webarena
WebArena 是一个可独立部署的逼真网页环境,专为构建和评估自主智能体(Autonomous Agents)而设计。它解决了当前 AI 代理研究缺乏真实、可控且可复现测试场景的痛点,让开发者无需依赖不稳定的公共网站即可进行大规模实验。
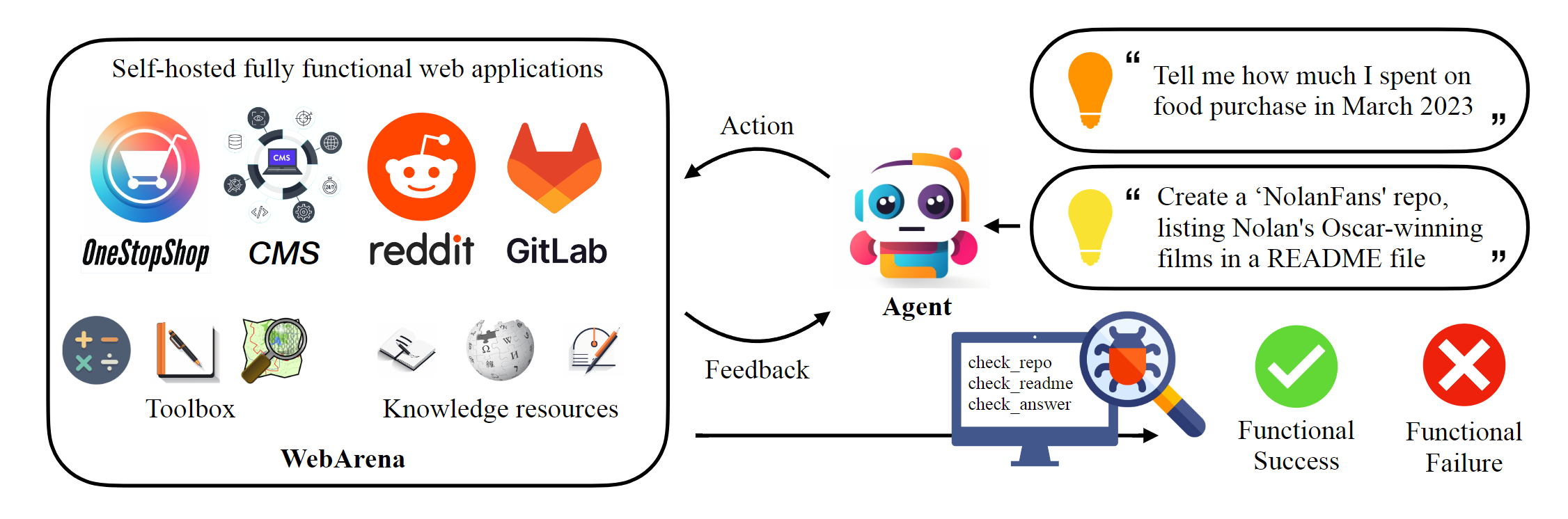
该工具主要面向 AI 研究人员、大模型开发者以及从事智能体系统设计的工程师。通过提供一套完整的本地化网页基础设施,WebArena 包含了电商、论坛、办公协作等多种真实网站场景,并预置了数百个具有明确目标的测试任务,能够精准量化智能体在复杂网页导航中的表现。
其核心技术亮点在于“自托管”架构,确保实验环境的高度一致性与结果的可复现性。此外,项目近期已与 AgentLab 框架深度集成,支持基于 BrowserGym 的并行实验加速,并统一纳入了 VisualWebArena 等主流基准测试。对于希望深入探索智能体在真实网络环境中决策能力、调试多步任务执行逻辑的专业用户而言,WebArena 提供了目前业界领先的标准化测试平台。
使用场景
某电商平台的算法团队正在研发一款能自动处理售后退款、查询订单状态的智能客服 Agent,需要在上线前对其网页操作能力进行严格验证。
没有 webarena 时
- 测试环境搭建困难:团队不得不连接真实的电商网站进行测试,不仅容易触发反爬虫机制,还可能导致产生真实的错误订单或垃圾数据,污染生产环境。
- 评估标准不统一:缺乏标准化的任务数据集,开发人员只能手动编写零散的测试脚本,难以量化对比不同模型版本在复杂网页导航任务上的成功率。
- 调试复现成本高:当 Agent 在真实网站上操作失败时,由于网络波动或页面动态变化,很难精确复现当时的错误现场,导致排查问题耗时耗力。
- 隐私与安全风险:在真实环境中测试需要处理真实的用户 Cookie 和敏感信息,存在数据泄露的合规风险。
使用 webarena 后
- 安全隔离的仿真环境:webarena 提供了一套可本地部署的独立网页环境(包含购物、论坛等真实站点镜像),团队可以在完全隔离的沙箱中让 Agent 随意试错,无需担心影响真实业务。
- 标准化基准评测:利用内置的 800+ 个真实任务场景和自动化评估指标,团队能快速跑分并生成可视化报告,精准定位 Agent 在“多步跳转”或“表单填写”等环节的短板。
- 高效的问题复现:借助 webarena 记录的执行轨迹功能,开发人员可以一键回放 Agent 失败时的完整操作路径,迅速锁定是提示词问题还是环境理解偏差。
- 零隐私负担:所有测试数据均为合成或脱敏数据,彻底消除了在处理用户敏感信息时的合规顾虑。
