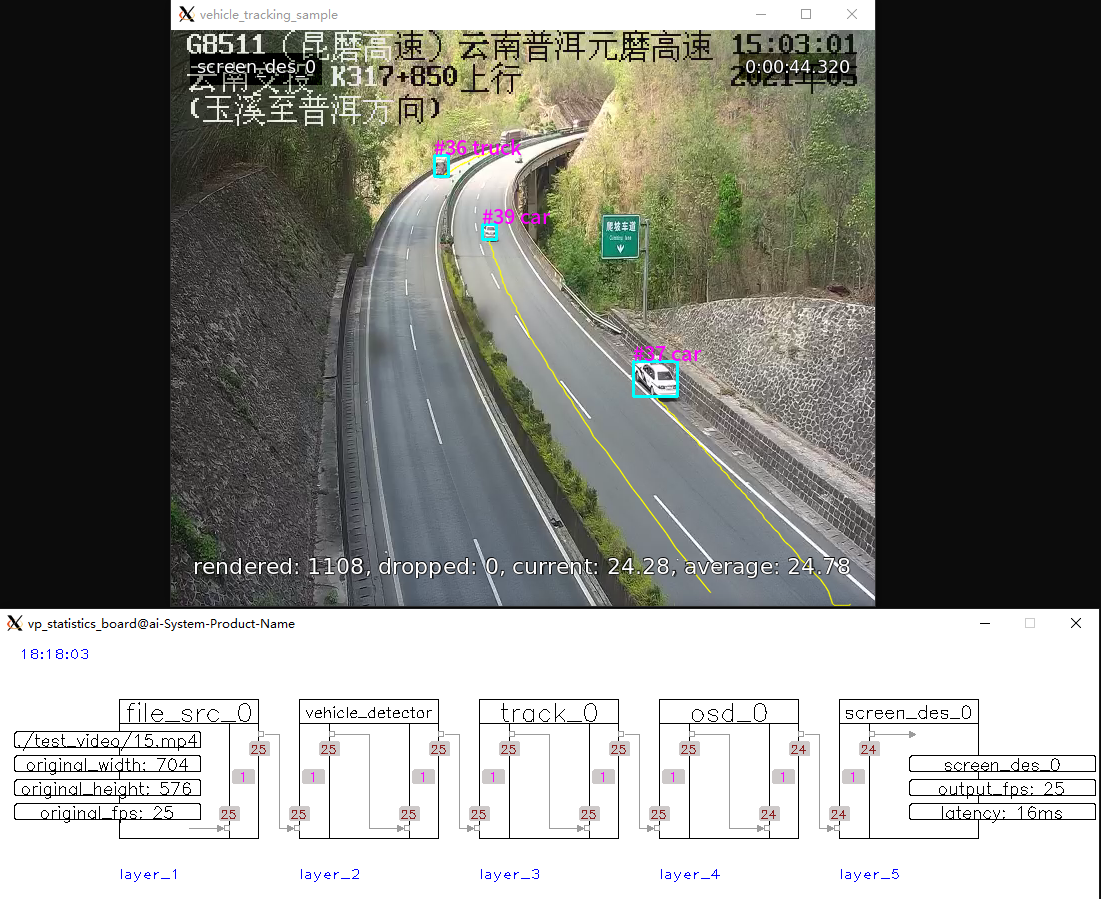 |
| 3 | mask_rcnn_sample | 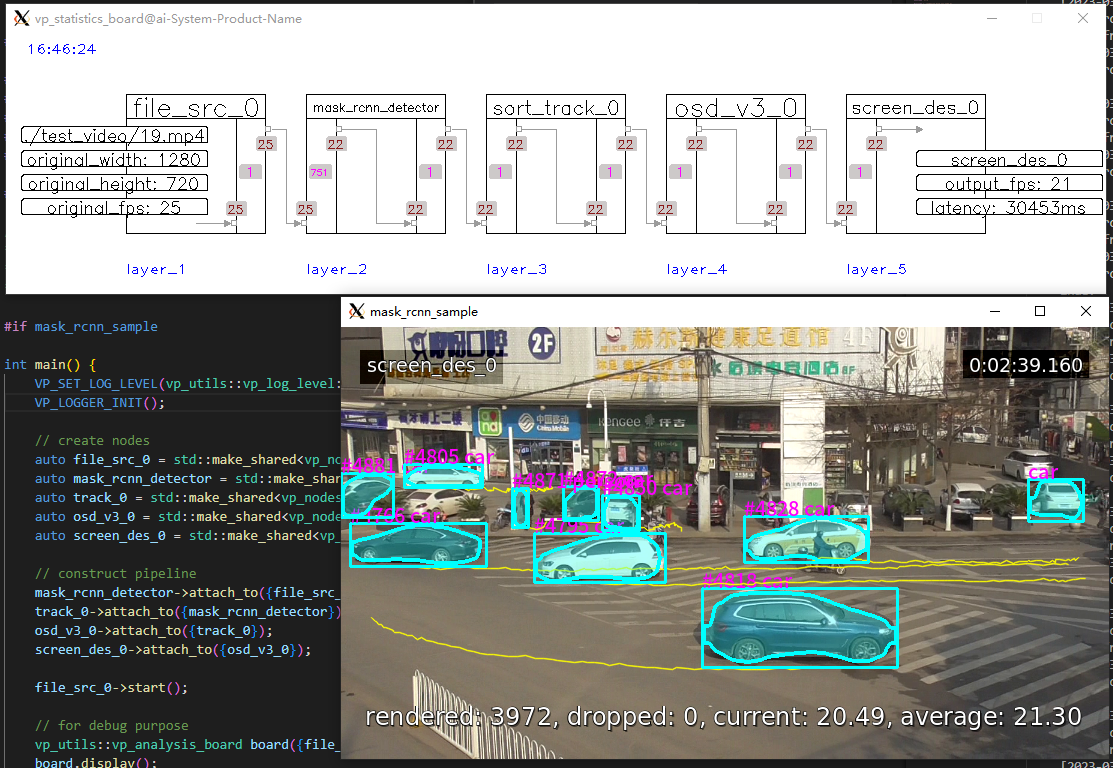 |
| 4 | openpose_sample | 