flow_grpo
flow_grpo 是一个专为生成式 AI 设计的开源训练框架,旨在通过在线强化学习(Online RL)优化流匹配(Flow Matching)模型。它主要解决了传统扩散或流模型在生成图像时难以精准控制细节(如复杂物体计数、文字渲染准确性)以及难以对齐人类审美偏好的难题。
该工具特别适合 AI 研究人员和开发者使用,尤其是那些希望微调 SD3.5、FLUX.1、Qwen-Image 或 Wan2.1 等主流模型,以提升特定任务表现的技术团队。普通设计师虽不直接参与训练,但可借助其产出的高质量模型获得更可控的生成效果。
flow_grpo 的核心亮点在于高效的训练策略:它支持“无分类器引导(No-CFG)”训练,利用强化学习过程自然实现蒸馏效果;引入了"Flow-GRPO-Fast"加速机制,仅需部分步骤即可完成训练;并采用了“系数保持采样(CPS)”技术,显著提升了生成样本的质量与评估得分。此外,项目还集成了 GRPO-Guard 安全机制及多种奖励模型(如 GenEval、PickScore),为社区提供了从训练到部署的完整解决方案。
使用场景
某电商设计团队正利用 SD3.5 模型批量生成带有精准品牌文案的商品海报,但在实际落地中遭遇了严重的“图文不符”与渲染模糊问题。
没有 flow_grpo 时
- 文字渲染不可控:模型生成的海报中品牌标语经常缺笔少画或拼写错误,需人工反复重绘筛选,效率极低。
- 对象计数不准:在生成“三件套装”等特定数量商品时,模型常出现多画或少画物体的幻觉,难以满足严格的商品展示需求。
- 训练资源浪费:传统微调方法依赖 Classifier-Free Guidance (CFG) 推理,导致训练和采样速度慢,且难以直接对齐人类审美偏好(如 PickScore)。
- 编辑一致性差:在进行局部修图时,修改后的区域与原图风格割裂,缺乏语义连贯性。
使用 flow_grpo 后
