wtpsplit
wtpsplit 是一款强大的开源文本分割工具,旨在将任意文本精准地拆分为句子或其他语义单元。它有效解决了传统方法在处理多语言、标点缺失或格式混乱文本时容易出错、效率低下的难题,尤其擅长应对复杂的自然语言场景。
这款工具非常适合开发者、数据科学家及 NLP 研究人员使用,无论是构建预处理流水线还是进行多语言学术研究,都能从中获益。wtpsplit 的核心亮点在于其集成了最新的 SaT(Segment Any Text)模型,支持全球 85 种语言,在准确性与计算效率之间取得了卓越的平衡。它不仅提供通用的分割模型,还创新性地支持 LoRA 适配技术,允许用户针对特定领域、语言风格进行微调,从而获得更贴合需求的分割效果。此外,wtpsplit 原生支持 ONNX 加速,结合 GPU 使用时推理速度可提升约 50%,确保在大规模数据处理任务中依然保持高效流畅。通过简洁的 Python 接口,用户可以轻松将其集成到现有项目中,实现鲁棒且灵活的文本结构化处理。
使用场景
某跨国舆情分析团队需要每日处理来自 85 种语言的社交媒体原始数据,将其切分为独立句子以进行情感打分和关键词提取。
没有 wtpsplit 时
- 多语言支持薄弱:传统规则或旧模型难以应对非英语语种(如泰语、阿拉伯语),导致大量句子切分错误或完全失效。
- 标点依赖严重:面对社交媒体中普遍存在的缺失标点、滥用换行或表情符号分隔的文本,现有工具无法准确识别语义边界。
- 处理效率低下:在大规模数据流中,重型模型推理速度慢,且缺乏 GPU/ONNX 加速选项,造成数据积压和实时性差。
- 领域适应性差:通用模型难以理解特定行业术语或网络俚语,导致长句被错误截断或短句被强行合并,影响下游分析精度。
使用 wtpsplit 后
- 全球语言覆盖:利用 SaT 模型原生支持 85 种语言的特性,统一处理流程,显著提升了小语种数据的切分准确率。
- 无标点鲁棒分割:基于自监督学习架构,wtpsplit 能精准识别无语义标点处的句子边界,完美适配嘈杂的社交文本。
- 极致推理性能:通过启用 ONNX GPU 加速,处理千条文本的速度提升约 50%,轻松满足实时舆情监控的低延迟需求。
- 灵活领域适配:借助 LoRA 模块,团队可快速加载针对“金融”或“电商”风格微调的权重,使切分结果更贴合业务语境。
wtpsplit 凭借其对多语言、无标点文本的鲁棒分割能力及高效的推理速度,成为了构建高质量多语言 NLP 流水线的关键基石。
运行环境要求
- 未说明
- 非必需
- 支持 NVIDIA GPU (通过 'cuda' 或 ONNX 的 'CUDAExecutionProvider') 和 TPU ('xla:0')
- 具体型号和显存大小未说明,但示例测试环境为 RTX 3090
未说明

快速开始
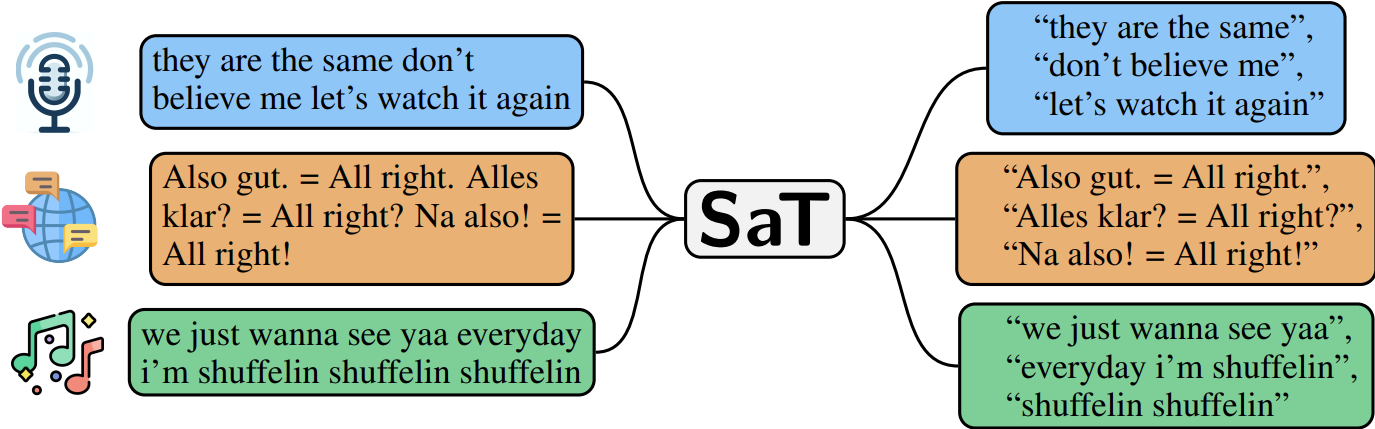
wtpsplit🪓
对任意文本进行分段——稳健、高效、可适应⚡
本仓库允许您将文本分割成句子或其他语义单元。它实现了以下模型:
- SaT — Segment Any Text: 一种稳健、高效且可适应的通用句子分割方法,作者为Markus Frohmann、Igor Sterner、Benjamin Minixhofer、Ivan Vulić 和 Markus Schedl(当前最先进,推荐使用)。
