combo
combo 是一个专为机器学习模型融合设计的 Python 工具箱,旨在帮助开发者轻松整合多个模型的预测结果以提升整体性能。在数据科学竞赛和实际业务中,单一模型往往难以达到最优效果,而通过集成学习(Ensemble Learning)将不同模型的优势结合,是解决这一痛点的关键策略。combo 正是为此而生,它统一了来自 scikit-learn、XGBoost 和 LightGBM 等主流库的模型接口,广泛支持分类、聚类及异常检测等核心任务。
这款工具特别适合机器学习工程师、数据科学家以及研究人员使用。无论是需要快速验证融合算法效果的参赛者,还是致力于探索前沿集成技术的学术研究者,都能从中获益。combo 的独特亮点在于其高度统一的 API 设计和丰富的算法覆盖,不仅包含了经典的堆叠(Stacking)方法,还集成了 DCS、DES、LSCP 等较新的动态选择算法。此外,底层利用 numba 和 joblib 进行了即时编译与并行化优化,确保了在处理大规模数据时的高效运行。配合详尽的文档与交互式示例,combo 让复杂的模型组合变得简单可控,是提升模型表现力的得力助手。
使用场景
某金融风控团队正在构建信用卡欺诈检测系统,需要整合逻辑回归、随机森林和 XGBoost 等多个异构模型的预测结果,以最大化识别准确率并降低误报率。
没有 combo 时
- 代码重复繁琐:工程师需手动编写大量胶水代码来对齐不同库(如 scikit-learn 与 XGBoost)的输出格式,才能进行简单的加权平均或投票。
- 高级算法缺失:难以快速落地 DCS(动态分类器选择)或 LSCP 等前沿集成策略,只能依赖基础的静态加权,导致模型上限受限。
- 性能瓶颈明显:在处理百万级交易数据时,串行的模型组合逻辑耗时过长,且缺乏原生的并行加速支持,影响实时拦截效率。
- 维护成本高昂:每新增一个基模型或调整组合策略,都需要重构底层数据流转逻辑,测试与调试周期漫长。
使用 combo 后
- 统一接口调用:通过 combo 标准化的 API,仅需几行代码即可无缝接入各类基模型,自动处理分数对齐与格式转换。
- 前沿策略即享:直接调用内置的 Stacking、DES 及 EAC 等高级算法模块,无需复现论文公式,瞬间提升模型泛化能力。
- 运行效率飞跃:利用工具内建的 Numba JIT 编译与 Joblib 并行化特性,大规模数据的组合预测速度提升数倍,满足实时风控要求。
- 扩展灵活便捷:新增模型或切换组合范式只需修改配置参数,大幅降低了实验迭代门槛与维护复杂度。
combo 将复杂的模型集成工程简化为标准化流程,让数据科学家能专注于策略创新而非底层代码实现。
运行环境要求
- 未说明
未说明
未说明

快速开始
combo:用于机器学习模型组合的 Python 工具箱
部署、文档与统计
.. image:: https://img.shields.io/pypi/v/combo.svg?color=brightgreen :target: https://pypi.org/project/combo/ :alt: PyPI 版本
{kind=link}
.. image:: https://readthedocs.org/projects/pycombo/badge/?version=latest :target: https://pycombo.readthedocs.io/en/latest/?badge=latest :alt: 文档状态
.. image:: https://mybinder.org/badge_logo.svg :target: https://mybinder.org/v2/gh/yzhao062/combo/master :alt: Binder
{kind=link}
.. image:: https://img.shields.io/github/stars/yzhao062/combo.svg :target: https://github.com/yzhao062/combo/stargazers :alt: GitHub 星标