- 文本精准呈现:通过引入在线强化学习,flow_grpo 显著提升了文字渲染能力,生成的品牌文案清晰准确,几乎无需后期修正。
- 逻辑计数可靠:利用 GenEval 作为奖励信号,模型能精确控制生成物体的数量,完美还原“三件套装”等复杂指令。
- 训练高效且免 CFG:flow_grpo 支持无 CFG 训练与系数保持采样(CPS),在将训练步数大幅缩减的同时,实现了类似蒸馏的效果,推理速度显著提升。
- 审美与编辑对齐:基于人类偏好(PickScore)进行优化,生成的图像更符合设计师审美,且在图像编辑任务中能保持极高的前后一致性。
flow_grpo 通过将在线强化学习融入流匹配模型,从根本上解决了生成式 AI 在商业场景中“看得见却用不了”的精度与效率瓶颈。
运行环境要求
- Linux
必需 NVIDIA GPU(文中提及使用 accelerate 进行多卡训练及 paddlepaddle-gpu),具体型号和显存未说明,需支持 CUDA
未说明
快速开始
Flow-GRPO:
通过在线强化学习训练流匹配模型
更改记录
2025-11-04
- 增加了 GRPO-Guard 🔥🔥。
更新历史
2025-11-04
- 增加了对 Bagel-7B 的支持。
2025-10-14
- 重构了 FlowGRPO-Fast,使其与 FlowGRPO 兼容,并在 SD3 上添加了 CPS 采样和无 CFG 训练。
2025-08-15
- 增加了对 Qwen-Image 和 Qwen-Image-Edit 的支持。
2025-08-15
- 感谢 Jing Wang 添加了 Wan2.1。训练命令如下:
accelerate launch --config_file scripts/accelerate_configs/multi_gpu.yaml --num_processes=1 --main_process_port 29503 scripts/train_wan2_1.py --config config/grpo.py:general_ocr_wan2_1
