py-gpt
py-gpt 是一款功能全面的桌面级 AI 助手,旨在将强大的大语言模型能力直接带入用户的本地电脑。它支持 Windows、Linux 和 Mac 系统,让用户无需依赖网页端,即可在本地环境中流畅使用 GPT-4/5、o1、Claude、Gemini、Grok 以及通过 Ollama 运行的本地模型(如 Llama 3、DeepSeek)。
这款工具解决了用户在多模型切换、数据隐私保护及复杂任务自动化方面的痛点。它不仅提供基础的聊天对话,更集成了“文件对话”(基于 LlamaIndex 的 RAG 技术)、代码生成与执行、系统命令控制、网络搜索、图像视频生成以及语音交互等高级功能。用户可以让 AI 读取本地文档、自动执行脚本,甚至通过插件扩展无限可能。
py-gpt 非常适合开发者、研究人员、数据分析师以及追求高效工作流的普通用户。对于技术人员,它是调试代码和管理本地模型的得力帮手;对于需要处理大量文档的研究者,其知识库检索功能能极大提升效率;而丰富的语音和多模态特性,也让它成为日常办公的理想伴侣。其独特的亮点在于高度模块化的插件系统与对多种前后端模型的统一支持,真正实现了“一个界面,掌控所有 AI 能力”。
使用场景
数据分析师小林需要快速从本地数百页的行业报告 PDF 中提取关键数据,编写 Python 脚本进行可视化分析,并生成带语音解说的工作汇报视频。
没有 py-gpt 时
- 工具切换繁琐:需要在浏览器聊天窗口、本地代码编辑器和独立的绘图软件之间反复复制粘贴,上下文极易断裂。
- 文件处理受限:网页版 AI 无法直接读取本地大量私有 PDF 文档,手动整理数据耗时耗力且容易出错。
- 自动化能力弱:生成的代码只能手动运行,无法让 AI 直接调用本地系统命令完成文件整理或环境配置。
- 多模态缺失:生成图表后,还需单独使用其他工具制作语音解说和视频,工作流被割裂成多个孤立环节。
使用 py-gpt 后
- 一站式桌面交互:py-gpt 作为本地桌面助手,让小林在同一个界面内完成对话、编码、运行和文件管理,无需切换应用。
- 本地文件深度对话:利用内置的 LlamaIndex 功能,py-gpt 直接索引并“阅读”本地数百页 PDF,精准提取数据供分析使用。
- 自主执行与代理:通过 Agents 模式,py-gpt 不仅能写出分析代码,还能直接在本地环境中运行脚本、安装依赖库并生成图表文件。
- 全流程多模态输出:py-gpt 串联了图像生成、TTS 语音合成及视频制作插件,一键将分析结果转化为带解说的汇报视频。
py-gpt 将割裂的 AI 工具链整合为本地化的自主智能工作流,极大提升了复杂任务的端到端交付效率。
运行环境要求
- Linux
- Windows
- macOS
- 未说明(支持本地模型如 Ollama,具体 GPU 需求取决于所选本地模型
- 云端 API 模式无本地 GPU 要求)
未说明
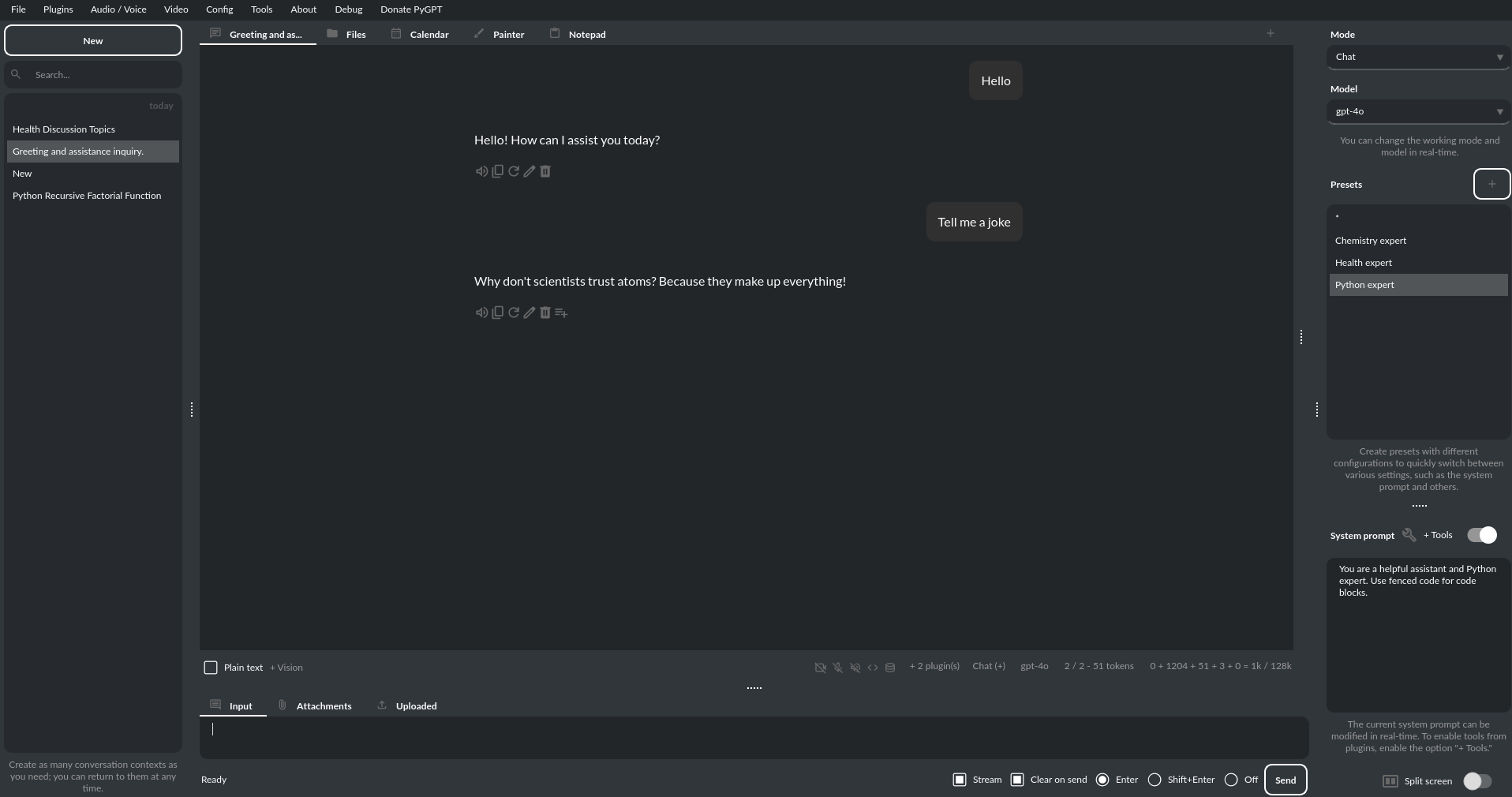
快速开始
PyGPT - 桌面AI助手
![]()
版本:2.7.12 | 构建日期:2026-02-06 | Python:>=3.10, <3.14
官方网站:https://pygpt.net | 文档:https://pygpt.readthedocs.io
Discord:https://pygpt.net/discord | Snap:https://snapcraft.io/pygpt | PyPI:https://pypi.org/project/pygpt-net
针对Linux(
zip)和Windows 10/11(msi)的64位编译版:https://pygpt.net/#download❤️ 捐赠:https://www.buymeacoffee.com/szczyglis | https://github.com/sponsors/szczyglis-dev
概述
PyGPT 是一款 一体化 的桌面AI助手,通过 OpenAI API 直接与 OpenAI 的语言模型进行交互,包括 GPT-5、GPT-4、o1、o3 等。此外,借助其他 SDK 和 LlamaIndex,该应用还支持其他 LLM,例如 HuggingFace 上的模型、通过 Ollama 提供的本地模型(如 gpt-oss、Llama 3、Mistral、DeepSeek V3/R1 或 Bielik),以及 Google Gemini、Anthropic Claude、Perplexity / Sonar 和 xAI Grok 等。
此助手提供多种操作模式,如聊天、助理、代理、文本补全,以及图像生成和分析等图像相关任务。PyGPT 具有文件系统功能,可进行文件读写,生成并运行Python代码,执行系统命令、自定义命令,并管理文件传输。它还允许模型通过 DuckDuckGo、Google 和 Microsoft Bing 进行网络搜索。
在音频交互方面,PyGPT 包括使用 Microsoft Azure、Google、Eleven Labs 和 OpenAI 文本转语音服务的语音合成功能。此外,它还具备由 OpenAI Whisper、Google 和 Bing 提供的语音识别能力,使应用程序能够理解语音命令并将音频输入转录为文本。它具有上下文记忆功能,支持保存和加载,使用户可以从对话中预设的点继续交互。通过直观的预设系统,提示的创建和管理变得更加便捷。
PyGPT 的功能可通过插件扩展,允许进行自定义增强(内置多个插件)。其多模态能力使其成为适用于多种AI辅助操作的灵活工具,例如基于文本的交互、系统自动化、日常协助、视觉应用、自然语言处理、代码生成和图像创作。
包含多种操作模式,如聊天、文本补全、助理、代理、视觉、文件聊天(通过 LlamaIndex)、命令执行、外部API调用和图像生成,使 PyGPT 成为许多AI驱动任务的多功能工具。
展示视频(mp4,版本 2.5.65,构建日期 2025-07-24):
https://github.com/user-attachments/assets/d8305109-8b1b-41cb-b3ba-8c654271a95c
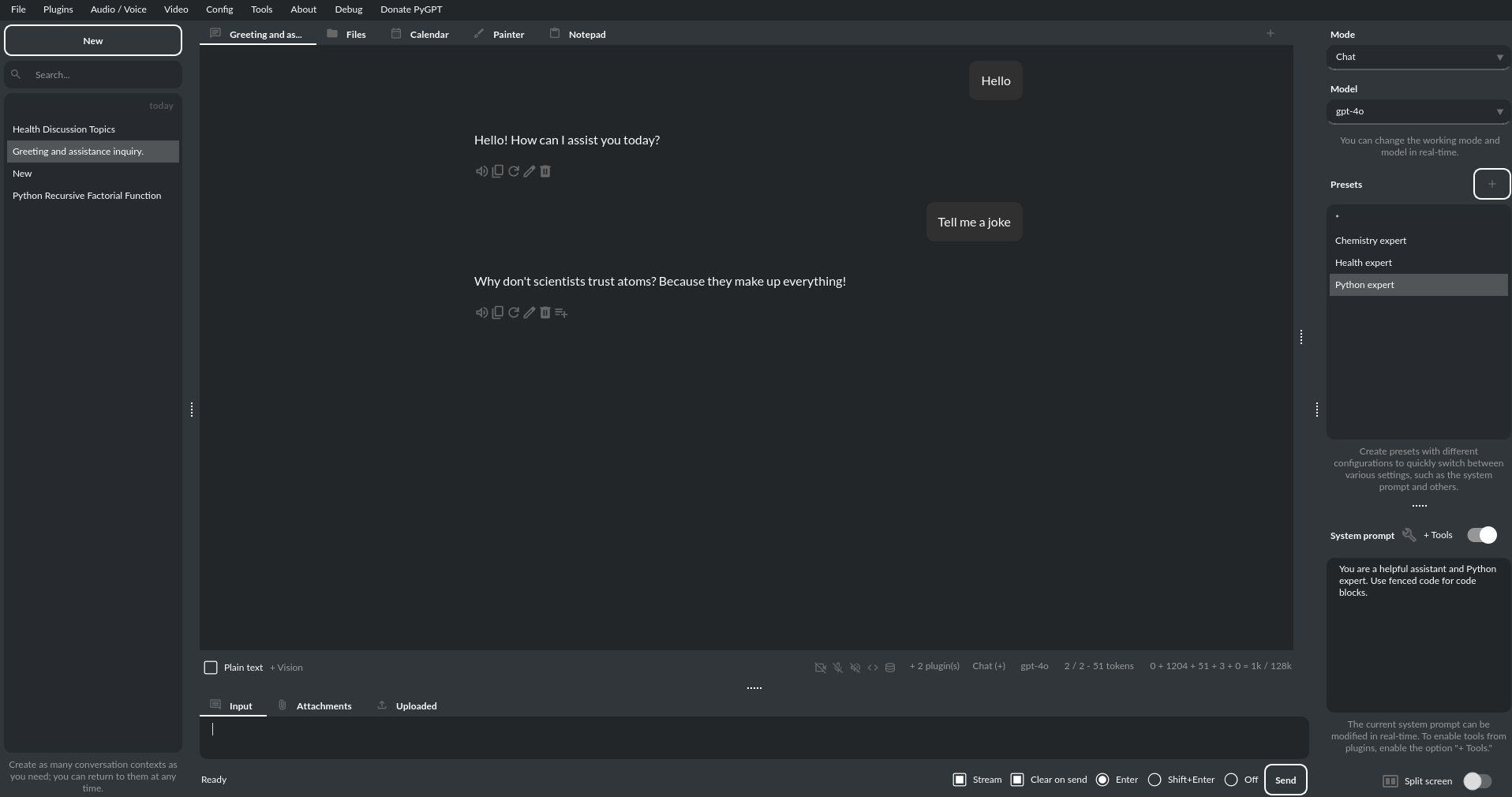
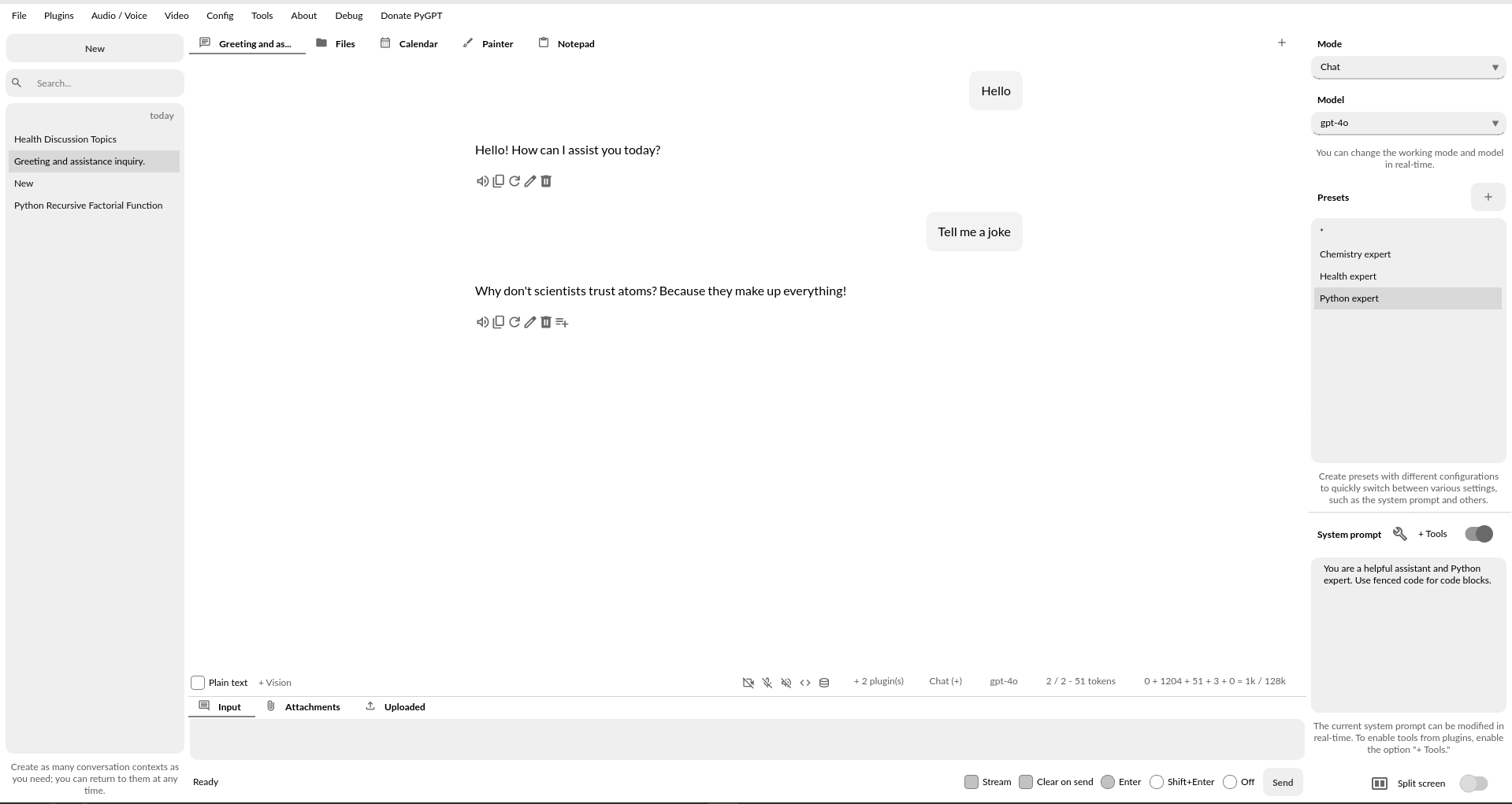
截图(版本 2.5.64,构建日期 2025-07-23):
深色主题:
浅色主题:
您可以在以下链接下载适用于Windows和Linux的64位编译版:https://pygpt.net/#download
特性
- 桌面AI助手,适用于
Linux、Windows和Mac,使用Python编写。 - 功能类似于
ChatGPT,但运行于本地桌面计算机上。 - 11种操作模式:聊天、文件聊天、实时+音频、研究(Perplexity)、补全、图像和视频生成、助理、专家、计算机使用、代理和自主模式。
- 支持多种模型,如
OpenAI GPT-5、GPT-4、o1、o3、o4、Google Gemini、Anthropic Claude、xAI Grok、DeepSeek V3/R1、Perplexity / Sonar,以及任何可通过LlamaIndex和Ollama访问的模型,如DeepSeek、gpt-oss、Llama 3、Mistral、Bielik等。 - 与自有文件聊天:集成
LlamaIndex支持,可与以下数据类型进行聊天:txt、pdf、csv、html、md、docx、json、epub、xlsx、xml、网页、Google、GitHub、视频/音频、图片及其他数据类型;或使用对话历史作为提供给模型的额外上下文。 - 内置向量数据库支持及自动化的文件和数据嵌入。
- 通过
DALL-E、gpt-image、Imagen、Gemini和Nano Banana等模型进行图像生成。 - 通过
Veo3和Sora2等模型进行视频生成。 - 通过
DuckDuckGo、Google和Microsoft Bing实现互联网访问。 - 使用
Microsoft Azure、Google、Eleven Labs和OpenAI文本转语音服务进行语音合成。 - 使用
OpenAI Whisper、Google和Microsoft 语音识别进行语音识别。 - 插件支持,内置插件如
文件I/O、代码解释器、网络搜索、Google、Facebook、X/Twitter、Slack、Telegram、GitHub、MCP等。 - 支持MCP。
- 在视觉模式下实时捕捉视频摄像头画面。
- 通过视觉模型进行图像分析。
- 内置针对残障人士的支持功能:可自定义的键盘快捷键、语音控制,以及通过语音合成将屏幕上的操作转换为音频。
- 处理并存储完整的对话上下文(短期和长期记忆)。
- 集成日历、每日笔记,并可根据选定日期在上下文中进行搜索。
- 执行工具和命令(通过插件:访问本地文件系统、Python代码解释器、执行系统命令等)。
- 自定义命令的创建和执行。
- 内置Crontab/任务调度器。
- 内置实时Python代码解释器。
- 管理文件和附件,提供上传、下载和整理选项。
- 对话历史具备回退到先前上下文的功能(长期记忆)。
- 可轻松管理提示,提供便捷可编辑的预设。
- 操作和界面直观易用。
- 内置记事本。
- 内置简单的绘图工具。
- 内置基于节点的代理构建器。
- 支持多种语言。
- 无需事先了解如何使用AI模型。
- 完全可配置。
- 主题支持。
- 实时代码语法高亮显示。
- 内置令牌使用量计算。
- 具备支持未来OpenAI模型的潜力。
- 开源;源代码可在
GitHub上获取。 - 使用用户自己的API密钥。
- 以及更多功能。
该应用程序是免费的、开源的,可在配备 Linux、Windows 10、Windows 11 和 Mac 的个人电脑上运行。
完整的Python源代码可在 GitHub 上获取。
PyGPT使用用户的API密钥——要使用GPT模型,您必须拥有注册的OpenAI账户和自己的API密钥。本地模型则不需要任何API密钥。
您还可以使用内置的LlamaIndex支持连接到其他大型语言模型(LLMs),例如HuggingFace上的模型。这可能需要额外的API密钥。
安装
二进制文件(Linux、Windows 10 和 11)
您可以下载适用于 Linux 和 Windows(10/11)的编译好的二进制版本。
PyGPT 的二进制文件需要在 Windows 10、11 或 Linux 系统上运行。只需从 https://pygpt.net 下载页面下载适合您系统的安装程序或压缩包,解压或安装后即可运行应用程序。目前尚无适用于 Mac 的二进制版本,因此在 Mac 上您必须通过 PyPi 或源代码来运行 PyGPT。当前仅提供 64 位二进制文件。
Linux 版本要求 GLIBC >= 2.35。
Microsoft Store(Windows)
对于 Windows 10/11,您可以直接从 Microsoft Store 安装 PyGPT:

Microsoft Store 链接:https://apps.microsoft.com/detail/XP99R4MX3X65VQ
AppImage(Linux)
您可以从发布页面下载最新的 Linux 版 PyGPT AppImage:
发布页面: https://github.com/szczyglis-dev/py-gpt/releases
提示: 请确保为下载的文件赋予执行权限:
chmod +x ./PyGPT-X.X.X-x86_64.AppImage
为了管理未来的更新,您可以使用 AppImageUpdate 工具:
可以从以下链接下载:https://github.com/AppImage/AppImageUpdate/releases
下载后,在终端中运行以下命令:
appimageupdatetool ./PyGPT-X.X.X-x86_64.AppImage
Snap Store(Linux)
您也可以直接从 Snap Store 安装 PyGPT:
sudo snap install pygpt
要管理未来的更新,请使用:
sudo snap refresh pygpt

使用摄像头: 在 Snap 版本中使用摄像头时,您需要通过以下命令连接摄像头:
sudo snap connect pygpt:camera
使用麦克风: 在 Snap 版本中使用麦克风时,您需要通过以下命令连接麦克风:
sudo snap connect pygpt:audio-record :audio-record
sudo snap connect pygpt:alsa
使用音频输出: 在 Snap 版本中使用音频输出时,您需要通过以下命令连接音频设备:
sudo snap connect pygpt:audio-playback
sudo snap connect pygpt:alsa
在 Snap 版本中连接 Docker 中的 IPython:
要在 Snap 版本中使用 IPython,您需要将 PyGPT 连接到 Docker 守护进程:
sudo snap connect pygpt:docker-executables docker:docker-executables
sudo snap connect pygpt:docker docker:docker-daemon
PyPi(pip)
该应用程序也可以通过 PyPi 使用 pip install 进行安装:
- 创建虚拟环境:
python3 -m venv venv
source venv/bin/activate
- 从 PyPi 安装:
pip install pygpt-net
- 安装完成后,运行以下命令启动应用程序:
pygpt
从 GitHub 源代码运行
另一种方法是从 GitHub 下载源代码,并使用 Python 解释器(>=3.10,<3.14)运行应用程序。
使用 pip 安装
- 克隆 Git 仓库或下载 .zip 文件:
git clone https://github.com/szczyglis-dev/py-gpt.git
cd py-gpt
- 创建一个新的虚拟环境:
python3 -m venv venv
source venv/bin/activate
- 安装依赖项:
pip install -r requirements.txt
- 运行应用程序:
python3 run.py
使用 Poetry 安装
- 克隆 Git 仓库或下载 .zip 文件:
git clone https://github.com/szczyglis-dev/py-gpt.git
cd py-gpt
- 安装 Poetry(如果尚未安装):
pip install poetry
- 创建一个使用 Python 3.10 的新虚拟环境:
poetry env use python3.10
poetry shell
或者(Poetry ≥ 2.0):
poetry env use python3.10
poetry env activate
- 安装依赖项:
poetry install
- 运行应用程序:
poetry run python3 run.py
提示: 您可以使用 PyInstaller 为您的系统创建编译后的应用程序版本(要求版本 ≥ 6.0.0)。
故障排除
如果您在 Linux 上使用较新版本的 PySide 时遇到 xcb 插件问题,例如以下错误:
qt.qpa.plugin: 无法加载 Qt 平台插件 "xcb",尽管它已被找到。
此应用程序无法启动,因为无法初始化任何 Qt 平台插件。
重新安装应用程序可能会解决此问题。
此时,请安装 libxcb:
sudo apt install libxcb-cursor0
如果您在 Linux 上遇到音频问题,请尝试安装 portaudio19-dev 和/或 libasound2:
sudo apt install portaudio19-dev
sudo apt install libasound2
sudo apt install libasound2-data
sudo apt install libasound2-plugins
Linux 上 GLIBC 版本问题
如果您在尝试运行 Linux 编译版本时遇到以下错误:
加载 Python 库 libpython3.10.so.1.0 出错:dlopen: /lib/x86_64-linux-gnu/libm.so.6: 找不到 GLIBC_2.35 版本(libpython3.10.so.1.0 需要该版本)
请尝试将 GLIBC 更新至 2.35 版本,或使用至少包含 2.35 版本 GLIBC 的较新操作系统。
Snap 版本中访问摄像头:
sudo snap connect pygpt:camera
Snap 版本中访问麦克风:
要在 Snap 版本中使用麦克风,您需要通过以下命令连接麦克风:
sudo snap connect pygpt:audio-record :audio-record
/var/lib/snapd/apparmor/profiles/snap.pygpt.pygpt
...
