TurboDiffusion
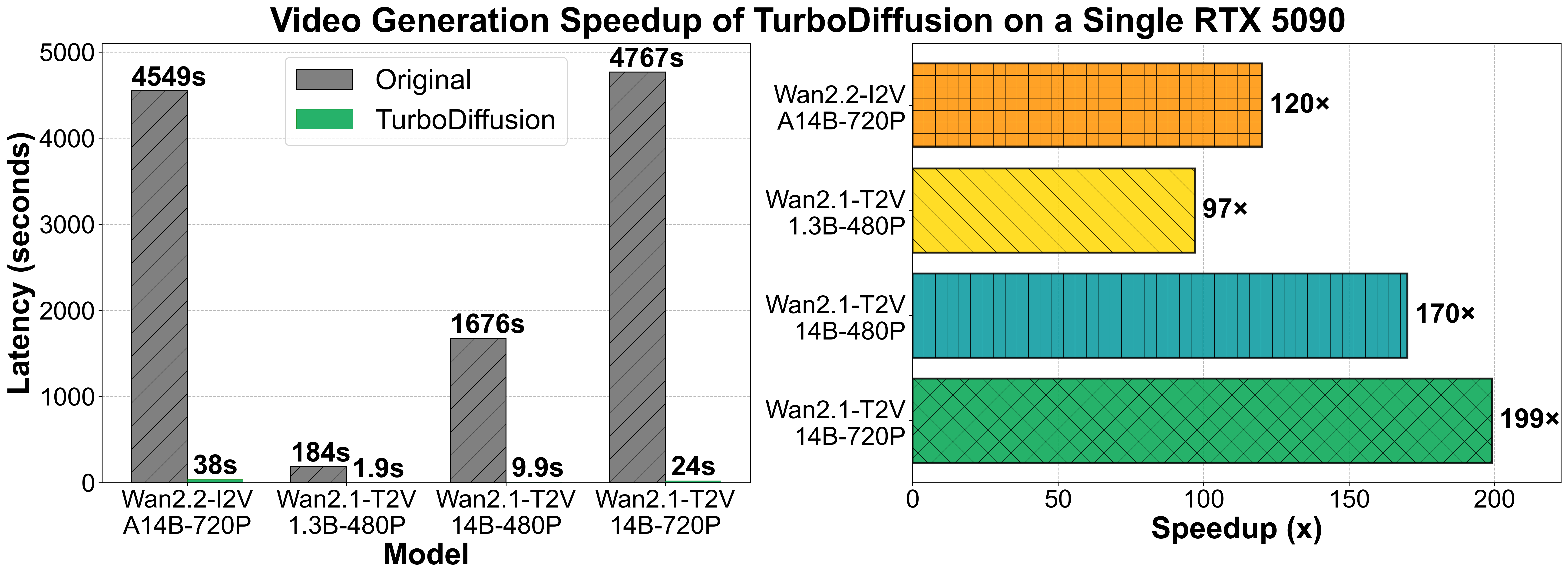
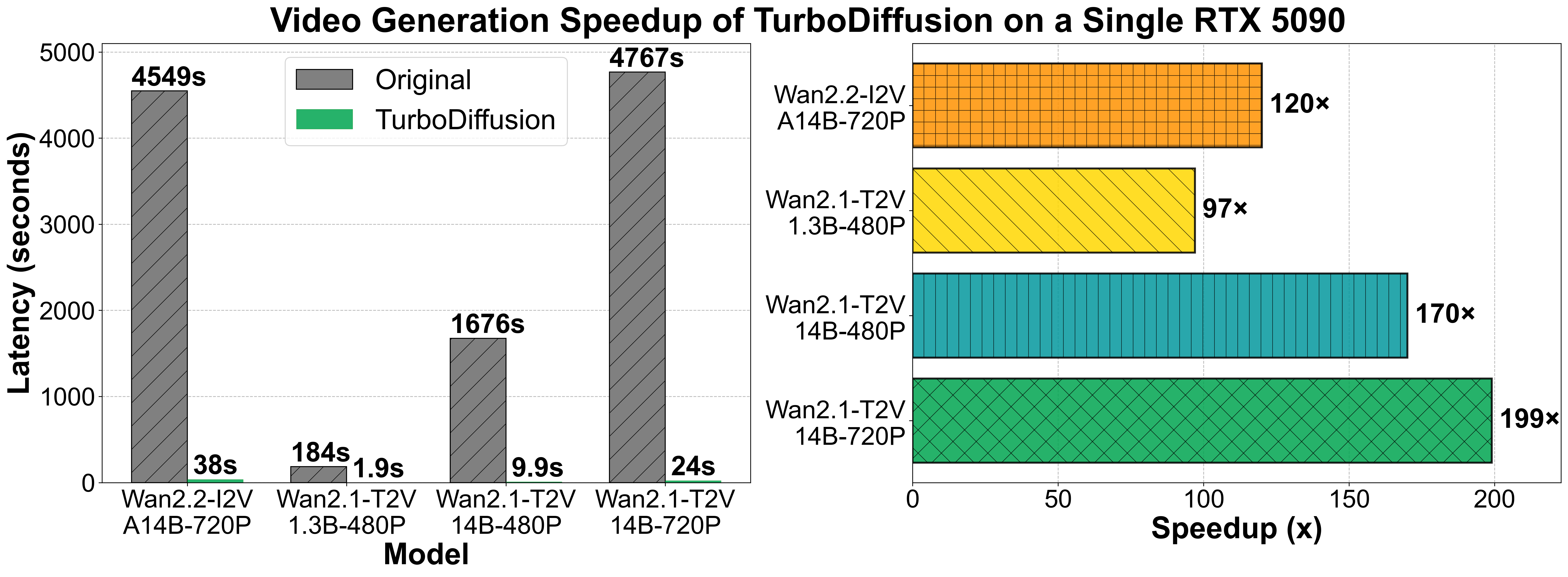
TurboDiffusion 是一款专为视频扩散模型打造的高效加速框架,旨在解决当前 AI 视频生成速度缓慢、耗时过长的核心痛点。通过在单张 RTX 5090 显卡上的实测,它能将端到端的视频生成速度提升 100 至 200 倍,把原本需要数分钟甚至更久的渲染过程压缩至秒级(例如生成一段 5 秒视频仅需约 1.9 秒),同时依然保持出色的画面质量。
这一工具特别适合需要快速迭代创意的视频设计师、希望降低计算成本的研究人员,以及追求高效工作流的开发者。其独特的技术亮点在于巧妙融合了多种前沿优化方案:利用 SageAttention 和 SLA(稀疏线性注意力)机制大幅加速注意力计算,并采用 rCM 技术进行时间步蒸馏,从而在极少的采样步数下实现高质量输出。目前,TurboDiffusion 已支持基于 Wan2.1 和 Wan2.2 系列的多个模型版本,涵盖文生视频与图生视频任务,并提供针对不同显存配置的量化与非量化检查点。需要注意的是,当前模型针对长英文提示词进行了优化,使用时建议配合相应的提示词策略以获得最佳效果。随着项目的持续更新,其生成质量与兼容性还将进一步提升。
使用场景
某短视频创作团队需要为电商大促快速生成大量高质量商品展示视频,以测试不同营销文案的视觉转化效果。
没有 TurboDiffusion 时
- 迭代周期漫长:在单张 RTX 4090/5090 显卡上生成一个 5 秒高清视频需耗时约 3 分钟(184 秒),一天仅能产出少量样本,无法应对紧急的营销节点。
- 创意验证受阻:由于单次生成成本过高,策划人员不敢随意尝试长篇幅或复杂的英文提示词,导致创意被局限在安全但平庸的范围内。
- 硬件资源瓶颈:若要并行生成多个视频进行 A/B 测试,必须租用昂贵的多卡集群,大幅推高了初创团队的运营成本。
- 反馈链路断裂:从“构思文案”到“看到画面”的等待时间过长,打断了创作者的心流,难以根据即时效果微调视频细节。
使用 TurboDiffusion 后
- 实时生成体验:借助 SageAttention 和 rCM 蒸馏技术,同一硬件环境下生成时间从 184 秒骤降至 1.9 秒,实现近乎实时的视频产出。
- 创意自由爆发:极速反馈让团队可以大胆使用详细的长英文提示词,快速遍历数十种分镜风格,精准锁定最佳视觉方案。
- 单机胜任量产:单张消费级显卡即可承担原本需要集群的任务,团队无需额外投入硬件预算,即可完成大规模视频素材制作。
- 工作流无缝闭环:创作者可像调整图片参数一样即时调整视频内容,实现了“修改提示词 - 即刻预览 - 再次优化”的高效闭环。
TurboDiffusion 将视频扩散模型的推理速度提升了 100 至 200 倍,彻底打破了 AI 视频生成的时效壁垒,让高质量视频创作真正进入“秒级”时代。
运行环境要求
- 未说明
- 必需 NVIDIA GPU
- 推荐 RTX 5090/4090(需使用量化模型,显存需求较低)或 H100(需使用非量化模型,显存需 >40GB)
未说明
快速开始
TurboDiffusion
本仓库提供了 TurboDiffusion 的官方实现,这是一个视频生成加速框架,在单张 RTX 5090 显卡上可将端到端扩散模型生成速度提升 $100 \sim 200\times$,同时保持视频质量。
TurboDiffusion 主要使用 SageAttention、SLA(稀疏线性注意力) 进行注意力机制加速,并采用 rCM(时间步蒸馏) 来进一步优化。
