sd-webui-inpaint-anything
sd-webui-inpaint-anything 是一款专为 Stable Diffusion Web UI 设计的智能修复扩展插件。它巧妙地将 Meta 发布的“分割一切”(Segment Anything)模型融入绘图流程,让用户只需在图片上简单点击或涂抹,即可自动精准识别并生成需要修改区域的蒙版,随后利用 Stable Diffusion 技术完成高质量的内容重绘或画面扩充。
传统修图往往需要用户手动精细绘制蒙版,不仅耗时且对操作技巧要求较高。sd-webui-inpaint-anything 彻底解决了这一痛点,将复杂的选区工作转化为直观的交互体验,大幅提升了创作效率与成品质量。无论是希望快速移除画面杂物、替换局部元素,还是进行创意扩图的创作者,都能从中受益。
该工具特别适合插画师、平面设计师以及广大 AI 绘画爱好者使用。其核心亮点在于支持多种先进的分割模型(如 SAM 2、MobileSAM 等),用户可根据显存配置灵活选择;同时提供针对动漫风格的优化选项,以及蒙版的微调功能(如扩张、修剪、叠加),确保选区完美贴合需求。作为 AUTOMATIC1111 界面的原生扩展,它无需切换软件即可实现从智能选区到最终生成的无缝衔接,是让 AI 绘图更加得心应手的实用利器。
使用场景
一位电商设计师需要快速移除产品宣传图中背景里杂乱的路人,同时保持主体商品的光影和细节完美无瑕。
没有 sd-webui-inpaint-anything 时
- 抠图耗时费力:设计师必须手动使用钢笔工具或画笔在 Photoshop 中逐帧描绘路人轮廓,遇到发丝或复杂边缘时极易出错,单张图片处理需耗费 15 分钟以上。
- 重绘边界生硬:传统蒙版难以精准控制修复范围,导致 AI 重绘后商品边缘常出现模糊、断裂或与背景融合不自然的“伪影”。
- 试错成本高昂:若对首次重绘效果不满意,需重新手动调整蒙版形状并再次生成,反复修改严重打断创作心流。
- 复杂场景束手无策:当背景物体与商品颜色相近或部分遮挡时,手动区分前景与背景极其困难,往往需要高超的合成技巧才能弥补。
使用 sd-webui-inpaint-anything 后
- 点选即得蒙版:依托 Segment Anything 模型,设计师只需在路人位置轻轻点击或简单涂抹,系统即可毫秒级自动生成高精度分割掩码,将准备时间缩短至 30 秒。
