ScreenAgent
ScreenAgent 是一款由视觉语言大模型驱动的智能体,能够像人类一样直接观察电脑屏幕截图,并通过模拟鼠标点击和键盘输入来操控图形界面。它主要解决了传统自动化脚本依赖特定 API、缺乏通用性且难以处理复杂多步任务的问题,让 AI 能够跨越不同操作系统和应用软件,自主完成文件管理、网页浏览甚至游戏操作等日常任务。
该项目特别适合人工智能研究人员、开发者以及对智能体技术感兴趣的技术爱好者使用。通过内置的“规划 - 执行 - 反思”闭环机制,ScreenAgent 不仅能将用户指令拆解为子任务逐步执行,还能根据操作结果自我评估并动态调整策略,显著提升了任务完成的准确率。其独特的技术亮点在于借鉴 VNC 远程桌面协议设计了通用的动作空间,无需针对特定软件进行适配即可实现跨平台控制;同时,项目开源了涵盖多种场景的高质量数据集,为训练和评估具备视觉定位与工具使用能力的智能体提供了宝贵资源。无论是用于探索多模态大模型的实际应用潜力,还是开发下一代自动化办公助手,ScreenAgent 都提供了一个坚实的研究框架与实践环境。
使用场景
一位数据分析师需要在每天早晨从多个内部网页系统中抓取最新销售数据,整理成 Excel 报表并发送给团队,这一过程涉及频繁的跨应用操作。
没有 ScreenAgent 时
- 重复劳动耗时:分析师每天需手动打开浏览器、登录三个不同系统、复制粘贴数据,耗时约 45 分钟,极易因疲劳产生复制错误。
- 流程僵化难维护:若使用传统 RPA 脚本,一旦网页按钮位置微调或弹出广告遮挡,脚本即刻失效,需要开发人员重新编写定位代码。
- 异常处理缺失:遇到系统加载缓慢或验证码弹窗时,自动化脚本无法判断状态,只能报错停止,仍需人工介入排查。
- 跨应用协同困难:将网页数据转入 Excel 并进行格式调整涉及鼠标拖拽和快捷键组合,传统 API 方案难以模拟这些图形界面操作。
使用 ScreenAgent 后
- 自然语言驱动自动化:分析师只需输入“抓取昨日销售数据并生成报表”,ScreenAgent 即可基于视觉大模型自主规划步骤,将准备时间缩短至 2 分钟。
- 视觉自适应能力强:依托屏幕截图识别,即使网页布局微调或有临时弹窗,ScreenAgent 也能像人类一样“看见”并调整点击坐标,无需重写代码。
- 智能反思与纠错:在执行中若发现数据未加载完成,ScreenAgent 会通过“反思”机制自动等待或刷新页面,确保持续运行直至任务完成。
- 通用键鼠模拟:直接模拟真实的鼠标拖拽、右键菜单和键盘快捷键,无缝衔接浏览器与 Excel 软件,完美复现人工操作流程。
ScreenAgent 通过将视觉理解与自主决策结合,把繁琐的跨应用手工操作转化为可自我修正的智能工作流,真正实现了“所见即所得”的电脑自动化控制。
运行环境要求
- Linux
- Windows
- macOS
- 运行本地模型(LLaVA, CogAgent, ScreenAgent)时需要 NVIDIA GPU,需支持 bf16 精度
- 使用 GPT-4V API 则无需本地 GPU
- 具体显存未说明,建议 16GB+ 以运行 13B 参数模型
未说明

快速开始
