Multi-Agent-Medical-Assistant
Multi-Agent-Medical-Assistant 是一款基于生成式人工智能的多智能体医疗助手,旨在为疾病诊断、医学研究及患者咨询提供智能化支持。它有效解决了传统医疗场景中信息检索效率低、影像分析门槛高以及最新医学资讯获取滞后等痛点,通过整合多方能力为用户提供精准辅助。
这款工具非常适合医疗从业者、科研人员以及希望深入了解病情的患者使用;同时,其模块化的代码架构也极具学习价值,是开发者研究多智能体协作与高级 RAG(检索增强生成)技术的理想范例。
在技术层面,Multi-Agent-Medical-Assistant 不仅融合了大型语言模型与计算机视觉模型以分析医学影像,还引入了“人在回路”机制,确保 AI 对影像的诊断结果能经过专业人员验证,提升安全性。系统支持实时网络搜索以获取前沿医学观点,并采用混合检索策略与语义分块技术优化知识库查询。值得一提的是,最新版本升级了文档处理能力,能更精准地解析包含图表和图像的复杂医疗文献,并在回答中附带可追溯的原始来源链接,让每一次交互都严谨可信。
使用场景
某三甲医院呼吸科主治医师在门诊高峰期,面对一位肺部 CT 影像异常且伴有复杂既往病史的患者,急需快速制定精准的诊疗方案并查阅最新临床指南。
没有 Multi-Agent-Medical-Assistant 时
- 多源信息整合耗时:医生需手动切换电子病历、影像系统和文献数据库,花费大量时间拼凑患者碎片化信息。
- 影像判读压力大:在高强度工作下,仅凭肉眼复核细微的肺结节特征容易产生视觉疲劳,增加漏诊风险。
- 指南更新滞后:难以实时获取全球最新的药物治疗方案或临床试验数据,诊疗建议可能依赖过时的知识库。
- 缺乏交叉验证:初步诊断结果缺少即时的第二意见参考,医生对复杂病例的决策信心不足。
使用 Multi-Agent-Medical-Assistant 后
- 智能信息聚合:系统自动调用 RAG 技术检索患者历史档案与本地向量库,秒级生成包含关键病史的结构化摘要。
- AI 辅助影像分析:计算机视觉代理自动标注 CT 影像中的可疑病灶并提供量化分析,作为医生的高效“第二双眼睛”。
- 实时前沿同步:联网搜索代理即时抓取并总结最新医学论文与指南,确保治疗方案符合当前国际最佳实践。
- 多代理协同会诊:不同专业背景的 AI 代理进行内部辩论与置信度评估,输出带有明确参考文献来源的综合诊断建议。
Multi-Agent-Medical-Assistant 通过多智能体协作将繁琐的信息搜集与初筛工作自动化,让医生能专注于核心决策,显著提升诊疗效率与准确性。
运行环境要求
- 未说明 (支持 Docker,理论上兼容 Linux/macOS/Windows)
未明确强制要求,但涉及计算机视觉模型(脑肿瘤检测、胸片分类、皮肤病变分割)和 PyTorch,建议配备 NVIDIA GPU 以加速推理
未说明 (建议 16GB+ 以运行多智能体系统和向量数据库)

快速开始

⚕️ 多智能体医疗助手 :基于AI的多智能体系统,用于医学诊断与辅助
![]()
![]()
![]()
[!IMPORTANT]
📋 从 v2.0 到 v2.1 及更高版本的更新:
- 文档处理升级:已将 Unstructured.io 替换为 Docling,用于解析文档并提取文本、表格和图像以进行嵌入。
