llm-server-docs
llm-server-docs 是一套详尽的端到端指南,旨在帮助用户在 Debian 系统上搭建完全本地化且隐私安全的个人大语言模型(LLM)服务器。它解决了用户依赖云端服务导致的数据隐私泄露、高昂 API 费用以及网络延迟等痛点,让所有数据处理均在本地完成。
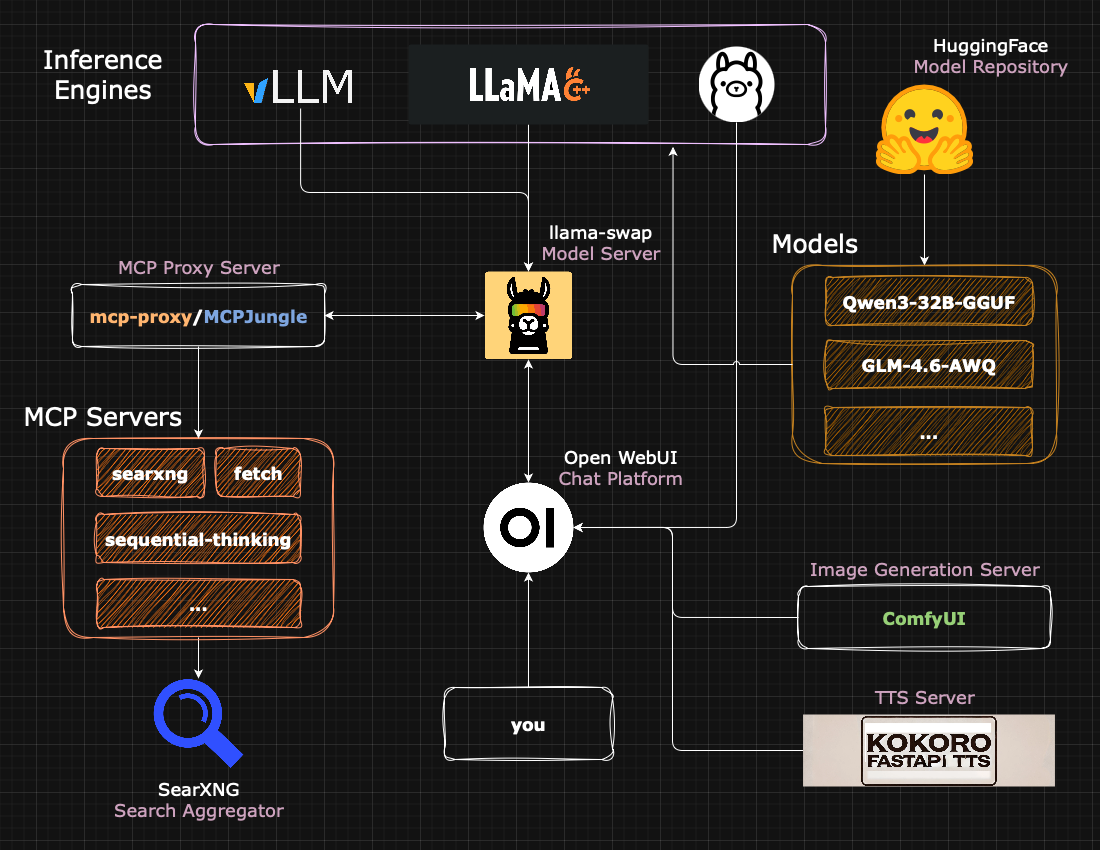
这套文档特别适合希望掌握数据主权的技术爱好者、开发者及研究人员。通过跟随指南,用户可以整合多种开源组件,构建功能完备的 AI 工作台:不仅支持基于 Ollama、llama.cpp 或 vLLM 的模型推理和 Open WebUI 聊天界面,还集成了联网搜索(SearXNG)、知识库检索(RAG)、图像生成(ComfyUI)以及语音合成(Kokoro)等高级功能。
其技术亮点在于提供了模块化的软件栈架构,并详细涵盖了从 Docker 容器加固、SSH 安全配置到利用 Tailscale 实现安全远程访问的全流程。此外,它还引入了 MCP(模型上下文协议)代理服务,增强了模型与外部工具的交互能力。无论是想部署私有知识库,还是构建多功能的本地 AI 助手,llm-server-docs 都能提供清晰、可操作的技术路径。
使用场景
某金融数据分析师需要在本地部署一套完全私有的 AI 系统,用于处理敏感财报数据并生成带语音播报的分析报告,同时要求具备联网检索最新市场动态的能力。
没有 llm-server-docs 时
- 集成噩梦:需手动分别配置 Ollama、Open WebUI、SearXNG 和 ComfyUI 等多个组件,容器网络互通和依赖冲突问题频发,耗时数天仍无法跑通全流程。
- 隐私风险:缺乏标准化的防火墙与 SSH 加固指南,远程访问时容易暴露端口,导致敏感金融数据存在泄露隐患。
- 功能割裂:文字生成、图片绘制、语音合成(TTS)及联网搜索功能分散在不同界面,无法在一个统一的聊天窗口中协同工作。
- 维护困难:缺少系统的模型管理(如 llama-swap)和自动更新脚本,切换不同参数量的模型或升级驱动时极易导致服务崩溃。
使用 llm-server-docs 后
- 一键全栈部署:依据文档在 Debian 上快速搭建起包含推理引擎、搜索、RAG 及多模态生成的完整软件栈,所有服务通过预定义的网络自动互联。
- 企业级安全:直接套用文档中的 Tailscale 组网、防火墙规则及 SSH 配置步骤,实现了无需公网 IP 的安全远程访问,确保数据不出内网。
- 统一交互体验:在 Open WebUI 单一界面中即可调用本地大模型分析财报、利用 SearXNG 检索实时股价、调用 ComfyUI 生成趋势图并由 Kokoro 播报结论。
- 弹性资源管理:通过集成的 llama-swap 和 systemd 服务管理,轻松在不同模型间切换以平衡速度与精度,且拥有清晰的版本更新路径。
llm-server-docs 将原本复杂琐碎的私有化 AI 基建工程,转化为可复用的标准化流程,让开发者能专注于业务逻辑而非环境调试。
运行环境要求
- Linux (Debian)
- 非必需(支持 CPU 模式)
- 推荐 NVIDIA GPU(如 RTX 3090),支持 AMD GPU
- 需安装 Nvidia Container Toolkit 或对应驱动以启用 GPU 加速
最低未说明,参考配置为 96GB DDR4 RAM

快速开始
本地 LLaMA 服务器搭建文档
简而言之:在 Debian 上搭建您自己的本地且完全私有的大语言模型服务器的端到端指南。该服务器配备聊天功能、网页搜索、RAG、模型管理、MCP 服务器、图像生成和 TTS,并提供配置 SSH、防火墙以及通过 Tailscale 实现安全远程访问的步骤。
软件栈:
- 推理引擎(Ollama、llama.cpp、vLLM)
- 搜索引擎(SearXNG)
- 模型服务器(llama-swap、
systemd服务) - 聊天平台(Open WebUI)
- MCP 代理服务器(mcp-proxy、MCPJungle)
- 文本转语音服务器(Kokoro FastAPI)
- 图像生成服务器(ComfyUI)
目录
- 本地 LLaMA 服务器搭建文档
简介
本仓库概述了运行本地语言模型服务器的步骤。虽然特别针对 Debian,但大多数 Linux 发行版也应遵循非常相似的流程。它旨在为像我这样首次搭建服务器的 Linux 初学者提供指导。
整个过程包括安装必要的驱动程序、设置 GPU 功率限制、配置自动登录,以及安排 init.bash 脚本在系统启动时运行。所有这些设置都基于我对语言模型服务器的理想配置——该服务器可以全天候运行,但许多部分都可以根据您的需求进行自定义。
[!重要提示] 本指南的任何部分均未使用 AI 编写——如果出现“幻觉”,那也是人类固有的特性。尽管我已尽最大努力确保每一步骤和每个命令的正确性,请务必在终端中执行前仔细检查一切内容。祝您使用愉快!
