LightMem
LightMem 是一个专为大语言模型和 AI 智能体设计的轻量级记忆增强框架,旨在让 AI 具备高效的长期记忆能力。它主要解决了传统 AI 在处理长上下文或复杂任务时容易“遗忘”关键信息,以及现有记忆方案资源消耗大、集成难度高的问题。通过提供极简的存储、检索与更新机制,LightMem 能帮助开发者快速构建拥有持久记忆的智能应用。
该工具非常适合 AI 应用开发者、研究人员以及希望提升 Agent 长期交互能力的工程团队使用。其核心亮点在于“轻量高效”与“灵活兼容”:采用模块化架构,仅需几行代码即可集成;支持自定义存储引擎和检索策略;同时广泛兼容云端 API(如 OpenAI、DeepSeek)及本地部署模型(如 Ollama、vLLM)。此外,LightMem 还配备了完善的基准评估框架,方便用户在 LoCoMo 等数据集上验证记忆模块性能。作为 ICLR 2026 收录成果,LightMem 以低资源占用和快速响应著称,是让 AI 记住过往交互、实现更连贯对话的理想选择。
使用场景
某初创团队正在开发一款面向资深用户的“个人法律案件追踪助手”,需要 AI 长期记住用户数月内上传的复杂案情细节、证据链变化及律师沟通记录。
没有 LightMem 时
- 上下文窗口爆炸:随着案件时间线拉长,历史对话远超模型上下文限制,导致早期关键证据被截断遗忘。
- 检索效率低下:每次回答需重新扫描数万字的完整历史记录,响应延迟高达数秒,用户体验极差。
- 记忆更新困难:当案件状态变更(如“已开庭”)时,难以精准定位并更新旧信息,常出现新旧事实矛盾的幻觉。
- 资源成本高昂:为维持长上下文不得不调用超大参数模型或支付昂贵的云 API 费用,初创团队难以负担。
使用 LightMem 后
- 长效记忆存储:LightMem 将案情结构化存入轻量级外部记忆库,自动管理时间跨度数月的案件细节,不再受上下文窗口限制。
- 毫秒级精准召回:针对用户提问,LightMem 仅检索相关片段注入上下文,响应速度提升 10 倍以上,实现实时交互。
- 动态记忆维护:利用其更新机制,当用户补充新证据时,LightMem 自动关联并修正旧有记忆节点,确保逻辑一致性。
- 低成本灵活部署:团队可利用 LightMem 的模块化架构,在本地 Ollama 小模型上运行,大幅降低算力成本且保护数据隐私。
LightMem 通过轻量高效的记忆增强机制,让资源有限的应用也能拥有像人类专家一样“过目不忘”且逻辑严密的长期案件追踪能力。
运行环境要求
- Linux
- macOS
- Windows
- 可选但推荐(用于加速 llmlingua-2 和嵌入模型)
- 配置中指定 device_map='cuda',暗示需要 NVIDIA GPU
- 具体显存和 CUDA 版本未说明,取决于所选本地模型(如 Ollama/vLLM 运行的模型大小)
未说明(建议 16GB+ 以运行本地大模型和压缩模型)

快速开始
LightMem: 轻量高效的内存增强生成

![]()

⭐ 如果你喜欢我们的项目,请在 GitHub 上给我们点个星,以获取最新更新!
