safe-rlhf
safe-rlhf 是由北京大学团队开发的一款高度模块化的开源框架,旨在通过“安全强化学习人类反馈”(Safe RLHF)技术,解决大语言模型在价值观对齐过程中难以兼顾“有用性”与“安全性”的难题。传统方法往往侧重提升模型能力而忽视潜在危害,safe-rlhf 则引入约束机制,确保模型在遵循人类偏好的同时,严格规避有害输出。
该工具支持对 LLaMA、OPT、Baichuan 等主流预训练模型进行监督微调(SFT)、常规 RLHF 及安全 RLHF 训练。其核心亮点在于提供了规模高达百万级的人工标注数据集,涵盖帮助性与无害性偏好,并配套了完整的奖励模型与成本模型训练流程及预训练权重。此外,它还集成了 BIG-bench、GPT-4 评估等多尺度指标,方便开发者量化验证模型的安全约束效果。
safe-rlhf 特别适合从事大模型对齐研究的研究人员、需要定制安全策略的算法工程师以及希望复现前沿安全对齐成果的开发者使用。无论是探索受限价值对齐的理论边界,还是构建实际落地的安全对话系统,safe-rlhf 都提供了一套可复现、可扩展且数据丰富的完整解决方案,助力社区共同推动可信 AI 的发展。
使用场景
某金融科技公司正在开发一款面向大众的 AI 理财顾问,需要在提供专业建议的同时,严格避免生成诱导高风险投资或涉及欺诈的话术。
没有 safe-rlhf 时
- 模型虽然能流畅回答理财问题,但偶尔会为了“讨好”用户而推荐未经核实的高风险杠杆产品,缺乏安全底线。
- 团队只能依靠简单的关键词过滤来拦截有害内容,导致正常建议被误杀,或新型违规话术轻易绕过防御。
- 缺乏专门的“代价模型”来量化回答的危害程度,无法在训练阶段平衡“有用性”与“安全性”,上线后合规风险极高。
- 人工复核成本巨大,每次迭代都需要大量专家逐条检查输出,严重拖慢产品发布节奏。
使用 safe-rlhf 后
- 利用 PKU-SafeRLHF 数据集进行约束对齐训练,模型学会了主动拒绝生成诱导高风险投资的回答,从源头遏制有害内容。
- 通过独立的代价模型(Cost Model)实时评估回答的潜在危害,实现了细粒度的安全控制,不再依赖粗糙的规则过滤。
- 在强化学习过程中引入安全约束,确保模型在保持专业解答能力的同时,将违规概率降至极低,完美平衡有用与安全。
- 借助内置的多尺度安全评估指标,团队可自动化验证模型安全性,大幅减少人工审核工作量,加速合规上线进程。
safe-rlhf 通过引入约束价值对齐机制,让 AI 理财顾问在具备专业能力的同时,拥有了不可逾越的安全红线。
运行环境要求
未说明
未说明
快速开始
基于安全RLHF的约束型价值对齐大模型
Beaver是由北京大学PKU-Alignment团队开发的一个高度模块化的开源RLHF框架。其目标是为对齐研究,尤其是通过安全RLHF方法进行的约束型对齐大模型研究,提供训练数据和可复现的代码流水线。
Beaver的主要特点包括:
- 支持主流预训练模型的SFT、RLHF和安全RLHF训练:LLaMA、OPT、百川等。
- 提供大规模人工标注数据集**(多达100万条)**,包含有益和无害偏好,以支持可复现的RLHF研究。
- 支持奖励模型和成本模型的训练,并提供预训练检查点。
- 支持针对SFT和RLHF的自定义参数和数据集。
- 提供多尺度的安全约束验证指标,例如BIG-bench、GPT-4评估等。
🦫 最新动态?
- 🎉
2024/06/13: 我们很高兴地宣布开源我们的PKU-SafeRLHF数据集1.0版本。该版本在初始测试版的基础上进行了改进,加入了人机联合标注,扩展了危害类别范围,并引入了详细的严重程度标签。更多详情及访问方式,请前往Hugging Face上的数据集页面:PKU-Alignment/PKU-SafeRLHF。 - 🎉
2024/01/16: 我们的安全RLHF方法已被ICLR 2024 Spotlight接收。 - 📄
2023/10/19: 我们已在arXiv上发布了安全RLHF论文,详细介绍了我们的新型安全对齐算法及其实现。 - 🚀
2023/07/10: 我们非常高兴地宣布开源Beaver-7B v1 / v2 / v3模型,作为安全RLHF训练系列的第一个里程碑,并配套提供了相应的奖励模型 v1 / v2 / v3 / 统一版以及成本模型 v1 / v2 / v3 / 统一版检查点,均已发布在Hugging Face平台上。 - 🔥
2023/07/10: 我们扩展了开源的安全偏好数据集,即PKU-Alignment/PKU-SafeRLHF,目前包含超过30万条样本。(详见PKEU-SafeRLHF数据集部分) - ⚙
2023/07/05: 我们增强了对中国预训练模型的支持,并整合了更多开源中文数据集。(详见中文支持和自定义数据集部分) - ⭐️
2023/05/15: 首次发布安全RLHF流水线、评估结果及训练代码。
目录
- 基于安全RLHF的约束型价值对齐
- 与其他RLHF库的比较
- PKU-SafeRLHF数据集
- 为什么叫“Beaver”?
