GLM-5
GLM-5 是一款面向复杂系统工程与长周期智能体任务的开源大语言模型。它旨在解决现有模型在处理高难度推理、全栈代码生成及需要长期规划的实际业务场景时,能力不足或规划连贯性较差的问题。无论是需要构建复杂软件系统的开发者、探索通用人工智能边界的研究人员,还是寻求自动化解决方案的企业用户,都能从中获益。
作为 GLM-4.5 的进化版,GLM-5 将参数量从 3550 亿扩展至 7440 亿(激活参数 400 亿),并将预训练数据量提升至 28.5 万亿词元。其独特技术亮点在于集成了 DeepSeek 稀疏注意力机制,在保持超长上下文处理能力的同时大幅降低了部署成本;同时,项目配套发布了名为"slime"的新型异步强化学习基础设施,显著提升了训练效率,使模型在推理、编程及智能体任务上达到了开源领域的顶尖水平,甚至在部分长周期任务中逼近业界最前沿的闭源模型。GLM-5 支持本地化部署,兼容 vLLM、SGLang 等主流框架,并提供 FP8 量化版本以优化资源占用,是追求高性能与低成本平衡的理想选择。
使用场景
某中型电商团队正试图将遗留的单体架构重构为微服务系统,并需开发一套能自动监控库存、动态调整定价的长期运营代理。
没有 GLM-5 时
- 长程任务易迷失:在处理跨越数周的模拟运营或复杂重构时,模型往往在中途忘记初始约束,导致逻辑断层或资源分配错误。
- 代码工程能力弱:生成的代码片段虽能运行,但缺乏系统级考量,难以直接整合进现有的复杂后端框架,需人工大量修补。
- 推理成本高企:为了维持较长的上下文窗口以理解整个项目结构,不得不使用昂贵的闭源模型或牺牲精度进行截断。
- 迭代效率低下:缺乏高效的强化学习反馈机制,模型在面对新出现的边缘案例时,无法快速自我修正策略。
使用 GLM-5 后
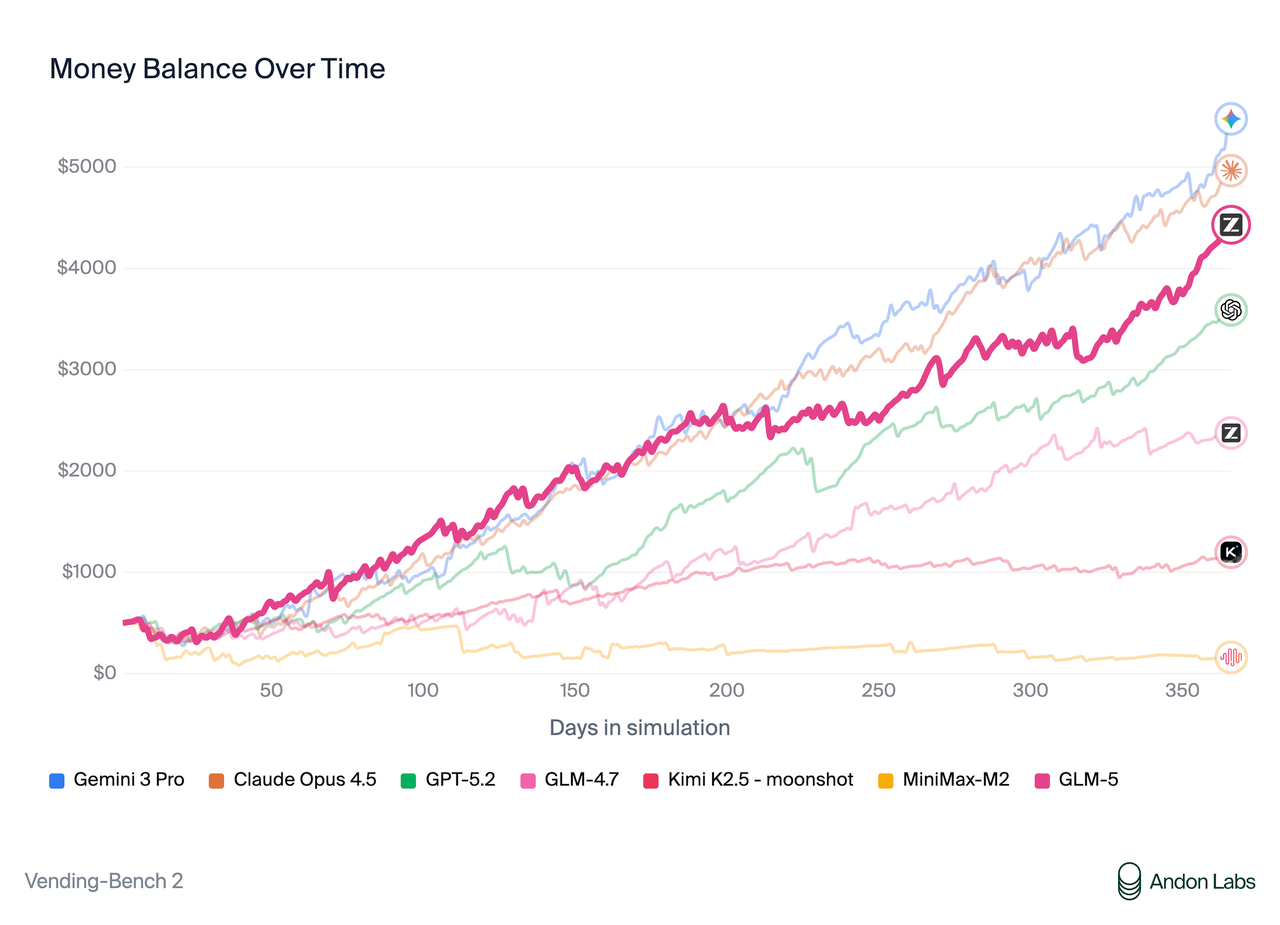
- 长程规划稳健:凭借 28.5T 令牌预训练和长上下文能力,GLM-5 能完整记住一年的运营目标,在模拟测试中最终账户余额高达 4,432 美元,展现出卓越的资源管理力。
- 系统级工程落地:从“氛围编程”升级为“代理工程”,GLM-5 生成的代码不仅符合语法,更具备架构意识,能直接处理前后端复杂的交互逻辑。
- 部署成本大幅降低:集成 DeepSeek 稀疏注意力机制(DSA),在保持超长上下文的同时显著减少了显存占用,使得本地部署 744B 大模型变得经济可行。
- 智能自我进化:基于异步强化学习基础设施,GLM-5 能在复杂任务中不断微调策略,准确处理突发流量和库存异常,表现接近顶尖闭源模型。
