InternVL
InternVL 是一个开源的多模态大语言模型系列,旨在让 AI 既能“看”懂图片,又能像人类一样进行深度对话与逻辑推理。它主要解决了当前开源模型在复杂视觉理解、高阶推理能力上往往落后于商业闭源模型(如 GPT-4o)的痛点,通过开放源代码和权重,打破了高性能多模态 AI 的技术壁垒。
无论是希望部署私有化智能助手的开发者、需要复现前沿算法的研究人员,还是寻求低成本高精度视觉分析方案的企业用户,都能从 InternVL 中获益。其独特亮点在于采用了创新的架构设计与训练策略,特别是最新的 InternVL3.5 版本,引入了混合专家(MoE)结构和级联强化学习(CascadeRL)技术,在保持高效推理的同时,显著提升了数学解题、代码生成及智能体任务的表现。作为目前开源社区中性能最接近顶尖商业模型的套件之一,InternVL 提供了从轻量级到超大规模的多种模型选择,并兼容主流开发框架,让用户能够轻松将其集成到各类应用中,自由探索多模态人工智能的无限可能。
使用场景
某电商平台的智能客服团队正试图升级系统,以自动处理用户上传的复杂商品故障图片(如电路板烧毁、衣物破损细节)并生成精准的诊断报告。
没有 InternVL 时
- 识别精度不足:传统 OCR 或专用小模型无法理解图片中的空间逻辑关系,常将“电容爆裂”误判为普通污渍,导致诊断结论完全错误。
- 多轮对话断裂:用户追问“这个损坏会影响保修吗?”时,系统无法结合上一轮的故障图进行上下文推理,只能机械回复通用条款。
- 高昂的 API 成本:若接入 GPT-4o 等商业闭源模型来处理海量并发请求,每月的 Token 支出将超出部门预算数倍。
- 数据隐私顾虑:将包含用户家庭环境背景的照片上传至第三方云端服务,存在合规风险和数据泄露隐患。
使用 InternVL 后
- 深度视觉推理:InternVL 凭借接近 GPT-4o 的多模态能力,能精准识别电路板上的微小烧痕并推断出“短路导致电源模块失效”的根本原因。
- 连贯图文交互:模型完美记忆历史对话与图片特征,能直接基于故障图回答“因属非人为电路老化,符合保修范围”,实现拟人化咨询。
- 低成本私有部署:利用开源的 InternVL3.5 系列模型(如 20B 版本),团队可在本地显卡集群免费部署,将单次推理成本降低至商业模型的十分之一。
- 数据完全可控:所有用户图片与对话数据均在内部服务器闭环处理,彻底消除了敏感信息外泄的合规风险。
InternVL 让企业以开源的低成本实现了媲美顶尖商业模型的多模态理解力,同时牢牢掌握了数据主权。
运行环境要求
- 未说明
需要 NVIDIA GPU(支持 AWQ 量化及 PaddleMIX),具体显存需求取决于模型规模(1B-241B),大模型(如 78B/241B)需多卡高显存环境
未说明
快速开始
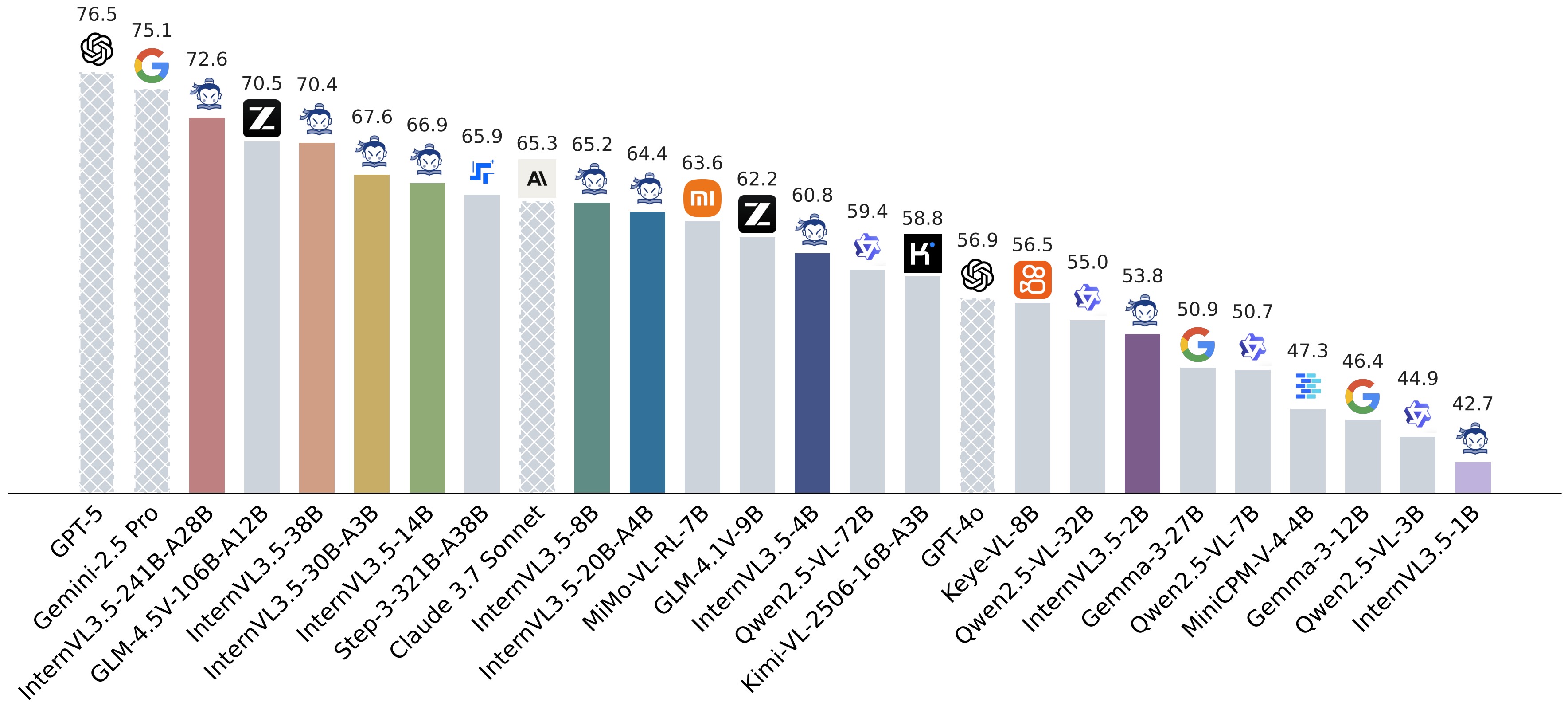
InternVL 系列:以开源套件弥合与商用多模态模型的差距 —— GPT-5 的开创性开源替代方案

[🆕 博客] [🤔 常见问题解答] [🗨️ 聊天演示] [📖 文档] [🌐 API] [🚀 快速入门]
[🔥 InternVL3.5 报告] [📜 InternVL3.0 报告] [📜 InternVL2.5 MPO] [📜 InternVL2.5 报告]
[📜 Mini-InternVL 论文] [📜 InternVL 2.0 博客] [📜 InternVL 1.5 论文] [📜 InternVL 1.0 论文]
[📖 2.0 中文解读] [📖 1.5 中文解读] [📖 1.0 中文解读]


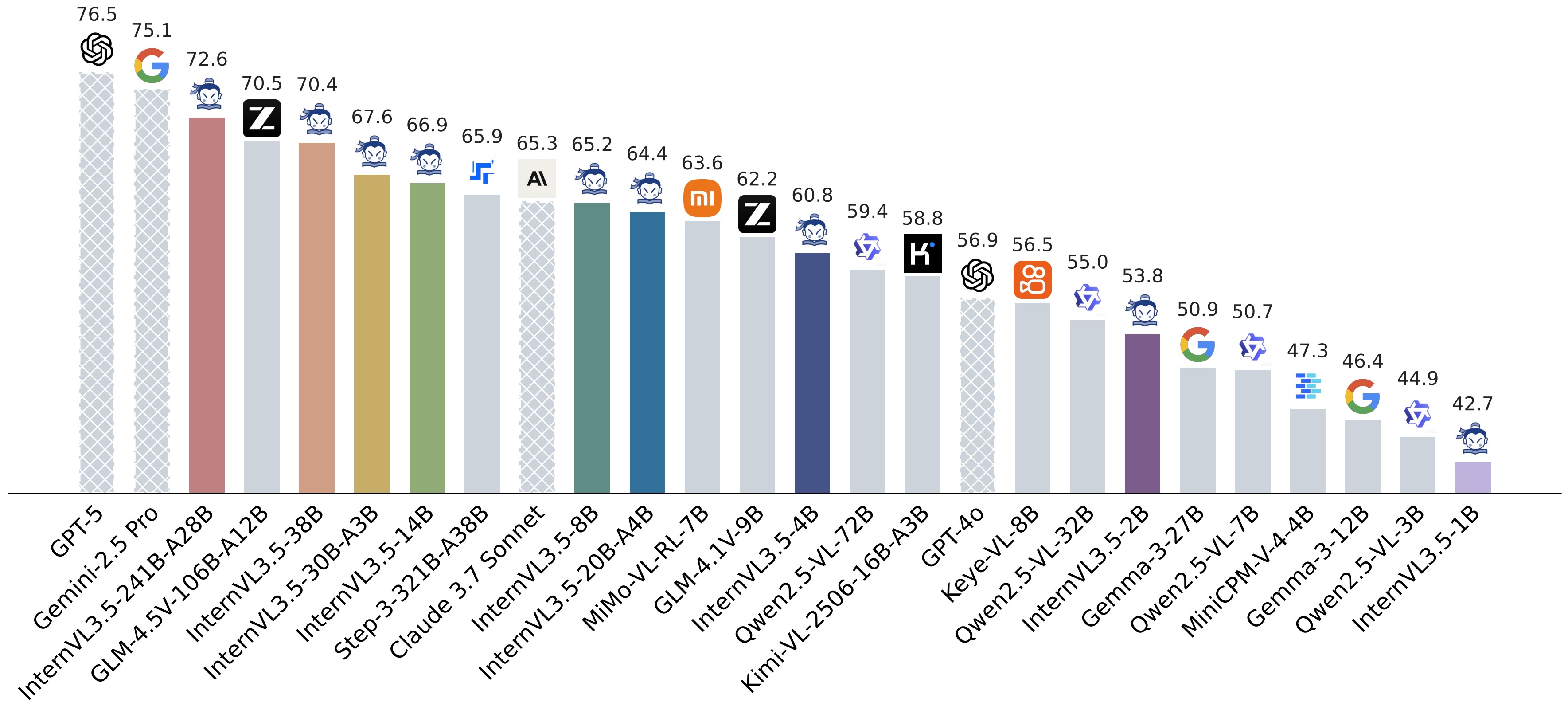
新闻 🚀🚀🚀
2025/08/30: 🔥 我们开源了 InternVL3_5-GPT-OSS-20B-A4B 和 CascadeRL 的训练代码,其中 CascadeRL 包含一个 离线强化学习阶段 和一个 在线强化学习阶段。这两个阶段的训练数据(MMPR-v1.2 和 MMPR-Tiny)也已开源。2025/08/26: 🚀 我们推出了 InternVL3.5,这是 InternVL 系列中一个新的开源多模态模型家族,显著提升了模型的通用性、推理能力和推理效率。我们最大的模型,即 InternVL3.5-241B-A28B,在开源多模态大语言模型中,在通用多模态任务、推理任务、文本任务和代理任务等方面均取得了最先进的成绩。我们还提供了一个 20B-A4B 版本(即 InternVL3_5-GPT-OSS-20B-A4B),该版本基于 GPT-OSS-20B-A4B 构建。值得注意的是,我们提供了两种模型格式:与之前发布一致的 GitHub 格式,以及符合官方transformers标准的 HF 格式。2025/04/17: 我们开源了 MPO 和 VisualPRM 的 数据构建流水线 和 训练脚本。此外,用于 MPO 和 VisualPRM 的数据构建脚本也一并发布,供参考。2025/04/11: 我们推出了 InternVL3,这是一个先进的多模态大语言模型系列,展现了卓越的整体性能。