stable-fast
stable-fast 是一个专为 NVIDIA GPU 设计的推理优化框架,旨在大幅提升 HuggingFace Diffusers 库中各类生成式模型(如图像生成、视频生成模型)的运行速度。它主要解决了传统加速方案(如 TensorRT)编译耗时过长的问题:以往可能需要数十分钟才能完成模型编译,而 stable-fast 仅需数秒即可就绪,同时还能保持业界领先的推理性能。
该工具特别适合需要高效部署扩散模型的开发者、研究人员以及追求本地快速生成的技术爱好者。无论是运行最新的 FLUX、Wan 2.1 视频模型,还是使用 Stable Video Diffusion,stable-fast 都能提供流畅的体验。其独特的技术亮点在于“开箱即用”地支持动态形状(dynamic shape)、LoRA 微调权重以及 ControlNet 控制网络,无需复杂的额外配置。这意味着用户在尝试不同分辨率或叠加多种插件时,无需重新编译模型,极大地提升了工作流的灵活性与效率。虽然目前针对最新架构的主动开发已转向新项目,但 stable-fast 依然是当前兼容旧款主流扩散模型、实现极速推理的可靠选择。
使用场景
一家专注于短视频营销的创意工作室,正利用 FLUX-dev 和 Wan 2.1 模型为客户批量生成带有特定品牌风格(LoRA)的高清宣传视频。
没有 stable-fast 时
- 编译等待漫长:每次切换新的 LoRA 风格或调整分辨率,基于 TensorRT 的方案都需要数十分钟重新编译模型,严重打断创作流。
- 动态适配困难:无法灵活支持动态形状(dynamic shape),一旦视频尺寸微调,就必须重新构建优化引擎,缺乏灵活性。
- 硬件资源闲置:在漫长的编译和低速推理过程中,昂贵的 NVIDIA GPU 利用率波动大,单位时间内的产出量极低。
- 新功能兼容慢:面对最新的 StableVideoDiffusionPipeline 等更新,旧有优化框架往往滞后,无法立即享受性能红利。
使用 stable-fast 后
- 秒级即时编译:stable-fast 将模型编译时间从几十分钟压缩至几秒钟,切换 LoRA 或调整参数几乎无需等待,实现“即改即看”。
- 原生动态支持:开箱即用支持动态形状、LoRA 和 ControlNet,无论视频分辨率如何变化,都能自动适配并保持高速推理。
- 推理性能飞跃:在 NVIDIA GPU 上达成 SOTA 级别的推理速度,显著缩短单视频生成耗时,使批量生产成为可能。
- 前沿模型同步:无缝支持最新的 FLUX-dev 和 Wan 2.1 架构,确保团队始终能用最快速度部署业界最先进的生成模型。
stable-fast 通过秒级编译与极致推理加速,将 AI 视频工作流从“等待编译”的瓶颈中解放,真正实现了创意到成片的实时转化。
运行环境要求
- Linux
- Windows (仅限 WSL2)
必需 NVIDIA GPU,需安装 CUDNN 和 CUBLAS,测试环境为 CUDA 12.1
未说明
快速开始
🚀稳定快速
🎉重要公告🎉
经过一年的延迟,我很高兴地宣布我计划构建一个新项目Comfy-WaveSpeed,以提供使用ComfyUI运行的所有模型的最快推理速度。
它刚刚开始,我希望它会成为一个很棒的项目👏。请继续关注它,并给我反馈👍!