GLM-5 通过突破长程规划与系统工程的瓶颈,让开源模型首次具备了独立驾驭复杂、长期自动化任务的核心能力。
运行环境要求
- Linux
- 必需
- 推荐使用 NVIDIA Hopper (H100/H800) 或 Blackwell (B200/GB200) 架构 GPU
- 部署 744B (40B active) 参数模型需多卡并行(示例命令显示 --tensor-parallel-size 8),显存需求极高,建议使用 FP8 量化版本以降低显存占用
未说明(取决于具体部署配置,通常需数百 GB 系统内存以支持大规模模型加载)
快速开始
GLM-5
👋 加入我们的 微信 或 Discord 社区。
📖 查看 GLM-5 的 技术报告。
📍 在 Z.ai API 平台 上使用 GLM-5 API 服务。
👉 一键访问 GLM-5。
简介
我们推出 GLM-5,旨在应对复杂系统工程和长周期代理任务。规模扩展仍然是提升通用人工智能(AGI)智能效率的最重要途径之一。与 GLM-4.5 相比,GLM-5 的参数量从 355B(32B 活性参数)增加到 744B(40B 活性参数),预训练数据也从 23T 增加至 28.5T 个标记。此外,GLM-5 集成了 DeepSeek 稀疏注意力机制(DSA),在保持长上下文能力的同时大幅降低了部署成本。
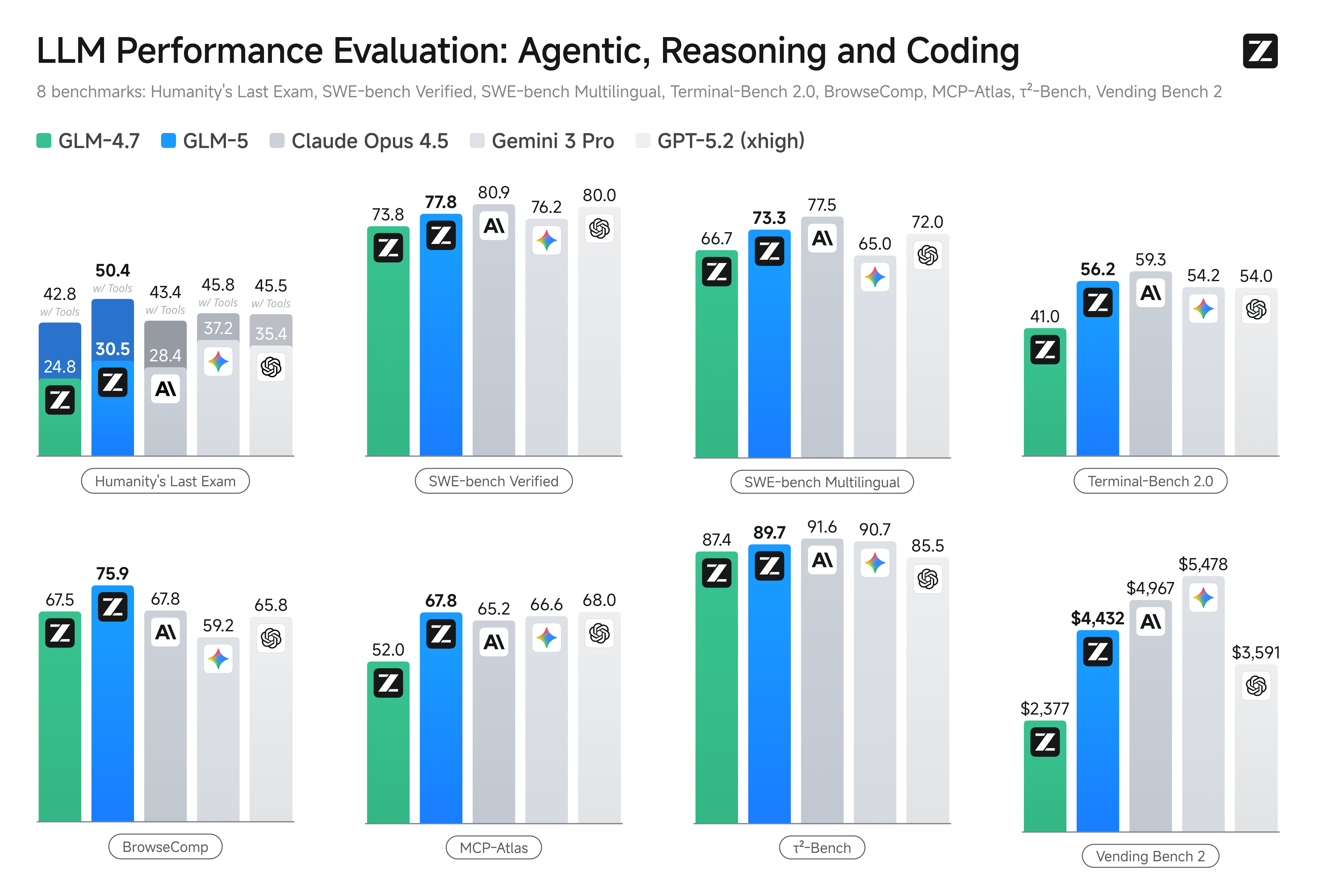
强化学习旨在弥合预训练模型的能力与卓越表现之间的差距。然而,由于 RL 训练效率低下,将其大规模应用于大语言模型仍面临挑战。为此,我们开发了 slime,一种新颖的 异步 RL 基础设施,可显著提升训练吞吐量和效率,从而实现更精细的后训练迭代。凭借预训练和后训练两方面的进步,GLM-5 在广泛的学术基准测试中相比 GLM-4.7 取得了显著提升,并在推理、编码和代理任务方面达到了全球开源模型中的顶尖水平,进一步缩小了与前沿模型的差距。
GLM-5 专为复杂系统工程和长周期代理任务而设计。在我们的内部评估套件 CC-Bench-V2 上,GLM-5 在前端、后端以及长周期任务中均显著优于 GLM-4.7,与 Claude Opus 4.5 的差距也进一步缩小。

在衡量长期运营能力的 Vending Bench 2 基准测试中,GLM-5 在开源模型中位居第一。该测试要求模型模拟运行一家自动售货机业务一年;GLM-5 最终账户余额达到 4,432 美元,接近 Claude Opus 4.5 的水平,展现出强大的长期规划和资源管理能力。
