GraphSAINT
GraphSAINT 是一个专为大规模图数据设计的高效训练框架,旨在帮助开发者和研究人员轻松训练深度图神经网络(GNN)。传统方法在处理大型图时,常因逐层采样导致“邻居爆炸”问题,使得计算成本随网络深度呈指数级增长,难以在显存中运行。GraphSAINT 创新性地采用了“图采样”策略,即在每个训练批次中直接采样出一个完整的子图,而非在网络层内部进行节点筛选。这种方法不仅将计算复杂度从指数级降低为线性级,显著提升了训练效率,还通过独特的归一化技术和轻量级采样器,有效消除了采样偏差并保留了关键的结构信息,从而保证了模型的高准确率。此外,GraphSAINT 具有极佳的灵活性,能够无缝兼容大多数现有的 GNN 架构,并支持在分布式环境中高效扩展。无论是需要处理百万级节点图的算法工程师,还是致力于探索新型图模型的研究人员,GraphSAINT 都能提供一个稳定、可扩展且易于集成的解决方案,让大规模图学习变得更加简单可行。
使用场景
某大型电商平台的算法团队正试图构建一个深度图神经网络(GNN),以在包含数千万用户和商品交互关系的超大图上进行实时欺诈检测。
没有 GraphSAINT 时
- 显存爆炸导致训练中断:随着 GNN 层数加深,传统“逐层采样”方法引发“邻居爆炸”效应,所需显存呈指数级增长,普通 GPU 根本无法加载模型。
- 关键信息丢失影响精度:为了强行适配显存限制,不得不大幅削减采样邻居数量,导致重要的欺诈关联路径被切断,模型误判率居高不下。
- 架构兼容性差:团队想尝试更先进的 JK-net 等复杂架构,但受限于原有采样逻辑对节点集合的严苛要求,无法顺利迁移和实验。
- 分布式通信开销大:在多卡并行训练时,由于每次反向传播涉及大量跨节点的稀疏数据交换,通信延迟成为主要瓶颈,训练效率极低。
使用 GraphSAINT 后
- 线性扩展解决显存难题:GraphSAINT 采用“子图采样”策略,直接构建完整的小型子图进行训练,将计算成本从指数级降为线性,轻松在单张 GPU 上运行深层网络。
- 偏差校正提升检测准确率:通过特有的归一化机制消除采样偏差,并保留关键拓扑结构的邻居,使得模型在大幅压缩数据量的同时,欺诈识别精度反而显著提升。
- 无缝支持多样模型架构:由于子图上的传播逻辑与全图一致,团队可以零代码修改地直接套用 JK-net 等各种先进 GNN 变体,加速了算法迭代。
- 高效并行降低通信负载:子图独立性极强,不仅天然适合多卡任务并行,还大幅减少了分布式环境下的通信开销,使训练速度提升了数倍。
GraphSAINT 通过革新性的子图采样范式,彻底解决了大规模图数据上深度学习的显存与效率瓶颈,让超大图上的高精度实时风控成为可能。
运行环境要求
- 未说明
- 训练可选 GPU(支持 --gpu 参数),验证/测试若显存不足可强制使用 CPU(--cpu_eval)
- 双 GPU 加速需支持内存池化并通过 NvLink 连接
- 未指定具体型号、显存大小或 CUDA 版本
未说明

快速开始
GraphSAINT:基于图采样的归纳学习方法
Hanqing Zeng*, Hongkuan Zhou*, Ajitesh Srivastava, Rajgopal Kannan, Viktor Prasanna
联系方式
Hanqing Zeng (zengh@usc.edu), Hongkuan Zhou (hongkuaz@usc.edu)
欢迎随时报告问题或提出建议!
