Awesome-Reasoning-Foundation-Models
Awesome-Reasoning-Foundation-Models 是一个专注于大模型推理能力的开源资源库,旨在系统梳理该领域的最新论文、基准测试与技术进展。随着人工智能从单纯的知识记忆向复杂逻辑推演进化,如何提升模型在数学、逻辑、因果及多模态场景下的“思考”能力成为关键挑战。该项目通过构建结构化的知识体系,有效解决了研究人员在面对海量碎片化文献时难以快速定位核心资源的痛点。
它特别适合 AI 研究人员、算法工程师以及对大模型底层机制感兴趣的技术开发者使用。无论是希望追踪前沿学术动态,还是寻找特定任务(如常识推理、智能体决策)的解决方案,都能在此获得指引。其独特亮点在于不仅按语言、视觉、多模态等基础模型类型进行分类,还深度整合了预训练、微调、对齐训练、混合专家模型(MoE)及上下文学习等关键推理技术。此外,该资源库依托于高质量的综述论文《A Survey of Reasoning with Foundation Models》,确保了内容的权威性与前瞻性,是探索大模型推理边界不可或缺的参考指南。
使用场景
某高校人工智能实验室的研究团队正致力于开发一款能解决复杂数学应用题的教育大模型,急需筛选最适合的推理架构与基准测试方案。
没有 Awesome-Reasoning-Foundation-Models 时
- 文献检索如大海捞针:研究人员需在 arXiv 上手动搜索"reasoning"、"math"、"CoT"等关键词,面对海量论文难以快速识别哪些是真正针对基础模型推理能力的最新成果。
- 技术路线选择盲目:缺乏系统分类,团队难以厘清“预训练”、“微调”与“思维链(In-context Learning)”在不同推理任务(如逻辑推理 vs 因果推理)中的具体适用性,导致实验方向频繁试错。
- 基准测试标准混乱:找不到权威且统一的评测榜单,不同论文使用的数据集各异,导致团队无法客观评估自家模型在数学或常识推理上的真实水平,复现对比极其耗时。
使用 Awesome-Reasoning-Foundation-Models 后
- 资源获取一站式完成:直接查阅该仓库整理的精选列表,迅速定位到最新的语言、视觉及多模态推理模型论文,将文献调研时间从数周缩短至几天。