webarena 通过构建高保真的独立网页沙箱,将自主智能体的研发从“高风险的真实试探”转变为“可量化、可复现的安全迭代”。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明
快速开始
WebArena:用于构建自主智能体的真实网络环境

WebArena 是一个独立、可自托管的网络环境,专为构建自主智能体而设计
![]()
![]()
![]()
![]()
官网 • 论文 • 排行榜 • TheAgentCompany
2024年12月5日更新
[!重要] 此仓库托管的是 WebArena 的 标准 实现,用于复现论文中报告的结果。由 AgentLab 对网络导航基础设施进行了显著增强,引入了多项关键特性:(1) 支持使用 BrowserGym 进行并行实验,(2) 在统一框架内集成流行的网络导航基准测试(例如 VisualWebArena),(3) 统一的排行榜报告,以及 (4) 更完善的环境边缘情况处理。我们强烈建议您在实验中使用此框架。
新闻
- [2024年12月20日] 请查看我们在更多具有深远影响的任务上的新基准测试,包括终端使用和编程任务,TheAgentCompany。
- [2023年12月21日] 我们发布了人类标注者在约170个任务上执行的轨迹记录。更多详情请参阅 资源页面。
- [2023年11月3日] 多项功能!
- 上传了最新的 执行轨迹
- 增加了 Amazon Machine Image,其中预装了所有网站,省去了您的安装步骤。
- Zeno x WebArena,让您无需费力即可分析 WebArena 上的智能体。请参阅此 笔记本,将您自己的数据上传至 Zeno,并访问 此页面 浏览我们的现有结果!
- [2023年10月24日] 我们重新检查了整个数据集,并修复了发现的标注错误。当前版本 (v0.2.0) 相对稳定,未来预计不会再对标注进行重大更新。包含更优提示及与人类表现对比的新结果,请参阅我们的 论文。
- [2023年8月4日] 添加了搭建您自己的 WebArena 环境的说明及 Docker 资源。详情请参阅 此页面。
- [2023年7月29日] 添加了 注释详尽的脚本,用于逐步演示环境设置过程。
安装
# Python 3.10+
conda create -n webarena python=3.10; conda activate webarena
pip install -r requirements.txt
playwright install
pip install -e .