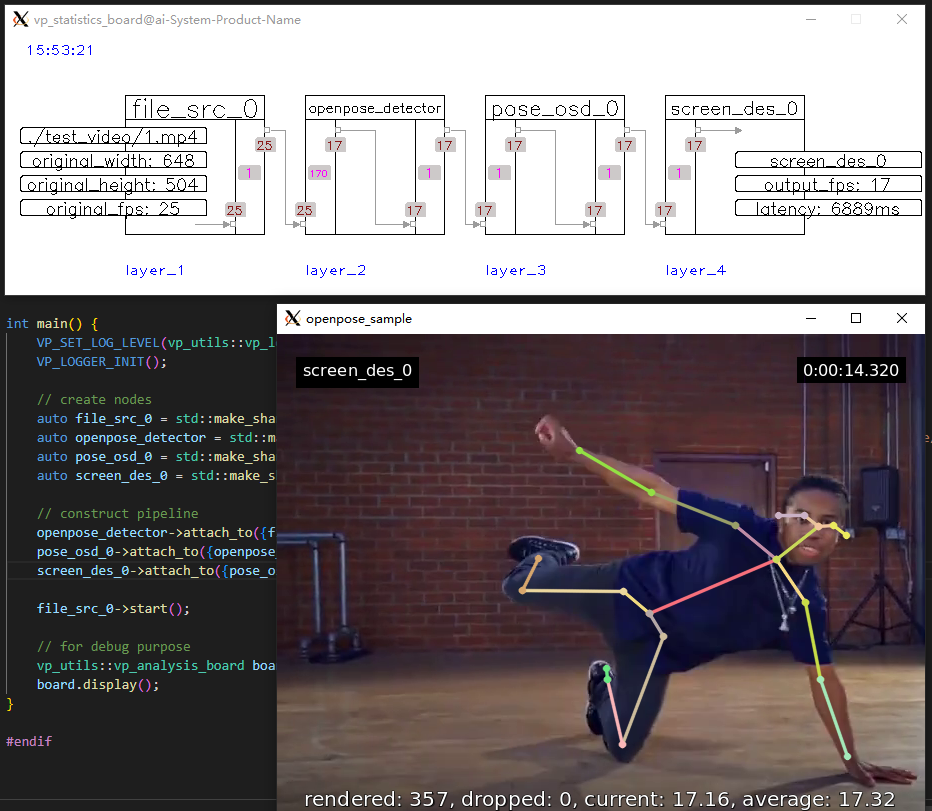 |
| 5 | face_swap_sample | 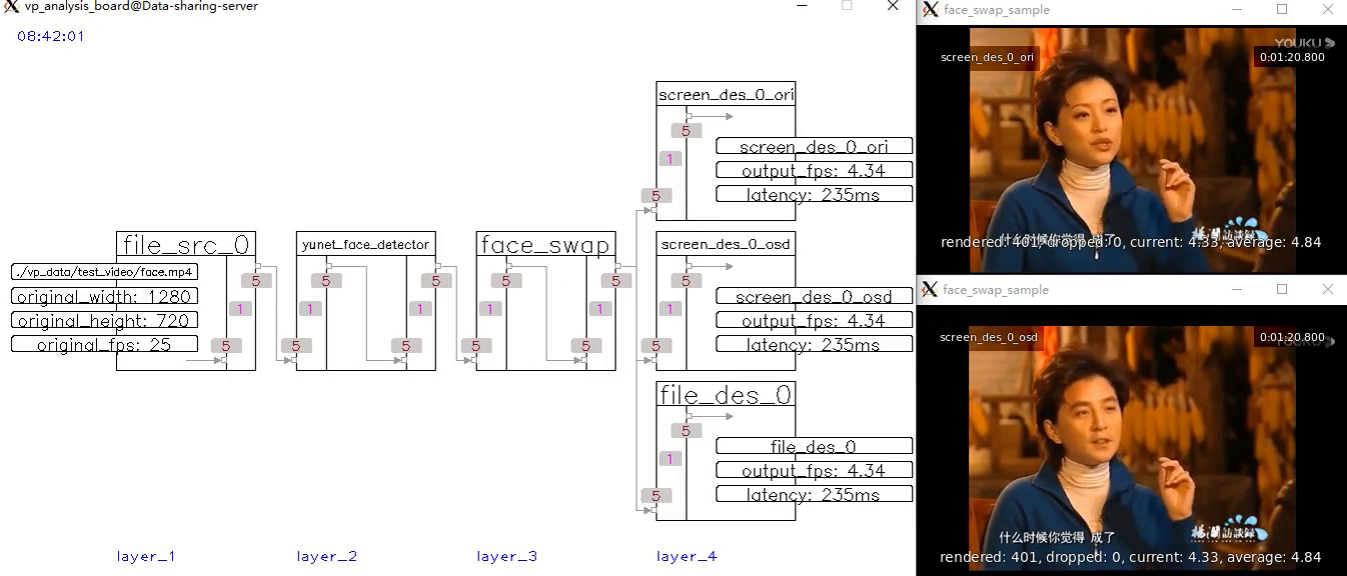 |
| 6 | mllm_analyse_sample | 