memsearch
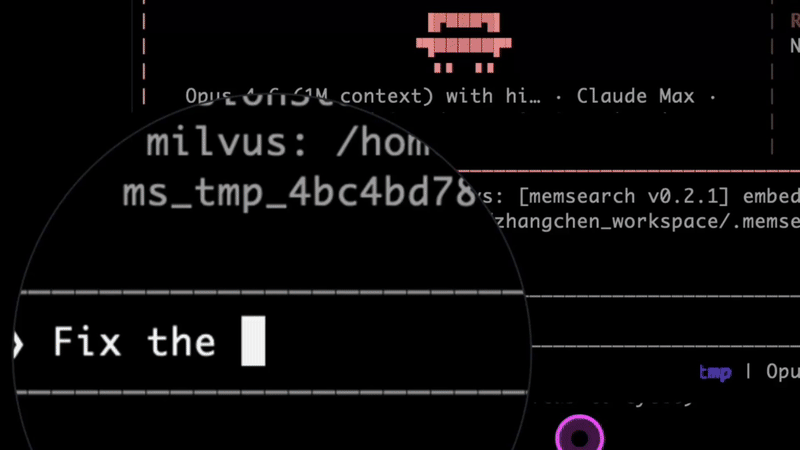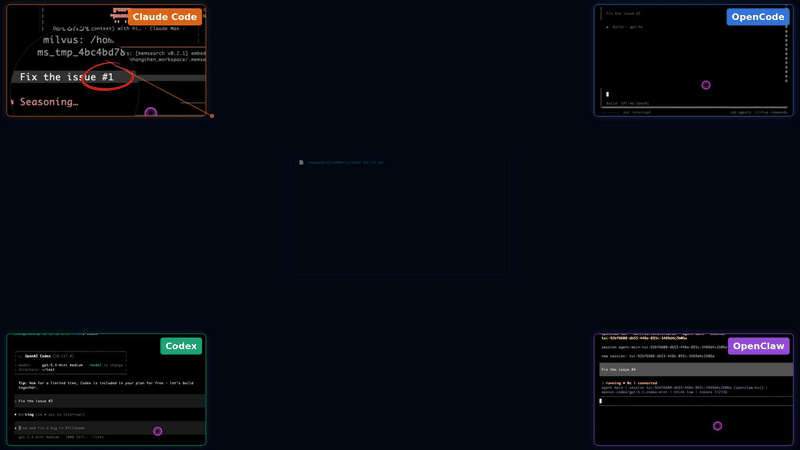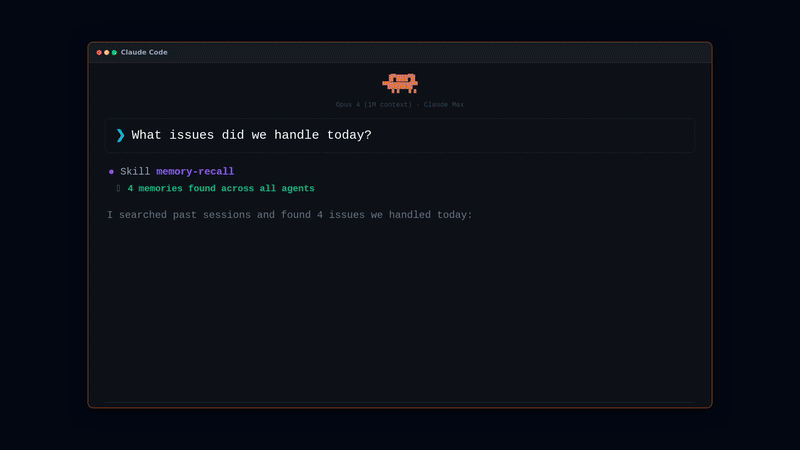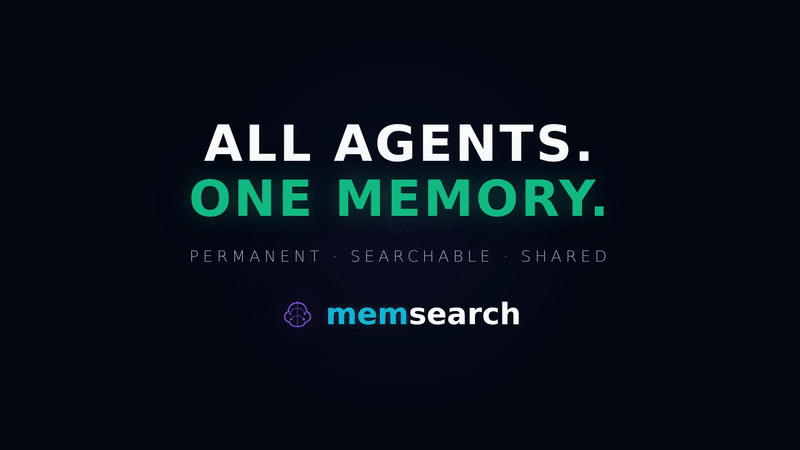
memsearch 是一款专为 AI 编程助手打造的跨平台语义记忆系统。它旨在解决不同 AI 代理之间记忆孤立、上下文无法共享的痛点,让用户在 Claude Code、OpenClaw、OpenCode 或 Codex CLI 等任意平台上的对话内容,都能自动转化为可被其他平台检索的知识库,实现“一次记录,处处可用”。
无论是希望提升工作效率的 AI 重度用户,还是致力于构建智能体的开发者,都能从中受益。普通用户只需安装对应插件,即可零配置获得持久的记忆能力;开发者则可通过其提供的 CLI 工具和 Python API,灵活地将记忆工程集成到自己的应用中。
memsearch 的独特之处在于坚持"Markdown 优先”理念,所有记忆均以人类可读、可版本控制的 .md 文件形式存储,确保数据透明可控。技术层面,它支持混合搜索(结合向量与关键词)、智能去重及文件实时监听同步,并通过三层渐进式检索机制,确保 AI 能精准召回历史上下文。作为一个轻量级独立库,memsearch 让 AI 真正拥有了连贯且可迁移的长期记忆。
使用场景
资深全栈工程师小李正在同时使用 Claude Code 和 Codex CLI 维护一个复杂的微服务架构,他需要在不同会话中频繁切换上下文并复用之前的决策逻辑。
没有 memsearch 时
- 记忆断层严重:在 Claude Code 中讨论确定的数据库重构方案,切换到 Codex CLI 时需要重新粘贴大量背景信息,否则新会话对历史一无所知。
