repomix
Repomix 是一款专为开发者设计的实用工具,它能将整个代码仓库智能打包成一个单一、紧凑且对人工智能友好的文件。在日常开发中,当我们需要让 Claude、ChatGPT、DeepSeek 等大语言模型(LLM)理解项目全貌时,逐个复制文件或处理复杂的目录结构往往既繁琐又容易出错。Repomix 完美解决了这一痛点,它自动过滤无关文件,将核心代码整理成适合 AI 阅读的格式,让用户只需一次操作即可将完整上下文投喂给 AI 助手。
这款工具特别适合软件工程师、技术研究人员以及需要频繁与 AI 协作进行代码审查、重构或功能开发的团队使用。其独特之处在于高度可定制的配置文件,支持用户灵活指定忽略规则、输出格式以及包含的元数据,确保生成的文件既精准又高效。此外,Repomix 不仅提供命令行版本方便集成到自动化流程中,还推出了在线网页版,无需安装即可快速体验。作为 2025 年 JSNation 开源奖"AI 驱动”类别的提名项目,Repomix 正成为连接人类代码与机器智能的高效桥梁,让 AI 辅助编程变得更加流畅自然。
使用场景
某初创团队的后端负责人需要在周末紧急向 AI 助手咨询如何重构一个包含 50+ 文件的遗留微服务架构,以修复严重的性能瓶颈。
没有 repomix 时
- 上下文割裂:开发者只能逐个复制粘贴文件给 AI,导致模型无法理解模块间的调用关系和依赖逻辑。
- 操作繁琐易错:手动筛选核心代码、排除
node_modules和日志文件耗时极长,且容易误删关键配置或遗漏重要接口定义。 - 提示词质量低:由于输入信息碎片化,AI 给出的建议往往基于局部代码,产生的重构方案经常引发新的编译错误或逻辑冲突。
- 协作效率低下:团队成员间难以统一发送给 AI 的代码版本,导致每个人得到的优化建议不一致,沟通成本激增。
使用 repomix 后
- 全景代码投喂:运行一条命令即可将整个项目打包成单个结构化文本文件,AI 能瞬间掌握完整的系统架构和数据流向。
- 智能过滤噪音:repomix 自动忽略构建产物、依赖包和环境配置文件,确保发送给大模型的每一行都是高价值的业务逻辑。
- 深度精准分析:基于完整上下文,AI 能准确识别跨文件的性能热点,提供包含具体修改路径的全局重构方案,准确率大幅提升。
- 标准化工作流:团队成员均可快速生成统一的代码包,确保所有人基于同一份“真相”与 AI 对话,加速技术决策落地。
repomix 通过将分散的代码库转化为 AI 可理解的单一视图,彻底消除了人与大模型之间的“上下文壁垒”,让复杂系统的智能重构变得简单高效。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明
快速开始

将您的代码库打包成适合 AI 的格式
需要讨论吗?加入我们的 Discord 吧!
分享您的经验与技巧
及时了解新功能
获取配置和使用方面的帮助


![]()
![]()


![]()
📦 Repomix 是一款强大的工具,可将您的整个仓库打包成一个单一的、适合 AI 处理的文件。
它非常适合在需要将您的代码库输入大型语言模型(LLMs)或其他 AI 工具时使用,例如 Claude、ChatGPT、DeepSeek、Perplexity、Gemini、Gemma、Llama、Grok 等。
请考虑赞助我。


🏆 开源奖项提名
我们深感荣幸!Repomix 已被提名为 JSNation 开源大奖 2025 中的 Powered by AI 类别。
这一切都离不开各位用户对 Repomix 的使用和支持。非常感谢!
🎉 新:Repomix 官网与 Discord 社区!
- 您可以在浏览器中访问 repomix.com 试用 Repomix
- 加入我们的 Discord 服务器 获取支持与交流
期待在那里见到您!
🌟 功能特性
- AI 优化:以易于 AI 理解和处理的方式格式化您的代码库。
- Token 计数:提供每个文件及整个仓库的 token 数量,有助于应对 LLM 的上下文限制。
- 简单易用:只需一条命令即可打包整个仓库。
- 可定制化:轻松配置包含或排除的内容。
- Git 感知:自动尊重您的
.gitignore、.ignore和.repomixignore文件。 - 安全优先:集成 Secretlint,进行强大的安全检查,以检测并防止敏感信息的引入。
- 代码压缩:通过
--compress选项,利用 Tree-sitter 提取关键代码元素,从而在保留结构的同时减少 token 数量。
🚀 快速入门
使用 CLI 工具 >_
您无需安装即可在项目目录中立即试用 Repomix:
npx repomix@latest
或者全局安装以便重复使用:
# 使用 npm 安装
npm install -g repomix
# 或者使用 yarn
yarn global add repomix
# 或者使用 bun
bun add -g repomix
# 或者使用 Homebrew(macOS/Linux)
brew install repomix
# 然后在任何项目目录中运行
repomix
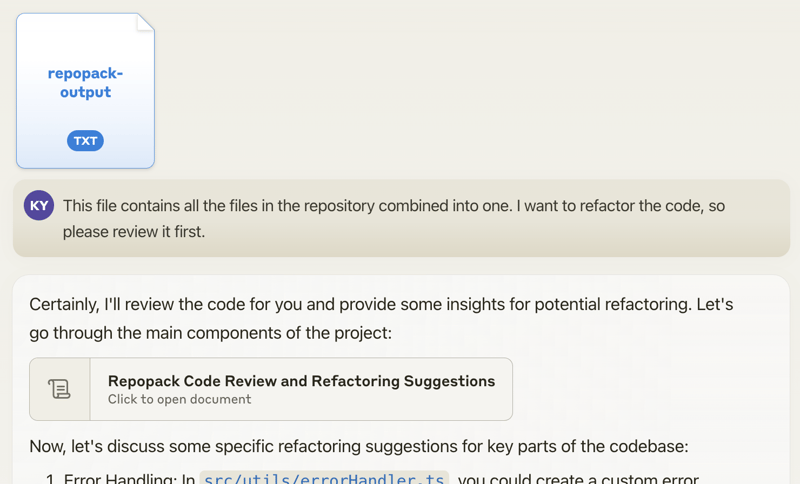
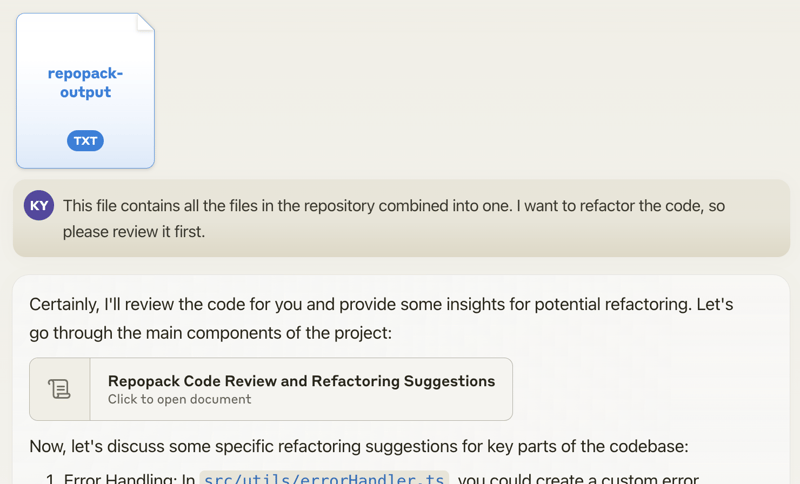
就这么简单!Repomix 会在您当前目录下生成一个 repomix-output.xml 文件,其中包含了您的整个仓库,并且是以适合 AI 的格式呈现的。
随后,您可以将此文件发送给 AI 助手,并附上类似如下的提示:
该文件包含了仓库中的所有文件,已合并为一个整体。
我想重构代码,请先审阅一下。
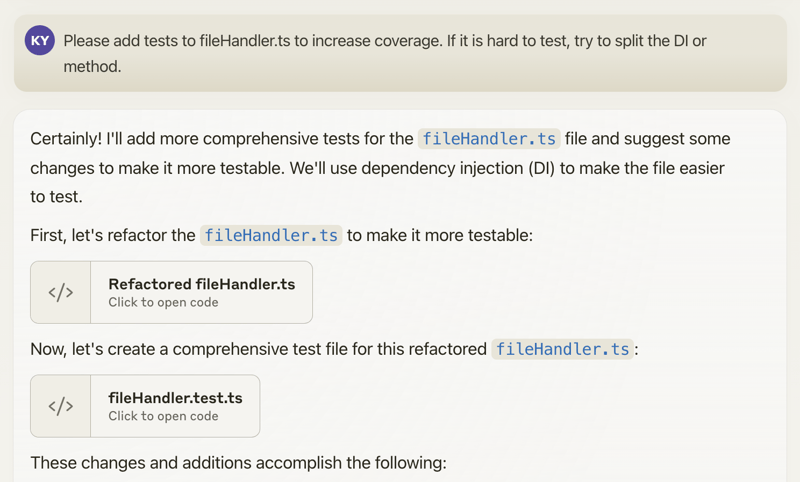
当您提出具体的修改建议时,AI 很有可能会根据这些建议生成相应的代码。借助 Claude 的 Artifacts 等功能,您甚至可以输出多个文件,从而生成相互依赖的多段代码。
祝编码愉快!🚀
使用官网 🌐
想快速试用吗?请访问官方网站 repomix.com。只需输入您的仓库名称,填写可选信息,然后点击 打包 按钮,即可查看生成的输出。
可用选项
网站提供了多项便捷功能:
- 可自定义的输出格式(XML、Markdown 或纯文本)
- 即时 token 数量估算
- 更多功能!