- WtP — 句号在哪里?自监督多语言无标点符号依赖的句子分割,作者为Benjamin Minixhofer、Jonas Pfeiffer 和 Ivan Vulić(旧版本,为保证结果可复现而保留)。
出于一致性考虑,沿用了“WtP”这一名称。我们的新模型 SaT 在 85 种语言上提供了更稳健、高效且可适应的句子分割功能,同时性能更高、计算成本更低。请参阅我们在 Segment any Text 论文 中展示的在 8 个不同语料库和 85 种语言上的最先进结果。
安装
pip install wtpsplit
或者,如果您需要 ONNX 支持,可以安装以下任一选项:
pip install wtpsplit[onnx-gpu]
pip install wtpsplit[onnx-cpu]
使用方法
from wtpsplit import SaT
sat = SaT("sat-3l")
# 可选:在 GPU 上运行以获得更好的性能
# 也支持 TPU,例如通过 sat.to("xla:0");此时需将 pad_last_batch 参数设为 True
sat.half().to("cuda")
sat.split("这是一个测试 这是另一个测试。")
# 返回 ["这是一个测试 ", "这是另一个测试。"]
# 为了提升性能,建议不要逐个调用 sat.split 对每段文本进行处理,而是直接传入文本列表:
sat.split(["这是一个测试 这是另一个测试。", "还有一些其他的文本..."])
# 返回一个迭代器,依次生成每段文本对应的句子列表
# 对于一般的句子分割任务,可以使用 '-sm' 模型:
sat_sm = SaT("sat-3l-sm")
sat_sm.half().to("cuda") # 可选,参考上述说明
sat_sm.split("这是一个测试 这是另一个测试")
# 返回 ["这是一个测试 ", "这是另一个测试"]
# 如果需要针对特定语言或领域/风格进行强适应性调整,可以使用经过微调的 LoRA 模块:
sat_adapted = SaT("sat-3l", style_or_domain="ud", language="en")
sat_adapted.half().to("cuda") # 可选,参考上述说明
sat_adapted.split("这是一个测试 这是另一个测试。")
# 返回 ['这是一个测试 ', '这是另一个测试']
ONNX 支持
🚀 现在您可以为 sat 和 sat-sm 模型启用更快的 ONNX 推理!🚀
sat = SaT("sat-3l-sm", ort_providers=["CUDAExecutionProvider", "CPUExecutionProvider"])
>>> from wtpsplit import SaT
>>> texts = ["这是一句话。这又是另一句话。"] * 1000
# PyTorch GPU
>>> model_pytorch = SaT("sat-3l-sm")
>>> model_pytorch.half().to("cuda");
>>> %timeit list(model_pytorch.split(texts))
