Awesome-Model-Merging-Methods-Theories-Applications
Awesome-Model-Merging-Methods-Theories-Applications 是一个专注于大语言模型(LLM)、多模态大模型及更广泛机器学习领域的“模型合并”技术资源库。它系统性地整理了相关的前沿论文、理论方法与应用案例,旨在填补该领域缺乏全面综述的空白。
在人工智能开发中,训练或微调大型模型往往需要昂贵的计算资源和原始数据。模型合并技术提供了一种高效的替代方案:无需重新训练或访问原始数据,仅通过整合多个现有模型的参数,即可创造出性能更强或功能更多样的新模型。本资源库正是为了帮助从业者深入理解并应用这一技术而生。
这里特别适合 AI 研究人员、算法工程师以及对模型优化感兴趣的开发者使用。其独特亮点在于构建了一套全新的分类体系,将合并方法细致划分为“合并前优化”(如权重对齐、子空间微调)、“合并中策略”(如动态路由、基于权重的合并)以及“理论基础分析”等多个维度。此外,资源库还特别标注了那些在 70 亿参数及以上规模模型中进行过实验验证的研究,为用户筛选高价值方案提供了直观参考。无论是希望降低算力成本,还是探索多任务学习、持续学习等应用场景,都能在这里找到系统的理论支持与实战指引。
使用场景
某 AI 初创团队急需构建一个既能精通医疗问诊又能处理法律条款的多功能大模型,但受限于算力预算无法从头训练。
没有 Awesome-Model-Merging-Methods-Theories-Applications 时
- 文献检索如大海捞针:团队需在 arXiv 上手动筛选数百篇论文,难以区分哪些方法适用于 7B 以上的大参数模型,极易遗漏关键前沿技术。
- 理论盲区导致试错成本高:缺乏对“权重对齐”或“子空间合并”等理论的系統梳理,工程师盲目尝试简单平均法,导致模型出现灾难性遗忘,能力相互抵消。
- 应用场景匹配困难:不清楚如何将合并技术具体落地到持续学习或多任务学习场景中,只能凭经验硬凑,开发周期被无限拉长。
- 复现基准缺失:找不到权威的评估基准和已验证的实验配置,每次调整超参数都像在“开盲盒”,资源浪费严重。
使用 Awesome-Model-Merging-Methods-Theories-Applications 后
- 精准锁定高价值方案:直接利用库中标记的"≥7B 模型”实验论文,快速定位到适合大模型的线性化微调或动态路由合并等高级方法。
- 理论指导规避陷阱:参考综述中关于锐度感知微调(Sharpness-aware Fine-tuning)的理论分析,预先优化单模型权重,成功避免了合并后的性能崩塌。
- 场景化落地路径清晰:依据库中整理的“多任务学习”与“少样本学习”应用案例,迅速设计出医疗与法律知识无损融合的技术路线。
- 复用成熟评估体系:直接采用推荐的 Benchmark 和评估指标,将原本数周的调优过程压缩至几天,显著提升了迭代效率。
Awesome-Model-Merging-Methods-Theories-Applications 通过提供系统化的方法论地图与实战指引,让团队在零数据重训的前提下,高效实现了多领域专家模型的低成本融合。
运行环境要求
未说明
未说明

快速开始
关于 “LLMs、MLLMs 及其扩展领域的模型合并:方法、理论、应用与机遇。ACM 计算综述,2026 年。” 的全面论文列表。
[!IMPORTANT] 欢迎贡献:
请通过 联系我们 或提交拉取请求,添加未列出的相关论文、内容澄清或分类调整;待您的论文被接收后,请及时更新相关信息。感谢!
💥 新闻 💥
摘要
模型合并是机器学习领域中一种高效的赋能技术,它无需收集原始训练数据,也无需高昂的计算成本。随着模型合并在各个领域的日益普及,全面理解现有的模型合并技术至关重要。然而,目前文献中缺乏对这些技术进行系统性、深入梳理的综述。为此,本综述全面概述了模型合并的方法与理论、其在不同领域和场景中的应用,以及未来的研究方向。具体而言,我们首先提出了一种新的分类方法,详尽地讨论了现有模型合并技术;其次,探讨了模型合并技术在大型语言模型、多模态大型语言模型以及持续学习、多任务学习、少样本学习等十余个机器学习子领域的应用;最后,我们指出了模型合并仍面临的挑战,并展望了未来的研究方向。
引用
如果您认为我们的论文或本资源有所帮助,请考虑引用以下内容:
@article{yang2026ModelMergingSurvey,
author = {Yang, Enneng and Shen, Li and Guo, Guibing and Wang, Xingwei and Cao, Xiaochun and Zhang, Jie and Tao, Dacheng},
title = {LLMs、MLLMs 及其扩展领域的模型合并:方法、理论、应用与机遇},
year = {2026},
issue_date = {2026年6月},
publisher = {计算机协会},
address = {美国纽约州纽约市},
volume = {58},
number = {8},
issn = {0360-0300},
url = {https://doi.org/10.1145/3787849},
doi = {10.1145/3787849},
journal = {ACM 计算综述},
month = feb,
articleno = {216},
numpages = {41}
}
谢谢!
框架
调查研究
| 论文标题 | 年份 | 会议/期刊 |
|---|---|---|
| 大语言模型时代的模型合并:方法、应用与未来方向 | 2026 | Arxiv |
| 通过模型合并扩展智能:综合综述 | 2025 | Arxiv |
| 通过模型融合 democratize AI:全面回顾与未来方向 | 2025 | Arxiv |
| 从任务特定模型到统一系统:模型合并方法综述 | 2025 | Arxiv |
| SoK:利用深度模型合并技术在损失景观中寻找共同点 | 2024 | Arxiv |
| LLMs、MLLMs 及其以外的模型合并:方法、理论、应用与机遇 | 2024 | Arxiv |
| 模型 MoErging 综述:为协作学习在专业专家之间进行回收与路由 | 2024 | Arxiv |
| 合并、集成与合作!大语言模型时代协作策略综述 | 2024 | Arxiv |
| 超越微调的学习:综述 | 2023 | Arxiv |
| 深度模型融合:综述 | 2023 | Arxiv |
基准测试/评估
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| crdt-merge | 2026 | Github | 基于 CRDT 的分布式模型合并,具有形式化的收敛保证。包含 25 种策略(SLERP、TIES、DARE、Fisher、进化等)。采用两层 OR-Set 架构,实现无冲突的多节点合并。 |
| 用于缓解社会偏见的模型合并算法实证调查 | 2025 | Arxiv | LLAMA-2-7B、LLAMA-3-8B、LLAMA-3.1-8B、QWEN2-7B |
| 大型语言模型中模型合并技术的系统性研究 | 2025 | Arxiv | Llama-3.2-3B-Instruct、Llama-3.1-8B-Instruct、Qwen3-4B、Qwen3-8B |
| FusionBench:深度模型融合的全面基准测试 | 2025 | JMLR | Mistral-7B-v0.1、MetaMath-Mistral-7B、dolphin-2.1-mistral-7b、speechless-code-mistral-7b-v1.0 |
| 迈向多层次模型协作中的性能一致性 | 2025 | ICCV | |
| 大型语言模型中的模型合并缩放规律 | 2025 | Arxiv | Qwen2.5 0.5、1.5、3、7、14、32、72B |
| FBMS:用于灵活贝叶斯模型选择和模型平均的 R 包 | 2025 | Arxiv | |
| 通过模型合并统一多模态大语言模型的能力与模态 | 2025 | Arxiv | Qwen2-VL-7B-Base、Vicuna-7B-v1.5 |
| MergeBench:领域专用 LLM 合并的基准测试 | 2025 | Arxiv | Llama-3.2-3B、Llama3.1-8B、Gemma-2-2B 和 Gemma-2-9B |
| Mergenetic:一个简单的进化式模型合并库 | 2025 | 系统演示 | Mistral-7B |
| RobustMerge:面向 MLLMs 的参数高效模型合并,具备方向鲁棒性 | 2025 | NeurIPS | LLaVA-v1.5-7B |
| 混合数据还是合并模型?通过模型合并平衡大型语言模型的有用性、诚实性和无害性 | 2025 | Arxiv | Llama-3-8B-Instruct、Mistral-7B-Instruct-v0.2 |
| 如何随时间合并您的多模态模型? | 2024 | Arxiv | |
| 混合数据还是合并模型?优化多样化的多任务学习 | 2024 | Arxiv | Aya 23 8B |
| 对大规模预训练模型中 Delta 参数编辑的统一视角 | 2024 | Arxiv | LLaMA3-8B-Instruct、Qwen2-7B-Instruct、Mistral-7B-Instruct-v0.3, |
| Model-GLUE:为野外大型模型动物园提供民主化的 LLM 扩展 | 2024 | NeurIPS 数据集与基准测试赛道 | Synthia-7B-v1.2、Llama-2-7b-evolcodealpaca、OpenHermes-7B、pygmalion-2-7b、Llama-2-7b-chat-hf、BeingWell_llama2_7b、MetaMath-7B-V1.0、vicuna-7b-v1.5、Platypus2-7B、GOAT-7B-Community、Llama-2-7b-WikiChat-fused、dolphin-llama2-7b、MetaMath-Llemma-7B、CodeLlama-7b-Instruct-hf、Magicoder-S-CL-7B、CrystalChat |
| 大规模模型合并的关键是什么? | 2024 | Arxiv | PaLM-2(1B、8B、24B、64B)、PaLM-2-IT(1B、8B、24B、64B) |
| 针对组合泛化能力的模型合并现实评估 | 2024 | Arxiv | |
| 为领域适应而微调大型语言模型:探索训练策略、缩放、模型合并及协同能力 | 2024 | Arxiv | Llama-3.1-8B、Mistral-7B-v0.3 |
| Arcee's MergeKit:大型语言模型合并工具包 | 2024 | Arxiv | Llama2-7B-Chat、Meditron-7B |
高级方法
合并前方法
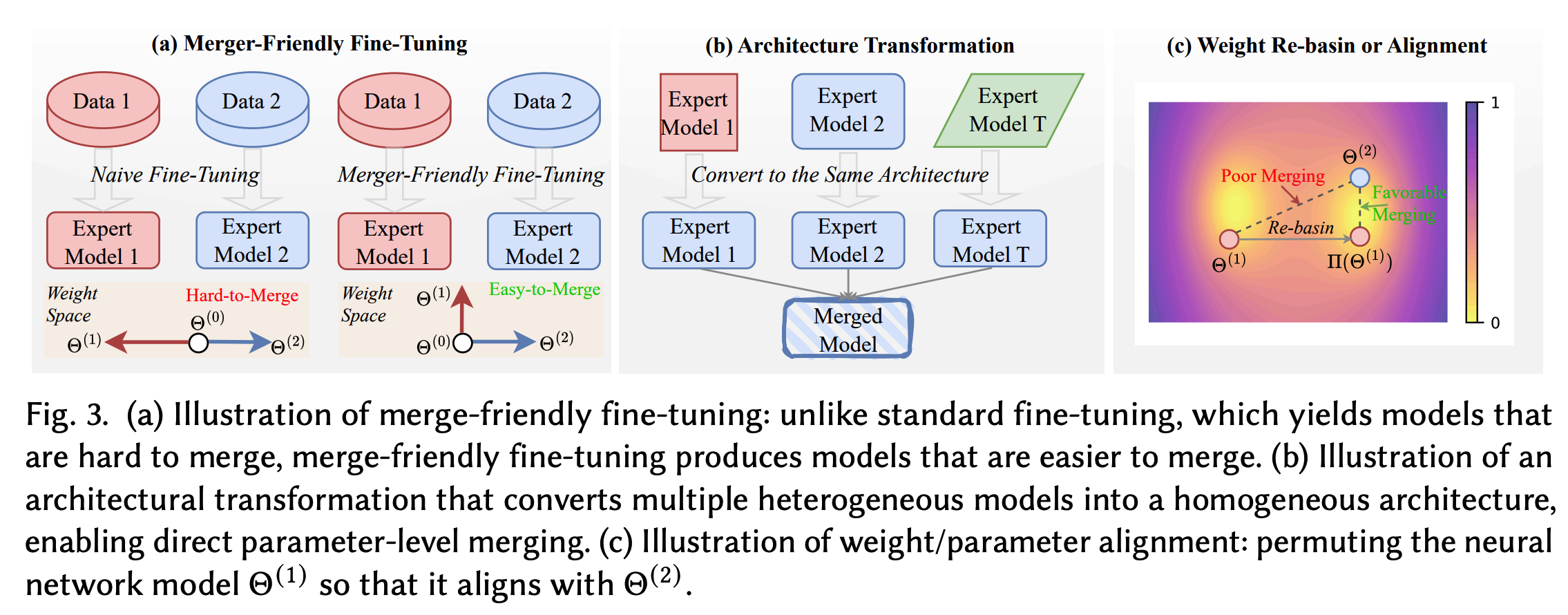
更好的微调
线性化微调
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 通过克罗内克分解近似曲率实现任务算术中的无数据权重解耦 | 2026 | ICLR | |
| 仅微调注意力模块:提升任务算术中的权重解耦 | 2025 | ICLR | |
| 切空间变换器用于组合、隐私和移除 | 2024 | ICLR | |
| 通过部分线性化实现参数高效的多任务模型融合 | 2024 | ICLR | |
| 切空间中的任务算术:改进预训练模型的编辑 | 2023 | NeurIPS |
子空间微调
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 解析LoRA干扰:用于稳健模型合并的正交子空间 | 2025 | Arxiv | Llama3-8B |
| 基于任务局部化稀疏微调的高效模型编辑 | 2025 | ICLR |
锐度感知微调
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 通过锐度感知微调缓解模型合并中的参数干扰 | 2025 | ICLR |
其他
