Kokoro-FastAPI
Kokoro-FastAPI 是一个为 Kokoro-82M 语音合成模型打造的轻量级封装工具,旨在让开发者能轻松部署高性能的文本转语音服务。它通过 Docker 容器化技术,屏蔽了底层环境配置的复杂性,解决了模型在 CPU 与 NVIDIA GPU 之间切换困难、依赖管理繁琐以及长文本处理需要手动拼接等痛点。
这款工具特别适合后端开发者、AI 应用构建者以及希望将高质量语音功能集成到现有系统(如 OpenWebUI、SillyTavern)的技术人员。普通用户若具备基础的 Docker 操作能力,也可快速搭建本地语音服务进行体验。
Kokoro-FastAPI 的技术亮点在于其灵活性与功能性并重:它不仅支持英语、日语、中文等多种语言,还提供兼容 OpenAI 标准的 API 接口,便于无缝对接各类应用。此外,它具备自动长文本拼接、基于音素的音频生成、逐词时间戳字幕输出以及多声音混合等高级特性。内置的 Web 监控界面让用户能直观查看系统状态,而其对 CPU ONNX 和 GPU PyTorch 的双重支持,则确保了在不同硬件环境下都能获得高效的推理性能。无论是用于原型开发还是生产环境部署,它都是一个稳定且易用的选择。
使用场景
一家小型游戏开发团队正在为独立 RPG 项目快速迭代多语言角色配音,需要频繁生成带有时间戳的对话音频以同步口型动画。
没有 Kokoro-FastAPI 时
- 开发者需手动配置复杂的 PyTorch 环境和模型依赖,在不同操作系统间迁移时经常遇到兼容性问题,耗费大量调试时间。
- 生成多语言(中、日、英)语音需要切换不同的模型或 API 服务,导致工作流割裂,且难以统一管理语音风格。
- 缺乏原生的字词级时间戳功能,团队必须编写额外的脚本强行对齐音频与文本,严重拖慢了口型动画的制作进度。
- 本地推理无法有效利用 NVIDIA GPU 加速,生成一段长对话耗时过长,无法满足每日构建版本的即时测试需求。
使用 Kokoro-FastAPI 后
- 通过 Docker 一键部署预构建镜像,自动处理 CPU 或 GPU 环境适配,团队成员可在几分钟内搭建好一致的本地开发服务。
- 单个接口即可支持中、日、英多语言混合输入,并能通过加权组合灵活混合不同音色,轻松实现角色情感变化的配音需求。
- 直接调用内置接口获取精确到单词的音频时间戳数据,无缝对接动画引擎,将口型同步流程从数小时缩短至分钟级。
- 自动识别并调用 NVIDIA GPU 进行加速推理,长文本语音生成速度提升显著,支持实时预览效果,大幅加快迭代循环。
Kokoro-FastAPI 将复杂的语音模型转化为标准化的生产管线,让小型团队也能以极低门槛实现高质量、多语言的自动化配音流程。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- 若使用 GPU 加速,需要 NVIDIA 显卡(支持 CUDA),测试环境为 NVIDIA 4060Ti 16GB (CUDA 12.1)
- Apple Silicon (M1/M2/M3) 目前不支持 GPU 加速(MPS 尚未可用),需使用 CPU 模式
未说明(测试环境为 64GB)
快速开始

FastKoko
针对Kokoro-82M文本转语音模型的Docker化FastAPI封装
- 多语言支持(英语、日语、中文,越南语即将加入)
- 兼容OpenAI的语音端点,可使用NVIDIA GPU加速或基于PyTorch的CPU推理
- ONNX支持即将推出;在此之前,请参阅v0.1.5及更早版本以获取旧版ONNX支持
- 调试端点用于监控系统状态,集成本地Web界面,地址为localhost:8880/web
- 基于音素的音频生成与音素序列生成
- 每个单词带时间戳的字幕生成
- 支持加权组合的多声线混合
集成指南
开始使用
最快启动方式(docker run)
提供了预构建的镜像可供运行,支持arm/multi-arch架构,并内置了模型。 完整的环境变量列表可在core/config.py文件中找到。
# 可以使用`latest`标签,但可能会包含一些影响稳定性的额外功能。
建议在常规使用中固定命名版本。
欢迎提供反馈和测试意见。
docker run -p 8880:8880 ghcr.io/remsky/kokoro-fastapi-cpu:latest # CPU,或者:
docker run --gpus all -p 8880:8880 ghcr.io/remsky/kokoro-fastapi-gpu:latest #NVIDIA GPU
快速启动方式(docker compose)
- 安装先决条件,并使用Docker Compose启动服务(完整设置,包括UI):
- 安装Docker
- 克隆仓库:
git clone https://github.com/remsky/Kokoro-FastAPI.git cd Kokoro-FastAPI cd docker/gpu # 对于GPU支持 # 或cd docker/cpu # 对于CPU支持 docker compose up --build # *注意:对于Apple Silicon(M1/M2)用户: # 当前的GPU版本依赖于CUDA,而CUDA并不支持Apple Silicon。 # 如果您使用的是M1/M2/M3 Mac,请使用`docker/cpu`设置。 # MPS(苹果的GPU加速)支持计划中,但尚未可用。 # 模型会自动下载,但如果需要,您可以手动下载: python docker/scripts/download_model.py --output api/src/models/v1_0 # 或者直接通过UV运行: ./start-gpu.sh # 对于GPU支持 ./start-cpu.sh # 对于CPU支持
直接运行(通过uv)
已经运行起来了吗?