- 检索效率低下:想要查找上周关于“支付网关超时”的排查结论,只能依靠模糊的记忆手动翻阅聊天记录或本地笔记,耗时且容易遗漏。
- 知识难以沉淀:关键的架构决策散落在各次对话的临时上下文中,无法形成可版本控制的文档,新人接手项目时极易重复踩坑。
- 多工具协同割裂:不同 AI 助手之间如同孤岛,无法共享语义记忆,导致每次切换工具都像是在重新开始一个新项目。
使用 memsearch 后
- 跨平台记忆无缝流转:在 Claude Code 中生成的架构决策自动同步为 Markdown 文件,Codex CLI 能立即感知并基于此继续开发,实现“一处对话,全局可用”。
- 语义检索精准高效:只需输入自然语言如“支付网关超时怎么解决的”,memsearch 即可通过混合搜索(向量 + 关键词)瞬间定位到相关历史片段和代码建议。
- 知识资产自动化管理:所有记忆以
.md文件形式存储,天然支持 Git 版本控制,团队可随时审查、编辑并沉淀为永久性的项目知识库。 - 实时同步零配置:后台文件监听器自动索引新增内容,无需手动触发更新,确保所有连接的 AI 代理始终拥有最新的项目上下文。
memsearch 将分散的 AI 对话转化为可持久化、可检索且跨平台流通的团队核心知识资产,彻底打破了智能体间的记忆孤岛。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- 默认使用 ONNX bge-m3 模型,可在 CPU 上运行
- 若使用其他提供商(如 Ollama)则取决于具体模型需求
未说明(默认本地模型约 558 MB,建议常规开发内存即可)
快速开始
 memsearch
memsearch
跨平台语义记忆,专为AI编码代理设计。




为什么选择 memsearch?