InternVL3-78B 在开源多模态大语言模型中,无论是在 感知能力 还是在 推理能力 方面,都达到了最先进水平。InternVL3-78B 的关键设计包括 可变视觉位置编码、原生多模态预训练、混合偏好优化以及 多模态测试时缩放。2025/03/13: 我们推出了 VisualPRM,这是一款具有 80 亿参数的先进多模态过程奖励模型,能够分别将 InternVL2.5-8B 和 InternVL2.5-78B 的整体推理性能提升 8.4 和 5.9 个百分点。该模型的训练数据,名为 VisualPRM400K,也已开源。更多详情请参阅我们的 论文 和 项目页面。2024/12/20: 我们发布了 InternVL2.5-MPO,该模型基于 MMPR-v1.1 使用 混合偏好优化 进行微调。与未使用 MPO 的同类模型相比,这些模型在 OpenCompass 排行榜上所有规模的模型平均高出 2 分。 这些模型可在 HF 链接 处获取。2024/12/17: InternVL2/2.5 已由 Paddle 团队在 PaddleMIX 中支持。2024/12/05: 我们发布了 InternVL2.5,这是一个先进的多模态大语言模型系列,参数范围从 10 亿到 780 亿不等。InternVL2_5-78B 是首个在 MMMU 基准测试 上得分超过 70% 的开源多模态大语言模型,其性能与 GPT-4o 等领先的闭源商用模型相当。这些模型可在 HF 链接 处获取。2024/11/14: 我们推出了 MMPR,这是一个高质量、大规模的多模态推理偏好数据集,以及 MPO,一种高效的偏好优化算法。由此产生的模型 InternVL2-8B-MPO 在 MathVista 测试中达到了 67.0 的准确率。更多详情请参阅我们的 论文、项目页面 和 文档。
更多新闻
2024/10/21: 我们发布了Mini-InternVL系列模型。这些模型以极小的规模实现了令人印象深刻的效果:4B参数量的模型仅用5%的模型规模就达到了90%的性能。更多详情请查看我们的项目页面和文档。2024/08/01: Chartmimic团队在他们的基准上评估了InternVL2系列模型。InternVL2-26B和76B模型在开源模型中分别取得了前两名的成绩,其中InternVL2 76B模型超越了GeminiProVision,并且与Claude-3-opus的表现相当。2024/08/01: InternVL2-Pro在CharXiv数据集上取得了开源模型中的SOTA性能,超越了许多闭源模型,如GPT-4V、Gemini 1.5 Flash和Claude 3 Sonnet。2024/07/24: MLVU团队在他们的基准上评估了InternVL-1.5。在选择题任务上的平均成绩为50.4%,而在生成式任务上的成绩为4.02。选择题任务的成绩在所有开源MLLM中排名第一。2024/07/04: 我们发布了InternVL2系列。InternVL2-Pro在MMMU基准上取得了62.0%的准确率,与GPT-4o等领先的闭源商用模型表现相当。2024/07/18: InternVL2-40B在Video-MME数据集上取得了开源模型中的SOTA性能,输入16帧时得分为61.2,输入32帧时得分为64.4。它显著优于其他开源模型,是目前最接近GPT-4o mini的开源模型。2024/07/18: InternVL2-Pro在DocVQA和InfoVQA基准上取得了SOTA性能。2024/06/19: 我们提出了“多模态 haystack 中的针”(MM-NIAH),这是首个旨在系统性评估现有MLLM理解长篇多模态文档能力的基准。2024/05/30: 我们发布了ShareGPT-4o,这是一个大规模数据集,计划开源包含20万张图片、1万段视频和1万段音频,并配有详细描述。2024/05/28: 感谢lmdeploy团队提供的AWQ量化支持。4-bit模型已在OpenGVLab/InternVL-Chat-V1-5-AWQ上线。2024/05/13: InternVL 1.0现在可以作为扩散模型的文本编码器,原生支持全球超过110种语言的多语言生成。更多详情请参见MuLan。2024/04/18: InternVL-Chat-V1-5已在HuggingFace链接发布,在MMMU、DocVQA、ChartQA、MathVista等多个基准上接近GPT-4V和Gemini Pro的性能。2024/02/27: InternVL被CVPR 2024接受(口头报告)!🎉2024/02/21: InternVL-Chat-V1-2-Plus在MathVista(59.9)、MMBench(83.8)和MMVP(58.7)上取得了SOTA性能。更多详情请参见我们的博客。2024/02/12: InternVL-Chat-V1-2已发布。在MMMU验证集上的得分为51.6,在MMBench测试集上的得分为82.3。更多详情请参考我们的博客和SFT数据。该模型现已在HuggingFace上线,训练和评估数据以及脚本均已开源。2024/01/24: InternVL-Chat-V1-1发布,支持中文并具有更强的OCR能力,详情请见此处。2024/01/16: 我们发布了自定义的mmcv/mmsegmentation/mmdetection代码OpenGVLab/InternVL-MMDetSeg,集成了DeepSpeed,可用于训练大规模的目标检测和分割模型。
