alpaca_farm
AlpacaFarm 是一个专为“从人类反馈中学习”(RLHF)技术设计的仿真框架。它核心解决了当前大模型对齐研究中成本高、门槛大的痛点:传统 RLHF 方法依赖昂贵且耗时的人工数据收集与评估,而 AlpacaFarm 允许开发者在不采集真实人类数据的情况下,利用 GPT-4 等强大模型自动模拟偏好反馈并执行自动化评估。这使得研究人员能够以极低的成本快速迭代和验证新的对齐算法。
该工具主要面向 AI 研究人员和算法开发者,特别是那些希望深入研究指令遵循模型优化,但受限于计算资源或数据获取渠道的团队。其独特亮点在于提供了一套完整的闭环系统:不仅包含经过验证的基准算法参考实现(如 PPO、Best-of-N),还集成了基于 API 模型的成对偏好模拟机制,以及标准化的自动评估流程。需要注意的是,由于数据集许可限制,AlpacaFarm 目前仅适用于学术研究用途,不支持商业应用。通过降低实验门槛,它致力于推动大模型对齐技术的普及与创新。
使用场景
某初创 AI 团队正在研发一款垂直领域的智能客服模型,急需通过人类反馈强化学习(RLHF)来提升回答的准确性和亲和力,但面临资源匮乏的困境。
没有 alpaca_farm 时
- 数据成本高昂:收集真实的人类偏好标注数据需要雇佣大量标注员或依赖众包平台,单次迭代成本高达数万美元,初创团队难以负担。
- 开发周期漫长:等待人工标注反馈往往需要数周时间,导致算法验证和模型迭代的周期被严重拉长,无法快速试错。
- 实验门槛极高:复现 PPO 等复杂的 RLHF 基线算法需要深厚的工程积累,团队需从零搭建训练框架,极易陷入底层代码调试而停滞不前。
- 评估标准不一:缺乏自动化的评估机制,每次模型效果验证都依赖人工抽检,主观性强且效率低下,难以量化改进幅度。
使用 alpaca_farm 后
- 零成本模拟反馈:利用 alpaca_farm 内置的 GPT-4 自动标注器模拟人类偏好,无需采集任何真实人工数据即可生成高质量的对齐训练集,将数据成本降至接近零。
- 即时迭代验证:仿真环境可瞬间生成海量偏好数据,团队能在几小时内完成原本需数周的“训练 - 评估”循环,大幅加速算法优化进程。
- 开箱即用基线:直接调用 alpaca_farm 提供的已验证参考实现(如 PPO、Best-of-N),团队可专注于核心策略改进,无需重复造轮子。
- 自动化客观评估:通过框架自带的自动评估流程,实时量化模型在指令遵循上的表现,确保每一次迭代都有据可依,显著提升研发效率。
alpaca_farm 通过高保真的仿真环境,让资源有限的团队也能以极低的成本高效开展前沿的 RLHF 对齐研究。
运行环境要求
- 未说明
- 需要 NVIDIA GPU
- 测试环境为 80GB A100 GPU:SFT 和奖励建模需 4 张,PPO 训练需至少 8 张,Best-of-n 解码需 1 张