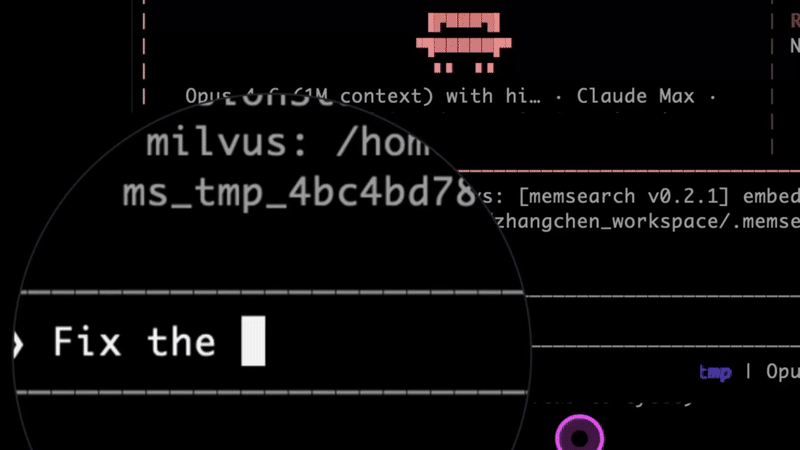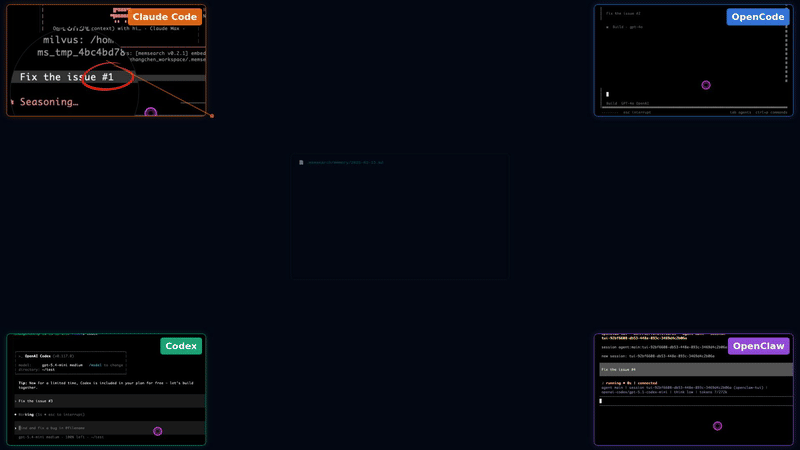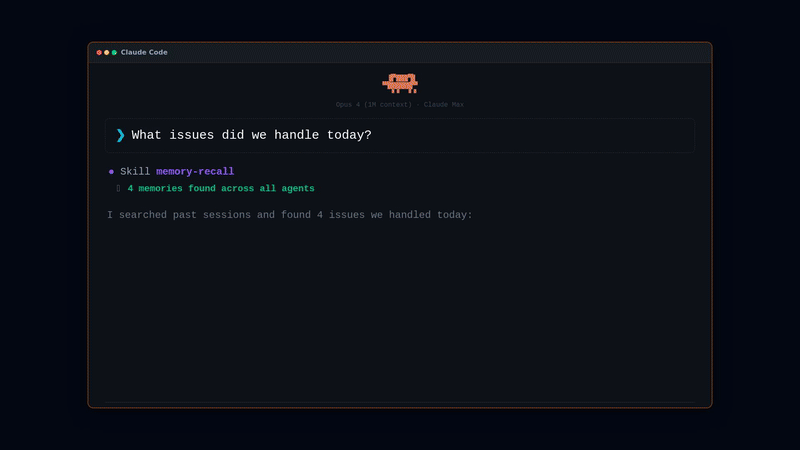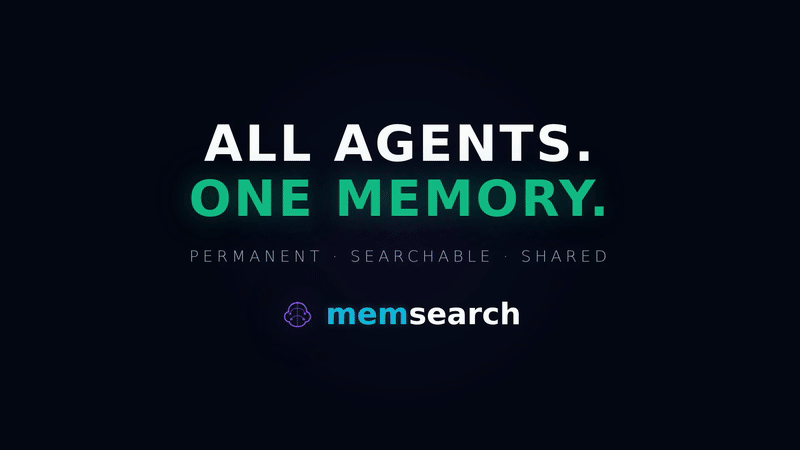
- 🌐 全平台,一内存 — 记忆可在 Claude Code、OpenClaw、OpenCode 和 Codex CLI 之间无缝流转。在一个代理中的对话内容会成为其他所有代理中可搜索的上下文——无需额外配置。
- 👥 对于代理用户而言,只需安装插件即可获得持久化记忆,几乎零操作;对于代理开发者而言,可以使用完整的 CLI 和 Python API 来构建记忆系统,并将其集成到自己的代理中。
- 📄 Markdown 是唯一可信的数据源 — 受 OpenClaw 启发。你的记忆以
.md文件形式存储,既人类可读、可编辑,又能进行版本控制。Milvus 则是一个“影子索引”:一个派生且可重建的缓存。 - 🔍 渐进式检索、混合搜索、智能去重、实时同步 — 三层召回机制(搜索 → 扩展 → 转录);稠密向量 + BM25 稀疏向量 + RRF 重排序;通过 SHA-256 内容哈希跳过未更改的内容;文件监听器可实时自动索引。
🧑💻 对于代理用户
选择你的平台,安装相应的插件,一切就绪。每个插件都会自动捕获对话,并提供语义化的记忆检索功能,无需任何配置。
对于 Claude Code 用户
# 安装
/plugin marketplace add zilliztech/memsearch
/plugin install memsearch
# 重启 Claude Code 以激活插件
重启后,你只需像往常一样与 Claude Code 对话即可。插件会自动记录每一轮对话。
验证是否正常工作 — 进行几次对话后,检查你的记忆文件:
ls .memsearch/memory/ # 应该能看到每日生成的 .md 文件
cat .memsearch/memory/$(date +%Y-%m-%d).md
回忆记忆 — 触发方式有两种:
/memory-recall 我们之前讨论过 Redis 的哪些内容?
或者直接自然地提问——当 Claude 感知到问题需要历史背景时,会自动调用该技能:
我们之前讨论过 Redis 缓存,当时选择的 TTL 是多少?
📖 Claude Code 插件文档 · 故障排除
对于 OpenClaw 用户
# 从 ClawHub 安装
openclaw plugins install clawhub:memsearch
openclaw gateway restart
安装完成后,你可以像往常一样在 TUI 中进行对话。插件会自动记录每一回合的交流。
验证是否正常工作 — 记忆文件会保存在你的代理工作目录中:
# 对主代理:
ls ~/.openclaw/workspace/.memsearch/memory/
# 对其他代理(如工作代理):
ls ~/.openclaw/workspace-work/.memsearch/memory/
回忆记忆 — 触发方式有两种:
/memory-recall 我们设置的批量大小上限是多少?
或者直接自然地提问——当 LLM 感知到问题需要历史信息时,会自动调用记忆工具:
我们之前讨论过批量大小限制,最终决定的是什么?
🔧 对于 OpenCode 用户
// 在 ~/.config/opencode/opencode.json 中添加
{ "plugin": ["@zilliz/memsearch-opencode"] }
安装完成后,你可以在 TUI 中像往常一样进行对话。后台守护进程会自动捕获对话内容。
验证是否正常工作:
ls .memsearch/memory/ # 经过几次对话后,会生成每日的 .md 文件
回忆记忆 — 触发方式有两种:
/memory-recall 我们之前讨论过身份验证的哪些内容?
或者直接自然地提问——当 LLM 感知到问题需要历史背景时,会自动调用记忆工具:
我们之前讨论过身份验证流程,具体采用了哪种方式?
🔧 对于 Codex CLI 用户
# 安装
bash memsearch/plugins/codex/scripts/install.sh
codex --yolo # 用于 ONNX 模型网络访问
安装完成后,你可以照常进行对话。钩子会捕获并总结每一轮交流。
验证是否正常工作:
ls .memsearch/memory/
回忆记忆 — 使用以下技能:
$memory-recall 我们之前讨论过部署的哪些内容?
