tessera
TESSERA 是一款由剑桥大学研发的开源基础模型,专为处理时间序列卫星影像而设计。它能够将全球范围内 10 米分辨率的地球观测数据,压缩为包含丰富时空信息的 128 维特征表示,广泛应用于土地分类、树冠高度预测、栖息地映射及碳核算等领域。
面对卫星数据体量巨大、常受云层遮挡且标注样本稀缺的挑战,TESSERA 提供了一种高效的解决方案。其核心创新在于利用“巴洛孪生(Barlow Twins)”自监督学习技术,强制对齐同一地点不同时间的无云样本,从而生成能完整代表整个时间序列(包括缺失观测)的嵌入向量。这种方法不仅有效克服了云污染干扰,还保留了传统方法容易丢失的季节性物候信号,让研究人员能更敏锐地捕捉生态系统动态和环境变化。
TESSERA 特别适合遥感领域的研究人员、数据科学家及开发者使用。它不仅支持直接调用预计算好的全球年度特征数据,大幅降低计算门槛,还提供开源代码供用户自定义训练和扩展。作为目前首个兼具开放性、全球覆盖能力与分析就绪特性的基础模型,TESSERA 在保持数据主权的同时,显著提升了从海量卫星数据中提取有价值洞察的效率与准确度。
使用场景
某省级农业监测中心正试图利用卫星时间序列数据,对全省冬小麦种植区进行精准的物候期识别与产量预估。
没有 tessera 时
- 数据清洗耗时巨大:面对海量且常被云层遮挡的卫星影像,团队需花费数周编写复杂算法去云插值,仍难以还原完整的作物生长曲线。
- 标注样本严重匮乏:训练高精度模型依赖大量人工标注的历史地块数据,但现有带标签数据集稀缺,导致模型泛化能力差,无法覆盖全省多样地貌。
- 计算资源不堪重负:处理 PB 级的时序遥感数据需要昂贵的 GPU 集群支持,常规方法难以在有限算力下完成全域 10 米分辨率的特征提取。
- 关键物候信号丢失:传统静态图像分析或简单平均法往往抹平了作物随季节变化的细微光谱特征,导致无法精准判断拔节、抽穗等关键农时。
使用 tessera 后
- 自动修复时序缺失:tessera 基于自监督学习,能直接从含云的原生时间序列中提取特征,无需繁琐的去云预处理即可生成包含完整生长周期的嵌入向量。
- 小样本实现高精度:借助其预训练的 128 维全局基础模型,团队仅需少量本地标注数据微调,即可在下游任务中达到甚至超越专用模型的分类精度。
- 开箱即用的全球覆盖:直接调用 tessera 生成的分析就绪型嵌入数据,瞬间完成全省 10 米分辨率的特征映射,将原本数月的计算工程缩短至小时级。
- 保留动态生态指纹:tessera 独特地保留了像素级的时间物候信号,使系统能敏锐捕捉作物生长的细微变化,显著提升了产量预测与灾害预警的准确性。
tessera 通过让机器“看懂”卫星影像的时间维度,将原本高门槛的地球观测数据分析变成了高效、低成本的标准化流程。
运行环境要求
- Linux
- Windows (通过 WSL)
- 非严格必需,但推荐使用以加速推理
- 测试环境使用单张 NVIDIA A30 GPU
推荐 128GB

快速开始
用于地球表征与分析的表面光谱时序嵌入(TESSERA)[CVPR2026]


![]()
目录
- 了解TESSERA
- 使用TESSERA
- 其他信息
了解TESSERA
简介
卫星遥感技术支持广泛的下游应用,包括生境制图、碳核算以及保护和可持续土地利用策略等。然而,卫星时间序列数据量庞大且常受云层干扰,这使得其使用颇具挑战:科学界提取可操作见解的能力往往受限于标注训练数据的稀缺性以及处理时序数据所需的巨大计算开销。我们工作的关键洞见——归功于克莱门特·阿茨贝格博士——在于,通过使用Barlow Twins算法强制对来自卫星时间序列的两组无云随机样本所提取的自编码器嵌入进行对齐,最终得到的嵌入能够代表整个时间序列,包括缺失的观测数据。
这一理念正是TESSERA的核心:它是一个开放的基础模型,在全球范围内以10米分辨率将每个像素的光谱—时序信号保存为128维潜在表示。该模型采用自监督学习方法,对数PB级的地球观测数据进行摘要化处理。我们在五个不同的下游任务中将我们的工作与最先进的特定任务模型及其他基础模型进行了比较,结果表明TESSERA的表现接近或优于这些基准模型。通过保留传统方法通常会丢失的时序物候信号,TESSERA为生态系统动态、农业粮食系统以及环境变化检测提供了新的洞见。此外,我们的开源实现支持结果的可重复性和扩展性,而隐私保护的设计则使研究人员能够保持数据主权。
