code-act
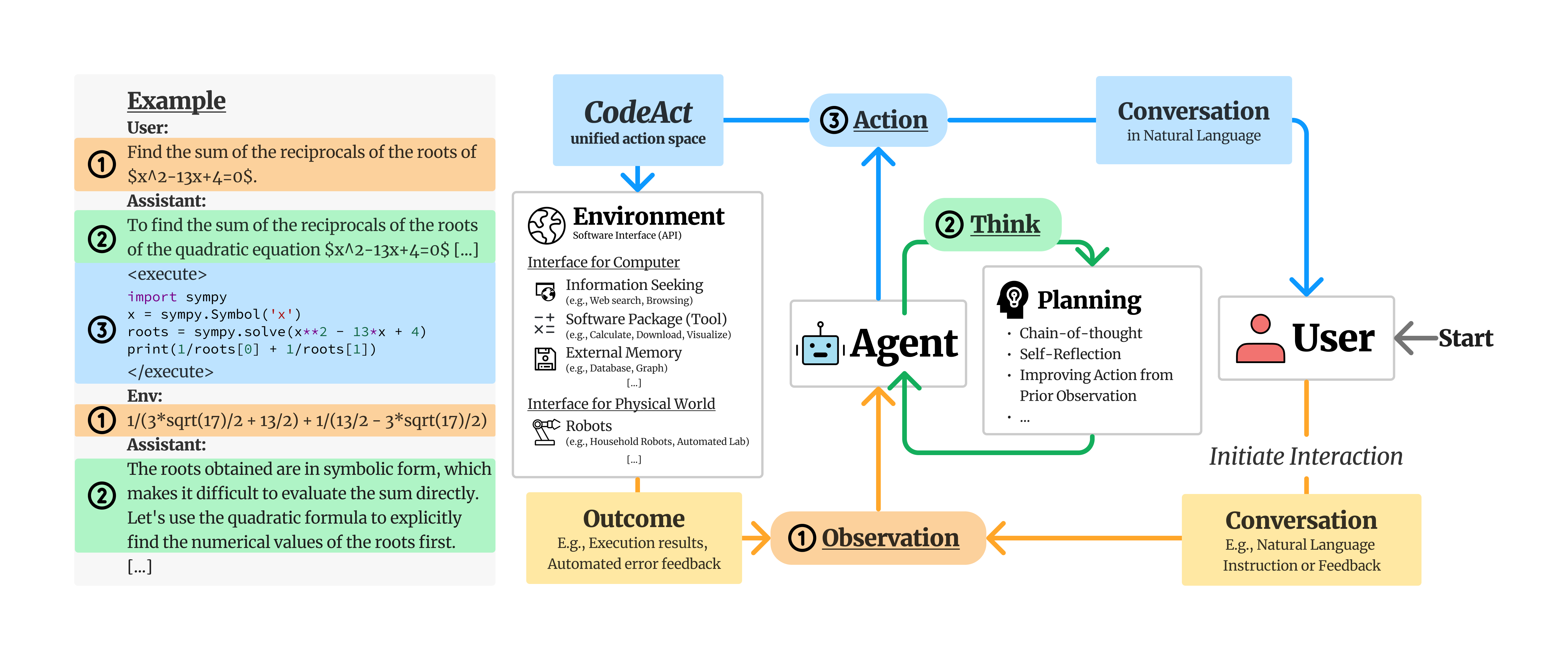
CodeAct 是一个旨在提升大语言模型(LLM)智能体能力的开源框架。它创新性地提出使用可执行的代码作为智能体的统一行动空间,替代传统的纯文本或 JSON 格式指令。通过集成 Python 解释器,CodeAct 允许模型在多轮交互中动态执行代码、根据运行结果自我修正错误或生成新动作,从而显著提高了处理复杂任务的成功率。
该方案主要解决了现有智能体在行动规划上不够灵活、难以利用执行反馈进行自我迭代的问题。实验数据显示,相较于传统方法,CodeAct 在多项基准测试中的任务成功率提升了高达 20%。项目不仅发布了核心方法论,还开源了包含 7000 条多轮交互数据的 CodeActInstruct 数据集,以及基于 Mistral 和 Llama 架构微调的 CodeActAgent 模型。
CodeAct 特别适合 AI 研究人员、开发者以及希望构建高自主性智能体应用的技术团队使用。其独特的技术亮点在于将“代码执行”与“多轮反思”紧密结合,使模型具备类似程序员的调试与进化能力。此外,项目提供了完善的部署支持,兼容 Ollama、llama.cpp 及 Kubernetes 等多种环境,方便用户快速在本地或云端搭建属于自己的智能体系统。
使用场景
某数据分析师需要在无预装环境的生产服务器上,根据动态变化的销售数据自动执行清洗、分析并生成可视化报告。
没有 code-act 时
- 动作空间割裂:模型只能输出自然语言建议或静态 JSON,无法直接调用服务器上的 Python 库(如 Pandas、Matplotlib),需人工复制代码执行。
- 缺乏自我修正:一旦生成的代码因环境差异报错,模型无法感知运行结果,只能盲目重试,导致任务中断。
- 多步协作困难:复杂任务需拆分为多次独立对话,上下文容易丢失,难以维持“观察 - 思考 - 行动”的闭环。
- 工具集成繁琐:开发者需手动编写大量胶水代码将 LLM 输出解析为函数调用,开发周期长且易出错。
使用 code-act 后