文档
🌟 入门指南
- 安装: 🌱 安装指南 | 📄 requirements.txt
- 聊天数据格式: 📝 元文件 | ✏️ 纯文本 | 🖼️ 单张图片 | 🖼️🖼️ 多张图片 | 🎥 视频
- 本地聊天演示: 🤖 Streamlit演示
- InternVL-Chat API: 🌐 InternVL2.5 API
- 教程: 🚀 使用LoRA微调增强InternVL2在COCO Caption上的表现
🏆 InternVL 家族
- InternVL 3.0: 📖 简介 | ⚡ 快速入门 | ✨ 微调 | 📊 评估 | 📦 部署 | 🎯 MPO
- InternVL 2.5: 📖 简介 | ⚡ 快速入门 | ✨ 微调 | 📊 评估 | 📦 部署 | 🎯 MPO
- InternVL 2.0: 📖 简介 | ⚡ 快速入门 | ✨ 微调 | 📊 评估 | 📦 部署 | 🎯 MPO
- InternVL 1.5: 📖 简介 | ⚡ 快速入门 | ✨ 微调 | 📊 评估 | 📦 部署
- InternVL 1.2: 📖 简介 | ⚡ 快速入门 | ✨ 微调 | 📊 评估
- InternVL 1.1: 📖 简介 | ⚡ 快速入门 | 📊 评估
- InternVL 1.0: 🖼️ 分类 | 📊 CLIP 基准测试 | 🎨 分割 | 💬 聊天-LLaVA | ✨ InternVL-G
模型库
多模态大语言模型(InternVL 3.5)
为保持与前几代的一致性,我们提供了两种模型格式:与之前版本一致的GitHub 格式,以及符合官方 Transformers 标准的Hugging Face 格式。
GitHub 格式
| 模型 | 视觉参数 | 语言参数 | 总参数 | Hugging Face 链接 | ModelScope 链接 |
|---|---|---|---|---|---|
| InternVL3.5-1B | 0.3B | 0.8B | 1.1B | 🤗 链接 | 🤖 链接 |
| InternVL3.5-2B | 0.3B | 2.0B | 2.3B | 🤗 链接 | 🤖 链接 |
| InternVL3.5-4B | 0.3B | 4.4B | 4.7B | 🤗 链接 | 🤖 链接 |
| InternVL3.5-8B | 0.3B | 8.2B | 8.5B | 🤗 链接 | 🤖 链接 |
| InternVL3.5-14B | 0.3B | 14.8B | 15.1B | 🤗 链接 | 🤖 链接 |
| InternVL3.5-38B | 5.5B | 32.8B | 38.4B | 🤗 链接 | 🤖 链接 |
| InternVL3.5-20B-A4B | 0.3B | 20.9B | 21.2B-A4B | 🤗 链接 | 🤖 链接 |
| InternVL3.5-30B-A3B | 0.3B | 30.5B | 30.8B-A3B | 🤗 链接 | 🤖 链接 |
| InternVL3.5-241B-A28B | 5.5B | 235.1B | 240.7B-A28B | 🤗 链接 | 🤖 链接 |
HuggingFace 格式
| 模型 | 视觉参数量 | 语言参数量 | 总参数量 | HF 链接 | ModelScope 链接 |
|---|---|---|---|---|---|
| InternVL3.5-1B-HF | 0.3B | 0.8B | 1.1B | 🤗 link | 🤖 link |
| InternVL3.5-2B-HF | 0.3B | 2.0B | 2.3B | 🤗 link | 🤖 link |
| InternVL3.5-4B-HF | 0.3B | 4.4B | 4.7B | 🤗 link | 🤖 link |
| InternVL3.5-8B-HF | 0.3B | 8.2B | 8.5B | 🤗 link | 🤖 link |
| InternVL3.5-14B-HF | 0.3B | 14.8B | 15.1B | 🤗 link | 🤖 link |
| InternVL3.5-38B-HF | 5.5B | 32.8B | 38.4B | 🤗 link | 🤖 link |
| InternVL3.5-20B-A4B-HF | 0.3B | 20.9B | 21.2B-A4B | 🤗 link | 🤖 link |
| InternVL3.5-30B-A3B-HF | 0.3B | 30.5B | 30.8B-A3B | 🤗 link | 🤖 link |
| InternVL3.5-241B-A28B-HF | 5.5B | 235.1B | 240.7B-A28B | 🤗 link | 🤖 link |