{kind=link}
.. image:: https://img.shields.io/github/forks/yzhao062/combo.svg?color=blue :target: https://github.com/yzhao062/combo/network :alt: GitHub 分支
{kind=link}
.. image:: https://pepy.tech/badge/combo :target: https://pepy.tech/project/combo :alt: 下载量
.. image:: https://pepy.tech/badge/combo/month :target: https://pepy.tech/project/combo :alt: 月度下载量
构建状态、覆盖率、可维护性与许可证
.. image:: https://github.com/yzhao062/combo/actions/workflows/testing.yml/badge.svg :target: https://github.com/yzhao062/combo/actions/workflows/testing.yml :alt: 测试
{kind=link}
.. image:: https://circleci.com/gh/yzhao062/combo.svg?style=svg :target: https://circleci.com/gh/yzhao062/combo :alt: Circle CI
{kind=link}
.. image:: https://ci.appveyor.com/api/projects/status/te7uieha87305ike/branch/master?svg=true :target: https://ci.appveyor.com/project/yzhao062/combo/branch/master :alt: 构建状态
.. image:: https://coveralls.io/repos/github/yzhao062/combo/badge.svg :target: https://coveralls.io/github/yzhao062/combo :alt: 覆盖率状态
{kind=link}
.. image:: https://api.codeclimate.com/v1/badges/465ebba81e990abb357b/maintainability :target: https://codeclimate.com/github/yzhao062/combo/maintainability :alt: 可维护性
.. image:: https://img.shields.io/github/license/yzhao062/combo.svg :target: https://github.com/yzhao062/combo/blob/master/LICENSE :alt: 许可证
{kind=link}
combo 是一个全面的 Python 工具箱,用于 组合机器学习(ML)模型和得分。
模型组合可以被视为 集成学习 <https://en.wikipedia.org/wiki/Ensemble_learning>_ 的一个子任务,
并且已广泛应用于实际任务和 Kaggle 等数据科学竞赛中 [#Bell2007Lessons]。
自推出以来,combo 已被用于或介绍于多项研究工作中 [#Raschka2020Machine] [#Zhao2019PyOD]_。
combo 库支持来自关键 ML 库(如 scikit-learn <https://scikit-learn.org/stable/index.html>、
