RLHF-Reward-Modeling
RLHF-Reward-Modeling 是一套专为训练大语言模型奖励模型(Reward Model)设计的开源工具集,旨在优化基于人类反馈的强化学习(RLHF)流程。它核心解决了如何准确量化模型输出质量、避免“奖励黑客”以及消除生成长度偏差等关键难题,为对齐人类偏好提供可靠信号。
这套工具非常适合 AI 研究人员和开发者使用,尤其是那些希望复现前沿成果或构建自定义对齐流程的团队。其独特亮点在于提供了多样化的建模方案:不仅包含经典的 Bradley-Terry 模型,还创新性地引入了生成式配对偏好模型(Pairwise Preference Model),利用模型的下一个词预测能力直接判断优劣;更推出了多目标混合专家模型 ArmoRM,曾在 RewardBench 榜单上斩获 8B 参数组别第一名。此外,项目还涵盖了过程监督与结果监督奖励模型(PRM/ORM)的训练代码,甚至最新集成了基于决策树的可解释性奖励模型,帮助开发者深入理解模型的偏好逻辑。无论是学术研究还是工程落地,RLHF-Reward-Modeling 都提供了详尽的代码、数据与超参数配置,让高质量的奖励模型训练变得可复现且高效。
使用场景
某医疗 AI 初创团队正在开发一款面向患者的智能问诊助手,急需通过人类反馈强化学习(RLHF)让模型的回答既符合医学严谨性,又具备人文关怀。
没有 RLHF-Reward-Modeling 时
- 奖励信号单一且偏差大:团队只能使用基础的 Bradley-Terry 模型,导致模型倾向于生成长篇大论的“废话”来骗取高分,无法识别简洁且准确的优质回答。
- 缺乏多维评估能力:难以同时平衡“医学准确性”、“语气同理心”和“安全性”等多个目标,往往顾此失彼,调整一个指标就会牺牲另一个。
- 标注数据利用率低:面对昂贵的医生标注数据,缺乏半监督自我训练机制,大量未标注的对话数据被闲置,模型迭代速度缓慢。
