TTS-WebUI
TTS-WebUI 是一个功能强大的开源音频处理平台,旨在为用户提供一个统一的网页界面,轻松访问和管理数十种顶尖的 AI 语音与音乐生成模型。它巧妙地将 Gradio 和 React 前端技术结合,通过插件化架构集成了包括 CosyVoice、GPT-SoVITS、XTTSv2、RVC、MusicGen 以及 Bark 在内的众多热门模型,覆盖了从文本转语音、高保真语音克隆、歌声转换到背景音乐生成的全方位需求。
过去,用户若想尝试不同的 AI 音频模型,往往需要分别配置复杂的环境、安装各自的依赖库,过程繁琐且容易出错。TTS-WebUI 完美解决了这一痛点,它将所有模型整合在一个简洁易用的界面中,支持一键安装和 Docker 部署,极大地降低了使用门槛。无论是希望快速生成配音内容的普通创作者、需要测试不同模型效果的研究人员,还是寻求高效工作流的开发者,都能从中受益。
其独特的技术亮点在于高度的可扩展性与兼容性,不仅支持本地运行,还提供 Google Colab 云端笔记本来方便资源有限的用户体验。此外,它还支持与 Silly Tavern 等流行前端集成,为角色扮演和互动叙事场景提供了丰富的声音表现力。TTS-WebUI 让探索前沿音频 AI 技术变得像浏览网页一样简单高效。
使用场景
一位独立游戏开发者正在为角色对话系统制作多语言语音包,需要同时处理旁白叙述、角色情感演绎及背景音效生成。
没有 TTS-WebUI 时
- 环境配置噩梦:为了尝试 Bark、CosyVoice 和 RVC 等不同模型,开发者需分别搭建多个独立的 Python 虚拟环境,依赖冲突频发,安装过程耗时数天。
- 工作流割裂:生成旁白用一套代码,克隆角色声音用另一套脚本,后期降噪又要切换软件,数据在不同工具间反复导出导入,极易出错。
- 试错成本高昂:调整语速、情感或音色参数时,每次修改都需重新运行复杂的命令行脚本,无法实时预览效果,导致创意验证效率极低。
- 资源管理混乱:不同模型对显存要求不一,缺乏统一调度,经常因显存溢出导致程序崩溃,难以在同一台机器上流畅运行多种模型。
使用 TTS-WebUI 后
- 一键集成部署:通过 TTS-WebUI 的单一安装包或 Docker 容器,瞬间集成了从 GPT-SoVITS 到 MusicGen 等二十余种主流模型,无需再关心底层依赖冲突。
- 统一操作界面:在基于 Gradio 和 React 的统一面板中,开发者可无缝切换文本转语音、声音克隆及音乐生成模块,所有音频资产在一个页面内完成全流程制作。
- 实时交互调优:利用可视化滑块即时调整参数并秒级试听,快速锁定最适合游戏氛围的音色与情感表现,将原本数小时的调试工作压缩至几分钟。
- 高效资源调度:TTS-WebUI 自动管理模型加载与显存释放,支持在同一会话中灵活调用轻量级 Piper 进行快速迭代,或调用重型模型进行最终渲染,稳定性显著提升。
TTS-WebUI 将碎片化的音频 AI 工具链整合为一站式创作平台,让开发者从繁琐的环境维护中解放,专注于内容创意本身。
运行环境要求
- Windows
- Linux
- macOS
支持多种 GPU/芯片(安装脚本会提示选择),具体显存需求取决于所选模型(每个模型额外需要 2-8GB 存储空间,隐含对显存有一定要求),未明确指定最低 CUDA 版本
未说明
快速开始