- 技术决策有的放矢:利用其清晰的分类体系(如数学推理、代理推理),团队快速锁定了适合教育场景的“混合专家(MoE)”与“对齐训练”技术组合,大幅减少了无效实验。
- 评估体系科学规范:参考仓库中汇总的权威基准测试(Benchmarks),建立了标准化的评估流程,不仅能准确量化模型提升效果,还能直接与业界最先进水平进行公平对标。
Awesome-Reasoning-Foundation-Models 通过系统化梳理前沿论文与评测标准,将研究团队从繁琐的信息筛选中解放出来,使其能专注于核心算法的创新与落地。
运行环境要求
未说明
未说明
快速开始
令人惊叹的推理基础模型
![]()
![]()
![]()
survey.pdf |
一个精心整理的、关于用于推理的大型AI模型或基础模型的精彩列表。
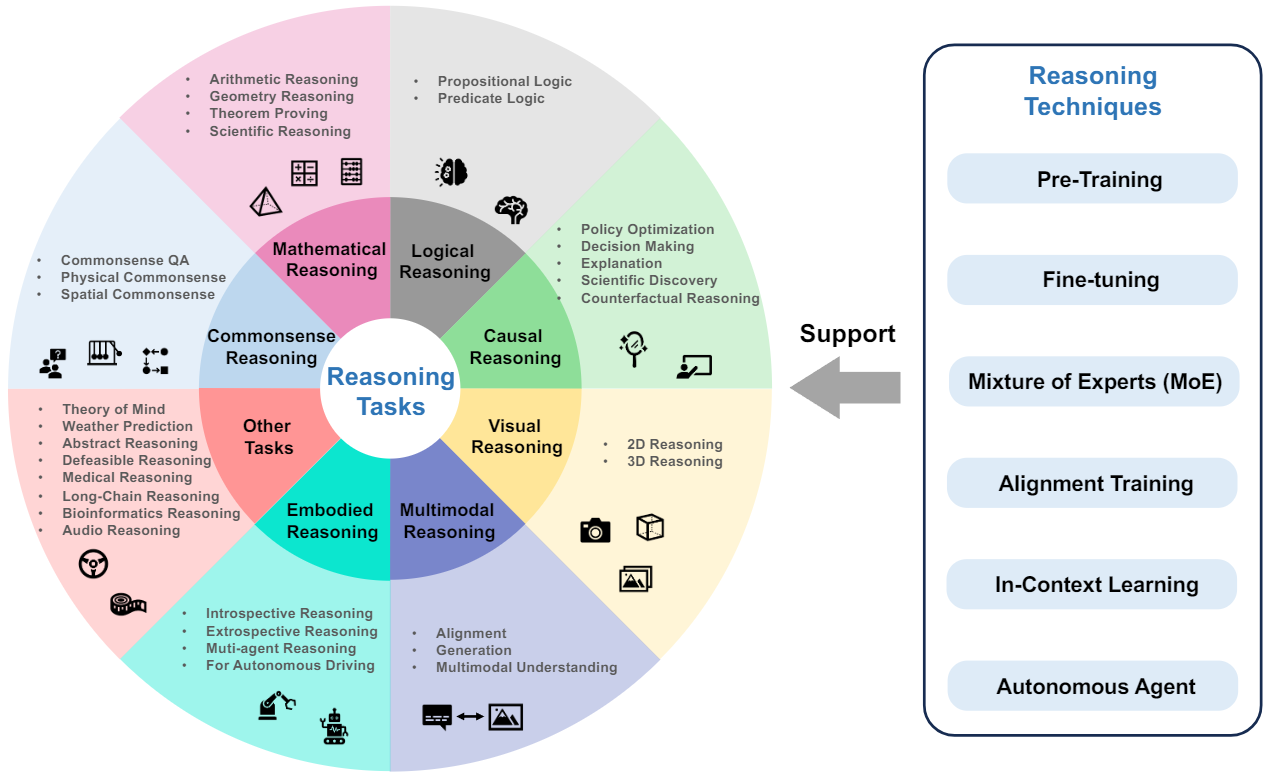
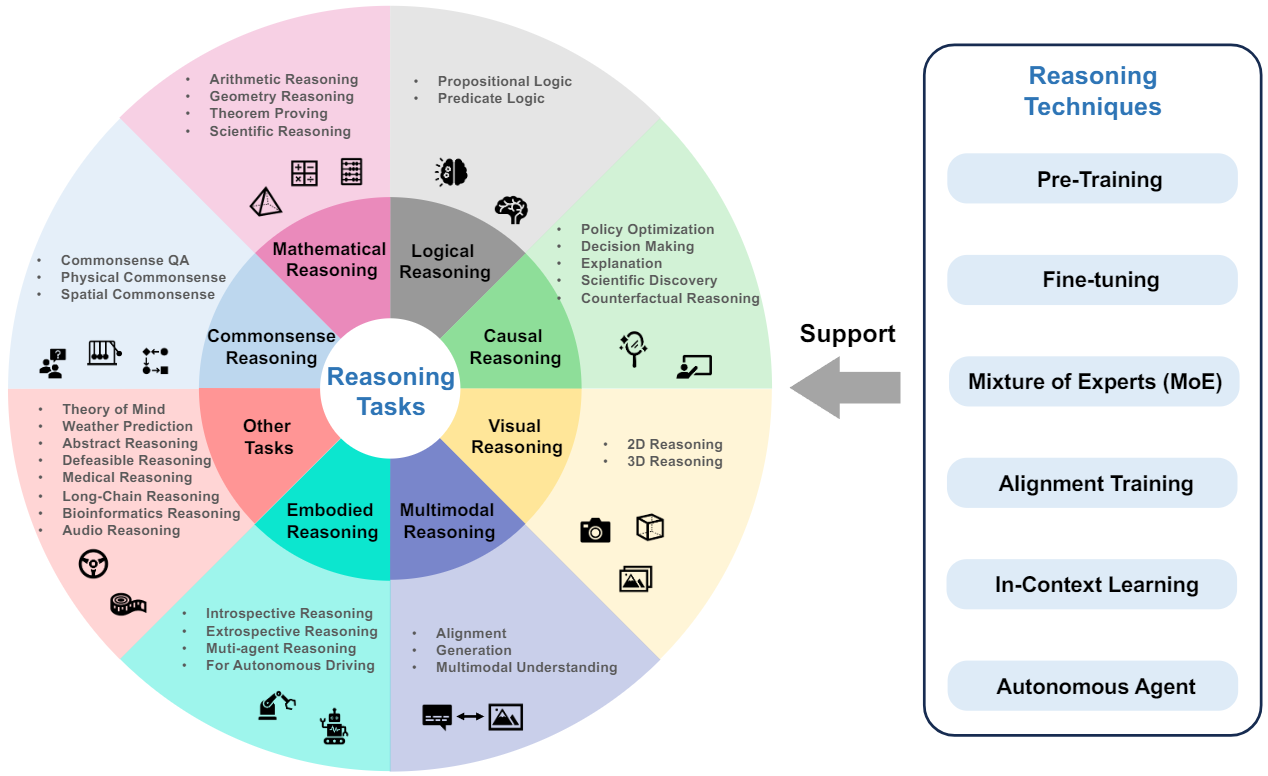
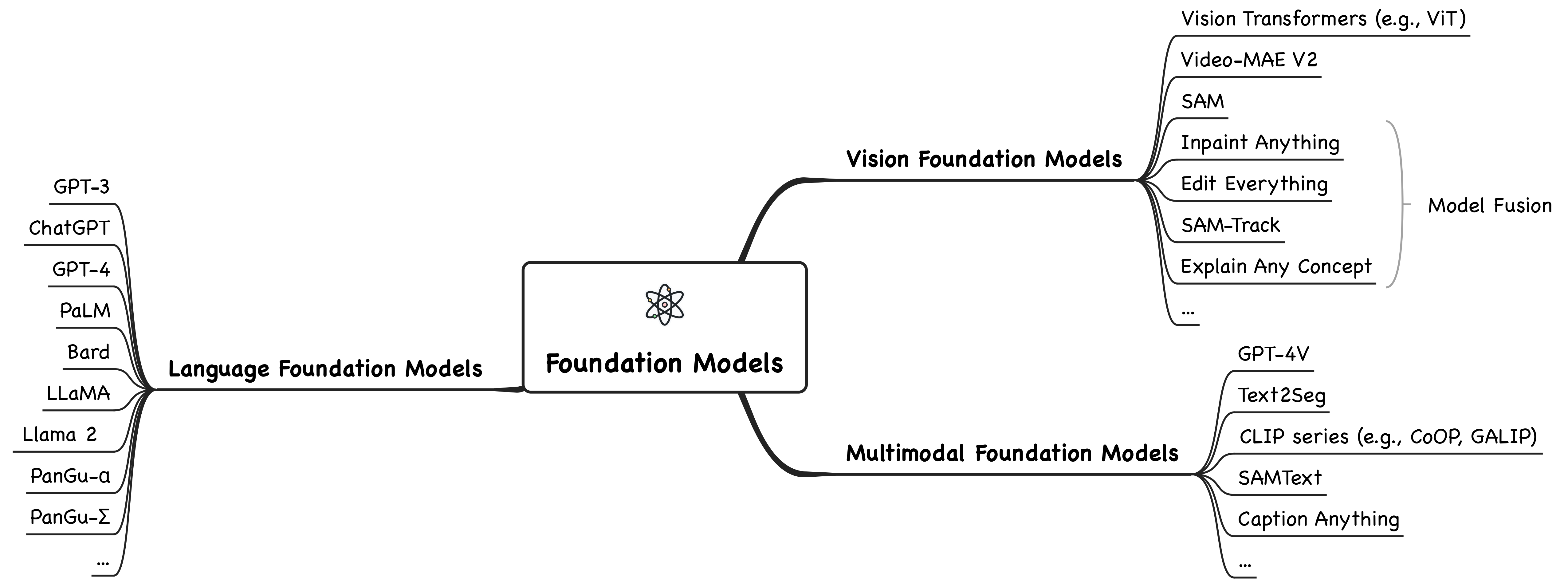
我们把当前的基础模型分为三类:语言基础模型、视觉基础模型和多模态基础模型。 此外,我们还详细介绍了这些基础模型在推理任务中的应用,包括常识推理、数学推理、逻辑推理、因果推理、视觉推理、音频推理、多模态推理、智能体推理等。 推理技术,如预训练、微调、对齐训练、专家混合模型、上下文学习和自主智能体,也被总结在此。
我们欢迎为本仓库贡献更多资源。如果您想贡献力量,请提交拉取请求!详情请参阅CONTRIBUTING。
目录
目录
0 概述
本仓库主要基于以下论文:
孙建凯()、郑传扬()、谢恩泽()、刘正颖()、楚睿航()、邱佳宁()、徐嘉琪()、丁明宇()、李洪洋()、耿孟哲()、吴岳()、王文海()、陈俊松()、尹章悦()、任晓哲()、傅杰()、何俊贤()、吴源()、刘奇()、刘希辉()、李宇()、董浩()、程宇()、张明()、彭安恒()、戴继峰()、罗平()、王京东()、温继荣()、邱锡鹏()、郭义克()、熊辉()、刘群()和李振国()
如果您觉得本仓库有所帮助,请考虑引用:
@article{sun2025survey,