LightMem 是一个专为大型语言模型和 AI 代理设计的轻量高效内存管理框架。它提供简单而强大的内存存储、检索和更新机制,帮助你快速构建具备长期记忆能力的智能应用。
🚀 轻量高效
极简设计,资源消耗低,响应速度快🎯 易于使用
简单的 API 设计——只需几行代码即可集成到你的应用中🔌 灵活可扩展
模块化架构,支持自定义存储引擎和检索策略🌐 广泛兼容
支持云端 API(OpenAI、DeepSeek)以及本地模型(Ollama、vLLM 等)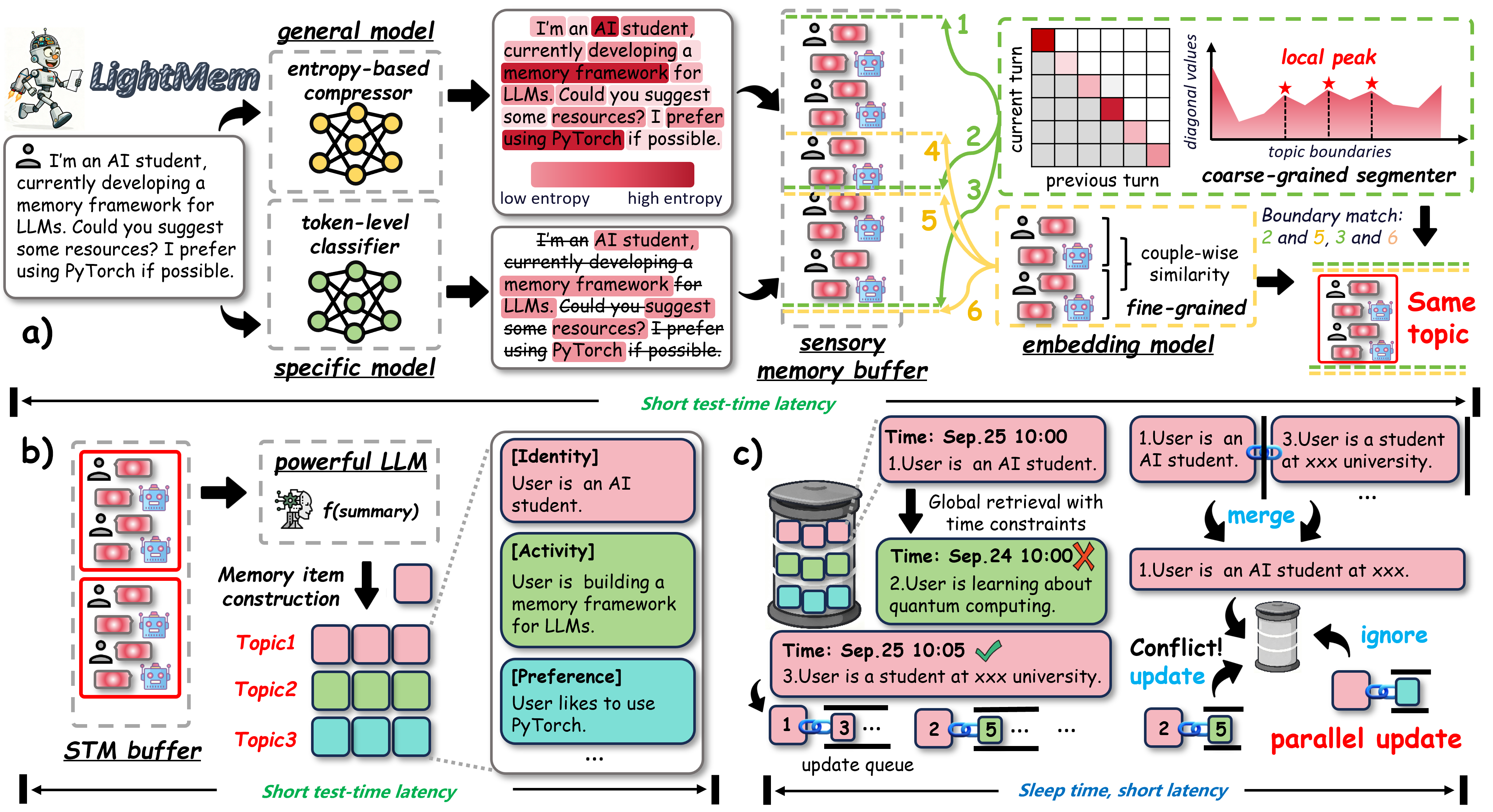
📢 最新消息
- [2026-03-21]:🚀 我们提供了更全面的 基准评估框架,支持在 LoCoMo 和 LongMemEval 等多个数据集上对 Mem0、A-MEM、EverMemOS、LangMem 等内存层进行基准测试。
- [2026-02-15]:🚀 StructMem 发布:一种分层内存框架,能够保留事件级别的记忆绑定及跨事件的记忆连接。
- [2026-01-26]:🎉🎉🎉 LightMem:轻量高效的内存增强生成 已被 ICLR 2026 接受!