论文:TurboDiffusion: 将视频扩散模型加速 100–200 倍
注意:当前的模型仅在 长英文提示词 上进行训练。若使用其他类型的提示词,请对其进行扩充以获得更好的效果。
检查点和论文尚未最终定稿,后续会持续更新以提升质量。
|
原始,端到端耗时:184秒
 |
TurboDiffusion,端到端耗时:1.9秒
 |
可用模型
| 模型名称 | 检查点链接 | 最佳分辨率 |
|---|---|---|
TurboWan2.2-I2V-A14B-720P |
Huggingface 模型 | 720p |
TurboWan2.1-T2V-1.3B-480P |
Huggingface 模型 | 480p |
TurboWan2.1-T2V-14B-480P |
Huggingface 模型 | 480p |
TurboWan2.1-T2V-14B-720P |
Huggingface 模型 | 720p |
注意:所有检查点均支持生成 480p 或 720p 分辨率的视频。“最佳分辨率”一栏表示该模型在该分辨率下能提供最佳的视频质量。
安装
基础环境:python>=3.9,torch>=2.7.0。建议使用 torch==2.8.0,因为更高版本可能导致显存不足(OOM)。
通过 pip 安装 TurboDiffusion:
conda create -n turbodiffusion python=3.12
conda activate turbodiffusion
pip install turbodiffusion --no-build-isolation
或从源码编译:
git clone https://github.com/thu-ml/TurboDiffusion.git
cd TurboDiffusion
git submodule update --init --recursive
pip install -e . --no-build-isolation
若需启用 SageSLA——基于 SageAttention 的快速 SLA 前向传播——请先安装 SpargeAttn:
pip install git+https://github.com/thu-ml/SpargeAttn.git --no-build-isolation
推理
对于显存大于 40GB 的 GPU,例如 H100,请使用未量化检查点(不含 -quant),并在命令中移除 --quant_linear。而对于 RTX 5090、RTX 4090 或类似显卡,请使用量化检查点(含 -quant),并在命令中添加 --quant_linear。
下载 VAE(适用于 Wan2.1 和 Wan2.2)以及 umT5 文本编码器检查点:
mkdir checkpoints cd checkpoints wget https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B/resolve/main/Wan2.1_VAE.pth wget https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B/resolve/main/models_t5_umt5-xxl-enc-bf16.pth下载我们的量化模型检查点(适用于 RTX 5090 或类似显卡):