⚙️ 配置(所有平台)
所有插件共享同一个 memsearch 后端。只需配置一次,即可在所有地方使用。
嵌入模型
默认为 ONNX bge-m3 — 在本地 CPU 上运行,无需 API 密钥,不产生费用。首次启动时,模型文件(约 558 MB)将从 HuggingFace Hub 下载。
memsearch config set embedding.provider onnx # 默认 — 本地,免费
memsearch config set embedding.provider openai # 需要 OPENAI_API_KEY
memsearch config set embedding.provider ollama # 本地,任意模型
所有提供商和模型:配置 — 嵌入模型提供商
Milvus 后端
只需更改 milvus_uri(以及可选的 milvus_token),即可切换部署模式:
Milvus Lite(默认)— 无需配置,单文件部署。非常适合快速上手:
# 开箱即用,无需任何设置
memsearch config get milvus.uri # → ~/.memsearch/milvus.db
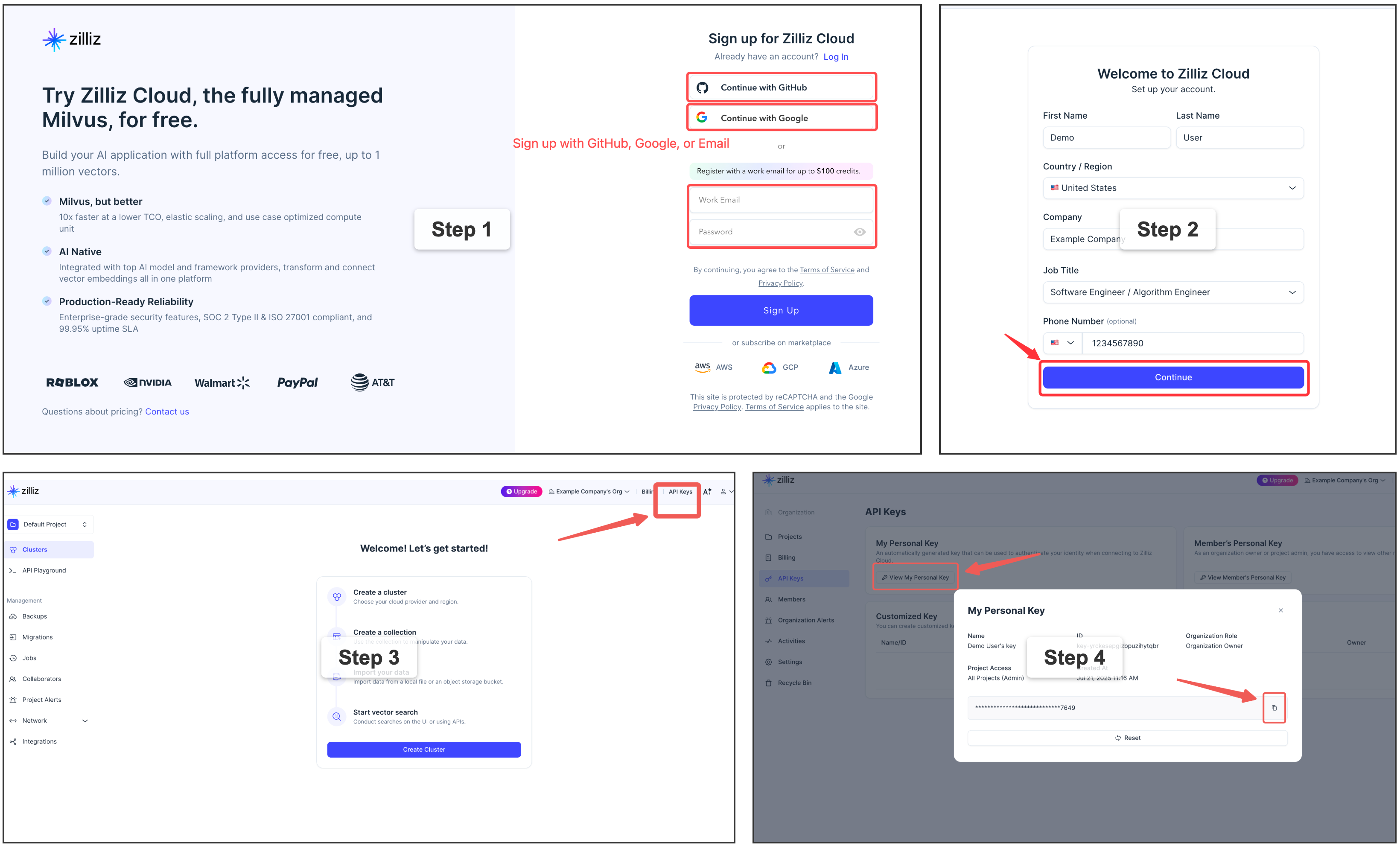
⭐ Zilliz Cloud(推荐)— 全托管服务,提供免费层级 — 注册 👇:
memsearch config set milvus.uri "https://in03-xxx.api.gcp-us-west1.zillizcloud.com"
memsearch config set milvus.token "your-api-key"
自托管 Milvus 服务器(Docker)— 适用于高级用户
适用于多用户或团队环境,并拥有专用的 Milvus 实例。需要 Docker。请参阅官方安装指南。
memsearch config set milvus.uri http://localhost:19530
🛠️ 适用于智能体开发者
除了开箱即用的插件之外,memsearch 还提供了完整的 CLI 和 Python API,用于将记忆功能集成到您自己的智能体中。无论您是为自定义智能体添加持久化上下文、构建基于记忆增强的 RAG 流程,还是一些框架相关的工程工作,驱动插件的核心引擎都可以作为库直接使用。
🏗️ 架构概览
┌──────────────────────────────────────────────────────────────┐
│ 🧑💻 适用于智能体用户(插件) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌────────┐ ┌──────┐ │
│ │ Claude │ │ OpenClaw │ │ OpenCode │ │ Codex │ │ Your │ │
│ │ Code │ │ Plugin │ │ Plugin │ │ Plugin │ │ App │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ └───┬────┘ └──┬───┘ │
│ └─────────────┴────────────┴───────────┴────────┘ │