TTS WebUI




视频
 |
 |
 |
|---|
示例
截图
.png) |
.png) |
.png) |
|---|
.png) |
.png) |
.png) |
|---|
支持的模型
* 这些模型默认不会安装,而是作为扩展提供。
安装
使用安装程序(推荐)
当前基础安装大小约为10.7 GB。每个模型还需要额外的2-8 GB空间。
- 下载最新版本并解压。
- 运行 start_tts_webui.bat 或 start_tts_webui.sh 启动服务器。它会提示您选择使用的 GPU/芯片。安装完成后,Gradio 服务器将在 http://localhost:7770 上启动,React UI 将在 http://localhost:3000 上启动。
- 输出日志将保存在 installer_scripts/output.log 文件中。
- 注意:启动脚本会设置一个 conda 环境和一个 Python 虚拟环境。因此,在此之前无需创建 venv;实际上,从其他 venv 启动可能会导致该脚本无法正常运行。
手动安装
先决条件:
- git
- Python 3.10 或 3.11(暂不支持 3.12)
- PyTorch
- ffmpeg(支持 vorbis 编码)
- (可选)NodeJS 22.9.0 用于 React UI
- SQLite(随 Python 附带)用于数据库支持
克隆仓库:
git clone https://github.com/rsxdalv/tts-webui.git cd tts-webui安装所需包:
pip install -r requirements.txt运行服务器:
python server.py --no-react对于 React UI:
cd react-ui npm install npm run build cd .. python server.py
有关详细的手动安装说明,请参阅手动安装指南。
Docker 设置
tts-webui 也可以在 Docker 容器中运行。在 Docker 中使用 CUDA 需要 NVIDIA Container Toolkit。要开始使用,可以从 GitHub Container Registry 拉取镜像:
docker pull ghcr.io/rsxdalv/tts-webui:main
镜像拉取完成后,可以使用 Docker Compose 启动容器:
端口分别为 7770(环境变量:TTS_PORT)用于 Gradio 后端,以及 3000(环境变量:UI_PORT)用于 React 前端。
docker compose up -d
容器需要一些时间来生成第一个输出,因为模型会在后台下载。可以通过查看容器日志来确认下载状态:
docker logs tts-webui
自己构建镜像
如果您希望自行构建 Docker 容器,可以使用附带的 Dockerfile:
docker build -t tts-webui .
请注意,需要编辑 docker-compose 文件以使用您刚刚构建的镜像。
更改记录
四月:
- 在依赖项中添加 torchcodec CPU
- 将 PyTorch 升级至 2.11.0
- 将 TorchAudio 锁定版本更新至 2.7.0
三月:
- 新特性:Next.js 从 13.5 升级至 16.2.1
十二月:
- 修复了一些小错误并进行了改进
- 重构:将 bark 配置加载提取到 WebUI 的独立函数中
- 杂项:从 tts-webui 中移除 postgres,因为它是一个对大多数用户来说不必要的重型依赖
- 新特性:添加数据库 API 服务器,用于管理生成的音频文件和元数据
十一月:
- 使用 iframe 直接在 Gradio UI 中添加扩展市场
- 将 voices-tortoise 移至 voices/tortoise/(并将 maha-tts 移至 voices/maha_tts/)
- 新特性:为 tts_webui 模块添加全面的测试套件
- 新特性:为扩展市场添加安装按钮
- 新特性:在扩展管理 UI 中添加检查依赖项的按钮
- 新特性(命令行):添加 extension-manager 命令以启动 GUI 工具
- 杂项:从 Google Colab 中移除 uv
- 杂项:将日志目录移动到 installer_scripts/logs/
- 新特性:添加通过 config.json 禁用装饰性扩展的功能
十月:
- 将 Gradio 更新至 5.49.1
- 将 @gradio/client 更新至 1.19.1
- 修复 Chatterbox 安装问题、路径问题以及 Silly Tavern 中的流媒体错误
- 创建新的扩展类别——对话式 AI
- 重新组织环境变量,引入新的 dotenv 管理器
- 将更多 UI 功能转换为扩展,并简化基础服务器
- 为 OpenAI TTS API 扩展添加 API_KEY
- 新特性:支持新的扩展格式——tabsInGroups
- 新特性:添加外部扩展安装程序,用于通过 JSON 管理和安装外部扩展
- 新特性:在文档和安装程序 UI 中添加指向 TTS WebUI 扩展目录的链接
- 新特性:添加日志查看器扩展,用于查看和管理日志文件
历史变更
有关 2025 年的详细变更列表,请参阅2025 年更改记录。
有关 2024 年的详细变更列表,请参阅2024 年更改记录。
有关 2023 年的详细变更列表,请参阅2023 年更改记录。
扩展
扩展可以直接从 WebUI 或 React UI 安装,也可以使用扩展管理器或外部扩展安装程序(一个内置工具,用于通过 JSON 添加自定义扩展)进行安装。
在内部,扩展只是使用 pip 安装的 Python 包。可以同时安装多个扩展,但它们之间可能存在兼容性问题。安装或更新扩展后,需要重启应用才能加载。
有关社区创建的精选扩展列表,请访问TTS WebUI 扩展目录。您还可以在那里找到有关发布您自己的扩展的信息。
更新需要通过迷你控制面板手动完成:
集成
Silly Tavern
将 OpenAI TTS API 扩展更新至最新版本
启动 API 并使用 Python Requests 测试
(OpenAI 客户端可能未安装,因此使用 Python OpenAI 客户端测试可能会失败)
当您成功生成音频时,前往 Silly Tavern 并添加一个新的 TTS API 默认提供商端点:
http://localhost:7778/v1/audio/speech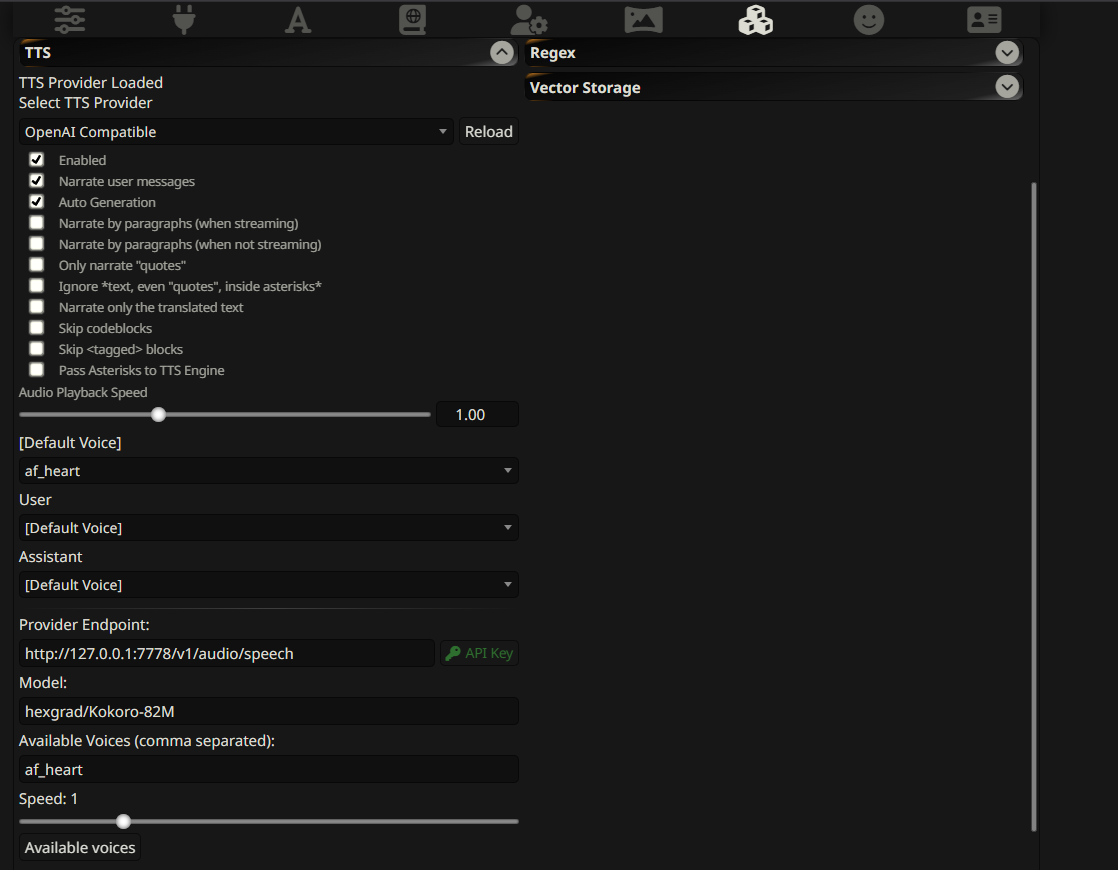
试试看!