多模态大语言模型(InternVL 3.0)
| 模型名称 | 视觉部分 | 语言部分 | HF 链接 | MS 链接 |
|---|---|---|---|---|
| InternVL3-1B | InternViT‑300M‑448px‑V2_5 | Qwen2.5‑0.5B | 🤗 link | 🤖 link |
| InternVL3-2B | InternViT-300M-448px-V2_5 | Qwen2.5-1.5B | 🤗 link | 🤖 link |
| InternVL3-8B | InternViT-300M-448px-V2_5 | Qwen2.5-7B | 🤗 link | 🤖 link |
| InternVL3-9B | InternViT-300M-448px-V2_5 | internlm3-8b-instruct | 🤗 link | 🤖 link |
| InternVL3-14B | InternViT-300M-448px-V2_5 | Qwen2.5-14B | 🤗 link | 🤖 link |
| InternVL3-38B | InternViT-6B-448px-V2_5 | Qwen2.5-32B | 🤗 link | 🤖 link |
| InternVL3-78B | InternViT-6B-448px-V2_5 | Qwen2.5-72B | 🤗 link | 🤖 link |
多模态大语言模型(InternVL 2.5)
| 模型名称 | 视觉部分 | 语言部分 | HF 链接 | MS 链接 |
|---|---|---|---|---|
| InternVL2_5-1B | InternViT‑300M‑448px‑V2_5 | Qwen2.5‑0.5B‑Instruct | 🤗链接 | 🤖链接 |
| InternVL2_5-2B | InternViT-300M-448px-V2_5 | internlm2_5-1_8b-chat | 🤗链接 | 🤖链接 |
| InternVL2_5-4B | InternViT-300M-448px-V2_5 | Qwen2.5-3B-Instruct | 🤗链接 | 🤖链接 |
| InternVL2_5-8B | InternViT-300M-448px-V2_5 | internlm2_5-7b-chat | 🤗链接 | 🤖链接 |
| InternVL2_5-26B | InternViT-6B-448px-V2_5 | internlm2_5-20b-chat | 🤗链接 | 🤖链接 |
| InternVL2_5-38B | InternViT-6B-448px-V2_5 | Qwen2.5-32B-Instruct | 🤗链接 | 🤖链接 |
| InternVL2_5-78B | InternViT-6B-448px-V2_5 | Qwen2.5-72B-Instruct | 🤗链接 | 🤖链接 |
| 模型名称 | 视觉部分 | 语言部分 | HF 链接 | MS 链接 |
|---|---|---|---|---|
| InternVL2_5-1B-MPO | InternViT‑300M‑448px‑V2_5 | Qwen2.5‑0.5B‑Instruct | 🤗链接 | 🤖链接 |
| InternVL2_5-2B-MPO | InternViT-300M-448px-V2_5 | internlm2_5-1_8b-chat | 🤗链接 | 🤖链接 |
| InternVL2_5-4B-MPO | InternViT-300M-448px-V2_5 | Qwen2.5-3B-Instruct | 🤗链接 | 🤖链接 |
| InternVL2_5-8B-MPO | InternViT-300M-448px-V2_5 | internlm2_5-7b-chat | 🤗链接 | 🤖链接 |
| InternVL2_5-26B-MPO | InternViT-6B-448px-V2_5 | internlm2_5-20b-chat | 🤗链接 | 🤖链接 |
| InternVL2_5-38B-MPO | InternViT-6B-448px-V2_5 | Qwen2.5-32B-Instruct | 🤗链接 | 🤖链接 |
| InternVL2_5-78B-MPO | InternViT-6B-448px-V2_5 | Qwen2.5-72B-Instruct | 🤗链接 | 🤖链接 |
多模态大语言模型(InternVL 2.0)
| 模型名称 | 视觉部分 | 语言部分 | HF 链接 | MS 链接 |
|---|---|---|---|---|
| InternVL2-1B | InternViT-300M-448px | Qwen2-0.5B-Instruct | 🤗链接 | 🤖链接 |
| InternVL2-2B | InternViT-300M-448px | internlm2-chat-1-8b | 🤗链接 | 🤖链接 |