# 对于 Wan2.1-T2V-1.3B wget https://huggingface.co/TurboDiffusion/TurboWan2.1-T2V-1.3B-480P/resolve/main/TurboWan2.1-T2V-1.3B-480P-quant.pth # 对于 Wan2.2-I2V-14B wget https://huggingface.co/TurboDiffusion/TurboWan2.2-I2V-A14B-720P/resolve/main/TurboWan2.2-I2V-A14B-high-720P-quant.pth wget https://huggingface.co/TurboDiffusion/TurboWan2.2-I2V-A14B-720P/resolve/main/TurboWan2.2-I2V-A14B-low-720P-quant.pth或者下载我们的未量化模型检查点(适用于 H100 或类似显卡):
# 对于 Wan2.1-T2V-1.3B wget https://huggingface.co/TurboDiffusion/TurboWan2.1-T2V-1.3B-480P/resolve/main/TurboWan2.1-T2V-1.3B-480P.pth # 对于 Wan2.2-I2V-14B wget https://huggingface.co/TurboDiffusion/TurboWan2.2-I2V-A14B-720P/resolve/main/TurboWan2.2-I2V-A14B-high-720P.pth wget https://huggingface.co/TurboDiffusion/TurboWan2.2-I2V-A14B-720P/resolve/main/TurboWan2.2-I2V-A14B-low-720P.pth使用 T2V 模型的推理脚本:
export PYTHONPATH=turbodiffusion # 参数说明: # --dit_path 微调后的 TurboDiffusion 检查点路径 # --model 使用的模型:Wan2.1-1.3B 或 Wan2.1-14B(默认:Wan2.1-1.3B) # --num_samples 生成视频的数量(默认:1) # --num_steps 采样步数,1–4 步(默认:4) # --sigma_max rCM 的初始 sigma 值(默认:80);数值越大(如 1600),多样性会降低,但可能提升质量 # --vae_path Wan2.1 VAE 的路径(默认:checkpoints/Wan2.1_VAE.pth) # --text_encoder_path umT5 文本编码器的路径(默认:checkpoints/models_t5_umt5-xxl-enc-bf16.pth) # --num_frames 生成的帧数(默认:81) # --prompt 视频生成的文本提示 # --resolution 输出分辨率:“480p” 或 “720p”(默认:480p) # --aspect_ratio 宽高比,格式为 W:H(默认:16:9) # --seed 随机种子,用于结果可重复性(默认:0) # --save_path 输出文件路径及扩展名(默认:output/generated_video.mp4) # --attention_type 使用的注意力模块:原生、SLA 或 SageSLA(默认:SageSLA) # --sla_topk SLA/SageSLA 注意力的 top-k 比例(默认:0.1),建议设置为 0.15 以获得更好的视频质量 # --quant_linear 启用线性层量化,使用量化检查点时需传递此参数 # --default_norm 使用 Wan 模型原有的 LayerNorm 和 RMSNorm
