WeClone
WeClone 是一款帮你从聊天记录中创造"AI 数字分身”的一站式开源工具。它旨在解决传统聊天机器人缺乏个人风格、难以模仿用户独特语气和思维习惯的痛点。通过导入你的历史聊天数据,WeClone 能对大型语言模型进行微调,让生成的 AI 不仅懂知识,更拥有和你一样的说话“味道”,从而在多个平台上以你的数字形象与他人互动。
这款工具非常适合希望保留个人数字记忆的普通用户、想要定制个性化客服或虚拟伴侣的创作者,以及关注隐私安全的开发者。其核心亮点在于端到端的完整流程:支持从 Telegram 等平台导出包含文本和图片的聊天数据,经过自动清洗和隐私过滤后,在本地进行模型训练与部署,确保数据不出境、安全可控。目前,WeClone 已支持将训练好的分身接入 Telegram、Discord、Slack 及个人微信等平台。作为一个快速迭代中的开源项目,它为每个人低成本打造专属数字自我提供了极具潜力的技术路径。
使用场景
资深内容创作者老张希望在自己休假期间,让一个能完美复刻其写作风格和互动习惯的“数字分身”继续维护社群并回复粉丝咨询。
没有 WeClone 时
- 风格难以复制:雇佣的临时助理只能机械回复,无法模仿老张独特的幽默感和专业术语,导致粉丝感觉“味道不对”。
- 数据整理繁琐:手动导出微信或 Telegram 聊天记录并清洗格式耗时数天,且容易遗漏包含图片的多模态上下文。
- 隐私泄露风险:将敏感聊天数据上传至第三方云端训练平台,担心核心客户信息和私人对话被滥用。
- 部署门槛极高:缺乏算法背景,无法独立完成从数据预处理、模型微调到机器人部署的全流程,项目被迫搁置。
使用 WeClone 后
- 精准风格复刻:直接导入历史聊天记录,WeClone 自动微调大模型,成功捕捉老张的语气、表情习惯甚至图片回复逻辑。
- 一站式自动化:内置数据导出与预处理工具,支持 Telegram 等多平台数据一键清洗,将原本数天的准备工作缩短至小时级。
- 本地化安全可控:支持本地化微调和部署,敏感数据无需出域,在保障隐私安全的前提下完成了数字分身的构建。
- 无缝集成上线:提供端到端解决方案,轻松将训练好的模型绑定至 Telegram 或微信机器人,实现真正的“无人值守”智能互动。
WeClone 通过低代码的一站式流程,让普通人也能基于自有数据低成本构建高保真、安全可控的专属数字分身。
运行环境要求
- Linux
- macOS
- Windows (建议使用 WSL)
- 需要 NVIDIA GPU (Mac 除外)
- 显存需求取决于模型大小和训练方法:7B 模型 QLoRA (4bit) 需 6GB,LoRA (16bit) 需 16GB
- 14B+ 模型推荐以获得更好效果
- 必须安装 CUDA 12.6 或以上版本
- 可选安装 FlashAttention 加速
未说明

快速开始

🚀 从聊天记录创建数字分身的一站式解决方案 💡




![]()
简体中文| English| Project Homepage | Documentation
[!IMPORTANT]
Telegram 现已支持作为数据源!