![]()
![]()
![]()
注意
stable-fast的积极开发已被暂停。目前,我正在从事一个基于torch._dynamo的新项目,目标是针对像stable-cascade、SD3和Sora这样的新型模型。
它将更快、更灵活,并且支持更多的硬件后端,而不仅仅是CUDA。
欢迎联系。
stable-fast在__所有__类型的扩散模型上都实现了最先进的推理性能,即使是使用最新的StableVideoDiffusionPipeline也是如此。
与需要花费数十分钟来编译模型的TensorRT或AITemplate不同,stable-fast只需几秒钟即可完成模型编译。
stable-fast还开箱即用地支持动态形状、LoRA和ControlNet。
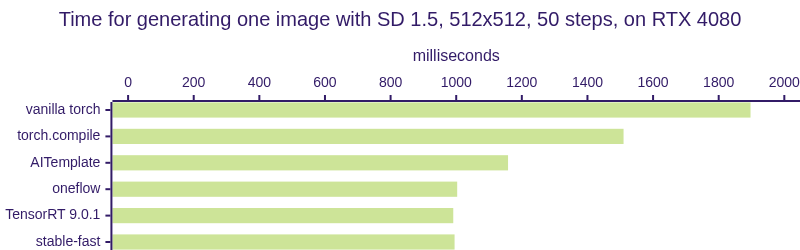
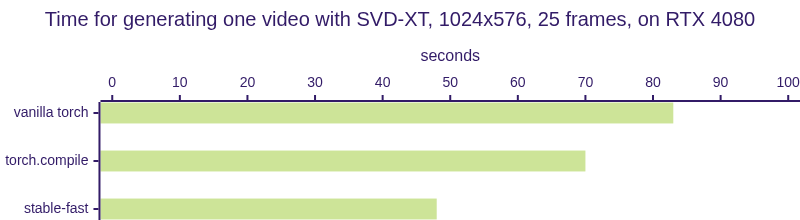
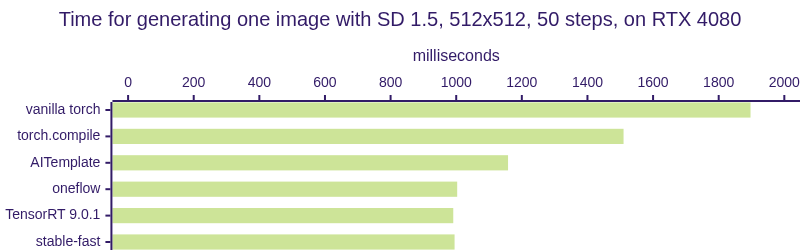
| 模型 | torch | torch.compile | AIT | oneflow | TensorRT | stable-fast |
|---|---|---|---|---|---|---|
| SD 1.5 (毫秒) | 1897 | 1510 | 1158 | 1003 | 991 | 995 |
| SVD-XT (秒) | 83 | 70 | 47 |
注意: 在基准测试期间,TensorRT是在静态批量大小和启用CUDA图的情况下进行测试的,而stable-fast则是在动态形状下运行的。
简介
这是什么?
stable-fast 是一个针对 HuggingFace Diffusers 在 NVIDIA GPU 上的超轻量级推理优化框架。
stable-fast 通过利用一些关键技术与特性,提供了极快的推理优化:
- CUDNN 卷积融合:
stable-fast实现了一系列功能完备且完全兼容的 CUDNN 卷积融合算子,适用于各种Conv + Bias + Add + Act计算模式的组合。 - 低精度与融合 GEMM:
stable-fast实现了一组以fp16精度进行计算的融合 GEMM 算子,其速度比 PyTorch 的默认设置更快(即以fp16读写数据,但以fp32进行计算)。 - 融合线性 GEGLU:
stable-fast能够将GEGLU(x, W, V, b, c) = GELU(xW + b) ⊗ (xV + c)融合为一个 CUDA 核心。 - NHWC 与融合 GroupNorm:
stable-fast使用 OpenAI 的Triton实现了一个高度优化的 NHWCGroupNorm + Silu融合算子,从而消除了对内存格式转换算子的需求。 - 全追踪模型:
stable-fast改进了torch.jit.trace接口,使其更适合追踪复杂模型。几乎StableDiffusionPipeline/StableVideoDiffusionPipeline的每一个部分都可以被追踪并转换为 TorchScript。它比torch.compile更加稳定,且 CPU 开销显著低于torch.compile,同时支持 ControlNet 和 LoRA。 - CUDA 图:
stable-fast可以将UNet、VAE和TextEncoder捕获为 CUDA 图格式,从而在小批量情况下降低 CPU 开销。该实现还支持动态形状。 - 融合多头注意力:
stable-fast直接使用 xformers,并使其与 TorchScript 兼容。
我的下一个目标是让 stable-fast 继续保持作为 diffusers 最快的推理优化框架之一,同时为 transformers 提供加速和显存占用减少的功能。
事实上,我已经使用 stable-fast 来优化 LLM,并取得了显著的加速效果。
不过,我还需要进一步完善,使其更加稳定、易于使用,并提供一个稳定的用户界面。
与其他加速库的区别
- 快速:
stable-fast专为 HuggingFace Diffusers 优化。它在众多库中都能达到高性能,并且仅需几秒钟即可完成非常快速的编译。在编译时间上,它显著快于torch.compile、TensorRT和AITemplate。 - 极简:
stable-fast作为一个 PyTorch 的插件框架运行。它充分利用现有的 PyTorch 功能和基础设施,能够与其他加速技术以及流行的微调技术和部署方案兼容。 - 最大兼容性:
stable-fast兼容所有版本的HuggingFace Diffusers和PyTorch。它同样兼容ControlNet和LoRA,甚至开箱即用就支持最新的StableVideoDiffusionPipeline!