- 统一代码行动空间:code-act 让模型直接生成可执行的 Python 代码片段,内置解释器即时运行,无缝调用各类数据科学库。
- 动态反馈与修正:模型能读取代码执行后的报错信息或输出结果,自动调整逻辑并重试,实现真正的自主调试。
- 多轮交互闭环:支持基于执行结果的多轮对话,模型可根据中间数据动态规划下一步操作,完整覆盖复杂分析流程。
- 开箱即用部署:依托预训练的 CodeActAgent 模型和标准化组件,无需额外开发解析层,快速搭建具备执行能力的智能体。
code-act 通过将“可执行代码”作为核心行动载体,彻底打通了大模型从“纸上谈兵”到“实地作战”的最后一步。
运行环境要求
- Linux
- macOS
- 使用 vLLM 部署时必需 NVIDIA GPU(需安装 nvidia-docker),具体显存未说明但模型为 7B 参数
- 使用 llama.cpp 在 macOS (M2 Max) 上推理可不依赖 NVIDIA GPU
未说明(建议根据 7B 模型推理需求配置,通常 16GB+)
快速开始
可执行代码动作催生更优秀的 LLM 代理
📃 论文 • 🤗 数据 (CodeActInstruct) • 🤗 模型 (CodeActAgent-Mistral-7b-v0.1) • 🤖 与 CodeActAgent 聊天!
我们提出使用可执行的代码来将 LLM 代理的动作整合进统一的动作空间(CodeAct)。 通过与 Python 解释器集成,CodeAct 能够执行代码动作,并在多轮交互中根据新的观测结果(例如代码执行结果)动态修正先前动作或发出新动作(请查看这个示例!)。
新闻
2024年4月10日:CodeActAgent Mistral 已经正式在 ollama 上发布!
2024年3月11日:我们还增加了对 llama.cpp 的支持,以便在笔记本电脑上运行 CodeActAgent(已在 MacOS 上测试),请参阅此处的说明!
2024年3月11日:我们现在支持通过 Kubernetes 部署 CodeActAgent 的所有组件(LLM 服务、代码执行器、MongoDB、聊天界面)!请查看这篇指南!
2024年2月2日:CodeAct 正式发布!
