pytorch-optimizer
pytorch-optimizer 是一个专为 PyTorch 框架设计的优化器集合库,旨在为深度学习模型训练提供更多样化、更高效的参数更新策略。它解决了原生 PyTorch 内置优化器种类有限的问题,让开发者和研究人员能够轻松尝试如 DiffGrad、A2Grad、AccSGD 等前沿学术算法,而无需手动复现复杂的数学公式或担心兼容性问题。
该工具完全兼容 PyTorch 原生的 optim 模块接口,用户只需替换导入路径即可无缝切换优化器,极大降低了实验门槛。无论是需要复现论文结果的科研人员,还是希望提升模型收敛速度与精度的算法工程师,都能从中受益。其核心亮点在于收录了多篇顶级会议论文提出的创新优化算法,并提供了经过测试的稳定实现,支持通过简单的 pip 命令一键安装。借助 pytorch-optimizer,用户可以快速验证不同优化策略对特定任务的效果,加速从理论到实践的转化过程,是深度学习领域不可或缺的实用辅助工具。
使用场景
某计算机视觉团队正在训练一个复杂的图像分割模型,但在调整学习率和收敛速度时遇到了瓶颈。
没有 pytorch-optimizer 时
- 开发者只能依赖 PyTorch 原生提供的 SGD 或 Adam 等基础优化器,难以应对损失函数曲面复杂或非凸优化的挑战。
- 若想尝试 DiffGrad、RAdam 或 AccSGD 等前沿算法,必须手动从论文复现代码,不仅耗时且极易引入实现错误。
- 不同优化器的接口定义不统一,每次切换实验都需要重写训练循环中的参数更新逻辑,导致代码维护成本高昂。
- 缺乏经过社区验证的高质量实现,模型训练过程容易出现梯度爆炸或不收敛,排查问题耗费大量算力资源。
使用 pytorch-optimizer 后
- 团队可直接调用库中集成的 DiffGrad 或 RAdam 等先进算法,仅需一行代码即可替换原有优化器,轻松突破收敛瓶颈。
- 无需再手动复现论文公式,所有优化器均经过严格测试与文档化,确保了数学实现的准确性与稳定性。
- 所有优化器完全兼容 PyTorch 原生
optim模块接口,切换算法时无需修改任何训练流程代码,极大提升了实验效率。 - 借助成熟的开源实现,模型在相同数据集下的收敛速度显著提升,且训练过程更加平稳,有效减少了调参试错的时间。
pytorch-optimizer 通过提供一站式的前沿优化器集合,让开发者能零成本地将理论成果转化为实际的模型性能提升。
运行环境要求
未说明
未说明

快速开始
torch-optimizer
.. image:: https://github.com/jettify/pytorch-optimizer/workflows/CI/badge.svg :target: https://github.com/jettify/pytorch-optimizer/actions?query=workflow%3ACI :alt: 主分支的 GitHub Actions 状态 .. image:: https://codecov.io/gh/jettify/pytorch-optimizer/branch/master/graph/badge.svg :target: https://codecov.io/gh/jettify/pytorch-optimizer .. image:: https://img.shields.io/pypi/pyversions/torch-optimizer.svg :target: https://pypi.org/project/torch-optimizer .. image:: https://readthedocs.org/projects/pytorch-optimizer/badge/?version=latest :target: https://pytorch-optimizer.readthedocs.io/en/latest/?badge=latest :alt: 文档状态 .. image:: https://img.shields.io/pypi/v/torch-optimizer.svg :target: https://pypi.python.org/pypi/torch-optimizer .. image:: https://static.deepsource.io/deepsource-badge-light-mini.svg :target: https://deepsource.io/gh/jettify/pytorch-optimizer/?ref=repository-badge
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
torch-optimizer -- 一个与 PyTorch_ 兼容、并基于 optim_ 模块的优化器集合。
简单示例
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.DiffGrad(model.parameters(), lr=0.001)
optimizer.step()
安装
安装过程非常简单,只需执行::
$ pip install torch_optimizer
文档
https://pytorch-optimizer.rtfd.io
引用
请引用这些优化算法的原始作者。如果您喜欢这个包,请这样引用:
@software{Novik_torchoptimizers,
title = {{torch-optimizer -- PyTorch 的优化算法集合。}},
author = {Novik, Mykola},
year = 2020,
month = 1,
version = {1.0.1}
}
或者使用 GitHub 提供的“引用此仓库”按钮。
支持的优化器
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| A2GradExp_ | https://arxiv.org/abs/1810.00553 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| A2GradInc_ | https://arxiv.org/abs/1810.00553 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| A2GradUni_ | https://arxiv.org/abs/1810.00553 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| AccSGD_ | https://arxiv.org/abs/1803.05591 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| AdaBelief_ | https://arxiv.org/abs/2010.07468 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| AdaBound_ | https://arxiv.org/abs/1902.09843 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| AdaMod_ | https://arxiv.org/abs/1910.12249 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Adafactor_ | https://arxiv.org/abs/1804.04235 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Adahessian_ | https://arxiv.org/abs/2006.00719 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| AdamP_ | https://arxiv.org/abs/2006.08217 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| AggMo_ | https://arxiv.org/abs/1804.00325 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Apollo_ | https://arxiv.org/abs/2009.13586 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| DiffGrad_ | https://arxiv.org/abs/1909.11015 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Lamb_ | https://arxiv.org/abs/1904.00962 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Lookahead_ | https://arxiv.org/abs/1907.08610 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| MADGRAD_ | https://arxiv.org/abs/2101.11075 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| NovoGrad_ | https://arxiv.org/abs/1905.11286 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| PID_ | https://www4.comp.polyu.edu.hk/~cslzhang/paper/CVPR18_PID.pdf |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| QHAdam_ | https://arxiv.org/abs/1810.06801 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| QHM_ | https://arxiv.org/abs/1810.06801 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| RAdam_ | https://arxiv.org/abs/1908.03265 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Ranger_ | https://medium.com/@lessw/new-deep-learning-optimizer-ranger-synergistic-combination-of-radam-lookahead-for-the-best-of-2dc83f79a48d |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| RangerQH_ | https://arxiv.org/abs/1810.06801 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| RangerVA_ | https://arxiv.org/abs/1908.00700v2 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| SGDP_ | https://arxiv.org/abs/2006.08217 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| SGDW_ | https://arxiv.org/abs/1608.03983 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| SWATS_ | https://arxiv.org/abs/1712.07628 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Shampoo_ | https://arxiv.org/abs/1802.09568 |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
| | |
| Yogi_ | https://papers.nips.cc/paper/8186-adaptive-methods-for-nonconvex-optimization |
+---------------+--------------------------------------------------------------------------------------------------------------------------------------+
可视化
可视化帮助我们观察不同算法如何处理简单的情况,例如:鞍点、局部最小值、山谷等,并可能提供对算法内部运作的有趣见解。选择 Rosenbrock_ 和 Rastrigin_ 这两个基准函数是因为:
- Rosenbrock_(也称为香蕉函数)是一个非凸函数,它有一个全局最小值
(1.0, 1.0)。这个全局最小值位于一个狭长、抛物线形状的平坦山谷中。找到这个山谷并不难,但要收敛到全局最小值却非常困难。优化算法可能会过度关注其中一个坐标轴,而难以沿着相对平坦的山谷前进。
.. image:: https://upload.wikimedia.org/wikipedia/commons/3/32/Rosenbrock_function.svg
{kind=link}
- Rastrigin_ 是一个非凸函数,在
(0.0, 0.0)处有一个全局最小值。由于其庞大的搜索空间和大量的局部最小值,寻找该函数的最小值是一个相当困难的问题。
.. image:: https://upload.wikimedia.org/wikipedia/commons/8/8b/Rastrigin_function.png
{kind=link}
每个优化器都执行 501 次优化步骤。学习率是通过超参数搜索算法找到的最佳值,其余调优参数则使用默认值。扩展脚本并调整其他优化器参数非常容易。
.. code::
python examples/viz_optimizers.py
警告
不要仅凭可视化结果来选择优化器。不同的优化方法具有独特的特性,可能针对不同的目的进行设计,或者需要显式的学习率调度等。最好的办法是在你的具体问题上尝试几种优化器,看看它们是否能提升性能。
如果你不确定该使用哪种优化器,可以先从内置的 SGD 或 Adam 开始。一旦训练逻辑准备就绪并建立了基线分数,再更换优化器,看看是否有改进。
A2GradExp
+--------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_A2GradExp.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_A2GradExp.png | +--------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------+
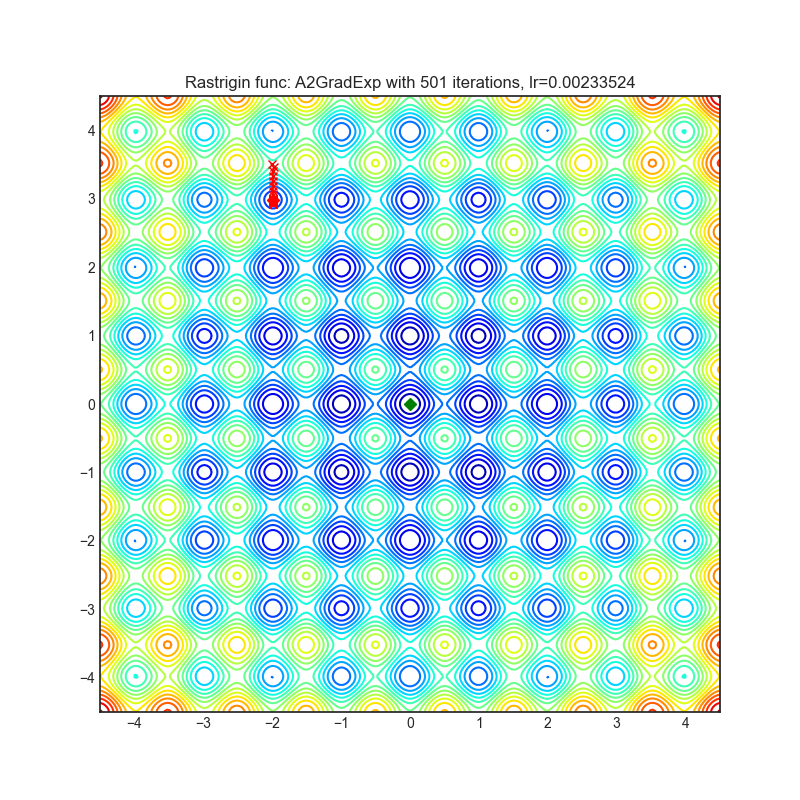{kind=link}
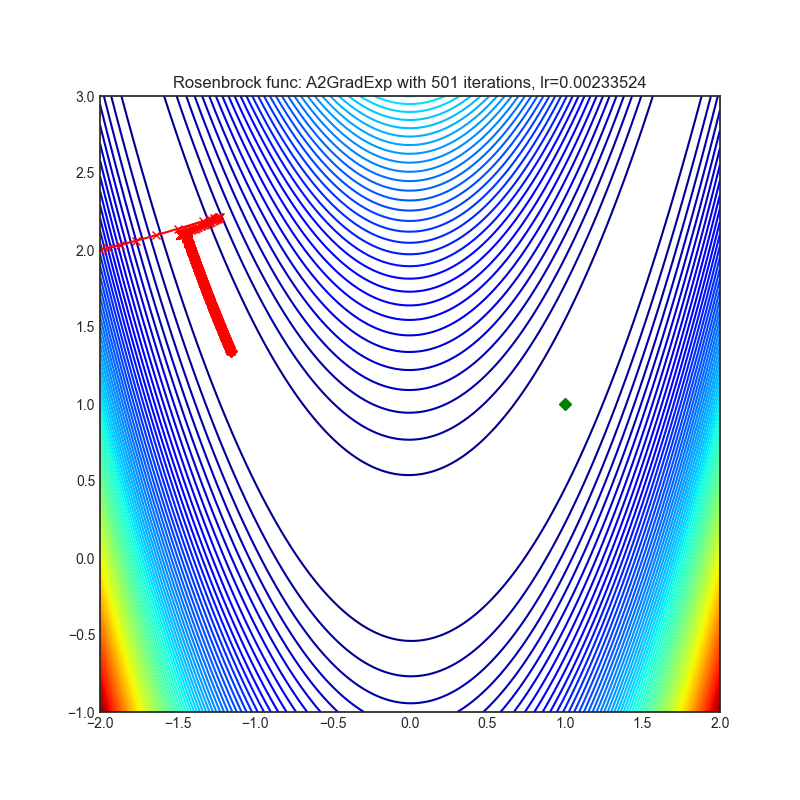{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.A2GradExp(
model.parameters(),
kappa=1000.0,
beta=10.0,
lips=10.0,
rho=0.5,
)
optimizer.step()
论文: 最优自适应与加速随机梯度下降 (2018) [https://arxiv.org/abs/1810.00553]
参考代码: https://github.com/severilov/A2Grad_optimizer
A2GradInc