安装
注意: stable-fast 目前仅在 Linux 和 Windows 的 WSL2 上进行了测试。
您需要先安装支持 CUDA 的 PyTorch(建议使用 1.12 至 2.1 版本)。
我仅在 CUDA 12.1 和 Python 3.10 环境下,使用 torch>=2.1.0、xformers>=0.0.22 和 triton>=2.1.0 对 stable-fast 进行了测试。
其他版本或许也能成功构建和运行,但无法保证。
安装预编译的 wheel 包
从 Releases 页面 下载适合您系统的 wheel 文件,并使用 pip3 install <wheel file> 进行安装。
目前已有适用于 Linux 和 Windows 的 wheel 包。
# 将 cu121 替换为您使用的 CUDA 版本,<wheel file> 替换为 wheel 文件的路径。
# 请确保 wheel 文件与您的 PyTorch 版本兼容。
pip3 install --index-url https://download.pytorch.org/whl/cu121 \
'torch>=2.1.0' 'xformers>=0.0.22' 'triton>=2.1.0' 'diffusers>=0.19.3' \
'<wheel file>'
从源码安装
# 请确保已安装 CUDNN/CUBLAS。
# https://developer.nvidia.com/cudnn
# https://developer.nvidia.com/cublas
# 首先安装带有 CUDA 支持的 PyTorch 及其他依赖包。
# Windows 用户:Triton 可能不可用,可跳过。
# 注意:必须安装 wheel 包,否则在构建时会遇到 `No module named 'torch'` 错误。
pip3 install wheel 'torch>=2.1.0' 'xformers>=0.0.22' 'triton>=2.1.0' 'diffusers>=0.19.3'
# (可选)这会使构建过程更快。
pip3 install ninja
# 如果您在不同类型的 GPU 上运行和构建,请设置 TORCH_CUDA_ARCH_LIST。
# 您也可以从 PyPI 安装最新稳定版。
# pip3 install -v -U stable-fast
pip3 install -v -U git+https://github.com/chengzeyi/stable-fast.git@main#egg=stable-fast
# (这可能需要数十分钟)
注意: 任何不在 sfast.compilers 中的用法均不保证向后兼容。
注意: 为了获得最佳性能,需要安装并启用 xformers 和 OpenAI 的 triton>=2.1.0。
您可能需要从源码构建 xformers,以使其与您的 PyTorch 兼容。
使用方法
优化 StableDiffusionPipeline
stable-fast 能直接优化 StableDiffusionPipeline 和 StableDiffusionPipelineXL。
import time
import torch
from diffusers import (StableDiffusionPipeline,
EulerAncestralDiscreteScheduler)
from sfast.compilers.diffusion_pipeline_compiler import (compile,
CompilationConfig)
def load_model():
model = StableDiffusionPipeline.from_pretrained(
'runwayml/stable-diffusion-v1-5',
torch_dtype=torch.float16)
model.scheduler = EulerAncestralDiscreteScheduler.from_config(
model.scheduler.config)
model.safety_checker = None
model.to(torch.device('cuda'))
return model
model = load_model()
config = CompilationConfig.Default()
# 建议启用 xformers 和 Triton 以获得最佳性能。
try:
import xformers
config.enable_xformers = True
except ImportError:
print('xformers 未安装,跳过')
try:
import triton
config.enable_triton = True
except ImportError:
print('Triton 未安装,跳过')
# 对于小批量和低分辨率的情况,建议启用 CUDA 图以减少 CPU 开销。
# 但这样做可能会增加 GPU 显存的使用量。
# 对于 StableVideoDiffusionPipeline,则无需启用。
config.enable_cuda_graph = True
model = compile(model, config)
kwarg_inputs = dict(
prompt=
'(masterpiece:1,2), best quality, masterpiece, best detailed face, a beautiful girl',
height=512,
width=512,
num_inference_steps=30,
num_images_per_prompt=1,
)
# 注意:请先预热。
# 初始几次调用会触发编译,可能会非常慢。
# 之后应该会非常快。
for _ in range 3:
output_image = model(**kwarg_inputs).images[0]