- [2026-01-17]:🚀 我们提供了一个全面的 基准评估框架,支持在 LoCoMo 和 LongMemEval 等多个数据集上对 Mem0、A-MEM、LangMem 等内存层进行基准测试。
- [2025-12-09]:🎬 发布了 演示视频,展示了长上下文处理能力,并附带针对各种场景的完整 [教程笔记本]!
- [2025-11-30]:🚌 LightMem 现在支持调用其 MCP 服务器 提供的多种工具。
- [2025-11-26]:🚀 增加了对 LoCoMo 数据集的完整支持,取得了领先的性能和效率,并提供了详细的 结果!以下是 复现脚本!
- [2025-11-09]:✨ LightMem 现在支持通过 Ollama、vLLM 和 Transformers 自动加载的方式进行本地部署!
- [2025-10-12]:🎉 LightMem 项目正式开源!
🧪 LoCoMo 和 LongMemEval 的复现脚本
我们提供了轻量级、开箱即用的脚本,用于复现 LoCoMo、LongMemEval 及其联合基线的结果。
| 数据集 | 描述 | 脚本 | 结果 |
|---|---|---|---|
| LongMemEval | 在 LongMemEval 上运行 LightMem,包括评估和离线内存更新。 | run_lightmem_longmemeval.md | LongMemEval 结果 |
| LoCoMo | 复现 LightMem 在 LoCoMo 上结果的脚本。 | run_lightmem_locomo.md | LoCoMo 结果 |
| LongMemEval & LoCoMo | 统一的基线脚本,用于同时运行这两个数据集。 | run_baselines.md | 基准结果 |
🧪 基准评估
我们提供了一个全面的 基准评估框架,支持在 LoCoMo 和 LongMemEval 等多个数据集上对 Mem0、A-MEM、LangMem 等内存层进行基准测试。
🎥 演示与教程
📚 实战教程
我们提供了与演示及其他用例相对应的即用型 Jupyter 笔记本。你可以在 tutorial-notebooks 目录中找到它们。
| 场景 | 描述 | 笔记本链接 |
|---|---|---|
| 旅行规划 | 使用记忆功能构建旅行代理的完整指南。 | LightMem_Example_travel.ipynb |
| 代码助手 | 使用记忆功能构建代码代理的完整指南。 | LightMem_Example_code.ipynb |
| LongMemEval | 如何使用 LightMem 在 LongMemEval 基准测试上进行评估的教程。 | LightMem_Example_longmemeval.ipynb |
☑️ 待办事项清单
LightMem 正在不断进化!以下是接下来的计划:
- 更新时的 KV 缓存离线预计算(无损)
- 在问答前进行 KV 缓存的在线预计算(有损)
- 集成更多模型并增强功能
- 协调使用上下文和长期记忆存储
- 多模态记忆
📑 目录
🔧 安装
安装步骤
选项 1:从源码安装
# 克隆仓库
git clone https://github.com/zjunlp/LightMem.git
cd LightMem
# 创建虚拟环境
conda create -n lightmem python=3.11 -y
conda activate lightmem
# 安装依赖
unset ALL_PROXY
pip install -e .
