DDNM
DDNM 是一款基于去噪扩散零空间模型的图像修复工具,曾荣获 ICLR 2023 口头报告奖。它的核心能力在于能够以“零样本”(Zero-Shot)方式处理各类图像退化问题,这意味着用户无需针对特定任务进行额外的模型训练或参数优化,即可直接获得高质量的修复结果。
DDNM 有效解决了传统方法中针对不同修复任务需单独训练模型的痛点,实现了“一个模型通吃多种场景”。它支持超分辨率、去噪、上色、图像补全、去模糊以及压缩感知等多种任务,甚至能处理任意尺寸的图片和老照片修复。其独特的技术亮点在于巧妙利用了扩散模型的零空间特性,既保留了预训练模型强大的生成先验知识,又通过数学推导确保修复后的图像严格符合观测数据的约束,从而在细节还原和真实性之间取得了极佳平衡。
这款工具非常适合计算机视觉研究人员探索扩散模型的新应用,也适合开发者快速集成图像修复功能到现有系统中。对于设计师或摄影爱好者而言,借助其提供的 Colab 演示和 Hugging Face 空间,无需深厚的编程背景也能轻松体验先进的 AI 修复技术,让受损或低质量的图片重焕生机。
使用场景
一家小型数字档案馆正在紧急处理一批受损严重的百年老照片,需要在无原始高清图参考的情况下完成修复与上色。
没有 DDNM 时
- 训练成本高昂:针对每种损坏类型(如划痕、噪点、褪色)需单独收集配对数据并训练专用模型,耗时数周且算力需求大。
- 泛化能力受限:遇到未见过的复杂退化组合(如同时存在模糊和彩色噪点)时,现有模型效果急剧下降,需重新调整网络结构。
- 流程繁琐割裂:去噪、超分、上色需串联多个独立工具,每一步的误差会累积,导致最终人脸细节失真或色彩怪异。
- 尺寸适配困难:传统模型通常固定输入分辨率,处理不同尺寸的老照片时需反复裁剪或缩放,破坏画面构图。
使用 DDNM 后
- 零样本即时修复:利用预训练的扩散模型先验,无需任何微调或训练,直接通过命令行一键处理任意类型的图像退化。
- 统一框架多任务:单个模型即可同步完成去噪、4 倍超分辨率及自动上色,保持人物面部特征一致,避免多阶段处理的伪影。
- 灵活适应未知退化:基于零空间投影机制,能有效处理训练集中未出现的复杂混合损伤,显著提升老旧照片的自然度。
- 任意尺寸支持:原生支持任意分辨率输入,完整保留老照片的原始构图与边缘细节,无需预处理裁剪。
DDNM 将原本需要数周建模优化的复杂修复流程,简化为单次推理的零样本任务,极大降低了历史影像数字化的技术门槛。
运行环境要求
- Linux
- macOS
- Windows
需要 NVIDIA GPU (示例提及 cu110),显存需求未明确说明 (建议 8GB+ 以运行高分辨率修复)
未说明

快速开始
使用去噪扩散零空间模型的零样本图像修复
📖论文|🖼️项目页面| 

Yinhuai Wang*、Jiwen Yu*、Jian Zhang
北京大学与PCL
*表示共同贡献
本仓库包含“使用Denoising Diffusion Null-Space Model进行零样本图像修复”的代码发布。DDNM可以在无需任何优化或训练的情况下解决各种图像修复任务!是的,以零样本的方式即可实现。
支持的应用:
- 任意尺寸🆕
- 老照片修复🆕
- 超分辨率
- 去噪
- 上色
- 修复缺失区域
- 去模糊
- 压缩感知

