simple_tensorflow_serving
simple_tensorflow_serving 是一款通用且易用的机器学习模型部署服务,旨在简化从模型训练到线上推理的最后一公里。它解决了开发者在部署不同框架模型时面临的接口不统一、环境配置复杂以及多版本管理困难等痛点,让用户无需编写大量服务端代码即可快速搭建高性能的推理接口。
这款工具非常适合机器学习工程师、后端开发人员以及算法研究人员使用。无论是需要快速验证原型的科研人员,还是追求稳定生产环境的开发团队,都能从中受益。其核心亮点在于极强的兼容性,不仅原生支持 TensorFlow,还广泛涵盖 PyTorch、MXNet、ONNX、Scikit-learn 等主流框架,真正实现了“一次部署,多框通用”。
此外,simple_tensorflow_serving 具备多项实用特性:支持 GPU 加速推理以提升性能;允许同时在线服务多个模型及其不同版本,并能自动检测更新实现动态加载;提供标准的 RESTful API,方便任何编程语言的客户端调用;甚至能根据模型自动生成客户端代码,大幅降低对接成本。配合 Docker 和 Kubernetes,它能轻松适应从本地测试到大规模集群的各种部署场景,是构建高效机器学习服务流水线的得力助手。
使用场景
某电商团队需要将训练好的 TensorFlow 商品推荐模型和 PyTorch 图像识别模型快速部署到生产环境,以支持实时用户行为分析。
没有 simple_tensorflow_serving 时
- 多框架适配难:团队需为 TensorFlow 和 PyTorch 分别编写不同的推理服务代码,维护两套独立的部署脚本,开发成本高昂。
- 版本更新繁琐:每次模型迭代都需要手动重启服务或编写复杂的热加载逻辑,导致服务中断风险高且上线周期长。
- 客户端对接慢:后端开发人员必须手动编写各语言(如 Python、Java)的 HTTP 请求封装代码,容易出错且效率低下。
- 缺乏监控可视:无法直观查看模型调用次数、延迟等统计指标,排查性能瓶颈如同“盲人摸象”。
使用 simple_tensorflow_serving 后
- 统一服务入口:通过一个配置文件即可同时托管 TensorFlow 和 PyTorch 等多个框架的模型,提供标准的 RESTful API 统一对外服务。
- 动态热更新:只需将新模型文件放入指定目录,simple_tensorflow_serving 自动检测并加载最新版本,实现零停机平滑升级。
- 自动生成客户端:利用
curl一键生成特定语言的客户端代码,开发人员无需手写请求逻辑,直接调用即可测试模型。 - 内置监控看板:访问 Web 仪表盘即可实时查看各模型的请求量与耗时统计,运维监控一目了然。
simple_tensorflow_serving 通过屏蔽底层框架差异与简化运维流程,让算法模型从“实验室”到“生产线”的部署时间从数天缩短至分钟级。
运行环境要求
- Linux
- 非必需
- 若需加速,需 NVIDIA GPU 及 CUDA 环境(通过 Docker 镜像 `latest-gpu` 部署,需挂载宿主机的 `/dev/nvidia*` 设备及 CUDA 库文件)
未说明
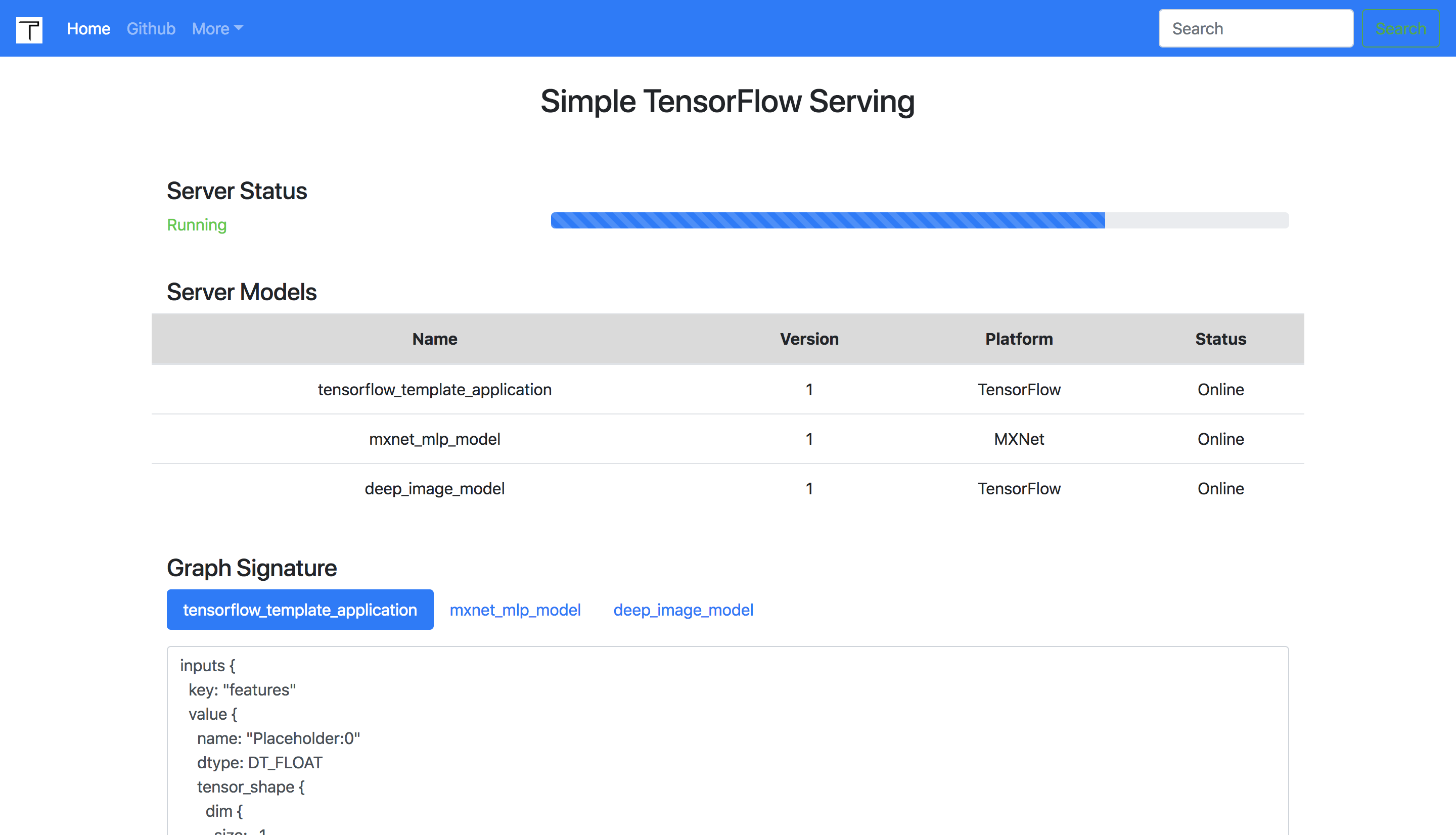
快速开始
简单的 TensorFlow Serving
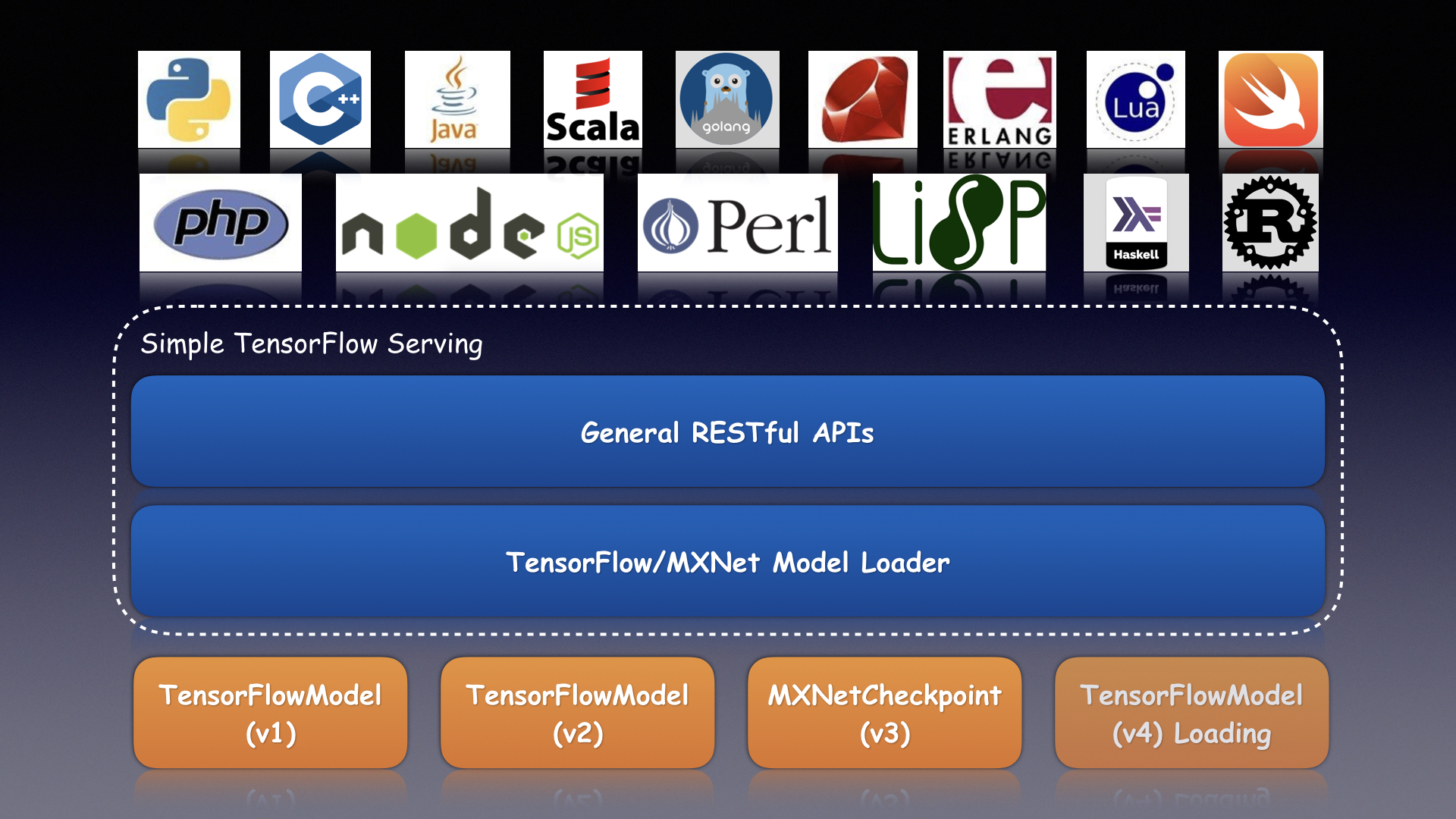
简介
简单的 TensorFlow Serving 是一种通用且易于使用的机器学习模型推理服务。更多信息请参阅 https://stfs.readthedocs.io。
- 支持分布式 TensorFlow 模型
- 支持通用的 RESTful/HTTP API
- 支持使用 GPU 加速进行推理
- 支持
curl及其他命令行工具 - 支持任何编程语言的客户端
- 支持通过模型自动生成客户端代码,无需手动编写
- 支持对图像模型使用原始文件进行推理
- 支持为详细请求提供统计指标
- 支持同时服务多个模型
- 支持模型版本的动态上线与下线
- 支持加载 TensorFlow 模型的新自定义算子
- 支持可配置的基本认证安全机制
- 支持 TensorFlow/MXNet/PyTorch/Caffe2/CNTK/ONNX/H2o/Scikit-learn/XGBoost/PMML/Spark MLlib 等多种框架的模型
安装
使用 pip 安装服务器。
pip install simple_tensorflow_serving
或者从 源代码 安装。
python ./setup.py install
python ./setup.py develop
bazel build simple_tensorflow_serving:server
也可以使用 Docker 镜像。
docker run -d -p 8500:8500 tobegit3hub/simple_tensorflow_serving
docker run -d -p 8500:8500 tobegit3hub/simple_tensorflow_serving:latest-gpu
docker run -d -p 8500:8500 tobegit3hub/simple_tensorflow_serving:latest-hdfs
docker run -d -p 8500:8500 tobegit3hub/simple_tensorflow_serving:latest-py34
docker-compose up -d
或者在 Kubernetes 中部署。
kubectl create -f ./simple_tensorflow_serving.yaml
快速入门
使用 TensorFlow 的 SavedModel 启动服务器。
simple_tensorflow_serving --model_base_path="./models/tensorflow_template_application_model"
在浏览器中访问 http://127.0.0.1:8500,查看仪表板。
生成 Python 客户端,并使用测试数据无需编码即可访问模型。
curl http://localhost:8500/v1/models/default/gen_client?language=python > client.py
python ./client.py