ScreenAgent  :由视觉语言大模型驱动的计算机控制代理
:由视觉语言大模型驱动的计算机控制代理
查看 ScreenAgent 论文 arxiv:2402.07945
新闻
- (2024-4-17) ScreenAgent 论文已被 IJCAI 2024 接收并将在会议上展示!
- (2024-5-19) ScreenAgent Web 客户端 发布,提供了一种更简便的方式,让用户通过大模型体验桌面控制。
我们构建了 ScreenAgent 项目,为视觉语言模型代理(VLM Agent)创建了一个与真实计算机屏幕交互的环境。在这个环境中,代理可以通过观察屏幕截图,并输出鼠标和键盘操作来操控图形用户界面。我们还设计了一套自动控制流程,包括规划、执行和反思三个阶段,引导代理持续与环境互动,完成多步骤任务。此外,我们还构建了 ScreenAgent 数据集,收集了完成各种日常计算机任务时的屏幕截图及操作序列。
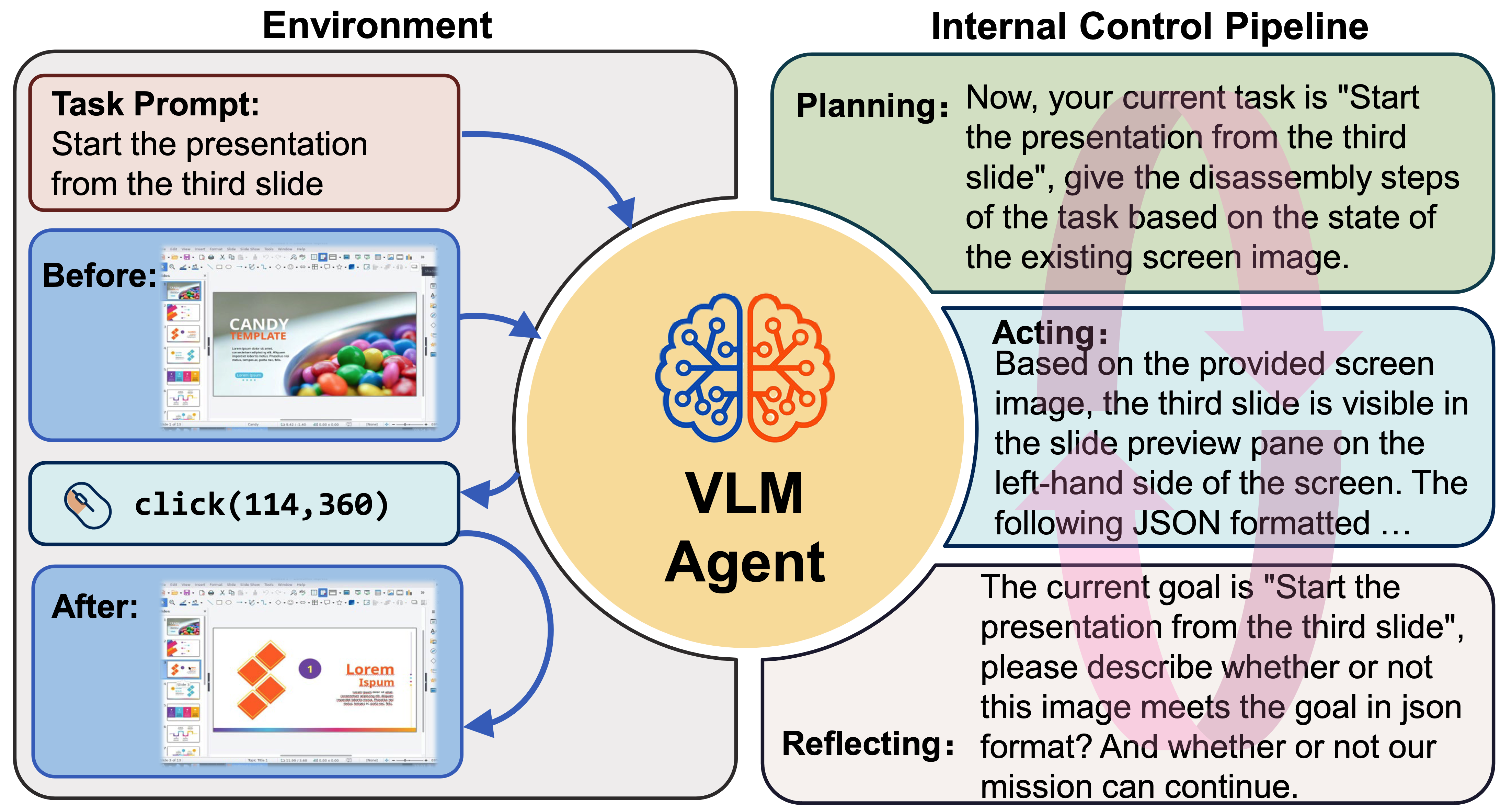
ScreenAgent 设计动机
为了引导 VLM 代理持续与计算机屏幕交互,我们构建了一个包含“规划-执行-反思”的流程。在规划阶段,代理需要将用户任务分解为子任务。在执行阶段,代理会观察屏幕截图,并给出具体的鼠标和键盘操作来执行这些子任务。控制器会执行这些操作,并将执行结果反馈给代理。在反思阶段,代理会观察执行结果,判断当前状态,并决定是继续执行、重试,还是调整计划。这一过程将持续进行,直到任务完成。
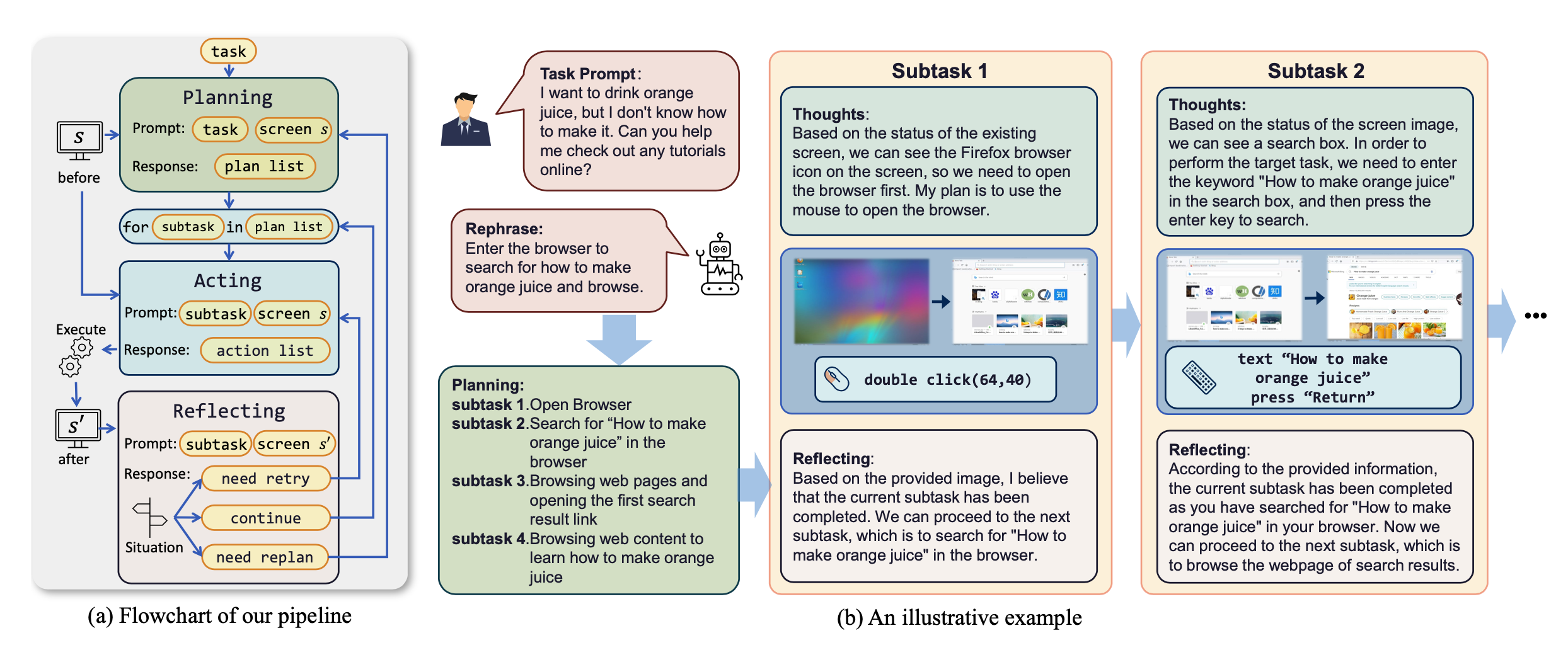
运行流程
我们参考了 VNC 远程桌面连接协议来设计代理的动作空间,这些动作都是最基本的鼠标和键盘操作。大多数鼠标点击操作都需要代理给出精确的屏幕坐标位置。与调用特定 API 来完成任务相比,这种方法更具通用性,可以应用于各种桌面操作系统和应用程序。
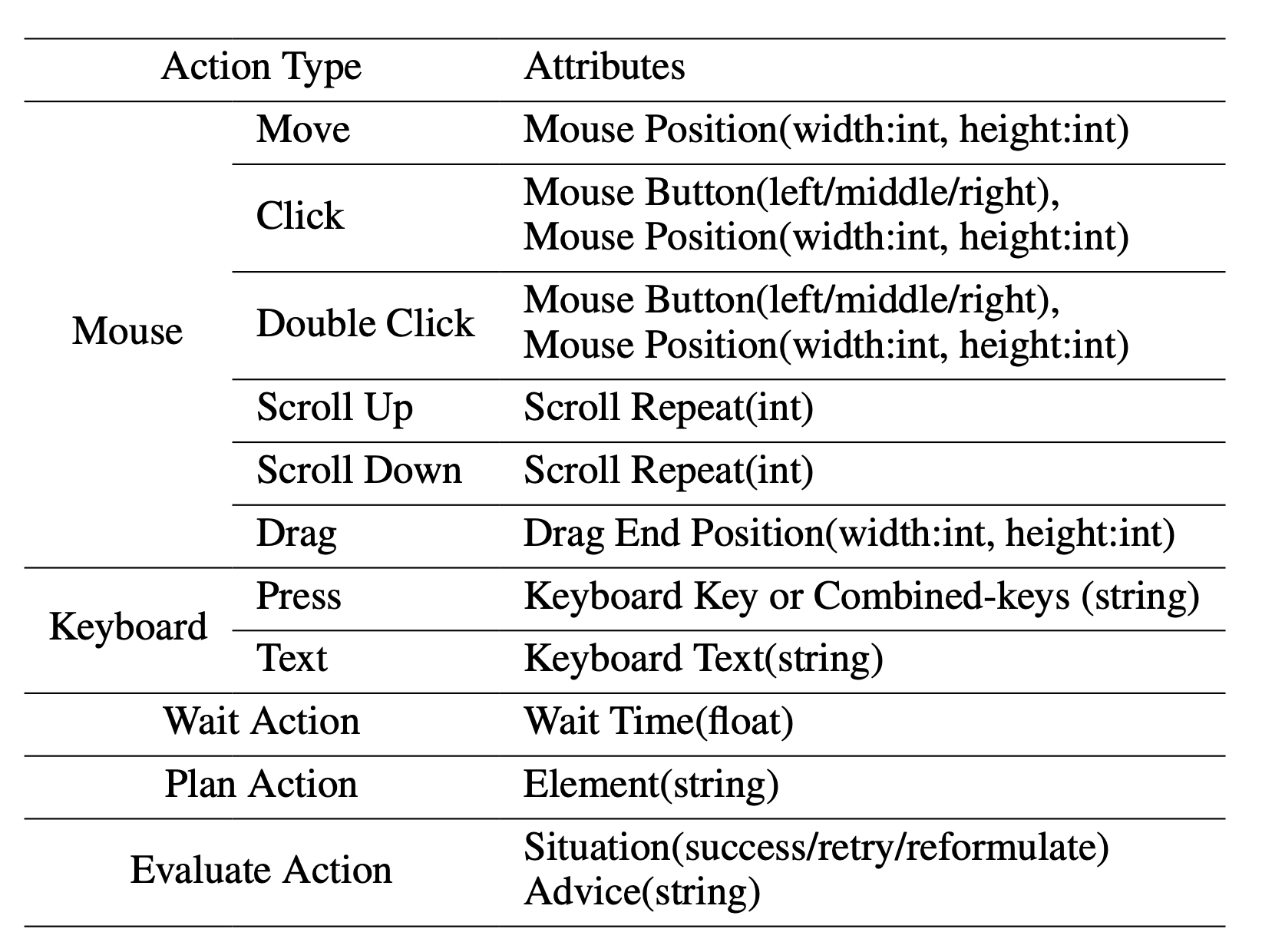
支持的动作类型及动作属性
教会代理使用计算机并非易事。这要求代理具备任务规划、图像理解、视觉定位和工具使用等多种综合能力。为此,我们手动标注了 ScreenAgent 数据集。该数据集涵盖了多种日常计算机任务,包括文件操作、网页浏览、游戏娱乐等场景。我们按照上述“规划-执行-反思”流程构建了一个个会话。
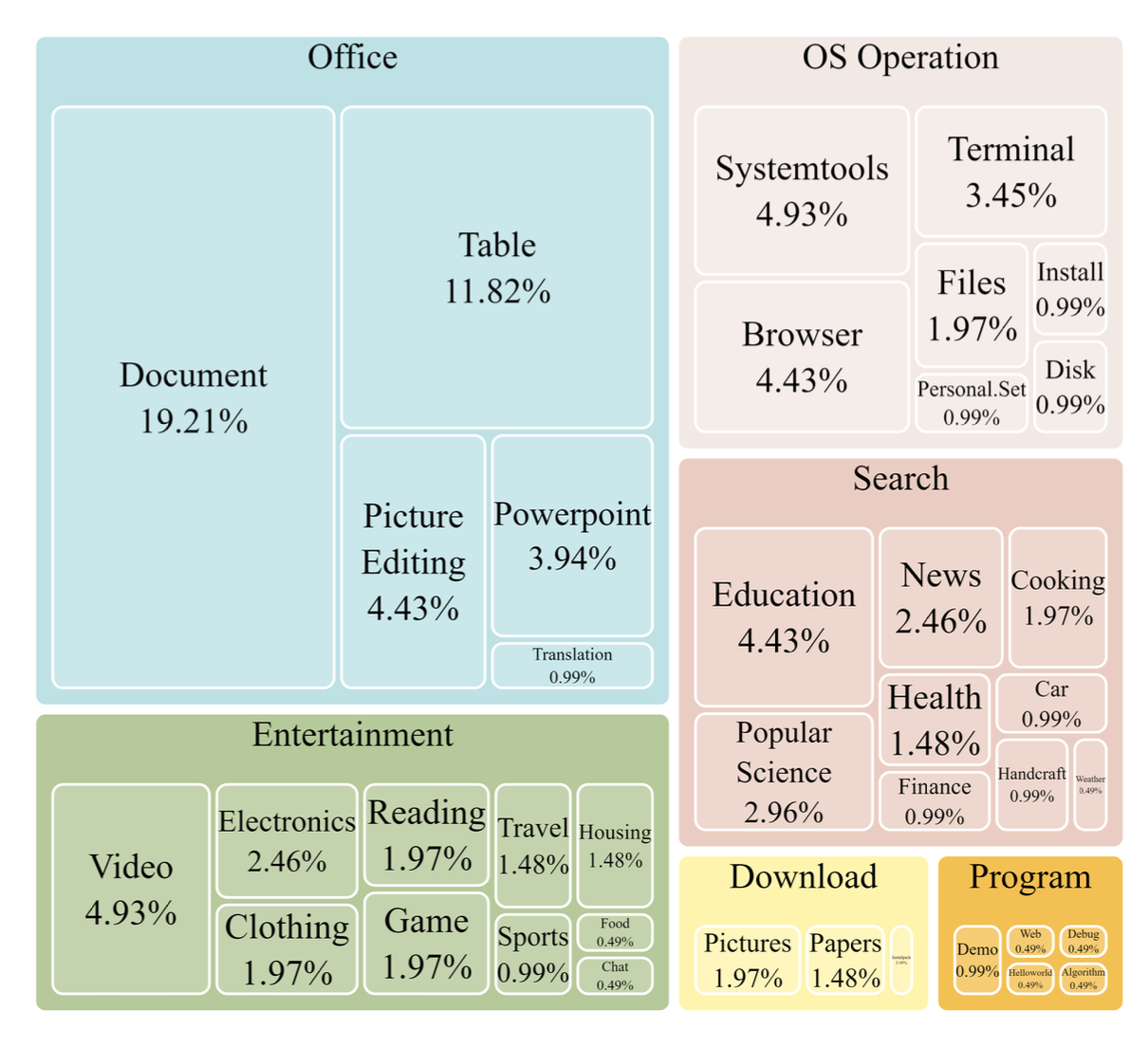
数据集任务类型分布
该项目主要包括以下几个部分:
ScreenAgent
├── client # 控制器客户端代码
│ ├── prompt # 提示模板
│ ├── config.yml # 控制器客户端配置文件模板
│ └── tasks.txt # 任务列表
├── data # 包含 ScreenAgent 数据集及其他视觉定位相关数据集
├── model_workers # VLM 推理服务
└── train # 模型训练代码
准备工作
第一步,准备待控制的桌面
首先,您需要准备一台安装了 VNC 服务器的待控制桌面操作系统,例如 TightVNC。或者您也可以使用带有 GUI 的 Docker 容器。我们已经准备了一个名为 niuniushan/screenagent-env 的容器。您可以使用以下命令拉取并启动该容器:
docker run -d --name ScreenAgent -e RESOLUTION=1024x768 -p 5900:5900 -p 8001:8001 -e VNC_PASSWORD=<VNC_PASSWORD> -e CLIPBOARD_SERVER_SECRET_TOKEN=<CLIPBOARD_SERVER_SECRET_TOKEN> -v /dev/shm:/dev/shm niuniushan/screenagent-env:latest
请将 <VNC_PASSWORD> 替换为您新的 VNC 密码,将 <CLIPBOARD_SERVER_SECRET_TOKEN> 替换为您剪贴板服务的密码。由于输入较长文本或 Unicode 字符依赖于剪贴板,如果未启用剪贴板服务,则只能通过依次按键输入 ASCII 字符串,而无法输入中文及其他 Unicode 字符。本镜像已内置剪贴板服务,默认监听 8001 端口。您需要设置密码以保护您的剪贴板服务。niuniushan/screenagent-env 是基于 fcwu/docker-ubuntu-vnc-desktop 构建的。有关该镜像的更多信息,请参阅 这里。
如果您希望使用现有的桌面环境,如 Windows、Linux 桌面或其他任何桌面环境,您需要运行任意 VNC 服务器,并记下其 IP 地址和端口号。若要启用剪贴板服务,请在您的桌面环境中执行以下步骤:
# 安装依赖
pip install fastapi pydantic uvicorn pyperclip
# 设置环境变量中的密码
export CLIPBOARD_SERVER_SECRET_TOKEN=<CLIPBOARD_SERVER_SECRET_TOKEN>
# 启动剪贴板服务
python client/clipboard_server.py
clipboard_server.py 将监听 8001 端口,接收来自控制器的长字符串键盘输入指令(文本形式)。
服务启动后,您可以测试剪贴板是否正常工作,例如:
curl --location 'http://localhost:8001/clipboard' \
--header 'Content-Type: application/json' \
--data '{
"text":"Hello world",
"token":"<CLIPBOARD_SERVER_SECRET_TOKEN>"
}'
如果一切正常,您将收到响应 {"success": True, "message": "Text copied to clipboard"}。如果遇到错误“Pyperclip could not find a copy/paste mechanism for your system.”,请在运行 python client/clipboard_server.py 前添加一个指定 X 服务器位置的环境变量:
export DISPLAY=:0.0
请根据您的系统环境进行相应调整。如果仍然遇到问题,请参考 这里。