- 智能边缘优化:生成的蒙版能自动识别物体细微边界(如头发丝),配合"Expand mask region"功能微调范围,确保重绘区域过渡自然,完美保留商品细节。
- 交互式灵活调整:若自动分割略有偏差,可直接使用"Add/Trim mask by sketch"功能通过笔刷增减区域,无需推翻重来,实时预览让调整过程直观高效。
- 一键批量重绘:结合 Stable Diffusion 的强大生成能力,输入提示词后即可针对特定掩码区域进行多次迭代重绘,轻松获得多种背景替换方案供选择。
sd-webui-inpaint-anything 通过将前沿的自动分割技术与生成式重绘无缝衔接,把原本繁琐的手工抠图流程转化为“点选即改”的智能化操作,极大提升了图像编辑的效率与质感。
运行环境要求
- Linux
- macOS
- Windows
- 必需 NVIDIA GPU(推荐),需支持 xformers 以优化显存
- 显存需求取决于所选 SAM 模型大小(Base/Large/Huge),Large 和 Huge 模型消耗更多显存
- 未明确具体 CUDA 版本,但需兼容 Stable Diffusion Web UI 环境
未说明
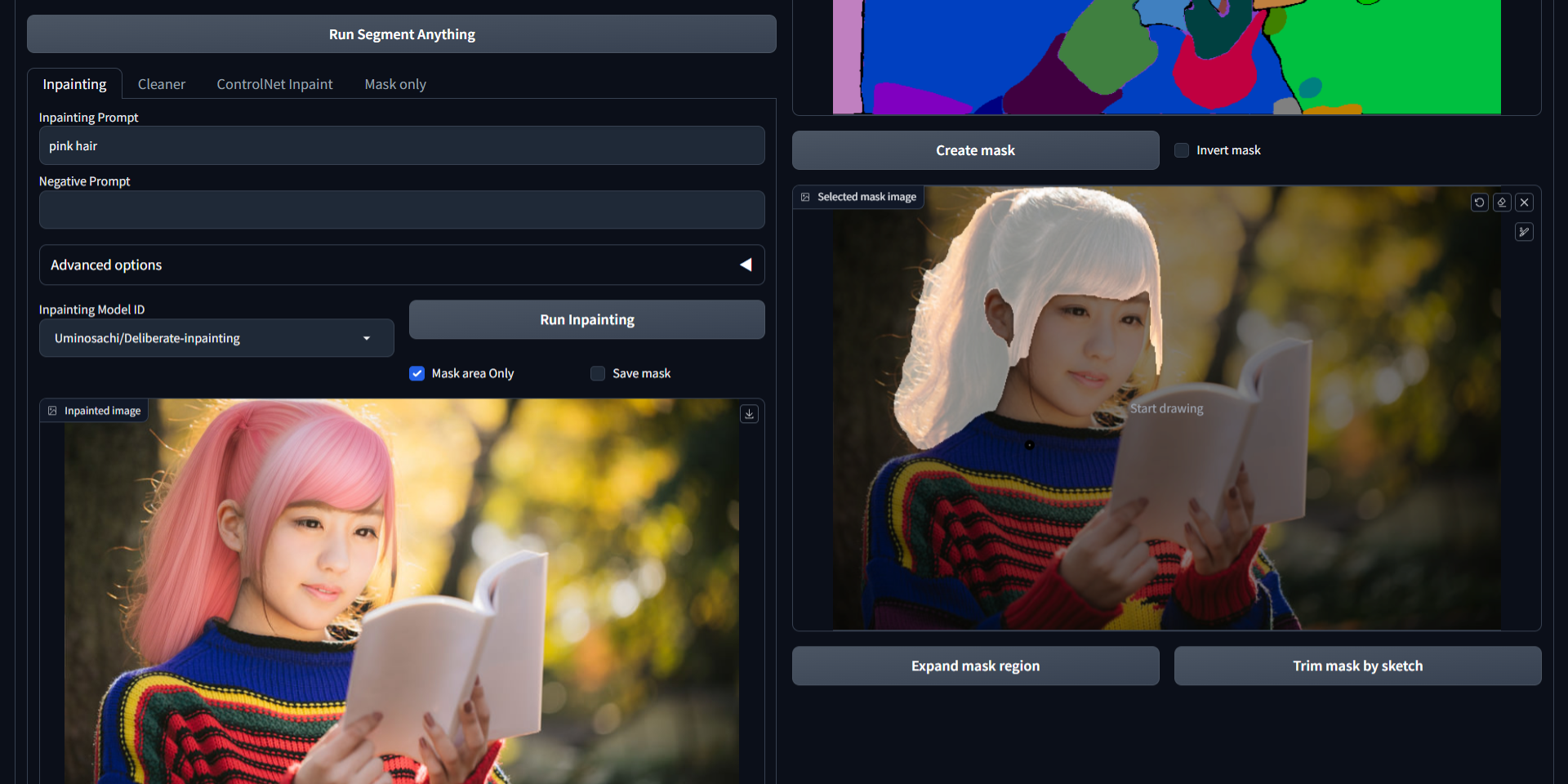
快速开始
Stable Diffusion Web UI 的任意修复插件
“任意修复”扩展程序在浏览器界面上,使用从 Segment Anything 输出中选择的任何掩码,执行稳定扩散图像修复。
借助 Segment Anything,用户只需指向所需区域即可指定掩码,而无需手动绘制。这不仅提高了创建掩码的效率和准确性,还能节省时间和精力,从而获得更高质量的修复效果。
安装
请按照以下步骤安装该软件:
- 打开 AUTOMATIC1111 的 Stable Diffusion Web UI 中的“Extensions”选项卡。
- 选择“Install from URL”选项。
- 在“URL for extension's git repository”字段中输入
https://github.com/Uminosachi/sd-webui-inpaint-anything.git。 - 点击“Install”按钮。
- 安装完成后,请重启 Web UI。
- 注意:此扩展支持 AUTOMATIC1111 的 Stable Diffusion Web UI v1.3.0 或更高版本。