/etc/httpd/conf/mime.types r
并重新加载配置文件。
或者,您也可以尝试移除并重新安装 snap:
`sudo snap remove --purge pygpt`
`sudo snap install pygpt`
**Windows 版本中对麦克风和音频的访问权限:**
如果您在 Windows 上使用非二进制 PIP/Python 版本时遇到音频或麦克风问题,请检查是否已安装 FFmpeg。如果没有安装,请先安装 FFmpeg,并将其添加到系统 PATH 中。您可以在此处找到相关教程:https://phoenixnap.com/kb/ffmpeg-windows。而二进制版本已经内置了 FFmpeg。
**Windows 与 VC++ 可再发行组件**
在 Windows 系统上,程序正常运行需要安装 `VC++ 可再发行组件`,该组件可在 Microsoft 官网下载:
https://learn.microsoft.com/en-us/cpp/windows/latest-supported-vc-redist
`PySide6` 使用的就是这一环境中的库——它是 PyGPT 的基础依赖之一。如果缺少这些库,可能会导致界面显示异常,甚至使应用程序无法启动。
此外,您可能还需要将路径 `C:\path\to\venv\Lib\python3.x\site-packages\PySide6` 添加到系统的 `PATH` 环境变量中。
**WebEngine/Chromium 渲染器及 OpenGL 相关问题**
如果您在使用 `WebEngine / Chromium` 渲染器时遇到问题,可以通过命令行参数强制启用旧版模式来解决:
``` ini
python3 run.py --legacy=1
同时,若要强制禁用 OpenGL 硬件加速,可以使用以下命令:
python3 run.py --disable-gpu=1
您也可以手动编辑配置文件以启用旧版模式:打开 %WORKDIR%/config.json 文件,将以下选项设置为:
"render.engine": "legacy",
"render.open_gl": false,
其他要求
运行本程序需要互联网连接(用于 API 通信)、一个已注册的 OpenAI 账户,以及有效的 API 密钥,这些信息必须输入到程序中。而本地模型,例如 Llama3,则无需 OpenAI 账户或任何 API 密钥。
调试与日志记录
请参阅“调试与日志记录”章节,了解如何更详细地记录日志并诊断问题的方法。
快速入门
配置 API 密钥
您可以为多个不同的服务提供商配置 API 密钥,例如 OpenAI、Anthropic、Google、xAI、Perplexity、OpenRouter 等。这种灵活性使您能够根据需求选择不同的服务提供商。
首次设置时,请在应用程序内配置您的 API 密钥。
操作步骤如下:进入菜单:
配置 -> 设置 -> API 密钥
在这里,您可以添加或管理任何受支持的服务提供商的 API 密钥。
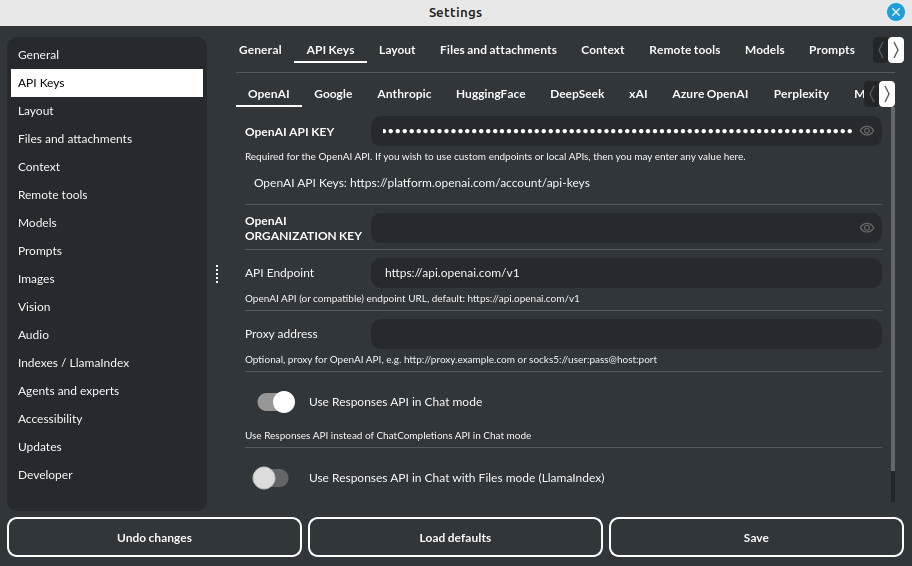
配置服务提供商:
- 选择服务提供商: 切换到相应提供商的标签页。
- 输入 API 密钥: 将所选服务提供商的 API 密钥粘贴进去。
示例:
- OpenAI: 您可以在 OpenAI 官网上注册并获取 API 密钥:https://platform.openai.com,然后前往 https://platform.openai.com/account/api-keys。
- Anthropic、Google 等: 请按照各自平台的指引操作。
注意: 您能否使用特定模型或服务,取决于您在相应服务提供商处的权限级别。如果您希望使用自定义 API 端点或不需要 API 密钥的本地 API,只需在 API 密钥字段中输入任意值,即可跳过密钥为空的提示。
工作模式
对话模式
+ 内联视觉与图像生成
在 PyGPT 中,此模式模拟了 ChatGPT,允许您与 GPT-5、GPT-4、o1、o3、Claude、Gemini、Grok、Perplexity (Sonar)、Deepseek 等多种模型进行对话。它通过 OpenAI SDK 的 Responses API 和 ChatCompletions API 进行工作;如果启用了原生 SDK,则也可使用 Google GenAI、Anthropic 或 xAI 的 SDK。您可以在 配置 -> 设置 -> API 密钥 中设置 ChatCompletions 的端点。
提示: 此模式直接使用服务提供商的 SDK。如果应用中未内置原生客户端,像 Sonar 或 Llama3 这样的模型仍可通过 LlamaIndex 或兼容 OpenAI 的 API 端点在对话模式下使用。当您使用非 OpenAI 模型时,程序会自动切换到这些端点。您可以在 设置 -> API 密钥 中启用或禁用每个服务提供商的原生 API SDK。如果禁用原生 SDK,程序将通过兼容的 ChatCompletions API 端点调用 OpenAI SDK。
目前内置的原生客户端包括:
- Anthropic SDK
- OpenAI SDK
- Google GenAI SDK
- xAI SDK
界面的主要部分是一个聊天窗口,显示您的对话记录。下方是用于输入消息的文本框。右侧可以设置或更改使用的模型和系统提示词。您还可以将这些设置保存为预设,以便快速在不同模型或任务之间切换。
在输入消息的地方上方,界面会实时显示您当前消息将消耗的 token 数量,帮助您监控用量。此外,此处还提供附件上传功能。有关附件使用的更多信息,请参阅“文件与附件”章节。
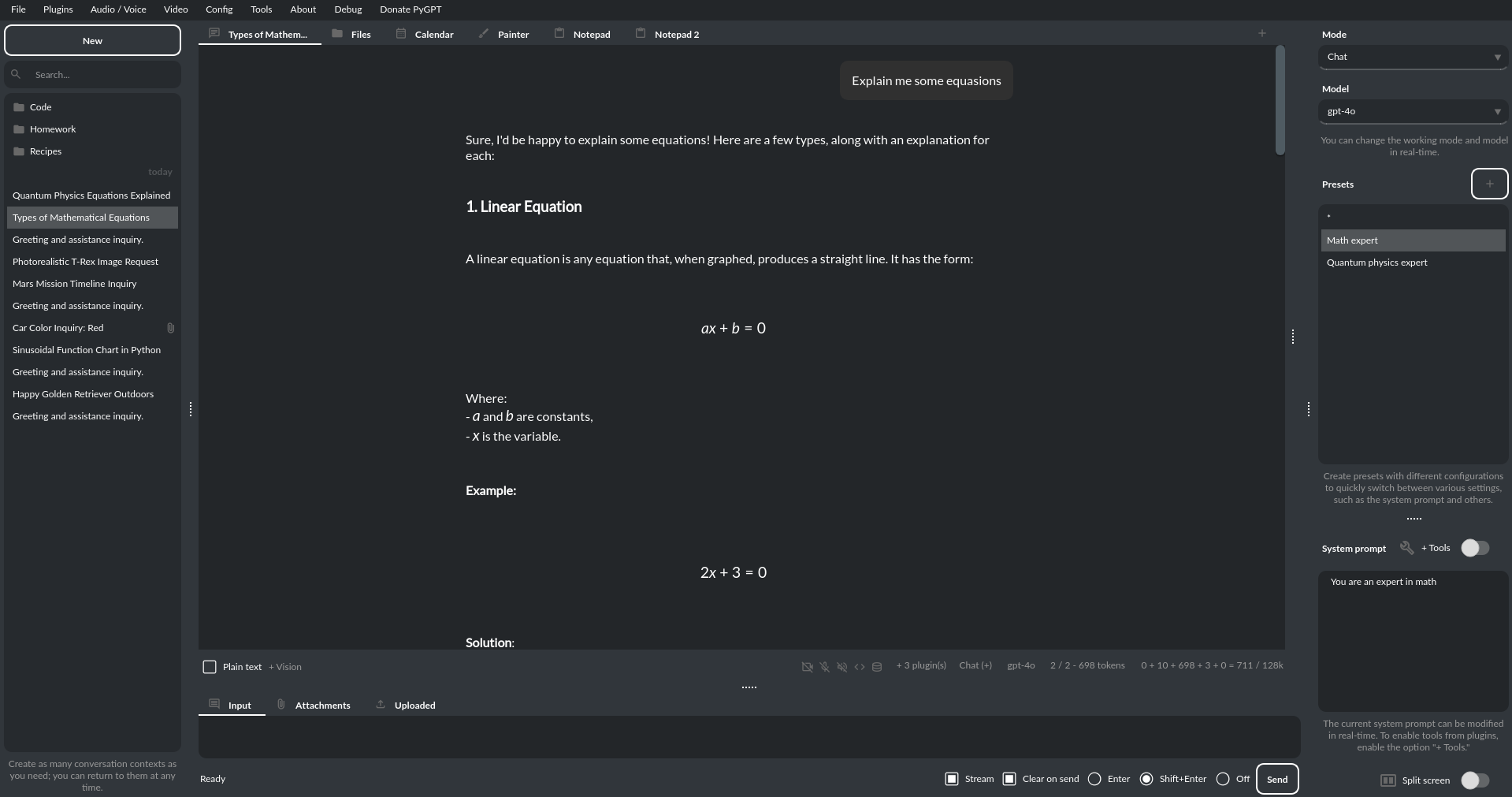
视觉功能: 如果您想发送磁盘上的照片或相机拍摄的图片进行分析,而所选模型不支持视觉功能,则必须在插件菜单中启用“视觉(内联)”插件。该插件允许您在任何对话模式下发送照片或相机图像进行分析。
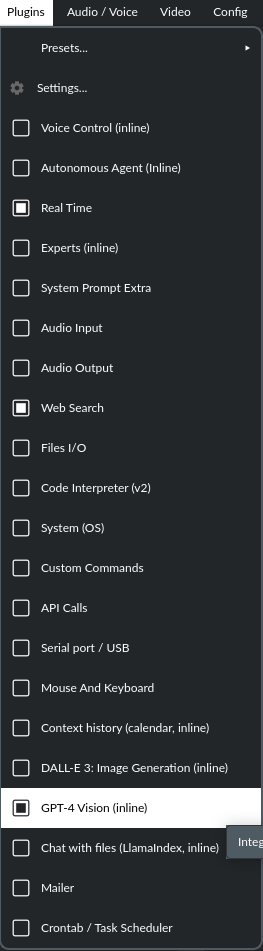
借助此插件,您可以使用相机拍摄一张图片,或将现有图片附加后发送,以讨论该照片的内容:
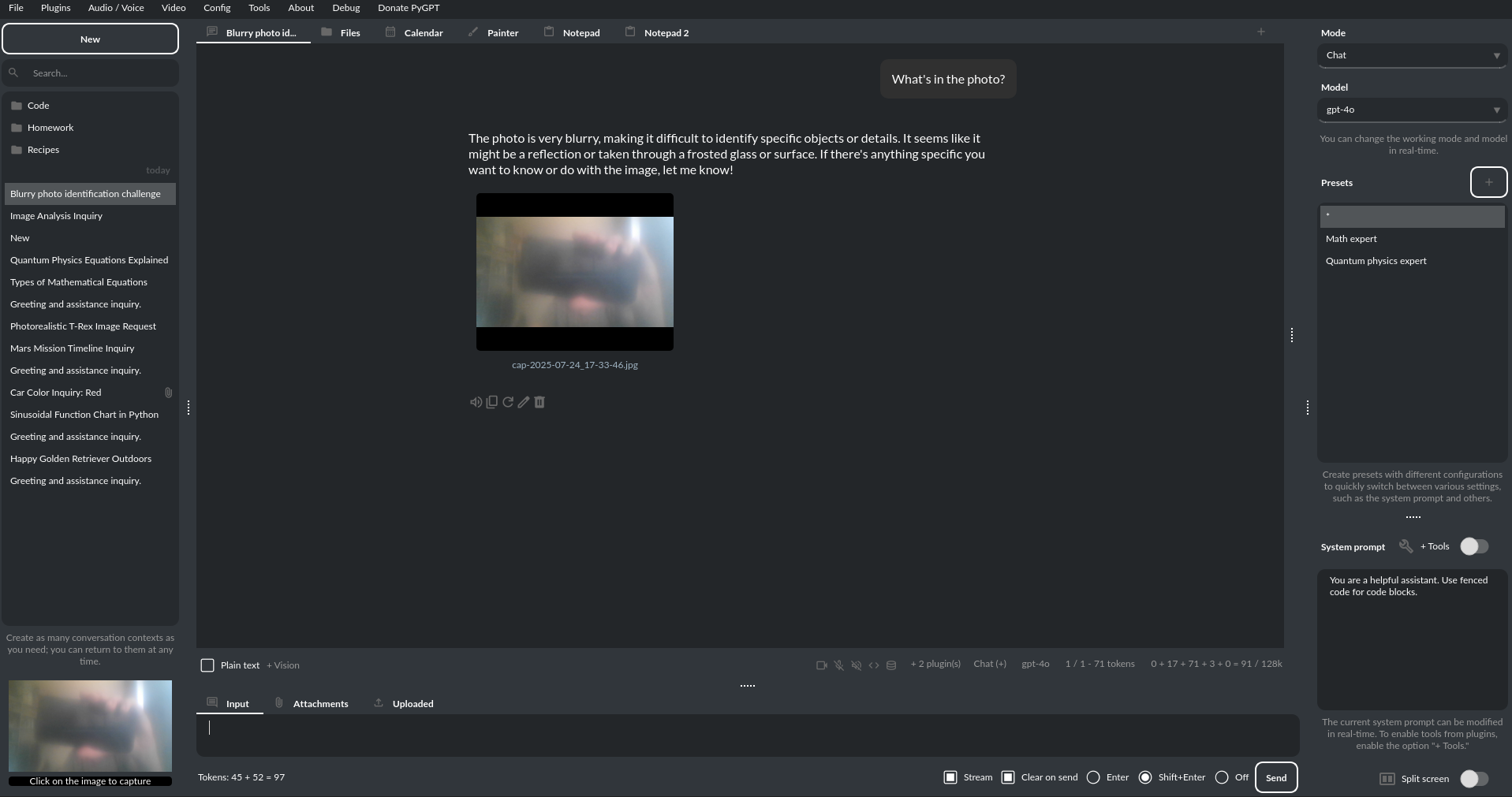
图像生成: 如果您希望在对话中直接生成图像,必须在插件菜单中启用“图像生成(内联)”插件。该插件允许您在对话模式下生成图像:
文件聊天模式(LlamaIndex)
此模式允许您通过对话与文档及整个上下文历史进行交互。它将 LlamaIndex 无缝集成到聊天界面中,使您可以立即查询已索引的文档。
提示: 如果您不想调用工具或命令,请取消勾选 +工具 复选框。这将在使用本地模型时加快响应速度。您还可以在以下路径启用 ReAct 代理以进行工具调用:设置 -> 索引 / LlamaIndex -> 聊天 -> 在文件聊天模式中使用 ReAct 代理进行工具调用。如果 ReAct 代理和 +工具 复选框同时启用,则流式模式将被禁用。
查询单个文件
您还可以使用 Files I/O 插件中的 query_file 命令“即时”查询单个文件。只需针对该文件提出问题,即可查询任何文件。系统会为正在查询的文件在内存中创建一个临时索引,并从中返回答案。自版本 2.1.9 起,还提供了一个用于查询网页及外部内容的类似命令:直接使用 LlamaIndex 查询网页内容。
例如:
如果您有一个文件:data/my_cars.txt,内容为 我的车是红色的。
您可以询问:查询 my_cars.txt 文件,我的车是什么颜色?
您将收到回复:红色。
注意:此命令仅针对当前查询对文件进行索引,不会将其持久化到数据库中。若要将查询过的文件也存储到标准索引中,您必须在插件设置中启用 自动索引读取的文件 选项。请务必勾选 +工具 复选框,以允许使用插件中的工具和命令。
使用文件聊天模式
在此模式下,您查询的是存储在向量存储数据库中的整个索引。首先,您需要对希望用作额外上下文的文件进行索引(嵌入)。嵌入会将您的文本数据转换为向量。如果您不熟悉嵌入及其工作原理,请参阅本文:
https://stackoverflow.blog/2023/11/09/an-intuitive-introduction-to-text-embeddings/
有关 OpenAI 官网上的可视化示例,请参见下图:

来源:https://cdn.openai.com/new-and-improved-embedding-model/draft-20221214a/vectors-3.svg
{kind=link}
要索引您的文件,只需将它们复制或上传到 data 目录,并点击 索引全部 按钮启动索引(嵌入),或者右键单击某个文件并选择 索引...。此外,您还可以通过激活 文件聊天模式(LlamaIndex,内联) 插件,在任何聊天模式中利用已索引文件中的数据。
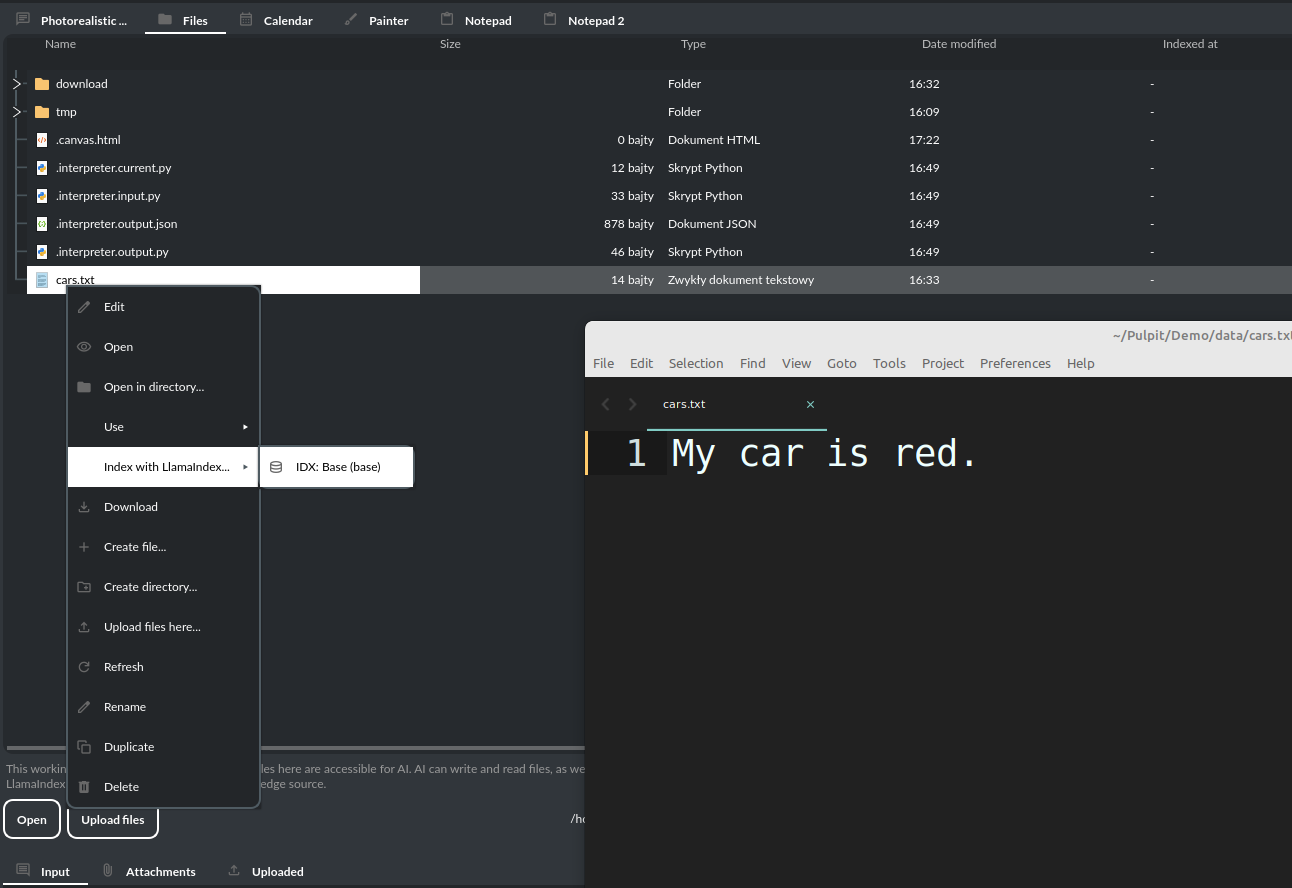
文件完成索引(嵌入到向量存储)后,您就可以在聊天模式中使用其中的上下文:
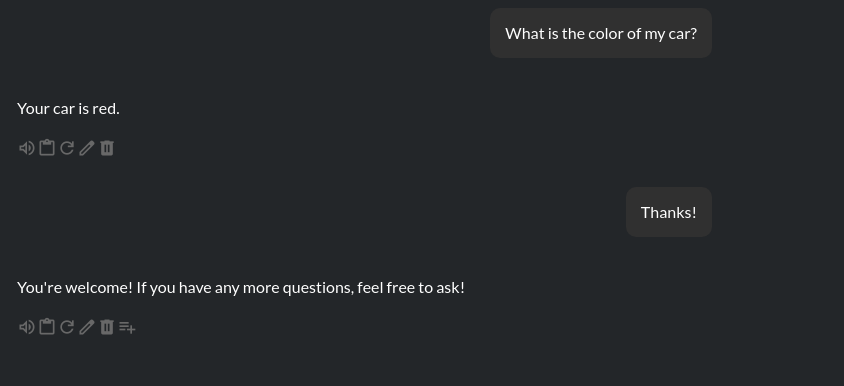
内置文件加载器:
文件:
- CSV 文件(csv)
- Epub 文件(epub)
- Excel .xlsx 表格(xlsx)
- HTML 文件(html、htm)
- IPYNB 笔记本文件(ipynb)
- 图像(视觉)(jpg、jpeg、png、gif、bmp、tiff、webp)
- JSON 文件(json)
- Markdown 文件(md)
- PDF 文档(pdf)
- 纯文本文件(txt)
- 视频/音频(mp4、avi、mov、mkv、webm、mp3、mpeg、mpga、m4a、wav)
- Word .docx 文档(docx)
- XML 文件(xml)
网页/外部内容:
- Bitbucket
- ChatGPT 检索插件
- GitHub Issues
- GitHub 仓库
- Google 日历
- Google 文档
- Google 云端硬盘
- Google Gmail
- Google Keep
- Google 表格
- Microsoft OneDrive
- RSS
- SQL 数据库
- 站点地图(XML)
- Twitter/X 帖子
- 网页(抓取任意网页内容)
- YouTube(转录)
您可以在 设置 / 索引 / LlamaIndex / 数据加载器 中配置数据加载器,为指定的加载器提供关键字参数列表。您也可以开发并提供自己的自定义加载器,并在应用程序中注册。
LlamaIndex 还与上下文数据库集成——您可以将数据库中的数据(您的上下文历史)作为讨论中的额外上下文。在 设置 / 索引 / LlamaIndex 部分,您可以选择索引现有上下文历史,或启用对新数据的实时索引(来自数据库)。
警告: 请注意,索引内容时会调用嵌入模型的 API。每次索引都会消耗额外的令牌。请务必在提供商的页面上控制所使用的令牌数量。
提示: 使用文件聊天模式时,您默认可以访问从 /data 目录手动索引的文件。不过,您也可以通过附加文件来使用额外的上下文——这种来自附件的额外上下文不会进入主索引,而只存在于仅供本次对话使用的临时索引中。
令牌限制: 当您在非查询模式下使用 文件聊天模式 时,LlamaIndex 会将额外的上下文添加到系统提示中。如果您同时使用插件(这也增加了系统提示中的指令),可能会超过允许的最大令牌数。如果出现“令牌使用过多”的警告,请关闭未使用的插件,或取消勾选 +工具 选项,以减少系统提示中使用的令牌数量。
可用的向量存储(由 LlamaIndex 提供):
- ChromaVectorStore
- ElasticsearchStore
- PinecodeVectorStore
- QdrantVectorStore
- RedisVectorStore
- SimpleVectorStore
您可以在 设置 -> LlamaIndex 窗口中,通过提供如 api_key 等配置选项来配置选定的向量存储。请参阅“配置 / 向量存储”部分以获取配置参考。
配置数据加载器
在 设置 -> LlamaIndex -> 数据加载器 部分,您可以定义要传递给数据加载器实例的附加关键字参数。请参阅“配置 / 数据加载器”部分以获取配置参考。
音频聊天模式
此模式的工作方式与普通聊天模式相同,但原生支持使用 Realtime 和 Live API 进行音频输入和输出。在此模式下,音频输入和输出直接由模型处理,无需借助外部插件。这使得音频通信更快、效果更好。
目前处于测试阶段。