优先级
- 简单性:解决方案的各个组件应相对容易设置。
- 稳定性:组件应稳定可靠,能够在无需干预的情况下连续运行数周。
- 安全性:组件应能够被严格保护,并在其存在已知漏洞时限制其对系统的潜在破坏能力。
- 可维护性:组件及其交互应足够简单,以便您能够随着它们的发展(因为它们一定会发展)对其进行维护。
- 美观性:最终结果应尽可能接近云服务商的聊天平台。家庭实验室解决方案不必给人一种随意拼凑的感觉。
- 模块化:设置中的组件应能轻松替换为更新、性能更强或维护更好的替代方案。标准协议(如 OpenAI 兼容性、MCP 等)在这方面有很大帮助,在本指南中,始终优先考虑这些标准协议而非捆绑式解决方案。
- 开源:代码应能被工程师社区验证。聊天平台和大语言模型涉及大量以自然语言传递的个人数据,因此了解这些数据不会离开您的机器非常重要。
前置条件
本指南适用于任何现代的 CPU 和 GPU 组合。此前,与 AMD 显卡的兼容性曾是个问题,但 Ollama 的最新版本已解决了这一问题,AMD 显卡现在已得到原生支持。
作为参考,本指南是在以下系统上构建的:
- CPU:Intel Core i5-12600KF
- 内存:96GB 3200MHz DDR4 RAM
- 存储:1TB M.2 NVMe SSD
- GPU:2x Nvidia RTX 3090(24GB)
[!NOTE] AMD 显卡:由于 AMD 最近使得在其显卡上设置功耗限制变得困难,因此会跳过针对 AMD 显卡的功耗限制步骤。自然地,请跳过所有涉及
nvidia-smi或nvidia-persistenced的步骤,以及init.bash脚本中的功耗限制部分。仅 CPU 系统:您可以跳过 GPU 驱动程序的安装和功耗限制步骤。指南的其余部分应能按预期工作。
[!NOTE] 本指南使用
~/(或/home/<your_username>)作为基础目录。如果您在其他目录下操作,请相应地修改所有命令。
要开始设置您的服务器,您需要以下内容:
- Debian 的全新安装
- 互联网连接
- 对 Linux 终端的基本了解
- 显示器、键盘和鼠标等外设
要在您新搭建的服务器硬件上安装 Debian:
- 从官方网站下载 Debian ISO。
- 使用 Rufus(Windows)或 Balena Etcher(MacOS)等工具创建可启动的 USB 启动盘。
- 从 USB 启动并安装 Debian。
有关 Debian 安装的更详细指南,请参阅 官方文档。对于尚不熟悉 Linux 的用户,建议使用图形化安装程序——安装过程中会提供文本模式和图形化两种选择。
此外,我建议安装一个轻量级的桌面环境,如 XFCE,以方便使用。GNOME 或 KDE 也是可选的;如果将服务器用作主要工作站,GNOME 可能是更好的选择,因为它功能更丰富(但也更占用资源),而 XFCE 则更为轻便。
通用步骤
允许 sudo 权限
为了完成本指南中的许多操作,我们需要以 root 用户身份执行。但在 root 用户允许我们使用之前,我们无法获得 root 权限。首先,我们将切换到 root 用户,并授予当前用户使用 sudo 执行命令的权限。
[!TIP]
sudo是“超级用户执行”的缩写——在 Linux 中,它向操作系统表明您希望以 root 用户的身份运行所执行的命令。在高度安全的系统中,应谨慎使用sudo(大多数进程应使用特定用户的权限),并且由于其具有与 root 用户相同的权限,稍有不慎就可能对系统造成影响。不必过度担心它的使用,只需知道如果使用不当,它确实可能带来危险。
切换到 root 用户:
su root运行以下命令,将您的用户添加到
sudo组(该组拥有我们所需的权限):sudo usermod -a -G sudo <username>将
<username>替换为您的用户名。保存并退出(
Ctrl+X)。关闭当前终端并打开一个新的会话。这是使更改生效的必要步骤。
(可选)通过运行带有
sudo的ls命令来测试新权限:sudo ls
更新系统软件包
- 运行以下命令更新系统:
sudo apt update sudo apt upgrade
接下来,我们将安装必要的 GPU 驱动程序,以便程序能够利用 GPU 的计算能力。
Nvidia 显卡
- 按照 Nvidia 的 CUDA Toolkit 下载指南,该网站会根据您的机器配置交互式地引导您完成下载。
- 运行以下命令:
sudo apt install linux-headers-amd64 sudo apt install nvidia-driver firmware-misc-nonfree - 重启服务器。
- 运行以下命令验证安装是否成功:
nvidia-smi
AMD 显卡
- 运行以下命令:
deb http://deb.debian.org/debian bookworm main contrib non-free-firmware apt install firmware-amd-graphics libgl1-mesa-dri libglx-mesa0 mesa-vulkan-drivers xserver-xorg-video-all - 重启服务器。
我们还将安装一些 Debian 默认未安装但后续可能需要的软件包:
sudo apt install libcurl cmake
设置启动脚本
在此步骤中,我们将创建一个名为 init.bash 的脚本。该脚本将在系统启动时运行,用于设置 GPU 功耗限制,并使用 Ollama 启动服务器。我们将 GPU 的功耗限制调低,因为测试和推理表明,即使功耗降低 30%,性能也只会下降 5% 至 15%。这一点对于 24 小时运行的服务器尤为重要。
运行以下命令:
touch init.bash nano init.bash在脚本中添加以下内容:
#!/bin/bash sudo nvidia-smi -pm 1 sudo nvidia-smi -pl <power_limit>将
<power_limit>替换为您希望设置的功耗限制值(单位:瓦)。例如,sudo nvidia-smi -pl 250。如果有多块 GPU,则需修改脚本以分别设置每块 GPU 的功耗限制:
sudo nvidia-smi -i 0 -pl <power_limit> sudo nvidia-smi -i 1 -pl <power_limit>保存并退出脚本。
将脚本设置为可执行:
chmod +x init.bash
将 init.bash 脚本添加到 crontab 中,即可安排它在系统启动时自动运行。
运行以下命令:
crontab -e在文件中添加以下行:
@reboot /path/to/init.bash将
/path/to/init.bash替换为init.bash脚本的实际路径。(可选)添加以下行以在午夜关闭服务器:
0 0 * * * /sbin/shutdown -h now保存并退出文件。
配置脚本权限
我们希望 init.bash 脚本能无需输入密码即可执行 nvidia-smi 命令。这可以通过为 nvidia-persistenced 和 nvidia-smi 授予无密码的 sudo 权限来实现,具体方法是编辑 sudoers 文件。
AMD 用户可以跳过此步骤,因为 AMD 显卡不支持功率限制功能。
- 运行以下命令以编辑 sudoers 文件:
sudo visudo - 在文件中添加以下两行:
<username> ALL=(ALL) NOPASSWD: /usr/bin/nvidia-persistenced <username> ALL=(ALL) NOPASSWD: /usr/bin/nvidia-smi请将
<username>替换为您的用户名。 - 保存并退出文件。
[!重要] 请确保将这些行添加到
%sudo ALL=(ALL:ALL) ALL之后。文件中行的顺序很重要——系统会使用最后匹配的一行,因此如果将这些行添加到%sudo ALL=(ALL:ALL) ALL之前,它们将被忽略。
配置自动登录(可选)
当服务器启动时,我们可能希望它自动登录到某个用户账户并运行 init.bash 脚本。这可以通过配置 lightdm 显示管理器来实现。
- 运行以下命令:
sudo nano /etc/lightdm/lightdm.conf - 找到以下被注释掉的行。它应该位于
[Seat:*]部分:# autologin-user= - 取消该行的注释,并添加您的用户名:
autologin-user=<username>请将
<username>替换为您的用户名。 - 保存并退出文件。
Docker
📖 文档
Docker 是一个容器化平台,允许您在隔离的环境中运行应用程序。本小节遵循 Docker 官方指南,介绍如何在 Debian 系统上安装 Docker 引擎。以下是相关命令,但建议您访问该指南,以防说明有所更新。
如果您的系统上已经安装了 Docker,最好重新安装一次,以避免出现损坏或过时的依赖项。以下命令会遍历系统已安装的软件包,并移除与 Docker 相关的软件包:
for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do sudo apt purge $pkg; done运行以下命令:
# 添加 Docker 官方 GPG 密钥: sudo apt update sudo apt install ca-certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/debian/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc # 将仓库添加到 Apt 源: sudo tee /etc/apt/sources.list.d/docker.sources <<EOF Types: deb URIs: https://download.docker.com/linux/debian Suites: $(. /etc/os-release && echo "$VERSION_CODENAME") Components: stable Signed-By: /etc/apt/keyrings/docker.asc EOF sudo apt update安装 Docker 相关软件包:
sudo apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin验证安装(可选):
sudo systemctl status docker如果服务未启动,请尝试手动启动 Docker 守护进程:
sudo systemctl start docker
将用户加入 Docker 组
为了让我们在使用 Docker 命令时无需再输入 sudo,而是可以直接以当前用户身份运行,我们需要将当前用户加入 docker 组。虽然这不是必须的,但这样做非常方便。本小节参考了 Docker 的安装后配置文档——建议您查看一下,以防自撰写以来内容有所变化。
[!警告] 加入
docker组意味着拥有对系统的高度访问权限,实际上等同于 Docker 守护进程的 root 权限。请仅将可信用户加入此组。
将当前用户加入 Docker 组:
sudo usermod -aG docker $USER应用更改:
newgrp docker验证新权限:检查正在运行的容器:
docker ps -a
如果您仍然遇到“权限拒绝”问题,且 Docker 命令仍需要使用 sudo,请注销并重新登录。
[!注意] 如果您决定不执行此操作,则每次使用 Docker 命令时都需要在前面加上
sudo。
Nvidia Container Toolkit
您很可能会希望通过 Docker 使用 GPU——这就需要安装 Nvidia Container Toolkit,它可以让 Docker 在 Nvidia 显卡上分配和释放显存。以下是安装步骤,但建议您参考 Nvidia 官方文档,以获取最新的命令。
配置软件源:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list更新软件包:
sudo apt update安装 Nvidia Container Toolkit 软件包:
sudo apt install -y nvidia-container-toolkit重启 Docker 守护进程:
sudo systemctl restart docker
创建网络
我们将通过 Docker 容器运行大多数服务。为了让多个容器相互通信,我们可以通过 UFW 开放端口(稍后会进行配置),但这种方式不如创建 Docker 网络高效。通过创建 Docker 网络,网络中的所有容器都可以安全地相互通信,而无需为每个服务单独开放端口,从而构建更安全的环境。
