wdoc
wdoc 是一款强大的检索增强生成(RAG)系统,专为从海量异构文档中提炼摘要和精准问答而设计。它诞生于处理复杂多源信息的实际需求,旨在解决传统工具在面对音频、视频、PDF、电子书及 Anki 卡片等多种格式时,难以统一检索且容易产生“幻觉”回答的痛点。
无论是需要跨学科文献研究的学生、处理大量病例记录的医疗从业者,还是希望构建私有知识库的开发者,wdoc 都能提供极大帮助。其核心优势在于“高召回率”与“精准溯源”:系统能同时检索数万个不同格式的文档,通过巧妙的语义分批聚合技术,结合高低成本大语言模型协作,最终输出带有确切来源引用的 Markdown 格式答案,让每一条信息都有据可查。
此外,wdoc 具备极高的灵活性,支持接入几乎所有大模型服务商(包括本地部署模型),并提供基于 Gradio 的 Docker Web 界面,让用户无需编写代码即可轻松上手。它不仅是一个高效的查询工具,更是一个可扩展的开发库,甚至能作为插件集成到 Open-WebUI 等平台,是管理繁杂信息流的得力助手。
使用场景
某医学研究员需要同时分析数百份格式各异的资料(包括讲座录音、PDF 论文、EPUB 教科书及 Anki 卡片),以撰写一份关于新型抗抑郁药副作用的综述报告。
没有 wdoc 时
- 格式割裂严重:必须手动打开不同软件分别处理音频、视频和文档,无法在同一语境下交叉验证信息。
- 检索效率低下:面对海量资料,传统关键词搜索难以定位具体段落,常遗漏关键细节或混淆相似概念。
- 溯源困难重重:AI 生成的总结往往缺乏明确出处,研究员需花费数小时人工核对原文,以防“幻觉”误导结论。
- 总结流于表面:通用工具仅能提取泛泛的要点,无法还原作者深层的推导逻辑和临床思考过程。
使用 wdoc 后
- 异构数据融合:wdoc 直接 ingest 所有类型的文件,将录音、课件和文本统一索引,实现跨媒介的无缝查询。
- 高精度语义召回:利用高级 RAG 技术,wdoc 能从数万份文档中精准锁定相关片段,并自动聚合语义批次生成答案。
- 答案自带溯源:输出的 Markdown 回答不仅逻辑清晰,还精确标注了引用来源的具体段落,让每一条结论都可信可查。
- 深度逻辑提炼:wdoc 生成的摘要能还原作者的思维路径,帮助研究员快速掌握复杂的临床论证而非仅仅获取结论。
wdoc 通过将杂乱的多源异构数据转化为可追溯、有深度的知识网络,极大提升了专业领域从信息收集到决策制定的效率。
运行环境要求
- Linux
- macOS
- Windows
非必需(支持本地 LLM 及云端 API,具体取决于所选模型后端)
未说明(处理大量文档时建议较大内存)

快速开始
![]()
wdoc

我是wdoc。我解决RAG问题。
- wdoc,模仿温斯顿“狼”沃尔夫
wdoc是一个功能强大的RAG(检索增强生成)系统,旨在对多种文件类型的文档进行摘要、搜索和查询。它特别适用于处理大量不同类型的文档,因此非常适合研究人员、学生以及需要处理海量信息来源的专业人士。
wdoc由一位精神科住院医师创建,他需要一种方法能够同时从多个来源(音频录音、视频讲座、Anki闪卡、PDF、EPUB等)获取明确的答案。面对现有的用于查询和摘要的RAG解决方案,他感到十分沮丧,于是便诞生了wdoc。
(在线文档可以在这里找到 https://wdoc.readthedocs.io/en/stable)
目标与项目规格:
wdoc的目标是为异构语料库中的问题生成完全实用的摘要和完全实用的带来源答案。它能够同时查询跨越多种文件类型的数万份文档。该项目还包含一个有观点的摘要功能,帮助用户高效地跟进大量信息。它主要使用LangChain和LiteLLM作为后端。当前状态:可用、经过测试、仍在积极开发中、计划添加数十项功能
- 我暂时没有停止开发的打算,所以如果你觉得它很有前景,请继续关注,因为我还有很多改进计划(见路线图部分)。
- 用户的测试对我帮助很大,因为这是我发现并快速修复许多小bug的最快方式。
- 主分支比开发分支更稳定,而开发分支则提供了更多功能。
- 欢迎提出功能请求和拉取请求。所有反馈,包括错别字报告,都将不胜感激。
- 请在提交PR之前先打开一个问题,因为可能已经有正在进行的改进。
关键特性:
- Docker Web UI:通过基于Gradio的Web界面,无需CLI交互即可轻松部署,简化文档处理流程。
- 高召回率和高特异性:它被设计用来通过精心设计的嵌入式搜索找到大量文档,然后利用语义批处理逐步聚合每个答案,最终生成一条引用来源并指向源文档确切位置的回答。
- 同时使用昂贵和廉价的LLM,以尽可能提高召回率,因为我们有能力在每次查询中抓取大量文档(通过嵌入)。
- 支持几乎任何LLM提供商,包括本地模型,甚至还能为超级机密内容提供额外的安全层。
- 目标是支持任何文件类型,并能同时从所有这些类型中进行查询(目前已实现15种以上!)
- 真正实用的AI驱动摘要:获取作者的思考过程,而不是模糊不清的要点总结。
- 真正实用的AI驱动查询:针对你的问题给出带有来源的缩进Markdown格式回答,而不是幻觉般的胡言乱语。
- 可扩展性:这既是一个工具,也是一个库。它甚至被改造成了Open-WebUI工具。此外,还提供了一个基于Docker的Web UI,方便部署。
- 网络搜索:初步支持使用DuckDuckGo进行网络搜索(通过ddgs库)
目录
全面参考
涵盖所有CLI参数、环境变量、文件类型以及完整Python API的单页综合参考资料可以在**SKILL.md**中找到。
说明性图表
为赶时间的人准备的超短指南
直接给我答案,我赶时间!