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| MergOPT:一种面向稳健模型合并的合并感知优化器 | 2026 | ICLR | Llama3.1-8B-Instruct |
架构转换
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 异构层权重融合的模型组装学习 | 2025 | ICLR研讨会 | |
| 无需训练的异构模型合并 | 2025 | Arxiv | |
| 大型语言模型的知识融合 | 2024 | ICLR | Llama-2 7B、OpenLLaMA 7B、MPT 7B |
| 聊天型LLM的知识融合:初步技术报告 | 2024 | Arxiv | NH2-Mixtral-8x7B、NH2-Solar-10.7B以及OpenChat-3.5-7B |
| 关于异构神经网络模型融合的跨层对齐 | 2023 | ICASSP | |
| GAN鸡尾酒:无需数据集即可混合GAN | 2022 | ECCV |
权重对齐
合并方法概述
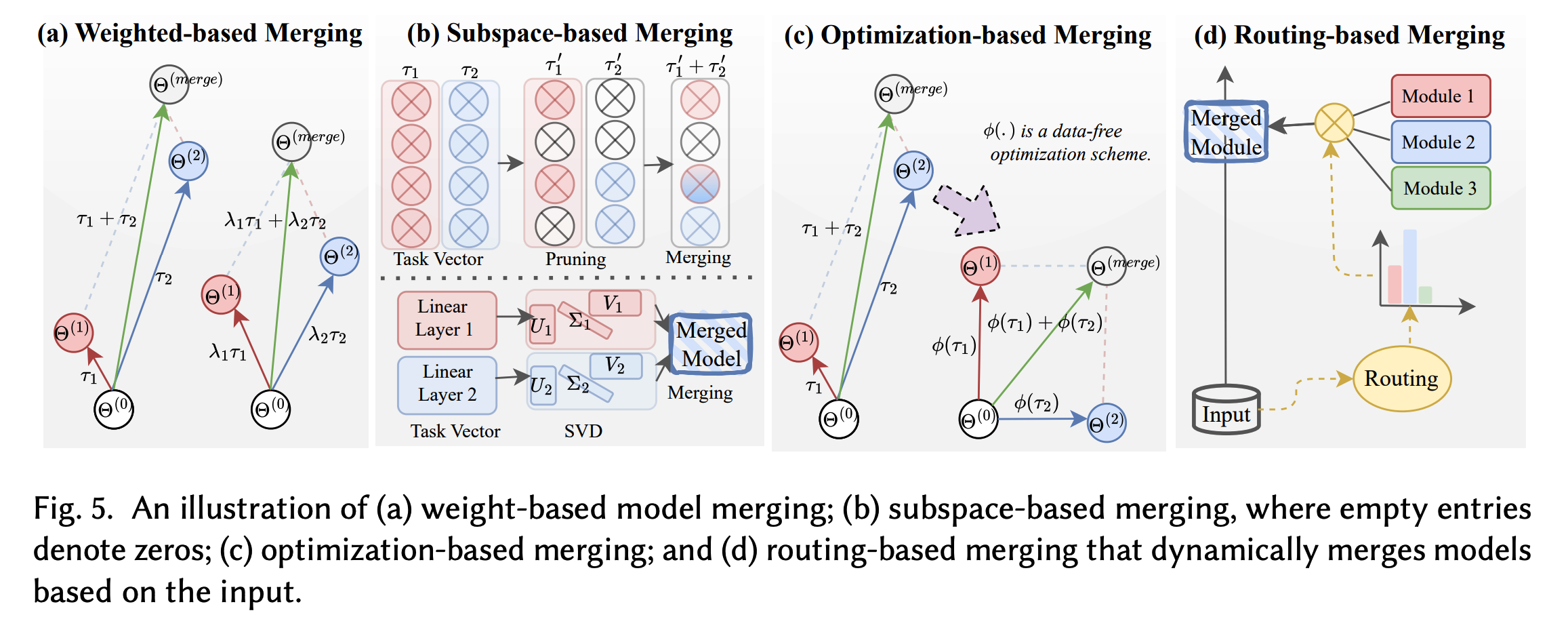
基本合并方法
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 利用算术运算组合参数高效的模块 | 2023 | NeurIPS | |
| 使用任务算术编辑模型 | 2023 | ICLR | |
| 基于最优传输的模型融合 | 2020 | NeurIPS | |
| 神经网络的权重平均及局部重采样方案 | 1996 | AAAI Workshop | |
| 通过平均加速随机逼近 | 1992 | IAM Journal on Control and Optimization | |
| 用四元数曲线实现旋转动画(球面线性插值(SLERP)模型合并) | 1985 | SIGGRAPH Computer Graphics |
基于加权的合并方法
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 无标签跨任务LoRA合并与零空间压缩 | 2026 | Arxiv | LLAMA-3 8B, LLAVA-1.5-7B |
| 均值是幻象:医学影像中异质领域迁移下的熵自适应模型合并 | 2026 | Arxiv | |
| LARV:用于模型合并的无数据逐层自适应缩放贴面 | 2026 | Arxiv | |
| Souper-Model:简单算术如何解锁最先进的LLM性能 | 2025 | Arxiv | xLAM-2-70b、CoALM-70B、watt-tool-70B、functionary-medium-70B、xLAM-2-8b、ToolACE-2-8B、watt-tool-8B、BitAgent-8B、CoALM-8B |
| 叠加任务特定特征进行模型合并 | 2025 | EMNLP | Llama-2-7B |
| T3:在VLM中进行测试时模型合并,用于零样本医学影像分析 | 2025 | Arxiv | |
| 权重编织:用于无数据模型合并的参数池化 | 2025 | Arxiv | |
| 专家合并:基于无监督专家对齐和重要性引导分层切块的模型合并 | 2025 | Arxiv | Mistral-7B、InternVL、Qwen2-VL |
| 变分任务向量组合 | 2025 | NeurIPS | |
| RegMean++:提升回归均值在模型合并中的有效性和泛化能力 | 2025 | Arxiv | |
| StatsMerging:通过任务特定教师蒸馏实现统计指导的模型合并 | 2025 | Arxiv | |
| SeMe:通过语义对齐实现无训练语言模型合并 | 2025 | Arxiv | |
| NAN:一种无需训练的模型合并系数估计解决方案 | 2025 | Arxiv | LLaMA2-13B、WizardLM-13B、WizardMath-13B、LLaVA-v1.5-13B、LLaVA-1.6-13B、Math-LLaVA |
| 利用子模块线性提高LLM中任务算术性能 | 2025 | ICLR | Llama-2-7B和Llama-2-13B |
| 层感知的任务算术:解耦任务特定与指令遵循知识 | 2025 | Arxiv | Gemma-2-9B、Llama-3-8B |
| Sens-Merging:基于敏感性引导的参数平衡用于大型语言模型合并 | 2025 | Arxiv | LLaMA-2 7B系列、Mistral 7B系列、LLaMA-2 13B系列 |
| RankMean:用于微调后大型语言模型合并的模块级重要性评分 | 2024 | ACL | |
| 非均匀逐参数模型合并 | 2024 | Arxiv | |
| 如何为多任务微调赋权?通过贝叶斯模型合并快速预览 | 2024 | Arxiv | |
| LiNeS:训练后层缩放防止遗忘并增强模型合并 | 2024 | Arxiv | |
| 瓶中合并:可微分适应性合并(DAM)以及从平均到自动化的路径 | 2024 | Arxiv | shisa-gamma-7b、WizardMath-7B-V1.1、Abel-7B-002、Llama-3-SauerkrautLM-8b-Instruct、Llama-3-Open-Ko-8B、llama-3-sqlcoder-8b、Meta-Llama-3-8B |
| 使用具有学习到各向异性缩放的任务向量进行知识组合 | 2024 | Arxiv | |
| MetaGPT:利用模型专属任务算术合并大型语言模型 | 2024 | EMNLP | LLaMA-2-7B、Mistral-7B、LLaMA-2-13B |
| 通过贝叶斯优化在LLM预训练中进行检查点合并 | 2024 | Arxiv | Baichuan2-220B、Baichuan2-440B、Baichuan2-660B、Baichuan2-1540B、Baichuan2-1760B、Baichuan2-1980B、Baichuan2-2200B、Baichuan2-2420B、DeepSeek-1400B、DeepSeek-1600B、DeepSeek-1800B、DeepSeek-2000B |
| Arcee’s MergeKit:大型语言模型合并工具包 | 2024 | Arxiv | Llama2-7B-Chat、Meditron-7B |
| 模型合并配方的进化优化 | 2024 | Arxiv | shisa-gamma-7b-v1、WizardMath-7B-V1.1、Arithmo2-Mistral-7B、Abel-7B-002、Mistral-7B-v0.1、LLaVA-1.6-Mistral-7B |
| XFT:通过简单合并升级版混合专家模型释放代码指令微调的力量 | 2024 | ACL | |
| AdaMerging:面向多任务学习的适应性模型合并 | 2024 | ICLR | |
| 基于不确定性梯度匹配的模型合并 | 2024 | ICLR | |
| 通过在任务子空间中匹配模型进行合并 | 2024 | TMLR | |
| 用于语言模型合并的费舍尔掩码节点 | 2024 | LREC-COLING | |
| 通过费舍尔平均进行纠删码神经网络推理 | 2024 | ISIT | |
| 通过合并语言模型权重实现无数据知识融合 | 2023 | ICLR | |
| 用费舍尔加权平均合并模型 | 2022 | NeurIPS |
基于子空间的合并方法(稀疏或低秩子空间)
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| Diet Your LLM: 通过合并任务特定重要性得分对大语言模型进行维度级全局剪枝 | 2026 | Arxiv | Gemma-2 9B, Qwen2.5-7B, Phi-4-mini |
| DC-Merge: 基于方向一致性的模型合并改进方法 | 2026 | CVPR | LLaVA |
| CoMoL: 基于动态核心空间合并的高效LoRA专家混合方法 | 2026 | Arxiv | Qwen3-8B 和 Llama3.1-8B |
| 本质子空间中的模型合并 | 2026 | Arxiv | |
| 超越参数算术:面向分布感知的稀疏互补融合用于模型合并 | 2026 | Arxiv | Mistral-7B、Qwen2.5-14B 和 Qwen2.5-32B |
| 正交模型合并 | 2026 | Arxiv | Llama-3.1-8B、Qwen2.5-VL-7B-Instruct、Llama-3.2-3B |
| 当共享知识成为负担:模型合并中的谱过累积问题 | 2026 | Arxiv | |
| 超越合并:基于激活引导旋转的流式大语言模型更新 | 2026 | Arxiv | Qwen2.5-7B、Qwen2.5-14B |
| AdaRank: 用于增强模型合并的自适应秩剪枝方法 | 2026 | ICLR | |
| 分解任务向量以实现精细化的模型编辑 | 2025 | Arxiv | |
| 保持独特,保持高效:在多任务合并中保留模型个性 | 2025 | Arxiv | Qwen-14B |
| 面向低秩权重的可逆模型合并 | 2025 | Arxiv | |
| 在知识感知子空间中净化任务向量以用于模型合并 | 2025 | Arxiv | LLaMA-2-7B |
| RobustMerge: 具有方向鲁棒性的参数高效多模态大语言模型合并方法 | 2025 | NeurIPS | LLaVA |
| 核心空间中精确高效的低秩模型合并 | 2025 | NeurIPS | |
| 通过模型合并实现高效的多源知识迁移 | 2025 | Arxiv | |
| 一刀切并不适用:面向分布的稀疏化技术以实现更精准的模型合并 | 2025 | Arxiv | |
| NegMerge: 基于符号共识的权重合并以支持机器去学习 | 2025 | ICML | |
| 子空间增强型模型合并 | 2025 | Arxiv | |
| 无需训练的大语言模型多任务学习合并 | 2025 | Arxiv | |
| 更智能地合并,更好地泛化:提升OOD数据上的模型合并性能 | 2025 | Arxiv | |
| 定位后合并:神经元级别的参数融合以缓解多模态大语言模型中的灾难性遗忘 | 2025 | Arxiv | Mistral-7B、Llama3-8B |
| CALM: 面向多任务学习的一致性感知局部合并方法 | 2025 | ICML | |
| 面向多目标领域适应的合并友好型后训练量化 | 2025 | ICML | |
| 结合参数剪枝的自适应LoRA合并以支持低资源生成 | 2025 | ACL | Llama-3-8B-Instruct |
| 分解-归一化-合并:在正确空间上进行模型合并可提升多任务处理能力 | 2025 | Arxiv | LLaMA3.1-8B |
| CAT合并:一种无需训练的解决模型合并冲突的方法 | 2025 | Arxiv | |
| LoRI: 减少多任务低秩适配中的跨任务干扰 | 2025 | Arxiv | Llama-3-8B 和 Mistral-7B |
| 任务向量量化以实现内存高效的模型合并 | 2025 | Arxiv | |
| 解耦神经元内的任务干扰:与神经机制对齐的模型合并 | 2025 | Arxiv | Llama-2-7b |
| 探索稀疏适配器以实现参数高效专家的可扩展合并 | 2025 | ICLR 2025 Workshop | |
| LEWIS(逐层稀疏)——一种无需训练的指导性模型合并方法 | 2025 | ICLR 2025 Workshop | Gemma-9b、LLaMA 3.1 8b |
| CABS: 冲突感知且平衡的稀疏化技术以提升模型合并效果 | 2025 | Arxiv | Mistral-7b-v0.1、WildMarcoroni-Variant1-7B 和 WestSeverus-7B-DPO-v2 |
| 面向多语种语音识别与翻译的低秩稀疏模型合并 | 2025 | Arxiv | |
| LED-合并:通过位置选举分离来缓解模型合并中的安全与效用冲突 | 2025 | Arxiv | Llama-3-8B、Mistral-7B 和 Llama2-13B |