作为兼容OpenAI的语音端点,在本地运行:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8880/v1", api_key="不需要"
)
with client.audio.speech.with_streaming_response.create(
model="kokoro",
voice="af_sky+af_bella", #单个或多个声线组合
input="Hello world!"
) as response:
response.stream_to_file("output.mp3")
功能
兼容OpenAI的语音端点
# 使用OpenAI的Python库
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8880/v1", api_key="不需要")
response = client.audio.speech.create(
model="kokoro",
voice="af_bella+af_sky", # 可在/api/src/core/openai_mappings.json中自定义
input="Hello world!",
response_format="mp3"
)
response.stream_to_file("output.mp3")
或者通过Requests:
import requests
response = requests.get("http://localhost:8880/v1/audio/voices")
voices = response.json()["voices"]
# 生成音频
response = requests.post(
"http://localhost:8880/v1/audio/speech",
json={
"model": "kokoro",
"input": "Hello world!",
"voice": "af_bella",
"response_format": "mp3", # 支持:mp3、wav、opus、flac
"speed": 1.0
}
)
# 保存音频
with open("output.mp3", "wb") as f:
f.write(response.content)
快速测试(从另一个终端运行):
python examples/assorted_checks/test_openai/test_openai_tts.py # 测试 OpenAI 兼容性
python examples/assorted_checks/test_voices/test_all_voices.py # 测试所有可用语音
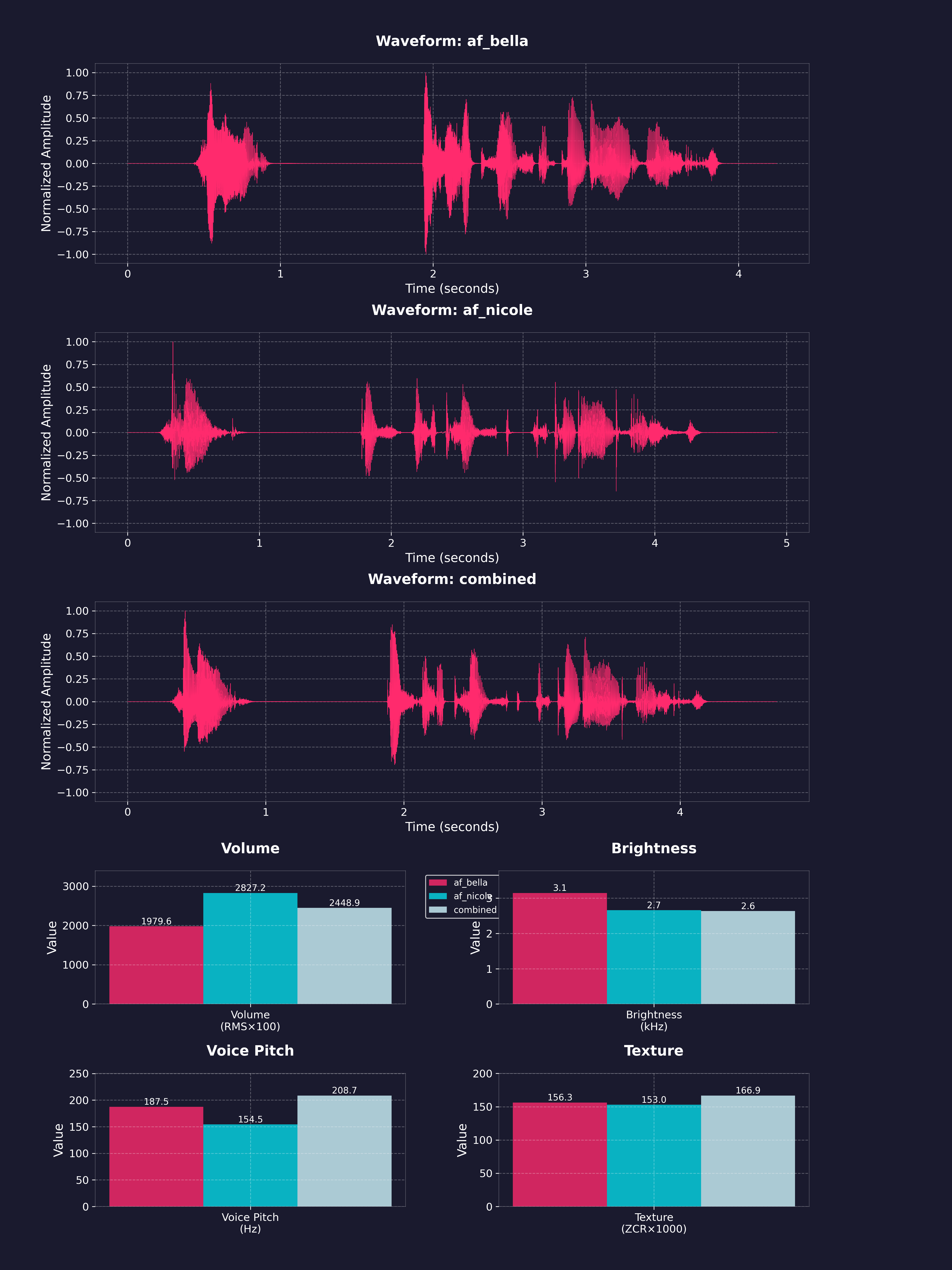
语音组合
- 使用比例进行加权语音组合(例如,“af_bella(2)+af_heart(1)”表示67%/33%的混合)