高级用法
多个模型
该服务支持同时服务多个模型及其不同版本。您可以使用以下配置运行服务器。
{
"model_config_list": [
{
"name": "tensorflow_template_application_model",
"base_path": "./models/tensorflow_template_application_model/",
"platform": "tensorflow"
}, {
"name": "deep_image_model",
"base_path": "./models/deep_image_model/",
"platform": "tensorflow"
}, {
"name": "mxnet_mlp_model",
"base_path": "./models/mxnet_mlp/mx_mlp",
"platform": "mxnet"
}
]
}
simple_tensorflow_serving --model_config_file="./examples/model_config_file.json"
添加或移除模型版本时,系统会自动检测并重新加载最新文件到内存中。您可以轻松选择指定的模型和版本进行推理。
endpoint = "http://127.0.0.1:8500"
input_data = {
"model_name": "default",
"model_version": 1,
"data": {
"keys": [[11.0], [2.0]],
"features": [[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1]]
}
}
result = requests.post(endpoint, json=input_data)
GPU 加速
如果您希望使用 GPU,请尝试带有 GPU 标签的 Docker 镜像,并将 CUDA 文件放置在 /usr/cuda_files/ 目录下。
export CUDA_SO="-v /usr/cuda_files/:/usr/cuda_files/"
export DEVICES=$(\ls /dev/nvidia* | xargs -I{} echo '--device {}:{}')
export LIBRARY_ENV="-e LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/cuda_files"
docker run -it -p 8500:8500 $CUDA_SO $DEVICES $LIBRARY_ENV tobegit3hub/simple_tensorflow_serving:latest-gpu
您可以在命令行参数或模型配置文件中设置会话配置和 GPU 选项。
simple_tensorflow_serving --model_base_path="./models/tensorflow_template_application_model" --session_config='{"log_device_placement": true, "allow_soft_placement": true, "allow_growth": true, "per_process_gpu_memory_fraction": 0.5}'
{
"model_config_list": [
{
"name": "default",
"base_path": "./models/tensorflow_template_application_model/",
"platform": "tensorflow",
"session_config": {
"log_device_placement": true,
"allow_soft_placement": true,
"allow_growth": true,
"per_process_gpu_memory_fraction": 0.5
}
}
]
}
自动生成的客户端
您可以为在线模型生成测试 JSON 数据。
curl http://localhost:8500/v1/models/default/gen_json
或者为您的模型生成不同语言(Bash、Python、Golang、JavaScript 等)的客户端,而无需编写任何代码。
curl http://localhost:8500/v1/models/default/gen_client?language=python > client.py
curl http://localhost:8500/v1/models/default/gen_client?language=bash > client.sh
curl http://localhost:8500/v1/models/default/gen_client?language=golang > client.go
curl http://localhost:8500/v1/models/default/gen_client?language=javascript > client.js
生成的代码应如下所示,可以直接测试:
#!/usr/bin/env python
import requests
def main():
endpoint = "http://127.0.0.1:8500"
json_data = {"model_name": "default", "data": {"keys": [[1], [1]], "features": [[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0], [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]]} }
result = requests.post(endpoint, json=json_data)
print(result.text)
if __name__ == "__main__":
main()
#!/usr/bin/env python
import requests
def main():
endpoint = "http://127.0.0.1:8500"
