nboost
NBoost 是一个可扩展的搜索增强平台,专为提升搜索引擎结果的相关性而设计。它通过部署先进的 Transformer 模型,充当用户与现有搜索引擎(如 Elasticsearch)之间的智能中间层。在传统搜索中,用户直接查询数据库获取结果;而引入 NBoost 后,系统会先由模型对初步检索到的内容进行二次排序和筛选,只将最匹配的答案返回给用户,从而显著优化搜索体验。
这一工具主要解决了传统关键词搜索难以理解语义、导致结果不够精准的问题,特别适用于需要高质量排序输入的场景,如智能问答系统或企业级知识库检索。NBoost 非常适合开发者、数据科学家以及研究人员使用,帮助他们快速构建针对特定领域优化的神经搜索引擎。
其核心技术亮点在于支持微调预训练模型,使其适应垂直领域的搜索需求,并具备出色的泛化能力,即便在与训练集不同的真实数据上也能表现优异。此外,NBoost 架构灵活,支持从本地部署到 Kubernetes 集群的各种环境,让高性能的神经重排序技术能够轻松集成到现有的搜索工作流中。
使用场景
某大型电商平台的搜索团队正致力于优化其基于 Elasticsearch 的商品检索系统,以解决用户在使用自然语言查询时难以找到精准商品的问题。
没有 nboost 时
- 关键词匹配局限:传统搜索引擎仅依赖关键词字面匹配,当用户搜索“适合夏天的透气跑鞋”时,无法理解语义,导致包含“夏季”、“网面”等近义词的相关商品被遗漏。
- 排序相关性低:返回结果主要依据文本频率打分,往往将标题堆砌关键词但实际不相关的商品排在前列,用户需要翻越多页才能找到目标。
- 长尾查询失效:面对复杂的自然语言长句查询,系统缺乏深度理解能力,召回率大幅下降,直接导致转化率流失。
- 模型部署困难:团队虽想引入 BERT 等 Transformer 模型进行优化,但缺乏 scalable 的部署架构,难以将其无缝集成到现有的高并发搜索流中。
使用 nboost 后
- 语义理解增强:nboost 作为中间层拦截查询,利用微调后的 Transformer 模型深刻理解“夏天透气”与“夏季网面”的语义关联,显著扩大相关商品的召回范围。
- 智能重排序:nboost 从 Elasticsearch 获取初筛结果后,通过神经重排序模型(Neural Rerank)精准评估相关性,将最符合用户意图的商品置顶展示。
- 复杂查询胜任:即使面对冗长的自然语言描述,nboost 也能准确捕捉核心需求,大幅提升长尾查询的命中率和用户满意度。
- 无缝弹性部署:借助 nboost 的平台化能力,团队轻松将先进的预训练模型部署为可扩展的 API,无需重构底层架构即可实现搜索能力的即时升级。
nboost 通过引入深度学习重排序机制,将传统的关键词搜索升级为懂语义的智能检索,在不改变原有基础设施的前提下实现了搜索相关性的质的飞跃。
运行环境要求
- 未说明 (支持 Docker 和 PyPi,通常兼容 Linux/macOS/Windows)
- 非必需
- 若需加速,支持 CUDA 的 GPU(文中提到 Tensorflow 1.14-1.15 或 PyTorch with CUDA)
- 不同模型速度差异大:TinyBERT 约 50ms/query,BERT-Base 约 300ms/query
- 未明确具体显存大小要求
未说明

快速开始





![]()

亮点 • 概述 • 基准测试 • 安装 • 入门 • Kubernetes • 文档 • 教程 • 贡献 • 发布说明 • 博客
它是什么
⚡NBoost 是一个可扩展的搜索引擎增强平台,用于开发和部署最先进的模型,以提高搜索结果的相关性。

NBoost 利用微调后的模型来构建特定领域的神经搜索引擎。该平台还可以改进其他需要排序输入的下游任务,例如问答系统。
概述
NBoost 的工作流程相对简单。请参考上面的示意图,假设这里的服务器是 Elasticsearch。