# 让我们看看吧!
# 注意:由于 CUDA 的异步特性,进度条可能会显示不准确。
begin = time.time()
output_image = model(**kwarg_inputs).images[0]
print(f'推理时间: {time.time() - begin:.3f}秒')
# 让我们在终端中查看它!
from sfast.utils.term_image import print_image
print_image(output_image, max_width=80)
更多详情请参考 examples/optimize_stable_diffusion_pipeline.py。
您可以通过此 Colab 了解其在 T4 GPU 上的运行情况:![]()
优化 LCM 流水线
stable-fast 能够优化最新的 latent consistency model 流水线,并实现显著的速度提升。
有关如何使用 LCM LoRA 优化普通 SD 模型的详细信息,请参阅 examples/optimize_lcm_lora.py。有关如何优化独立的 LCM 模型的详细信息,请参阅 examples/optimize_lcm_pipeline.py。
优化 StableVideoDiffusionPipeline
stable-fast 能够优化最新的 StableVideoDiffusionPipeline,并实现 2 倍 的速度提升。
更多详情请参阅 examples/optimize_stable_video_diffusion_pipeline.py。
动态切换 LoRA
支持动态切换 LoRA,但需要进行一些额外的操作。
之所以可行,是因为编译后的图和 CUDA Graph 与原始 UNet 模型共享相同的底层数据(指针)。因此,您只需就地更新原始 UNet 模型的参数即可。
以下代码假设您已经加载了一个 LoRA 并编译了模型,现在想要切换到另一个 LoRA。
如果您未启用 CUDA 图且保持 preserve_parameters = True,操作会简单得多。甚至可能不需要执行以下代码。
# load_state_dict with assign=True 需要 torch >= 2.1.0
def update_state_dict(dst, src):
for key, value in src.items():
# 进行就地复制。
# 由于追踪的前向函数共享相同的底层数据(指针),此修改将反映在追踪的前向函数中。
dst[key].copy_(value)
# 将“另一个”LoRA 切换到 UNet
def switch_lora(unet, lora):
# 存储原始 UNet 参数
state_dict = unet.state_dict()
# 加载另一个 LoRA 到 unet
unet.load_attn_procs(lora)
# 将当前 UNet 参数就地复制到原始 unet 参数
update_state_dict(state_dict,unet.state_dict())
# 将原始 UNet 参数重新加载回模型。
# 我们使用 assign=True,因为我们仍希望保留原始 UNet 参数的引用
unet.load_state_dict(state_dict,assign=True)
switch_lora(compiled_model.unet,lora_b_path)
模型量化
stable-fast 扩展了 PyTorch 的 quantize_dynamic 功能,在 CUDA 后端提供了一种动态量化的线性算子。
启用后,您可以为 diffusers 获得轻微的 VRAM 减少,为 transformers 获得显著的 VRAM 减少,并有可能提高速度(但并非总是如此)。
对于 SD XL,预计在图像尺寸为 1024x1024 时,VRAM 可减少 2GB。
def quantize_unet(m):
from diffusers.utils import USE_PEFT_BACKEND
assert USE_PEFT_BACKEND
m = torch.quantization.quantize_dynamic(m,{torch.nn.Linear},
dtype=torch.qint8,
inplace=True)
return m
model.unet = quantize_unet(model.unet)
if hasattr(model,'controlnet'):
model.controlnet = quantize_unet(model.controlnet)
更多详情请参阅 examples/optimize_stable_diffusion_pipeline.py。
提高 PyTorch 性能的一些常用方法
# 强烈建议使用 TCMalloc 来减少 CPU 开销
# https://github.com/google/tcmalloc
LD_PRELOAD=/path/to/libtcmalloc.so python3 ...
import packaging.version
import torch
if packaging.version.parse(torch.__version__) >= packaging.version.parse('1.12.0'):
torch.backends.cuda.matmul.allow_tf32 = True
性能对比
不同硬件/软件/平台/驱动程序配置下的性能差异非常大。
准确地进行基准测试非常困难,而准备基准测试环境本身也是一项艰巨的任务。
我曾在一些平台上进行过测试,但结果仍然可能存在误差。
需要注意的是,在进行基准测试时,由于 CUDA 的异步特性,tqdm 显示的进度条可能会不准确。
为了解决这个问题,我使用 CUDA Event 来精确测量每秒迭代次数。
stable-fast 在较新的 GPU 和较新版本的 CUDA 上表现更佳。
在较旧的 GPU 上,性能提升可能有限。
在基准测试过程中,由于 CUDA 的异步特性,进度条可能会显示不准确。
RTX 4080(512x512,批次大小 1,fp16,在 WSL2 中)