- 需安装 flash-attn 和 apex 以启用优化
未说明

快速开始

AlpacaFarm:一个用于研究从人类反馈中学习方法的仿真框架
![]()
![]()
![]()
![]()
自动标注器变更:OpenAI已将text-davinci-003 弃用,因此我们无法再使用原有的标注池来自动生成偏好(用于微调或评估)。为此,我们改用了来自AlpacaEval 1的GPT-4标注器。所有结果应与AlpacaEval 1中的模型进行比较,而非原始的AlpacaFarm结果。请注意,在这种新设置下可能不会出现过度优化现象(参见论文中的图4)。由此带来的不便,我们深表歉意。
关于从人类反馈中学习的研究与开发颇具挑战性,因为像RLHF这样的方法既复杂又成本高昂。AlpacaFarm是一个仿真平台,能够在远低于常规成本的情况下开展相关研究与开发,从而推动指令遵循和对齐领域的普惠性研究。
本仓库包含以下内容的代码:
运行代码所需的数据托管在HuggingFace上:https://huggingface.co/datasets/tatsu-lab/alpaca_farm。
使用与许可说明:AlpacaFarm仅限于科研用途,并据此授权使用。数据集采用CC BY NC 4.0许可(仅允许非商业用途),使用该数据集训练的模型不得用于科研以外的场景。权重差异同样适用CC BY NC 4.0许可(仅允许非商业用途)。
AlpacaFarm简介
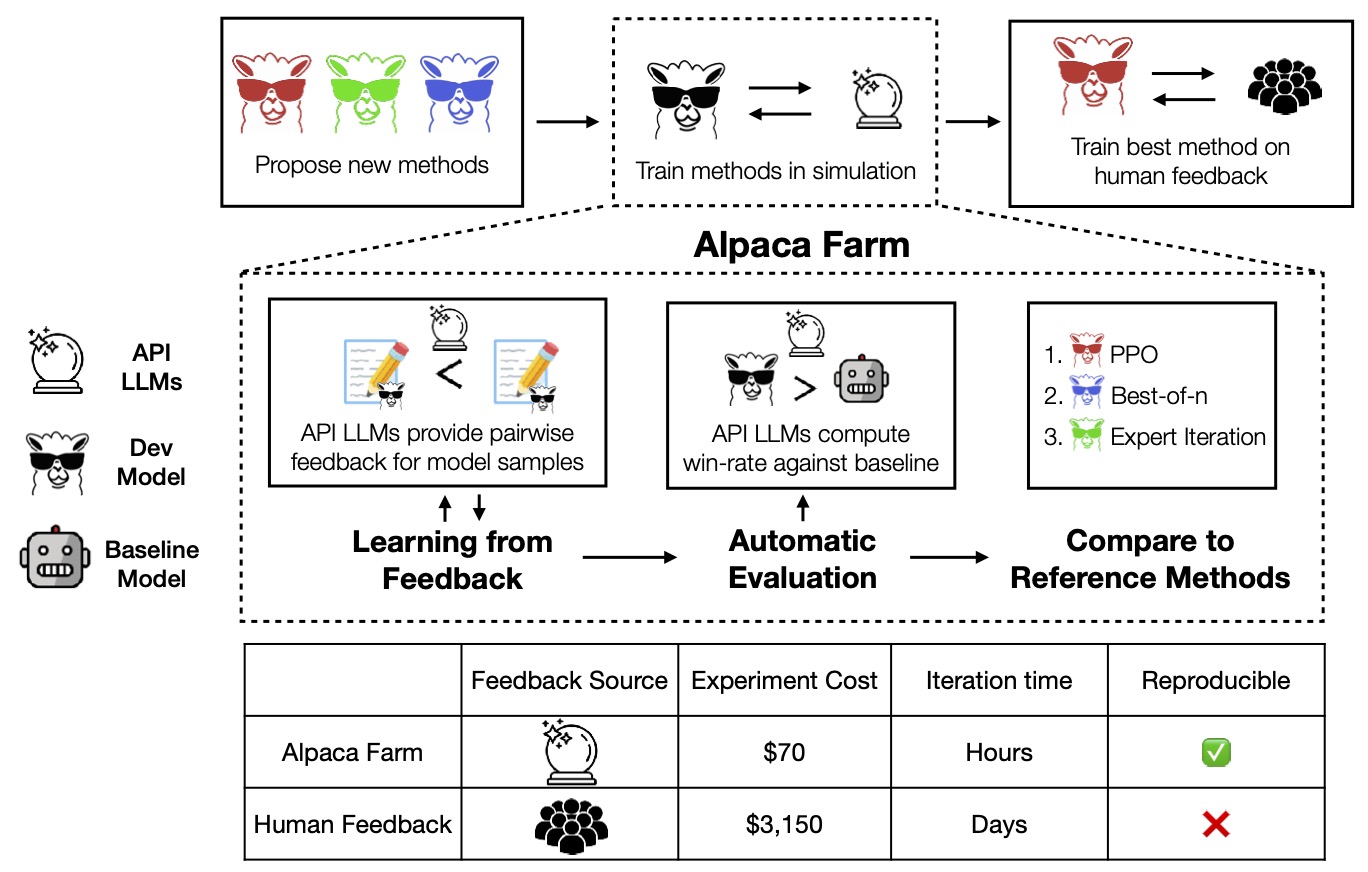
指令遵循模型通常分为三个步骤进行开发:
- 基于示范的监督微调
- 从人类反馈中学习;通常是成对偏好
- 人工交互式评估
AlpacaFarm的目标是提供三个关键组件,以解决第2步和第3步的问题:低成本地模拟来自API模型(如GPT-4、ChatGPT)的成对反馈,为方法开发提供自动化评估工具,以及提供用于比较和修改的学习算法参考实现。
安装
要安装稳定版本,请运行:
pip install alpaca-farm
若要从main分支的最新提交安装,请运行:
pip install git+https://github.com/tatsu-lab/alpaca_farm.git
为了启用FlashAttention及其他优化功能,还需安装flash-attn和apex这两个包。
模拟成对偏好
笔记本示例:![]()
在所有的评估和标注中,我们使用AlpacaEval,结合我们的自动标注池及额外噪声,以模拟人类标注的变异性。
开始之前,需将环境变量OPENAI_API_KEY设置为您的OpenAI API密钥,(可选)还将OPENAI_ORG设置为您所在的组织ID。您可以通过以下命令完成设置:
export OPENAI_API_KEY="sk..."