概述
GraphSAINT 是一个通用且灵活的框架,用于在大规模图上训练 GNN。GraphSAINT 提出了一种新颖的 mini-batch 方法,专门针对具有复杂关系的数据(即图)进行了优化。传统的 GNN 训练方式是:1) 在完整的训练图上构建 GNN;2) 对于每个 mini-batch,选择输出层中的一些节点作为根节点,然后从根节点反向追踪层间连接,直到到达输入层;3) 基于根节点上的损失进行前向和反向传播。而 GraphSAINT 的训练方式是:1) 对于每个 mini-batch,从完整的训练图中采样一个小子图;2) 在这个小子图上构建一个完整的 GNN,GNN 层内不再进行采样;3) 基于子图节点上的损失进行前向和反向传播。
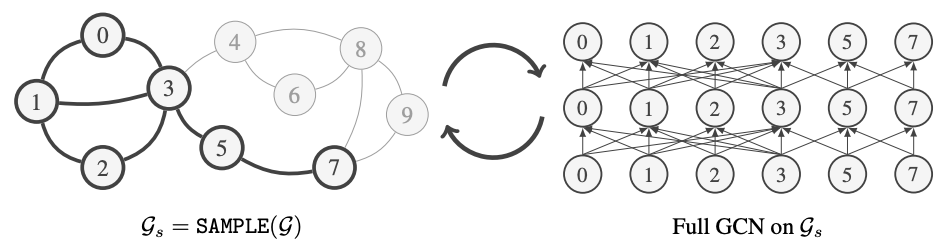
GraphSAINT 采用的是“图采样”式的训练,而其他方法则是“层采样”式的训练。为什么改变采样的视角如此重要呢?GraphSAINT 能够实现以下几点:
准确性:我们通过简单而有效的归一化操作,消除了图采样带来的偏差。此外,由于任何采样过程都会因为丢弃邻居而导致信息丢失,我们提出了轻量级的图采样器,能够根据拓扑特征保留重要的邻居。实际上,图采样也可以被理解为一种数据增强或训练正则化手段(例如,边采样可以看作是 DropEdge 的 mini-batch 版本)。
效率:对于许多基于层采样的方法来说,“邻居爆炸”是一个令人头疼的问题,而 GraphSAINT 则凭借其图采样的理念提供了一个干净的解决方案。由于每个 GNN 层都是完整的且未经过采样,无论网络深度如何,邻居的数量始终保持不变。因此,每批次的计算成本会随着 GNN 深度的增加从指数级降低到线性级。
灵活性:GraphSAINT 中 mini-batch 子图上的层传播与在完整图上的传播几乎完全相同。因此,大多数为完整图设计的 GNN 架构都可以无缝地使用 GraphSAINT 进行训练。相比之下,一些层采样算法仅支持有限数量的 GNN 架构。以 JK-Net 为例,跳跃式知识连接要求浅层的节点样本必须是深层节点样本的超集——而 FastGCN 和 AS-GCN 的 mini-batch 格式并不满足这一条件。
可扩展性:GraphSAINT 在以下三个方面实现了可扩展性:1) 图规模:我们的子图大小无需随训练图规模成比例增长。因此,即使面对百万节点的图,子图仍然可以轻松容纳在 GPU 内存中;2) 模型规模:通过解决“邻居爆炸”问题,训练成本与 GNN 的宽度和深度呈线性关系;3) 并行资源数量:图采样可以通过简单的任务并行化实现高度可扩展。此外,解决“邻居爆炸”问题还意味着通信开销的大幅减少,这在分布式环境中尤为重要(参见我们发表在 IEEE/IPDPS '19 上的文章,或 硬件加速器开发 相关工作)。
【新闻】:请查看我们最新的工作,它将子图采样推广到了训练和推理两个阶段:shaDow-GNN(NeurIPS'21)!