使用浏览器扩展 🧩
只需一键,即可从任何 GitHub 仓库直接访问 Repomix!我们的 Chrome 扩展会在 GitHub 仓库页面上添加一个便捷的“Repomix”按钮。
安装
- Chrome 扩展:Repomix - Chrome 网上应用店
- Firefox 插件:Repomix - Firefox 附加组件
功能
- 一键访问任意 GitHub 仓库的 Repomix
- 更多精彩功能即将推出!
使用 VSCode 扩展 ⚡️
由社区维护的 VSCode 扩展 Repomix Runner(由 massdo 创建)让您只需点击几下,就能在编辑器内直接运行 Repomix。您可以对任意文件夹运行它,无缝管理输出,并通过 VSCode 直观的界面控制所有操作。
想将输出保存为文件还是仅获取内容?需要自动清理吗?这款扩展都能满足您的需求。此外,它还能与您现有的 repomix.config.json 配置文件顺畅兼容。
立即前往 VSCode 市场 体验吧!源代码可在 GitHub 上找到。
替代工具 🛠️
如果您使用 Python,不妨试试 Gitingest,它更适合 Python 生态系统和数据科学工作流:
https://github.com/cyclotruc/gitingest
📊 使用方法
打包整个仓库:
repomix
打包特定目录:
repomix path/to/directory
使用 glob 模式 打包特定文件或目录:
repomix --include "src/**/*.ts,**/*.md"
排除特定文件或目录:
repomix --ignore "**/*.log,tmp/"
打包远程仓库:
repomix --remote https://github.com/yamadashy/repomix
# 也可以使用 GitHub 的简写方式:
repomix --remote yamadashy/repomix
# 可以指定分支名、标签或提交哈希:
repomix --remote https://github.com/yamadashy/repomix --remote-branch main
# 或者使用特定的提交哈希:
repomix --remote https://github.com/yamadashy/repomix --remote-branch 935b695
# 另一种便捷的方式是直接指定分支的 URL:
repomix --remote https://github.com/yamadashy/repomix/tree/main
# 提交的 URL 也同样支持:
repomix --remote https://github.com/yamadashy/repomix/commit/836abcd7335137228ad77feb28655d85712680f1
从文件列表中打包文件(通过标准输入管道传递):
# 使用 find 命令
find src -name "*.ts" -type f | repomix --stdin
# 使用 git 获取已跟踪文件
git ls-files "*.ts" | repomix --stdin
# 使用 grep 查找包含特定内容的文件
grep -l "TODO" **/*.ts | repomix --stdin
# 使用 ripgrep 查找包含特定内容的文件
rg -l "TODO|FIXME" --type ts | repomix --stdin
# 使用 ripgrep (rg) 查找文件
rg --files --type ts | repomix --stdin
# 使用 sharkdp/fd 查找文件
fd -e ts | repomix --stdin
# 使用 fzf 从所有文件中选择
fzf -m | repomix --stdin
# 使用 fzf 进行交互式文件选择
find . -name "*.ts" -type f | fzf -m | repomix --stdin
# 使用 ls 并结合 glob 模式
ls src/**/*.ts | repomix --stdin
# 从包含文件路径的文件中读取
cat file-list.txt | repomix --stdin
# 直接使用 echo 输入
echo -e "src/index.ts\nsrc/utils.ts" | repomix --stdin
--stdin 选项允许您将文件路径列表通过管道传递给 Repomix,从而为您提供极大的灵活性来选择要打包的文件。
使用 --stdin 时,指定的文件会有效加入包含模式中。这意味着正常的包含和忽略规则仍然适用——如果通过 stdin 指定的文件匹配忽略模式,它们仍会被排除。
[!注意] 使用
--stdin时,文件路径可以是相对路径或绝对路径,Repomix 会自动处理路径解析和去重。
在输出中包含 Git 日志:
# 包含默认数量的 Git 日志(50 条提交)
repomix --include-logs
# 包含特定数量的 Git 日志
repomix --include-logs --include-logs-count 10
# 结合差异查看,获得更全面的 Git 上下文
repomix --include-logs --include-diffs
Git 日志会包含每次提交的日期、消息以及文件路径,为 AI 分析代码演进和开发模式提供宝贵背景信息。
压缩输出:
repomix --compress
# 也可以用于远程仓库:
repomix --remote yamadashy/repomix --compress
初始化新的配置文件 (repomix.config.json):
repomix --init
生成打包文件后,您可以将其用于 ChatGPT、DeepSeek、Perplexity、Gemini、Gemma、Llama、Grok 等生成式 AI 工具。
Docker 使用 🐳
您也可以通过 Docker 运行 Repomix。这在您希望在一个隔离的环境中运行 Repomix,或者更倾向于使用容器时非常有用。
基本用法(当前目录):
docker run -v .:/app -it --rm ghcr.io/yamadashy/repomix
打包特定目录:
docker run -v .:/app -it --rm ghcr.io/yamadashy/repomix path/to/directory
处理远程仓库并将输出保存到 output 目录:
docker run -v ./output:/app -it --rm ghcr.io/yamadashy/repomix --remote https://github.com/yamadashy/repomix
提示示例
使用 Repomix 生成打包文件后,您可以将其与 ChatGPT、DeepSeek、Perplexity、Gemini、Gemma、Llama、Grok 等 AI 工具一起使用。 以下是一些示例提示,帮助您入门:
代码审查与重构
进行全面的代码审查并获取重构建议:
此文件包含我的整个代码库。请审查整体结构,并针对可维护性和可扩展性提出改进建议或重构机会。
文档生成
生成项目文档:
根据此文件中的代码库,请生成一份详细的 README.md 文件,包括项目概述、主要功能、设置说明和使用示例。
测试用例生成
生成测试用例:
分析此文件中的代码,为主要函数和类建议一套全面的单元测试。请包含边界情况和潜在的错误场景。
代码质量评估
评估代码质量和对最佳实践的遵循情况:
审查代码库是否符合编码最佳实践和行业标准。找出在可读性、可维护性和效率方面可以改进的地方。建议具体的更改,使代码更符合最佳实践。
库概览
获取库的高层次理解
此文件包含了整个库的代码库。请提供该库的全面概述,包括其主要用途、关键特性以及整体架构。
您可以根据自己的具体需求和所使用的 AI 工具的功能,自由修改这些提示。
社区讨论
查看我们的 社区讨论,用户们在这里分享:
- 他们正在使用哪些 AI 工具与 Repomix 配合
- 他们发现的有效提示
- Repomix 如何帮助了他们
- 充分利用 AI 代码分析的技巧和窍门
欢迎加入讨论并分享您的经验!您的见解可以帮助其他人更好地使用 Repomix。
输出文件格式
Repomix 会生成一个单一文件,其中不同部分的代码库之间有清晰的分隔符。 为了增强 AI 的理解能力,输出文件以面向 AI 的说明开头,使 AI 模型更容易理解打包仓库的上下文和结构。
XML 格式(默认)
XML 格式以层次化的方式组织内容:
此文件是整个代码库的合并表示,将所有仓库文件整合为一个文档。
<file_summary>
(元数据和 AI 使用说明)
</file_summary>
<directory_structure>
src/
cli/
cliOutput.ts
index.ts
(...剩余目录)
</directory_structure>
<files>
<file path="src/index.js">
// 文件内容在此处
</file>
(...剩余文件)
</files>
<instruction>
(来自 `output.instructionFilePath` 的自定义指令)
</instruction>
对于那些对 XML 标签在 AI 场景中的潜力感兴趣的人:
https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/use-xml-tags
当您的提示涉及多个组件,如上下文、指令和示例时,XML 标签可能会带来重大改变。它们有助于 Claude 更准确地解析您的提示,从而产生更高质量的输出。
这意味着,Repomix 生成的 XML 输出不仅是一种不同的格式,而且可能是一种更有效的方式,将您的代码库输入到 AI 系统中,用于分析、代码审查或其他任务。
Markdown 格式
要以 Markdown 格式生成输出,请使用 --style markdown 选项:
repomix --style markdown
Markdown 格式以层次化的方式组织内容:
此文件是整个代码库的合并表示,将所有仓库文件整合为一个文档。
# 文件摘要
(元数据和 AI 使用说明)
# 仓库结构
```
src/
cli/
cliOutput.ts
index.ts
```
(...剩余目录)