+--------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_A2GradInc.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_A2GradInc.png | +--------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------+
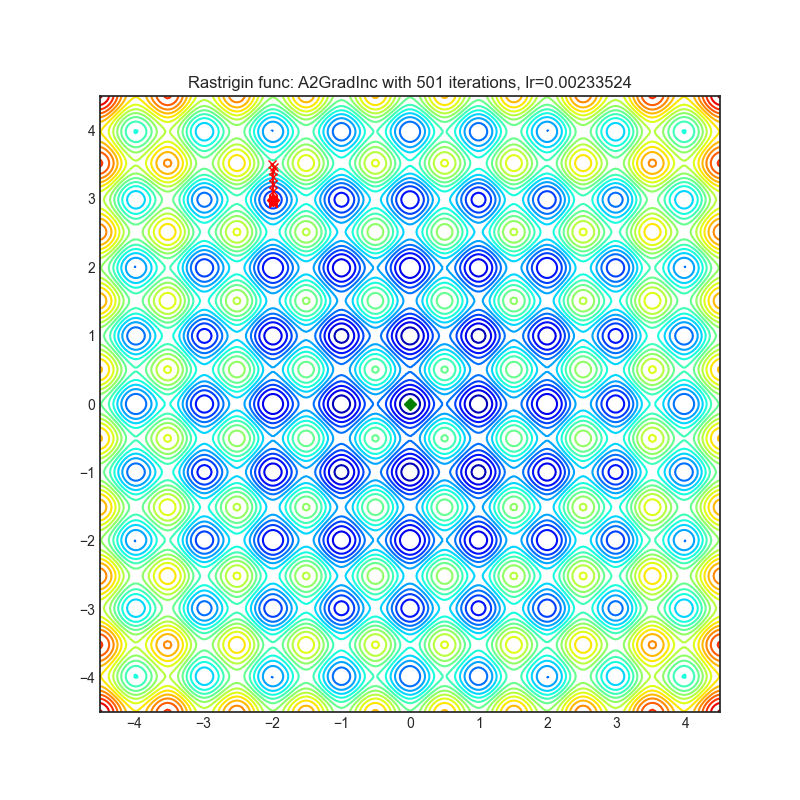{kind=link}
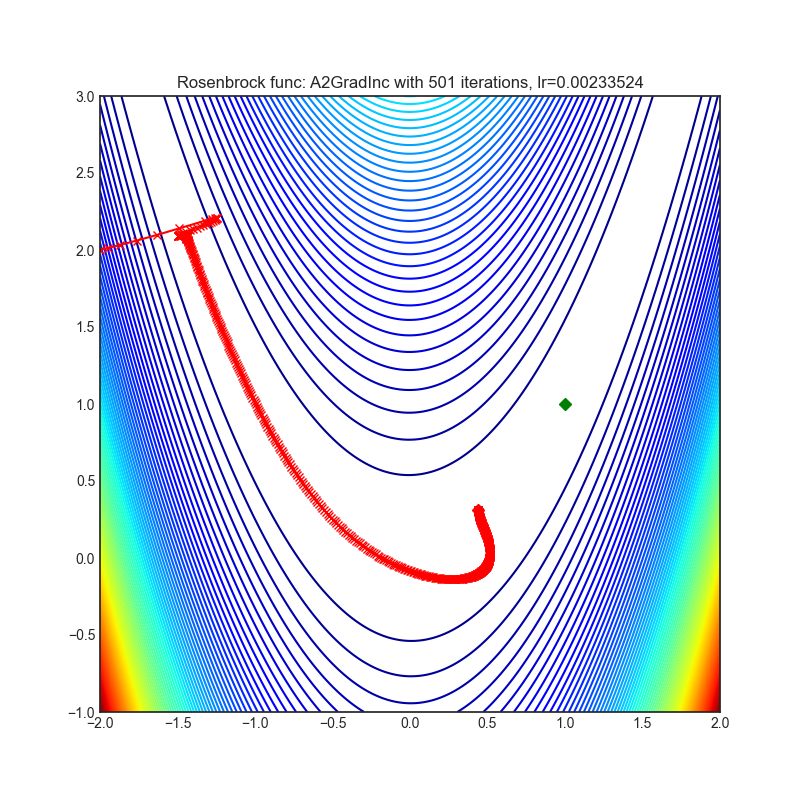{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.A2GradInc(
model.parameters(),
kappa=1000.0,
beta=10.0,
lips=10.0,
)
optimizer.step()
论文: 最优自适应与加速随机梯度下降 (2018) [https://arxiv.org/abs/1810.00553]
参考代码: https://github.com/severilov/A2Grad_optimizer
A2GradUni
+--------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_A2GradUni.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_A2GradUni.png | +--------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------+
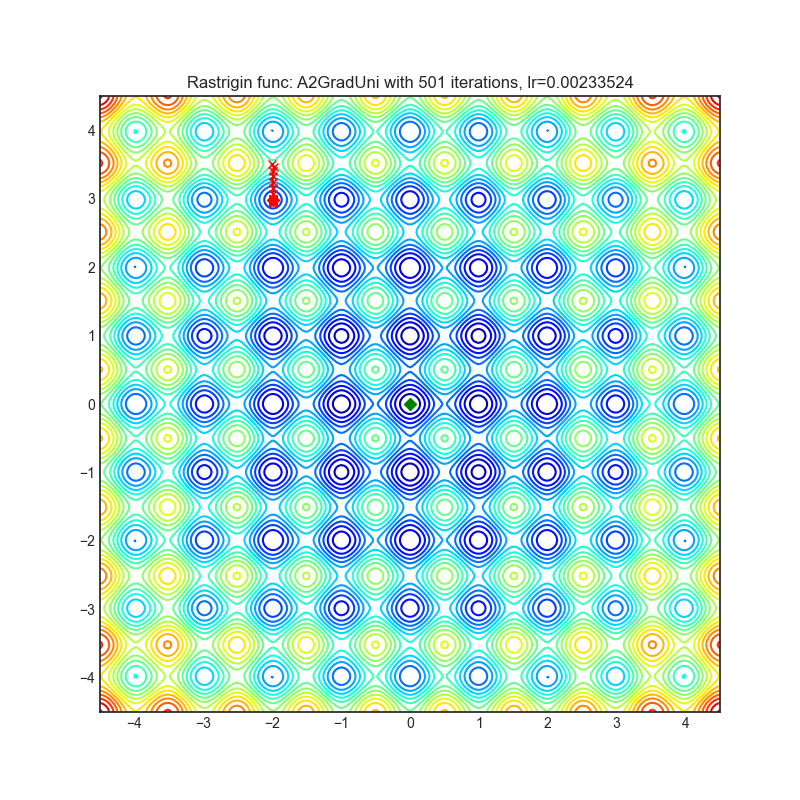{kind=link}
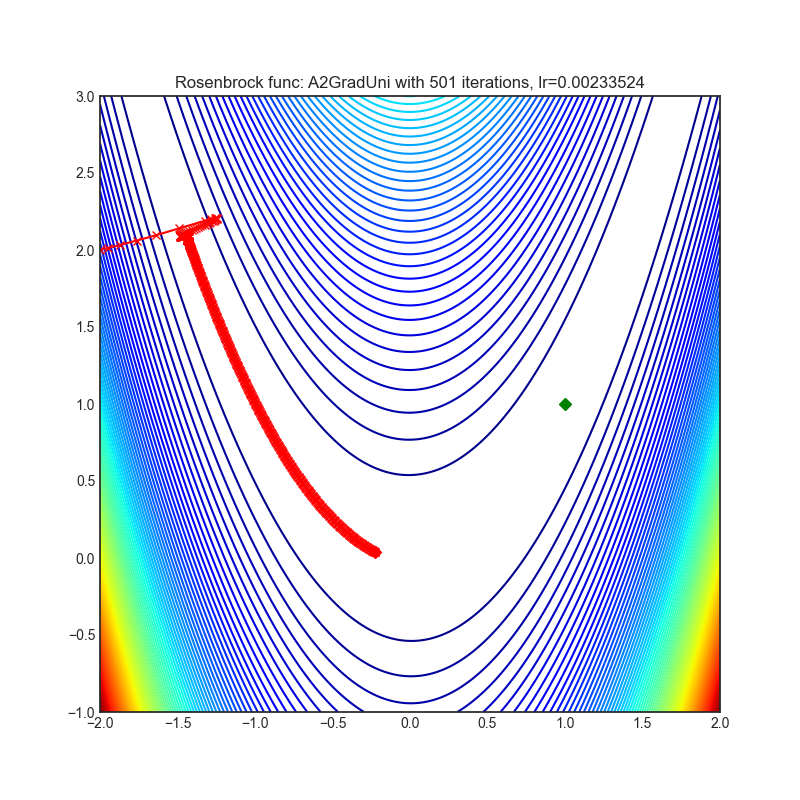{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.A2GradUni(
model.parameters(),
kappa=1000.0,
beta=10.0,
lips=10.0,
)
optimizer.step()
论文: 最优自适应与加速随机梯度下降 (2018) [https://arxiv.org/abs/1810.00553]
参考代码: https://github.com/severilov/A2Grad_optimizer
AccSGD
+-----------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_AccSGD.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_AccSGD.png | +-----------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------+
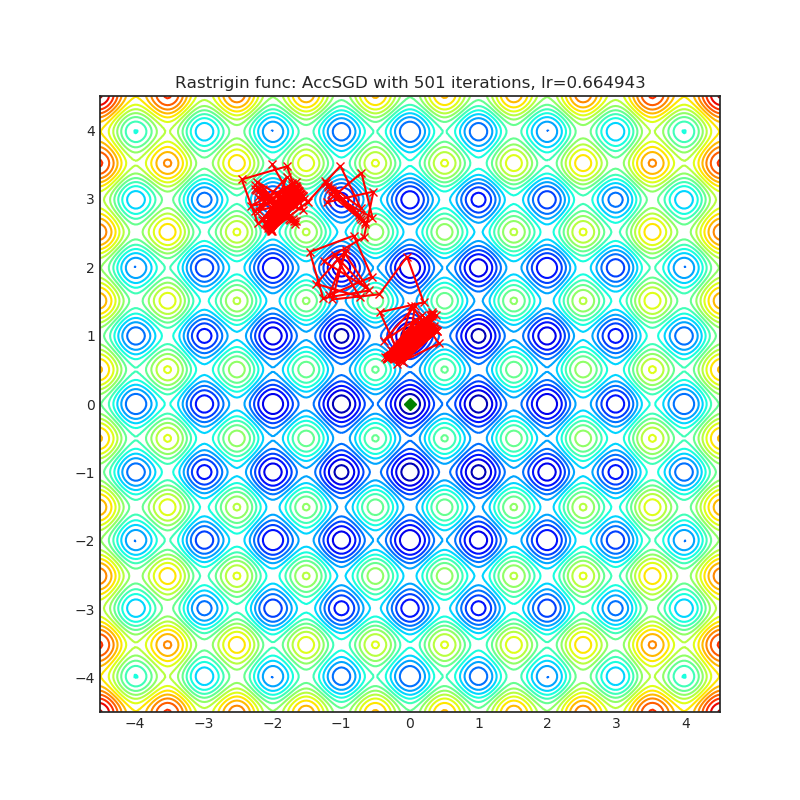{kind=link}
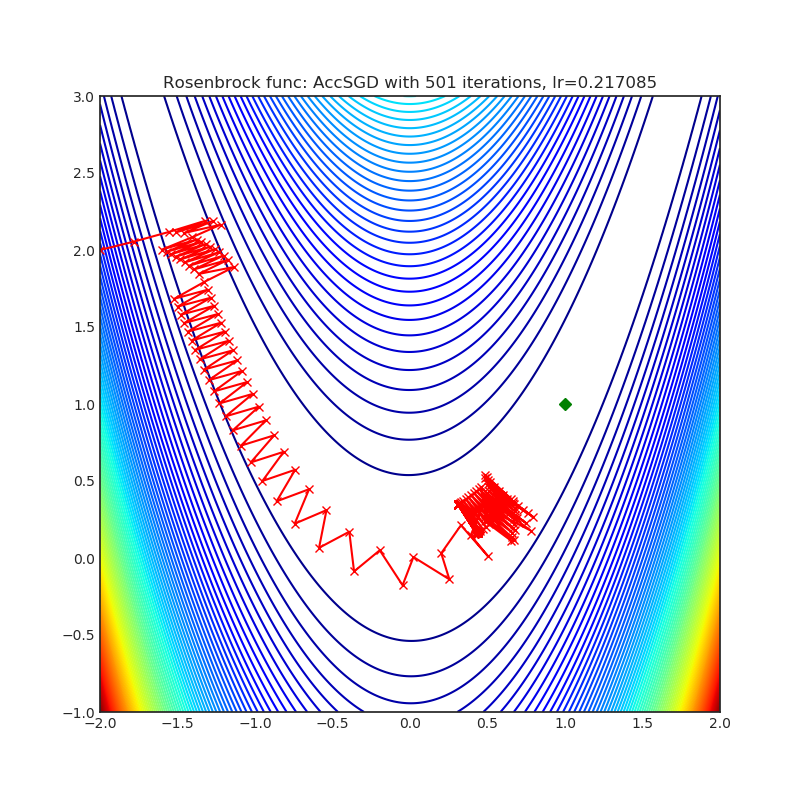{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.AccSGD(
model.parameters(),
lr=1e-3,
kappa=1000.0,
xi=10.0,
small_const=0.7,
weight_decay=0
)
optimizer.step()
论文: 关于现有动量方案在随机优化中的不足 (2019) [https://arxiv.org/abs/1803.05591]
参考代码: https://github.com/rahulkidambi/AccSGD
AdaBelief
+-------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_AdaBelief.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_AdaBelief.png | +-------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+
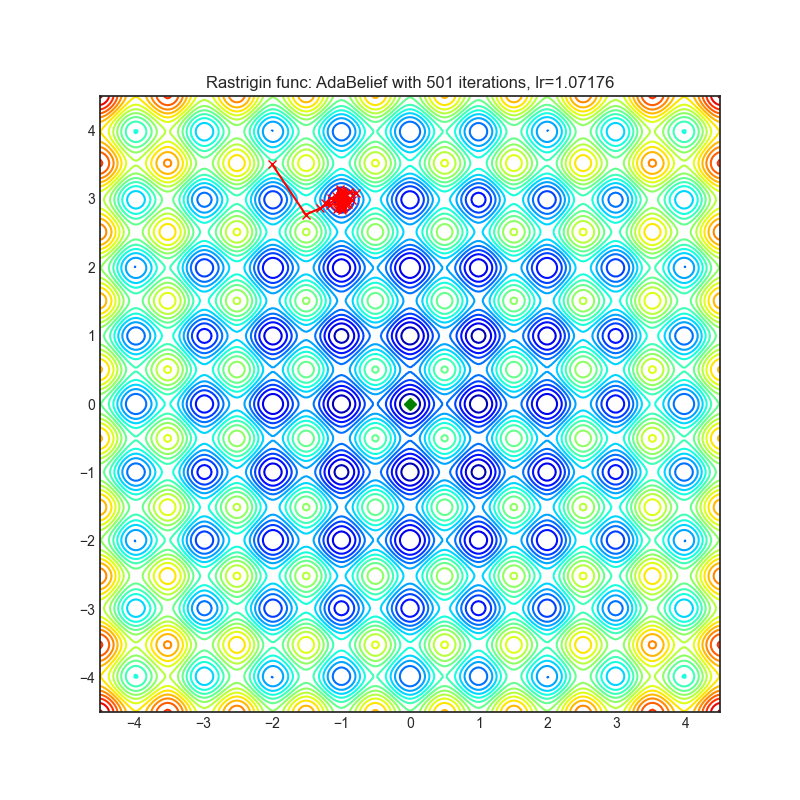{kind=link}
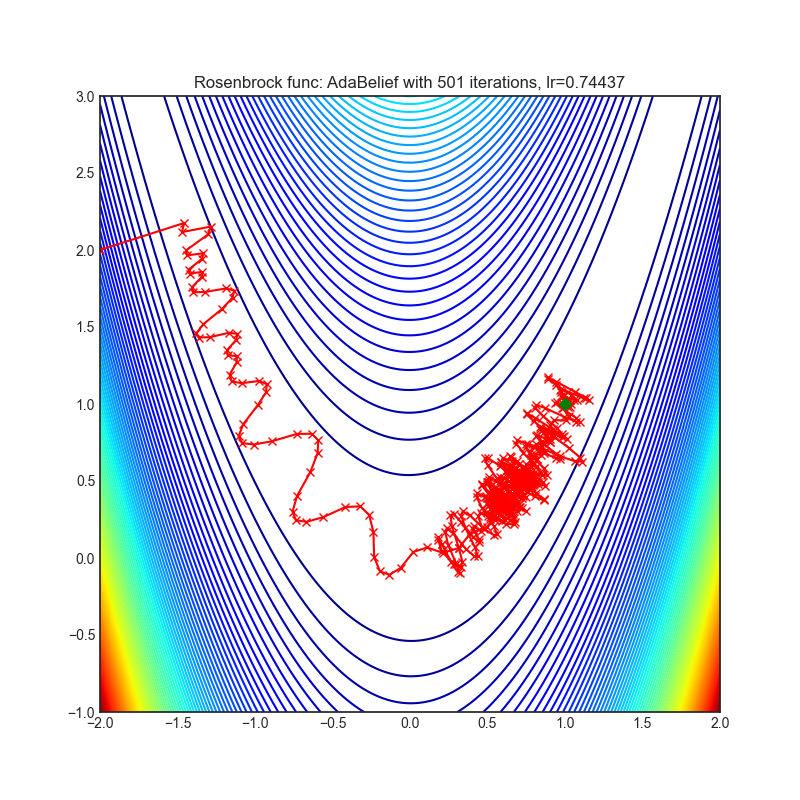{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.AdaBelief(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-3,
weight_decay=0,
amsgrad=False,
weight_decouple=False,
fixed_decay=False,
rectify=False,
)
optimizer.step()
论文: AdaBelief优化器,根据对观测梯度的信任度自适应调整步长 (2020) [https://arxiv.org/abs/2010.07468]
参考代码: https://github.com/juntang-zhuang/Adabelief-Optimizer
AdaBound
+------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_AdaBound.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_AdaBound.png | +------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+
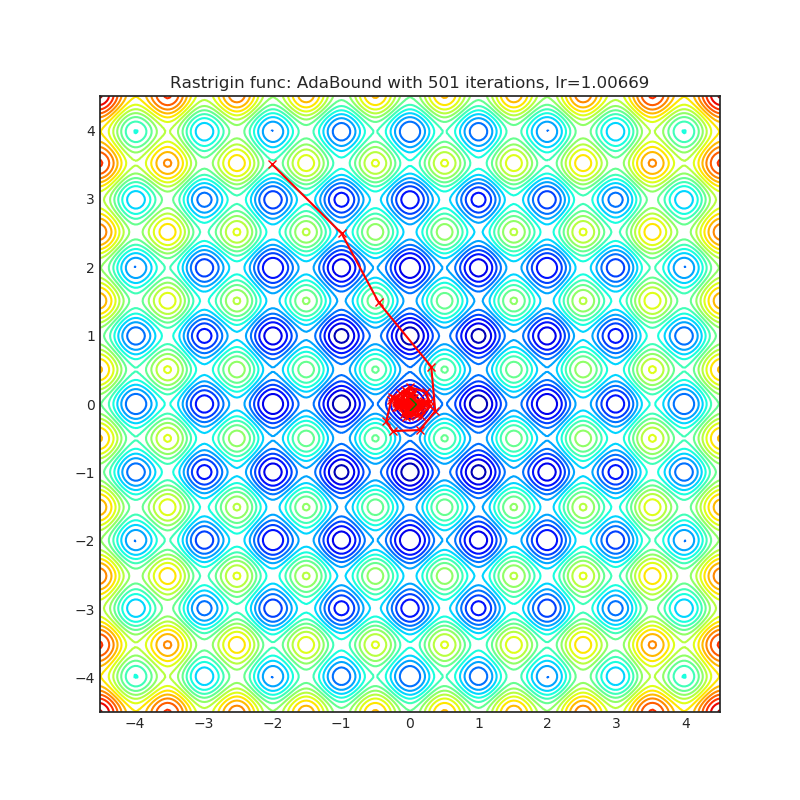{kind=link}
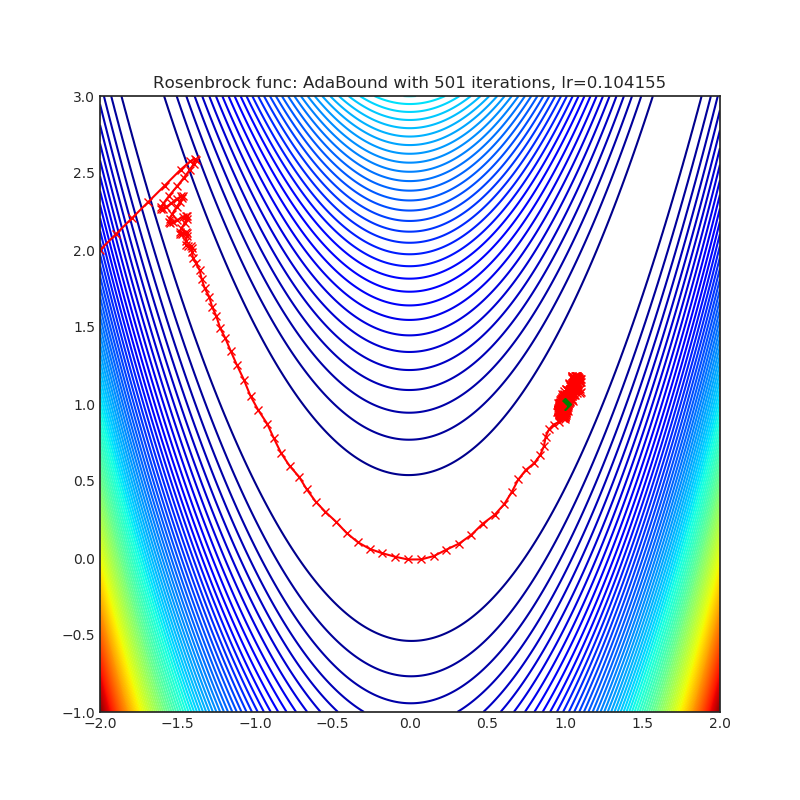{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.AdaBound(
m.parameters(),
lr= 1e-3,
betas= (0.9, 0.999),
final_lr = 0.1,
gamma=1e-3,
eps= 1e-8,
weight_decay=0,
amsbound=False,
)
optimizer.step()
论文: 带有动态学习率边界值的自适应梯度方法 (2019) [https://arxiv.org/abs/1902.09843]
参考代码: https://github.com/Luolc/AdaBound
AdaMod
AdaMod方法通过自适应和动量式的上界来限制自适应学习率。动态学习率的上下界基于自适应学习率自身的指数移动平均值,这有助于平滑意外出现的大学习率,并稳定深度神经网络的训练过程。
+------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_AdaMod.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_AdaMod.png | +------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+
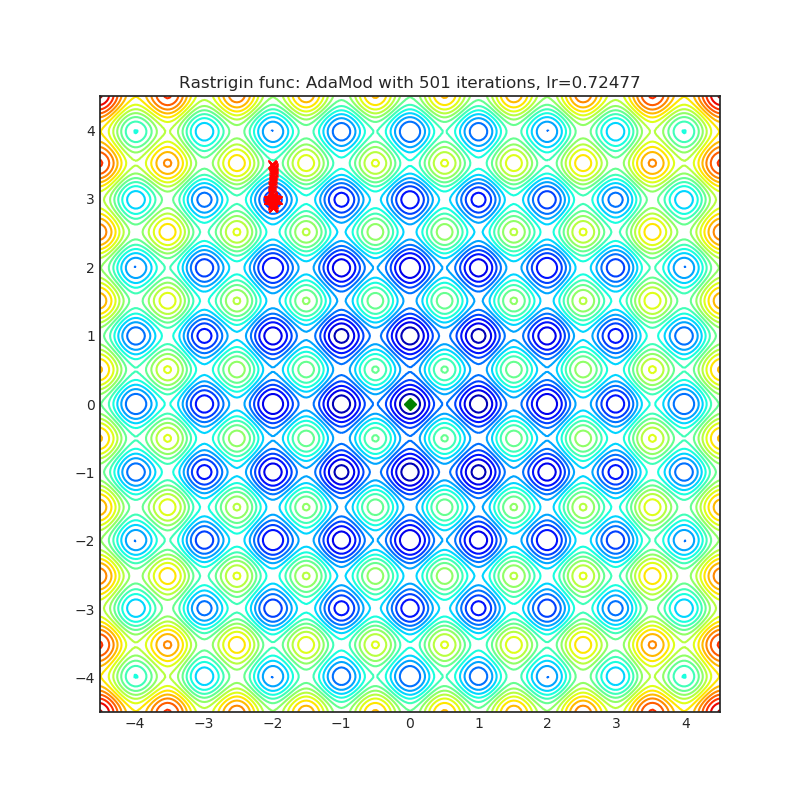{kind=link}
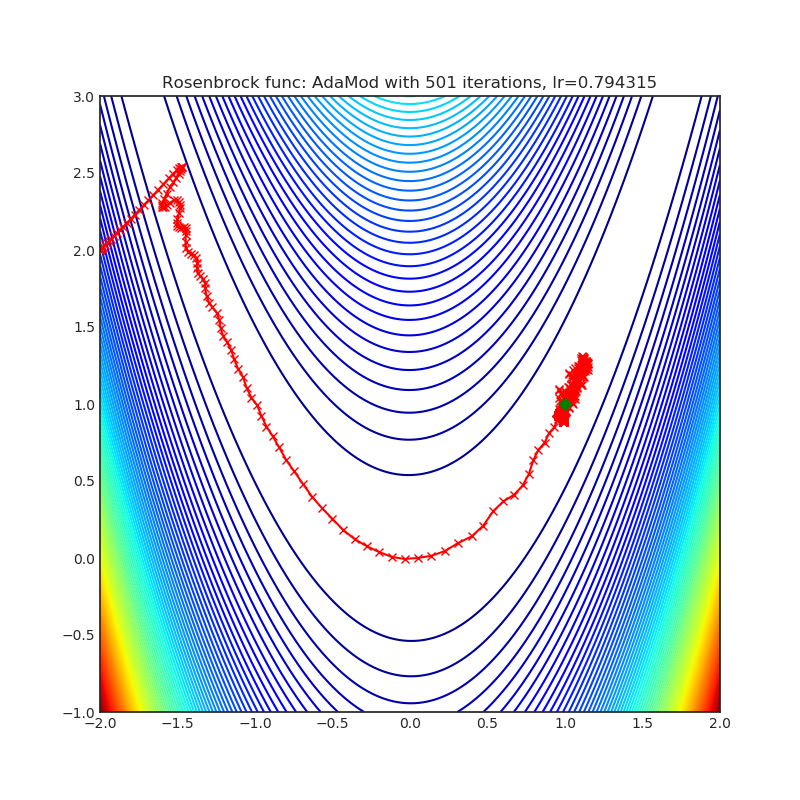{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.AdaMod(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
beta3=0.999,
eps=1e-8,
weight_decay=0,
)
optimizer.step()