在传统搜索请求中,用户向 Elasticsearch 发送查询,并获得结果。

在NBoost 搜索请求中,用户将查询发送给 模型。然后,模型会从 Elasticsearch 请求结果,并挑选出最佳的结果返回给用户。
基准测试
🔬 注意,我们在与模型训练时不同的数据集上评估这些模型(MS Marco vs TREC-CAR),这表明这些模型具有广泛的通用性,可以应用于许多其他实际的搜索问题。
| 微调模型 | 依赖项 | 评估集 | 搜索提升[1] | GPU 上的速度 |
|---|---|---|---|---|
nboost/pt-tinybert-msmarco (默认) |
必应查询 | +45% (0.26 vs 0.18) | ~50ms/查询 | |
nboost/pt-bert-base-uncased-msmarco |
必应查询 | +62% (0.29 vs 0.18) | ~300 ms/查询 | |
nboost/pt-bert-large-msmarco |
必应查询 | +77% (0.32 vs 0.18) | - | |
nboost/pt-biobert-base-msmarco |
生物医学 | +66% (0.17 vs 0.10) | ~300 ms/查询 |
重现方法请见此处。
[1] MRR 与 BM25 相比,BM25 是 Elasticsearch 的默认值。对前 50 个结果进行重新排名。
[2] https://github.com/nyu-dl/dl4marco-bert
要使用这些微调模型之一与 NBoost 配合使用,只需运行 nboost --model_dir bert-base-uncased-msmarco 等命令,它就会自动下载并缓存模型。
通过使用预训练的语言理解模型,您可以将搜索相关性指标提高近 2 倍,而无需额外的配置。在评估性能时,通常需要在模型准确性和速度之间做出权衡,因此我们在上面同时列出了这两项指标。此排行榜仍在不断完善中,我们计划推出更多前沿模型!
安装 NBoost
获取 NBoost 有两种方式:作为 Docker 镜像或作为 PyPi 包。对于云用户,我们强烈建议使用 Docker 版本的 NBoost。
🚸 根据您选择的模型,您需要安装相应的 Tensorflow 或 Pytorch 依赖项。我们已在下方打包好这些依赖项。
以下是安装 NBoost 的步骤:
| 依赖 | 🐳 Docker | 📦 Pypi | 🐙 Kubernetes |
|---|---|---|---|
| Pytorch (推荐) | koursaros/nboost:latest-pt |
pip install nboost[pt] |
helm install nboost/nboost --set image.tag=latest-pt |
| Tensorflow | koursaros/nboost:latest-tf |
pip install nboost[tf] |
helm install nboost/nboost --set image.tag=latest-tf |
| 全部 | koursaros/nboost:latest-all |
pip install nboost[all] |
helm install nboost/nboost --set image.tag=latest-all |
| - (用于测试) | koursaros/nboost:latest-alpine |
pip install nboost |
helm install nboost/nboost --set image.tag=latest-alpine |
无论你以何种方式安装,只要在运行 $ nboost --help 或 $ docker run koursaros/nboost --help 后看到以下消息,就说明你可以开始使用了!

入门指南
📡代理

|
代理是NBoost的核心。代理本质上是一个封装层,用于支持模型的服务化。它可以理解来自特定搜索API(如Elasticsearch)的请求消息。当代理接收到请求时,它会增加客户端要求的结果数量,以便模型能够对更多结果进行重新排序,并返回(希望是)更优的结果。 例如,如果客户端通过Elasticsearch查询“brown dogs”,并要求返回10条结果,那么代理可能会将请求结果数量提升至100条,然后再从中筛选出最优质的10条结果返回给客户端。 |
在3分钟内为Elasticsearch搭建神经网络代理
在这个示例中,我们将搭建一个代理,使其位于客户端和Elasticsearch之间,从而提升搜索结果的质量!
使用TensorFlow安装NBoost
如果你想在GPU上运行此示例,请确保已安装TensorFlow 1.14-1.15、PyTorch或ONNX Runtime,并且支持CUDA以实现建模功能。不过,如果你只想在CPU上运行也没关系。无论哪种情况,只需运行:
pip install nboost[pt]
搭建Elasticsearch服务器
🔔 如果你已经有一个Elasticsearch服务器,可以跳过这一步!
如果没有Elasticsearch也不用担心!我们建议使用Docker在本地搭建一个Elasticsearch集群(前提是已安装Docker)。首先,拉取ES镜像:
docker pull elasticsearch:7.4.2
镜像下载完成后,可以通过以下命令运行Elasticsearch服务器:
docker run -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.4.2
部署代理
现在我们可以部署我们的神经网络代理了!操作非常简单,只需运行:
nboost \
--uhost localhost \
--uport 9200 \
--search_route "/<index>/_search" \
--query_path url.query.q \
--topk_path url.query.size \
--default_topk 10 \
--choices_path body.hits.hits \
--cvalues_path _source.passage
📢
--uhost和--uport应与上述Elasticsearch服务器保持一致!Uhost和uport分别是upstream-host和upstream-port的缩写,指代上游服务器。
如果出现以下提示:Listening: <host>:<port>,那就说明一切准备就绪!
索引一些数据
NBoost内置了一个便捷的索引工具(nboost-index)。为了演示目的,我们将通过NBoost索引一组关于旅行和酒店的文章片段(微软TREC 2019深度学习数据集)。你可以通过以下命令将这些数据添加到你的Elasticsearch服务器中:
travel.csv随NBoost一起提供
nboost-index --file travel.csv --index_name travel --delim , --id_col
现在让我们来测试一下吧!向Elasticsearch发送如下请求:
curl "http://localhost:8000/travel/_search?pretty&q=passage:vegas&size=2"
如果Elasticsearch返回的结果中带有nboost标签,那么恭喜你,一切正常运作!

