LanPaint
LanPaint 是一款专为 Stable Diffusion 系列模型打造的高质量图像修复(Inpainting)采样器,无需额外训练即可直接提升现有模型的修复效果。它主要解决了传统修复方法在复杂场景下边缘生硬、内容不协调或细节模糊的痛点,让 AI 在生成最终像素前能进行多轮“思考”迭代,从而以更优的计算策略换取更自然、逼真的修复画质。
该工具特别适合希望突破模型原生修复极限的创作者、设计师以及研究人员使用。对于普通用户,若通过 ComfyUI 工作流操作,也能轻松获得专业级的图像编辑能力;对于开发者,它提供了清晰的接口以集成到各类扩散模型应用中。
LanPaint 的核心技术亮点在于其独特的“思考模式”(Think Mode),这是一种基于渐进式精确条件采样的算法。它不依赖昂贵的重新训练,而是通过优化采样过程,让模型在去噪前充分理解掩码区域与周围环境的逻辑关系。目前,LanPaint 不仅全面支持 ComfyUI 插件化部署,还率先实现了对 Z-Image、Z-Image-Base 等新型架构的支持,甚至拓展到了基于 Wan 2.2 的视频修复与扩展(Outpainting)领域,展现了极强的通用性与前瞻性。
使用场景
一位电商设计师急需为促销海报移除模特衣服上过时的品牌 Logo,并自然替换为新的活动标语,同时必须保持衣物褶皱和光影的完美连贯。
没有 LanPaint 时
- 边缘融合生硬:传统重绘采样器往往无法理解掩码周围的复杂纹理,导致修补区域与原始衣物之间出现明显的接缝或光晕。
- 结构逻辑断裂:直接重绘容易忽略衣物的物理褶皱走向,新生成的文字像浮在表面,缺乏随布料起伏的真实立体感。
- 模型兼容性差:为了获得较好效果,不得不专门寻找支持重绘的微调模型,无法直接利用手头现有的高质量通用大模型。
- 反复试错成本高:需要多次调整蒙版羽化值和重绘幅度,耗费大量时间微调参数仍难以达到“无痕”效果。
使用 LanPaint 后
- 智能“思考”上下文:LanPaint 的"Think Mode"让模型在去噪前进行多步推理,精准捕捉周围像素特征,实现了掩码边界的天衣无缝融合。
- 完美保留几何结构:生成的新标语严格遵循原有衣物的褶皱形态和光照方向,仿佛原本就印在衣服上一样自然逼真。
- 通用模型即插即用:无需重新训练或切换特定模型,直接在 ComfyUI 中调用任意 Stable Diffusion 模型即可实现电影级的重绘质量。
- 一次生成即达标:凭借渐进式精确采样技术,大幅减少了重复生成的次数,将原本半小时的修图工作缩短至几分钟。
LanPaint 通过让模型在重绘前深度“思考”,彻底解决了复杂场景下局部编辑的结构断层问题,让任何开源模型都能瞬间具备专业级的图像修复能力。
运行环境要求
- 未说明 (基于 ComfyUI,通常支持 Windows
- Linux
- macOS)
- 必需 (NVIDIA GPU 推荐)
- 显存需求取决于具体模型和视频帧数:视频修复建议限制在 40 帧以内以保证稳定性,长序列处理资源消耗显著增加
- 具体型号未说明,但需支持所选扩散模型(如 Wan 2.2, Flux, SDXL 等)的运行需求
未说明 (视频处理和多步“思考”模式会显著增加内存占用)

快速开始
LanPaint:带有“思考模式”的通用修复采样器

适用于所有模型的通用修复能力。LanPaint 采样器允许模型在去噪之前通过多次迭代进行“思考”,从而使您能够投入更多计算时间以获得更优质的修复效果。
这是被 TMLR 接受的论文《LanPaint:无需训练的扩散修复,具有渐近精确且快速的条件采样》(https://arxiv.org/abs/2502.03491)的官方实现。
该仓库是用于 ComfyUI 的扩展插件。
Diffusers 支持:由 @charrywhite 提供的 LanPaint-Diffusers
用于复现论文结果的基准测试代码:LanPaintBench。
引用
@article{
zheng2025lanpaint,
title={LanPaint: Training-Free Diffusion Inpainting with Asymptotically Exact and Fast Conditional Sampling},
author={Candi Zheng and Yuan Lan and Yang Wang},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2025},
url={https://openreview.net/forum?id=JPC8JyOUSW},
note={}
}
🎉 新消息 2026:加入我们的 Discord!
加入我们的 Discord,分享经验、讨论功能并探索未来开发方向。
v1.5.0 修复了一个重要的隐藏 bug,该 bug 会降低性能并可能导致图像模糊(尤其是在使用 z-image-base 时),同时也提升了 LanPaint 在其他模型上的整体性能。
如果您的修复结果出现奇怪的(发光或破损)遮罩边界,请查看此 issue。
🎬 新功能:LanPaint 现在支持基于 Z-Image 的修复和外扩!