| 面向多模态大型语言模型的参数高效合并及互补参数适配 | 2025 | Arxiv | |
| 最优脑迭代合并:缓解大语言模型合并中的干扰 | 2025 | Arxiv | Llama-2-13b、WizardMath-13B-V1.0、WizardLM13B-V1.2、llama-2-13b-codealpaca |
| 叠加奇异特征以进行模型合并 | 2025 | Arxiv | Llama-2-7B |
| STAR: 谱截断与重缩放用于模型合并 | 2025 | NAACL | Mistral-7B-Instruct |
| 不让任何任务掉队:结合通用与任务特定子空间的各向同性模型合并 | 2025 | Arxiv | |
| 无需再训练即可实时合并模型:一种用于可扩展持续模型合并的顺序方法 | 2025 | NeurIPS | |
| 将多任务模型合并建模为自适应投影梯度下降 | 2025 | Arxiv | |
| 重新审视用于模型合并的权重平均法 | 2024 | Arxiv | |
| 任务奇异向量:减少模型合并中的任务干扰 | 2025 | CVPR | |
| 少即是多:采用二值任务切换实现高效模型合并 | 2024 | Arxiv | |
| FREE-合并:利用傅里叶变换实现轻量级专家参与的模型合并 | 2024 | Arxiv | Qwen-14B (LoRA)、 LLaMa2-13B、WizardLM-13B、WizardMath-13B、WizardCoderPython-13B |
| 超越任务向量:基于重要性指标的选择性任务算术 | 2024 | Arxiv | |
| 用于模型合并的参数竞争平衡 | 2024 | NeurIPS | Llama-2-7b |
| 语言模型就像超级马里奥:从同源模型中免费吸收能力 | 2024 | ICML | WizardLM-13B、WizardMath-13B、llama-2-13b-codealpaca、Mistral-7B |
| 定位任务信息以改善模型合并与压缩 | 2024 | ICML | |
| 稀疏模型汤:通过模型平均实现更好剪枝的配方 | 2024 | ICLR | |
| 利用SVD进行模型合并以理清复杂关系 | 2024 | Arxiv | Llama3-8B |
| NegMerge: 基于共识的权重否定以实现强大的机器去学习 | 2024 | Arxiv | |
| 定位并拼接:通过稀疏任务算术实现高效模型合并 | 2024 | Arxiv | |
| 通过因果干预定位激活参数以进行模型合并 | 2024 | Arxiv | Llama-2-chat-7B |
| PAFT: 一种用于有效微调大语言模型的并行训练范式 | 2024 | Arxiv | Mistral-7B-v0.1、Llama-3-8B、Neurotic-7B、MoMo-70B |
| DELLA-合并:通过基于幅度的采样减少模型合并中的干扰 | 2024 | Arxiv | Llama-2-13b-code-alpaca、WizardLM、Wizard-Math、WizardCoder-Python |
| EMR-合并:无需调优的高性能模型合并 | 2024 | NeurIPS | |
| DPPA: 用于大语言模型到模型合并的剪枝方法 | 2024 | Arxiv | LLaMa 2 |
| 模型 breadcrumbs: 利用稀疏掩码实现多任务模型合并的规模化 | 2023 | Arxiv | |
| 基于具体子空间学习的干扰消除以实现多任务模型融合 | 2023 | Arxiv | |
| ComPEFT: 通过稀疏化和量化实现参数高效更新通信的压缩方法 | 2023 | Arxiv | LLaMA 7B、13B、33B 和 65B |
| 有效且参数高效的复用微调模型 | 2023 | Openreview | |
| 解决模型合并时的干扰问题 | 2023 | NeurIPS | |
| 微调语言模型中的任务特定技能定位 | 2023 | ICML |
基于路由的合并方法(动态合并)
校准后方法
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| MAGIC: 通过幅度校准实现卓越的模型合并 | 2025 | Arxiv | OLMo-3-7B |
| 迈向最小化模型合并中的特征漂移:用于自适应知识整合的逐层任务向量融合 | 2025 | NeurIPS | |
| 通过适应性合并进行多任务模型融合 | 2025 | ICASSP | |
| 在模型合并中使用概率建模进行表征手术 | 2025 | ICML | |
| 用于增强模型合并的参数高效干预 | 2024 | Arxiv | |
| 按任务为您的模型调色以改善多任务模型合并 | 2024 | Arxiv | |
| SurgeryV2: 通过深度表征手术弥合模型合并与多任务学习之间的差距 | 2024 | Arxiv | |
| 用于多任务模型合并的表征手术 | 2024 | ICML |
其他合并方法
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 任务对齐:计算机视觉中简单有效的模型合并代理 | 2026 | Arxiv | |
| 基于无数据协方差估计的模型合并 | 2026 | Arxiv | |
| 解决干扰(RI):解耦模型以改进模型合并 | 2026 | Arxiv | |
| BD-Merging:基于证据引导的对比学习的偏见感知动态模型合并 | 2026 | Arxiv | |
| ACE-Merging:自适应协方差估计的无数据模型合并 | 2026 | Arxiv | |
| 面向图神经网络的无训练跨架构合并 | 2026 | Arxiv | |
| 用于跨预训练模型传输任务向量的梯度符号掩码 | 2026 | ICLR | Flan-T5 |
| 在不同架构之间无训练地传输任务向量 | 2026 | Arxiv | |
| MergePipe:面向可扩展LLM合并的预算感知参数管理系统 | 2026 | Arxiv | Llama3.1-8B、Llama-3.2-3B、Qwen3-0.6B、Qwen3-1.7B和Qwen3-8B |
| DisTaC:通过蒸馏调节任务向量以实现稳健模型合并 | 2026 | ICLR | |
| 面向模型合并的稀疏性感知进化 | 2026 | Arxiv | |
| AutoMerge:基于搜索的有效模型复用框架 | 2026 | Arxiv | Llama2-7B-Chat、Llama2-7B-Code |
| 通过多教师知识蒸馏进行模型合并 | 2025 | Arxiv | |
| 通过动量感知优化连接训练与合并 | 2025 | Arxiv | |
| 从系数到方向:通过方向对齐重新思考模型合并 | 2025 | Arxiv | |
| 摆脱优化停滞:通过差异向量迈出超越任务算术的步伐 | 2025 | Arxiv | |
| 具有功能双重锚点的模型合并 | 2025 | Arxiv | |
| 面向拥有海量模型库的语言模型即服务的黑盒模型合并 | 2025 | Arxiv | |
| 通过合并链重新思考逐层模型合并 | 2025 | Arxiv | Llama 3-8B |
| 竞争与吸引促进模型融合 | 2025 | Arxiv | WizardMath 7B v1.0、AgentEvol 7B |
| PSO-Merging:基于粒子群优化的模型合并 | 2025 | Arxiv | Llama-3-8B、Llama-2-13B和Mistral-7B-v0.3 |
| DisTaC:通过蒸馏调节任务向量以实现稳健模型合并 | 2025 | Arxiv | |
| 通过灵活模型合并应对准确率与规模之间的权衡 | 2025 | Arxiv | |
| 高效多任务推理:基于Gromov-Wasserstein特征对齐的模型合并 | 2025 | Arxiv | |
| 强化模型合并 | 2025 | Arxiv | |
| FW-Merging:利用Frank-Wolfe优化扩展模型合并 | 2025 | Arxiv | LLaMA2-7B |
| 谁引发了干扰就该结束它:通过任务向量指导无数据模型合并 | 2025 | Arxiv | WizardLM-13B (语言模型)、WizardMath-13B (数学)和 llama-2-13b-codealpaca (代码) |
| GNNMERGE:无需访问训练数据即可合并GNN模型 | 2025 | Arxiv | |
| MERGE3:在消费级GPU上进行高效的进化式合并 | 2025 | ICML | Mistral-7B |
| 大型语言模型的激活信息驱动合并 | 2025 | Arxiv | Llama-2-13B、WizardLM-13B、WizardMath-13B、llama-2-13b-code-alpaca |
| 通过渐进式逐层蒸馏实现可扩展模型合并 | 2025 | Arxiv | WizardLM-13B、WizardMath-13B和llama-2-13b-code-alpaca |
| 好吧,我自己来合并:自动模型合并的多精度框架 | 2025 | Arxiv | Llama-2-13B、WizardLM13B、WizardMath-13B、llama-2-13b-code-alpaca |
| 信任区域内的任务算术:一种无训练的模型合并方法,用于应对知识冲突 | 2025 | ICLR | |
| 微调对齐分类器以合并输出:迈向更优的模型合并评估协议 | 2024 | Arxiv | |
| 通过自适应权重解耦进行多任务模型合并 | 2024 | Arxiv | |
| 重新思考加权平均模型合并 | 2024 | Arxiv | |
| ATM:通过交替调整与合并改进模型合并 | 2024 | Arxiv | |
| HM3:面向预训练模型的层次化多目标模型合并 | 2024 | Arxiv | Llama-2-7B-Chat、WizardMath-7B、CodeLlama-7B |
| 权重范围对齐:一种令人沮丧的简单模型合并方法 | 2024 | Arxiv | |
| 变形时刻:通过多目标优化释放多个LLM的潜力 | 2024 | Arxiv | Qwen1.5-7B-Chat、解放后的Qwen1.5-7B、firefly-qwen1.5-en-7B |
| 朝着在不同数据集之间实现数据高效且不降低性能的模型合并 | 2024 | JMLR | |
| SOLAR 10.7B:通过简单而有效的深度扩展规模化大型语言模型 | 2023 | Arxiv | SOLAR 10.7B、SOLAR 10.7B-Instruct |
模型合并的理论或分析
基础模型中模型合并的应用

大语言模型中的模型合并
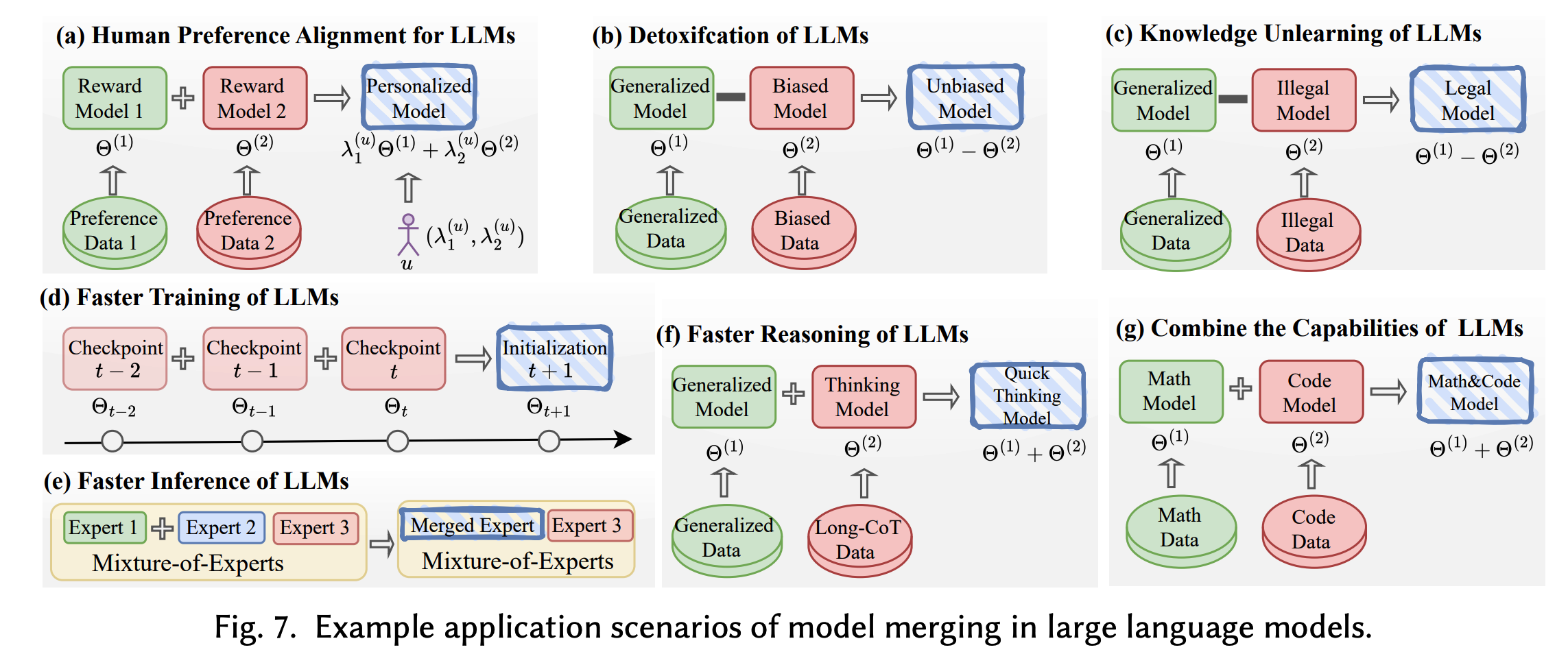
针对大语言模型的人类偏好对齐
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 导航对齐-校准权衡:通过模型合并实现帕累托最优边界 | 2025 | Arxiv | Gemma-3-12B、Gemma-3-27B、Qwen2.5-7B |
| BILLY:通过合并人格向量引导大型语言模型进行创意生成 | 2025 | Arxiv | Qwen-2.5-7B-Instruct、Llama-3.1-8B-Instruct |
| 人格向量:通过模型合并调节大型语言模型的人格特质 | 2025 | EMNLP | Llama-3.1-8B-Instruct、Qwen2.5-7B-Instruct |
| SafeMERGE:通过选择性逐层模型合并保持微调后LLM的安全对齐 | 2025 | Arxiv | Llama-2-7B-Chat、Qwen-2-7B-Instruct |
| 骨头汤:一种用于可控多目标生成的搜索与混合模型合并方法 | 2025 | Arxiv | LLaMA-2 7B |
| 更好的RLHF的模型汤:通过权重空间平均提升LLM的对齐效果 | 2024 | NeurIPS 2024 Workshop | Llama2-7B、Mistral-7B、Gemma-2B |
| 通过预训练和后训练模型合并保护微调后的LLM | 2024 | Arxiv | Llama-3-8B-Instruct |