🧩新闻
- 现已提供高质量结果的Colab演示!
安装
代码
git clone https://github.com/wyhuai/DDNM.git
环境
pip install numpy torch blobfile tqdm pyYaml pillow # 例如torch 1.7.1+cu110。
预训练模型
要修复人脸图像,请下载此模型(来自SDEdit)并将其放入DDNM/exp/logs/celeba/。
https://drive.google.com/file/d/1wSoA5fm_d6JBZk4RZ1SzWLMgev4WqH21/view?usp=share_link
要修复一般图像,请下载此模型(来自guided-diffusion)并将其放入DDNM/exp/logs/imagenet/。
wget https://openaipublic.blob.core.windows.net/diffusion/jul-2021/256x256_diffusion_uncond.pt
快速入门
运行以下命令可立即获得4倍超分辨率结果。结果应位于DDNM/exp/image_samples/demo。
python main.py --ni --simplified --config celeba_hq.yml --path_y celeba_hq --eta 0.85 --deg "sr_averagepooling" --deg_scale 4.0 --sigma_y 0 -i demo
设置
详细的采样命令如下:
python main.py --ni --simplified --config {CONFIG}.yml --path_y {PATH_Y} --eta {ETA} --deg {DEGRADATION} --deg_scale {DEGRADATION_SCALE} --sigma_y {SIGMA_Y} -i {IMAGE_FOLDER}
选项说明如下:
- 本仓库实现了两种版本的DDNM。一种基于SVD的版本,在处理噪声任务时更为精确。另一种是简化版,不涉及SVD,用户可以灵活定义自己的退化类型。使用
--simplified可激活简化版DDNM。若不加--simplified则为基于SVD的DDNM。 PATH_Y是测试数据集的文件夹名称,位于DDNM/exp/datasets。ETA是DDIM的超参数。(默认值:0.85)DEGREDATION是支持的任务,包括cs_walshhadamard、cs_blockbased、inpainting、denoising、deblur_uni、deblur_gauss、deblur_aniso、sr_averagepooling、sr_bicubic、colorization、mask_color_sr以及用户自定义的diy。DEGRADATION_SCALE是退化的尺度。例如,--deg sr_bicubic --deg_scale 4将产生4倍超分辨率效果。SIGMA_Y是观测到的噪声水平。CONFIG是配置文件的名称(详见configs/目录),其中包含批量大小和采样步数等超参数。IMAGE_FOLDER是保存结果的文件夹名称。
对于配置文件,例如celeba_hq.yml,您可以修改以下属性:
sampling:
batch_size: 1
time_travel:
T_sampling: 100 # 采样步数
travel_length: 1 # 时间旅行参数l和s,参见论文第3.3节。
travel_repeat: 1 # 时间旅行参数r,参见论文第3.3节。
复现论文中的结果
定量评估
数据集下载链接:[Google云端硬盘] [百度网盘]
下载CelebA测试集并将其放入DDNM/exp/datasets/celeba/。
下载ImageNet测试集并将其放入DDNM/exp/datasets/imagenet/,同时替换文件DDNM/exp/imagenet_val_1k.txt。
运行以下命令。您可以通过增加batch_size来加快评估速度。
sh evaluation.sh
高质量结果
您可以尝试这个Colab演示来获得高质量结果。请注意,首页图中展示的高质量结果大多是由将DDNM应用于RePaint中的模型生成的。
🔥真实世界应用
演示:真实世界的超分辨率。


运行以下命令
python main.py --ni --simplified --config celeba_hq.yml --path_y solvay --eta 0.85 --deg "sr_averagepooling" --deg_scale 4.0 --sigma_y 0.1 -i demo
演示:老照片修复。
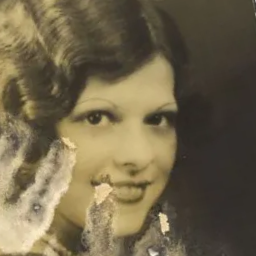

运行以下命令
python main.py --ni --simplified --config oldphoto.yml --path_y oldphoto --eta 0.85 --deg "mask_color_sr" --deg_scale 2.0 --sigma_y 0.02 -i demo
尝试你自己的照片。
你可以使用 DDNM 来恢复你自己退化的图像。DDNM 为你提供了完全的灵活性,可以自定义退化算子和噪声水平。请注意,这些定义对获得良好的结果至关重要。你可以参考以下指导:
- 如果你使用的是 CelebA 预训练模型,可以尝试使用 GFPGAN 中的工具来裁剪和对齐你的照片。
- 如果你的照片上有局部伪影,可以尝试使用 LaMa 中的工具绘制遮罩来覆盖这些伪影,并将此遮罩保存到
DDNM/exp/inp_masks/mask.png。然后运行DDNM/exp/inp_masks/get_mask.py生成mask.npy。 - 如果你的照片褪色了,你需要一个灰度算子作为退化的一部分。
- 如果你的照片模糊,你需要一个下采样算子作为退化的一部分。同时,还需要设置合适的超分辨率缩放比例
--deg_scale。 - 如果你的照片存在全局性的伪影,例如类似 JPEG 的伪影或未知噪声,你需要设置合适的
sigma_y来去除这些伪影。 - 在
DDNM/guided_diffusion/diffusion.py中搜索args.deg =='diy',并相应地修改 $\mathbf{A}$ 的定义。 然后运行:
python main.py --ni --simplified --config celeba_hq.yml --path_y {YOUR_OWN_PATH} --eta 0.85 --deg "diy" --deg_scale {YOUR_OWN_SCALE} --sigma_y {YOUR_OWN_LEVEL} -i diy
🆕DDNM 适用于任意尺寸