# 144 ms ± 252 μs 每循环(7 次运行,每次 10 次循环的平均值 ± 标准差)
# 已经相当快了,但...
# onnxruntime GPU
>>> model_ort = SaT("sat-3l-sm", ort_providers=["CUDAExecutionProvider", "CPUExecutionProvider"])
>>> %timeit list(model_ort.split(texts))
# 94.9 ms ± 165 μs 每循环(7 次运行,每次 10 次循环的平均值 ± 标准差)
# ...这应该会快约 50%!(在 RTX 3090 上测试过)
如果您希望将 LoRA 与 ONNX 模型结合使用:
- 运行
scripts/export_to_onnx_sat.py,并将use_lora设置为True,同时指定合适的output_dir: <OUTPUT_DIR>。- 如果您已有本地的 LoRA 模块,请使用
lora_path。 - 如果您希望从 Hugging Face Hub 加载 LoRA 模块,则使用
style_or_domain和language。
- 如果您已有本地的 LoRA 模块,请使用
- 加载已合并 LoRA 权重的 ONNX 模型:
sat = SaT(<OUTPUT_DIR>, onnx_providers=["CUDAExecutionProvider", "CPUExecutionProvider"])
可用模型
如果您需要一个通用的句子分割模型,建议使用 -sm 模型(如 sat-3l-sm)。对于对速度敏感的应用场景,我们推荐 3 层模型(sat-3l 和 sat-3l-sm),它们在速度和性能之间取得了很好的平衡。而性能最佳的则是我们的 12 层模型:sat-12l 和 sat-12l-sm。
| 模型 | 英语得分 | 多语言得分 |
|---|---|---|
| sat-1l | 88.5 | 84.3 |
| sat-1l-sm | 88.2 | 87.9 |
| sat-3l | 93.7 | 89.2 |
| sat-3l-lora | 96.7 | 94.8 |
| sat-3l-sm | 96.5 | 93.5 |
| sat-6l | 94.1 | 89.7 |
| sat-6l-sm | 96.9 | 95.1 |
| sat-9l | 94.3 | 90.3 |
| sat-12l | 94.0 | 90.4 |
| sat-12l-lora | 97.3 | 95.9 |
| sat-12l-sm | 97.4 | 96.0 |
以上分数分别为“英语”和“多语言”类别下的宏平均 F1 分数,分别基于所有可用数据集计算得出。“adapted”表示通过 LoRA 进行适配;详细信息请参阅 论文。
作为对比,以下是其他一些工具的英语得分:
| 模型 | 英语得分 |
|---|---|
| PySBD | 69.6 |
| SpaCy(单语句分割器) | 92.9 |
| SpaCy(多语句分割器) | 91.5 |
| Ersatz | 91.4 |
Punkt (nltk.sent_tokenize) |
92.2 |
| WtP (3l) | 93.9 |
请注意,本库同样支持之前的 WtP 模型。您可以以与 SaT 模型基本相同的方式使用它们:
from wtpsplit import WtP
wtp = WtP("wtp-bert-mini")
# 与 SaT 模型类似的功能
wtp.split(“这是一个测试 这是另一个测试。”)
有关 WtP 的更多详细信息以及复现细节,请参阅 WtP 文档。
段落分割
由于 SaT 模型经过训练可以预测换行概率,因此除了句子之外,它们还可以将文本分割成段落。
# 返回一个段落列表,每个段落包含一个句子列表
# 可通过 `paragraph_threshold` 参数调整段落阈值。
sat.split(text, do_paragraph_segmentation=True)
(新增!v2.2+)长度约束分割
使用 min_length 和 max_length 参数控制片段长度。这在需要将文本分割为特定大小限制的片段时非常有用(例如,用于嵌入模型、存储或下游处理)。
基本用法
from wtpsplit import SaT
sat = SaT("sat-3l-sm")
text = (
"起初,上帝创造了天地。 地是空虚混沌,渊面黑暗;上帝的灵运行在水面上。 上帝说:‘要有光!’于是就有了光。 上帝看着光,觉得甚好;于是将光与暗分开。 上帝称光为昼,称暗为夜。 这样,就有了晚上和早晨,这是第一天。"
)
# 将文本按最大片段长度 120 字符进行分割
segments = sat.split(text, max_length=120)
for i, s in enumerate(segments):
print(f"[{len(s):3d} 字] {s}")
# [ 55 字] 起初,上帝创造了天地。
# [ 86 字] 地是空虚混沌,渊面黑暗。
# [112 字] 上帝的灵运行在水面上。上帝说:‘要有光!’于是就有了光。
# [ 86 字] 上帝看着光,觉得甚好;于是将光与暗分开。
# [115 字] 上帝称光为昼,称暗为夜。这样,就有了晚上和早晨,这是第一天。
assert "".join(segments) == text # 文本被完整保留
# 同时强制最小和最大长度
sat.split(text, min_length=80, max_length=200)
# 使用贪心算法以获得更快但次优的结果
sat.split(text, max_length=120, algorithm="greedy")
长度偏好先验
使用先验来影响片段长度分布。可用的先验包括:
| 先验 | 最佳用途 |
|---|---|
"uniform"(默认) |
只强制最大长度,让模型自行决定 |
"gaussian" |
偏好接近目标长度的片段(直观) |
"lognormal" |
右偏偏好(对较长片段更宽容) |
"clipped_polynomial" |