| InternVL2-4B | InternViT-300M-448px | Phi‑3‑mini‑128k‑instruct | 🤗链接 | 🤖链接 |
| InternVL2-8B | InternViT-300M-448px | internlm2_5-7b-chat | 🤗链接 | 🤖链接 |
| InternVL2-26B | InternViT-6B-448px-V1-5 | internlm2-chat-20b | 🤗链接 | 🤖链接 |
| InternVL2-40B | InternViT‑6B‑448px‑V1‑5 | Nous‑Hermes‑2‑Yi‑34B | 🤗链接 | 🤖链接 |
| InternVL2‑Llama3-76B | InternViT-6B-448px-V1-5 | Hermes‑2‑Theta‑ Llama‑3‑70B |
🤗链接 | 🤖链接 |
多模态大语言模型(InternVL 1.0-1.5)
| 模型 | 日期 | HF 链接 | MS 链接 | 备注 |
|---|---|---|---|---|
| Mini‑InternVL‑Chat‑4B‑V1‑5 | 2024.05.28 | 🤗链接 | 🤖链接 | 🚀🚀 模型规模为原版的16%,性能却达到90% |
| Mini-InternVL-Chat-2B-V1-5 | 2024.05.19 | 🤗链接 | 🤖链接 | 🚀 模型规模为原版的8%,性能却达到80% |
| InternVL-Chat-V1-5 | 2024.04.18 | 🤗链接 | 🤖链接 | 支持4K图像;OCR能力极强;在MMMU、DocVQA、ChartQA、MathVista等多个基准测试中,性能接近GPT-4V和Gemini Pro。 |
| InternVL-Chat-V1-2-Plus | 2024.02.21 | 🤗链接 | 🤖链接 | 使用了更多SFT数据,性能更强。 |
| InternVL-Chat-V1-2 | 2024.02.11 | 🤗链接 | 🤖链接 | 将LLM规模扩大到34B。 |
| InternVL-Chat-V1-1 | 2024.01.24 | 🤗链接 | 🤖链接 | 支持中文,并且OCR能力更强。 |
| InternVL-Chat-19B | 2023.12.25 | 🤗链接 | 🤖链接 | 英文多模态对话。 |
| InternVL-Chat-13B | 2023.12.25 | 🤗链接 | 🤖链接 | 英文多模态对话。 |
类CLIP模型(InternVL 1.0-2.5)
| 模型 | 日期 | HF 链接 | MS 链接 | 备注 |
|---|---|---|---|---|
| InternViT-300M-448px-V2_5 | 2024.12.05 | 🤗 链接 | 🤖 链接 | 🚀🚀 更强大的轻量级视觉编码器。(🔥新) |
| InternViT-6B-448px-V2_5 | 2024.12.05 | 🤗 链接 | 🤖 链接 | 🚀🚀 更强大的视觉编码器,用于提取视觉特征。(🔥新) |
| InternViT-300M-448px | 2024.05.25 | 🤗 链接 | 🤖 链接 | 蒸馏后的小型视觉基础模型,参数量为3亿 |
| InternViT‑6B‑448px‑V1‑5 | 2024.04.20 | 🤗 链接 | 🤖 链接 | 通过增量预训练支持动态分辨率和超强的OCR特征提取能力 |
| InternViT-6B-448px-V1-2 | 2024.02.11 | 🤗 链接 | 🤖 链接 | 通过增量预训练支持448分辨率 |
| InternViT-6B-448px-V1-0 | 2024.01.30 | 🤗 链接 | 🤖 链接 | 通过增量预训练支持448分辨率 |
| InternViT-6B-224px | 2023.12.22 | 🤗 链接 | 🤖 链接 | InternViT-6B的第一个版本,由InternVL‑14B‑224px中提取而来 |
视觉-语言基础模型(InternVL 1.0)
| 模型 | 日期 | HF 链接 | MS 链接 | 备注 |
|---|---|---|---|---|
| InternVL‑14B‑224px | 2023.12.22 | 🤗 链接 | 🤖 链接 | 视觉-语言基础模型,由InternViT-6B与QLLaMA结合而成,可用于类似CLIP的图文检索任务 |
待办事项
- 发布InternVL2.5系列的训练/评估代码
- 支持liger内核以节省显存
- 发布MPO的代码、模型和数据
- 支持多模态打包数据集
- 支持vLLM和Ollama
- 在在线演示中支持视频和PDF输入
- 发布集成VisionLLMv2的InternVL2
- 使用readthedocs重新构建文档
- 支持使用LoRA微调不同的LLM
- 发布InternVL2的
requirements.txt - 发布InternVL2系列的训练/评估代码
- 发布InternVL1.5和InternVL2的Streamlit网页界面
InternVL能做什么?