input_data = {"keys": [[1.0], [1.0]], "features": [[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0], [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]]}
result = requests.post(endpoint, json=input_data)
print(result.text)
if __name__ == "__main__":
main()
图像模型
对于图像模型,我们可以直接使用原始图像文件进行请求,而无需构造数组数据。
现在开始服务类似于 deep_image_model 的图像模型。
simple_tensorflow_serving --model_base_path="./models/deep_image_model/"
然后使用与您的模型形状相同的原始图像文件进行请求。
curl -X POST -F 'image=@./images/mew.jpg' -F "model_version=1" 127.0.0.1:8500
TensorFlow Estimator 模型
如果我们使用 TensorFlow Estimator API 导出模型,模型签名应如下所示。
inputs {
key: "inputs"
value {
name: "input_example_tensor:0"
dtype: DT_STRING
tensor_shape {
dim {
size: -1
}
}
}
}
outputs {
key: "classes"
value {
name: "linear/binary_logistic_head/_classification_output_alternatives/classes_tensor:0"
dtype: DT_STRING
tensor_shape {
dim {
size: -1
}
dim {
size: -1
}
}
}
}
outputs {
key: "scores"
value {
name: "linear/binary_logistic_head/predictions/probabilities:0"
dtype: DT_FLOAT
tensor_shape {
dim {
size: -1
}
dim {
size: 2
}
}
}
}
method_name: "tensorflow/serving/classify"
我们需要构造用于推理的字符串张量,并使用 base64 对字符串进行编码以供 HTTP 使用。以下是示例 Python 代码。
def _float_feature(value):
return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def main():
# 原始输入数据
feature_dict = {"a": _bytes_feature("10"), "b": _float_feature(10)}
# 将 Example 创建为 base64 字符串
example_proto = tf.train.Example(features=tf.train.Features(feature=feature_dict))
tensor_proto = tf.contrib.util.make_tensor_proto(example_proto.SerializeToString(), dtype=tf.string)
tensor_string = tensor_proto.string_val.pop()
base64_tensor_string = base64.urlsafe_b64encode(tensor_string)
# 向服务器发送请求
endpoint = "http://127.0.0.1:8500"
json_data = {"model_name": "default", "base64_decode": True, "data": {"inputs": [base64_tensor_string]}}
result = requests.post(endpoint, json=json_data)
print(result.json())
自定义 Op
如果您的模型依赖于新的 TensorFlow 自定义 Op,您可以在加载 so 文件的同时运行服务器。
simple_tensorflow_serving --model_base_path="./model/" --custom_op_paths="./foo_op/"
请查看 ./examples/custom_op/ 中的完整示例。
身份验证
对于企业用户,我们可以为所有 API 启用基本身份验证,并拒绝任何匿名请求。
现在使用配置的用户名和密码启动服务器。
./server.py --model_base_path="./models/tensorflow_template_application_model/" --enable_auth=True --auth_username="admin" --auth_password="admin"
如果您使用 Web 仪表板,只需输入您的凭据即可。如果您使用客户端,则需要在请求中提供用户名和密码。
curl -u admin:admin -H "Content-Type: application/json" -X POST -d '{"data": {"keys": [[11.0], [2.0]], "features": [[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1]]}}' http://127.0.0.1:8500
endpoint = "http://127.0.0.1:8500"
input_data = {
"data": {
"keys": [[11.0], [2.0]],
"features": [[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1]]
}
}
auth = requests.auth.HTTPBasicAuth("admin", "admin")
result = requests.post(endpoint, json=input_data, auth=auth)