- 增强的 RAG 参考信息:在本地存储中重新排序后的检索片段底部,添加了指向源文档和参考图像的链接,这些链接会显示在 RAG 响应中。
如需使用基于 Unstructured.io 的解决方案,请参阅发布版本 - v2.0。
📚 目录
📌 概述
多智能体医疗助手是一款基于AI的聊天机器人,旨在协助进行医学诊断、研究以及患者互动。
🚀 由多智能体智能驱动,该系统集成了:
- 🤖 大型语言模型 (LLMs)
- 🖼️ 计算机视觉模型,用于医学影像分析
- 📚 检索增强生成 (RAG),利用向量数据库
- 🌐 实时网络搜索,以获取最新的医学见解
- 👨⚕️ 人工参与验证,用于核实基于AI的医学影像诊断结果
您将从该项目中学到的内容 📖
🔹 👨💻 多智能体编排,采用结构化的图工作流
🔹 🔍 高级 RAG 技术——混合检索、语义分块和向量搜索
🔹 ⚡ 基于置信度的路由及智能体之间的交接
🔹 🔒 可扩展、生产就绪的AI,具有模块化代码和强大的异常处理机制
📂 对于学习者:请查看 agents/README.md,了解关于智能体工作流的详细分解! 🎯
💫 演示
https://github.com/user-attachments/assets/d27d4a2e-1c7d-45e2-bbc5-b3d95ccd5b35
如果您喜欢这里的内容并希望支持该项目的开发者,您可以点击 ! :)
! :)
📂 如需更详细的演示视频:请查看 Multi-Agent-Medical-Assistant-v1.9。 📽️
🛡️ 技术流程图
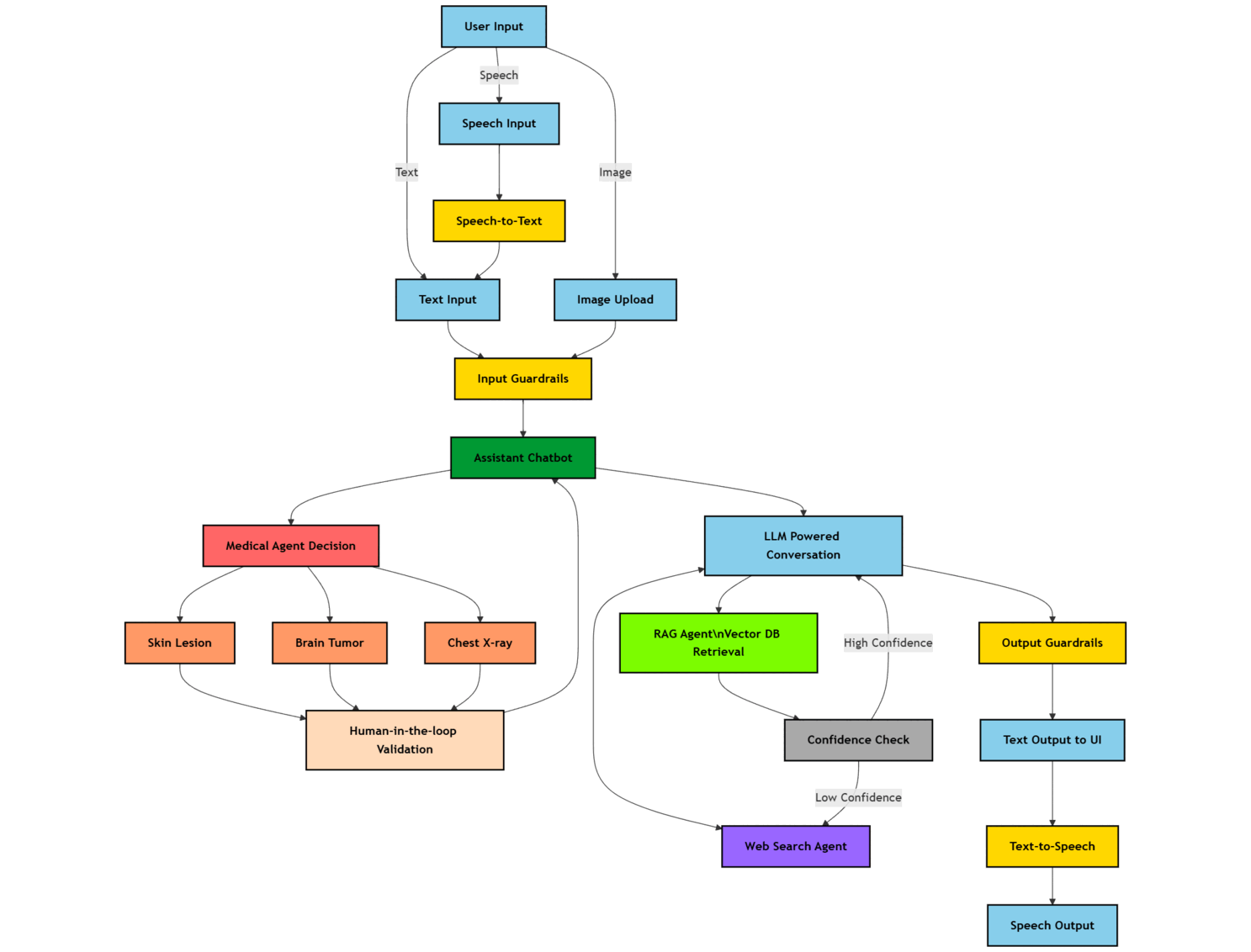
✨ 核心功能
🤖 多智能体架构:各专业智能体协同工作,完成诊断、信息检索、推理等任务
🔍 先进的代理式RAG检索系统:
- 基于Docling的解析,从PDF中提取文本、表格和图像。
- 对Markdown格式的文本、表格以及LLM生成的图像摘要进行嵌入。
- LLM驱动的语义分块,并结合结构边界感知。
- LLM驱动的查询扩展,引入相关医学领域术语。
- Qdrant混合搜索,结合BM25稀疏关键词检索与稠密向量检索。
- 使用HuggingFace Cross-Encoder对检索到的文档片段进行重排序,以确保LLM响应的准确性。
- 输入输出约束机制,保证响应的安全性和相关性。
- 检索结果中附带参考文档片段中的源文档链接及图片。
- 基于置信度的智能体间交接机制,在RAG与网络搜索之间切换,防止幻觉产生。
🏥 医学影像分析
- 脑肿瘤检测(待开发)
- 胸部X光疾病分类
- 面部皮肤病变分割
🌐 实时研究整合:网络搜索智能体可获取最新的医学研究论文和发现
📊 基于置信度的验证:通过对数似然概率的分析,确保医疗建议的高度准确性
🎙️ 语音交互能力:通过Eleven Labs API实现流畅的语音转文本和文本转语音功能
👩⚕️ 专家监督系统:在最终输出前由医疗专业人士进行人工审核
⚔️ 输入输出约束机制:确保医疗响应安全、公正且可靠,同时过滤有害或误导性内容
💻 直观用户界面:专为技术背景较浅的医护人员设计
[!NOTE]
即将推出的功能:
- 脑肿瘤医学计算机视觉模型集成。
- 欢迎提出建议和贡献。
🛠️ 技术栈
| 组件 | 技术 |
|---|---|