运行应用程序
- 如果您打算使用内存高效的 xformers,请在启动命令中添加
--xformers参数。例如,运行./webui.sh --xformers或webui.bat --xformers。 - 注意:如果您在浏览器中启用了隐私保护扩展程序(如 DuckDuckGo),可能无法从您的草图中获取掩码。
- 注意:在 Gradio 3.23.0 或更早版本中,分割图像可能会在 Web UI 上显示得较小。
下载模型
- 导航到 Web UI 中的“Inpaint Anything”选项卡。
- 点击位于 Segment Anything Model ID 旁边的“Download model”按钮。这包括 SAM 2、高精度 Segment Anything 模型 ID、Fast Segment Anything 和 更快的 Segment Anything (MobileSAM)。
- 请注意,SAM 有三种尺寸:Base、Large 和 Huge。请记住,尺寸越大,VRAM 消耗越多。
- 等待下载完成。
- 下载的模型文件将存储在此应用程序仓库的
models目录中。
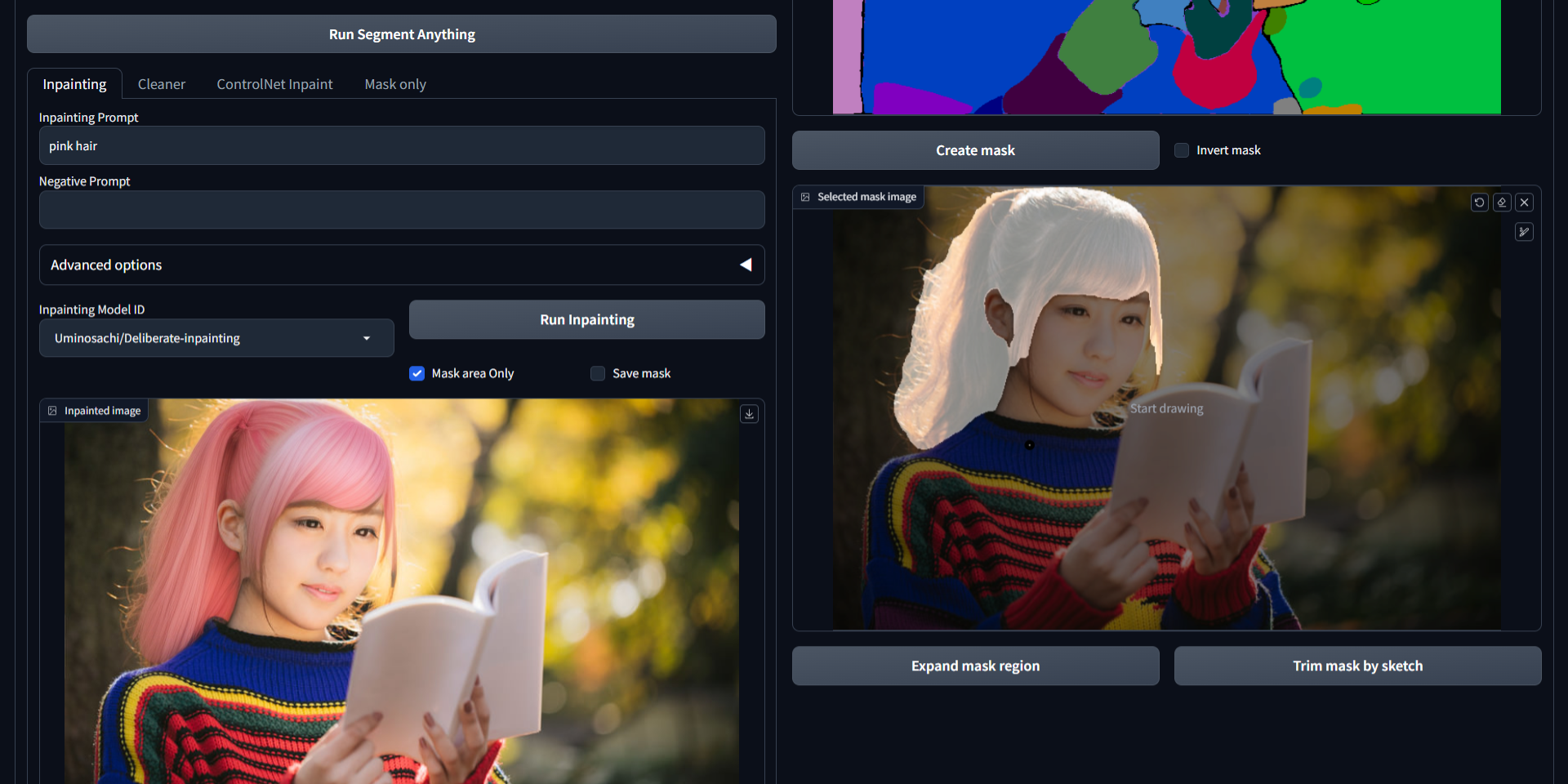
使用方法
- 将您的图像拖放到输入图像区域。
- 可以通过“Padding options”实现外扩,配置缩放比例和平衡,然后点击“Run Padding”按钮。
- 勾选“Anime Style”复选框可以增强对动漫风格图像的分割掩码检测,但会略微降低掩码质量。
- 点击“Run Segment Anything”按钮。
- 使用草图工具标记您想要修复的区域。您可以撤销操作并调整笔刷大小。
- 将鼠标悬停在 SAM 图像或掩码图像上,按
S键进入全屏模式,或按R键重置缩放。
- 将鼠标悬停在 SAM 图像或掩码图像上,按
- 点击“Create mask”按钮。掩码将显示在选定的掩码图像区域。
掩码调整
- “Expand mask region”按钮:用于稍微扩大掩码区域,以获得更广泛的覆盖范围。
- “Trim mask by sketch”按钮:单击此按钮可将草图区域排除在掩码之外。
- “Add mask by sketch”按钮:单击此按钮可将草图区域添加到掩码中。
修复选项卡
- 输入您所需的 Prompt 和 Negative Prompt,然后选择修复模型 ID。