刚才发生了什么?
让我们来看看NBoost前端界面。打开浏览器,访问localhost:8000/nboost。
如果无法访问浏览器,也可以通过
curl http://localhost:8000/nboost/status获取相同信息。
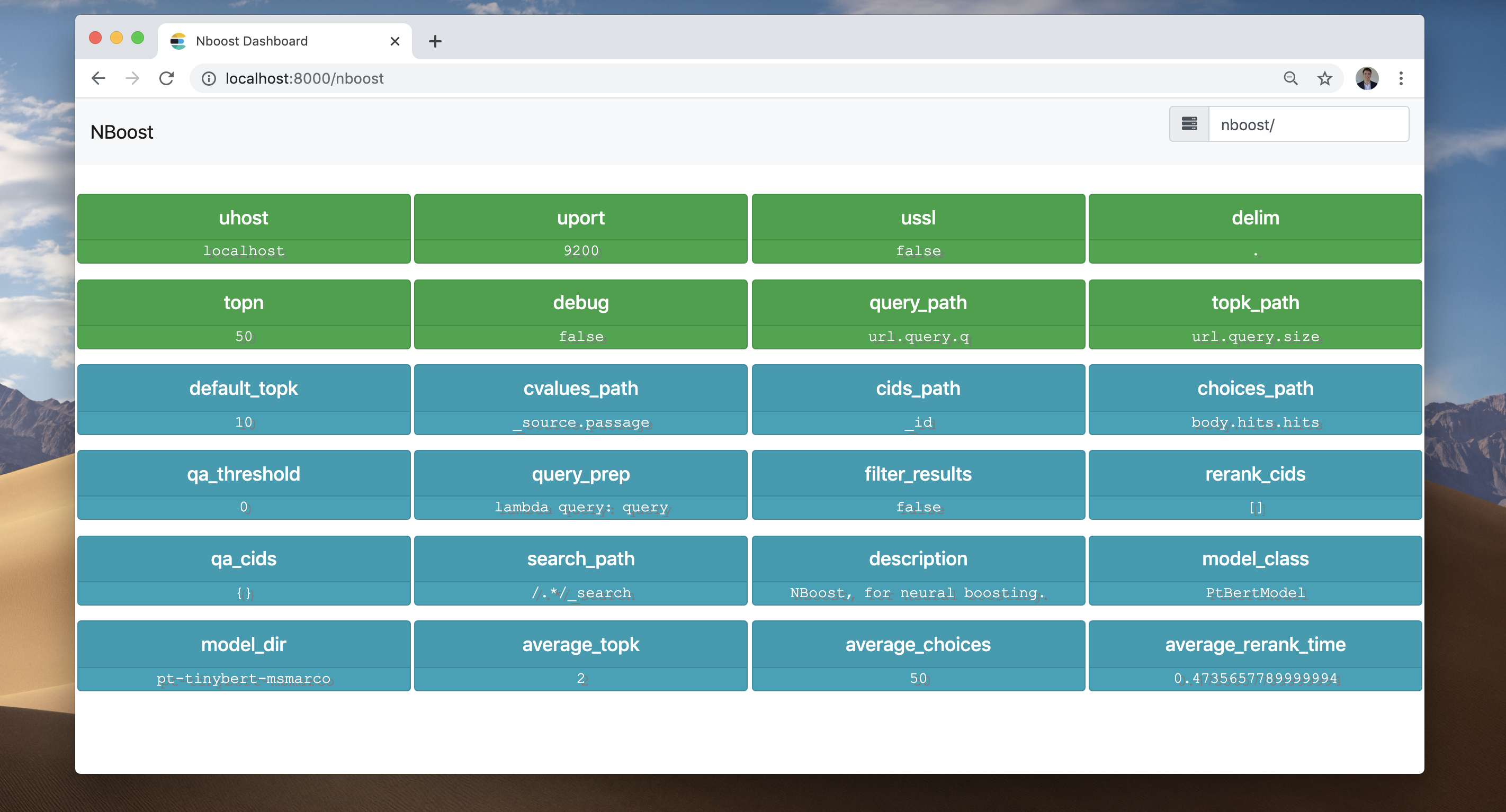
前端记录了所有发生的事情:
- NBoost收到了一条请求,要求返回2条搜索结果。(average_topk)
- NBoost连接到了
localhost:9200的服务器。 - NBoost向服务器发送了请求,要求返回50条搜索结果。(topn)
- NBoost从服务器接收到了50条搜索结果。(average_choices)
- 模型从中挑选出最优质的2条搜索结果,并将其返回给客户端。
轻松玩转Elasticsearch
若需增加并行代理的数量,只需增加--workers参数即可。对于更健壮的部署方案,还可以通过Kubernetes来分发代理(见下文)。
Kubernetes