| 🔹 后端框架 | FastAPI |
| 🔹 智能体编排 | LangGraph |
| 🔹 文档解析 | Docling |
| 🔹 知识存储 | Qdrant向量数据库 |
| 🔹 医学影像 | 计算机视觉模型 |
| • 脑肿瘤:目标检测(PyTorch) | |
| • 胸部X光:图像分类(PyTorch) | |
| • 皮肤病变:语义分割(PyTorch) | |
| 🔹 约束机制 | LangChain |
| 🔹 语音处理 | Eleven Labs API |
| 🔹 前端 | HTML, CSS, JavaScript |
| 🔹 部署 | Docker, GitHub Actions CI/CD |
🚀 安装与设置
📌 选项1:使用Docker
前提条件:
- 系统已安装Docker
- 所需服务的API密钥
1️⃣ 克隆仓库
git clone https://github.com/souvikmajumder26/Multi-Agent-Medical-Assistant.git
cd Multi-Agent-Medical-Assistant
2️⃣ 创建环境文件
- 在根目录下创建
.env文件,并添加以下API密钥:
[!NOTE]
您可以使用任何您选择的LLM和嵌入模型...
- 如果使用Azure OpenAI,则无需修改。
- 如果直接使用OpenAI,请修改
config.py中的LLM和嵌入模型定义,并提供相应的环境变量。- 如果使用本地模型,可能需要在整个代码库中进行适当的代码更改,尤其是在“agents”部分。 [!WARNING]
请确保.env文件中的API密钥正确无误,并具备必要的权限。 变量名后不得有空格。
# LLM配置(开发中使用Azure Open AI - gpt-4o)
# 如果使用其他LLM API密钥或本地LLM,需进行相应代码修改
deployment_name=
model_name=gpt-4o
azure_endpoint=
openai_api_key=
openai_api_version=
# 嵌入模型配置(开发中使用Azure Open AI - text-embedding-ada-002)
# 如果使用其他嵌入模型,需进行相应代码修改
embedding_deployment_name=
embedding_model_name=text-embedding-ada-002
embedding_azure_endpoint=
embedding_openai_api_key=
embedding_openai_api_version=
# 语音API密钥(新注册Eleven Labs账户可获得免费额度)
ELEVEN_LABS_API_KEY=
# 网络搜索API密钥(新注册Tavily账户可获得免费额度)
TAVILY_API_KEY=
# Hugging Face Token - 使用reranker模型 "ms-marco-TinyBERT-L-6"
HUGGINGFACE_TOKEN=
# (可选)如果使用Qdrant服务器版本,本地部署则无需API密钥
QDRANT_URL=
QDRANT_API_KEY=
3️⃣ 构建Docker镜像
docker build -t medical-assistant .
