yolov13
YOLOv13 是一款新一代实时目标检测开源模型,旨在以极高的效率和精度识别图像或视频中的物体。它主要解决了传统检测器在复杂场景下难以捕捉高阶视觉关联、以及模型轻量化与高性能难以兼得的痛点,让设备在保持快速响应的同时,也能精准处理细节丰富的画面。
这款工具非常适合计算机视觉开发者、算法研究人员以及需要部署边缘检测应用的工程师使用。无论是进行学术研究、模型训练,还是将检测功能集成到 Android 手机、华为昇腾或瑞芯微等硬件设备中,YOLOv13 都提供了完善的支持和便捷的接口。
其核心技术亮点在于引入了“超图增强自适应视觉感知”机制。通过 HyperACE 模块,它能将特征像素视为超图节点,自适应地探索并聚合多尺度间的高阶关联信息;配合 FullPAD 全流水线聚合分发范式,实现了整个网络层级的细粒度信息流动与协同。此外,YOLOv13 采用基于深度可分离卷积的轻量化模块,在大幅减少参数量和计算成本的同时,依然保留了强大的感受野,提供了从 Nano 到 X-Large 多种尺寸变体,满足不同场景的性能需求。
使用场景
某智慧物流园区的技术团队正致力于升级其自动化分拣系统,需要在高速传送带上实时精准识别各类形状不规则、部分遮挡的快递包裹。
没有 yolov13 时
- 面对包裹堆叠或严重遮挡场景,传统检测模型因缺乏高阶特征关联能力,频繁出现漏检或误判,导致分拣错误率居高不下。
- 为了维持一定的识别精度,不得不部署重型模型,致使边缘计算设备推理延迟高,无法匹配传送带的高速运转节奏。
- 多尺度特征融合不够精细,小尺寸标签或异形包裹在复杂背景下极易丢失,需人工介入复核,增加了运营成本。
- 模型参数量大且计算冗余,难以在功耗受限的嵌入式工控机或移动端设备上流畅运行,部署灵活性差。
使用 yolov13 后
- 借助 HyperACE 超图自适应增强技术,yolov13 能敏锐捕捉像素间的高阶关联,即使在包裹紧密堆叠时也能实现极高精度的完整识别。
- 依托 FullPAD 全流水线聚合范式,yolov13 在保持实时高速推理的同时显著提升了梯度传播效率,完美适配高速分拣节拍。
- 通过细粒度的信息流协同机制,yolov13 强化了对多尺度特征的感知,轻松锁定微小标签及异形件,基本消除了人工复核需求。
- 基于深度可分离卷积的轻量化设计大幅降低了参数与算力消耗,使 yolov13 能轻松部署于各类边缘设备及安卓终端,扩展性极强。
yolov13 通过超图增强与全链路优化,在极端复杂的工业场景中实现了速度与精度的双重突破,重新定义了实时物体检测的效率标杆。
运行环境要求
- Linux
需要 NVIDIA GPU 以支持 Flash Attention 加速,预编译包指定 CUDA 11 (cu11),具体显存需求未说明(建议根据模型规模 N/S/L/X 配置 4GB-24GB+)
未说明

快速开始

YOLOv13:基于超图增强自适应视觉感知的实时目标检测
更新
2025年11月18日:YOLOv13演示与教程已上线。感谢HyperAI!
2025年7月19日:HuggingFace Spaces演示已上线。感谢Atalay!
2025年6月27日:支持将YOLOv13转换为华为Ascend(OM)、Rockchip(RKNN)格式。感谢kaylorchen!
2025年6月25日:支持FastAPI REST API。感谢MohibShaikh!