- 比例会自动归一化为总和100%
- 可通过任何端点以括号内添加权重的方式实现
- 生成的语音包可保存以供将来使用
组合语音并生成音频:
import requests
response = requests.get("http://localhost:8880/v1/audio/voices")
voices = response.json()["voices"]
# 示例1:简单语音组合(50%/50%混合)
response = requests.post(
"http://localhost:8880/v1/audio/speech",
json={
"input": "Hello world!",
"voice": "af_bella+af_sky", # 等权重
"response_format": "mp3"
}
)
# 示例2:加权语音组合(67%/33%混合)
response = requests.post(
"http://localhost:8880/v1/audio/speech",
json={
"input": "Hello world!",
"voice": "af_bella(2)+af_sky(1)", # 2:1比例 = 67%/33%
"response_format": "mp3"
}
)
# 示例3:将组合语音下载为 .pt 文件
response = requests.post(
"http://localhost:8880/v1/audio/voices/combine",
json="af_bella(2)+af_sky(1)" # 2:1比例 = 67%/33%
)
# 保存 .pt 文件
with open("combined_voice.pt", "wb") as f:
f.write(response.content)
# 使用下载的语音文件
response = requests.post(
"http://localhost:8880/v1/audio/speech",
json={
"input": "Hello world!",
"voice": "combined_voice", # 使用保存的语音文件
"response_format": "mp3"
}
)
多种输出音频格式
- mp3
- wav
- opus
- flac
- m4a
- pcm
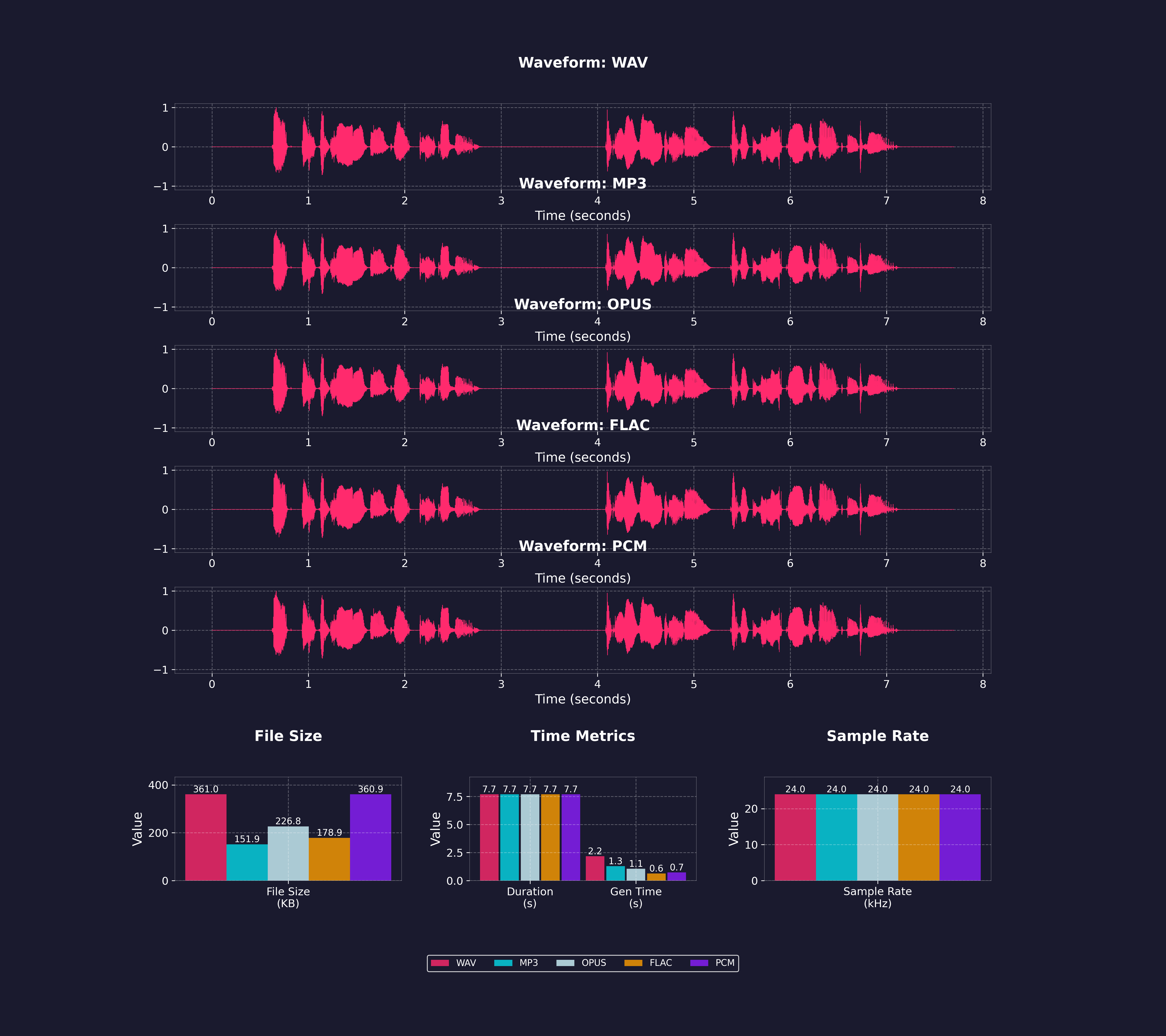
流式传输支持
# OpenAI 兼容的流式传输
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8880/v1", api_key="not-needed")
# 流式传输到文件
with client.audio.speech.with_streaming_response.create(
model="kokoro",
voice="af_bella",
input="Hello world!"