现阶段仅支持 OpenAI 实时模型(通过 Realtime API)和 Google Gemini 实时模型(通过 Live API)。
研究模式
此模式(使用 Sonar 和 R1 模型时)基于 Perplexity API 运行:https://perplexity.ai。
它允许进行深度网络搜索,并利用 Perplexity AI 中提供的 Sonar 模型。
此模式需要一个 Perplexity API 密钥,可在 https://perplexity.ai 上生成。
自版本 2.5.27 起,此模式也支持 OpenAI 的深度研究模型。
完成模式
这是一种较旧的操作模式,允许用户以标准的文本补全方式进行工作。不过,它在文本处理上提供了更大的灵活性,使您可以按照自己喜欢的方式启动整个对话。
与聊天模式类似,在界面右侧有便捷的预设选项。这些预设可以帮助您微调指令,并快速在不同的配置和预制提示模板之间切换。
此外,该模式还提供为AI和用户添加标签的功能,从而可以模拟特定角色之间的对话——例如,您可以根据提示中预定义的内容,创建蝙蝠侠与小丑之间的对话。这一功能为设置各种有趣的对话场景提供了丰富的创意可能性,让交流更具吸引力和探索性。
自版本 2.0.107 起,davinci 模型已被弃用,完成模式中已替换为 gpt-3.5-turbo-instruct 模型。
图像和视频生成
PyGPT 支持使用 DALL-E 3、gpt-image-1、Imagen 3/4 和 Nano Banana 等模型快速简便地创建图像;同时也可以利用 Veo3 和 Sora2 进行视频生成。
图像和视频的生成类似于一次聊天对话:用户输入提示后触发生成过程,随后可将生成的图像或视频下载、保存到本地,并在屏幕上显示。您可以在“图像生成”模式下直接向模型发送原始提示,也可以让模型为您推荐最佳提示。
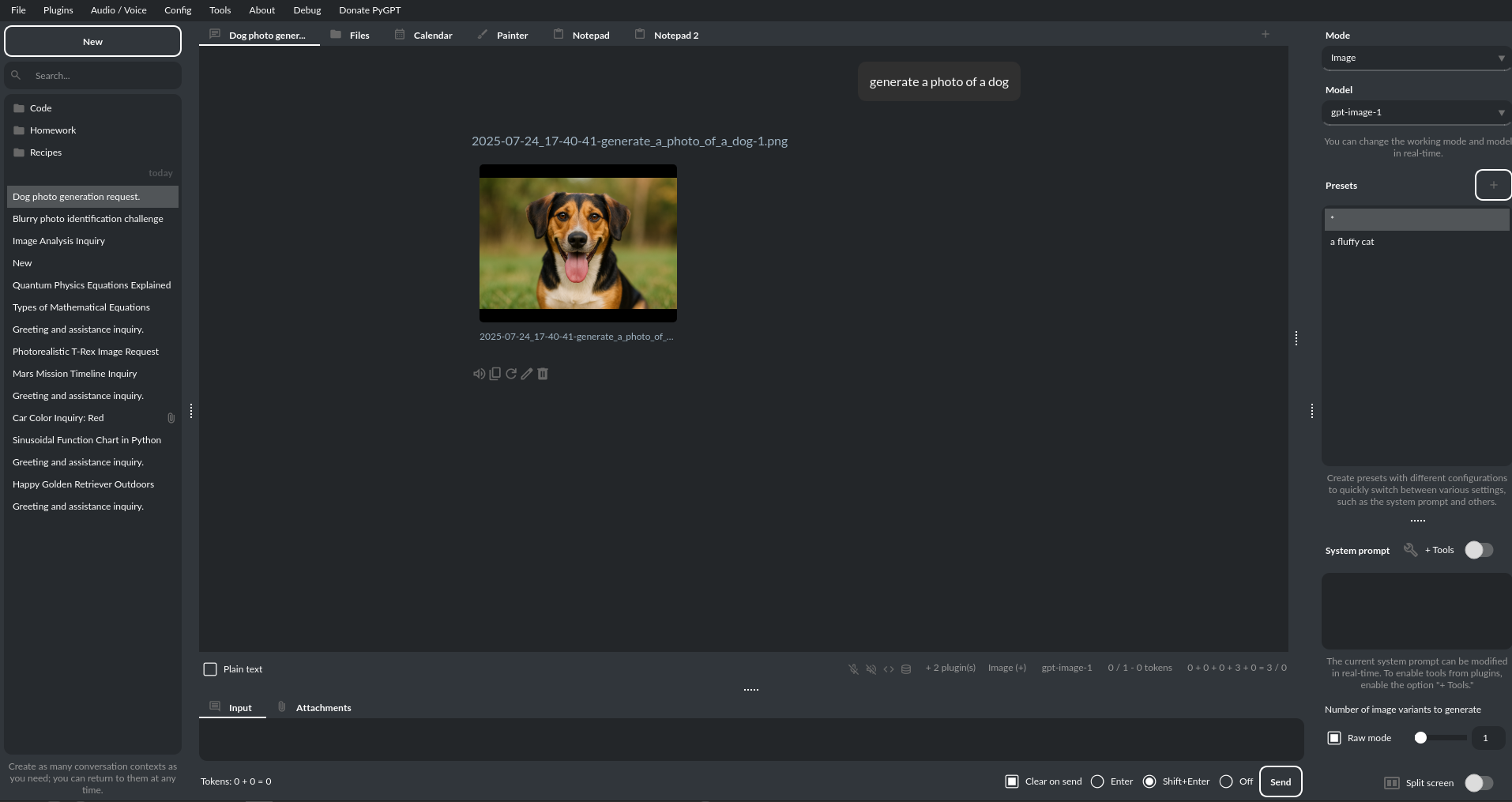
通过插件“图像生成(内联)”,所有模式下均可使用图像生成功能。只需在任何模式下,例如 GPT 或 Gemini,请求生成一张图像,模型就会直接在当前会话中完成,无需切换模式。
若希望在聊天模式中直接生成图像,需在插件菜单中启用“图像生成(内联)”插件。
该插件允许您在聊天模式中生成图像:
对于 OpenAI 模型,您还可以在“配置 -> 设置 -> 远程工具”中启用远程图像生成功能。启用后,在聊天模式下无需插件即可原生支持图像生成。
要使用 Imagen 模型,必须在“配置 -> 设置 -> API 密钥 -> Google -> 高级选项”中启用 VertexAI。
重混、编辑或扩展
如果您想基于之前的图像或视频进行重混或扩展,而不是从头开始创作新内容,请在工具箱中勾选“重混/扩展”选项。当前上下文中最后生成的图像或视频将作为您的提示参考,以便您请求对生成内容进行修改。如果启用了“重混/扩展”选项,则上传图片附件作为参考将不会生效。
原始模式
提供了一种切换提示生成模式的选项。
如果启用“原始模式”,模型将按您提供的内容原样接收提示。
如果禁用“原始模式”,模型将根据您的指示自动生成最佳提示。
图像存储
生成图像后,您可以通过右键单击轻松将其保存到磁盘的任意位置。此外,您还可以选择删除图像,或在浏览器中以全尺寸查看。
提示:请使用预设来保存您准备好的提示,这样以后可以快速再次使用它们来生成新图像。
应用程序会保留所有提示的历史记录,方便您随时回顾任何会话,并重复使用之前的提示来创建新图像。
图像将被存储在 PyGPT 用户数据文件夹中的 img 目录下。
助手模式
此模式使用 OpenAI 的 助手 API。
该模式在基础聊天功能的基础上进行了扩展,增加了诸如用于执行代码的 代码解释器、用于访问文件的 检索文件 以及用于增强交互和与其他 API 或服务集成的自定义 函数 等外部工具。在此模式下,您可以轻松上传和下载文件。PyGPT 简化了文件管理流程,使您能够快速上传文档并管理由模型生成的文件。
设置新助手非常简单——只需单击一下即可,助手会立即与 OpenAI API 同步。您之前在 OpenAI 上创建的助手也可以无缝导入到 PyGPT 中。
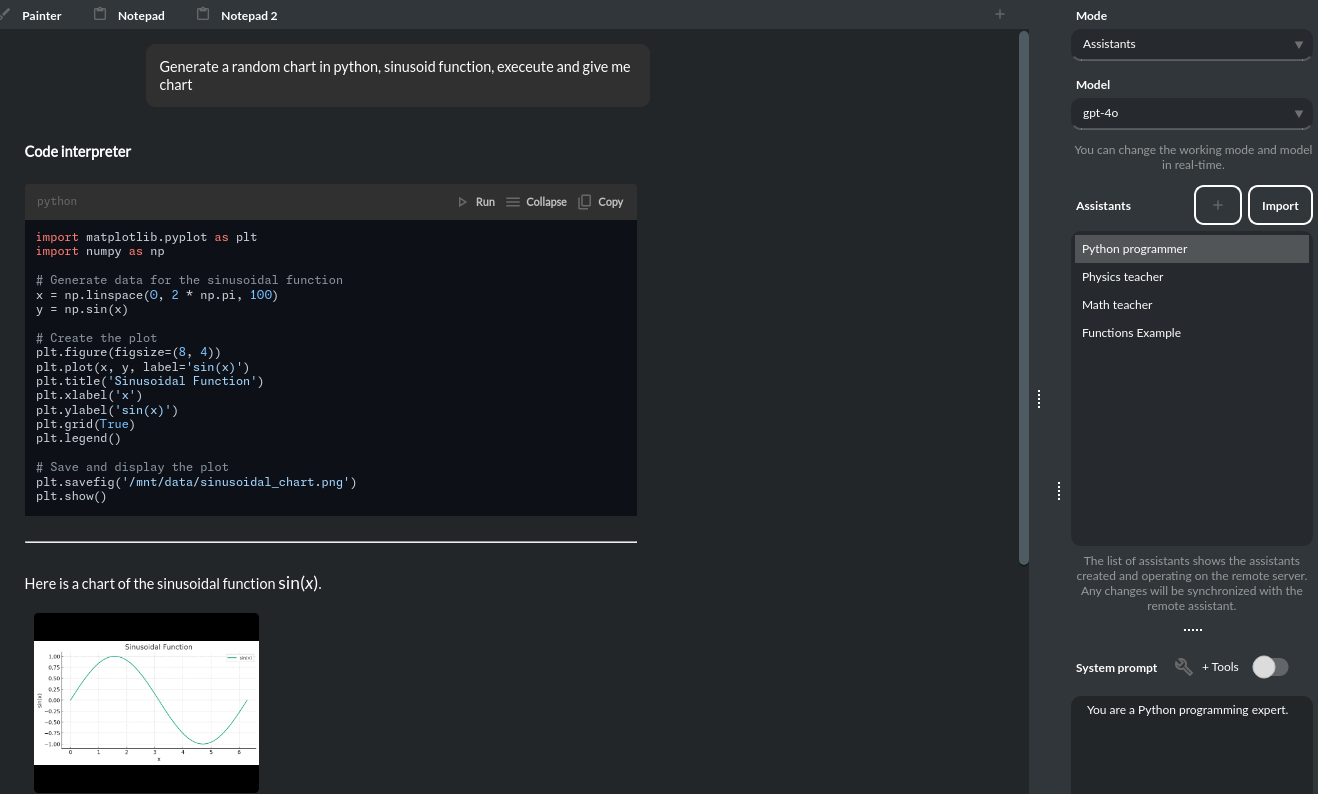
在助手模式下,您可以将文件存储在远程向量数据库中(每个助手对应一个),并通过应用轻松管理这些文件:
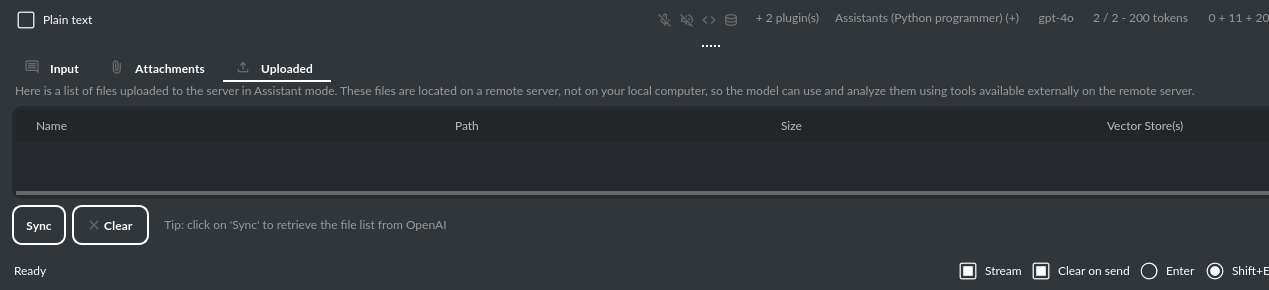
请注意,此模式下无法计算 token 使用量。尽管如此,仍支持文件(附件)上传。只需转到“文件”选项卡,即可轻松管理文件和附件,这些文件可以发送到 OpenAI API。
向量数据库(通过助手 API)
助手模式支持使用 OpenAI API 提供的外部向量数据库。此功能允许您将文件存储在数据库中,然后通过助手 API 对其进行搜索。每个助手可以关联一个向量数据库;如果已关联数据库,所有在此模式下上传的文件都将存储在该数据库中。如果助手未关联向量数据库,则会在上传文件时自动创建一个临时数据库,该数据库仅在当前线程中可用。临时数据库中的文件将在 7 天后自动删除。
要启用向量数据库功能,请在助手设置中勾选“与文件聊天”复选框,这将激活助手 API 中的“文件搜索”工具。
要管理外部向量数据库,可在助手创建和编辑窗口的向量数据库选择列表旁点击 DB 图标(见下图)。在该管理窗口中,您可以创建新的向量数据库、编辑现有数据库,或从 OpenAI 服务器导入所有现有数据库的列表:
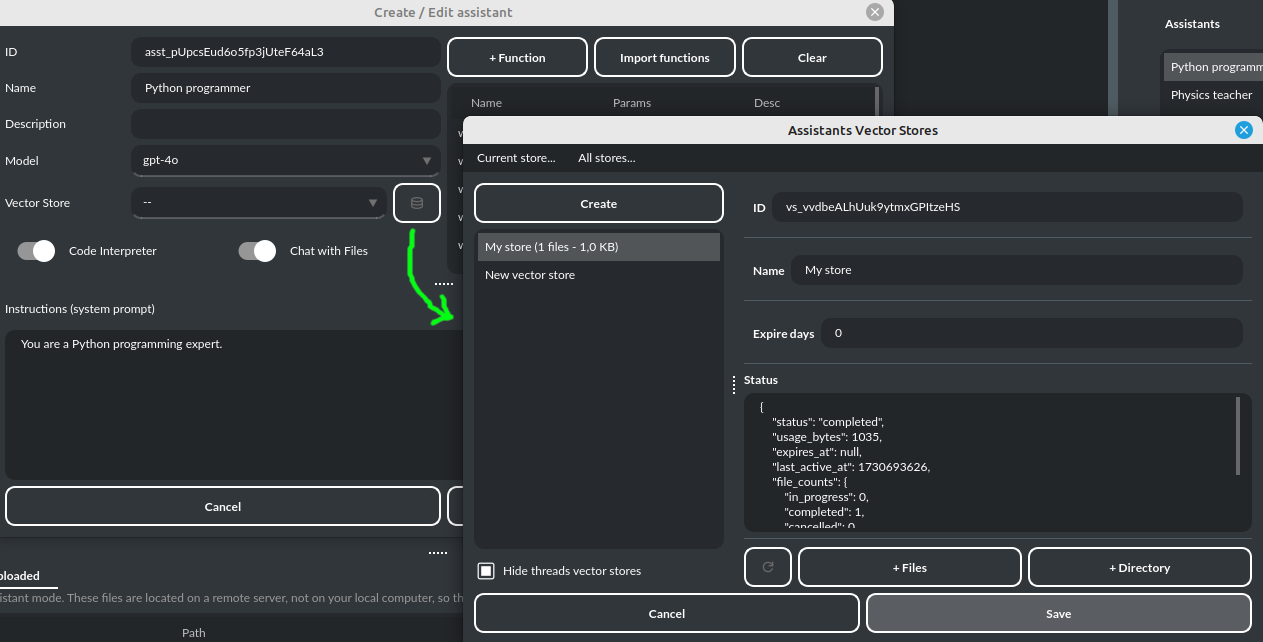
您可以通过设置“过期天数”来指定文件在数据库中自动保存的时长,超过该时长后文件将被删除(因为在 OpenAI 上存储文件会产生费用)。如果将值设置为 0,则文件不会自动删除。
正在使用的向量数据库名称将显示在已上传文件列表中,位于右侧字段上:如果文件存储在数据库中,此处将显示数据库名称;否则,将显示该文件仅在线程内可用的信息:

代理(LlamaIndex)
此模式允许使用 LlamaIndex 提供的代理功能。
内置代理(工作流):
- FunctionAgent
- ReAct
- 结构化规划器(子任务分解)
- CodeAct(与代码解释器插件连接)
- 监督者 + 工作者
内置代理(旧版):
- OpenAI 助手
未来,内置代理列表将进一步扩展。
您可以通过位于“工具 → 代理构建器”中的内置可视化节点式编辑器,创建自定义类型(工作流/模式)。
此外,您还可以通过创建一个继承自 pygpt_net.provider.agents.base 的新提供者来开发自己的代理。
工具与插件
在此模式下,所有已启用插件的命令均可使用(插件命令会实时自动转换为代理可用的工具)。
RAG — 使用索引
如果在代理预设中选择了某个索引,则系统会自动为该代理添加一个从索引读取数据的工具,从而实现 RAG 功能。
目前暂不支持多模态,仅支持文本输入。视觉支持将在未来加入。
循环/评估模式
您可以将代理设置为自主运行模式,在循环中持续执行,并对当前输出进行评估。当您勾选“循环/评估”复选框后,代理在给出最终响应后,将由另一个代理以百分比形式(0% 至 100%)对其质量进行评分。若得分低于您设定的期望值(可通过屏幕右下角的滑块调整,默认值为 75%),则会向该代理发送提示,要求其改进和优化响应内容。
将期望得分设为 0%,意味着每次代理生成结果时都会对其进行评估,并持续促使它自我改进。这样,您就可以让代理进入一个自主循环,直到它成功满足要求为止。
评估方式有两种可供选择:
- 按已完成任务的百分比
- 按最终响应的准确度(得分)
您还可以通过以下路径设置此类循环中的步骤上限:「设置 → 代理与专家 → LlamaIndex 代理 → 最大评估步骤」。默认值为 3,即代理最多尝试三次改进或修正其答案。若将上限设为零,则无限制,代理可无限期地在此模式下运行(请注意 Token 消耗!)。
用于评估响应的提示信息可在「设置 → 提示语 → 代理:循环中的评估提示」中进行修改。您可以根据实际需求调整提示内容,例如针对不同反馈强度的需求,定制更严格或更宽松的评价标准。
代理(OpenAI)
该模式基于集成到应用程序中的 openai-agents 库运行:
https://github.com/openai/openai-agents-python
它允许运行适用于 OpenAI 模型以及与 OpenAI API 兼容的模型的代理。
在该模式下,您可以使用“专家模式”预设中预先配置的专家——它们将以代理的形式启动(类型为 openai_agents_experts,支持启动一个主代理和若干子代理,并将查询适当地路由到相应的子代理)。
代理类型(工作流/模式):
带专家的代理—— 使用附加的专家作为子代理带专家和反馈的代理—— 使用附加的专家作为子代理,并结合循环中的反馈代理带反馈的代理—— 单一代理配合循环中的反馈代理规划者—— 规划代理,内部包含三个子代理:规划者、基础代理和反馈代理研究机器人—— 研究员,内部包含三个子代理:规划者、搜索者和作为基础代理的写作者简单代理—— 单一代理。进化—— 在每一代(循环)中,从给定的父代代理中选择最佳响应;在下一代中,循环重复进行。B2B—— 机器人之间的通信,涉及两个机器人相互交互,同时保留人类参与其中。主管 + 工人—— 一个代理(主管)充当用户与另一个代理(工人)之间的桥梁。用户向主管提出请求,主管随后向工人发送指令,直到工人完成任务。
您可以通过内置的可视化节点式编辑器创建自己的类型(工作流/模式),该编辑器位于“工具 -> 代理构建器”中。
此外,还添加了一些预定义的示例预设:
编码员专家代理规划者研究员简单代理带反馈的写作者两个机器人主管 + 工人
在“代理(OpenAI)”模式下,根据“配置 -> 设置 -> 远程工具”菜单中的配置,所有远程工具均可供基础代理使用。
对于专家的远程工具,可以在预设配置中为每个专家单独选择。
本地工具(来自插件)则根据已启用的插件,对代理和专家可用,与其他模式相同。
在带有反馈和计划的代理中,可以为每个代理在预设配置中允许使用工具。这些代理还具有可在预设中配置的独立提示。
不同类型代理的工作方式说明:
以下是不同类型代理的工作模式。您可以根据这些模式,通过修改特定任务预设中的相应提示,为不同任务创建代理。
简单代理
- 代理完成其任务后即停止工作。
带反馈的代理
- 第一个代理回答问题。
- 第二个代理(反馈代理)评估答案,必要时返回给第一个代理以强制纠正。
- 循环重复,直到反馈代理对评估结果满意为止。
带专家的代理
- 代理自行完成分配的任务,或将其委派给最合适的专家(另一名代理)。
带专家和反馈的代理
- 第一个代理回答问题,或将任务委派给最合适的专家。
- 第二个代理(反馈代理)评估答案,必要时返回给第一个代理以强制纠正。
- 循环重复,直到反馈代理对评估结果满意为止。
研究机器人
- 第一个代理(规划者)准备用于搜索的短语列表。
- 第二个代理(搜索者)根据这些短语查找信息并生成摘要。
- 第三个代理(写作者)基于摘要撰写报告。
规划者
- 第一个代理(规划者)将任务分解为子任务,并将清单发送给第二个代理。
- 第二个代理根据准备好的任务清单执行任务。
- 第三个代理负责反馈,评估任务完成情况,必要时要求纠正,并将请求返回给第一个代理。循环重复进行。
进化
- 您可以选择每一代(迭代)中工作的代理数量(父代)。
- 每个代理针对同一问题准备不同的答案。
- 下一代代理(选择者)会从这一代中选出表现最佳的代理(产生最佳答案)。
- 另一个代理(反馈代理)验证最佳答案并提出改进建议。
- 改进最佳答案的请求会被发送给新的一对代理(新的父代)。
- 在下一代中再次从这对新代理中选出最佳答案,循环重复进行。
B2B
- 人类提供讨论主题。
- 机器人1生成回复并发送给机器人2。
- 机器人2接收机器人1的回复作为输入,作出回应,并将回复再次发送回机器人1作为其输入。此循环不断重复。
- 人类可随时中断循环并更新整个讨论内容。
主管 + 工人
- 人类向主管提出请求。
- 主管为工人准备指令并发送给工人。
- 工人完成任务并将结果返回给主管。
- 如果任务已完成,主管将结果返回给用户;如果未完成,主管会再次向工人发送指令以完成任务,或询问用户是否有其他问题。
- 循环重复,直到任务完成为止。
提示:自版本 2.5.97 起,您可以在所有代理类型中分配和使用专家。
限制:
- 当为专家选择“计算机使用”工具,或选择“computer-use”模型时,该模型将无法使用其他任何工具。
代理(自主)
这是代理模式的旧版本,目前仍作为遗留功能提供。不过,建议使用更新的模式:代理(LlamaIndex)。
警告:请谨慎使用此模式 - 自主模式与其他插件连接时,可能会产生意外结果!