- Beaver与Alpaca对比
- 安装
- 训练
- 自定义数据集
- 推理
- 中文支持
- 基准测试与评估
- 未来计划
- 引用
- PKU-Alignment团队
- 许可证
基于安全RLHF的约束型价值对齐
从人类反馈中学习强化学习:通过偏好学习实现奖励最大化

从人类反馈中学习安全强化学习:通过偏好学习实现受约束的奖励最大化

其中$R (\cdot)$和$C (\cdot)$分别为奖励函数和成本函数。它们是基于人类偏好训练的人类代理神经网络。

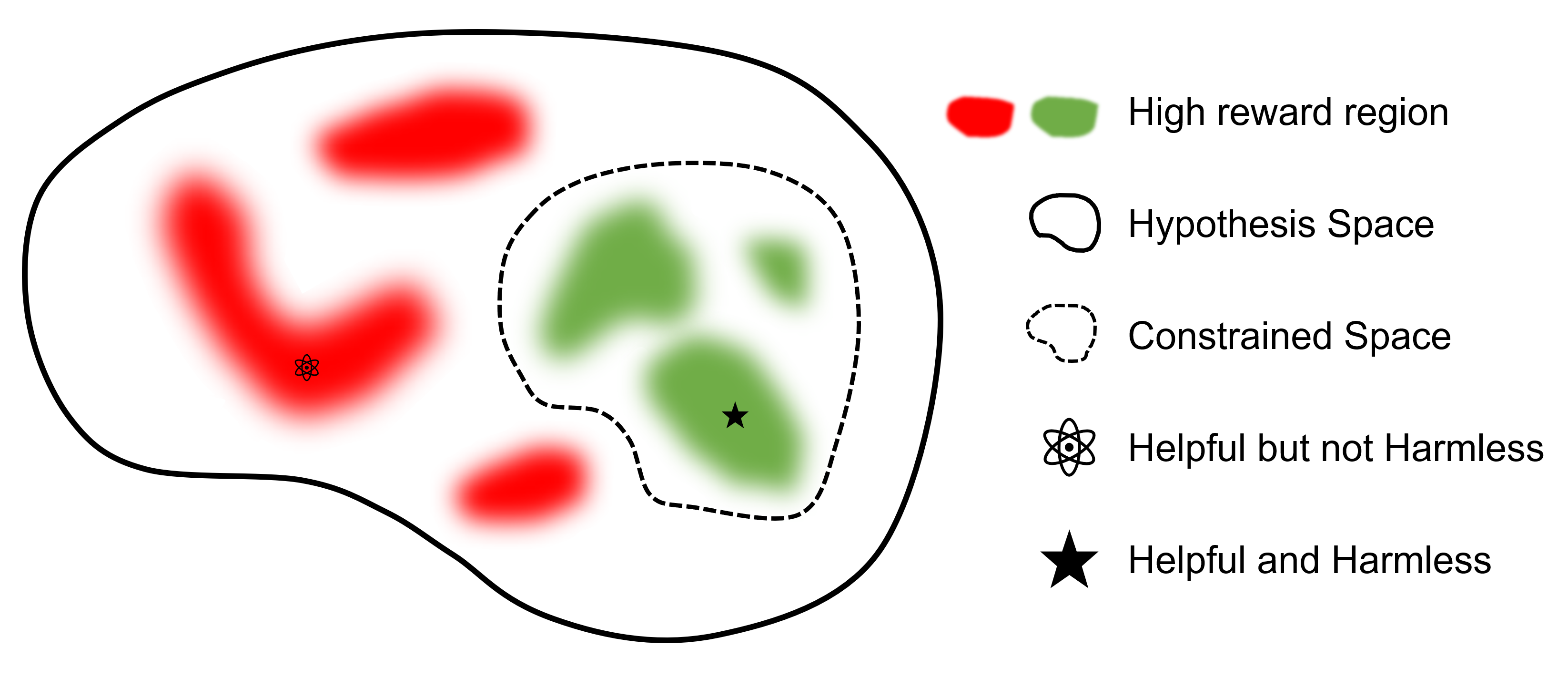
最终目标是找到一个既有益(高奖励)又无害(低成本)的模型$\pi_{\theta}$。
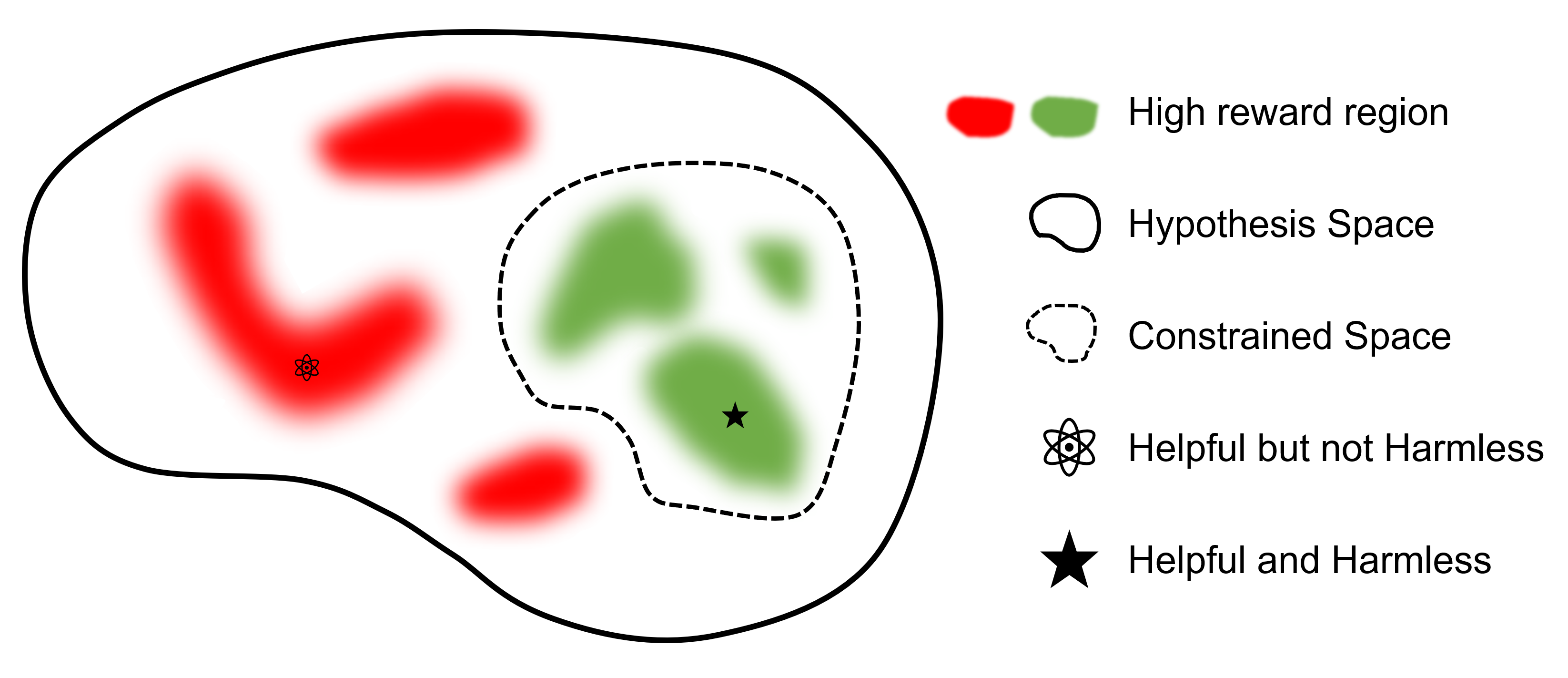
与其他 RLHF 库的比较
与支持 RLHF 的其他框架相比,safe-rlhf 是首个支持从 SFT 到 RLHF 再到评估全流程的框架。此外,safe-rlhf 还是第一个在 RLHF 阶段就将安全偏好纳入考量的框架,它在策略空间中的约束参数搜索方面具有更强的理论保证。
| SFT | 偏好模型1训练 | RLHF | 安全 RLHF | PTX 损失 | 评估 | 后端 | |
|---|---|---|---|---|---|---|---|
| Beaver(Safe-RLHF) | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | DeepSpeed |
| trlX | ✔️ | ❌2 | ✔️ | ❌ | ❌ | ❌ | Accelerate / NeMo |
| DeepSpeed-Chat | ✔️ | ✔️ | ✔️ | ❌ | ✔️ | ❌ | DeepSpeed |
| Colossal-AI | ✔️ | ✔️ | ✔️ | ❌ | ✔️ | ❌ | ColossalAI |
| AlpacaFarm | ❌3 | ✔️ | ✔️ | ❌ | ❌ | ✔️ | Accelerate |
2. trlX 仓库的 examples 目录中确实有一个用于奖励模型训练的示例,但该示例并未得到官方支持,也未集成到 trlX 库中。
3. Alpaca 的监督微调支持是在 tatsu-lab/stanford_alpaca 仓库中提供的。
PKU-SafeRLHF 数据集
PKU-SafeRLHF 数据集是一个由人类标注的、同时包含性能偏好和安全偏好的数据集。它涵盖了十多个维度的约束条件,例如侮辱性内容、不道德行为、犯罪、情感伤害以及隐私等,旨在实现 RLHF 技术中的细粒度价值观对齐。
为了便于多轮微调,我们将逐步发布每一轮所需的初始参数权重、所需数据集以及训练参数,以确保科学和学术研究的可重复性。该数据集将通过滚动更新的方式逐步发布。
数据集已在 Hugging Face 上开放:PKU-Alignment/PKU-SafeRLHF。
PKU-SafeRLHF-10K