注:示例列表可在 examples.md 中找到
Docker 快速入门:如果您想要一个实验性的 Web 界面,请查看 Docker 部署指南。
首先,我们来看看如何 查询 一份 PDF 文件。
link="https://situational-awareness.ai/wp-content/uploads/2024/06/situationalawareness.pdf"
wdoc --path=$link --task=query --filetype="online_pdf" --query="What does it say about alphago?" --query_retrievers='basic_multiquery' --top_k=auto_200_500
- 这将:
- 将
--path中的内容解析为一个用于下载 PDF 的链接(否则该 URL 可能只是一个网页,但在大多数情况下,您可以将其保留为默认值auto,因为系统内置了启发式算法来检测最合适的解析器)。 - 将文本切分成多个块,并为每个块创建嵌入向量。
- 对用户查询进行嵌入处理(使用
basic模型),并让默认的大型语言模型生成替代查询,同时对这些替代查询也创建嵌入向量。 - 使用这些嵌入向量在所有文本块中进行搜索,找出最相关的 200 个文档。
- 将这 200 个文档逐一传递给小型语言模型(默认为 openrouter/google/gemini-2.5-flash),以判断它们是否与用户查询相关。
- 如果这 200 个文档中有超过 90% 被判定为相关,则再次以更高的
top_k值进行搜索,重复此过程,直到文档开始变得不相关,或者已检索到 500 个文档为止。 - 接着,将每个相关的文档发送给强大的大型语言模型(默认为 openrouter/google/gemini-3.1-pro-preview),提取相关信息,并为每个相关文档生成一个答案。
- 然后,对所有这些“中间”答案进行“语义分批”处理(即先创建嵌入向量,再进行层次聚类,最后将语义相似的多个中间答案组合成一个小批次,并按语义顺序排序)。每个批次会被合并为一个答案,最终形成针对相关文档的单个答案(或进一步合并为针对多个批次的单一答案)。
- 重复步骤 7 和 8(即逐步聚合各个批次),直到只剩下一个答案,然后将其返回给用户。
- 将
接下来,我们看看如何总结一份 PDF 文件。
link="https://situational-awareness.ai/wp-content/uploads/2024/06/situationalawareness.pdf"
wdoc --path=$link --task=summarize --filetype="online_pdf"
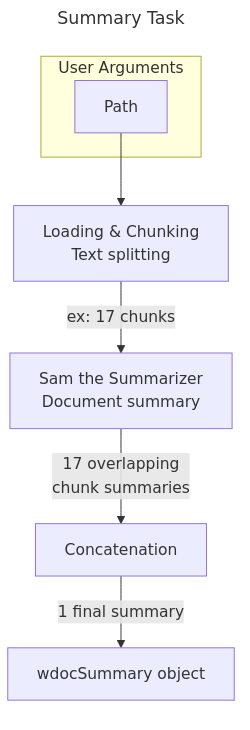
这将:
- 将文本分割成多个块。
- 将每个块传递给强大的大型语言模型(默认为 openrouter/google/gemini-3.1-pro-preview),生成非常详细的摘要。格式为 Markdown 列表,每条列出一个观点,并根据逻辑关系进行缩进。
- 在处理每个新块时,语言模型会参考前一个块的内容以获取上下文信息。
- 最后,将所有摘要拼接在一起并返回给用户。
对于像书籍这样非常大的文档,可以递归地将生成的摘要再次输入
wdoc,例如使用--summary_n_recursion=2参数。查询和总结这两个任务也可以结合使用,只需指定
--task summarize_then_query,即可先对文档进行总结,最后还会提供一个提示,方便您进一步提问以澄清细节。如需了解更多,请参阅 examples.md。
请注意,还有一个官方 Open-WebUI 工具,使用起来更加简单。
功能
- 15+ 种文件类型:还支持组合使用,以递归方式加载,或定义复杂的异构语料库,例如文件列表、链接列表、正则表达式、YouTube 播放列表等。请参阅 文件类型 和 递归文件类型。所有文件类型都可以无缝地结合在同一索引中,这意味着您可以同时查询 Anki 词库和工作 PDF 文件)。它还支持从音频文件和 YouTube 视频中去除静音!甚至还有一个
ddg文件类型,可用于使用 DuckDuckGo 搜索网络。 - 100 多种 LLM 和多种嵌入模型:得益于 litellm,支持 OpenAI、Mistral、Claude、Ollama、Openrouter 等任何 LLM。支持的嵌入引擎列表可在 这里 查看,至少包括 OpenAI(或任何兼容 OpenAI API 的模型)、Cohere、Azure、Bedrock、NVIDIA NIM、Hugging Face、Mistral、Ollama、Gemini、Vertex、Voyage 等。
- 本地私有 LLM:在私有模式下,会采取措施确保数据不会离开您的计算机并传输到 LLM 提供商:不使用 API 密钥,所有