据我们所知,TESSERA在易用性、规模和准确性方面均属空前:目前尚无其他基础模型能够仅基于像素级别的光谱—时序特征,就提供分析就绪的输出、完全开放,并实现全球范围内的年度覆盖,且分辨率为10米。
以下是TESSERA表征地图的一些可视化结果(使用前三个通道作为RGB):

论文
以下是与TESSERA相关的出版物和预印本,按时间顺序排列:
Lisaius, M. C., Blake, A., Keshav, S., & Atzberger, C. (2024). 利用Barlow Twins从云层干扰的遥感时间序列中创建表征。IEEE应用地球观测与遥感专题期刊,17卷,第13162–13168页。IEEE应用地球观测与遥感专题期刊。https://doi.org/10.1109/JSTARS.2024.3426044
Z. Feng, C. Atzberger, S. Jaffer, J. Knezevic, S. Sormunen, R. Young, M.C. Lisaius, M. Immitzer, T. Jackson, J. Ball, D.A. Coomes, A. Madhavapeddy, A. Blake, S. Keshav (2025), TESSERA:用于地球表征与分析的表面光谱时序嵌入,即将发表于CVPR 2026。ArXiv预印本。https://arxiv.org/abs/2506.20380
Lisaius, M. C., Blake, A., Atzberger, C., & Keshav, S. (2026). 向更完善的作物类型分类迈进:一种适用于小田块的紧凑嵌入方法。已被2026年ISPRS会议论文集接受。国际摄影测量与遥感学会。
Z. Feng, C. Atzberger, S. Jaffer, J. Knezevic, S. Sormunen, R. Young, M.C. Lisaius, M. Immitzer, T. Jackson, J. Ball, D.A. Coomes, A. Madhavapeddy, A. Blake, S. Keshav, (2026) TESSERA地理空间基础模型在多样化环境制图任务中的应用,SSRN预印本。http://ssrn.com/abstract=6142416
Young, R., & Keshav, S. (2026). 基于校准不确定度量化对GEDI生物量估算值的插值,ArXiv预印本。https://doi.org/10.48550/ArXiv.2601.16834
Lisaius, M. C., Keshav, S., Blake, A., & Atzberger, C. (2026). 基于嵌入的塞内加尔花生种植区作物类型分类(ArXiv:2601.16900)。ArXiv预印本。https://doi.org/10.48550/arXiv.2601.16900
Ball, J.G.C, Wicklein J.A. , Feng, Z., Knezevic, J., Jaffer, S., Atzberger, C., Dalponte, M., and Coomes, D. 地理空间基础模型助力温带山地森林中的数据高效树种制图,BioArxiv,https://doi.org/10.64898/2026.02.23.707022
演示文稿
- TESSERA 在“AI 为善”研讨会上的概述,Frank Feng,2026年1月22日
- TESSERA:用于地球表征与分析的预计算 FAIR 全球像素嵌入 IEEE GRSS 讲座,Frank Feng,2025年12月12日
- 2页摘要(PPTX) 用于 CRI 快闪演讲,S. Keshav,2025年10月7日
- 基础模型概述(PPTX),剑桥大学生态学小组会议,DAB,James Ball,2025年10月6日
- TESSERA 概述演示文稿,重点介绍生态应用(PDF),马里兰大学,Frank Feng,2025年10月1日