该模式会激活自主模式,AI 将与自身展开对话。
您可以设置此循环运行任意次数。在此过程中,模型将进行自我对话,回答自己的问题和评论,以寻找最佳解决方案,并对之前生成的步骤进行批判性评估。
警告: 将运行步骤数(迭代次数)设置为 0 会激活无限循环,这可能导致大量请求并产生极高的 token 消耗,请谨慎使用!每次启动无限循环时,系统都会显示确认提示。
此模式类似于 Auto-GPT,可用于生成更复杂的推理,并通过将问题分解为子任务来解决,模型会自主地逐一执行这些子任务,直到目标达成。
您还可以为多个代理创建带有自定义指令的预设,整合各种工作流、指令和目标以实现特定任务。
所有插件都适用于代理,因此您可以为代理启用文件访问、命令执行、网络搜索、图像生成、视觉分析等功能。将代理与插件结合使用,可以构建一个完全自主、自给自足的系统。当前启用的所有插件都会自动对代理可用。
当启用 自动停止 选项时,代理会在达到目标后尝试停止。
与 自动停止 相反,当启用 始终继续... 选项时,代理会使用“始终继续”的提示生成额外的推理,并在看似任务已完成的情况下自动进入下一步。
选项
代理本质上是一种虚拟模式,它会在内部按顺序执行所选的基础模式。
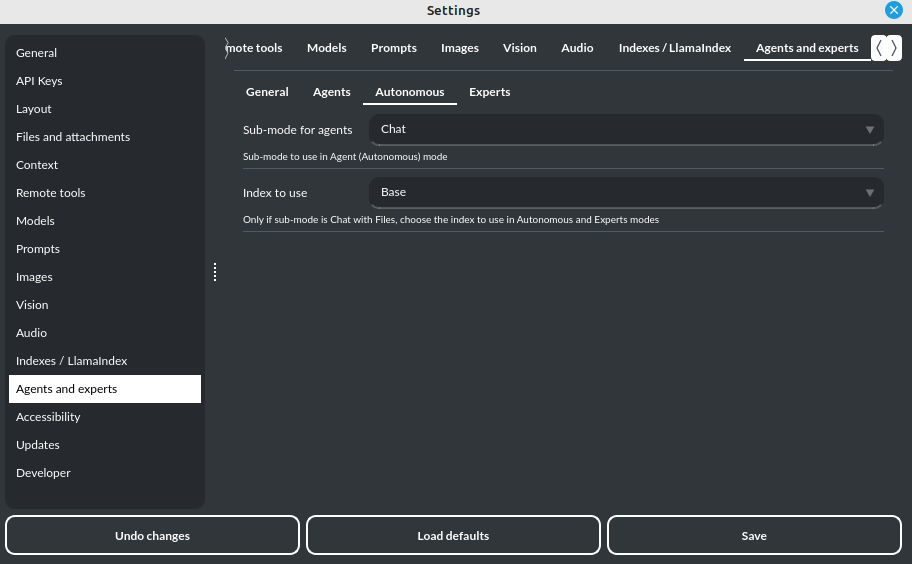
您可以在设置中选择代理应使用的内部模式:
设置 / 代理(自主) / 要使用的子模式
默认模式为:聊天。
如果您希望在运行代理时使用 LlamaIndex 模式,还可以通过以下选项指定 LlamaIndex 应使用的索引:
设置 / 代理与专家 / 要使用的索引
专家(协作模式)
专家模式允许您创建专家(使用预设),并在对话中咨询他们。在此模式下,会创建一个用于进行对话的主上下文。在该上下文中,模型可以向专家发出请求以执行任务,并将结果返回到主线程。当专家在后台被调用时,会为其创建一个独立的上下文及记忆空间。这意味着,在同一个主上下文生命周期内,每个专家都可以通过其独立且隔离的上下文访问自己的记忆。
简单来说——您可以将专家想象成一个在后台运行的独立模型实例,随时可以被调用来提供帮助,拥有自己的上下文和记忆,以及针对特定主题的专业指令。
专家之间不会共享上下文,它们之间的唯一联系点是主对话线程。在这个主线程中,模型充当专家的管理者,可以根据需要在专家之间交换数据。
专家是根据预设中的名称来选择的;例如,将您的专家命名为:ID = python_expert,名称 = “Python 程序员”,这样就会创建一个模型在涉及 Python 编程相关事务时会尝试调用的专家。您也可以手动请求调用某个专家:
调用 Python 专家生成一些代码。
专家可以被启用或禁用——要启用或禁用专家,请使用右键菜单从预设列表中选择 启用/禁用 选项。只有已启用的专家才能在对话中使用。
专家也可以在 代理(自主) 模式中使用——只需使用预设创建一个新的代理即可。只需将相应的专家移至活动列表,即可自动使其可供代理使用。
您还可以在“内联”模式下使用专家——通过启用 专家(内联) 插件即可。这使得专家可以在任何模式下使用,例如普通聊天模式。
专家模式与代理模式一样,也是一种“虚拟”模式——您需要为其选择一个目标运行模式,这可以在设置中的 设置 / 代理(自主) / 专家使用的子模式 中完成。
您也可以随时请求获取当前活跃的专家列表:
给我一份当前活跃的专家名单。
计算机使用
此模式允许对计算机进行自主控制。
在此模式下,模型会接管鼠标和键盘,并能够在用户的环境中进行导航。这里使用的是 Computer use 远程工具:https://platform.openai.com/docs/guides/tools-computer-use,结合 鼠标与键盘 插件。
使用示例:
点击开始菜单打开它,在列表中搜索记事本并运行。
您可以通过工具箱底部的列表更改导航模式运行的环境。
可用环境:
- 浏览器
- Linux
- Windows
- Mac
您还可以在沙盒环境中运行此模式(使用 Playwright - https://playwright.dev/)——只需在工具箱中启用 沙盒 开关即可。您的系统上必须安装 Playwright 浏览器。为此,请运行:
pip install playwright
playwright install <chromium|firefox|webkit>
之后,在 鼠标与键盘 插件设置中,将已安装浏览器的目录路径设置到 沙盒(Playwright)/ 浏览器目录 选项中。
编译好的二进制版本和 Snap 版本在其软件包中已预装了 chromium 浏览器。
提示: 请勿在计算机使用模式下启用 鼠标与键盘 插件——它已经“在后台”与计算机使用模式连接在一起了。
上下文与记忆
短期与长期记忆
PyGPT 具有持续聊天模式,能够保持长时间的对话上下文。它会保存整个对话历史,并将其自动附加到您发送给 AI 的每一条新消息(提示)中。此外,您还可以随时回顾过去的对话。应用程序会记录您的聊天历史,使您能够从上次中断的地方继续讨论。
处理多个上下文
在应用程序界面的左侧,有一个面板显示已保存的对话列表。您可以保存多个上下文,并轻松地在它们之间切换。此功能使您能够随时返回并从之前的对话中的任意位置继续。PyGPT 会自动为每个上下文生成摘要,类似于 ChatGPT 的工作方式,并且允许您自行修改这些标题。
您可以通过以下设置选项在设置中禁用上下文支持:
配置 -> 设置 -> 使用上下文
清除历史记录
您可以通过选择菜单选项来清除整个内存(所有上下文):
文件 -> 清除历史记录...
上下文存储
在应用程序端,上下文存储在工作目录下的 SQLite 数据库中(db.sqlite)。此外,所有历史记录也会保存为 .txt 文件,以便于阅读。
一旦对话开始,聊天的标题就会被生成并在左侧列表中显示。这一过程与 ChatGPT 类似,即总结对话的主题,并基于该总结创建线程标题。您可以随时更改线程名称。
文件与附件
上传附件
在对话中使用您自己的文件作为额外上下文
您可以在任何对话中使用自己的文件(例如进行分析)。这可以通过两种方式实现:一是将您的文件索引(嵌入)到向量数据库中,这样在“带文件的聊天”会话期间它们将始终可用;二是添加文件附件(该附件仅在上传它的那次对话中可用)。
附件
PyGPT 让用户可以轻松上传文件并将其发送给模型以执行分析等任务,类似于在 ChatGPT 中附加文件。在文本输入区域旁边有一个专门用于管理文件上传的“附件”选项卡。
提示:在群组中上传的附件在该群组的所有上下文中均可用。
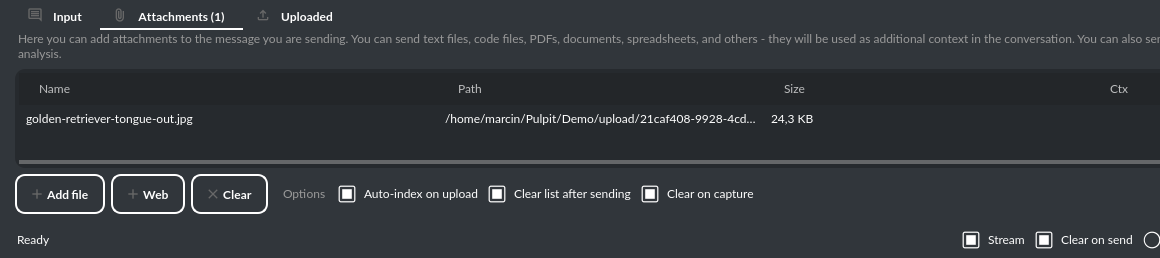
您可以使用附件为对话提供额外上下文。上传的文件将通过 LlamaIndex 的加载器转换为文本,然后嵌入到向量存储中。您可以通过 LlamaIndex 支持的应用程序格式上传任何文件。支持的格式包括:
文本类型:
- CSV 文件 (csv)
- Epub 文件 (epub)
- Excel .xlsx 表格 (xlsx)
- HTML 文件 (html, htm)
- IPYNB 笔记本文件 (ipynb)
- JSON 文件 (json)
- Markdown 文件 (md)
- PDF 文档 (pdf)
- 纯文本文件 (txt 等)
- Word .docx 文档 (docx)
- XML 文件 (xml)
媒体类型:
- 图像(使用视觉模型)(jpg, jpeg, png, gif, bmp, tiff, webp)
- 视频/音频 (mp4, avi, mov, mkv, webm, mp3, mpeg, mpga, m4a, wav)
压缩文件:
- zip
- tar、tar.gz、tar.bz2
上传的附件内容将在当前对话中使用,并在整个对话过程中可用(按上下文划分)。处理附件提供的额外上下文有三种模式:
完整上下文:提供最佳效果。此模式会将读取文件的全部内容附加到用户的提示中。此过程在后台进行,如果您上传了大量内容,可能需要消耗大量的 token。RAG:索引后的附件将仅通过 LlamaIndex 进行实时查询。此操作不需要额外的 token,但可能无法 1:1 地访问文件的全部内容。摘要:在查询时,系统会在后台生成一个额外的查询,并由单独的模型执行,以总结附件内容并将所需信息返回给主模型。您可以在“文件和附件”部分的设置中更改用于摘要的模型。
在 RAG 和 摘要 模式下,您可以启用一个附加设置:设置 -> 文件和附件 -> 在 RAG 查询中使用历史记录。这有助于更好地准备 RAG 查询。当此选项开启时,系统会考虑整个对话上下文,而不仅仅是用户最后的查询。这样可以更有效地在索引中搜索额外的上下文。在 RAG 限制 选项中,您可以设置应考虑多少条最近的对话记录(0 = 无限制,默认:3)。
重要提示:使用 完整上下文 模式时,文件的全部内容都会包含在提示中,每次使用都可能导致较高的 token 消耗。如果您希望减少 token 的使用量,建议改用 RAG 模式,它只会查询向量数据库中的索引附件以提供额外上下文。
图像作为额外上下文
JPG、PNG 等图像文件属于特殊情况。默认情况下,图像不会用作额外上下文,而是会使用视觉模型进行实时分析。如果您希望将它们用作额外上下文,则必须在设置中启用“允许图像作为额外上下文”选项:文件和附件 -> 允许图像作为额外上下文。
上传大文件与自动索引
要使用 RAG 模式,文件必须先被索引到向量数据库中。如果“附件”选项卡中的“上传时自动索引”选项已启用,此过程将在上传时自动完成。然而,对于大型文件来说,索引可能需要较长时间。因此,如果您使用的是不依赖索引的 完整上下文 模式,可以关闭“自动索引”选项,以加快附件的上传速度。在这种情况下,只有在首次调用 RAG 模式时才会对附件进行索引,而在那之前,附件将以 完整上下文 和 摘要 的形式可用。
嵌入
在使用 RAG 查询附件时,文档会被索引到一个临时的向量存储中。由于有多个提供商和模型可供选择,您可以在“配置 -> 设置 -> 文件和附件”中选择用于查询附件的模型。您还可以在“配置 -> 设置 -> 索引 / LlamaIndex -> 嵌入 -> 默认嵌入模型”列表中为指定的提供商选择嵌入模型。默认情况下,使用 RAG 查询附件时,将使用与 RAG 查询模型相对应的默认嵌入模型和提供商。如果未为特定提供商提供默认配置,则将使用全局嵌入配置。
例如,如果 RAG 查询模型是 gpt-4o-mini,则将使用 OpenAI 提供商的默认模型。如果 OpenAI 的默认模型未在列表中指定,则将使用全局提供商和模型。
下载文件
PyGPT 支持自动下载并保存由模型生成的文件。此过程在后台进行,文件会被保存到用户工作目录下的 data 文件夹中。用户可以通过导航至“Files”(文件)选项卡来查看或管理这些文件,该选项卡提供了一个针对此特定目录的文件浏览器。在这里,用户可以方便地处理所有由 AI 发送的文件。
这个 data 目录也是应用程序存储由 AI 在本地生成的文件的地方,例如代码文件或其他从模型请求的数据。用户可以选择直接从存储的文件中执行代码并读取其内容,然后将结果反馈给 AI。这一无需手动干预的过程由内置插件系统和模型触发的命令来管理。此外,您还可以对该目录中的文件进行索引(使用集成的 LlamaIndex),并将这些内容作为额外的上下文提供给对话。
Files I/O 插件负责处理 data 目录中的文件操作,而 Code Interpreter 插件则允许执行这些文件中的代码。
为了使模型能够管理文件或执行 Python 代码,必须启用 + Tools 选项,并同时激活上述插件:
预设
什么是预设?
PyGPT 中的预设本质上是用于存储和快速应用不同配置的模板。每个预设包含您希望使用的模式设置(如聊天、完成或图像生成)、初始系统提示、分配给 AI 的名称、会话用户名,以及对话所需的“温度”参数。较高的“温度”设置会使 AI 提供更具创造性的回复,而较低的设置则会促使 AI 给出更可预测的回应。这些预设可以在各种模式下使用,并且适用于通过 OpenAI API 或 LlamaIndex 访问的模型。
应用程序允许您根据需要创建任意数量的预设,并轻松地在它们之间切换。此外,您还可以克隆现有预设,这对于基于先前设置的配置创建变体并进行实验非常有用。
示例用法
应用程序包含多个示例预设,可以帮助您熟悉其使用机制。
个人资料
您可以为应用程序创建多个个人资料并在它们之间切换。每个个人资料都使用自己的配置、设置、上下文历史记录以及独立的用户文件夹。这使您能够设置不同的环境,并只需单击一下即可快速切换,从而更改整个配置。
应用程序允许您创建新个人资料、编辑现有个人资料以及复制当前个人资料。
要创建新个人资料,请从菜单中选择:Config -> Profile -> New Profile...
要编辑已保存的个人资料,请从菜单中选择:Config -> Profile -> Edit Profiles...
要切换到已创建的个人资料,请从菜单中选择:Config -> Profile -> [个人资料名称]
每个个人资料都使用其自己的用户目录(workdir)。您可以将新创建或编辑后的个人资料与现有的 workdir 及其配置关联起来。
当前活动个人资料的名称会显示在窗口标题中,格式为 (Profile Name)。
模型
内置模型
截至2026年2月6日,PyGPT 已预配置了一系列模型:
bielik-11b-v2.3-instruct:Q4_K_M(Ollama)chatgpt-4o-latest(OpenAI)claude-3-5-sonnet-20240620(Anthropic)claude-3-7-sonnet(Anthropic)claude-3-opus(Anthropic)claude-3-opus(Anthropic)claude-opus-4-0(Anthropic)claude-sonnet-4-0(Anthropic)claude-opus-4-5(Anthropic)claude-sonnet-4-5(Anthropic)codellama(Ollama)codex-mini(OpenAI)dall-e-2(OpenAI)dall-e-3(OpenAI)deep-research-pro-preview-12-2025(Google)deepseek-chat(DeepSeek)deepseek-r1:1.5b(Ollama)deepseek-r1:14b(Ollama)deepseek-r1:32b(Ollama)deepseek-r1:7b(Ollama)deepseek-reasoner(DeepSeek)gemini-2.5-computer-use-preview-10-2025(Google)gemini-1.5-flash(Google)gemini-1.5-pro(Google)gemini-2.0-flash-exp(Google)gemini-2.5-flash(Google)gemini-2.5-flash-preview-native-audio-dialog(Google,实时)gemini-2.5-pro(Google)gemini-3-flash-preview(Google)gemini-3-pro-image-preview(Google)gemini-3-pro-preview(Google)gpt-3.5-turbo(OpenAI)gpt-3.5-turbo-16k(OpenAI)gpt-3.5-turbo-instruct(OpenAI)gpt-4(OpenAI)gpt-4-32k(OpenAI)gpt-4-turbo(OpenAI)gpt-4-vision-preview(OpenAI)gpt-4.1(OpenAI)gpt-4.1-mini(OpenAI)gpt-4.1-nano(OpenAI)gpt-4o(OpenAI)gpt-4o-realtime-preview(OpenAI,实时)gpt-4o-mini(OpenAI)gpt-5(OpenAI)gpt-5-mini(OpenAI)gpt-5-nano(OpenAI)gpt-5.2(OpenAI)gpt-image-1(OpenAI)gpt-image-1.5(OpenAI)gpt-oss:20b(OpenAI - 通过 Ollama 和 HuggingFace Router)gpt-oss:120b(OpenAI - 通过 Ollama 和 HuggingFace Router)gpt-realtime(OpenAI,实时)grok-2-vision(xAI)grok-3(xAI)grok-3-fast(xAI)grok-3-mini(xAI)grok-3-mini-fast(xAI)grok-4(xAI)grok-imagine-image(xAI)grok-imagine-video(xAI)llama2-uncensored(Ollama)llama3.1(Ollama)llama3.1:70b(Ollama)mistral(Ollama)mistral-large(Ollama)mistral-small3.1(Ollama)nano-banana-pro-preview(Google)o1(OpenAI)o1-mini(OpenAI)o1-pro(OpenAI)o3(OpenAI)o3-deep-research(OpenAI)o3-mini(OpenAI)o3-pro(OpenAI)o4-mini(OpenAI)o4-mini-deep-research(OpenAI)qwen2:7b(Ollama)qwen2.5-coder:7b(Ollama)qwen3:8b(Ollama)qwen3:30b-a3b(Ollama)r1(Perplexity)sonar(Perplexity)sonar-deep-research(Perplexity)sonar-pro(Perplexity)sonar-reasoning(Perplexity)sonar-reasoning-pro(Perplexity)sora-2(OpenAI)veo-3.0-generate-preview(Google)veo-3.0-fast-generate-preview(Google)veo-3.1-generate-preview(Google)veo-3.1-fast-generate-preview(Google)
所有模型均在配置文件 models.json 中指定,您可以对其进行自定义。该文件位于您的工作目录中。您可以在其中添加由 OpenAI API(或兼容接口)、Google Gen AI API、Anthropic API、xAI API 直接提供的新模型,以及受 LlamaIndex 或 Ollama 支持的模型。LlamaIndex 的配置则放置在 llama_index 键下。
您可以通过手动编辑 models.json 文件,或使用菜单 Config -> Models -> Import 中的模型导入工具来导入新模型。
提示: 列表中的模型按提供方而非制造商排序。同一制造商的模型可能通过不同的提供方获取(例如,OpenAI 模型可通过 OpenAI API 或 OpenRouter 提供)。如果您希望通过特定提供方使用某款模型,需在 Config -> Models -> Edit 中配置该提供方,或直接通过 Config -> Models -> Import 导入。
提示: Anthropic 和 Deepseek API 提供方使用 VoyageAI 进行嵌入(用于“聊天与文件”及附件 RAG),因此若要使用这些提供方的嵌入功能,还需配置 Voyage API 密钥。
添加自定义模型
您也可以添加自己的模型。更多信息请参阅“扩展 PyGPT / 添加新模型”部分。
内置支持以下 LLM 提供方:
AnthropicAzure OpenAI(原生 SDK)Deepseek APIGoogle(原生 SDK)HuggingFace APIHuggingFace Router(OpenAI 兼容 ChatCompletions 封装)本地模型(OpenAI API 兼容)Mistral AIOllamaOpenAI(原生 SDK)OpenRouterPerplexityxAI(原生 SDK)
如何使用本地或非 GPT 模型
Llama 3、Mistral、DeepSeek、Qwen、gpt-oss 等本地模型
如何使用本地安装的 Llama 3、DeepSeek、Mistral 等模型:
选择工作模式:“聊天”或“聊天与文件”。
在模型列表中选择、编辑或添加新模型(使用
ollama提供方)。您可以通过菜单Config -> Models -> Edit编辑模型设置,并在“高级”部分配置模型参数。从这里下载并安装 Ollama:https://github.com/ollama/ollama
例如,在 Linux 上:
curl -fsSL https://ollama.com/install.sh | sh
- 在本地机器上运行模型(例如 Llama 3)。以 Linux 为例:
ollama run llama3.1
- 返回 PyGPT,在模型列表中选择正确的模型,即可通过本地运行的 Ollama 与所选模型进行对话。
可用示例模型
llama3.1codellamamistralllama2-uncensoreddeepseek-r1
等等。
您还可以通过编辑模型列表添加更多模型。
实时导入器
您也可以使用 Config -> Models -> Import... 工具,从正在运行的 Ollama 实例中实时导入模型。
自定义 Ollama 端点
Ollama 的默认端点为:http://localhost:11434
您可以通过在 Settings -> General -> Advanced -> Application environment 中设置环境变量 OLLAMA_API_BASE 来全局更改此端点。
此外,您还可以在特定模型的配置中更改其“base_url”:
进入 Config -> Models -> Edit,然后在“高级 -> [LlamaIndex] ENV Vars”部分添加如下变量:
名称:OLLAMA_API_BASE
值:http://my_endpoint.com:11434
Ollama 支持的所有模型列表
https://github.com/ollama/ollama
重要提示: 请务必在模型设置的 **kwargs 列表中正确指定模型名称。
使用本地嵌入
参考:https://docs.llamaindex.ai/en/stable/examples/embeddings/ollama_embedding/
您可以使用 Ollama 实例进行嵌入。只需在以下路径中选择 ollama 提供方:
Config -> Settings -> Indexes / LlamaIndex -> Embeddings -> 嵌入提供方
在嵌入提供方的 **kwargs 列表中定义诸如模型名称和 Ollama 基础 URL 等参数,例如:
名称:
model_name,值:llama3.1,类型:str名称:
base_url,值:http://localhost:11434,类型:str
Google Gemini、Anthropic Claude、xAI Grok 等
如果您希望在“文件聊天”和“智能体(LlamaIndex)”模式中使用非 OpenAI 模型,请务必在模型配置字段中设置所需的参数,例如 API 密钥。“聊天”模式通过 OpenAI SDK(兼容 API)运行,“文件聊天”和“智能体(LlamaIndex)”模式则通过 LlamaIndex 运行。
Google Gemini
所需环境变量:
- GOOGLE_API_KEY = {api_key_google}
所需关键字参数:
- model
Anthropic Claude
所需环境变量:
- ANTHROPIC_API_KEY = {api_key_anthropic}
所需关键字参数:
- model
xAI Grok(仅限聊天模式)
所需环境变量:
- OPENAI_API_KEY = {api_key_xai}
- OPENAI_API_BASE = {api_endpoint_xai}
所需关键字参数:
- model
Mistral AI
所需环境变量:
- MISTRAL_API_KEY = {api_key_mistral}
所需关键字参数:
- model
Perplexity
所需环境变量:
- PPLX_API_KEY = {api_key_perplexity}
所需关键字参数:
- model
HuggingFace API
所需环境变量:
- HUGGING_FACE_TOKEN = {api_key_hugging_face}
所需关键字参数:
- model_name | model
- token
- provider = auto
插件
概述
PyGPT 可以通过插件扩展功能,添加新特性。
目前可用的插件如下,模型可立即使用:
API 调用- 该插件允许您通过自定义的 API 调用将模型连接到外部服务。音频输入- 提供语音识别功能。音频输出- 提供语音合成功能。自主智能体(内联)- 支持自主对话(AI 对 AI),管理循环并将输出反馈回输入。这是内联智能体模式。Bitbucket- 访问 Bitbucket API,管理代码仓库、问题和拉取请求。文件聊天(LlamaIndex,内联)- 该插件将 LlamaIndex 存储集成到任何聊天中,并从索引文件及数据库中的历史上下文中提供额外的知识。代码解释器- 负责生成并执行 Python 代码,功能类似于 ChatGPT 上的代码解释器,但为本地运行。这意味着模型可以与任何脚本、应用程序或代码进行交互。多个插件可以协同工作以完成一系列任务;例如,“文件”插件可以将生成的 Python 代码写入文件,然后由“代码解释器”执行并将其结果返回给模型。上下文历史记录(日历,内联)- 提供对上下文历史数据库的访问权限。Crontab / 任务调度器- 该插件提供基于 cron 的作业调度功能——您可以使用 cron 语法安排任务/提示,在指定时间发送。自定义命令- 允许您在系统上创建并执行自定义命令。专家(内联)- 在任何聊天模式下调用专家。这是内联专家模式。Facebook- 管理 Facebook 页面上的用户信息、主页、帖子和照片。文件 I/O- 提供对本地文件系统的访问权限,使模型能够读写文件,以及列出和创建目录。GitHub- 访问 GitHub API,管理代码仓库、问题和拉取请求。Google- 访问 Gmail、Drive、Docs、Maps、Calendar、Contacts、Colab、YouTube、Keep 等,用于管理电子邮件、文件、日程、笔记、视频信息和联系人。图像生成(内联)- 将 DALL-E 3 图像生成功能集成到任何聊天和模式中。只需启用并在聊天模式下请求图像,使用 GPT-4 等标准模型即可。该插件无需启用“+ 工具”选项。邮件客户端- 提供发送、接收和阅读电子邮件的功能。MCP- 通过模型上下文协议(MCP)访问远程工具,包括 stdio、SSE 和可流式传输的 HTTP 传输方式,并支持按服务器的允许/拒绝过滤、Authorization 头部认证以及工具缓存。鼠标和键盘- 允许模型控制鼠标和键盘。OpenStreetMap- 使用 OpenStreetMap 服务(Nominatim、OSRM、staticmap)进行搜索、地理编码、规划路线和生成静态地图。实时- 自动将当前日期和时间附加到系统提示中,告知模型当前时间。串口 / USB- 该插件提供读取和向 USB 端口发送数据的命令。服务器(SSH/FTP)- 使用 FTP、SFTP 和 SSH 连接到远程服务器。执行远程命令、上传、下载等操作。Slack- 处理 Slack 上的用户、对话、消息和文件。系统提示补充(追加)- 将列表中的额外系统提示自动追加到每个当前的系统提示中。您可以为每个系统提示添加额外的指令,这些指令会自动附加到系统提示中。系统(操作系统)- 允许您在系统上创建并执行自定义命令。Telegram- 发送消息、照片和文档;管理聊天和联系人。Tuya(物联网)- 通过 Tuya Cloud API 管理 Tuya 智能家居设备。视觉(内联)- 将视觉能力集成到任何聊天模式中,而不仅仅是视觉模式。当插件启用时,如果收到图片附件或进行视觉捕捉,模型会在后台临时切换到视觉模式。语音控制(内联)- 在对话中提供语音控制命令执行功能。网络搜索- 提供连接到互联网、搜索网页获取最新数据以及使用 LlamaIndex 数据加载器索引外部内容的能力。维基百科- 在维基百科中搜索信息。Wolfram Alpha- 使用 Wolfram Alpha 进行计算和求解:简短答案、完整的 JSON pod、数学运算(求解、求导、积分)、单位换算、矩阵运算和图表绘制。X/Twitter- 与推文和用户互动,管理书签和媒体,点赞、转发等。
API 调用
PyGPT 允许您通过自定义的 API 调用将模型连接到外部服务。
要激活此功能,请在“插件”菜单中启用“API 调用”插件。
在此插件中,您可以提供允许的 API 调用列表、其参数和请求类型。模型会将提供的占位符替换为所需参数,并向外部服务发起 API 调用。
文档:https://pygpt.readthedocs.io/en/latest/plugins.html#api-calls
音频输入
该插件支持语音识别(默认使用 OpenAI 的 Whisper 模型,也可选择 Google 和 Bing)。它允许您用自己的声音向 AI 发出语音命令。Whisper 不需要额外的 API 密钥或额外配置;它使用主 OpenAI 密钥。在插件的配置选项中,您应调整插件对麦克风响应的音量级别(最小能量)。一旦插件启用,底部靠近“发送”按钮的位置会出现一个新的“说话”选项——启用后,应用程序将响应来自麦克风的语音。
该插件还可以扩展其他语音识别提供商。
文档:https://pygpt.readthedocs.io/en/latest/plugins.html#audio-input
音频输出
该插件允许您使用 OpenAI 的 TTS 模型,或 Microsoft Azure、Google 和 Eleven Labs 等其他服务,将文本转换为语音。您还可以添加更多文本转语音提供商。OpenAI TTS 无需任何额外的 API 密钥或配置;它直接使用您的 OpenAI 主 API 密钥。
而 Microsoft Azure 则需要 Azure API 密钥。在使用 Microsoft Azure、Google 或 Eleven Labs 进行语音合成之前,您必须先使用相应的 API 密钥、区域和语音选项(如适用)对音频插件进行配置。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#audio-output
自主代理(内联)
警告:请谨慎使用自主模式! —— 当此模式与其他插件结合使用时,可能会产生意想不到的结果!
