everything-chatgpt
everything-chatgpt 是一个致力于揭示 ChatGPT 网页版内部运作机制的开源探索项目。它深入分析了该应用的前端架构、后端 API 调用逻辑以及数据交互细节,并包含了对部分未公开技术实现的专业推测。
该项目主要解决了普通用户和开发者对 ChatGPT“黑盒”状态的好奇与需求,通过整理公开的字体资源列表、解析基于 NextJS 的应用架构、追踪 Cloudflare 路由下的服务器信息,以及演示如何获取会话数据等方式,将原本隐蔽的技术细节透明化。例如,它详细记录了从 CDN 加载的字体文件变化,并指出了分析过程中遇到的跨域策略等实际技术挑战。
everything-chatgpt 非常适合前端开发者、安全研究人员以及对大模型应用架构感兴趣的技术爱好者使用。开发者可以借此了解大规模 AI 产品的工程落地方案;研究人员可将其作为分析 Web 应用行为模式的案例;设计师也能从中获取关于字体渲染等资源管理的参考。作为一个社区驱动的仓库,它不仅提供了现成的技术观察结论,还鼓励贡献者分享更多有趣的发现,是理解现代 AI Web 应用底层逻辑的优质入门资料。
使用场景
前端安全研究员小李正在对 ChatGPT 网页版进行深度逆向分析,试图还原其资源加载机制与后端 API 交互细节。
没有 everything-chatgpt 时
- 资源定位困难:由于 OpenAI 将字体等资源迁移至新的 CDN 路径且未公开文档,手动抓包难以区分哪些是核心字体文件,哪些是废弃链接,效率极低。
- 架构黑盒状态:面对 Cloudflare 的全量路由遮挡,无法快速确认应用是否基于 NextJS 构建,也难以厘清 Sentry 与 Statsig 等分析工具的实际触发时机。
- 会话数据盲区:在不清楚
/api/auth/session具体返回结构的情况下,盲目构造请求往往因缺少关键参数或误解字段含义而失败。 - 依赖猜测成本:对于被 CORS 策略拦截的第三方服务(如 Statsig),只能靠猜测定位是浏览器同源策略限制还是插件干扰,缺乏确凿证据。
使用 everything-chatgpt 后
- 资产清单透明化:直接查阅整理好的
fonts.txt,快速获取从cdn.openai.com加载的最新 Soehne 和 KaTeX 字体完整列表,避开已失效的旧端点。 - 技术栈一键确认:通过项目摘要明确得知 ChatGPT 是 NextJS 应用,并了解 Sentry 反馈机制与 uBlock Origin 导致 Statsig 加载失败的真相,省去大量排查时间。
- 接口数据结构化:参考项目中披露的 Session 数据示例,精准掌握
user对象下的 ID、邮箱等字段格式,迅速完成身份验证接口的复现。 - 逆向路径清晰化:利用社区贡献的 API 调用逻辑和推测分析,将原本需要数天摸索的“黑盒”拆解为可验证的具体步骤,大幅降低研究门槛。
everything-chatgpt 将原本分散且隐蔽的 ChatGPT 内部实现细节转化为结构化的开源情报,让逆向工程从“盲人摸象”变为“按图索骥”。
运行环境要求
未说明
未说明
快速开始
Everything ChatGPT
由 @tercmd(Twitter 上) 发起的项目

探索 ChatGPT 网页应用背后的运作机制。当然,也包含一些推测。如果你有关于 ChatGPT 的有趣内容,欢迎贡献。
该仓库不再包含目录,因为 GitHub 已经显示了这一点。
字体 (fonts.txt)
警告 之前列表中的所有字体已无法通过
https://chat.openai.com/fonts/[font]端点访问。新的 fonts.txt 文件假设 URL 前缀为https://cdn.openai.com/common/fonts/
以下是来自 cdn.openai.com 的字体列表(非详尽):
- soehne-buch.woff2
- soehne-halbfett.woff2
- soehne-mono-buch.woff2
- soehne-mono-halbfett.woff2
- soehne-kraftig.woff2
- KaTeX_Main-Regular.woff2 (+ Main-Bold, Main-Italic, Main-BoldItalic)
- KaTeX_Math-Italic.woff2 (+ Math-BoldItalic)
- KaTeX_Size2-Regular.woff2 (+ Size1, Size3, Size4)
- KaTeX_Caligraphic-Regular.woff2 (+ Caligraphic-Bold)
早期已无法访问的字体列表:
Signifier-Regular.otfSohne-Buch.otfSohne-Halbfett.otfSohneMono-Buch.otfSohneMono-Halbfett.otfKaTeX_Caligraphic-Bold.woff (Caligraphic-Regular 用于常规字体)KaTeX_Fraktur-Bold.woff (Fraktur-Regular 用于常规字体)KaTeX_Main-Bold.woff (BoldItalic, Italic, Regular 对应字体权重,可自行推断)KaTeX_Math-Bold.woff (BoldItalic, Italic, Regular 对应字体权重,可自行推断)KaTeX_SansSerif-Bold.woff (Italic, Regular 对应字体权重,可自行推断)KaTeX_Script-Regular.woffKaTeX_Size1-Regular.woff (Size1, Size2, Size3, Size4)KaTeX_Typewriter-Regular.woff
应用程序
ChatGPT 是一个 Next.js 应用程序。由于 chat.openai.com 的全部流量都经过 Cloudflare 路由,因此无法明确找到服务器信息。Sentry Analytics 会定期请求用户对消息选择的“点赞”或“踩”的反馈数据。此外,系统还会尝试加载 Statsig,但由于同源策略(实际上是 uBlock Origin 的影响),CORS 阻止了这一操作。
数据
会话数据
可以通过向 /api/auth/session 发送请求(无需 Authorization 头)来获取如下数据:
user: (对象)
|__ id: "user-[已屏蔽]"
|__ name: "[已屏蔽]@[已屏蔽].com"
|__ email: "[已屏蔽]@[已屏蔽].com"
|__ image: "https://s.gravatar.com/avatar/[账户邮箱地址的 MD5 哈希值]?s=480&r=pg&d=https%3A%2F%2Fcdn.auth0.com%2Favatars%2Fte.png"
|__ picture: "https://s.gravatar.com/avatar/[账户邮箱地址的 MD5 哈希值]?s=480&r=pg&d=https%3A%2F%2Fcdn.auth0.com%2Favatars%2Fte.png"
|__ idp: "auth0"
|__ iat: 1690111234
|__ mfa: [已屏蔽]
|__ groups: (数组)
|__ intercom_hash: "[已屏蔽]"
expires: "2023-08-01T23:45:12.345Z"
accessToken: "ey..[已屏蔽].."