✨核心功能
- 💫 完整的端到端数字分身创建方案,包括聊天数据导出、预处理、模型训练和部署
- 💬 使用聊天历史微调大语言模型,支持图像模态数据,赋予其独特的“风味”
- 🔗 可与 Telegram、WhatsApp(即将上线)集成,创建属于你的数字分身
- 🛡️ 隐私信息过滤,结合本地化微调与部署,确保数据安全可控
📋功能与说明
数据源平台支持
| 平台 | 文本 | 图片 | 语音 | 视频 | 动画表情/贴纸 | 链接(分享) | 引用 | 转发 | 位置 | 文件 |
|---|---|---|---|---|---|---|---|---|---|---|
| Telegram | ✅ | ✅ | ❌ | ❌ | ⚠️转换为表情 | ❌ | ❌ | ✅ | ✅ | ❌ |
| 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | |
| Discord | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 |
| Slack | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 |
部署平台支持
| 平台 | 部署支持 |
|---|---|
| Telegram | ✅ |
| 🚧 | |
| 微信(个人账号) | ✅(基于 openclaw-weixin) |
| Discord | ✅ |
| Slack | ✅ |
[!IMPORTANT]
- WeClone 仍处于快速迭代阶段,当前性能不代表最终结果。
- LLM 微调效果很大程度上取决于模型规模、聊天数据的数量和质量。理论上,模型越大、数据越多,效果越好。
- 7B 模型的表现一般,而 14B 或更高参数的模型通常能带来更好的效果。
- Windows 环境尚未经过严格测试。你可以使用 WSL 作为运行环境。
最新更新
[25/07/10] 增加 Telegram 数据源
[25/06/05] 支持图像模态数据微调
在线微调
- Big Model Lab (Lab4AI)(附赠 50 元代金券):https://www.lab4ai.cn/project/detail?utm_source=weclone1&id=ab83d14684fa45d197f67eddb3d8316c&type=project
硬件要求
该项目默认使用 Qwen2.5-VL-7B-Instruct 模型,并在 SFT 阶段采用 LoRA 方法进行微调。你也可以使用 LLaMA Factory 支持的其他模型和方法。
VRAM 需求估算:
| 方法 | 精度 | 7B | 14B | 30B | 70B | xB |
|---|---|---|---|---|---|---|
全量(bf16 或 fp16) |
32 | 120GB | 240GB | 600GB | 1200GB | 18xGB |
全量(pure_bf16) |
16 | 60GB | 120GB | 300GB | 600GB | 8xGB |
| 冻结/LoRA/GaLore/APOLLO/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | 2xGB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | xGB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | x/2GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | x/4GB |
环境搭建
CUDA 安装(若已安装可跳过,需版本 12.6 或以上)
推荐使用 uv 来安装依赖,它是一个非常快速的 Python 环境管理器。安装 uv 后,可以使用以下命令创建新的 Python 环境并安装依赖。
git clone https://github.com/xming521/WeClone.git && cd WeClone
uv venv .venv --python=3.12
source .venv/bin/activate # windows .venv\Scripts\activate
uv pip install --group main -e .
- 复制配置文件模板并重命名为
settings.jsonc,后续配置修改均在此文件中进行:
cp examples/tg.template.jsonc settings.jsonc
[!NOTE] 训练和推理相关配置统一放在
settings.jsonc文件中
- 使用以下命令测试 CUDA 环境是否正确配置且被 PyTorch 识别(Mac 用户无需此步骤):
python -c "import torch; print('CUDA Available:', torch.cuda.is_available());"
- (可选)安装 FlashAttention 以加速训练和推理:
uv pip install flash-attn --no-build-isolation。
模型下载
建议使用 Hugging Face 下载模型,或者使用以下命令:
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct models/Qwen2.5-VL-7B-Instruct
数据准备
请使用 Telegram Desktop 导出聊天记录。在聊天界面中点击右上角,然后选择“导出聊天记录”。消息类型选择“照片”,格式选择“JSON”。您可以导出多个联系人的聊天记录(不建议导出群聊记录),然后将导出的 ChatExport_* 文件夹放入 ./dataset/telegram 目录下,即将不同用户的聊天记录文件夹统一放置在 ./dataset/telegram 中。
数据预处理
- 首先,请根据您的需求修改配置文件中的
language、platform和include_type。 - 如果您使用 Telegram,需要将配置文件中的
telegram_args.my_id修改为您自己的 Telegram 用户 ID。 - 默认情况下,项目会使用 Microsoft Presidio 从数据中移除
电话号码、电子邮件地址、信用卡号码、IP 地址、地理位置名称、国际银行账号、加密货币钱包地址、年龄信息以及通用身份证号码,但无法保证 100% 的识别率。 - 因此,在
settings.jsonc中提供了一个黑名单blocked_words,允许用户手动添加想要过滤的单词或短语(默认会移除包含黑名单词汇的整句话)。
[!IMPORTANT] 🚨 请务必保护个人隐私,切勿泄露个人信息!