- TESSERA 概述演示文稿(PPTX),詹姆斯库克大学,S. Keshav,2025年9月29日
- TESSERA 概述演示文稿,剑桥大学,DAB,Frank Feng,2025年5月20日
- 面向地球观测的自监督学习(PPTX),S. Keshav,埃克塞特,2025年4月
许可证
TESSERA 软件采用标准的 MIT 许可证发布。嵌入和模型权重则采用 CC0 许可证发布:本质上,它们可以自由地用于商业和非商业目的。尽管我们法律上并不要求署名,但我们仍希望得到署名。
使用 TESSERA
使用 GeoTessera 访问嵌入(推荐)
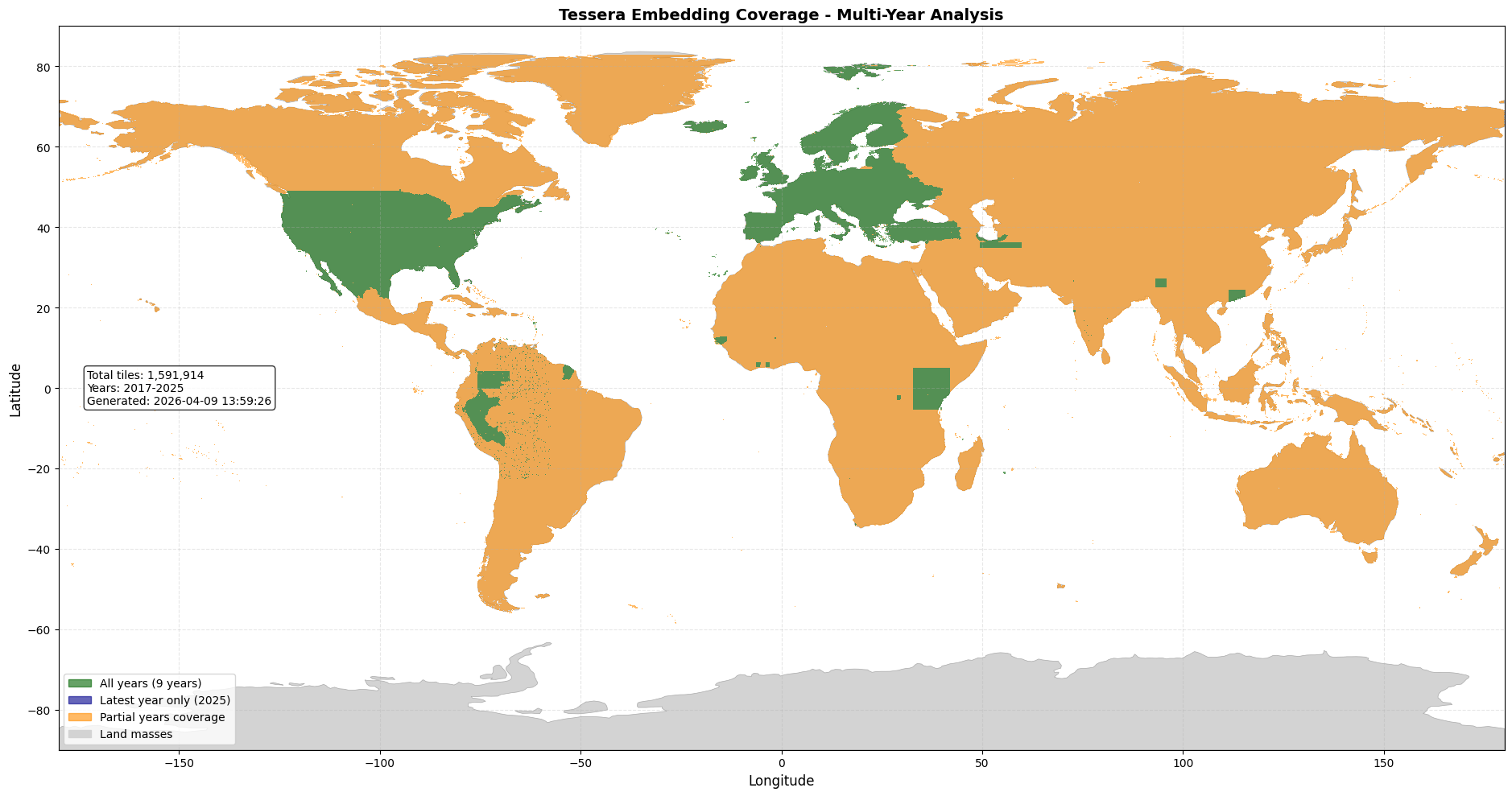
我们已为整个地球生成了 2024 年 10 米分辨率的嵌入数据。这些数据可以通过 GeoTessera 库下载并用于下游应用,从而节省大量的计算时间和资源。我们将逐步向后扩展覆盖范围,直至 2017 年。当前的覆盖地图如下:
TESSERA 用户组
欢迎感兴趣的用户加入我们的 Zulip 讨论群组。
创建您自己的嵌入
如果您想使用我们的软件创建自己的嵌入,请按照以下说明操作。请注意,这是一项计算上极具挑战性的任务,您需要访问大量的计算和存储资源。
硬件要求
1. 存储要求
运行此流程需要大量的存储空间。尽管该流程在处理后会清理一些中间文件,但下载的原始 Sentinel-2 和 Sentinel-1 文件仍将占用相当大的磁盘空间。例如,处理 2022 年的一个 100km×100km 区域以输出 TESSERA 表征图(10m 分辨率)至少需要 1TB 的存储空间。
2. 内存要求
我们使用的是预处理数据,最初来自 Microsoft Planetary Computer。然而,下一代嵌入将使用 ASF DAAC 的 OPERA 数据。无论哪种情况,大部分地理预处理工作都已经完成。尽管如此,我们仍建议至少配备 128GB 的内存。
3. CPU 和 GPU
该流程对 CPU 和 GPU 没有严格的要求,但更多的 CPU 核心和更强大的 GPU 可以显著加快推理速度。在处理 2022 年的一个 110km×110km 区域时,我们的测试表明,使用 128 核 CPU 和单个 NVIDIA A30 GPU 进行推理(CPU 和 GPU 各承担 50% 的推理工作)大约需要 10 小时才能完成。
4. 操作系统
对于数据预处理流程,我们几乎支持所有 Linux 系统。对于 Windows,我们建议使用 WSL。目前我们不支持 MacOS。
对于模型推理部分,我们仅在 Linux 和 Windows WSL 上进行了测试,并且运行正常。
数据预处理
概述
我们强烈建议您在运行流程之前先快速浏览整个教程。
在此步骤中,我们将一整年的 Sentinel-1 和 Sentinel-2 数据沿时间维度堆叠起来,生成一个合成图像。对于 Sentinel-2,合成图像的形状为 (T,H,W,B),其中 T 是该年有效观测的数量,B 是波段数量(我们选择了 10 个波段)。对于 Sentinel-1,我们提取了上升和下降轨道的数据。以上升轨道为例,合成图像的形状为 (T',H,W,B'),其中 T' 是该年有效上升观测的数量,B' 为 2,因为我们只获取 VV 和 VH 波段。
我们最初从 Microsoft Planetary Computer 获取 Sentinel-1 和 Sentinel-2 数据:
- Sentinel-1 数据源:https://planetarycomputer.microsoft.com/dataset/sentinel-1-rtc
- Sentinel-2 数据源:https://planetarycomputer.microsoft.com/dataset/sentinel-2-l2a
新一代嵌入将使用 ASF DAAC 的 OPERA 数据:
- Sentinel-1 数据源:https://registry.opendata.aws/nasa-operal2rtc-s1v1/
- Sentinel-2 数据源:https://registry.opendata.aws/sentinel-2-l2a-cogs/