该插件会在标准聊天模式中激活自主模式,此时 AI 将与自身展开对话。您可以设置循环运行任意次数。在此过程中,模型会不断进行自我对话,回答自己的问题和评论,以寻找最佳解决方案,并对先前生成的内容进行批判性评估。
此模式类似于 Auto-GPT,可用于进行更复杂的推理,并通过将问题分解为子任务来逐步解决,直到目标达成。该插件能够与其他插件协同工作,因此可以利用诸如网络搜索、文件系统访问或使用 DALL-E 进行图像生成等工具。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#autonomous-agent-inline
Bitbucket
Bitbucket 插件可与 Bitbucket Cloud API 无缝集成,提供管理代码库、问题和拉取请求的功能。该插件具有高度可配置的认证选项、缓存功能,并能高效地处理 HTTP 请求。
- 获取已认证用户的详细信息。
- 获取特定用户的信息。
- 列出可用的工作区。
- 列出工作区中的代码库。
- 获取特定代码库的详细信息。
- 创建新的代码库。
- 删除现有代码库。
- 获取代码库中某个文件的内容。
- 向代码库上传文件。
- 从代码库中删除文件。
- 列出代码库中的问题。
- 创建新问题。
- 对现有问题发表评论。
- 更新问题的详细信息。
- 列出代码库中的拉取请求。
- 创建新的拉取请求。
- 合并现有的拉取请求。
- 搜索代码库。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#bitbucket
文件聊天(LlamaIndex,内联)
该插件将 LlamaIndex 存储集成到任何聊天中,并将额外的知识引入上下文中。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#chat-with-files-llamaindex-inline
代码解释器
执行代码
自版本 2.4.13 起内置了 IPython。
该插件的工作方式与 ChatGPT 中的 代码解释器 类似,主要区别在于它在用户的本地系统上运行。它可以执行模型生成的任何 Python 代码。当与 文件 I/O 插件结合使用时,它能够运行保存在 data 目录中的文件中的代码。您也可以准备自己的代码文件,并让模型使用它们,或者为此目的添加您自己的插件。您可以在主机上或 Docker 容器中执行命令和代码。
IPython: 自版本 2.4.13 起,强烈建议采用新的选项:IPython,它相比之前的流程有了显著改进。IPython 提供了一个强大的内核环境来执行代码,允许您通过保留先前命令的结果来维持会话状态。这一特性对于迭代开发和数据分析尤其有用,因为它使您能够在先前计算的基础上继续工作,而不必从头开始。此外,IPython 还支持使用魔法命令,例如 !pip install <package_name>,这些命令可以直接在会话中安装新包。这种能力简化了依赖项管理过程,增强了开发环境的灵活性。总体而言,IPython 提供了更高效、更友好的代码执行和管理体验。
要在沙盒模式下使用 IPython,您的系统上必须安装 Docker。
安装说明请参见:https://docs.docker.com/engine/install/
提示:在 Snap 版本中连接 Docker 中的 IPython:
要在 Snap 版本中使用 IPython,您必须将 PyGPT 连接到 Docker 守护进程:
sudo snap connect pygpt:docker-executables docker:docker-executables
sudo snap connect pygpt:docker docker:docker-daemon
代码解释器: 内置了实时 Python 代码解释器。单击 <> 图标即可打开解释器窗口。解释器的输入和输出都与插件相连。执行代码产生的任何输出都会显示在解释器中。此外,您还可以要求模型获取解释器窗口中的内容。
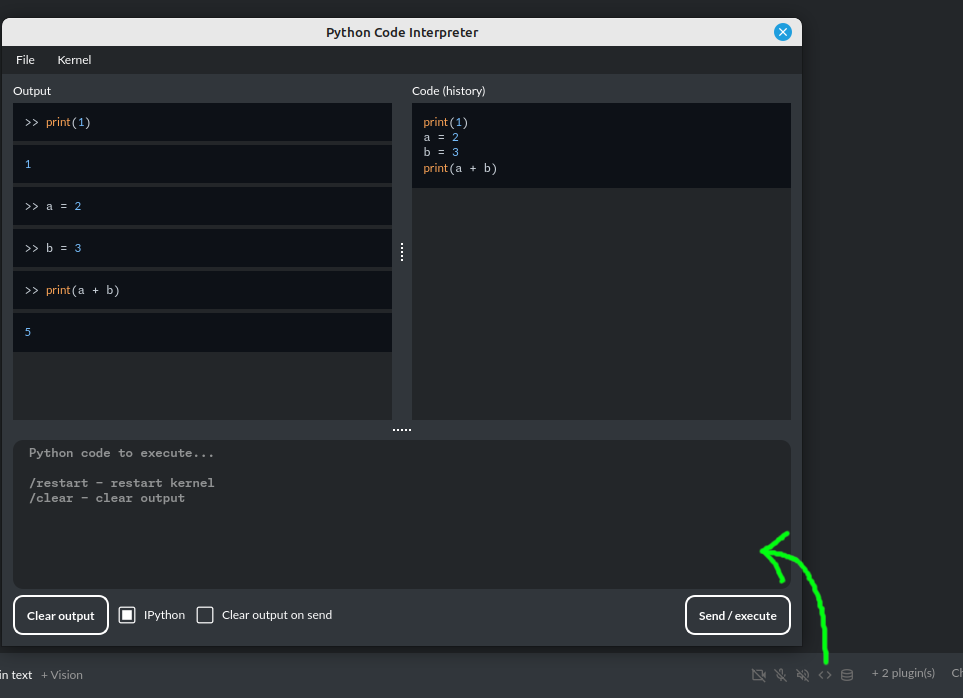
信息: 在编译版本中使用 IPython 执行 Python 代码需要启用沙盒(Docker 容器)。您可以通过 插件 -> 设置 来连接 Docker 容器。
提示: 始终记得启用 + 工具 选项,以允许插件执行命令。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#code-interpreter
上下文历史记录(日历,内联)
提供对上下文历史数据库的访问权限。 该插件还允许读取和创建每日笔记。
使用示例,您可以询问如下内容:
给我今天的日记
为今天保存一条新笔记
用...更新我的今日笔记
获取昨天的对话列表
获取 ID 为 123 的对话内容
等等。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#context-history-calendar-inline
Crontab / 任务调度器
该插件提供基于 cron 的作业调度功能——您可以使用 cron 语法安排任务/提示,在指定时间发送。
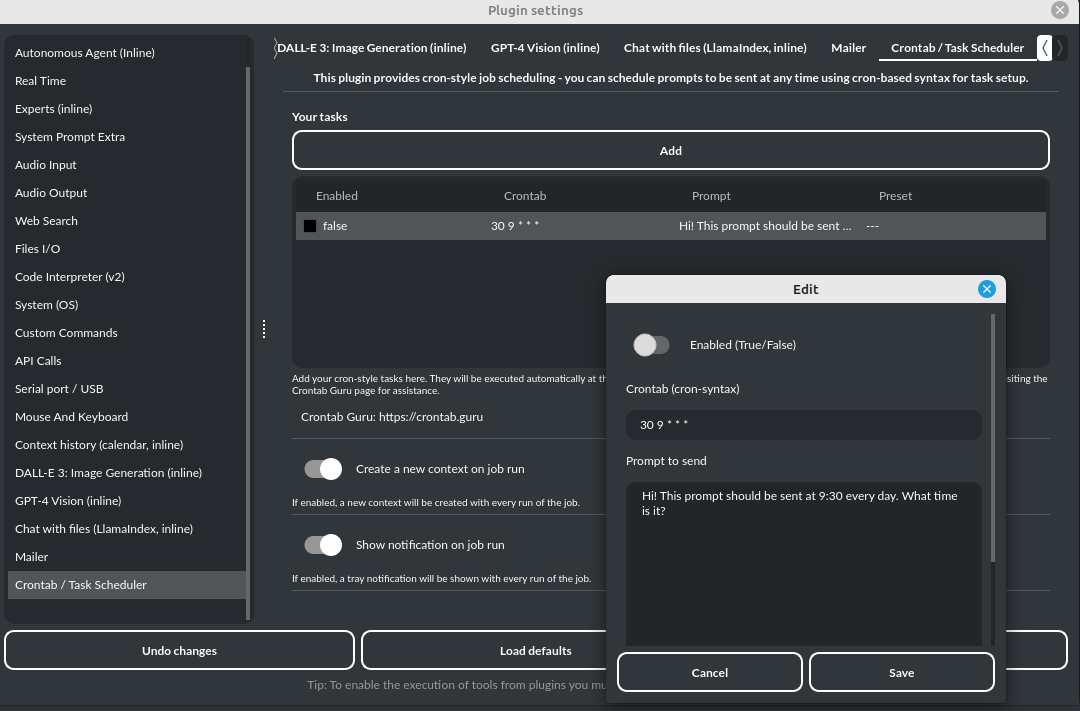
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#crontab-task-scheduler
自定义命令
借助 Custom Commands 插件,您可以将 PyGPT 与您的操作系统以及脚本或应用程序集成。您可以定义无限数量的自定义命令,并指示模型在何时以及如何执行它们。配置非常简单,PyGPT 还包含一个简单的教程命令,用于测试和学习其工作原理:
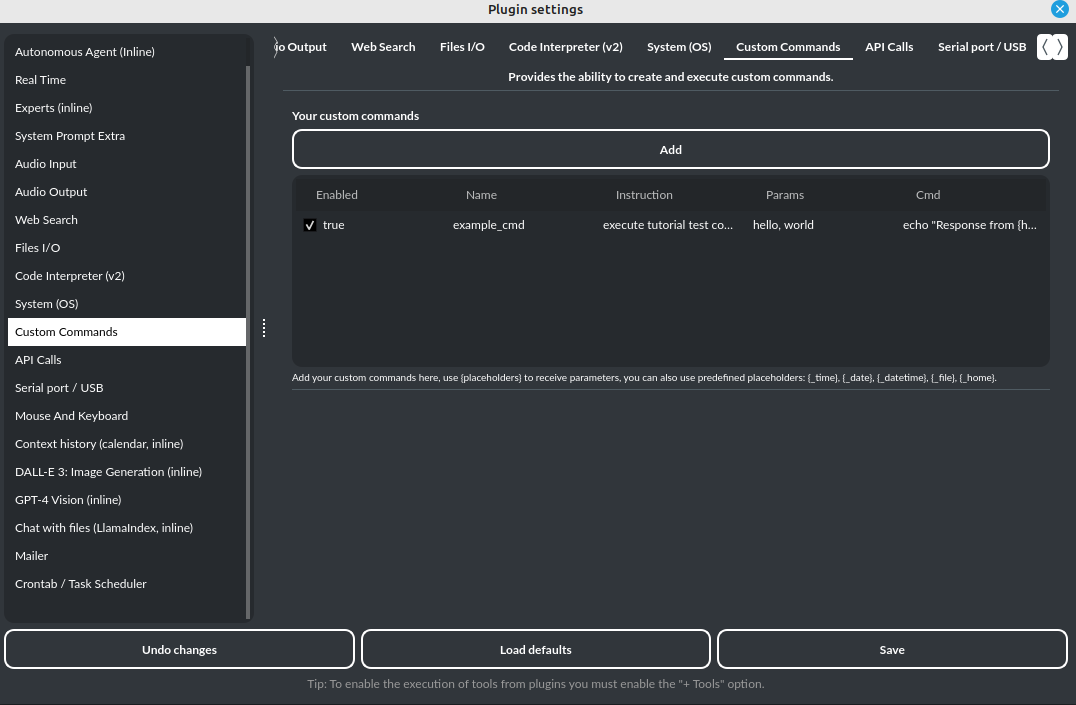
文档:https://pygpt.readthedocs.io/en/latest/plugins.html#custom-commands
专家(内联)
该插件允许在任何聊天模式下调用专家。这就是内联专家(协作)模式。
更多详情请参阅“工作模式 -> 专家”部分。
该插件通过 Facebook 的 Graph API 实现与 Facebook 的集成,支持管理页面、帖子和上传媒体等多种操作。它使用 OAuth2 进行身份验证,并支持自动的令牌交换流程。
- 获取已认证用户的基本信息。
- 列出用户有权访问的所有 Facebook 页面。
- 将指定的 Facebook 页面设置为默认页面。
- 获取 Facebook 页面上的帖子列表。
- 在 Facebook 页面上创建新帖子。
- 删除 Facebook 页面上的帖子。
- 向 Facebook 页面上传照片。
文档:https://pygpt.readthedocs.io/en/latest/plugins.html#facebook
文件 I/O
该插件允许在本地文件系统中进行文件管理。它使模型能够创建、读取、写入和查询位于用户工作目录中的 data 目录下的文件。借助此插件,AI 还可以生成 Python 代码文件,并在用户的系统中执行这些代码。
插件功能包括:
- 以附件形式发送文件。
- 读取文件。
- 追加内容到文件。
- 写入文件。
- 删除文件和目录。
- 列出文件和目录。
- 创建目录。
- 下载文件。
- 复制文件和目录。
- 移动(重命名)文件和目录。
- 读取文件信息。
- 使用 LlamaIndex 对文件和目录进行索引。
- 使用 LlamaIndex 查询文件。
- 搜索文件和目录。
如果要创建的文件(同名)已存在,则会在文件名前添加包含日期和时间的前缀。
文档:https://pygpt.readthedocs.io/en/latest/plugins.html#files-i-o
GitHub
该插件提供了与 GitHub 的无缝集成,允许通过 GitHub 的 API 执行各种操作,如仓库管理、问题跟踪、拉取请求等。此插件需要身份验证,可以通过个人访问令牌 (PAT) 或 OAuth 设备流进行配置。
- 获取您的 GitHub 个人资料详细信息。
- 获取特定 GitHub 用户的信息。
- 列出用户或组织的仓库。
- 获取特定仓库的详细信息。
- 创建新仓库。
- 删除现有仓库。
- 获取仓库中某个文件的内容。
- 向仓库中上传或更新文件。
- 删除仓库中的文件。
- 列出仓库中的问题。
- 在仓库中创建新问题。
- 为现有问题添加评论。
- 关闭现有问题。
- 列出仓库中的拉取请求。
- 创建新的拉取请求。
- 合并现有的拉取请求。
- 根据查询搜索仓库。
- 根据查询搜索问题。
- 根据查询搜索代码。
文档:https://pygpt.readthedocs.io/en/latest/plugins.html#github
Google(Gmail、Drive、日历、联系人、YouTube、Keep、Docs、地图、Colab)
该插件集成了多种 Google 服务,通过 Google API 实现电子邮件管理、日历事件、联系人处理和文档操作等功能。
Gmail
- 列出 Gmail 中的近期邮件。
- 列出 Gmail 中的所有邮件。
- 搜索 Gmail 中的邮件。
- 根据 ID 获取 Gmail 中的邮件详情。
- 通过 Gmail 发送邮件。
Google 日历
- 列出近期的日历事件。
- 列出今天的日历事件。
- 列出明天的日历事件。
- 列出所有的日历事件。
- 根据特定日期获取日历事件。
- 向日历中添加新事件。
- 从日历中删除事件。
Google Keep
- 列出 Google Keep 中的笔记。
- 向 Google Keep 中添加新笔记。
Google Drive
- 列出 Google Drive 中的文件。
- 根据路径查找 Google Drive 中的文件。
- 从 Google Drive 下载文件。
- 向 Google Drive 上传文件。
YouTube
- 获取 YouTube 视频的相关信息。
- 获取 YouTube 视频的字幕文本。
Google 联系人
- 列出 Google 联系人中的所有联系人。
- 向 Google 联系人中添加新联系人。
Google Docs
- 创建新文档。
- 获取现有文档。
- 列出文档。
- 向文档中追加文本。
- 替换文档中的文本。
- 向文档中插入标题。
- 导出文档。
- 从模板复制内容。
Google 地图
- 地址编码。
- 坐标反向地理编码。
- 获取地点之间的路线。
- 使用距离矩阵。
- 按文本搜索地点。
- 查找附近地点。
- 生成静态地图图像。
Google Colab
- 列出笔记本。
- 创建新笔记本。
- 添加代码单元格。
- 添加 Markdown 单元格。
- 获取笔记本的链接。
- 重命名笔记本。
- 复制笔记本。
图像生成(内联)
该插件将 DALL-E 3 图像生成功能与任何聊天模式集成。只需启用它,并在聊天模式下使用标准模型(如 GPT-4)请求生成图像即可。该插件无需启用 + Tools 选项。
文档:https://pygpt.readthedocs.io/en/latest/plugins.html#image-generation-inline
邮件客户端
支持发送、接收和阅读收件箱中的电子邮件。目前仅支持 SMTP 协议。更多选项即将推出。
文档:https://pygpt.readthedocs.io/en/latest/plugins.html#mailer
MCP(模型上下文协议)
借助 MCP 插件,您可以将 PyGPT 连接到由 Model Context Protocol 服务器(stdio、Streamable HTTP 或 SSE)暴露的远程工具。该插件会发现您配置的服务器上可用的工具,并将其作为可调用命令发布给模型,同时提供正确的参数架构。您可以按服务器对工具进行白名单/黑名单设置,并可选择缓存发现结果以提高速度。
文档:https://pygpt.readthedocs.io/en/latest/plugins.html#mcp
鼠标与键盘
引入版本:2.4.4(2024-11-09)
警告:请谨慎使用此插件——启用所有选项将使模型获得对鼠标和键盘的完全控制权。
该插件允许模型控制鼠标和键盘。借助此插件,您可以向模型发送任务,例如“打开记事本,在其中输入一些内容”或“打开网页浏览器,进行搜索,找到相关内容”。
插件功能包括:
- 获取鼠标光标位置
- 控制鼠标光标位置
- 控制鼠标点击
- 控制鼠标滚动
- 控制键盘(按键、输入文本)
- 截取屏幕截图
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#mouse-and-keyboard
OpenStreetMap
利用 OpenStreetMap 服务提供日常地图工具:
- 通过 Nominatim 进行正反地理编码
- 支持可选的附近或边界框过滤器的搜索
- 通过 OSRM 进行路线规划(驾车、步行、骑行)
- 生成 openstreetmap.org URL(中心点/缩放级别或边界框;可选标记)
- 实用辅助功能:打开以某点为中心的 OSM 网站 URL;下载单个 XYZ 图块
图片将保存在用户数据目录下的 data/openstreetmap/ 文件夹中。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#openstreetmap
实时
此插件会自动将当前日期和时间添加到您发送的每个系统提示中。您可以选择仅包含日期、仅包含时间,或同时包含两者。
启用后,它会在将系统提示发送给模型之前,悄悄地将其与当前时间信息结合。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#real-time
串口/USB
提供用于读取和向 USB 端口发送数据的命令。
提示: 在 Snap 版本中,您必须先连接接口:https://snapcraft.io/docs/serial-port-interface
您可以向使用串口通信的 Arduino 或其他控制器发送命令。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#serial-port-usb
服务器(SSH/FTP)
服务器插件提供了通过 SSH、SFTP 和 FTP 协议远程管理服务器的集成。该插件允许在远程服务器上执行命令、传输文件以及管理目录。
出于安全考虑,模型不会看到任何凭据,只会显示服务器名称和端口字段(详见文档)。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#server-ssh-ftp
Slack
Slack 插件与 Slack Web API 集成,使应用程序能够与 Slack 工作区交互。该插件支持 OAuth2 认证,可实现与 Slack 服务的无缝集成,从而执行诸如发布消息、获取用户信息和管理对话等操作。
- 获取用户列表。
- 列出所有对话。
- 访问对话历史记录。
- 获取对话回复。
- 打开对话。
- 在聊天中发送消息。
- 删除聊天消息。
- 向 Slack 上传文件。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#slack
系统(操作系统)
该插件提供对操作系统的访问权限,并执行系统命令。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#system-os
系统提示扩展(附加)
该插件会将额外的系统提示(附加数据)从列表中附加到每个当前的系统提示中。您可以为每个系统提示添加额外的指令,这些指令将自动附加到系统提示中。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#system-prompt-extra-append
Telegram
该插件分别通过 Bot API 和 Telethon 库,实现了与 Telegram 的机器人和用户账户的集成。它允许发送和接收消息、管理聊天以及处理更新。
- 向聊天或频道发送文本消息。
- 向聊天或频道发送带有可选标题的照片。
- 向聊天或频道发送文档或文件。
- 获取特定聊天或频道的信息。
- 在机器人模式下轮询更新。
- 使用文件标识符下载文件。
- 在用户模式下列出联系人。
- 在用户模式下列出最近的对话或聊天。
- 在用户模式下从特定聊天或频道获取最近的消息。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#telegram
Tuya(物联网)
Tuya 插件与 Tuya 智能家居平台集成,通过 Tuya Cloud API 实现与您的智能设备的无缝交互。该插件提供了一个友好的界面,让您可以直接从助手管理并控制设备。
- 请提供您的 Tuya Cloud 凭据以启用通信。
- 访问并列出连接到您 Tuya 应用程序账户的所有智能设备。
- 获取每个设备的详细信息,包括其状态和支持的功能。
- 使用缓存数据按设备名称轻松搜索设备,以便快速访问。
- 控制设备的开关、切换状态,并设置特定的设备参数。
- 向设备发送自定义命令以实现更高级的控制。
- 读取传感器数值并进行归一化处理,以便于理解。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#tuya-iot
视觉(内联)
该插件在所有聊天模式中都集成了视觉功能,而不仅限于视觉模式。一旦启用,当检测到图像附件或视觉捕捉时,模型就会在后台无缝切换到视觉处理。