关于本仓库
本仓库包含了我们两篇论文的源代码(ICLR '20 和 IEEE/IPDPS '19,详见【引用与致谢】部分)。
./graphsaint 目录包含 ICLR '20 论文中提出的 mini-batch 训练算法的 Python 实现。我们提供了两种实现版本,分别基于 Tensorflow 和 PyTorch。这两个版本遵循相同的算法。需要注意的是,我们论文中的所有实验均基于 Tensorflow 版本。而在公开图基准上的新实验则采用了 PyTorch 版本。
./ipdps19_cpp 目录包含了 IEEE/IPDPS '19 论文中描述的并行训练技术的 C++ 实现(详见 ./ipdps19_cpp/README.md)。本仓库的其余部分则专注于 ICLR '20 中的 GraphSAINT。
本仓库支持的 GNN 架构如下:
| GNN 架构 | Tensorflow | PyTorch | C++ |
|---|---|---|---|
| GraphSAGE | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
| GAT | :heavy_check_mark: | :heavy_check_mark: | |
| JK-Net | :heavy_check_mark: | ||
| GaAN | :heavy_check_mark: | ||
| MixHop | :heavy_check_mark: | :heavy_check_mark: |
本仓库支持的图采样器如下:
| 采样器 | Tensorflow | PyTorch | C++ |
|---|---|---|---|
| 节点 | :heavy_check_mark: | :heavy_check_mark: | |
| 边 | :heavy_check_mark: | :heavy_check_mark: | |
| RW | :heavy_check_mark: | :heavy_check_mark: | |
| MRW | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
| 全图 | :heavy_check_mark: | :heavy_check_mark: |
其中:
- RW:随机游走采样器
- MRW:多维随机游走采样器
- 全图:始终返回完整的训练图,用作基线,实际上并未进行真正的采样。
您可以轻松添加自己的采样器和 GNN 层。详情请参阅【自定义】部分。
结果
新增:我们正在 Open Graph Benchmark 上测试 GraphSAINT。目前,我们已有 ogbn-products 图的数据结果。需要注意的是,排行榜上使用其他方法训练的 ogbn-products 准确率大多是在直推式设置下得出的。而我们的结果是在归纳式学习设置下得到的(归纳式学习难度更高)。
ICLR '20 中的所有结果都可以通过运行 ./train_config/ 中的配置文件来复现。例如,./train_config/table2/*.yml 存储了我们论文中表 2 的所有配置文件。./train_config/explore/*,yml 则存储了用于更深 GNN 和各种 GNN 架构(GAT、JK 等)的配置文件。此外,与 OGB 相关的结果是通过 ./train_config/open_graph_benchmark/*.yml 中的配置文件训练得到的。
测试集 F1-mic 分数汇总如下。
| 采样器 | 深度 | GNN | PPI | PPI (large) | Flickr | Yelp | Amazon | ogbn-products | |
|---|---|---|---|---|---|---|---|---|---|
| Node | 2 | SAGE | 0.960 | 0.507 | 0.962 | 0.641 | 0.782 | ||
| Edge | 2 | SAGE | 0.981 | 0.510 | 0.966 | 0.653 | 0.807 | ||
| RW | 2 | SAGE | 0.981 | 0.941 | 0.511 | 0.966 | 0.653 | 0.815 | |
| MRW | 2 | SAGE | 0.980 | 0.510 | 0.964 | 0.652 | 0.809 | ||
| RW | 5 | SAGE | 0.995 | ||||||
| Edge | 4 | JK | 0.970 | ||||||
| RW | 2 | GAT | 0.510 | 0.967 | 0.652 | 0.815 | |||
| RW | 2 | GaAN | 0.508 | 0.968 | 0.651 | ||||
| RW | 2 | MixHop | 0.967 | ||||||
| Edge | 3 | GAT | 0.8027 |
依赖项
- python >= 3.6.8
- tensorflow >=1.12.0 / pytorch >= 1.1.0
- cython >=0.29.2
- numpy >= 1.14.3
- scipy >= 1.1.0
- scikit-learn >= 0.19.1
- pyyaml >= 3.12
- g++ >= 5.4.0
- openmp >= 4.0
数据集
我们论文中使用的所有数据集均可下载:
- PPI
- PPI-large(PPI 的更大版本)
- Flickr
- Yelp
- Amazon
- ogbn-products
- ...(更多即将添加)
这些数据集可通过 Google Drive 链接 下载(或者通过 百度网盘链接(提取码:f1ao))。请将下载的文件夹重命名为根目录下的 data 文件夹。目录结构应如下所示:
GraphSAINT/
│ README.md
│ run_graphsaint.sh
│ ...
│
└───graphsaint/
│ │ globals.py
│ │ cython_sampler.pyx
│ │ ...
│ │
│ └───tensorflow_version/
│ │ │ train.py
│ │ │ model.py
│ │ │ ...
│ │
│ └───pytorch_version/
│ │ train.py
│ │ model.py
│ │ ...
│
└───data/
│ └───ppi/
│ │ │ adj_train.npz
│ │ │ adj_full.npz
│ │ │ ...
│ │
│ └───reddit/
│ │ │ ...
│ │
│ └───...