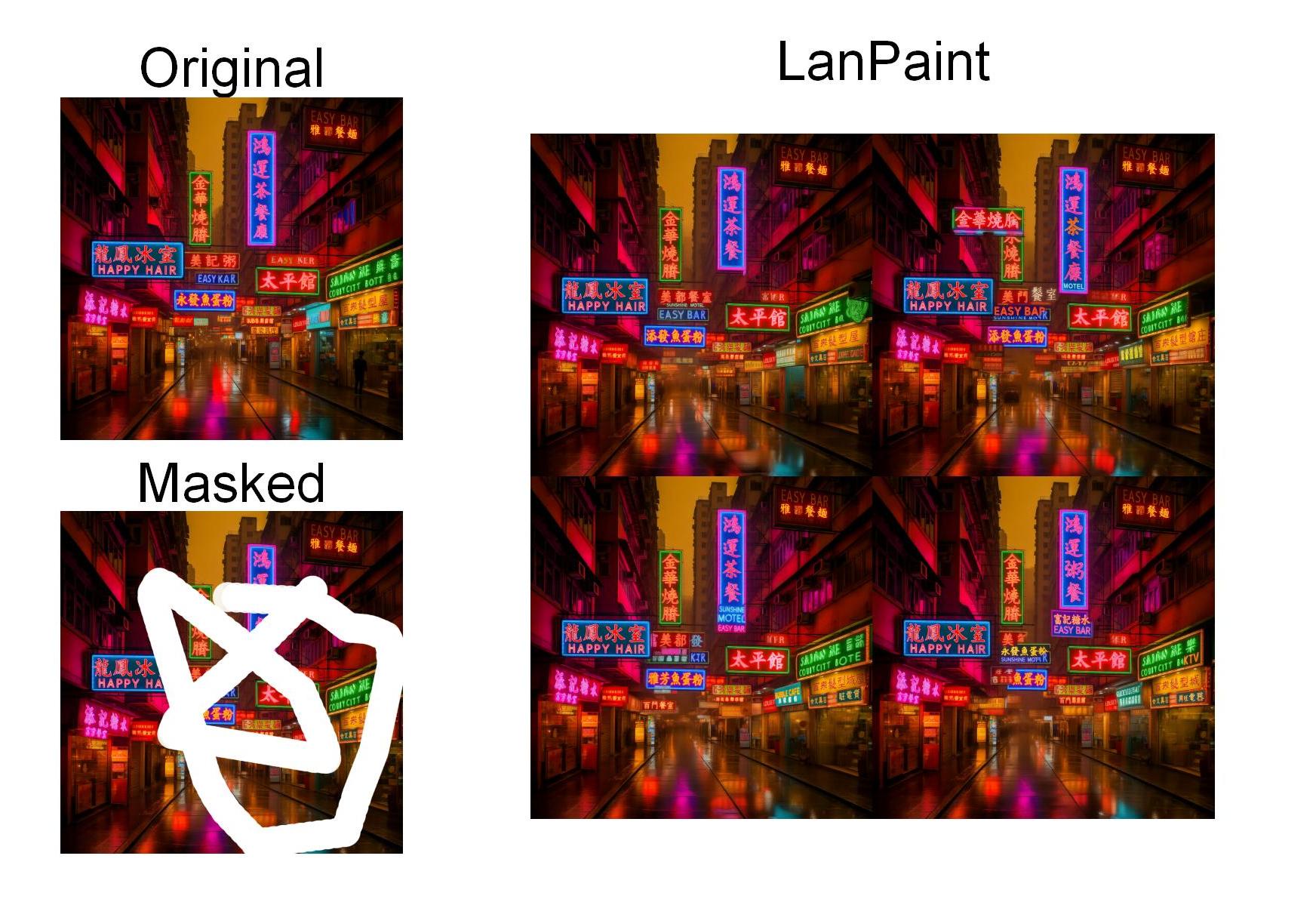
| 原图 | 遮罩 | 修复后 |
|---|---|---|
 |
 |
 |
🎬 新功能:LanPaint 现在也支持 Z-Image-Base!
| 原图 | 遮罩 | 修复后 |
|---|---|---|
 |
 |
 |
🎬 新功能:LanPaint 现在支持基于 Wan 2.2 的视频修复和外扩!