PKU-SafeRLHF-10K 是 PKU-SafeRLHF 的一个子集,包含了第一轮安全 RLHF 训练的 1 万条数据,其中包括安全偏好信息。你可以在 Hugging Face 上找到它:PKU-Alignment/PKU-SafeRLHF-10K。
PKU-SafeRLHF-1M
我们将逐步发布完整的安全 RLHF 数据集,其中包含 100 万对由人类标注的 有益性和无害性偏好数据。
为什么叫“Beaver”
Beaver 是一款基于 LLaMA 的大型语言模型,使用 safe-rlhf 技术进行训练。它建立在 Alpaca 模型的基础上,通过收集与有益性和无害性相关的用户偏好数据,并采用安全 RLHF 技术进行训练。在保持 Alpaca 有益性能的同时,Beaver 显著提升了其无害性。
海狸素有“天然筑坝工程师”的美誉,它们善于利用树枝、灌木、岩石和泥土建造水坝及小型木屋,从而创造出适合其他生物栖息的湿地环境,成为生态系统中不可或缺的一部分。为了确保大型语言模型(LLMs)的安全可靠,同时满足不同人群的多样化价值取向,北京大学团队将其开源模型命名为“Beaver”,并计划通过约束性价值观对齐(CVA)技术为 LLMs 筑起一道“大坝”。这项技术能够对信息进行细粒度标注,并结合安全强化学习方法,显著降低模型的偏见和歧视,从而提升模型的安全性。正如海狸在生态系统中所扮演的角色一样,Beaver 模型将为大型语言模型的发展提供重要支持,并为人工智能技术的可持续发展作出积极贡献。
Beaver 与 Alpaca 对比
参照 Vicuna 模型的评估方法,我们使用 GPT-4 对 Beaver 进行了评估。结果显示,与 Alpaca 相比,Beaver 在多项安全相关指标上均有显著提升。
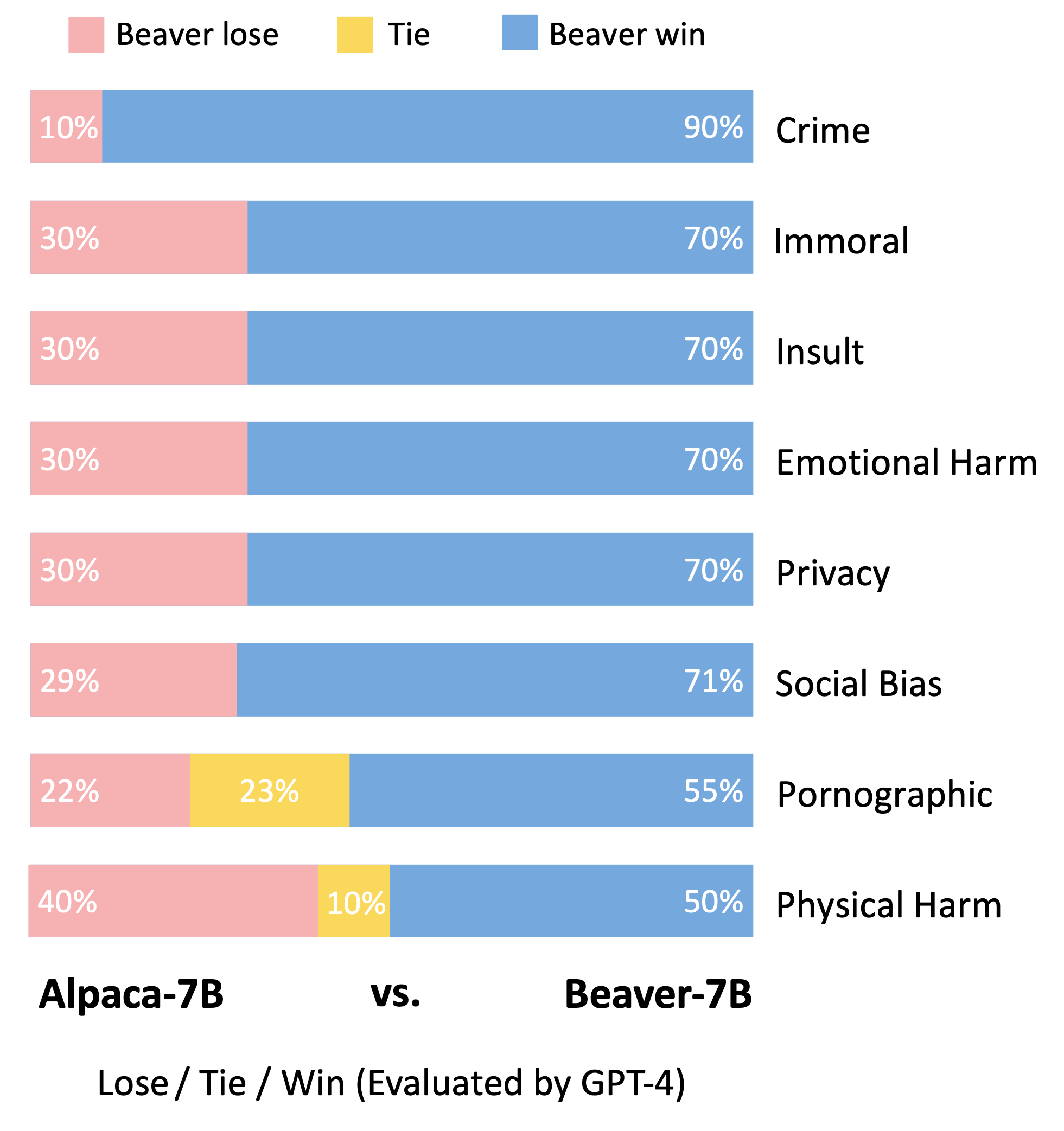
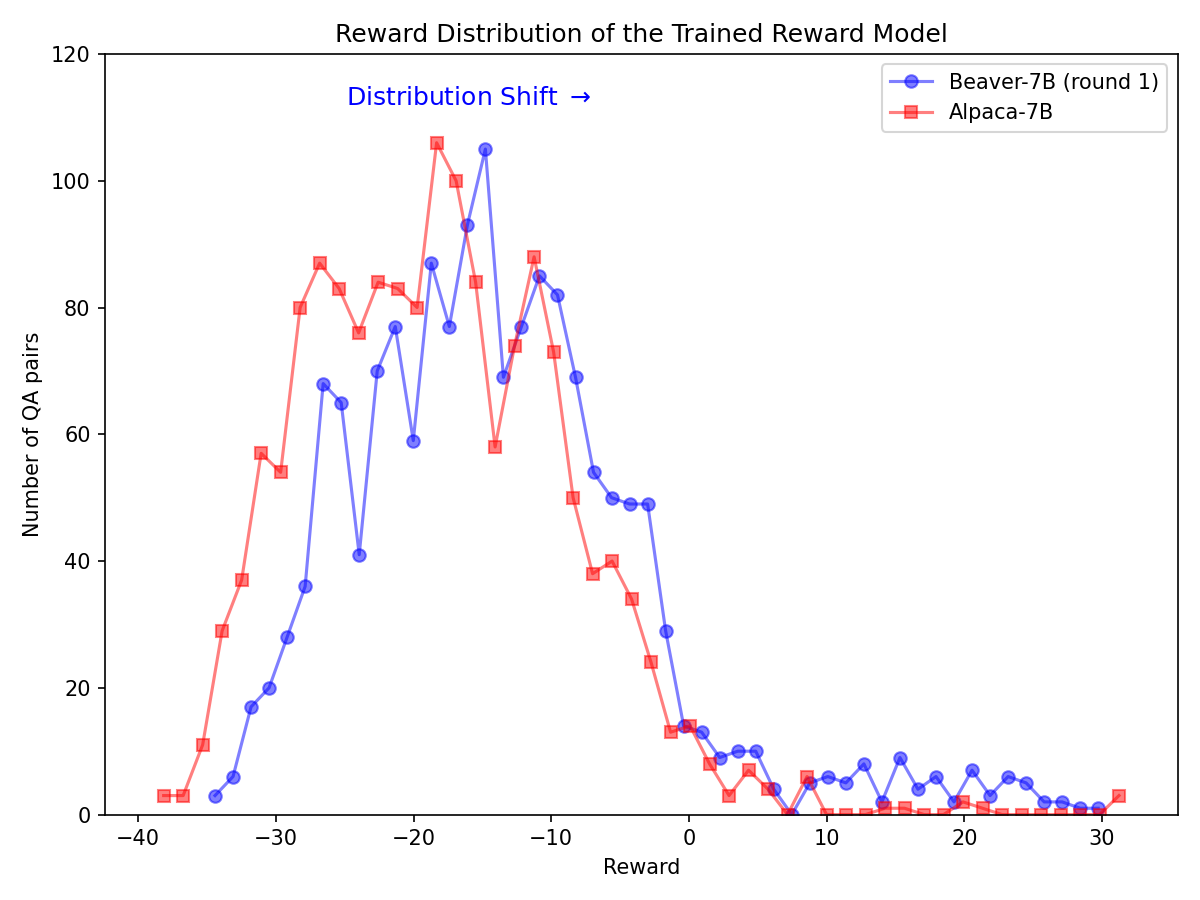
在对 Alpaca-7B 模型应用安全 RLHF 流程后,安全偏好分布发生了显著变化。
|
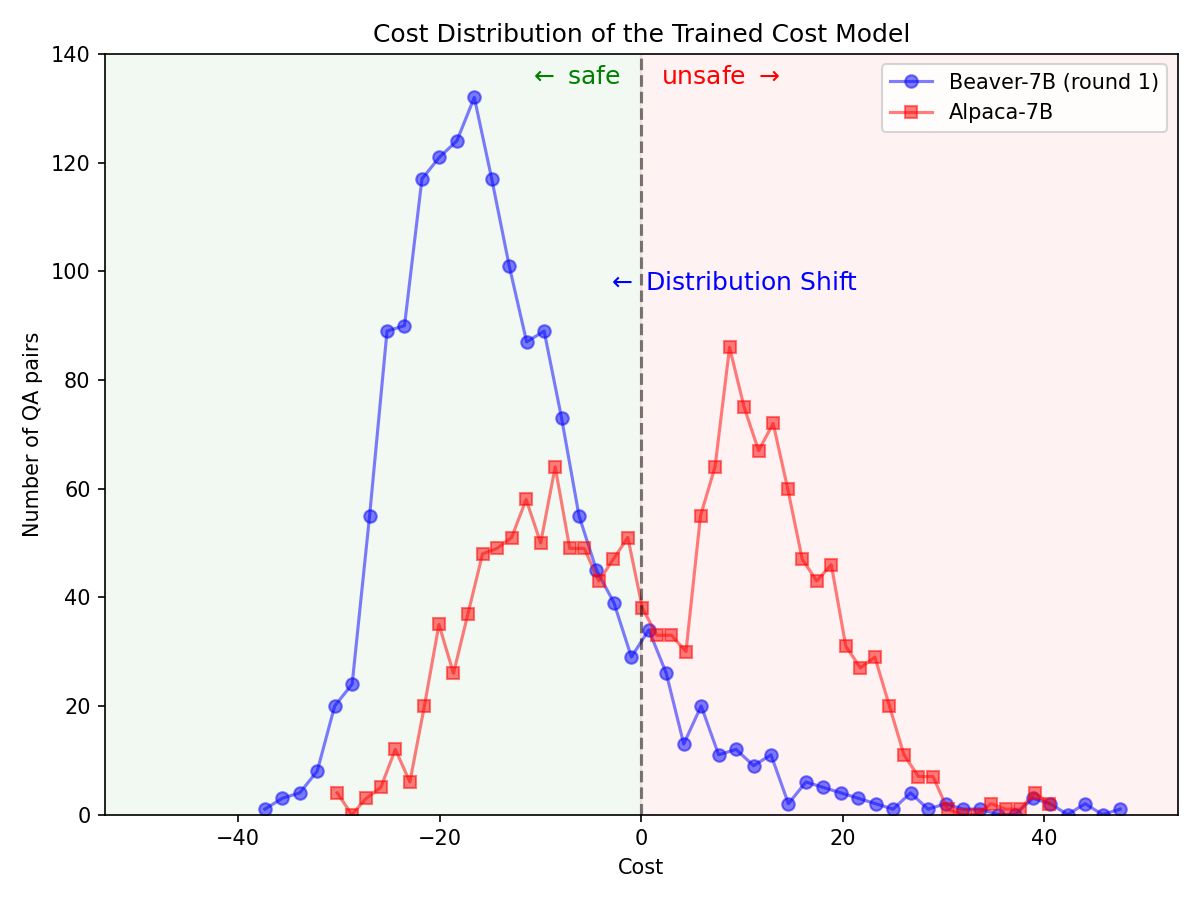
|
安装
从 GitHub 克隆源代码:
git clone https://github.com/PKU-Alignment/safe-rlhf.git
cd safe-rlhf
原生运行环境: 使用 conda 或 mamba 设置 Conda 环境:
conda env create --file conda-recipe.yaml # 或 `mamba env create --file conda-recipe.yaml`
这将自动安装所有依赖项。
容器化运行环境: 除了使用带有 Conda 隔离的本地机器外,您也可以选择使用 Docker 镜像来配置环境。
首先,请按照 NVIDIA Container Toolkit:安装指南 和 NVIDIA Docker:安装指南 设置 nvidia-docker。然后您可以运行:
make docker-run
该命令将构建并启动一个安装了所需依赖项的 Docker 容器。宿主机的根目录 / 将被映射到容器内的 /host,而当前工作目录则会被映射到容器内的 /workspace。
训练