xgboost <https://xgboost.ai/> 和 LightGBM <https://github.com/microsoft/LightGBM>_)的模型和得分组合,
适用于分类、聚类、异常检测等关键任务。下图展示了一些具有代表性的组合方法。
.. image:: https://raw.githubusercontent.com/yzhao062/combo/master/docs/figs/framework_demo.png :target: https://raw.githubusercontent.com/yzhao062/combo/master/docs/figs/framework_demo.png :alt: 组合框架演示
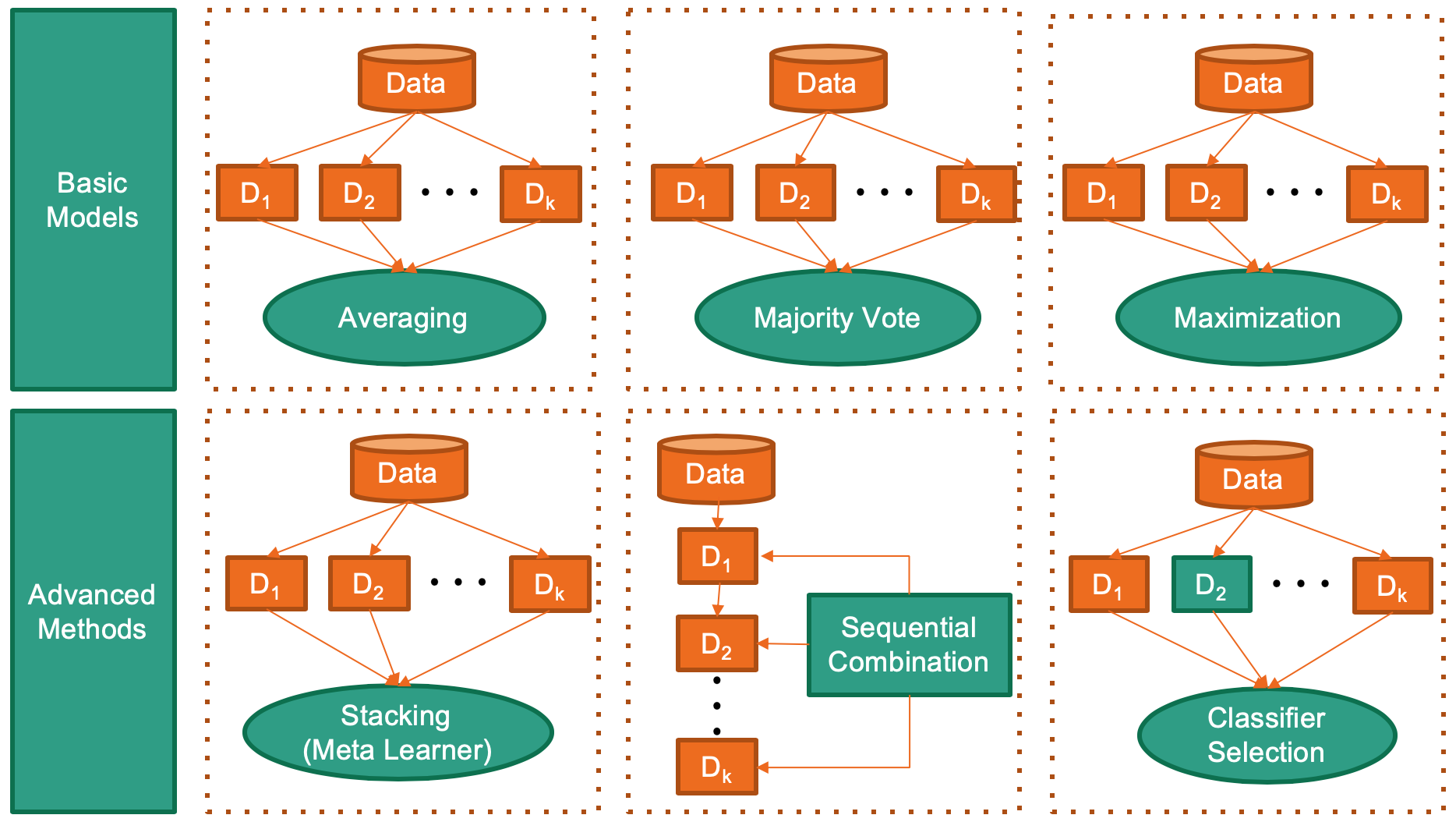{kind=link}
combo 的特点包括:
- 统一的 API、详尽的文档和交互式示例,覆盖多种算法。
- 先进且最新的模型,如 Stacking/DCS/DES/EAC/LSCP。
- 全面的覆盖范围,涵盖分类、聚类、异常检测及原始得分。
- 在可能的情况下,通过 JIT 和并行化优化性能,使用
numba <https://github.com/numba/numba>_ 和joblib <https://github.com/joblib/joblib>_。
API 演示\ :
.. code-block:: python
from combo.models.classifier_stacking import Stacking
初始化一组基础分类器
classifiers = [DecisionTreeClassifier(), LogisticRegression(), KNeighborsClassifier(), RandomForestClassifier(), GradientBoostingClassifier()]
clf = Stacking(base_estimators=classifiers) # 初始化 Stacking 模型 clf.fit(X_train, y_train) # 拟合模型
对未见数据进行预测
y_test_labels = clf.predict(X_test) # 标签预测 y_test_proba = clf.predict_proba(X_test) # 概率预测
引用 combo\ :
combo 论文 <http://www.andrew.cmu.edu/user/yuezhao2/papers/20-aaai-combo.pdf>_ 已发表于
AAAI 2020 <https://aaai.org/Conferences/AAAI-20/>_(演示环节)。
如果您在科学出版物中使用 combo,我们非常感谢您引用以下论文::
@inproceedings{zhao2020combo,
title={Combining Machine Learning Models and Scores using combo library},
author={Zhao, Yue and Wang, Xuejian and Cheng, Cheng and Ding, Xueying},
booktitle={Thirty-Fourth AAAI Conference on Artificial Intelligence},
month = {Feb},
year={2020},
address = {New York, USA}
}
或者::
Zhao, Y., Wang, X., Cheng, C. and Ding, X., 2020. Combining Machine Learning Models and Scores using combo library. Thirty-Fourth AAAI Conference on Artificial Intelligence.