我们将这个网络命名为 app-net:您可以根据需要命名,只需确保后续使用该网络的相关命令也相应更新。
运行以下命令:
docker network create app-net
完成!现在,当我们创建容器时,可以这样引用该网络:
Docker Run
docker run <container> --network app-net
Docker Compose
services:
<container>:
# 添加这一行
networks:
- app-net
# 添加这一行
networks:
app-net:
external: true
将
<container>替换为实际的服务名称——别忘了同时添加其他参数。
配置完成后,我们现在可以通过容器名和端口来调用它们。假设我们要从 open-webui 调用 llama-swap 中的 /health 端点(这两个是我们稍后会创建的实际容器),以确保容器之间能够互相访问和通信。运行以下命令(按 CTRL+C 退出):
docker exec -i open-webui curl http://llama-swap:8080/health
你也可以反过来执行一次,以进一步确认:
docker exec -it llama-swap curl http://open-webui:8080
[!重要] 这里的端口始终是容器内部运行的端口。例如,如果一个容器以 1111:8080 的形式运行,那么 1111 是宿主机上的端口(你可以通过
http://localhost:1111或http://<server_ip>:1111访问它),而 8080 则是容器内部实际运行的端口。因此,试图通过app-net网络使用 1111 端口访问该容器是无效的。在服务中指定 URL 时记住这一点,可以避免许多“为什么不起作用?”的困扰。
加固 Docker 容器
在软件领域,“加固”是指提高系统的安全性及对网络攻击的抵御能力。通常,这包括减少攻击者可能利用的入侵途径,同时也涉及在攻击者成功入侵后,限制其可执行的操作。本质上,我们将同时采取预防和应对措施——尽管常说“预防胜于治疗”。本小节参考了 Reddit 上的一条评论链接,由用户 u/arnedam 提供。另一个有用的参考资料是 OWASP 的 Docker 安全备忘录链接。
在很大程度上,我们所追求的安全目标可以通过应用“最小权限原则”(PoLP)来实现——也就是说,只赋予容器完成其功能所需的精确权限,不多也不少。对于每一条建议,我都列出了潜在的风险以及相应的缓解措施(并说明其如何解决问题);虽然并非严格必要,但了解系统面临哪些风险,有助于你在部署服务时更安全地思考。
[!注] 本小节对于面向公众的服务至关重要。然而,即使你仅打算通过私有网络访问你的服务(推荐方式),这样做也绝不会多余——因为它能够在服务器或服务遭到入侵时,限制攻击者所能造成的损害范围。
以普通用户而非 root 用户运行服务:
user: "<your_user_id>:<your_group_id>"使用
id -u查找<your_user_id>,使用id -g查找<your_group_id>。风险:若未特别指定,容器默认以 root 用户身份运行。被攻陷的 root 权限容器可能造成各种破坏,从执行恶意代码到窥探或删除系统文件等。
缓解措施:通过指定容器运行的用户,可以将容器的权限限制在该用户的权限范围内,而普通用户的权限几乎总是低于 root 用户。
将文件系统设置为只读:
read_only: true风险:默认情况下,容器被允许读取和写入其有权访问的文件。这意味着一旦容器被攻陷,攻击者就可能写入恶意文件或代码,并窃取或删除关键信息。
缓解措施:启用只读模式后,攻击者将无法向容器可访问的系统区域写入恶意代码或删除重要数据。
[!警告] 使用
read_only: true指令时需谨慎:如果服务依赖于文件写操作,比如许多会写入/tmp目录的服务,这些子进程将会失败。若这些子进程至关重要,容器甚至可能无法启动。请预期此设置并不能完全适用于所有容器——你很可能需要在大多数挂载卷上单独添加:ro选项。
限制容器可使用的物理资源:
# 容器最多可运行的进程数 pids_limit: 512 # 容器的最大内存限制 mem_limit: 3g # 容器最多可使用的 CPU 核心数——可以是小数 cpus: 3风险:默认情况下,容器被赋予无限制的资源分配能力。这意味着一旦容器被攻陷,它就能占用大量 CPU、内存和显存来执行恶意代码。
缓解措施:为资源设置固定上限,可以在容器被攻陷时防止攻击者耗尽服务器的所有物理资源进行破坏,例如利用你的机器运行僵尸网络。
Docker Swarm
如果你使用 Docker Swarm(本指南未涉及),则需要采用略有不同的格式:
deploy: resources: limits: pids: 512 memory: 3g cpus: 3禁用容器中的
tty和stdin:tty: false stdin_open: false风险:
stdin允许向容器输入命令(输入注入),而tty则提供了一个活跃的 Shell 环境——两者结合使容器具备完整的交互式 Shell 功能,从而可能执行潜在的恶意命令。缓解措施:禁用这些功能后,攻击者将无法通过容器执行代码,从而大大降低任意代码执行(ACE)漏洞的风险。
禁止容器提升自身权限:
security_opt: - "no-new-privileges=true"风险:在拥有交互式 Shell 环境的情况下,容器可以提升自身的访问权限。这甚至可能覆盖之前设置的
user指令,从而使容器获得对系统的 root 权限。缓解措施:添加此行后,攻击者将无法覆盖我们先前设置的
user指令,也无法授予已被攻陷的容器 root 权限。移除容器的默认能力:
cap_drop: - ALL
風險:容器在默认情况下会被授予大量權限。然而,大多數容器並不需要這些權限。額外的存取權限會增加攻擊面,一旦容器被攻破,尤其是當這些能力能夠影響主機內核時,風險將進一步擴大。
**緩解措施**:添加此配置將取消容器預設的寬鬆權限,確保只授予容器完成其功能所需的系統能力。
`cap_drop` 設為 `ALL` 對於需要多種能力的容器來說可能過於激進。在此情況下,在上述配置之後,建議審查以下常見的能力。它們並非全部必要,也不應全部添加——僅作為某些容器可能需要的能力的起點。
```yaml
cap_add:
# 低風險
# 隨意更改檔案的 UID 和 GID(參見 chown(2))
- CHOWN
# 隨意操作程序的 GID 及輔助 GID 列表
- SETGID
# 隨意操作程序的 UID
- SETUID
# 將套接字綁定到 Internet 域的特權端口(端口号小於 1024)
- NET_BIND_SERVICE
# 高風險——可能影響重要的系統級配置
# 執行各種網路相關操作
- NET_ADMIN
# 使用 RAW 和 PACKET 套接字
- NET_RAW
# 執行一系列系統管理操作
- SYS_ADMIN
```
這段配置將首先移除所有能力,然後精準地重新添加容器運作所需的能力。完整的權限清單可參考[這裡](https://docs.docker.com/engine/containers/run/#runtime-privilege-and-linux-capabilities)。
如果容器缺乏必要的能力,將無法正常運行。若不小心移除了某項必需的能力,您可以:
1. 理想的做法是查看上述能力列表,並通過試錯的方式逐步添加所需能力。大型語言模型可以在此過程中提供很大幫助,特別是當它們具備閱讀文件或服務源代碼的能力時。您也可以暫時忽略此指令,待所有配置都完成後再回頭處理。
2. 不太理想的選擇是直接放棄並完全移除 `cap_drop` 指令。雖然不推薦這樣做,但在私有服務中,只要其他安全措施到位,這種做法也未必是最不安全的配置。
防止過度日誌記錄:
logging: driver: "json-file" options: max-file: "10" max-size: "20m"風險:如同 zip 炸彈,日誌炸彈也可能通過遞歸生成大量日誌文件來使系統不堪重負,最終導致系統無法運作。
緩解措施:透過限制日誌文件的最大數量(10個)和單個文件的最大大小(20MB),可以有效遏制此類攻擊。
如遇問題,您可以根據實際情況合理調整這些限制。
限制臨時文件目錄的權限:
tmpfs: - /tmp:rw,noexec,nosuid,nodev,size=512m風險:如果被允許下載文件,已被入侵的容器可能會將惡意文件植入文件系統並執行它。
緩解措施:設置一個權限極為受限的臨時文件區域,可以阻斷這一潛在的攻擊途徑。容器只能在此小型沙盒中下載文件,且文件大小固定、無腳本執行權限。
掛載只讀卷:
volumes: - /path/to/mount1:/mount1:ro - /path/to/mount2:/mount2:ro風險:為了訪問主機的文件系統,Docker 容器需要將目錄以「卷」的形式掛載。這樣容器就能像主機本身一樣讀取和寫入數據。通常並不需要為每個掛載點都開放寫入權限,否則一旦容器被攻破,就可能刪除或覆蓋重要資訊,造成嚴重的網絡攻擊。
緩解措施:盡可能將卷掛載為只讀模式,從而消除容器通過寫入操作破壞這些卷中數據的可能性。這雖然無法阻止間諜軟件的活動,但能有效減少攻擊造成的數據損失。
請將
/path/to/mount1和/path/to/mount2替換為實際的目錄路徑。
[!重要] 對於那些對 CPU 核心和記憶體資源自由分配至關重要的容器——例如 llama-swap——您不應按照步驟 3 中所示的方式限制容器可使用的最大資源量。
以下是一個整合好的片段,可供您複製並貼入現有服務的 Compose 文件中:
services:
<service_name>:
# 1
user: "<your_user_id>:<your_group_id>"
# 2 - 僅在容器不進行寫操作時取消註釋
# read_only: true
# 3
pids_limit: 512
mem_limit: 3g
cpus: 3
# 4
tty: false
stdin_open: false
# 5
security_opt:
- "no-new-privileges=true"
# 6
cap_drop:
- ALL
# 如有需要,請添加 cap_add 部分
# 7
logging:
driver: "json-file"
options:
max-file: "10"
max-size: "20m"
# 8
tmpfs:
- /tmp:rw,noexec,nosuid,nodev,size=512m
# 9
volumes:
- /path/to/mount1:/mount1:ro
- /path/to/mount2:/mount2:ro
有用的命令
在设置这台服务器的过程中(或者在深入服务部署的复杂流程中),你很可能会频繁使用 Docker。对于不熟悉 Docker 的用户,以下是一些有助于更轻松地导航和排查容器问题的命令:
- 查看所有可用或正在运行的容器:
docker ps -a - 重启某个容器:
docker restart <container_name> - 实时查看容器日志:
docker logs -f <container_name>(按CTRL+C退出) - 重命名容器:
docker rename <container_name> <new_container_name> - 有时,一个服务会启动多个容器,例如
xyz-server和xyz-db。要同时重启这两个容器,请从包含 Compose 文件的目录内执行以下命令:docker compose restart - 重新创建服务:
docker compose down && docker compose up -d - 测试容器配置:
docker compose config --quiet - 查看容器的解析后配置:
docker compose config - 列出 Docker 网络:
docker network ls
[!TIP] 在设置 Docker 容器或服务时,并没有固定的规则。不过,我的建议是:
使用 Docker Compose 是最整洁的方式(通过docker-compose.yaml文件运行docker compose up -d,而不是直接使用docker run -d <image_name>)。除非你对家庭实验室及其设置做了详细的记录,否则这种方式几乎可以自动记录并维护清晰的服务运行轨迹,每个目录对应一个 Compose 文件是最常见的做法。
[!TIP] 有时,仅仅重启容器并不能使配置更改生效。如果你发现对服务所做的更改没有生效,在继续其他故障排除之前,可以先尝试完全重建该服务。
HuggingFace CLI