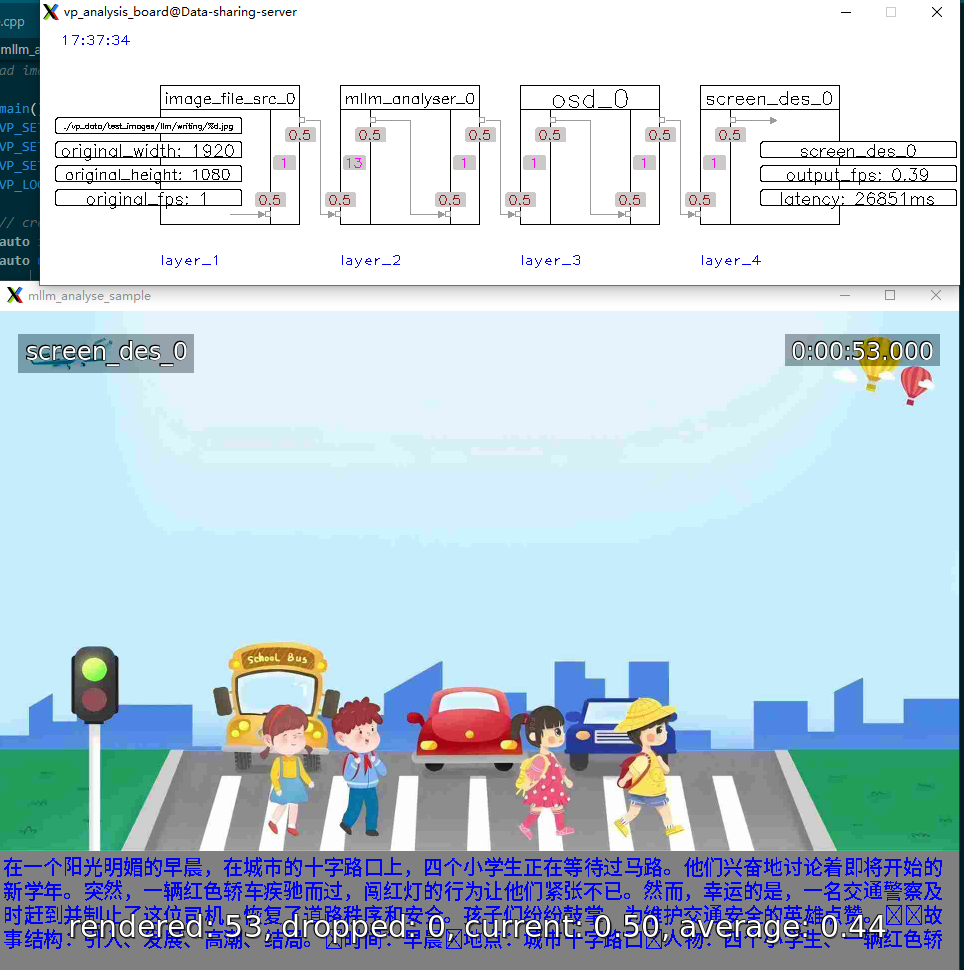 |
总共提供了超过 40 个原型示例。点击此处 查看更多。
更多信息
微信讨论群

致谢

版本历史
v0.12024/04/28常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。