) as response:
response.stream_to_file("output.mp3")
# 流式传输到扬声器(需要 PyAudio)
import pyaudio
player = pyaudio.PyAudio().open(
format=pyaudio.paInt16,
channels=1,
rate=24000,
output=True
)
with client.audio.speech.with_streaming_response.create(
model="kokoro",
voice="af_bella",
response_format="pcm",
input="Hello world!"
) as response:
for chunk in response.iter_bytes(chunk_size=1024):
player.write(chunk)
或者通过 requests:
import requests
response = requests.post(
"http://localhost:8880/v1/audio/speech",
json={
"input": "Hello world!",
"voice": "af_bella",
"response_format": "pcm"
},
stream=True
)
for chunk in response.iter_content(chunk_size=1024):
if chunk:
# 处理流式传输的每个数据块
pass
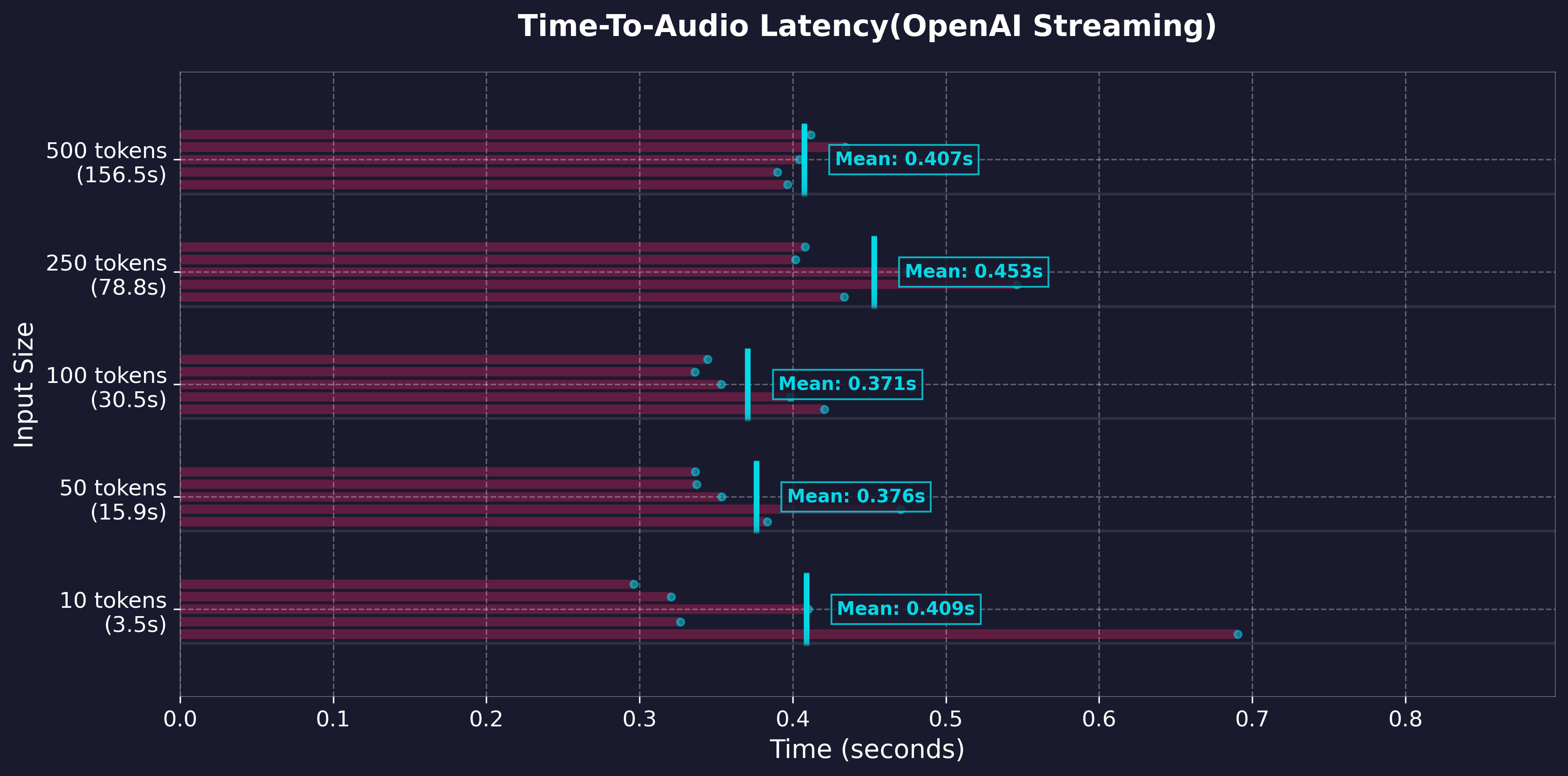
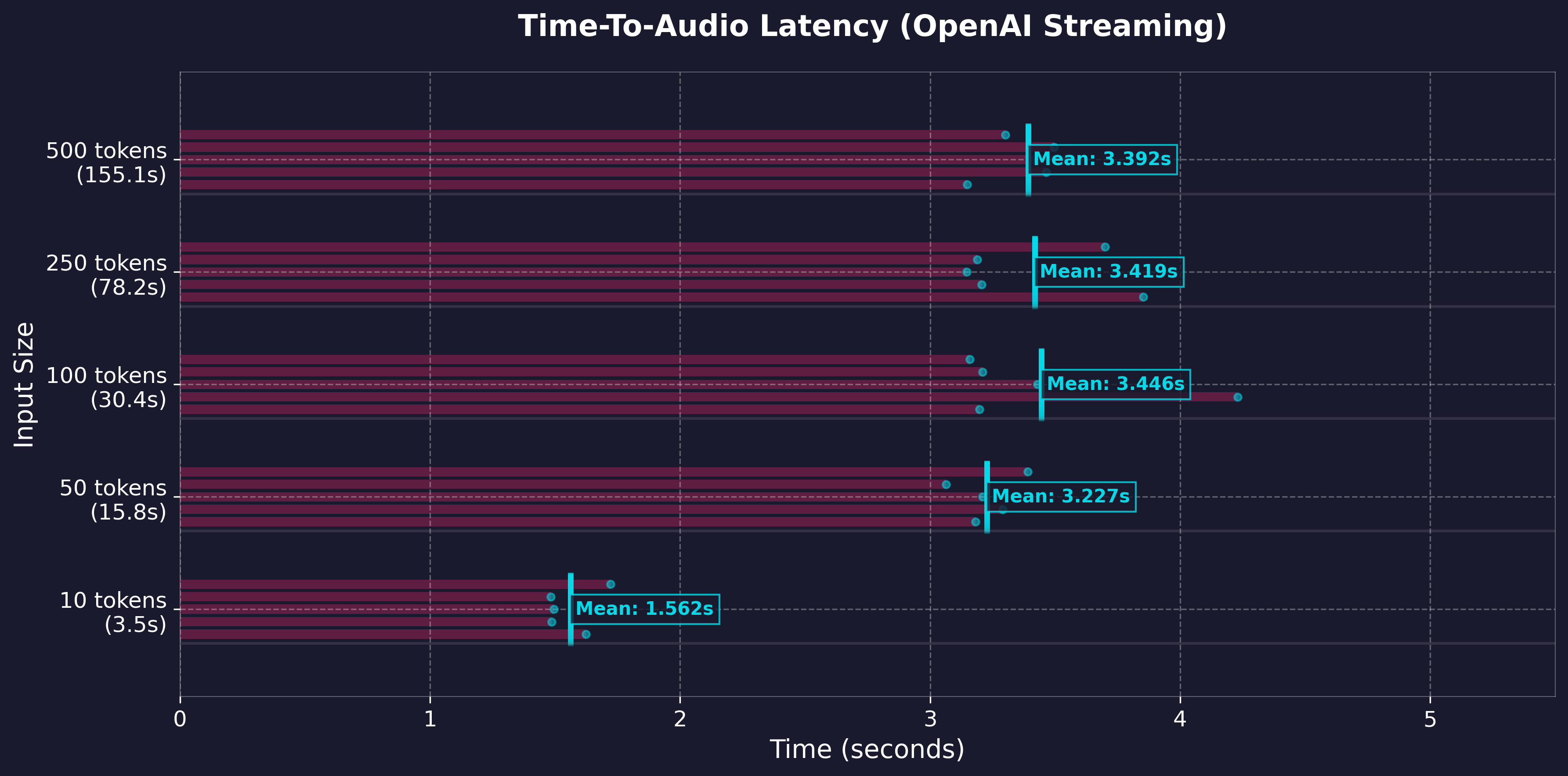
关键流式传输指标:
- 首个 token 延迟 @ 数据块大小
- ~300ms (GPU) @ 400
- ~3500ms (CPU) @ 200 (较旧的 i7)
- ~<1s (CPU) @ 200 (M3 Pro)