python turbodiffusion/inference/wan2.1_t2v_infer.py
--model Wan2.1-1.3B
--dit_path checkpoints/TurboWan2.1-T2V-1.3B-480P-quant.pth
--resolution 480p
--prompt "一位时尚的女性走在东京的一条街道上,街道上布满了温暖明亮的霓虹灯和动态的城市广告牌。她身穿黑色皮夹克、红色长裙和黑色靴子,手提黑色手袋,戴着太阳镜和红唇膏。她步伐自信而随意。街道湿润发亮,倒映着五彩斑斓的灯光,宛如一面镜子。街上行人来来往往。"
--num_samples 1
--num_steps 4
--quant_linear
--attention_type sagesla
--sla_topk 0.1
```
或者用于 **I2V** 模型的脚本:
```bash
export PYTHONPATH=turbodiffusion
# --image_path 输入图像的路径
# --high_noise_model_path 高噪声 TurboDiffusion 检查点的路径
# --low_noise_model_path 低噪声 TurboDiffusion 检查点的路径
# --boundary 切换高噪声模型与低噪声模型的时间步边界(默认:0.9)
# --model 使用的模型:Wan2.2-A14B(默认:Wan2.2-A14B)
# --num_samples 生成视频的数量(默认:1)
# --num_steps 采样步数,1–4步(默认:4)
# --sigma_max rCM 的初始 sigma 值(默认:200);较大的值(如 1600)会降低多样性,但可能提升质量
# --vae_path Wan2.2 VAE 的路径(默认:checkpoints/Wan2.2_VAE.pth)
# --text_encoder_path umT5 文本编码器的路径(默认:checkpoints/models_t5_umt5-xxl-enc-bf16.pth)
# --num_frames 生成的帧数(默认:81)
# --prompt 视频生成的文本提示
# --resolution 输出分辨率:“480p”或“720p”(默认:720p)
# --aspect_ratio 宽高比,格式为 W:H(默认:16:9)
# --adaptive_resolution 根据输入图像大小启用自适应分辨率
# --ode 使用 ODE 进行采样(更清晰但不如 SDE 稳健)
# --seed 随机种子,用于结果的可重复性(默认:0)
# --save_path 输出文件路径,包含扩展名(默认:output/generated_video.mp4)
# --attention_type 使用的注意力模块:original、sla 或 sagesla(默认:sagesla)
# --sla_topk SLA/SageSLA 注意力的 top-k 比例(默认:0.1),建议设置为 0.15 以获得更好的视频质量
# --quant_linear 启用线性层量化,若使用量化检查点则需传递此参数
# --default_norm 使用 Wan 模型原有的 LayerNorm 和 RMSNorm
python turbodiffusion/inference/wan2.2_i2v_infer.py \
--model Wan2.2-A14B \