选项 2:通过 pip 安装
pip install lightmem # 即将推出
⚡ 快速入门
修改
API Configuration中的JUDGE_MODEL、LLM_MODEL及其对应的API_KEY和BASE_URL。从 microsoft/llmlingua-2-bert-base-multilingual-cased-meetingbank 下载
LLMLINGUA_MODEL,从 sentence-transformers/all-MiniLM-L6-v2 下载EMBEDDING_MODEL,并在Model Paths中修改它们的路径。从 longmemeval-cleaned 下载数据集,并在
Data Configuration中修改路径。
cd experiments
python run_lightmem_qwen.py
🏗️ 架构
🗺️ 核心模块概览
LightMem 采用模块化设计,将内存管理过程分解为多个可插拔组件。向用户公开的核心目录结构如下,便于自定义和扩展:
LightMem/
├── src/lightmem/ # 主包
│ ├── __init__.py # 包初始化
│ ├── configs/ # 配置文件
│ ├── factory/ # 工厂方法
│ ├── memory/ # 核心内存管理
│ └── memory_toolkits/ # 内存工具包
├── mcp/ # LightMem MCP 服务器
├── experiments/ # 实验脚本
├── datasets/ # 数据集文件
└── examples/ # 示例
🧩 各模块支持的后端
下表列出了每个配置模块当前识别的后端值。请使用 model_name 字段(或相应的配置对象)来选择这些后端之一。
| 模块 (config) | 支持的后端 |
|---|---|
PreCompressorConfig |
llmlingua-2, entropy_compress |
TopicSegmenterConfig |
llmlingua-2 |
MemoryManagerConfig |
openai, deepseek, ollama, vllm, 等 |
TextEmbedderConfig |
huggingface |
MMEmbedderConfig |
huggingface |
RetrieverConfig |
qdrant, FAISS, BM25 |
💡 示例
初始化 LightMem
import os
from datetime import datetime
from lightmem.memory.lightmem import LightMemory
LOGS_ROOT = "./logs"
RUN_TIMESTAMP = datetime.now().strftime("%Y%m%d_%H%M%S")
RUN_LOG_DIR = os.path.join(LOGS_ROOT, RUN_TIMESTAMP)
os.makedirs(RUN_LOG_DIR, exist_ok=True)
API_KEY='your_api_key'
API_BASE_URL='your_api_base_url'
LLM_MODEL='your_model_name' # 如 'gpt-4o-mini' (API) 或 'gemma3:latest' (本地 Ollama) ...
EMBEDDING_MODEL_PATH='/your/path/to/models/all-MiniLM-L6-v2'
LLMLINGUA_MODEL_PATH='/your/path/to/models/llmlingua-2-bert-base-multilingual-cased-meetingbank'
config_dict = {
"pre_compress": True,
"pre_compressor": {
"model_name": "llmlingua-2",
"configs": {
"llmlingua_config": {
"model_name": LLMLINGUA_MODEL_PATH,
"device_map": "cuda",
"use_llmlingua2": True,
},
}
},
"topic_segment": True,
"precomp_topic_shared": True,
"topic_segmenter": {
"model_name": "llmlingua-2",
},
"messages_use": "user_only",
"metadata_generate": True,
"text_summary": True,
"memory_manager": {
"model_name": 'xxx', # 如 'openai' 或 'ollama' ...
"configs": {
"model": LLM_MODEL,
"api_key": API_KEY,
"max_tokens": 16000,
"xxx_base_url": API_BASE_URL # API 模型特定,如 'openai_base_url' 或 'deepseek_base_url' ...
}
},
"extract_threshold": 0.1,
"index_strategy": "embedding",
"text_embedder": {
"model_name": "huggingface",
"configs": {
"model": EMBEDDING_MODEL_PATH,
"embedding_dims": 384,
"model_kwargs": {"device": "cuda"},
},
},
"retrieve_strategy": "embedding",
"embedding_retriever": {
"model_name": "qdrant",
"configs": {
"collection_name": "my_long_term_chat",
"embedding_model_dims": 384,
"path": "./my_long_term_chat",
}
},
"summary_retriever": {
"model_name": "qdrant",
"configs": {
"collection_name": "my_chat_summaries",
"embedding_model_dims": 384,
"path": "./my_chat_summaries",
}
},
"update": "offline",
"logging": {
"level": "DEBUG",
"file_enabled": True,
"log_dir": RUN_LOG_DIR,
}
}
lightmem = LightMemory.from_config(config_dict)
添加记忆
session = {
"timestamp": "2025-01-10",
"turns": [
[
{"role": "user", "content": "我最喜欢的冰淇淋口味是开心果,我的狗叫雷克斯。"},
{"role": "assistant", "content": "明白了。开心果确实是个不错的选择。"}],
]
}
for turn_messages in session["turns"]:
timestamp = session["timestamp"]
for msg in turn_messages:
msg["time_stamp"] = timestamp
store_result = lightmem.add_memory(
messages=turn_messages,
force_segment=True,
force_extract=True
)
离线更新
lightmem.construct_update_queue_all_entries()
lightmem.offline_update_all_entries(score_threshold=0.8)
生成摘要
summary_result = lightmem.summarize()
检索记忆
question = "我的狗叫什么名字?"
related_memories = lightmem.retrieve(question, limit=5)
print(related_memories)
MCP 服务器
LightMem 还支持模型上下文协议(MCP)服务器:
# 在根目录运行
cd LightMem
# 环境
pip install '.[mcp]'
# MCP 检查器 [可选]
npx @modelcontextprotocol/inspector python mcp/server.py
# 通过 HTTP 启动 API (http://127.0.0.1:8000/mcp)
fastmcp run mcp/server.py:mcp --transport http --port 8000
您本地客户端的 MCP 配置 json 文件可能如下所示:
{
"yourMcpServers": {
"LightMem": {
"url": "http://127.0.0.1:8000/mcp",
"otherParameters": "..."