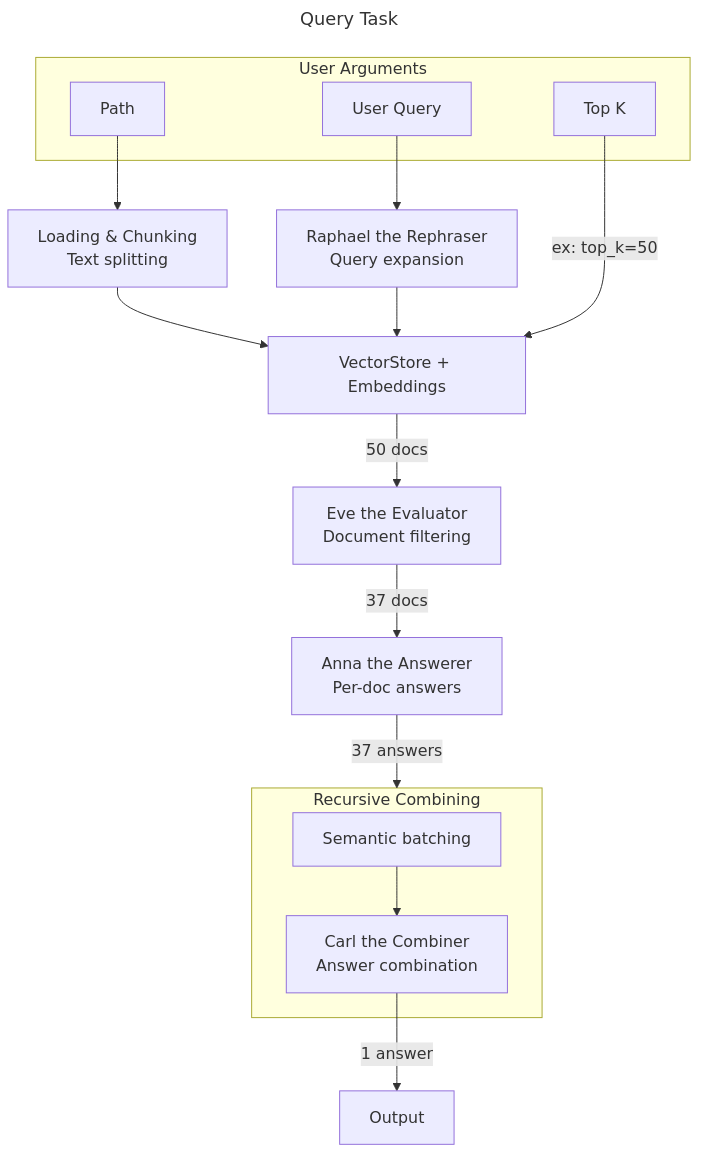
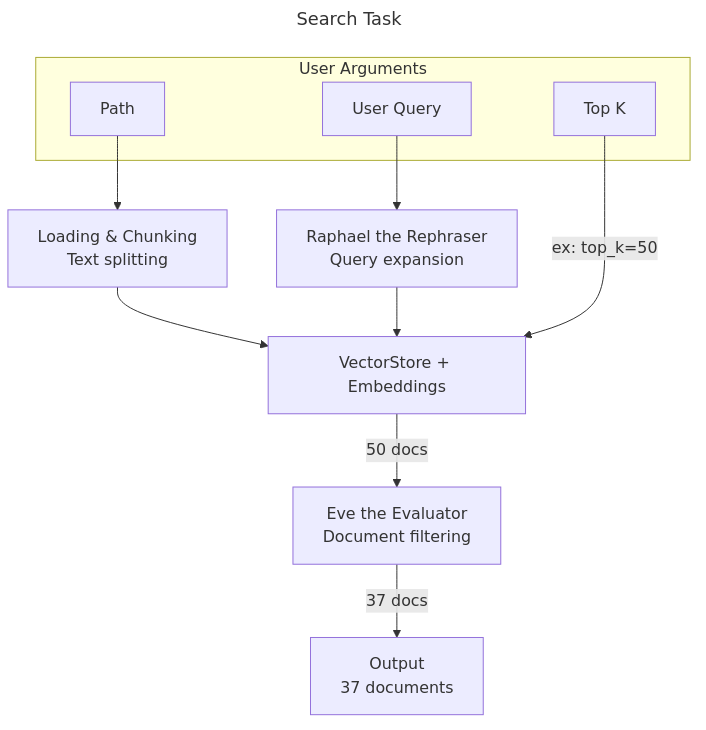
api_base均由用户设置,缓存与其余部分隔离,出站连接通过重载 Python 套接字进行审查等。 - 高级 RAG 查询大量多样化文档:
- 文档通过嵌入检索获得。
- 随后使用一个弱 LLM 模型(“Eve the Evaluator”)来判断哪些文档不相关。
- 再使用强 LLM(“Anna the Answerer”)根据剩余的每一份文档回答问题。
- 最后,所有相关答案将由“Carl the Combiner”合并成一条简短的 Markdown 格式答案。在合并之前,这些答案会先按语义聚类和语义顺序分批处理,使用 SciPy 的层次聚类和叶序排列方法,这样 LLM 就能更轻松地以自底向上的逻辑方式整合答案。 “Eve the Evaluator”、“Anna the Answerer”和“Carl the Combiner”是系统提示中为每个 LLM 赋予的名称,这样您可以轻松地为特定步骤添加额外指令。此外还有用于摘要的“Sam the Summarizer”以及用于扩展查询的“Raphael the Rephraser”。
- 每份文档都由唯一哈希值标识,答案也会注明来源,因此您清楚每条信息来自哪份文档。
- 支持特殊语法,如“QE >>>> QA”,其中 QE 是用于筛选嵌入的过滤性问题,而 QA 则是您真正想要得到答案的问题。
- 网络搜索:初步支持使用 DuckDuckGo 进行网络搜索。只需输入
wdoc web "How is Nvidia today this month?"即可。 - 高级摘要:
- 不再生成无法使用的“高层次要点”,而是将作者的推理、论点、思考过程等内容压缩成易于浏览的 Markdown 文件。
- 摘要随后会经过多次检查,确保逻辑缩进等正确无误。
- 摘要可以采用与原文相同的语言,也可以直接翻译。
- 多项任务:请参阅 支持的任务。
- 信任但需验证:答案会注明来源:
wdoc会跟踪答案中所用每份文档的哈希值,方便您核实每一项断言。 - Markdown 格式的答案和摘要:使用 rich。
- 合理的嵌入策略:默认使用诸如 多查询检索器 等复杂嵌入技术,同时也包含 SVM、KNN、父级检索器等,且可自定义。
- 文档齐全:大量 docstring、代码注释以及详细的
--help说明等。请查看 examples.md,其中列出了 Shell 和 Python 示例。完整的帮助信息可在 help.md 文件中找到,或通过python -m wdoc --help获取。我致力于维护详尽的文档。单页完整文档可在 网站 上查阅。 - 可脚本化/可扩展:您可以将
wdoc作为可执行文件或库来使用。请参阅下方的 使用 wdoc 编写的脚本。甚至还有一款 开放 Web UI 工具。 - 严格类型检查:借助出色的 beartype 库,在不降低性能的情况下实现运行时类型检查!可通过环境变量选择关闭类型检查:
WDOC_TYPECHECKING="disabled / warn / crash" wdoc(默认为warn)。 - LLM(及嵌入)缓存:加速处理速度,同时优化索引的存储和加载(对于大型语料库非常实用)。
- 优秀的 PDF 解析:PDF 解析器通常不太可靠,因此我们采用了 15 种不同的加载器,并根据解析评分保留最佳结果。其中包括通过 openparse 实现的表格支持(默认无需 GPU),或通过 UnstructuredPDFLoader 实现。
- Langfuse 支持:如果您设置了相应的 Langfuse 环境变量,它们将会被使用。请参阅 这篇指南 或 这篇 了解更多(注意:若处于私有模式,则此功能会被禁用,以避免任何数据泄露)。
- 文档过滤:可根据文档内容或元数据的正则表达式进行过滤。
- 二进制嵌入支持:自定义 LangChain 向量存储,以使用二进制嵌入,这可能带来 约 32 倍的压缩比、更快的搜索速度,且通常几乎不会损失准确性。
- 快速高效:并行加载、解析、嵌入、查询文档等。
- Shell 自动补全:使用 python-fire。
- 通知回调:例如,可以使用 ntfy.sh 将摘要发送到您的手机上。
- 黑客思维:我是一位友好的开发者!如果您有任何功能请求或其他问题,请随时提交 Issue。
任务
- query:提供文档并针对其内容提问。
- search:仅返回文档及其元数据。对于 Anki 用户,可以直接在浏览器中打开卡片。
- summarize:提供文档并生成摘要。摘要提示可在
utils/prompts.py中找到。 - summarize_then_query:先对文档进行摘要,然后允许您直接就摘要内容提问。
文件类型
