CHINESE-OCR
CHINESE-OCR 是一款基于深度学习技术的开源工具,专为解决自然场景下的中文文字检测与识别难题而设计。它能够自动处理图片中文字的旋转问题(支持 0 至 270 度方向检测),精准定位文字区域,并实现对不定长中文文本的端到端识别,有效克服了传统 OCR 在复杂背景和倾斜文字面前准确率低的痛点。
该项目技术架构成熟,融合了经典的 CTPN(卷积神经网络 + 循环神经网络)用于高精度文本行检测,以及 CRNN(CNN+RNN+CTC)模型进行无需字符级标注的高效序列识别。特别值得一提的是,它同时提供了 Keras 和 PyTorch 两种主流框架的实现版本,既方便初学者快速上手理解算法原理,也满足了研究人员对模型稳定性和扩展性的需求。此外,项目还包含了针对数学公式识别的改进探索,展现了其在特定垂直领域的潜力。
CHINESE-OCR 非常适合计算机视觉开发者、AI 研究人员以及需要定制私有化 OCR 解决方案的企业技术人员使用。通过提供详细的训练指南、预训练模型及数据集链接,用户可以轻松复现结果或基于自有数据进行微调训练,是学习和部署中文场景文字识别系统的优质起点。
使用场景
某电商运营团队每天需处理数千张用户上传的含中文商品海报,从中提取促销文字以构建搜索索引。
没有 CHINESE-OCR 时
- 人工逐张截图并手动录入文字,耗时费力且错误率高,严重拖慢数据入库速度。
- 通用 OCR 工具对自然场景中的倾斜、弯曲或复杂背景文字识别率极低,大量关键促销信息被遗漏。
- 无法自动判断文字方向(如 90 度竖排标题),导致识别结果乱序或完全失败,需额外开发预处理脚本。
- 面对不定长中文文本,传统分段识别方案容易割裂语义,后续还需人工校对拼接,维护成本高昂。
使用 CHINESE-OCR 后
- 通过 CTPN+CRNN 端到端流水线,自动检测并识别海报中任意角度的中文文本,全流程无需人工干预,效率提升 10 倍以上。
- 内置 0/90/180/270 度方向检测模块,精准纠正竖排或旋转标题,确保输出文本顺序与视觉逻辑一致。
- 基于 CTC 解码机制实现不定长中文连续识别,完整保留“满 200 减 50"等长句语义,避免字符割裂问题。
- 支持 TensorFlow/Keras/PyTorch 多框架部署,团队可快速集成至现有 Python 3.6 服务中,并利用预训练模型立即投产。
CHINESE-OCR 将非结构化的商品图片转化为高可用文本数据,让电商搜索与推荐系统真正“看懂”用户生成的中文内容。
运行环境要求
- Linux
可选(支持 CPU 和 GPU 环境),未指定具体显卡型号、显存大小或 CUDA 版本
未说明

快速开始
本文基于tensorflow、keras/pytorch实现对自然场景的文字检测及端到端的OCR中文文字识别
update20190706
- 为解决本项目中对数学公式预测的准确性,做了其他的改进和尝试,效果还不错,https://github.com/xiaofengShi/Image2Katex 希望能有所帮助,另外,这几月换了工作,并且转了方向,还是cv方向,不过不做ocr相关了,目前主要做显著目标检测以及搜索意图相关,对repo的提问回答较慢,请见谅。
实现功能
- 文字方向检测 0、90、180、270度检测
- 文字检测 后期将切换到keras版本文本检测 实现keras端到端的文本检测及识别
- 不定长OCR识别
环境部署
Bash
##GPU环境
sh setup.sh
## CPU环境
sh setup-cpu.sh
##CPU python3环境
sh setup-python3.sh
使用环境:python3.6+tensorflow1.7+cpu/gpu
模型训练
- 一共分为3个网络 1. 文本方向检测网络-Classify(vgg16)
- 2. 文本区域检测网络-CTPN(CNN+RNN)
- 3. EndToEnd文本识别网络-CRNN(CNN+GRU/LSTM+CTC)
文字方向检测-vgg分类
基于图像分类,在VGG16模型的基础上,训练0、90、180、270度检测的分类模型.