}
}
}
📁 实验结果
为确保透明度和可重复性,我们已将实验结果分享至 Google Drive。其中包括模型输出、评估日志以及本研究中使用的预测数据。
🔗 点击此处访问数据:Google Drive - 实验结果
欢迎下载、探索并使用这些资源进行研究或参考。
LOCOMO:
概述
主干模型:gpt-4o-mini,评判模型:gpt-4o-mini 和 qwen2.5-32b-instruct
| 方法 | ACC(%) gpt-4o-mini | ACC(%) qwen2.5-32b-instruct | 记忆相关 Tokens(k) 总计 | QA Tokens(k) 总计 | 总计(k) | 调用次数 | 总运行时间(s) |
|---|---|---|---|---|---|---|---|
| FullText | 73.83 | 73.18 | – | 54,884.479 | 54,884.479 | – | 6,971 |
| NaiveRAG | 63.64 | 63.12 | – | 3,870.187 | 3,870.187 | – | 1,884 |
| A-MEM | 64.16 | 60.71 | 11,494.344 | 10,170.567 | 21,664.907 | 11,754 | 67,084 |
| MemoryOS(eval) | 58.25 | 61.04 | 2,870.036 | 7,649.343 | 10,519.379 | 5,534 | 26,129 |
| MemoryOS(pypi) | 54.87 | 55.91 | 5,264.801 | 6,126.111 | 11,390.004 | 10,160 | 37,912 |
| Mem0 | 36.49 | 37.01 | 24,304.872 | 1,488.618 | 25,793.490 | 19,070 | 120,175 |
| Mem0(api) | 61.69 | 61.69 | 68,347.720 | 4,169.909 | 72,517.629 | 6,022 | 10,445 |
| Mem0-g(api) | 60.32 | 59.48 | 69,684.818 | 4,389.147 | 74,073.965 | 6,022 | 10,926 |
主干模型:qwen3-30b-a3b-instruct-2507,评判模型:gpt-4o-mini 和 qwen2.5-32b-instruct
| 方法 | ACC(%) gpt-4o-mini | ACC(%) qwen2.5-32b-instruct | 记忆相关 Tokens(k) 总计 | QA Tokens(k) 总计 | 总计(k) | 调用次数 | 总运行时间(s) |
|---|---|---|---|---|---|---|---|
| FullText | 74.87 | 74.35 | – | 60,873.076 | 60,873.076 | – | 10,555 |
| NaiveRAG | 66.95 | 64.68 | – | 4,271.052 | 4,271.052 | – | 1,252 |
| A-MEM | 56.10 | 54.81 | 16,267.997 | 17,340.881 | 33,608.878 | 11,754 | 69,339 |
| MemoryOS(eval) | 61.04 | 59.81 | 3,615.087 | 9,703.169 | 11,946.442 | 4,147 | 13,710 |
| MemoryOS(pypi) | 51.30 | 51.95 | 6,663.527 | 7,764.991 | 14,428.518 | 10,046 | 20,830 |
| Mem0 | 43.31 | 43.25 | 17,994.035 | 1,765.570 | 19,759.605 | 16,145 | 46,500 |
详情
主干模型:gpt-4o-mini,评判模型:gpt-4o-mini 和 qwen2.5-32b-instruct
| 方法 | 摘要 Tokens(k) 输入 | 摘要 Tokens(k) 输出 | 更新 Tokens(k) 输入 | 更新 Tokens(k) 输出 | QA Tokens(k) 输入 | QA Tokens(k) 输出 | 记忆相关运行时间(s) | QA 运行时间(s) |
|---|---|---|---|---|---|---|---|---|
| FullText | – | – | – | – | 54,858.770 | 25.709 | – | 6,971 |
| NaiveRAG | – | – | – | – | 3,851.029 | 19.158 | – | 1,884 |
| A-MEM | 1,827.373 | 492.883 | 7,298.878 | 1,875.210 | 10,113.252 | 57.315 | 60,607 | 6,477 |
| MemoryOS(eval) | 1,109.849 | 333.970 | 780.807 | 645.410 | 7,638.539 | 10.804 | 24,220 | 1,909 |