目前,我们的流程仅接受 TIFF 格式的输入。输入 ROI TIFF 的分辨率可以不同(例如 30m),但流程会 始终以配置的 RESOLUTION(默认 10m)生成 Sentinel-1 和 Sentinel-2 输出,同时保持 ROI 的范围/边界完全一致。对于 TIFF 中有效的 ROI 区域,值为 1;否则为 0。如果您只有 shapefile 文件也没关系——我们提供了一个 convert_shp_to_tiff.py 脚本。
下载源代码
首先,创建一个空的工作目录:
mkdir tessera_project
cd tessera_project
git clone https://github.com/ucam-eo/tessera.git
为了更方便地运行流程,我们建议将数据输出目录放在与 tessera_infer 和 tessera_preprocessing 同一层次的位置:
tessera_project
┣ tessera_infer
┣ tessera_preprocessing
┣ my_data
┣ roi.shp(您的 shapefile)
┗ roi.tiff(我们建议使用 convert_shp_to_tiff.py 生成)
roi.tiff 可以使用位于 tessera_preprocessing/convert_shp_to_tiff.py 中的 convert_shp_to_tiff.py 脚本生成。要使用它,只需在主函数中指定您的 shapefile 路径,它就会在同一目录下输出同名的 TIFF 文件。
⚠️注意:如果您的 ROI 相对较大,例如 100 km × 100 km,我们强烈建议您事先将 TIFF 分割成不超过 20 km × 20 km 的小块。然后依次在流程中处理每个小 TIFF 文件。过大的 ROI 可能会导致后端瓦片提供商出现问题。
Python 环境
我们需要一些地理处理库(幸运的是,我们不会使用 GDAL,因为它的环境配置非常麻烦),以及一些机器学习库(PyTorch,不过你需要根据各自的硬件自行安装)。我们已经将一些常用包列在 requirements.txt 文件中,你可以通过以下命令进行安装:
pip install -r requirements.txt
注意:如果你在一个受管环境中工作,可能需要先创建一个虚拟环境,使用以下命令:
python3 -m venv venv
source venv/bin/activate
脚本配置
首先,进入 tessera_preprocessing 文件夹:
cd tessera_preprocessing
然后编辑 s1_s2_downloader.sh 文件,设置 ROI 的 TIFF 文件路径、输出目录和临时目录,以及数据源:
# === 基本配置 ===
INPUT_TIFF="/绝对路径/到/你的/data_dir/roi.tiff"
OUT_DIR="/绝对路径/到/你的/data_dir"
export TEMP_DIR="/绝对路径/到/你的/temp_dir" # 临时文件目录
mkdir -p "$OUT_DIR"
# Python 环境路径
PYTHON_ENV="/绝对路径/到/你的/python_env/bin/python"
# === Sentinel-1 和 Sentinel-2 处理配置 ===
YEAR=2022 # 范围 [2017-2025]
RESOLUTION=10.0 # 输出分辨率(米)。ROI TIFF 可以是任意分辨率;范围会保持不变。
# === 数据源配置 ===
# mpc: Microsoft Planetary Computer (sentinel-1-rtc, sentinel-2-l2a)
# aws: AWS Open Data 后端 (S1=OPERA RTC-S1 通过 ASF/CMR + ASF Earthdata Cloud COGs, S2=Earth-search Sentinel-2 L2A COGs)
DATA_SOURCE="mpc" # 选项:mpc/aws
注意:RESOLUTION 控制输出像素大小。该流程会固定 ROI 的边界,并将 ROI 掩膜重新采样到输出网格中。
AWS 凭证(仅当 DATA_SOURCE="aws" 时需要)