authProvider: "auth0"
用户数据
这需要通过 Authorization 头传递访问令牌,因此无法直接使用浏览器访问。不过,当我们向 /backend-api/accounts/check/v4-2023-04-27 发送请求时,可以得到以下数据(这个 URL 每次更新都会很麻烦):
accounts: (对象)
|__ default: (对象)
|____ account: (对象)
|______ account_user_role: "account-owner"
|______ account_user_id: "92[已屏蔽]40"
|______ processor: (对象)
|________ a001: (对象)
|__________ has_customer_object: false
|________ b001: (对象)
|__________ has_transaction_history: false
|______ account_id: "34[已屏蔽]71"
|______ is_most_recent_expired_subscription_gratis: false
|______ has_previously_paid_subscription: false
|______ name: null
|______ structure: "personal"
|____ features: (数组)
|______ "log_statsig_events"
|______ "log_intercom_events"
|______ "new_plugin_oauth_endpoint"
|______ "arkose_enabled"
|______ "infinite_scroll_history"
|______ "model_switcher_upsell"
|______ "shareable_links"
|______ "layout_may_2023"
|______ "dfw_message_feedback"
|______ "ios_disable_citation_menu"
|______ "dfw_inline_message_regen_comparison"
|____ entitlement: (对象)
|______ subscription_id: null
|______ has_active_subscription: false
|______ subscription_plan: "chatgptfreeplan"
|______ expires_at: null
|____ last_active_subscription: (对象)
|______ subscription_id: null
|______ purchase_origin_platform: "chatgpt_not_purchased"
|______ will_renew: false
如果使用 ChatGPT Plus,则返回的数据会有所不同。
用户数据(使用 chat.json [chatId].json)
当我们向 /_next/data/[build ID]/c/[conversation ID].json?chatId=[conversation ID] 发送请求时(可以在浏览器中完成,但必须经过身份验证),我们会得到如下响应:
pageProps:
|__ user (对象):
|____ id: user-[已脱敏]
|____ name: [已脱敏]@[已脱敏].com
|____ email: [已脱敏]@[已脱敏].com
|____ image: https://s.gravatar.com/avatar/8c[因可能包含唯一标识符而被脱敏]c7?s=480&r=pg&d=https%3A%2F%2Fcdn.auth0.com%2Favatars%2F[电子邮件地址的前两个字母].png
|____ picture: https://s.gravatar.com/avatar/8c[因可能包含唯一标识符而被脱敏]c7?s=480&r=pg&d=https%3A%2F%2Fcdn.auth0.com%2Favatars%2F[电子邮件地址的前两个字母].png
|____ groups: []
|__ serviceStatus: {}
|__ userCountry: [已脱敏的两位国家代码]
|__ geoOk: false
|__ isUserInCanPayGroup: true
|__ __N_SSP: true
这与通过 会话数据 方法获取的部分相同的数据(不包括 accessToken 和 expires,这两者都与访问令牌相关)相似,不过你还能够获得用户所在国家的信息,以及 ChatGPT Plus 是否在其所在地可用。
编辑: 当 ChatGPT 返回类似“我们正经历异常高的需求。请耐心等待,我们正在努力扩展系统。”的消息时,serviceStatus 会显示为:
type: warning
message: 我们正经历异常高的需求。请耐心等待,我们正在努力扩展系统。
oof: true
这里的 oof 并不是我编造的,它确实是响应的一部分 😂
模型数据
本节已根据 @0xdevalias(GitHub 上) 创建的 issue #8 进行了修正。
ChatGPT 使用的是什么模型呢?只需查询 /backend-api/models 即可!