论文: 一种用于随机学习的自适应与动量式约束方法。 (2019) [https://arxiv.org/abs/1910.12249]
参考代码: https://github.com/lancopku/AdaMod
Adafactor
+------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Adafactor.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Adafactor.png | +------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+
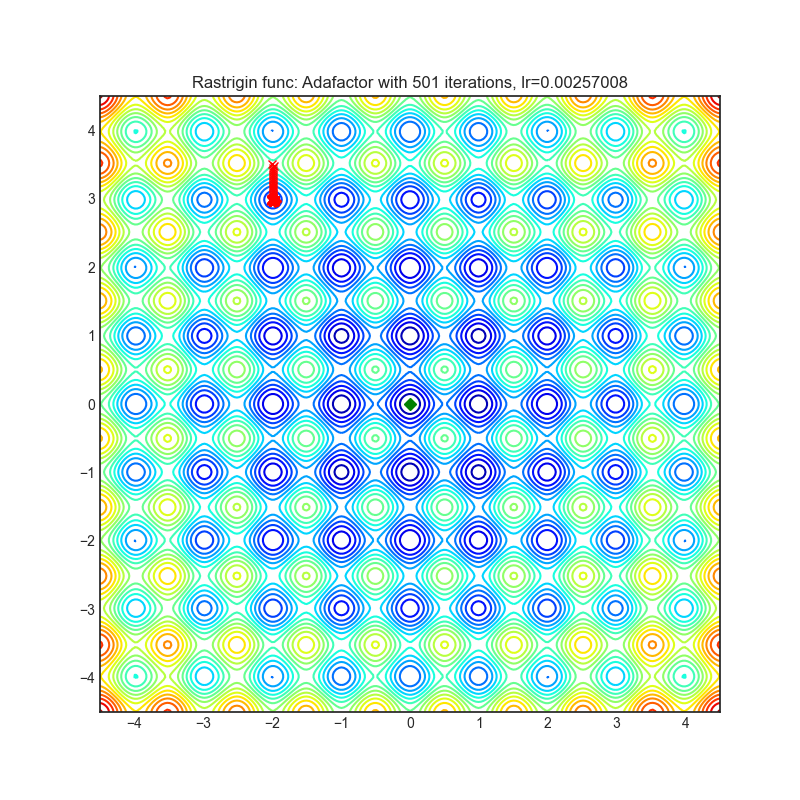{kind=link}
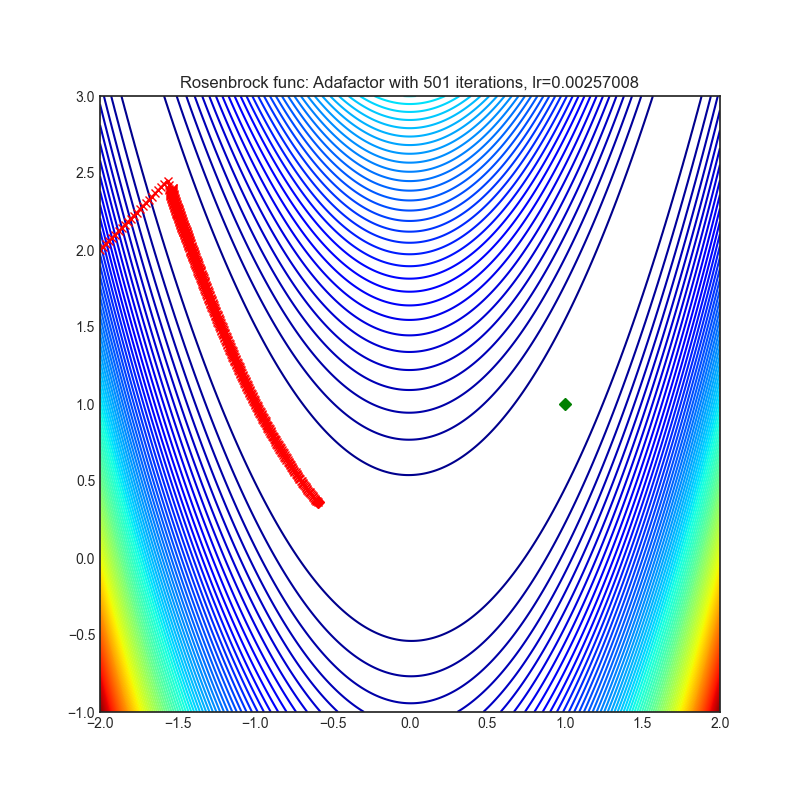{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.Adafactor(
m.parameters(),
lr= 1e-3,
eps2= (1e-30, 1e-3),
clip_threshold=1.0,
decay_rate=-0.8,
beta1=None,
weight_decay=0.0,
scale_parameter=True,
relative_step=True,
warmup_init=False,
)
optimizer.step()
论文: Adafactor:具有次线性内存开销的自适应学习率方法。 (2018) [https://arxiv.org/abs/1804.04235]
参考代码: https://github.com/pytorch/fairseq/blob/master/fairseq/optim/adafactor.py
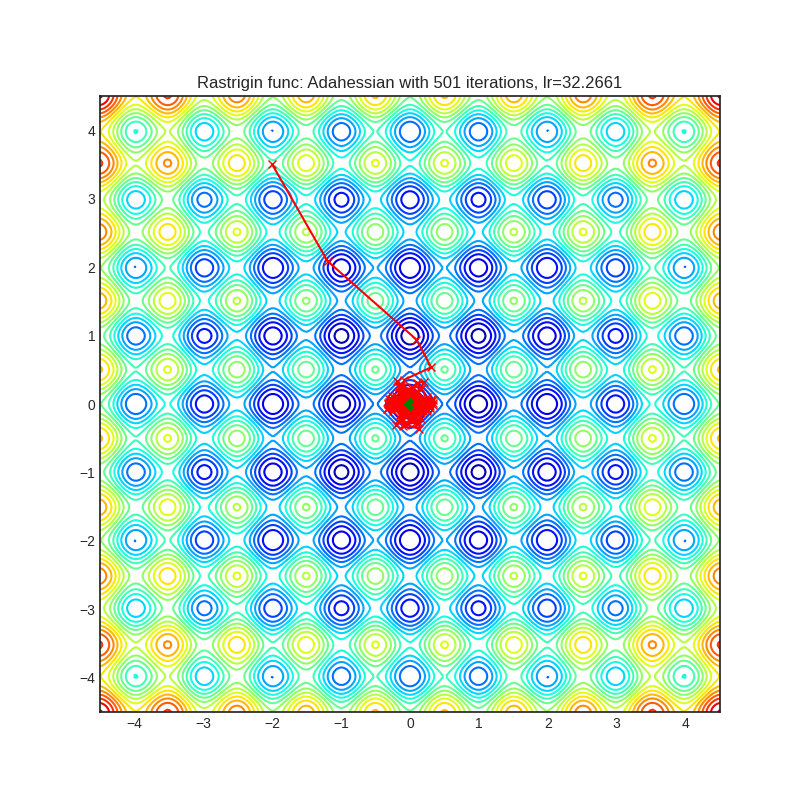
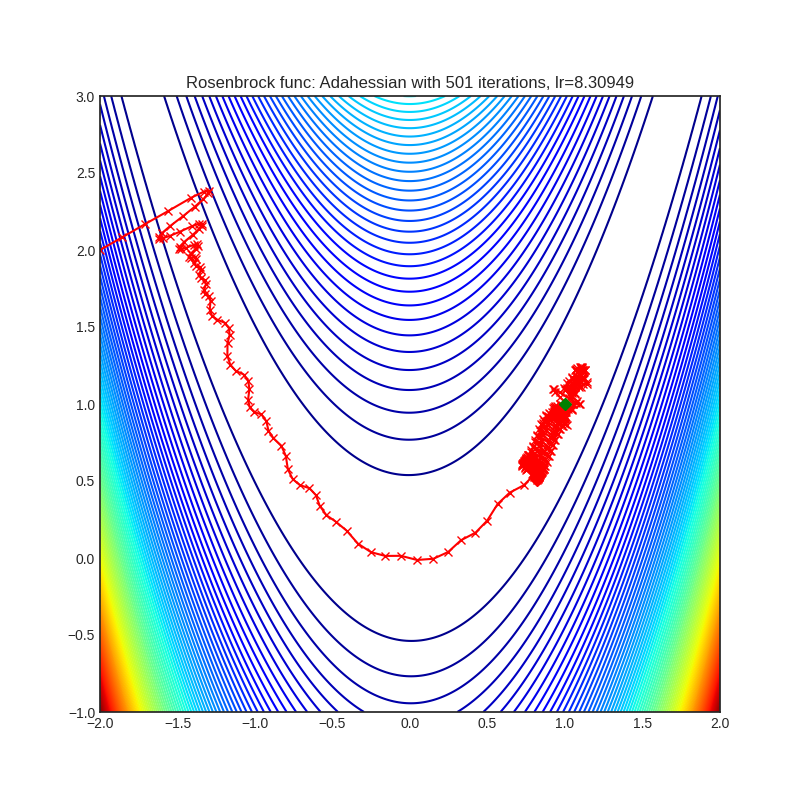
Adahessian
+-------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Adahessian.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Adahessian.png | +-------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------+
{kind=link}
{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.Adahessian(
m.parameters(),
lr= 1.0,
betas= (0.9, 0.999),
eps= 1e-4,
weight_decay=0.0,
hessian_power=1.0,
)
loss_fn(m(input), target).backward(create_graph = True) # create_graph=True是计算Hessian矩阵所必需的
optimizer.step()
论文: ADAHESSIAN:一种用于机器学习的自适应二阶优化器 (2020) [https://arxiv.org/abs/2006.00719]
参考代码: https://github.com/amirgholami/adahessian
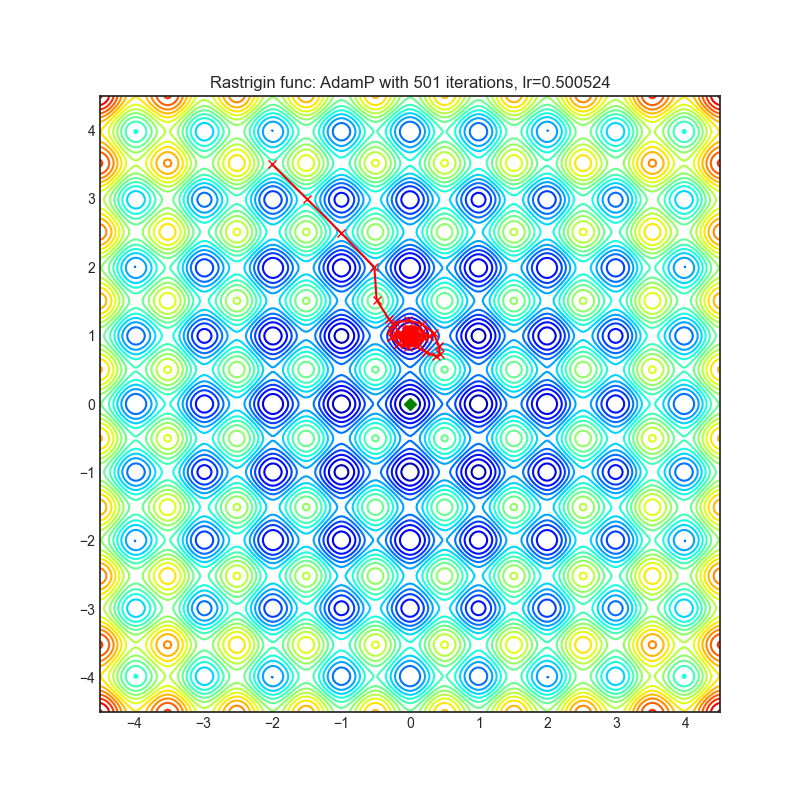
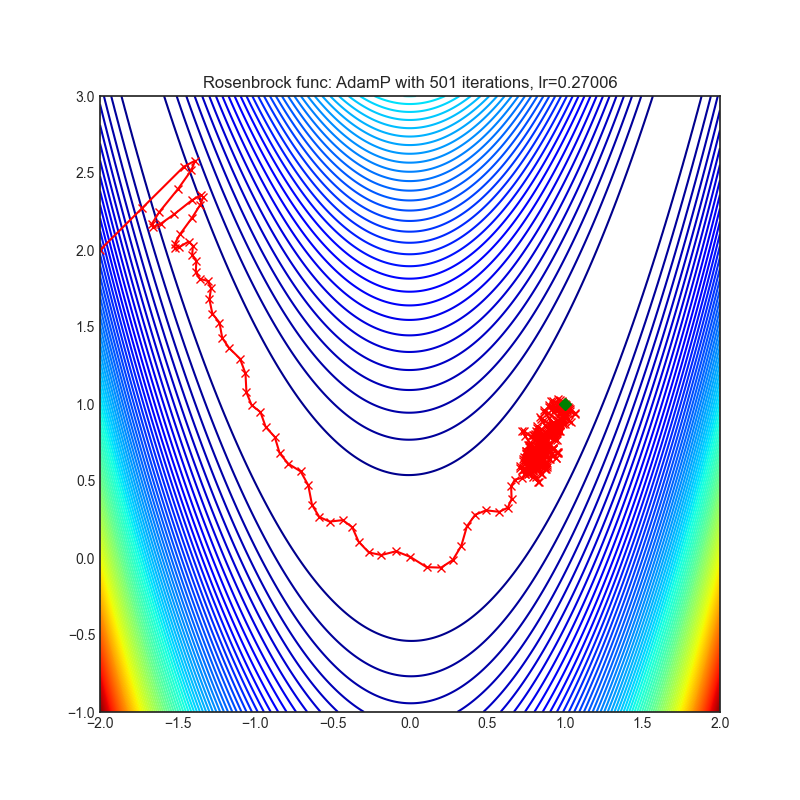
AdamP
AdamP提出了一种简单而有效的解决方案:在应用于尺度不变权重(例如,在BN层之前的卷积权重)的Adam优化器的每次迭代中,AdamP会从更新向量中移除径向分量(即与权重向量平行的部分)。直观地说,这一操作可以防止沿径向方向的不必要更新,因为这种更新只会增加权重范数,而不会对损失的最小化产生任何贡献。
+------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_AdamP.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_AdamP.png | +------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+
{kind=link}
{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.AdamP(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
delta = 0.1,
wd_ratio = 0.1
)
optimizer.step()
论文: 减缓基于动量的优化器中权重范数的增长。 (2020) [https://arxiv.org/abs/2006.08217]
参考代码: https://github.com/clovaai/AdamP
AggMo
+------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_AggMo.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_AggMo.png | +------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+
{kind=link}
{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.AggMo(
m.parameters(),
lr= 1e-3,
betas=(0.0, 0.9, 0.99),
weight_decay=0,
)
optimizer.step()
论文: 聚合动量:通过被动阻尼实现稳定性。 (2019) [https://arxiv.org/abs/1804.00325]
参考代码: https://github.com/AtheMathmo/AggMo
Apollo
+------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Apollo.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Apollo.png | +------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+
{kind=link}
{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.Apollo(
m.parameters(),
lr= 1e-2,
beta=0.9,
eps=1e-4,
warmup=0,
init_lr=0.01,
weight_decay=0,
)
optimizer.step()
论文: Apollo: 一种用于非凸随机优化的自适应参数化对角拟牛顿法。 (2020) [https://arxiv.org/abs/2009.13586]
参考代码: https://github.com/XuezheMax/apollo
DiffGrad
基于当前梯度与前一时刻梯度之差的优化器,其步长会针对每个参数进行调整,使得梯度变化较快的参数采用较大的步长,而梯度变化较慢的参数则采用较小的步长。
+------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_DiffGrad.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_DiffGrad.png | +------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+
{kind=link}