提示: 在标准模式(如“聊天”模式,而非“视觉”模式)中使用 视觉(内联) 插件时,聊天窗口底部会出现一个特殊的“+ 视觉”复选框。每当您提供需要分析的内容(如上传的照片)时,该复选框将自动启用。复选框启用后,将使用视觉模型。如果您希望在图像分析完成后退出视觉模式,只需取消选中该复选框即可。下次提供需要分析的图像内容时,它会再次自动启用。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#vision-inline
语音控制(内联)
该插件在对话中提供语音控制命令执行功能。
更多详情请参阅“无障碍”部分。
网络搜索
PyGPT 允许您将模型连接到互联网,并在您提出查询时实时进行网络搜索。
要激活此功能,请在“插件”菜单中启用 网络搜索 插件。
网络搜索由 Google 自定义搜索引擎 和 Microsoft Bing API 提供,并可扩展至其他搜索引擎提供商。
文档链接:https://pygpt.readthedocs.io/en/latest/plugins.html#web-search
维基百科
维基百科插件允许与维基百科进行全方位互动,包括语言设置、文章搜索、摘要获取以及随机文章发现等功能。该插件提供了多种选项来优化您的搜索体验。
- 设置您偏好的维基百科查询语言。
- 检索并查看当前的语言设置。
- 浏览支持的语言列表。
- 使用关键词搜索文章或获取查询建议。
- 获取文章摘要和详细页面内容。
- 按地理位置或随机方式发现文章。
- 直接在您的网页浏览器中打开文章。
文档:https://pygpt.readthedocs.io/en/latest/plugins.html#wikipedia
Wolfram Alpha
通过 Wolfram Alpha 提供计算知识服务:简短答案、完整的 JSON 数据包、数值与符号数学运算(求解、求导、积分)、单位换算、矩阵运算以及以图片形式呈现的图表。生成的图片将保存在用户数据目录下的 data/wolframalpha/ 文件夹中。
文档:https://pygpt.readthedocs.io/en/latest/plugins.html#wolfram-alpha
X/Twitter
X/Twitter 插件与 X 平台集成,支持推文发布、转发、点赞、媒体上传等全方位互动功能。该插件需要 OAuth2 认证,并提供多种配置选项,以便有效管理 API 交互。
- 通过用户名获取用户详情。
- 使用用户的唯一 ID 拉取用户信息。
- 查看特定用户的最新推文。
- 使用特定关键词或话题标签搜索最近的推文。
- 创建并发布一条新推文。
- 从您的个人主页删除现有推文。
- 对特定推文回复新评论。
- 引用某条推文,并添加您自己的评论或想法。
- 点赞某条推文以表达欣赏或支持。
- 取消对之前点赞的推文的点赞。
- 转发某条推文,与您的关注者分享。
- 撤销转发,将其从您的主页移除。
- 隐藏对某条推文的特定回复。
- 列出所有书签中的推文,方便快速访问。
- 将某条推文添加到书签中,以备日后参考。
- 从书签中移除某条推文。
- 上传图片或视频等媒体文件用于推文发布。
- 为上传的媒体设置替代文本,以提升可访问性。
文档:https://pygpt.readthedocs.io/en/latest/plugins.html#x-twitter
创建您自己的插件
您可以随时为 PyGPT 创建自己的插件。插件可以用 Python 编写,然后在应用启动前注册到程序中。应用程序自带的所有插件都存储在 plugin 目录下,您可以将其作为编写自定义插件的示例。
PyGPT 可以通过以下方式扩展:
- 自定义模型
- 自定义插件
- 自定义大语言模型
- 自定义向量存储提供商
- 自定义数据加载器
- 自定义音频输入提供商
- 自定义音频输出提供商
- 自定义网络搜索引擎提供商
- 自定义智能体(如 LlamaIndex 或 OpenAI 智能体)
更多详细信息,请参阅“扩展 PyGPT / 添加自定义插件”章节。
函数、命令和工具
提示 请记住启用 + 工具 复选框,以允许执行插件中的工具和命令。
从版本 2.2.20 开始,PyGPT 默认使用原生 API 函数调用。您可以通过关闭选项 配置 -> 设置 -> 提示词 -> 使用原生 API 函数调用 恢复到内部语法(如下所述)。此外,您还必须在模型高级设置中启用 工具调用 复选框,才能使用指定模型的原生函数调用。
在后台,PyGPT 使用一种内部语法来定义命令及其参数,这些命令随后可以由模型使用,并在应用程序端甚至直接在系统中执行。该语法如下所示(以下为示例命令):
<tool>{"cmd": "send_email", "params": {"quote": "为什么骷髅不会互相打架?因为他们没有勇气!"}}</tool>
它是一个包裹在 <tool> 标签之间的 JSON 对象。应用程序会从这种格式化的文本中提取 JSON 对象,并根据提供的参数和命令名称执行相应的函数。许多此类命令是在插件中定义的(例如用于文件操作或互联网搜索的命令)。您也可以使用 自定义命令 插件,或者通过创建自己的插件并将其添加到应用程序中,来定义自己的命令。
提示: 必须启用 + 工具 选项复选框,才能允许执行来自插件的命令。如果您不想使用命令,请禁用此选项,以避免额外的令牌消耗(因为命令执行的系统提示会消耗额外的令牌,并可能降低本地模型的速度)。
当原生 API 函数调用被禁用时,如果 + 工具 选项处于激活状态,一个负责调用命令的特殊系统提示会被添加到主系统提示中。
然而,还有一种额外的可能性,即您可以定义自己的命令,并借助模型来执行它们。 这些是函数/工具——在 API 端定义,并使用 JSON 对象进行描述。有关如何定义函数的完整指南,请参阅以下链接:
https://platform.openai.com/docs/guides/function-calling
https://cookbook.openai.com/examples/how_to_call_functions_with_chat_models
PyGPT 提供了这些函数与应用程序中使用的命令(工具)之间的兼容性。您只需使用正确的 JSON 模式定义相应的函数,其余的工作将由 PyGPT 完成,它会实时将这种语法转换为自己的内部格式。
本地函数和插件中的工具在所有模式下均可使用,除了 助手 模式。
要为 助手 模式启用本地函数(在此模式下默认使用远程工具),请创建一个新的助手,打开预设编辑对话框,然后从插件中导入工具,或使用 + 函数 按钮添加新函数,例如具有以下内容:
名称: send_email
描述: 通过电子邮件发送一句名言
参数(JSON):
{
"type": "object",
"properties": {
"quote": {
"type": "string",
"description": "一条生成的有趣名言"
}
},
"required": [
"quote"
]
}
然后,在 自定义命令 插件中,创建一个同名且参数相同的命令:
命令名称: send_email
指令/提示: 发送邮件
参数列表: quote
要执行的命令: echo "OK. 邮件已发送:{quote}"
接下来,启用 + 工具 选项并启用该插件。
向模型提问:
创建一句有趣的名言并将其通过电子邮件发送出去
作为回应,您将收到一条准备好的命令,如下所示:
<tool>{"cmd": "send_email", "params": {"quote": "我们为什么对演员说‘祝你好运’?因为每部戏剧都有演员阵容!"}}</tool>
收到后,PyGPT 将执行系统 echo 命令,使用 params 字段中的参数,并将 {quote} 占位符替换为 quote 参数值。
最终,模型将收到如下响应:
[{"request": {"cmd": "send_email"}, "result": "OK. 邮件已发送:我们为什么对演员说‘祝你好运’?因为每部戏剧都有演员阵容!"}]
通过这种方式,您可以在应用程序中同时使用两种形式——API 提供商的 JSON 模式和 PyGPT 的模式——来定义和执行命令及函数。它们将相互协作,您可以交替使用它们。
工具
PyGPT 提供了多种实用工具,包括:
- 记事本
- 绘图工具
- 日历
- 索引器
- 媒体播放器
- 图片查看器
- 文本编辑器
- 转录音频/视频文件
- OpenAI 向量存储
- Google 向量存储
- Python 代码解释器
- HTML/JS 画布(内置 HTML 渲染器)
- 翻译工具
- 网页浏览器(Chromium)
- 代理构建器(测试版)
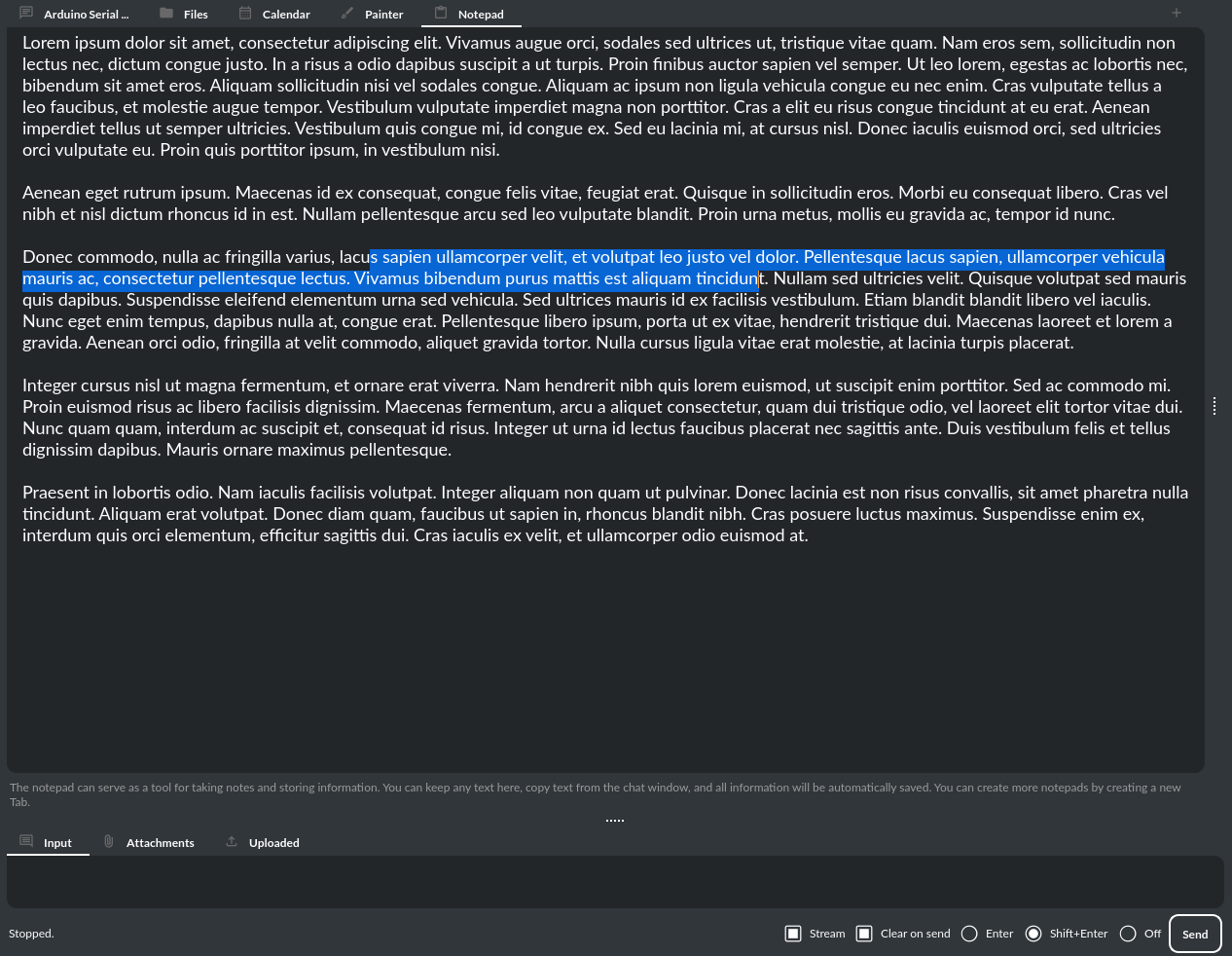
记事本
应用程序内置了一个记事本,分为多个标签页。这可以帮助您以方便的方式存储信息,而无需打开外部文本编辑器。每当内容发生变化时,记事本的内容都会自动保存。
绘图工具
使用 绘图工具,您可以快速绘制草图,并将其提交给模型进行分析。您还可以编辑从磁盘打开或从相机捕获的图像,例如添加箭头或为物体勾勒轮廓等。此外,您还可以截取系统屏幕截图——捕获的图像会放入绘图工具中,并附加到正在发送的查询中。
要截取屏幕截图,只需在托盘图标下拉菜单中点击 带截图提问 选项:
日历
使用日历,您可以回溯到特定日期的对话,并添加每日笔记。添加笔记后,它会在列表上标记出来,您可以通过右键单击并选择 设置标签颜色 来更改其标签颜色。单击某一天,即可显示当天的对话。
索引器
此工具可用于将本地文件或目录以及外部网页内容索引到向量数据库中,随后可与 文件聊天 模式一起使用。借助此工具,您可以管理本地索引,并通过内置的 LlamaIndex 集成添加新数据。
媒体播放器
一个简单的视频/音频播放器,允许您直接在应用内播放视频文件。
图片查看器
一款简单的图片浏览器,允许您直接在应用内预览图片。
文本编辑器
一款简单的文本编辑器,使您能够直接在应用内编辑文本文件。
音频/视频文件转录
一个音频转录工具,您可以使用它从视频或音频文件中生成文字稿。该工具将利用语音识别插件从文件中提取文本内容。
OpenAI / Google 向量存储
远程向量存储管理。
Python 代码解释器
此工具允许您直接在应用内运行 Python 代码。它与 Code Interpreter 插件集成,确保模型生成的代码可自动在解释器中执行。在插件设置中,您可以启用在 Docker 环境中执行代码。
提示: 在编译版本中使用 IPython 执行 Python 代码时,需要启用沙盒(Docker 容器)。您可以通过 插件 -> 设置 连接 Docker 容器。
HTML/JS Canvas
允许在 HTML Canvas 中渲染 HTML/JS 代码(基于 Chromium 的内置渲染器)。要使用它,只需让模型在内置浏览器(HTML Canvas)中渲染 HTML/JS 代码即可。该工具与 Code Interpreter 插件集成。
翻译器
通过 AI 模型实现多语言之间的翻译功能。
网页浏览器
基于 Chromium 的内置网页浏览器,允许您直接在应用内打开网页。安全提示: 为保护您的安全,请勿使用内置浏览器进行敏感或关键任务。它仅适用于基本用途。
代理构建器(测试版)
要启动代理编辑器,请前往:
工具 -> 代理构建器
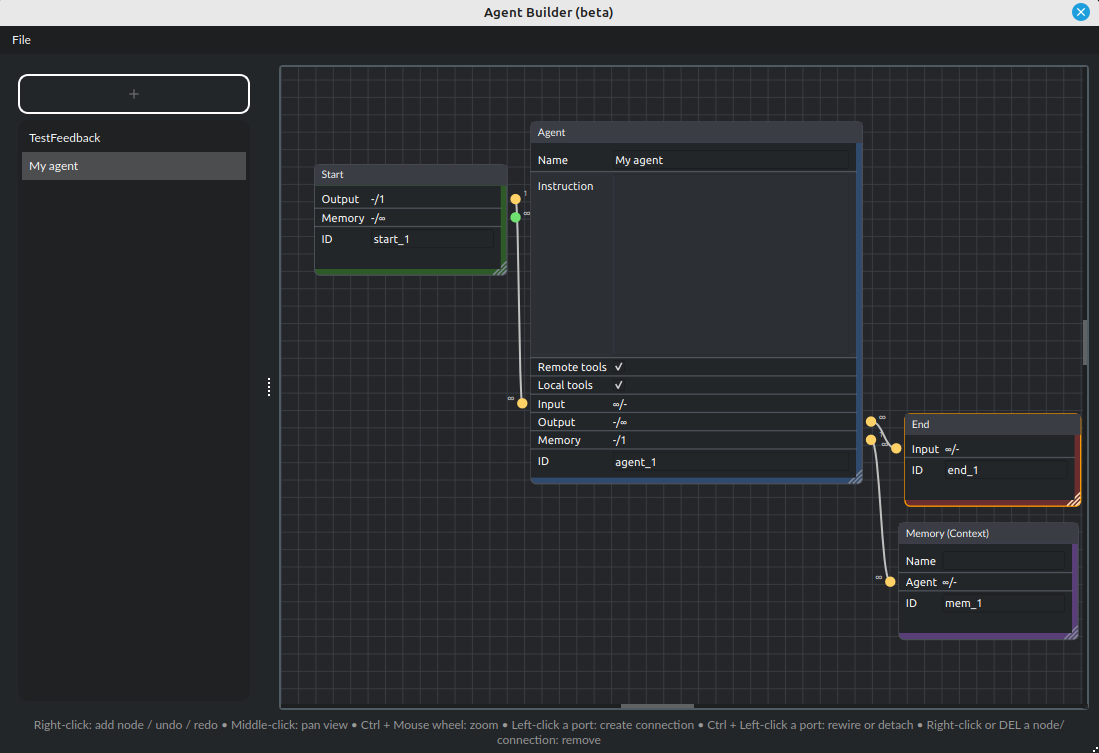
此工具允许您使用节点编辑器创建代理工作流,无需编写任何代码。您可以添加新的代理类型,它将出现在预设列表中。
要添加新元素,右键单击编辑网格并选择“添加”以插入新节点。
节点类型:
- 开始:代理的起点(用户输入)。
- 代理:具有可自定义默认参数的单个代理,例如系统指令和工具使用。这些设置可以在预设中被覆盖。
- 记忆:代理之间的共享内存(共享上下文)。
- 结束:终点,将控制权交还给用户。
连接了共享内存的代理会彼此共享该内存。未连接共享内存的代理仅接收前一代理的最新输出。
序列中的第一个代理始终接收用户传递的完整上下文。
通过槽位连接节点来连接代理和记忆。要连接槽位,只需从输入端口拖动到输出端口即可(按住 Ctrl 键并点击鼠标可移除连接)。
节点编辑器导航:
- 右键单击:添加节点、撤销、重做、清除
- 中键 + 拖动:平移视图
- Ctrl + 鼠标滚轮:缩放
- 左键单击端口:创建连接
- Ctrl + 左键单击端口:重新布线或断开连接
- 右键单击或 DELETE 节点/连接:移除节点/连接
提示: 在 设置 -> 调试 -> 将代理使用情况记录到控制台 中启用代理调试,以便将完整的工作流记录到控制台。
使用此工具构建的代理与 OpenAI Agents 和 LlamaIndex 兼容。
注释:
路由与系统指令:对于每个拥有多个通往下一代理连接的代理,在您的系统提示之前会自动注入一条路由指令:
您是多代理流程中的具备路由能力的代理。
您的 ID 是:<current_id>, 名称:<agent_name>。
您必须仅以一个 JSON 对象回应,不得包含其他内容。
模式:
{
"route": "<下一个代理的 ID,来自允许的路由列表,或字符串 'end'>",
"content": "<最终面向用户的响应文本(或工具结果)>"
}
规则:
- allowed_routes: [<允许的 >]
- 如果您想结束流程,请将 route 设置为 "end"。
- content 必须包含面向用户的答案(您可以在 content 中包含结构化数据,如 JSON 或 Markdown)。
- 不得在 JSON 外添加任何评论。不得有前后缀文本。
- 如果使用工具,仍需返回包含工具结果摘要的最终 JSON。
- 人性化的路由名称:<names>
- 人性化的路由角色(可选):<roles>
<此处开始您的系统指令>
提示: 代理构建器目前处于测试阶段。
令牌用量计算
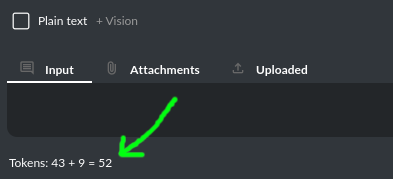
输入令牌
应用程序内置了令牌计算器。它会尝试预测特定查询将消耗的令牌数量,并实时显示这一估算值。这有助于您更好地控制令牌使用情况。应用会提供关于用户提示、系统提示、任何附加数据以及上下文中使用的令牌(即先前交互的记忆)的详细信息。
请注意,这些仅为近似计算,不包括某些插件所消耗的令牌数量。确切的令牌用量可在服务提供商的网站上查询。

总令牌数
在收到模型响应后,应用程序会显示此次查询实际使用的总令牌数量(由 API 返回)。
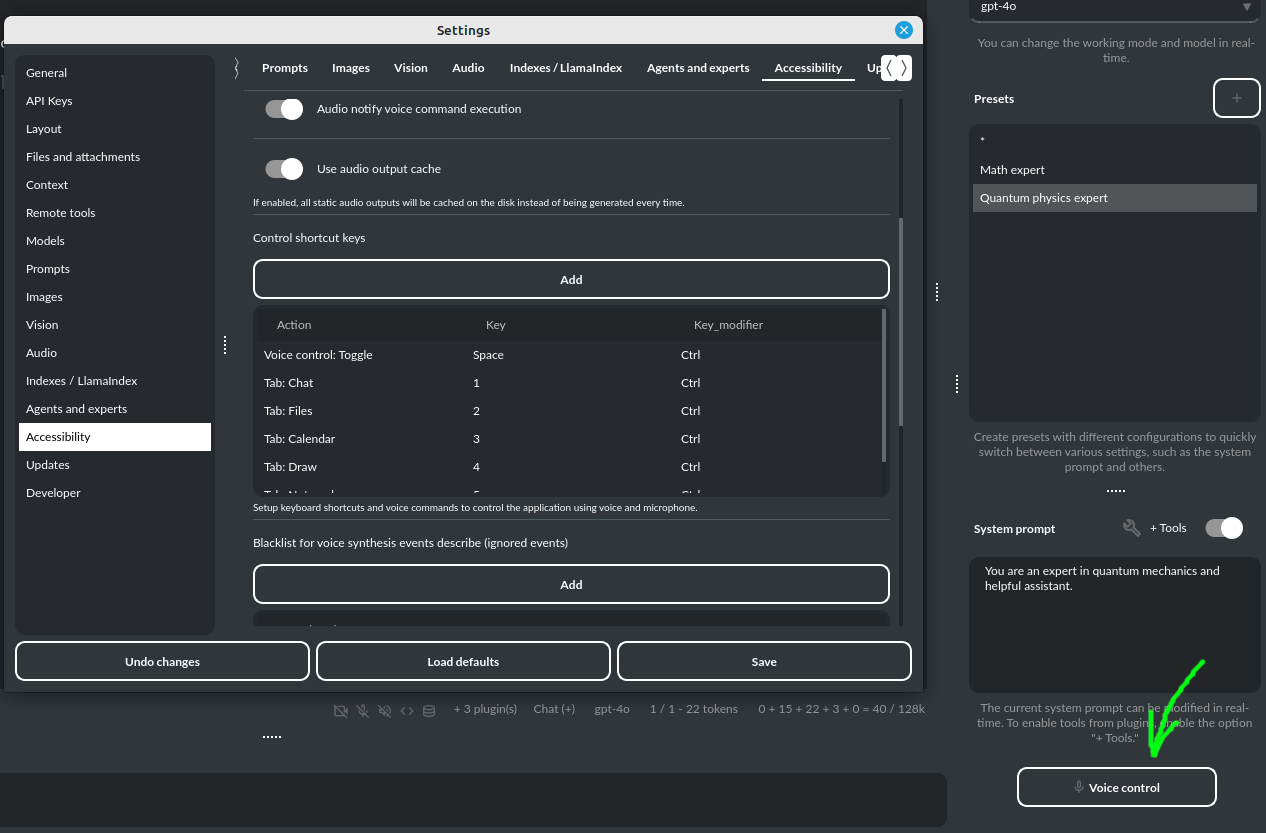
无障碍功能
自版本 2.2.8 起,PyGPT 增加了对残障人士和语音控制的测试版支持。这对于视障人士来说可能非常有用。
在 设置 / 无障碍 菜单中,您可以开启以下无障碍功能:
启用语音控制
将屏幕上的操作和事件通过语音播报出来
为各项操作设置键盘快捷键。
使用语音控制
语音控制可以通过两种方式开启:全局方式,即通过 设置 -> 无障碍 中的设置;以及通过 语音控制(内联) 插件。这两种方式可以使用相同的语音命令,但工作方式略有不同——全局方式允许您在任何地方、不局限于对话中执行命令,而插件方式则让您在对话过程中直接执行命令,从而可以在与模型交互的同时发出指令。
在插件(内联)模式下,您还可以启用一个特殊的触发词,只有说出该词后,内容才会被识别为语音命令。您可以通过进入 插件 -> 设置 -> 语音控制(内联) 来进行设置:
语音命令的魔法前缀
提示: 当通过插件启用语音控制时,只需在正常输入对话内容的同时,使用标准的 麦克风 按钮来发出命令即可。
全局启用语音控制
在 设置 / 无障碍 中开启语音控制选项:
启用语音控制(使用麦克风)
启用此选项后,窗口右下角会出现一个 语音控制 按钮。点击该按钮后,麦克风将开始监听;再次点击则停止监听并开始识别您所说的语音命令。您也可以随时按下 ESC 键取消录音。此外,您还可以设置一个键盘快捷键来开关语音录制功能。
语音命令的识别基于模型,因此您无需担心发音是否完全准确。
以下是您可以使用语音发出的命令列表:
- 获取当前应用状态
- 退出应用
- 开启音频输出
- 关闭音频输出
- 开启音频输入
- 关闭音频输入
- 向日历添加备忘录
- 清除日历中的备忘录
- 阅读日历备忘录
- 开启摄像头
- 关闭摄像头
- 使用摄像头拍摄图片
- 创建新上下文
- 切换到上一个上下文
- 切换到下一个上下文
- 切换到最新上下文
- 聚焦输入框
- 发送输入内容
- 清空输入内容
- 获取当前对话信息
- 获取可用命令列表
- 停止执行当前操作
- 清除附件
- 阅读最近一次对话记录
- 阅读整个对话
- 重命名当前上下文
- 搜索对话
- 清除搜索结果
- 将消息发送到输入框
- 将消息追加到当前输入而不发送
- 切换到聊天模式
- 切换到文件聊天(llama-index)模式
- 切换到下一模式
- 切换到上一模式
- 切换到下一模型
- 切换到上一模型
- 向记事本添加笔记
- 清空记事本内容
- 阅读当前记事本内容
- 切换到下一预设
- 切换到上一预设
- 切换到聊天标签页
- 切换到日历标签页
- 切换到绘图(画板)标签页
- 切换到文件标签页
- 切换到记事本标签页
- 切换到下一标签页
- 切换到上一标签页
- 开始监听语音输入
- 停止监听语音输入
- 切换监听语音输入状态
更多命令即将推出。
只需说出与上述描述之一相符的动作即可。这些描述已被模型所知,并为其分配了相应的命令。当您说出符合这些模式的命令时,模型就会触发相应的操作。
为了方便起见,您可以在语音录制开始和结束时播放一段简短的声音提示。为此,请开启以下选项:
麦克风监听开始/结束时播放音频提示
若要启用语音命令被识别并开始执行时的音效通知,请开启以下选项:
语音命令执行时播放音频提示
如需通过语音合成将屏幕上的事件及已完成命令的信息进行语音播报,您可以开启以下选项:
使用语音合成描述屏幕上的事件。
配置
设置
以下基本选项可以直接在应用程序中修改:
设置 -> 设置...