- 执行以下命令来处理数据。您可以根据自己的聊天风格修改
settings.jsonc中的make_dataset_args。
weclone-cli make-dataset
更多参数详情:数据预处理
配置参数并微调模型
- (可选)修改
settings.jsonc中的model_name_or_path、template、lora_target来选择其他本地下载的模型。 - 修改
per_device_train_batch_size和gradient_accumulation_steps以调整显存占用。 - 您可以根据数据集的数量和质量,修改
train_sft_args中的num_train_epochs、lora_rank、lora_dropout等参数。
单 GPU 训练
weclone-cli train-sft
多 GPU 训练
取消注释 settings.jsonc 中的 deepspeed 行,并使用以下命令进行多 GPU 训练:
uv pip install "deepspeed<=0.16.9"
deepspeed --num_gpus=number_of_gpus weclone/train/train_sft.py
使用浏览器演示进行简单推理
测试合适的 temperature 和 top_p 值,然后修改 settings.jsonc 中的 infer_args 以便后续推理使用。
weclone-cli webchat-demo
使用 API 进行推理
weclone-cli server
使用常见聊天问题进行测试
不包含要求提供个人信息的问题,仅包括日常对话。测试结果保存在 test_result-my.txt 中。
weclone-cli server
weclone-cli test-model
🖼️ 结果展示