{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.DiffGrad(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
)
optimizer.step()
论文: diffGrad: 一种用于卷积神经网络的优化方法。 (2019) [https://arxiv.org/abs/1909.11015]
参考代码: https://github.com/shivram1987/diffGrad
Lamb
+--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Lamb.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Lamb.png | +--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+
{kind=link}
{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.Lamb(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
)
optimizer.step()
论文: 深度学习的大批量优化:76分钟内训练BERT (2019) [https://arxiv.org/abs/1904.00962]
参考代码: https://github.com/cybertronai/pytorch-lamb
Lookahead
+-----------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_LookaheadYogi.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_LookaheadYogi.png | +-----------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------+
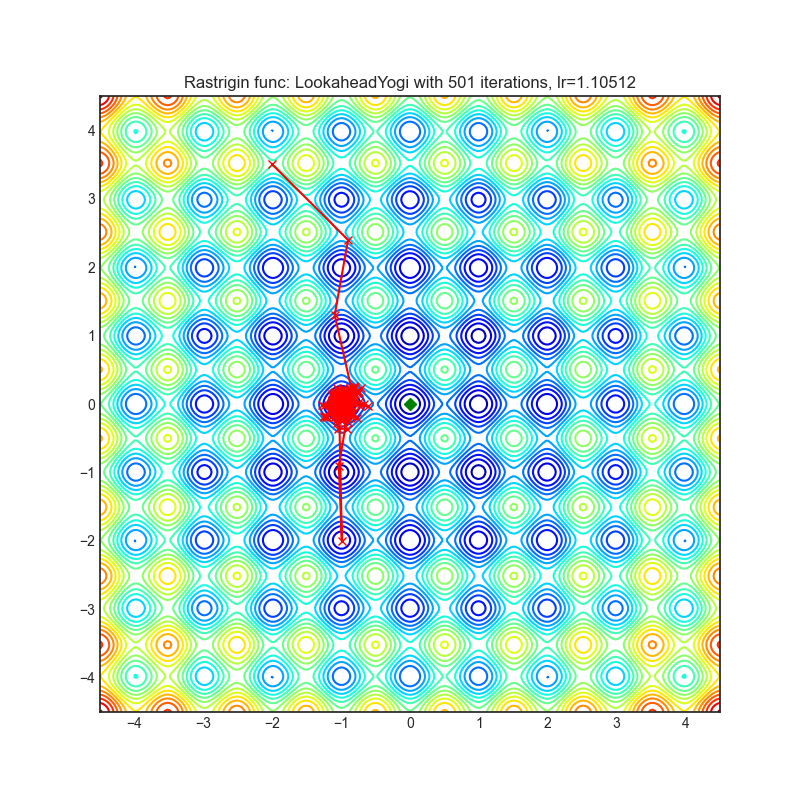{kind=link}
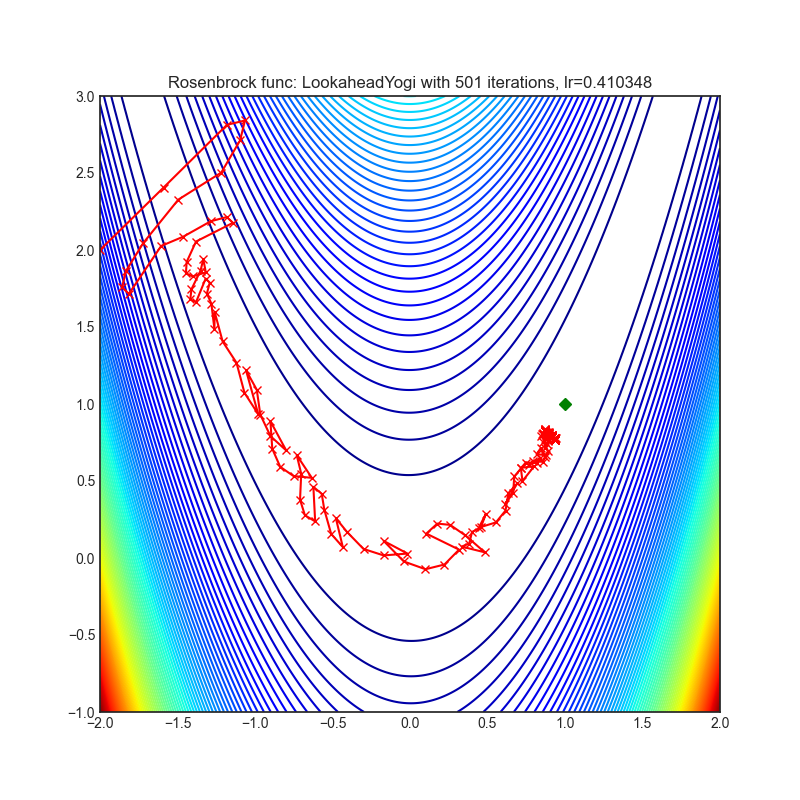{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
# 基础优化器,可以使用任何其他优化器,如Adam或DiffGrad
yogi = optim.Yogi(
m.parameters(),
lr= 1e-2,
betas=(0.9, 0.999),
eps=1e-3,
initial_accumulator=1e-6,
weight_decay=0,
)
optimizer = optim.Lookahead(yogi, k=5, alpha=0.5)
optimizer.step()
论文: Lookahead 优化器:k 步向前,1 步向后 (2019) [https://arxiv.org/abs/1907.08610]
参考代码: https://github.com/alphadl/lookahead.pytorch
MADGRAD
+-----------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_MADGRAD.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_MADGRAD.png | +-----------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------+
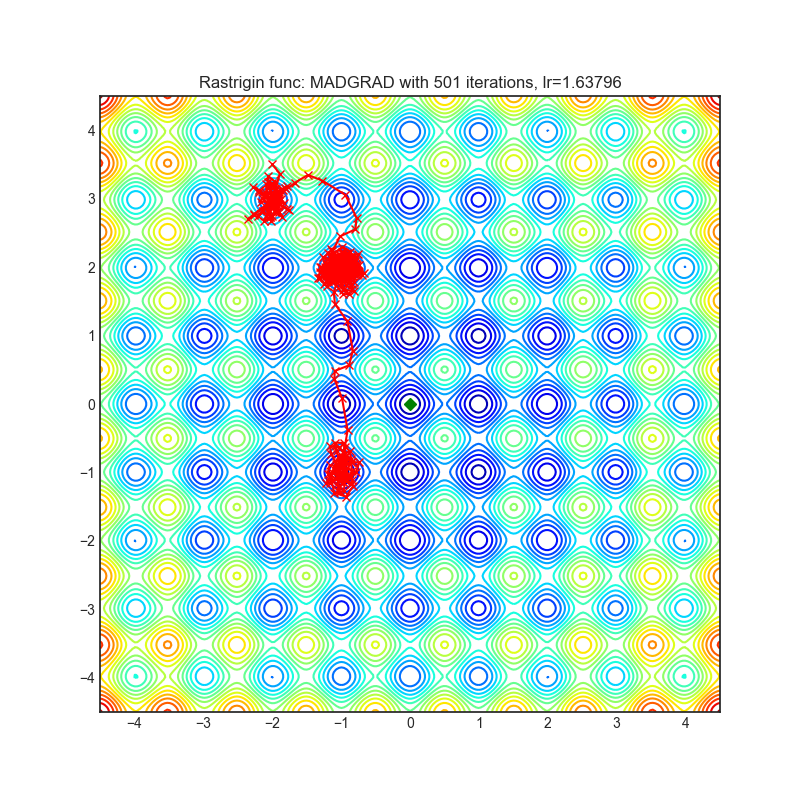{kind=link}
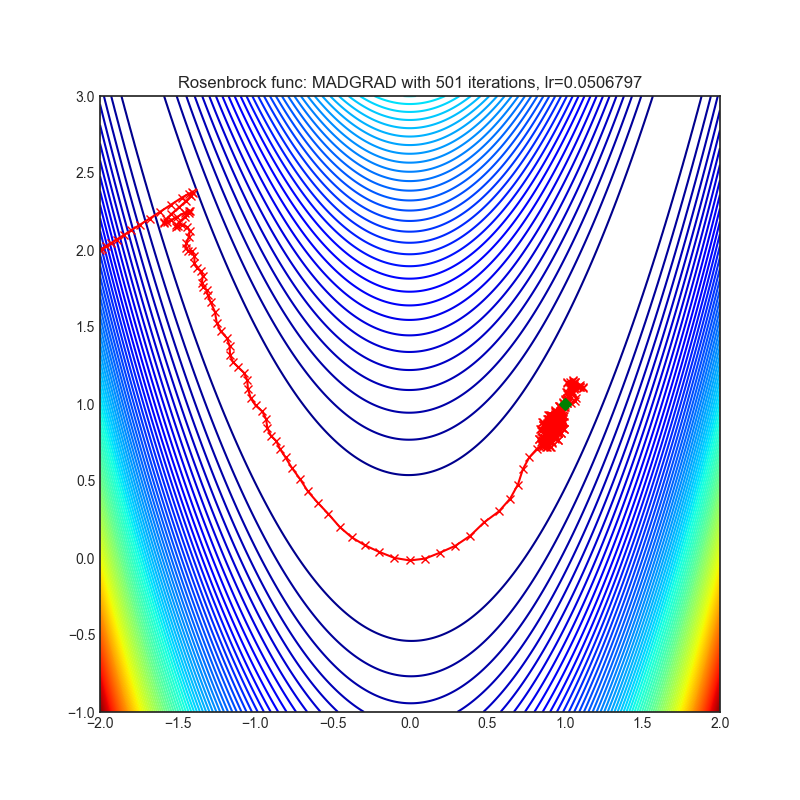{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.MADGRAD(
m.parameters(),
lr=1e-2,
momentum=0.9,
weight_decay=0,
eps=1e-6,
)
optimizer.step()
论文: 无需妥协的自适应性:一种用于随机优化的动量化、自适应、双重平均梯度方法 (2021) [https://arxiv.org/abs/2101.11075]
参考代码: https://github.com/facebookresearch/madgrad
NovoGrad
+------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_NovoGrad.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_NovoGrad.png | +------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+
{kind=link}
{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.NovoGrad(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
grad_averaging=False,
amsgrad=False,
)
optimizer.step()
论文: 用于深度网络训练的分层自适应矩随机梯度方法 (2019) [https://arxiv.org/abs/1905.11286]
参考代码: https://github.com/NVIDIA/DeepLearningExamples/
PID
+-------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_PID.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_PID.png | +-------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------+
{kind=link}
{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.PID(
m.parameters(),
lr=1e-3,
momentum=0,
dampening=0,
weight_decay=1e-2,
integral=5.0,
derivative=10.0,
)
optimizer.step()
论文: 基于 PID 控制器的深度网络随机优化方法 (2018) [http://www4.comp.polyu.edu.hk/~cslzhang/paper/CVPR18_PID.pdf]
参考代码: https://github.com/tensorboy/PIDOptimizer
QHAdam
+----------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_QHAdam.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_QHAdam.png | +----------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------+
{kind=link}
{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.QHAdam(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
nus=(1.0, 1.0),
weight_decay=0,
decouple_weight_decay=False,
eps=1e-8,
)
optimizer.step()
论文: 深度学习中的拟双曲动量和 Adam (2019) [https://arxiv.org/abs/1810.06801]
