examples
examples 是 Weights & Biases(W&B)官方提供的一系列深度学习示例项目集合,旨在帮助开发者快速上手并充分利用 W&B 平台的强大功能。在机器学习开发过程中,研究人员往往面临实验记录混乱、超参数调整难以追踪、模型版本管理复杂等痛点。examples 通过提供涵盖图像分类、自然语言处理等多个领域的实战代码,演示了如何将 W&B 的实验追踪、可视化报表、数据制品管理、超参数搜索(Sweeps)以及模型注册等核心功能无缝集成到工作流中。
这套资源特别适合人工智能领域的开发者、算法工程师及科研人员使用。无论你是刚接触 W&B 的新手,还是希望优化现有训练流程的资深从业者,都能从中找到有价值的参考。其独特亮点在于“所见即所得”的学习体验:用户无需从零搭建监控体系,只需运行示例代码,即可直观看到训练指标如何被自动记录、实验结果如何生成交互式图表,以及如何高效对比不同模型表现。通过借鉴这些最佳实践,团队能够更专注于模型创新,显著提升从数据集准备到模型部署的整体研发效率,让构建更好的模型变得更快、更透明。
使用场景
某初创公司的算法团队正在开发一个基于 Transformer 的文本分类模型,需要在两周内完成从原型验证到超参数调优的全过程。
没有 examples 时
- 起步困难:团队成员需从零编写 W&B 集成代码,反复查阅文档才能搞懂如何正确记录实验指标和超参数,浪费大量宝贵时间。
- 流程混乱:由于缺乏标准参考,不同成员记录日志的格式不统一,导致后期无法在面板上横向对比不同实验的效果。
- 功能盲区:团队仅使用了基础的日志记录功能,完全不知道如何利用 W&B 的 Sweeps 进行自动化超参数搜索,或如何通过 Artifacts 管理模型版本。
- 调试低效:遇到训练发散或数据异常时,因未预设好数据可视化(Tables)和系统资源监控,只能靠打印日志盲目猜测原因。
使用 examples 后
- 快速落地:直接复用 examples 中成熟的深度学习项目模板,几分钟内即可接入完整的实验追踪体系,立即开始核心模型迭代。
- 规范统一:参照示例中的最佳实践,团队建立了标准化的实验记录规范,确保所有成员的实验数据都能在同一个 Dashboard 中清晰对比。
- 进阶赋能:通过模仿 examples 中的配置,轻松启动了自动化超参数扫描(Sweeps),并学会了使用 Artifacts 版本化存储数据集与模型,提升复现性。
- 洞察深入:利用示例中预置的数据可视化图表和系统监控面板,迅速定位到是特定批次数据导致了梯度爆炸,大幅缩短调试周期。
examples 将原本需要数天摸索的配置工作缩短为几小时的直接应用,让团队能专注于模型创新而非工具搭建。
运行环境要求
- 未说明
未说明
未说明

快速开始
![]()
![]()
使用 W&B 更快地构建更优秀的模型。跟踪并可视化机器学习流水线中的各个环节,从数据集到生产环境中的机器学习模型。立即开始使用 W&B,注册免费账户!
🚀 入门指南
再也不用担心进度丢失。
在短短5分钟内,保存所有用于比较和复现模型所需的内容——架构、超参数、权重、模型预测、GPU使用情况、Git提交记录,甚至数据集。W&B 对个人用户和学术项目免费,并且上手非常简单。
查看我们的 示例脚本库 和 示例 Colab, 或者继续阅读以获取代码片段及更多信息!