--low_noise_model_path checkpoints/TurboWan2.2-I2V-A14B-low-720P-quant.pth \
--high_noise_model_path checkpoints/TurboWan2.2-I2V-A14B-high-720P-quant.pth \
--resolution 720p \
--adaptive_resolution \
--image_path assets/i2v_inputs/i2v_input_0.jpg \
--prompt "第一人称自拍视角视频,极其凌乱且速度极快。一只戴着太阳镜的白猫站在冲浪板上,神情淡定,突然冲浪板猛地侧滑,猫和相机一同跌入水中;画面急剧下坠,被汹涌的气泡、旋转的湍流和模糊的水痕吞没,仿佛相机仍在下沉。阴影渐浓,压力波使画面边缘扭曲变形,松散的气泡从镜头旁飞速向上涌动,显示相机仍在继续下落。随后,猫猛然跃起,带着镜头穿过翻滚的气泡和迅速变亮的水面,阳光重新洒满四周;相机急速上升,水流从镜头上飞溅而下,最终在一阵耀眼的光芒和水花中冲出水面,画面瞬间恢复成歪斜而狂乱的自拍,猫也重新浮出水面。" \
--num_samples 1 \
--num_steps 4 \
--quant_linear \
--attention_type sagesla \
--sla_topk 0.1 \
--ode
```
通过终端进行的交互式推理可在 `turbodiffusion/serve/` 中使用。这允许进行多轮视频生成,而无需重新加载模型。
评估
我们在 单块 RTX 5090 显卡 上对视频生成进行了评估。E2E 时间指端到端扩散生成延迟,不包括文本编码和 VAE 解码。
万-2.2-I2V-A14B-720P
|
原版,端到端时间:4549秒
 |
TurboDiffusion,端到端时间:38秒
 |
|
原版,端到端时间:4549秒
 |
TurboDiffusion,端到端时间:38秒
 |
|
原版,端到端时间:4549秒
 |
TurboDiffusion,端到端时间:38秒
 |
|
原版,端到端时间:4549秒
 |
TurboDiffusion,端到端时间:38秒
 |
|
原版,端到端时间:4549秒
 |
TurboDiffusion,端到端时间:38秒
 |
|
原版,端到端时间:4549秒
 |
TurboDiffusion,端到端时间:38秒
 |
|
原版,端到端时间:4549秒
 |
TurboDiffusion,端到端时间:38秒
 |
万-2.1-T2V-1.3B-480P
|
原版,端到端时间:184秒
 |
FastVideo,端到端时间:5.3秒
 |
TurboDiffusion,端到端时间:1.9秒
 |
|
原版,端到端时间:184秒
 |
FastVideo,端到端时间:5.3秒
 |
TurboDiffusion,端到端时间:1.9秒
 |
|
原版,端到端时间:184秒
 |
FastVideo,端到端时间:5.3秒
 |
TurboDiffusion,端到端时间:1.9秒
 |
|
原版,端到端时间:184秒
 |
FastVideo,端到端时间:5.3秒
 |
TurboDiffusion,端到端时间:1.9秒
 |
|
原版,端到端时间:184秒
 |
FastVideo,端到端时间:5.3秒
 |
TurboDiffusion,端到端时间:1.9秒
 |
|
原版,端到端时间:184秒
|
FastVideo,端到端时间:5.3秒
 |
TurboDiffusion,端到端时间:1.9秒
|
|
原版,端到端时间:184秒
 |
FastVideo,端到端时间:5.3秒