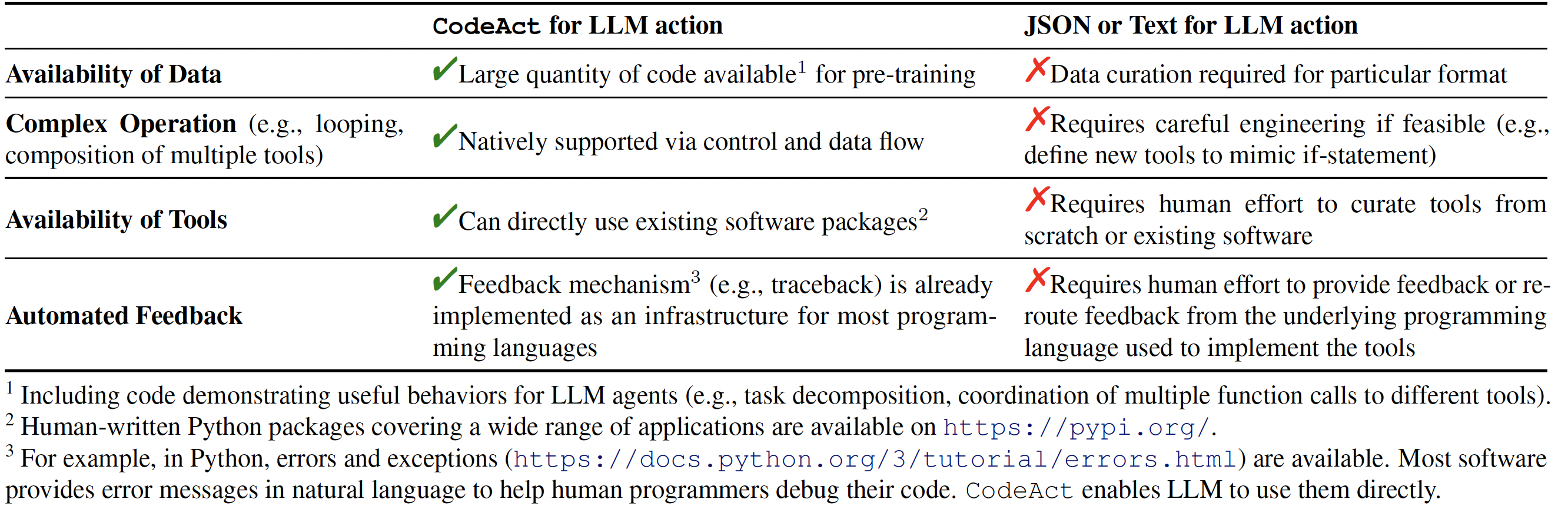
为什么选择 CodeAct?
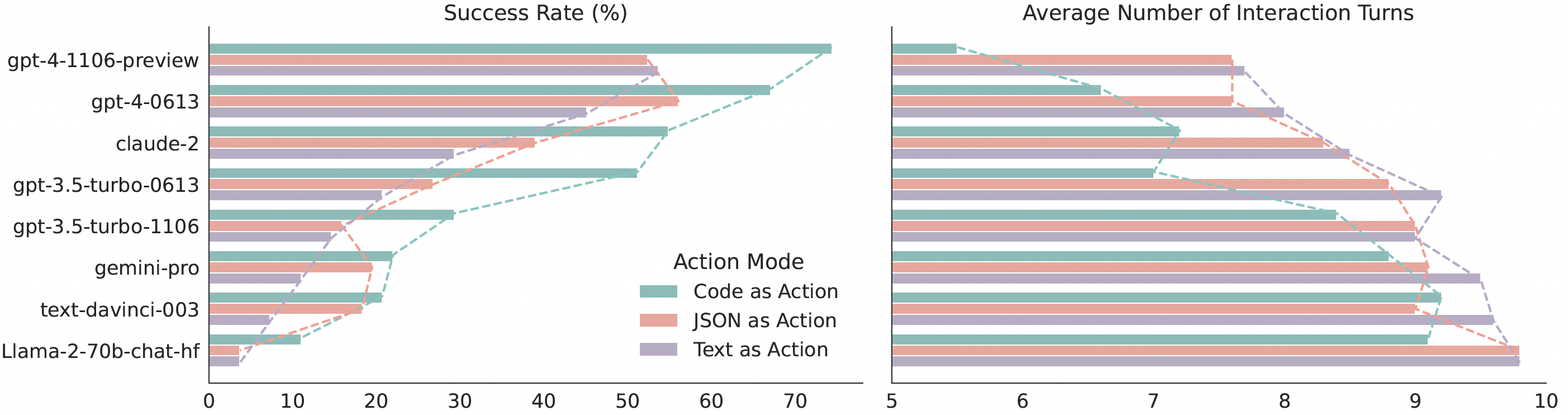
我们在 API-Bank 上对 17 种 LLM 以及一个新整理的基准测试集 M3ToolEval 进行了深入分析,结果显示 CodeAct 在成功率方面优于广泛使用的文本和 JSON 等替代方案(最高可高出 20%)。更多详细分析请参阅我们的论文!