参考代码: https://github.com/facebookresearch/qhoptim
QHM
+-------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_QHM.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_QHM.png | +-------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------+
{kind=link}
{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.QHM(
m.parameters(),
lr=1e-3,
momentum=0,
nu=0.7,
weight_decay=1e-2,
weight_decay_type='grad',
)
optimizer.step()
论文: 深度学习中的拟双曲动量和 Adam (2019) [https://arxiv.org/abs/1810.06801]
参考代码: https://github.com/facebookresearch/qhoptim
RAdam
+---------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_RAdam.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_RAdam.png | +---------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------+
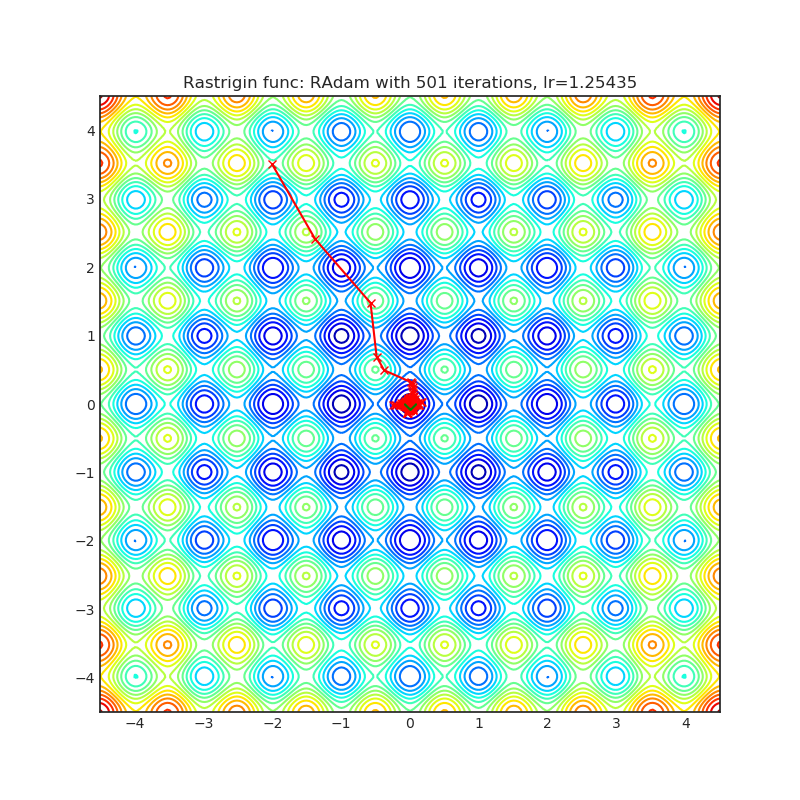{kind=link}
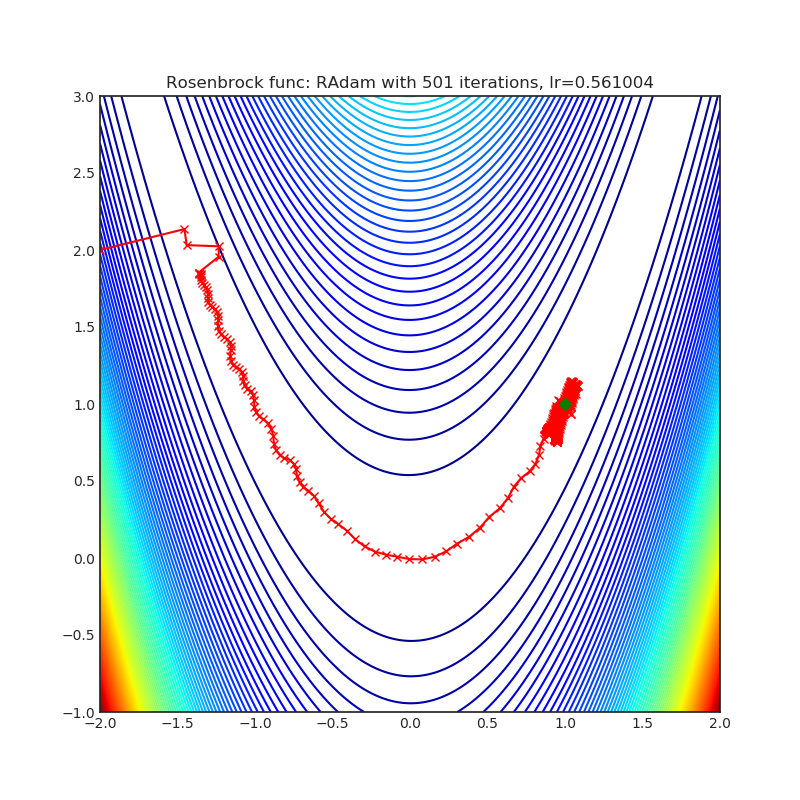{kind=link}
已弃用,请使用 PyTorch_ 提供的版本。
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.RAdam(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
)
optimizer.step()
论文: 关于自适应学习率的方差及更多 (2019) [https://arxiv.org/abs/1908.03265]
参考代码: https://github.com/LiyuanLucasLiu/RAdam
Ranger
+----------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Ranger.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Ranger.png | +----------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------+
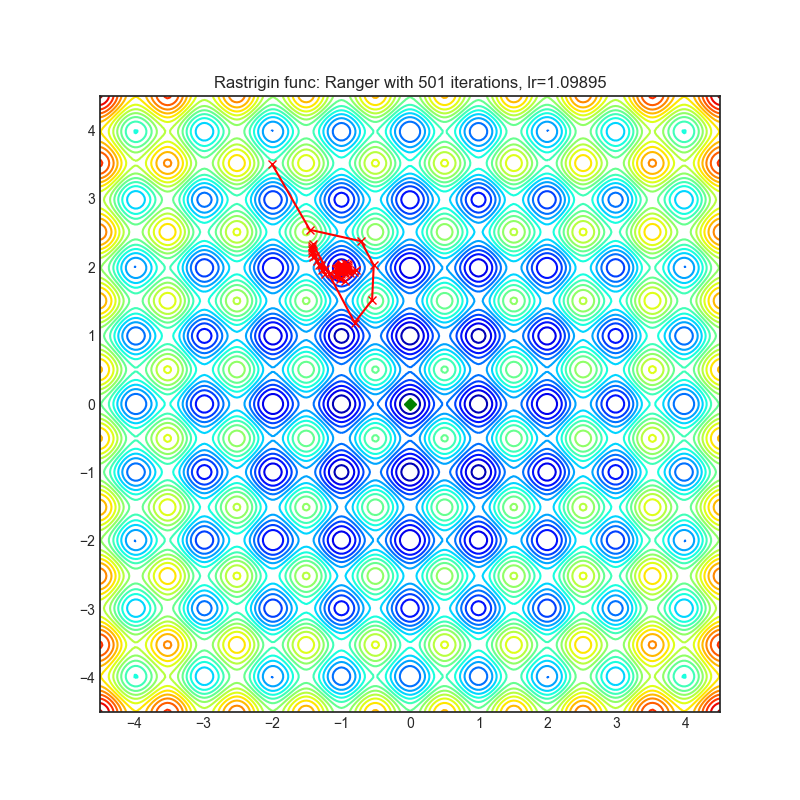{kind=link}
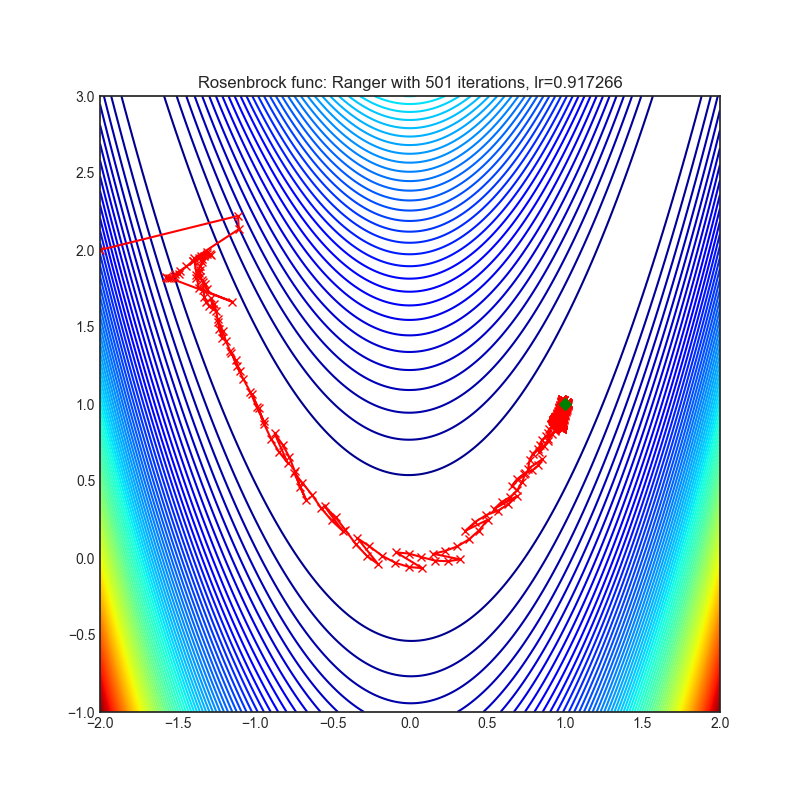{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.Ranger(
m.parameters(),
lr=1e-3,
alpha=0.5,
k=6,
N_sma_threshhold=5,
betas=(.95, 0.999),
eps=1e-5,
weight_decay=0
)
optimizer.step()
论文: 新型深度学习优化器,Ranger:RAdam与LookAhead的协同组合,兼得两者之优 (2019) [https://medium.com/@lessw/new-deep-learning-optimizer-ranger-synergistic-combination-of-radam-lookahead-for-the-best-of-2dc83f79a48d]
参考代码: https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
RangerQH
+------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_RangerQH.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_RangerQH.png | +------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+
{kind=link}
{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.RangerQH(
m.parameters(),
lr=1e-3,
betas=(0.9, 0.999),
nus=(.7, 1.0),
weight_decay=0.0,
k=6,
alpha=.5,
decouple_weight_decay=False,
eps=1e-8,
)
optimizer.step()
论文: 深度学习中的准双曲动量和Adam (2018) [https://arxiv.org/abs/1810.06801]
参考代码: https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
RangerVA
+------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_RangerVA.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_RangerVA.png | +------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+
{kind=link}
{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.RangerVA(
m.parameters(),
lr=1e-3,
alpha=0.5,
k=6,
n_sma_threshhold=5,
betas=(.95, 0.999),
eps=1e-5,
weight_decay=0,
amsgrad=True,
transformer='softplus',
smooth=50,
grad_transformer='square'
)
optimizer.step.
论文: 校准自适应学习率以改善ADAM的收敛性 (2019) [https://arxiv.org/abs/1908.00700v2]
参考代码: https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
SGDP
+--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_SGDP.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_SGDP.png | +--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+
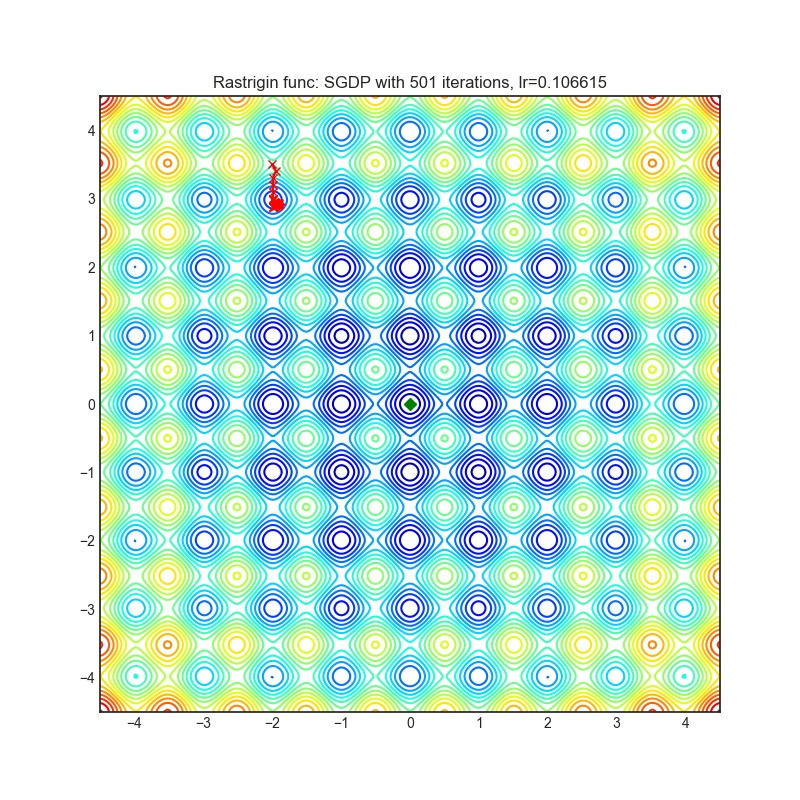{kind=link}
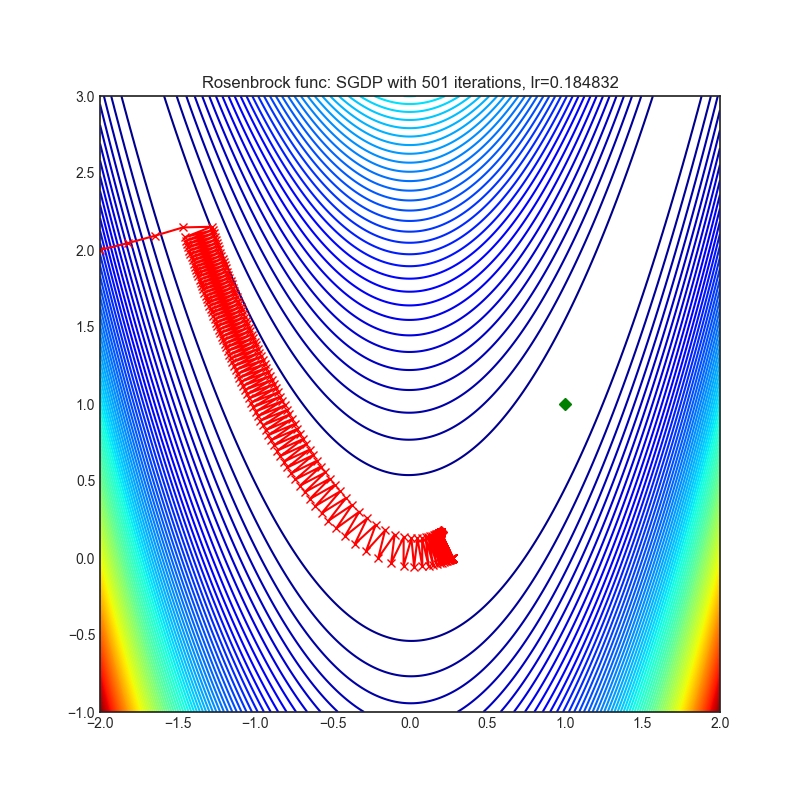{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.SGDP(
m.parameters(),
lr= 1e-3,
momentum=0,
dampening=0,
weight_decay=1e-2,
nesterov=False,
delta = 0.1,
wd_ratio = 0.1
)
optimizer.step.