 |
TurboDiffusion,端到端时间:1.9秒
 |
|
原版,端到端时间:184秒
 |
FastVideo,端到端时间:5.3秒
 |
TurboDiffusion,端到端时间:1.9秒
 |
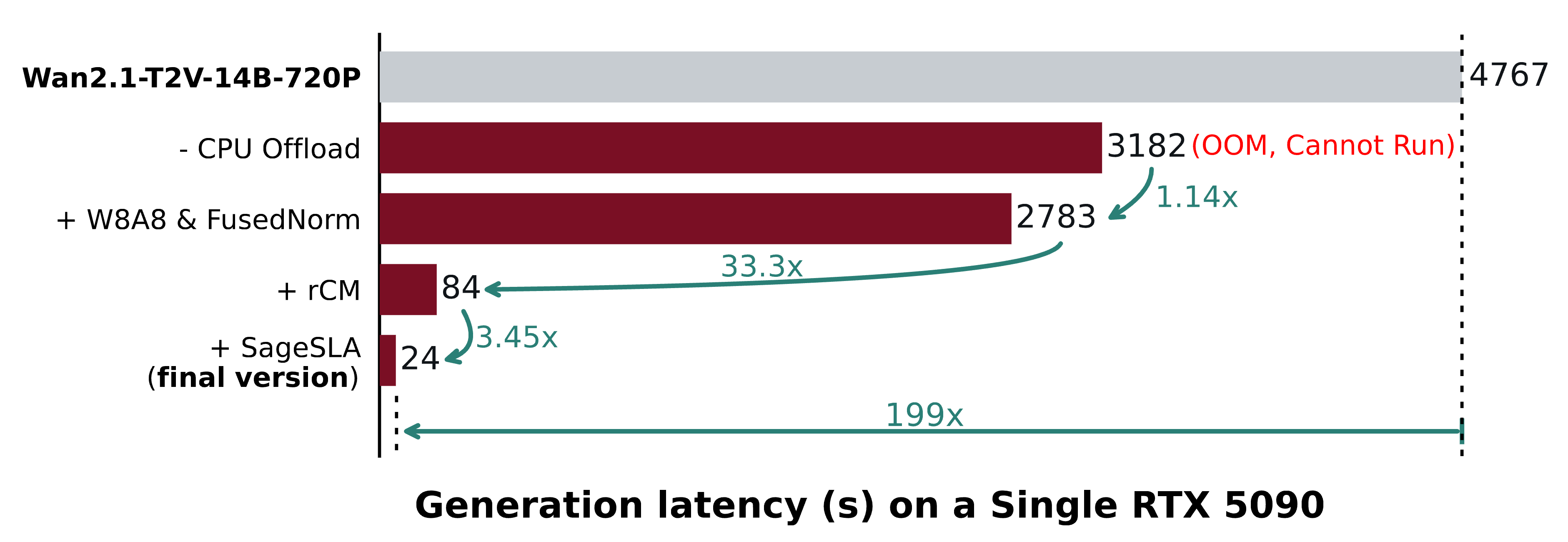
万-2.1-T2V-14B-720P
|
原版,端到端时间:4767秒
 |
FastVideo,端到端时间:72.6秒
 |
TurboDiffusion,端到端时间:24秒
 |
|
原版,端到端时间:4767秒
 |
FastVideo,端到端时间:72.6秒
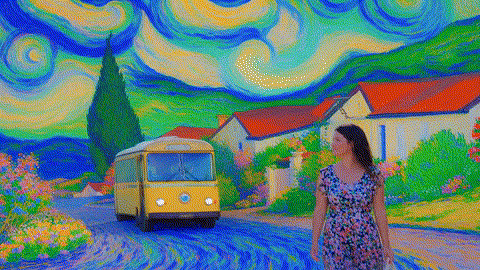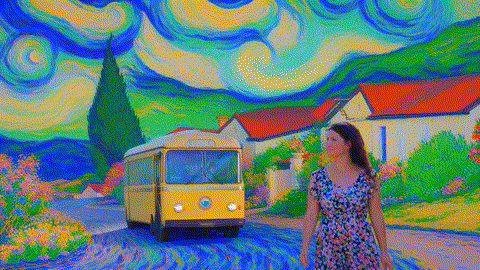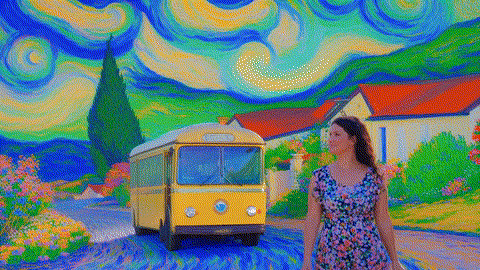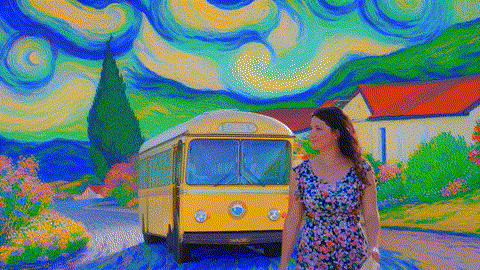 |
TurboDiffusion,端到端时间:24秒
 |
|
原版,端到端时间:4767秒
 |
FastVideo,端到端时间:72.6秒
 |
TurboDiffusion,端到端时间:24秒
 |
万-2.1-T2V-14B-480P
|
原版,端到端时间:1676秒
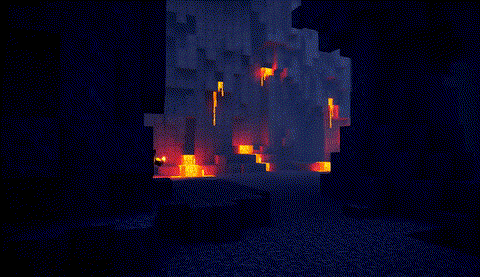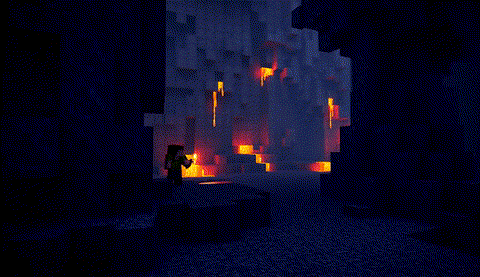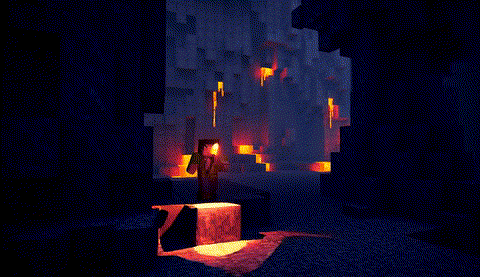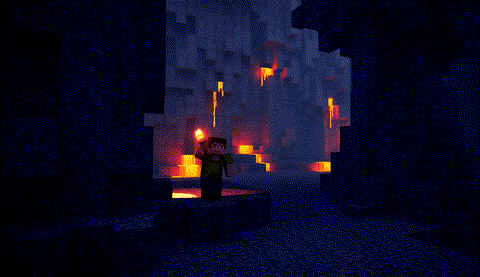 |
FastVideo,端到端时间:26.3秒
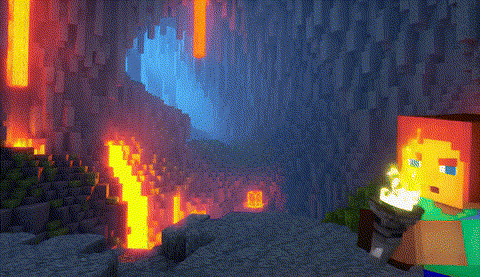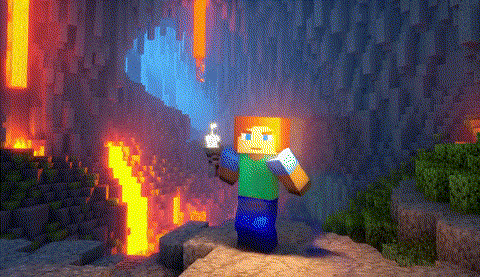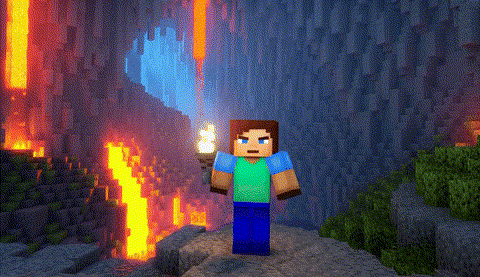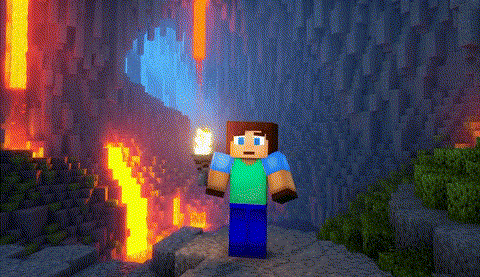 |
TurboDiffusion,端到端时间:9.9秒
 |
|
原版,端到端时间:1676秒
 |
FastVideo,端到端时间:26.3秒
 |
TurboDiffusion,端到端时间:9.9秒
 |
|
原版,端到端时间:1676秒
 |
FastVideo,端到端时间:26.3秒
 |
TurboDiffusion,端到端时间:9.9秒
 |
|
原版,端到端时间:1676秒
 |
FastVideo,端到端时间:26.3秒
 |
TurboDiffusion,端到端时间:9.9秒
 |
训练
在这个仓库中,我们提供了基于Wan2.1及其合成数据的训练代码。训练基于rCM代码库(https://github.com/NVlabs/rcm),并得到了FSDP2、Ulysses CP和选择性激活检查点(SAC)等基础设施的支持。有关rCM训练的说明,请参阅原始rCM仓库;SLA(稀疏线性注意力)的训练指南则在此处提供。
额外安装
对于rCM/SLA训练,还需运行以下命令:
pip install megatron-core hydra-core wandb webdataset
pip install --no-build-isolation transformer_engine[pytorch]
检查点下载
将Wan2.1预训练检查点以.pth格式以及VAE/文本编码器下载至assets/checkpoints目录:
# 确保已安装git lfs
git clone https://huggingface.co/worstcoder/Wan assets/checkpoints
FSDP2依赖于分布式检查点(DCP)来加载和保存检查点。在开始训练之前,需先将.pth格式的教师检查点转换为.dcp格式:
python -m torch.distributed.checkpoint.format_utils torch_to_dcp assets/checkpoints/Wan2.1-T2V-1.3B.pth assets/checkpoints/Wan2.1-T2V-1.3B.dcp
训练结束后,保存的.dcp检查点可以使用脚本scripts/dcp_to_pth.py转换回.pth格式。
数据集下载
我们提供了Wan2.1-14B合成数据集。使用以下命令将其下载至assets/datasets目录:
# 确保已安装git lfs
git clone https://huggingface.co/datasets/worstcoder/Wan_datasets assets/datasets
开始训练
我们通过使启用SLA的模型预测与全注意力预训练模型的预测相一致,实现了白盒SLA训练。与原始论文中的黑盒训练不同——后者是利用扩散损失对预训练模型进行调优——白盒训练能够缓解分布偏移问题,并且对训练数据的敏感度较低。
单节点训练示例:
WORKDIR="/path/to/TurboDiffusion"
cd $WORKDIR
export PYTHONPATH=turbodiffusion
# 环境变量 "IMAGINAIRE_OUTPUT_ROOT" 是用于保存实验输出文件的路径
export IMAGINAIRE_OUTPUT_ROOT=${WORKDIR}/outputs
CHECKPOINT_ROOT=${WORKDIR}/assets/checkpoints
DATASET_ROOT=${WORKDIR}/assets/datasets/Wan2.1_14B_480p_16:9_Euler-step100_shift-3.0_cfg-5.0_seed-0_250K
# 您的 Wandb 信息
export WANDB_API_KEY=xxx
export WANDB_ENTITY=xxx
registry=registry_sla
experiment=wan2pt1_1pt3B_res480p_t2v_SLA
torchrun --nproc_per_node=8 \
-m scripts.train --config=turbodiffusion/rcm/configs/${registry}.py -- experiment=${experiment} \
model.config.teacher_ckpt=${CHECKPOINT_ROOT}/Wan2.1-T2V-1.3B.dcp \
model.config.tokenizer.vae_pth=${CHECKPOINT_ROOT}/Wan2.1_VAE.pth \
model.config.text_encoder_path=${CHECKPOINT_ROOT}/models_t5_umt5-xxl-enc-bf16.pth \
model.config.neg_embed_path=${CHECKPOINT_ROOT}/umT5_wan_negative_emb.pt \
dataloader_train.tar_path_pattern=${DATASET_ROOT}/shard*.tar