这是我个人的游戏电脑😄。它的 CPU 比云服务器提供商的更强大。
| 框架 | SD 1.5 | SD XL (1024x1024) | SD 1.5 ControlNet |
|---|---|---|---|
| Vanilla PyTorch (2.1.0) | 29.5 it/s | 4.6 it/s | 19.7 it/s |
| torch.compile (2.1.0,max-autotune) | 40.0 it/s | 6.1 it/s | 21.8 it/s |
| AITemplate | 44.2 it/s | ||
| OneFlow | 53.6 it/s | ||
| AUTO1111 WebUI | 17.2 it/s | 3.6 it/s | |
| AUTO1111 WebUI(带 SDPA) | 24.5 it/s | 4.3 it/s | |
| TensorRT(AUTO1111 WebUI) | 40.8 it/s | ||
| TensorRT 官方演示 | 52.6 it/s | ||
| stable-fast(带 xformers & Triton) | 51.6 it/s | 9.1 it/s | 36.7 it/s |
H100
感谢 @Consceleratus 和 @harishp 的帮助,我在 H100 上进行了速度测试。
| 框架 | SD 1.5 | SD XL (1024x1024) | SD 1.5 ControlNet |
|---|---|---|---|
| Vanilla PyTorch (2.1.0) | 54.5 it/s | 14.9 it/s | 35.8 it/s |
| torch.compile (2.1.0,max-autotune) | 66.0 it/s | 18.5 it/s | |
| stable-fast(带 xformers & Triton) | 104.6 it/s | 21.6 it/s | 72.6 it/s |
A100
感谢 @SuperSecureHuman 和 @jon-chuang 的帮助,现在可以在 A100 上进行基准测试了。
| 框架 | SD 1.5 | SD XL (1024×1024) | SD 1.5 ControlNet |
|---|---|---|---|
| 原生 PyTorch (2.1.0) | 35.6 it/s | 8.7 it/s | 25.1 it/s |
| torch.compile (2.1.0, max-autotune) | 41.9 it/s | 10.0 it/s | |
| stable-fast (使用 xformers 和 Triton) | 61.8 it/s | 11.9 it/s | 41.1 it/s |
兼容性
| 模型 | 支持 |
|---|---|
| Hugging Face Diffusers (1.5/2.1/XL) | 是 |
| 使用 ControlNet | 是 |
| 使用 LoRA | 是 |
| 隐式一致性模型 | 是 |
| SDXL Turbo | 是 |
| Stable Video Diffusion | 是 |
| 功能 | 支持 |
|---|---|
| 动态形状 | 是 |
| 文本到图像 | 是 |
| 图像到图像 | 是 |
| 图像修复 | 是 |
| UI 框架 | 支持 | 链接 |
|---|---|---|
| AUTOMATIC1111 | 开发中 | |
| SD Next | 是 | SD Next |
| ComfyUI | 是 | ComfyUI_stable_fast |
| 操作系统 | 支持 |
|---|---|
| Linux | 是 |
| Windows | 是 |
| Windows WSL | 是 |
故障排除
更多详情请参阅 doc/troubleshooting.md。
您也可以加入 Discord 频道 寻求帮助。
版本历史
nightly2024/11/27v1.0.52024/05/09v1.0.42024/03/14v1.0.32024/01/31v1.0.22024/01/19v1.0.12023/12/28v1.0.02023/12/19v0.0.15.post12023/12/18v0.0.152023/12/13v0.0.142023/12/11v0.0.13.post42023/12/11v0.0.13.post32023/12/05v0.0.13.post12023/12/05v0.0.132023/12/05v0.0.12.post62023/11/29v0.0.12.post52023/11/28v0.0.12.post42023/11/27v0.0.12.post32023/11/25v0.0.12.post22023/11/25v0.0.12.post12023/11/24常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
AutoGPT
AutoGPT 是一个旨在让每个人都能轻松使用和构建 AI 的强大平台,核心功能是帮助用户创建、部署和管理能够自动执行复杂任务的连续型 AI 智能体。它解决了传统 AI 应用中需要频繁人工干预、难以自动化长流程工作的痛点,让用户只需设定目标,AI 即可自主规划步骤、调用工具并持续运行直至完成任务。 无论是开发者、研究人员,还是希望提升工作效率的普通用户,都能从 AutoGPT 中受益。开发者可利用其低代码界面快速定制专属智能体;研究人员能基于开源架构探索多智能体协作机制;而非技术背景用户也可直接选用预置的智能体模板,立即投入实际工作场景。 AutoGPT 的技术亮点在于其模块化“积木式”工作流设计——用户通过连接功能块即可构建复杂逻辑,每个块负责单一动作,灵活且易于调试。同时,平台支持本地自托管与云端部署两种模式,兼顾数据隐私与使用便捷性。配合完善的文档和一键安装脚本,即使是初次接触的用户也能在几分钟内启动自己的第一个 AI 智能体。AutoGPT 正致力于降低 AI 应用门槛,让人人都能成为 AI 的创造者与受益者。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。