📖 文档
HuggingFace 是领先的开源机器学习/人工智能平台,它托管了模型(包括大型语言模型)、数据集以及可用于测试模型的演示应用。在本指南中,我们将使用 HuggingFace 下载流行的开源大型语言模型。
[!NOTE] 仅适用于 llama.cpp/vLLM。
创建一个新的虚拟环境:
python3 -m venv hf-env source hf-env/bin/activate使用
pip安装huggingface_hub包:pip install -U "huggingface_hub[cli]"在 https://huggingface.com 上创建一个认证令牌。
登录到 HF Hub:
hf auth login按提示输入你的令牌。
运行以下命令以验证登录:
hf auth whoami输出应为你的用户名。
管理模型
模型可以下载到默认位置(.cache/huggingface/hub)或你指定的任何本地目录。可以通过 --local-dir 命令行参数来定义模型存储位置。如果不指定此参数,则模型将被存储在默认位置。将模型存储在推理引擎相关包所在的文件夹中是一种良好的实践——这样,运行模型推理所需的一切都集中在一个地方。然而,如果你经常在多个后端中使用相同的模型(例如,同时用 llama.cpp 和 vLLM 使用 Qwen_QwQ-32B-Q4_K_M.gguf),则要么设置一个通用的模型目录,要么直接使用 HF 的默认选项而不指定该参数。
首先,激活包含 huggingface_hub 的虚拟环境:
source hf-env/bin/activate
下载模型
模型通过其 HuggingFace 标签进行下载。这里我们以 bartowski/Qwen_QwQ-32B-GGUF 为例。要下载模型,请运行:
hf download bartowski/Qwen_QwQ-32B-GGUF Qwen_QwQ-32B-Q4_K_M.gguf --local-dir models
请确保在运行此命令时位于正确的目录中。
删除模型
要删除指定位置的模型,请运行:
rm <model_name>
要删除默认位置的模型,请运行:
hf delete-cache
这将启动一个交互式会话,你可以从中移除 HuggingFace 目录中的模型。如果你一直将模型保存在不同于 .cache/huggingface 的位置,那么从那里删除模型虽然能释放空间,但元数据仍会保留在 HF 缓存中,直到被正确删除。这可以通过上述命令完成,也可以直接删除 .cache/huggingface/hub 中的模型目录。
搜索引擎
[!NOTE] 此步骤是可选的,但强烈推荐用于通过来自权威来源的相关搜索结果为大型语言模型提供上下文信息。通过 MCP 工具调用进行有针对性的网络搜索,可以使 LLM 生成的报告更不容易出现随机幻觉。
SearXNG
为了支持基于搜索的工作流,我们不希望依赖可能监控搜索的搜索引擎提供商。虽然使用任何搜索引擎都存在这个问题,但像 SearXNG 这样的元搜索引擎可以在一定程度上缓解这一问题。SearXNG 会聚合超过 245 个搜索服务的结果,并且不会跟踪或分析用户行为。你可以在互联网上使用托管实例,但考虑到本指南的重点以及搭建过程非常简单,我们将自己在端口 5050 上启动一个实例。
启动容器:
docker pull searxng/searxng export PORT=5050 docker run \ -d -p ${PORT}:8080 \ --name searxng \ --network app-net \ -v "${PWD}/searxng:/etc/searxng" \ -e "BASE_URL=http://0.0.0.0:$PORT/" \ -e "INSTANCE_NAME=searxng" \ --restart unless-stopped \ searxng/searxng编辑
settings.yml以支持 JSON 格式:sudo nano searxng/settings.yml添加以下内容:
search: # ...其他参数... formats: - html - json # 添加这一行使用
docker restart searxng重启容器。
Open WebUI 集成
如果你想要一个简单的网页搜索工作流,并跳过 MCP 服务器或代理型架构的搭建,Open WebUI 原生支持网页搜索功能。前往 管理面板 > 设置 > 网页搜索,并设置以下值:
- 启用
网页搜索 - 网页搜索引擎:
searxng - Searxng 查询 URL:
http://searxng:8080/search?q=<query> - API 密钥:
任意你喜欢的值
推理引擎
推理引擎是此设置的主要组件之一。它是一段代码,能够读取包含权重的模型文件,并从中生成有用的输出。本指南提供了 llama.cpp、vLLM 和 Ollama 三种选择——这些都是流行的推理引擎,各有侧重和优势(注意:Ollama 内部使用 llama.cpp,只是一个 CLI 封装)。对于初学者来说,直接上手 llama.cpp 和 vLLM 的命令行参数可能会有些困难。如果你是高级用户,并且喜欢通过精细控制服务参数来获得灵活性,那么使用 llama.cpp 或 vLLM 将会是非常棒的体验,最终的选择主要取决于你决定使用的量化格式。然而,如果你是新手或还不太熟悉这些工具,Ollama 可以作为一个便捷的过渡方案,帮助你逐步掌握所需技能;或者,如果你觉得当前的知识水平已经足够,它也可以作为你的最终选择!
Ollama
Ollama 将被安装为一个服务,因此会在系统启动时自动运行。
- 从官方仓库下载 Ollama:
curl -fsSL https://ollama.com/install.sh | sh
我们希望 LAN 中的其他设备能够访问到 API 端点。对于 Ollama 而言,这意味着需要在 ollama.service 中设置 OLLAMA_HOST=0.0.0.0。
- 运行以下命令编辑服务配置:
systemctl edit ollama.service - 找到
[Service]部分,在其下添加Environment="OLLAMA_HOST=0.0.0.0"。配置应如下所示:[Service] Environment="OLLAMA_HOST=0.0.0.0" - 保存并退出。
- 重新加载配置:
systemctl daemon-reload systemctl restart ollama
[!TIP] 如果你是手动安装 Ollama,或者没有将其作为服务运行,请记得执行
ollama serve来正确启动服务器。如果遇到问题,可以参考 Ollama 的故障排除步骤。
llama.cpp
克隆 llama.cpp 的 GitHub 仓库:
git clone https://github.com/ggml-org/llama.cpp.git cd llama.cpp构建二进制文件:
CPU
cmake -B build cmake --build build --config ReleaseCUDA
cmake -B build -DGGML_CUDA=ON cmake --build build --config Release对于希望使用 Metal、Vulkan 等底层图形 API 的系统,请参阅完整的 llama.cpp 构建文档,以利用加速推理功能。
vLLM
vLLM 自带一个与 OpenAI 兼容的 API,我们可以像使用 Ollama 一样直接调用。与 Ollama 只能运行 GGUF 模型文件不同,vLLM 原生支持 AWQ、GPTQ、GGUF、BitsAndBytes 以及 safetensors(默认发布格式)。
手动安装(推荐)
创建用于 vLLM 的目录和虚拟环境:
mkdir vllm cd vllm python3 -m venv .venv source .venv/bin/activate使用
pip安装 vLLM:pip install vllm使用所需的参数启动服务。默认端口是 8000,但这里我使用 8556 端口,以免与其他服务冲突:
vllm serve <model> --port 8556若要将其作为服务运行,可将以下内容添加到
init.bash文件中,以便在系统启动时自动运行 vLLM:source .venv/bin/activate vllm serve <model> --port 8556请将
<model>替换为你从 HuggingFace 复制的所需模型标签。
Docker 安装
- 运行以下命令:
docker run --gpus all \ -v ~/.cache/huggingface:/root/.cache/huggingface \ --env "HUGGING_FACE_HUB_TOKEN=<your_hf_hub_token>" \ -p 8556:8000 \ --ipc=host \ vllm/vllm-openai:latest \ --model <model>请将
<your_hf_hub_token>替换为你自己的 HuggingFace Hub 令牌,并将<model>替换为你从 HuggingFace 复制的所需模型标签。
若要运行不同的模型:
首先停止现有容器:
docker ps -a docker stop <vllm_container_ID>如果你希望未来再次运行完全相同的配置,可以跳过此步骤。否则,为了不使 Docker 容器环境变得杂乱,请执行以下命令删除容器:
docker rm <vllm_container_ID>然后使用安装时的 Docker 命令,替换为所需的模型重新运行:
docker run --gpus all \ -v ~/.cache/huggingface:/root/.cache/huggingface \ --env "HUGGING_FACE_HUB_TOKEN=<your_hf_hub_token>" \ -p 8556:8000 \ --ipc=host \ vllm/vllm-openai:latest \ --model <model>
Open WebUI 集成
[!NOTE] 仅适用于 llama.cpp/vLLM。
前往 管理面板 > 设置 > 连接,设置以下值:
- 启用
OpenAI API - API 基础 URL:
http://host.docker.internal:<port>/v1 - API 密钥:
任意值
[!NOTE]
host.docker.internal是一个特殊的主机名,它会解析为 Docker 分配给宿主机的内部 IP 地址。这使得容器能够与运行在宿主机上的服务(如数据库或 Web 服务器)进行通信,而无需知道宿主机的具体 IP 地址。它简化了容器与宿主机服务之间的通信,从而更容易开发和部署应用程序。
Ollama 与 llama.cpp
| 方面 | Ollama(封装层) | llama.cpp(原生实现) |
|---|---|---|
| 安装/配置 | 一键安装及 CLI 模型管理 | 需手动设置和配置 |
| Open WebUI 集成 | 一级支持 | 需配置 OpenAI 兼容的 API 端点 |
| 模型切换 | 服务器端原生支持模型切换 | 需手动管理端口或使用 llama-swap 工具 |
| 可定制性 | 有限:模型文件操作较为繁琐 | 可通过 CLI 完全控制参数 |
| 透明度 | 默认设置可能覆盖模型参数(如上下文长度) | 参数设置完全透明 |
| GGUF 支持 | 继承 llama.cpp 的业界最佳实现 | GGUF 实现最为出色 |
| GPU-CPU 分离 | 继承 llama.cpp 的高效分离机制 | 开箱即用地实现 GPU-CPU 分离 |
vLLM 与 Ollama/llama.cpp
| 特性 | vLLM | Ollama/llama.cpp |
|---|---|---|
| 视觉模型 | 支持 Qwen 2.5 VL、Llama 3.2 Vision 等 | Ollama 支持部分视觉模型,llama.cpp 不支持任何视觉模型(需通过 llama-server) |
| 量化 | 支持 AWQ、GPTQ、BnB 等 | 仅支持 GGUF |
| 多 GPU 推理 | 是 | 是 |
| 张量并行 | 是 | 否 |
综上所述:
- Ollama:最适合追求“开箱即用”体验的用户。
- llama.cpp:最适合希望完全掌控推理服务,并熟悉引擎参数配置的用户。
- vLLM:最适合以下场景的用户:(i) 运行非 GGUF 格式的量化模型;(ii) 使用张量并行进行多 GPU 推理;(iii) 使用视觉模型。