 CodeAct 与文本/JSON 作为动作方式的比较。
CodeAct 与文本/JSON 作为动作方式的比较。
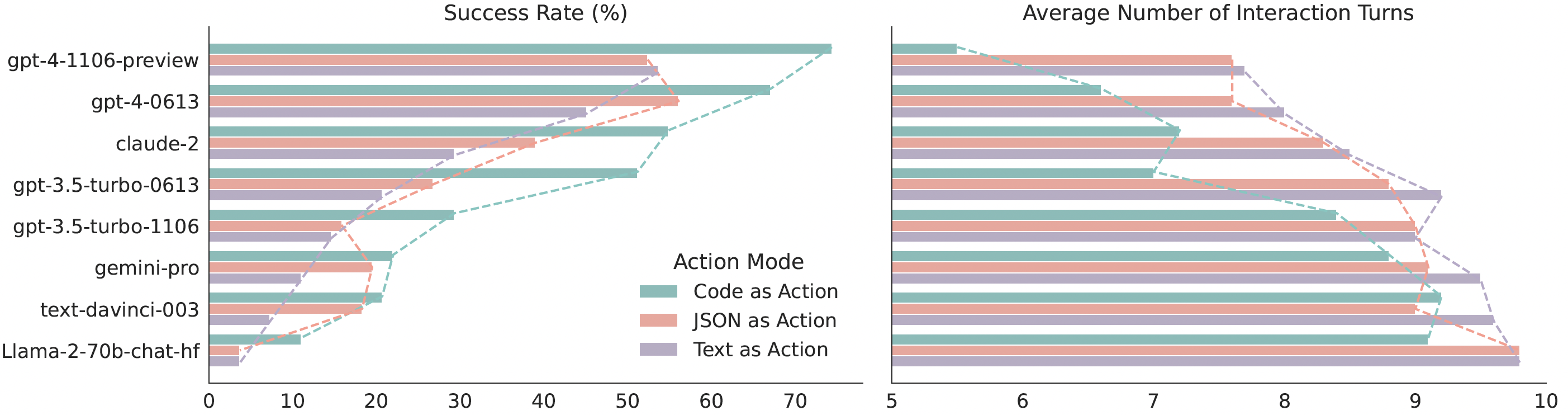 在 M3ToolEval 上对比 CodeAct 与 {文本、JSON} 的量化结果。
在 M3ToolEval 上对比 CodeAct 与 {文本、JSON} 的量化结果。
📁 CodeActInstruct
我们收集了一个指令微调数据集 CodeActInstruct,包含 7,000 条使用 CodeAct 的多轮对话。该数据集已在 huggingface 数据集 🤗 上发布。有关数据收集的详细信息,请参阅论文及本节。
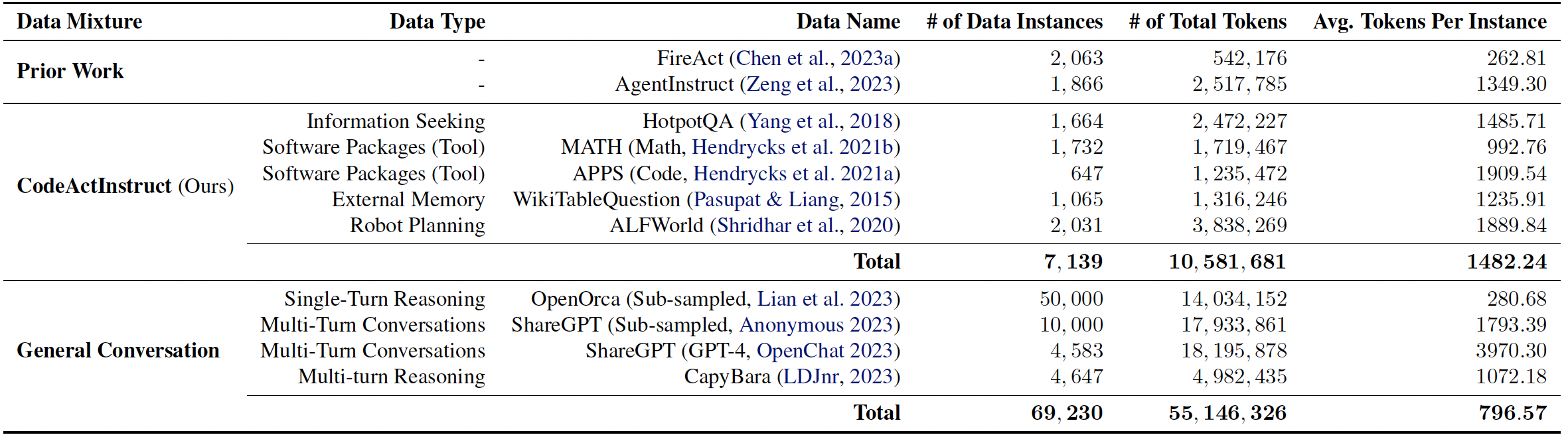 数据集统计。标记统计使用 Llama-2 分词器计算。
数据集统计。标记统计使用 Llama-2 分词器计算。
🪄 CodeActAgent