| SafetyDPO:文本到图像生成的可扩展安全对齐方法 | 2024 | Arxiv | |
| H3Fusion:对齐LLM的有益、无害、诚实融合 | 2024 | Arxiv | LLaMA-2 7B |
| 百川对齐技术报告 | 2024 | Arxiv | Qwen2-Nova-72B、Llama3-PBM-Nova-70B |
| 条件化语言策略:一种可引导的多目标微调通用框架 | 2024 | Arxiv | |
| DogeRM:通过模型合并为奖励模型注入领域知识 | 2024 | Arxiv | MetaMath-7B、MAmmoTH-7B、LLaMA2-7B |
| PAFT:一种用于高效LLM微调的并行训练范式 | 2024 | Arxiv | Mistral-7B-v0.1、Llama-3-8B |
| 模型合并与安全对齐:一坏毁全局 | 2024 | Arxiv | Mistral-0.2-7B-Instruct、LLaMA-3-8B-Instruct、OpenBioLLM-8B、MAmmoTH2-7B、WizardMath-1.1-7B |
| 通过安全补丁实现大型语言模型全面的后期安全对齐 | 2024 | Arxiv | LLaMA-2-7B-Chat、LLaMA-3-8B-Instruct、Mistral7B-Instruct-v0.1和Gemma1.1-7B-it |
| 分散后再合并:通过降低对齐税来突破指令微调的极限 | 2024 | Arxiv | Llama-2-7b |
| 在线合并优化器:通过奖励提升和对齐中的税收缓解 | 2024 | Arxiv | Qwen1.5-7B、LLaMa3-8B |
| 基于子空间导向的模型融合的大语言模型安全再对齐框架 | 2024 | Arxiv | WizardLM-7B |
| 弱到强的外推加速对齐 | 2024 | Arxiv | zephyr-7b、starling-7b、snorkel-7b、llama3-8b、internlm2-7b、internlm2-20b、tulu-2-dpo-7b、tulu-2-dpo-13b、tulu-2-dpo-70b |
| 语言模型就是荷马·辛普森!通过任务算术对微调后的语言模型进行安全再对齐 | 2024 | Arxiv | Llama-2-7BChat |
| 奖励汤:通过插值在不同奖励上微调的权重实现帕累托最优对齐 | 2023 | NeurIPS | LLaMA-7b |
| 个性化汤:通过事后参数合并实现个性化大型语言模型对齐 | 2023 | Arxiv | Tulu-7B LM |
LLM的去毒化
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 手术式、廉价且灵活:通过单向量消融缓解语言模型的虚假拒绝 | 2025 | ICLR | GEMMA-7B-IT、LLAMA2-7B/13B/70B-CHAT、LLAMA3-8B-INST |
| 3DM:蒸馏、动态剔除与合并,用于去偏见的多模态大型语言模型 | 2025 | ACL | LLaVA-1.5-7b、InternVL-2.5-8b、LLaVA-1.5-7b和ChatGLM4-9b |
| 扩展后再推理:通过提前层间插值得以增强大型语言模型的事实性 | 2025 | Arxiv | LLAMA3-8B-Instruct、Mistral-7B-Instruct-v0.2 |
| 偏见向量:用任务算术方法缓解语言模型中的偏见 | 2024 | Arxiv | |
| 去芜存菁:通过参数高效的模块操作实现模型缺陷的遗忘 | 2024 | AAAI | LLaMA-7B |
| 通过遗忘机制缓解语言模型的社会偏见 | 2024 | Arxiv | LLaMA-2 7B |
| 基于实例级前缀的细粒度去毒化大型语言模型 | 2024 | Arxiv | Llama-2-7B、Llama-2-chat-7B、Vicuna-7B、Llama-2-13B |
| 用算术运算组合参数高效的模块 | 2023 | NeurIPS | |
| 用任务算术编辑模型 | 2023 | ICLR | |
| 弹性权重移除用于忠实而抽象的对话生成 | 2023 | Arxiv |
LLM的知识编辑/遗忘
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 用于大型语言模型去训练的逐参数任务算术 | 2026 | Arxiv | Llama3.2 1B Instruct |
| 用于知识编辑的模型合并 | 2025 | ACL | Qwen2.5-7B-Instruct |
| 通过大规模模型合并实现微调数据的精确去训练 | 2025 | Arxiv | |
| ZJUKLAB在SemEval-2025任务4中的表现:通过模型合并进行去训练 | 2025 | Arxiv | OLMo-7B-0724-Instruct |
| 通过大规模模型合并实现微调数据的精确去训练 | 2025 | ICLR 2025 Workshop MCDC | |
| NegMerge:用于强大机器去训练的一致性权重否定 | 2024 | Arxiv | |
| 拆分、去训练、合并:利用数据属性提升LLM中去训练的有效性 | 2024 | Arxiv | ZEPHYR-7B-BETA, LLAMA2-7B |
| 通过机器去训练迈向更安全的大型语言模型 | 2024 | ACL | LLAMA2-7B, LLAMA2-13B |
| 使用任务算术编辑模型 | 2023 | ICLR | |
| 先遗忘后学习:利用参数算术更新大型语言模型中的知识 | 2023 | Arxiv | LLAMA2-7B, LLAMA-7B, BLOOM-7B |
| 融合以遗忘:通过模型融合减少偏见并实现选择性记忆 | 2023 | Arxiv |
加快LLM的训练速度
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 混搭学习:通过重混过往检查点加速微调 | 2026 | Arxiv | |
| GTR-Turbo:合并后的检查点实际上是代理式VLM训练的免费教师 | 2025 | Arxiv | Qwen2.5-VL-7B |
| 专家之汤:通过参数平均预训练专家模型 | 2025 | ICML | |
| 局部混合专家:通过模型合并实现几乎免费的测试时训练 | 2025 | Arxiv | |
| 合并以混合:通过模型合并混合数据集 | 2025 | Arxiv | Llama-3-8B-Instruct |
| 大型语言模型预训练中的模型合并 | 2025 | Arxiv | Seed-MoE-1.3B/13B, SeedMoE-10B/100B, Seed-MoE-15B/150B |
| 基于指标加权平均的参数高效检查点合并 | 2025 | Arxiv | |
| DEM:用于混合数据分布训练的分布编辑模型 | 2024 | Arxiv | OpenLLaMA 7B和13B |
| LLM预训练中基于贝叶斯优化的检查点合并 | 2024 | Arxiv | Baichuan2-220B, Baichuan2-440B, Baichuan2-660B, Baichuan2-1540B, Baichuan2-1760B, Baichuan2-1980B, Baichuan2-2200B, Baichuan2-2420B, DeepSeek-1400B, DeepSeek-1600B, DeepSeek-1800B, DeepSeek-2000B |
| ColD融合:分布式多任务微调的协作下降 | 2023 | ACL | |
| 早期权重平均结合高学习率用于LLM预训练 | 2023 | NeurIPS Workshop | |
| 别再浪费我的时间了!用最新的权重平均节省Imagenet和BERT训练的数天时间 | 2022 | NeurIPS Workshop | |
| 融合微调过的模型以改善预训练 | 2022 | Arxiv |
提高LLM的推理速度
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 多目标进化合并实现高效推理模型 | 2026 | Arxiv | DeepSeek-R1-Distill-Qwen 1.5B、7B和14B |
| 基于费舍尔信息的无数据层适应性合并,适用于长短期推理的LLM | 2026 | Arxiv | Qwen2.5-Math-7B,DeepSeek-R1-Distill-Qwen-7B |
| RAIN-合并:一种无需梯度的方法,可在保持思维格式的同时增强大型推理模型的指令遵循能力 | 2026 | ICLR | Qwen2.5-1.5B/14B/32B, 和 Llama-3.1-8B |
| 推理模式对齐合并以实现自适应推理 | 2026 | Arxiv | (i) Qwen3-4B-Thinking (Long-CoT) 和 Qwen3-4B-Instruct (Short-CoT); (ii) DeepSeekR1-Distill-Qwen-1.5B (Long-CoT) 和 Qwen2.5- Math-1.5B (Short-CoT) |
| 重新审视模型插值以实现高效推理 | 2025 | Arxiv | Qwen3-4B |
| 通过模型合并解锁高效长短期LLM推理 | 2025 | Arxiv | Qwen2.5-32B, DeepSeek-R1-32B |
| Kimi k1.5:利用LLM扩展强化学习 | 2025 | Arxiv | Kimi k1.5 |
提升基于MoE的LLM的计算效率
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| REAM: 融合提升大模型专家剪枝效果 | 2026 | Arxiv | Qwen3-30B-A3B-Instruct-2507, Qwen3-Coder-Next, GLM-4.5-Air |
| 用于缓解奖励欺骗的再利用与融合MoE奖励模型 | 2025 | Arxiv | |
| PuzzleMoE: 基于稀疏专家融合与位打包推理的大规模混合专家模型高效压缩 | 2025 | Arxiv | Mixtral-8x7B, Deepseek-MoE |
| 图基础模型中混合专家结构的增强型专家融合 | 2025 | Arxiv | LLaMA-3.1-8B |
| 基于纳什讨价还价的稀疏混合专家中的专家融合 | 2025 | Arxiv | Qwen1.5-MoE-14B, DeepSeek-MoE-16B |
| MergeMoE: 通过专家输出融合实现MoE模型高效压缩 | 2025 | Arxiv | DeepSeekMoE, Qwen1.5-MoE-A2.7B, 和 Qwen3-30B-A3B |
| 更快、更小、更智能:面向在线MoE推理的任务感知专家融合 | 2025 | Arxiv | |
| Sub-MoE: 基于子空间专家融合的高效混合专家LLM压缩 | 2025 | Arxiv | Mixtral 8x7B, Qwen3- 235B-A22B, Qwen1.5-MoE-A2.7B, 和 DeepSeekMoE-16B-Base |
| 关于混合专家架构的线性模式连通性 | 2025 | NeurIPS | |
| 先融合,再压缩:从路由策略中揭示高效SMoe的秘密 | 2024 | ICLR | fairseq-moe15b SMoE |
| 将专家合并为一:提升混合专家的计算效率 | 2023 | EMNLP |
通过模型融合混合数据集
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| OPTIMER: 对于持续预训练而言,最优分布向量融合优于数据混合 | 2026 | Arxiv | Gemma 3 27B |
| 线性模型融合解锁简单且可扩展的多模态数据混合优化 | 2026 | Arxiv | Qwen2-VL-2B 和 Intern3.5-VL-2B |
| 将搜索与训练解耦:通过模型融合规模化大型语言模型预训练的数据混合 | 2026 | Arxiv | Qwen3-1.7B |