如有任何问题,请随时在我们的 Discourse 论坛 提问。
🤝 轻松集成任意框架
安装 wandb 库并登录:
pip install wandb
wandb login
灵活的集成方式适用于任何 Python 脚本:
import wandb
# 1. 开始一个 W&B 实验
wandb.init(project='gpt3')
# 2. 保存模型输入和超参数
config = wandb.config
config.learning_rate = 0.01
# 模型训练代码在此...
# 3. 随时间记录指标,以便可视化性能
for i in range(10):
wandb.log({"loss": loss})
在 Colab 中尝试 →
如有任何问题,请随时在我们的 Discourse 论坛 提问。

📈 跟踪模型与数据流水线的超参数
在脚本开头只需设置一次 wandb.config,即可保存您的超参数、输入设置(如数据集名称或模型类型)以及其他实验中的自变量。这对于分析实验结果以及未来复现实验非常有帮助。设置配置还能让您 可视化 模型架构或数据流水线的特征与模型性能之间的关系(如上图所示)。
wandb.init()
wandb.config.epochs = 4
wandb.config.batch_size = 32
wandb.config.learning_rate = 0.001
wandb.config.architecture = "resnet"
🏗 使用你喜欢的框架
在 W&B 中使用你喜欢的框架。W&B 的集成使你能够快速、轻松地在现有项目中设置实验跟踪和数据版本控制。有关如何将 W&B 与你选择的框架集成的更多信息,请参阅 W&B 开发者指南中的集成章节。
🔥 PyTorch
调用 .watch 并传入你的 PyTorch 模型,即可自动记录梯度并存储网络拓扑结构。接下来,使用 .log 来跟踪其他指标。以下示例展示了如何操作:
import wandb
# 1. 开始一个新的运行
run = wandb.init(project="gpt4")
# 2. 保存模型输入和超参数
config = run.config
config.dropout = 0.01
# 3. 记录梯度和模型参数
run.watch(model)
for batch_idx, (data, target) in enumerate(train_loader):
...
if batch_idx % args.log_interval == 0:
# 4. 记录指标以可视化性能
run.log({"loss": loss})
- 运行一个示例 Google Colab 笔记本。
- 阅读开发者指南,了解如何将 PyTorch 与 W&B 集成的技术细节。
- 探索W&B 报告。
🌊 TensorFlow/Keras
在训练过程中调用 `model.fit` 时,使用 W&B 回调函数可自动将指标保存到 W&B。以下代码示例展示了将 W&B 与 Keras 集成时脚本可能的样子:
# 此脚本需要安装以下库:
# tensorflow, numpy
import wandb
from wandb.keras import WandbMetricsLogger, WandbModelCheckpoint
import random
import numpy as np
import tensorflow as tf
# 开始一次运行,跟踪超参数
run = wandb.init(
# 设置本次运行将被记录的 W&B 项目
project="my-awesome-project",
# 使用 wandb.config 跟踪超参数和运行元数据
config={
"layer_1": 512,
"activation_1": "relu",
"dropout": random.uniform(0.01, 0.80),
"layer_2": 10,
"activation_2": "softmax",
"optimizer": "sgd",
"loss": "sparse_categorical_crossentropy",
"metric": "accuracy",
"epoch": 8,
"batch_size": 256,
},
)
# [可选] 使用 wandb.config 作为你的配置
config = run.config
# 获取数据
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train, y_train = x_train[::5], y_train[::5]
x_test, y_test = x_test[::20], y_test[::20]
labels = [str(digit) for digit in range(np.max(y_train) + 1)]
# 构建模型
model = tf.keras.models.Sequential(
[
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(config.layer_1, activation=config.activation_1),
tf.keras.layers.Dropout(config.dropout),
tf.keras.layers.Dense(config.layer_2, activation=config.activation_2),
]
)
# 编译模型
model.compile(optimizer=config.optimizer, loss=config.loss, metrics=[config.metric])
# WandbMetricsLogger 将训练和验证指标记录到 wandb
# WandbModelCheckpoint 将模型检查点上传到 wandb
history = model.fit(
x=x_train,
y=y_train,
epochs=config.epoch,
batch_size=config.batch_size,
validation_data=(x_test, y_test),
callbacks=[
WandbMetricsLogger(log_freq=5),
WandbModelCheckpoint("models"),
],
)
# [可选] 结束 W&B 运行,在笔记本中是必需的
run.finish()
立即开始将你的 Keras 模型与 W&B 集成吧:
- 运行一个示例 Google Colab 笔记本
- 阅读开发者指南,了解如何将 Keras 与 W&B 集成的技术细节。
- 探索W&B 报告。
🤗 Huggingface Transformers
在使用 HuggingFace Trainer 运行脚本时,将 wandb 传递给 report_to 参数。W&B 将自动记录损失、评估指标、模型拓扑和梯度。
注意:运行脚本的环境必须已安装 wandb。
以下示例展示了如何将 W&B 与 Hugging Face 集成:
# 此脚本需要安装以下库:
# numpy, transformers, datasets
import wandb
import os
import numpy as np
from datasets import load_dataset
from transformers import TrainingArguments, Trainer
from transformers import AutoTokenizer, AutoModelForSequenceClassification
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return {"accuracy": np.mean(predictions == labels)}