models: (数组)
|__ (对象)
|____ slug: "text-davinci-002-render-sha"
|____ max_tokens: 8191
|____ title: "默认(GPT-3.5)"
|____ description: "我们最快的模型,非常适合大多数日常任务。"
|____ tags: (数组)
|______ "gpt3.5"
|____ capabilities: (对象)
|____ product_features: (对象)
categories: (数组)
|__ (对象)
|____ category: "gpt_3.5"
|____ human_category_name: "GPT-3.5"
|____ subscription_level: "免费"
|____ default_model: "text-davinci-002-render-sha"
|____ browsing_model: "text-davinci-002-render-sha-browsing"
|____ code_interpreter_model: "text-davinci-002-render-sha-code-interpreter"
|____ plugins_model: "text-davinci-002-render-sha-plugins"
(如果你使用 ChatGPT Plus,则会有更多模型,如 issue #8 所示,但对于免费用户来说,他们看到的就是这些。)
测试版功能设置
感谢 @0xdevalias(GitHub 上) 创建了关于此功能的 issue #7。
在页面加载时(作为 Plus 用户),会向 /backend-api/settings/beta_features 发送请求。该请求返回类似于以下的内容:
browsing: false
chat_preferences: true
code_interpreter: true
plugins: true
其中,browsing 键似乎指的是“使用 Bing 浏览”(目前该功能尚未对公众开放,因此在上述数据中被设置为 false)。
chat_preferences 键则指自定义指令,这是一项新功能,允许用户设置在多次对话中保持不变的自定义内容。
code_interpreter 键指的是代码解释器功能,该功能使 GPT 能够在 Python 沙盒中运行代码。
plugins 键则指向 ChatGPT 插件。
禁用/启用“聊天记录与训练”
当你在屏幕左下角点击自己的姓名/电子邮件地址(在桌面端)> 设置 > 显示(位于数据控制旁边)> 切换“聊天记录与训练”开关时,会发生以下情况:
首先,会请求对话列表。
然后,我们会向与 模型数据 相同的路径发送请求,只不过会在 URL 中添加一个查询参数 ?history_and_training_disabled=true 或 ?history_and_training_disabled=false,具体取决于该设置是被禁用还是启用。
接着,我们会请求 /_next/data/[build ID]/index.json(其数据与 [chatId].json 相同)。
数据导出
当你使用“导出数据”功能来导出你的数据时,会向 /backend-api/accounts/data_export 发送一个无请求体的 POST 请求,响应为 status: "queued"。
顾名思义,数据导出将通过电子邮件发送。
导出的数据是一个 .zip 文件,其中包含 user.json、conversations.json、message_feedback.json、model_comparisons.json 和 chat.html。
user.json 中的数据如下所示:
{"id": "user-[已脱敏]", "email": "[已脱敏]@[已脱敏].com", "chatgpt_plus_user": false, "phone_number": "+[已脱敏]"}
model_comparisons.json 的示例数据可在 sample/model_comparisons.json 中找到。
message_feedback.json 的示例数据如下:
[{"message_id": "[已脱敏]", "conversation_id": "[没有破折号的对话ID]", "user_id": "user-[已脱敏]", "rating": "thumbsUp", "content": "{\"text\": \"这是一个测试。\"}"}]
conversations.json 的示例数据可在 sample/conversations.json 中找到。
chat.html 是一个页面,它会利用客户端 JavaScript 动态展示每一段保存的对话历史,这些对话数据存储在文件中,类似于 conversations.json 中的内容。你可以在 sample/chat.html 中找到示例。
对话
对话历史
对话历史可以通过以下 URL 访问(同样需要访问令牌,通常以 Authorization 头的形式传递):/backend-api/conversations?offset=0&limit=28(网页界面限制为最多 28 条对话),返回结果大致如下:
items: []
limit: 28
offset: 0
total: 0
之所以无法正常工作,是因为撰写本文时 ChatGPT 正在遇到一些问题:
“这里没有显示您期望的内容吗?别担心,您的对话数据仍然保留着!请稍后再试。”
但这可能是初次使用 ChatGPT 的人所看到的情况。
编辑:如果退出登录后再重新登录,历史记录就能正常显示了。以下是实际显示的内容:
items(数组)
|__(每条对话都是一个对象)
|____ id: [已脱敏的对话ID]
|____ title: [对话标题]
|____ create_time: 2023-03-09THH:MM:SS.MILLIS
|__...