要标注您模型输出的成对样本,可使用如下代码。如需更多详细信息或处理不同格式输出的功能,请参阅示例笔记本。
from alpaca_farm.auto_annotations import PairwiseAutoAnnotator
import json
# 加载一些数据
with open("examples/data/outputs_pairs.json") as f:
outputs_pairs = json.load(f)[:6]
print(outputs_pairs[-1:])
# [{'instruction': '如果您能帮我给朋友们写一封邀请他们周五共进晚餐的邮件,我将不胜感激。',
# 'input': '',
# 'output_1': "亲爱的朋友们:\r\n\r\n希望这封信能带给您美好的问候。我非常高兴地邀请您们于本周五共进晚餐。我们将在[地点]晚上7点见面。期待与您们相聚。\r\n\r\n此致,\r\n[姓名]",
# 'output_2': "大家好!\n\n我将于本周五晚上举办一场晚宴,诚挚邀请各位前来。届时我们将享用丰盛的美食,并畅聊一番。\n\n请告知我您是否能出席——我非常期待与各位见面!\n\n祝好,\n[您的名字]"}]
annotator = PairwiseAutoAnnotator()
annotated = annotator.annotate_pairs(outputs_pairs)
print(annotated[-1:])
# [{'instruction': '如果您能帮我写一封邀请朋友周五共进晚餐的邮件,我将不胜感激。',
# 'input': '',
# 'output_1': "亲爱的朋友们:\r\n\r\n希望这封信能带给您美好的问候。我非常高兴地邀请您们于本周五共进晚餐。我们将在[地点]晚上7点见面。期待与您们相聚。\r\n\r\n此致,\r\n[姓名]",
# 'output_2': "大家好!\n\n我将于本周五晚上举办一场晚宴,诚挚邀请各位前来。我们将准备美味佳肴,一起度过愉快的时光。\n\n请告知我您是否能出席——我非常期待与各位见面!\n\n祝好,\n[您的名字]",
# 'annotator': 'chatgpt_2',
# 'preference': 2}]
如果您拥有的不是成对样本,而是一组采样输出,则可以使用以下代码:
multisample_outputs = [dict(instruction="重复以下内容", input="yes", output=["yes", "no", "maybe", "repeat"])]
print(annotator.annotate_samples(multisample_outputs))
# [{'sample_id': 0,
# 'instruction': '重复以下内容',
# 'input': 'yes',
# 'output_1': 'yes',
# 'output_2': 'maybe',
# 'annotator': 'chatgpt_2',
# 'preference': 1}]
运行自动评估
在所有评估中,我们使用 AlpacaEval 及其自动标注器池。
要开始使用,请将环境变量 OPENAI_API_KEY 设置为您的 OpenAI API 密钥,并(可选)将 OPENAI_ORG 设置为您所在的组织 ID。您可以通过运行以下命令来完成:
export OPENAI_API_KEY="sk..."
将您的模型添加到 Alpaca Leaderboard 的最简单方法是运行以下代码,该代码仅需要您在我们的评估数据上生成的模型输出。
from alpaca_farm.auto_annotations import alpaca_leaderboard
import datasets
# 在 Alpaca 评估数据上进行预测
alpaca_eval_data = datasets.load_dataset("tatsu-lab/alpaca_farm", "alpaca_farm_evaluation")["eval"]
... # 使用这些数据为您的模型生成输出并保存
path_to_outputs = "examples/data/eval_gpt-3.5-turbo-0301.json"
# 输出应为如下格式的 JSON 列表:
# [{'instruction': '哪些著名演员的职业生涯始于百老汇?', 'input': '', 'output': '一些职业生涯始于百老汇的著名演员包括休·杰克曼、梅丽尔·斯特里普、丹泽尔·华盛顿、奥德拉·麦克唐纳和林-曼努埃尔·米兰达。', 'generator': 'gpt-3.5-turbo-0301', 'dataset': 'helpful_base', 'datasplit': 'eval'},