# 下载并准备数据
dataset = load_dataset("yelp_review_full")
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
small_train_dataset = dataset["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = dataset["test"].shuffle(seed=42).select(range(300))
small_train_dataset = small_train_dataset.map(tokenize_function, batched=True)
small_eval_dataset = small_eval_dataset.map(tokenize_function, batched=True)
# 下载模型
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=5
)
# 设置本次运行将被记录的 W&B 项目
os.environ["WANDB_PROJECT"] = "my-awesome-project"
# 将你训练好的模型检查点保存到 W&B
os.environ["WANDB_LOG_MODEL"] = "true"
# 关闭 watch 以加快日志记录速度
os.environ["WANDB_WATCH"] = "false"
# 将“wandb”传递给 `report_to` 参数以启用 W&B 日志记录
training_args = TrainingArguments(
output_dir="models",
report_to="wandb",
logging_steps=5,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
evaluation_strategy="steps",
eval_steps=20,
max_steps=100,
save_steps=100,
)
# 定义训练器并开始训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
# [可选] 完成 wandb 运行,在笔记本中是必需的
wandb.finish()
- 运行一个示例 Google Colab Notebook。
- 阅读开发者指南,了解如何将 Hugging Face 与 W&B 集成的技术细节。
⚡️ PyTorch Lightning
使用 Lightning 构建可扩展、结构化、高性能的 PyTorch 模型,并通过 W&B 进行日志记录。
# 此脚本需要安装以下库:
# torch, torchvision, pytorch_lightning
import wandb
import os
from torch import optim, nn, utils
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
import pytorch_lightning as pl
from pytorch_lightning.loggers import WandbLogger
class LitAutoEncoder(pl.LightningModule):
def __init__(self, lr=1e-3, inp_size=28, optimizer="Adam"):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(inp_size * inp_size, 64), nn.ReLU(), nn.Linear(64, 3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 64), nn.ReLU(), nn.Linear(64, inp_size * inp_size)
)
self.lr = lr
# 将超参数保存到 self.hparams 中,由 wandb 自动记录
self.save_hyperparameters()
def training_step(self, batch, batch_idx):
x, y = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = nn.functional.mse_loss(x_hat, x)
# 将指标记录到 wandb
self.log("train_loss", loss)
return loss
def configure_optimizers(self):
optimizer = optim.Adam(self.parameters(), lr=self.lr)
return optimizer
# 初始化自编码器
autoencoder = LitAutoEncoder(lr=1e-3, inp_size=28)
# 准备数据
batch_size = 32
dataset = MNIST(os.getcwd(), download=True, transform=ToTensor())
train_loader = utils.data.DataLoader(dataset, shuffle=True)
# 初始化 wandb 日志记录器并命名你的 wandb 项目
wandb_logger = WandbLogger(project="my-awesome-project")
# 将你的批量大小添加到 wandb 配置中
wandb_logger.experiment.config["batch_size"] = batch_size
# 将 wandb_logger 传递给 Trainer
trainer = pl.Trainer(limit_train_batches=750, max_epochs=5, logger=wandb_logger)
# 训练模型
trainer.fit(model=autoencoder, train_dataloaders=train_loader)
# [可选] 完成 wandb 运行,在笔记本中是必需的
wandb.finish()
- 运行一个示例 Google Colab Notebook。
- 阅读开发者指南,了解如何将 PyTorch Lightning 与 W&B 集成的技术细节。
💨 XGBoost
使用 W&B 回调函数,当您在训练过程中调用 `model.fit` 时,自动将指标保存到 W&B。以下代码示例展示了您的脚本在与 XGBoost 集成 W&B 时可能的样子:
# 此脚本需要安装以下库:
# numpy, xgboost
import wandb
from wandb.xgboost import WandbCallback
import numpy as np
import xgboost as xgb
# 设置 XGBoost 参数
param = {
"objective": "multi:softmax",
"eta": 0.1,
"max_depth": 6,
"nthread": 4,
"num_class": 6,
}
# 开始一个新的 wandb 运行以跟踪此脚本
run = wandb.init(
# 设置此运行将被记录的 wandb 项目
project="my-awesome-project",
# 跟踪超参数和运行元数据
config=param,
)
# 从 wandb Artifacts 下载数据并准备数据
run.use_artifact("wandb/intro/dermatology_data:v0", type="dataset").download(".")