TSL/SSL
它支持 TSL/SSL,您可以生成自签名的密钥文件用于测试。
openssl req -x509 -newkey rsa:4096 -nodes -out /tmp/secret.pem -keyout /tmp/secret.key -days 365
然后使用证书文件运行服务器。
simple_tensorflow_serving --enable_ssl=True --secret_pem=/tmp/secret.pem --secret_key=/tmp/secret.key --model_base_path="./models/tensorflow_template_application_model"
支持的模型
对于 MXNet 模型,您可以使用以下命令和配置进行加载。
simple_tensorflow_serving --model_base_path="./models/mxnet_mlp/mx_mlp" --model_platform="mxnet"
endpoint = "http://127.0.0.1:8500"
input_data = {
"model_name": "default",
"model_version": 1,
"data": {
"data": [[12.0, 2.0]]
}
}
result = requests.post(endpoint, json=input_data)
print(result.text)
对于 ONNX 模型,您可以使用以下命令和配置进行加载。
simple_tensorflow_serving --model_base_path="./models/onnx_mnist_model/onnx_model.proto" --model_platform="onnx"
endpoint = "http://127.0.0.1:8500"
input_data = {
"model_name": "default",
"model_version": 1,
"data": {
"data": [[...]]
}
}
result = requests.post(endpoint, json=input_data)
print(result.text)
对于 H2o 模型,您可以使用以下命令和配置进行加载。
# 使用 "java -jar h2o.jar" 启动 H2o 服务器
simple_tensorflow_serving --model_base_path="./models/h2o_prostate_model/GLM_model_python_1525255083960_17" --model_platform="h2o"
endpoint = "http://127.0.0.1:8500"
input_data = {
"model_name": "default",
"model_version": 1,
"data": {
"data": [[...]]
}
}
result = requests.post(endpoint, json=input_data)
print(result.text)
对于 Scikit-learn 模型,您可以使用以下命令和配置进行加载。
simple_tensorflow_serving --model_base_path="./models/scikitlearn_iris/model.joblib" --model_platform="scikitlearn"
simple_tensorflow_serving --model_base_path="./models/scikitlearn_iris/model.pkl" --model_platform="scikitlearn"
endpoint = "http://127.0.0.1:8500"
input_data = {
"model_name": "default",
"model_version": 1,
"data": {
"data": [[...]]
}
}
result = requests.post(endpoint, json=input_data)
print(result.text)
对于 XGBoost 模型,您可以使用以下命令和配置进行加载。
simple_tensorflow_serving --model_base_path="./models/xgboost_iris/model.bst" --model_platform="xgboost"
simple_tensorflow_serving --model_base_path="./models/xgboost_iris/model.joblib" --model_platform="xgboost"
simple_tensorflow_serving --model_base_path="./models/xgboost_iris/model.pkl" --model_platform="xgboost"
endpoint = "http://127.0.0.1:8500"
input_data = {
"model_name": "default",
"model版本": 1,
"data": {
"data": [[...]]
}
}
result = requests.post(endpoint, json=input_data)
print(result.text)
对于 PMML 模型,您可以使用以下命令和配置进行加载。这依赖于 Openscoring 和 Openscoring-Python 来加载模型。
java -jar ./third_party/openscoring/openscoring-server-executable-1.4-SNAPSHOT.jar
simple_tensorflow_serving --model_base_path="./models/pmml_iris/DecisionTreeIris.pmml" --model_platform="pmml"
endpoint = "http://127.0.0.1:8500"
input_data = {
"model_name": "default",
"model版本": 1,
"data": {
"data": [[...]]