2025-08-14
- 增加了 Flow-GRPO-Fast 与 Flow-GRPO 的奖励曲线对比。在 Pickscore 奖励下,仅需两步训练,Flow-GRPO-Fast 的表现即可与 Flow-GRPO 相媲美。
2025-08-04
- 增加了对 FLUX.1-Kontext-dev 的支持。针对计数任务,我们使用 Geneval 奖励来检测物体数量,并利用 CLIP 特征相似性确保原始图像与编辑后图像的一致性。这一实现提供了一个可运行的流水线,但训练集仅有 800 个样本。要使 Flow-GRPO 真正有效地应用于编辑任务,仍需社区进一步探索。
2025-07-31
- 增加了 Flow-GRPO-Fast。
2025-07-28
- 增加了对 FLUX.1-dev 的支持。
- 增加了对 CLIPScore 作为奖励模型的支持。
- 引入了
config.sample.same_latent参数,用于控制是否对相同提示重复使用同一噪声,从而解决 Issue #7 问题。
2025-05-15
- 🔥我们在 https://gongyeliu.github.io/Flow-GRPO 展示了三个任务的图像示例及其训练演变过程,请大家查看!
- 🔥我们现在也在 https://huggingface.co/spaces/jieliu/SD3.5-M-Flow-GRPO 提供了这三个任务的在线演示,欢迎大家试用!
🤗 模型
| 任务 | 模型 |
|---|---|
| GenEval | 🤗GenEval |
| 文本渲染 | 🤗Text |
| 人类偏好对齐 | 🤗PickScore |
训练速度
为提升训练效率,我们为 Flow-GRPO 提供了一组更优的参数设置。以下调整显著加快了训练速度:
- 在训练或测试过程中不使用 CFG — RL 过程实际上起到了 CFG 蒸馏 的作用。
- 使用来自 Flow-GRPO-Fast 或 MixGRPO 的窗口机制 — 只在部分步骤上进行训练。
- 采用 系数保持采样 (CPS) — CPS 在 GenEval 任务上带来了显著提升,并生成了更高品质的样本。典型的设置是
noise_level = 0.8,无需针对不同模型或步数进行调整即可取得良好效果。
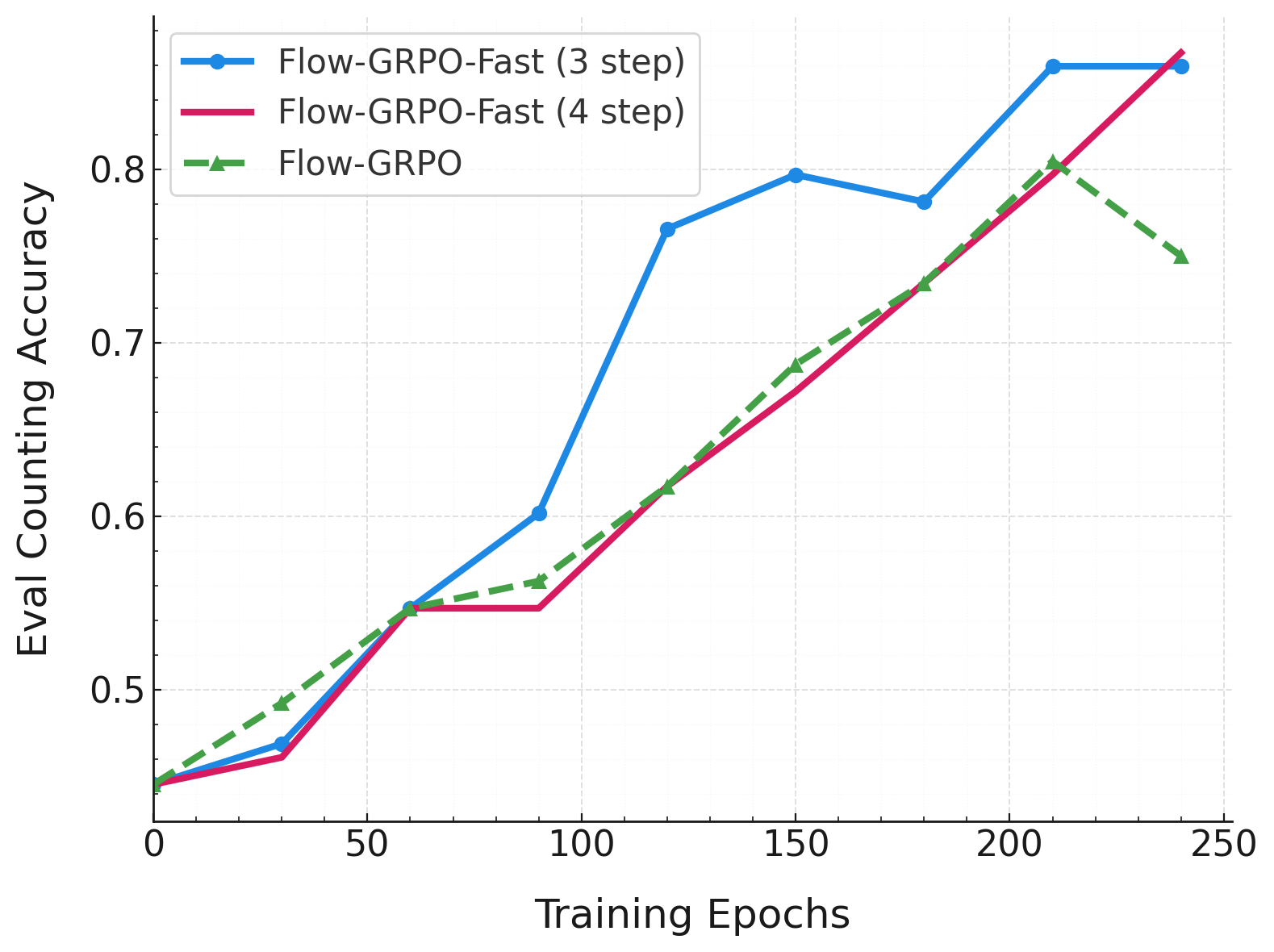
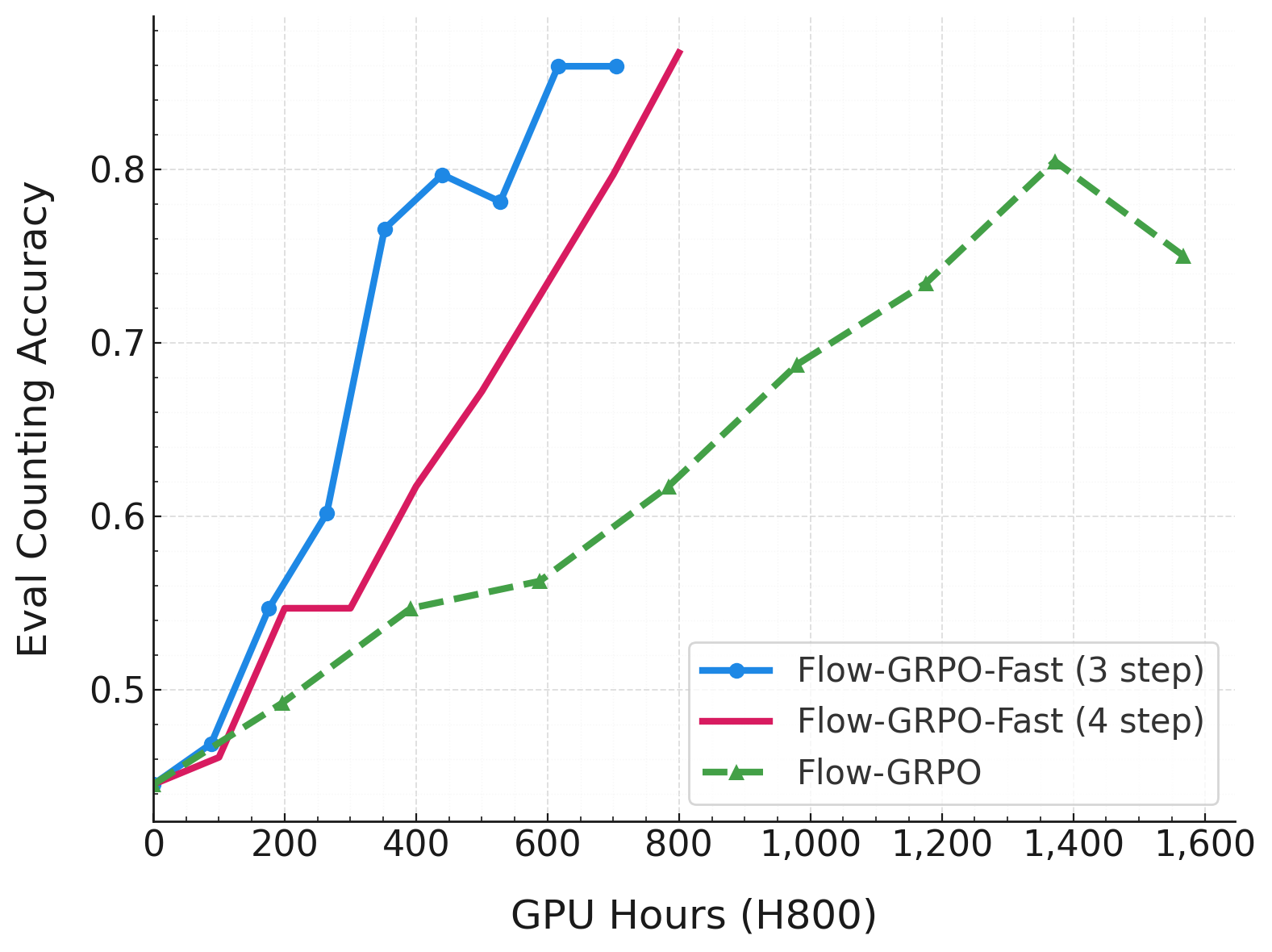
下图展示了分别以 GenEval 和 Pickscore 为奖励时的测试集性能曲线,其中训练和评估均未使用 CFG。实验配置分别为 geneval_sd3_fast_nocfg 和 pickscore_sd3_fast_nocfg,使用的脚本来自 scripts/multi_node/sd3_fast。


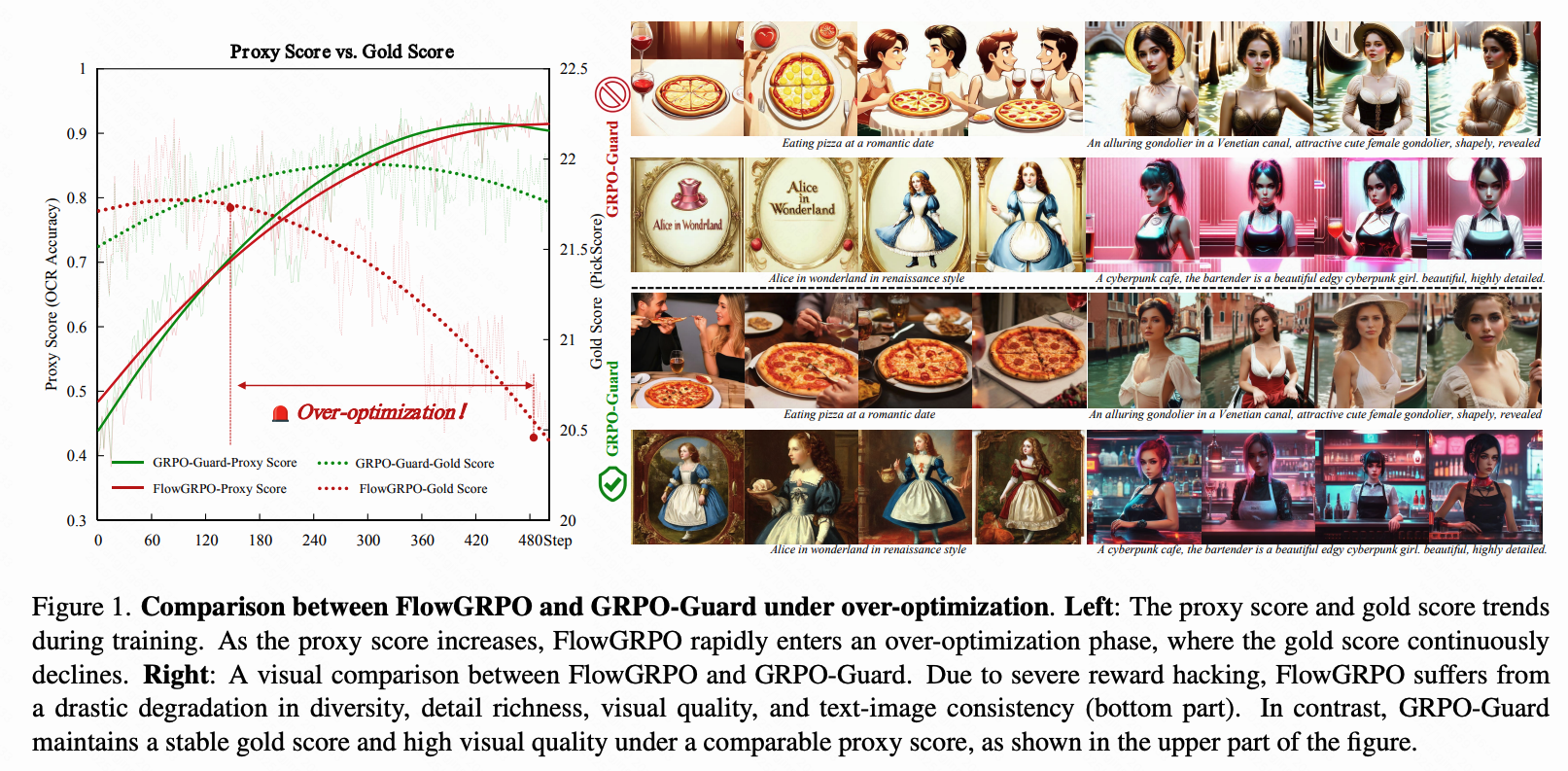
🛡️ 过度优化(GRPO-Guard) 🔥🔥
为缓解流匹配中的隐性过度优化问题,我们的团队提出了 GRPO-Guard(🔥项目页面)。
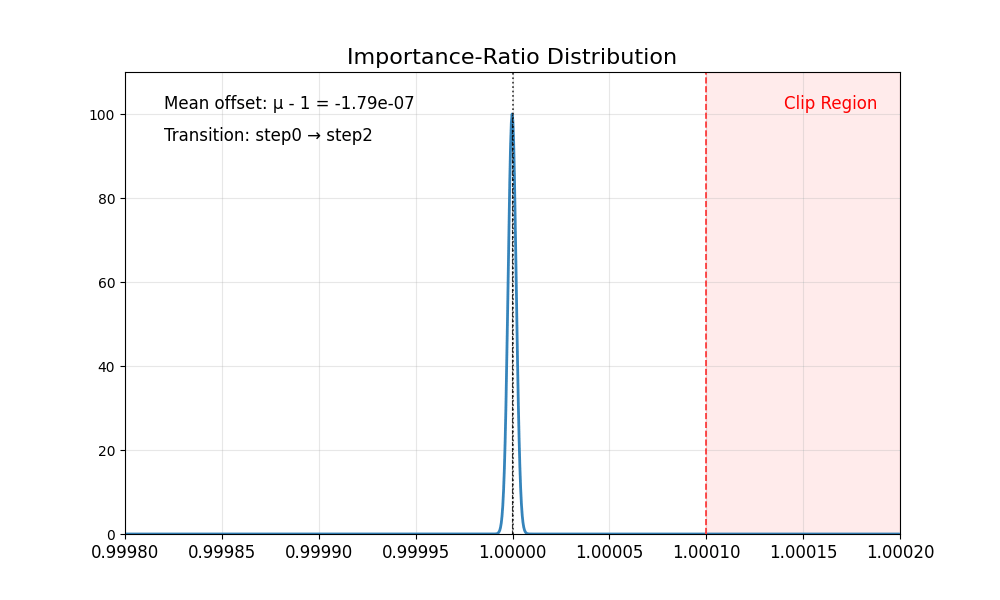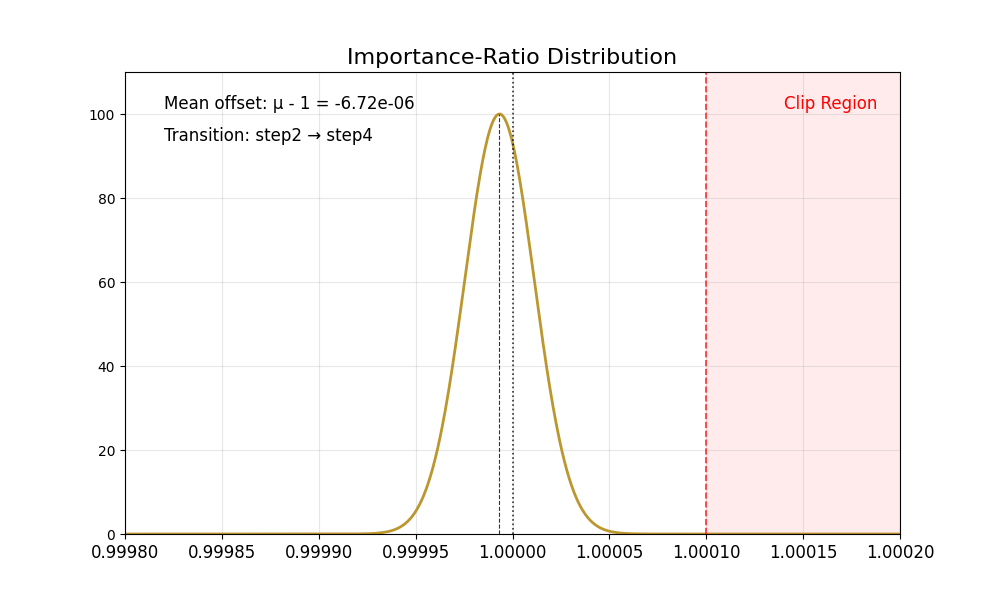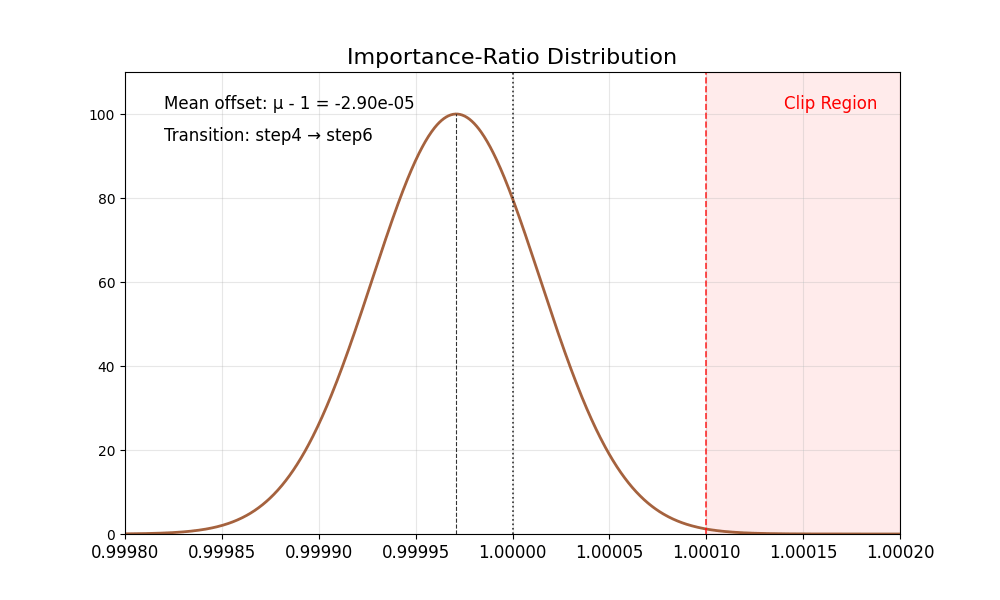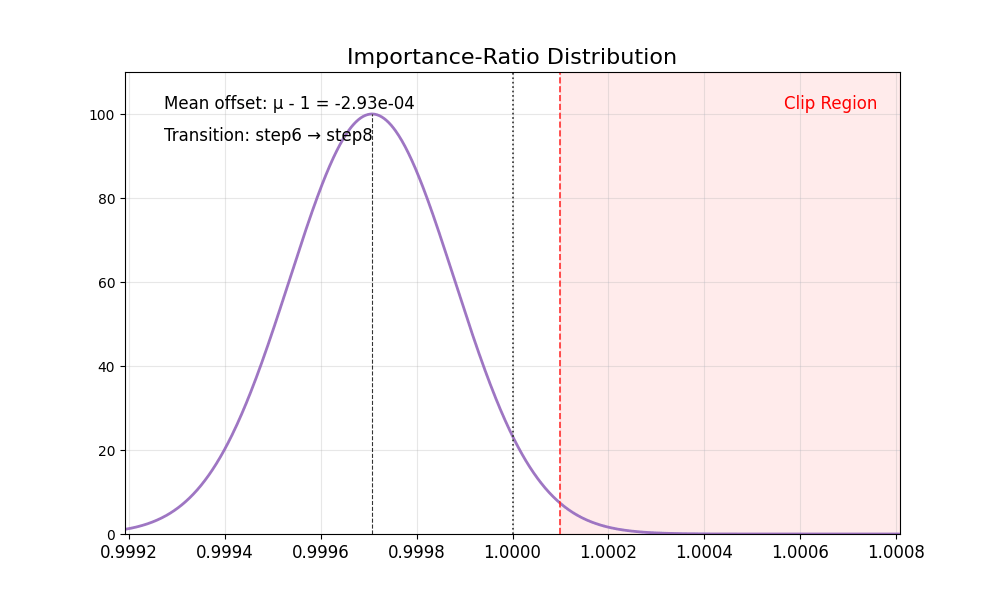
我们首先观察到重要性比率存在固有偏差:
其均值始终 低于 1,且在低噪声步骤时尤为显著(例如 SD3.5-M 中的第 8 步)。
方差在不同步骤间变化明显。