data = np.loadtxt(
"./dermatology.data",
delimiter=",",
converters={33: lambda x: int(x == "?"), 34: lambda x: int(x) - 1},
)
sz = data.shape
train = data[: int(sz[0] * 0.7), :]
test = data[int(sz[0] * 0.7) :, :]
train_X = train[:, :33]
train_Y = train[:, 34]
test_X = test[:, :33]
test_Y = test[:, 34]
xg_train = xgb.DMatrix(train_X, label=train_Y)
xg_test = xgb.DMatrix(test_X, label=test_Y)
watchlist = [(xg_train, "train"), (xg_test, "test")]
# 向 wandb 运行添加另一个配置
num_round = 5
run.config["num_round"] = 5
run.config["data_shape"] = sz
# 将 WandbCallback 传递给 booster,以记录其配置和指标
bst = xgb.train(
param, xg_train, num_round, evals=watchlist, callbacks=[WandbCallback()]
)
# 获取预测
pred = bst.predict(xg_test)
error_rate = np.sum(pred != test_Y) / test_Y.shape[0]
# 将你的测试指标记录到 wandb
run.summary["Error Rate"] = error_rate
# [可选] 完成 wandb 运行,在笔记本中是必需的
run.finish()
- 运行一个示例 Google Colab Notebook。
- 阅读开发者指南,了解如何将 XGBoost 与 W&B 集成的技术细节。
🧮 Sci-Kit Learn
使用 wandb 可视化并比较你的 scikit-learn 模型的性能:# 此脚本需要安装以下库:
# numpy, sklearn
import wandb
from wandb.sklearn import plot_precision_recall, plot_feature_importances
from wandb.sklearn import plot_class_proportions, plot_learning_curve, plot_roc
import numpy as np