}
}
result = requests.post(endpoint, json=input_data)
print(result.text)
支持的客户端
以下是 Bash 中的示例客户端。
curl -H "Content-Type: application/json" -X POST -d '{"data": {"keys": [[1.0], [2.0]], "features": [[10, 10, 10, 8, 6, 1, 8, 9, 1], [6, 2, 1, 1, 1, 1, 7, 1, 1]]}}' http://127.0.0.1:8500
以下是 Python 中的示例客户端。
endpoint = "http://127.0.0.1:8500"
payload = {"data": {"keys": [[11.0], [2.0]], "features": [[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1]]}}
result = requests.post(endpoint, json=payload)
以下是 C++ 中的示例客户端。
以下是 Java 中的示例客户端。
以下是 Scala 中的示例客户端。
以下是 Go 中的示例客户端。
endpoint := "http://127.0.0.1:8500"
dataByte := []byte(`{"data": {"keys": [[11.0], [2.0]], "features": [[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1]]}}`)
var dataInterface map[string]interface{}
json.Unmarshal(dataByte, &dataInterface)
dataJson, _ := json.Marshal(dataInterface)
resp, err := http.Post(endpoint, "application/json", bytes.NewBuffer(dataJson))
以下是 Ruby 中的示例客户端。
endpoint = "http://127.0.0.1:8500"
uri = URI.parse(endpoint)
header = {"Content-Type" => "application/json"}
input_data = {"data" => {"keys"=> [[11.0], [2.0]], "features"=> [[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1]]}}
http = Net::HTTP.new(uri.host, uri.port)