将 Ollama 作为服务运行时,不会导致体验下降,因为未使用的模型会在一段时间后从显存中卸载。而使用 vLLM 或 llama.cpp 作为服务时,模型会一直驻留在内存中,因此除非它们是你的主要推理引擎,否则不建议将其与 Ollama 一起以自动化、持续运行的方式部署。简而言之:
| 主要引擎 | 次要引擎 | 是否将次要引擎作为服务运行? |
|---|---|---|
| Ollama | llama.cpp/vLLM | 否 |
| llama.cpp/vLLM | Ollama | 是 |
模型服务器
[!NOTE] 仅在手动安装 llama.cpp/vLLM 时需要。Ollama 通过其 CLI 自动管理模型加载与卸载。
虽然上述步骤可以帮助你快速搭建一个兼容 OpenAI 的 LLM 服务器,但它们无法保证在关闭终端窗口或重启物理服务器后,该服务仍能持续运行。此外,这些方法也无法让聊天平台可靠地引用和动态切换不同模型——而在实际应用中,不同模型往往擅长处理不同的任务。通过 Docker 运行推理引擎可以借助 -d(detach)标志实现持久化,但 (i) llama.cpp 和 vLLM 通常并未针对 Docker 进行优化;(ii) Docker 无法按需切换模型。因此,我们需要一个专门的服务器来管理模型的加载、卸载、切换以及列出可用模型的功能。
llama-swap
[!TIP] 这是我推荐运行 llama.cpp/vLLM 模型的方式。
llama-swap 是一个轻量级的 LLM 代理服务器,能够解决我们前面提到的问题。它是一个高度可配置的工具,允许通过单一入口访问来自不同后端的模型。模型可以分组设置,轻松地进行上线或下线操作,使用自定义超参数进行配置,并且可以通过 llama-swap 的 Web UI 中的流式日志进行监控。
在下面的安装步骤中,我们将使用 Qwen3-4B-Instruct-2507-UD-Q4_K_XL.gguf 作为 llama.cpp 的模型,而 vLLM 则使用 Qwen/Qwen3-4B-Instruct-2507。我们还将使用 7000 端口来提供这些模型的服务。
创建一个新的目录,并在其中创建
config.yaml文件:sudo mkdir llama-swap cd llama-swap sudo nano config.yaml输入以下内容并保存:
llama.cpp
models: "qwen3-4b": proxy: "http://127.0.0.1:7000" cmd: | /app/llama-server -m /models/Qwen3-4B-Instruct-2507-UD-Q4_K_XL.gguf # 或者使用 `-hf unsloth/Qwen3-4B-Instruct-2507-GGUF:Q4_K_XL` 来从 HuggingFace 加载 --port 7000vLLM(Docker)
models: "qwen3-4b": proxy: "http://127.0.0.1:7000" cmd: | docker run --name qwen-vllm --init --rm -p 7000:8080 --ipc=host \ vllm/vllm-openai:latest -m /models/Qwen/Qwen3-4B-Instruct-2507 cmdStop: docker stop qwen-vllmvLLM(本地)
models: "qwen3-4b": proxy: "http://127.0.0.1:7000" cmd: | source /app/vllm/.venv/bin/activate && \ /app/vllm/.venv/bin/vllm serve \ --port 7000 \ --host 0.0.0.0 \ -m /models/Qwen/Qwen3-4B-Instruct-2507 cmdStop: pkill -f "vllm serve"安装容器:
我们在这里使用
cuda标签,但 llama-swap 也提供了cpu、intel、vulkan和musa等标签。发布版本可以在 这里 找到。llama.cpp
docker run -d --gpus all --restart unless-stopped --network app-net --pull=always --name llama-swap -p 9292:8080 \ -v /path/to/models:/models \ -v /home/<your_username>/llama-swap/config.yaml:/app/config.yaml \ -v /home/<your_username>/llama.cpp/build/bin/llama-server:/app/llama-server \ ghcr.io/mostlygeek/llama-swap:cudavLLM(Docker/本地)
docker run -d --gpus all --restart unless-stopped --network app-net --pull=always --name llama-swap -p 9292:8080 \ -v /path/to/models:/models \ -v /home/<your_username>/vllm:/app/vllm \ -v /home/<your_username>/llama-swap/config.yaml:/app/config.yaml \ ghcr.io/mostlygeek/llama-swap:cuda请将
<your_username>替换为您的实际用户名,将/path/to/models替换为您模型文件所在的路径。
[!NOTE] llama-swap 更倾向于使用基于 Docker 的 vLLM,因为这样环境更加整洁,并且能够更好地响应服务器发送的 SIGTERM 信号。我在这里同时列出了两种方式。
以上步骤应该会启动一个运行在 http://localhost:9292 的 llama-swap 实例,您可以通过运行 curl http://localhost:9292/health 来确认其是否正常工作。强烈建议您阅读 配置文档。llama-swap 文档非常详尽,且高度可配置——充分利用它的功能,您可以根据需要定制一套适合自己的部署方案。
systemd 服务
另一种让模型在系统重启后仍然保持运行的方法是将推理引擎放入一个 .service 文件中,该文件会在 Linux 系统启动时随系统一同运行,从而确保服务器开启时模型始终可用。如果您可以接受无法切换模型或后端的限制,并且只运行一个模型,那么这是一种开销最低的解决方案,效果也非常不错。
让我们将即将创建的服务命名为 llm-server.service。我们假设所有模型都位于 models 子目录中——您可以根据需要进行调整。
创建
systemd服务文件:sudo nano /etc/systemd/system/llm-server.service配置服务文件:
llama.cpp
[Unit] Description=LLM Server Service After=network.target [Service] User=<user> Group=<user> WorkingDirectory=/home/<user>/llama.cpp/build/bin/ ExecStart=/home/<user>/llama.cpp/build/bin/llama-server \ --port <port> \ --host 0.0.0.0 \ -m /home/<user>/llama.cpp/models/<model> \ --no-webui # [其他引擎参数] Restart=always RestartSec=10s [Install] WantedBy=multi-user.targetvLLM
[Unit] Description=LLM Server Service After=network.target [Service] User=<user> Group=<user> WorkingDirectory=/home/<user>/vllm/ ExecStart=/bin/bash -c 'source .venv/bin/activate && vllm serve --port <port> --host 0.0.0.0 -m /home/<user>/vllm/models/<model>' Restart=always RestartSec=10s [Install] WantedBy=multi-user.target请将
<user>,<port>和<model>分别替换为您的 Linux 用户名、期望的服务端口以及所需的模型名称。重新加载
systemd守护进程:sudo systemctl daemon-reload启动服务:
如果
llm-server.service尚未存在:sudo systemctl enable llm-server.service sudo systemctl start llm-server如果
llm-server.service已经存在:sudo systemctl restart llm-server(可选)检查服务状态:
sudo systemctl status llm-server
Open WebUI 集成
llama-swap
导航到 Admin Panel > Settings > Connections,并设置以下值:
- 启用 OpenAI API
- API 基础 URL:
http://llama-swap:8080/v1 - API 密钥:
anything-you-like
systemd 服务
按照上述步骤操作。
- 启用 OpenAI API
- API 基础 URL:
http://localhost:<port>/v1 - API 密钥:
anything-you-like
请将
<port>替换为您的期望端口。
聊天平台
Open WebUI
Open WebUI 是一个用于管理模型和聊天的基于 Web 的界面,提供美观且高性能的用户界面,方便您与模型进行交互。如果您希望通过 Web 界面访问您的模型,那么这就是您需要的操作。如果您习惯使用命令行,或者希望通过插件/扩展来调用模型,则可以跳过此步骤。
若不支持 Nvidia GPU,请运行以下命令进行安装:
docker run -d -p 3000:8080 --network app-net --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
对于配备 Nvidia GPU 的系统,请运行以下命令:
docker run -d -p 3000:8080 --network app-net --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
您可以通过浏览器访问 http://localhost:3000,或在同网络下的其他设备上访问 http://<server_ip>:3000。无需将此内容添加到 init.bash 脚本中,因为 Open WebUI 将通过 Docker 引擎在系统启动时自动运行。
有关 Open WebUI 的更多信息,请参阅 此处。
MCP 代理服务器
模型上下文协议(MCP)是一种以标准化方式将工具(用代码编写的函数或脚本)与大型语言模型连接起来的协议。通常,模型正在被越来越多地训练为能够原生调用工具,从而支持智能体任务——例如,让模型通过序列化思维生成多个想法、执行多次有针对性的网络搜索,并利用实时信息给出响应。对大多数人来说,更重要的是,MCP 还使模型能够调用第三方工具,如 GitHub、Azure 等。Anthropic 维护并整理的完整工具列表可在 此处 查看。
互联网上大多数关于 MCP 的指南都会建议您通过 VS Code、Cline 等客户端启动 MCP 服务器,因为大多数智能体应用场景都与编程或 Anthropic 的专有应用 Claude Desktop 相关,而这与本指南所追求的隐私保护目标并不一致。确实也有一些聊天客户端支持从其 UI 中直接管理 MCP 服务器(如 LobeChat、Cherry Studio 等),但我们希望以集中且模块化的方式管理 MCP 服务器。这样,(i) 它们不会绑定到特定客户端,而是可供您使用的任何客户端调用;(ii) 如果将来您更换聊天平台,您的 MCP 服务器也无需做任何更改,因为它们作为独立的服务运行——虽然初期维护工作稍多,但长期来看灵活性更高。我们可以通过搭建一个 MCP 代理服务器来实现这一点。