├────────────────────────────┬─────────────────────────────────┤
│ 🛠️ 适用于智能体开发者 │ 使用 ↓ 自行构建 │
│ ┌─────────────────────────┴──────────────────────────────┐ │
│ │ memsearch CLI / Python API │ │
│ │ index · search · expand · watch · compact │ │
│ └─────────────────────────┬──────────────────────────────┘ │
│ ┌─────────────────────────┴──────────────────────────────┐ │
│ │ 核心:分块器 → 嵌入模型 → Milvus │ │
│ │ 混合搜索(BM25 + 稠密向量 + RRF) │ │
│ └────────────────────────────────────────────────────────┘ │
├──────────────────────────────────────────────────────────────┤
│ 📄 Markdown 文件(事实来源) │
│ memory/2026-03-27.md · memory/2026-03-26.md · ... │
└──────────────────────────────────────────────────────────────┘
插件位于 CLI/API 层之上。API 负责索引、搜索以及与 Milvus 的同步。Markdown 文件始终是事实来源——Milvus 是一个可重建的影子索引。插件层以下的部分,正是智能体开发者所使用的部分。
插件的工作原理(以 Claude Code 为例)
捕获 — 每次对话轮次结束后:
用户提问 → 智能体回复 → 停止钩子触发
│
┌────────────────────┘
▼
解析最后一轮对话
│
▼
大语言模型总结(俳句风格)
"- 用户询问了 X。"
"- Claude 回答了 Y。"
│
▼
追加到 memory/2026-03-27.md
并附带 <!-- session:UUID --> 标记
│
▼
memsearch 索引 → Milvus
召回 — 三层渐进式搜索:
用户:“我们之前讨论过批处理大小吗?”
│
▼
L1 memsearch 搜索“批处理大小” → 排序后的文本片段
│ (还需要更多吗?)
▼
L2 memsearch 展开 <chunk_hash> → 整个 .md 片段
│ (需要原始内容吗?)
▼
L3 解析转录本 <session.jsonl> → 原始对话记录
📄 Markdown 作为事实来源
插件追加 ──→ .md 文件 ←── 可由人工编辑
│
▼
memsearch 监视器(实时监视)
│
检测到文件变更
│
▼
重新对变更的 .md 文件进行分块
│
对每个分块计算哈希值(SHA-256)
│
┌───────────┴───────────┐
▼ ▼
分块未变? 分块是新生成的还是已更改?