- 可调整的分块设置,适用于实时播放
注:音调方面可能会因分块过小而出现瑕疵
处理细节
性能基准测试
基准测试是在本地 API 上进行的,文本长度最长可达长篇小说级别(约1.5小时的输出),测量了处理时间和实时因子。测试环境如下:
- Windows 11 家庭版,搭载 WSL2
- NVIDIA 4060Ti 16GB 显卡,CUDA 12.1
- 第11代 i7-11700,2.5GHz
- 64GB 内存
- WAV 原生输出
- H.G. Wells 的《时间机器》(全文)
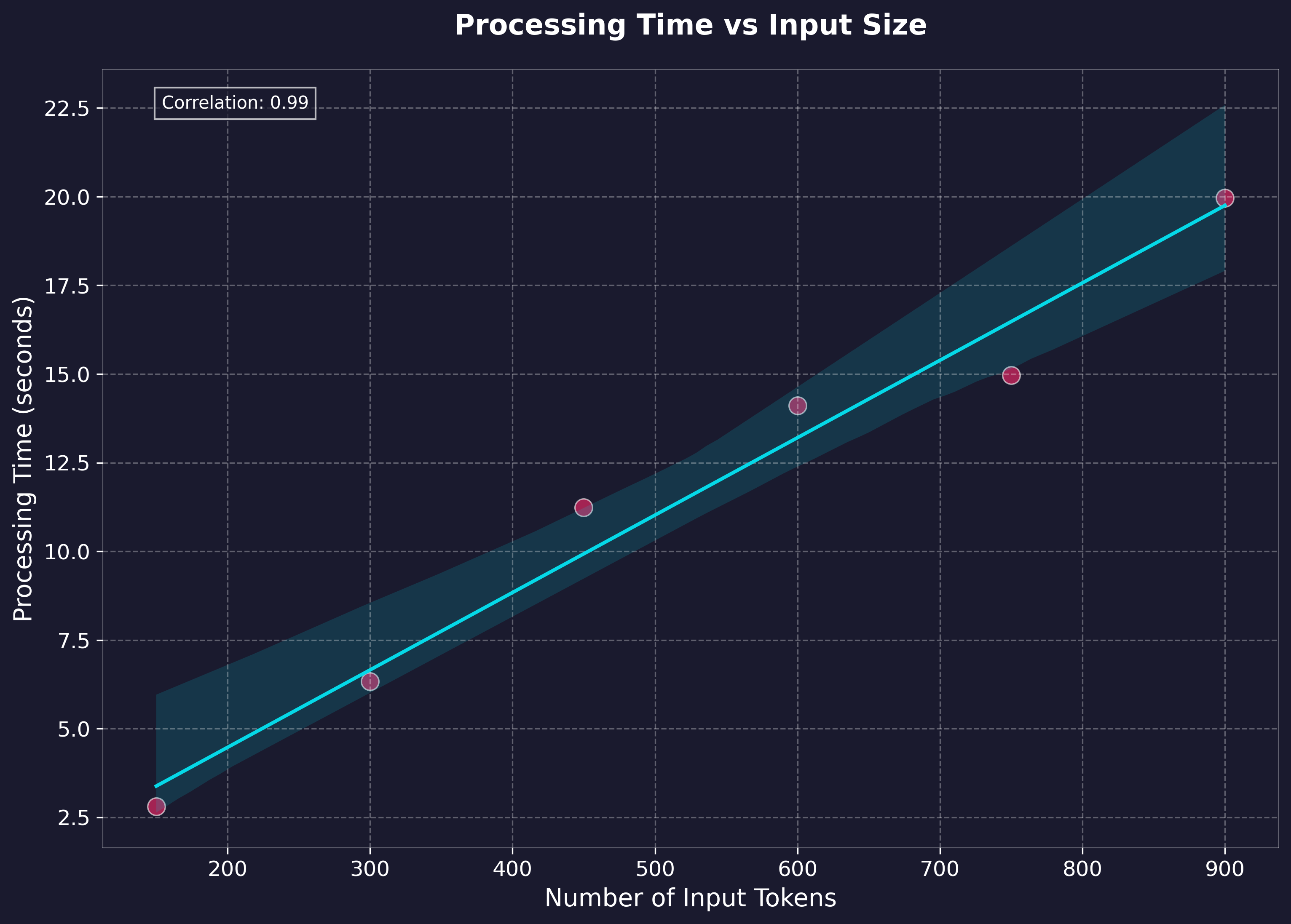
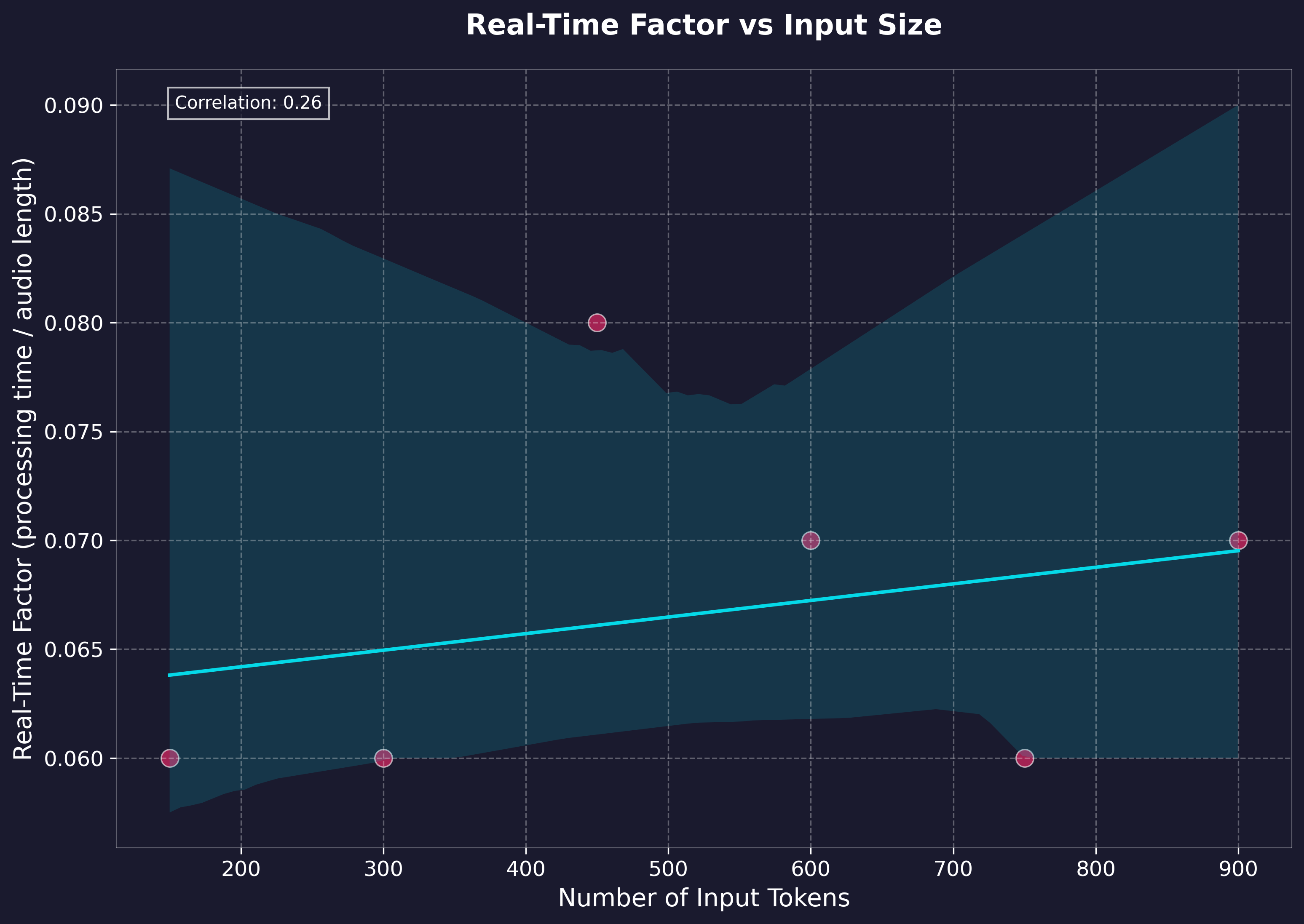
关键性能指标:
- 实时速度:介于35倍至100倍之间(生成时间与音频输出长度之比)
- 平均处理速率:137.67 tokens/秒(cl100k_base)
GPU 与 CPU 对比
# GPU:需要支持 CUDA 12.8 的 NVIDIA 显卡(实时速度约为35倍至100倍)
cd docker/gpu
docker compose up --build
# CPU:PyTorch CPU 推理
cd docker/cpu
docker compose up --build
注:为了支持流式传输而进行的结构调整可能导致整体速度有所下降。正在进一步调查中。
自然边界检测
- 自动在句子边界处分割和拼接
- 有助于减少伪影,并支持长文本处理,因为基础模型目前仅配置为生成约30秒的输出。
该模型一次最多可处理510个音素化标记的片段,但这样往往会导致语速过快或其他伪影。因此,服务器端额外增加了一层切块逻辑,根据 TARGET_MIN_TOKENS、TARGET_MAX_TOKENS 和 ABSOLUTE_MAX_TOKENS 参数动态生成灵活的片段,这些参数可通过环境变量配置,默认值分别为175、250和450。
带时间戳的字幕与音素
不使用流式传输生成带单词级时间戳的音频:
import requests
import base64
import json
response = requests.post(
"http://localhost:8880/dev/captioned_speech",
json={
"model": "kokoro",
"input": "你好,世界!",
"voice": "af_bella",
"speed": 1.0,
"response_format": "mp3",
"stream": False,
},
stream=False
)
with open("output.mp3","wb") as f:
audio_json=json.loads(response.content)
# 将Base64编码的音频流解码为字节
chunk_audio=base64.b64decode(audio_json["audio"].encode("utf-8"))
# 处理流式传输的音频块
f.write(chunk_audio)
# 打印单词级时间戳
print(audio_json["timestamps"])
使用流式传输生成带单词级时间戳的音频:
import requests
import base64
import json
response = requests.post(
"http://localhost:8880/dev/captioned_speech",
json={
"model": "kokoro",
"input": "你好,世界!",
"voice": "af_bella",
"speed": 1.0,
"response_format": "mp3",
"stream": True,
},
stream=True
)
f=open("output.mp3","wb")
for chunk in response.iter_lines(decode_unicode=True):
if chunk:
chunk_json=json.loads(chunk)
# 将Base64编码的音频流解码为字节
chunk_audio=base64.b64decode(chunk_json["audio"].encode("utf-8"))
# 处理流式传输的音频块
f.write(chunk_audio)
# 打印单词级时间戳
print(chunk_json["timestamps"])
音素与标记路由
将文本转换为音素,或直接从音素生成音频:
import requests
def get_phonemes(text: str, language: str = "a"):
"""获取输入文本的音素和标记"""
response = requests.post(
"http://localhost:8880/dev/phonemize",
json={"text": text, "language": language} # "a" 表示美式英语
)
response.raise_for_status()
result = response.json()
return result["phonemes"], result["tokens"]
def generate_audio_from_phonemes(phonemes: str, voice: str = "af_bella"):
"""根据音素生成音频"""
response = requests.post(
"http://localhost:8880/dev/generate_from_phonemes",
json={"phonemes": phonemes, "voice": voice},
headers={"Accept": "audio/wav"}
)
if response.status_code != 200:
print(f"错误:{response.text}")
return None
return response.content
# 示例用法
text = "你好,世界!"