CodeActAgent 基于 CodeActInstruct 和通用对话进行训练,在同类规模的开源模型中,其跨领域代理任务表现尤为出色,同时并未牺牲通用性能(如知识储备、对话能力等)。我们发布了两个版本的 CodeActAgent:
- CodeActAgent-Mistral-7b-v0.1(推荐,模型链接):以 Mistral-7b-v0.1 为基础模型,上下文窗口为 32k。
- CodeActAgent-Llama-7b(模型链接):以 Llama-2-7b 为基础模型,上下文窗口为 4k。
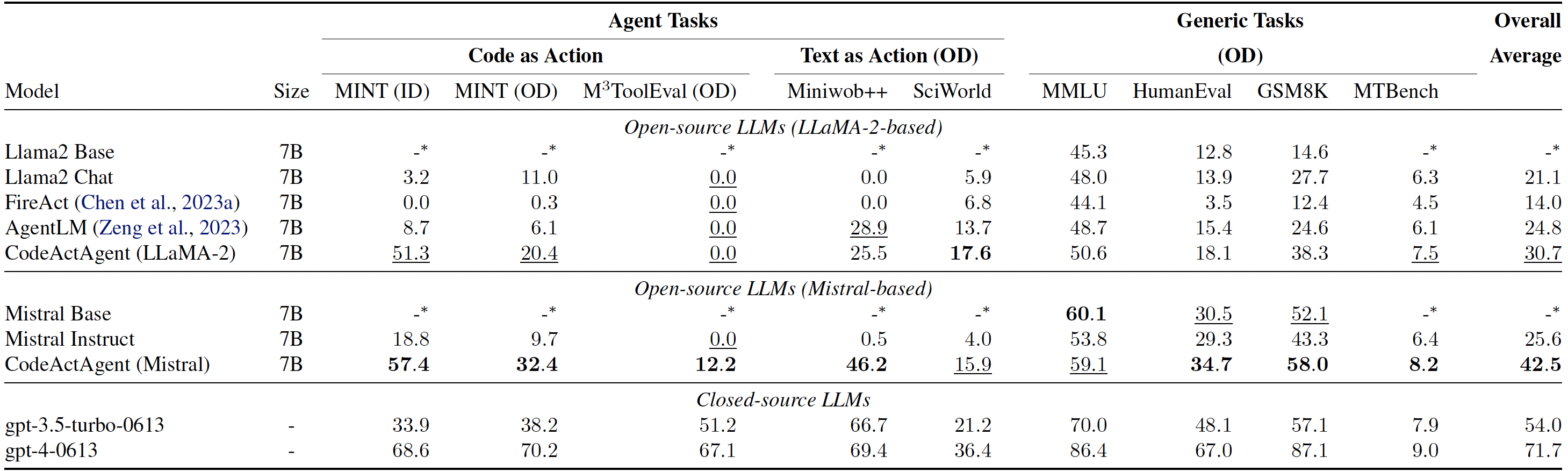 CodeActAgent 的评估结果。ID 和 OD 分别代表域内和域外评估。总体平均性能将 MT-Bench 得分标准化,使其与其他任务保持一致,并排除域内任务以确保公平比较。
CodeActAgent 的评估结果。ID 和 OD 分别代表域内和域外评估。总体平均性能将 MT-Bench 得分标准化,使其与其他任务保持一致,并排除域内任务以确保公平比较。
有关数据收集、模型训练、评估等方面的更多细节,请参阅:page_with_curl: 我们的论文!