# 仓库文件
## 文件:src/index.js
```
// 文件内容在此处
```
(...剩余文件)
# 指令
(来自 `output.instructionFilePath` 的自定义指令)
这种格式提供了清晰、易读的结构,既便于人类阅读,也易于 AI 系统解析。
JSON 格式
要以 JSON 格式生成输出,请使用 --style json 选项:
repomix --style json
JSON 格式以驼峰命名法的属性名将内容组织成一个层次化的 JSON 对象:
{
"fileSummary": {
"generationHeader": "此文件是整个代码库的合并表示,由 Repomix 整合为一个文档。",
"purpose": "此文件包含整个仓库内容的打包表示...",
"fileFormat": "内容按如下方式组织...",
"usageGuidelines": "- 此文件应被视为只读...",
"notes": "- 一些文件可能已根据 .gitignore、.ignore 和 .repomixignore 规则被排除..."
},
"userProvidedHeader": "如果指定了自定义头部文本",
"directoryStructure": "src/\n cli/\n cliOutput.ts\n index.ts\n config/\n configLoader.ts",
"files": {
"src/index.js": "// 文件内容在此处",
"src/utils.js": "// 文件内容在此处"
},
"instruction": "来自 instructionFilePath 的自定义指令"
}
此格式非常适合:
- 程序化处理:易于使用 JSON 库解析和操作
- API 集成:可直接被 Web 服务和应用程序消费
- AI 工具兼容性:适合机器学习和 AI 系统的结构化格式
- 数据分析:使用
jq等工具轻松提取特定信息
使用 jq 处理 JSON 输出
JSON 格式使得以编程方式提取特定信息变得非常容易:
# 列出所有文件路径
cat repomix-output.json | jq -r '.files | keys[]'
# 统计总文件数
cat repomix-output.json | jq '.files | keys | length'
# 提取特定文件内容
cat repomix-output.json | jq -r '.files["README.md"]'
cat repomix-output.json | jq -r '.files["src/index.js"]'
# 按扩展名查找文件
cat repomix-output.json | jq -r '.files | keys[] | select(endswith(".ts"))'
# 查找包含特定文本的文件
cat repomix-output.json | jq -r '.files | to_entries[] | select(.value | contains("function")) | .key'
# 提取目录结构
cat repomix-output.json | jq -r '.directoryStructure'
# 获取文件摘要信息
cat repomix-output.json | jq '.fileSummary.purpose'
cat repomix-output.json | jq -r '.fileSummary.generationHeader'
# 提取用户提供的头部(如果存在)
cat repomix-output.json | jq -r '.userProvidedHeader // "没有提供头部"'
# 创建包含文件大小的文件列表
cat repomix-output.json | jq -r '.files | to_entries[] | "\(.key): \(.value | length) characters"'
纯文本格式
要以纯文本格式生成输出,请使用 --style plain 选项:
repomix --style plain
此文件是整个代码库的合并表示,将所有仓库文件整合为一个文档。
================================================================
文件摘要
================================================================
(元数据和 AI 使用说明)
================================================================
目录结构
================================================================
src/
cli/
cliOutput.ts
index.ts
config/
configLoader.ts
(...剩余目录)
================================================================
文件
================================================================
================
文件:src/index.js
================
// 文件内容在此处
================
文件:src/utils.js
================
// 文件内容在此处
(...剩余文件)
================================================================
指令
================================================================
(来自 `output.instructionFilePath` 的自定义指令)
命令行选项
基本选项
-v, --version:显示版本信息并退出
CLI 输入/输出选项
| 选项 | 描述 |
|---|---|
--verbose |
启用详细的调试日志记录(显示文件处理、令牌计数和配置详情) |
--quiet |
抑制除错误以外的所有控制台输出(适用于脚本编写) |
--stdout |
将打包后的输出直接写入标准输出,而不是文件(抑制所有日志记录) |
--stdin |
从标准输入读取文件路径,每行一个(指定的文件会直接被处理) |
--copy |
处理完成后将生成的输出复制到系统剪贴板 |
--token-count-tree [threshold] |
显示带有令牌计数的文件树;可选阈值用于仅显示包含 ≥N 个令牌的文件(例如,--token-count-tree 100) |
--top-files-len <number> |
在摘要中显示的最大文件数量(默认:5) |
Repomix 输出选项
| 选项 | 描述 |
|---|---|
-o, --output <file> |
输出文件路径(默认:repomix-output.xml,使用-表示标准输出) |
--style <style> |
输出格式:xml、markdown、json 或 plain(默认:xml) |
--parsable-style |
转义特殊字符以确保有效的 XML/Markdown(当输出包含破坏格式的代码时需要) |
--compress |
使用 Tree-sitter 解析提取核心代码结构(类、函数、接口等) |
--output-show-line-numbers |
在输出中每行前添加行号 |
--no-file-summary |
从输出中省略文件摘要部分 |
--no-directory-structure |
从输出中省略目录树可视化 |
--no-files |
仅生成元数据而不包含文件内容(适用于仓库分析) |
--remove-comments |
在打包前移除所有代码注释 |
--remove-empty-lines |
移除所有文件中的空行 |
--truncate-base64 |
截断过长的 base64 数据字符串以减小输出大小 |
--header-text <text> |
自定义文本,包含在输出开头 |
--instruction-file-path <path> |
包含自定义指令的文件路径,将这些指令加入输出 |
--split-output <size> |
将输出拆分为多个编号文件(例如,repomix-output.1.xml);大小如 500kb、2mb 或 1.5mb |
--include-empty-directories |
在目录结构中包含没有文件的文件夹 |
--include-full-directory-structure |
在输出中显示完整的目录树,包括未被 --include 模式匹配的文件 |
--no-git-sort-by-changes |
不按 Git 更改频率排序文件(默认:更改最多的文件排在前面) |
--include-diffs |
添加 Git 差异部分,显示工作树和暂存更改 |
--include-logs |
添加 Git 提交历史,包括提交信息和更改的文件 |
--include-logs-count <count> |
使用 --include-logs 时包含的最近提交次数(默认:50) |
文件选择选项
| 选项 | 描述 |
|---|---|
--include <patterns> |
仅包含匹配这些 glob 模式的文件(逗号分隔,例如 "src/**/*.js,*.md") |
-i, --ignore <patterns> |
额外的排除模式(逗号分隔,例如 "*.test.js,docs/**") |
--no-gitignore |
不使用 .gitignore 规则来过滤文件 |
--no-dot-ignore |
不使用 .ignore 规则来过滤文件 |
--no-default-patterns |
不应用内置的忽略模式(node_modules、.git、构建目录等) |
远程仓库选项
| 选项 | 描述 |
|---|---|
--remote <url> |
克隆并打包远程仓库(GitHub URL 或 user/repo 格式) |