重要链接与资源\ :
awesome-ensemble-learning <https://github.com/yzhao062/awesome-ensemble-learning>_(集成学习相关书籍、论文等)在 Github 上查看最新代码 <https://github.com/yzhao062/combo>_查看文档与 API <https://pycombo.readthedocs.io/>_查看所有示例 <https://github.com/yzhao062/combo/tree/master/examples>_观看 AAAI 2020 的演示视频 <https://youtu.be/PaSJ49Ij7w4>_运行交互式 Jupyter 笔记本 <https://mybinder.org/v2/gh/yzhao062/combo/master>_
目录\ :
安装 <#installation>_API 备忘录与参考 <#api-cheatsheet--reference>_已实现的算法 <#implemented-algorithms>_示例 1:使用 Stacking/DCS/DES 进行分类器组合 <#example-of-stackingdcsdes>_示例 2:简单的分类器组合 <#example-of-classifier-combination>_示例 3:聚类组合 <#example-of-clustering-combination>_示例 4:异常检测器组合 <#example-of-outlier-detector-combination>_开发状态 <#development-status>_纳入标准 <#inclusion-criteria>_
安装 ^^^^^^^^^^^^
建议使用 pip 进行安装。请确保安装的是 最新版本,因为 combo 更新频繁:
.. code-block:: bash
pip install combo # 普通安装 pip install --upgrade combo # 或根据需要更新 pip install --pre combo # 或包含预发布版本以获取新功能
此外,您也可以克隆并运行 setup.py 文件:
.. code-block:: bash
git clone https://github.com/yzhao062/combo.git cd combo pip install .
所需依赖\ :
- Python 3.5、3.6 或 3.7
- joblib
- matplotlib(运行示例时可选)
- numpy>=1.13
- numba>=0.35
- pyod
- scipy>=0.19.1
- scikit_learn>=0.20
关于 Python 2 的说明:
Python 2.7 的维护将于 2020 年 1 月 1 日停止(参见 官方公告 <https://github.com/python/devguide/pull/344>)。
为与 Python 社区的变更以及 combo 所依赖的库(如 scikit-learn)保持一致,
combo 仅支持 Python 3.5 及以上版本,我们建议您使用 Python 3.5 或更高版本以获得最新的功能和错误修复。更多信息请参阅 迁移到要求 Python 3 <https://python3statement.org/>。
API 备忘录与参考 ^^^^^^^^^^^^^^^^^^
完整 API 参考:(https://pycombo.readthedocs.io/en/latest/api.html)。 以下 API 在大多数模型中保持一致(API 备忘录:https://pycombo.readthedocs.io/en/latest/api_cc.html)。
- fit(X, y):拟合估计器。对于无监督方法,y 是可选的。
- predict(X):在估计器拟合完成后,对特定样本进行预测。
- predict_proba(X):在估计器拟合完成后,预测样本属于每个类别的概率。
- fit_predict(X, y):拟合估计器并在 X 上进行预测。对于无监督方法,y 是可选的。
对于原始分数组合(在生成分数矩阵之后),
可以直接使用 "score_comb.py" <https://github.com/yzhao062/combo/blob/master/combo/models/score_comb.py>_ 中的各个方法。
原始分数组合 API:(https://pycombo.readthedocs.io/en/latest/api.html#score-combination)。
已实现的算法 ^^^^^^^^^^^^^^
combo 按任务将组合框架分组。通用方法是基础方法,可以应用于各种任务。