| 多任务代码LLM:数据混合还是模型融合? | 2026 | Arxiv | Qwen Coder 2.5 7B, DeepSeek 7B |
| MergeMix: 基于可学习模型融合优化训练中期数据混合 | 2026 | Arxiv | 8B 和 16B MoE |
| 合并以混合:通过模型融合混合数据集 | 2025 | Arxiv | Llama-3-8B-Instruct |
LLM代理融合
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 强化学习驱动的代理模型中的行为知识融合 | 2026 | Arxiv | RL训练的代理模型 |
| ARM: 基于角色条件的神经元移植,实现无需训练的一般化LLM代理融合 | 2026 | Arxiv | Simia-Tau-SFT-Qwen3-8B, SimiaOfficeBench-SFT-Qwen3-8B, 和 Simia-AgentBench-SFT-Qwen3-8B |
| 划分、优化、融合:面向LLM代理的可扩展细粒度生成式优化 | 2025 | EMNLP | o3-mini |
| AgentMerge: 提升微调后LLM代理的泛化能力) | 2024 | NeurIPS | Llama3.1-8B |
| 通过CycleQD实现大型语言模型的代理技能获取 | 2024 | Arxiv | Llama3-8B-Instruct |
结合专家LLM的能力
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 合并与征服:通过添加目标语言权重指导多语言模型 | 2026 | Arxiv | Llama 3.1 8B、Qwen3 8B、Qwen3 14B |
| 偏好对齐的LoRA合并:保持子空间覆盖并解决方向各向异性 | 2026 | Arxiv | LLaMA-3-8B |
| 无标签跨任务LoRA合并与零空间压缩 | 2026 | Arxiv | LLAMA-3 8B、LLAVA-1.5-7B |
| AdaLTM:自适应逐层任务向量合并,用于结合ASR知识的分类语音情感识别 | 2026 | Arxiv | |
| 基于Fisher–Rao流形的功能导向LLM合并 | 2026 | Arxiv | Qwen2.5-14B、Qwen2.5-14B-Instruct-1M、Qwen2.5-Coder-14B-Instruct、DeepSeek-R1-Distill-Qwen-14B、OpenReasoning-Nemotron-14B |
| 自适应合并下LoRA复用的吸引力与现实 | 2026 | Arxiv | Llama3.1 8B-Instruct |
| LS-Merge:在隐空间中合并语言模型 | 2026 | ICLR | Gemma-3-1B-it、Gemma-3-4B-it、Llama-3-1B-instruct、Llama-2-7b |
| 基于Bagging的模型合并用于鲁棒的通用文本嵌入 | 2026 | Arxiv | Qwen3-4B |
| 面向设备端大型语言模型的适配器数据驱动聚类与合并 | 2026 | Arxiv | Llama 3.2 3B、Qwen 2.5 1.5B和StableLM 2 1.6B |
| 通过特定语言模型合并提高训练效率、降低维护成本 | 2026 | Arxiv | Llama-3.1-8b-Instruct |
| SimMerge:从相似性信号中学习选择合并算子 | 2026 | Arxiv | 7B至111B |
| 多阶段进化式模型合并与元数据驱动课程学习,用于情感专用大型语言建模 | 2026 | Arxiv | |
| ReasonAny:通过简单有效的模型合并将推理能力融入任何模型 | 2026 | Arxiv | QwQ-32B-Preview、Meditron3-Qwen2.5-7B和MMed-Llama3-8B、WiroAIFinance-Qwen-7B和WiroAI-Finance-Llama8B |
| 通过模型合并可靠地保存多语言LLM中的文化知识 | 2025 | Arxiv | Qwen-2.5-3B |
| AlignMerge——基于Fisher引导的几何约束实现对齐保留的大语言模型合并 | 2025 | Arxiv | LLaMA-3 8B、Mistral 7B、Qwen 2、Phi-3.5、Gemma 2 |
| 成长与合并:高效语言适配的扩展策略 | 2025 | Arxiv | |
| 仅使用目标未标注语言数据调整聊天语言模型 | 2025 | TMLR | Qwen2.5 7B、Llama 3.1 8B、Qwen3 14B |
| RCP-Merging:以推理能力为先验,将长链式思维模型与领域特定模型合并 | 2026 | AAAI | Qwen2.5-7B、Llama3.1-8B |
| Souper-Model:简单算术如何解锁最先进的LLM性能 | 2025 | Arxiv | xLAM-2-70b、CoALM-70B、watt-tool-70B、functionary-medium-70B、xLAM-2-8b、ToolACE-2-8B、watt-tool-8B、BitAgent-8B、CoALM-8B |
| SPEAR-MM:通过模型合并进行参数选择性评估与恢复,以实现高效的金融LLM适配 | 2025 | Arxiv | |
| 为领域专用LLM合并持续预训练模型:以金融为例 | 2025 | Arxiv | Llama-3-8B、Llama-2-7B |
| 提取并组合能力,构建多语言增强型大型语言模型 | 2025 | EMNLP | LLaMA-3 8B |
| 通过模型合并弥合阿拉伯语医学LLM中的方言差距 | 2025 | arabicnlp | |
| 通过模型合并使多语言模型适应代码混合任务 | 2025 | Arxiv | |
| 协调多样模型:用于一致性生成的逐层合并策略 | 2025 | Arxiv | Llama-3.1-8B-Instruct和Gemma-3-12B-Instruct |
| ABC:通过模型合并迈向通用代码样式器 | 2025 | ACM关于编程语言的会议 | Qwen2.5-Coder、Deepseek-Coder |
| 家庭事务:语言迁移与合并,以使小型LLM适应法罗语 | 2025 | Arxiv | |
| 专家合并:无监督专家对齐与重要性引导的分层切块进行模型合并 | 2025 | Arxiv | Mistral-7B、InternVL、Qwen2-VL |
| 思考光谱:通过模型合并对LLM可调推理能力的实证研究 | 2025 | Arxiv | Qwen3-30B-A3B-Thinking-2507、Qwen3-30B-A3B-Instruct-2507 |
| MLM:多语言LoRA合并 2025 | NeurIPS WorkShop | LLaMA-3.2 (1B和3B) | |
| 大型语言模型中的模型合并缩放规律 | 2025 | Arxiv | Qwen2.5 0.5、1.5、3、7、14、32、72B |
| 利用优化动力学进行曲率感知的模型合并 | 2025 | Arxiv | Llama-3.1-8B |
| Kwai Keye-VL 1.5技术报告 | 2025 | Arxiv | Keye-VL-8B |
| 推理向量:通过任务算术转移链式思维能力 | 2025 | Arxiv | QWEN2.5-7B |
| 用于模型合并优化的替代基准 | 2025 | Arxiv | EvoLLM-JP-v1-7B、shisa-gamma-7b-v1 |
| 张量化聚类LoRA合并用于多任务干扰 | 2025 | Arxiv | Mistral-7B |
| 设备端大型语言模型的高效组合式多任务处理 | 2025 | Arxiv | Llama 3.1 70B |
| HydraOpt:导航适配器合并的效率与性能权衡 | 2025 | Arxiv | |
| 探索稀疏适配器以实现参数高效专家的可扩展合并 | 2025 | Arxiv | |
| 为增强代码生成而合并大型语言模型:跨编程语言的模型合并技术比较研究 | 2025 | DiVA开放获取 | CodeQwen1.5-7B、DeepSeek-Coder-6.7b-Base、CodeLlama-34B |
| 关于任务算术公平性的探讨:任务向量的作用 | 2025 | Arxiv | LLaMA2-7B |
| 模型合并对于LLM跨语言迁移的不可思议有效性 | 2025 | Arxiv | FALCON 3 7B、QWEN2.5 7B Instruct、LLAMA 3.1 8B Instruct、AYA Expanse 8B |
| 模型合并竟然是可认证的:低样本学习的非空泛化界 | 2025 | Arxiv | MetaMath-Mistral-7B、Dolphin-2.1-Mistral-7B和Speechless-Code-Mistral-7Bv1.0 |
| 无需训练的LLM合并用于多任务学习 | 2025 | ACL | Echelon-AI/Med-Qwen2-7B、shtdbb/qwen2-7b-med、Qwen2-Instruct |
| ParamΔ用于直接权重混合:零成本的训后大型语言模型 | 2025 | Arxiv | Llama3-inst-70B、Llama3-base-70B、Llama3.1-base-70B |
| 超越“啊哈!”:迈向大型推理模型中系统性的元能力对齐 | 2025 | Arxiv | Qwen2.5-7B、Qwen2.5-32B |
| 统一的多任务学习与模型融合,用于高效的语言模型护栏 | 2025 | Arxiv | |
| 通过模型合并,一天内将特定语言LLM适配为推理模型——一份公开配方 | 2025 | Arxiv | Typhoon2 R1 70B、Deepseek R1 70B |
| 通过微调迁移实现高效模型开发 | 2025 | Arxiv | Llama 3.1 8B |
| Command A:一款企业级大型语言模型 | 2025 | Arxiv | Command R7B |
| 外推合并:借助外推与合并不断改进 | 2025 | Arxiv | Qwen2-7B、Meta-Llama-3-8B、Mistral-Nemo-Base-2407-12B、Qwen1.5-14B |
| Light-R1:从头开始及更进一步的长期COT课程SFT、DPO和RL | 2025 | Arxiv | Light-R1-32B |
| FuseChat-3.0:偏好优化遇上异构模型融合 | 2025 | Arxiv | Gemma-2-27B-it、Mistral-Large-Instruct-2407、Qwen-2.5-72B-Instruct以及Llama-3.1-70B-Instruct |
| 表面自我提升的推理者受益于模型合并 | 2025 | Arxiv | Llama2-7B |
| 受自然启发的大语言模型群体进化 | 2025 | Arxiv | |
| 层次感知的任务算术:解耦任务特异性和指令遵循知识 | 2025 | Arxiv | Gemma-2-9B、Llama-3-8B |
| Mixup模型合并:通过随机线性插值提升模型合并性能 | 2025 | Arxiv | WizardLM-13B、WizardMath-13B、llama-2-13b-code-alpaca |
| LoRE-Merging:探索低秩估计用于大型语言模型合并 | 2025 | Arxiv | NuminaMath-7B、DeepSeek-Math-7B-Base、LLaMA系列模型、WizardMath-13B |
| 语言与领域特定模型的合并:对技术词汇习得的影响 | 2025 | Arxiv | ContactDoctor-8B |
| 通过模型合并将文本偏好转移到视觉-语言理解 | 2025 | Arxiv | Llama-3.2-11B-Vision -Instruct、Llama-3.1-Tulu-2-8B-uf-mean-rm、Llama-3.1-Tulu-3-8B-RM |
| 最佳脑迭代合并:缓解LLM合并中的干扰 | 2025 | Arxiv | Llama-2-13b、WizardMath-13B-V1.0、WizardLM13B-V1.2、llama-2-13b-codealpaca |