请将上述信息填写到客户端配置文件 client/config.yml 中的 remote_vnc_server 项中。
第2步,准备控制器代码的运行环境
您需要运行控制器代码,它具有三项任务:首先,控制器将连接到VNC服务器,采集屏幕截图,并发送鼠标和键盘等命令;其次,控制器内部维护一个状态机,实现规划、行动和反思的自动化控制流程,引导智能体与环境持续交互;最后,控制器会根据提示词模板构建完整的提示信息,将其发送至大模型推理API,并解析大模型生成回复中的控制命令。控制器是一个基于PyQt5的程序,您需要安装一些依赖项:
pip install -r client/requirements.txt
第3步,准备大模型推理器或API
请为智能体选择一个视觉语言模型(VLM)。我们在model_workers中提供了4种模型的推理器,分别是:GPT-4V、LLaVA-1.5、CogAgent和ScreenAgent。您也可以自行实现推理器,或使用第三方API。您可以参考client/interface_api中的代码来实现新的API调用接口。
请参照client/config.yml中的llm_api部分准备配置文件,仅保留llm_api下的一个模型。
llm_api:
# 从以下模型中选择一个使用:
GPT4V:
model_name: "gpt-4-vision-preview"
openai_api_key: "<YOUR-OPENAI-API-KEY>"
target_url: "https://api.openai.com/v1/chat/completions"
LLaVA:
model_name: "LLaVA-1.5"
target_url: "http://localhost:40000/worker_generate"
CogAgent:
target_url: "http://localhost:40000/worker_generate"
ScreenAgent:
target_url: "http://localhost:40000/worker_generate"
# 所有模型的通用设置
temperature: 1.0
top_p: 0.9
max_tokens: 500
如果您使用GPT-4V作为智能体
请在client/config.yml中将llm_api设置为GPT4V,并填写您的OpenAI API Key,请务必注意您的账户余额。
如果您使用LLaVA-1.5作为智能体
请参考LLaVA项目下载并准备LLaVA-1.5模型,例如:
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA
conda create -n llava python=3.10 -y
conda activate llava
pip install --upgrade pip # 启用PEP 660支持
pip install -e .
model_workers/llava_model_worker.py提供了一个用于LLaVA-1.5的非流式输出推理器。您可以将其复制到llava/serve/model_worker目录下,并使用以下命令启动:
cd llava
python -m llava.serve.llava_model_worker --host 0.0.0.0 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b --no-register
如果您使用CogAgent作为智能体
请参考CogVLM项目下载并准备CogAgent模型。从这里下载CogAgent权重的压缩版cogagent-chat.zip,解压后放置在train/saved_models/cogagent-chat目录下。
train/cogagent_model_worker.py提供了一个用于CogAgent的非流式输出推理器。您可以使用以下命令启动它:
cd train
RANK=0 WORLD_SIZE=1 LOCAL_RANK=0 python ./cogagent_model_worker.py --host 0.0.0.0 --port 40000 --from_pretrained "saved_models/cogagent-chat" --bf16 --max_length 2048
如果您使用ScreenAgent作为智能体
ScreenAgent是在CogAgent基础上训练的。从这里下载ScreenAgent-2312.zip格式的权重文件,解压后放置在train/saved_models/ScreenAgent-2312目录下。您可以使用以下命令启动它:
cd train
RANK=0 WORLD_SIZE=1 LOCAL_RANK=0 python ./cogagent_model_worker.py --host 0.0.0.0 --port 40000 --from_pretrained "./saved_models/ScreenAgent-2312" --bf16 --max_length 2048
运行
准备工作完成后,您可以运行控制器:
cd client
python run_controller.py -c config.yml
控制器界面如下所示。您需要先双击左侧选择一个任务,然后按下“开始自动化”按钮。控制器将按照规划-行动-反思的流程自动运行。它会采集当前屏幕图像,填充提示词模板,将图像和完整提示词发送到大模型推理器,解析大模型的回复,向VNC服务器发送鼠标和键盘控制命令,并重复这一过程。
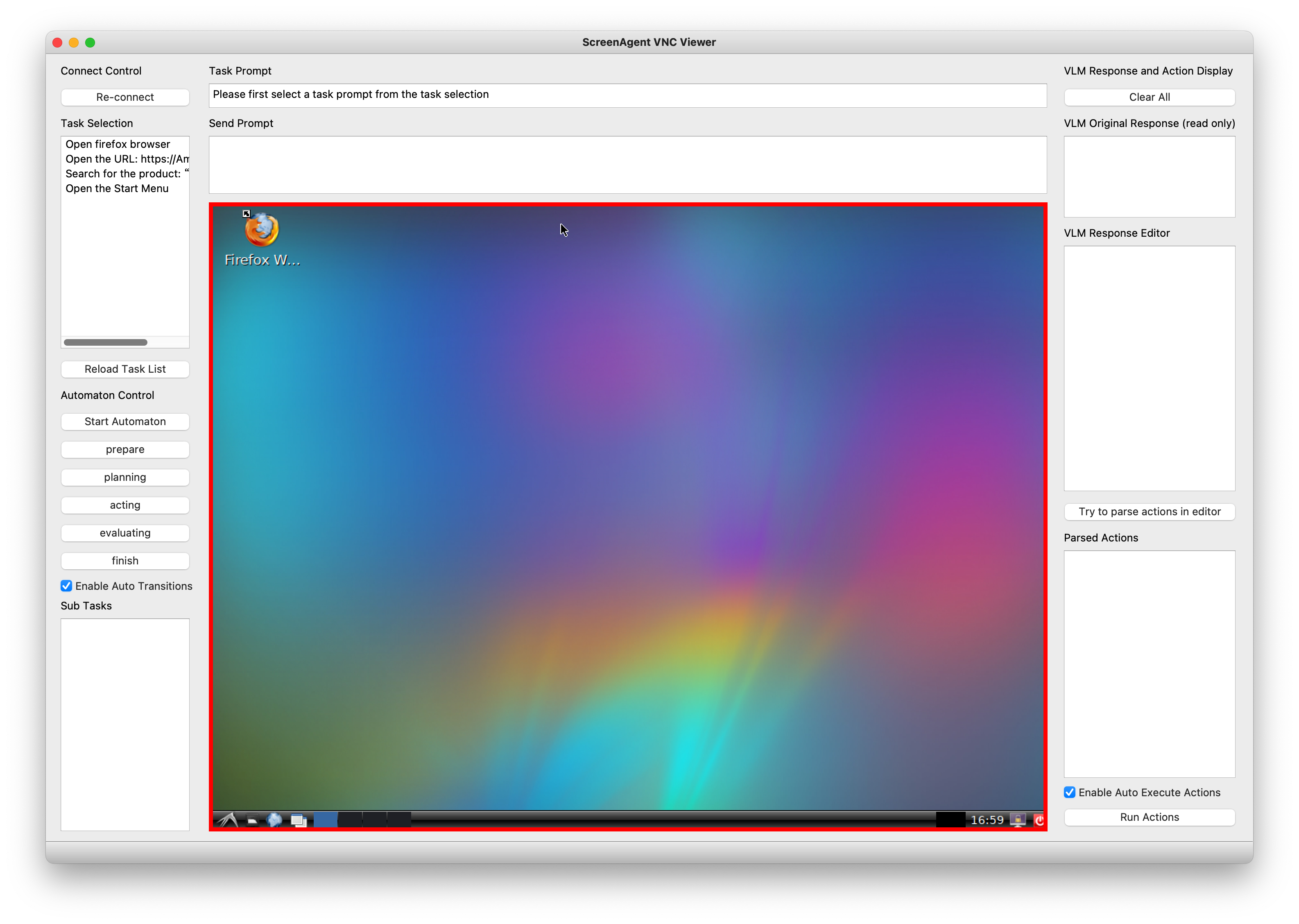
控制器界面
如果屏幕卡住,可以尝试点击“重新连接”按钮。控制器将尝试重新连接到VNC服务器。
数据集
所有数据集及数据处理代码均位于data目录下。我们使用了三个现有的数据集:COCO2014、Rico & widget-caption以及Mind2Web。
COCO数据集
我们使用COCO 2014验证集图片作为视觉定位能力的训练数据。您可以从这里下载COCO 2014训练集图片。我们在此使用的标注信息是refcoco,由unc划分。
├── COCO
├── prompts # 用于训练智能体视觉定位能力的提示词模板