- 黑盒决策难解释:当模型给出错误偏好判断时,开发人员无法追溯具体是哪个因素导致了误判,调试过程如同盲人摸象。
使用 RLHF-Reward-Modeling 后
- 消除长度偏见:利用
odin-rm模块成功解耦了回复长度与奖励分数的关联,使模型能精准识别短小精悍的正确诊断建议。 - 多目标动态融合:通过
armo-rm的多目标混合专家架构,模型能根据上下文动态权衡医学事实与沟通态度,输出综合质量更高的回答。 - 数据效能倍增:借助
pair-pm中的半监督自训练技术(SSRM),团队利用海量未标注日志显著提升了奖励模型的泛化能力,减少了对人工标注的依赖。 - 决策透明可溯:引入
decision_tree奖励模型,团队可以清晰地看到模型是依据“包含禁忌症提示”还是“语气温暖”等具体规则做出的偏好判断,极大降低了调试成本。
RLHF-Reward-Modeling 通过提供从去偏、多目标优化到可解释性的一站式解决方案,将医疗助手的对齐训练周期缩短了一半,并显著提升了最终上线的安全性与用户满意度。
运行环境要求
- 未说明
- 需要 NVIDIA GPU
- 示例配置:4x A40 (48GB) 可训练 7B 模型 (max_length 4096, DeepSpeed Zero-3 + gradient checkpointing)
- 4x A100 (80GB) 可训练 7B 模型 (max_length 4096, gradient checkpointing)
未说明
快速开始
RLHF-奖励建模
结构
该项目的初始版本专注于布拉德利-特里奖励建模和成对偏好模型。此后,我们引入了更多先进的技术来构建偏好模型。项目的结构如下:
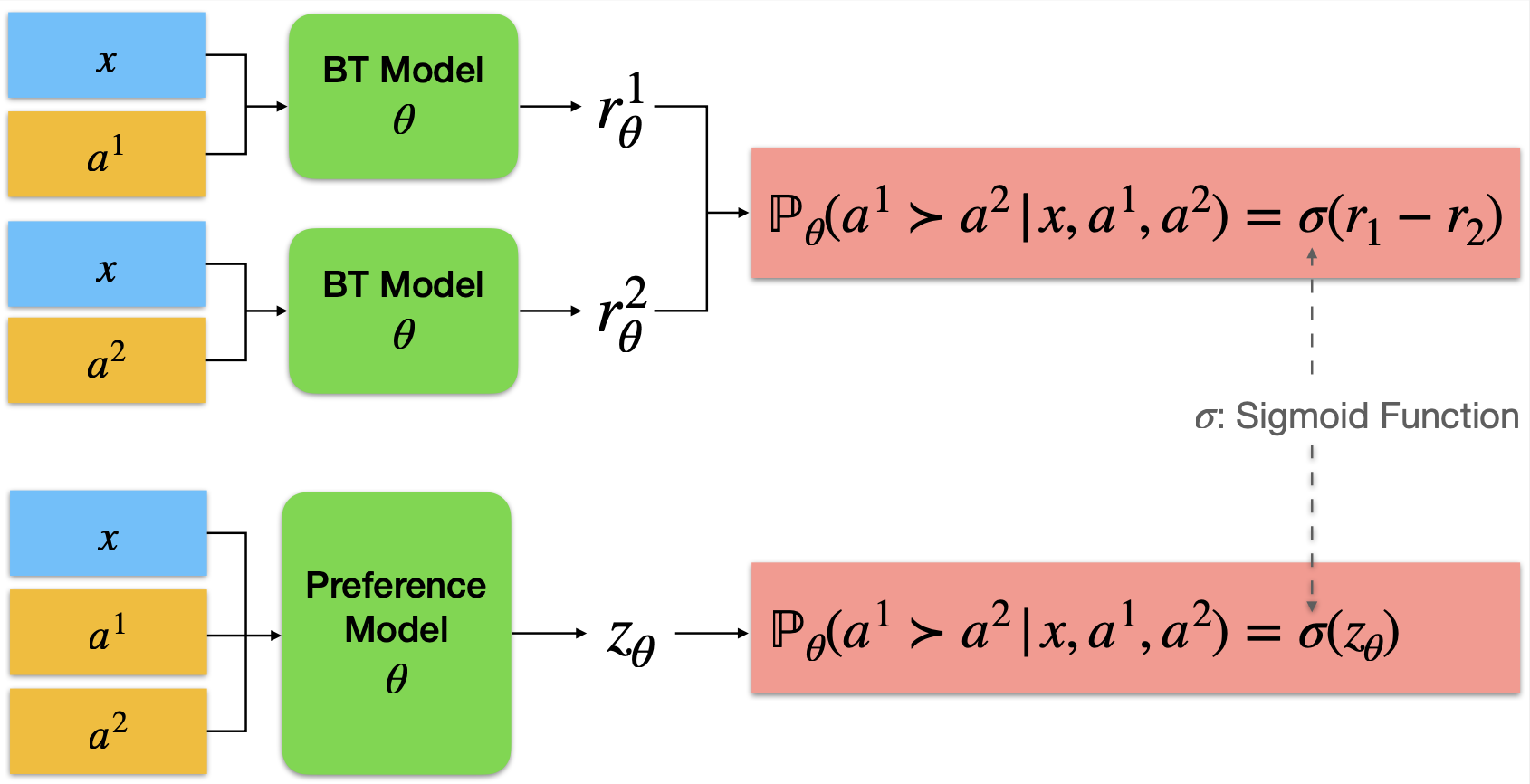