- anki: Anki 数据库集合的任意子集。图像的
alt和title属性可以展示给大模型,这意味着如果你使用了 ankiOCR 插件,这些信息将有助于为大模型提供笔记的上下文。 - auto: 默认选项,自动猜测文件类型。
- epub: 由于 epub 格式本身定义不够清晰,因此测试较少。
- json_dict: 包含单个 JSON 字典的文本文件。
- local_audio: 支持多种音频格式,可选择使用 OpenAI 的 Whisper 模型或 Deepgram 的 Nova-3 模型。支持自动去除静音等功能。注意:对于 Whisper 无法处理的大文件(通常大于 25MB),系统会自动将其拆分为较小的文件进行转录,然后再合并。此外,音频转录内容会被转换为带有规律时间戳的文本,从而允许用户询问大模型某段内容是在何时出现的。
- local_html: 适用于网站数据转储。
- local_video: 先提取音频,然后按 local_audio 处理。
- logseq_markdown: 借助我的另一个项目 LogseqMarkdownParser,你可以直接使用你的 Logseq 图谱。
- online_media: 使用 youtube_dl 尝试下载视频或音频;若失败,则通过 Playwright 加载页面来拦截可能有效的 URL。随后按 local_audio 处理(但也可处理视频)。
- online_pdf: 通过 URL 获取 PDF,然后按 pdf 类型处理(见上文)。
- pdf: 实现了 15 种默认加载器,系统会根据启发式算法选择最佳方案并提前停止。表格支持可通过 openparse 或 UnstructuredPDFLoader 实现。易于扩展更多支持。
- powerpoint: .ppt、.pptx、.odp 等。
- string: 命令行会提示你输入文本,方便粘贴内容,尤其适合付费文章!
- text: 直接以路径形式传递文本内容。
- txt: .txt、Markdown 等。
- url: 尝试多种方式加载网页,并通过启发式算法找到解析效果最好的版本。
- word: .doc、.docx、.odt 等。
- youtube: 文本内容来自 YouTube 字幕或翻译,或者更好的是,使用 Whisper 或 Deepgram 进行转录。需要注意的是,YouTube 字幕会附带时间码(因此你可以询问“作者是在什么时候提到某某内容的”),但其采样频率较低(不是每秒一个时间码,而是每 15 秒一个)。在总结时,YouTube 章节也会作为上下文提供给大模型,这可能会显著提升总结效果。
递归文件类型
- ddg: 使用 DuckDuckGo 进行在线网页搜索。这不是代理搜索,我们仅对 DuckDuckGo 检索到的 URL 使用
wdoc进行处理并返回结果。此功能仅支持query任务。 - json_entries: 将路径指向一个文件,其中每行都是一个包含加载参数的 JSON 字典。例如,用于加载其他多种递归类型。示例可在
docs/json_entries_example.json中找到。 - link_file: 将每行包含一个 URL 的文本文件转换为相应的加载器参数。支持任何类型的链接,例如网页、PDF 链接和 YouTube 链接都可以放在同一文件中。非常适合批量总结内容!
- recursive_paths: 将路径、正则表达式模式和文件类型结合,递归地查找所有匹配的文件,并按照指定的文件类型进行处理(例如多个 PDF 或大量 HTML 文件等)。
- toml_entries: 读取 .toml 文件。示例可在
docs/toml_entries_example.toml中找到。 - youtube playlists: 获取每个视频的链接,然后按 youtube 类型处理。
操作指南与示例
请参阅 examples.md。
开始使用
wdoc 主要在 Python 3.13.5 上开发和测试,但为了兼容性,也可以在 Python 版本 >=3.11 上安装。如果条件允许,请尽量使用 Python 3.13。
直接安装
- 安装方法:
- 使用 pip:
pip install -U wdoc[full](如果你想尝试依赖项更少的版本,可以使用pip install -U wdoc,但你需要手动为你的用例安装缺失的依赖)。 - 或者获取特定的 Git 分支:
dev分支:pip install git+https://github.com/thiswillbeyourgithub/wdoc@dev[full]main分支:pip install git+https://github.com/thiswillbeyourgithub/wdoc@main[full]
- 你也可以使用 uvx 或 pipx。但由于我对它们不太熟悉,不确定是否会导致缓存等问题。如果你试过的话,请告诉我!