必须非常接近目标长度 |
# 高斯先验(推荐):偏好接近目标长度的片段
sat.split(text, max_length=100,prior_type="gaussian",
prior_kwargs={"target_length": 50, "spread": 10})
# 对数正态先验:右偏(对较长片段更宽容)
sat.split(text, max_length=100,prior_type="lognormal",
prior_kwargs={"target_length": 70, "spread": 25})
# 截断多项式:在目标长度上下一定范围内硬性截断
sat.split(text, max_length=100,prior_type="clipped_polynomial",
prior_kwargs={"target_length": 60, "spread": 25})
语言感知的默认设置
传递 lang_code 参数,即可根据语言特定的语料库统计信息使用语言相关的 target_length 和 spread 默认值:
# 德语的平均句长较长 → 自动使用 target_length=90,spread=35
sat.split(text, max_length=150,prior_type="gaussian",
prior_kwargs={"lang_code": "de"})
# 中文的平均句长较短 → 自动使用 target_length=45,spread=15
sat.split(text,max_length=100,prior_type="gaussian",
prior_kwargs={"lang_code": "zh"})
当使用 LoRA 并指定语言时,这些设置会自动应用:
sat = SaT("sat-3l", style_or_domain="ud", language="de")
sat.split(text,max_length=150,prior_type="gaussian") # 自动使用德语默认值
工作原理
维特比算法会找到全局最优的分割点,从而在以下两者之间取得平衡:
- 模型对句子边界的预测(自然分隔的位置)
- 您的长度偏好(通过先验;如果提供)
文本重建:
# 如果有长度约束(max_length 或 min_length):
original_text = "".join(segments) # 片段可能包含换行符
# 如果没有长度约束(SaT 默认且 split_on_input_newlines=True):
original_text = "\n".join(segments)
注意:使用长度约束时,片段可能会包含换行符。如果您希望去除这些换行符,可以在后处理阶段进行清理。
注意:当设置了
max_length时,threshold参数将被忽略。维特比/贪心算法会直接使用原始模型概率,而不是基于阈值的过滤。
有关更多信息,请参阅 长度约束文档。
适应性
SaT 模型可以通过 LoRA 技术针对特定领域和风格进行适配。我们为 sat-3l 和 sat-12l 提供了适用于 81 种语言的通用依存关系、OPUS100、Ersatz 和 TED(即 ASR 风格转录演讲)句子风格的训练好的 LoRA 模块。此外,我们还提供了适用于 6 种语言的法律文件(法律和判决)、4 对语言组合中的代码转换以及 3 种语言的推文的 LoRA 模块。有关详细信息,请参阅我们的论文 arXiv:2406.16678。
我们还为 sat-12-no-limited-lookahead 提供了 16 种体裁的诗句分割模块。
加载 LoRA 模块的方式如下:
# 需要同时指定 lang_code 和 style_or_domain
# 可用的模块请查看 <model_repository>/loras 文件夹
sat_lora = SaT("sat-3l", style_or_domain="ud", language="en")
sat_lora.split("你好,这是一个测试。但现在情况不同了。现在下一个开始了,looool")
# 接下来是一个非常不同的领域
sat_lora_distinct = SaT("sat-12l", style_or_domain="code-switching", language="es-en")
sat_lora_distinct.split("早上在那里,每当我讲些什么,他就会回应我。")
您也可以自由调整分割阈值,较高的阈值会导致更保守的分割:
sat.split("这是一个测试 这是另一个测试。", threshold=0.4)
# LoRA 模块同样适用;但其阈值更高
sat_lora.split("你好,这是一个测试。但现在情况不同了。现在下一个开始了,looool", threshold=0.7)
高级用法
获取文本中换行符或句子边界的概率:
# 返回换行符概率(支持批量处理!)
sat.predict_proba(text)
在 HuggingFace transformers 中加载 SaT 模型:
# 导入库以注册自定义模型
import wtpsplit.models
from transformers import AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained("segment-any-text/sat-3l-sm") # 或者其他模型名称;请参阅 https://huggingface.co/segment-any-text
通过LoRA适配您自己的语料库
我们的模型可以通过LoRA高效且强大地进行适配。仅需10至100个经过分段标注的训练句子,性能即可显著提升。具体操作如下:
克隆仓库并安装依赖项:
git clone https://github.com/segment-any-text/wtpsplit
cd wtpsplit
pip install -r requirements.txt
pip install adapters==0.2.1 --no-dependencies
cd ..