参阅
有关深入的查询DSL及其他搜索API解决方案(如Bing API),请参阅文档。
通过Kubernetes部署NBoost
我们可以使用Helm轻松地在Kubernetes集群中部署NBoost。
添加 NBoost Helm 仓库
首先,我们需要在您的 Kubernetes 集群中注册该仓库。
helm repo add nboost https://raw.githubusercontent.com/koursaros-ai/nboost/master/charts/
helm repo update
部署若干 NBoost 副本
让我们尝试部署四个副本:
helm install --name nboost --set replicaCount=4 nboost/nboost
所有可能的 --set 参数(参考 values.yaml)列于下文:
| 参数 | 描述 | 默认值 |
|---|---|---|
replicaCount |
部署的副本数量 | 3 |
image.repository |
NBoost 镜像名称 | koursaros/nboost |
image.tag |
NBoost 镜像标签 | latest-pt |
args.model |
模型类名称 | nil |
args.model_dir |
微调后的模型名称或目录 | pt-bert-base-uncased-msmarco |
args.qa |
是否使用问答插件 | False |
args.qa_model_dir |
问答模型的名称或目录 | distilbert-base-uncased-distilled-squad |
args.host |
代理服务器的主机名 | 0.0.0.0 |
args.port |
代理服务器监听的端口 | 8000 |
args.uhost |
上游搜索 API 服务器的主机名 | elasticsearch-master |
args.uport |
上游服务器的端口 | 9200 |
args.data_dir |
缓存模型二进制文件的目录 | nil |
args.max_seq_len |
最大组合 token 长度 | 64 |
args.bufsize |
HTTP 缓冲区大小(字节) | 2048 |
args.batch_size |
重新排序模型的批处理大小 | 4 |
args.multiplier |
结果放大倍数 | 5 |
args.workers |
服务代理的线程数量 | 10 |
args.query_path |
请求中用于查找查询的 JsonPath | nil |
args.topk_path |
用于查找请求结果数量的 JsonPath | nil |
args.choices_path |
用于查找待重新排序选项数组的 JsonPath | nil |
args.cvalues_path |
用于查找选项字符串值的 JsonPath | nil |
args.cids_path |
用于查找选项 ID 的 JsonPath | nil |
args.search_path |
用于标记需通过 nboost 重新排序的 URL 路径 | nil |
service.type |
Kubernetes 服务类型 | LoadBalancer |
resources |
Pod 的资源需求和限制 | {} |
nodeSelector |
用于分配 Pod 的节点标签 | {} |
affinity |
用于分配 Pod 的亲和性设置 | {} |
tolerations |
用于分配 Pod 的容忍度标签 | [] |
image.pullPolicy |
镜像拉取策略 | IfNotPresent |
imagePullSecrets |
Docker 注册表 Secret 名称数组 | [](不会将镜像拉取 Secret 添加到已部署的 Pod 中) |
nameOverride |
用于覆盖 Chart.name 的字符串 | nil |
fullnameOverride |
用于覆盖 Chart.fullname 的字符串 | nil |
serviceAccount.create |
指定是否创建服务账户 | nil |
serviceAccount.name |
要使用的服务账户名称。若未设置且 create 为 true,则会使用 fullname 模板生成名称 | nil |
podSecurityContext.fsGroup |
容器的组 ID | nil |
securityContext.runAsUser |
容器的用户 ID | 1001 |
ingress.enabled |
启用 Ingress 资源 | false |
ingress.hostName |
您安装的主机名 | nil |
ingress.path |
URL 结构中的路径 | [] |
ingress.tls |
启用带有 TLS 的 Ingress | [] |
ingress.tls.secretName |
要使用的 TLS 类型 Secret | chart-example-tls |
文档