request = Net::HTTP::Post.new(uri.request_uri, header)
request.body = input_data.to_json
response = http.request(request)
以下是 JavaScript 中的示例客户端。
var options = {
uri: "http://127.0.0.1:8500",
method: "POST",
json: {"data": {"keys": [[11.0], [2.0]], "features": [[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1]]}}
};
request(options, function (error, response, body) {});
以下是 PHP 中的示例客户端。
$endpoint = "127.0.0.1:8500";
$inputData = array(
"keys" => [[11.0], [2.0]],
"features" => [[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1]],
);
$jsonData = array(
"data" => $inputData,
);
$ch = curl_init($endpoint);
curl_setopt_array($ch, array(
CURLOPT_POST => TRUE,
CURLOPT_RETURNTRANSFER => TRUE,
CURLOPT_HTTPHEADER => array(
"Content-Type: application/json"
),
CURLOPT_POSTFIELDS => json_encode($jsonData)
));
$response = curl_exec($ch);
以下是 Erlang 中的示例客户端。
ssl:start(),
application:start(inets),
httpc:request(post,
{"http://127.0.0.1:8500", [],
"application/json",
"{\"data\": {\"keys\": [[11.0], [2.0]], \"features\": [[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1]]}}"
}, [], []).
以下是 Lua 中的示例客户端。
local endpoint = "http://127.0.0.1:8500"
keys_array = {}
keys_array[1] = {1.0}
keys_array[2] = {2.0}
features_array = {}
features_array[1] = {1, 1, 1, 1, 1, 1, 1, 1, 1}