该代理服务器会将通过 stdio(标准输入输出)协议运行的 MCP 服务器(只能由同一设备上的应用程序访问)转换为可通过 HTTP 流传输的形式。任何支持 MCP 的客户端都可以使用这种流式 HTTP 接口,因此它们也能使用我们在物理服务器上部署的所有 MCP 服务器。这样一来,您就可以在一个地方集中管理所有的 MCP 服务器:创建、编辑或删除服务器,并在不同的客户端(如 Open WebUI、VS Code 等)中使用它们。
我们将使用 fetch、sequential-thinking 和 searxng 这三个 MCP 服务器作为起点。后续添加更多服务器的过程与此完全相同。
mcp-proxy
🌟 GitHub
mcp-proxy 是一个服务器代理,允许在不同传输协议之间切换(stdio 与可流式传输的 HTTP 互转)。我将使用 3131 端口以避免端口冲突,您也可以根据需要自行更改。此外,我还会对 mcp-proxy 进行扩展,加入 uv 支持:大多数 MCP 服务器要么使用 npx,要么使用 uv,如果不配置 uv,将会影响您运行所需 MCP 服务器的能力。如果您不需要 uv,则 (i) 不需在 compose 文件中添加 build 部分,(ii) 可跳过第 4 步。
创建一个 compose 文件:
mkdir mcp-proxy cd mcp-proxy sudo nano docker-compose.yaml输入以下内容:
services: mcp-proxy: container_name: mcp-proxy build: context: . dockerfile: Dockerfile networks: - app-net volumes: - .:/config - /:/<server_hostname>:ro restart: unless-stopped ports: - 3131:3131 command: "--pass-environment --port=3131 --host 0.0.0.0 --transport streamablehttp --named-server-config /config/servers.json" networks: app-net: external: true请将
<server_hostname>替换为您实际的服务器主机名(或其他名称)。这主要在添加filesystem或类似需要读写文件系统的 MCP 服务器时有用。如果您的目标并非如此,可以跳过此步骤。创建一个
servers.json文件:{ "mcpServers": { "fetch": { "disabled": false, "timeout": 60, "command": "uvx", "args": [ "mcp-server-fetch" ], "transportType": "stdio" }, "sequential-thinking": { "command": "npx", "args": [ "-y", "@modelcontextprotocol/server-sequential-thinking" ] }, "searxng": { "command": "npx", "args": ["-y", "mcp-searxng"], "env": { "SEARXNG_URL": "http://searxng:8080/search?q=<query>" } } } }创建一个
Dockerfile:sudo nano Dockerfile输入以下内容:
FROM ghcr.io/sparfenyuk/mcp-proxy:latest # 安装 nvm 和 Node.js 的依赖 RUN apk add --update npm # 安装 'uv' 包 RUN python3 -m ensurepip && pip install --no-cache-dir uv ENV PATH="/usr/local/bin:/usr/bin:$PATH" \ UV_PYTHON_PREFERENCE=only-system ENTRYPOINT ["catatonit", "--", "mcp-proxy"]使用
docker compose up -d启动容器。
您的 mcp-proxy 容器现在应该已经成功运行!添加服务器非常简单:只需将相关服务器信息添加到 servers.json 文件中(您可以直接使用 MCP 服务器开发者为 VS Code 提供的配置,两者完全一致),然后通过 docker restart mcp-proxy 重启容器即可。
MCPJungle
🌟 GitHub
MCPJungle 是另一款 MCP 代理服务器,但其侧重点有所不同。它更注重提供“生产级”的使用体验,而这些功能在应用程序的开发模式下默认是禁用的。我们将在本教程中使用该容器的标准开发版本,并将其运行在 4141 端口。
创建一个
docker-compose文件:mkdir mcpjungle cd mcpjungle sudo nano docker-compose.yaml输入以下内容并保存:
# MCPJungle Docker Compose 配置文件,适用于个人用户。 # 如果您希望在本地运行 MCPJungle 来管理您的个人 MCP 和网关,请使用此配置文件。 # MCPJungle 服务器以开发模式运行。 services: db: image: postgres:latest container_name: mcpjungle-db environment: POSTGRES_USER: mcpjungle POSTGRES_PASSWORD: mcpjungle POSTGRES_DB: mcpjungle ports: - "5432:5432" networks: - app-net volumes: - db_data:/var/lib/postgresql/data healthcheck: test: ["CMD-SHELL", "PGPASSWORD=mcpjungle pg_isready -U mcpjungle"] interval: 10s timeout: 5s retries: 5 restart: unless-stopped mcpjungle: image: mcpjungle/mcpjungle:${MCPJUNGLE_IMAGE_TAG:-latest-stdio} container_name: mcpjungle-server environment: DATABASE_URL: postgres://mcpjungle:mcpjungle@db:5432/mcpjungle SERVER_MODE: ${SERVER_MODE:-development} OTEL_ENABLED: ${OTEL_ENABLED:-false} ports: - "4141:8080" networks: - app-net volumes: # 将主机文件系统的当前目录挂载进来,以便 MCP 服务器可以访问文件系统 - .:/host/project:ro - /home/<your_username>:/host:ro # 其他选项: # - ${HOME}:/host/home:ro # - /tmp:/host/tmp:rw depends_on: db: condition: service_healthy restart: always volumes: db_data: networks: app-net: external: true使用
docker compose up -d启动容器。创建一个工具文件:
sudo nano fetch.json输入以下内容并保存:
{ "name": "fetch", "transport": "stdio", "command": "npx", "args": ["mcp-server-fetch"] }注册工具:
docker exec -i mcpjungle-server /mcpjungle register -c /host/project/fetch.json
对每个提到的工具重复步骤 3 和 4。sequential-thinking 和 searxng 的命令如下所示。
sequential-thinking
{
"name": "sequential-thinking",
"transport": "stdio",
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-sequential-thinking"]
}
searxng
{
"name": "searxng",
"transport": "stdio",
"command": "npx",
"args": ["-y", "mcp-searxng"],
"env": {
"SEARXNG_URL": "http://searxng:8080/search?q=<query>"
}
}
对比
选择哪项服务完全取决于您:我使用 mcp-proxy,是因为我觉得它的工作流程比 MCPJungle 稍微简单一些。以下是两者的对比及其各自的优势。
mcp-proxy > MCPJungle
- 服务器只需添加到
servers.json文件中,容器重启时会自动注册——而 MCPJungle 则需要通过 CLI 手动注册工具。 - 使用大多数客户端都能接受的标准 MCP 语法进行配置。
- 占用资源更少,因为它不需要单独启动数据库容器。
- 使用有状态连接——而 MCPJungle 每次调用工具时都会建立一个新的连接,这可能会导致一定的性能开销。
MCPJungle > mcp-proxy
- 将所有工具整合到一个端点下,非常便于集成到聊天前端。
- 能够通过工具组、访问控制以及选择性启用/禁用工具来创建高度可配置的设置。
- 支持遥测等企业级功能。
Open WebUI 集成
Open WebUI 最近增加了对流式 HTTP 的支持——过去您可能需要使用 mcpo,即 Open WebUI 自动生成的兼容 OpenAPI 的 HTTP 服务器,而现在您可以直接使用已搭建好的 MCP 服务器,无需任何修改。
mcp-proxy
导航至 Admin Panel > Settings > External Tools。点击 + 按钮添加新工具,并输入以下信息:
- URL:
http://mcp-proxy:<port>/servers/<tool_name>/mcp - API 密钥:
任意值 - ID:
<tool_name> - 名称:
<tool_name>
将
<port>替换为 MCP 服务的端口号,将<tool_name>替换为您要添加的具体工具名称。
MCPJungle
按照上述步骤操作。由于 MCPJungle 的设计是将所有工具暴露在一个端点下,因此您只需添加一次即可:
- URL:
http://mcpjungle-server:8080/mcp - API 密钥:
任意值 - ID:
<tool_name> - 名称:
<tool_name>
[!IMPORTANT] 在 Open WebUI 中配置模型(通过
Admin Panel > Settings > Models > my-cool-model > Advanced Params)时,需将Function Calling参数从Default更改为Native。这一步将使模型能够使用多个工具调用来生成单个响应,而不仅仅是一个工具调用。
VS Code/Claude Desktop 集成
将您的 MCP 代理服务器集成到其他客户端(如 VS Code、Claude Desktop、Zed 等)中的步骤类似,甚至完全相同。
在您的 mcp.json 文件中添加以下键值对:
"your-mcp-proxy-name": {
"timeout": 60,
"type": "stdio",
"command": "npx",
"args": [
"mcp-remote",
"http://<your-server-url>/mcp",
"--allow-http"
]
}
文本转语音服务器
Kokoro FastAPI
🌟 GitHub
Kokoro FastAPI 是一款文本转语音服务器,它封装了 Kokoro-82M 模型,并提供了与 OpenAI 兼容的 API 推理接口。这款模型属于最先进的 TTS 模型之一。该项目的文档非常出色,几乎涵盖了该项目的全部使用场景。
要安装 Kokoro FastAPI,请执行以下命令:
git clone https://github.com/remsky/Kokoro-FastAPI.git
cd Kokoro-FastAPI
docker compose up --build