=================== ====================================================================================================== ===== =========================================== 任务 算法 年份 参考 =================== ====================================================================================================== ===== =========================================== 通用 平均与加权平均:对所有分数或预测结果求平均,可带权重 无 [#Zhou2012Ensemble]_ 通用 最大化:通过取最大分数进行简单组合 无 [#Zhou2012Ensemble]_ 通用 中位数:对所有分数或预测结果取中位数 无 [#Zhou2012Ensemble]_ 通用 多数投票与加权多数投票 无 [#Zhou2012Ensemble]_ 分类 SimpleClassifierAggregator:使用上述通用方法组合分类器 无 无 分类 DCS:动态分类器选择(利用局部准确率估计组合多个分类器) 1997 [#Woods1997Combination]_ 分类 DES:动态集成选择(从动态分类器选择到动态集成选择) 2008 [#Ko2008From]_ 分类 Stacking(元集成):使用元学习器学习基分类器的结果 无 [#Gorman2016Kaggle]_ 聚类 Clusterer Ensemble:通过重新标记组合多个聚类结果 2006 [#Zhou2006Clusterer]_ 聚类 使用证据积累(EAC)组合多个聚类结果 2002 [#Fred2005Combining]_ 异常检测 SimpleDetectorCombination:使用上述通用方法组合异常检测器 无 [#Aggarwal2017Outlier]_ 异常检测 最大值平均(AOM):将基检测器分成子组取最大值后再求平均 2015 [#Aggarwal2015Theoretical]_ 异常检测 平均值最大(MOA):将基检测器分成子组取平均值后再取最大值 2015 [#Aggarwal2015Theoretical]_ 异常检测 XGBOD:一种用于异常检测的半监督组合框架 2018 [#Zhao2018XGBOD]_ 异常检测 局部选择性组合(LSCP) 2019 [#Zhao2019LSCP]_ =================== ====================================================================================================== ===== ===========================================
所选已实现模型的比较如下所示
(\ 图 <https://raw.githubusercontent.com/yzhao062/combo/master/examples/compare_selected_classifiers.png>\ ,
compare_selected_classifiers.py <https://github.com/yzhao062/combo/blob/master/examples/compare_selected_classifiers.py>, 交互式 Jupyter 笔记本 <https://mybinder.org/v2/gh/yzhao062/combo/master>_\ )。
对于 Jupyter 笔记本,请导航至 "/notebooks/compare_selected_classifiers.ipynb"。
.. image:: https://raw.githubusercontent.com/yzhao062/combo/master/examples/compare_selected_classifiers.png :target: https://raw.githubusercontent.com/yzhao062/combo/master/examples/compare_selected_classifiers.png :alt: 所选模型比较
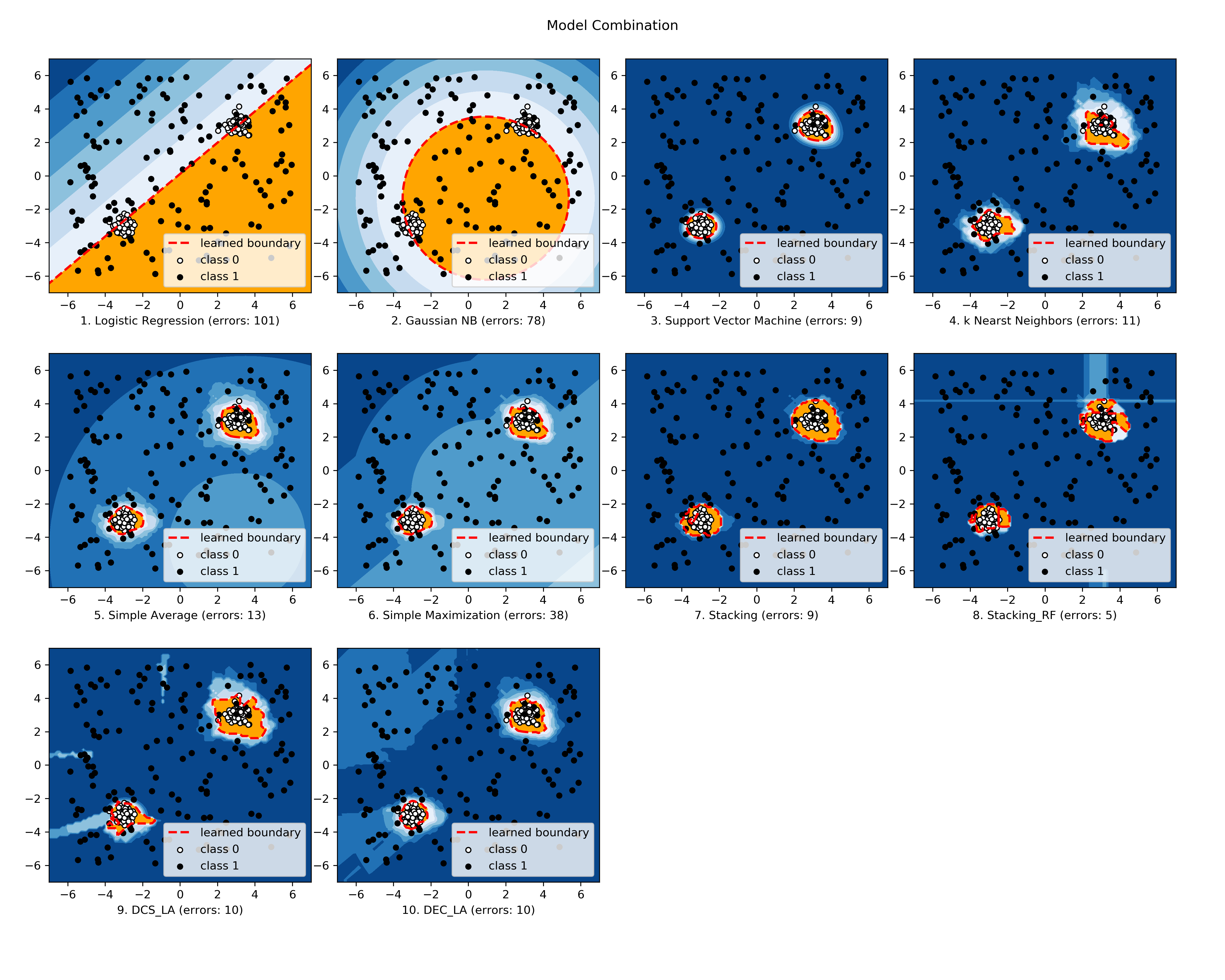{kind=link}
所有已实现的模式都配有示例,更多信息请查看
"combo 示例" <https://github.com/yzhao062/combo/blob/master/examples>_。
Stacking/DCS/DES 示例 ^^^^^^^^^^^^^^^^^^^^^
"examples/classifier_stacking_example.py" <https://github.com/yzhao062/combo/blob/master/examples/classifier_stacking_example.py>_