├── train2014 # COCO 2014训练集
└── annotations # COCO 2014标注
Rico & widget-caption数据集
Rico数据集包含大量Android应用的屏幕截图和控件信息。您可以从这里下载Rico数据集的“1. UI Screenshots and View Hierarchies (6 GB)”部分,文件名为unique_uis.tar.gz。请将解压后的combined文件夹放入data/Rico目录下。
widget-caption是基于Rico的控件信息标注。请将https://github.com/google-research-datasets/widget-caption项目克隆到data/Rico目录下。
最终的目录结构如下:
├── Rico
├── prompts # 用于训练智能体视觉定位能力的提示词模板
├── combined # Rico数据集的屏幕截图
└── widget-caption
├── split
│ ├── dev.txt
│ ├── test.txt
│ └── train.txt
└── widget_captions.csv
Mind2Web 数据集
Mind2Web 是一个真实的模拟网页浏览数据集。您需要下载原始数据集并进行处理。首先,使用 Globus 工具从这里下载原始网页截图。文件夹名为 raw_dump,放置在 data/Mind2Web/raw_dump 目录下,然后使用以下命令处理数据集:
cd data/Mind2Web
python convert_dataset.py
这段代码会从 Hugging Face 数据集中下载 osunlp/Mind2Web 数据集的处理后版本。请确保网络畅通。同时,这一步骤将涉及将英文指令翻译成中文指令。
cd data/Mind2Web
python convert_dataset.py
这段代码会从 Hugging Face 数据集中下载 osunlp/Mind2Web 数据集的处理后版本。请确保网络畅通。这一步骤将涉及将英文指令翻译成中文指令。您需要在 data/Mind2Web/translate.py 中调用您自己的翻译 API。
目录结构如下:
├── Mind2Web
├── convert_dataset.py
├── translate.py
├── prompts # 用于训练 Agent 网页浏览能力的提示词模板
├── raw_dump # 从 Globus 下载的 Mind2Web 原始数据
└── processed_dataset # 由 convert_dataset.py 创建
ScreenAgent 数据集
ScreenAgent 是本文中标注的数据集,分为训练集和测试集,目录结构如下:
├── data
├── ScreenAgent
├── train
│ ├── <session id>
│ │ ├── images
│ │ │ ├── <timestamp-1>.jpg
│ │ │ └── ...
│ │ ├── <timestamp-1>.json
│ │ └── ...
│ ├── ...