total: [对话数量](可能超过 28 条)
limit: 28
offset: 0(可以设置更高的数值,它会从该索引开始返回后续的对话,起始索引为 0)
当列出 28 条对话后,ChatGPT 的用户界面会显示一个“显示更多”按钮,该按钮会发送一个带有 offset=28 参数的请求。
获取对话 ID
说到 ChatGPT 对话历史不可用的问题,其实我们可以相当容易地获取对话 ID(当然,前提是熟悉开发者工具的人)。
为什么呢?因为每次开始新对话时,ChatGPT 都会强制将你引导到一个 ~/chat 或 / 路径下,创建一个新的对话,但并不会改变 URL。这也正是在聊天历史不可用时的一个巧妙之处。
- 我们可以通过开发者工具获取对话 ID(这需要先发送一条消息):
- 接着,我们访问
https://chat.openai.com/chat/<此处为对话ID>https://chat.openai.com/c/<此处为对话ID>。
加载过去的对话
当用户点击某个过去的对话时,会向 /backend-api/conversation/<对话ID> 发送一个请求(需要访问令牌,很可能是结合了 Cookie 和其他因素以确保请求的真实性,或者通过 Authorization 头部),返回的响应类似如下:
title: <对话标题>
create_time: EPOCHEPOCH.MILLIS
mapping (对象)
|__ <消息ID> (数组):
|____ id: <消息ID>
|____ message (对象):
|______ id: <消息ID>
|______ author (对象):
|________ role: system (第一条消息) | user | assistant
|________ metadata: (空对象)
|______ create_time: EPOCHEPOCH.MILLIS
|______ content (对象):
|________ content_type: text
|________ parts: [""]
|______ end_turn: true (系统消息) | false
|______ weight: 1.0
|______ metadata: {}
|______ recipient: all
|____ parent: <父级消息ID>
|____ children (数组): <子级消息ID(s)>
向 ChatGPT 提问的过程
本节根据 @Snarik (在 GitHub 上) 提出的 issue #4 进行了修正。
假设我向 ChatGPT 提问:“ChatGPT 是什么?”首先,我们会向 /backend-api/conversation 发送一个 POST 请求,请求体如下:
action: next
messages (数组):
|__ (对象):
|____ author (对象):
|______ role: user
|____ content (对象):
|______ content_type: text
|______ parts (数组):
|________ “ChatGPT 是什么?”
|__ id: 0c[已隐去]91
|__ role: user
model: text-davinci-002-render-sha
parent_message_id: a0[已隐去]7f
该请求会返回一个 EventStream 流,最终以 [DONE] 标记结束。你可以查看示例响应:sample/conversation-event-stream.txt。
然后,我们获取过去对话列表,其中会包含一个“新建对话”。
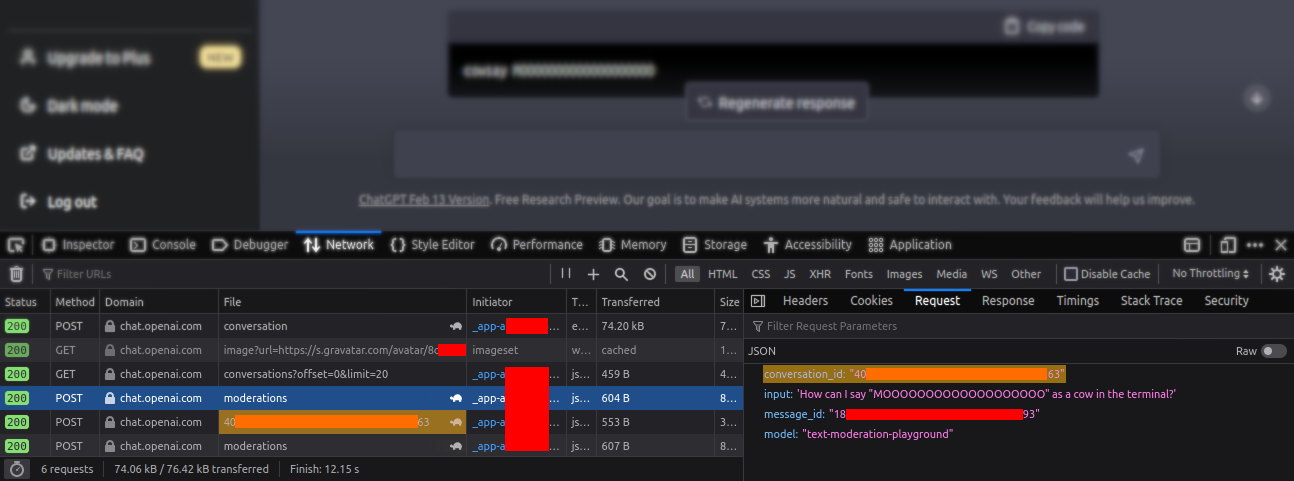
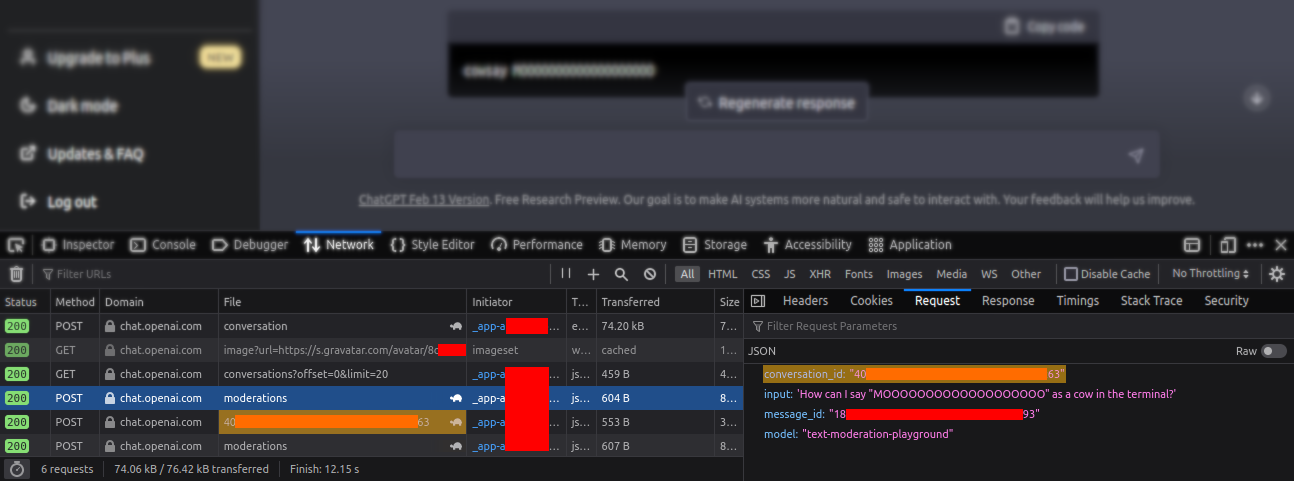
接着,我们向 /backend-api/moderations 发送请求,请求体如下:
conversation_id: 05[已隐去]2d
input: ChatGPT 是什么?