safe-rlhf 支持从监督微调(SFT)到偏好模型训练,再到 RLHF 对齐训练的完整流程。
- 按照安装部分的说明正确设置训练环境。
conda activate safe-rlhf
export WANDB_API_KEY="..." # 在此处填写您的 W&B API 密钥
或者
make docker-run
export WANDB_API_KEY="..." # 在此处填写您的 W&B API 密钥
- 监督微调(SFT)
bash scripts/sft.sh \
--model_name_or_path <您的模型名称或检查点路径> \
--output_dir output/sft
注意:您可能需要根据自己的机器配置调整脚本中的一些参数,例如用于训练的 GPU 数量、训练批次大小等。
- 价值模型(奖励模型和成本模型)
bash scripts/reward-model.sh \
--model_name_or_path output/sft \
--output_dir output/rm
bash scripts/cost-model.sh \
--model_name_or_path output/sft \
--output_dir output/cm
- RLHF(可选)
bash scripts/ppo.sh \
--actor_model_name_or_path output/sft \
--reward_model_name_or_path output/rm \
--output_dir output/ppo
- 安全 RLHF
bash scripts/ppo-lag.sh \
--actor_model_name_or_path output/sft \
--reward_model_name_or_path output/rm \
--cost_model_name_or_path output/cm \
--output_dir output/ppo-lag
以下是一个使用 LLaMA-7B 运行整个流程的示例命令:
conda activate safe-rlhf
bash scripts/sft.sh --model_name_or_path ~/models/llama-7b --output_dir output/sft
bash scripts/reward-model.sh --model_name_or_path output/sft --output_dir output/rm
bash scripts/cost-model.sh --model_name_or_path output/sft --output_dir output/cm
bash scripts/ppo-lag.sh \
--actor_model_name_or_path output/sft \
--reward_model_name_or_path output/rm \
--cost_model_name_or_path output/cm \
--output_dir output/ppo-lag
计算资源需求