features_array[2] = {1, 1, 1, 1, 1, 1, 1, 1, 1}
local input_data = {
["keys"] = keys_array,
["features"] = features_array,
}
local json_data = {
["data"] = input_data
}
request_body = json:encode (json_data)
local response_body = {}
local res, code, response_headers = http.request{
url = endpoint,
method = "POST",
headers =
{
["Content-Type"] = "application/json";
["Content-Length"] = #request_body;
},
source = ltn12.source.string(request_body),
sink = ltn12.sink.table(response_body),
}
以下是 Rust 中的示例客户端。
以下是 Swift 中的示例客户端。
以下是 Perl 中的示例客户端。
my $endpoint = "http://127.0.0.1:8500";
my $json = '{"data": {"keys": [[11.0], [2.0]], "features": [[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1]]}}';
my $req = HTTP::Request->new( 'POST', $endpoint );
$req->header( 'Content-Type' => 'application/json' );
$req->content( $json );
$ua = LWP::UserAgent->new;
$response = $ua->request($req);
以下是 Lisp 中的示例客户端。
以下是 Haskell 中的示例客户端。
以下是 Clojure 中的示例客户端。
以下是 R 中的示例客户端。
endpoint <- "http://127.0.0.1:8500"
body <- list(data = list(a = 1), keys = 1)
json_data <- list(
data = list(
keys = list(list(1.0), list(2.0)), features = list(list(1, 1, 1, 1, 1, 1, 1, 1, 1), list(1, 1, 1, 1, 1, 1, 1, 1, 1))
)
)
r <- POST(endpoint, body = json_data, encode = "json")