- 按照以下格式创建数据:
import torch
torch.save(
{
"language_code": {
"sentence": {
"dummy-dataset": {
"meta": {
"train_data": ["训练句1", "训练句2"],
},
"data": [
"测试句1",
"测试句2",
]
}
}
}
},
"dummy-dataset.pth"
)
请注意,单个句子内不应包含换行符!否则会引发错误。列表中的每个条目都应为一个完整的句子,且不得含有\n字符。因此,您的语料库应已预先进行良好的分割。
- 创建或调整配置文件;通过
model_name_or_path指定基础模型,并通过text_path提供训练数据的.pth文件:
configs/lora/lora_dummy_config.json
我们建议从该配置开始,必要时调整model_name_or_path、output_dir和text_path。您也可以根据需要进一步调整adapter_config及批量大小等参数,但这属于实验性内容。
- 训练LoRA:
python3 wtpsplit/train/train_lora.py configs/lora/lora_dummy_config.json
- 训练完成后,将保存的模块路径提供给SaT:
sat_lora_adapted = SaT("model-used", lora_path="dummy_lora_path")
sat_lora_adapted.split("一些领域特定或风格化的文本")
重要提示: 推理时使用的模型变体必须与训练时一致(例如,sat-12l-sm和sat-12l的配置不同,基于前者训练的适配器无法加载到后者上)。
请根据您的需求调整上述代码中的数据集名称、语言和模型。
复现论文结果
configs/ 目录下包含了论文中关于基础模型、sm模型以及LoRA模块的运行配置文件。您可以按如下方式分别启动训练:
python3 wtpsplit/train/train.py configs/<config_name>.json
python3 wtpsplit/train/train_sm.py configs/<config_name>.json
python3 wtpsplit/train/train_lora.py configs/<config_name>.json
此外:
wtpsplit/data_acquisition包含从mC4语料库获取评估数据和原始文本的代码。wtpsplit/evaluation包含以下代码:- 通过
intrinsic.py进行句子分割结果的内在评估。 - 通过
intrinsic_pairwise.py进行短序列评估(即句子对/k-mer的分割结果)。 - LLM基线评估(
llm_sentence.py)、法律基线评估(legal_baselines.py)。 - 基于PySBD、nltk等工具的基线评估结果见
intrinsic_baselines.py和intrinsic_baselines_multi.py。 - 原始评估结果以JSON格式存储在
evaluation_results/中。 - 统计显著性检验的代码及结果位于
stat_tests/。 - 标点符号标注实验见
punct_annotation.py和punct_annotation_wtp.py(仅适用于WtP)。 - 机器翻译方面的外在评估见
extrinsic.py(仅适用于WtP)。
- 通过
请确保提前安装 requirements.txt 中列出的软件包。
支持的语言
支持语言表
| iso | 名称 |
|---|---|
| af | 南非语 |
| am | 阿姆哈拉语 |
| ar | 阿拉伯语 |
| az | 阿塞拜疆语 |
| be | 白俄罗斯语 |
| bg | 保加利亚语 |
| bn | 孟加拉语 |
| ca | 加泰罗尼亚语 |
| ceb | 宿务语 |
| cs | 捷克语 |
| cy | 威尔士语 |
| da | 丹麦语 |
| de | 德语 |
| el | 希腊语 |
| en | 英语 |
| eo | 世界语 |
| es | 西班牙语 |
| et | 爱沙尼亚语 |
| eu | 巴斯克语 |
| fa | 波斯语 |
| fi | 芬兰语 |
| fr | 法语 |
| fy | 西弗里斯兰语 |
| ga | 爱尔兰语 |
| gd | 苏格兰盖尔语 |
| gl | 加利西亚语 |
| gu | 古吉拉特语 |
| ha | 豪萨语 |
| he | 希伯来语 |
| hi | 印地语 |
| hu | 匈牙利语 |
| hy | 亚美尼亚语 |
| id | 印度尼西亚语 |
| ig | 伊博语 |
| is | 冰岛语 |
| it | 意大利语 |
| ja | 日本语 |
| jv | 爪哇语 |
| ka | 格鲁吉亚语 |
| kk | 哈萨克语 |
| km | 高棉语 |
| kn | 卡纳达语 |
| ko | 韩语 |
| ku | 库尔德语 |
| ky | 吉尔吉斯语 |
| la | 拉丁语 |