- 使用 uvx:
uvx wdoc[full]@latest --help - 使用 pipx:
pipx run wdoc[full] --help
- 使用 uvx:
- 无论如何,建议:
- 安装
wdoc[full]版本,除非有特殊限制。 - 同时尝试安装
pdftotext:pip install -U wdoc[pdftotext],以及添加fasttext支持:pip install -U wdoc[fasttext]。
- 安装
- 如果你计划贡献代码,还需要
wdoc[dev]来使用提交钩子。 - Claude Code 用户:为了让 Claude Code 了解
wdoc的 CLI 和 Python API,请安装 SKILL.md 参考文件:mkdir -p ~/.claude/skills/wdoc && wget -O ~/.claude/skills/wdoc/SKILL.md https://raw.githubusercontent.com/thiswillbeyourgithub/wdoc/main/SKILL.md
- 使用 pip:
- 将你想要使用的后端 API 密钥添加为环境变量:例如
export ANTHROPIC_API_KEY="***my_key***" - 启动非常简单,只需运行
wdoc --task=query --path=MYDOC [ARGS]即可。- 如果由于某种原因失败了,可以尝试使用
python -m wdoc。如果仍然不行,可以试试uvx wdoc@latest;作为最后的手段,可以克隆这个仓库并进入目录后再试一次。如有问题,请随时提交 issue。 - 要启用 Shell 自动补全功能:如果你使用 zsh,运行
eval $(cat shell_completions/wdoc_completion.zsh)。同时提供适用于bash和fish的补全脚本。你也可以通过wdoc -- --completion MYSHELL > my_completion_file生成自己的补全文件。 - 请注意,如果你处理大量文档(尤其是递归类型的文件),可能需要较长时间(这也取决于并行处理能力,但可能会遇到内存错误)。
- 查看 examples.md,其中列出了 Shell 和 Python 的示例。
- 如果由于某种原因失败了,可以尝试使用
- 要对本地文档提问:
wdoc query --path="PATH/TO/YOUR/FILE" --filetype="auto"- 如果你想通过直接加载之前运行生成的嵌入来减少启动时间(尽管嵌入本身始终会被缓存),可以在之前的命令中添加
--saveas="some/path",将生成的嵌入保存到文件中,并在后续每次调用时替换为--loadfrom "some/path"。
- 如果你想通过直接加载之前运行生成的嵌入来减少启动时间(尽管嵌入本身始终会被缓存),可以在之前的命令中添加
- 要进行在线搜索,可以这样操作:
wdoc --task=query --path='How is Nvidia doing this month?' --query='How is Nvidia doing this month' --filetype=ddg。但如果path或query中有任何一个缺失,我们会用另一个来代替。也可以这样使用:wdoc web 'How is Nvidia doing this month?'。 - 更多信息请阅读文档:
wdoc --help
实验性 Docker 界面
你还可以使用实验性的 Docker 界面,在浏览器中(包括在智能手机上)使用 wdoc。
详细说明请参阅 Docker README。
使用 wdoc 制作的脚本
- 更多内容将在 scripts 文件夹 中陆续发布。
- Ntfy Summarizer:利用 ntfy.sh 自动从你的 Android 手机总结文档。
- TheFiche:直接以 logseq 页面的形式为特定概念创建摘要。
- FilteredDeckCreator:根据
wdoc检索到的卡片,直接为 anki 创建筛选后的学习卡片组。 - 官方 Open-WebUI 工具,托管于 这里。
- MediaURLFinder 简单地利用
find_online_media加载器助手,结合playwright和yt-dlp查找所有媒体资源的 URL(视频、音频等)。这在仅靠yt-dlp无法找到资源 URL 时特别有用。
常见问题解答
常见问题解答
这是为谁准备的?
wdoc专为希望进行强大文档查询并获得深度 AI 驱动文档摘要的高级用户设计。
什么是 RAG?
- RAG 系统(检索增强生成)本质上是基于大型语言模型对文本语料库进行搜索。
为什么要再做一个 RAG 系统?不能用现有的其他系统吗?
为什么
wdoc比大多数 RAG 系统更适合用于文档问答?- 它同时使用了强模型和查询评估模型。首先通过嵌入技术找到合适的文档,然后由查询评估模型过滤掉与问题无关的文档;接着,强模型会根据剩余的每一份文档回答问题,并将所有答案以整洁的 Markdown 格式整合在一起。此外,
wdoc具有高度可定制性。
- 它同时使用了强模型和查询评估模型。首先通过嵌入技术找到合适的文档,然后由查询评估模型过滤掉与问题无关的文档;接着,强模型会根据剩余的每一份文档回答问题,并将所有答案以整洁的 Markdown 格式整合在一起。此外,
能否在
wdoc的文档上使用wdoc?- 当然可以!
wdoc --task=query --path https://wdoc.readthedocs.io/en/latest/all_docs.html
- 当然可以!