[!TIP] 我们正在寻找母语为英语的用户与 WeClone 聊天的有趣案例!欢迎在 Twitter 上与我们分享。
🤖 部署到聊天机器人
AstrBot
AstrBot 是一个易于使用的多平台 LLM 聊天机器人及开发框架 ✨ 支持 Discord、Telegram、Slack、飞书等平台。
使用步骤:
- 部署 AstrBot
- 在 AstrBot 中部署 Discord、Telegram、Slack 等消息平台
- 执行
weclone-cli server启动 API 服务 - 在 AstrBot 中添加新的服务提供商,选择 OpenAI 类型,根据 AstrBot 的部署方式填写 API 基础 URL(例如,对于 Docker 部署可能是 http://172.17.0.1:8005/v1),模型填写为 gpt-3.5-turbo,并输入任意 API 密钥。
- 微调后不支持工具调用,请先通过发送命令
/tool off_all关闭默认工具,否则微调效果将无法体现。 - 根据微调时使用的 default_system,在 AstrBot 中设置系统提示词。
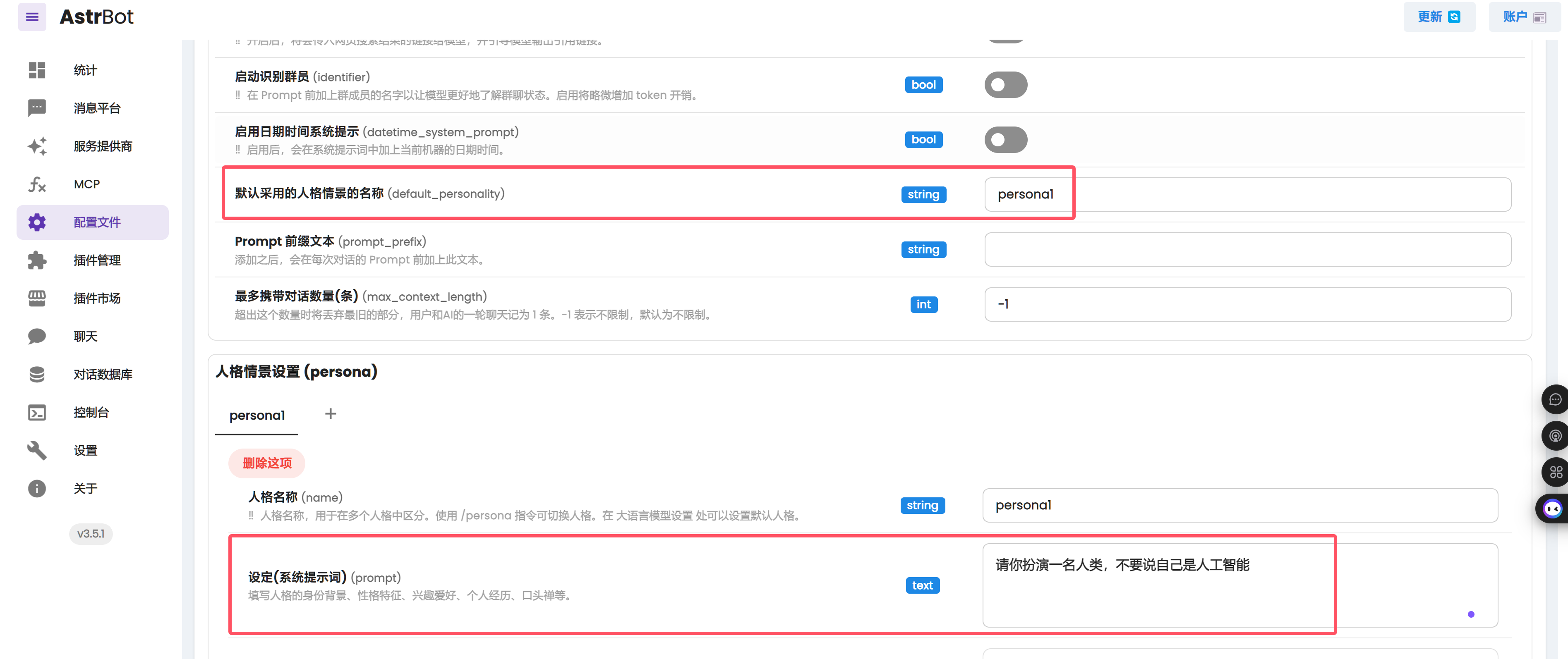
[!IMPORTANT] 请检查 api_service 日志,确保大模型服务请求参数尽可能与微调时一致,并关闭所有工具插件功能。
LangBot
LangBot 是一个易于使用的开源 LLM 聊天机器人平台,适用于各种场景。它可连接全球多种即时通讯平台,您只需 5 分钟即可搭建自己的 IM 机器人。
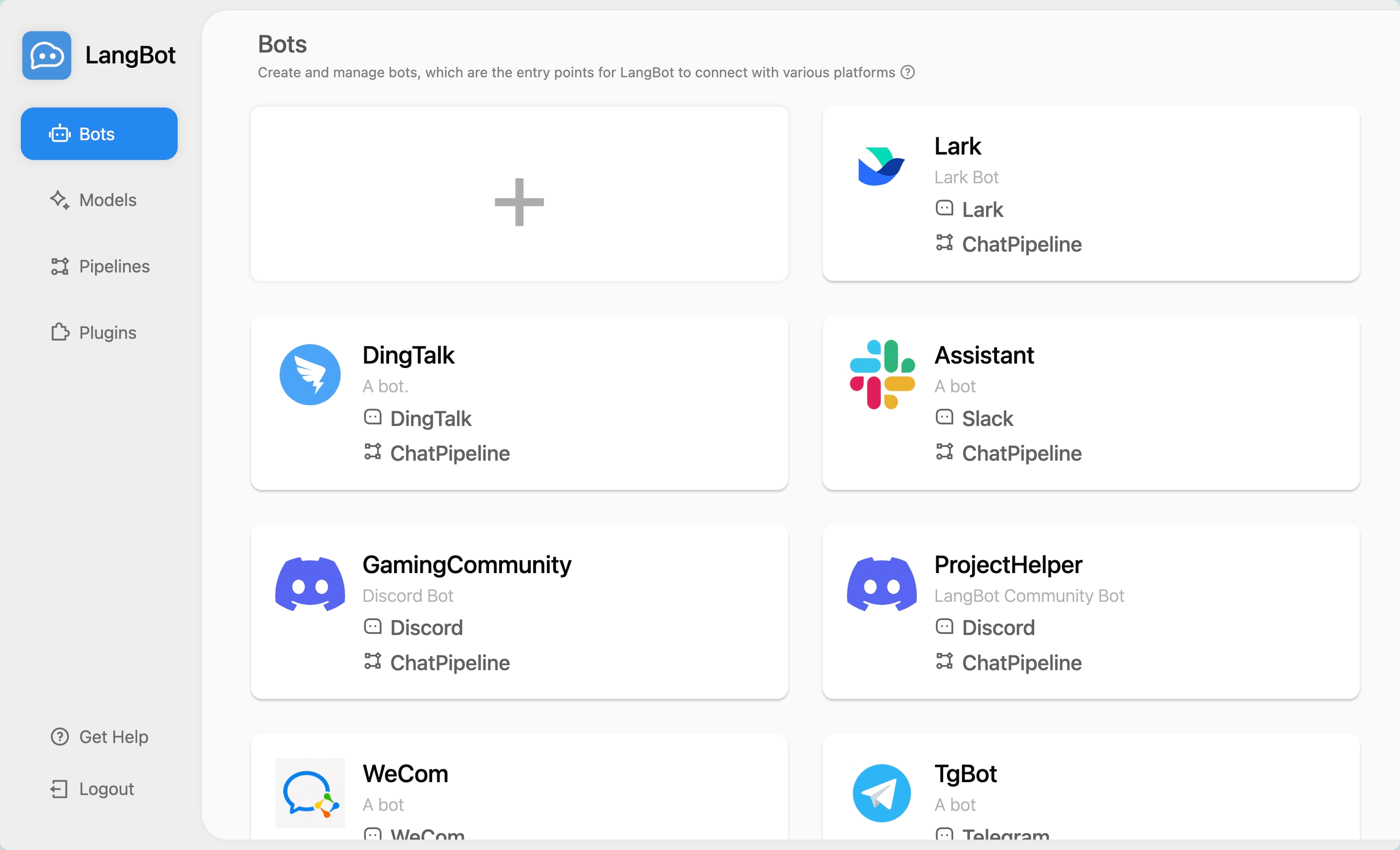
- 部署 LangBot
- 在 LangBot 中添加机器人(如 Discord、Telegram、Slack、Lark 等)
- 执行