| 一份公开配方:通过模型合并一天内将特定语言LLM适配为推理模型 | 2025 | Arxiv | Typhoon2 70B Instruct、DeepSeek R1 70B Distill、Llama 3.1 70B、Llama 3.3 70B |
| 好吧,我自己来合并:一个用于自动化模型合并的多保真度框架 | 2025 | Arxiv | WizardLM-13B、WizardMath-13B以及llama-2-13b-code-alpaca |
| 参数空间中的技能扩展与组合 | 2025 | Arxiv | |
| InfiFusion:通过LLM融合实现增强跨模型推理的统一框架 | 2025 | Arxiv | Qwen2.5-Coder-14B-Instruct、Qwen2.5-14B-Instruct以及Mistral-Small-24B-Instruct-2501 |
| 通道合并:为合并后的专家保留专长 | 2025 | AAAI | Dolphin-2.2.1-Mistral-7B、Speechless-Code-Mistral-7B、MetaMathMistral-7B、Chinese-Mistral-7BInstruct-v0.1 |
| 加权奖励偏好优化用于隐式模型融合 | 2025 | ICLR | LLaMA3-8B-Instruct |
| 通过免训练融合提升多模态LLM的感知能力 | 2024 | Arxiv | MiniGemini-8B和SLIME-8B |
| AgentMerge:提升微调LLM代理的泛化能力 | 2024 | Arxiv | Llama3.1-8B |
| JRadiEvo:一种通过模型合并进化优化增强的日本放射科报告生成模型 | 2024 | Arxiv | Bunny-v1_1-Llama-3-8B-V、MMed-Llama-3-8B-EnIns、OpenBioLLM-Llama3-8B、Llama-3-Swallow-8B-Instruct-v0.1 |
| 如果不能使用它们,就回收利用:规模化合并优化可缓解性能权衡 | 2024 | Arxiv | Command R+ 104B |
| 通过CycleQD为大型语言模型获取代理技能 | 2024 | Arxiv | Llama3-8B-Instruct |
| 协作式向LLM添加新知识 | 2024 | Arxiv | Meta-Llama-3-8B |
| 不受约束的模型合并用于增强LLM的推理能力 | 2024 | Arxiv | CodeLlama-7B-Ins、CodeLlama-70B-Ins、Deepseek-Coder-Ins-v1.5、Qwen2.5-Math-7B-Ins、WizardMath-7B-V1.1、OpenMath-Mistral 7B、MetaMath-7B、MetaMath-70B |
| LoRA浓汤:为实际技能组合任务合并LoRA | 2024 | Arxiv | Llama-7b、Llama2-7b-chat |
| 合并以学习:通过模型合并高效地为语言模型添加技能 | 2024 | Arxiv | Llama 2 7B |
| 探索模型亲缘关系以合并大型语言模型 | 2024 | Arxiv | Mistral-7B、Mistral-7b-instruct-v0.2、MetaMath-mistral-7b、Open-chat-3.5-1210 |
| 瓶中合并:可微分自适应合并(DAM)以及从平均到自动化的路径 | 2024 | Arxiv | shisa-gamma-7b、WizardMath-7B-V1.1、Abel-7B-002、Llama-3-SauerkrautLM-8b-Instruct、Llama-3-Open-Ko-8B、llama-3-sqlcoder-8b、Meta-Llama-3-8B |
| 层交换用于大型语言模型的零样本跨语言迁移 | 2024 | Arxiv | LLAMA 3.1 8B |
| 规模化模型合并的关键是什么? | 2024 | Arxiv | PaLM-2(1B、8B、24B、64B)、PaLM-2-IT(1B、8B、24B、64B) |
| HM3:针对预训练模型的层次化多目标模型合并 | 2024 | Arxiv | Llama-2-7B-Chat、WizardMath-7B、CodeLlama-7B |
| FUSECHAT:聊天模型的知识融合 | 2024 | Arxiv | OpenChat-3.5-7B、Starling-LM-7B-alpha、NH2-SOLAR-10.7B、InternLM2-Chat-20B、Mixtral-8x7B-Instruct以及Qwen-1.5-Chat-72B |
| SQL-GEN:通过合成数据和模型合并弥合文本转SQL的方言鸿沟 | 2024 | Arxiv | CodeLlama 7B |
| 变形时刻:通过多目标优化释放多个LLM的潜力 | 2024 | Arxiv | Qwen1.5-7B-Chat、解放的Qwen1.5-7B、firefly-qwen1.5-en-7B |
| 通过演化语言模型权重进行知识融合 | 2024 | ACL | |
| LLM合并:通过合并高效构建LLM | 2024 | NeurIPS 2024竞赛赛道 | LLaMA-7B、Mistral-7B、Gemma-7B |
| 通过权重解耦将模型合并从微调扩展到预训练大型语言模型 | 2024 | Arxiv | Qwen1.5-7B、Qwen1.5-Chat-7B、Sailor-7B、Qwen1.5-14B、Qwen1.5-Chat-14B、Sailor-14B、WizardLM-13B、WizardMath-13B、llama-2-13b-code-alpaca |
| 变形时刻:通过多目标优化释放多个LLM的潜力 | 2024 | Arxiv | Qwen1.5-7B-Chat、解放的Qwen1.5-7B、firefly-qwen1.5-en-7B |
| MetaGPT:利用模型专属任务算术合并大型语言模型 | 2024 | Arxiv | LLaMA-2-7B、Mistral-7B、LLaMA-2-13B |
| PROMETHEUS 2:一款开源语言模型,专门用于评估其他语言模型 | 2024 | Arxiv | Mistral-Instruct-7B、Mixtral-Instruct-8x7B |
| 大型语言模型的知识融合 | 2024 | ICLR | Llama-2 7B、OpenLLaMA 7B、MPT 7B |
| 语言模型就像超级马里奥:如同免费午餐般吸收同源模型的能力 | 2024 | ICML | WizardLM-13B、WizardMath-13B以及llama-2-13b-code-alpaca、Mistral-7B |
| 通过语言模型算术控制文本生成 | 2024 | ICML | MPT-7B、Pythia-12B、Llama-2-Chat-13B |
| MeteoRA:嵌入式多任务LoRA用于大型语言模型 | 2024 | Arxiv | LlaMA2-13B和LlaMA3-8B(LoRA) |
| 模型合并配方的进化优化 | 2024 | Arxiv | shisa-gamma-7b-v1、WizardMath-7B-V1.1、Arithmo2-Mistral-7B、Abel-7B-002、Mistral-7B-v0.1、LLaVA-1.6-Mistral-7B |
| Branch-Train-MiX:将专家LLM混合进混合专家LLM | 2024 | Arxiv | Llama-2-7B |
| 聊天LLM的知识融合:初步技术报告 | 2024 | Arxiv | NH2-Mixtral-8x7B、NH2-Solar-10.7B、OpenChat-3.5-7B |
注:以下论文均来自:NeurIPS 2024 LLM 融合竞赛
| 论文标题 | 年份 | 会议/期刊 | 模型 |
|---|---|---|---|
| LLM 融合:通过融合高效构建 LLM | 2024 | NeurIPS LLM 融合竞赛 | - |
| 结合知识图谱与提示工程的大语言模型融合方法探索 | 2024 | NeurIPS LLM 融合竞赛 | meta-llama/Llama-2-7b;microsoft_phi1/2/3 |
| 基于任务向量几何中位数的模型融合 | 2024 | NeurIPS LLM 融合竞赛 | flan_t5_xl |
| 用于 NeurIPS 2024 LLM 融合竞赛的插值式逐层融合 | 2024 | NeurIPS LLM 融合竞赛 | suzume-llama-3-8B-multilingual-orpo-borda-top75、Barcenas-Llama3-8bORPO、Llama-3-8B-Ultra-Instruct-SaltSprinkle、MAmmoTH2-8B-Plus、Daredevil-8B |
| 一种模型融合方法 | 2024 | NeurIPS LLM 融合竞赛 | - |
| 适用于 NeurIPS 2024 LLM 融合竞赛的可微分 DARE-TIES 方法 | 2024 | NeurIPS LLM 融合竞赛 | suzume-llama-3-8B-multilingualorpo-borda-top75、MAmmoTH2-8B-Plus 和 Llama-3-Refueled |
| LLM 融合竞赛技术报告:通过策略性模型选择、融合及超参数优化实现高效模型融合 | 2024 | NeurIPS LLM 融合竞赛 | MaziyarPanahi/Llama3-8B-Instruct-v0.8、MaziyarPanahi/Llama-3-8B-Instruct-v0.9、shenzhiwang/Llama3-8B-Chinese-Chat、lightblue/suzume-llama-3-8B-multilingual |
| 简单的 Llama 融合:我们需要什么样的 LLM? | 2024 | NeurIPS LLM 融合竞赛 | Hermes-2-Pro-Llama-3-8B 和 Daredevil-8B |
| NeurIPS 2024 LLM 融合竞赛技术报告:通过融合高效构建大语言模型 | 2024 | NeurIPS LLM 融合竞赛 | Mistral-7B-Instruct94 v2、Llama3-8B-Instruct、Flan-T5-large、Gemma-7B-Instruct 和 WizardLM-2-7B |
| MoD:一种基于分布的大语言模型融合方法 | 2024 | NeurIPS LLM 融合竞赛 | Qwen2.5-1.5B 和 Qwen2.5-7B |
多模态大语言模型中的模型融合
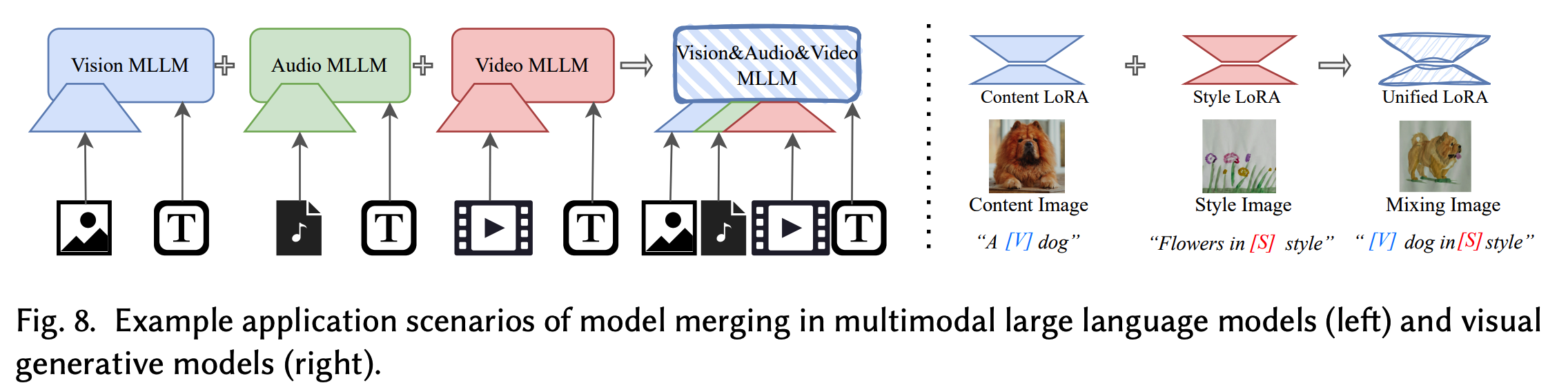
用于多模态融合的模型融合
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 联合训练大型自回归多模态模型 | 2024 | ICLR | |
| 多模态大语言模型的模型组合 | 2024 | ACL | Vicuna-7B-v1.5 |
| π-Tuning:通过最优多任务插值迁移多模态基础模型 | 2023 | ICML | |
| 多模态模型融合的实证研究 | 2023 | EMNLP | |
| UnIVAL:面向图像、视频、音频和语言任务的统一模型 | 2023 | TMLR |
用于跨模态知识迁移的模型融合
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 改进语音识别和音频事件分类的多模态注意力融合 | 2024 | ICASSP Workshop |
结合专家级多模态大语言模型的能力
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 推理存在于层中:通过层选择性融合恢复视频-语言模型中的时间推理能力 | 2026 | Arxiv | LongVA-7B, InternVL3-8B, Qwen3-VL-4B |
| 一个模型就能搞定所有?通往魔多山的多语言模型融合之旅 | 2026 | Arxiv | Qwen-2.5-3B-Instruct |