理想情况下,重要性比率的分布应具有均值为 1 且方差稳定的特性。裁剪操作会将过于自信的正样本或负样本截断至区间 [1−ϵ,1+ϵ] 之外,从而确保梯度更新的稳定性。然而,重要性比率的偏差破坏了这一机制——正样本的梯度不再受到适当约束,导致策略模型陷入过度优化。结果是代理分数持续上升,而黄金分数却不断下降,最终造成图像质量严重退化。
下表总结了这些有偏的比率分布。
| FlowGRPO | GRPO-Guard |
|---|---|
 |
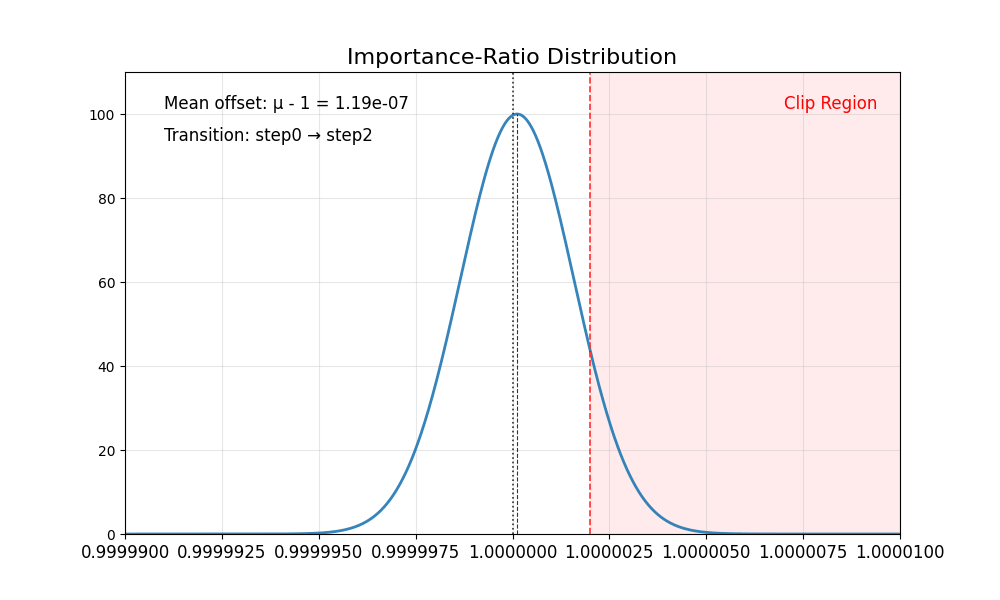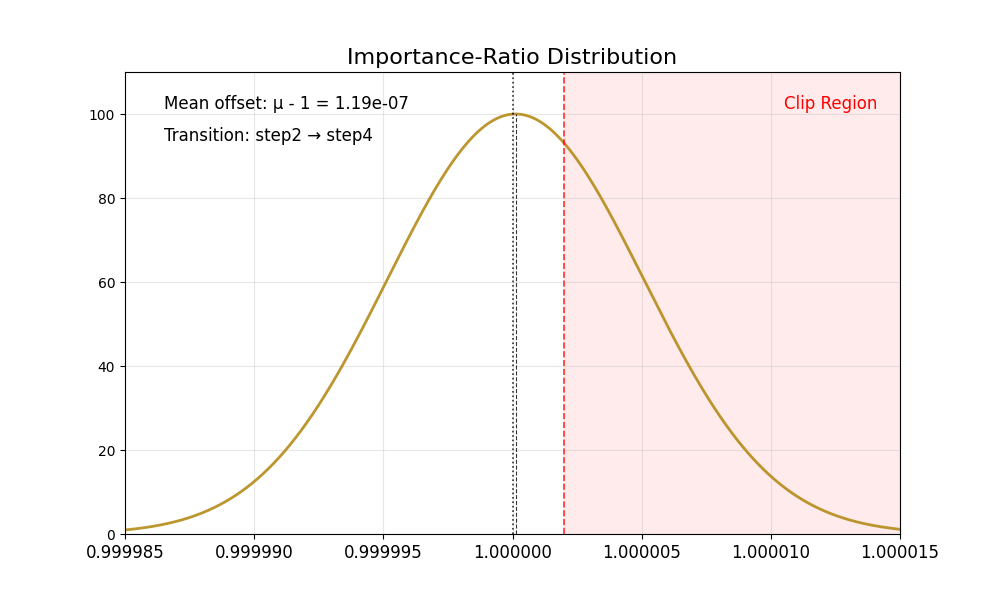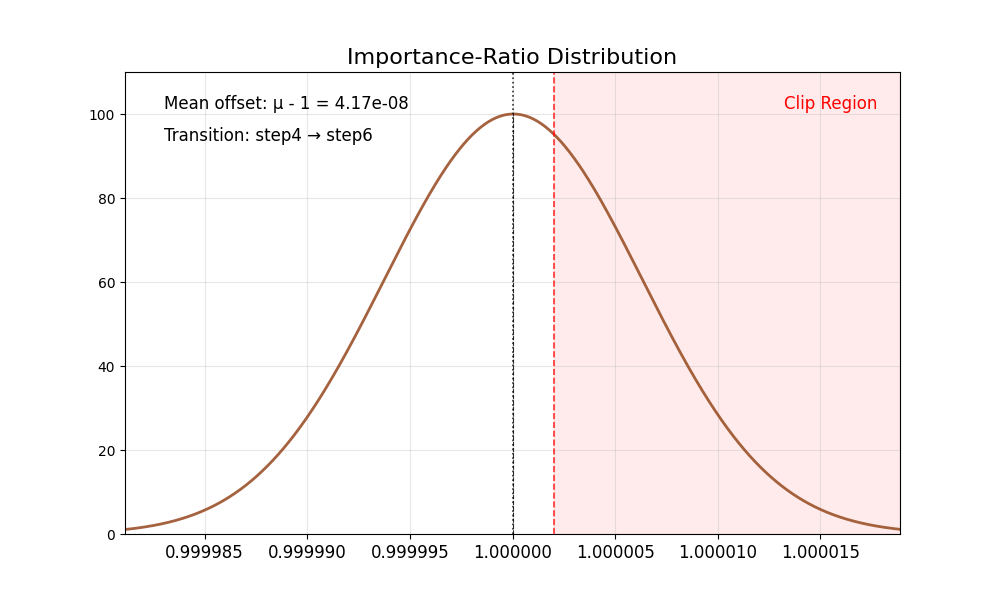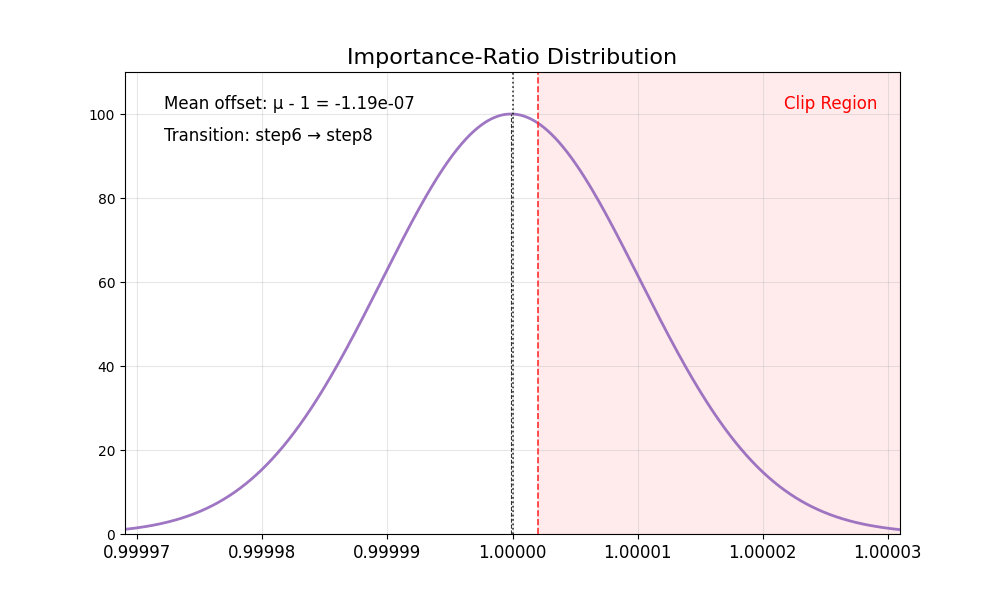 |
| 裁剪机制失衡,无法约束过于自信的正样本。 | 裁剪机制失衡,无法约束过于自信的正样本。 |
为解决这一问题,GRPO-Guard 引入了两种有效缓解过度优化的机制:
- RatioNorm:修正重要性比率的分布偏差,并统一各去噪步骤的统计特性。
- 梯度重加权:基于 RatioNorm 进一步对不同去噪步骤的梯度进行重加权,以平衡它们的贡献,防止在特定噪声水平下出现过度优化。
下图比较了 GRPO-Guard 和 FlowGRPO 在文本渲染任务中的过度优化情况。GRPO-Guard 保持了与 FlowGRPO 相同的代理分数上升趋势,同时避免了黄金分数的快速下降,从而维持了较高的图像质量和多样性。
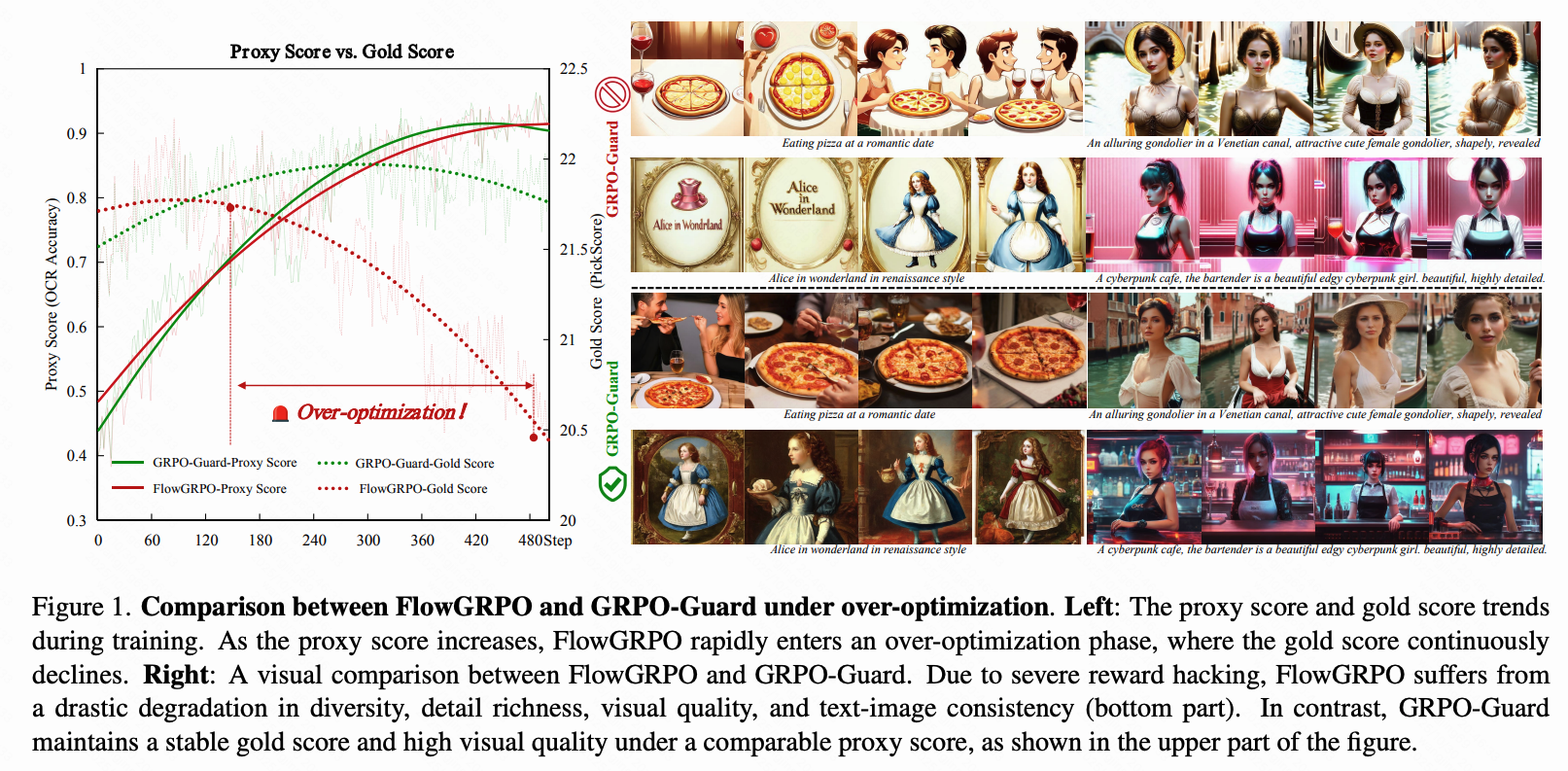
开始训练
下载基础模型并设置奖励模型后,运行以下脚本即可开始针对 SD3.5-M 文本渲染任务的 GRPO-Guard 训练。
# 主节点
bash scripts/multi_node/sd3_grpo_guard.sh 0