Earth-search 上的 Sentinel-2 是公开数据,不需要凭证。
Sentinel-1 OPERA RTC-S1 是通过 ASF Earthdata Cloud(COG over HTTPS)访问的。你需要一个 Earthdata Login 令牌:
- 创建 Earthdata 账户:通过 NASA Earthdata Login。
- 批准应用:注册账户后,可以前往“Applications”选项卡,将 Alaska Satellite Facility Data Access 添加到已批准的应用列表中。
- 获取 EDL Bearer 令牌 / JWT:点击“Generate Token”,并将其存储在本地(不要提交)。
推荐方式(简单且明确):
nano ~/.edl_bearer_token
# 粘贴令牌,保存并退出(Ctrl-O Enter,然后 Ctrl-X)
chmod 600 ~/.edl_bearer_token
AWS S1 下载器会使用此令牌从 ASF Earthdata Cloud 读取 COG 文件。
如果你想获取临时的 S3 凭证(进阶操作;通常此流程不需要),请参考 ASF 的指导文档:
https://cumulus.asf.alaska.edu/s3credentialsREADME
在上述配置下方,还有一些可以根据你计算机性能进行调整的额外配置。
首先,为 s1_s2_downloader.sh 文件赋予执行权限:
chmod +x s1_s2_downloader.sh
然后,我们可以运行:
bash s1_s2_downloader.sh
由于网络条件的原因,某些瓦片的处理可能会超时。我们的脚本包含复杂的超时管理机制,以避免这些问题。然而,有时仍有一些瓦片会失败。再次运行上述命令通常可以解决这个问题。
如果所有的 Sentinel-1 和 Sentinel-2 数据都正确生成,就可以沿时间维度进行堆叠。这一步我们使用两个由 Rust 生成的可执行文件,速度非常快。你可以打开 s1_s2_stacker.sh 并修改以下内容:
# === 基本配置 ===
BASE_DIR="/绝对路径/到/你的/data_dir"
OUT_DIR="${BASE_DIR}/data_processed"
DOWNSAMPLE_RATE=1
通常情况下,我们不会修改 DOWNSAMPLE_RATE,这样在堆叠过程中就不会进行下采样。上述代码中的 BASE_DIR 与你在 s1_s2_downloader.sh 中修改的 OUT_DIR 是相同的。
同样地,为 s1_s2_stacker.sh 文件赋予执行权限:
chmod +x s1_s2_stacker.sh
然后你可以执行堆叠操作:
bash s1_s2_stacker.sh
成功后,你会在 /绝对路径/到/你的/data_dir/data_processed 目录下得到一些 .npy 文件。通常这些 .npy 文件体积较大,因此我们会将它们分割成更小、更易管理的单元。
执行以下命令:
python dpixel_retiler.py \
--tiff_path /绝对路径/到/你的/data_dir/roi.tif \
--d_pixel_dir /绝对路径/到/你的/data_dir/data_processed \
--patch_size 500 \
--out_dir /绝对路径/到/你的/data_dir/retiled_d_pixel \
--num_workers 16 \
--overwrite \
--block_size 2000
你可以自行调整上述的 patch_size 和 block_size。以上配置是针对分辨率为 10 米、形状为 (5000,5000) 的 TIFF 文件的推荐配置。
如果上述代码顺利运行,你将在 my_data/retiled_d_pixel 目录下得到一些子文件夹。
推理
概述
一旦数据预处理完成,我们就可以开始推理了。在继续之前,请检查 my_data/retiled_d_pixel 文件夹中是否存在如下子文件夹:
retiled_d_pixel
┣ 0_3500_500_4000
┣ 0_4000_500_4500