视觉感知(点击展开)
线性探针图像分类 [查看详情]
ViT-22B使用私有的JFT-3B数据集。
方法 参数量 IN-1K IN-ReaL IN-V2 IN-A IN-R IN-Sketch OpenCLIP-G 1.8B 86.2 89.4 77.2 63.8 87.8 66.4 DINOv2-g 1.1B 86.5 89.6 78.4 75.9 78.8 62.5 EVA-01-CLIP-g 1.1B 86.5 89.3 77.4 70.5 87.7 63.1 MAWS-ViT-6.5B 6.5B 87.8 - - - - - ViT-22B* 21.7B 89.5 90.9 83.2 83.8 87.4 - InternViT-6B(我们) 5.9B 88.2 90.4 79.9 77.5 89.8 69.1 语义分割 [查看详情]
方法 解码器 训练/总参数量 裁剪尺寸 mIoU OpenCLIP-G(冻结) 线性 0.3M / 1.8B 512 39.3 ViT-22B(冻结) 线性 0.9M / 21.7B 504 34.6 InternViT-6B(冻结) 线性 0.5M / 5.9B 504 47.2 (+12.6) ViT-22B(冻结) UperNet 0.8B / 22.5B 504 52.7 InternViT-6B(冻结) UperNet 0.4B / 6.3B 504 54.9 (+2.2) ViT-22B UperNet 22.5B / 22.5B 504 55.3 InternViT-6B UperNet 6.3B / 6.3B 504 58.9 (+3.6) 零样本图像分类 [查看详情]
方法 IN-1K IN-A IN-R IN-V2 IN-Sketch ObjectNet OpenCLIP-G 80.1 69.3 92.1 73.6 68.9 73.0 EVA-02-CLIP-E+ 82.0 82.1 94.5 75.7 71.6 79.6 ViT-22B* 85.9 90.1 96.0 80.9 - 87.6 InternVL-C(我们) 83.2 83.8 95.5 77.3 73.9 80.6 多语言零样本图像分类 [查看详情]
EN:英语,ZH:中文,JP:日语,Ar:阿拉伯语,IT:意大利语
| 方法 | IN-1K (EN) | IN-1K (ZH) | IN-1K (JP) | IN-1K (AR) | IN-1K (IT) |
|---|---|---|---|---|---|
| Taiyi-CLIP-ViT-H | - | 54.4 | - | - | - |
| WuKong-ViT-L-G | - | 57.5 | - | - | - |
| CN-CLIP-ViT-H | - | 59.6 | - | - | - |
| AltCLIP-ViT-L | 74.5 | 59.6 | - | - | - |
| EVA-02-CLIP-E+ | 82.0 | - | - | - | 41.2 |
| OpenCLIP-XLM-R-H | 77.0 | 55.7 | 53.1 | 37.0 | 56.8 |
| InternVL-C (ours) | 83.2 | 64.5 | 61.5 | 44.9 | 65.7 |
零样本视频分类
方法 帧数 K400 K600 K700 OpenCLIP-G 1 65.9 66.1 59.2 EVA-02-CLIP-E+ 1 69.8 69.3 63.4 InternVL-C (ours) 1 71.0 71.3 65.7 ViCLIP 8 75.7 73.5 66.4 InternVL-C (ours) 8 79.4 78.8 71.5
跨模态检索(点击展开)
英文零样本图文检索 [查看详情]
模型 Flickr30K COCO 平均 图像到文本 文本到图像 图像到文本 文本到图像 R@1 R@5 R@10 R@1 R@5 R@10 R@1 R@5 R@10 R@1 R@5 R@10 OpenCLIP-G 92.9 99.3 99.8 79.5 95.0 97.1 67.3 86.9 92.6 51.4 74.9 83.0 85.0 EVA-02-CLIP-E+ 93.9 99.4 99.8 78.8 94.2 96.8 68.8 87.8 92.8 51.1 75.0 82.7 85.1 EVA-CLIP-8B 95.6 99.6 99.9 80.8 95.5 97.6 70.3 89.3 93.9 53.0 76.0 83.4 86.2 InternVL-C (ours) 94.7 99.6 99.9 81.7 96.0 98.2 70.6 89.0 93.5 54.1 77.3 84.6 86.6 InternVL-G (ours) 95.7 99.7 99.9 85.0 97.0 98.6 74.9 91.3 95.2 58.6 81.3 88.0 88.8 中文零样本图文检索 [查看详情]
模型 Flickr30K-CN COCO-CN 平均 图像到文本 文本到图像 图像到文本 文本到图像 R@1 R@5 R@10 R@1 R@5 R@10 R@1 R@5 R@10 R@1 R@5 R@10 trCN-CLIP-ViT-H 81.6 97.5 98.8 71.2 91.4 95.5 63.0 86.6 92.9 69.2 89.9 96.1 86.1 纹。OpenCLIP-XLM-R-H 86.1 97.5 99.2 71.0 90.5 94.9 70.0 91.5 97.0 66.1 90.8 96.0 87.6 纹。InternVL-C (ours) 90.3 98.8 99.7 75.1 92.9 96.4 68.8 92.0 96.7 68.9 91.9 96.5 99.7 89.0 InternVL-G (ours) 92.9 99.4 99.8 77.7 94.8 97.3 71.4 93.9 97.7 73.8 94.4 98.1 XTD 上的多语言零样本图文检索 [查看详情]
方法 英文 西班牙文 法文 中文 意大利文 韩文 俄文 日文 平均 AltCLIP 95.4 94.1 92.9 95.1 94.2 94.4 91.8 91.7 93.7 OpenCLIP-XLM-R-H 97.3 96.1 94.5 94.7 96.0 90.2 93.9 94.0 94.6 InternVL-C(我们) 97.3 95.7 95.1 95.6 96.0 92.2 93.3 95.5 95.1 InternVL-G(我们) 98.6 97.7 96.5 96.7 96.9 95.1 94.8 96.1 96.6 多模态对话
使用 HuggingFace 快速入门
使用 InternViT-6B 进行视觉特征提取(点击展开)
import torch from PIL import Image from transformers import AutoModel, CLIPImageProcessor model = AutoModel.from_pretrained( 'OpenGVLab/InternViT-6B-448px-V2_5', torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, trust_remote_code=True).cuda().eval() image = Image.open('./examples/image1.jpg').convert('RGB') image_processor = CLIPImageProcessor.from_pretrained('OpenGVLab/InternViT-6B-448px-V1-5') pixel_values = image_processor(images=image, return_tensors='pt').pixel_values pixel_values = pixel_values.to(torch.bfloat16).cuda() outputs = model(pixel_values)使用 InternVL-C(对比型)和 InternVL-G(生成型)进行跨模态检索(点击展开)
import torch from PIL import Image from transformers import AutoModel, CLIPImageProcessor from transformers import AutoTokenizer model = AutoModel.from_pretrained( 'OpenGVLab/InternVL-14B-224px', torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, trust_remote_code=True).cuda().eval() image_processor = CLIPImageProcessor.from_pretrained('OpenGVLab/InternVL-14B-224px') tokenizer = AutoTokenizer.from_pretrained( 'OpenGVLab/InternVL-14B-224px', use_fast=False, add_eos_token=True) tokenizer.pad_token_id = 0 # 设置 pad_token_id 为 0 images = [ Image.open('./examples/image1.jpg').convert('RGB'), Image.open('./examples/image2.jpg').convert('RGB'), Image.open('./examples/image3.jpg').convert('RGB') ] prefix = 'summarize:' texts = [ prefix + 'a photo of a red panda', # 英文 prefix + '一张熊猫的照片', # 中文 prefix + '二匹の猫の写真' # 日文 ] pixel_values = image_processor(images=images, return_tensors='pt').pixel_values pixel_values = pixel_values.to(torch.bfloat16).cuda() input_ids = tokenizer(texts, return_tensors='pt', max_length=80, truncation=True, padding='max_length').input_ids.cuda() # InternVL-C logits_per_image, logits_per_text = model( image=pixel_values, text=input_ids, mode='InternVL-C') probs = logits_per_image.softmax(dim=-1) # tensor([[9.9609e-01, 5.2185e-03, 6.0070e-08], # [2.2949e-02, 9.7656e-01, 5.9903e-06], # [3.2932e-06, 7.4863e-05, 1.0000e+00]], device='cuda:0', # dtype=torch.bfloat16, grad_fn=<SoftmaxBackward0>) # InternVL-G logits_per_image, logits_per_text = model( image=pixel_values, text=input_ids, mode='InternVL-G') probs = logits_per_image.softmax(dim=-1) # tensor([[9.9609e-01, 3.1738e-03, 3.6322e-08], # [8.6060e-03, 9.9219e-01, 2.8759e-06], # [1.7583e-06, 3.1233e-05, 1.0000e+00]], device='cuda:0', # dtype=torch.bfloat16, grad_fn=<SoftmaxBackward0>) # 请将 add_eos_token 设置为 False 以进行生成 tokenizer.add_eos_token = False image = Image.open('./examples/image1.jpg').convert('RGB') pixel_values = image_processor(images=image, return_tensors='pt').pixel_values pixel_values = pixel_values.to(torch.bfloat16).cuda() tokenized = tokenizer("English caption:", return_tensors='pt') pred = model.generate( pixel_values=pixel_values, input_ids=tokenized.input_ids.cuda(), attention_mask=tokenized.attention_mask.cuda(), num_beams=5, min_new_tokens=8, ) caption = tokenizer.decode(pred[0].cpu(), skip_special_tokens=True).strip() # 英文说明:一只红熊猫坐在木制平台上使用 InternVL 2.5 进行多模态对话(点击展开)