# ...]
alpaca_leaderboard(path_to_outputs, name="我的酷炫模型")
# 胜率 标准误差 总样本数 平均长度
# gpt35_turbo_instruct 81.71 1.33 801 1018
# alpaca-farm-ppo-sim-gpt4-20k 44.10 1.74 805 511
# 我的酷炫模型 41.54 2.01 597 327
# alpaca-farm-ppo-human 41.24 1.73 805 803
# alpaca-7b 26.46 1.54 805 396
# text_davinci_001 15.17 1.24 804 296
运行参考方法
我们提供了几种基于成对反馈学习方法的参考实现。这些方法的示例代码可在 examples/ 目录中找到。其中包括 监督微调、奖励建模、使用 PPO 的 RLHF、最佳 n 次解码 等。
下面给出了一些用于复现我们论文中模型成果的示例命令。说明:
- 所有训练代码均在启用 FlashAttention 的情况下,在配备 8 张 80GB A100 显卡的机器上进行了测试。
- 最佳 n 次解码是在单张 80GB 显卡上测试的。
- 监督微调和奖励建模可以在 4 张 80GB A100 显卡上完成,而 PPO 训练目前至少需要 8 张 80GB 显卡。
- 在运行以下代码之前,请确保将您的 LLaMA 检查点和分词器转换为 HuggingFace 格式,并将其存储在
<your_path_to_hf_converted_llama_ckpt_and_tokenizer>。
监督微调 (SFT)
要复现我们在论文中从 LLaMA 微调得到的 SFT10k 模型,请运行以下命令:
bash examples/scripts/sft.sh \
<your_output_dir_for_sft10k> \
<your_wandb_run_name> \
<your_path_to_hf_converted_llama_ckpt_and_tokenizer>
SFT10k 模型将被保存到 <your_output_dir>,WandB 实验名称将为 <your_wandb_run_name>。
奖励建模
要复现我们在论文中训练的奖励模型,请运行以下命令:
bash examples/scripts/reward_modeling.sh \
<your_output_dir_for_reward_model> \
<your_wandb_run_name> \
<your_output_dir_for_sft10k> \
<preference_dataset_name>
将 <preference_dataset_name> 设置为 "alpaca_noisy_multi_preference" 以获得模拟偏好奖励模型,或设置为 "alpaca_human_preference" 以获得人类偏好奖励模型。
使用 PPO 的 RLHF
要复现我们在论文中使用模拟奖励模型训练的 RLHF PPO 模型,请运行以下命令:
bash examples/scripts/rlhf_ppo.sh \
<your_output_dir_for_ppo> \
<your_wandb_run_name> \
<your_output_dir_for_reward_model> \
<your_output_dir_for_sft10k> \
<kl_coef>
<your_output_dir_for_reward_model> 应指向根据上一步训练得到的模拟奖励模型或人类奖励模型。请注意,人类奖励 PPO 的 KL 惩罚系数远大于模拟 PPO。将 <kl_coef> 设置为 0.0067 用于模拟 PPO,设置为 0.02 用于人类 PPO,即可恢复我们的原始结果。通常情况下,PPO 模型在 20–80 个 PPO 步骤内(即不到四次遍历整个指令集)的表现会显著优于 SFT,而随着 PPO 步骤的增加,性能则会逐渐下降。
最佳 n 次解码
要复现我们在 AlpacaFarm 评估套件上的最佳 n 次推理时解码结果,请运行以下命令:
python examples/best_of_n.py \
--task "run_best_of_n" \
--decoder_name_or_path <your_output_dir_for_decoder> \ # 可以是 SFT 模型,甚至经过 PPO 调优的模型。
--scorer_name_or_path <your_output_dir_for_reward_model> \
--num_return_sequences 16 \ # 这就是最佳 n 次解码中的 n。
--per_device_batch_size 4 \ # 如果内存不足,可以适当减少此值。
--split "eval" \
--mixed_precision "bf16" \
--tf32 True \
--flash_attn True \
--output_path <your_output_path_to_store_samples>
随后,您可以直接将 <your_output_path_to_store_samples> 中生成的样本用于我们的自动化评估。
专家迭代
要复现我们在 AlpacaFarm 评估套件上的专家迭代结果,首先需要生成最佳 n 次样本。请运行以下命令:
python examples/best_of_n.py \
--task "run_best_of_n" \
--decoder_name_or_path <your_output_dir_for_decoder> \ # SFT10k 模型。
--scorer_name_or_path <your_output_dir_for_reward_model> \
--num_return_sequences 16 \ # 这就是最佳 n 次解码中的 n。
--per_device_batch_size 4 \ # 如果内存不足,可以适当减少此值。
--split "unlabeled" \
--mixed_precision "bf16" \
--tf32 True \
--flash_attn True \
--output_path '<your_output_dir_for_expiter_data>/best_of_n_samples.json'
然后,使用最佳 n 次样本从 SFT10k 检查点出发进行监督微调:
bash examples/scripts/expiter.sh \