为什么
wdoc还能生成摘要?- 我空闲时间很少,因此需要一个量身定制的摘要功能来及时了解新闻动态。但大多数摘要系统质量很差,只是简单地给出高层次的要点,而没有正确处理文本分块。于是我自己开发了一个专门的摘要器。摘要提示可以在
utils/prompts.py中找到,其重点在于提取作者的论点、推理过程和思想脉络,然后使用 Markdown 缩进的项目符号列表使内容易于阅读。 效果非常好!该提示的数据类未被冻结,因此你可以根据需要提供自己的提示。
- 我空闲时间很少,因此需要一个量身定制的摘要功能来及时了解新闻动态。但大多数摘要系统质量很差,只是简单地给出高层次的要点,而没有正确处理文本分块。于是我自己开发了一个专门的摘要器。摘要提示可以在
wdoc支持哪些任务?- 请参阅 任务。
wdoc支持哪些 LLM 提供商?- 借助 litellm,
wdoc几乎支持任何 LLM 提供商。它甚至支持本地 LLM 和本地嵌入(详见 examples.md)。支持的嵌入引擎列表可在 这里 查看,其中包括至少 OpenAI(或任何兼容 OpenAI API 的模型)、Cohere、Azure、Bedrock、NVIDIA NIM、Hugging Face、Mistral、Ollama、Gemini、Vertex、Voyage 等。
- 借助 litellm,
你用
wdoc来做什么?- 我会关注各种不同的信息来源以了解最新动态:YouTube、网站等。借助
wdoc,我可以自动生成精美的 Markdown 摘要,并直接将其导入我的 Logseq 数据库,形成一系列TODO块。 - 我用它向我庞大的医学知识语料库提出技术性问题。
- 我还使用
--private参数查询个人文档。 - 有时我会先对文档进行摘要,然后再在同一命令中直接提问。
- 我也会用它来询问整个 YouTube 播放列表的相关问题。
- 其他使用场景则构成了我创建的 使用
wdoc制作的脚本部分。
- 我会关注各种不同的信息来源以了解最新动态:YouTube、网站等。借助
这个名字有什么含义?
- 我最喜欢的角色之一(也可以说是我的榜样)是 温斯顿·沃尔夫,但在经过一番犹豫后,我决定“WolfDoc”会让人感到困惑,“WinstonDoc”又像是微软会起的名字。另外,“wd”和“wdoc”这两个名称当时还未被占用,而“doctools”已经被注册了。该项目最初的名字是“DocToolsLLM”,这是一个结合了“医生”和“工具”的双关语。
如何在不编写代码的情况下改进特定任务的提示?
query任务中的每个提示都扮演着 WDOC-CORP© 公司员工的角色,分别是“Eve the Evaluator”(负责筛选相关文档的 LLM)、“Anna the Answerer”(根据筛选后的文档回答问题的 LLM)以及“Carl the Combiner”(将 Answerer 的答案整合为一个整体的 LLM)。此外还有“Sam the Summarizer”用于生成摘要,以及“Raphael the Rephraser”用于扩展你的查询。只要你以提示的方式与它们对话,它们就会听从你的指令。
如何将
wdoc的解析器用于我自己的文档?- 如果你在 Shell 命令行界面中,可以轻松使用
wdoc parse my_file.pdf。- 添加
--format=langchain_dict可以将文本和元数据以字典列表的形式输出,否则只会得到纯文本。还有其他格式,例如--format=xml,使其更符合 LLM 的要求,类似于 files-to-prompt。
- 添加
- 如果你想用 Python 处理文档:
from wdoc import wdoc list_of_docs = wdoc.parse_doc(path=my_path) - 另一个例子是使用
wdoc解析 Anki 词库:wdoc parse --filetype "anki" --anki_profile "Main" --anki_deck "mydeck::subdeck1" --anki_notetype "my_notetype" --anki_template "<header>\n{header}\n</header>\n<body>\n{body}\n</body>\n<personal_notes>\n{more}\n</personal_notes>\n<tags>{tags}</tags>\n{image_ocr_alt}" --anki_tag_filter "a::tag::regex::.*something.*" --format=text
- 如果你在 Shell 命令行界面中,可以轻松使用
如果我的 PDF 文件被加密了,该怎么办?
- 如果你在 Linux 系统上,可以尝试运行
qpdf --decrypt input.pdf output.pdf。- 我在这个仓库里制作了一个简单粗暴的批处理脚本:PDF_batch_decryptor。
- 如果你在 Linux 系统上,可以尝试运行
如何添加我自己的 PDF 解析器?
- 编写一个 Python 类,并将其添加到此处:
wdoc.utils.loaders.pdf_loaders['parser_name']=parser_object,然后在调用wdoc时指定--pdf_parsers=parser_name。- 该类必须在
__init__方法中接收一个path参数,并包含一个无参数但返回List[Document]的load方法。可以参考OpenparseDocumentParser类作为示例。
- 该类必须在
- 编写一个 Python 类,并将其添加到此处:
如果我频繁遇到速率限制,该怎么办?
- 最简单的方法是添加
debug参数。这将禁用多线程、多进程和 LLM 并发。另一种较为温和的方式是将环境变量WDOC_LLM_MAX_CONCURRENCY设置为较低的值。
- 最简单的方法是添加
如何运行测试?
- 请查看
./tests/run_all_tests.sh文件。
- 请查看
如何在不进行分块的情况下查询文本?/ 如何以全文作为上下文进行查询?
- 如果你将环境变量
WDOC_MAX_CHUNK_SIZE设置为一个非常高的值,并使用一个根据 litellm 元数据具有足够上下文窗口的模型,那么就不会发生分块,LLM 将以全文作为上下文进行处理。
- 如果你将环境变量
有没有办法将
wdoc与 Open-WebUI 一起使用?- 是的!我维护了一个官方 Open-WebUI 工具,托管在这里。
wdoc有 Web 界面吗?- 有!提供了一个基于 Docker 的 Gradio 实验性 Web 界面,可以轻松部署和使用,无需命令行交互。
我可以将 shell 管道与
wdoc一起使用吗?- 可以!通过 shell 管道发送的数据(无论是字符串还是二进制数据)都会自动保存到一个临时文件中,然后作为
--path=[temp_file]参数传递。例如cat **/*.txt | wdoc --task=query、echo $my_url | wdoc parse,甚至cat my_file.pdf | wdoc parse --filetype=pdf。对于二进制输入,强烈建议使用--filetype参数,因为python-magic版本 ≤0.4.27 在没有指定文件类型时会出错(参见这个问题)。
- 可以!通过 shell 管道发送的数据(无论是字符串还是二进制数据)都会自动保存到一个临时文件中,然后作为
是否可以在运行时设置环境变量?