| 原始视频 | 遮罩(编辑 T 恤文字) | 修复结果 |
|---|---|---|
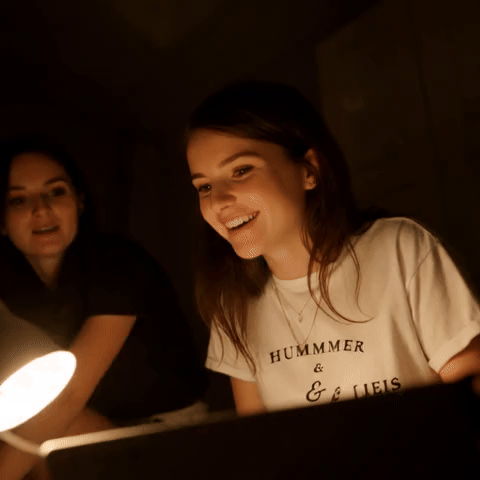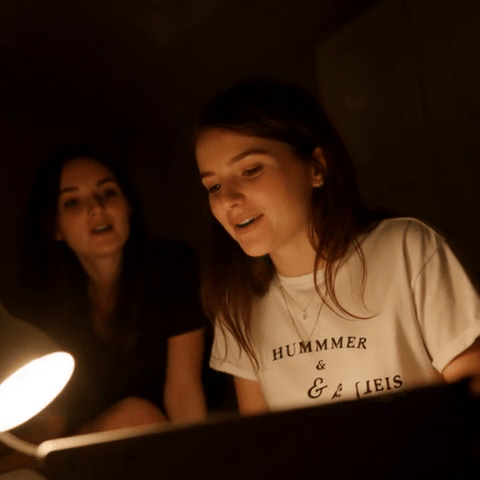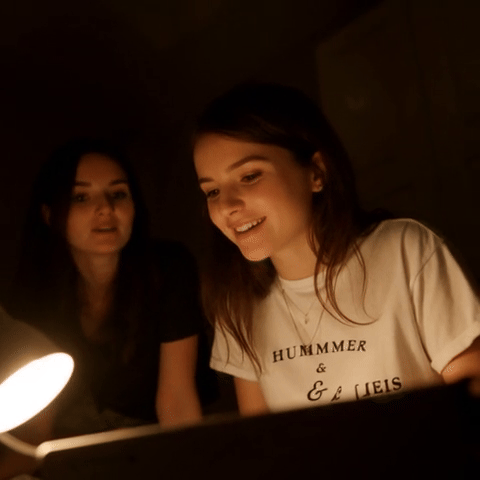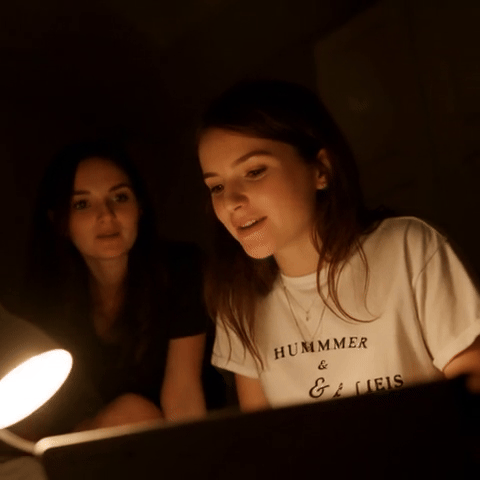 |
 |
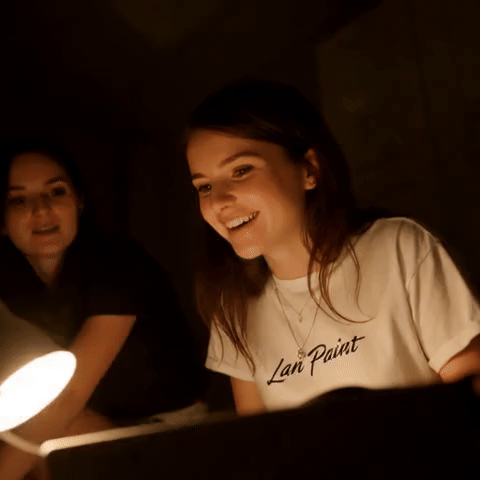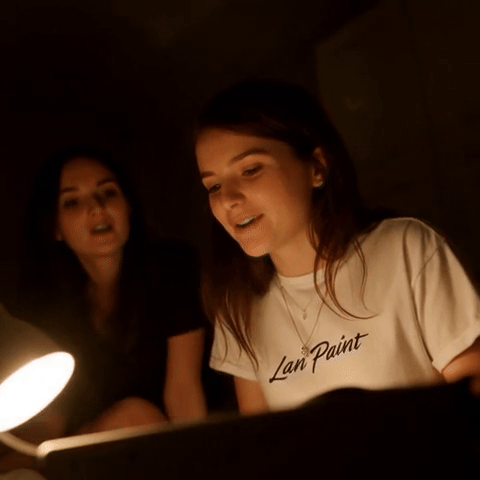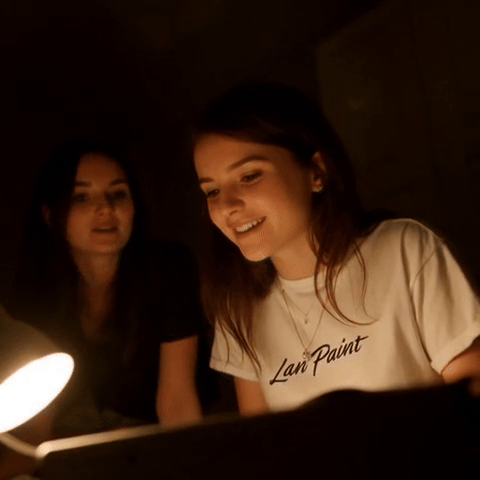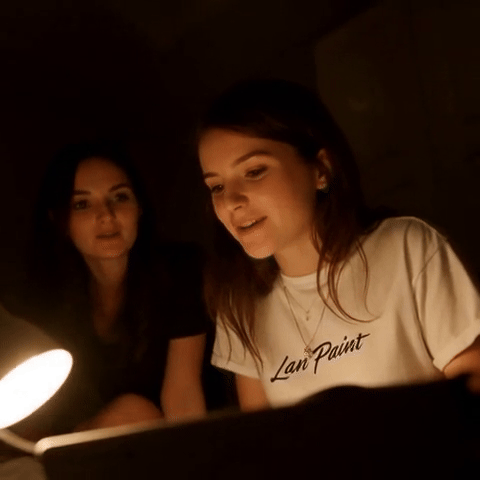 |
视频修复示例:81 帧,具有时间一致性
请查看我们最新的 Wan 2.2 视频示例、Wan 2.2 图像示例,以及对 Qwen Image Edit 2509 的支持。
目录
功能特性
- 通用兼容性 – 可立即与几乎任何模型(Z-image、Z-image-base、Hunyuan、Wan 2.2、Qwen Image/Edit、HiDream、SD 3.5、Flux系列、SDXL、SD 1.5 或自定义 LoRA)及 ControlNet 配合使用。

- 无需训练 – 直接与您现有的模型配合使用,开箱即用。
- 易于使用 – 工作流程与标准 ComfyUI KSampler 完全相同。
- 灵活的掩码处理 – 支持任意形状、大小和位置的掩码,用于图像修复或扩展。
- 无需变通方法 – 生成 100% 全新内容(无混合或平滑处理),不依赖部分去噪技术。
- 超越图像修复 – 您甚至可以将其用作生成一致角色的简单方式。
警告:由于与 LoRA 训练类似的问题,LanPaint 在蒸馏模型上性能有所下降,例如 Flux.dev。请使用较低的 flux 引导值(1.0–2.0)来缓解此问题参见此处。
快速入门
- 安装 ComfyUI:按照官方ComfyUI 安装指南在您的系统上设置 ComfyUI。或确保您的 ComfyUI 版本 > 0.3.11。
- 安装 ComfyUI 管理器:添加ComfyUI 管理器,以便轻松管理扩展插件。
- 安装 LanPaint 节点:
- 通过 ComfyUI 管理器:在管理器中搜索“LanPaint”并直接安装。
- 手动安装:在 ComfyUI 管理器中点击“通过 Git URL 安装”,并输入以下 GitHub 仓库链接:
或者将此仓库克隆到https://github.com/scraed/LanPaint.gitComfyUI/custom_nodes文件夹中。
- 重启 ComfyUI:重启 ComfyUI 以加载 LanPaint 节点。
安装完成后,您将在 ComfyUI 的“采样”类别下找到 LanPaint 节点。像使用默认的 KSampler 一样使用它们,即可实现高质量的图像修复!
使用示例说明:
- 导航至 example 文件夹(例如 example_1),下载所有图片。
- 将 InPainted_Drag_Me_to_ComfyUI.png 拖入 ComfyUI,以加载工作流。
- 下载所需的模型(例如点击“本示例所用模型”)。
- 在 ComfyUI 中加载该模型。
- 将 Masked_Load_Me_in_Loader.png 上传至 “用于图像修复的掩码图像” 组中的 “加载图像” 节点(从左数第二个),或 “准备图像” 节点。
- 提交任务队列,您将获得 LanPaint 的修复结果。部分示例还提供了以下方法的修复结果作为对比:
视频示例(测试版)
LanPaint 现已支持使用 Wan 2.2 进行视频修复,能够在保持时间一致性的同时,无缝修复视频帧中的遮挡区域。
注意:LanPaint 支持较长序列的视频修复(例如 81 帧),但处理时间会显著增加(详情请参阅资源消耗部分),且性能可能变得不稳定。为获得最佳效果和稳定性,我们建议将视频修复限制在40 帧或更少。
Wan 2.2 视频修复
示例:Wan2.2 t2v 14B,480p 视频(1:6),40 帧,LanPaint K Sampler,2 步思考
| 原始视频 | 掩码(添加一顶白帽) | 修复结果 |
|---|---|---|
 |
 |
 |
您需要遵循 ComfyUI 版本的Wan2.2 T2V 工作流,以下载并安装 T2V 模型。
Wan 2.2 5B 视频修复
与 Wan 2.2 14B 类似,但工作流略有不同。查看工作流与掩码
Wan 2.2 视频扩展
借助基于 Wan 2.2 的 LanPaint 视频扩展功能,您可以将视频画面延伸至原始边界之外。此功能允许您扩展视频画布,同时保持流畅的运动和连贯的上下文。
示例:Wan2.2 t2v 14B,480p 视频(1:1 扩展至 11:6),40 帧,LanPaint K Sampler,2 步思考
| 原始视频 | 掩码(扩展至 880x480) | 扩展结果 |
|---|---|---|
 |
 |
 |
您需要遵循 ComfyUI 版本的Wan2.2 T2V 工作流,以下载并安装 T2V 模型。
资源消耗
| 处理模式 | 分辨率 | 处理帧数 | 所需显存 | 总运行时间(20步) |
|---|---|---|---|---|
| 修复填充 | 880×480(11:6) | 40帧 | 39.8 GB | 05:37 分钟 |
| 修复填充 | 480×480(1:1) | 40帧 | 38.0 GB | 05:35 分钟 |
| 扩展填充 | 880×480(11:6) | 40帧 | 40.2 GB | 05:36 分钟 |
| 修复填充 | 880×480(11:6) | 81帧 | 43.3 GB | 16:23 分钟 |
| 修复填充 | 480×480(1:1) | 81帧 | 39.8 GB | 14:25 分钟 |
| 扩展填充 | 880×480(11:6) | 81帧 | 42.6 GB | 13:46 分钟 |
测试平台:所有测试均在NVIDIA RTX Pro 6000上进行。
所用模型:wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors和wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors。
处理步骤:20次采样步骤 × 2(LanPaint的思考步骤)。
注:显存需求由模型而非LanPaint本身决定。为进一步降低显存占用,建议减少生成帧数,并将CLIP加载至CPU。
图像示例
Hunyuan T2I 示例:修复填充(LanPaint K采样器,5步思考)
我们很高兴地宣布,LanPaint现已支持使用Hunyuan文本到图像生成模型进行修复填充。
您需要按照ComfyUI版本的Hunyuan工作流下载并安装该模型。
Wan2.2 示例:修复填充(LanPaint K采样器,5步思考)
我们很高兴地宣布,LanPaint现已支持使用Wan2.2 T2V模型进行Wan2.2文本到图像生成。

您需要按照ComfyUI版本的Wan2.2 T2V工作流下载并安装T2V模型。
Z-image 示例:修复填充(LanPaint K采样器,5步思考)