该服务器有两种使用方式:API 和 UI。默认情况下,API 在 8880 端口提供服务,UI 则在 7860 端口提供服务。
Open WebUI 集成
前往 管理面板 > 设置 > 音频,并设置以下值:
- 文本转语音引擎:
OpenAI - API 基础 URL:
http://host.docker.internal:8880/v1 - API 密钥:
anything-you-like - 设置模型:
kokoro - 响应拆分:无(这一点至关重要——Kokoro 使用一种新颖的音频拆分系统)
该服务器可以通过两种方式使用:API 和 UI。默认情况下,API 在 8880 端口提供服务,UI 在 7860 端口提供服务。
图像生成服务器
ComfyUI
ComfyUI 是一款流行的开源基于图的工具,用于使用图像生成模型(如 Stable Diffusion XL、Stable Diffusion 3 和 Flux 系列模型)生成图像。
克隆并进入仓库:
git clone https://github.com/comfyanonymous/ComfyUI cd ComfyUI设置一个新的虚拟环境:
python3 -m venv comfyui-env source comfyui-env/bin/activate下载平台特定的依赖项:
Nvidia 显卡
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121AMD 显卡
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.0Intel 显卡
请阅读 ComfyUI 的 GitHub 页面上的安装说明:ComfyUI 安装指南。
下载通用依赖项:
pip install -r requirements.txt
现在,我们需要下载并加载一个模型。这里我们将使用 Black Forest Labs 推出的新一代中端模型 FLUX.1 [dev],它非常适合 RTX 3090 24GB 显存的显卡。为了尽可能简化设置,我们将使用可以直接加载到 ComfyUI 中的完整检查点。如果需要完全自定义的工作流,也可以分别下载 CLIP、VAE 和模型。请按照 ComfyUI 创作者提供的此指南,以完全自定义的方式安装 FLUX.1 模型。
[!注意] FLUX.1 [schnell] HuggingFace(较小,适合 <24GB 显存)
FLUX.1 [dev] HuggingFace(较大,适合 24GB 显存)
将您所需的模型下载到
/models/checkpoints目录中。如果您希望 ComfyUI 在启动时自动运行并作为服务有效运行,请将以下行添加到
init.bash文件中:cd /path/to/comfyui source comfyui/bin/activate python main.py --listen请将
/path/to/comfyui替换为init.bash文件的正确相对路径。否则,如果您只想运行一次,只需在终端窗口中执行上述命令即可。
Open WebUI 集成
前往 管理面板 > 设置 > 图像,并设置以下值:
- 图像生成引擎:
ComfyUI - API 基础 URL:
http://localhost:8188
[!提示] 要在 Open WebUI 中使用 FLUX.1 [dev],您要么需要超过 24GB 的显存,要么主要在 CPU 上使用小型语言模型。然而,FLUX.1 [schnell] 和小型语言模型应该可以很好地适应 24GB 显存,如果您打算经常同时使用文本和图像生成功能,这将带来更快的体验。
SSH
启用 SSH 可让您远程连接到服务器。配置好 SSH 后,您可以使用 PuTTY 或终端等 SSH 客户端,从同一网络中的其他设备连接到服务器。这样,在完成初始设置后,您就可以无需显示器、键盘或鼠标地以无头模式运行您的服务器。
在服务器上:
- 运行以下命令:
sudo apt install openssh-server - 启动 SSH 服务:
sudo systemctl start ssh - 设置 SSH 服务在开机时自动启动:
sudo systemctl enable ssh - 查找服务器的 IP 地址:
ip a
在客户端上:
- 使用 SSH 连接到服务器:
ssh <username>@<ip_address>请将
<username>替换为您的用户名,<ip_address>替换为服务器的 IP 地址。
[!注意] 如果您预计会频繁通过隧道访问您的服务器,强烈建议您遵循此指南,使用
ssh-keygen和ssh-copy-id启用无密码 SSH。尽管该指南是为 Raspberry Pi OS 编写的,但它在我使用的 Debian 系统上同样完美运行。
防火墙
设置防火墙对于保护您的服务器至关重要。Uncomplicated Firewall (UFW) 是一款简单易用的 Linux 防火墙。您可以使用 UFW 允许或拒绝进出您服务器的流量。
安装 UFW:
sudo apt install ufw允许 SSH、HTTPS 和 HTTP 流量进入本地网络:
# 允许 <ip_range> 范围内的所有主机访问 <port> 端口 sudo ufw allow from <ip_range> to any port <port> proto tcp首先运行上述命令,为我们的本地网络开放 22(SSH)、80(HTTP)和 443(HTTPS)端口。由于我们使用
app-netDocker 网络来运行容器,因此无需再开放其他端口。请谨慎开放端口,最好仅对特定 IP 或本地网络开放。如果要为特定 IP 开放端口,只需将 IP 范围替换为单个 IP,效果将完全相同。
[!提示] 您可以通过运行
ip route show来查找本地网络的 IP 地址范围。结果可能如下所示:me@my-cool-server:~$ ip route show 默认网关 via <router_ip> dev enp3s0 proto dhcp src <server_ip> metric 100 <network_ip_range> dev enp3s0 proto kernel scope link src <server_ip> metric 100 # 更多路由
启用 UFW:
sudo ufw enable检查 UFW 状态:
sudo ufw status verbose
[!警告] 如果在未允许 22 端口访问的情况下启用 UFW,将会中断您现有的 SSH 连接。如果您采用无头设置,这意味着需要将显示器连接到服务器,然后再通过 UFW 允许 SSH 访问。在更改 UFW 配置时,请务必确保已允许该端口访问。
有关设置 UFW 的更多信息,请参阅此指南。
远程访问
远程访问是指在家庭网络之外访问您的服务器的能力。例如,当您离开家时,将无法再通过 http://<your_server_ip> 访问服务器,因为您的网络环境已从家庭网络切换到了其他网络(可能是移动运营商的网络,也可能是其他地方的本地网络)。这意味着您将无法访问服务器上运行的服务。网络上有许多解决方案可以解决这一问题,我们将在下面探讨其中一些易于使用的方案。
Tailscale
Tailscale 是一种点对点 VPN 服务,它将多种功能整合到一个平台中。最常见的用例是将各种不同类型的设备(Windows、Linux、macOS、iOS、Android 等)连接到同一个虚拟网络。这样一来,这些设备虽然连接在不同的物理网络上,但仍能像处于同一局域网内一样相互通信。Tailscale 并非完全开源(其图形界面为专有),但它基于 Wireguard VPN 协议,而服务的核心部分则是开源的。关于该服务的全面文档可以在 这里 找到,其中涵盖了此处未提及的诸多主题——建议仔细阅读以充分利用该服务。
在 Tailscale 中,网络被称为 tailnet。创建和管理 tailnet 需要先注册一个 Tailscale 账户(这是 VPN 服务的常见要求),但实际的连接是点对点的,无需经过 Tailscale 的任何服务器中转。由于这种连接基于 Wireguard 协议,因此您的所有流量都会被 100% 加密,只有 tailnet 上的设备才能解密并查看这些数据。
安装
首先,通过 Tailscale 的管理控制台创建一个 tailnet。然后,在您希望接入该 tailnet 的任何客户端设备上下载 Tailscale 应用程序。对于 Windows、macOS、iOS 和 Android,您可以在各自的操作系统的应用商店中找到相应的应用程序。登录后,您的设备就会被添加到该 tailnet 中。
对于 Linux,安装步骤如下:
安装 Tailscale
curl -fsSL https://tailscale.com/install.sh | sh启动服务
sudo tailscale up
如果需要使用 SSH,可以运行 sudo tailscale up --ssh。
出口节点
出口节点允许您在保持在 tailnet 内的同时访问其他网络。例如,您可以使用此功能让网络中的某台服务器充当其他设备的隧道。这样,您不仅可以访问这台设备(因为它们都在同一个 tailnet 中),还可以访问该服务器所在主机网络上的所有设备。这对于访问网络中非 Tailscale 设备非常有用。
要将某台设备设置为出口节点,可以运行 sudo tailscale up --advertise-exit-node。若要允许通过该设备访问本地网络,则需添加 --exit-node-allow-lan-access 标志。
本地 DNS
如果您 tailnet 中的某台设备运行着类似 Pi-hole 的 DNS 污点池 服务,您可能希望其他设备也将其作为自己的 DNS 服务器。假设这台设备名为 poplar,那么 tailnet 中的所有设备发出的网络请求都会被发送到 poplar,由它根据 Pi-hole 的配置决定是否响应或拒绝该请求。然而,由于 poplar 本身也是 tailnet 中的一台设备,它会按照这条规则将网络请求发送给自己,而不是发送到能够真正解析请求的服务器。因此,我们不希望这些设备接受 tailnet 的 DNS 设置,而是继续遵循它们原本配置的规则。
要拒绝 tailnet 的 DNS 设置,可以运行 sudo tailscale up --accept-dns=false。
第三方 VPN 集成
Tailscale 提供与 Mullvad VPN 配合使用的出口节点插件。该插件可以让您体验传统的 VPN 服务,将您的请求路由到位于其他地区的代理服务器,从而有效隐藏您的 IP 地址,并绕过网站服务的地理限制。您可以通过管理控制台为指定设备配置此功能。Mullvad VPN 已经 证明了其无日志政策,并且无论您选择支付多长时间的费用,每月只需固定支付 5 美元。
要在您的某台设备上使用 Mullvad 出口节点,首先通过运行 sudo tailscale exit-node list 查找出您想要使用的出口节点,记下其 IP 地址,然后运行 sudo tailscale up --exit-node=<your_chosen_exit_node_ip>。
[!WARNING]
请确保已在管理控制台中允许该设备使用 Mullvad 插件。
更新
定期更新系统有助于保持软件的最佳运行状态,并及时应用最新的安全补丁。Ollama 的更新可以支持新的模型架构推理,而 Open WebUI 的更新则带来了语音通话、函数调用、流水线等新功能。
我将这些“核心功能”组件的更新步骤单独整理成一节,因为这样更便于查阅,而不必在多个子章节中寻找更新说明。
一般步骤
通过以下命令升级 Debian 软件包:
sudo apt update
sudo apt upgrade
Nvidia 驱动与 CUDA
请按照 Nvidia 的官方指南 这里 安装最新的 CUDA 驱动程序。
[!WARNING]
请勿跳过此步骤。在升级 Debian 软件包后未安装最新驱动程序会导致系统各组件不同步,进而引发功能故障。更新时应一次性完成所有重要组件的升级。此外,完成此步骤后重启系统是个好习惯,以确保在更新关键驱动程序后系统能够正常运行。
Ollama
重新运行安装 Ollama 的命令即可完成更新:
curl -fsSL https://ollama.com/install.sh | sh
llama.cpp
进入 llama.cpp 目录并执行以下命令:
cd llama.cpp
git pull
# 根据您的配置重新编译——如需 CUDA 支持,请取消注释 `-DGGML_CUDA=ON`
cmake -B build # -DGGML_CUDA=ON
cmake --build build --config Release
vLLM