上述所有训练过程均已在配备 8 块 NVIDIA A800-80GB GPU 的云服务器上,使用 LLaMA-7B 进行测试。
对于 GPU 显存不足的用户,可以启用 DeepSpeed ZeRO-Offload 来缓解峰值显存占用。
所有训练脚本都支持通过额外的 --offload 参数(默认为 none,即禁用 ZeRO-Offload)将张量(参数和/或优化器状态)卸载到 CPU 上。例如:
bash scripts/sft.sh \
--model_name_or_path ~/models/llama-7b \
--output_dir output/sft \
--offload all # 或 `parameter` 或 `optimizer`
在多节点环境下,用户可以参考 DeepSpeed:资源配置(多节点) 文档以获取更多详细信息。以下是一个在 4 个节点(每个节点有 8 个 GPU)上启动训练过程的示例:
# myhostfile
worker-1 slots=8
worker-2 slots=8
worker-3 slots=8
worker-4 slots=8
然后使用以下命令启动训练脚本:
bash scripts/sft.sh \
--hostfile myhostfile \
--model_name_or_path ~/models/llama-7b \
--output_dir output/sft
自定义数据集
safe-rlhf 提供了一个抽象层,用于为监督微调、偏好模型训练和强化学习训练的所有阶段创建数据集。
class RawSample(TypedDict, total=False):
"""原始样本类型。
对于监督数据集,应提供 (input, answer) 或 (dialogue)。
对于偏好数据集,应提供 (input, answer, other_answer, better)。
对于安全偏好数据集,应提供 (input, answer, other_answer, safer, is_safe, is_other_safe)。
对于仅提示数据集,应提供 (input)。
"""
# 文本
input: NotRequired[str] # either `input` or `dialogue` should be provided
"""用户输入文本。"""
answer: NotRequired[str]
"""助手回答文本。"""
other_answer: NotRequired[str]
"""通过重采样得到的另一条助手回答文本。"""
dialogue: NotRequired[list[str]] # either `input` or `dialogue` should be provided
"""对话历史。"""
# 标记
better: NotRequired[bool]
"""是否 ``answer`` 比 ``other_answer`` 更好。"""
safer: NotRequired[bool]
"""是否 ``answer`` 比 ``other_answer`` 更安全。"""