- 点击“Run Inpainting”按钮(请注意,首次下载模型可能需要一些时间)。
- 在高级选项中,您可以调整采样器、采样步数、指导尺度和种子。
- 如果启用“Mask area Only”选项,则修改仅限于指定的掩码区域。
- 调整迭代滑块,以使用不同种子多次进行修复。
- 修复过程由 diffusers 提供支持。
小贴士
- 您可以直接将修复后的图像拖放到 Web UI 的输入图像字段中。(在 Chrome 和 Edge 浏览器中效果较好)
- 要加载保存在 PNG 文件中的提示词,请按照以下步骤操作:
- 将图像拖放到 Web UI 的“PNG Info”选项卡中,然后点击“Send to txt2img (or img2img)”。
- 导航到“Inpaint Anything”选项卡中的“Inpainting”部分,点击“Get prompt from: txt2img (or img2img)”按钮。
模型缓存
- 保存在 HuggingFace 缓存中的修复模型,如果其 repo_id 包含
inpaint(不区分大小写),也会被添加到修复模型 ID 下拉列表中。- 如果您想使用特定模型,可以提前使用以下 Python 命令将其缓存起来(Linux 和 MacOS 使用
venv/bin/python):
venv\Scripts\python.exefrom diffusers import StableDiffusionInpaintPipeline pipe = StableDiffusionInpaintPipeline.from_pretrained("Uminosachi/dreamshaper_5-inpainting") exit() - 如果您想使用特定模型,可以提前使用以下 Python 命令将其缓存起来(Linux 和 MacOS 使用
- 下载的模型通常存储在您的主目录中。对于 Linux 和 MacOS 用户,可以在
/home/username/.cache/huggingface/hub找到;对于 Windows 用户,则位于C:\Users\username\.cache\huggingface\hub。- 在执行修复时,如果控制台输出以下错误信息,请尝试从上述缓存文件夹中删除相应模型:
An error occurred while trying to fetch model name...