如果是手动安装,请进入您的虚拟环境并通过 pip 更新:
source vllm/.venv/bin/activate
pip install vllm --upgrade
如果是 Docker 安装,只需重新运行 Docker 命令即可,因为 Docker 会自动拉取 vLLM 的最新镜像。
llama-swap
首先停止并删除当前容器:
docker stop llama-swap
docker rm llama-swap
然后按照 llama-swap 章节 中的说明重新运行容器命令。
Open WebUI
要一次性更新 Open WebUI,运行以下命令:
docker run --rm --volume /var/run/docker.sock:/var/run/docker.sock containrrr/watchtower --run-once open-webui
若希望自动保持更新,运行以下命令:
docker run -d --name watchtower --volume /var/run/docker.sock:/var/run/docker.sock containrrr/watchtower open-webui
mcp-proxy/MCPJungle
进入相应目录并拉取最新容器镜像:
cd mcp-proxy # 或 mcpjungle
docker compose down
docker compose pull
docker compose up -d
Kokoro FastAPI
进入相应目录并拉取最新容器镜像:
cd Kokoro-FastAPI
docker compose pull
docker compose up -d
ComfyUI
进入目录,拉取最新更改并更新依赖:
cd ComfyUI
git pull
source comfyui-env/bin/activate
pip install -r requirements.txt
故障排除
Docker
- 由于我们希望使用普通用户而非 root 用户来运行服务,当尝试挂载并非由当前用户拥有的卷时,可能会遇到权限问题。解决方法有以下两种:
更改目录的所有权:
sudo chown -R $(id -u):$(id -g) /path/to/volume使用访问控制列表(ACL)为当前用户授予权限:
# 授予特定用户的读写权限 sudo setfacl -R -m u:$(id -u):rw /path/to/volume # 授予组的读写权限 sudo setfacl -R -m g:$(id -g):rw /path/to/volume如果系统未安装
acl包,请先运行sudo apt update && sudo apt install acl进行安装。官方包页面可在 这里 查阅。请将
/path/to/volume替换为实际路径。我更倾向于使用 ACL,因为它能在不必要地更改所有权的情况下干净地解决问题,且根据我的经验,出错的概率更低。不过,如果资源明确应归特定用户所有,则出于职责分离的原则,建议直接更改所有权。具体选择可根据实际情况决定,两者都是可行的方案。但请注意,不要在容器已运行时随意更改权限。
ssh
- 如果在使用
ssh-copy-id设置无密码 SSH 时遇到问题,可在执行ssh-copy-id前先在客户端运行ssh-keygen -t rsa。这会生成ssh-copy-id所需的 RSA 密钥对,并将其复制到服务器。
Nvidia 驱动程序
如果 Nvidia 驱动程序无法正常工作,可尝试在 BIOS 中禁用安全启动。我曾遇到所有软件包均为最新版本、
nvidia-detect能正确识别 GPU,但nvidia-smi却一直报错“NVIDIA-SMI 已失败,因为它无法与 NVIDIA 驱动程序通信”。最终通过禁用安全启动解决了该问题。更好的做法是自行签名 Nvidia 驱动程序,但考虑到这台服务器并不关键,且可以承受安全启动被禁用的情况,因此选择了后者。如果出现
docker: Error response from daemon: unknown or invalid runtime name: nvidia.错误,很可能是在 Docker 命令中使用了--runtime nvidia参数。此参数适用于现已弃用的nvidia-docker(详情见 这里)。移除该参数即可解决此问题。
Ollama
如果收到
could not connect to ollama app, is it running?错误,说明 Ollama 实例未能正确启动。这可能是由于手动安装或希望按需运行而非作为服务所致。要一次性启动 Ollama 服务器,运行:ollama serve然后,在另一个终端中,您应该能够通过以下命令正常使用模型:
ollama run <model>如需详细了解如何手动配置 Ollama 以作为服务(即开机自启动),请参阅官方文档 此处。除非您的系统受到限制而无法使用 Ollama 的自动安装程序,否则通常无需进行此类操作。
如果在运行
systemctl edit ollama.service后收到Failed to open "/etc/systemd/system/ollama.service.d/.#override.confb927ee3c846beff8": Permission denied错误,只需创建该文件即可消除问题。具体步骤如下:- 运行:
sudo mkdir -p /etc/systemd/system/ollama.service.d sudo nano /etc/systemd/system/ollama.service.d/override.conf - 再次尝试后续步骤。
- 运行:
如果仍然无法连接到 API 端点,请检查防火墙设置。Debian 上 UFW(Uncomplicated Firewall)指南是一个不错的参考资源。
vLLM
- 如果遇到
RuntimeError: An error occurred while downloading using `hf_transfer`. Consider disabling HF_HUB_ENABLE_HF_TRANSFER for better error handling.错误,可在 HuggingFace Hub 令牌后的--env标志中添加HF_HUB_ENABLE_HF_TRANSFER=0。若仍无法解决问题:- 确保当前用户拥有 HuggingFace 写入缓存所需的全部权限。要为当前用户(以及
huggingface-cli)授予对 HF 缓存的读写权限,运行:sudo chmod 777 ~/.cache/huggingface sudo chmod 777 ~/.cache/huggingface/hub - 手动通过 HuggingFace CLI 下载模型,并在引擎参数中指定
--download-dir=~/.cache/huggingface/hub。如果.cache/huggingface目录存在问题,可在引擎参数中指定其他下载目录,并确保在所有huggingface-cli命令中同时使用--local-dir标志。
- 确保当前用户拥有 HuggingFace 写入缓存所需的全部权限。要为当前用户(以及
Open WebUI
- 如果遇到
Ollama: llama runner process has terminated: signal: killed错误,需检查设置 > 常规 > 高级参数中的相关设置。对我而言,将上下文长度设置得过高以至于某些模型无法处理,会导致 Ollama 服务器崩溃。请将其恢复为默认值(或适当提高,但务必确保不超过所用模型的限制),即可解决此问题。
监控
要监控 GPU 使用率、功耗和温度,可以使用 nvidia-smi 命令。要监控 GPU 使用情况,运行:
watch -n 1 nvidia-smi
此命令会每秒更新一次 GPU 使用情况,且不会使终端界面过于杂乱。按 Ctrl+C 可退出。
备注
这是我首次搭建服务器并接触 Linux,因此部分步骤可能存在更优解。随着学习的深入,我会持续更新本仓库。
软件
- 我选择了 Debian,因为它据称是最稳定的 Linux 发行版之一。同时,我也选择了 XFCE 桌面环境,因为它轻量级,而我当时还不太习惯完全使用命令行。
- 使用普通用户进行自动登录,除非有特殊原因,否则不要以 root 用户登录。
- 如果需要在不切换用户的前提下切换到 root 用户,可以在命令行中运行
sudo -i。 - 如果某个使用 Docker 容器的服务无法正常工作,可以尝试运行
docker ps -a查看容器是否正在运行。如果未运行,再尝试执行docker compose up -d。如果容器正在运行但仍然有问题,可以尝试运行docker restart <container_id>来重启容器。 - 如果无论怎么操作都无法解决问题,可以尝试重启服务器。这通常是解决许多问题的常见方法。在花费数小时排查之前,不妨先试试这个办法。唉。
- 虽然需要一些时间来熟悉,但与 Ollama 相比,使用 llama.cpp 和 vLLM 等推理引擎,确实能够最大限度地发挥硬件性能。如果你正在阅读本指南,并且还没有选择直接使用云服务提供商,那么可以合理推断你更倾向于将所有内容本地化部署。因此,通过优化服务器配置,尽量让本地体验接近云服务提供商的效果。
硬件
- 在默认设置下,我的 EVGA FTW3 Ultra RTX 3090 显卡功耗为 350W。我将其功耗上限设置为 250W,对于我的使用场景(主要是 VS Code 中的代码补全和聊天问答)来说,性能下降几乎可以忽略不计。
- 使用功率监测仪,我对服务器的功耗进行了多日测量——平均运行功耗约为 60W。在处理提示和生成 token 时,功耗会短暂飙升至 350W,但这种情况只会持续几秒钟。在其余生成时间内,功耗通常维持在 250W 的限制水平,而在模型停止使用约 20 秒后,功耗又会回落到平均值。
- 确保电源供应有足够的余量来应对瞬时峰值(尤其是在多 GPU 配置中),否则可能会出现随机关机的情况。显卡的实际功耗可能会超过其额定值,甚至突破你为其设置的软件限值。我通常会按照系统总功耗估算值的 150% 来选择电源。
参考资料
将用户添加到 sudo 组:
下载 Nvidia 驱动程序:
- https://developer.nvidia.com/cuda-downloads?target_os=Linux&target_arch=x86_64&Distribution=Debian
- https://wiki.debian.org/NvidiaGraphicsDrivers
下载 AMD 驱动程序:
安全启动:
监控 GPU 使用情况和功耗:
无密码 sudo:
- https://stackoverflow.com/questions/25215604/use-sudo-without-password-inside-a-script
- https://www.reddit.com/r/Fedora/comments/11lh9nn/set_nvidia_gpu_power_and_temp_limit_on_boot/
- https://askubuntu.com/questions/100051/why-is-sudoers-nopasswd-option-not-working
自动登录:
- https://forums.debian.net/viewtopic.php?t=149849
- https://wiki.archlinux.org/title/LightDM#Enabling_autologin
将 Ollama 对外暴露到局域网:
- https://github.com/ollama/ollama/blob/main/docs/faq.md#setting-environment-variables-on-linux
- https://github.com/ollama/ollama/issues/703
防火墙:
无密码 ssh:
将 CUDA 添加到 PATH:
文档:
致谢
向开源社区的所有杰出贡献者致以诚挚的敬意。如果没有这些项目及参考指南的众多贡献者们的努力,本指南便不会存在。若想及时了解机器学习、大语言模型以及其他视觉/语音模型领域的最新进展,请关注 r/LocalLLaMA。如果你想进一步探索或深入研究适合新服务器的自托管应用,不妨访问 r/selfhosted。
[!NOTE] 如果你发现某些项目非常有用,请为它们点个赞;如果你有能力,也可以考虑为它们做出贡献。如果你觉得本指南对你有所帮助,也欢迎为它点个赞,这样可以帮助更多人找到它。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备