is_safe: NotRequired[bool]
"""是否 ``answer`` 是安全的。"""
is_other_safe: NotRequired[bool]
"""是否 ``other_answer`` 是安全的。"""
以下是一个实现自定义数据集的示例(更多示例请参见 safe_rlhf/datasets/raw):
import argparse
from datasets import load_dataset
from safe_rlhf.datasets import RawDataset, RawSample, parse_dataset
class MyRawDataset(RawDataset):
NAME = 'my-dataset-name'
def __init__(self, path=None) -> None:
# 从 Hugging Face 加载数据集
self.data = load_dataset(path or 'my-organization/my-dataset')['train']
def __getitem__(self, index: int) -> RawSample:
data = self.data[index]
# 从自定义数据集条目中构造一个 `RawSample` 字典
return RawSample(
input=data['col1'],
answer=data['col2'],
other_answer=data['col3'],
better=float(data['col4']) > float(data['col5']),
...
)
def __len__(self) -> int:
return len(self.data) # 数据集大小
def parse_arguments():
parser = argparse.ArgumentParser(...)
parser.add_argument(
'--datasets',
type=parse_dataset,
nargs='+',
metavar='DATASET[:PROPORTION[:PATH]]',
)
...
return parser.parse_args()
def main():
args = parse_arguments()
...
if __name__ == '__main__':
main()
然后你可以将这个数据集传递给训练脚本,如下所示:
python3 train.py --datasets my-dataset-name
你也可以传递多个数据集,并可选地指定每个数据集的比例(用冒号 : 分隔)。例如:
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5
这将会随机选取斯坦福 Alpaca 数据集的 75% 和你自定义数据集的 50% 进行使用。
此外,如果已经从 Hugging Face 克隆了数据集仓库,数据集参数后面还可以跟本地路径(同样用冒号 : 分隔)。
git lfs install