--remote-branch <name> |
特定分支、标签或提交(默认:仓库的默认分支) |
--remote-trust-config |
信任并加载来自远程仓库的配置文件(出于安全考虑,默认关闭) |
配置选项
| 选项 | 描述 |
|---|---|
-c, --config <path> |
使用自定义配置文件,而非 repomix.config.json |
--init |
创建一个新的带有默认设置的 repomix.config.json 文件 |
--global |
使用 --init 时,在主目录而非当前目录创建配置文件 |
安全选项
--no-security-check:跳过对敏感数据(如 API 密钥和密码)的扫描
令牌计数选项
--token-count-encoding <encoding>:用于计数的分词器模型:o200k_base(GPT-4o)、cl100k_base(GPT-3.5/4)等(默认:o200k_base)
MCP
--mcp:作为模型上下文协议服务器运行,用于 AI 工具集成
代理技能生成
| 选项 | 描述 |
|---|---|
--skill-generate [name] |
生成 Claude 代理技能格式的输出,保存到 .claude/skills/<name>/ 目录(若省略名称,则自动生成) |
--skill-output <path> |
直接指定技能输出目录路径(跳过位置提示) |
-f, --force |
跳过所有确认提示(例如,覆盖技能目录) |
示例
# 基本用法
repomix
# 自定义输出
repomix -o output.xml --style xml
# 输出到标准输出
repomix --stdout > custom-output.txt
# 将输出发送到标准输出,然后通过管道传递给另一个命令(例如 simonw/llm)
repomix --stdout | llm "请解释这段代码的作用。"
# 自定义输出并压缩
repomix --compress
# 处理特定文件
repomix --include "src/**/*.ts" --ignore "**/*.test.ts"
# 将输出拆分为多个文件(每个部分的最大大小)
repomix --split-output 20mb
# 远程仓库及分支
repomix --remote https://github.com/user/repo/tree/main
# 远程仓库与提交
repomix --remote https://github.com/user/repo/commit/836abcd7335137228ad77feb28655d85712680f1
# 远程仓库与简写
repomix --remote user/repo
更新 Repomix
要更新全局安装的 Repomix:
# 使用 npm
npm update -g repomix
# 使用 yarn
yarn global upgrade repomix
# 使用 bun
bun update -g repomix
通常使用 npx repomix 更为方便,因为它始终使用最新版本。
远程仓库处理
Repomix 支持无需手动克隆即可处理远程 Git 仓库。此功能允许您通过一条命令快速分析任何公开的 Git 仓库。
要处理远程仓库,请使用 --remote 选项并后接仓库 URL:
repomix --remote https://github.com/yamadashy/repomix
您也可以使用 GitHub 的简写格式:
repomix --remote yamadashy/repomix
您可以指定分支名称、标签或提交哈希值:
# 使用 --remote-branch 选项
repomix --remote https://github.com/yamadashy/repomix --remote-branch main
# 使用分支的 URL
repomix --remote https://github.com/yamadashy/repomix/tree/main
或者使用特定的提交哈希值:
# 使用 --remote-branch 选项
repomix --remote https://github.com/yamadashy/repomix --remote-branch 935b695
# 使用提交的 URL
repomix --remote https://github.com/yamadashy/repomix/commit/836abcd7335137228ad77feb28655d85712680f1
[!NOTE] 出于安全考虑,远程仓库中的配置文件(
repomix.config.*)默认不会被加载。这可以防止不受信任的仓库通过配置文件执行代码。您的全局配置和 CLI 选项仍然会生效。若要信任远程仓库的配置文件,请使用--remote-trust-config或设置REPOMIX_REMOTE_TRUST_CONFIG=true。当结合
--config和--remote使用时,需要提供绝对路径(例如:--config /home/user/repomix.config.json)。
代码压缩
--compress 选项利用 Tree-sitter 实现智能代码提取,专注于关键函数和类的签名,同时移除实现细节。这有助于减少 token 数量,同时保留重要的结构信息。
repomix --compress
例如,以下代码:
import { ShoppingItem } from './shopping-item';
/**
* 计算购物商品的总价
*/
const calculateTotal = (
items: ShoppingItem[]
) => {
let total = 0;
for (const item of items) {
total += item.price * item.quantity;
}
return total;
}
// 购物商品接口
interface Item {
name: string;
price: number;
quantity: number;
}
将被压缩为:
import { ShoppingItem } from './shopping-item';
⋮----
/**
* 计算购物商品的总价
*/
const calculateTotal = (
items: ShoppingItem[]
) => {
⋮----
// 购物商品接口
interface Item {
name: string;
price: number;
quantity: number;
}
[!NOTE] 这是一个实验性功能,我们将根据用户反馈和实际使用情况持续改进。
Token 数优化
了解代码库中 token 的分布对于优化 AI 交互至关重要。使用 --token-count-tree 选项可视化项目中各部分的 token 使用情况:
repomix --token-count-tree
这将显示一个包含 token 数量的代码库层级视图:
🔢 Token Count Tree:
────────────────────
└── src/ (70,925 tokens)
├── cli/ (12,714 tokens)
│ ├── actions/ (7,546 tokens)
│ └── reporters/ (990 tokens)
└── core/ (41,600 tokens)
├── file/ (10,098 tokens)
└── output/ (5,808 tokens)
您还可以设置最小 token 阈值,以重点关注较大的文件:
repomix --token-count-tree 1000 # 只显示 1000+ tokens 的文件/目录
这有助于您:
- 识别 token 较多的文件,这些文件可能会超出 AI 上下文限制
- 优化文件选择,使用
--include和--ignore模式 - 规划压缩策略,针对最大的贡献者
- 平衡内容与上下文,在准备代码进行 AI 分析时
大型代码库的输出分割
当处理大型代码库时,打包后的输出可能会超过某些 AI 工具对文件大小的限制(例如,Google AI Studio 的 1MB 限制)。使用 --split-output 可自动将输出拆分为多个文件:
repomix --split-output 1mb
这将生成编号文件,如:
repomix-output.1.xmlrepomix-output.2.xmlrepomix-output.3.xml
可以使用单位指定大小:500kb、1mb、2mb、1.5mb 等。支持小数。
[!NOTE] 文件按顶级目录分组,以保持上下文一致性。单个文件或目录绝不会被拆分到多个输出文件中。
MCP 服务器集成
Repomix 支持 模型上下文协议 (MCP),允许 AI 助手直接与您的代码库交互。作为 MCP 服务器运行时,Repomix 提供工具,使 AI 助手能够打包本地或远程仓库以进行分析,而无需手动准备文件。
repomix --mcp
配置 MCP 服务器
要将 Repomix 用作与 Claude 等 AI 助手兼容的 MCP 服务器,您需要配置 MCP 设置:
适用于 VS Code:
您可以通过以下方法之一在 VS Code 中安装 Repomix MCP 服务器:
- 使用安装徽章:
- 使用命令行:
code --add-mcp '{"name":"repomix","command":"npx","args":["-y","repomix","--mcp"]}'
对于 VS Code Insiders:
code-insiders --add-mcp '{"name":"repomix","command":"npx","args":["-y","repomix","--mcp"]}'
适用于 Cline(VS Code 扩展):
编辑 cline_mcp_settings.json 文件:
{
"mcpServers": {
"repomix": {
"command": "npx",
"args": [
"-y",
"repomix",
"--mcp"
]
}
}
}
适用于 Cursor:
在 Cursor 中,从 Cursor Settings > MCP > + Add new global MCP server 添加一个新的 MCP 服务器,配置与 Cline 类似。
适用于 Claude Desktop:
编辑 claude_desktop_config.json 文件,配置与 Cline 的配置类似。
适用于 Claude Code:
要在 Claude Code 中将 Repomix 配置为 MCP 服务器,请使用以下命令:
claude mcp add repomix -- npx -y repomix --mcp
或者,您也可以使用官方的 Repomix 插件(请参阅下方的 Claude Code 插件 部分)。
使用 Docker 替代 npx:
您可以使用 Docker 作为替代方案,以运行 Repomix 作为 MCP 服务器:
{
"mcpServers": {
"repomix-docker": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"ghcr.io/yamadashy/repomix",
"--mcp"
]
}
}
}
配置完成后,您的 AI 助手可以直接利用 Repomix 的功能来分析代码库,而无需手动准备文件,从而提高代码分析工作流的效率。
可用的 MCP 工具
当作为 MCP 服务器运行时,Repomix 提供以下工具:
pack_codebase:将本地代码目录打包成一个整合的 XML 文件,用于 AI 分析
- 参数:
directory:要打包的目录的绝对路径compress:(可选,默认:false)启用 Tree-sitter 压缩,提取核心代码签名和结构,同时移除实现细节。这可将 token 使用量减少约 70%,同时保留语义含义。通常情况下不需要此功能,因为grep_repomix_output支持增量内容检索。仅在需要完整代码库内容的大规模仓库中才使用此选项。includePatterns:(可选)使用 fast-glob 模式指定要包含的文件。多个模式可用逗号分隔(例如:“/*.{js,ts}”、“src/,docs/**”)。只有匹配的文件会被处理。ignorePatterns:(可选)使用 fast-glob 模式指定要排除的额外文件。多个模式可用逗号分隔(例如:“test/,*.spec.js”、“node_modules/,dist/**”)。这些模式会补充.gitignore、.ignore和内置的排除规则。topFilesLength:(可选,默认:10)在代码库分析的指标摘要中显示按大小排列的前若干个最大文件。
- 参数:
attach_packed_output:附加现有的 Repomix 打包输出文件,用于 AI 分析
- 参数:
path:包含repomix-output.xml文件的目录路径,或直接指向打包后的仓库 XML 文件的路径topFilesLength:(可选,默认:10)在指标摘要中显示按大小排列的前若干个最大文件
- 特点:
- 接受包含
repomix-output.xml文件的目录,或直接指向 XML 文件的路径 - 将文件注册到 MCP 服务器,并返回与
pack_codebase工具相同的结构 - 提供对现有打包输出的安全访问,无需重新处理
- 适用于处理先前生成的打包仓库。
- 接受包含
- 参数:
pack_remote_repository:从 GitHub 获取、克隆并打包一个仓库,生成用于 AI 分析的整合 XML 文件
- 参数:
remote:GitHub 仓库的 URL 或用户/仓库格式(例如:“yamadashy/repomix”、“https://github.com/user/repo”或“https://github.com/user/repo/tree/branch”)compress:(可选,默认:false)启用 Tree-sitter 压缩,提取核心代码签名和结构,同时移除实现细节。这可将 token 使用量减少约 70%,同时保留语义含义。通常情况下不需要此功能,因为grep_repomix_output支持增量内容检索。仅在需要完整代码库内容的大规模仓库中才使用此选项。includePatterns:(可选)使用 fast-glob 模式指定要包含的文件。多个模式可用逗号分隔(例如:“/*.{js,ts}”、“src/,docs/**”)。只有匹配的文件会被处理。ignorePatterns:(可选)使用 fast-glob 模式指定要排除的额外文件。多个模式可用逗号分隔(例如:“test/,*.spec.js”、“node_modules/,dist/**”)。这些模式会补充.gitignore、.ignore和内置的排除规则。topFilesLength:(可选,默认:10)在代码库分析的指标摘要中显示按大小排列的前若干个最大文件。
- 参数:
read_repomix_output:读取 Repomix 生成的输出文件内容。支持对大文件按行范围进行部分读取。
- 参数:
outputId:要读取的 Repomix 输出文件 IDstartLine:(可选)起始行号(从 1 开始,包括该行)。未指定时从开头开始读取。endLine:(可选)结束行号(从 1 开始,包括该行)。未指定时读取到文件末尾。
- 特点:
- 专为基于 Web 的环境或沙盒应用设计
- 使用文件 ID 检索先前生成的输出内容
- 提供对打包代码库的安全访问,无需文件系统权限
- 支持对大文件的部分读取。
- 参数:
grep_repomix_output:使用类似 grep 的功能,在 Repomix 输出文件中搜索模式,采用 JavaScript RegExp 语法
- 参数:
outputId:要搜索的 Repomix 输出文件 IDpattern:搜索模式(JavaScript RegExp 正则表达式语法)contextLines:(可选,默认:0)在每个匹配结果前后显示的上下文行数。如果指定了beforeLines或afterLines,则优先使用这些值。beforeLines:(可选)在每个匹配结果之前显示的上下文行数(类似于 grep -B)。优先于contextLines。afterLines:(可选)在每个匹配结果之后显示的上下文行数(类似于 grep -A)。优先于contextLines。ignoreCase:(可选,默认:false)执行不区分大小写的匹配。
- 特点:
- 使用 JavaScript RegExp 语法实现强大的模式匹配
- 支持上下文行显示,便于理解匹配结果
- 可单独控制匹配前后的上下文行数
- 提供区分大小写和不区分大小写的搜索选项。
- 参数:
file_system_read_file:使用绝对路径从本地文件系统读取文件。内置安全验证机制,可检测并阻止访问包含敏感信息的文件。
- 参数:
path:要读取的文件的绝对路径
- 安全特性:
- 采用 Secretlint 进行安全验证
- 阻止访问包含敏感信息的文件(如 API 密钥、密码、机密等)
- 验证绝对路径,防止目录遍历攻击。
- 参数:
file_system_read_directory: 使用绝对路径列出目录内容。返回一个格式化的列表,显示文件和子目录,并带有清晰的标识。
- 参数:
path: 要列出的目录的绝对路径
- 特点:
- 以清晰的标识(
[FILE]或[DIR])显示文件和目录 - 提供安全的目录遍历功能,并进行适当的错误处理
- 验证路径是否为绝对路径
- 有助于探索项目结构和理解代码库组织
- 以清晰的标识(
Claude Code 插件
Repomix 为 Claude Code 提供了官方插件,可与 AI 驱动的开发环境无缝集成。
安装
1. 添加 Repomix 插件市场:
/plugin marketplace add yamadashy/repomix
2. 安装插件:
# 安装 MCP 服务器插件(推荐的基础插件)
/plugin install repomix-mcp@repomix
# 安装命令插件(扩展功能)
/plugin install repomix-commands@repomix
# 安装仓库探索插件(AI 驱动的分析)
/plugin install repomix-explorer@repomix
注意:推荐将 repomix-mcp 插件作为基础。repomix-commands 插件提供便捷的斜杠命令,而 repomix-explorer 则增加了 AI 驱动的分析能力。虽然可以单独安装,但同时使用这三款插件能带来最全面的体验。
或者,使用交互式插件安装程序:
/plugin
这将打开一个交互式界面,您可以在其中浏览并安装可用的插件。
可用插件
1. repomix-mcp(MCP 服务器插件)
基础插件,通过 MCP 服务器集成提供 AI 驱动的代码库分析功能。
特点:
- 打包本地和远程仓库
- 搜索打包后的结果
- 在内置安全扫描(Secretlint)下读取文件
- 自动 Tree-sitter 压缩(约减少 70% 的标记数量)
2. repomix-commands(斜杠命令插件)
提供便捷的斜杠命令,支持自然语言,方便快速操作。
可用命令:
/repomix-commands:pack-local- 以多种选项打包本地代码库/repomix-commands:pack-remote- 打包并分析远程 GitHub 仓库
示例用法:
/repomix-commands:pack-local
将该项目打包成带压缩的 Markdown 格式
/repomix-commands:pack-remote yamadashy/repomix
仅打包 yamadashy/repomix 仓库中的 TypeScript 文件
3. repomix-explorer(AI 分析代理插件)
AI 驱动的仓库分析代理,利用 Repomix CLI 智能地探索代码库。
特点:
- 以自然语言进行代码库探索和分析
- 智能发现模式并理解代码结构
- 使用 grep 和有针对性的文件读取进行增量分析
- 自动管理大型仓库的上下文
可用命令:
/repomix-explorer:explore-local- 在 AI 协助下分析本地代码库/repomix-explorer:explore-remote- 在 AI 协助下分析远程 GitHub 仓库
示例用法:
/repomix-explorer:explore-local ./src