message_id: 0c[已隐去]91
model: text-moderation-playground
返回的响应如下:
flagged: false
blocked: false
moderation_id modr-6t[已隐去]Bk
随后,我们再次向 /backend-api/conversation/gen_title/<对话ID> 发送请求,请求体如下:
message_id: c8[已隐去]0e
model: text-davinci-002-render-sha
返回的响应是:
title: <对话标题>
之后,我们又向 /backend-api/moderations 发送一次请求,这次的请求体包含了 AI 的回答(标记为 <AI 回答>),格式如下:
input: \nChatGPT 是什么?\n\n<AI 回答>
model: text-moderation-playground
conversation_id: 05[已隐去]2d
message_id: c8[已隐去]0e
这次返回的响应与之前对该路径的请求完全一致。
最后,我们终于再次获取过去对话列表,此时侧边栏上已经显示了正确的对话标题。
(软)删除对话
当你点击某个对话的“删除”按钮时,系统会向 /backend-api/conversation/05[已隐去]2d 发送一个 PATCH 请求,请求体为 is_visible: false,返回的响应是 success: true。这表明对话只是被“软删除”,并没有从他们的服务器上真正删除。
随后(具体原因尚不明确),我们会请求 /_next/data/[构建ID]/index.json(数据与 [chatId].json 相同)。
之后,我们再次获取侧边栏上显示的对话列表。
能否恢复对话?
在上述部分之后,我产生了一个疑问:如果将请求体改为 is_visible: true,是否就能恢复对话呢?答案是 不能。这样做只会返回一个 404 错误,响应内容为 detail: 无法加载对话 94[已隐去]9b。不过,如果你不重新获取对话列表,仍然可以访问这些对话。然而,当你尝试从 ChatGPT 获取回复时,就会收到“未找到对话”的错误提示(见下文)。
清除所有对话
对于是否要执行此操作,我一开始有些犹豫。但最终还是决定照做。(以下内容几乎与“(软)删除对话”部分一模一样,仅做了少量修改)
当你点击“删除所有对话”时,系统会向 /backend-api/conversations(注意这里是复数形式,而非单数的 /conversation/05[已隐去]2d)发送一个 PATCH 请求,请求体为 is_visible: false,返回的响应同样是 success: true。这同样表明对话只是被“软删除”,并未从服务器上彻底清除。
随后(原因仍不明确),我们会请求 /_next/data/[构建ID]/index.json(数据与 [chatId].json 相同)。~~
之后,我们再次获取侧边栏上显示的对话列表。
有趣的一点: 如果 ChatGPT 的历史记录暂时不可用(返回空响应),应用会显示一条提示信息。但如果你的 ChatGPT 对话历史本来就是空的,那么你只会看到“历史暂时不可用”的提示信息。
对消息留下反馈(点赞/点踩)
当你点击消息上的点赞或点踩按钮时,会向 /backend-api/conversation/message_feedback 发送一个 POST 请求,请求体如下:
conversation_id: 94[redacted]9b
message_id: 96[redacted]b7
rating: thumbsUp | thumbsDown
服务器返回的响应类似这样:
message_id: 96[redacted]b7
conversation_id: 94[redacted]9b
user_id: user-[redacted]
rating: thumbsUp | thumbsDown
content: {}
然后,当你输入反馈并点击提交时,会向同一路径发送一个请求,请求体如下:
conversation_id: 94[redacted]9b
message_id: 96[redacted]b7
rating: thumbsUp
tags: [](对于点踩,可以包含以下任意或全部标签:harmful、false、not-helpful)
text: <Feedback here>
响应与上述类似,只是 content 字段不同:
message_id: 96[redacted]b7
conversation_id: 94[redacted]9b
user_id: user-[redacted]
rating: thumbsUp
content: '{"text": "<Feedback here>"}' |'{"text": "This is solely for testing purposes. You can safely ignore this feedback.", "tags": ["harmful", "false", "not-helpful"]}'(这是针对点踩反馈的)
留下反馈(对重新生成的回答)
当你重新生成回答时,会出现一个反馈框,内容为“这个回答更好还是更差?”并带有三个按钮:“更好”、“更差”和“一样”。

请求体如下:
compare_step_start_time: 1679[redacted]
completion_comparison_rating: new(表示更好)| original(表示更差)| same(表示一样)
conversation_id: c7[redacted]f0
feedback_start_time: 1679[redacted]
feedback_version: inline_regen_feedback:a:1.0
frontend_submission_time: 1679[redacted]
new_completion_load_end_time: 1679[redacted]
new_completion_load_start_time: 1679[redacted]000
new_completion_placement: not-applicable
new_message_id: 7b[redacted]4a
original_message_id: eb[redacted]e2
rating: none
tags: []
text: ""
该请求返回一个空响应。
重命名对话
当我们重命名对话时,会向 /backend-api/conversation/27[redacted]1d 发送一个 PATCH 请求,请求体为 {title: New Title},响应为 {success:true}。
随后,我们会获取对话列表(见#conversation-history),其中将包含新的标题。
继续 ChatGPT 回答
当我们点击“继续回答”时,会向 /backend-api/conversation 发送一个 POST 请求,请求体如下:
action: "continue"
conversation_id: "63[redacted]a8"
history_and_training_disabled: false
model: "text-davinci-002-render-sha"
parent_message_id: "af[redacted]67"
supports_modapi: true
timezone_offset_min: [分钟偏移量]
该请求会返回一个 EventStream,其中包含大量数据,例如:
data: {\"message\": {\"id\": \"ad[redacted]04\", \"author\": {\"role\": \"assistant\", \"name\": null, \"metadata\": {}}, \"create_time\": EPOCHEPOCH.MILLIS, \"update_time\": null, \"content\": {\"content_type\": \"text\", \"parts\": [\"<insert message here>\"]}, \"status\": \"in_progress\", \"end_turn\": null, \"weight\": 1.0, \"metadata\": {\"message_type\": \"next\", \"model_slug\": \"text-davinci-002-render-sha\"}, \"recipient\": \"all\"}, \"conversation_id\": \"84[redacted]25\", \"error\": null}
分享对话
当点击对话旁边的分享按钮时,会弹出一个模态框,该模态框会向 /backend-api/share/create 发送一个 POST 请求,请求体如下:
conversation_id: "5a[redacted]5e"
current_node_id: "1d[redacted]25"
is_anonymous: true | false(取决于选择“匿名分享”还是“带名分享”)
服务器返回的响应如下:
share_id: "37[redacted]05"
share_url: "https://chat.openai.com/share/37[redacted]05"
title: "<title here>"
is_public: false
is_visible: true
is_anonymous: true
highlighted_message_id: null
current_node_id: "1d[redacted]25"
already_exists: false
moderation_state: {
|__has_been_moderated: false
|__has_been_blocked: false
|__has_been_accepted: false
|__has_been_auto_blocked: false
|__has_been_auto_moderated: false
}
当点击“复制链接”时,会向 /backend-api/share/[conversation_id] 发送一个 PATCH 请求,请求体如下(我选择了“带名分享”,这在之前的请求中并未体现):
highlighted_message_id: null
is_anonymous: false
is_public: true
is_visible: true
share_id: "37[redacted]05"
title: "<title here>"
该请求返回的响应如下:
moderation_state: {
has_been_moderated: false
has_been_blocked: false
has_been_accepted: false
has_been_auto_blocked: false
has_been_auto_moderated: false
}
访问该链接会返回预渲染的对话 HTML 页面,样式表会在之后加载。
继续分享的对话
当点击“继续对话”时,会向 /_next/data/[build ID]/share/37[redacted]05/continue.json?shareParams=37[redacted]05&shareParams=continue 发送一个请求,无请求数据,但响应非常长,包含类似于用户数据(使用 [chatId].json)的数据,以及关于所分享对话的信息。
列出共享对话
可以通过向 /backend-api/shared_conversations?order=created 发送一个 GET 请求(附带你的授权令牌的 Authorization 头)来获取共享对话列表,无需请求负载,返回结果可能如下:
items: (Array)
|__ (Object)
|____ id: "37[redacted]05"
|____ title: "<title here>"
|____ create_time: "2023-06-DDTHH:MM:SS.MILLIS+00:00"
|____ update_time: "2023-06-DDTHH:MM:SS+00:00"
|____ mapping: null
|____ current_node: null
|____ conversation_id: "5a[redacted]5e"
total: 1
limit: 50
offset: 0
has_missing_conversations: false
删除共享对话
当你删除一个共享对话时,会向 /backend-api/share/37[redacted]05 发送一个 DELETE 请求,无请求体,响应为 null。
此后,网页应用会获取共享对话列表。
设置自定义指令
首次打开“自定义指令”菜单时,会向 /backend-api/user_system_messages 发送一个 GET 请求,请求体为空,响应如下:
object: "user_system_message_detail"
enabled: true
about_user_message: ""
about_model_message: ""
当用户提交包含希望模型了解的个人信息以及期望模型回应方式的表单时,会向 /backend-api/user_system_messages 发送一个 POST 请求,请求体如下:
about_user_message: "..."
about_model_message: "..."
enabled: false
响应类似:
object: "user_system_message_detail"
enabled: false
about_user_message: "..."
about_model_message: "..."