模型下载
| 模型 | 下载链接 | 模型大小 | 精度 |
|---|---|---|---|
| GLM-5 | 🤗 Hugging Face 🤖 ModelScope |
744B-A40B | BF16 |
| GLM-5-FP8 | 🤗 Hugging Face 🤖 ModelScope |
744B-A40B | FP8 |
在本地部署 GLM-5
准备环境
vLLM、SGLang 和 xLLM 均支持 GLM-5 的本地部署。以下提供一个简单的部署指南。
vLLM
使用 Docker(版本 0.18.0 或更高):
docker pull vllm/vllm-openai:v0.18.0然后升级 transformers 库(版本 5.4.0 或更高):
pip install -U transformersSGLang
使用 Docker:
docker pull lmsysorg/sglang:glm5-hopper # 适用于 Hopper GPU docker pull lmsysorg/sglang:glm5-blackwell # 适用于 Blackwell GPU
部署
vLLM
vllm serve zai-org/GLM-5-FP8 \ --tensor-parallel-size 8 \ --gpu-memory-utilization 0.85 \ --speculative-config.method mtp \ --speculative-config.num_speculative_tokens 1 \ --tool-call-parser glm47 \ --reasoning-parser glm45 \ --enable-auto-tool-choice \ --served-model-name glm-5-fp8更多详情请参阅 recipes。
SGLang
sglang serve \ --model-path zai-org/GLM-5-FP8 \ --tp-size 8 \ --tool-call-parser glm47 \ --reasoning-parser glm45 \ --speculative-algorithm EAGLE \ --speculative-num-steps 3 \ --speculative-eagle-topk 1 \ --speculative-num-draft-tokens 4 \ --mem-fraction-static 0.85 \ --served-model-name glm-5-fp8更多详情请参阅 sglang 烹饪书。