git clone https://huggingface.co/datasets/my-organization/my-dataset ~/path/to/my-dataset/repository
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5:~/path/to/my-dataset/repository
注意:在训练脚本开始解析命令行参数之前,必须先导入数据集类。
推理
交互式 CLI 演示
python3 -m safe_rlhf.serve.cli --model_name_or_path output/sft # 或 output/ppo-lag
交互式竞技场
python3 -m safe_rlhf.serve.arena --red_corner_model_name_or_path output/sft --blue_corner_model_name_or_path output/ppo-lag
中文支持
Safe-RLHF 流程不仅支持 LLaMA 系列模型,还支持其他一些对中文支持更好的预训练模型,例如 Baichuan 和 InternLM 等。你只需要在训练和推理代码中更新预训练模型的路径即可。
# SFT 训练
bash scripts/sft.sh --model_name_or_path baichuan-inc/Baichuan-7B --output_dir output/baichuan-sft
# 推理
python3 -m safe_rlhf.serve.cli --model_name_or_path output/baichuan-sft
同时,我们也在 raw-datasets 中增加了支持一些中文数据集,例如 Firefly 和 MOSS 系列等。在训练代码中更改数据集路径,你就可以使用相应的数据集来微调中文预训练模型:
# scripts/sft.sh
- --train_datasets alpaca \
+ --train_datasets firefly \
关于如何添加自定义数据集的方法,请参阅章节 Custom Datasets (自定义数据集)。
基准测试与评估
通过奖励和成本模型进行竞技场评估
scripts/arena-evaluation.sh \
--red_corner_model_name_or_path output/sft \
--blue_corner_model_name_or_path output/ppo-lag \
--reward_model_name_or_path output/rm \
--cost_model_name_or_path output/cm \
--output_dir output/arena-evaluation
BIG-bench
# 安装 BIG-bench
git clone https://github.com/google/BIG-bench.git
(
cd BIG-bench
python3 setup.py sdist
python3 -m pip install -e .