| MemoryOS(pypi) | 1,007.729 | 294.601 | 3,037.509 | 924.962 | 6,116.239 | 9.872 | 33,325 | 4,587 |
| Mem0 | 8,127.398 | 253.187 | 12,722.011 | 3,202.276 | 1,478.830 | 9.788 | 118,268 | 1,907 |
| Mem0(api) | \ | \ | \ | \ | 4,156.850 | 13.059 | 4,328 | 6,117 |
| Mem0-g(api) | \ | \ | \ | \ | 4,375.900 | 13.247 | 5,381 | 5,545 |
主干模型:qwen3-30b-a3b-instruct-2507,评判模型:gpt-4o-mini 和 qwen2.5-32b-instruct
| 方法 | 摘要令牌数(千)输入 | 摘要令牌数(千)输出 | 更新令牌数(千)输入 | 更新令牌数(千)输出 | QA 令牌数(千)输入 | QA 令牌数(千)输出 | 运行时(秒)内存消耗 | 运行时(秒)QA |
|---|---|---|---|---|---|---|---|---|
| FullText | – | – | – | – | 60,838.694 | 34.382 | – | 10,555 |
| NaiveRAG | – | – | – | – | 4,239.030 | 32.022 | – | 1,252 |
| A-MEM | 1,582.942 | 608.507 | 9,241.928 | 4,835.070 | 17,528.876 | 82.005 | 55,439 | 13,900 |
| MemoryOS(eval) | 1,222.139 | 531.157 | 1,044.307 | 817.484 | 9,679.996 | 23.173 | 12,697 | 1,012 |
| MemoryOS(pypi) | 2,288.533 | 516.024 | 2,422.693 | 1,436.277 | 7,743.391 | 21.600 | 19,822 | 1,007 |
| Mem0 | 8,270.874 | 186.354 | 7,638.827 | 1,897.980 | 1,739.246 | 26.324 | 45,407 | 1,093 |
性能指标
主干模型:gpt-4o-mini,评判模型:gpt-4o-mini
| 方法 | 整体 ↑ | 多轮 | 开放 | 单轮 | 温度 |
|---|---|---|---|---|---|
| FullText | 73.83 | 68.79 | 56.25 | 86.56 | 50.16 |
| NaiveRAG | 63.64 | 55.32 | 47.92 | 70.99 | 56.39 |
| A-MEM | 64.16 | 56.03 | 31.25 | 72.06 | 60.44 |
| MemoryOS(eval) | 58.25 | 56.74 | 45.83 | 67.06 | 40.19 |
| MemoryOS(pypi) | 54.87 | 52.13 | 43.75 | 63.97 | 36.76 |
| Mem0 | 36.49 | 30.85 | 34.38 | 38.41 | 37.07 |
| Mem0(api) | 61.69 | 56.38 | 43.75 | 66.47 | 59.19 |
| Mem0-g(api) | 60.32 | 54.26 | 39.58 | 65.99 | 57.01 |
主干模型:gpt-4o-mini,评判模型:qwen2.5-32b-instruct
| 方法 | 整体 ↑ | 多轮 | 开放 | 单轮 | 温度 |
|---|---|---|---|---|---|
| FullText | 73.18 | 68.09 | 54.17 | 86.21 | 49.22 |
| NaiveRAG | 63.12 | 53.55 | 50.00 | 71.34 | 53.89 |
| A-MEM | 60.71 | 53.55 | 32.29 | 69.08 | 53.58 |
| MemoryOS(eval) | 61.04 | 64.18 | 40.62 | 70.15 | 40.50 |
| MemoryOS(pypi) | 55.91 | 52.48 | 41.67 | 66.35 | 35.83 |
| Mem0 | 37.01 | 31.91 | 37.50 | 38.53 | 37.38 |
| Mem0(api) | 61.69 | 54.26 | 46.88 | 67.66 | 57.01 |
| Mem0-g(api) | 59.48 | 55.32 | 42.71 | 65.04 | 53.58 |
主干模型:qwen3-30b-a3b-instruct-2507,评判模型:gpt-4o-mini
| 方法 | 整体 ↑ | 多轮 | 开放 | 单轮 | 温度 |
|---|---|---|---|---|---|