┣ 0_4500_500_5000
┣ 0_5000_500_5500
┣ 0_5500_500_6000
┣ 0_6000_500_6500
每个子文件夹应包含以下文件:
0_3500_500_4000
┣ bands.npy
┣ doys.npy
┣ masks.npy
┣ roi.tiff
┣ sar_ascending.npy
┣ sar_ascending_doy.npy
┣ sar_descending.npy
┗ sar_descending_doy.npy
如果这些文件存在,就可以开始推理。否则,请检查第一步是否成功完成。
推理需要 PyTorch。由于每个系统的 CUDA 版本可能略有不同,我们无法像数据预处理那样提供一个封装好的 Docker Python 环境。幸运的是,推理所需的 Python 环境比数据预处理要简单得多,因为它不使用 GDAL 或 SNAP 等地理处理库。
PyTorch 准备
如果你尚未安装 PyTorch,可以参考以下步骤。否则,可以跳过本节。
首先,检查你的系统 CUDA 版本:
nvidia-smi
然后访问 https://pytorch.org/,根据你的 CUDA 版本选择合适的版本进行安装,例如:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
模型权重
接下来,从 Google Drive 下载模型权重,并将 .pt 文件放入 tessera_infer/checkpoints 目录中:
tessera_infer
┗ checkpoints
┗ best_model_fsdp_20250427_084307.pt
┗ configs
┗ src
请注意,上述检查点是一个早期阶段的模型,它原生生成 float32 嵌入。因此,这个模型并不是用于生成 geotessera 库中 int8 嵌入的那个模型。我们很快会将用于创建 geotessera 嵌入的具体检查点部署到完整的流水线中。
QAT 模型权重(量化输出)
对于量化推理,请使用来自 Google Drive 的 QAT 检查点,并将其放置在 tessera_infer_QAT/checkpoints 目录下:
tessera_infer_QAT
┣ checkpoints
┃ ┗ best_model_fsdp_20250608_220648_QAT.pt
┣ configs
┗ src
QAT 流水线会输出量化后的嵌入,格式为 int8 + 缩放值:
tile_name.npy:int8 嵌入张量,形状为(H, W, 128)tile_name_scales.npy:float32 缩放图,形状为(H, W)
配置 Bash 脚本
为了简化推理配置,我们提供了 tessera_infer/infer_all_tiles.sh。您只需编辑几个参数即可:
a. 基础数据目录:
BASE_DATA_DIR="your_data_directory"
这是您的数据存储文件夹,与之前 Bash 脚本中的 BASE_DATA_DIR 相同,例如 /maps/usr/tessera_project/my_data。
b. Python 环境:
export PYTHON_ENV="your_python_path"
在此处填写您的 Python 环境的绝对路径,例如 /home/user/anaconda3/envs/tessera_env/bin/python。
c. CPU/GPU 分割:
CPU_GPU_SPLIT="1:1" # 格式:CPU:GPU 比例
该脚本支持同时使用 CPU 和 GPU 进行推理。此比例指定了每个设备将处理的 retiled_patches 的比例。默认为 1:1(均分)。如果仅使用 GPU 进行推理,则设置为 0:1。
d. CPU 相关设置
MAX_CONCURRENT_PROCESSES_CPU=20
用于瓦片推理的最大 CPU 进程数。例如,若设置为 20,则会同时处理 20 个瓦片。
AVAILABLE_CORES=$((TOTAL_CPU_CORES / 2)) # 使用 50% 的核心
要使用的 CPU 核心数。请根据需要调整此值,以避免占用过多的 CPU 资源!