清理选项卡
- 选择清理模型 ID。
- 点击“Run Cleaner”按钮(请注意,首次下载模型可能需要一些时间)。
- 清理过程由 Lama Cleaner 执行。
修复 Web UI 选项卡
- 当您拥有修复模型时,此选项卡将变为可用。
- 所需模型的文件名应包含
inpaint(不区分大小写),并且必须位于stable-diffusion-webui/models目录中。 - 一旦模型被识别,它就会出现在修复模型 ID 下拉列表中。
- 当 Web UI 左上角的稳定扩散检查点与所选修复模型 ID 匹配时,修复过程可以快速执行,无需加载模型。
ControlNet 修复选项卡
- 要执行图像修复,请使用 Web UI 左上角的 Stable Diffusion 检查点,并将其与 ControlNet 修复模型配对。
- 输入您所需的提示词和负面提示词。
- 单击
运行 ControlNet 修复按钮以开始处理。- 在高级选项中,您可以调整采样器、采样步数、指导尺度、去噪强度和种子。
- 可以在 ControlNet 选项中修改控制权重和控制模式。
- 如果多 ControlNet 设置配置为 2 或更高,则可以使用仅参考控制。
- 如果
extensions/sd-webui-controlnet/models目录中存在 IP-Adapter 模型,并且 ControlNet 版本已更新,则可以使用 IP-Adapter。
- 请确保安装支持
inpaint_only预处理器和 ControlNet 修复模型的 ControlNet 扩展。 - 需要:sd-webui-controlnet 扩展以及位于
extensions/sd-webui-controlnet/models目录中的 ControlNet-v1-1 修复模型。
仅掩码选项卡
- 提供仅保存掩码而不进行其他处理的功能,以便随后可以在 AUTOMATIC1111 中的 img2img 的
修复上传功能中,使用您已有的任何模型/扩展/工具来应用该掩码。 将掩码作为图像的 Alpha 通道保存按钮:将掩码保存为 RGBA 图像,并将其放入输入图像的 Alpha 通道中。获取掩码按钮:将掩码保存为 RGB 图像。- 点击
获取掩码按钮后,您可以使用掩码图像下方的发送到 img2img 修复按钮,将输入图像和掩码同时发送到 img2img 选项卡。
自动保存图像
- 修复后的图像将自动保存在
outputs/inpaint-anything目录下,对应当前日期的文件夹中。 - 您可以通过 Web UI 的
设置选项卡中的Inpaint Anything部分,切换到outputs/img2img-images目录。
开发
借助 Inpaint Anything 库,您可以使用来自其他扩展的草图进行分割并创建掩码。
许可证
源代码采用 Apache 2.0 许可证授权。
参考文献
- Ravi, N., Gabeur, V., Hu, Y.-T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädel, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K. V., Carion, N., Wu, C.-Y., Girshick, R., Dollár, P., & Feichtenhofer, C. (2024). SAM 2:图像与视频中的任意分割。arXiv 预印本。
- Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W-Y., Dollár, P., & Girshick, R. (2023). 任意分割。arXiv:2304.02643。
- Ke, L., Ye, M., Danelljan, M., Liu, Y., Tai, Y-W., Tang, C-K., & Yu, F. (2023). 高质量的任意分割。arXiv:2306.01567。
- Zhao, X., Ding, W., An, Y., Du, Y., Yu, T., Li, M., Tang, M., & Wang, J. (2023). 快速任意分割。arXiv:2306.12156 [cs.CV]。
- Zhang, C., Han, D., Qiao, Y., Kim, J. U., Bae, S-H., Lee, S., & Hong, C. S. (2023). 更快速的任意分割:面向移动应用的轻量级 SAM。arXiv:2306.14289。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
AutoGPT
AutoGPT 是一个旨在让每个人都能轻松使用和构建 AI 的强大平台,核心功能是帮助用户创建、部署和管理能够自动执行复杂任务的连续型 AI 智能体。它解决了传统 AI 应用中需要频繁人工干预、难以自动化长流程工作的痛点,让用户只需设定目标,AI 即可自主规划步骤、调用工具并持续运行直至完成任务。 无论是开发者、研究人员,还是希望提升工作效率的普通用户,都能从 AutoGPT 中受益。开发者可利用其低代码界面快速定制专属智能体;研究人员能基于开源架构探索多智能体协作机制;而非技术背景用户也可直接选用预置的智能体模板,立即投入实际工作场景。 AutoGPT 的技术亮点在于其模块化“积木式”工作流设计——用户通过连接功能块即可构建复杂逻辑,每个块负责单一动作,灵活且易于调试。同时,平台支持本地自托管与云端部署两种模式,兼顾数据隐私与使用便捷性。配合完善的文档和一键安装脚本,即使是初次接触的用户也能在几分钟内启动自己的第一个 AI 智能体。AutoGPT 正致力于降低 AI 应用门槛,让人人都能成为 AI 的创造者与受益者。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。