详细代码参考angle/predict.py文件,训练图片8000张,准确率88.23%
模型地址BaiduCloud
文字区域检测CTPN
关于ctpn网络,网上有很多对其进行介绍讲解的,算法是2016年提出的,在印书体识别用的很多,本人也写过一篇相应的博文深度学习-TextDetection,在文章中结合本repo的代码对ctpn的原理进行了详细的讲解。CTPN网路结构如下
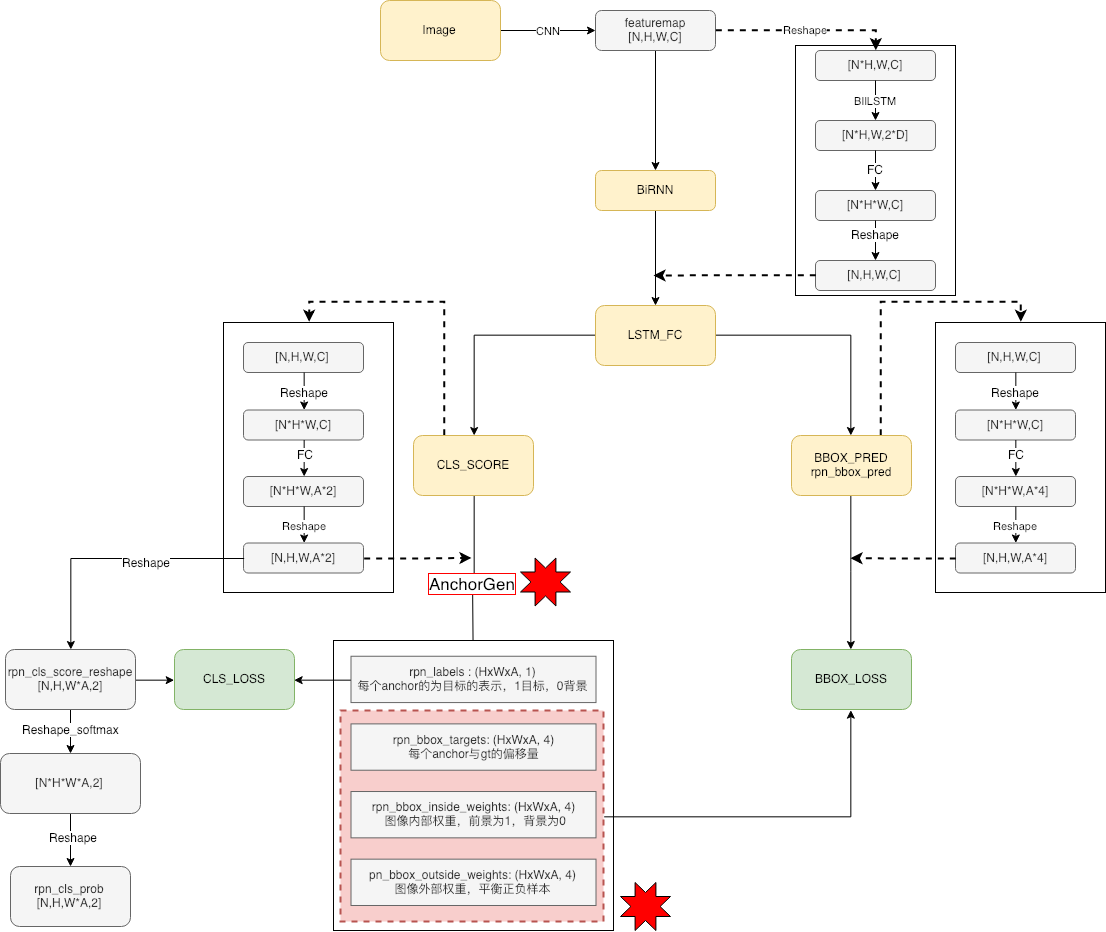
ctpn是一种基于目标检测方法的文本检测模型,在本repo的ctpn中anchor的设置为固定宽度,高度不同,相关代码如下:
def generate_anchors(base_size=16, ratios=[0.5, 1, 2],
scales=2 ** np.arange(3, 6)):
heights = [11, 16, 23, 33, 48, 68, 97, 139, 198, 283]
widths = [16]
sizes = []
for h in heights:
for w in widths:
sizes.append((h, w))
return generate_basic_anchors(sizes)
基于这种设置,ctpn只能检测水平方向的文本,如果想要ctpn可以支持垂直文本检测,可以在anchor生成函数上进行修改。更详细的内容可以参考博客讲解。
OCR 端到端识别:CRNN
ocr识别采用GRU+CTC端到到识别技术,实现不分隔识别不定长文字
提供keras 与pytorch版本的训练代码,在理解keras的基础上,可以切换到pytorch版本,此版本更稳定
- 此外参考了了tensorflow版本的资源仓库:TF:LSTM-CTC_loss
为什么使用ctc
ctc是一种解码机制,在使用ctpn提取到待检测文本行之后,我们要识别提取到的区域内的文本内容,目前广泛存在两种解码机制。
一种是seq2seq机制,输入的是图像,经过卷积编码之后再使用RNN解码,为了提高识别的准确率,一般会加入attention机制。
另一种就是ctc解码机制,但是对于ctc解码要满足一个前提,那就是输入序列的长度不小于输出序列的长度。ctc主要用于序列解码,我们不需要对序列中的每个元素进行标记,只需要知道输入序列对应的整个label是什么即可,针对ocr项目,也就是输入一张图像上面写着“欢迎来到中国”这几个字,我们只需要是这几个字,而没必要知道这几个字在输入图像中所在的具体位置,实际上如果知道每个字所在的位置,就是单字符识别了,的确会降低任务的复杂多,但是现实中我们没有这么多标记号位置的数据,这个时候CTC就显得很重要了。关于ctc解码机制,本人同样谢了一个对应的博客CTC算法原理,在文章中进行了详细的讲解,,如有疑问,请提交提问。
本repo中使用的是CNN+RNN+CTC的机制,实际上可以使用CNN+CTC的机制,CNN推荐选择densenet或者resnet
使用说明
使用预训练测试
运行demo.py 写入测试图片的路径即可,如果想要显示ctpn的结果,修改文件./ctpn/ctpn/other.py 的draw_boxes函数的最后部分,cv2.inwrite('dest_path',img),如此,可以得到ctpn检测的文字区域框以及图像的ocr识别结果
使用自己的数据训练
1 对ctpn进行训练
- 定位到路径--./ctpn/ctpn/train_net.py
- 预训练的vgg网络路径VGG_imagenet.npy 将预训练权重下载下来,pretrained_model指向该路径即可, 此外整个模型的预训练权重checkpoint