e. GPU 相关设置:
MAX_CONCURRENT_PROCESSES_GPU=1
用于推理的最大 GPU 进程数。如果系统中只有 1 个 GPU,则将其设置为 1。
GPU_BATCH_SIZE=1024 # 对于 GPU 可以更大,若占用内存过多则需降低
PyTorch 推理时一次处理的样本数量。如果该值占用过多 GPU 内存或导致 GPU OOM 错误,请相应地减少它。
f. 其他设置 还有其他可配置的参数,请根据需要进行调整。
开始推理
一切准备就绪后,进入 tessera_infer 文件夹:
cd tessera_infer
然后为 infer_all_tiles.sh 赋予执行权限:
chmod +x infer_all_tiles.sh
最后运行脚本:
bash infer_all_tiles.sh
如果成功,您将看到类似以下的日志:
(base) zf281@daintree:/scratch/zf281/tessera_project/tessera_infer$ bash infer_all_tiles.sh
[INFO] 总 CPU 核心数:256,使用:192
[INFO] CPU:GPU 分割比例 = 1:1(总计:2)
==== 设置目录 ====
[SUCCESS] 已创建必要目录
==== 扫描瓦片 ====
[INFO] 瓦片目录:/scratch/zf281/jovana/retiled_d_pixel
[INFO] 输出目录:/scratch/zf281/jovana/representation_retiled
[SUCCESS] 共找到 226 个瓦片
[INFO] 示例瓦片:
- 0_3500_500_4000
- 0_4000_500_4500
- 0_4500_500_5000
- ...
同时,在 tessera_infer 文件夹中会生成一个 logs 文件夹,其中包含每个 CPU 和 GPU 进程的更详细日志。
QAT 推理(CPU + GPU,带 AMX 自动回退)
我们还在 tessera_infer_QAT 中提供了 QAT 推理流水线:
cd tessera_infer_QAT
chmod +x infer_all_tiles.sh
bash infer_all_tiles.sh
在运行前,请编辑 tessera_infer_QAT/infer_all_tiles.sh 中的以下参数:
BASE_DATA_DIR="/absolute_path_to_your_data_dir"
export PYTHON_ENV="/absolute_path_to_your_python/bin/python"
CPU_GPU_SPLIT="1:1" # CPU:GPU 比例,例如 1:0 或 0:1
CHECKPOINT_PATH="checkpoints/best_model_fsdp_20250608_220648_QAT.pt"
注意事项:
- QAT 现在支持在一次运行中同时进行 CPU 和 GPU 推理(按比例分割,与
tessera_infer的方式相同)。 - 在 CPU 上,当可用时会自动检测并启用 AMX。
- 如果 AMX 不可用,则会自动回退到默认的 CPU 推理。
拼接最终表征地图
推理通常需要较长时间,具体取决于您的 ROI 大小和硬件性能。完成推理后,您可以在 my_data/representation_retiled 中找到许多 .npy 文件:
representation_retiled
┣ 0_3500_500_4000.npy
┣ 0_4000_500_4500.npy
┣ 0_4500_500_5000.npy
┣ 0_5000_500_5500.npy
┣ 0_5500_500_6000.npy
┣ 0_6000_500_6500.npy
┣ 0_6500_500_7000.npy
┣ 0_7000_500_7500.npy
┣ 1000_0_1500_500.npy
┣ 1000_1000_1500_1500.npy
┣ 1000_1500_1500_2000.npy
┣ 1000_2000_1500_2500.npy
最后一步是使用 tessera_infer/stitch_tiled_representation.py 将它们拼接在一起:
python stitch_tiled_representation.py \
--d_pixel_retiled_path /path/to/d_pixel_retiled \
--representation_retiled_path /path/to/representation_retiled \
--downstream_tiff /path/to/downstream.tiff \
--out_dir /path/to/output_directory
例如:
python stitch_tiled_representation.py \
--d_pixel_retiled_path /maps/usr/tessera_project/my_data/d_pixel_retiled \
--representation_retiled_path /maps/usr/tessera_project/my_data/representation_retiled \
--downstream_tiff /maps/usr/tessera_project/my_data/downstream.tiff \
--out_dir /maps/usr/tessera_project/my_data