stop_for_status(r)
content(r, "parsed", "text/html")
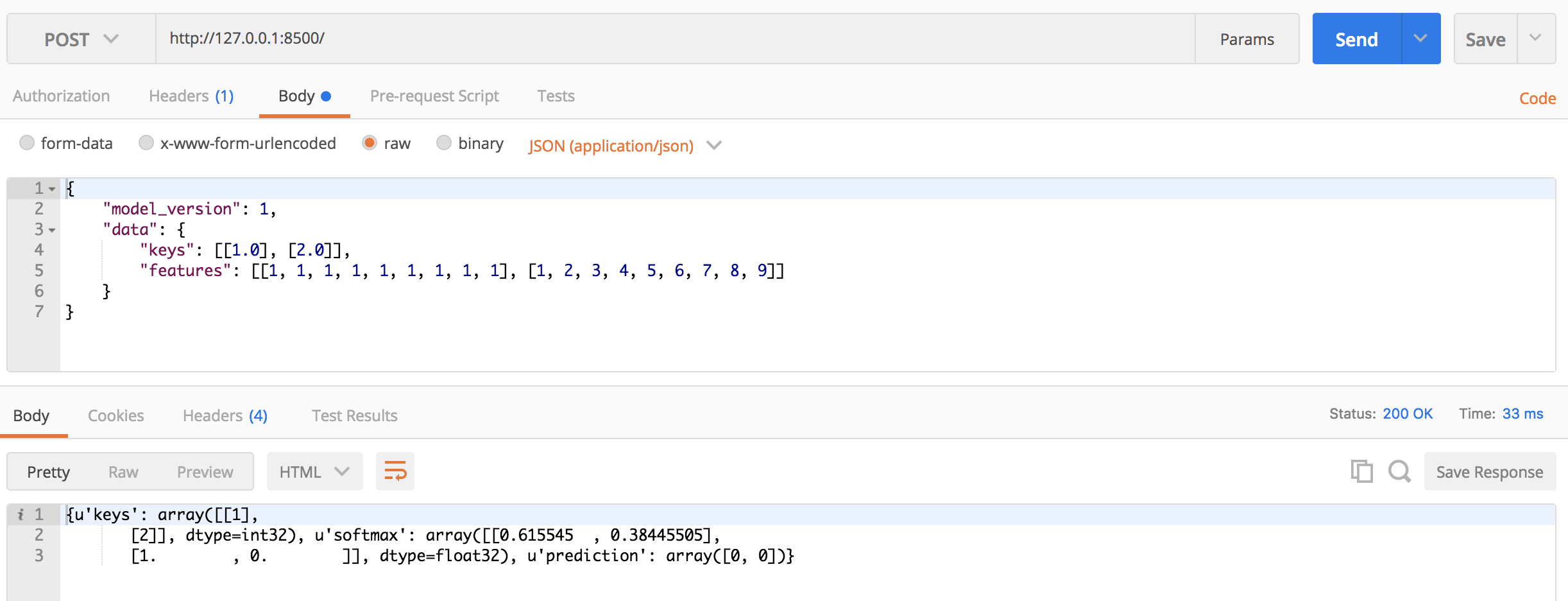
以下是 Postman 的示例。
性能
你可以使用任何 WSGI 服务器来运行 SimpleTensorFlowServing,以获得更好的性能。我们已经进行了基准测试,并与 TensorFlow Serving 进行了比较。更多详细信息请参见 benchmark。
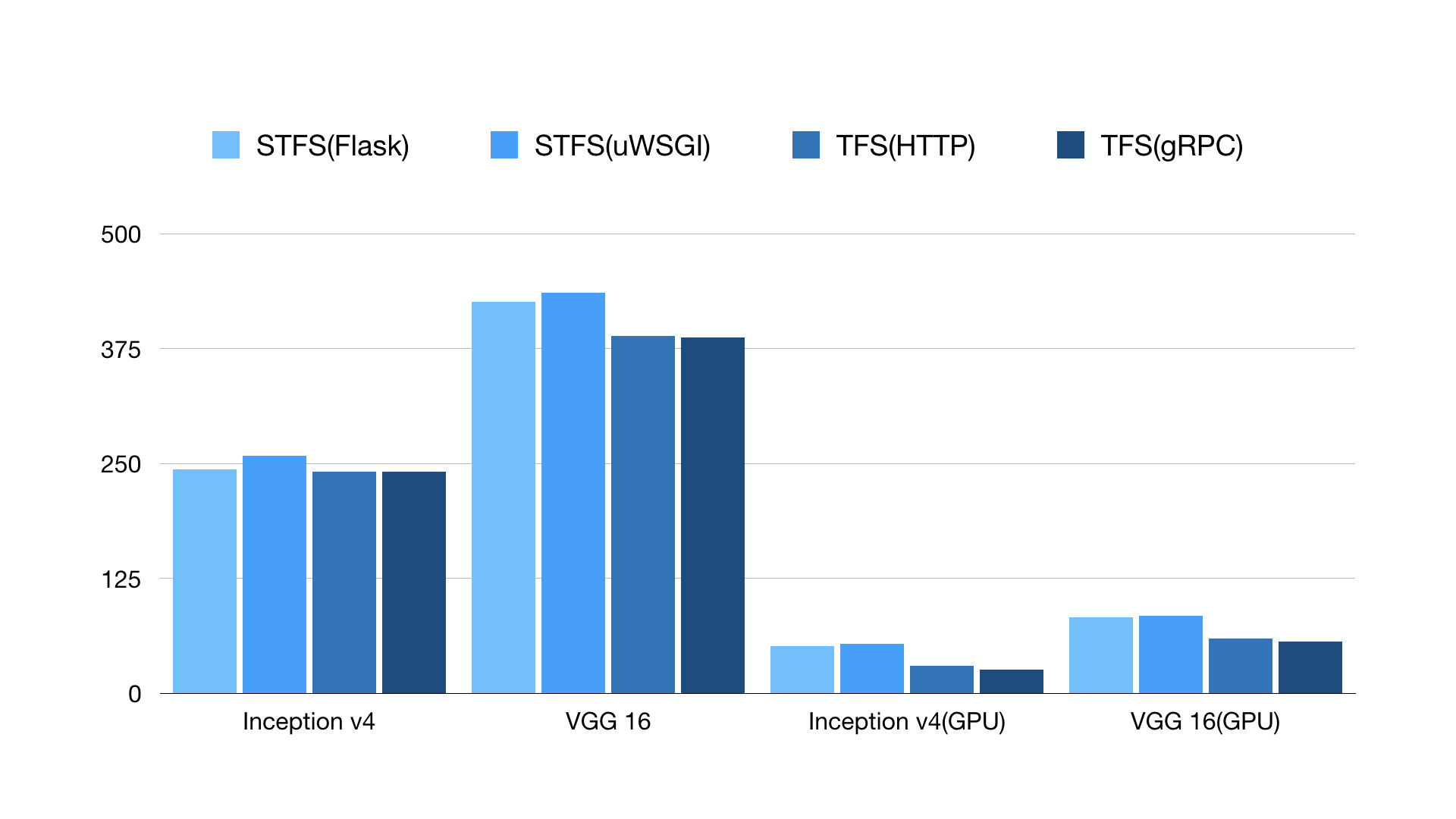
对于不同的模型,STFS(Simple TensorFlow Serving)和 TFS(TensorFlow Serving)的性能相似。纵坐标是推理延迟(微秒),越低越好。
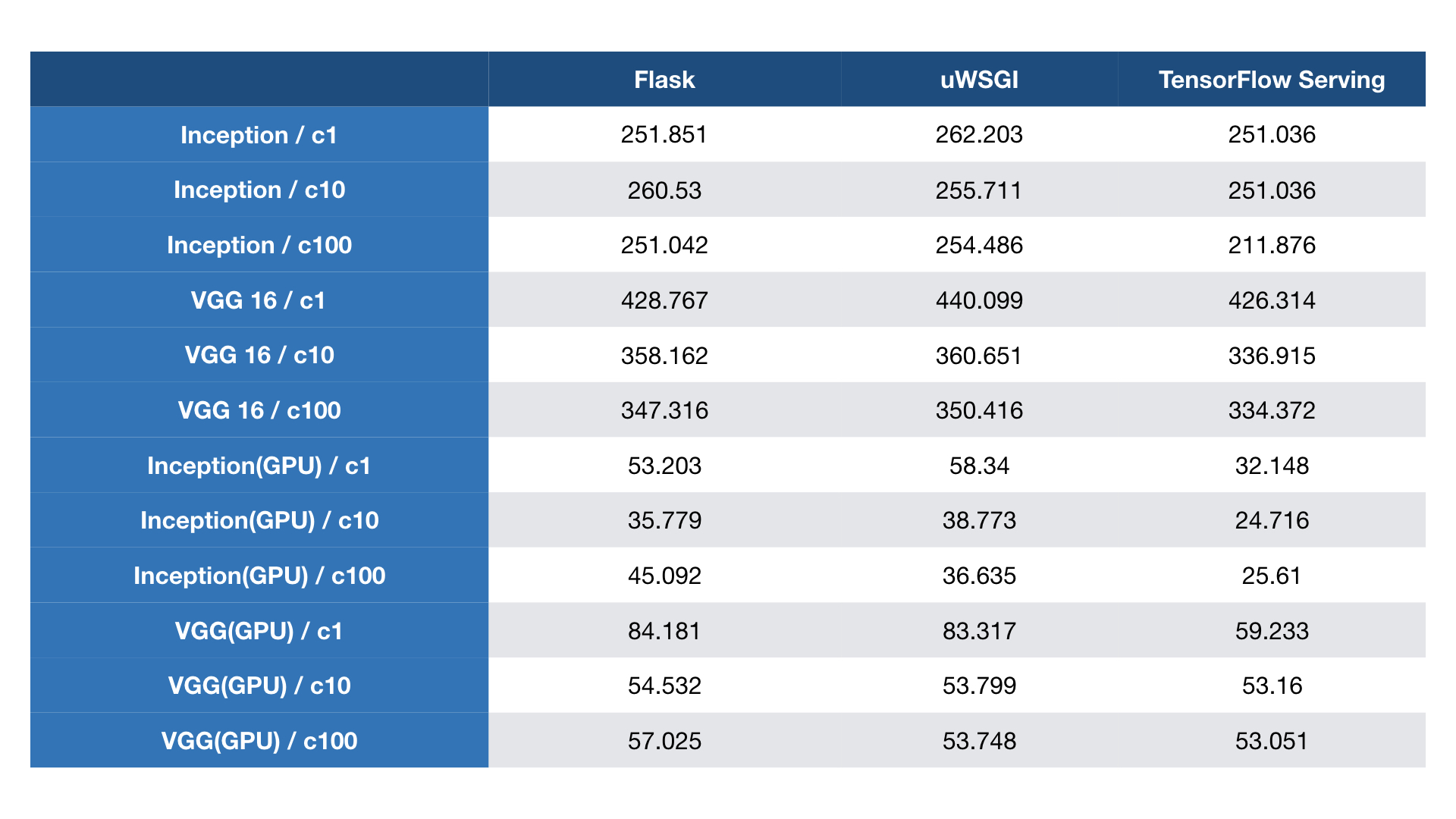
然后我们使用 ab 工具在 CPU 和 GPU 上测试并发客户端。TensorFlow Serving 在 GPU 上表现得更好。
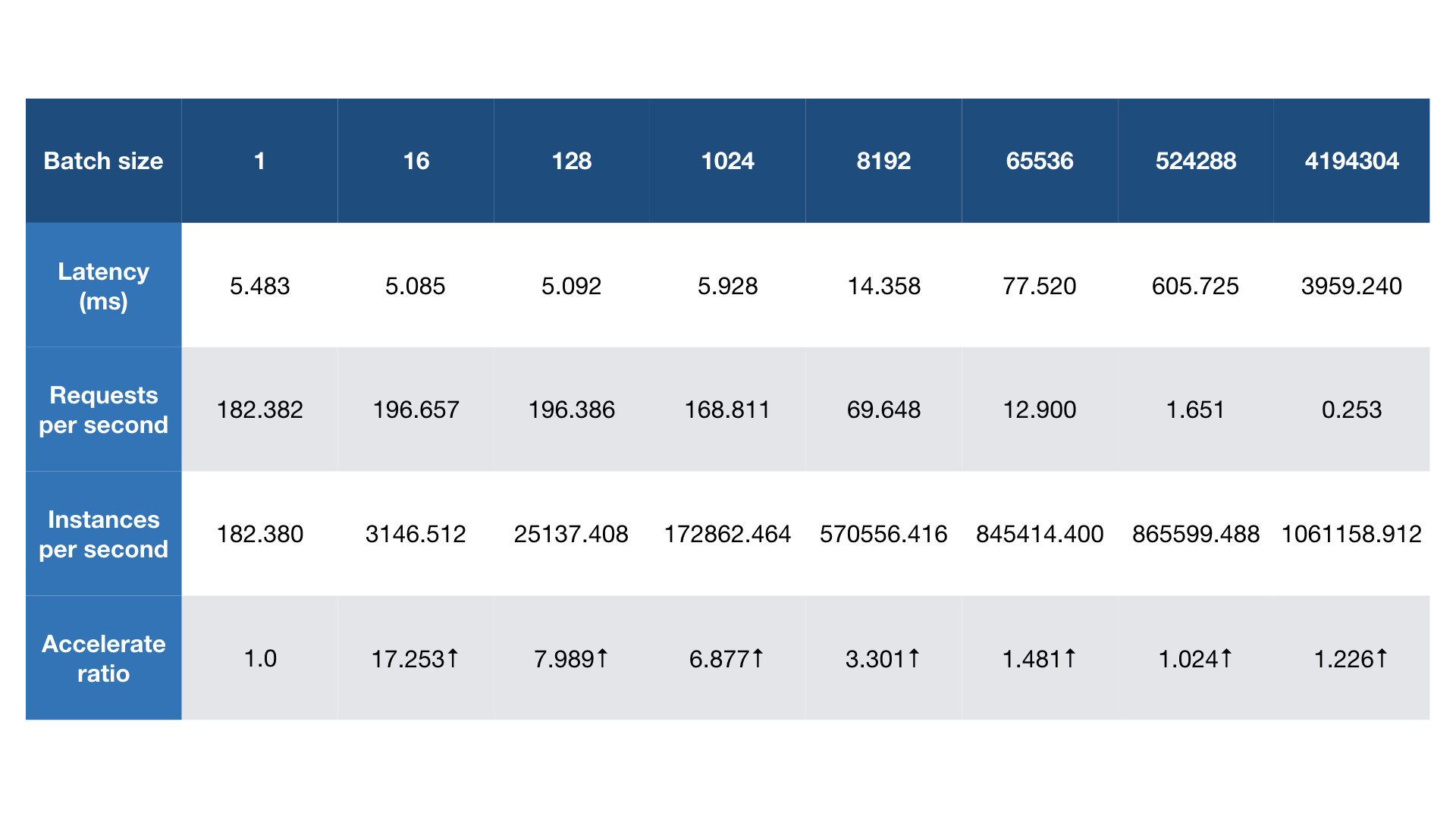
对于 最简单的模型,每个请求仅需约 1.9 微秒,而一个 Simple TensorFlow Serving 实例可以达到 5000+ QPS。通过增加批处理大小,每秒可以推理超过 100 万个实例。
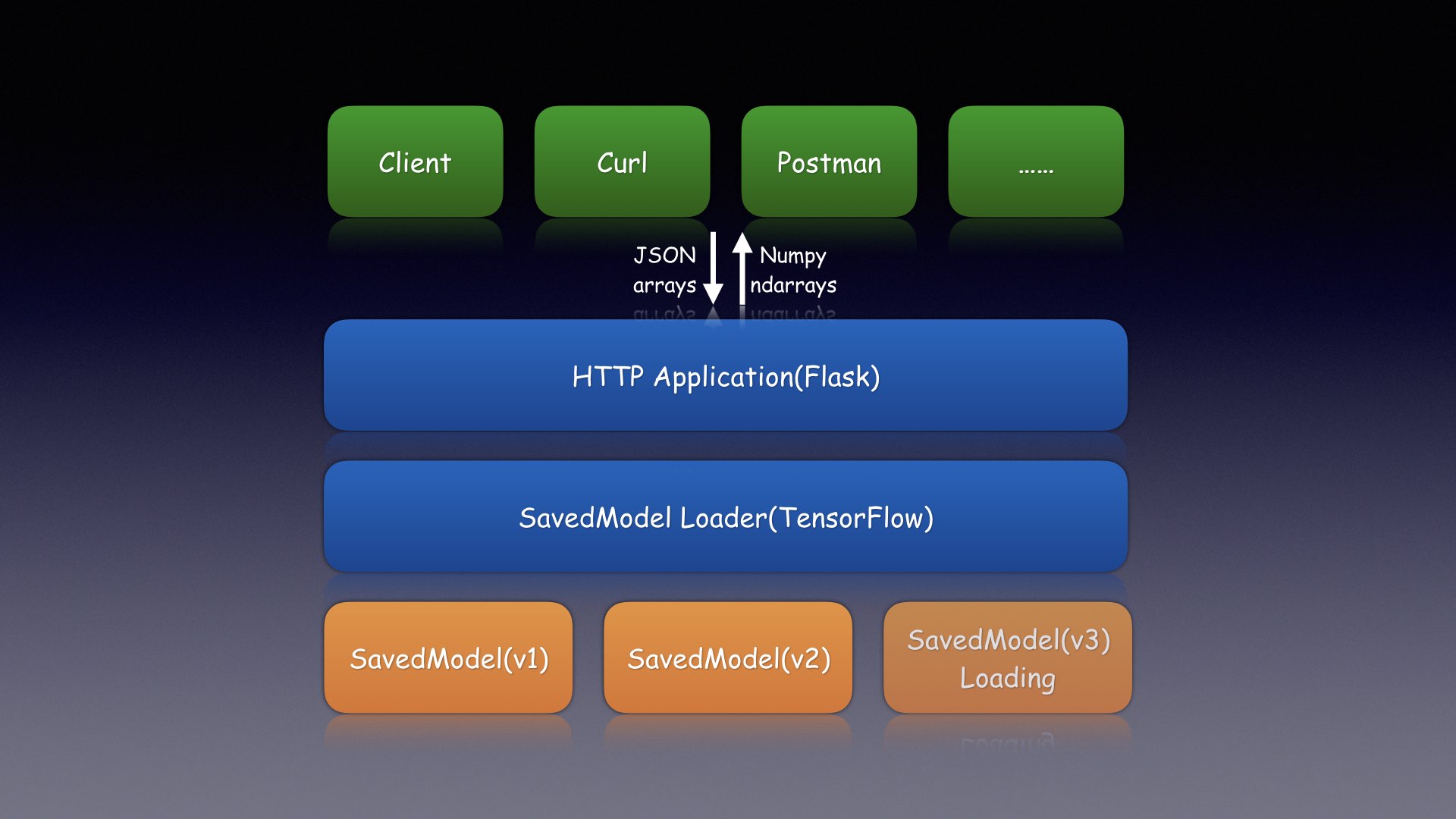
工作原理
simple_tensorflow_serving使用flask应用程序启动 HTTP 服务器。- 使用 Python API
tf.saved_model.loader加载 TensorFlow 模型。 - 根据请求的 JSON 主体构造 feed_dict 数据。
// 方法:POST,内容类型:application/json { "model_version": 1, // 可选 "data": { "keys": [[1], [2]], "features": [[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0], [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0]] } } - 使用 TensorFlow Python API 通过 feed_dict 数据执行
sess.run()。 - 对于支持多个版本的情况,会启动独立线程来加载模型。
- 对于生成的客户端,它会读取用户的模型,并使用 Jinja 模板渲染代码。
贡献
欢迎为该项目提交问题或拉取请求。非常欢迎添加更多语言的客户端,以便访问 TensorFlow 模型。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备