- 基本可以。实际上,在导入
wdoc时,wdoc/utils/env.py中的代码会创建一个数据类来存储wdoc使用的环境变量。这样做主要是为了确保运行时的类型检查,并保证当wdoc代码内部通过该数据类访问某个环境变量时,始终会与系统环境中的值进行比较。如果你决定在整个代码中更改环境变量,那么这些新值会在wdoc内部生效。不过这种方式有些脆弱,因为某些环境变量用于存储函数或类的默认值,因此只在代码导入时使用一次,后续可能会不同步。此外,如果wdoc怀疑WDOC_PRIVATE_MODE环境变量不同步,它会故意崩溃,以确保安全。另外需要注意的是,如果发现类似WDOC_LANGFUSE_PUBLIC_KEY的环境变量,wdoc会用其覆盖LANGFUSE_PUBLIC_KEY。这是因为litellm(可能还有其他库)会查找这个环境变量来启用langfuse回调。整个机制允许为特定用户或在使用open-webui的wdoc工具时设置环境变量。欢迎对此功能提出反馈。
- 基本可以。实际上,在导入
如何使用 Sphinx 构建 autodoc?
- 我一直使用的命令是
sphinx-apidoc -o docs/source/ wdoc --force,需要从本仓库的根目录执行。
- 我一直使用的命令是
为什么我无法在其他 LangChain 项目中加载向量存储?
- 在
wdoc/utils/customs/binary_faiss_vectorstore.py中,我们创建了BinaryFAISS和CompressedFAISS。后者与 FAISS 类似,只是对序列化的索引进行了 zlib 压缩;而前者则在此基础上增加了二进制嵌入,从而实现更快、更紧凑的嵌入表示。如果你想完全禁用压缩,可以使用环境变量WDOC_MOD_FAISS_COMPRESSION=false。
- 在
测试套件使用的是哪个 Python 版本?
- 推荐的 Python 版本是
3.12.11。
- 推荐的 Python 版本是
为什么在线搜索只支持“query”任务?
wdoc处理摘要的方式是将“整篇文档”分割成连续的“子文档”,然后逐个生成摘要。但如果一开始就有多篇文档(比如不同的网页),这种“顺序”就失去了意义。
路线图
点击查看更多
此待办事项列表由 MdXLogseqTODOSync 自动维护。
Most urgent
- figure out a good way to skip merging batches that are too large before trying to merge them
- probably means adding an env var to store a max value, document it in the help.md
- then check after batch creation if a batch is that large
- if it is put it in a separate var, to be concatenated later with the rest of the answers
- add more tests
- add test for the private mode
- add test for the testing models
- add test for the recursive loader functions
- add test for each loader
- rewrite the python API to make it more useable. (also related to https://github.com/thiswillbeyourgithub/wdoc/issues/13)
- pay attention to how to modify the init and main.py files
- pay attention to how the --help flag works
- pay attention to how the USAGE document is structured
- support other vector databases
- learn how to set a github action for test code coverage
- allow anki to use anki type search queries
- refactor the tasks to use langgraph, as it seems easier to do complex recursive tasks with it
- use async for the langchain chains
- figure out a good way to skip merging batches that are too large before trying to merge them
Features
- use clusters of semantic ordering instead of just the order you dumbass
- ability to cap the search documents capped by a number of tokens instead of a number of documents
- Add prompt caching for claude
- add a "fast summary" feature that does not use recursive summary if you care more about speed than overlapping summaries
- count how many time each source is used, as it can be relevant to infer answer quality
- add an html format output. It would display a nice UI with proper dropdowns for sources etc
- if a model supports structured output we should make use of it to get the thinking and answer part. Opt in because some models hide their thoughts.
- add an intermediate step for queries that asks the LLM for appropriate headers for the md output. Then for each intermediate answer attribute it a list of 1 to 3 headers (because a given intermediate answer can contain several pieces of information), then do the batch merge of intermediate answer per header.
- this needs to be scalable and easy to add recursion to (because then we can do this for subheaders and so on)
- the end goal is to have a scalable solution to answer queries about extremely large documents for impossibly vast questions
- use apprise instead of ntfy for the scripts
- add crawl4ai parser: https://github.com/unclecode/crawl4ai
- Way to add the title (or all metadata) of a document to its own text. Enabled by default. Because this would allow searching among many documents that don't refer to the original title (for example: material safety datasheets)
- default value is "author" "page" title"
- pay attention to avoid including personnal info (for example use relative paths instead of absolute paths)
- add a /save PATH command to save the chat and metadata to a json file
- add image support printing via icat or via the other lib you found last time, would be useful for summaries etc
- add wdoc to tldr pages
- add an audio backend to use the subtitles from a video file directly
- store the anki images as 'imagekeys' as the idea works for other parsers too
- investigate asking the LLM to add leading emojis to the bullet point for improved reading
- add a key/val arg to specify the trust we have in a doc, call it context
- add a way to open the documents automatically, based on platform dirs etc. For ex if okular is installed, open pdfs directly at the right page
- the best way would be to create opener.py that does a bit like loader but for all filetypes and platforms
- use a cli selector like in mnemonics creator
- add shortcut to sort by score or by name
- display metadata and score in a previewer
- add an argument --whole_text to avoid chunking (this would just increase the chunk size to a super large number I guess)
- add apprise callback support
- add a filetype "custom_parser" and an argument "--custom_parser" containing a path to a python file. Must receive a docdict and a few other things and return a list of documents
- add bespoke-minicheck from ollama to fact check when using RAG: https://ollama.com/library/bespoke-minicheck
- or via their API directly : https://docs.bespokelabs.ai/bespoke-minicheck/api but they don't seem to properly disclose what they do with the data
- add a langchain code loader that uses aider to get the repomap
- add a pikepdf loader because it can be used to automatically decrypt pdfs
- add a query_branching_nb argument that asks an LLM to identify a list of keywords from the intermediate answers, then look again for documents using this keyword and filtering via the weak llm
- write a script that shows how to use bertopic on the documents of wdoc
- add a retriever where the LLM answer without any context
- add support for readabilipy for parsing html
- add an obsidian loader
- add a /chat command to the prompt, it would enable starting an interactive session directly with the llm
- find a way to make it work with llm from simonw
- make images an actual filetype
Enhancements
- store the available tasks in a dataclass in misc.py
- turn arugments that contain a _ into arguments with a -
- in the cli launcher function, manually convert arguments
- maybe add support for docling to parse documents?