→ 跳过(无需 API 调用) → 嵌入 → 更新至 Milvus
│ │
└───────────┬───────────┘
▼
┌──────────────────┐
│ Milvus(影子索引) │
│ 始终保持同步 │
│ 可重建 │
└──────────────────┘
📦 安装
# 作为全局 CLI 工具安装 — 当您主要使用 `memsearch` 命令,或者使用任何智能体插件(Claude Code、Codex、OpenClaw、OpenCode)时,建议采用此方式。这些插件都会调用 CLI。
uv tool install memsearch # 通过 uv
pipx install memsearch # 通过 pipx
pip install memsearch # 通过普通 pip
# 作为项目依赖项安装 — 如果您希望导入
# 从您自己的 Python 代码中使用 `memsearch`(例如通过 MemSearch 类)。
uv add memsearch # 使用 uv,添加到 pyproject.toml
pip install memsearch # 安装到已激活的虚拟环境中
可选的嵌入提供商
# 作为 CLI 工具(推荐——本地 ONNX,无需 API 密钥)
uv tool install "memsearch[onnx]"
pipx install "memsearch[onnx]"
pip install "memsearch[onnx]"
# 作为项目依赖项
uv add "memsearch[onnx]"
# 其他选项:[openai]、[google]、[voyage]、[jina]、[mistral]、[ollama]、[local]、[all]
🐍 Python API — 为您的代理赋予记忆能力
from memsearch import MemSearch
mem = MemSearch(paths=["./memory"])
await mem.index() # 索引 Markdown 文件
results = await mem.search("Redis 配置", top_k=3) # 语义搜索
scoped = await mem.search("定价", top_k=3, source_prefix="./memory/product")
print(results[0]["content"], results[0]["score"]) # 内容 + 相似度
完整示例——带有记忆的代理(OpenAI)——点击展开
import asyncio
from datetime import date
from pathlib import Path
from openai import OpenAI
from memsearch import MemSearch
MEMORY_DIR = "./memory"
llm = OpenAI() # 您的 LLM 客户端
mem = MemSearch(paths=[MEMORY_DIR]) # MemSearch 处理其余部分
def save_memory(content: str):
"""将笔记追加到今天的记忆日志中(类似于 OpenClaw 的每日 Markdown 格式)。"""
p = Path(MEMORY_DIR) / f"{date.today()}.md"
p.parent.mkdir(parents=True, exist_ok=True)
with open(p, "a") as f:
f.write(f"\n{content}\n")
async def agent_chat(user_input: str) -> str:
# 1. 回忆——搜索过往记忆以获取相关上下文
memories = await mem.search(user_input, top_k=3)
context = "\n".join(f"- {m['content'][:200]}" for m in memories)
# 2. 思考——调用 LLM 并结合记忆上下文
resp = llm.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": f"你有以下记忆:\n{context}"},
{"role": "user", "content": user_input},
],
)
answer = resp.choices[0].message.content
# 3. 记住——保存此次对话并将其索引
save_memory(f"## {user_input}\n{answer}")
await mem.index()
return answer
async def main():
# 预先存储一些知识
save_memory("## 团队\n- Alice:前端负责人\n- Bob:后端负责人")
save_memory("## 决策\n我们选择了 Redis 作为缓存方案,而非 Memcached。")
await mem.index() # 或者使用 mem.watch() 在后台自动索引
# 代理现在可以回忆起这些记忆
print(await agent_chat("我们的前端负责人是谁?"))
print(await agent_chat("我们选择了哪种缓存方案?"))
asyncio.run(main())
Anthropic Claude 示例——点击展开
pip install memsearch anthropic
import asyncio
from datetime import date
from pathlib import Path
from anthropic import Anthropic
from memsearch import MemSearch
MEMORY_DIR = "./memory"
llm = Anthropic()
mem = MemSearch(paths=[MEMORY_DIR])
def save_memory(content: str):
p = Path(MEMORY_DIR) / f"{date.today()}.md"
p.parent.mkdir(parents=True, exist_ok=True)
with open(p, "a") as f:
f.write(f"\n{content}\n")
async def agent_chat(user_input: str) -> str:
# 1. 回忆
memories = await mem.search(user_input, top_k=3)
context = "\n".join(f"- {m['content'][:200]}" for m in memories)
# 2. 思考——调用 Claude 并结合记忆上下文
resp = llm.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=1024,
system=f"你有以下记忆:\n{context}",
messages=[{"role": "用户", "内容": user输入}],
)
answer = resp.content[0].text
# 3. 记住
save_memory(f"## {user输入}\n{答案}")
await mem.index()
return answer
async def main():
save_memory("## 团队\n- Alice:前端负责人\n- Bob:后端负责人")
await mem.index()
print(await agent_chat("我们的前端负责人是谁?"))