try:
# 将文本转换为音素
phonemes, tokens = get_phonemes(text)
print(f"音素:{phonemes}") # 例如:ðɪs ɪz ˈoʊnli ɐ tˈɛst
print(f"标记:{tokens}") # 包括开始和结束标记的标记ID
# 生成并保存音频
if audio_bytes := generate_audio_from_phonemes(phonemes):
with open("speech.wav", "wb") as f:
f.write(audio_bytes)
print(f"已生成 {len(audio_bytes)} 字节的音频")
except Exception as e:
print(f"错误:{e}")
更多示例请参阅 examples/phoneme_examples/generate_phonemes.py。
调试端点
通过以下端点监控系统状态和资源使用情况:
/debug/threads- 获取线程信息和堆栈跟踪/debug/storage- 监控临时文件和输出目录的使用情况/debug/system- 获取系统信息(CPU、内存、GPU)/debug/session_pools- 查看 ONNX 会话和 CUDA 流的状态
这些端点对于调试资源耗尽或性能问题非常有用。
日志记录
全局 API 的 loguru 日志级别 可以通过 API_LOG_LEVEL 环境变量设置。默认值为 DEBUG。
Docker
修改相应的 compose yml 文件,或在命令行中追加:
docker run --env 'API_LOG_LEVEL=WARNING' ...
直接通过 UV
Linux 和 macOS
export API_LOG_LEVEL=WARNING
./start-cpu.sh 或 ./start-gpu.sh
Windows
$env:API_LOG_LEVEL = 'WARNING'
.\start-cpu.ps1 或 .\start-gpu.ps1
已知问题与故障排除
缺失词语及部分时间戳
API 会对输入文本自动进行文本归一化处理,这可能会错误地移除或更改某些短语。您可以通过在请求 JSON 中添加 "normalization_options":{"normalize": false} 来禁用此功能:
import requests
response = requests.post(
"http://localhost:8880/v1/audio/speech",
json={
"input": "Hello world!",
"voice": "af_heart",
"response_format": "pcm",
"normalization_options":
{
"normalize": False
}
},
stream=True
)
for chunk in response.iter_content(chunk_size=1024):
if chunk:
# 处理流式传输的块
pass
版本控制与开发
分支策略:
release分支: 包含最新的稳定版本,推荐用于生产环境。基于该分支构建的 Docker 镜像会打上特定版本标签(例如v0.3.0)。master分支: 用于活跃开发。该分支可能包含实验性功能、正在进行的更改或尚未进入稳定版的修复。如果您希望使用最新代码,请使用此分支,但请注意其稳定性可能较低。latestDocker 标签通常指向该分支的构建。
注意:该项目本质上是一个以开发为主的项目。
如果您遇到问题,可能需要回退到 release 标签中的某个版本,或者从源码构建并进行调试,同时提交 PR。
开源是社区共同努力的结果,而每个人每天的时间都是有限的。如果您想支持这项工作,欢迎提交 PR、请我喝杯咖啡,或报告您在使用过程中发现的任何 bug 或功能需求等。

Linux GPU 权限问题
部分 Linux 用户在以非 root 用户身份运行时可能会遇到 GPU 权限问题。 我们无法保证解决方案的有效性,但以下是一些常见的解决方法,请务必根据您的安全需求谨慎选择。
选项 1:容器组(可能是最佳选择)
services:
kokoro-tts:
# ... 现有配置 ...
group_add:
- "video"
- "render"
选项 2:主机系统组
services:
kokoro-tts:
# ... 现有配置 ...
user: "${UID}:${GID}"
group_add:
- "video"
注意:可能需要将主机用户添加到相关组中:sudo usermod -aG docker,video $USER,并重启系统。
选项 3:设备权限(谨慎使用)
services:
kokoro-tts:
# ... 现有配置 ...
devices:
- /dev/nvidia0:/dev/nvidia0
- /dev/nvidiactl:/dev/nvidiactl
- /dev/nvidia-uvm:/dev/nvidia-uvm
⚠️ 警告:会降低系统安全性。仅适用于开发环境。
前提条件:必须正确配置 NVIDIA GPU、驱动程序和容器工具包。
更多详细信息请访问 NVIDIA 容器工具包安装指南。
模型与许可证
许可证
本项目采用 Apache License 2.0 许可证——详情如下:- Kokoro 模型权重采用 Apache 2.0 许可证(详见 模型页面)
- 本仓库中的 FastAPI 封装代码也采用 Apache 2.0 许可证,以保持一致
- 基于 StyleTTS2 改编的推理代码则采用 MIT 许可证
完整的 Apache 2.0 许可证文本可在以下网址找到:https://www.apache.org/licenses/LICENSE-2.0
贡献者统计


由 contrib.rocks 制作。
版本历史
v0.2.4-master2025/12/13v0.2.42025/06/18v0.2.32025/03/07v0.2.22025/02/13v0.2.12025/02/10v0.2.02025/02/07v0.1.42025/01/31v0.1.02025/01/14v0.0.5post12025/01/13v0.1.0-pre2025/01/12v0.0.52025/01/11v0.0.42025/01/09v0.0.32025/01/07v0.0.22025/01/04v0.0.12025/01/02常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。