# 其他节点
bash scripts/multi_node/sd3_grpo_guard.sh 1
Flow-GRPO-Fast
我们提出了 Flow-GRPO-Fast,它是 Flow-GRPO 的加速版本,每条轨迹只需在 一到两个去噪步骤 上进行训练。对于每个提示,我们首先使用 ODE 采样生成一条确定性轨迹。在随机选择的一个中间步骤,我们会注入噪声并切换到 SDE 采样以生成一组样本。随后的流程将继续使用 ODE 采样。这样,随机性就被限制在一到两个步骤内,从而使训练能够集中在这几个步骤上。这一少步训练的想法主要由 Ziyang Yuan 在我们六月初的讨论中提出。
Flow-GRPO-Fast 带来了显著的效率提升:
- 每条轨迹仅需训练一到两次,大大降低了训练成本。
- 分支前的采样只需单个提示,无需扩展分组,进一步加快了数据收集速度。
在 PickScore 上的实验表明,Flow-GRPO-Fast 的奖励性能与 Flow-GRPO 相当,但训练速度更快。图中横轴表示训练轮次。每次迭代训练 2 步的 Flow-GRPO-Fast 表现优于 Flow-GRPO,而每次迭代仅训练 1 步的 Flow-GRPO-Fast 则略逊于 Flow-GRPO。无论哪种情况,与 Flow-GRPO 每次迭代训练 10 步相比,整个训练过程都显著加快。
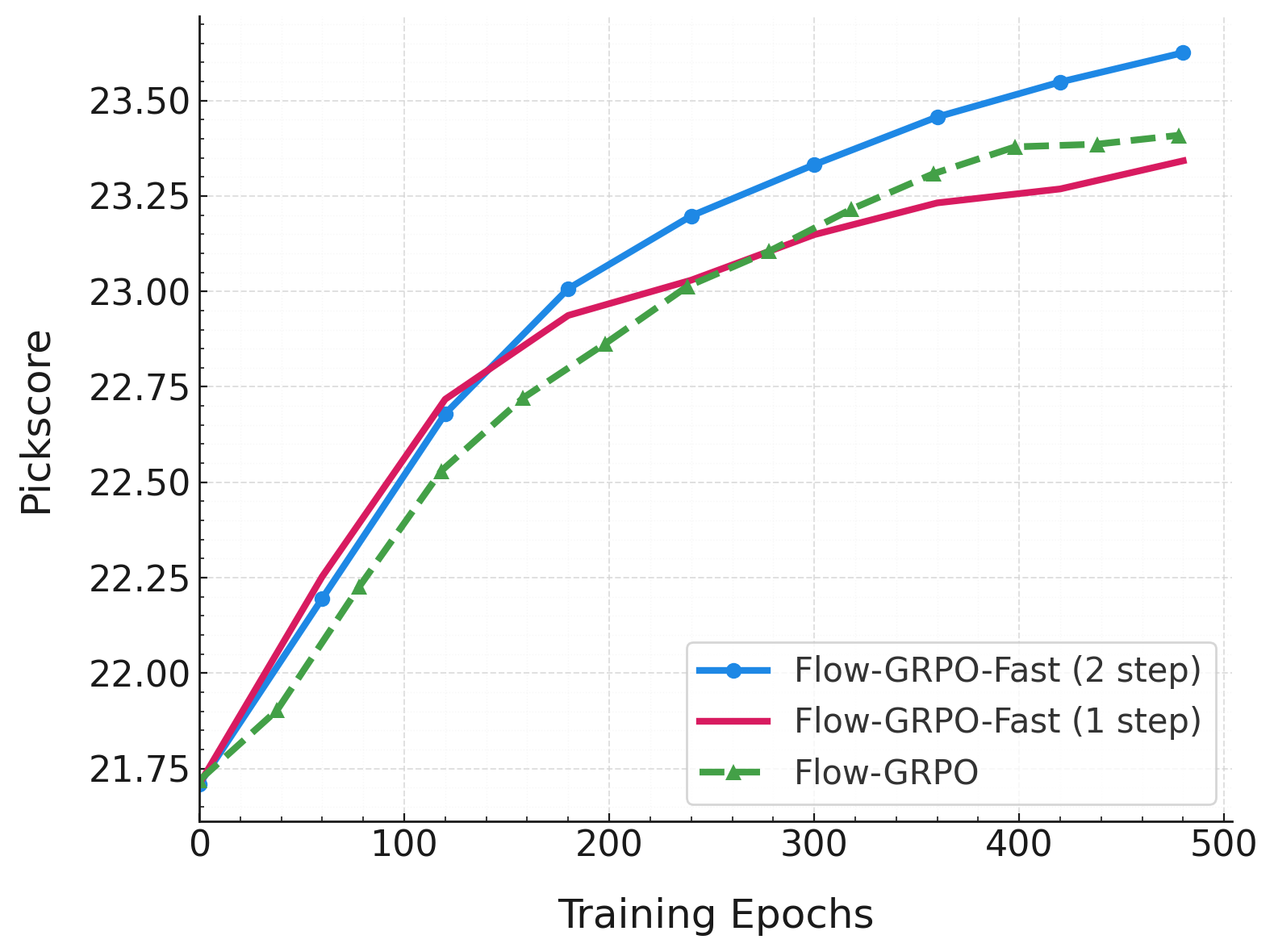
请使用 scripts/multi_node/sd3_fast 中的脚本运行这些实验。
🚀 快速入门
1. 环境搭建
克隆本仓库并安装依赖包。
git clone https://github.com/yifan123/flow_grpo.git
cd flow_grpo
conda create -n flow_grpo python=3.10.16
pip install -e .