asyncio.run(main())
Ollama(完全本地,无需 API 密钥)——点击展开
pip install "memsearch[ollama]"
ollama pull nomic-embed-text # 嵌入模型
ollama pull llama3.2 # 对话模型
import asyncio
from datetime import date
from pathlib import Path
from ollama import chat
from memsearch import MemSearch
MEMORY_DIR = "./memory"
mem = MemSearch(paths=[MEMORY_DIR], embedding_provider="ollama")
def save_memory(content: str):
p = Path(MEMORY_DIR) / f"{date.today()}.md"
p.parent.mkdir(parents=True, exist_ok=True)
with open(p, "a") as f:
f.write(f"\n{content}\n")
async def agent_chat(user_input: str) -> str:
# 1. 回忆
memories = await mem.search(user_input, top_k=3)
context = "\n".join(f"- {m['content'][:200]}" for m in memories)
# 2. 思考——在本地调用 Ollama
resp = chat(
model="llama3.2",
messages=[
{"role": "系统", "内容": f"你有以下记忆:\n{context}"},
{"role": "用户", "内容": user输入},
],
)
answer = resp.message.content
# 3. 记住
save_memory(f"## {user输入}\n{答案}")
await mem.index()
return answer
async def main():
save_memory("## 团队\n- Alice:前端负责人\n- Bob:后端负责人")
await mem.index()
print(await agent_chat("我们的前端负责人是谁?"))
asyncio.run(main())
📖 完整的 Python API 参考文档:Python API 文档
⌨️ CLI 使用方法
设置:
memsearch config init # 交互式设置向导
memsearch config set embedding.provider onnx # 切换嵌入提供商
memsearch config set milvus.uri http://localhost:19530 # 切换 Milvus 后端
索引与搜索:
memsearch index ./memory/ # 索引 Markdown 文件
memsearch index ./memory/ ./notes/ --force # 重新嵌入所有内容
memsearch search "Redis 缓存" # 混合搜索(BM25 + 向量)
memsearch search "认证流程" --top-k 10 --json-output # 输出 JSON 格式以便脚本处理
memsearch expand <chunk_hash> # 显示某个分块周围的完整段落
实时同步与维护:
memsearch watch ./memory/ # 实时文件监视器(文件更改时自动索引)
memsearch compact # 基于 LLM 的分块摘要
memsearch stats # 显示已索引的分块数量
memsearch reset --yes # 清除所有已索引的数据并重新构建
📖 包含所有标志的完整 CLI 参考文档:CLI 文档
⚙️ 配置
嵌入模型和 Milvus 后端设置 → 配置(所有平台)
设置优先级:内置默认值 → ~/.memsearch/config.toml → .memsearch.toml → CLI 标志。
📖 完整配置指南:配置
🔗 链接
- 📖 文档 — 完整指南、API 参考和架构细节
- 🔌 平台插件 — Claude Code、OpenClaw、OpenCode、Codex CLI
- 💡 设计哲学 — 为什么使用 Markdown、为什么选择 Milvus、竞争对手对比
- 🦞 OpenClaw — 激发 memsearch 灵感的内存架构
- 🗄️ Milvus | Zilliz Cloud — 为 memsearch 提供支持的向量数据库
🤝 贡献
欢迎提交 bug 报告、功能请求和拉取请求!请参阅 贡献指南,了解开发环境搭建、测试以及插件开发的相关说明。如有疑问或想参与讨论,请加入我们的 Discord 社区。
📄 许可证
版本历史
v0.3.12026/04/16v0.3.02026/04/14v0.2.42026/04/10v0.2.32026/04/08v0.2.22026/03/31v0.2.12026/03/31v0.2.02026/03/30v0.1.192026/03/23v0.1.182026/03/22v0.1.172026/03/19v0.1.162026/03/09常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。