LanPaint还支持使用Z-image文本到图像模型进行修复填充。
查看原图/掩码图/修复填充图对比
| 原图 | 掩码图 | 修复填充图 |
|---|---|---|
|
|
|
查看Z-image扩展填充(原图/掩码图/扩展填充图)
| 原图 | 掩码图 | 扩展填充图 |
|---|---|---|
|
 |
 |
您可以从Z-image下载适用于ComfyUI的Z-image模型。
Z-image-base 示例:修复填充(LanPaint K采样器,3步思考)
LanPaint也支持使用Z-image-base模型进行修复填充。
警告(稳定性):Z-image-base与LanPaint结合时容易发散。请从较小的LanPaint_StepSize和较少的思考次数(较低的LanPaint_NumSteps)开始,仅在稳定的情况下逐步增加。
查看原图/掩码图/修复填充图对比
| 原图 | 掩码图 | 修复填充图 |
|---|---|---|
|
|
|
工作流模板(JSON):Z_image_base_Inpaint.json
Wan2.2 示例:部分修复填充(LanPaint K采样器,5步思考)
有时我们并不希望完全替换原有内容,而是让修复后的图像保留一些原始图像的特征。实现这一目标的一种方法是使用编辑模型,如Qwen Image Edit进行修复填充。另一种方法则是进行部分修复填充:让扩散过程从中间步骤开始,而不是从第0步开始。

您需要按照ComfyUI版本的Wan2.2 T2V工作流下载并安装T2V模型。
Qwen Edit 2509 示例:修复填充
请查看我们最新更新的Mased Qwen Edit工作流,适用于Qwen Image Edit 2509。您可以在Qwen Image Edit 2509 Comfy下载该模型。此工作流同样支持Qwen Image Edit 2511。

示例 Qwen 编辑 2508:InPaint
 请查看 Mased Qwen 编辑工作流。您需要按照 ComfyUI 版本的 Qwen 图像编辑工作流 下载并安装模型。
请查看 Mased Qwen 编辑工作流。您需要按照 ComfyUI 版本的 Qwen 图像编辑工作流 下载并安装模型。
示例 Qwen 图像:InPaint(LanPaint K 采样器,5 步思考)
您需要按照 ComfyUI 版本的 Qwen 图像工作流 下载并安装模型。
以下示例使用随机种子 0 生成一批 4 张图像,用于展示方差并进行公平比较。(注意:生成 4 张图像可能会超出您的 GPU 显存;请根据需要调整批次大小。)
 同时请查看 Qwen Inpaint 工作流 和 Qwen Outpaint 工作流。您需要按照 ComfyUI 版本的 Qwen 图像工作流 下载并安装模型。
同时请查看 Qwen Inpaint 工作流 和 Qwen Outpaint 工作流。您需要按照 ComfyUI 版本的 Qwen 图像工作流 下载并安装模型。
示例 HiDream:InPaint(LanPaint K 采样器,5 步思考)

您需要按照 ComfyUI 版本的 HiDream 工作流 下载并安装模型。
示例 HiDream:OutPaint(LanPaint K 采样器,5 步思考)
.jpg)
您需要按照 ComfyUI 版本的 HiDream 工作流 下载并安装模型。感谢 Amazon90 提供此示例。
示例 SD 3.5:InPaint(LanPaint K 采样器,5 步思考)

您需要按照 ComfyUI 版本的 SD 3.5 工作流 下载并安装模型。
示例 Flux.2.Dev:InPaint(LanPaint K 采样器,5 步思考)