bradley-terry-rm用于训练经典的布拉德利-特里奖励模型;pair-pm用于训练成对偏好模型,该模型以一个提示和两个回答作为输入,直接预测第一个回答更受偏好的概率。我们将这一问题形式化为用户与模型之间的对话,以利用模型的下一个 token 预测能力,这种做法在后续文献中被称为生成式奖励模型。SSRM:论文《通过迭代自训练的半监督奖励建模》(arXiv:2409.06903)的代码实现;RRM:利用因果推断扩充偏好数据集,并缓解奖励欺骗问题。详情参见 arXiv:2409.13156v1。
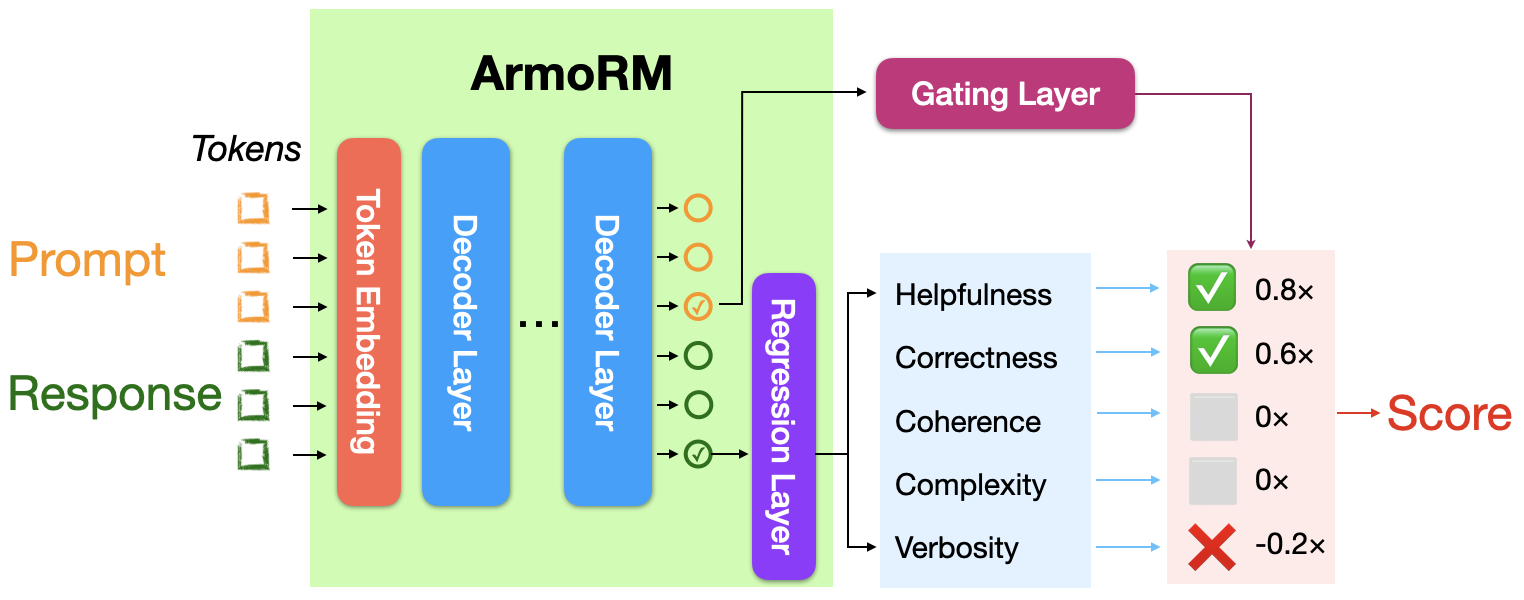
armo-rm用于训练 ArmoRM,该模型以多目标奖励模型为基础,通过上下文相关的专家混合方法对奖励向量进行聚合。具体细节请参阅我们的技术报告《[ArmoRM] 基于多目标奖励建模与专家混合的可解释偏好》(arXiv:2406.12845)。odin-rm用于将奖励建模从长度偏差中解耦。详情参见 arXiv:2402.07319。math-rm:用于使用下一个 token 预测来训练过程监督奖励(PRM)和结果监督奖励(ORM)的代码。我们开源了数据、代码、超参数和模型,提供一套易于复现且稳健的方案。decision_tree:用于使用和训练决策树奖励模型的代码。技术细节请参阅文章《通过决策树视角解读语言模型偏好》(rlhflow.github.io/posts/2025-01-22-decision-tree-reward-model/)。
新闻
🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥
🚀 [2025年1月] 决策树奖励模型训练代码已在decision_tree/文件夹下发布!Decision-Tree-Reward-Gemma-2-27B 在RewardBench上取得了新的最先进分数(95.4%)!