🚀 将 CodeActAgent 应用于您的应用!
聊天界面演示。
一个 CodeActAgent 系统包含以下组件:
- LLM 服务:我们以 vLLM 为例,但任何能够将模型部署为 OpenAI 兼容 API 的服务软件均可。
- 交互界面:
- 代码执行引擎:该服务将启动一个 API,接收来自聊天界面或 Python 脚本的代码执行请求,然后为 每 次聊天会话启动一个独立的 Docker 容器来执行代码。
🌟 如果您拥有 Kubernetes 集群:您可以按照我们的Kubernetes 部署指南,只需一条命令即可启动所有这些组件!
请按照以下指南使用 Docker 进行设置。
将模型部署为 OpenAI 兼容 API
使用 VLLM 通过 Docker(需要 nvidia-docker)
# 首先下载模型,以下是 CodeActAgent-Mistral 的示例
cd $YOUR_DIR_TO_DOWNLOADED_MISTRAL_MODEL
git lfs install
git clone https://huggingface.co/xingyaoww/CodeActAgent-Mistral-7b-v0.1
./scripts/chat/start_vllm.sh $YOUR_DIR_TO_DOWNLOADED_MISTRAL_MODEL/CodeActAgent-Mistral-7b-v0.1
# 或者
# ./scripts/chat_ui/start_vllm.sh $YOUR_DIR_TO_DOWNLOADED_LLAMA_MODEL/CodeActAgent-Llama-7b
此脚本(需要 Docker)将基于 CUDA_VISIBLE_DEVICES 将模型托管到端口 8080,您可以通过 http://localhost:8080/v1 的 OPENAI_API_BASE 访问模型(默认设置)。有关详细说明,请参阅 OpenAI API 的官方文档。您也可以参考 vLLM 的官方说明以获取更多信息。
使用 LLama.cpp(适用于笔记本电脑!)
此方法已在 MacOS(M2 Max,Ventura 13.6)上测试过。
安装 LLama.cpp
git clone https://github.com/ggerganov/llama.cpp.git
# 可选:创建一个 conda 环境进行安装
conda create -n llamacpp python=3.10
# 安装 llama cpp 的依赖项
cd llama.cpp
conda activate llamacpp
pip install -r requirements.txt
# 构建(详情请参阅 https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#build)
make
(可选) 将模型转换为 gguf 格式
或者,您也可以跳过以下步骤,直接下载预转换好的量化版本(q8_0)在这里。
# 如果尚未下载模型,请先下载
git lfs install
git clone https://huggingface.co/xingyaoww/CodeActAgent-Mistral-7b-v0.1
# 假设您当前位于 llama.cpp 目录下
python convert.py ./CodeActAgent-Mistral-7b-v0.1 --outtype f16 --outfile CodeActAgent-Mistral-7b-v0.1.f16.gguf
# (可选)量化以加快推理速度
./quantize CodeActAgent-Mistral-7b-v0.1.f16.gguf CodeActAgent-Mistral-7b-v0.1.q8_0.gguf Q8_0
部署为兼容 OpenAI 的 API
有关参数的详细说明,请参阅 此处。
./server -m CodeActAgent-Mistral-7b-v0.1.q8_0.gguf -c 8192 --port 8080
现在,您可以通过 http://localhost:8080/v1 访问兼容 OpenAI 的服务器,模型名称为 CodeActAgent-Mistral-7b-v0.1.q8_0.gguf。在下一部分的交互界面中(无论是聊天 UI 配置文件还是 Python 脚本),您需要将模型名称从 CodeActAgent-Mistral-7b-v0.1 更改为 CodeActAgent-Mistral-7b-v0.1.q8_0.gguf!