# 可选,仅开发环境
pip install -e ".[dev]"
mypy --install-types --non-interactive browser_env agents evaluation_harness
pip install pre-commit
pre-commit install
快速入门
请参阅 此脚本 的快速入门指南,了解如何设置浏览器环境并使用我们托管的演示站点与其交互。该脚本仅用于教学目的;如需进行 可重复 的实验,请参阅下一节。简而言之,使用 WebArena 与使用 OpenAI Gym 非常相似。以下代码片段展示了如何与环境交互。
from browser_env import ScriptBrowserEnv, create_id_based_action
# 初始化环境
env = ScriptBrowserEnv(
headless=False,
observation_type="accessibility_tree",
current_viewport_only=True,
viewport_size={"width": 1280, "height": 720},
)
# 根据 JSON 文件中的配置准备环境
config_file = "config_files/0.json"
obs, info = env.reset(options={"config_file": config_file})
# 通过 obs["text"] 获取文本观测值(例如 HTML、无障碍树)
# 创建随机动作
id = random.randint(0, 1000)
action = create_id_based_action(f"click [id]")
# 执行动作
obs, _, terminated, _, info = env.step(action)
端到端评估
[!重要] 为确保评估的准确性,请按照步骤1和步骤2设置您自己的WebArena网站。演示站点仅用于浏览,以帮助您更好地理解内容。在评估完812个示例后,请按照此处的说明将环境重置为初始状态。
设置独立环境。 详细信息请参阅此页面。
配置每个网站的URL。
export SHOPPING="<your_shopping_site_domain>:7770"
export SHOPPING_ADMIN="<your_e_commerce_cms_domain>:7780/admin"
export REDDIT="<your_reddit_domain>:9999"
export GITLAB="<your_gitlab_domain>:8023"
export MAP="<your_map_domain>:3000"
export WIKIPEDIA="<your_wikipedia_domain>:8888/wikipedia_en_all_maxi_2022-05/A/User:The_other_Kiwix_guy/Landing"
export HOMEPAGE="<your_homepage_domain>:4399" # 这是一个占位符
建议更新GitHub工作流中的环境变量,以确保单元测试的正确性。
- 为每个测试示例生成配置文件。
python scripts/generate_test_data.py
您将在config_files文件夹中看到生成的*.json文件。每个文件包含一个测试示例的配置。
- 获取所有网站的自动登录Cookie。
mkdir -p ./.auth
python browser_env/auto_login.py
导出
OPENAI_API_KEY=your_key,有效的OpenAI API密钥应以sk-开头。启动评估。
python run.py \
--instruction_path agent/prompts/jsons/p_cot_id_actree_2s.json \ # 这是我们论文中使用的推理代理提示
--test_start_idx 0 \
--test_end_idx 1 \
--model gpt-3.5-turbo \
--result_dir <your_result_dir>
该脚本将使用GPT-3.5推理代理运行第一个示例。轨迹将保存在<your_result_dir>/0.html中。
开发基于提示的代理
- 定义提示。我们提供了两个基线代理,其对应的提示列于此处。每个提示是一个字典,包含以下键:
prompt = {
"intro": <总体指导方针,包括任务描述、可用操作、提示等>,
"examples": [
(
example_1_observation,
example_1_response
),
(
example_2_observation,
example_2_response
),
...
],
"template": <如何组织观察、先前操作、指令、URL等不同信息>,
"meta_data": {
"observation": <代理使用的观察空间>,
"action_type": <代理使用的动作空间>,
"keywords": <模板中使用的关键词,程序随后会枚举模板中的所有关键词,以检查是否都已正确替换为相应内容>,
"prompt_constructor": <使用的提示构造器,提示构造器会构建输入并传递给LLM,并从生成结果中提取动作,详情如下>,
"action_splitter": <可在哪个分隔符内提取动作,由提示构造器使用>
}
}
- 实现提示构造器。一个使用思维链/ReAct风格推理的提示构造器示例如下此处。提示构造器是一个类,包含以下方法:
construct: 构建输入并传递给LLM。_extract_action: 给定LLM的生成结果,如何提取对应于动作的短语。
引用
如果您使用我们的环境或数据,请引用我们的论文:
@article{zhou2023webarena,
title={WebArena: A Realistic Web Environment for Building Autonomous Agents},
author={Zhou, Shuyan and Xu, Frank F and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Bisk, Yonatan and Fried, Daniel and Alon, Uri and others},
journal={arXiv preprint arXiv:2307.13854},
year={2023}
}
版本历史
v0.2.02023/10/21v0.1.02023/08/23常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备