- when querying hard stuff the number of drop documents after batching is non negligible, we should remove those from the list of documents to display and instead store those in another variable
- check if using html syntax is less costly and confusing to LLMs than markdown with tall those indentation. Or maybe json. It would be simple to turn that into markdown afterwards.
- check that the task search work on things other than anki
- create a custom custom retriever, derived from multiquery retriever that does actual parallel requests. Right now it's not the case (maybe in async but I don't plan on using async for now). This retriever seems a good part of the slow down.
- stop using your own youtube timecode parser and instead use langchain's chunk transcript format
- implement usearch instead of faiss, it seems in all points faster, supports quantized embeddings, i trust their langchain implementation more
- Use an env var to drop_params of litellm
- add more specific exceptions for file loading error. One exception for all, one for batch and one for individual loader
- use heuristics to find the best number of clusters when doing semantic reranking
- arg to use jina v3 embeddings for semantic batching because it allows specifying tasks that seem appropriate for that
- add an env variable or arg to overload the backend url for whisper. Then set it always for you and mention it there: https://github.com/fedirz/faster-whisper-server/issues/5
- find a way to set a max cost at which to crash if it exceeds a maximum cost during a query, probably via the price callback
- anki_profile should be able to be a path
- store wdoc's version and indexing timestamp in the metadata of the document
- arg --oneoff that does not trigger the chat after replying. Allowing to not hog all the RAM if ran in multiple terminals for example through SSH
- add a (high) token threshold above which two texts are not combined but just concatenated in the semantic order. It would avoid it loosing context. Use a --- separator
- compute the cost of whisper and deepgram
- use a pydantic basemodel for output instead of a dict
- same for summaries, it should at least contain the method to substitute the sources and then back
- investigate storing the vectors in a sqlite3 file
- make a plugin to llm that looks like file-to-prompt from simonw
- Always bind a user metadata to litellm for langfuse etc
- Add more metadata to each request to langfuse more informative
- add a reranker to better sort the output of the retrievers. Right now with the multiquery it returns way too many and I'm thinking it might be a bad idea to just crop at top_k as I'm doing currently
- add a status argument that just outputs the logs location and size, the cache location and size, the number of documents etc
- add the python magic of the file as a file metadata
- add an env var to specify the threshold for relevant document by the query eval llm
- find a way to return the evaluations for each document also
- move retrievers.py in an embeddings folder
- stop using lambda functions in the chains because it makes the code barely readable
- when doing recursive summary: tell the model that if it's really sure that there are no modifications to do: it should just reply "EXIT" and it would save time and money instead of waiting for it to copy back the exact content
- add image parsing as base64 metadata from pdf
- use multiple small chains instead of one large and complicated and hard to maintain
- add an arg to bypass query combine, useful for small models
- tell the llm to write a special message if the parsing failed or we got a 404 or paywall etc
- catch this text and crash
- add check that all metadata is only made of int float and str
- move the code that filters embeddings inside the embeddings.py file
- this way we can dynamically refilter using the chat prompt
- task summary then query should keep in context both the full text and the summary
- if there's only one intermediate answer, pass it as answer without trying to recombine
- filter_metadata should support an OR syntax
- add a --show_models argument to display the list of available models
- add a way to open the documents automatically, based on platform dirs etc. For ex if okular is installed, open pdfs directly at the right page
- the best way would be to create opener.py that does a bit like loader but for all filetypes and platforms
- add an image filetype: it will be either OCR'd using format and/or will be captioned using a multimodal llm, for example gpt4o mini
- nanollava is a 0.5b that probably can be used for that with proper prompting
- add a key/val arg to specify the trust we have in a doc, call this metadata context in the prompt
- add an arg to return just the dict of all documents and embeddings. Notably useful to debug documents
- use a class for the cli prompt, instead of a dumb function
- arg to disable eval llm filtering
- just answer 1 directly if no eval llm is set
- display the number of documents and tokens in the bottom toolbar
- add a demo gif
- investigate asking the LLM to add leading emojis to the bullet point for quicker reading of summaries
- see how easy or hard it is to use an async chain
- ability to cap the search documents capped by a number of tokens instead of a number of documents
- for anki, allow using a query instead of loading with ankipandas
- add a "try_all" filetype that will try each filetype and keep the first that works
- add textract extractor : https://textract.readthedocs.io/en/stable/
- write a langchain compatible tool for agents
- add bespoke-minicheck from ollama to fact check when using RAG: https://ollama.com/library/bespoke-minicheck
- or via their API directly : https://docs.bespokelabs.ai/bespoke-minicheck/api but they don't seem to properly disclose what they do with the data
版本历史
5.0.02026/01/044.1.22025/10/284.1.12025/10/274.1.02025/10/214.0.22025/10/154.0.12025/10/074.0.02025/10/053.3.12025/07/263.3.02025/07/193.2.52025/05/173.2.42025/05/153.2.32025/05/133.2.12025/05/033.2.02025/05/033.1.02025/04/183.0.22025/04/183.0.12025/04/183.0.02025/04/162.9.02025/03/172.8.02025/03/15常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备