最终,您将在 my_data 目录中得到一张拼接后的表征地图,其形状为 (H,W,128),其中 H 和 W 与您最初的 roi.tiff 匹配。该表征地图是一个 NumPy 数组。如果您想将其转换为 TIFF 格式以便在 QGIS 等软件中查看,可以使用 tessera_infer/convert_npy2tiff.py 脚本。只需修改主函数如下:
npy_path = "/maps/usr/tessera_project/my_data/stitched_representation.npy" # 更改为实际的 npy 文件路径
ref_tiff_path = "/maps/usr/tessera_project/my_data/roi.tiff" # 更改为实际的参考 tiff 文件路径
out_dir = "/maps/usr/tessera_project/my_data/" # 更改为实际的输出目录
下游任务
如果您想复现论文中的下游任务,可以访问 https://github.com/ucam-eo/tessera-downstream-task。那里提供了许多示例。
附加信息
团队
剑桥大学教职人员
博士后
- James Ball
博士生
- Madeleine Lisaius
- Zhengpeng (Frank) Feng
- Robin Young
- Jovana Knezevic
本科生
- Zejia Yang(Part II 学生,与 Frank Feng 合作研究空间特征提取器的 MAE 预训练)
实习生
- Kenzy Soror(滑铁卢大学,与 Robin Young 合作)
- Artyom Gabtraupov(滑铁卢大学,与 Robin Young 合作)
- Gabriel Mahler(剑桥大学,与 Anil Madhavapeddy 和 Silviu Petrovan 合作,研究 刺猬栖息地与追踪)
- Pan Leyu(帝国理工学院,与 Frank Feng 合作,研究基于 OSM 生成的文本嵌入)
合作伙伴
- Clement Atzberger,dClimate Labs
- Andrew Blake,Mantle Labs
访问学者
- Silja Sormunnen,芬兰阿尔托大学
- Isabel Mansley(爱丁堡大学,与 David Coomes 和 Anil Madhavapeddy 合作,研究 苏格兰栖息地 mapping
联系方式
技术问题请发送至 Frank Feng(zf281@cam.ac.uk),或在我们的 Zulip 论坛 提问。非技术类问题可发送至 S. Keshav 教授(sk818@cam.ac.uk)。
引用
如果您在研究中使用 TESSERA,请引用以下 arXiv 论文:
@misc{feng2025tesseratemporalembeddingssurface,
title={TESSERA: 地表光谱的时间嵌入用于地球表征与分析},
author={Zhengpeng Feng 等},
year={2025},
eprint={2506.20380},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2506.20380},
}
致谢
我们衷心感谢 UKRI 以及剑桥大学的 DAWN 超级计算机团队对本项目的慷慨支持。同时,我们也感谢 AMD、Vultr、Dirac 高性能计算设施、微软 AI For Good 实验室、Robert Sansom 博士、dClimate 以及 亚马逊云服务 (AWS) 在其 AWS Open Data 计划(https://opendata.aws/)下的支持。没有他们的支持、计算资源和技术协助,这项工作将无法实现。
星标历史

使用条款
TESSERA 使用条款与伦理准则
许可协议
TESSERA 数据和嵌入以 知识共享零协议 CC-0 的形式提供。这意味着您可以:
- 分享——以任何媒介或格式复制并重新分发该材料
- 改编——为任何目的(包括商业用途)混编、转换或在此基础上进行创作
目的与预期用途
TESSERA 的开发旨在推动科学研究,并支持环境监测、生态保护、可持续农业以及对地球系统的理解。我们设计此工具是为了实现以下目标:
- 科学研究与教育
- 环境监测与保护
- 农业与粮食安全分析
- 气候变化研究与适应规划
- 可持续土地利用与资源管理
- 有益于社会和环境的公共利益应用
伦理准则
尽管 CC0 许可允许广泛使用,但我们强烈建议用户考虑其工作的伦理影响。这些伦理准则仅供参考,并不构成具有法律约束力的限制。我们请求用户:
负责任地行动:
- 在分析特定地点时,考虑隐私影响
- 尊重受影响社区的权利与尊严
- 注意潜在的双重用途问题
保持透明:
- 准确描述数据的特性(年度分辨率、10 米空间分辨率)
- 承认您在应用中的局限性
- 不要歪曲 TESSERA 的能力
支持积极影响:
- 考虑您的工作如何促进社会福祉
- 在适当情况下与受影响社区沟通
- 分享能够增进公众知识的研究成果
数据特性
用户应了解,TESSERA 提供:
- 年度时间分辨率——数据代表每年的汇总信息,而非实时或高频监测
- 10 米空间分辨率——适用于景观尺度的分析
- 光谱-时间嵌入——是压缩后的表示形式,而非原始影像
请在您的工作中准确反映这些特性。
社区标准
我们鼓励负责任地使用,并欢迎社区反馈。如果您对潜在的应用有任何担忧,或对改进这些准则有建议,请随时与我们联系。 我们保留根据社区意见和新出现的情况更新这些准则的权利,但此类更新不会追溯性地影响以 CC-0 许可发布的数据。
联系方式
如有疑问或反馈,请发送邮件至 sk818@cam.ac.uk。
最后更新:2026年2月25日
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备