查看原图 / 掩码图 / 修补图对比
| 原图 | 掩码图 | 修补图 |
|---|---|---|
 |
 |
 |
(注:Flux.2.Dev 上未启用“提示优先”模式,因为它不使用 CFG 引导。)
示例 Flux 2 klein:InPaint(LanPaint K 采样器,2 步思考)
查看原图 / 掩码图 / 修补图对比
| 原图 | 掩码图 | 修补图 |
|---|---|---|
 |
 |
 |
本示例所用模型。如果您在 Comfy 0.11 和 0.12 上遇到质量问题,请查看 此问题。
示例 Flux:InPaint(LanPaint K 采样器,5 步思考)

查看工作流与掩码
本示例所用模型
(注:Flux 上未启用“提示优先”模式,因为它不使用 CFG 引导。)
示例 SDXL 0:角色一致性(侧视图生成)(LanPaint K 采样器,5 步思考)
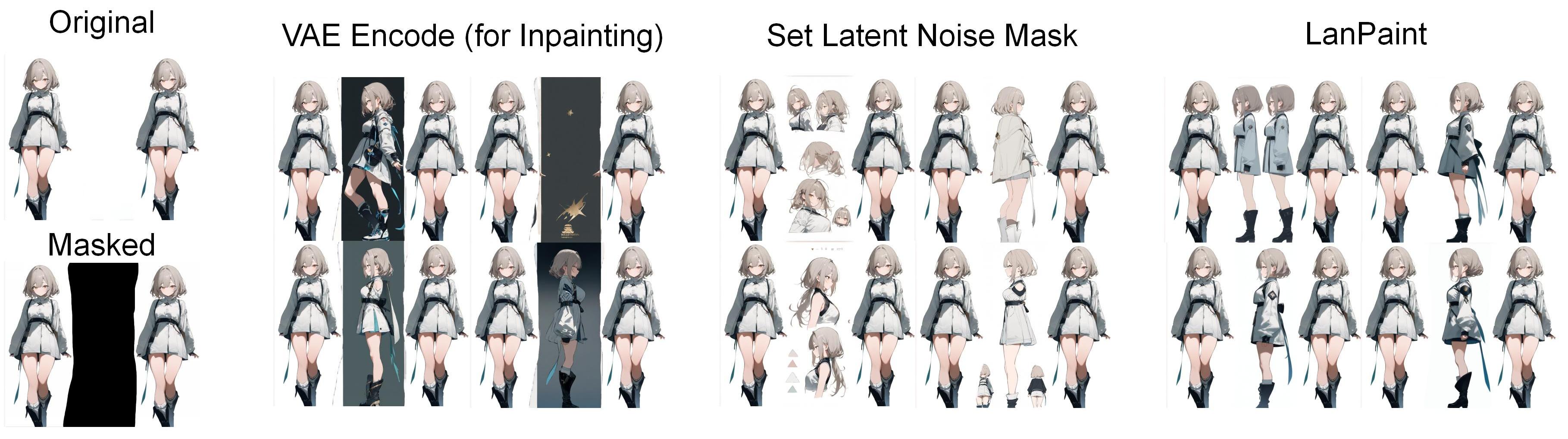
(技巧 1:您可以通过 Photoshop 多次复制角色图像来强化角色特征。这里我额外制作了一张副本。)
(技巧 2:使用诸如多视角、多角度、克隆、转身等提示词。请使用 LanPaint 的“提示优先”模式(不支持 Flux)。)
(技巧 3:请记住,LanPaint 可以进行修补:遮盖不一致的区域并再次尝试!)
示例 SDXL 1:篮子变篮球(LanPaint K 采样器,2 步思考)。

示例 SDXL 2:白衬衫变蓝衬衫(LanPaint K 采样器,5 步思考)

示例 SDXL 3:微笑变悲伤(LanPaint K 采样器,5 步思考)

示例 SDXL 4:损伤修复(LanPaint K采样器,5步思考)

示例 SDXL 5:大规模损伤修复(LanPaint K采样器,20步思考)

更多用例如在微调模型上进行修复,以及人脸替换,感谢Amazon90。
使用方法
工作流设置
与默认的 ComfyUI KSampler 相同——只需将节点替换为 LanPaint KSampler 即可。修复工作流与 SetLatentNoiseMask 的修复工作流一致。
注意
- LanPaint 需要二值掩码(值为 0 或 1),不能带有透明度或平滑处理。为确保兼容性,请在您的掩码编辑器中将掩码的透明度和硬度设置为最大值。在修复过程中,任何带有平滑或渐变的掩码都会自动转换为二值掩码。
- LanPaint 在很大程度上依赖于文本提示来指导修复过程——请明确描述您希望在遮罩区域内生成的内容。如果结果出现伪影或不匹配的元素,请使用有针对性的负面提示来纠正。
基础采样器
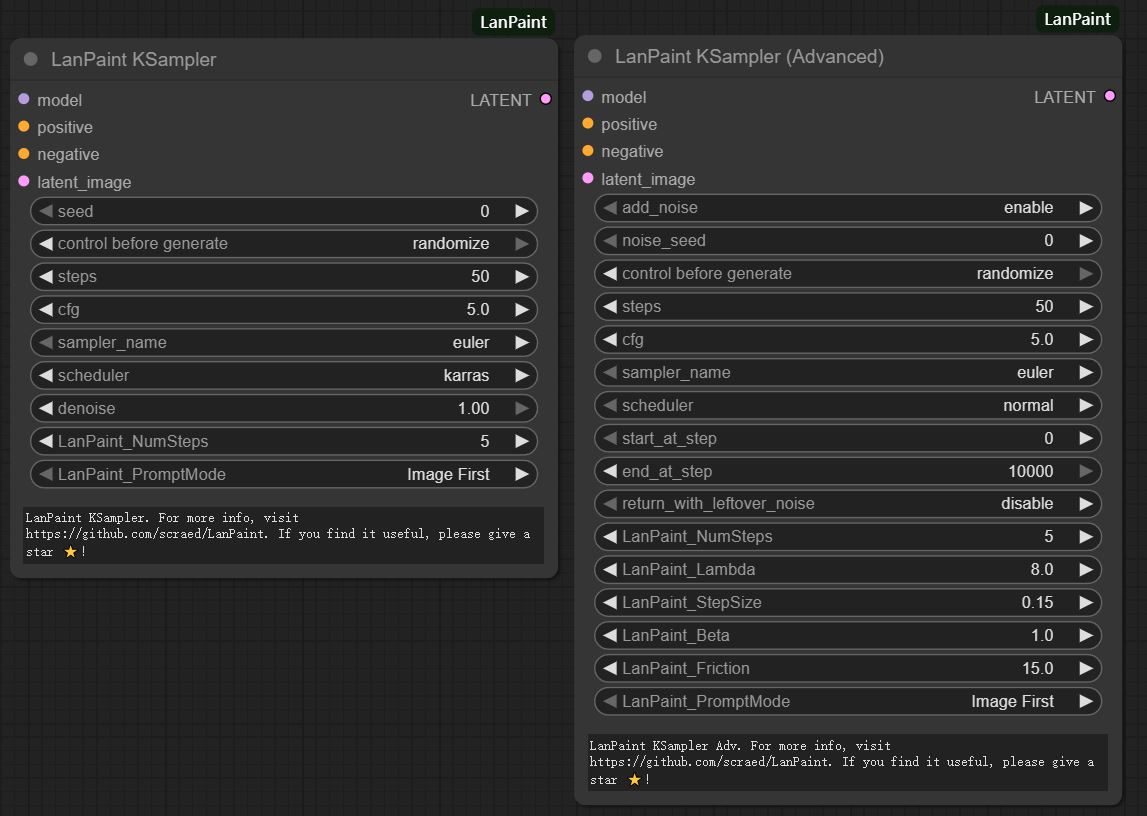
- LanPaint KSampler:最基础且易于使用的修复采样器。
- LanPaint KSampler(高级):全面控制所有参数。
LanPaint KSampler
简化界面,配有推荐默认值:
- 步数:20–50。步数越多,“思考”越充分,效果越好。
- LanPaint NumSteps:去噪前的思考轮次。大多数任务建议设置为 5(即比无思考采样慢 5 倍)。对于更具挑战性的任务,可设置为 10。
- LanPaint Prompt 模式:图像优先模式与提示优先模式。图像优先模式更注重图像本身,会根据图像上下文进行修复(可能忽略提示);而提示优先模式则更强调提示内容。建议在需要保持角色一致性等任务时使用提示优先模式。(从技术层面讲,提示优先模式会将 BIG 分数中的 CFG 缩放系数调整为负值以强化提示,但这可能会降低图像质量。)
LanPaint KSampler(高级)