论文: 减缓基于动量的优化器中权重范数的增长 (2020) [https://arxiv.org/abs/2006.08217]
参考代码: https://github.com/clovaai/AdamP
SGDW
+--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_SGDW.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_SGDW.png | +--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+
{kind=link}
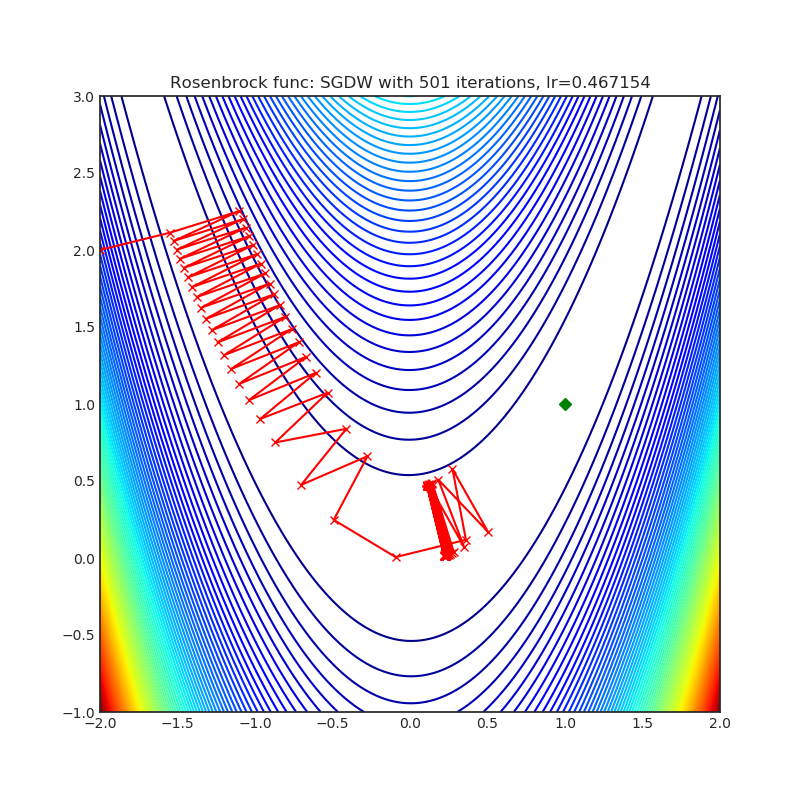{kind=link}
.. code:: python
import torch_optimizer as optim
# model = ...
optimizer = optim.SGDW(
m.parameters(),
lr= 1e-3,
momentum=0,
dampening=0,
weight_decay=1e-2,
nesterov=False,
)
optimizer.step.
论文: SGDR:带有热重启的随机梯度下降 (2017) [https://arxiv.org/abs/1608.03983]
参考代码: https://github.com/pytorch/pytorch/pull/22466
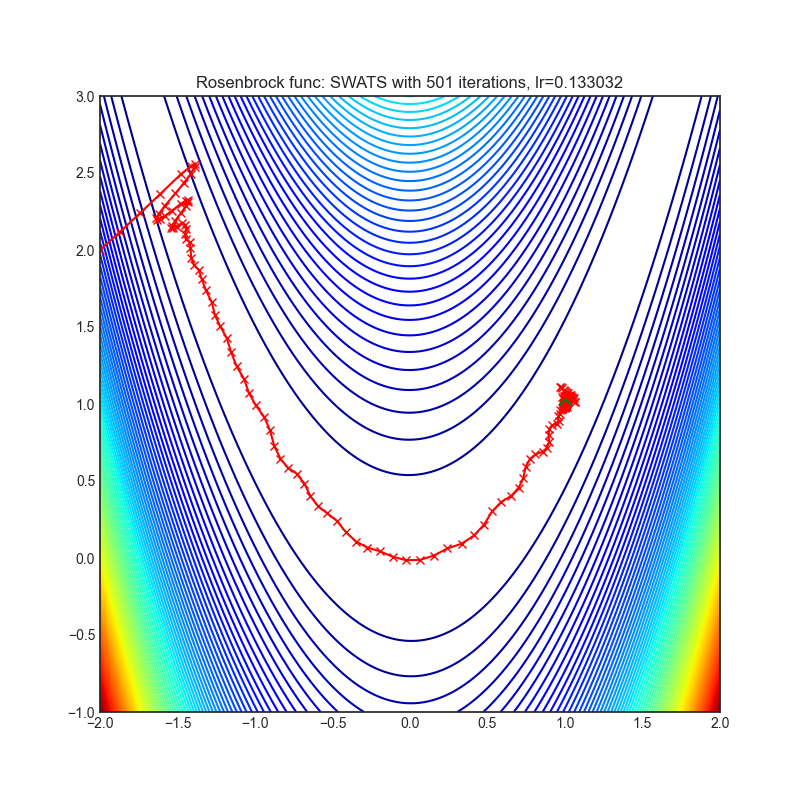
SWATS
+---------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_SWATS.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_SWATS.png | +---------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------+
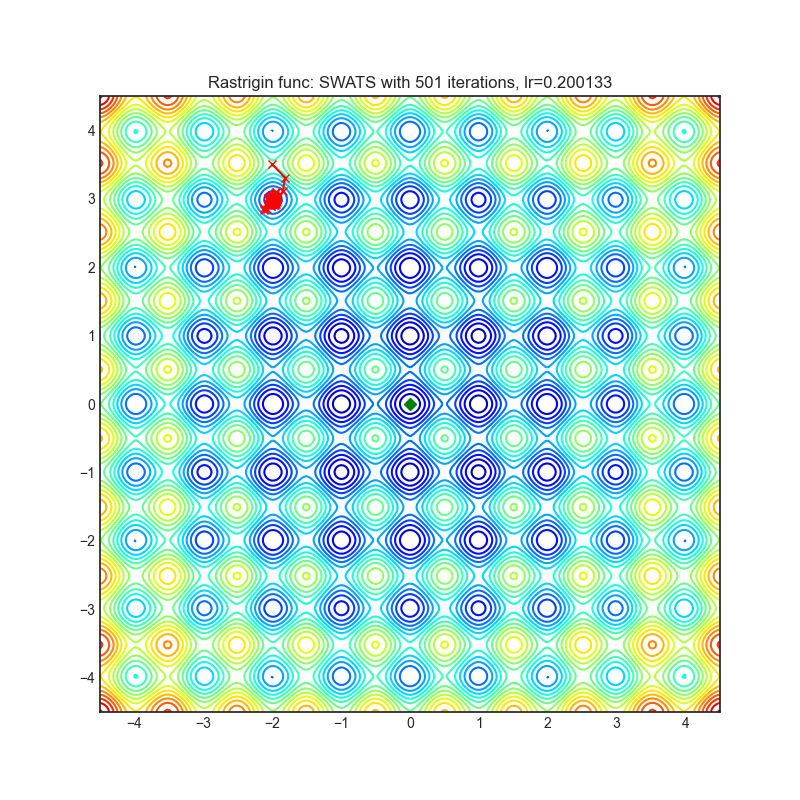{kind=link}
{kind=link}
.. code:: python
import torch_optimizer as optim
模型 = ...
optimizer = optim.SWATS(
model.parameters(),
lr=1e-1,
betas=(0.9, 0.999),
eps=1e-3,
weight_decay= 0.0,
amsgrad=False,
nesterov=False,
)
optimizer.step()
论文: 通过从 Adam 切换到 SGD 提升泛化性能 (2017) [https://arxiv.org/abs/1712.07628]
参考代码: https://github.com/Mrpatekful/swats
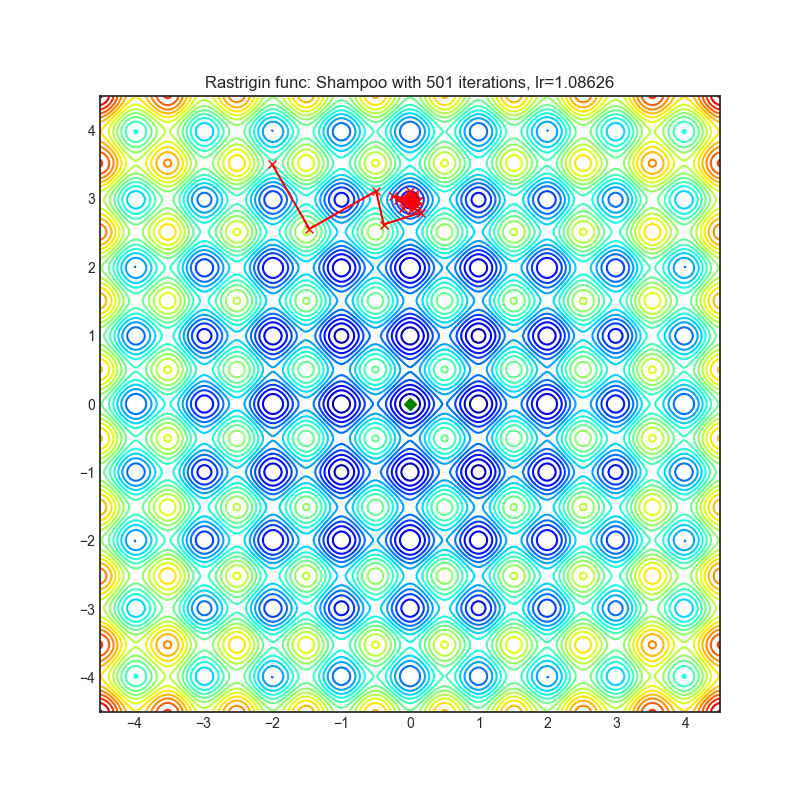
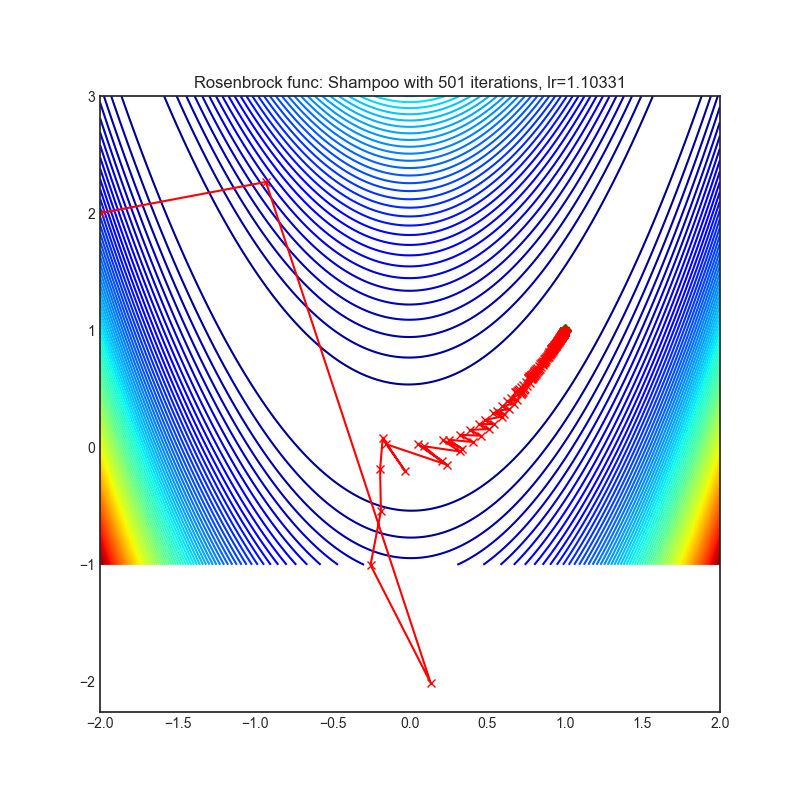
Shampoo
+-----------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Shampoo.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Shampoo.png | +-----------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------+