展示了 stacking(元集成)的基本 API。"examples/classifier_dcs_la_example.py" <https://github.com/yzhao062/combo/blob/master/examples/classifier_dcs_la_example.py>_
展示了基于局部准确率的动态分类器选择的基本 API。"examples/classifier_des_la_example.py" <https://github.com/yzhao062/combo/blob/master/examples/classifier_des_la_example.py>_
展示了基于局部准确率的动态集成选择的基本 API。
需要注意的是,这些模型的基本 API 是一致的。
#. 初始化一组分类器作为基估计器
.. code-block:: python
# 初始化一组分类器
classifiers = [DecisionTreeClassifier(random_state=random_state),
LogisticRegression(random_state=random_state),
KNeighborsClassifier(),
RandomForestClassifier(random_state=random_state),
GradientBoostingClassifier(random_state=random_state)]
#. 使用 Stacking 进行初始化、拟合、预测和评估
.. code-block:: python
from combo.models.classifier_stacking import Stacking
clf = Stacking(基分类器=classifiers, 折数=4, 是否打乱数据=False, 保留原始数据=True, 使用概率预测=False, 随机种子=random_state)
clf.fit(X_train, y_train)
y_test_predict = clf.predict(X_test)
evaluate_print('Stacking | ', y_test, y_test_predict)
#. 查看 classifier_stacking_example.py 的示例输出
.. code-block:: bash
决策树 | 准确率:0.9386, ROC:0.9383, F1:0.9521
逻辑回归 | 准确率:0.9649, ROC:0.9615, F1:0.973
K近邻 | 准确率:0.9561, ROC:0.9519, F1:0.9662
梯度提升 | 准确率:0.9605, ROC:0.9524, F1:0.9699
随机森林 | 准确率:0.9605, ROC:0.961, F1:0.9693
Stacking | 准确率:0.9868, ROC:0.9841, F1:0.9899
分类器组合示例 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
"examples/classifier_comb_example.py" <https://github.com/yzhao062/combo/blob/master/examples/classifier_comb_example.py>_
演示了使用多个分类器进行预测的基本 API。需要注意的是,所有其他算法的 API 都是统一或相似的。
#. 初始化一组分类器作为基估计器
.. code-block:: python
# 初始化一组分类器
classifiers = [DecisionTreeClassifier(random_state=random_state),
LogisticRegression(random_state=random_state),
KNeighborsClassifier(),
RandomForestClassifier(random_state=random_state),
GradientBoostingClassifier(random_state=random_state)]
#. 使用简单的聚合器(平均)初始化、拟合、预测并评估
.. code-block:: python
from combo.models.classifier_comb import SimpleClassifierAggregator
clf = SimpleClassifierAggregator(classifiers, method='average')
clf.fit(X_train, y_train)
y_test_predicted = clf.predict(X_test)
evaluate_print('通过平均组合 |', y_test, y_test_predicted)
#. 查看 classifier_comb_example.py 的示例输出
.. code-block:: bash
决策树 | 准确率:0.9386, ROC:0.9383, F1:0.9521