│
我们还提供了一个脚本,可以将我们的数据格式转换为 GraphSAGE 格式。要运行该脚本,
python convert.py <数据集名称>
例如,python convert.py ppi 会将 PPI 数据集转换为 GraphSAGE 格式,并保存到 ./data.ignore/ppi/。
新增:对于从 OGB 格式到 GraphSAINT 格式的转换,请使用 ./data/open_graph_benchmark/ogbn_converter.py 脚本。目前,该脚本可以处理 ogbn-products 和 ogbn-arxiv。
Cython 实现的并行图采样器
我们有一个需要编译的 Cython 模块,才能开始训练。请在根目录下运行以下命令来编译该模块:
python graphsaint/setup.py build_ext --inplace
训练配置
训练所需的超参数可以通过配置文件设置:./train_config/<name>.yml。
用于复现表 2 结果的配置文件已打包在 ./train_config/table2/ 中。
有关配置文件格式的详细说明,请参阅 ./train_config/README.md。
运行训练
首先,请编译 Cython 采样器(见上文)。
我们建议查看 ./graphsaint/globals.py 中定义的可用命令行参数(TensorFlow 和 PyTorch 版本共用)。通过正确设置这些标志,您可以最大化采样步骤中的 CPU 利用率(通过指定可用核心数量),选择日志文件的存放目录,并开启或关闭日志记录器(Tensorboard、Timeline 等)等。
注意:对于论文中比较的所有方法(GraphSAINT、GCN、GraphSAGE、FastGCN、S-GCN、AS-GCN、ClusterGCN),采样或聚类仅在训练过程中进行。为了获得验证集/测试集的准确率,我们会对整个图(包括训练、验证和测试节点)运行全批量 GNN,并仅针对验证/测试节点计算 F1 分数。详情请参阅 issue #11。
为简化实现,在验证/测试集评估时,我们使用完整的图邻接矩阵进行层传播。对于 Amazon 或 Yelp 数据集,这可能会导致某些 GPU 内存不足的问题。如果出现内存不足错误,请使用 --cpu_eval 标志强制在 CPU 上进行验证/测试集评估(而小批量训练仍将在 GPU 上进行)。其他标志说明如下。
要在 CPU 上运行代码
python -m graphsaint.<tensorflow/pytorch>_version.train --data_prefix ./data/<数据集名称> --train_config <train_config yml 路径> --gpu -1
要在 GPU 上运行代码
python -m graphsaint.<tensorflow/pytorch>_version.train --data_prefix ./data/<数据集名称> --train_config <train_config yml 路径> --gpu <GPU 编号>
例如,--gpu 0 表示在第一块 GPU 上运行。此外,还可以使用 --gpu <GPU 编号> --cpu_eval 来让 GPU 执行小批量训练,而 CPU 执行验证/测试评估。
我们还实现了双 GPU 训练以进一步加快运行速度。只需添加 --dualGPU 标志,并使用 --gpu 标志指定两块 GPU 即可。目前,此功能仅适用于支持显存池化且通过 NvLink 连接的 GPU。
新增:我们已准备了专门用于训练 OGB 图的脚本。相关脚本和说明请参阅 ./graphsaint/open_graph_benchmark/。
自定义
以下我们将介绍如何根据您的研究或产品需求自定义此代码库。
如何准备您自己的数据集?
假设您的完整图包含 N 个节点。每个节点有 C 个类别,以及长度为 F 的初始属性向量。如果您的训练/验证/测试划分比例为 a/b/c(即 a+b+c=1),则:
adj_full.npz:一个以 CSR 格式存储的稀疏矩阵,类型为 scipy.sparse.csr_matrix。其形状为 N×N。矩阵中的非零元素对应于完整图中的所有边。连接两节点的边是属于训练、验证还是测试节点并不重要。对于无权图,非零元素均为 1。
adj_train.npz:一个以 CSR 格式存储的稀疏矩阵,类型为 scipy.sparse.csr_matrix。其形状同样为 N×N。然而,矩阵中的非零元素仅对应于连接两个训练节点的边。图采样器只会从这个 adj_train 中选取节点和边,而不会从 adj_full 中选取。因此,在训练过程中既不会泄露属性信息,也不会泄露结构信息。另外请注意,只有 adj_train 中 aN 行和 aN 列包含非零元素。参见问题 #11。对于无权图,非零元素均为 1。
role.json:一个包含三个键的字典。键 'tr' 对应所有训练节点的索引列表,键 'va' 对应所有验证节点的索引列表,键 'te' 对应所有测试节点的索引列表。请注意,在原始数据中,节点可能具有字符串类型的 ID。您需要为节点重新分配数值 ID(0 至 N-1),以便能够通过索引访问邻接矩阵、特征矩阵和类别标签。
class_map.json:一个长度为 N 的字典。每个键是节点的索引,每个值要么是一个长度为 C 的二进制列表(用于多分类问题),要么是一个整数标量(0 至 C-1,用于单分类问题)。
feats.npy:一个形状为 N×F 的 numpy 数组。第 i 行对应节点 i 的属性向量。
如何添加您自己的采样器?