Text Generation WebUI (oobabooga/text-generation-webui)
- 在 text-generation-webui 中安装 https://github.com/rsxdalv/text-to-tts-webui 扩展
- 启动 API 并使用 Python Requests 测试
- 使用面板进行配置:
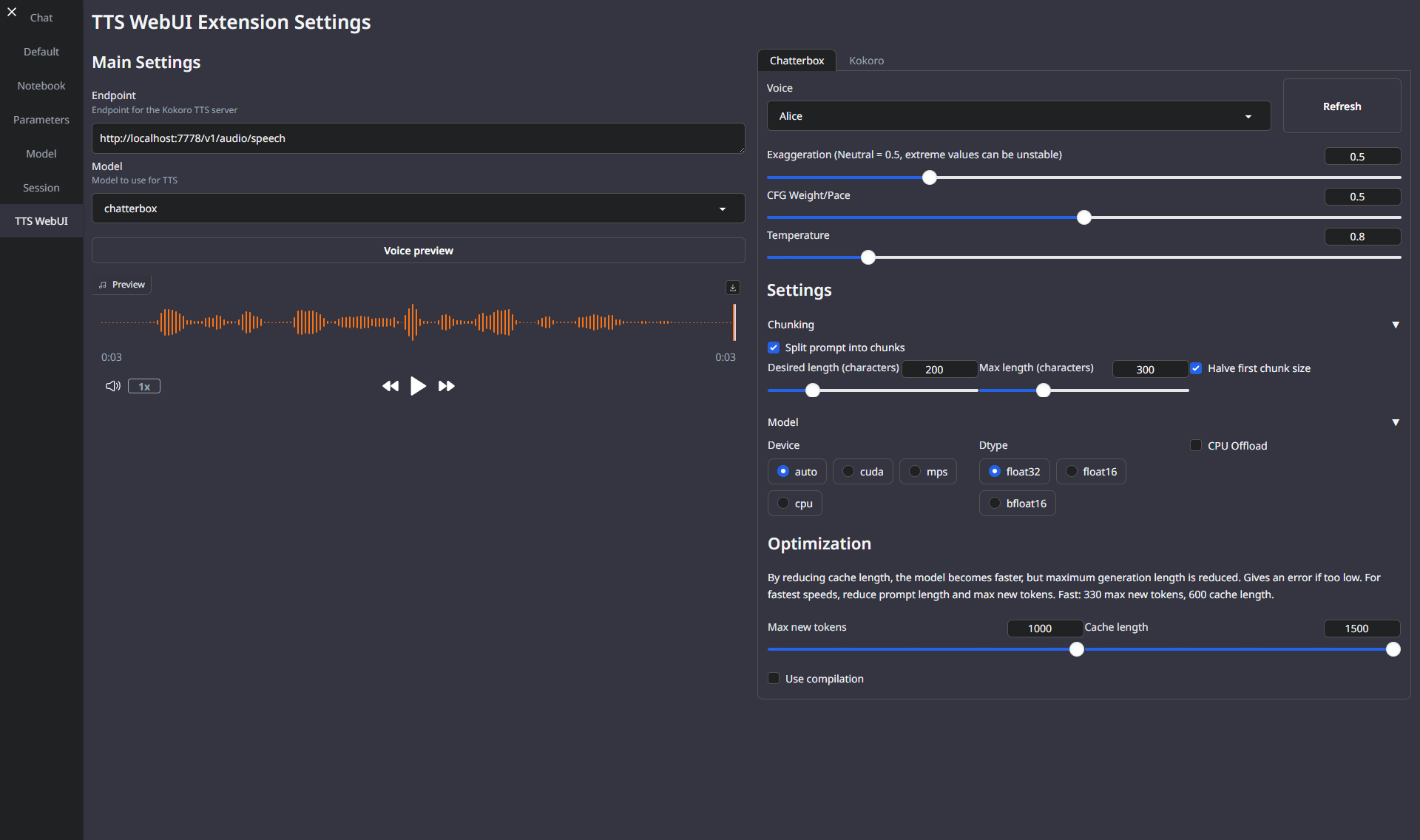
OpenWebUI
- 在 TTS WebUI 中启用 OpenAI API 扩展
- 启动 API 并使用 Python Requests 测试
- 当您成功生成音频时,前往 OpenWebUI 并添加一个新的 TTS API
默认提供商端点:
http://localhost:7778/v1/audio/speech - 试试看!