└── test
JSON 文件中各字段的含义:
- session_id:会话 ID
- task_prompt:任务总体目标
- task_prompt_en:任务总体目标(英文)
- task_prompt_zh:任务总体目标(中文)
- send_prompt:发送给模型的完整提示
- send_prompt_en:发送给模型的完整提示(英文)
- send_prompt_zh:发送给模型的完整提示(中文)
- LLM_response:模型给出的原始回复文本,即 RLHF 中的拒绝响应
- LLM_response_editer:人工修正后的回复文本,即 RLHF 中的选择响应
- LLM_response_editer_en:人工修正后的回复文本(英文)
- LLM_response_editer_zh:人工修正后的回复文本(中文)
- video_height, video_width:图像的高度和宽度
- saved_image_name:截图文件名,位于每个会话的 images 文件夹下
- actions:从 LLM_response_editer 中解析出的动作序列
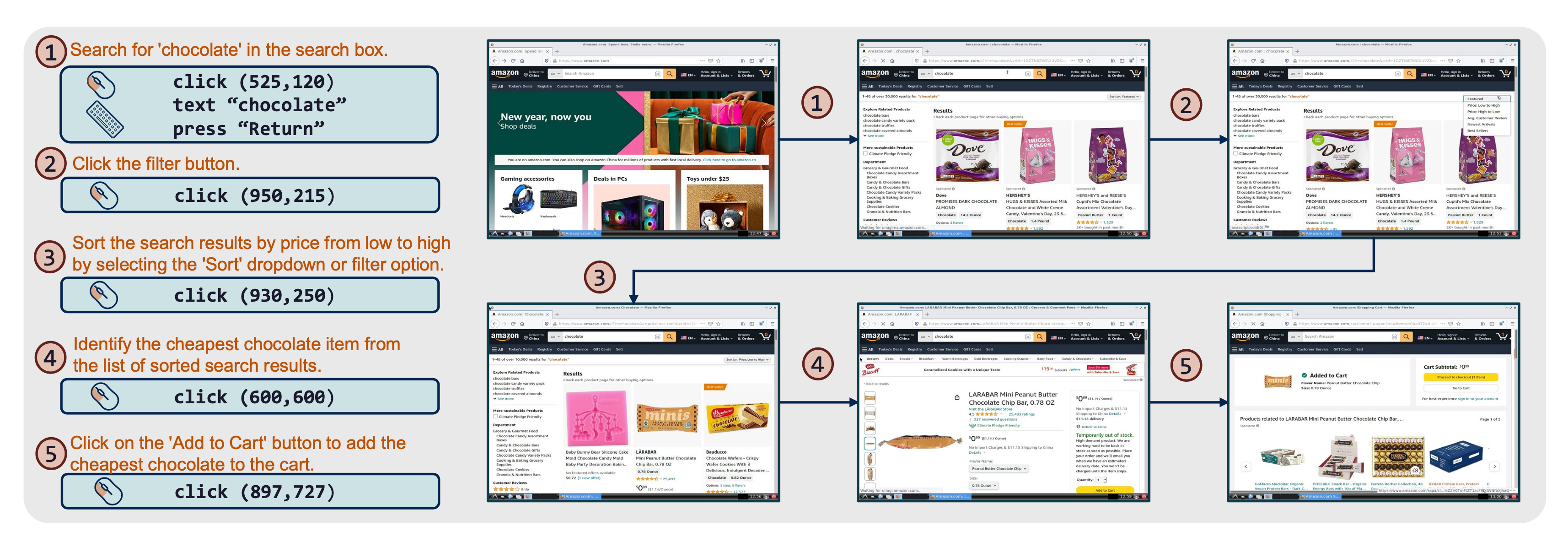
ScreenAgent 数据集中的一例
训练 ScreenAgent
如果您想训练自己的模型,或复现 ScreenAgent 模型,请先准备好上述数据集,并检查 train/dataset/mixture_dataset.py 文件中的所有数据集路径。如果您只想使用部分数据集或添加新的数据集,请修改 train/dataset/mixture_dataset.py 中的 make_supervised_data_module 函数。请从这里下载 CogAgent 权重的单机版 cogagent-chat.zip,解压后放置在 train/saved_models/ 目录下。
您需要关注并检查以下文件:
train
├── data -> ../data
├── dataset
│ └── mixture_dataset.py
├── finetune_ScreenAgent.sh
└── saved_models
└── cogagent-chat # 解压 cogagent-chat.zip
├── 1
│ └── mp_rank_00_model_states.pt
├── latest
└── model_config.json
请根据您的设备情况修改 train/finetune_ScreenAgent.sh 中的参数,然后运行:
cd train
bash finetune_ScreenAgent.sh
最后,如果您想将单机分布式训练的权重合并为一个单独的权重文件,请参考 train/merge_model.sh 代码。请确保该文件中的模型并行度 MP_SIZE 与 train/finetune_ScreenAgent.sh 中的 WORLD_SIZE 一致。将 --from-pretrained 后的参数修改为训练过程中保存的检查点位置。合并后的权重文件将保存为 train/saved_models/merged_model 文件夹。
待办事项
- 提供 Hugging Face Transformers 权重。
- 简化控制器设计,提供无渲染模式。
- 集成 Gym。
- 添加技能库,以支持更复杂的函数调用。
相关项目
- Mobile-Agent:具有视觉感知能力的自主多模态移动设备代理 http://arxiv.org/abs/2401.16158
- UFO:面向Windows操作系统交互的UI导向型代理 http://arxiv.org/abs/2402.07939
- ScreenAI:用于理解UI和信息图表的视觉语言模型 http://arxiv.org/abs/2402.04615
- AppAgent:作为智能手机用户的多模态代理 http://arxiv.org/abs/2312.13771
- CogAgent:用于GUI代理的视觉语言模型 http://arxiv.org/abs/2312.08914
- Screen2Words:基于多模态学习的自动移动UI摘要 http://arxiv.org/abs/2108.03353
- 具有规划、长上下文理解和程序合成能力的真实世界Web代理 http://arxiv.org/abs/2307.12856
- 用于智能手机GUI自动化的综合认知LLM代理 http://arxiv.org/abs/2402.11941
- 通往通用计算机控制之路:以《荒野大镖客2》为例的多模态代理 https://arxiv.org/abs/2403.03186
- 在多个模拟世界中扩展可指令代理 技术报告链接
- Android in the Zoo:用于GUI代理的动作链思维 http://arxiv.org/abs/2403.02713
- OmniACT:一个数据集和基准,旨在支持桌面和网页上的多模态通用自主代理 http://arxiv.org/abs/2402.17553
- 用于智能手机GUI自动化的综合认知LLM代理 http://arxiv.org/abs/2402.11941
- 从截图中提升语言理解能力 http://arxiv.org/abs/2402.14073
- AndroidEnv:一个针对Android的强化学习平台 http://arxiv.org/abs/2105.13231
- SeeClick:利用GUI接地机制构建先进的视觉GUI代理 https://arxiv.org/abs/2401.10935
- AgentStudio:用于构建通用虚拟代理的工具包 https://arxiv.org/abs/2403.17918
- ReALM:将指代消解视为语言建模 https://arxiv.org/abs/2403.20329
- AutoWebGLM:自举并强化基于大型语言模型的网页导航代理 https://arxiv.org/abs/2404.03648