- ctpn数据集还是百度云 数据集下载完成并解压后,将.ctpn/lib/datasets/pascal_voc.py 文件中的pascal_voc 类中的参数self.devkit_path指向数据集的路径即可
2 对crnn进行训练
- keras版本 ./train/keras_train/train_batch.py model_path--指向预训练权重位置 MODEL_PATH---指向模型训练保存的位置 keras模型预训练权重
- pythorch版本./train/pytorch-train/crnn_main.py
parser.add_argument(
'--crnn',
help="path to crnn (to continue training)",
default=预训练权重的路径,看你下载的预训练权重在哪啦)
parser.add_argument(
'--experiment',
help='Where to store samples and models',
default=模型训练的权重保存位置,这个自己指定)
识别结果展示
文字检测及OCR识别结果

===========================================================

===========================================================
主要是因为训练的时候,只包含中文和英文字母,因此很多公式结构是识别不出来的
看看纯文字的

===========================================================

===========================================================
未完待续
tensorflow版本crnn,计划尝试当前的各种trick(dropuout,bn,learning_decay等)
可以看到,对于纯文字的识别结果还是阔以的呢,感觉可以在crnn网络在加以改进,现在的crnn中的cnn有点浅,
并且rnn层为单层双向+attention,目前正在针对这个地方进行改动,使用迁移学习,以restnet为特征提取层,
使用多层双向动态rnn+attention+ctc的机制,将模型加深,目前正在进行模型搭建,结果好的话就发上来,不好的话只能凉凉了~~~~
训练数据集补充
列举可用于文本检测和识别领域模型训练的一些大型公开数据集, 不涉及仅用于模型fine-tune任务的小型数据集。
Chinese Text in the Wild(CTW)
该数据集包含32285张图像,1018402个中文字符(来自于腾讯街景), 包含平面文本,凸起文本,城市文本,农村文本,低亮度文本,远处文本,部分遮挡文本。图像大小2048*2048,数据集大小为31GB。以(8:1:1)的比例将数据集分为训练集(25887张图像,812872个汉字),测试集(3269张图像,103519个汉字),验证集(3129张图像,103519个汉字)。
文献链接:https://arxiv.org/pdf/1803.00085.pdf
数据集下载地址:https://ctwdataset.github.io/
Reading Chinese Text in the Wild(RCTW-17)
该数据集包含12263张图像,训练集8034张,测试集4229张,共11.4GB。大部分图像由手机相机拍摄,含有少量的屏幕截图,图像中包含中文文本与少量英文文本。图像分辨率大小不等。