4️⃣ 运行Docker容器
docker run -d --name medical-assistant-app -p 8000:8000 --env-file .env medical-assistant
应用将可通过http://localhost:8000访问。
5️⃣ 从Docker容器中将数据导入向量数据库
- 导入单个文档:
docker exec medical-assistant-app python ingest_rag_data.py --file ./data/raw/brain_tumors_ucni.pdf
- 导入目录下的多个文档:
docker exec medical-assistant-app python ingest_rag_data.py --dir ./data/raw
容器管理:
停止容器
docker stop medical-assistant-app
启动容器
docker start medical-assistant-app
查看日志
docker logs medical-assistant-app
删除容器
docker rm medical-assistant-app
故障排除:
容器健康检查
容器内置了健康检查功能,可监控应用状态。您可以通过以下命令查看健康状态:
docker inspect --format='{{.State.Health.Status}}' medical-assistant-app
容器无法启动
若容器未能成功启动,请查看日志以排查错误:
docker logs medical-assistant-app
📌 选项2:不使用Docker
1️⃣ 克隆仓库
git clone https://github.com/souvikmajumder26/Multi-Agent-Medical-Assistant.git
cd Multi-Agent-Medical-Assistant
2️⃣ 创建并激活虚拟环境
- 如果使用 conda:
conda create --name <environment-name> python=3.11
conda activate <environment-name>
- 如果使用 Python venv:
python -m venv <environment-name>
source <environment-name>/bin/activate # 对于 Mac/Linux
<environment-name>\Scripts\activate # 对于 Windows
3️⃣ 安装依赖
[!IMPORTANT]
需要安装 ffmpeg 才能使语音服务正常工作。
- 如果使用 conda:
conda install -c conda-forge ffmpeg
pip install -r requirements.txt
- 如果使用 Python venv:
winget install ffmpeg
pip install -r requirements.txt
4️⃣ 设置 API 密钥
- 创建一个
.env文件,并按照Option 1中所示添加所需的 API 密钥。
5️⃣ 运行应用程序
- 在激活的环境中运行以下命令。
python app.py
应用程序将可在以下地址访问:http://localhost:8000
6️⃣ 向向量数据库中导入额外数据
根据需要运行以下任一命令。
- 每次导入一份文档:
python ingest_rag_data.py --file ./data/raw/brain_tumors_ucni.pdf
- 从目录中批量导入文档:
python ingest_rag_data.py --dir ./data/raw
🧠 使用方法
[!NOTE]
- 第一次运行可能会有些卡顿并出现错误,请耐心等待,并查看控制台以了解下载和安装的进度。
- 第一次运行时会下载许多模型,例如用于 Tesseract OCR 的 YOLO 模型、计算机视觉代理模型、交叉编码器重排序模型等。
- 下载完成后请再次尝试,所有功能应该都能顺利运行,因为这些功能都经过了充分测试。
- 上传医学图像以进行 基于 AI 的诊断。可以使用特定任务的计算机视觉模型代理——从“sample_images”文件夹中上传图像进行尝试。
- 提出医学相关问题,利用 检索增强生成(RAG) 技术获取记忆中的信息,或通过 网络搜索 获取最新信息。
- 使用 基于语音 的交互方式(语音转文本和文本转语音)。
- 通过 人工参与验证 来审查 AI 生成的见解。
🤝 贡献
欢迎各位贡献!请查看 issues 标签页,了解功能请求和改进建议。
⚖️ 许可证
本项目采用 Apache-2.0 许可证。详细信息请参阅 LICENSE 文件。
📝 引用
@misc{Souvik2025,
Author = {Souvik Majumder},
Title = {多智能体医疗助手},
Year = {2025},
Publisher = {GitHub},
Journal = {GitHub 仓库},
Howpublished = {\url{https://github.com/souvikmajumder26/Multi-Agent-Medical-Assistant}}
}
📬 联系方式
如有任何问题或合作意向,请联系 Souvik Majumder:
🔗 LinkedIn: https://www.linkedin.com/in/souvikmajumder26
🔗 GitHub: https://github.com/souvikmajumder26
版本历史
v2.1.22025/05/02v2.1.12025/04/29v2.02025/04/07v1.92025/04/07v1.82025/03/31v1.72025/03/26v1.62025/03/24v1.52025/03/21v1.42025/03/20v1.32025/03/19v1.22025/03/17相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备