<your_output_dir_for_expiter> \
<your_wandb_run_name> \
<your_output_dir_for_sft10k> \
<your_output_dir_for_expiter_data>
Quark
要复现我们在 AlpacaFarm 评估套件上的 Quark 结果,请运行以下命令:
bash examples/scripts/rlhf_quark.sh \
<your_output_dir_for_quark> \
<your_wandb_run_name> \
<your_output_dir_for_reward_model> \
<your_output_dir_for_sft10k> \
<kl_coef>
直接偏好优化 (DPO)
要复现我们在 AlpacaFarm 评估套件上的 DPO 结果,请运行以下命令:
bash examples/scripts/dpo.sh \
<your_output_dir_for_dpo> \
<your_wandb_run_name> \
<your_output_dir_for_sft10k>
OpenAI 模型
要使用我们的提示和解码超参数运行 OpenAI 参考模型,请执行以下命令:
python examples/oai_baselines.py \
--model_name <oai_model_name> \
--save_path <save_path>
随后,您可以直接将 <save_path> 中生成的样本用于我们的自动化评估。
下载预训练的 AlpacaFarm 模型
我们提供了奖励模型以及所有参考方法的模型检查点,详见我们论文 [2] 的表 2。具体而言,我们在 AlpacaFarm 模拟环境及人类偏好数据上分别对每种参考方法进行了微调,并发布了两种版本的模型。当前可用的模型列表(此处可查)包括:
sft10k:我们收集偏好数据所用的监督学习基础模型。reward-model-sim:基于 AlpacaFarm 偏好数据训练的奖励模型。reward-model-human:基于人类偏好数据训练的奖励模型。ppo-sim:在模拟环境中训练的最佳 PPO 检查点。ppo-human:基于人类数据训练的最佳 PPO 检查点。expiter-sim:在模拟环境中训练的最佳专家迭代检查点。expiter-human:基于人类数据训练的最佳专家迭代检查点。feedme-sim:基于模拟偏好训练的 FeedME 方法。feedme-human:基于人类偏好训练的 FeedME 方法。reward-condition-sim:基于模拟偏好训练的奖励条件化方法。
要下载并恢复这些检查点,首先请确保已拥有一个 转换为 Hugging Face 格式 的 LLaMA-7B 检查点,且 transformers>=4.29.2。然后,运行以下命令以下载所有 AlpacaFarm 模型:
python -m pretrained_models.recover_model_weights \
--llama-7b-hf-dir <your_path_to_hf_converted_llama_ckpt_and_tokenizer> \
--alpaca-farm-model-name all
或者,指定特定的模型名称以仅下载该模型:
python -m pretrained_models.recover_model_weights \
--llama-7b-hf-dir <your_path_to_hf_converted_llama_ckpt_and_tokenizer> \
--alpaca-farm-model-name <one_of_the_model_names_from_above> \
--models-save-dir <dir_to_save_all_models>
若要单独下载任一奖励模型,则需先将 sft10k 下载至 <dir_to_save_all_models>。
引用
如果您使用本仓库中的数据或代码,请考虑引用我们的工作。
@misc{dubois2023alpacafarm,
title={AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback},
author={Yann Dubois and Xuechen Li and Rohan Taori and Tianyi Zhang and Ishaan Gulrajani and Jimmy Ba and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto},
year={2023},
eprint={2305.14387},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
如果您使用 alpaca-farm>=0.2.0 版本,请务必注明标注者已变更(因为 text-davinci-003 已被弃用)。此时的偏好数据和胜率来自 AlpacaEval 1,与我们论文中的数值不可直接比较。您可以这样引用 AlpacaEval:
@misc{alpaca_eval,
author = {Xuechen Li and Tianyi Zhang and Yann Dubois and Rohan Taori and Ishaan Gulrajani and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {AlpacaEval: An Automatic Evaluator of Instruction-following Models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tatsu-lab/alpaca_eval}}
}
版本历史
v0.2.02024/02/24v0.1.122023/12/05v0.1.112023/12/04v0.1.102023/12/02v0.1.92023/08/04v0.1.82023/07/09v0.1.62023/06/23v0.1.52023/06/15v0.1.42023/06/12v0.1.32023/06/11v0.1.22023/06/11v0.1.12023/06/11v0.1.02023/05/23常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器