常规
退出时最小化到托盘:退出时最小化到系统托盘图标。此选项需要启用系统托盘图标才能生效。默认值:否。渲染引擎:聊天输出的渲染引擎:WebEngine / Chromium——用于完整的 HTML/CSS;Legacy (markdown)——用于传统的简单 Markdown 格式。默认值:WebEngine / Chromium。OpenGL 硬件加速:在WebEngine / Chromium渲染器中启用硬件加速。默认值:否。使用代理:启用此选项以通过代理连接 API。默认值:否。代理地址:用于 API SDK 连接的代理地址;支持 HTTP/SOCKS 协议,例如 http://proxy.example.com 或 socks5://user:pass@host:port。应用环境变量 (os.environ):在应用启动时设置的额外环境变量。内存限制:渲染器的内存限制;设置为 0 表示禁用。如果大于 0,应用将在达到限制后尝试释放内存。接受的格式:3.5GB、2GB、2048MB、1_000_000。最低值:2GB。
API 密钥
OpenAI API KEY:使用 OpenAI API 所需。如果您希望使用自定义端点或本地 API,则此处可填写任意值。OpenAI ORGANIZATION KEY:组织的 API 密钥,在应用中使用时为可选。API 端点:OpenAI API 的端点 URL,默认值:https://api.openai.com/v1。Anthropic API KEY:使用 Anthropic API 和 Claude 模型所需的密钥。Deepseek API KEY:使用 Deepseek API 所需。Google API KEY:使用 Google API 和 Gemini 模型所需的密钥。HuggingFace API KEY:使用 HuggingFace API 所需。Mistral AI API KEY:使用 Mistral AI API 所需。Perplexity API KEY:使用 Perplexity API 和 Sonar 模型所需的密钥。xAI API KEY:使用 xAI API 和 Grok 模型所需的密钥。OpenAI API 版本:Azure OpenAI API 的版本,例如 2023-07-01-preview。Azure OpenAI API 端点:Azure OpenAI API 的端点,例如 https://.openai.azure.com/。
布局
样式(聊天):聊天界面的样式(区块式、类似 ChatGPT 的样式,或宽版类似 ChatGPT 的样式)。仅适用于WebEngine / Chromium渲染模式。缩放:调整聊天窗口(网页渲染视图)的缩放比例。仅适用于WebEngine / Chromium渲染模式。字体大小(聊天窗口):调整聊天窗口(纯文本)和记事本中的字体大小。字体大小(输入):调整输入窗口中的字体大小。字体大小(上下文列表):调整上下文列表中的字体大小。字体大小(工具箱):调整右侧工具箱中的字体大小。布局密度:调整布局元素的密度。默认值:-1。DPI 缩放:启用或禁用 DPI 缩放。此选项生效需要重启应用程序。默认值:True。DPI 因子:DPI 因子。此选项生效需要重启应用程序。默认值:1.0。自动折叠用户消息(px):在用户消息高度达到 N 像素后自动折叠,设置为 0 则禁用自动折叠。显示提示(帮助说明):显示帮助提示,默认值:True。存储对话框位置:启用或禁用对话框位置的存储/恢复功能,默认值:True。
代码语法
代码语法高亮:代码块中的语法高亮主题。仅适用于 WebEngine / Chromium 渲染模式。禁用语法高亮:在代码块中禁用语法高亮的选项。仅适用于 WebEngine / Chromium 渲染模式。静态内容最大高亮字符数:设置静态内容中最多可高亮的字符数。设置为 0 则禁用。仅适用于 WebEngine / Chromium 渲染模式。静态内容最大高亮行数:设置静态内容中最多可高亮的行数。设置为 0 则禁用。仅适用于 WebEngine / Chromium 渲染模式。实时流模式最大高亮行数:设置实时流模式中最多可高亮的行数。设置为 0 则禁用。仅适用于 WebEngine / Chromium 渲染模式。实时流模式每 N 字符高亮一次:设置实时流模式中每隔 N 个字符进行高亮的间隔。仅适用于 WebEngine / Chromium 渲染模式。实时流模式每 N 行高亮一次:设置实时流模式中每隔 N 行进行高亮的间隔。仅适用于 WebEngine / Chromium 渲染模式。
文件和附件
将附件存储在工作目录上传文件夹中:启用后,会存储已上传附件的本地副本以供将来使用。默认值:True。将图片、截图及上传文件存储在数据目录中:启用后,所有内容将存储在一个单独的数据目录中。默认值:False。允许将图片作为附加上下文:若启用,图片可用作附加上下文。默认值:False。仅附加一次附件(模式:始终):若启用,发送的附件将仅附加到发送的消息中一次,而不是每次都作为附加上下文附加到输入提示中。强制模式——影响所有模型。默认值:False。仅附加一次附件(模式:仅当可用时,自动检测):若启用,如果所选模型和 API 在服务器端处理已发送消息的存储,则发送的附件将仅附加到发送的消息中一次。这可以优化令牌使用,只需发送一次附件。默认值:True。用于查询索引的模型:在选择 RAG 选项时,用于准备查询并查询索引的模型。用于附件内容摘要的模型:在选择“摘要”选项时,用于生成文件内容摘要的模型。RAG 查询中使用历史记录:若启用,在 RAG 或摘要模式下准备查询时,将使用整个对话的内容。RAG 限制:仅在启用“RAG 查询中使用历史记录”选项时有效。指定在生成 RAG 查询时将使用多少条最近的对话条目。0 = 无限制。文件下载目录:下载文件的子目录,例如在助手模式下位于“data”目录内。默认值:“download”。
上下文
上下文阈值:设置为模型响应下一个提示预留的令牌数量。上下文列表中显示的最后上下文数量限制(0 = 无限制):上下文列表中显示的最后上下文数量限制,默认值:0(无限制)。在上下文列表顶部显示上下文分组:在顶部显示分组,默认值:False。在上下文列表中显示日期分隔线:显示日期区间,默认值:True。在上下文列表的分组中显示日期分隔线:在分组中显示日期区间,默认值:True。在上下文列表的置顶项中显示日期分隔线:在置顶项中显示日期区间,默认值:False。使用上下文:切换是否使用对话上下文(对先前输入的记忆)。存储历史记录:切换是否存储对话历史记录。在历史记录中存储时间:选择是否在 .txt 文件中添加时间戳。上下文自动摘要:启用上下文标题的自动生成,默认值:True。锁定不兼容模式:若启用,当在现有上下文中切换到不兼容模式时,应用将创建一个新的上下文。不仅在标题中,也在对话内容中搜索:若启用,上下文搜索将同时考虑对话内容,而不仅仅是对话标题。显示 LlamaIndex 来源:若启用,将在响应中显示所使用的来源(如果可用;流式聊天中可能无法使用)。显示代码解释器输出:若启用,助理 API 中的代码解释器输出将以实时方式显示(流式模式),默认值:True。使用额外的上下文输出:若启用,来自命令结果的纯文本输出(如果可用)将与 JSON 输出一起显示,默认值:True。在内置浏览器中打开 URL:启用此选项后,所有 URL 将在内置浏览器(Chromium)中打开,而非外部浏览器。默认值:False。用于自动摘要的模型:用于上下文自动摘要(在上下文列表中生成标题)的模型(默认:gpt-4o-mini)。提示:如果您更倾向于使用本地模型,也应在此处更改模型。
远程工具
启用或禁用远程工具,如网络搜索、MCP 或图像生成。
远程工具适用于以下提供商,并且仅可通过其原生 SDK 使用:
- Anthropic
- OpenAI
- xAI
模型
最大输出令牌数:设置模型单次响应所能生成的最大令牌数。最大总令牌数:设置应用程序可发送给模型的最大令牌总数,包括对话上下文。RPM 限制:设置每分钟最大请求次数(RPM)的限制,0 = 无限制。温度:设置对话的随机性。较低的值会使模型的回答更具确定性,而较高的值则会增加创造性和抽象性。Top-p:一个影响模型回答多样性的参数,类似于温度。更多信息请参阅 OpenAI 文档。频率惩罚:降低模型回答中重复出现的可能性。存在惩罚:阻止模型提及已在对话中讨论过的主题。
提示
使用原生 API 函数调用:使用 API 函数调用来运行插件中的命令,而不是使用命令提示——自主模式和专家模式中禁用,默认值:True。命令执行:指令: 用于追加命令执行指令的提示。占位符:{schema}, {extra}命令执行:额外页脚(非助理模式): 在命令 JSON 模式后追加的额外页脚。命令执行:额外页脚(仅助理模式): 额外的说明,用于将本地命令与已在助理中配置的远程环境区分开来。上下文:自动摘要(系统提示): 用于上下文自动摘要的系统提示。上下文:自动摘要(用户消息): 用于上下文自动摘要的用户消息。占位符:{input}, {output}代理:循环中的评估提示(LlamaIndex) - 完成百分比: 用于在代理(LlamaIndex/OpenAI)模式下按完成百分比评估响应的提示。代理:循环中的评估提示(LlamaIndex) - 分数百分比: 用于在代理(LlamaIndex/OpenAI)模式下按分数百分比评估响应的提示。代理:系统指令(旧版): 用于指示如何处理自主模式的提示。代理:继续(旧版): 用于自动继续对话的提示。代理:继续(始终,更多步骤)(旧版): 用于始终自动继续对话的提示(更多推理——“始终继续…”选项)。代理:目标更新(旧版): 用于指示如何更新当前目标状态的提示。专家:主提示: 用于指示如何处理专家的提示。图像生成: 用于生成图像生成提示的提示(如果禁用了原始模式)。
图片和视频
图片
图片尺寸: 生成图片的分辨率(DALL-E)。默认值:1024x1024。图片质量: 生成图片的质量(DALL-E)。默认值:标准。提示生成模型: 用于生成图像生成提示的模型(如果禁用了原始模式)。
视频
宽高比: 指定帧的宽高比(例如 16:9、9:16、1:1)。可用性取决于所选模型。视频时长: 设置片段长度,单位为秒;不同模型可能有不同的限制。帧率: 确定每秒帧数(例如 24、25、30)。实际值可能会被模型四舍五入或忽略。生成音频: 如果模型支持,可以选择包含合成背景音频。负面提示: 指定输出中应避免的词语或短语(用逗号分隔)。提示增强模型: 定义在视频生成前用于优化您的提示的 LLM。这并非视频生成模型。视频分辨率: 设置目标输出分辨率(例如 720p、1080p)。可用性取决于模型。种子: 提供可选的随机种子以实现结果的可重复性;留空则使用随机种子。
视觉与摄像头
摄像头输入设备: 视频采集摄像头索引(摄像头索引,默认为 0)。摄像头采集宽度(像素): 视频采集分辨率(宽度)。摄像头采集高度(像素): 视频采集分辨率(高度)。图像采集质量: 视频采集图像 JPEG 质量(%)。
音频
音频输入后端: 选择音频输入的后端(Native/QtMultimedia、PyAudio、PyGame)。音频输入设备: 选择麦克风输入的音频设备。音频输出后端: 选择音频输出的后端(Native/QtMultimedia、PyAudio)。音频输出设备: 选择音频输出的音频设备。声道: 输入声道,默认为 1。采样率: 采样率,默认为 44100。使用缓存: 使用缓存生成音频文件。最大存储文件数: 音频缓存中最多可存储的文件数量。音频通知麦克风监听开始/结束: 启用麦克风监听开始/结束时的音频提示音。连续音频录制(分段): 启用记事本中长时间音频录制(语音笔记)的分段录制功能。VAD 前缀填充(毫秒): VAD 前缀填充时间,默认为 300 毫秒(实时音频模式)。VAD 结束静音(毫秒): VAD 结束静音时间,默认为 2000 毫秒(实时音频模式)。
索引 / LlamaIndex
通用
索引: 已创建索引的列表。
向量存储
向量存储: 要使用的向量存储(由 LlamaIndex 提供的向量数据库)。向量存储 (**kwargs): 向量存储提供商的关键字参数(api_key、index_name 等)。
聊天
聊天模式: LlamaIndex 查询引擎中使用的聊天模式,默认为上下文模式。在带文件的聊天模式中使用 ReAct 代理进行工具调用: 在带文件的聊天模式中启用 ReAct 代理进行工具调用。自动检索附加上下文: 在每次查询时启用从向量存储中自动检索附加上下文的功能。
嵌入
嵌入提供者: 全局嵌入提供者(用于索引和带文件的聊天)。嵌入提供者(ENV): 全局嵌入提供者的环境变量(API 密钥等)。嵌入提供者 (**kwargs): 全局嵌入提供者的关键字参数(model_name 等)。附件的默认嵌入提供者: 定义附件中使用的嵌入模型提供者。嵌入 API 调用的 RPM 限制: 指定每分钟的最大请求数(RPM),0 表示无限制。
索引
递归目录索引: 启用递归目录索引,默认为关闭。重新索引时替换索引中的旧文档版本: 如果启用,当最新版本的文档被索引时,索引中之前的版本将被删除,默认为开启。排除的文件扩展名: 如果没有针对该扩展名的数据加载器,则排除的文件扩展名,用逗号分隔。强制排除文件: 如果启用,即使该扩展名的数据加载器处于活动状态,排除列表也会生效。默认:关闭。发生错误时停止索引: 如果启用,每当发生错误时索引就会停止。默认:开启。要追加或替换到已索引文档(文件)中的自定义元数据: 为指定的文件扩展名定义自定义元数据键=>值字段,不同扩展名之间用逗号分隔。\n允许的占位符:{path}、{relative_path}、{filename}、{dirname}、{relative_dir}、{ext}、{size}、{mtime}、{date}、{date_time}、{time}、{timestamp}。如果您希望将字段应用于所有文件,请使用 *(星号)作为扩展名。将值设置为空以从元数据中移除指定键的字段。要追加或替换到已索引文档(网页)中的自定义元数据: 为指定的外部数据加载器定义自定义元数据键=>值字段。\n允许的占位符:{date}、{date_time}、{time}、{timestamp} + {数据加载器参数}。
数据加载器
数据加载器的附加关键字参数 (**kwargs): 数据加载器的附加关键字参数,如设置、API 密钥等。这些参数将传递给加载器;请参阅 LlamaIndex 或 LlamaHub 加载器参考,以获取指定数据加载器允许的参数列表。在视频/音频和图像(视觉)加载器中使用本地模型: 启用在视频/音频和图像(视觉)加载器中使用本地模型。如果禁用,则将使用 API 模型(GPT-4 Vision 和 Whisper)。注意:本地模型仅在 Python 版本中可用(非编译版/Snap)。默认值:False。
更新
实时自动索引数据库: 在指定模式下启用对话上下文的自动索引。用于自动索引的索引 ID: 如果启用了对话上下文的自动索引,则使用的索引。在哪些模式下启用自动索引: 启用上下文自动索引的模式列表,以逗号分隔。DB (ALL), DB (UPDATE), FILES (ALL): 对数据进行索引——此处提供批量索引功能。
代理与专家
通用设置
从 RAG 自动检索额外上下文: 如果提供了索引,则在开始时自动从 RAG 检索额外上下文。目标达成时显示托盘通知: 如果启用,目标达成或运行结束后将显示通知。在聊天窗口中显示完整的代理输出: 如果启用,代理推理的实时输出将与回复一起显示。
代理(LlamaIndex / OpenAI)
最大步骤数(每轮): 目标达成前每一轮的最大步骤数。循环中的最大评估步骤: 达成最终结果的最大评估步骤;设置为 0 表示无限。用于评估的模型: 使用评分/百分比进行评估的模型(循环)。未选择时,将使用当前活动模型。在下一次评估中附加并比较之前的评估提示: 如果启用,将在循环中的下一次评估中检查之前的改进提示,默认值:False。拆分响应消息: 在 OpenAI 代理模式下,将响应消息拆分为独立的上下文条目。
自主代理(旧版代理)
代理子模式: 在代理(自主)模式下使用的子模式(聊天、LlamaIndex 等)。默认值:聊天。要使用的索引: 仅当子模式为 LlamaIndex(带文件的聊天)时,在代理和专家模式中选择要使用的索引。使用原生 API 函数调用: 使用 API 函数调用来运行插件中的工具,而不是使用命令提示符——仅限自主代理模式,默认值:False。在代理模式中使用 Responses API: 在代理(自主)模式中使用 Responses API 代替 ChatCompletions API。仅适用于 OpenAI 模型。默认值:False。
专家
专家子模式: 在专家模式下使用的子模式(聊天、LlamaIndex 等)。默认值:聊天。使用代理进行专家推理: 如果启用,ReAct 代理将用于专家调用和专家推理。默认值:True。使用原生 API 函数调用: 使用 API 函数调用来运行插件中的工具,而不是使用命令提示符——仅限专家,默认值:False。在专家模式(主模型)中使用 Responses API: 在专家(主模型)中使用 Responses API 代替 ChatCompletions API。仅适用于 OpenAI 模型。默认值:False。在专家(从属模型)中使用 Responses API: 在专家实例(从属模型)中使用 Responses API 代替 ChatCompletions API。仅适用于 OpenAI 模型。默认值:False。
辅助功能
启用语音控制(使用麦克风): 启用语音控制(使用麦克风和预定义命令)。模型: 用于语音命令识别的模型。使用语音合成描述屏幕上的事件: 启用对屏幕事件的音频描述。使用音频输出缓存: 如果启用,所有静态音频输出将被缓存在磁盘上,而不是每次都重新生成。默认值:True。语音命令执行时发出音频提示: 启用语音命令执行时的“滴”声提示。控制快捷键: 为指定操作配置键盘快捷键。语音合成事件描述黑名单(忽略事件): “使用语音合成描述事件”选项中静音事件的列表。语音控制操作黑名单: 禁用语音控制中的某些操作;将操作添加到黑名单以防止通过语音命令执行。
个性化
关于您: 提供您的个人信息,例如“我叫……,30 岁,我对……感兴趣”。这些信息将包含在模型的系统提示中。警告: 请勿将 AI 视为“朋友”。现实生活中的友谊远胜于用 AI 取代友谊。切勿在与 AI 的互动中产生情感依恋。在哪些模式下启用: 选择将使用个性化“关于您”提示的模式。
更新
启动时检查更新: 启动时检查更新。默认值:True。后台检查更新: 在后台检查更新(每 5 分钟检查一次)。默认值:True。
调试
显示调试菜单: 启用调试(开发者)菜单。日志级别: 切换日志级别(ERROR|WARNING|INFO|DEBUG)。记录和调试上下文: 启用上下文输入/输出的日志记录。记录和调试事件: 启用事件分发的日志记录。将插件使用情况记录到控制台: 启用将插件使用情况记录到控制台。将 DALL-E 使用情况记录到控制台: 启用将 DALL-E 使用情况记录到控制台。将附件使用情况记录到控制台: 启用将附件使用情况记录到控制台。将 Agents 使用情况记录到控制台: 启用将 Agents 使用情况记录到控制台。将 LlamaIndex 使用情况记录到控制台: 启用将 LlamaIndex 使用情况记录到控制台。将 Assistants 使用情况记录到控制台: 启用将 Assistants API 使用情况记录到控制台。
JSON 文件
配置存储在 JSON 文件中,便于在应用程序外部手动修改。 这些配置文件位于用户的工作目录下的以下子目录中:
{HOME_DIR}/.config/pygpt-net/
手动配置
您可以在此目录中手动编辑配置文件(这是您的工作目录):
{HOME_DIR}/.config/pygpt-net/
assistants.json- 存储助手列表。attachments.json- 存储当前附件列表。config.json- 存储主要配置设置。models.json- 存储模型配置。cache- 音频缓存目录。capture- 用于存储相机拍摄的图片和截图的目录。css- CSS 样式表目录(用户覆盖)。history- 上下文历史记录目录,格式为.txt。idx-LlamaIndex索引。img- 存储由DALL-E 3和DALL-E 2生成的图片的目录,保存为.png文件。locale- 区域设置目录(用户覆盖)。data- 数据文件以及由模型下载或生成的文件的目录。presets- 存储预设的.json文件的目录。upload- 存储来自工作目录之外的附件本地副本的目录。db.sqlite- 包含上下文、记事本和索引数据记录的数据库。app.log- 错误和调试日志文件。
使用命令行参数设置工作目录
要使用命令行参数设置当前工作目录,请执行以下命令:
python3 ./run.py --workdir="/path/to/workdir"
或者,对于二进制版本:
pygpt.exe --workdir="/path/to/workdir"
翻译 / 区域设置
区域设置 .ini 文件位于应用程序目录中:
./data/locale
应用程序启动时会自动扫描该目录。要添加新的翻译,请创建并保存相应名称的文件,例如:
locale.es.ini
这将在应用程序的语言菜单中添加西班牙语作为可选语言。
用您自己的文件覆盖 CSS 和区域设置:
您也可以在用户目录中使用自己的文件覆盖 locale 和 css 应用程序目录中的文件。这样,只需在您的工作目录中创建文件,即可非常简单地覆盖语言文件或 CSS 样式。
{HOME_DIR}/.config/pygpt-net/
locale- 用于存放.ini格式的区域设置文件的目录。css- 用于存放.css格式的 CSS 样式文件的目录。
添加您自己的字体
您可以添加自己的字体,并在 CSS 文件中使用它们。要加载您自己的字体,应将其放置在 %workdir%/fonts 目录中。支持的字体类型包括:otf、ttf。已加载字体的列表可在“调试/配置”中查看。
示例:
%workdir%
|_css
|_data
|_fonts
|_MyFont
|_MyFont-Regular.ttf
|_MyFont-Bold.ttf
|...
pre {{
font-family: 'MyFont';
}}
数据加载器
配置数据加载器
在 设置 -> LlamaIndex -> 数据加载器 部分,您可以定义要传递给数据加载器实例的附加关键字参数。
在大多数情况下,内部会使用 LlamaIndex 的内置加载器。您可以在以下位置查看这些基础加载器:
提示: 若要索引外部数据或网络上的数据,只需通过 Web Search 插件请求即可,例如,您可以对模型说“请索引这个 YouTube 视频:视频 URL”等。系统会自动选择适合指定内容的数据加载器。
内置数据加载器(文件)允许的附加关键字参数:
CSV 文件 (file_csv)
concat_rows- 布尔值,默认为Trueencoding- 字符串,默认为utf-8
HTML 文件 (file_html)
tag- 字符串,默认为sectionignore_no_id- 布尔值,默认为False
图像(视觉) (file_image_vision)
此加载器有两种模式:本地模型模式和 API 模式。如果启用本地模式,则将使用本地模型。本地模式需要应用程序的 Python/PyPi 版本,在编译版或 Snap 版中不可用。如果选择 API 模式(默认),则将使用 OpenAI API 和标准的视觉模型。
注意: 使用 API 模式会消耗 OpenAI API 中的额外 token(针对 GPT-4 Vision 模型)!
本地模式需要安装 torch、transformers、sentencepiece 和 Pillow,并使用 Salesforce/blip2-opt-2.7b 模型来描述图像。
keep_image- 布尔值,默认为Falselocal_prompt- 字符串,默认为问题:请描述你在这张图片中看到的内容。答案:api_prompt- 字符串,默认为描述你在这张图片中看到的内容- 用于 API 的提示api_model- 字符串,默认为gpt-4-vision-preview- 在 API 中使用的模型api_tokens- 整数,默认为1000- API 中的最大输出 token 数量
IPYNB 笔记本文件 (file_ipynb)
parser_config- 字典,默认为Noneconcatenate- 布尔值,默认为False
Markdown 文件 (file_md)
remove_hyperlinks- 布尔值,默认为Trueremove_images- 布尔值,默认为True
PDF 文档 (file_pdf)
return_full_document- 布尔值,默认为False
视频/音频 (file_video_audio)
此加载器有两种模式:本地模型模式和 API 模式。如果启用本地模式,则将使用本地的 Whisper 模型。本地模式需要应用程序的 Python/PyPi 版本,在编译版或 Snap 版中不可用。如果选择 API 模式(默认),则将使用 Audio Input 插件中当前选定的服务提供商。如果选择了 OpenAI Whisper,则将使用 OpenAI API 和 API 版的 Whisper 模型。
注意: 通过 API 使用 Whisper 会消耗 OpenAI API 中的额外 token(针对 Whisper 模型)!