以上展示了使用 DDNM 将 64x256 输入图像超分辨率至 256x1024 结果的示例。相关理论细节可在该 论文 的第 3.3 节中找到。
我们在文件夹 hq_demo 中实现了基于 RePaint 的 掩码移位修复 功能。你可以尝试这个 Colab 演示。![]()
或者,你也可以在自己的设备上尝试该功能,需要下载预训练模型:
wget https://openaipublic.blob.core.windows.net/diffusion/jul-2021/256x256_classifier.pt
wget https://openaipublic.blob.core.windows.net/diffusion/jul-2021/256x256_diffusion.pt
并将它们放入 hq_demo/data/pretrained 目录。然后运行:
cd hq_demo
sh evaluation.sh
该脚本包含了最高可达 2K 分辨率的超分辨率结果。某些演示可能需要数小时才能完成。通过在 hq_demo/confs/inet256.yml 中设置较小的采样步长或时间旅行参数,可以加快速度,但可能会降低生成质量。
😊将 DDNM 应用于你自己的扩散模型
在你自己的扩散模型上实现一个基础的 DDNM 非常简单!你可以参考以下步骤:
- 将这些算子实现复制到核心扩散采样文件中,然后定义你的任务类型,例如设置
IR_mode="super resolution"。
def color2gray(x):
coef=1/3
x = x[:,0,:,:] * coef + x[:,1,:,:]*coef + x[:,2,:,:]*coef
return x.repeat(1,3,1,1)
def gray2color(x):
x = x[:,0,:,:]
coef=1/3
base = coef**2 + coef**2 + coef**2
return th.stack((x*coef/base, x*coef/base, x*coef/base), 1)
def PatchUpsample(x, scale):
n, c, h, w = x.shape
x = torch.zeros(n,c,h,scale,w,scale) + x.view(n,c,h,1,w,1)
return x.view(n,c,scale*h,scale*w)
# A 及其伪逆 Ap 的实现
if IR_mode=="colorization":
A = color2gray
Ap = gray2color
elif IR_mode=="inpainting":
A = lambda z: z*mask
Ap = A
elif IR_mode=="super resolution":
A = torch.nn.AdaptiveAvgPool2d((256//scale,256//scale))
Ap = lambda z: PatchUpsample(z, scale)
elif IR_mode=="old photo restoration":
A1 = lambda z: z*mask
A1p = A1
A2 = color2gray
A2p = gray2color
A3 = torch.nn.AdaptiveAvgPool2d((256//scale,256//scale))
A3p = lambda z: PatchUpsample(z, scale)
A = lambda z: A3(A2(A1(z)))
Ap = lambda z: A1p(A2p(A3p(z)))
- 在目标代码中找到变量 $\mathbf{x}_{0|t}$,并使用该函数的结果来修改 $\mathbf{x}_{t-1}$ 的采样过程。你可能需要提供输入的退化图像 $\mathbf{y}$ 和对应的噪声水平 $\sigma_\mathbf{y}$。
# DDNM+ 的核心实现,简化的去噪方案(第 3.3 节)。
# 如需更精确的去噪,请参阅论文(附录 I)和源代码。
def ddnm_plus_core(x0t, y, sigma_y=0, sigma_t, a_t):
#式 19
if sigma_t >= a_t*sigma_y:
lambda_t = 1
gamma_t = sigma_t**2 - (a_t*lambda_t*sigma_y)**2
else:
lambda_t = sigma_t/(a_t*sigma_y)
gamma_t = 0
#式 17
x0t= x0t + lambda_t*Ap(y - A(x0t))
return x0t, gamma_t
- 实际上,这个仓库就包含了上述简化实现:可以在
DDNM/guided_diffusion/diffusion.py中搜索arg.simplified查看相关代码。
参考文献
如果你觉得这个仓库对你的研究有帮助,请引用以下工作。
@article{wang2022zero,
title={Zero-Shot Image Restoration Using Denoising Diffusion Null-Space Model},
author={Wang, Yinhuai and Yu, Jiwen and Zhang, Jian},
journal={The Eleventh International Conference on Learning Representations},
year={2023}
}
本实现基于或受以下项目启发:
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
opencv
OpenCV 是一个功能强大的开源计算机视觉库,被誉为机器视觉领域的“瑞士军刀”。它主要解决让计算机“看懂”图像和视频的核心难题,提供了从基础的图像读取、色彩转换、边缘检测,到复杂的人脸识别、物体追踪、3D 重建及深度学习模型部署等全方位算法支持。无论是处理静态图片还是分析实时视频流,OpenCV 都能高效完成特征提取与模式识别任务。 这款工具特别适合计算机视觉开发者、人工智能研究人员以及机器人工程师使用。对于希望将视觉感知能力集成到应用中的软件工程师,或是需要快速验证算法原型的学术研究者,OpenCV 都是不可或缺的基础设施。虽然普通用户通常不会直接操作代码,但日常生活中使用的扫码支付、美颜相机和自动驾驶系统,背后往往都有它的身影。 OpenCV 的独特亮点在于其卓越的性能与广泛的兼容性。它采用 C++ 编写以确保高速运算,同时提供 Python、Java 等多种语言接口,极大降低了开发门槛。库中内置了数千种优化算法,并支持跨平台运行,能够无缝对接各类硬件加速器。作为社区驱动的项目,OpenCV 拥有活跃的生态系统和丰富的学习资源,持续推动着视觉技术的前沿发展。