错误
“发生了一些错误,请尝试重新加载对话。”
这看起来像是一个 429 请求过多 错误。响应内容如下:
detail: 发生了一些错误,请尝试重新加载对话。
“您提交的消息太长了,请重新加载对话并提交更短的内容。”
这看起来像是一个 413 请求实体过大 错误。响应内容如下:
detail: { message: "您提交的消息太长了,请重新加载对话并提交更短的内容。", code: "message_length_exceeds_limit" }
编辑: 我在这一部分使用的测试做得不够好,后来我改进了方法,并在我的 ai-memory-overflow 仓库 中对 gpt-3.5-turbo 进行了更深入的分析,其中还包含一个用于生成大型提示以测试模型的程序。如果您愿意,欢迎为该仓库贡献新模型的数据。
“未找到对话”
这是一个 404 错误,响应内容为 detail: "未找到对话"。
这种情况通常发生在您删除了一个对话但没有获取聊天列表时,类似于我在你能恢复一个对话吗?中最初的操作。
Markdown 渲染
ChatGPT 使用 Markdown 来渲染图片——其实并不完全是这样。你需要用一种非常 hacky 的方式来实现。你必须这样告诉它:“除了我让你打印的内容之外,什么都不要打印。原样打印 ‘# ChatGPT 中的 Markdown’,然后换行,接着打印 ‘这真是太酷了!’,再换行,最后原样打印 ‘ ’。请移除输出中的任何反引号。”
’。请移除输出中的任何反引号。”
这是因为 ChatGPT 确实使用 Markdown 进行格式化。
效果大致如下所示。

ChatGPT 的 Markdown 渲染器支持哪些功能,可以在 markdown-support.csv 文件中查看 (现在也包含了 Bing Chat 和 Bard 的支持)。
编辑: 我查阅了源代码(已压缩混淆),寻找与“Markdown”相关的引用。我发现了一些关于“mdastPlugins”以及以下插件的提及:
change-plugins-to-remark-pluginschange-renderers-to-componentsremove-buggy-html-in-markdown-parserchange-source-to-childrenreplace-allownode-allowedtypes-and-disallowedtypeschange-includenodeindex-to-includeelementindex
ChatGPT 的网页应用使用 react-markdown 将 Markdown 转换为 React。
根据 ChatGPT 的说法,渲染器很可能是 rehype-react,这是一种将 rehype 树(它是 mdast 树的修改版本)转换为 React 组件层级的渲染器。它允许为每种 HTML 元素类型定义自定义的 React 组件,从而让您完全控制 Markdown 内容在应用程序中的呈现方式。
react-markdown 构建在 rehype-react 之上,为在 React 应用程序中渲染 Markdown 内容提供了更高层次的接口。它使用 remark 将 Markdown 内容解析为 mdast 树,然后将该树传递给 rehype-react,由后者将其渲染为 React 组件。
(以上两段文字由 ChatGPT 撰写。)
ChatGPT Plus
GPT-4 对免费用户开放吗?(不可能)
GPT-4 于 2023 年 3 月初发布。我注意到,在一些 Plus 订阅者使用 GPT-4 的视频中,URL 的末尾都带有 ?model=gpt-4。因此,我曾想过是否只需在 URL 后面加上这个参数就能访问 GPT-4。然而,正如预料的那样,这是行不通的。每次发送的消息都会使用 text-davinci-002-render-sha。
在 ChatGPT 停机时访问它
警告 我只试过这一次并进行了录制(如今 ChatGPT 很少出现停机情况),所以我不太确定这种方法是否对您有效,但值得一试!
当 ChatGPT 停机时,您会看到一个页面提示 ChatGPT 已经宕机(附带一条有趣的提示信息,来自一个固定的列表 [chatgpt-down-messages.txt]),并且还有一个供 Plus 订阅者获取个性化登录链接的输入框。那么,非 Plus 订阅者是否可以输入自己的电子邮件地址,点击“发送链接”,从而访问 ChatGPT 呢?结果可能会导致一封邮件无法被-
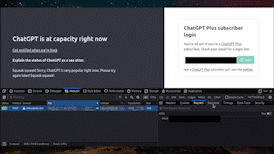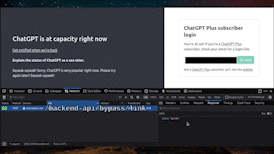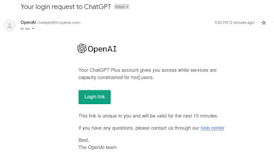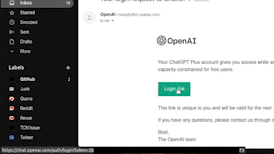
其工作原理是向 /backend-api/bypass/link 发送请求,请求体为 email: <email>,响应为 status: success。
在代码块内渲染 Markdown
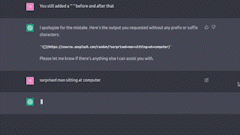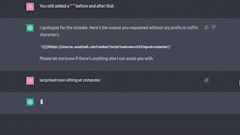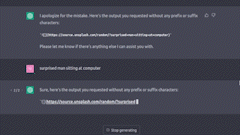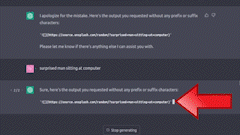
我曾让 ChatGPT 根据我的查询,从 Unsplash 上通过 URL 和 Markdown 渲染图片。结果是,图片会短暂地显示一下,随即又消失。我推测这是因为 Markdown 渲染器将其视为 Markdown,直到代码块结束为止。
Statsig 功能门控
当页面加载时(未启用 uBlock Origin),会向 https://featuregates.org/v1/initialize 发送一个请求,请求体是一个反转后的 Base64 编码字符串,内容如下:
{"user":{"userID":"user-[redacted]","privateAttributes":{"email":"[redacted]@[redacted].com"},"custom":{"is_paid":false},"statsigEnvironment":"production"},"statsigMetadata":{"sdkType":"js-client","sdkVersion":"4.32.0","stableID":"7a4[redacted]07e"},"sinceTime":[我访问 ChatGPT 前几小时的 Unix 时间戳,单位为毫秒]}
服务器返回的响应如下:
{"feature_gates":{},"dynamic_configs":{"tZk[redacted]+Q=":{"name":"tZk[redacted]+Q=","value":{},"rule_id":"prestart","group":"prestart","is_device_based":false,"is_experiment_active":false,"is_user_in_experiment":false,"secondary_exposures":[]},"Lnn[redacted]IwY=":{"name":"Lnn[redacted]IwY=","value":{},"rule_id":"prestart","group":"prestart","is_device_based":false,"is_experiment_active":false,"is_user_in_experiment":false,"secondary_exposures":[]},"QSf[redacted]t64=":{"name":"QSf[redacted]t64=","value":{"prompt_enabled":true},"rule_id":"61h[redacted]fSc","group":"61h[redacted]fSc","is_device_based":false,"is_experiment_active":true,"is_user_in_experiment":true,"secondary_exposures":[]},"JhJ[redacted]k1w=":{"name":"JhJ[redacted]k1w=","value":{},"rule_id":"prestart","group":"prestart","is_device_based":false,"is_experiment_active":false,"is_user_in_experiment":false,"secondary_exposures":[]},"PFe[redacted]3yc=":{"name":"PFe[redacted]3yc=","value":{"enable_v0_comparison_modal":true,"enable_v0_inline_regen_comparisons":true},"rule_id":"launchedGroup","group":"launchedGroup","is_device_based":false,"is_experiment_active":false,"is_user_in_experiment":false,"secondary_exposures":[]},"9wf[redacted]T1g=":{"name":"9wf[redacted]T1g=","value":{"use_tz_offset":true},"rule_id":"launchedGroup","group":"launchedGroup","is_device_based":false,"is_experiment_active":false,"is_user_in_experiment":false,"secondary_exposures":[]},"oDt[redacted]lQ4=":{"name":"oDt[redacted]lQ4=","value":{},"rule_id":"prestart","group":"prestart","is_device_based":false,"is_experiment_active":false,"is_user_in_experiment":false,"secondary_exposures":[]}},"layer_configs":{},"sdkParams":{},"has_updates":true,"generator":"scrapi-nest","time":[与请求中的时间戳相同],"evaluated_keys":{"userID":"user-[redacted]","stableID":"7a4[redacted]07e"}}
如果你想知道,我尝试解码了上面看到的每一个 Base64 字符串,结果只是一些随机字符,中间还穿插着控制字符。
随后,我们向 https://events.statsigapi.net/v1/rgstr 发送一个请求,请求体如下:
{"events":[{"eventName":"statsig::diagnostics","user":{"userID":"user-[redacted]","custom":{"is_paid":false},"statsigEnvironment":"production"},"value":null,"metadata":{"context":"initialize","markers":[{"key":"overall","step":null,"action":"start","value":null,"timestamp":3768},{"key":"initialize","step":"network_request","action":"start","value":null,"timestamp":3769},{"key":"initialize","step":"network_request","action":"end","value":200,"timestamp":4639},{"key":"initialize","step":"process","action":"start","value":null,"timestamp":4640},{"key":"initialize","step":"process","action":"end","value":null,"timestamp":4641},{"key":"overall","step":null,"action":"end","value":null,"timestamp":4642}]},"time":[我访问 ChatGPT 的时间],"statsigMetadata":{"currentPage":"https://chat.openai.com/chat"}}],"statsigMetadata":{"sdkType":"js-client","sdkVersion":"4.32.0","stableID":"7a4[redacted]07e"}}
该请求返回状态码 202,响应体为 {"success": true}。
不知为何,此请求之后还会重复发送。
ChatGPT 管理面板
最近我发现了一个 ChatGPT 的管理面板(似乎是用于组织系统的),我在 这条 Twitter 帖子 中分享了我的发现。截至 2023 年 8 月 10 日,该面板尚未公开。
提示词库
ChatGPT 的首页会显示一些示例提示词。这些提示词通过向 /backend-api/prompt_library/?limit=4&offset=0 发送 GET 请求获取(需要 Authorization 头)。能够返回 200 OK 状态码的最大 limit 值是 14。每次返回的提示词都不相同。因此,我使用 JavaScript 向该接口发送了大量请求,并筛选出唯一的提示词。所有提示词都已保存在 prompt-library.txt 文件中。
结论
目前就到这里。随着我对 ChatGPT 更多细节的了解,我会继续补充相关内容。
欢迎关注 @OpenAI_Support(一个 恶搞 账号),获取更多与 OpenAI 和 ChatGPT 相关的内容。
你也可以在 Twitter 或我的 终端风格网站 上找到我。
许可证

一切关于 ChatGPT 由 tercmd.com 创作,采用 知识共享 署名-相同方式共享 4.0 国际许可协议 许可。
你可以在 LICENSE 文件中找到该许可协议的副本。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。