这里我们以较小的
OpenGVLab/InternVL2_5-8B模型为例:import numpy as np import torch import torchvision.transforms as T from decord import VideoReader, cpu from PIL import Image from torchvision.transforms.functional import InterpolationMode from transformers import AutoModel, AutoTokenizer IMAGENET_MEAN = (0.485, 0.456, 0.406) IMAGENET_STD = (0.229, 0.224, 0.225) def build_transform(input_size): MEAN, STD = IMAGENET_MEAN, IMAGENET_STD transform = T.Compose([ T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img), T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC), T.ToTensor(), T.Normalize(mean=MEAN, std=STD) ]) return transform def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size): best_ratio_diff = float('inf') best_ratio = (1, 1) area = width * height for ratio in target_ratios: target_aspect_ratio = ratio[0] / ratio[1] ratio_diff = abs(aspect_ratio - target_aspect_ratio) if ratio_diff < best_ratio_diff: best_ratio_diff = ratio_diff best_ratio = ratio elif ratio_diff == best_ratio_diff: if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]: best_ratio = ratio return best_ratio def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False): orig_width, orig_height = image.size aspect_ratio = orig_width / orig_height # 计算现有图像的宽高比 target_ratios = set( (i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if i * j <= max_num and i * j >= min_num) target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1]) # 找到最接近目标宽高比的比率 target_aspect_ratio = find_closest_aspect_ratio( aspect_ratio, target_ratios, orig_width, orig_height, image_size) # 计算目标宽度和高度 target_width = image_size * target_aspect_ratio[0] target_height = image_size * target_aspect_ratio[1] blocks = target_aspect_ratio[0] * target_aspect_ratio[1] # 调整图像大小 resized_img = image.resize((target_width, target_height)) processed_images = [] for i in range(blocks): box = ( (i % (target_width // image_size)) * image_size, (i // (target_width // image_size)) * image_size, ((i % (target_width // image_size)) + 1) * image_size, ((i // (target_width // image_size)) + 1) * image_size ) # 将图像分割 split_img = resized_img.crop(box) processed_images.append(split_img) assert len(processed_images) == blocks if use_thumbnail and len(processed_images) != 1: thumbnail_img = image.resize((image_size, image_size)) processed_images.append(thumbnail_img) return processed_images def load_image(image_file, input_size=448, max_num=12): image = Image.open(image_file).convert('RGB') transform = build_transform(input_size=input_size) images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num) pixel_values = [transform(image) for image in images] pixel_values = torch.stack(pixel_values) return pixel_values # 如果你有一块 80G 的 A100 显卡,可以将整个模型放在单张显卡上。 # 否则,你需要使用多张显卡来加载模型,请参考“多GPU”部分。 path = 'OpenGVLab/InternVL2_5-8B' model = AutoModel.from_pretrained( path, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, trust_remote_code=True).eval().cuda() tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False) # 设置 `max_num` 中的最大切片数量 pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda() generation_config = dict(max_new_tokens=1024, do_sample=False) # 纯文本对话 question = '你好,你是谁?' response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True) print(f'用户: {question}\n助手: {response}') question = '你能给我讲个故事吗?' response, history = model.chat(tokenizer, None, question, generation_config, history=history,return_history=True) print(f'用户: {question}\n助手: {response}') # 单图单轮对话 question = '<image>\n请简要描述这张图片。' response = model.chat(tokenizer, pixel_values,question,generation_config) print(f'用户: {question}\n助手: {response}') # 单图多轮对话 question = '<image>\n请详细描述这张图片。' response,history = model.chat(tokenizer,pixel_values,question,generation_config,history=None,return_history=True) print(f'用户: {question}\n助手: {response}') question = '请根据这张图片写一首诗。' response,history = model.chat(tokenizer,pixel_values,question,generation_config,history=history,return_history=True) print(f'用户: {question}\n助手: {response}') # 多图多轮对话,拼接图像 pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda() pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda() pixel_values = torch.cat((pixel_values1,pixel_values2),dim=0) question = '<image>\n请详细描述这两张图片。' response,history = model.chat(tokenizer,pixel_values,question,generation_config, history=None,return_history=True) print(f'用户: {question}\n助手: {response}') question = '这两张图片有哪些相似之处和不同之处?' response,history = model.chat(tokenizer,pixel_values,question,generation_config, history=history,return_history=True) print(f'用户: {question}\n助手: {response}') # 多图多轮对话,独立图像 pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda() pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda() pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0) num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)] question = '图1: <image>\n图2: <image>\n请详细描述这两张图片。' response, history = model.chat(tokenizer, pixel_values, question, generation_config, num_patches_list=num_patches_list, history=None, return_history=True) print(f'用户: {question}\n助手: {response}') question = '这两张图片有哪些相似之处和不同之处?' response, history = model.chat(tokenizer, pixel_values, question, generation_config, num_patches_list=num_patches_list, history=history, return_history=True) print(f'用户: {question}\n助手: {response}') # 批量推理,每个样本一张图(单图批处理) pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda() pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda() num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)] pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0) questions = ['<image>\n请详细描述这张图片。'] * len(num_patches_list) responses = model.batch_chat(tokenizer, pixel_values, num_patches_list=num_patches_list, questions=questions, generation_config=generation_config) for question, response in zip(questions, responses): print(f'用户: {question}\n助手: {response}') # 视频多轮对话 def get_index(bound, fps, max_frame, first_idx=0, num_segments=32): if bound: start, end = bound[0], bound[1] else: start, end = -100000, 100000 start_idx = max(first_idx, round(start * fps)) end_idx = min(round(end * fps), max_frame) seg_size = float(end_idx - start_idx) / num_segments frame_indices = np.array([ int(start_idx + (seg_size / 2) + np.round(seg_size * idx)) for idx in range(num_segments) ]) return frame_indices def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32): vr = VideoReader(video_path, ctx=cpu(0), num_threads=1) max_frame = len(vr) - 1 fps = float(vr.get_avg_fps()) pixel_values_list, num_patches_list = [], [] transform = build_transform(input_size=input_size) frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments) for frame_index in frame_indices: img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB') img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num) pixel_values = [transform(tile) for tile in img] pixel_values = torch.stack(pixel_values) num_patches_list.append(pixel_values.shape[0]) pixel_values_list.append(pixel_values) pixel_values = torch.cat(pixel_values_list) return pixel_values, num_patches_list video_path = './examples/red-panda.mp4' pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1) pixel_values = pixel_values.to(torch.bfloat16).cuda() video_prefix = ''.join([f'第{i+1}帧: <image>\n' for i in range(len(num_patches_list))]) question = video_prefix + '这只红熊猫在做什么?' # 第1帧: <image>\n第2帧: <image>\n...\n第8帧: <image>\n{question} response, history = model.chat(tokenizer, pixel_values, question, generation_config, num_patches_list=num_patches_list, history=None, return_history=True) print(f'用户: {question}\n助手: {response}') question = '请详细描述这段视频。' response, history = model.chat(tokenizer, pixel_values, question, generation_config, num_patches_list=num_patches_list, history=history, return_history=True) print(f'用户: {question}\n助手: {response}')许可证
本项目采用 MIT 许可证 发布。项目中部分代码和模型来源于其他来源,受其各自许可证的约束。
引用
如果您在研究中使用了本项目,请考虑引用以下文献:
@article{wang2025internvl3_5, title={InternVL3.5: 在通用性、推理能力和效率方面推进开源多模态模型}, author={Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others}, journal={arXiv预印本 arXiv:2508.18265}, year={2025} } @article{zhu2025internvl3, title={Internvl3:探索开源多模态模型的高级训练与测试时优化方案}, author={Zhu, Jinguo and Wang, Weiyun and Chen, Zhe and Liu, Zhaoyang and Ye, Shenglong and Gu, Lixin and Tian, Hao and Duan, Yuchen and Su, Weijie and Shao, Jie and others}, journal={arXiv预印本 arXiv:2504.10479}, year={2025} } @article{chen2024expanding, title={通过模型、数据及测试时缩放扩展开源多模态模型的性能边界}, author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others}, journal={arXiv预印本 arXiv:2412.05271}, year={2024} } @article{wang2024mpo, title={基于混合偏好优化提升多模态大语言模型的推理能力}, author={Wang, Weiyun and Chen, Zhe and Wang, Wenhai and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Zhu, Jinguo and Zhu, Xizhou and Lu, Lewei and Qiao, Yu and Dai, Jifeng}, journal={arXiv预印本 arXiv:2411.10442}, year={2024} } @article{gao2024mini, title={Mini-InternVL:参数仅占5%却保持90%性能的灵活迁移袖珍型多模态模型}, author={Gao, Zhangwei and Chen, Zhe and Cui, Erfei and Ren, Yiming and Wang, Weiyun and Zhu, Jinguo and Tian, Hao and Ye, Shenglong and He, Junjun and Zhu, Xizhou and others}, journal={视觉智能}, volume={2}, number={1}, pages={1--17}, year={2024}, publisher={Springer} } @article{chen2024far, title={我们距离GPT-4v还有多远?借助开源工具集缩小与商业多模态模型的差距}, author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others}, journal={中国科学:信息科学}, volume={67}, number={12}, pages={220101}, year={2024}, publisher={Springer} } @inproceedings{chen2024internvl, title={Internvl:扩大视觉基础模型规模并对其对齐以适应通用视觉-语言任务}, author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others}, booktitle={IEEE/CVF计算机视觉与模式识别会议论文集}, pages={24185--24198}, year={2024} }致谢
InternVL 的构建参考了以下项目的代码:OpenAI CLIP、Open CLIP、CLIP基准测试、EVA、InternImage、ViT-Adapter、MMSegmentation、Transformers、DINOv2、BLIP-2、Qwen-VL 以及 LLaVA-1.5。感谢这些项目团队的杰出工作!
扫描下方二维码,加入我们的微信群。

版本历史
v1.5.02024/05/08v1.2.32024/03/04v1.2.22024/02/21v1.22024/02/13v1.12024/02/13data2024/01/22常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
349.3k|★★★☆☆|2周前n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
184.7k|★★☆☆☆|今天AutoGPT
AutoGPT 是一个旨在让每个人都能轻松使用和构建 AI 的强大平台,核心功能是帮助用户创建、部署和管理能够自动执行复杂任务的连续型 AI 智能体。它解决了传统 AI 应用中需要频繁人工干预、难以自动化长流程工作的痛点,让用户只需设定目标,AI 即可自主规划步骤、调用工具并持续运行直至完成任务。 无论是开发者、研究人员,还是希望提升工作效率的普通用户,都能从 AutoGPT 中受益。开发者可利用其低代码界面快速定制专属智能体;研究人员能基于开源架构探索多智能体协作机制;而非技术背景用户也可直接选用预置的智能体模板,立即投入实际工作场景。 AutoGPT 的技术亮点在于其模块化“积木式”工作流设计——用户通过连接功能块即可构建复杂逻辑,每个块负责单一动作,灵活且易于调试。同时,平台支持本地自托管与云端部署两种模式,兼顾数据隐私与使用便捷性。配合完善的文档和一键安装脚本,即使是初次接触的用户也能在几分钟内启动自己的第一个 AI 智能体。AutoGPT 正致力于降低 AI 应用门槛,让人人都能成为 AI 的创造者与受益者。
183.6k|★★★☆☆|今天stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
162.1k|★★★☆☆|2周前everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
161.7k|★★☆☆☆|今天opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
144.3k|★☆☆☆☆|4天前