完全参数控制: 关键参数
| 参数 | 范围 | 描述 |
|---|---|---|
Steps |
0–100 | 扩散采样的总步数。数值越高,修复效果越好。建议设置为 20–50。 |
LanPaint_NumSteps |
0–20 | 每个去噪步骤中的推理迭代次数(“思考深度”)。简单任务:2–5。困难任务:5–10 |
LanPaint_Lambda |
0.1–50 | 内容对齐强度(数值越高,约束越严格)。建议设置为 4.0–10.0 |
LanPaint_StepSize |
0.1–1.0 | 每次思考步骤的大小。建议设置为 0.1–0.5。 |
LanPaint_Beta |
0.1–2.0 | 遮罩区域与非遮罩区域之间的步长比例。较小的值可以抵消较高的 Lambda 值。建议设置为 1.0 |
LanPaint_Friction |
0.0–100.0 | 朗之万动力学的摩擦力。数值越高,速度越慢但越稳定;数值越低,速度越快但越不稳定。建议设置为 10.0–20.0 |
LanPaint_EarlyStop |
0–10 | 在最终采样步骤之前停止 LanPaint 迭代。有助于在某些情况下去除伪影。建议设置为 1–5 |
LanPaint_PromptMode |
图像优先 / 提示优先 | 图像优先模式侧重于图像上下文,可能忽略提示。提示优先模式则更注重提示内容。 |
如需了解每个参数的详细说明,只需将鼠标悬停在相应输入字段上,即可查看包含附加信息的工具提示。
LanPaint Mask Blend
此节点根据掩码将原始图像与修复后的图像混合。如果您希望未遮罩区域的像素与原始图像完全一致,此节点非常有用。
LanPaint KSampler(高级)调优指南
针对具有挑战性的修复任务:
1️⃣ 提升质量 如果修复结果未达到预期,请增加总采样步数(非常重要!)、LanPaint_NumSteps(思考迭代次数)或LanPaint_Lambda。
2️⃣ 提升速度 减少LanPaint_NumSteps以加快生成速度!若希望获得更好的效果但仍需减少步数,可考虑: - 增大 LanPaint_StepSize以加快思考过程。 - 降低 LanPaint_Friction以使朗之万动力学更快收敛。
3️⃣ 解决不稳定问题:
如果发现结果纹理异常,可尝试:
- 降低LanPaint_Friction以提高朗之万动力学的稳定性。
- 减小LanPaint_StepSize以使用更小的步长。
- 如果使用了较高的 Lambda 值,可适当降低LanPaint_Beta。
⚠️ 注意事项:
- 为有效调优,请固定种子,并逐步调整参数,同时观察结果。这有助于隔离每个设置的影响。最好使用一批图像进行测试,以免过度拟合单张图像。
社区展示
看看社区是如何使用 LanPaint 的吧!以下是一些用户创建的教程:
- AI绘画进阶148-三大王炸!庆祝高允贞出道6周年!T8即将直播?当AI绘画学会深度思考?!万能修复神器LanPaint,万物皆可修!-T8 Comfyui教程
- AI绘画进阶151-真相了!T8竟是个AI?!LanPaint进阶(二),人物一致性,多视角实验性测试,新参数讲解,工作流分享-T8 Comfyui教程
- 重绘和三视图角色一致性解决新方案!LanPaint节点尝试
- ComfyUI: HiDream with Perturbation Upscale, LanPaint Inpainting (Workflow Tutorial)
- ComfyUI必备LanPaint插件超详细使用教程
欢迎提交 PR 将您的教程/视频添加到这里,或通过Issue提供详细信息!