| lt | 立陶宛语 |
| lv | 拉脱维亚语 |
| mg | 马达加斯加语 |
| mk | 马其顿语 |
| ml | 马拉雅拉姆语 |
| mn | 蒙古语 |
| mr | 马拉地语 |
| ms | 马来语 |
| mt | 马耳他语 |
| my | 缅甸语 |
| ne | 尼泊尔语 |
| nl | 荷兰语 |
| no | 挪威语 |
| pa | 旁遮普语 |
| pl | 波兰语 |
| ps | 普什图语 |
| pt | 葡萄牙语 |
| ro | 罗马尼亚语 |
| ru | 俄语 |
| si | 僧伽罗语 |
| sk | 斯洛伐克语 |
| sl | 斯洛文尼亚语 |
| sq | 阿尔巴尼亚语 |
| sr | 塞尔维亚语 |
| sv | 瑞典语 |
| ta | 泰米尔语 |
| te | 泰卢固语 |
| tg | 塔吉克语 |
| th | 泰语 |
| tr | 土耳其语 |
| uk | 乌克兰语 |
| ur | 乌尔都语 |
| uz | 乌兹别克语 |
| vi | 越南语 |
| xh | 豪萨语 |
| yi | 意第绪语 |
| yo | 约鲁巴语 |
| zh | 中文 |
| zu | 祖鲁语 |
有关详细信息,请参阅我们的 Segment any Text 论文。
社区移植版本
- Rust: wtsplit-rs 由 @19h 开发
注:社区移植版本由独立维护,可能具有不同的功能集或更新计划。
引用
对于 SaT 模型,请引用我们的论文:
@inproceedings{frohmann-etal-2024-segment,
title = "分割任意文本:一种鲁棒、高效且可适应的通用句子分割方法",
author = "Frohmann, Markus 与 Sterner, Igor 与 Vuli{\'c}, Ivan 与 Minixhofer, Benjamin 与 Schedl, Markus",
editor = "Al-Onaizan, Yaser 与 Bansal, Mohit 与 Chen, Yun-Nung",
booktitle = "2024年自然语言处理经验方法会议论文集",
month = nov,
year = "2024",
address = "美国佛罗里达州迈阿密",
publisher = "计算语言学协会",
url = "https://aclanthology.org/2024.emnlp-main.665",
pages = "11908--11941"
}
对于该库和 WtP 模型,请引用:
@inproceedings{minixhofer-etal-2023-wheres,
title = "句号在哪里?自监督多语言无标点符号依赖的句子分割",
author = "Minixhofer, Benjamin 与 Pfeiffer, Jonas 与 Vuli{\'c}, Ivan",
booktitle = "第61届计算语言学协会年会论文集(第一卷:长文)",
month = jul,
year = "2023",
address = "加拿大多伦多",
publisher = "计算语言学协会",
url = "https://aclanthology.org/2023.acl-long.398",
pages = "7215--7235"
}
致谢
本研究全部或部分由奥地利科学基金会(FWF)资助,项目编号为 P36413、P33526 和 DFH-23;同时,也得到了上奥地利州以及联邦教育、科学与研究部通过 LIT-2021-YOU-215 资助的支持。此外,Ivan Vulić 和 Benjamin Minixhofer 还获得了英国皇家学会大学研究 fellowship“面向真正多语世界的包容性与可持续语言技术”(编号 221137)的资助。本研究还得到了谷歌 TPU 研究云(TRC)提供的 Cloud TPU 支持。此外,本工作还获得了 Cohere For AI Research Grant 的算力资助,该资助旨在支持学术合作伙伴开展以发布有益的科研成果和数据为目标的研究。我们还要感谢 Simone Teufel 提供的富有成效的讨论。
如有任何问题,请提交 issue 或发送邮件至 markus.frohmann@gmail.com,我将尽快回复您。
版本历史
2.2.02026/02/262.1.72025/11/192.1.62025/06/232.1.52025/04/012.1.42025/01/252.1.22024/12/142.1.12024/10/272.1.02024/09/242.0.82024/09/092.0.72024/09/022.0.52024/07/082.0.42024/07/012.0.32024/06/261.3.02024/01/221.2.32023/07/181.2.22023/07/141.2.12023/07/111.2.02023/07/071.1.02023/06/171.0.12023/05/31常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器