- Octopus v2:用于超级代理的设备端语言模型 https://arxiv.org/pdf/2404.01744.pdf
- Mobile-Env:一个用于评估LLM与GUI交互的平台和基准 https://arxiv.org/abs/2305.08144
- OSWorld:在真实计算机环境中对多模态代理进行开放式任务的基准测试 https://arxiv.org/abs/2404.07972
- Ferret-UI:利用多模态LLM实现 grounded移动UI理解 https://arxiv.org/abs/2404.05719
- VisualWebBench:多模态LLM在网页理解和接地方面已经发展到何种程度? https://arxiv.org/abs/2404.05955
- OS-Copilot:迈向具备自我改进能力的通用计算机代理 https://arxiv.org/abs/2402.07456
- VisualWebBench:多模态LLM在网页理解和接地方面已经发展到何种程度? https://arxiv.org/abs/2404.05955
- AutoDroid:基于LLM的Android任务自动化 https://arxiv.org/abs/2308.15272
- 通过强化学习微调大型视觉语言模型,使其成为决策代理 https://rl4vlm.github.io
- WebArena:一个用于构建自主代理的真实网络环境 https://arxiv.org/abs/2307.13854
- Synapse:基于轨迹示例提示的记忆增强型计算机控制方法 https://openreview.net/pdf?id=Pc8AU1aF5e
- gpt-computer-assistant https://github.com/onuratakan/gpt-computer-assistant
- Mobile-Agent:强大的移动设备操作助手系列 https://github.com/X-PLUG/MobileAgent
- GUI Odyssey:一个用于移动设备跨应用GUI导航的综合数据集 https://github.com/OpenGVLab/GUI-Odyssey
- ASSISTGUI:面向任务的PC图形用户界面自动化 https://showlab.github.io/assistgui/
- You Only Look at Screens:多模态动作链代理 https://arxiv.org/abs/2309.11436 https://github.com/cooelf/Auto-GUI
- E-ANT:一个用于高效自动GUI导航的大规模数据集 https://arxiv.org/pdf/2406.14250
- AndroidWorld https://github.com/google-research/android_world
- AppWorld:一个可控的应用和人物世界,用于基准测试交互式编码代理 https://arxiv.org/abs/2407.18901 https://appworld.dev/
- Read Anywhere Pointed:基于树状透镜接地的布局感知GUI屏幕阅读 https://arxiv.org/abs/2406.19263
- Cradle:赋能基础代理迈向通用计算机控制 https://arxiv.org/abs/2403.03186
- 针对语言模型代理的树搜索 https://arxiv.org/abs/2407.01476
- LaVague:面向开发者的Web代理框架 https://github.com/lavague-ai/LaVague
- WebLlama:https://github.com/McGill-NLP/webllama
- AutoCrawler:一种渐进式理解型Web代理,用于生成网络爬虫 https://arxiv.org/abs/2404.12753
引用
@article{niu2024screenagent,
title={ScreenAgent:一种由视觉语言模型驱动的计算机控制代理},
author={牛润良、李金东、王世奇、付亚丽、胡西宇、冷雪源、孔赫、常毅、王琪},
year={2024},
eprint={2402.07945},
archivePrefix={arXiv},
primaryClass={cs.HC}
}
许可证
代码许可证:MIT
数据集许可证:Apache-2.0
模型许可证:CogVLM许可证
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
AutoGPT
AutoGPT 是一个旨在让每个人都能轻松使用和构建 AI 的强大平台,核心功能是帮助用户创建、部署和管理能够自动执行复杂任务的连续型 AI 智能体。它解决了传统 AI 应用中需要频繁人工干预、难以自动化长流程工作的痛点,让用户只需设定目标,AI 即可自主规划步骤、调用工具并持续运行直至完成任务。 无论是开发者、研究人员,还是希望提升工作效率的普通用户,都能从 AutoGPT 中受益。开发者可利用其低代码界面快速定制专属智能体;研究人员能基于开源架构探索多智能体协作机制;而非技术背景用户也可直接选用预置的智能体模板,立即投入实际工作场景。 AutoGPT 的技术亮点在于其模块化“积木式”工作流设计——用户通过连接功能块即可构建复杂逻辑,每个块负责单一动作,灵活且易于调试。同时,平台支持本地自托管与云端部署两种模式,兼顾数据隐私与使用便捷性。配合完善的文档和一键安装脚本,即使是初次接触的用户也能在几分钟内启动自己的第一个 AI 智能体。AutoGPT 正致力于降低 AI 应用门槛,让人人都能成为 AI 的创造者与受益者。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信