常见问题解答
更新
- 2026年3月2日
v1.5.0:修复了一个隐藏的性能瓶颈问题,该问题会导致图像模糊(尤其是在z-image-base上),同时也提升了其他模型上 LanPaint 的整体性能。
- 2026年1月30日
- 添加 Z-image-base 的文档及 Example_25 工作流示意图。
- 2025年8月8日
- 增加对 Qwen 图像模型的支持。
- 2025年6月21日
- 更新算法,提升稳定性和外扩绘图性能。
- 添加外扩绘图示例。
- 支持自定义采样器(感谢 MINENEMA)。
- 2025年6月4日
- 增加更多采样器支持。
- 在高级采样器中加入提前停止功能。
- 2025年5月28日
- 对 Langevin 求解器进行重大更新。现在速度更快、稳定性更高。
- 大幅简化了高级采样器的参数设置。
- 修复了 Flux 和 SD 3.5 上的性能问题。
- 2025年4月16日
- 增加对 Primary HiDream 的支持。
- 2025年3月22日
- 增加对 Primary Flux 的支持。
- 新增“戏弄模式”。
- 2025年3月10日
- LanPaint 进行了一次重大更新!所有示例现均采用 LanPaint K 采样器,界面更加简洁,性能和稳定性也得到了提升。
- 2025年3月6日:
- 修复了字符串不可调用错误和解包错误。特别感谢 jamesWalker55 和 EricBCoding。
待办事项
- 尝试实现细节增强模块。
提供无 GUI 的推理代码。请参阅我们的本地 Python 基准测试代码 LanPaintBench。
引用
@article{
zheng2025lanpaint,
title={LanPaint:无需训练的扩散模型内补画技术——渐近精确且快速的条件采样},
author={Candi Zheng, Yuan Lan, Yang Wang},
journal={机器学习研究汇刊},
issn={2835-8856},
year={2025},
url={https://openreview.net/forum?id=JPC8JyOUSW},
note={}
}
版本历史
1.5.32026/04/111.5.22026/03/261.5.02026/03/021.4.132026/02/021.4.112026/01/271.4.102026/01/131.4.82025/12/251.4.72025/12/151.4.62025/12/061.4.52025/12/041.4.42025/11/221.4.32025/11/171.4.22025/10/261.4.12025/10/161.4.02025/10/021.3.22025/09/171.3.12025/08/251.3.02025/08/211.2.02025/08/081.1.02025/06/21常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
AutoGPT
AutoGPT 是一个旨在让每个人都能轻松使用和构建 AI 的强大平台,核心功能是帮助用户创建、部署和管理能够自动执行复杂任务的连续型 AI 智能体。它解决了传统 AI 应用中需要频繁人工干预、难以自动化长流程工作的痛点,让用户只需设定目标,AI 即可自主规划步骤、调用工具并持续运行直至完成任务。 无论是开发者、研究人员,还是希望提升工作效率的普通用户,都能从 AutoGPT 中受益。开发者可利用其低代码界面快速定制专属智能体;研究人员能基于开源架构探索多智能体协作机制;而非技术背景用户也可直接选用预置的智能体模板,立即投入实际工作场景。 AutoGPT 的技术亮点在于其模块化“积木式”工作流设计——用户通过连接功能块即可构建复杂逻辑,每个块负责单一动作,灵活且易于调试。同时,平台支持本地自托管与云端部署两种模式,兼顾数据隐私与使用便捷性。配合完善的文档和一键安装脚本,即使是初次接触的用户也能在几分钟内启动自己的第一个 AI 智能体。AutoGPT 正致力于降低 AI 应用门槛,让人人都能成为 AI 的创造者与受益者。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。