xLLM 和其他 Ascend NPU
请参阅此处的部署指南 here.
引用
如果您在研究中使用了 GLM-5,请引用我们的技术报告:
@misc{glm5team2026glm5vibecodingagentic,
title={GLM-5:从氛围编码到智能体工程},
author={GLM-5团队和:以及曾傲寒、吕欣、侯振宇、杜正啸、郑钦凯、陈斌、殷达、葛晨迪、黄成华、谢承兴、朱晨正、尹聪峰、王存祥、潘耿政、曾浩、张浩科、王浩然、陈辉龙、张佳杰、焦健、郭嘉琪、王京森、杜景钊、吴金柱、王克东、李磊、范林、钟露辰、刘明道、赵明明、杜鹏帆、董倩、陆锐、双莉、曹淑琳、刘松、蒋婷、陈晓东、张晓涵、黄宣诚、董雪珍、徐亚博、魏瑶、安一凡、牛怡琳、朱一彤、文元昊、岑玉阔、白宇诗、乔仲培、王子涵、王梓康、朱子林、刘子强、李子轩、王博杰、温博思、黄灿、蔡昌鹏、于超、李晨、胡承伟、张晨辉、张丹、林道言、杨大勇、王迪、艾丁、朱尔乐、易方舟、陈飞宇、文国洪、孙海龙、赵海莎、胡海怡、张瀚辰、刘汉睿、张涵宇、彭浩、泰浩、张浩波、刘鹤、王洪伟、闫洪喜、葛洪宇、刘欢、楚欢鹏、赵佳妮、王家琛、赵佳静、任佳敏、王佳鹏、张佳鑫、桂佳艺、赵佳悦、李继杰、安晶、李静、袁景威、杜金花、刘金鑫、支俊凯、段俊文、周凯越、魏康健、王可、罗克云、张来强、沙雷刚、许亮、吴林东、丁林涛、陈璐、李明浩、林念义、塔潘、邹强、宋荣军、杨瑞奇、涂尚青、杨尚通、吴绍祥、张圣炎、李世杰、李双、范淑仪、秦伟、田伟、张卫宁、于文博、梁文杰、匡翔、程向梦、李向阳、严小泉、胡晓伟、凌晓英、范兴、夏兴业、张新源、张鑫泽、潘西瑞、邹旭、张勋凯、刘雅迪、吴燕东、李延福、王一东、朱一凡、谭一君、周怡琳、潘一鸣、张颖、苏银佩、耿一鹏、颜永、谭永林、毕月安、沈宇涵、杨宇豪、李宇江、刘宇楠、王云清、李云涛、吴雨蓉、张宇涛、段宇曦、张宇轩、刘泽震、姜正涛、严振河、张哲宇、魏志祥、陈卓、冯卓尔、姚子俊、柴子威、王子源、张祖洲、徐彬、黄敏列、王洪宁、李娟子、董宇霄、唐杰},
year={2026},
eprint={2602.15763},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2602.15763},
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备