| FullText | 74.87 | 69.86 | 57.29 | 87.40 | 51.71 |
| NaiveRAG | 66.95 | 62.41 | 57.29 | 76.81 | 47.98 |
| A-MEM | 56.10 | 57.45 | 43.75 | 67.90 | 27.73 |
| MemoryOS(eval) | 61.04 | 62.77 | 51.04 | 72.29 | 33.02 |
| MemoryOS(pypi) | 51.30 | 52.48 | 40.62 | 61.59 | 26.48 |
| Mem0 | 43.31 | 42.91 | 46.88 | 46.37 | 34.58 |
| Mem0(api) | 61.69 | 54.26 | 46.88 | 67.66 | 57.01 |
| Mem0-g(api) | 59.48 | 55.32 | 42.71 | 65.04 | 53.58 |
主干模型:qwen3-30b-a3b-instruct-2507,评判模型:qwen2.5-32b-instruct
| 方法 | 整体 ↑ | 多轮 | 开放 | 单轮 | 温度 |
|---|---|---|---|---|---|
| FullText | 74.35 | 68.09 | 63.54 | 86.33 | 51.71 |
| NaiveRAG | 64.68 | 60.28 | 52.08 | 75.62 | 43.61 |
| A-MEM | 54.81 | 56.74 | 39.58 | 67.42 | 24.61 |
| MemoryOS(eval) | 59.81 | 63.12 | 48.96 | 70.51 | 32.09 |
| MemoryOS(pypi) | 51.95 | 55.67 | 39.58 | 61.47 | 27.41 |
| Mem0 | 43.25 | 45.04 | 46.88 | 45.78 | 33.96 |
| Mem0(api) | 61.69 | 54.26 | 46.88 | 67.66 | 57.01 |
| Mem0-g(api) | 59.48 | 55.32 | 42.71 | 65.04 | 53.58 |
⚙️ 配置
LightMem 的所有行为都通过 BaseMemoryConfigs 配置类进行控制。用户可以通过提供自定义配置来定制预处理、记忆提取、检索策略和更新机制等方面。
关键配置选项(用法)
| 选项 | 默认值 | 使用说明(允许值及行为) |
|---|---|---|
pre_compress |
False |
True / False。若为 True,输入的消息会在存储前使用 pre_compressor 配置进行预压缩。这可以降低存储和索引成本,但可能会丢失细粒度细节。若为 False,则消息会未经预压缩直接存储。 |
pre_compressor |
None |
dict / object。预压缩组件的配置(PreCompressorConfig),包含字段如 model_name(例如 llmlingua-2、entropy_compress)和 configs(模型特定参数)。仅在 pre_compress=True 时生效。 |
topic_segment |
False |
True / False。启用基于主题的长对话分割功能。当为 True时,长对话会被拆分为多个主题片段,每个片段可独立索引/存储(需配合 topic_segmenter 使用)。当为 False时,消息按顺序存储。 |
precomp_topic_shared |
False |
True / False。若为 True,预压缩和主题分割可以共享中间结果,避免重复计算。这可能提升性能,但需要仔细配置以防止跨主题信息泄露。 |
topic_segmenter |
None |
dict / object。主题分割的配置(TopicSegmenterConfig),包括 model_name 和 configs(片段长度、重叠等)。仅在 topic_segment=True 时使用。 |
messages_use |
'user_only' |
'user_only' / 'assistant_only' / 'hybrid'。控制用于生成元数据和摘要的消息类型:user_only 使用用户输入,assistant_only 使用助手回复,hybrid 则同时使用两者。选择 hybrid 会增加处理量,但能提供更丰富的上下文信息。 |
metadata_generate |
True |
True / False。若为 True,将提取并存储关键词、实体等元数据,以支持基于属性和过滤条件的检索。若为 False,则不进行元数据提取。 |
text_summary |
True |
True / False。若为 True,会生成文本摘要并与原文一同存储(可降低检索成本并加快查阅速度)。若为 False,则仅存储原文。摘要质量取决于 memory_manager 的配置。 |
memory_manager |
MemoryManagerConfig() |