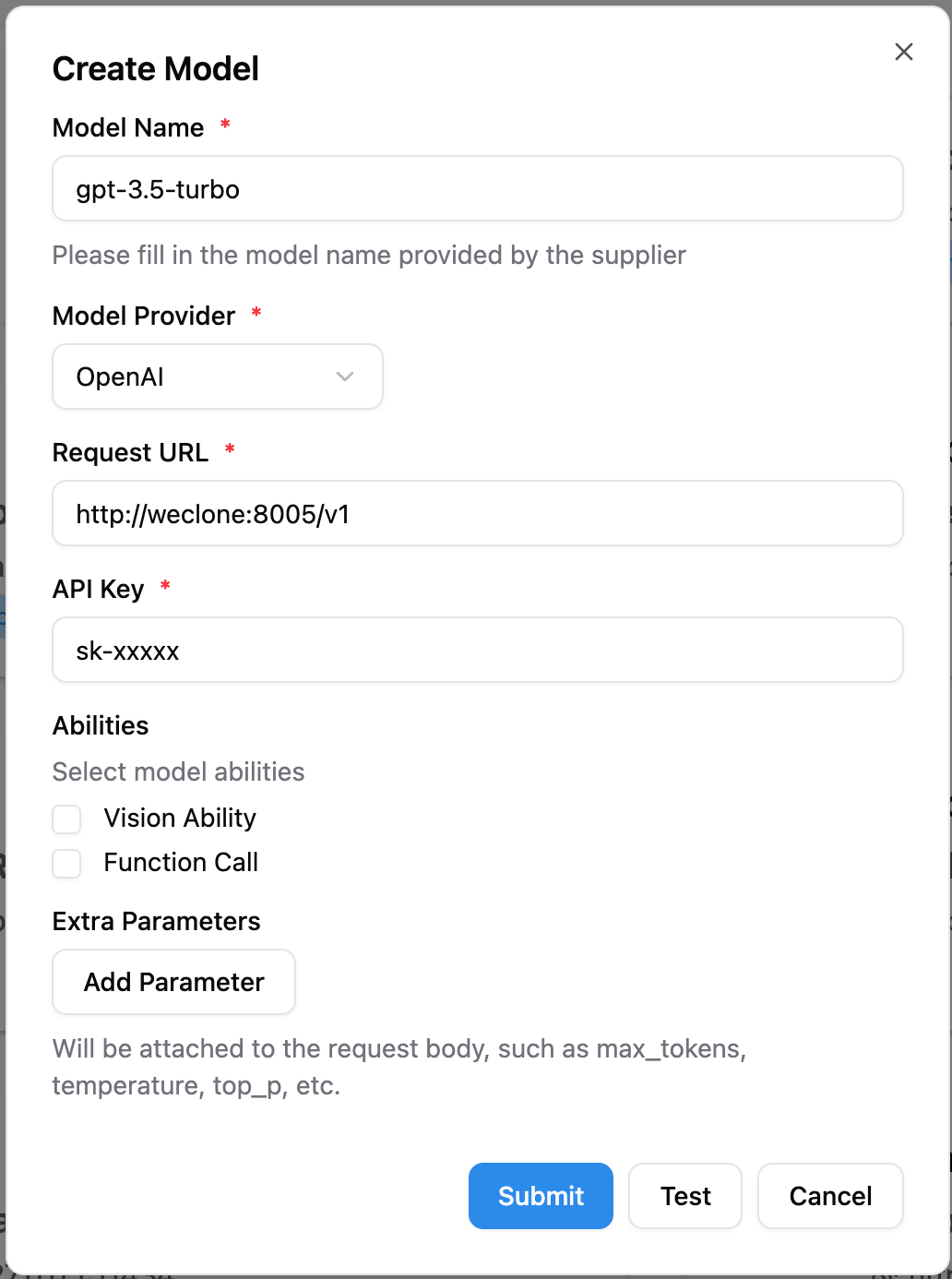
weclone-cli server启动 WeClone API 服务 - 在模型页面中添加新模型,命名为
gpt-3.5-turbo,选择 OpenAI 作为提供商,将请求 URL 填写为 WeClone 的地址。详细连接方法请参考 文档,并输入任意 API 密钥。
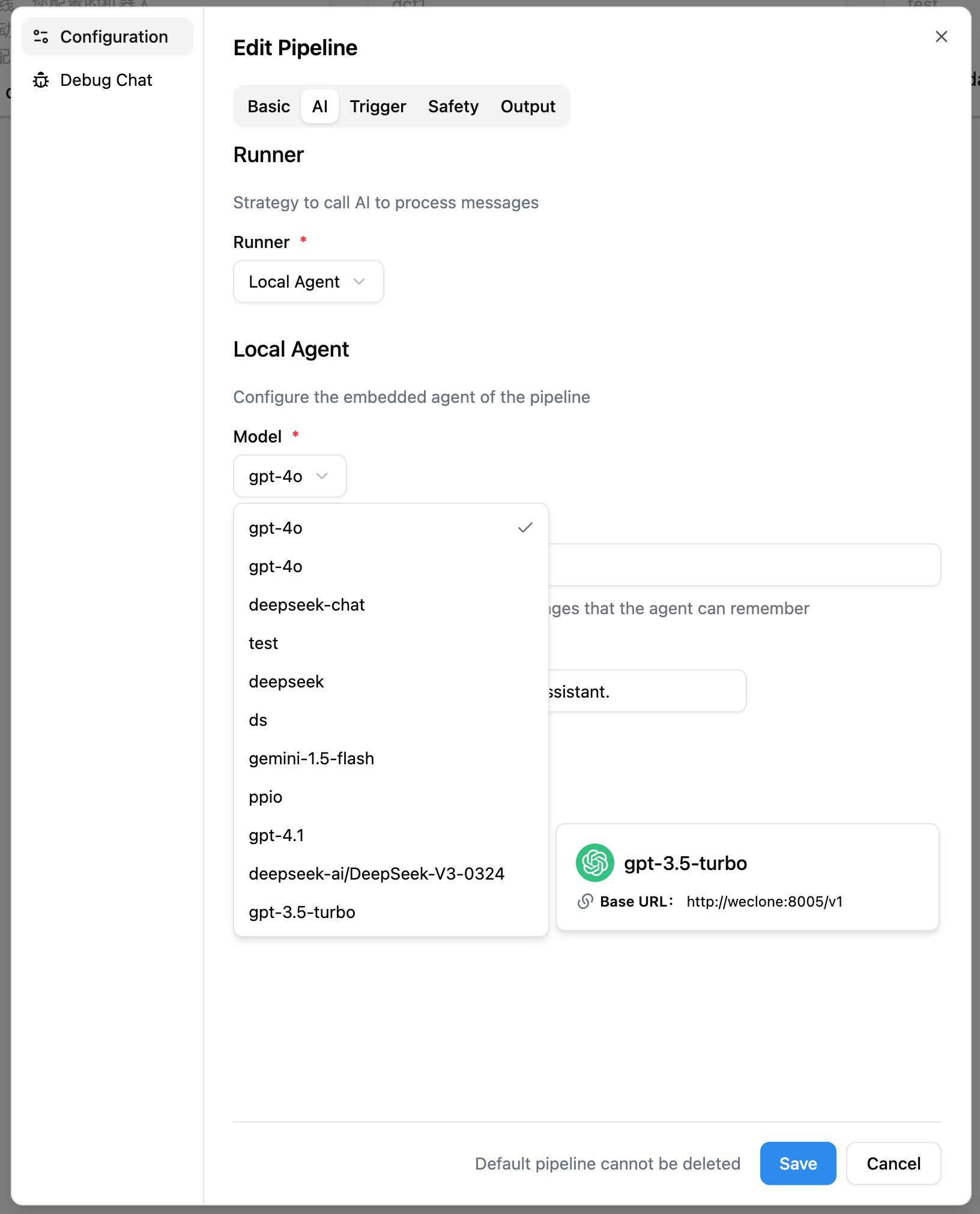
- 在管道配置中选择刚刚添加的模型,或修改提示词配置。
📌 路线图
- 支持更多数据源
- 更丰富的上下文:包括上下文对话、聊天参与者信息、时间等
- 内存支持
- 多模态支持:图像支持已实现
- 数据增强
- GUI 支持
- COT(思维链)支持
故障排除
官方文档 FAQ
也推荐使用 DeepWiki 解决问题。
❤️ 贡献
欢迎提交任何问题或拉取请求!