逻辑回归 | 准确率:0.9649, ROC:0.9615, F1:0.973
K近邻 | 准确率:0.9561, ROC:0.9519, F1:0.9662
梯度提升 | 准确率:0.9605, ROC:0.9524, F1:0.9699
随机森林 | 准确率:0.9605, ROC:0.961, F1:0.9693
通过平均组合 | 准确率:0.9693, ROC:0.9677, F1:0.9763
通过加权平均组合 | 准确率:0.9781, ROC:0.9716, F1:0.9833
通过最大值组合 | 准确率:0.9518, ROC:0.9312, F1:0.9642
通过加权投票组合| 准确率:0.9649, ROC:0.9644, F1:0.9728
通过中位数组合| 准确率:0.9693, ROC:0.9677, F1:0.9763
聚类组合示例 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
"examples/cluster_comb_example.py" <https://github.com/yzhao062/combo/blob/master/examples/cluster_comb_example.py>_
演示了组合多个基本聚类估计器的基本 API。"examples/cluster_eac_example.py" <https://github.com/yzhao062/combo/blob/master/examples/cluster_eac_example.py>_
演示了使用证据积累(EAC)组合多个聚类结果的基本 API。
#. 初始化一组聚类方法作为基估计器
.. code-block:: python
# 初始化一组估计器
estimators = [KMeans(n_clusters=n_clusters),
MiniBatchKMeans(n_clusters=n_clusters),
AgglomerativeClustering(n_clusters=n_clusters)]
#. 初始化 Clusterer Ensemble 类并拟合模型
.. code-block:: python
from combo.models.cluster_comb import ClustererEnsemble
# 通过 Clusterer Ensemble 组合
clf = ClustererEnsemble(estimators, n_clusters=n_clusters)
clf.fit(X)
#. 获取对齐后的结果
.. code-block:: python
# 在 X 上生成标签
aligned_labels = clf.aligned_labels_
predicted_labels = clf.labels_
异常检测器组合示例 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
"examples/detector_comb_example.py" <https://github.com/yzhao062/combo/blob/master/examples/detector_comb_example.py>_
演示了组合多个基本异常检测器的基本 API。
#. 初始化一组异常检测方法作为基估计器
.. code-block:: python
# 初始化一组估计器
detectors = [KNN(), LOF(), OCSVM()]
#. 初始化一个简单的平均聚合器,拟合模型并进行预测。
.. code-block:: python
from combo.models.detector combination import SimpleDetectorAggregator
clf = SimpleDetectorAggregator(base_estimators=detectors)
clf_name = '通过平均聚合'
clf.fit(X_train)
y_train_pred = clf.labels_ # 二元标签(0:内点,1:异常点)
y_train_scores = clf.decision_scores_ # 原始异常分数
# 对测试数据进行预测
y_test_pred = clf.predict(X_test) # 异常标签(0 或 1)
y_test_scores = clf.decision_function(X_test) # 异常分数
#. 使用 ROC 曲线和排名 n 的精确率评估预测结果
.. code-block:: python
# 评估并打印结果
print("\n在训练数据上:")
evaluate_print(clf_name, y_train, y_train_scores)
print("\n在测试数据上:")
evaluate_print(clf_name, y_test, y_test_scores)
#. 查看训练和测试数据上的示例输出。
.. code-block:: bash