🚀 [2024年11月] PRM和ORM的训练代码已在math-rm/文件夹下发布!
🚀 [2024年9月] ArmoRM的训练代码已在armo-rm/文件夹下发布!
🚀 [2024年9月] 关于通过迭代自训练进行半监督奖励建模的代码已在pair-pm/文件夹下发布。
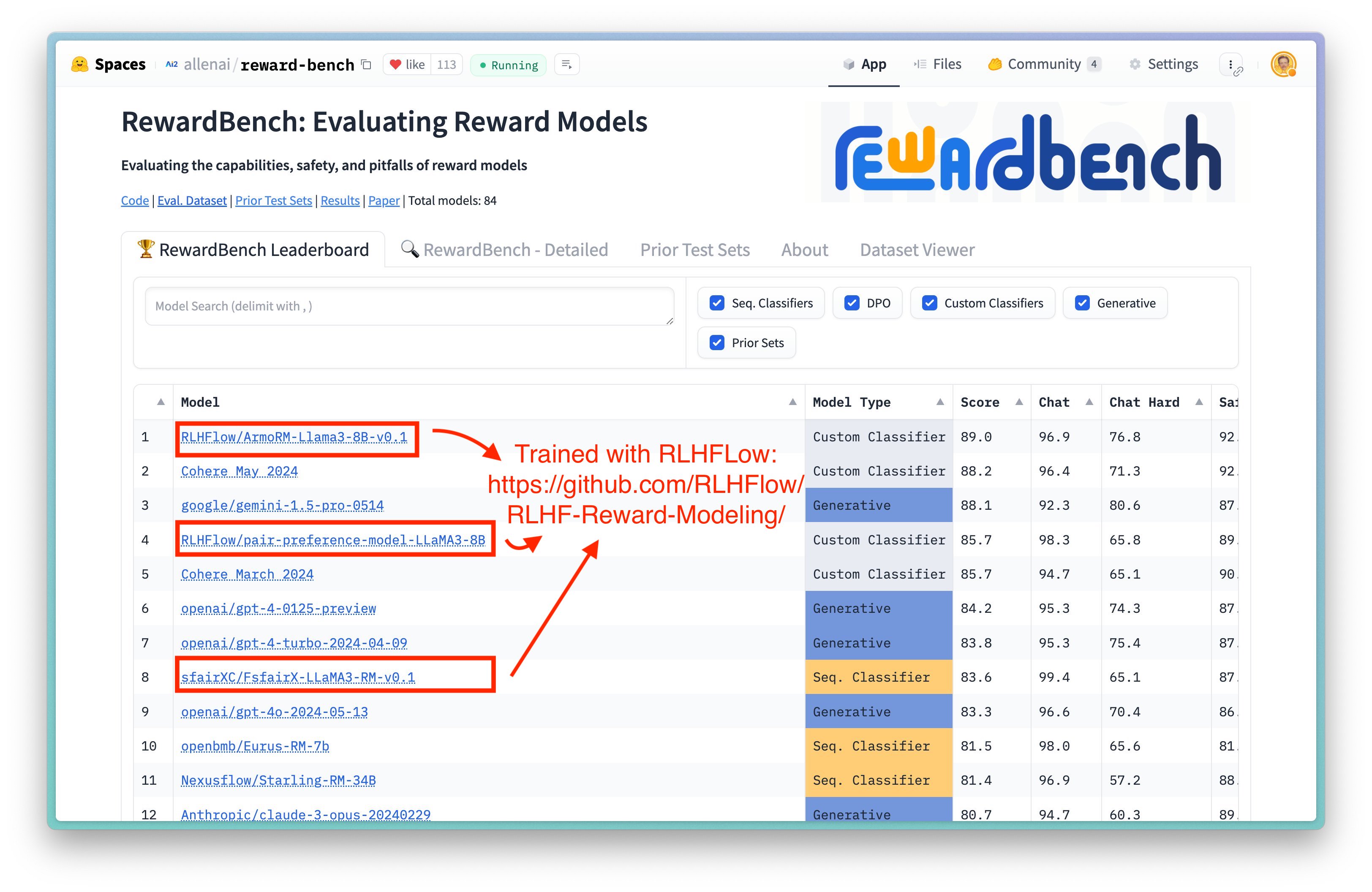
🚀 [2024年6月] 我们的ArmoRM 是RewardBench上排名第一的8B模型!