请参考 turbodiffusion/rcm/configs/experiments/sla/wan2pt1_t2v.py 中的 14B 配置,或根据需要进行修改。
模型合并
可以通过 turbodiffusion/scripts/merge_models.py 将 SLA 训练得到的参数更新合并到 rCM 检查点中,从而使 rCM 能够执行稀疏注意力推理。请将 --base 指定为 rCM 模型,--diff_base 指定为预训练模型,--diff_target 指定为经过 SLA 微调的模型。
ComfyUI 集成
我们感谢社区的努力 Comfyui_turbodiffusion,他们将 TurboDiffusion 集成到了 ComfyUI 中。
路线图
我们正在积极开发以下功能和改进:
- 整理并发布训练代码
- 优化基础设施以支持扁平化上下文并行
- vLLM-Omni 集成
- 支持更多视频生成模型
- 支持自回归视频生成模型
- 更多硬件级算子优化
我们欢迎社区成员帮助维护和扩展 TurboDiffusion。欢迎加入 TurboDiffusion 团队,共同贡献!
引用
如果您使用了本代码或认为我们的工作有价值,请引用:
@article{zhang2025turbodiffusion,
title={TurboDiffusion: 加速视频扩散模型 100-200 倍},
author={张金涛、郑凯文、蒋凯、王浩旭、斯托伊卡、冈萨雷斯、陈建飞、朱俊},
journal={arXiv 预印本 arXiv:2512.16093},
year={2025}
}
@software{turbodiffusion2025,
title={TurboDiffusion: 加速视频扩散模型 100-200 倍},
author={TurboDiffusion 团队},
url={https://github.com/thu-ml/TurboDiffusion},
year={2025}
}
@inproceedings{zhang2025sageattention,
title={SageAttention: 精确的 8 位注意力机制,用于即插即用的推理加速},
author={张金涛、魏佳、张鹏乐、朱俊、陈建飞},
booktitle={国际表征学习大会 (ICLR)},
year={2025}
}
@article{zhang2025sla,
title={SLA: 通过可微调的稀疏线性注意力超越扩散 Transformer 中的稀疏性},
author={张金涛、王浩旭、蒋凯、杨硕、郑凯文、奚浩成、王子腾、朱洪洲、赵敏、斯托伊卡等},
journal={arXiv 预印本 arXiv:2509.24006},
year={2025}
}
@article{zheng2025rcm,
title={基于分数正则化的连续时间一致性的大规模扩散蒸馏},
author={郑凯文、王宇基、马千里、陈华宇、张金涛、巴拉吉、陈建飞、刘明宇、朱俊、张钦生},
journal={arXiv 预印本 arXiv:2510.08431},
year={2025}
}
@inproceedings{zhang2024sageattention2,
title={Sageattention2: 高效注意力机制,具有彻底的异常值平滑处理和每线程 int4 定点量化},
author={张金涛、黄浩峰、张鹏乐、魏佳、朱俊、陈建飞},
booktitle={国际机器学习大会 (ICML)},
year={2025}
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器