| 不再拔河:通过稳定性感知的任务向量融合,协调视觉-语言模型的准确性和鲁棒性 | 2026 | ICLR | LLaVA-1.5-7B, OpenFlamingo-9B |
| SSAM:用于多模态大语言模型融合的奇异子空间对齐 | 2026 | Arxiv | |
| ES-Merging:基于嵌入空间信号的生物启发式多模态大语言模型融合 | 2026 | Arxiv | |
| VisCodex:通过融合视觉与编码模型实现统一的多模态代码生成 | 2026 | ICLR | VisCodex-8B, VisCodex-33B |
| FRISM:通过子空间级别的模型融合向视觉-语言模型注入细粒度推理能力 | 2026 | Arxiv | Qwen2.5-VL-7B-Instruct, DeepSeekR1-Distill-Qwen-7B, Qwen2.5-VL-32B-Instruct, QwQ-32B |
| PlaM:无需训练的高原引导型模型融合,提升多模态大语言模型的视觉接地能力 | 2026 | Arxiv | LLaVA-v1.5-7B, Qwen2.5-VL-7B-Instruct, Qwen3-VL-8B-Instruct |
| 哪里重要、什么重要:面向多模态少样本上下文学习的敏感性感知任务向量 | 2026 | AAAI | Qwen-VL-7B, Idefics2-8B |
| MergeVLA:迈向通用视觉-语言-行动智能体的跨技能模型融合 | 2025 | Arxiv | Qwen2.5-0.5B |
| Tiny-R1V:通过模型融合构建轻量级多模态统一推理模型 | 2025 | Arxiv | |
| 在发展上合理的多模态模型中,通过模型融合保持纯语言性能 | 2025 | Arxiv | |
| 专家融合:基于无监督专家对齐和重要性指导的层块划分进行模型融合 | 2025 | Arxiv | Mistral-7B, InternVL, Qwen2-VL |
| UQ-Merge:不确定性引导的多模态大语言模型融合 | 2025 | ACL | LLaVA-v1.5-7B |
| Graft:通过高效的参数协同为多模态大语言模型整合领域知识 | 2025 | Arxiv | Qwen2-VL-2B |
| 通过模型融合统一多模态大语言模型的能力和模态 | 2025 | Arxiv | Qwen2-VL-7B-Base, Vicuna-7B-v1.5 |
| 让推理走进视觉:通过模型融合理解感知与推理 | 2025 | ICML | LLaVA-NeXT-8B, Idefics2-8B, InternVL2-76B |
| REMEDY:大型视觉-语言模型中的配方融合动态 | 2025 | ICLR | LLaVA-1.5(Vicuna-7B) |
| RobustMerge:具有方向鲁棒性的参数高效多模态大语言模型融合 | 2025 | NeurIPS | LLaVA-v1.5-7B |
| 针对多模态大语言模型的参数高效融合,结合互补的参数适配 | 2025 | Arxiv | LLaVA |
| AdaMMS:面向异构多模态大语言模型的模型融合,采用无监督系数优化 | 2025 | Arxiv | LLaVA-OneVision-7B, Qwen2-VL-7B, LLaVA-v1.5-7B, CogVLM-chat-7B |
| 通过模型融合将文本偏好迁移到视觉-语言理解中 | 2025 | Arxiv | Llama-3.2-11B-Vision-Instruct, Llama-3.1-Tulu-2-8B-uf-meanrm, Llama-3.1-Tulu-3-8B-RM, Llama-3.1-8B |
图像生成模型中的模型合并
生成模型中的风格混合
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| DiffGraph: 一种自动化代理驱动的模型合并框架,用于野外文本到图像生成 | 2026 | Arxiv | Stable Diffusion v1.5, FLUX.1 Dev |
| GimmBO: 基于贝叶斯优化的交互式生成图像模型合并 | 2026 | Arxiv | |
| 重新思考适配器合并中的LoRA正交性:来自正交蒙特卡洛丢弃的见解 | 2025 | Arxiv | |
| BlockLoRA: 基于分块参数化低秩适应的扩散模型模块化定制 | 2025 | Arxiv | |
| LoRA.rar: 通过超网络学习合并LoRA以实现主题-风格条件下的图像生成 | 2024 | Arxiv | LLaVA-Critic 7b |
| IterIS: 用于LoRA合并的迭代推理求解对齐方法 | 2024 | Arxiv | |
| 扩散汤:文本到图像扩散模型的模型合并 | 2024 | ECCV | |
| MaxFusion: 文本到图像扩散模型中的即插即用多模态生成 | 2024 | Arxiv | |
| MoLE: LoRA专家混合体 | 2024 | ICLR | |
| LoRA作曲家:利用低秩适应在无需训练的扩散模型中实现多概念定制 | 2024 | Arxiv | |
| 用于图像生成的多LoRA组合 | 2024 | Arxiv | |
| 秀之混合:用于扩散模型多概念定制的去中心化低秩适应 | 2023 | NeurIPS | |
| 合并LoRA | 2023 | (github) | |
| ZipLoRA: 通过有效合并LoRA实现任意主题、任意风格的生成 | 2023 | Arxiv | |
| GAN鸡尾酒:无需数据集即可混合GAN | 2022 | ECCV |
降低生成模型的训练成本
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 保存检查点的线性组合使一致性与扩散模型更好 | 2024 | Arxiv | |
| 加速STABLE-DIFFUSION的统一模块:LCM-LORA | 2024 | Arxiv |
提升扩散模型的忠实度(或生成质量)
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 解耦后再合并:迈向更好的扩散模型训练 | 2024 | Arxiv | |
| SELMA: 利用自动生成的数据学习并合并技能特定的文本到图像专家 | 2024 | Arxiv |
深度伪造检测
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 面向深度伪造检测的实时感知残差模型合并 | 2025 | Arxiv |
视频生成模型中的模型合并
提升运动建模能力
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 外推并解耦图像到视频生成模型:运动建模比你想象的更容易 | 2025 | CVPR | Dynamicrafter,SVD |
模型合并 在不同机器学习子领域的应用

持续学习中的模型合并
通过模型合并缓解灾难性遗忘
多任务/多目标/多领域/辅助学习中的模型合并
多任务学习中用于知识迁移的模型合并
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| G-Merging: 基于图模型的参数高效多任务知识整合 | 2026 | ICLR | |
| 多任务代码大模型:数据混合还是模型合并? | 2026 | Arxiv | Qwen Coder 2.5 7B, DeepSeek 7B |
| DivMerge: 一种基于差异性的多任务模型合并方法 | 2025 | Arxiv | |
| 单输入多输出模型合并:利用基础模型进行密集型多任务学习 | 2025 | Arxiv | |
| 改进通用文本嵌入模型:通过模型合并解决任务冲突与数据不平衡问题 | 2024 | Arxiv | |
| LiNeS: 训练后层缩放防止遗忘并增强模型合并效果 | 2024 | Arxiv | |
| 混合数据还是合并模型?面向多样化多任务学习的优化策略 | 2024 | Arxiv | Aya 23 8B |
| 可折叠超网:不同初始化和任务的Transformer模型的可扩展合并 | 2024 | Arxiv | |
| 任务提示向量:通过多任务软提示迁移实现有效初始化 | 2024 | Arxiv | |
| 模型合并方案的进化优化 | 2024 | Arxiv | shisa-gamma-7b-v1, WizardMath-7B-V1.1, Arithmo2-Mistral-7B, Abel-7B-002, Mistral-7B-v0.1, LLaVA-1.6-Mistral-7B |
| 语言模型就是超级马里奥:免费吸收同源模型的能力 | 2024 | ICML | WizardLM-13B、WizardMath-13B以及llama-2-13b-codealpaca、Mistral-7B |
| 多任务模型合并中的表征手术 | 2024 | ICML | |
| 通过加权集成专家混合进行多任务模型合并 | 2024 | ICML | |
| ZipIt! 在无需训练的情况下合并来自不同任务的模型 | 2024 | ICLR | |
| AdaMerging: 面向多任务学习的自适应模型合并 | 2024 | ICLR | |
| 决策Transformer的合并:通过权重平均形成多任务策略 | 2023 | Arxiv | |
| 解决模型合并时的干扰问题 | 2023 | NeurIPS | |
| 使用任务算术编辑模型 | 2023 | ICLR |
多目标优化中用于知识迁移的模型合并
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 从参数到表征:可控模型合并的闭式解法 | 2026 | AAAI | |
| 合并与引导:统一模型合并与引导解码以实现可控的多目标生成 | 2025 | Arxiv | LLaMA-2-7B |
| 帕累托合并:面向偏好感知的多目标优化模型合并 | 2025 | ICML | |
| 骨汤:一种寻找与融合的模型合并方法,用于可控的多目标生成 | 2025 | Arxiv | LLaMA-2 7B |
| 只合并一次:学习偏好感知模型合并的帕累托前沿 | 2024 | Arxiv | |
| 通过基于专家混合的模型融合实现高效的帕累托集近似 | 2024 | Arxiv | |
| MAP:基于二次近似的摊销帕累托前沿低计算量模型合并 | 2024 | Arxiv | Llama3-8B |
多领域学习中用于知识迁移的模型合并
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 跨不连通模态的领域自适应模型合并 | 2026 | Arxiv | |
| 通过子空间感知的模型合并弥合领域差距 | 2026 | Arxiv | |
| 探索模型合并在ASR多领域适应中的潜力与局限性 | 2026 | Arxiv | |
| 混合还是合并:迈向大型语言模型的多领域强化学习 | 2026 | Arxiv | Qwen3-4B-Base |
| MMGRid:通过模型合并实现时间感知与跨领域的生成式推荐 | 2026 | Arxiv | Qwen3-0.6B |
| MergeRec:面向数据隔离的跨领域序列推荐的模型合并 | 2026 | KDD | |
| DEM:用于混合数据分布训练的分布编辑模型 | 2024 | Arxiv | OpenLLaMA-7B、OpenLLaMA-13B |
| 来自不同任务和领域的视觉Transformer的合并 | 2023 | Arxiv |
辅助学习中用于知识迁移的模型合并
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| ForkMerge:缓解辅助任务学习中的负迁移 | 2023 | NeurIPS |
分布外/领域泛化中的模型融合
用于更好分布外泛化的模型融合
用于更好领域泛化或领域适应的模型融合
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 选择与融合:迈向使用大语言模型的可适应且可扩展的命名实体识别 | 2025 | Arxiv | Qwen2.5-7B, Llama3.1-8B |