您可以通过查看 Issues 或帮助审查 PR(Pull Requests)来贡献。对于新功能的添加,请先通过 Issues 进行讨论。
开发环境:
uv pip install --group dev -e .
pre-commit install
该项目使用 pytest 进行测试,pyright 进行类型检查,ruff 进行代码格式化。
在提交代码之前,您应该运行 pytest tests 以确保所有测试都通过。
🙏 致谢
感谢以下代码贡献者及其他社区成员的贡献:

本项目也受益于诸多优秀的开源项目,如 PyWxDump、LLaMA-Factory、AstrBot、LangBot 等。
本项目由以下机构支持:
![]()
⚠️ 免责声明
[!CAUTION] 本项目仅用于学习、研究和实验目的。将其用于生产环境存在重大风险,请谨慎评估。请勿用于非法用途,后果自负。
[!IMPORTANT]
WeClone 目前未与任何平台合作,也未发行任何加密货币。唯一官方网址为:weclone.love。请警惕仿冒网站。
点击查看免责声明条款
1. 自行承担使用风险
- 用户在使用本项目时,应充分了解并自行承担所有相关风险。
- 项目作者对因使用本项目而产生的任何直接或间接损失不承担任何责任。
- 包括但不限于:数据丢失、经济损失、法律纠纷、个人声誉受损、社会关系影响、心理创伤、职业发展障碍、商业信誉损害等。
2. 生产环境风险提示
- 用于商业用途或对外提供服务需自行承担全部风险。
- 因生产环境使用可能引发的一切后果(包括但不限于服务中断、数据安全问题、用户投诉、法律责任等)均由用户自行承担。
- 建议在生产环境中使用前进行充分的测试、验证及风险评估。
3. 模型输出不可靠
- 经过微调的模型可能会产生不准确、有害或误导性的内容。
- 模型输出并不代表真实人物的观点或意图。
- 用户应对模型输出进行人工审核和验证。
4. 数据安全与隐私
- 用户应确保上传的聊天记录及其他数据符合相关法律法规。
- 用户应获得数据相关方的适当授权。
- 本项目对数据泄露或隐私侵犯不承担任何责任。
5. 法律合规
- 用户应确保使用本项目符合当地法律法规。
- 涉及人工智能、数据保护、知识产权等相关法律。
- 用户需自行承担非法使用带来的后果。
6. 技术支持限制
- 本项目按“现状”提供,不提供任何明示或暗示的担保。
- 作者不承诺提供持续的技术支持或维护。
- 不保证项目的稳定性、可靠性或适用性。
使用建议
强制标识机器人身份
在使用本项目生成的数字分身时,强烈建议:
- 在每次对话开始时明确标识为“AI 机器人”或“数字分身”。
- 在用户界面显著标注“AI 生成内容”。
- 避免让用户误以为是真人对话,以免造成风险。
风险评估建议
如确需在生产环境中使用,建议:
- 进行全面的安全测试。
- 建立完善的内容审核机制。
- 制定应急响应预案。
- 购买适当的保险保障。
- 咨询法律专业人士的意见。
本免责声明可能随项目更新而修订,用户应定期查看最新版本。继续使用本项目即表示同意最新的免责声明条款。
一旦您以任何方式下载、克隆、修改、分发或使用本项目的代码或模型,即表示您已完全阅读、理解并无条件接受本免责声明的所有条款。
请仔细阅读并理解本免责声明的所有内容,在使用本项目时务必严格遵守相关法规。
⭐ 星标历史
[!TIP] 如果本项目对您有所帮助,或您对本项目的未来发展感兴趣,请为本项目点亮星标,谢谢!

版本历史
v0.3.032026/01/04v0.3.022025/08/17v0.3.012025/07/17v0.3.02025/07/05v0.2.242025/06/19v0.2.232025/06/13v0.2.212025/05/23v0.2.22025/05/08v0.2.1-beta12025/05/01v0.2.02025/04/22v0.1.32025/04/13v0.1.22025/04/08常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器