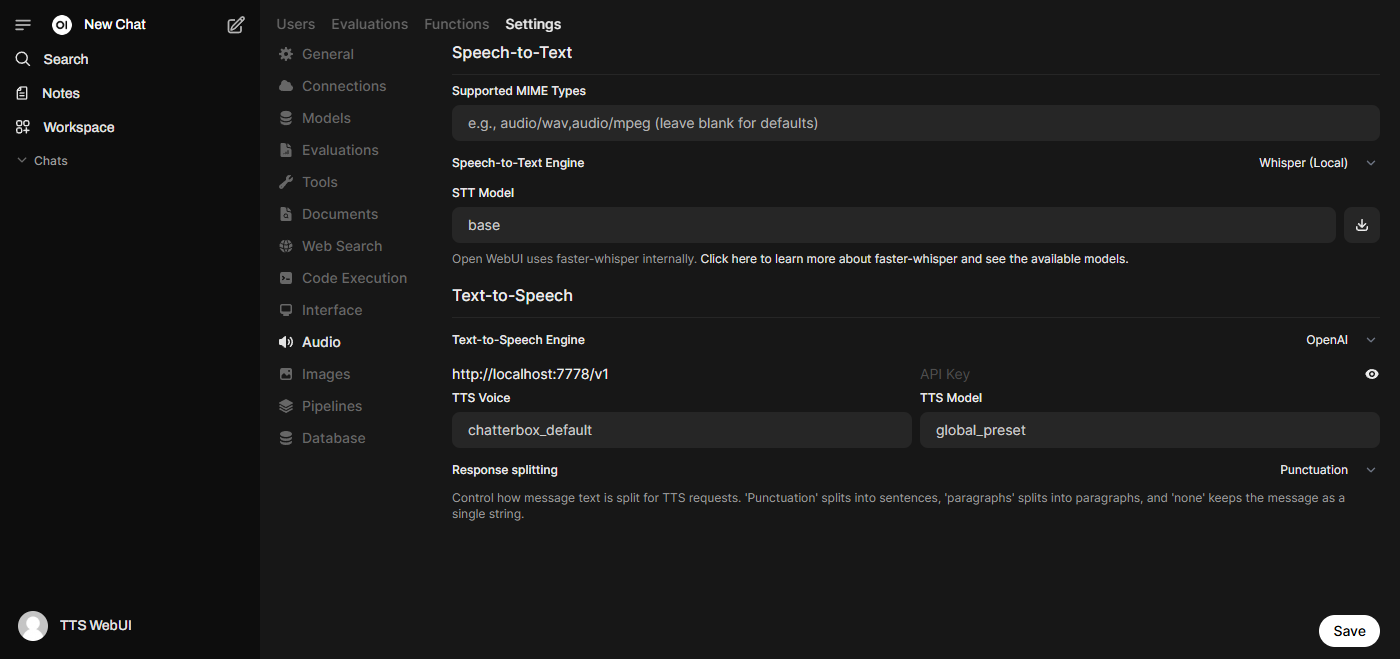
OpenAI 兼容 API
按照上述说明,您可以安装一个 OpenAI 兼容的 API,并将其与 Silly Tavern 或其他 OpenAI 兼容客户端一起使用。
兼容性 / 错误
控制台中的红色消息
这些消息:
---- 需要 ----,但您安装了 ----,两者不兼容。
是完全正常的。这既是 pip 的局限性,也是因为这个 Web UI 将许多不同的 AI 项目整合在一起。由于这些项目之间并不总是相互兼容的,它们会抱怨其他已安装的项目。这是正常且预期的现象。最终,尽管有警告或错误提示,这些项目仍然可以协同工作。 目前尚不清楚这种情况是否能够被解决,但这正是我们的期望。
Bark 的额外语音及提示词示例
Bark 说明文档
关于管理 AI 项目的模型、缓存和系统空间的信息
https://github.com/rsxdalv/tts-webui/discussions/186#discussioncomment-7291274
开源库
本项目使用了以下开源库:
suno-ai/bark - MIT 许可证
- 描述:Bark 模型的推理代码。
- 仓库:suno/bark
tortoise-tts - Apache-2.0 许可证
- 描述:一个适用于多种平台的灵活文本到语音合成库。
- 仓库:neonbjb/tortoise-tts
ffmpeg - LGPL 许可证
- 描述:一个完整且跨平台的视频和音频处理解决方案。
- 仓库:FFmpeg
- 用途:编码 Vorbis Ogg 文件
ffmpeg-python - Apache 2.0 许可证
- 描述:用于处理多媒体文件的 FFmpeg 库的 Python 绑定。
- 仓库:kkroening/ffmpeg-python
audiocraft - MIT 许可证
- 描述:一个用于音频生成和 MusicGen 的库。
- 仓库:facebookresearch/audiocraft
vocos - MIT 许可证
- 描述:一种改进的 encodec 样本解码器。
- 仓库:charactr-platform/vocos
RVC - MIT 许可证
- 描述:一个基于 VITS 的易用语音转换框架。
- 仓库:RVC-Project/Retrieval-based-Voice-Conversion-WebUI
伦理与负责任的使用
这项技术旨在促进赋能与创造力,而非造成伤害。
通过使用本 AI 模型,您确认并同意遵守以下准则,以负责任、合乎伦理且合法的方式使用该 AI 模型。
- 非恶意意图:请勿将本 AI 模型用于恶意、有害或非法活动。它仅应用于合法且合乎道德的目的,以促进积极互动、知识共享和建设性对话。
- 禁止冒充:请勿使用本 AI 模型冒充或伪装成他人,包括个人、组织或实体。不得利用其进行欺骗、诈骗或操纵他人行为。
- 禁止欺诈行为:本 AI 模型不得用于任何形式的欺诈目的,例如金融诈骗、网络钓鱼或其他旨在获取敏感信息、谋取经济利益或未经授权访问系统的欺骗性行为。
- 遵守法律:请确保您对本 AI 模型的使用符合所在司法管辖区关于 AI 使用、数据保护、隐私、知识产权及其他相关法律义务的适用法律法规和政策。