dict / object。控制用于生成摘要和元数据的模型(MemoryManagerConfig),例如 model_name(openai、ollama 等)和 configs。更改此配置会影响摘要的风格、长度和成本。 |
extract_threshold |
0.5 |
浮点数(0.0 - 1.0)。用于决定内容是否足够重要,从而被提取为元数据或高亮显示。较高值(如 0.8)表示更保守的提取策略;较低值(如 0.2)则会提取更多内容(可能导致噪声增加)。 |
index_strategy |
None |
'embedding' / 'context' / 'hybrid' / None。决定记忆如何被索引:embedding 使用向量索引(需配备嵌入器和检索器)进行语义搜索;context 使用基于文本/上下文的检索方式(需配备上下文检索器)进行关键词或文档相似度匹配;hybrid 则结合上下文过滤与向量重排序,以提高鲁棒性和准确性。 |
text_embedder |
None |
dict / object。文本嵌入模型的配置(TextEmbedderConfig),包含 model_name(如 huggingface)和 configs(批量大小、设备、嵌入维度等)。当 index_strategy 或 retrieve_strategy 包含 'embedding' 时必需。 |
multimodal_embedder |
None |
dict / object。多模态/图像嵌入器的配置(MMEmbedderConfig)。用于非文本模态的数据。 |
history_db_path |
os.path.join(lightmem_dir, "history.db") |
str。用于持久化对话历史和轻量级状态的路径。有助于在重启后恢复状态。 |
retrieve_strategy |
'embedding' |
'embedding' / 'context' / 'hybrid'。查询时用于获取相关记忆的策略。应根据数据和查询类型选择:语义查询 -> 'embedding';关键词/结构化查询 -> 'context';混合查询 -> 'hybrid'。 |
context_retriever |
None |
dict / object。基于上下文的检索器配置(ContextRetrieverConfig),例如 model_name='BM25' 和 configs 如 top_k。仅在 retrieve_strategy 包含 'context' 时使用。 |
embedding_retriever |
None |
dict / object。向量存储的配置(EmbeddingRetrieverConfig),例如 model_name='qdrant' 和连接/索引参数。仅在 retrieve_strategy 包含 'embedding' 时使用。 |
summary_retriever |
None |
dict / object。针对摘要的专用向量存储配置(EmbeddingRetrieverConfig)。配置后,摘要将被存储在单独的集合中,实现分层检索。在 StructMem 模式下,可用于独立存储和检索会话/主题摘要,而不受详细记忆的影响。 |
update |
'offline' |
'online' / 'offline'。'offline':批量或定时更新,以节省成本并聚合变更——这是完全支持且功能完整的模式。'online':保留用于未来开发(目前仅为占位符,设置该模式时不会持久化内存)。 |
kv_cache |
False |
True / False。若为 True,尝试预先计算并持久化模型的 KV 缓存,以加速重复的 LLM 调用(需 LLM 运行时支持,并可能增加存储需求)。缓存将存储在 kv_cache_path 中。 |
kv_cache_path |
os.path.join(lightmem_dir, "kv_cache.db") |
str。当 kv_cache=True 时,KV 缓存的存储文件路径。 |
graph_mem |
False |
True / False。若为 True,部分记忆将以图结构(节点和关系)组织,以支持复杂的关系查询和推理。这需要额外的图处理和存储资源。 |
extraction_mode |
'flat' |
'flat' / 'event'。记忆提取模式:'flat' 将事实性条目提取为独立单元,适合一般知识的保存;'event' 则提取事件级别的结构,包含事实性和关系性成分,保留时间关联和因果关系。建议在叙事性强或对时间敏感的场景中使用 'event'。 |
version |
'v1.1' |
str。配置/API 版本。仅在了解兼容性影响时才更改。 |
logging |
'None' |
dict / object。日志记录的配置,用于启用日志功能。 |
🏆 贡献者

JizhanFang |

Xinle-Deng |

Xubqpanda |

HaomingX |

453251 |

James-TYQ |

evy568 |

Norah-Feathertail |

TongjiCst |
🔗 相关项目






常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备