🚀 [2024年5月] RewardBench上排名前三的开源8B奖励模型(ArmoRM, Pair Pref. Model, BT RM)均使用本仓库训练而成!
🚀 [2024年5月] 成对偏好模型 的训练代码现已开放(pair-pm/)!
🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥
技术报告
模型:
- 绝对评分多目标奖励模型(ArmoRM):ArmoRM-Llama3-8B-v0.1
- 成对偏好奖励模型:pair-preference-model-LLaMA3-8B
- 布拉德利-特里奖励模型:FsfairX-LLaMA3-RM-v0.1
架构
- 布拉德利-特里(BT)奖励模型和成对偏好模型
- 绝对评分多目标奖励模型(ArmoRM)
- 布拉德利-特里(BT)奖励模型和成对偏好模型
-
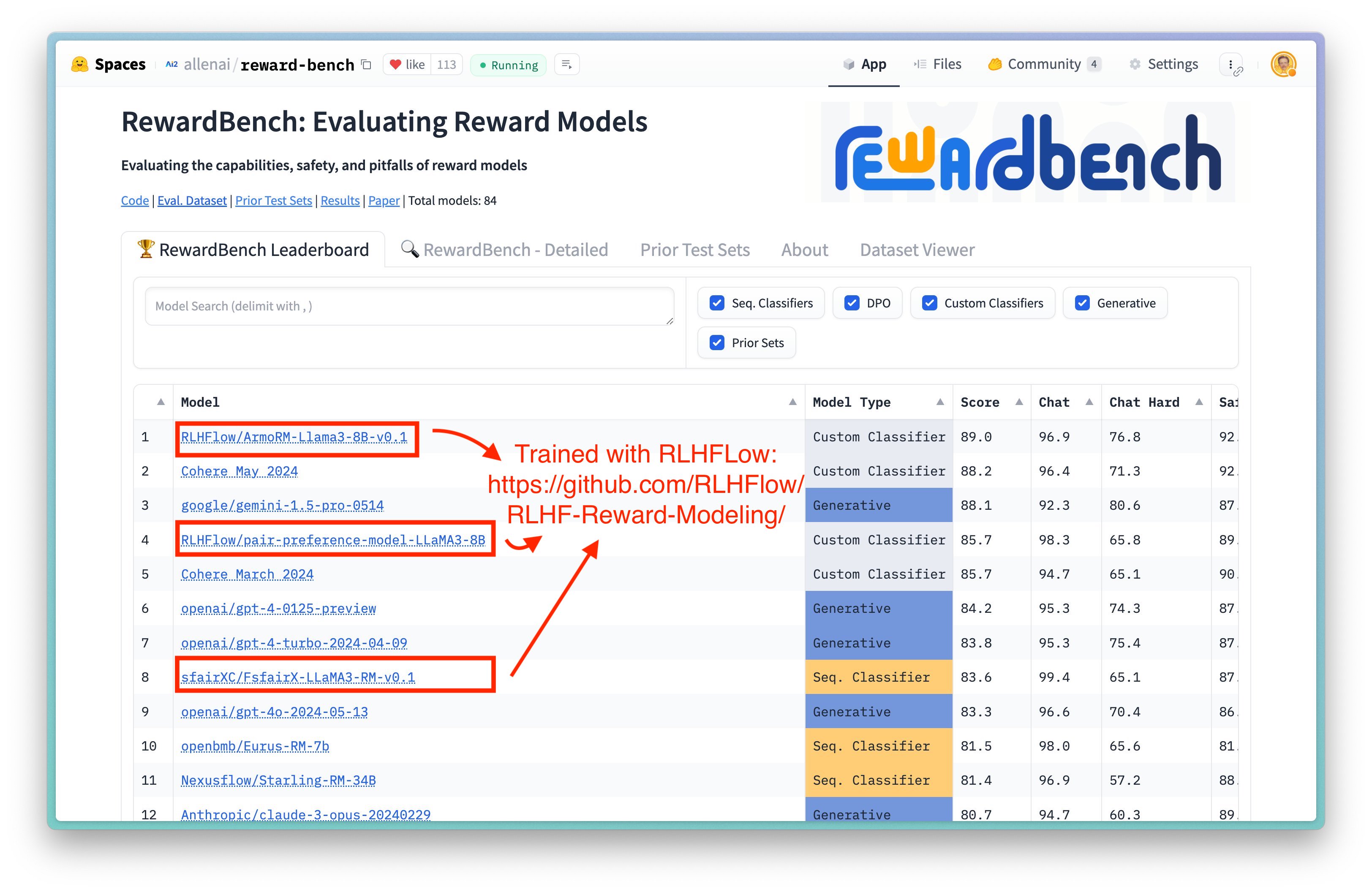
模型 基础模型 方法 分数 对话 困难题对话 安全性 理性思考 先验集合(0.5权重) ArmoRM-Llama3-8B-v0.1 (我们) Llama-3 8B ArmoRM + MoE 89.0 96.9 76.8 92.2 97.3 74.3 Cohere 2024年5月 未知 未知 88.2 96.4 71.3 92.7 97.7 78.2 pair-preference-model (我们) Llama-3 8B SliC-HF 85.7 98.3 65.8 89.7 94.7 74.6 GPT-4 Turbo(0125版本) GPT-4 Turbo LLM作为裁判 84.3 95.3 74.3 87.2 86.9 70.9 FsfairX-LLaMA3-RM-v0.1 (我们) Llama-3 8B 布拉德利-特里 83.6 99.4 65.1 87.8 86.4 74.9 Starling-RM-34B Yi-34B 布拉德利-特里 81.4 96.9 57.2 88.2 88.5 71.4 评估结果(摘自RLHF工作流)
简而言之:这是一个用于训练基于DRL的RLHF(PPO)[1]、迭代SFT(拒绝采样微调)[2]以及迭代DPO[3]的奖励/偏好模型的仓库。
- 4块A40 48G显卡:我们可以使用Deepspeed Zero-3 + 梯度检查点,以max_length 4096训练Gemma-7B-it;
- 4块A100 80G显卡:我们可以使用梯度检查点训练Gemma-7B-it,max_length同样为4096;
- 训练得到的奖励模型在RewardBench排行榜上达到了开源RMs的最先进水平。
- 欢迎查看我们的博客文章!