2025年6月24日:🔥 YOLOv13论文可下载:🔗 YOLOv13:基于超图增强自适应视觉感知的实时目标检测。
2025年6月22日:发布YOLOv13模型权重。
2025年6月21日:YOLOv13代码已开源。
目录
技术简介 💡
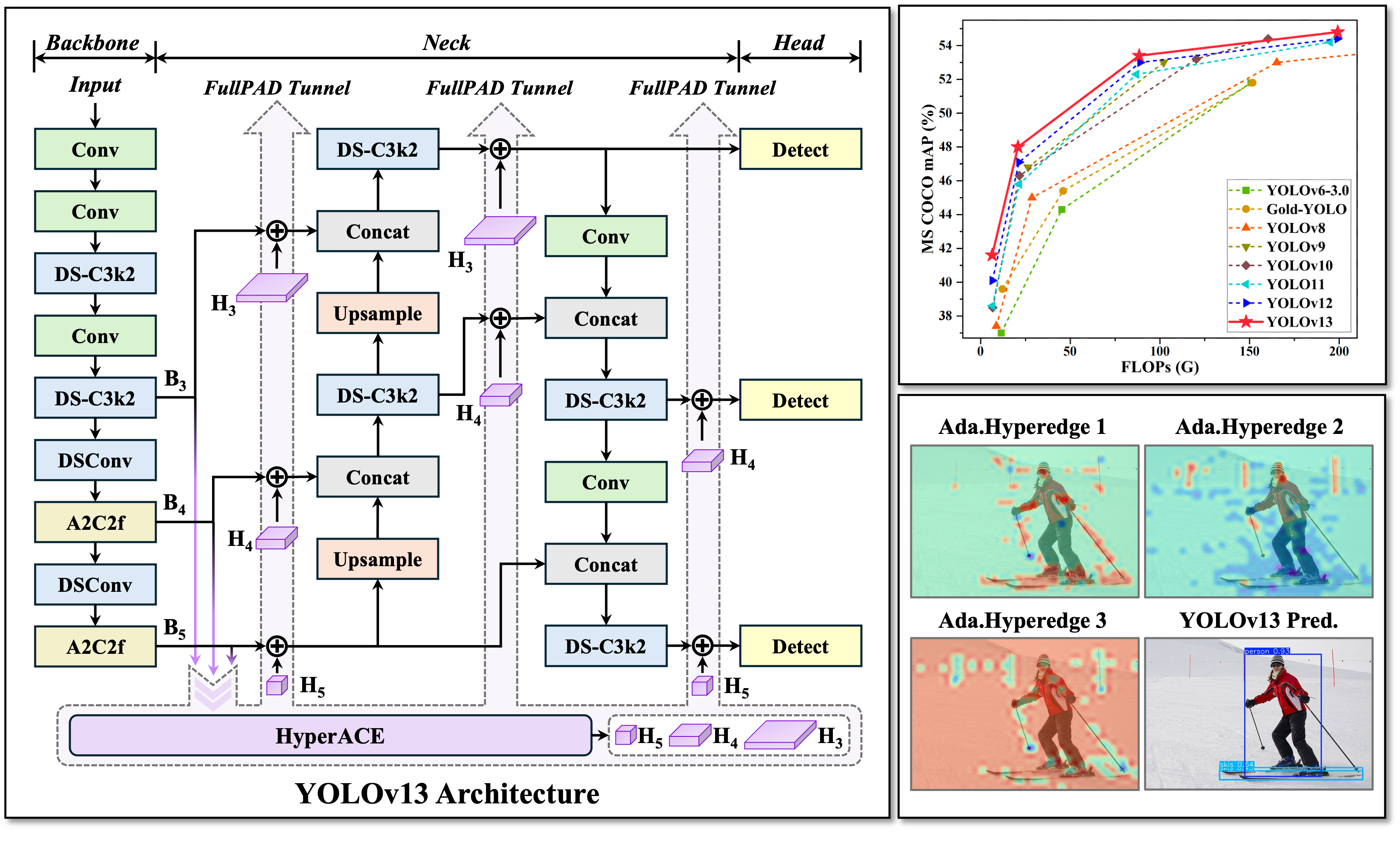
隆重推出YOLOv13——新一代实时检测器,具备前沿的性能与效率。YOLOv13家族包含Nano、Small、Large和X-Large四种变体,其核心技术包括:
HyperACE:基于超图的自适应相关性增强
- 将多尺度特征图中的像素视为超图顶点。
- 采用可学习的超边构建模块,自适应地探索顶点间的高阶相关性。
- 利用线性复杂度的消息传递模块,在高阶相关性的引导下有效聚合多尺度特征,从而实现对复杂场景的有效视觉感知。
FullPAD:全管道聚合与分配范式
- 使用HyperACE聚合骨干网络的多尺度特征,并在超图空间中提取高阶相关性。
- FullPAD范式进一步利用三条独立通道,分别将这些相关性增强的特征传递至骨干与颈部之间的连接处、颈部内部层以及颈部与头部之间的连接处。通过这种方式,YOLOv13实现了整个网络中细粒度的信息流动与表征协同。
- FullPAD显著改善了梯度传播,提升了检测性能。
基于DS的模块实现模型轻量化
- 用基于深度可分离卷积的模块(DSConv、DS-Bottleneck、DS-C3k、DS-C3k2)替代大卷积核卷积,在大幅减少参数和计算量的同时保持感受野不变。
- 在不牺牲精度的前提下,实现更快的推理速度。
YOLOv13无缝结合超图计算与端到端信息协作,提供更准确、鲁棒且高效的实时检测解决方案。
主要结果 🏆
1. MS COCO基准测试
表1. 与其他最先进实时目标检测器在MS COCO数据集上的定量对比
| 方法 | FLOPs (G) | 参数(M) | AP50:95val | AP50val | AP75val | 延迟(ms) |
|---|---|---|---|---|---|---|
| YOLOv6-3.0-N | 11.4 | 4.7 | 37.0 | 52.7 | – | 2.74 |
| Gold-YOLO-N | 12.1 | 5.6 | 39.6 | 55.7 | – | 2.97 |
| YOLOv8-N | 8.7 | 3.2 | 37.4 | 52.6 | 40.5 | 1.77 |
| YOLOv10-N | 6.7 | 2.3 | 38.5 | 53.8 | 41.7 | 1.84 |
| YOLO11-N | 6.5 | 2.6 | 38.6 | 54.2 | 41.6 | 1.53 |
| YOLOv12-N | 6.5 | 2.6 | 40.1 | 56.0 | 43.4 | 1.83 |
| YOLOv13-N | 6.4 | 2.5 | 41.6 | 57.8 | 45.1 | 1.97 |
| YOLOv6-3.0-S | 45.3 | 18.5 | 44.3 | 61.2 | – | 3.42 |
| Gold-YOLO-S | 46.0 | 21.5 | 45.4 | 62.5 | – | 3.82 |
| YOLOv8-S | 28.6 | 11.2 | 45.0 | 61.8 | 48.7 | 2.33 |
| RT-DETR-R18 | 60.0 | 20.0 | 46.5 | 63.8 | – | 4.58 |
| RT-DETRv2-R18 | 60.0 | 20.0 | 47.9 | 64.9 | – | 4.58 |