查找所有与身份验证相关的代码
/repomix-explorer:explore-remote facebook/react
向我展示主要的组件架构
该代理会自动执行以下步骤:
- 运行
npx repomix@latest来打包仓库 - 使用 Grep 和 Read 工具高效搜索打包结果
- 提供全面的分析,而不会消耗过多的上下文
优势
- 无缝集成:Claude 可直接分析代码库,无需手动准备
- 自然语言:使用对话式的命令,无需记忆 CLI 语法
- 始终最新:自动使用
npx repomix@latest获取最新功能 - 内置安全性:自动 Secretlint 扫描防止敏感数据泄露
- 优化标记数:Tree-sitter 压缩适用于大型代码库
更多详情,请参阅 .claude/plugins/ 目录下的插件文档。
代理技能生成
Repomix 可以生成 Claude 代理技能 格式的输出,创建一个结构化的 Skills 目录,可用作 AI 助手的可重用代码库参考。此功能在需要引用远程仓库中的实现时尤为强大。
基本用法
# 从本地目录生成 Skills
repomix --skill-generate
# 生成自定义 Skills 名称
repomix --skill-generate my-project-reference
# 从远程仓库生成
repomix --remote https://github.com/user/repo --skill-generate
运行命令时,Repomix 会提示您选择保存 Skills 的位置:
- 个人 Skills (
~/.claude/skills/) - 在您机器上的所有项目中均可使用 - 项目 Skills (
.claude/skills/) - 可通过 git 与团队共享
非交互式用法
对于 CI 流水线和自动化脚本,您可以使用 --skill-output 和 --force 跳过所有交互式提示:
# 直接指定输出目录
repomix --skill-generate --skill-output ./my-skills
# 使用 --force 跳过覆盖确认
repomix --skill-generate --skill-output ./my-skills --force
# 完整的非交互式示例
repomix --remote user/repo --skill-generate my-skill --skill-output ./output --force
生成的结构
Skills 以如下结构生成:
.claude/skills/<skill-name>/
├── SKILL.md # 主要的 Skills 元数据及文档
└── references/
├── summary.md # 目的、格式和统计信息
├── project-structure.md # 包含行数的目录树
├── files.md # 所有文件内容(便于 grep 搜索)
└── tech-stacks.md # 使用的语言、框架和依赖项
包含的内容
- SKILL.md:包含 Skills 元数据、文件/行/标记数量、概述以及使用说明
- summary.md:解释 Skills 的目的、使用指南,并按文件类型和语言提供统计分解
- project-structure.md:包含每文件行数的目录树,便于快速查找文件
- files.md:所有文件内容,带有语法高亮标题,优化以便于 grep 搜索
- tech-stacks.md:根据依赖文件(
package.json、requirements.txt、Cargo.toml等)自动检测每个包的技术栈
自动生成 Skills 名称
如果没有提供名称,Repomix 会自动生成一个:
repomix src/ --skill-generate # → repomix-reference-src
repomix --remote user/repo --skill-generate # → repomix-reference-repo
repomix --skill-generate CustomName # → custom-name(标准化为 kebab-case)
与 Repomix 功能的集成
技能生成尊重所有标准的 Repomix 选项:
# 使用文件过滤生成技能
repomix --skill-generate --include "src/**/*.ts" --ignore "**/*.test.ts"
# 使用压缩生成技能
repomix --skill-generate --compress
# 从远程仓库生成技能
repomix --remote yamadashy/repomix --skill-generate
Repomix Explorer 技能(代理技能)
Repomix 提供了一个开箱即用的 Repomix Explorer 技能,使 AI 编码助手能够使用 Repomix CLI 分析和探索代码库。该技能专为与多种 AI 工具配合使用而设计,包括 Claude Code、Cursor、Codex、GitHub Copilot 等。
快速安装
npx add-skill yamadashy/repomix --skill repomix-explorer
此命令会将该技能安装到你的 AI 助手的技能目录中(例如 .claude/skills/),使其立即可用。
功能简介
安装完成后,你可以通过自然语言指令来分析代码库。
分析远程仓库:
“这个仓库的结构是怎样的?
https://github.com/facebook/react”
探索本地代码库:
“这个项目里有什么内容?
~/projects/my-app”
这不仅有助于理解代码库,还能在需要参考其他仓库实现功能时提供帮助。
⚙️ 配置
为了灵活性和易用性,Repomix 支持多种配置文件格式。
配置文件格式
Repomix 会按照以下优先级自动查找配置文件:
- TypeScript (
repomix.config.ts,repomix.config.mts,repomix.config.cts) - JavaScript/ES 模块 (
repomix.config.js,repomix.config.mjs,repomix.config.cjs) - JSON (
repomix.config.json5,repomix.config.jsonc,repomix.config.json)
JSON 配置
在项目根目录下创建一个 repomix.config.json 文件:
repomix --init
这将生成一个包含默认设置的 repomix.config.json 文件。
TypeScript 配置
TypeScript 配置文件提供了最佳的开发体验,支持完整的类型检查和 IDE 支持。
安装:
若要使用 TypeScript 或 JavaScript 配置并结合 defineConfig,你需要将 Repomix 作为开发依赖项安装:
npm install -D repomix
示例:
// repomix.config.ts
import { defineConfig } from 'repomix';
export default defineConfig({
output: {
filePath: 'output.xml',
style: 'xml',
removeComments: true,
},
ignore: {
customPatterns: ['**/node_modules/**', '**/dist/**'],
},
});
优点:
- ✅ 在 IDE 中进行完整的 TypeScript 类型检查
- ✅ 出色的 IDE 自动补全和 IntelliSense
- ✅ 可使用动态值(时间戳、环境变量等)
动态值示例:
// repomix.config.ts
import { defineConfig } from 'repomix';
// 生成基于时间戳的文件名
const timestamp = new Date().toISOString().slice(0, 19).replace(/[:.]/g, '-');
export default defineConfig({
output: {
filePath: `output-${timestamp}.xml`,
style: 'xml',
},
});
JavaScript 配置
JavaScript 配置文件的功能与 TypeScript 配置相同,同样支持 defineConfig 和动态值。
配置选项
以下是配置选项的说明:
| 选项 | 描述 | 默认值 |
|---|---|---|
input.maxFileSize |
要处理的最大文件大小,单位为字节。超过此大小的文件将被跳过 | 50000000 |
output.filePath |
输出文件的名称 | "repomix-output.xml" |
output.style |
输出的格式(xml、markdown、json、plain) |
"xml" |
output.parsableStyle |
是否根据所选的样式模式对输出进行转义。请注意,这可能会增加 token 数量。 | false |
output.compress |
是否执行智能代码提取以减少 token 数量 | false |
output.headerText |
自定义文本,用于包含在文件头部 | null |
output.instructionFilePath |
包含详细自定义指令的文件路径 | null |
output.fileSummary |
是否在输出开头包含摘要部分 | true |
output.directoryStructure |
是否在输出中包含目录结构 | true |
output.files |
是否在输出中包含文件内容 | true |
output.removeComments |
是否从支持的文件类型中移除注释 | false |
output.removeEmptyLines |
是否从输出中移除空行 | false |
output.showLineNumbers |
是否在输出的每一行添加行号 | false |
output.truncateBase64 |
是否截断长的 base64 数据字符串(例如图片),以减少 token 数量 | false |