安装说明
建议为布拉德利-特里奖励模型和成对偏好模型分别创建独立的环境。安装说明已在相应文件夹中提供。
数据集准备
数据集应按标准格式进行预处理,其中每个样本包含两个对话“选择”和“拒绝”,且它们共享相同的提示。以下是对比对中的拒绝样本示例。
[
{ "content": "请列出世界上最稀有的五种动物。", "role": "user" },
{ "content": "您是指真正稀有的动物,还是相对于人类人口数量而言稀有的动物呢?", "role": "assistant" },
{ "content": "是真正稀有的那些。", "role": "user" },
{ "content": "好的,这是我找到的:", "role": "assistant" },
]
我们将许多开源偏好数据集预处理为标准格式,并上传至Hugging Face Hub。您可以在这里找到这些数据集。此外,我们还搜索并发现以下一些混合偏好数据集非常有用。
- hendrydong/preference_700K
- RLHFlow/UltraFeedback-preference-standard,详细信息可在数据集卡片中查阅。
评估结果
您可以使用 benchmark 提供的数据集,通过以下命令对生成的奖励模型进行评估。
CUDA_VISIBLE_DEVICES=1 python ./useful_code/eval_reward_bench_bt.py --reward_name_or_path ./models/gemma_2b_mixture2_last_checkpoint --record_dir ./bench_mark_eval.txt
待办事项
- 布拉德利-特里奖励模型
- 偏好模型
- 多目标奖励模型
- LLM作为评判者
我们的模型和代码已应用于多项学术研究项目,例如:
- Xu Zhangchen 等人:“Magpie:从零开始,仅通过提示对齐的LLM合成对齐数据。”
- Chen, Lichang 等人:“OPTune:高效的在线偏好调优。”
- Xie, Tengyang 等人:“探索性偏好优化:利用隐式Q*-近似实现样本高效的RLHF。” arXiv预印本 arXiv:2405.21046 (2024)。
- Zhong, Han 等人:“DPO遇上PPO:用于RLHF的强化标记优化。” arXiv预印本 arXiv:2404.18922 (2024)。
- Zheng, Chujie 等人:“弱到强的外推加速了对齐过程。” arXiv预印本 arXiv:2404.16792 (2024)。
- Ye, Chenlu 等人:“在一般KL正则化偏好下,基于人类反馈的纳什学习的理论分析。” arXiv预印本 arXiv:2402.07314 (2024)。
- Chen, Ruijun 等人:“用于策略优化的自进化微调”
- Li Bolian 等人:“用于高效解码时对齐的级联奖励采样”
- Zhang, Yuheng 等人:“迭代纳什策略优化:通过无悔学习将LLM与一般偏好对齐”
- Lin Tzu-Han 等人:“DogeRM:通过模型融合为奖励模型注入领域知识”
- Yang Rui 等人:“隐藏状态正则化使LLM能够学习通用奖励模型”
- Junsoo Park 等人:“OffsetBias:利用去偏数据调优评估者”
- Meng Yu 等人:“SimPO:无需参考奖励的简单偏好优化”
- Song Yifan 等人:“善、恶与贪婪:LLM的评估不应忽视非确定性”
- Wenxuan Zhou 等人:“WPO:通过加权偏好优化增强RLHF”
- Han Xia 等人:“逆Q*:无需偏好数据即可对大型语言模型进行对齐的标记级强化学习”
- Wang Haoyu 等人:“通过生成不安全解码路径探测大型语言模型的安全响应边界”
- He Yifei 等人:“通过迭代自训练进行半监督奖励建模”
- Tao leitian 等人:“你的弱LLM其实是对齐的强大教师”
- Guijin Son 等人:“LLM作为评判者与奖励模型:它们能做什么,不能做什么”
- Nicolai Dorka 等人:“在RLHF中使用分位数回归构建分布型奖励模型”
- Zhaolin Gao 等人:“Rebel:通过回归相对奖励进行强化学习”
贡献者
感谢迄今为止的所有贡献者(由 contrib.rocks 制作)。

引用
如果您在工作中发现本仓库的内容有所帮助,请考虑引用:
@article{dong2024rlhf,
title={RLHF工作流:从奖励建模到在线RLHF},
author={Dong, Hanze and Xiong, Wei and Pang, Bo and Wang, Haoxiang and Zhao, Han and Zhou, Yingbo and Jiang, Nan and Sahoo, Doyen and Xiong, Caiming and Zhang, Tong},
journal={arXiv预印本 arXiv:2405.07863},
year={2024}
}
@inproceedings{ArmoRM,
title={通过多目标奖励建模和专家混合实现可解释的偏好},
author={Haoxiang Wang and Wei Xiong and Tengyang Xie and Han Zhao and Tong Zhang},
booktitle={2024年自然语言处理经验方法会议},
year={2024}
}
@article{xiong2024iterative,
title={基于人类反馈的迭代偏好学习:在KL约束下弥合RLHF的理论与实践},
author={Wei Xiong and Hanze Dong and Chenlu Ye and Ziqi Wang and Han Zhong and Heng Ji and Nan Jiang and Tong Zhang},
year={2024},
journal={ICML}
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。