http://mclab.eic.hust.edu.cn/icdar2017chinese/dataset.html
文献:http://arxiv.org/pdf/1708.09585v2
ICPR MWI 2018 挑战赛
大赛提供20000张图像作为数据集,其中50%作为训练集,50%作为测试集。主要由合成图像,产品描述,网络广告构成。该数据集数据量充分,中英文混合,涵盖数十种字体,字体大小不一,多种版式,背景复杂。文件大小为2GB。
https://tianchi.aliyun.com/competition/information.htm?raceId=231651&_is_login_redirect=true&accounttraceid=595a06c3-7530-4b8a-ad3d-40165e22dbfe
Total-Text
该数据集共1555张图像,11459文本行,包含水平文本,倾斜文本,弯曲文本。文件大小441MB。大部分为英文文本,少量中文文本。训练集:1255张 测试集:300
http://www.cs-chan.com/source/ICDAR2017/totaltext.zip
http:// arxiv.org/pdf/1710.10400v
Google FSNS(谷歌街景文本数据集)
该数据集是从谷歌法国街景图片上获得的一百多万张街道名字标志,每一张包含同一街道标志牌的不同视角,图像大小为600*150,训练集1044868张,验证集16150张,测试集20404张。
http://rrc.cvc.uab.es/?ch=6&com=downloads
http:// arxiv.org/pdf/1702.03970v1
COCO-TEXT
该数据集,包括63686幅图像,173589个文本实例,包括手写版和打印版,清晰版和非清晰版。文件大小12.58GB,训练集:43686张,测试集:10000张,验证集:10000张
http://arxiv.org/pdf/1601.07140v2
https://vision.cornell.edu/se3/coco-text-2/
Synthetic Data for Text Localisation
在复杂背景下人工合成的自然场景文本数据。包含858750张图像,共7266866个单词实例,28971487个字符,文件大小为41GB。该合成算法,不需要人工标注就可知道文字的label信息和位置信息,可得到大量自然场景文本标注数据。
下载地址:http://www.robots.ox.ac.uk/~vgg/data/scenetext/
文献:http://www.robots.ox.ac.uk/~ankush/textloc.pdf
Code: https://github.com/ankush-me/SynthText (英文版)
Code https://github.com/wang-tf/Chinese_OCR_synthetic_data(中文版)
Synthetic Word Dataset
合成文本识别数据集,包含9百万张图像,涵盖了9万个英语单词。文件大小为10GB
http://www.robots.ox.ac.uk/~vgg/data/text/
Caffe-ocr中文合成数据
数据利用中文语料库,通过字体、大小、灰度、模糊、透视、拉伸等变化随机生成,共360万张图片,图像分辨率为280x32,涵盖了汉字、标点、英文、数字共5990个字符。文件大小约为8.6GB
https://pan.baidu.com/s/1dFda6R3
参考
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备