output.copyToClipboard |
是否在保存文件的同时,还将输出复制到系统剪贴板 | false |
output.splitOutput |
根据每个部分的最大大小(例如 1000000 表示约 1MB),将输出拆分为多个带编号的文件。这样可以确保每个文件都小于限制,并避免文件跨部分拆分 |
未设置 |
output.topFilesLength |
摘要中要显示的顶级文件数量。如果设置为 0,则不显示摘要 | 5 |
output.tokenCountTree |
是否显示带有 token 数量摘要的文件树。可以是布尔值或数字(表示最小 token 数量阈值) | false |
output.includeEmptyDirectories |
是否在仓库结构中包含空目录 | false |
output.includeFullDirectoryStructure |
使用 include 模式时,是否显示完整的目录树(同时尊重忽略模式),尽管只处理包含的文件。这为 AI 分析提供了完整的仓库上下文 |
false |
output.git.sortByChanges |
是否按 git 更改次数对文件进行排序(更改次数较多的文件会排在底部) | true |
output.git.sortByChangesMaxCommits |
用于分析 git 更改的最大提交次数 | 100 |
output.git.includeDiffs |
是否在输出中包含 git 差异(分别包括工作树和暂存区的更改) | false |
output.git.includeLogs |
是否在输出中包含 git 日志(包括提交历史、日期、消息和文件路径) | false |
output.git.includeLogsCount |
要包含的 git 日志提交数量 | 50 |
include |
要包含的文件模式(使用 glob 模式) | [] |
ignore.useGitignore |
是否使用项目 .gitignore 文件中的模式 |
true |
ignore.useDotIgnore |
是否使用项目 .ignore 文件中的模式 |
true |
ignore.useDefaultPatterns |
是否使用默认的忽略模式 | true |
ignore.customPatterns |
额外的忽略模式(使用 glob 模式) | [] |
security.enableSecurityCheck |
是否对文件执行安全检查 | true |
tokenCount.encoding |
与 OpenAI 兼容的 tokenization 的编码方式(例如,GPT-4o 使用 o200k_base,GPT-4/3.5 使用 cl100k_base)。由 gpt-tokenizer 提供支持。 |
"o200k_base" |
配置文件支持 JSON5 语法,该语法允许:
- 注释(单行和多行)
- 对象和数组中的尾随逗号
- 不加引号的属性名
- 更宽松的字符串语法
模式验证
您可以通过添加 $schema 属性来为配置文件启用模式验证:
{
"$schema": "https://repomix.com/schemas/latest/schema.json",
"output": {
"filePath": "repomix-output.xml",
"style": "xml"
}
}
这将在支持 JSON 模式的编辑器中提供自动补全和验证功能。
示例配置
示例配置:
{
"$schema": "https://repomix.com/schemas/latest/schema.json",
"input": {
"maxFileSize": 50000000
},
"output": {
"filePath": "repomix-output.xml",
"style": "xml",
"parsableStyle": false,
"compress": false,
"headerText": "打包文件的自定义头部信息。",
"fileSummary": true,
"directoryStructure": true,
"files": true,
"removeComments": false,
"removeEmptyLines": false,
"topFilesLength": 5,
"tokenCountTree": false, // 或 true,或设置一个数字如 10 作为最小标记阈值
"showLineNumbers": false,
"truncateBase64": false,
"copyToClipboard": false,
"splitOutput": null, // 或设置一个数字如 1000000 表示每份约 1MB
"includeEmptyDirectories": false,
"git": {
"sortByChanges": true,
"sortByChangesMaxCommits": 100,
"includeDiffs": false,
"includeLogs": false,
"includeLogsCount": 50
}
},
"include": ["**/*"],
"ignore": {
"useGitignore": true,
"useDefaultPatterns": true,
// 您也可以在 .repomixignore 文件中指定模式
"customPatterns": [
"additional-folder",
"**/*.log"
],
},
"security": {
"enableSecurityCheck": true
},
"tokenCount": {
"encoding": "o200k_base"
}
}
全局配置
要创建全局配置文件,请运行以下命令:
repomix --init --global
全局配置文件将被创建在以下位置:
- Windows:
%LOCALAPPDATA%\Repomix\repomix.config.json - macOS/Linux:
$XDG_CONFIG_HOME/repomix/repomix.config.json或~/.config/repomix/repomix.config.json
注意:如果存在本地配置文件,它将优先于全局配置文件。
包含与忽略
包含模式
Repomix 现在支持使用 glob 模式 来指定需要包含的文件。这使得文件选择更加灵活和强大:
- 使用
**/*.js可以包含任意目录下的所有 JavaScript 文件。 - 使用
src/**/*可以包含src目录及其子目录中的所有文件。 - 您还可以组合多个模式,例如
["src/**/*.js", "**/*.md"],以同时包含src中的 JavaScript 文件和所有 Markdown 文件。
忽略模式
Repomix 提供了多种方法来设置忽略模式,以便在打包过程中排除特定的文件或目录:
- .gitignore:默认情况下,项目中的
.gitignore文件以及.git/info/exclude中列出的模式会被使用。此行为可以通过ignore.useGitignore设置或--no-gitignore命令行选项进行控制。 - .ignore:您可以在项目根目录下使用
.ignore文件,其格式与.gitignore相同。此类文件通常被 ripgrep 和 silver searcher 等工具所尊重,从而减少维护多个忽略文件的需求。此行为可以通过ignore.useDotIgnore设置或--no-dot-ignore命令行选项进行控制。 - 默认模式:Repomix 自带一组常用的排除文件和目录列表(例如 node_modules、.git、二进制文件等)。此功能可以通过
ignore.useDefaultPatterns设置或--no-default-patterns命令行选项进行控制。更多详细信息请参阅 defaultIgnore.ts。 - .repomixignore:您可以在项目根目录下创建
.repomixignore文件,用于定义 Repomix 特有的忽略模式。该文件的格式与.gitignore相同。 - 自定义模式:您还可以通过配置文件中的
ignore.customPatterns选项指定额外的忽略模式。此外,您也可以使用-i, --ignore命令行选项覆盖此设置。
优先级顺序(从高到低)如下:
- 自定义模式 (
ignore.customPatterns) - 忽略文件(
.repomixignore、.ignore、.gitignore和.git/info/exclude):- 在嵌套目录中,深层目录中的文件具有更高的优先级。
- 在同一目录中,这些文件会按任意顺序合并。
- 默认模式(如果
ignore.useDefaultPatterns为真且未使用--no-default-patterns)
这种方法允许根据您的项目需求灵活地配置文件排除规则。它有助于优化生成的打包文件大小,确保安全敏感文件和大型二进制文件被排除,同时防止机密信息泄露。
注意:默认情况下,二进制文件不会包含在打包输出中,但它们的路径会在输出文件的“仓库结构”部分列出。这样既提供了完整的仓库结构概览,又保持了打包文件的高效性和文本特性。
自定义说明
output.instructionFilePath 选项允许您指定一个单独的文件,其中包含关于您项目的详细说明或背景信息。这使 AI 系统能够更好地理解您项目的具体背景和要求,从而可能产生更相关和定制化的分析或建议。
以下是使用此功能的一个示例:
- 在项目根目录下创建名为
repomix-instruction.md的文件:
# 编码规范
- 遵循 Airbnb JavaScript 风格指南
- 在适当的情况下,建议将文件拆分为更小、更专注的单元
- 对不明显的逻辑添加注释。所有文本应使用英语
- 所有新功能都应附有相应的单元测试
# 生成全面的输出
- 包含所有内容,除非另有说明,否则不得缩写
- 在保证输出质量的同时,优化对大型代码库的处理
- 在您的
repomix.config.json中添加instructionFilePath选项:
{
"output": {
"instructionFilePath": "repomix-instruction.md",
// 其他选项...