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# 加载并处理数据
wbcd = datasets.load_breast_cancer()
feature_names = wbcd.feature_names
labels = wbcd.target_names
test_size = 0.2
X_train, X_test, y_train, y_test = train_test_split(
wbcd.data, wbcd.target, test_size=test_size
)
# 训练模型
model = RandomForestClassifier()
model.fit(X_train, y_train)
model_params = model.get_params()
# 获取预测
y_pred = model.predict(X_test)
y_probas = model.predict_proba(X_test)
importances = model.feature_importances_
indices = np.argsort(importances)[::-1]
# 开始一个新的 wandb 运行并添加你的模型超参数
run = wandb.init(project="my-awesome-project", config=model_params)
# 向 wandb 添加额外的配置
run.config.update(
{
"test_size": test_size,
"train_len": len(X_train),
"test_len": len(X_test),
}
)
# 将额外的可视化记录到 wandb
plot_class_proportions(y_train, y_test, labels)
plot_learning_curve(model, X_train, y_train)
plot_roc(y_test, y_probas, labels)
plot_precision_recall(y_test, y_probas, labels)
plot_feature_importances(model)
# [可选] 完成 wandb 运行,在笔记本中是必需的
run.finish()
- 运行一个示例 Google Colab 笔记本。
- 阅读开发者指南,了解如何将 Scikit-Learn 与 W&B 集成的技术细节。
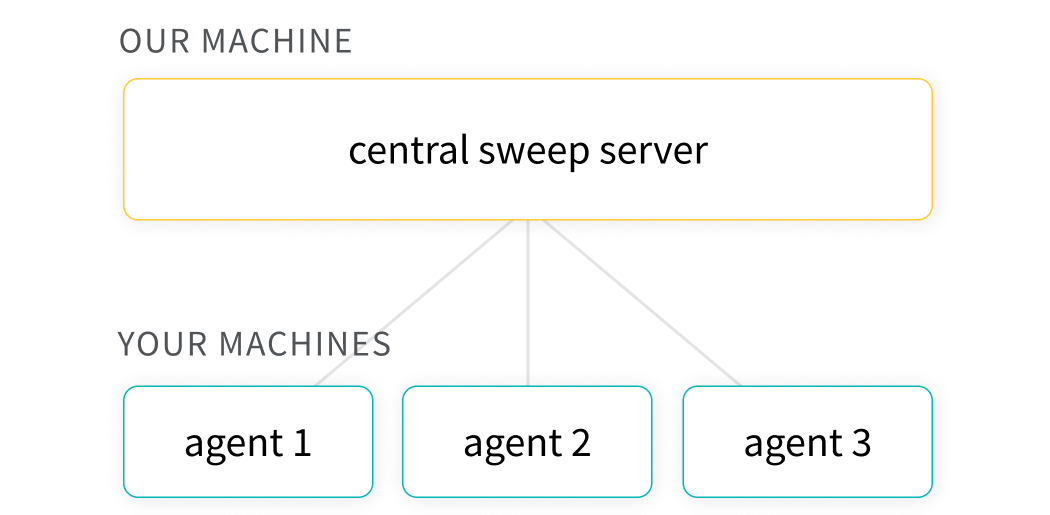
🧹 使用 Sweeps 优化超参数
使用 Weights & Biases 的 Sweeps 功能,自动化超参数优化并探索可能的模型空间。
在 Colab 中尝试 PyTorch 的 Sweeps →