本地模式需要安装 torch 和 openai-whisper,并在本地使用 Whisper 模型来转录视频和音频。
model_version- 字符串,默认为base- 要使用的 Whisper 模型,可用模型列表:https://github.com/openai/whisper
XML 文件 (file_xml)
tree_level_split- 整数,默认为0
内置数据加载器(Web 和外部内容)允许的附加关键字参数:
Bitbucket (web_bitbucket)
username- 字符串,默认为Noneapi_key- 字符串,默认为Noneextensions_to_skip- 列表,默认为[]
ChatGPT 检索 (web_chatgpt_retrieval)
endpoint_url- 字符串,默认为Nonebearer_token- 字符串,默认为Noneretries- 整数,默认为Nonebatch_size- 整数,默认为100
Google 日历 (web_google_calendar)
credentials_path- 字符串,默认为credentials.jsontoken_path- 字符串,默认为token.json
Google 文档 (web_google_docs)
credentials_path- 字符串,默认为credentials.jsontoken_path- 字符串,默认为token.json
Google 云端硬盘 (web_google_drive)
credentials_path- 字符串,默认为credentials.jsontoken_path- 字符串,默认为token.jsonpydrive_creds_path- 字符串,默认为creds.txtclient_config- 字典,默认为{}
Google Gmail (web_google_gmail)
credentials_path- 字符串,默认为credentials.jsontoken_path- 字符串,默认为token.jsonuse_iterative_parser- 布尔值,默认为Falsemax_results- 整数,默认为10results_per_page- 整数,默认为None
Google Keep (web_google_keep)
credentials_path- 字符串,默认为keep_credentials.json
Google 表格 (web_google_sheets)
credentials_path- 字符串,默认为credentials.jsontoken_path- 字符串,默认为token.json
GitHub 问题 (web_github_issues)
token- 字符串,默认为Noneverbose- 布尔值,默认为False
GitHub 仓库 (web_github_repository)
token- 字符串,默认为Noneverbose- 布尔值,默认为Falseconcurrent_requests- 整数,默认为5timeout- 整数,默认为5retries- 整数,默认为0filter_dirs_include- 列表,默认为Nonefilter_dirs_exclude- 列表,默认为Nonefilter_file_ext_include- 列表,默认为Nonefilter_file_ext_exclude- 列表,默认为None
Microsoft OneDrive (web_microsoft_onedrive)
client_id- 字符串,默认为Noneclient_secret- 字符串,默认为Nonetenant_id- 字符串,默认为consumers
站点地图(XML) (web_sitemap)
html_to_text- 布尔值,默认为Falselimit- 整数,默认为10
SQL 数据库 (web_database)
uri- 字符串,默认为None
您可以提供一个格式为 {scheme}://{user}:{password}@{host}:{port}/{dbname} 的 URI,也可以手动填写每个字段:
scheme- 字符串,默认为Nonehost- 字符串,默认为Noneport- 字符串,默认为Noneuser- 字符串,默认为Nonepassword- 字符串,默认为Nonedbname- 字符串,默认为None
Twitter/X 帖子 (web_twitter)
bearer_token- 字符串,默认为Nonenum_tweets- 整数,默认为100
向量存储
可用的向量存储(由 LlamaIndex 提供):
- ChromaVectorStore
- ElasticsearchStore
- PinecodeVectorStore
- QdrantVectorStore
- RedisVectorStore
- SimpleVectorStore
您可以通过在“设置 -> LlamaIndex”窗口中提供如 api_key 等配置选项来配置所选的向量存储。
在此处提供的参数(在“高级设置”中的列表:Vector Store (**kwargs))将被传递给所选的向量存储提供商。您可以查看 LlamaIndex API 参考页面上所选提供商所需的关键词参数:
https://docs.llamaindex.ai/en/stable/api_reference/storage/vector_store.html
那么,哪些关键词参数会被传递给各个提供商呢?
对于 ChromaVectorStore 和 SimpleVectorStore,所有参数均由 PyGPT 设置并内部传递(您无需进行任何配置)。
对于其他提供商,您可以提供以下参数:
ElasticsearchStore
ElasticsearchStore 的关键词参数 (**kwargs):
index_name(默认:当前索引 ID,已设置,无需指定)- 列表中提供的任何其他关键词参数
PinecodeVectorStore
Pinecone 的关键词参数 (**kwargs):
api_keyindex_name(默认:当前索引 ID,已设置,无需指定)
QdrantVectorStore
QdrantVectorStore 的关键词参数 (**kwargs):
url- 字符串,默认值为http://localhost:6333api_key- 字符串,默认值为None(用于 Qdrant Cloud)collection_name(默认:当前索引 ID,已设置,无需指定)- 列表中提供的任何其他关键词参数
RedisVectorStore
RedisVectorStore 的关键词参数 (**kwargs):
index_name(默认:当前索引 ID,已设置,无需指定)- 列表中提供的任何其他关键词参数
您可以通过创建自定义提供商并在应用启动时注册它来扩展可用提供商列表。
默认情况下,在使用“与文件聊天”功能时,您处于基于聊天的模式。如果您只想查询索引(而不进行聊天),可以启用“仅查询索引(无聊天)”选项。
添加自定义向量存储和数据加载器
您可以为您的数据创建自定义向量存储提供商或数据加载器,并为应用程序开发自定义启动程序。
有关更多详细信息,请参阅“扩展 PyGPT / 添加自定义向量存储提供商”部分。
更新
更新 PyGPT
PyGPT 自带一个集成的更新通知系统。当发布包含新功能的新版本时,您将在应用内收到提醒。
要获取新版本,只需下载并用它替换旧版本即可。您所有的自定义设置,如配置、预设、索引和过往对话,都将保留,并可在新版本中立即使用。
调试与日志记录
在“设置 -> 开发者”对话框中,您可以启用“显示调试菜单”选项以打开调试菜单。该菜单允许您检查应用程序各组件的状态。在调试菜单中,有一个“Logger”选项,可打开日志窗口。在该窗口中,程序的运行情况会实时显示。
日志级别:
默认情况下,所有错误和异常都会被记录到以下文件中:
{HOME_DIR}/.config/pygpt-net/app.log
要提高日志级别(默认为 ERROR 级别),请使用 --debug 参数运行应用程序:
python3 run.py --debug=1
或者
python3 run.py --debug=2
值 1 会启用 INFO 日志级别。
值 2 会启用 DEBUG 日志级别(记录最多的信息)。
兼容性(旧版)模式
如果您遇到 WebEngine / Chromium 渲染器的问题,可以通过命令行参数强制启用旧版模式:
python3 run.py --legacy=1
要强制禁用 OpenGL 硬件加速:
python3 run.py --disable-gpu=1
您也可以手动启用旧版模式,方法是编辑配置文件:在编辑器中打开 %WORKDIR%/config.json 配置文件,并设置以下选项:
"render.engine": "legacy",
"render.open_gl": false,
扩展 PyGPT
快速入门
您可以随时为 PyGPT 创建自己的扩展。
PyGPT 可以通过以下方式扩展:
- 自定义模型
- 自定义插件
- 自定义 LLM 包装器
- 自定义向量存储提供商
- 自定义数据加载器
- 自定义音频输入提供商
- 自定义音频输出提供商
- 自定义网页搜索引擎提供商
- 自定义智能体(LlamaIndex 或 OpenAI 智能体)
示例(教程文件)
请参阅本仓库中的 examples 目录,其中包含自定义启动程序、插件、向量存储、LLM(LlamaIndex)提供商和数据加载器的示例:
examples/custom_launcher.pyexamples/example_audio_input.pyexamples/example_audio_output.pyexamples/example_data_loader.pyexamples/example_llm.pyexamples/example_plugin.pyexamples/example_vector_store.pyexamples/example_web_search.py
这些示例文件可以用作您为 PyGPT 创建自定义扩展的起点。
通过自定义插件、LLM 包装器和向量存储扩展 PyGPT:
- 您可以将自定义插件实例、LLM 包装器和向量存储提供商传递给启动程序。
- 这在您希望用自有的插件、向量存储和 LLM 扩展 PyGPT 时非常有用。
要注册自定义插件:
- 将插件实例列表作为
plugins关键词参数传递。
要注册自定义 LLM 包装器:
- 将 LLM 包装器实例列表作为
llms关键词参数传递。
要注册自定义向量存储提供商:
- 将向量存储提供商实例列表作为
vector_stores关键词参数传递。
要注册自定义数据加载器:
- 将数据加载器实例列表作为
loaders关键词参数传递。
要注册自定义音频输入提供商:
- 将音频输入提供商实例列表作为
audio_input关键词参数传递。
要注册自定义音频输出提供商:
- 将音频输出提供商实例列表作为
audio_output关键词参数传递。
要注册自定义网页提供商:
- 将网页提供商实例列表作为
web关键词参数传递。
添加自定义模型
要使用 OpenAI API 或 LlamaIndex 封装添加新模型,请在 配置 -> 模型 中使用编辑器,或手动编辑 models.json 文件,插入该模型的配置详情。如果您通过 LlamaIndex 添加模型,务必包含模型名称、其支持的模式(chat、completion 或两者兼备)、LLM 提供商(如 OpenAI 或 HuggingFace),以及对于基于外部 API 的模型,可选的 API KEY 和其他必要的环境设置。
模型配置示例 - %WORKDIR%/models.json:
"gpt-3.5-turbo": {
"id": "gpt-3.5-turbo",
"name": "gpt-3.5-turbo",
"mode": [
"chat",
"assistant",
"langchain",
"llama_index"
],
"provider": "openai"
"llama_index": {
"args": [
{
"name": "model",
"value": "gpt-3.5-turbo",
"type": "str"
}
],
"env": [
{
"name": "OPENAI_API_KEY",
"value": "{api_key}"
}
]
},
"ctx": 4096,
"tokens": 4096,
"default": false
},
内置支持以下 LLM 提供商:
- Anthropic
- Azure OpenAI
- Deepseek API
- HuggingFace
- 本地模型(兼容 OpenAI API)
- Ollama
- OpenAI
- OpenRouter
- Perplexity
- xAI
提示:models.json 中的 {api_key} 是设置中主 OpenAI API 密钥的占位符,它将被配置的实际密钥值替换。
添加自定义插件
创建您自己的插件
您可以为 PyGPT 创建自己的插件。插件可以用 Python 编写,然后在应用程序启动前注册到应用中。所有随应用附带的插件都存储在 plugin 目录中,您可以将其用作编写您自己的插件的代码示例。
示例(教程文件)
请参阅此 examples 目录中的示例插件:
examples/example_plugin.py
这些示例文件可用作创建您自己的 PyGPT 插件的起点。
要注册自定义插件:
- 创建一个应用程序的自定义启动脚本。
- 将自定义插件实例列表作为
plugins关键字参数传递。
自定义启动脚本示例:
# custom_launcher.py
from pygpt_net.app import run
from plugins import CustomPlugin, OtherCustomPlugin
from llms import CustomLLM
from vector_stores import CustomVectorStore
plugins = [
CustomPlugin(),
OtherCustomPlugin(),
]
llms = [
CustomLLM(),
]
vector_stores = [
CustomVectorStore(),
]
run(
plugins=plugins,
llms=llms,
vector_stores=vector_stores,
)
处理事件
在插件中,您可以接收并修改分发的事件。为此,创建一个名为 handle(self, event, *args, **kwargs) 的方法,并按如下方式处理接收到的事件:
# custom_plugin.py
from pygpt_net.core.events import Event
def handle(self, event: Event, *args, **kwargs):
"""
处理分发的事件
:param event: 事件对象
"""
name = event.name
data = event.data
ctx = event.ctx
if name == Event.INPUT_BEFORE:
self.some_method(data['value'])
elif name == Event.CTX_BEGIN:
self.some_other_method(ctx)
else:
# ...
事件列表
事件名称在 pygpt_net.core.events 模块的 Event 类中定义。
语法:事件名称 - 触发时机,事件数据 (数据类型):
AI_NAME- 在准备 AI 名称时触发,data['value'](字符串,AI 助手的名称)AGENT_PROMPT- 在评估模式下生成代理提示时触发,data['value'](字符串,提示文本)AUDIO_INPUT_RECORD_START- 开始录音输入AUDIO_INPUT_RECORD_STOP- 停止录音输入AUDIO_INPUT_RECORD_TOGGLE- 切换录音输入状态AUDIO_INPUT_TRANSCRIBE- 在转录音频文件时触发,data['path'](字符串,音频文件路径)AUDIO_INPUT_STOP- 强制停止音频输入AUDIO_INPUT_TOGGLE- 当语音输入被启用或禁用时触发,data['value'](布尔值,True/False)AUDIO_OUTPUT_STOP- 强制停止音频输出AUDIO_OUTPUT_TOGGLE- 当语音输出被启用或禁用时触发,data['value'](布尔值,True/False)AUDIO_READ_TEXT- 使用语音合成朗读文本时触发,data['text'](字符串,待朗读的文本)CMD_EXECUTE- 当执行命令时触发,data['commands'](列表,包含命令及其参数)CMD_INLINE- 当执行内联命令时触发,data['commands'](列表,包含命令及其参数)CMD_SYNTAX- 在添加命令语法时触发,data['prompt'], data['syntax'](字符串、列表,提示语和命令使用语法的列表)CMD_SYNTAX_INLINE- 在内联模式下添加命令语法时触发,data['prompt'], data['syntax'](字符串、列表,提示语和命令使用语法的列表)CTX_AFTER- 上下文项发送之后触发,ctxCTX_BEFORE- 上下文项发送之前触发,ctxCTX_BEGIN- 创建上下文项时触发,ctxCTX_END- 处理上下文项结束时触发,ctxCTX_SELECT- 在从列表中选择上下文时触发,data['value'](整数,上下文元 ID)DISABLE- 当插件被禁用时触发,data['value'](字符串,插件 ID)ENABLE- 当插件被启用时触发,data['value'](字符串,插件 ID)FORCE_STOP- 当强制停止插件时触发INPUT_BEFORE- 从文本框接收到输入时触发,data['value'](字符串,待发送的文本)MODE_BEFORE- 在选择模式之前触发,data['value'], data['prompt'](字符串,模式 ID 和提示语)MODE_SELECT- 选择模式时触发,data['value'](字符串,模式 ID)MODEL_BEFORE- 在选择模型之前触发,data['value'](字符串,模型 ID)MODEL_SELECT- 选择模型时触发,data['value'](字符串,模型 ID)PLUGIN_SETTINGS_CHANGED- 当插件设置更新时触发(保存设置)PLUGIN_OPTION_GET- 请求插件选项值时触发,data['name'], data['value'](字符串,任意,请求的选项名称及当前值)POST_PROMPT- 准备系统提示之后触发,data['value'](字符串,系统提示)POST_PROMPT_ASYNC- 准备系统提示之后,在异步线程发起请求之前触发,data['value'](字符串,系统提示)POST_PROMPT_END- 准备系统提示之后,在异步线程发起请求之前,在最后阶段触发,data['value'](字符串,系统提示)PRE_PROMPT- 准备系统提示之前触发,data['value'](字符串,系统提示)SYSTEM_PROMPT- 准备系统提示时触发,data['value'](字符串,系统提示)TOOL_OUTPUT_RENDER- 当渲染来自插件工具的额外内容时触发,data['content'](字符串,内容)UI_ATTACHMENTS- 当附件上传组件渲染时触发,data['value'](布尔值,显示 True/False)UI_VISION- 当视觉相关组件渲染时触发,data['value'](布尔值,显示 True/False)USER_NAME- 准备用户名称时触发,data['value'](字符串,用户名)USER_SEND- 在输入文本发送之前触发,data['value'](字符串,输入文本)
您可以通过将 stop 设置为 True 来随时阻止接收到的事件继续传播:
event.stop = True
可以通过启用“配置 -> 设置 -> 开发者 -> 记录并调试事件”选项来调试事件流。
添加自定义 LLM 提供商
通过 LlamaIndex 处理 LLM 的方式是通过独立的封装器实现。这使得可以轻松添加对任何可通过 LlamaIndex 使用的提供商和模型的支持。所有内置的模型及其提供商的封装器都位于 pygpt_net.provider.llms 中。
这些封装器会在应用启动时通过 launcher.add_llm() 方法加载到应用中:
# app.py
from pygpt_net.provider.api.openai import OpenAILLM
from pygpt_net.provider.llms.azure_openai import AzureOpenAILLM
from pygpt_net.provider.llms.anthropic import AnthropicLLM
from pygpt_net.provider.llms.hugging_face import HuggingFaceLLM
from pygpt_net.provider.llms.ollama import OllamaLLM
from pygpt_net.provider.llms.google import GoogleLLM
def run(**kwargs):
"""运行应用程序"""
# 初始化应用
launcher = Launcher()
launcher.init()
# 注册插件
...
# 注册 Langchain 和 LlamaIndex 的 LLM 封装器
launcher.add_llm(OpenAILLM())
launcher.add_llm(AzureOpenAILLM())
launcher.add_llm(AnthropicLLM())
launcher.add_llm(HuggingFaceLLM())
launcher.add_llm(OllamaLLM())
launcher.add_llm(GoogleLLM())
# 启动应用
launcher.run()
要添加默认未包含的提供商支持,您可以创建自己的封装器,向应用返回自定义模型,然后将此自定义封装器传递给启动器。
使用自定义插件和 LLM 封装器扩展 PyGPT 非常简单:
- 直接将自定义插件和 LLM 封装器的实例传递给启动器。
注册自定义 LLM 封装器的方法:
- 将 LLM 封装器实例的列表作为
llms关键字参数提供。
示例:
# launcher.py
from pygpt_net.app import run
from plugins import CustomPlugin, OtherCustomPlugin
from llms import CustomLLM
plugins = [
CustomPlugin(),
OtherCustomPlugin(),
]
llms = [
CustomLLM(), # <--- 自定义大模型提供商(封装器)
]
vector_stores = []
run(
plugins=plugins,
llms=llms,
vector_stores=vector_stores,
)
示例(教程文件)
请参阅本仓库中的 examples 目录,其中包含自定义启动器、插件、向量存储、大模型提供商和数据加载器的示例:
examples/custom_launcher.pyexamples/example_audio_input.pyexamples/example_audio_output.pyexamples/example_data_loader.pyexamples/example_llm.py<-- 可用作示例examples/example_plugin.pyexamples/example_vector_store.pyexamples/example_web_search.py
这些示例文件可以作为您为 PyGPT 创建自定义扩展的起点。
要将您自己的模型或提供商集成到 PyGPT 中,您还可以参考位于 pygpt_net.provider.llms 中的类。这些示例可作为您自定义类的更复杂示例。请确保您的自定义封装类包含两个必要方法:chat 和 completion。这两个方法应返回模型在“聊天”和“完成”模式下运行所需的相应对象。
每个大模型提供商(封装器)都继承自 BaseLLM 类,并且可以提供两个组件:用于 LlamaIndex 的提供商,以及用于嵌入的提供商。
添加自定义向量存储提供商
您可以为自己的数据创建自定义向量存储提供商或数据加载器,并为应用程序开发自定义启动器。要注册您的自定义向量存储提供商或数据加载器,只需将其实例传递给 vector_stores 关键字参数,或将加载器实例传递给 loaders 关键字参数即可:
# app.py
# 向量存储
from pygpt_net.provider.vector_stores.chroma import ChromaProvider
from pygpt_net.provider.vector_stores.elasticsearch import ElasticsearchProvider
from pygpt_net.provider.vector_stores.pinecode import PinecodeProvider
from pygpt_net.provider.vector_stores.qdrant import QdrantProvider
from pygpt_net.provider.vector_stores.redis import RedisProvider
from pygpt_net.provider.vector_stores.simple import SimpleProvider
def run(**kwargs):
# ...
# 注册基础向量存储提供商(LlamaIndex)
launcher.add_vector_store(ChromaProvider())
launcher.add_vector_store(ElasticsearchProvider())
launcher.add_vector_store(PinecodeProvider())
launcher.add_vector_store(QdrantProvider())
launcher.add_vector_store(RedisProvider())
launcher.add_vector_store(SimpleProvider())
# 注册自定义向量存储提供商(LlamaIndex)
vector_stores = kwargs.get('vector_stores', None)
if isinstance(vector_stores, list):
for store in vector_stores:
launcher.add_vector_store(store)
# ...
要注册您的自定义向量存储提供商,只需将其实例传递给 vector_stores 关键字参数即可:
# custom_launcher.py
from pygpt_net.app import run
from plugins import CustomPlugin, OtherCustomPlugin
from llms import CustomLLM
from vector_stores import CustomVectorStore
plugins = [
CustomPlugin(),
OtherCustomPlugin(),
]
llms = [
CustomLLM(),
]
vector_stores = [
CustomVectorStore(), # <--- 自定义向量存储提供商
]
run(
plugins=plugins,
llms=llms,
vector_stores=vector_stores,
)
向量存储提供商必须是 pygpt_net.provider.vector_stores.base.BaseStore 的实例。
您可以查看 pygpt_net.provider.vector_stores 中内置提供商的代码,并在创建自定义提供商时将其作为示例。
添加自定义数据加载器
# custom_launcher.py
from pygpt_net.app import run
from plugins import CustomPlugin, OtherCustomPlugin
from llms import CustomLLM
from vector_stores import CustomVectorStore
from loaders import CustomLoader
plugins = [
CustomPlugin(),
OtherCustomPlugin(),
]
llms = [
CustomLLM(),
]
vector_stores = [
CustomVectorStore(),
]
loaders = [
CustomLoader(), # <---- 自定义数据加载器
]
run(
plugins=plugins,
llms=llms,
vector_stores=vector_stores, # <--- 包含自定义向量存储提供商的列表
loaders=loaders # <--- 包含自定义数据加载器的列表
)
数据加载器必须是 pygpt_net.provider.loaders.base.BaseLoader 的实例。
您可以查看 pygpt_net.provider.loaders 中内置加载器的代码,并在创建自定义加载器时将其用作示例。
免责声明
本应用与 OpenAI 并无官方关联。作者对因使用本应用而产生的任何损害不承担任何责任。本应用按“原样”提供,不附带任何形式的保证。 提醒用户注意令牌使用情况——务必在 API 官网核实模型所使用的令牌数量,并以负责任的方式使用本应用。启用诸如网络搜索之类的插件可能会消耗额外的令牌,而这些令牌不会显示在主界面上。
请始终在 OpenAI、Google、Anthropic、xAI 等网站上监控您的实际令牌使用情况。
更改日志
最近的更新:
2.7.12(2026-02-06)
- xAI SDK 升级至 v1.6.1。
- 在 xAI 提供商中新增视频生成支持。
- 新增模型:grok-imagine-image 和 grok-imagine-video。
- UI 改进,标签页和列之间的导航更加流畅。
- 优化了附件添加功能。新增仅在 API 端存储消息时才附加一次附件的选项,以及强制仅附加一次附件的选项。
- 更新了库文件。
2.7.11(2026-02-05)
- 改进了列之间的焦点处理。
- 修复了模型调试器更新问题。
2.7.10(2026-02-03)
- 修复了在创建新预设时头像可能被覆盖的问题。
- 修复了在第二列打开新标签页时未创建新上下文的问题。
- 在输入框中新增提示历史导航功能(Ctrl + 上/下箭头键)。
- 在加载图片查看器时,新增初始图像居中显示功能。
- 在记事本小部件中新增标记/取消标记功能。
- 新增 18 种语言:阿拉伯语 (ar)、保加利亚语 (bg)、捷克语 (cs)、丹麦语 (da)、芬兰语 (fi)、希伯来语 (he)、印地语 (hi)、匈牙利语 (hu)、日语 (ja)、韩语 (ko)、荷兰语 (nl)、挪威语 (no)、葡萄牙语 (pt)、罗马尼亚语 (ro)、俄语 (ru)、斯洛伐克语 (sk)、瑞典语 (sv)、土耳其语 (tr)。
2.7.9(2026-01-08)
- 改进了实时音频模式。
- 在实时音频模式中新增 xAI 提供商及 Grok 支持。
2.7.8(2026-01-06)
- 新增 xAI Collections 远程工具,并将集合管理集成到远程向量存储工具中。
- 将远程向量存储工具统一为适用于所有提供商的单一工具。
- 新增 xAI Grok 音频输入输出提供商(Grok 的实时音频支持即将推出!)。
- 增强了图片查看器工具,增加了包含上一张/下一张等更多选项的工具箱。
2.7.7(2026-01-05)
- 在 xAI 中新增 Responses API 支持。
- 新增 xAI 远程工具:远程 MCP、代码执行。
- 新增 Anthropic 远程工具:远程 MCP、网页抓取、代码执行。
2.7.6(2026-01-03)
- 修复了与 xAI SDK 的兼容性问题,并解决了 Grok 模型返回空响应的问题。
- 修复了 Snap 软件包中缺失的库文件。
- 在图片查看器中新增缩放和拖动功能。
- 在文本区域和网页小部件中新增缩放菜单。
- 新增使用鼠标中键点击关闭标签页的功能。
致谢与链接
官方网站: https://pygpt.net
文档: https://pygpt.readthedocs.io
支持与捐赠: https://pygpt.net/#donate
GitHub: https://github.com/szczyglis-dev/py-gpt
Discord: https://pygpt.net/discord
Snap 商店: https://snapcraft.io/pygpt
微软商店: https://apps.microsoft.com/detail/XP99R4MX3X65VQ
PyPI: https://pypi.org/project/pygpt-net
作者: Marcin Szczygliński(波兰,欧盟)
联系方式: info@pygpt.net
许可证: MIT 许可证
特别感谢
GitHub 社区:
第三方库
本项目所使用的外部库完整列表位于仓库主目录下的 requirements.txt 文件中。
所有使用的 SVG 图标均来自 Google 提供的 Material Design Icons:
https://github.com/google/material-design-icons
https://fonts.google.com/icons
Monaspace 字体由 GitHub 提供:https://github.com/githubnext/monaspace
集成到应用中的 LlamaIndex 离线加载器代码来源于 LlamaHub:https://llamahub.ai
Awesome ChatGPT Prompts(用于模板中):https://github.com/f/awesome-chatgpt-prompts/
代码语法高亮由:https://highlightjs.org 提供
Markdown 解析由:https://github.com/markdown-it/markdown-it 提供
LaTeX 支持由:https://katex.org 提供
Playwright:https://playwright.dev/
版本历史
v2.7.122026/02/06v2.7.112026/02/05v2.7.102026/02/03v2.7.92026/01/08v2.7.82026/01/06v2.7.72026/01/05v2.7.62026/01/03v2.7.52026/01/03v2.7.42025/12/31v2.7.32025/12/30v2.7.22025/12/29v2.7.12025/12/28v2.5.972025/08/11v2.7.02025/12/28v2.6.672025/12/26v2.6.662025/12/26v2.6.652025/09/28v2.6.642025/09/27v2.6.632025/09/27v2.6.622025/09/26常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。