NBoost 的官方文档托管在 nboost.readthedocs.io 上。每次发布新版本时,文档都会自动构建、更新并归档。
贡献
我们非常欢迎您的贡献!您可以对代码进行修正或改进,并提交到 NBoost 仓库。以下是具体步骤:
- 创建一个新分支,例如
fix-nboost-typo-1。 - 修复或优化代码库。
- 提交更改。请注意,提交信息必须遵循 命名规范,例如
Fix/model-bert: 提高可读性并调整章节顺序。 - 发起拉取请求。同样,拉取请求的标题也必须遵循 命名规范。您可以直接使用其中一条提交信息作为拉取请求的标题,例如
Fix/model-bert: 提高可读性并调整章节顺序。 - 提交拉取请求,并等待所有检查通过(通常需要 10 分钟):
- 代码风格检查
- 提交和拉取请求格式检查
- 所有单元测试
- 请求核心团队中的一位开发者进行评审。
- 合并!
更多详细信息请参阅 贡献指南。
引用 NBoost
如果您在学术论文中使用了 NBoost,我们非常希望您能对其进行引用。以下是两种引用 NBoost 的方式:
\footnote{https://github.com/koursaros-ai/nboost}@misc{koursaros2019NBoost, title={NBoost: 神经网络增强搜索结果}, author={Thienes, Cole 和 Pertschuk, Jack}, howpublished={\url{https://github.com/koursaros-ai/nboost}}, year={2019} }
许可证
如果您下载了 NBoost 的二进制文件或源代码,请注意,NBoost 的二进制文件和源代码均采用 Apache License, Version 2.0 许可证授权。
Koursaros AI 很高兴将这款开源软件贡献给社区。版权所有 © 2019。保留所有权利。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
AutoGPT
AutoGPT 是一个旨在让每个人都能轻松使用和构建 AI 的强大平台,核心功能是帮助用户创建、部署和管理能够自动执行复杂任务的连续型 AI 智能体。它解决了传统 AI 应用中需要频繁人工干预、难以自动化长流程工作的痛点,让用户只需设定目标,AI 即可自主规划步骤、调用工具并持续运行直至完成任务。 无论是开发者、研究人员,还是希望提升工作效率的普通用户,都能从 AutoGPT 中受益。开发者可利用其低代码界面快速定制专属智能体;研究人员能基于开源架构探索多智能体协作机制;而非技术背景用户也可直接选用预置的智能体模板,立即投入实际工作场景。 AutoGPT 的技术亮点在于其模块化“积木式”工作流设计——用户通过连接功能块即可构建复杂逻辑,每个块负责单一动作,灵活且易于调试。同时,平台支持本地自托管与云端部署两种模式,兼顾数据隐私与使用便捷性。配合完善的文档和一键安装脚本,即使是初次接触的用户也能在几分钟内启动自己的第一个 AI 智能体。AutoGPT 正致力于降低 AI 应用门槛,让人人都能成为 AI 的创造者与受益者。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信