在训练数据上:
通过平均聚合 ROC:0.9994, 排名 n 的精确率:0.95
在测试数据上:
通过平均聚合 ROC:1.0, 排名 n 的精确率:1.0
开发状态 ^^^^^^^^^^^^^^^^^^
截至 2020 年 2 月,combo 目前仍处于 开发阶段。我们已经制定了具体的计划,并将在接下来的几个月内逐步实施。
与我们构建的其他库类似,例如 Python 异常检测工具箱(pyod <https://github.com/yzhao062/pyod>_),combo 也计划发表在《机器学习研究期刊》(JMLR)的开源软件专栏(http://www.jmlr.org/mloss/)。我们已在 AAAI 2020 上提交了一篇演示论文,以汇报项目进展。
请关注并点赞以获取最新更新!如有任何建议或想法,欢迎随时发送邮件至 zhaoy@cmu.edu。
纳入标准 ^^^^^^^^^^^^^^
与 scikit-learn 类似,我们主要考虑将经过充分验证的算法纳入其中。一般而言,这些算法应至少发表两年以上,被引用超过 50 次,并且具有实用性。
然而,我们也鼓励新提出的模型的作者分享并将其实现添加到 combo 中,以提高机器学习的可访问性和可重复性。这一例外仅适用于那些能够承诺至少维护其模型两年以上的作者。
参考文献 ^^^^^^^^^
.. [#Aggarwal2015Theoretical] Aggarwal, C.C. 和 Sathe, S., 2015. 异常值集成的理论基础与算法. ACM SIGKDD 探索通讯, 17(1), 页24–47.
.. [#Aggarwal2017Outlier] Aggarwal, C.C. 和 Sathe, S., 2017. 异常值集成:导论. Springer.
.. [#Bell2007Lessons] Bell, R.M. 和 Koren, Y., 2007. Netflix 奖项挑战赛的经验教训. SIGKDD 探索, 9(2), 页75–79.
.. [#Gorman2016Kaggle] Gorman, B. (2016). Kaggle 用户实践模型堆叠指南. [在线] Kaggle.com 官方博客. 可获取于: http://blog.kaggle.com/2016/12/27/a-kagglers-guide-to-model-stacking-in-practice [访问日期: 2019年7月26日].
.. [#Ko2008From] Ko, A.H., Sabourin, R. 和 Britto Jr, A.S., 2008. 从动态分类器选择到动态集成选择. 模式识别, 41(5), 页1718–1731.
.. [#Fred2005Combining] Fred, A. L. N. 和 Jain, A. K. (2005). 利用证据积累结合多个聚类方法. IEEE 模式分析与机器智能汇刊, 27(6), 835–850. https://doi.org/10.1109/TPAMI.2005.113
.. [#Raschka2020Machine] Raschka, S., Patterson, J. 和 Nolet, C., 2020. Python 中的机器学习:数据科学、机器学习和人工智能领域的主要进展与技术趋势. arXiv 预印本 arXiv:2002.04803.
.. [#Woods1997Combination] Woods, K., Kegelmeyer, W.P. 和 Bowyer, K., 1997. 基于局部准确率估计的多分类器组合. IEEE 模式分析与机器智能汇刊, 19(4), 页405–410.
.. [#Zhao2018XGBOD] Zhao, Y. 和 Hryniewicki, M.K. XGBOD:利用无监督表示学习改进有监督异常检测. IEEE 国际神经网络联合会议, 2018年.
.. [#Zhao2019LSCP] Zhao, Y., Nasrullah, Z., Hryniewicki, M.K. 和 Li, Z., 2019年5月. LSCP:并行异常值集成中的局部选择性组合. 载于 2019年 SIAM 国际数据挖掘会议(SDM)论文集, 页585–593. 工业与应用数学学会.
.. [#Zhao2019PyOD] Zhao, Y., Nasrullah, Z. 和 Li, Z., 2019. PyOD:用于可扩展异常检测的 Python 工具箱. 机器学习研究期刊, 20, 页1–7.
.. [#Zhou2006Clusterer] Zhou, Z.H. 和 Tang, W., 2006. 聚类器集成. 基于知识的系统, 19(1), 页77–83.
.. [#Zhou2012Ensemble] Zhou, Z.H., 2012. 集成方法:基础与算法. Chapman and Hall/CRC.
版本历史
V0.1.02020/02/19常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器