2. 模型下载
为避免多 GPU 训练时重复下载和潜在的存储浪费,请提前下载所需模型。
模型
- SD3.5:
stabilityai/stable-diffusion-3.5-medium - Flux:
black-forest-labs/FLUX.1-dev
奖励模型
- PickScore:
laion/CLIP-ViT-H-14-laion2B-s32B-b79Kyuvalkirstain/PickScore_v1
- CLIPScore:
openai/clip-vit-large-patch14 - 美学评分:
openai/clip-vit-large-patch14
3. 奖励模型准备
上述步骤仅安装了当前仓库中的内容。由于每个奖励模型可能依赖于不同的版本,将它们合并到同一个 Conda 环境中可能会导致版本冲突。为避免这种情况,我们采用了受 ddpo-pytorch 启发的远程服务器设置。你只需安装计划使用的特定奖励模型即可。
GenEval
请创建一个新的 Conda 虚拟环境,并按照 reward-server 中的说明安装相应的依赖项。
OCR
请安装 paddle-ocr:
pip install paddlepaddle-gpu==2.6.2
pip install paddleocr==2.9.1
pip install python-Levenshtein
然后,使用 Python 命令行预下载模型:
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=False, lang="en", use_gpu=False, show_log=False)
Pickscore
PickScore 无需额外安装。请注意,原始的 pickscore 数据集对应于本仓库中的 dataset/pickscore,其中包含一些不适宜的内容。我们强烈建议使用 pickapic_v1_no_images_training_sfw,即 Pick-a-Pic 数据集的 SFW 版本,它对应于本仓库中的 dataset/pickscore_sfw。
DeQA
请创建一个新的 Conda 虚拟环境,并按照 reward-server 中的说明安装相应的依赖项。
UnifiedReward
由于 sglang 可能与其他环境发生冲突,我们建议创建一个新的 conda 环境。
conda create -n sglang python=3.10.16
conda activate sglang
pip install "sglang[all]"
我们使用 sglang 来部署奖励服务。安装 sglang 后,请运行以下命令启动 UnifiedReward:
python -m sglang.launch_server --model-path CodeGoat24/UnifiedReward-7b-v1.5 --api-key flowgrpo --port 17140 --chat-template chatml-llava --enable-p2p-check --mem-fraction-static 0.85
ImageReward
请安装 imagereward:
pip install image-reward
pip install git+https://github.com/openai/CLIP.git
4. 开始训练
GRPO
单节点训练
# sd3
bash scripts/single_node/grpo.sh
# flux
bash scripts/single_node/grpo_flux.sh
SD3 的多节点训练:
# 主节点
bash scripts/multi_node/sd3.sh 0
# 其他节点
bash scripts/multi_node/sd3.sh 1
bash scripts/multi_node/sd3.sh 2
bash scripts/multi_node/sd3.sh 3
FLUX.1-dev 的多节点训练:
# 主节点
bash scripts/multi_node/flux.sh 0
# 其他节点
bash scripts/multi_node/flux.sh 1
bash scripts/multi_node/flux.sh 2
bash scripts/multi_node/flux.sh 3
对于 Flow-GRPO-Fast,请使用 scripts/multi_node/flux_fast.sh。有关 Geneval(配置中使用 geneval_flux_fast)和 PickScore(配置中使用 pickscore_flux_fast)的 W&B 日志,请参阅相关链接。
FLUX.1-Kontext-dev 的多节点训练:
请先下载 generated_images.zip 并将其解压到 counting_edit 目录下。你也可以使用 counting_edit 目录中的脚本自行生成数据。
请从主分支安装 diffusers 以支持 FLUX.1-Kontext-dev:
pip install git+https://github.com/huggingface/diffusers.git
升级 Diffusers 后,某些包如 PEFT 也可能需要升级。如果遇到任何错误,请根据错误信息进行相应升级。 然后,运行以下脚本:
# 主节点
bash scripts/multi_node/flux_kontext.sh 0
# 其他节点
bash scripts/multi_node/flux_kontext.sh 1
bash scripts/multi_node/flux_kontext.sh 2
bash scripts/multi_node/flux_kontext.sh 3
Qwen-Image 的多节点训练:
在 Qwen-Image 的实现中,我们统一了 Flow-GRPO 和 Flow-GRPO-Fast。你可以通过 config.sample.sde_window_size 控制 SDE 窗口的大小,并用 config.sample.sde_window_range 调整窗口的位置。
请从主分支安装 diffusers 以支持 Qwen-Image:
pip install git+https://github.com/huggingface/diffusers.git
然后运行以下脚本:
# 主节点
bash scripts/multi_node/qwenimage.sh 0
# 其他节点
bash scripts/multi_node/qwenimage.sh 1
bash scripts/multi_node/qwenimage.sh 2
bash scripts/multi_node/qwenimage.sh 3
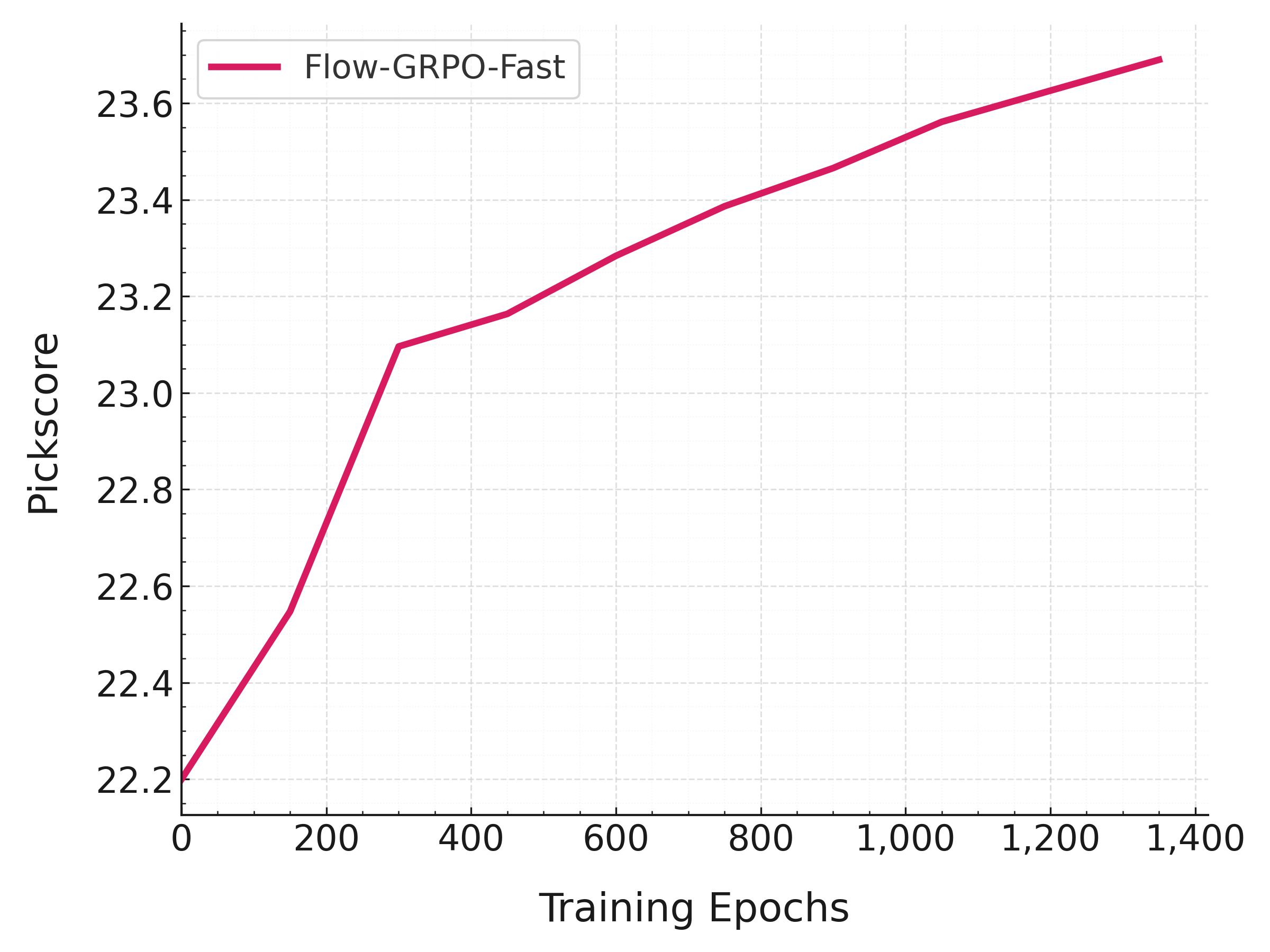
使用提供的配置,Qwen-Image 在测试集上的奖励曲线如下所示。
Qwen-Image-Edit 的多节点训练:
与 Flux Kontext 类似,首先请下载 generated_images.zip 并将其解压到 counting_edit 目录下。你也可以使用 counting_edit 目录中的脚本自行生成数据。
请从主分支安装 diffusers 以支持 Qwen-Image-Edit:
pip install git+https://github.com/huggingface/diffusers.git
然后运行以下脚本:
# 主节点
bash scripts/multi_node/qwenimage_edit.sh 0
# 其他节点
bash scripts/multi_node/qwenimage_edit.sh 1
bash scripts/multi_node/qwenimage_edit.sh 2
bash scripts/multi_node/qwenimage_edit.sh 3
使用提供的配置,Qwen-Image-Edit 在测试集上的奖励曲线如下所示。
Bagel 的多节点训练:
请先将 transformers 升级到 版本>=4.44.0,并安装 flash-attn:
pip install transformers==4.44.0
pip install flash-attn==2.7.4.post1 --no-build-isolation
然后运行以下脚本:
# 主节点
bash scripts/multi_node/bagel/main.sh 0