- 确认:通过使用本 AI 模型,您确认并同意遵守上述准则,以负责任、合乎伦理且合法的方式使用该 AI 模型。
许可证
代码库与依赖项
代码库采用 MIT 许可证。然而,需要注意的是,在安装依赖项时,您还需遵守它们各自的许可证条款。尽管大多数许可证较为宽松,但也可能存在一些不兼容的情况。因此,务必明确:宽松许可证仅适用于代码库本身,而不涵盖整个项目。
尽管如此,我们的目标是在整个项目中保持与 MIT 许可证的兼容性。如果您发现某个依赖项与 MIT 许可证不兼容,请随时提交问题并告知我们。
已知的非宽松许可证依赖项:
| 库名 | 许可证 | 备注 |
|---|---|---|
| encodec | CC BY-NC 4.0 | 新版本为 MIT,但需手动安装 |
| diffq | CC BY-NC 4.0 | 未来可选,运行并非必需,可卸载,应与 demucs 一起更新 |
| lameenc | GPL 许可证 | 未来版本将改为 LGPL,但需手动安装 |
| unidecode | GPL 许可证 | 非关键组件,可用其他库替代,问题:https://github.com/neonbjb/tortoise-tts/issues/494 |
模型权重
模型权重有不同的许可证,请注意您所使用的模型的许可证。
其中最值得注意的是:
- Bark:MIT
- Tortoise:未知(根据仓库信息为 Apache-2.0,但 HuggingFace 上没有许可证文件)
- MusicGen:CC BY-NC 4.0
- AudioGen:CC BY-NC 4.0
版本历史
v1.1.02026/04/05v1.0.02026/04/05v0.5.12026/04/04v0.4.02025/11/23v0.3.02025/11/14v0.0.12025/09/29v0.0.02025/08/16常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
AutoGPT
AutoGPT 是一个旨在让每个人都能轻松使用和构建 AI 的强大平台,核心功能是帮助用户创建、部署和管理能够自动执行复杂任务的连续型 AI 智能体。它解决了传统 AI 应用中需要频繁人工干预、难以自动化长流程工作的痛点,让用户只需设定目标,AI 即可自主规划步骤、调用工具并持续运行直至完成任务。 无论是开发者、研究人员,还是希望提升工作效率的普通用户,都能从 AutoGPT 中受益。开发者可利用其低代码界面快速定制专属智能体;研究人员能基于开源架构探索多智能体协作机制;而非技术背景用户也可直接选用预置的智能体模板,立即投入实际工作场景。 AutoGPT 的技术亮点在于其模块化“积木式”工作流设计——用户通过连接功能块即可构建复杂逻辑,每个块负责单一动作,灵活且易于调试。同时,平台支持本地自托管与云端部署两种模式,兼顾数据隐私与使用便捷性。配合完善的文档和一键安装脚本,即使是初次接触的用户也能在几分钟内启动自己的第一个 AI 智能体。AutoGPT 正致力于降低 AI 应用门槛,让人人都能成为 AI 的创造者与受益者。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信