| YOLOv9-S | 26.4 | 7.1 | 46.8 | 63.4 | 50.7 | 3.44 |
| YOLOv10-S | 21.6 | 7.2 | 46.3 | 63.0 | 50.4 | 2.53 |
| YOLO11-S | 21.5 | 9.4 | 45.8 | 62.6 | 49.8 | 2.56 |
| YOLOv12-S | 21.4 | 9.3 | 47.1 | 64.2 | 51.0 | 2.82 |
| YOLOv13-S | 20.8 | 9.0 | 48.0 | 65.2 | 52.0 | 2.98 |
| YOLOv6-3.0-L | 150.7 | 59.6 | 51.8 | 69.2 | – | 9.01 |
| Gold-YOLO-L | 151.7 | 75.1 | 51.8 | 68.9 | – | 10.69 |
| YOLOv8-L | 165.2 | 43.7 | 53.0 | 69.8 | 57.7 | 8.13 |
| RT-DETR-R50 | 136.0 | 42.0 | 53.1 | 71.3 | – | 6.93 |
| RT-DETRv2-R50 | 136.0 | 42.0 | 53.4 | 71.6 | – | 6.93 |
| YOLOv9-C | 102.1 | 25.3 | 53.0 | 70.2 | 57.8 | 6.64 |
| YOLOv10-L | 120.3 | 24.4 | 53.2 | 70.1 | 57.2 | 7.31 |
| YOLO11-L | 86.9 | 25.3 | 52.3 | 69.2 | 55.7 | 6.23 |
| YOLOv12-L | 88.9 | 26.4 | 53.0 | 70.0 | 57.9 | 7.10 |
| YOLOv13-L | 88.4 | 27.6 | 53.4 | 70.9 | 58.1 | 8.63 |
| YOLOv8-X | 257.8 | 68.2 | 54.0 | 71.0 | 58.8 | 12.83 |
| RT-DETR-R101 | 259.0 | 76.0 | 54.3 | 72.7 | – | 13.51 |
| RT-DETRv2-R101 | 259.0 | 76.0 | 54.3 | 72.8 | – | 13.51 |
| YOLOv10-X | 160.4 | 29.5 | 54.4 | 71.3 | 59.3 | 10.70 |
| YOLO11-X | 194.9 | 56.9 | 54.2 | 71.0 | 59.1 | 11.35 |
| YOLOv12-X | 199.0 | 59.1 | 54.4 | 71.1 | 59.3 | 12.46 |
| YOLOv13-X | 199.2 | 64.0 | 54.8 | 72.0 | 59.8 | 14.67 |
2. 可视化
YOLOv10-N/S、YOLO11-N/S、YOLOv12-N/S 和 YOLOv13-N/S 的可视化示例。

自适应超边的代表性可视化示例。第一列和第二列中的超边主要关注前景中物体之间的高阶交互;第三列则主要关注背景与部分前景之间的高阶交互。这些超边的可视化能够直观地反映出 YOLOv13 所建模的高阶视觉关联。
快速入门 🚀
1. 安装依赖
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
conda create -n yolov13 python=3.11
conda activate yolov13
pip install -r requirements.txt
pip install -e .