{kind=link}
{kind=link}
.. code:: python
import torch_optimizer as optim
# 模型 = ...
optimizer = optim.Shampoo(
m.parameters(),
lr=1e-1,
momentum=0.0,
weight_decay=0.0,
epsilon=1e-4,
update_freq=1,
)
optimizer.step()
论文: Shampoo: 预条件随机张量优化 (2018) [https://arxiv.org/abs/1802.09568]
参考代码: https://github.com/moskomule/shampoo.pytorch
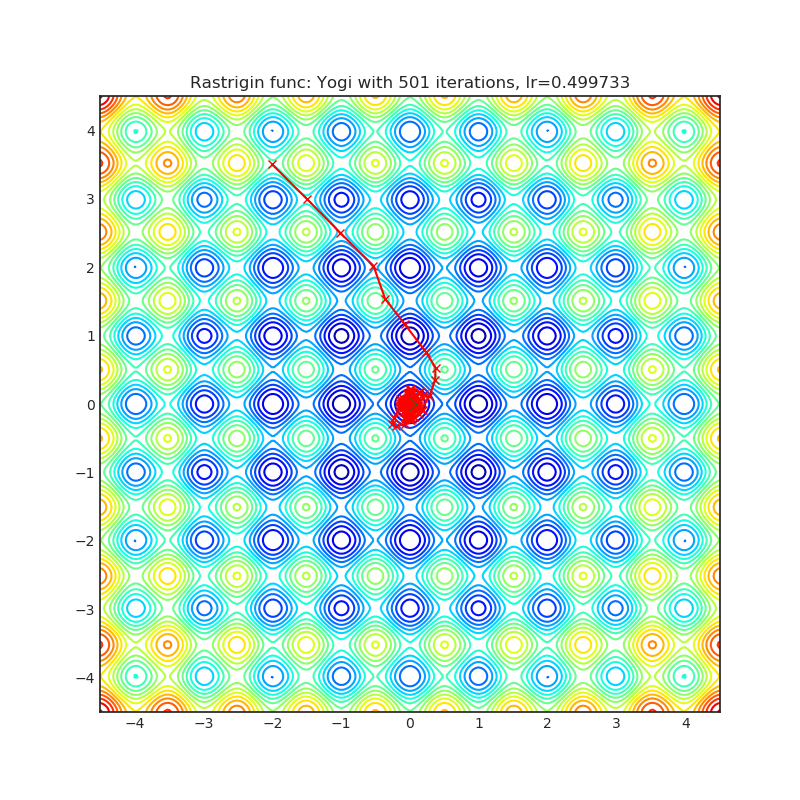
Yogi
Yogi 是一种基于 ADAM 的优化算法,具有更精细的有效学习率控制,并且在收敛性方面与 ADAM 具有相似的理论保证。
+--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Yogi.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Yogi.png | +--------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+
{kind=link}
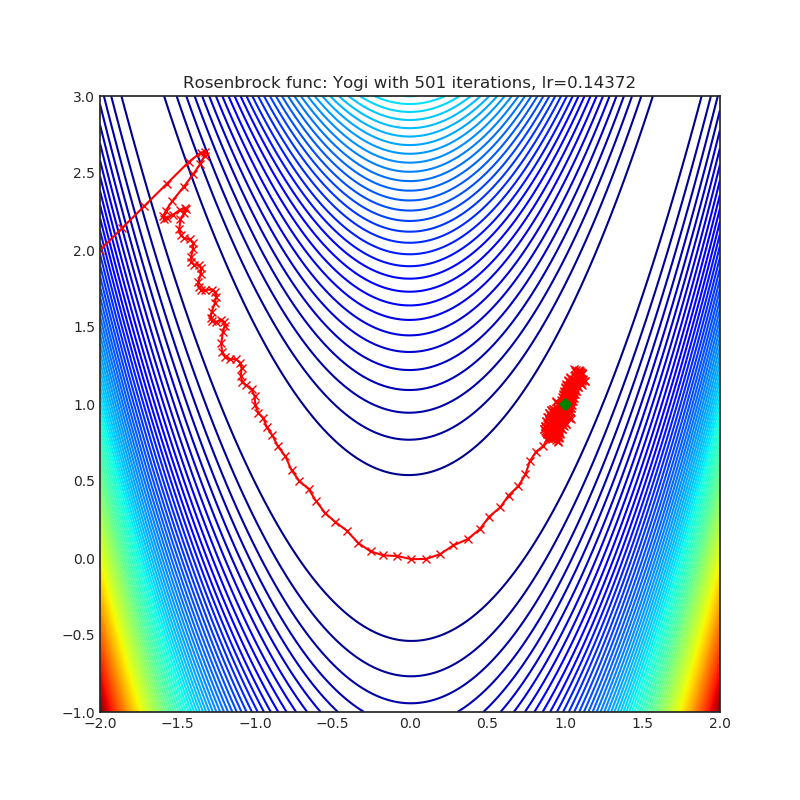{kind=link}
.. code:: python
import torch_optimizer as optim
# 模型 = ...
optimizer = optim.Yogi(
m.parameters(),
lr= 1e-2,
betas=(0.9, 0.999),
eps=1e-3,
initial_accumulator=1e-6,
weight_decay=0,
)
optimizer.step()
论文: 非凸优化的自适应方法 (2018) [https://papers.nips.cc/paper/8186-adaptive-methods-for-nonconvex-optimization]
参考代码: https://github.com/4rtemi5/Yogi-Optimizer_Keras
Adam(PyTorch 内置)
+---------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_Adam.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_Adam.png | +---------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+
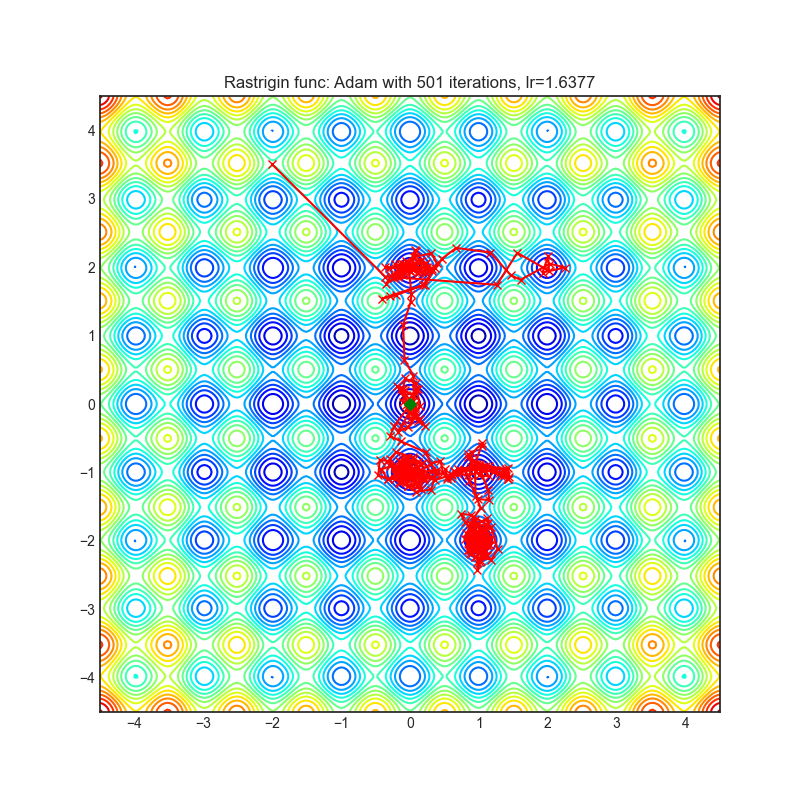{kind=link}
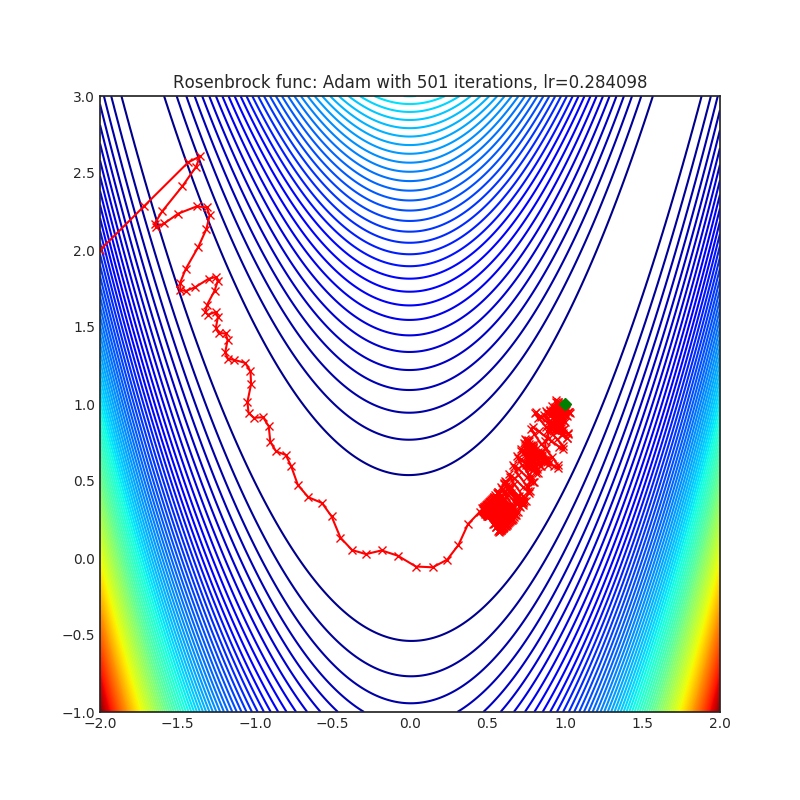{kind=link}
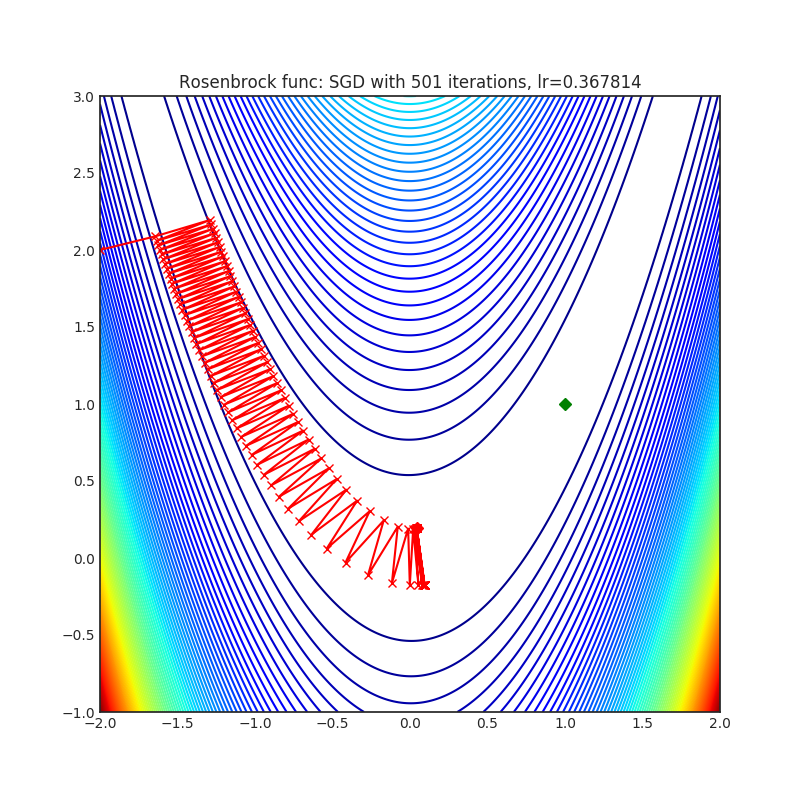
SGD(PyTorch 内置)
+--------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------+ | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rastrigin_SGD.png | .. image:: https://raw.githubusercontent.com/jettify/pytorch-optimizer/master/docs/rosenbrock_SGD.png | +--------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------+
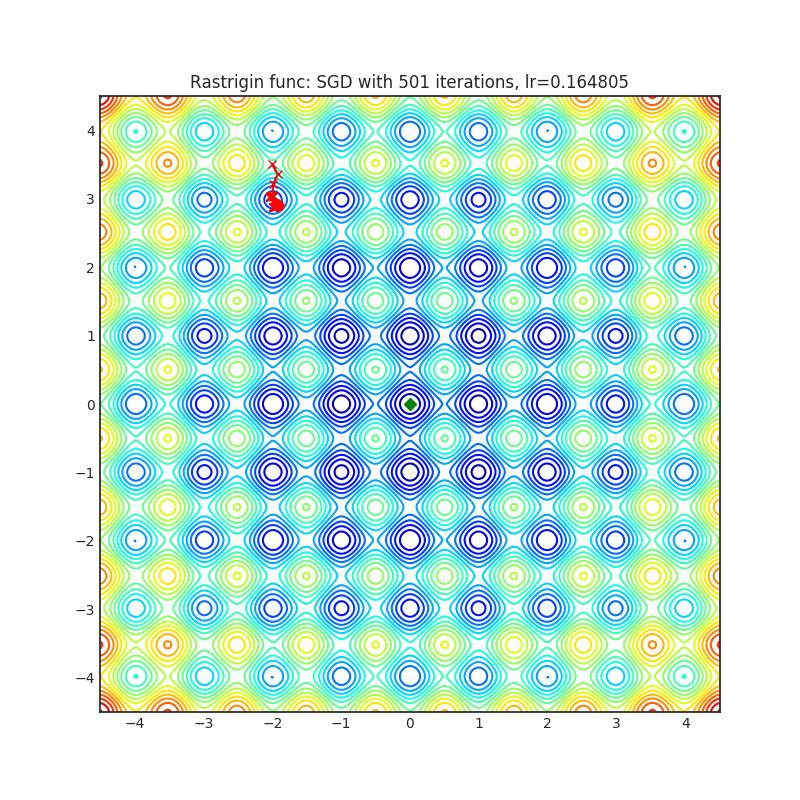{kind=link}
{kind=link}
.. _Python: https://www.python.org .. _PyTorch: https://github.com/pytorch/pytorch .. _Rastrigin: https://en.wikipedia.org/wiki/Rastrigin_function .. _Rosenbrock: https://en.wikipedia.org/wiki/Rosenbrock_function .. _benchmark: https://en.wikipedia.org/wiki/Test_functions_for_optimization .. _optim: https://pytorch.org/docs/stable/optim.html
版本历史
v0.3.02021/10/31v0.2.02021/10/26v0.1.02021/01/01v0.0.1a172020/11/27v0.0.1a162020/10/20v0.0.1a152020/08/11v0.0.1a142020/07/13v0.0.1a132020/06/17v0.0.1a122020/04/26v0.0.1a112020/04/05v0.0.1a102020/03/15v0.0.1a92020/03/04v0.0.1a82020/03/02v0.0.1a72020/02/27v0.0.1a62020/02/22v0.0.1a52020/02/15v0.0.1a42020/02/11v0.0.1a32020/02/09v0.0.1a22020/02/03v0.0.1a12020/01/22常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
AutoGPT
AutoGPT 是一个旨在让每个人都能轻松使用和构建 AI 的强大平台,核心功能是帮助用户创建、部署和管理能够自动执行复杂任务的连续型 AI 智能体。它解决了传统 AI 应用中需要频繁人工干预、难以自动化长流程工作的痛点,让用户只需设定目标,AI 即可自主规划步骤、调用工具并持续运行直至完成任务。 无论是开发者、研究人员,还是希望提升工作效率的普通用户,都能从 AutoGPT 中受益。开发者可利用其低代码界面快速定制专属智能体;研究人员能基于开源架构探索多智能体协作机制;而非技术背景用户也可直接选用预置的智能体模板,立即投入实际工作场景。 AutoGPT 的技术亮点在于其模块化“积木式”工作流设计——用户通过连接功能块即可构建复杂逻辑,每个块负责单一动作,灵活且易于调试。同时,平台支持本地自托管与云端部署两种模式,兼顾数据隐私与使用便捷性。配合完善的文档和一键安装脚本,即使是初次接触的用户也能在几分钟内启动自己的第一个 AI 智能体。AutoGPT 正致力于降低 AI 应用门槛,让人人都能成为 AI 的创造者与受益者。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。