在 Colab 中尝试 TensorFlow 的 Sweeps →
使用 W&B Sweeps 的优势
- 设置快速: 只需几行代码即可运行 W&B 的 Sweeps。
- 透明: 我们会引用所使用的所有算法,并且我们的代码是开源的。
- 强大: 我们的 Sweeps 完全可自定义和配置。您可以在数十台机器上启动 Sweeps,其操作方式与在笔记本电脑上启动 Sweeps 一样简单。
5 分钟入门 →
常见用例
- 探索: 高效地采样超参数组合的空间,以发现有前景的区域,并对您的模型建立直观的理解。
- 优化: 使用 Sweeps 找到性能最优的超参数集合。
- K 折交叉验证: 这里有一个简短的代码示例展示了如何使用 W&B Sweeps 进行 K 折交叉验证。
可视化 Sweeps 结果
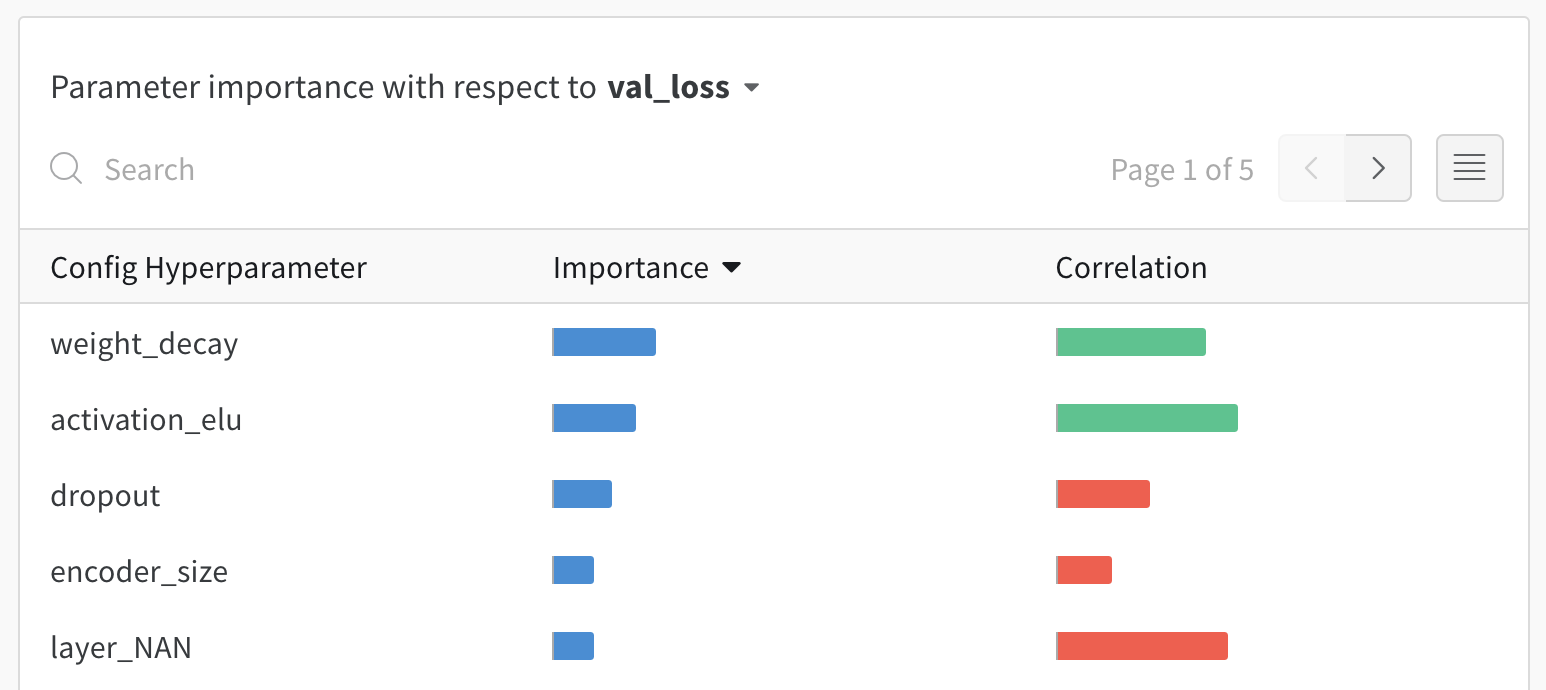
超参数重要性图显示了哪些超参数是对目标指标的最佳预测因子,并且与理想的指标值高度相关。
平行坐标图将超参数值映射到模型指标上。它们有助于找到导致最佳模型性能的超参数组合。

📜 使用 Reports 分享洞察
Reports 让您能够组织可视化内容、描述您的发现,并与合作者分享更新。
常见用例
- 笔记: 添加一张图表,并附上简短的个人备注。
- 协作: 与同事分享您的发现。
- 工作日志: 跟踪您已经尝试过的内容,并规划下一步行动。
在 The Gallery → 探索 Reports | 阅读文档
一旦您在 W&B 中有了实验数据,只需点击几下,就可以在 Reports 中可视化和记录结果。这里有一个快速的演示视频。

🏺 使用 Artifacts 对数据集和模型进行版本控制
Git 和 GitHub 使代码版本控制变得容易,但它们并不适合跟踪机器学习流水线中的其他部分: 数据集、模型以及其他大型二进制文件。
而 W&B 的 Artifacts 则非常适合这一点。只需添加几行额外的代码, 您就可以开始跟踪您和团队的输出, 并且这些输出都会直接链接到相应的运行中。
在 Colab 中尝试 Artifacts,并观看视频教程

常见用例
- 流水线管理: 将您的运行的输入和输出以图的形式进行跟踪和可视化。
- 不要重复劳动™: 防止计算资源的重复使用。
- 团队数据共享: 在没有繁琐流程的情况下,协作处理模型和数据集。

使用 Tables 可视化和查询数据
对表格数据进行分组、排序、筛选,生成计算列,并创建图表。
让您把更多时间花在获取洞察上,而不是手动构建图表。
# 记录我的表格
wandb.log({"table": my_dataframe})

在 Colab 或这些示例中尝试 Tables
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器