YOLOv13 支持 Flash Attention 加速。
2. 验证
YOLOv13-N
YOLOv13-S
YOLOv13-L
YOLOv13-X
使用以下代码在 COCO 数据集上验证 YOLOv13 模型。请确保将 {n/s/l/x} 替换为所需的模型规模(nano、small、plus 或 ultra)。
from ultralytics import YOLO
model = YOLO('yolov13{n/s/l/x}.pt') # 替换为所需的模型规模
3. 训练
使用以下代码训练 YOLOv13 模型。请确保将 yolov13n.yaml 替换为所需的模型配置文件路径,将 coco.yaml 替换为您的 COCO 数据集配置文件。
from ultralytics import YOLO
model = YOLO('yolov13n.yaml')
# 训练模型
results = model.train(
data='coco.yaml',
epochs=600,
batch=256,
imgsz=640,
scale=0.5, # S:0.9; L:0.9; X:0.9
mosaic=1.0,
mixup=0.0, # S:0.05; L:0.15; X:0.2
copy_paste=0.1, # S:0.15; L:0.5; X:0.6
device="0,1,2,3",
)
# 在验证集上评估模型性能
metrics = model.val('coco.yaml')
# 对图像进行目标检测
results = model("path/to/your/image.jpg")
results[0].show()
4. 预测
使用以下代码利用 YOLOv13 模型进行目标检测。请确保将 {n/s/l/x} 替换为所需的模型规模。
from ultralytics import YOLO
model = YOLO('yolov13{n/s/l/x}.pt') # 替换为所需的模型规模
model.predict()
5. 导出
使用以下代码将 YOLOv13 模型导出为 ONNX 或 TensorRT 格式。请确保将 {n/s/l/x} 替换为所需的模型规模。
from ultralytics import YOLO
model = YOLO('yolov13{n/s/l/x}.pt') # 替换为所需的模型规模
model.export(format="engine", half=True) # 或 format="onnx"
相关项目 🔗
- 该代码基于 Ultralytics。感谢他们的出色工作!
- 其他关于超图计算的优秀工作:
引用 YOLOv13 📝
@article{yolov13,
title={YOLOv13:基于超图增强的自适应视觉感知的实时目标检测},
author={Lei, Mengqi and Li, Siqi and Wu, Yihong and et al.},
journal={arXiv preprint arXiv:2506.17733},
year={2025}
}
版本历史
yolov132025/06/22常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
AutoGPT
AutoGPT 是一个旨在让每个人都能轻松使用和构建 AI 的强大平台,核心功能是帮助用户创建、部署和管理能够自动执行复杂任务的连续型 AI 智能体。它解决了传统 AI 应用中需要频繁人工干预、难以自动化长流程工作的痛点,让用户只需设定目标,AI 即可自主规划步骤、调用工具并持续运行直至完成任务。 无论是开发者、研究人员,还是希望提升工作效率的普通用户,都能从 AutoGPT 中受益。开发者可利用其低代码界面快速定制专属智能体;研究人员能基于开源架构探索多智能体协作机制;而非技术背景用户也可直接选用预置的智能体模板,立即投入实际工作场景。 AutoGPT 的技术亮点在于其模块化“积木式”工作流设计——用户通过连接功能块即可构建复杂逻辑,每个块负责单一动作,灵活且易于调试。同时,平台支持本地自托管与云端部署两种模式,兼顾数据隐私与使用便捷性。配合完善的文档和一键安装脚本,即使是初次接触的用户也能在几分钟内启动自己的第一个 AI 智能体。AutoGPT 正致力于降低 AI 应用门槛,让人人都能成为 AI 的创造者与受益者。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。