| 为基于CLIP的领域泛化协调并合并源模型 | 2025 | Arxiv | |
| 模型融合在组合泛化方面的现实评估 | 2024 | Arxiv | |
| 用于分割任务中无监督领域适应的逐层模型融合 | 2024 | Arxiv | |
| 用于多目标领域适应的无训练模型融合 | 2024 | Arxiv | |
| 通过持续预训练和模型融合实现Llama3-70B-Instruct的领域适应:一项综合评估 | 2024 | Arxiv | Llama3-70B |
| 平均集成:改进模型选择并提升领域泛化性能 | 2022 | NeurIPS | |
| Swad:通过寻找平坦极小值实现领域泛化 | 2021 | NeurIPS |
联邦学习中的模型合并
用于本地知识聚合的模型合并
零样本/少样本学习中的模型合并
零样本学习中用于跨任务泛化的模型合并
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| TTS中的任务向量:迈向情感丰富的方言语音合成 | 2026 | Arxiv | |
| 模型合并提升生物声学基础模型的零样本泛化能力 | 2025 | NeurIPS Workshop | LLAMA-3.1-8B-INSTRUCT |
| 探索用于零样本信息检索的任务算术 | 2025 | SIGIR | LLama-2-7b |
| 通过层次聚类实现稀疏混合专家模型的无重新训练合并 | 2024 | Arxiv | Qwen 60x2.7B, Qwen 45x2.7B, Qwen 30x2.7B, Mixtral 8x7B, Mixtral 6x7B, Mixtral 4x7B |
| 大型语言模型中用于零样本跨语言迁移的层交换 | 2024 | Arxiv | LLAMA 3.1 8B |
| 学习在专业专家之间路由以实现零样本泛化 | 2024 | ICML | |
| 通过构建和复用LoRA库迈向模块化LLM | 2024 | ICML | Mistral-7B |
| 聊天向量:一种为LLM赋予新语言聊天能力的简单方法 | 2024 | ACL | LLaMA-2 13B, Chinese-LLaMA-13B, Chinese-Alpaca-13B, Mistral-7B, llama-2-ko-7b |
| 释放模型合并对低资源语言的潜力 | 2024 | Arxiv | Llama-2-7B |
| 扩散汤:用于文生图扩散模型的模型合并 | 2024 | Arxiv | |
| 无需训练却有收获:用于无训练语言适配器增强的语言算术 | 2024 | Arxiv | |
| MaxFusion:文生图扩散模型中的即插即用多模态生成 | 2024 | Arxiv | |
| AdaMergeX:通过自适应适配器合并实现大型语言模型的跨语言迁移 | 2024 | Arxiv | Llama2-7b |
| 用于多模态大型语言模型的模型组合 | 2024 | Arxiv | Vicuna-7B-v1.5 |
| 探索相比指令微调训练专家语言模型的优势 | 2023 | ICML | |
| 针对下游任务泛化的LoRA适配器的令牌级适应 | 2023 | Arxiv | Llama-2-7b |
| 利用参数高效的层进行语言和任务算术,实现零样本摘要生成 | 2023 | Arxiv | PaLM 2-S |
少样本学习中用于跨任务泛化的模型合并
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 支持语言下的任务算术用于低资源ASR | 2026 | Arxiv | |
| 通过复用预微调的LoRA解锁视觉基础模型的免微调少样本适应性 | 2025 | CVPR | |
| LoRA-Flow:用于生成任务中大型语言模型的动态LoRA融合 | 2024 | ACL | Llama-2- 7B |
| LoraHub:通过动态LoRA组合实现高效的跨任务泛化 | 2024 | COLM | Llama-2-7B, Llama-2-13B |
| LoraRetriever:面向野外混合任务的输入感知LoRA检索与组合 | 2024 | ACL | |
| 结合参数高效模块是否能提升少样本迁移准确率? | 2024 | Arxiv | |
| MerA:用于少样本学习的预训练适配器合并 | 2023 | Arxiv | |
| 用于跨任务泛化的多头适配器路由 | 2023 | NeurIPS |
对抗学习中的模型融合
模型融合作为一种攻击手段
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 当安全模型融合为危险:利用大语言模型融合中的潜在漏洞 | 2026 | Arxiv | Tulu-2-7b, Llama-3.1-Tulu-3-8B-DPO, OpenChat-3.5-0106 |
| 后门向量:从任务算术视角看后门攻击与防御 | 2025 | Arxiv | |
| 现在合并,日后后悔:模型融合的隐性代价是对抗可迁移性 | 2025 | Arxiv | |
| 谨慎合并陌生的大语言模型:一种可窃取隐私的网络钓鱼模型 | 2025 | ACL | Llama-3.2-3b-it, Gemma-2-2b-it, Qwen-2.5-3b-it, 和 Phi-3.5-mini-it |
| 合并劫持:针对大型语言模型模型融合的后门攻击 | 2025 | Arxiv | LLaMA3.1-8B |
| 从纯净到危险:从“无害”的良性组件中植入后门到融合模型 | 2025 | Arxiv | LLaMA2-7B-chat, Mistral-7B-v0.1 |
| 合并即窃取:通过模型融合从对齐的大语言模型中窃取目标PII | 2025 | Arxiv | |
| 谨慎合并陌生的大语言模型:一种可窃取隐私的网络钓鱼模型 | 2025 | Arxiv | |
| LoBAM:基于LoRA的模型融合后门攻击 | 2024 | Arxiv | |
| BadMerging:针对模型融合的后门攻击 | 2024 | CCS | |
| LoRA即攻击!在共享与协作场景下刺穿大语言模型的安全性 | 2024 | ACL | Llama-2-7B |
模型融合作为一种防御或知识产权保护手段
| 论文标题 | 年份 | 会议/期刊 | 备注 |
|---|---|---|---|
| 通过模块切换防御后门攻击 | 2026 | ICLR | |
| 通过尺度敏感的损失景观使模型不可融合 | 2026 | Arxiv | |
| 融合触发器,破解后门:面向指令微调语言模型的防御性投毒 | 2026 | Arxiv | Llama2-7B 和 Qwen3-8B |
| 不要合并我的模型!保护开源大语言模型免受未经授权的模型融合侵害 | 2026 | AAAI | LLaMA-2-13B, WizardLM-13B, WizardMath-13B, LLaMA-2-13B-Code Alpaca |
| 通过双阶段权重保护防御未经授权的模型融合 | 2025 | Arxiv | |
| 模型反融合:让你的模型无法被融合以实现安全的模型共享 | 2025 | Arxiv | |
| 海报:研究模型融合中对抗样本的可迁移性 | 2025 | ASIA CCS | |
| RouteMark:基于路由的模型融合中用于知识产权归属的指纹 | 2025 | Arxiv | |
| MergeGuard:高效阻止机器学习模型中的木马攻击 | 2025 | Arxiv | |
| BadJudge:作为裁判的大语言模型的后门漏洞 | 2025 | Arxiv | Mistral-7B-Instruct-v0.2, Meta-Llama3-8B |
| 扰乱模型融合:一种不牺牲准确性的参数级防御 | 2025 | ICCV | |
| 大型语言模型融合以增强对图神经网络的链接窃取攻击 | 2024 | Arxiv | Vicuna-7B, Vicuna-13B |
| 通过自适应模型融合为语言模型提供强有力的版权保护 | 2024 | ICML | LLaMa2 7B, StarCoder 7B |
| 针对预训练大型视觉模型的对抗鲁棒性提升的超对抗调优 | 2024 | Arxiv | |
| REEF:大型语言模型的表征编码指纹 | 2024 | Arxiv | Evollm-jp-7b, Shisa-gamma-7b-v1, Wizardmath-7b-1.1, Abel-7b-002, Llama-2-7b, Openllama-2-7b, Mpt-7b, Internlm2-chat-20b, Mixtral-8x7b-instruct, Qwen-1.5-chat-72b |
| 通过安全感知子空间缓解多任务模型融合的后门效应 | 2024 | Arxiv | |
| MergePrint:针对大型语言模型融合的稳健指纹识别 | 2024 | Arxiv | LLaMA-2-7B, WizardMath-7B-V1.0, LLaMA-2-7B-CHAT |
| 通过机器遗忘避免版权侵权 | 2024 | Arxiv | Llama3-8B |
| 融合提升自我批判能力以抵御越狱攻击 | 2024 | Arxiv | Mistral-7B, Mixtral-8x7B |
| 你是否合并了我的模型?关于大型语言模型知识产权保护方法对抗模型融合的鲁棒性 | 2024 | Arxiv | LLaMA-2-7B, LLaMA-2-7B-CHAT, WizardMath-7B-V1.0 |
| 免费午餐来了:用模型融合净化被植入后门的模型 | 2024 | ACL | |
| 重新审视适配器与对抗训练 | 2023 | ICLR | |
| 为模型汤调味以增强其对抗性和自然分布偏移下的鲁棒性 | 2023 | CVPR |
其他应用
星星历史

联系方式
我们欢迎所有研究人员为本仓库(“基础模型或机器学习中的模型合并”)贡献力量。
如果您有一篇尚未添加到库中的相关论文,请与我们联系。
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
n8n
n8n 是一款面向技术团队的公平代码(fair-code)工作流自动化平台,旨在让用户在享受低代码快速构建便利的同时,保留编写自定义代码的灵活性。它主要解决了传统自动化工具要么过于封闭难以扩展、要么完全依赖手写代码效率低下的痛点,帮助用户轻松连接 400 多种应用与服务,实现复杂业务流程的自动化。 n8n 特别适合开发者、工程师以及具备一定技术背景的业务人员使用。其核心亮点在于“按需编码”:既可以通过直观的可视化界面拖拽节点搭建流程,也能随时插入 JavaScript 或 Python 代码、调用 npm 包来处理复杂逻辑。此外,n8n 原生集成了基于 LangChain 的 AI 能力,支持用户利用自有数据和模型构建智能体工作流。在部署方面,n8n 提供极高的自由度,支持完全自托管以保障数据隐私和控制权,也提供云端服务选项。凭借活跃的社区生态和数百个现成模板,n8n 让构建强大且可控的自动化系统变得简单高效。
AutoGPT
AutoGPT 是一个旨在让每个人都能轻松使用和构建 AI 的强大平台,核心功能是帮助用户创建、部署和管理能够自动执行复杂任务的连续型 AI 智能体。它解决了传统 AI 应用中需要频繁人工干预、难以自动化长流程工作的痛点,让用户只需设定目标,AI 即可自主规划步骤、调用工具并持续运行直至完成任务。 无论是开发者、研究人员,还是希望提升工作效率的普通用户,都能从 AutoGPT 中受益。开发者可利用其低代码界面快速定制专属智能体;研究人员能基于开源架构探索多智能体协作机制;而非技术背景用户也可直接选用预置的智能体模板,立即投入实际工作场景。 AutoGPT 的技术亮点在于其模块化“积木式”工作流设计——用户通过连接功能块即可构建复杂逻辑,每个块负责单一动作,灵活且易于调试。同时,平台支持本地自托管与云端部署两种模式,兼顾数据隐私与使用便捷性。配合完善的文档和一键安装脚本,即使是初次接触的用户也能在几分钟内启动自己的第一个 AI 智能体。AutoGPT 正致力于降低 AI 应用门槛,让人人都能成为 AI 的创造者与受益者。
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。