}
}
当 Repomix 生成输出时,它会将 repomix-instruction.md 的内容插入到专门的部分中。
注意:说明内容会附加在输出文件的末尾。这种放置方式对于 AI 系统尤其有效。Anthropic 在其文档中对此进行了说明:
将长篇数据置于顶部:将您的长文档和输入内容(约 20K+ 令牌)放在提示的顶部,位于您的查询、说明和示例之前。这可以显著提升 Claude 在所有模型上的表现。在测试中,将查询放在最后可使响应质量提高多达 30%,尤其是在处理复杂的多文档输入时。
注释移除
当 output.removeComments 设置为 true 时,Repomix 会尝试从支持的文件类型中移除注释。此功能有助于减小输出文件的大小,并专注于代码的核心内容。
支持的语言包括:HTML、CSS、JavaScript、TypeScript、Vue、Svelte、Python、PHP、Ruby、C、C#、Java、Go、Rust、Swift、Kotlin、Dart、Shell 和 YAML。
注意:注释移除过程较为保守,以避免意外移除代码。在复杂情况下,部分注释可能会被保留。
🔍 安全检查
Repomix 包含一项安全检查功能,该功能使用 Secretlint 来检测文件中可能包含的敏感信息。此功能可帮助您在共享打包后的仓库之前识别潜在的安全风险。
安全检查结果将在打包过程完成后显示在 CLI 输出中。如果检测到任何可疑文件,您将看到这些文件的列表以及一条警告消息。
示例输出:
🔍 安全检查:
──────────────────
检测到 2 个可疑文件:
1. src/utils/test.txt
2. tests/utils/secretLintUtils.test.ts
请检查这些文件中是否包含潜在的敏感信息。
默认情况下,Repomix 的安全检查功能是启用的。您可以通过在配置文件中将 security.enableSecurityCheck 设置为 false 来禁用它:
{
"security": {
"enableSecurityCheck": false
}
}
或者使用命令行选项 --no-security-check:
repomix --no-security-check
[!NOTE] 禁用安全检查可能会暴露敏感信息。请谨慎使用此选项,仅在必要时使用,例如处理包含示例凭据的测试文件或文档时。
🤖 使用 Repomix 与 GitHub Actions
您还可以在 GitHub Actions 工作流中使用 Repomix。这对于自动化代码库的打包流程以便进行 AI 分析非常有用。
基本用法:
- name: 使用 Repomix 打包仓库
uses: yamadashy/repomix/.github/actions/repomix@main
with:
output: repomix-output.xml
style: xml
使用 --style 参数生成不同格式的输出:
- name: 使用 Repomix 打包仓库
uses: yamadashy/repomix/.github/actions/repomix@main
with:
output: repomix-output.md
style: markdown
- name: 使用 Repomix 打包仓库(JSON 格式)
uses: yamadashy/repomix/.github/actions/repomix@main
with:
output: repomix-output.json
style: json
对特定目录进行压缩打包:
- name: 使用 Repomix 打包仓库
uses: yamadashy/repomix/.github/actions/repomix@main
with:
directories: src tests
include: "**/*.ts,**/*.md"
ignore: "**/*.test.ts"
output: repomix-output.txt
compress: true
将输出文件作为构件上传:
- name: 使用 Repomix 打包仓库
uses: yamadashy/repomix/.github/actions/repomix@main
with:
directories: src
output: repomix-output.txt
compress: true
- name: 上传 Repomix 输出
uses: actions/upload-artifact@v4
with:
name: repomix-output
path: repomix-output.txt
完整的工作流示例:
name: 使用 Repomix 打包仓库
on:
workflow_dispatch:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
pack-repo:
runs-on: ubuntu-latest
steps:
- name: 检出代码
uses: actions/checkout@v4
- name: 使用 Repomix 打包仓库
uses: yamadashy/repomix/.github/actions/repomix@main
with:
output: repomix-output.xml
- name: 上传 Repomix 输出
uses: actions/upload-artifact@v4
with:
name: repomix-output.xml
path: repomix-output.xml
retention-days: 30
完整的工作流示例请参见 此处。
Action 输入参数
| 名称 | 描述 | 默认值 |
|---|---|---|
directories |
要处理的目录列表,以空格分隔(例如 src tests docs) |
. |
include |
要包含的文件的 glob 模式,以逗号分隔(例如 **/*.ts,**/*.md) |
"" |
ignore |
要忽略的文件的 glob 模式,以逗号分隔(例如 **/*.test.ts,**/node_modules/**) |
"" |
output |
打包文件的相对路径(扩展名决定格式:.txt、.md、.xml) |
repomix-output.xml |
compress |
启用智能压缩以通过去除实现细节来减小输出大小 | true |
style |
输出样式(xml、markdown、json、plain) |
xml |
additional-args |
用于 repomix CLI 的额外原始参数(例如 --no-file-summary --no-security-check) |
"" |
repomix-version |
要安装的 npm 包版本(支持 semver 范围、标签或具体版本,如 0.2.25) |
latest |
Action 输出参数
| 名称 | 描述 |
|---|---|
output_file |
生成的输出文件路径。可在后续步骤中用于上传构件、LLM 处理或其他操作。该文件包含基于指定选项的代码库格式化表示。 |
📚 将 Repomix 用作库
除了将 Repomix 用作 CLI 工具外,您还可以将其作为库集成到您的 Node.js 应用程序中。
安装
npm install repomix
基本用法
import { runCli, type CliOptions } from 'repomix';
// 使用自定义选项处理当前目录
async function packProject() {
const options = {
output: 'output.xml',
style: 'xml',
compress: true,
quiet: true
} as CliOptions;
const result = await runCli(['.'], process.cwd(), options);
return result.packResult;
}
处理远程仓库
import { runCli, type CliOptions } from 'repomix';
// 克隆并处理一个 GitHub 仓库
async function processRemoteRepo(repoUrl) {
const options = {
remote: repoUrl,
output: 'output.xml',
compress: true
} as CliOptions;
return await runCli(['.'], process.cwd(), options);
}
使用核心组件
如果你需要更精细的控制,可以使用低级 API:
import { searchFiles, collectFiles, processFiles, TokenCounter } from 'repomix';
async function analyzeFiles(directory) {
// 查找并收集文件
const { filePaths } = await searchFiles(directory, { /* 配置 */ });
const rawFiles = await collectFiles(filePaths, directory);
const processedFiles = await processFiles(rawFiles, { /* 配置 */ });
// 统计 token 数量
const tokenCounter = new TokenCounter('o200k_base');
// 返回分析结果
return processedFiles.map(file => ({
path: file.path,
tokens: tokenCounter.countTokens(file.content)
}));
}
更多示例,请查看源代码中的 website/server/src/remoteRepo.ts,其中展示了 repomix.com 是如何使用该库的。
打包
在使用 Rolldown 或 esbuild 等工具打包 repomix 时,某些依赖项必须保持外部引用,并且需要复制 WASM 文件:
外部依赖(不能打包):
tinypool- 使用文件路径启动工作线程
需要复制的 WASM 文件:
web-tree-sitter.wasm→ 与打包后的 JS 文件位于同一目录(用于代码压缩功能)- Tree-sitter 语言文件 → 放置在
REPOMIX_WASM_DIR环境变量指定的目录中
有关实际操作示例,请参阅 website/server/scripts/bundle.mjs。
🌍 社区项目
探索由 Repomix 社区打造的精彩项目!
- Repomix Runner - VSCode 插件,用于将文件打包成单个输出以供 AI 处理
- Repomix Desktop - 基于 Python 和 CustomTkinter 构建的 Repomix 图形化桌面应用
- Python Repomix - 基于 AST 的压缩实现的 Python 版本
- Rulefy - 利用 Claude AI 将 GitHub 仓库转换为自定义 Cursor AI 规则
- Codebase MCP - 使用 Repomix 进行 AI 驱动代码库分析的 MCP 服务器
- vibe-tools - 面向 AI 代理的 CLI 工具集,支持网页搜索、代码库分析和浏览器自动化
更多详情,请访问我们的 社区项目页面。
🤝 贡献
我们欢迎社区的贡献!如需开始,请参阅我们的 贡献指南。
贡献者

🔒 隐私政策
请参阅我们的 隐私政策。
📜 许可证
本项目采用 MIT 许可证。
版本历史
v1.13.12026/03/26v1.13.02026/03/24v1.12.02026/02/28v1.11.12026/01/18v1.11.02025/12/23v1.10.22025/12/16v1.10.12025/12/14v1.10.02025/12/12v1.9.22025/11/28v1.9.12025/11/15v1.9.02025/11/08v1.8.02025/10/18v1.7.02025/10/12v1.6.12025/10/02v1.6.02025/09/21v1.5.02025/09/14v1.4.22025/09/01v1.4.12025/08/30v1.4.02025/08/23v1.3.02025/08/11常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器