所有采样器都作为 GraphSampler 类的子类实现于 ./graphsaint/graph_samplers.py 文件中。您可以采用两种方式来实现自己的采样器子类:
- 使用纯 Python 实现。重写父类的
par_sample函数。我们在./graphsaint/graph_samplers.py文件中的NodeSamplingVanillaPython类中提供了一个基本示例。- 优点:易于实现
- 缺点:执行速度可能较慢。将纯 Python 函数并行化并非易事。
- 使用 Cython 实现。您需要在
./graphsaint/cython_sampler.pyx文件中添加一个Sampler类的子类。在该子类中,您只需重写__cinit__和sample函数。sample函数定义了采样器的顺序行为。我们会自动通过同时启动多个采样器来实现任务级并行化。- 优点:可融入并行执行框架,执行速度接近 C++ 级别。
- 缺点:编码难度较大。
如何支持您自己的 GNN 层?
在 ./graphsaint/<tensorflow 或 pytorch>_version/layers.py 文件中添加一层。此外,您还需要对 ./graphsaint/<tensorflow 或 pytorch>_version/models.py 文件中的 GraphSAINT 类的 __init__ 方法进行一些小的更新,以便模型能够根据 YAML 配置文件中的关键字查找正确的类。
引用与致谢
本研究得到 DARPA FA8750-17-C-0086 项目、NSF CCF-1919289 和 OAC-1911229 项目的资助。
我们感谢 Matthias Fey 在 PyTorch Geometric 库中提供的参考实现。
我们感谢 OGB 团队在大规模实验中使用 GraphSAINT。
- ICLR 2020:
@inproceedings{graphsaint-iclr20,
title={{GraphSAINT}: 基于图采样的归纳学习方法},
author={Hanqing Zeng 和 Hongkuan Zhou 和 Ajitesh Srivastava 和 Rajgopal Kannan 和 Viktor Prasanna},
booktitle={国际表征学习会议},
year={2020},
url={https://openreview.net/forum?id=BJe8pkHFwS}
}
- IEEE/IPDPS 2019:
@INPROCEEDINGS{graphsaint-ipdps19,
author={Hanqing Zeng 和 Hongkuan Zhou 和 Ajitesh Srivastava 和 Rajgopal Kannan 和 Viktor Prasanna},
booktitle={2019 年 IEEE 国际并行与分布式处理研讨会 (IPDPS)},
title={准确、高效且可扩展的图嵌入},
year={2019},
month={五月},
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
AutoGPT
AutoGPT 是一个旨在让每个人都能轻松使用和构建 AI 的强大平台,核心功能是帮助用户创建、部署和管理能够自动执行复杂任务的连续型 AI 智能体。它解决了传统 AI 应用中需要频繁人工干预、难以自动化长流程工作的痛点,让用户只需设定目标,AI 即可自主规划步骤、调用工具并持续运行直至完成任务。 无论是开发者、研究人员,还是希望提升工作效率的普通用户,都能从 AutoGPT 中受益。开发者可利用其低代码界面快速定制专属智能体;研究人员能基于开源架构探索多智能体协作机制;而非技术背景用户也可直接选用预置的智能体模板,立即投入实际工作场景。 AutoGPT 的技术亮点在于其模块化“积木式”工作流设计——用户通过连接功能块即可构建复杂逻辑,每个块负责单一动作,灵活且易于调试。同时,平台支持本地自托管与云端部署两种模式,兼顾数据隐私与使用便捷性。配合完善的文档和一键安装脚本,即使是初次接触的用户也能在几分钟内启动自己的第一个 AI 智能体。AutoGPT 正致力于降低 AI 应用门槛,让人人都能成为 AI 的创造者与受益者。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。