# 其他节点
bash scripts/multi_node/bagel/main.sh 1
bash scripts/multi_node/bagel/main.sh 2
bash scripts/multi_node/bagel/main.sh 3
根据提供的配置,Bagel 在测试集上的奖励(PickScore)曲线如下所示(使用 32 张 GPU)。

【注】:关于资源需求与 OOM
默认的训练脚本采用全参数模式,这至少需要 8 张 80GB 显存的 GPU。如果遇到 OOM 问题,可以切换到 LoRA 训练,配置文件位于 config/grpo.py:pickscore_bagel_lora。
DPO / OnlineDPO / SFT / OnlineSFT
单节点训练:
bash scripts/single_node/dpo.sh
bash scripts/single_node/sft.sh
多节点训练:
请在 scripts/multi_node 的 bash 文件中更新入口 Python 脚本和配置文件名称。
常见问题解答
尽可能使用 fp16 进行训练,因为它比 bf16 具有更高的精度,从而减少数据收集与训练之间的对数概率误差。对于 Flux 和 Wan 模型,由于 fp16 推理无法生成有效的图像或视频,因此必须使用 bf16 进行训练。需要注意的是,对数概率误差在高噪声步骤时较小,而在低噪声步骤时较大。在这种情况下,仅在高噪声步骤上进行训练会取得更好的效果。感谢 Jing Wang 提出的这些观察结果。
使用 Flow-GRPO-Fast 时,请设置相对较小的
clip_range,否则训练可能会崩溃。在实现新模型时,请检查使用不同批次大小是否会导致输出略有差异。SD3 存在这一问题,因此我确保训练时的批次大小与数据收集时的批次大小一致。
如何支持其他模型
要将新模型集成到该框架中,请按照以下步骤操作:
1. 添加适用于您模型的以下文件:
flow_grpo/diffusers_patch/sd3_pipeline_with_logprob.py: 此文件改编自 pipeline_stable_diffusion_3.py。您可以参考 diffusers 中针对您模型的相关代码。scripts/train_sd3.py: 该脚本基于 DreamBooth 示例中的 train_dreambooth_lora_sd3.py。flow_grpo/diffusers_patch/sd3_sde_with_logprob.py: 该文件负责处理 SDE 采样。大多数情况下无需修改此文件。但是,如果您的dt或velocity定义在符号或约定上有所不同,请相应调整。
2. 验证 SDE 采样:
在 sde_demo.py 中将 noise_level = 0,以检查生成的图像是否正常。这有助于验证您的 SDE 实现是否正确。
3. 确保策略一致性:
将 config.sample.num_batches_per_epoch = 1 和 config.train.gradient_accumulation_steps = 1 设置为 1,以强制执行纯在线策略设置,即采集样本的模型与正在训练的模型完全相同。
在此设置下,ratio 应保持精确为 1。如果不是,请检查采样和训练代码路径是否存在差异——例如通过使用 torch.compile 或其他模型包装器——并确保两者共享相同的逻辑。
4. 调整奖励行为:
首先将 config.train.beta = 0,以观察训练过程中奖励是否增加。您可能还需要根据您的模型调整此处的噪声级别 here。其他超参数通常与模型无关,可保持默认值。
🏁 多奖励训练
对于多奖励设置,您可以传入一个字典,其中每个键是奖励名称,对应的值是其权重。 例如:
{
"pickscore": 0.5,
"ocr": 0.2,
"aesthetic": 0.3
}
这意味着最终奖励是各个奖励的加权总和。
目前支持以下奖励模型:
- Geneval 根据复杂的组合式提示评估 T2I 模型。
- OCR 提供基于 OCR 的奖励。
- PickScore 是一种基于人类偏好的通用 T2I 奖励模型。
- DeQA 是一种基于多模态 LLM 的图像质量评估模型,用于衡量失真和纹理损伤对感知质量的影响。
- ImageReward 是一种通用的 T2I 奖励模型,能够捕捉文本与图像的对齐程度、视觉保真度以及安全性。
- QwenVL 是一种实验性的奖励模型,采用提示工程方法。
- Aesthetic 是一种基于 CLIP 的线性回归模型,用于预测图像的美学评分。
- JPEG_Compressibility 以图像大小作为质量的代理指标。
- UnifiedReward 是用于多模态理解和生成的最先进奖励模型,位居人类偏好排行榜榜首。
✨ 重要超参数
您可以通过调整 config/grpo.py 中的参数来优化不同的超参数。经验表明,config.sample.train_batch_size * num_gpu / config.sample.num_image_per_prompt * config.sample.num_batches_per_epoch = 48,即 group_number=48,group_size=24。
此外,建议将 config.train.gradient_accumulation_steps = config.sample.num_batches_per_epoch // 2。
🤗 致谢
本仓库基于 ddpo-pytorch 和 diffusers。我们感谢作者们为 AIGC 社区所做的宝贵贡献。特别感谢 Kevin Black 提供的优秀 ddpo-pytorch 仓库。
⭐引用
如果您在研究或项目中使用了 Flow-GRPO,我们将不胜感激您能引用以下论文:
@article{liu2025flow,
title={Flow-grpo: Training flow matching models via online rl},
author={Liu, Jie and Liu, Gongye and Liang, Jiajun and Li, Yangguang and Liu, Jiaheng and Wang, Xintao and Wan, Pengfei and Zhang, Di and Ouyang, Wanli},
journal={arXiv preprint arXiv:2505.05470},
year={2025}
}
如果您在研究或项目中使用了 GRPO-Guard,我们将不胜感激您能引用以下论文:
@misc{wang2025grpoguardmitigatingimplicitoveroptimization,
title={GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping},
author={Jing Wang and Jiajun Liang and Jie Liu and Henglin Liu and Gongye Liu and Jun Zheng and Wanyuan Pang and Ao Ma and Zhenyu Xie and Xintao Wang and Meng Wang and Pengfei Wan and Xiaodan Liang},
year={2025},
eprint={2510.22319},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.22319},
}
如果您在研究或项目中使用了 Flow-DPO,我们将不胜感激您能引用以下论文:
@article{liu2025improving,
title={Improving video generation with human feedback},
author={Liu, Jie and Liu, Gongye and Liang, Jiajun and Yuan, Ziyang and Liu, Xiaokun and Zheng, Mingwu and Wu, Xiele and Wang, Qiulin and Qin, Wenyu and Xia, Menghan and others},
journal={arXiv preprint arXiv:2501.13918},
year={2025}
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。