(可选)测试 OpenAI 兼容 API 是否正常工作
curl -X POST 'http://localhost:8080/v1/chat/completions' -d '{
"model": "CodeActAgent-Mistral-7b-v0.1.q8_0.gguf",
"messages": [
{"role": "system", "content": "你是一个 helpful assistant。"},
{"role": "user", "content": "如何搭建一个网站?"}
]
}'
启动您的代码执行引擎!
我们基于 JupyterKernelGateway 实现了一个容器化的代码执行引擎。其核心思想是为每个聊天会话启动一个 Docker 容器 内的 Jupyter 服务器,以支持来自模型的代码执行请求(该会话将在设定的时间后超时)。这需要本地已安装 Docker。
# 在 8081 端口启动代码执行服务器
./scripts/chat/code_execution/start_jupyter_server.sh 8081
与系统互动!
通过简单的 Python 脚本
如果您不想搭建复杂的界面,只想在命令行上简单体验一下,我们已经为您准备好了!
# 在运行此脚本之前,请确保已启动模型服务器(vLLM 或 llama.cpp)和代码执行引擎!
python3 scripts/chat/demo.py --model_name xingyaoww/CodeActAgent-Mistral-7b-v0.1 --openai_api_base http://$YOUR_API_HOST:$YOUR_API_PORT/v1 --jupyter_kernel_url http://$YOUR_CODE_EXEC_ENGINE_HOST:$YOUR_CODE_EXEC_ENGINE_PORT/execute
通过 Chat-UI
如果您已经部署了模型和代码执行引擎,就可以像 这个 一样运行您自己的聊天界面!
如果需要用户管理功能,您可能需要启动自己的 MongoDB 实例:
./scripts/chat/start_mongodb.sh $YOUR_MONGO_DB_PASSWORD
# 数据库将创建在 pwd/data/mongodb 目录下,并可通过 localhost:27017 访问
然后,您可以配置您的 Chat-UI 界面。
cp chat-ui/.env.template chat-ui/.env.local
# 请务必根据您的实际情况修改 .env.local 文件:
# 1. JUPYTER_API_URL
# 2. 模型端点(搜索 'TODO_OPENAI_BASE_URL');
# 如果您使用 llama.cpp 推理模型,还需将模型名称更改为 CodeActAgent-Mistral-7b-v0.1.q8_0.gguf
# 3. MONGODB_URL - 您可以留空,Chat-UI 会自动启动一个数据库(但容器停止后该数据库将被删除)
现在,您可以构建并启动您自己的 Web 应用程序(需使用 Docker)!
./scripts/chat/run_chat_ui.sh
# 默认会在 localhost:5173 启动界面
# 运行此脚本以进入调试模式
# ./scripts/chat/run_chat_ui_debug.sh
如需更多信息(例如不使用 Docker 的情况),请查看 Chat-UI 的 文档!
🎥 复现论文中的实验
git clone https://github.com/xingyaoww/code-act
# 克隆所有子模块
git submodule update --init --recursive
📂 数据生成(可选)
推荐: 您可以从 Hugging Face 数据集 🤗 下载处理好的 CodeActInstruct 数据集。
为复现实验: 您也可以按照 docs/DATA_GENERATION.md 中的说明,自行生成交互数据。
📘 模型训练
我们使用 Megatron-LLM 的一个分支进行训练。详细的训练步骤请参考 docs/MODEL_TRAINING.md。
📊 评估
详细的评估方法请参阅 docs/EVALUATION.md。
📚 引用
@inproceedings{wang2024executable,
title={Executable Code Actions Elicit Better LLM Agents},
author={Xingyao Wang and Yangyi Chen and Lifan Yuan and Yizhe Zhang and Yunzhu Li and Hao Peng and Heng Ji},
year={2024},
eprint={2402.01030},
booktitle={ICML}
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备