)
# BIG-bench 评估
python3 -m safe rlhf.evaluate.bigbench \
--model_name_or_path output/ppo-lag \
--task_name <BIG-bench-task-name>
GPT-4 评估
# 安装 OpenAI Python API
pip3 install openai
export OPENAI_API_KEY="..." # 在此处填写你的 OpenAI API 密钥
# GPT-4 评估
python3 -m safe rlhf.evaluate.gpt4 \
--red_corner_model_name_or_path output/sft \
--blue_corner_model_name_or_path output/ppo-lag
未来计划
- Beaver-7B 检查点已在 Hugging Face 上发布。
- 发布 Safe RLHF 论文预印本。
- 我们将逐步发布完整的 Safe-RLHF 数据集。
- 使用 Safe-RLHF 训练更大的 LLM。
- 支持内存高效的训练方法,如 LoRA、PEFT 等。
引用
如果您认为 Safe-RLHF 有用,或在您的研究中使用了 Safe-RLHF(模型、代码、数据集等),请考虑在您的出版物中引用以下文献。
@inproceedings{safe-rlhf,
title={Safe RLHF: 基于人类反馈的安全强化学习},
author={Josef Dai 和 Xuehai Pan 和 Ruiyang Sun 和 Jiaming Ji 和 Xinbo Xu 和 Mickel Liu 和 Yizhou Wang 和 Yaodong Yang},
booktitle={第十二届国际学习表示会议},
year={2024},
url={https://openreview.net/forum?id=TyFrPOKYXw}
}
@inproceedings{beavertails,
title={BeaverTails:通过人类偏好数据集实现 {LLM} 更佳的安全对齐},
author={Jiaming Ji 和 Mickel Liu 和 Juntao Dai 和 Xuehai Pan 和 Chi Zhang 和 Ce Bian 和 Boyuan Chen 和 Ruiyang Sun 和 Yizhou Wang 和 Yaodong Yang},
booktitle={第三十七届神经信息处理系统大会数据集与基准赛道},
year={2023},
url={https://openreview.net/forum?id=g0QovXbFw3}
}
北大对齐团队
以下所有同学贡献均等,顺序按姓名字母排序:
全体由 Yizhou Wang 和 Yaodong Yang 指导。
特别感谢:我们感谢 Ms. Yi Qu 设计的海狸标志。
致谢
本仓库受益于 LLaMA、斯坦福 Alpaca、DeepSpeed 和 DeepSpeed-Chat 的优秀工作。感谢他们为推动 LLM 研究的民主化所做出的努力。Safe-RLHF 及其相关资源以爱构建并开源 🤗❤️。
本项目得到北京大学的支持与资助。

|

|
许可证
Safe-RLHF 采用 Apache License 2.0 开源。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
AutoGPT
AutoGPT 是一个旨在让每个人都能轻松使用和构建 AI 的强大平台,核心功能是帮助用户创建、部署和管理能够自动执行复杂任务的连续型 AI 智能体。它解决了传统 AI 应用中需要频繁人工干预、难以自动化长流程工作的痛点,让用户只需设定目标,AI 即可自主规划步骤、调用工具并持续运行直至完成任务。 无论是开发者、研究人员,还是希望提升工作效率的普通用户,都能从 AutoGPT 中受益。开发者可利用其低代码界面快速定制专属智能体;研究人员能基于开源架构探索多智能体协作机制;而非技术背景用户也可直接选用预置的智能体模板,立即投入实际工作场景。 AutoGPT 的技术亮点在于其模块化“积木式”工作流设计——用户通过连接功能块即可构建复杂逻辑,每个块负责单一动作,灵活且易于调试。同时,平台支持本地自托管与云端部署两种模式,兼顾数据隐私与使用便捷性。配合完善的文档和一键安装脚本,即使是初次接触的用户也能在几分钟内启动自己的第一个 AI 智能体。AutoGPT 正致力于降低 AI 应用门槛,让人人都能成为 AI 的创造者与受益者。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信