author = {孙建凯、郑传扬、谢恩泽、刘正颖、楚睿航、邱佳宁、徐嘉琪、丁明宇、李洪洋、耿孟哲、吴岳、王文海、陈俊松、尹章悦、任晓哲、傅杰、何俊贤、吴源、刘奇、刘希辉、李宇、董浩、程宇、张明、彭安恒、戴继峰、罗平、王京东、温继荣、邱锡鹏、郭义克、熊辉、刘群、李振国},
title = {基础模型推理综述:概念、方法与展望},
year = {2025},
publisher = {美国计算机协会},
address = {纽约, 美国},
issn = {0360-0300},
url = {https://doi.org/10.1145/3729218},
doi = {10.1145/3729218},
abstract = {推理是解决复杂问题的关键能力,在谈判、医学诊断和刑事侦查等多种现实场景中发挥着核心作用。它也是通用人工智能(AGI)领域的基本方法论。随着基础模型的不断发展,人们对其在推理任务中的能力越来越感兴趣。本文介绍了可用于或可适配于推理的代表性基础模型,并重点展示了各类推理任务、方法和基准测试的最新进展。随后,我们探讨了基础模型中推理能力出现的潜在未来方向。同时,我们也讨论了多模态学习、自主智能体和超级对齐在推理背景下的相关性。通过探讨这些未来的研究方向,我们希望激励研究人员进一步探索这一领域,推动基础模型(例如大型语言模型LLM)在推理方面的更多进展,并为AGI的发展做出贡献。},
journal = {ACM 计算机科学评论},
month = apr,
keywords = {推理、基础模型、多模态、AI智能体、通用人工智能、LLM}
}
1 相关综述与链接
相关综述
优秀多模态推理资源 - [链接]
2 基础模型
基础模型
目录 - 2
2.1 语言基础模型
LFMs
2023/10|Mistral| Mistral 7B - [论文] [代码]2023/07|Llama 2| Llama 2:开放的基础及微调聊天模型 - [论文] [代码] [博客]2023/07|InternLM| InternLM:一款逐步增强能力的多语言语言模型 - [论文] [代码] [项目]2023/05|PaLM 2| PaLM 2技术报告 -2023/03|PanGu-Σ| PanGu-Σ:迈向采用稀疏异构计算的万亿参数语言模型 - [论文]2023/03|Vicuna| Vicuna:一款以90%* ChatGPT质量惊艳GPT-4的开源聊天机器人 - [博客] [代码]2023/02|LLaMA| LLaMA:开放且高效的语言基础模型 - [论文] [代码] [博客]2022/11|ChatGPT| Chatgpt:优化语言模型以用于对话 - [博客]2022/04|PaLM| PaLM:通过Pathways扩展语言建模能力 - [论文] [博客]2021/09|FLAN| 微调后的语言模型是零样本学习者 -2021/07|Codex| 评估基于代码训练的大语言模型 -2021/05|GPT-3| 语言模型是少样本学习者 - [论文] [代码]2021/04|PanGu-α| PanGu-α:大规模自回归预训练中文语言模型,采用自动并行计算 - [论文] [代码]2019/08|Sentence-BERT| [Sentence-BERT:使用暹罗BERT网络生成句子嵌入] - [论文]2019/07|RoBERTa| RoBERTa:一种鲁棒优化的BERT预训练方法 -2018/10|BERT| BERT:用于语言理解的深度双向Transformer预训练 - [论文] [代码] [博客]
2.2 视觉基础模型
VFMs
2024/01|Depth Anything|Yang et al.
Depth Anything:释放大规模无标注数据的力量
[arXiv] [paper] [code] [project]2023/05|SAA+|Cao et al.
无需训练的任意异常分割:基于混合提示正则化的方案
[arXiv] [paper] [code]2023/05|Explain Any Concept| 解释任意概念:Segment Anything 配合基于概念的解释方法 - [Paper] [Code]2023/05|SAMRS| SAMRS:利用 Segment Anything 模型扩展遥感分割数据集 - [Paper] [Code]2023/04|Edit Everything| 编辑一切:一种文本引导的图像生成系统 - [Paper] [Code]2023/04|Inpaint Anything| 修复任意内容:Segment Anything 结合图像修复技术 - [Paper] [Code]2023/04|SAM|Kirillov et al., ICCV 2023
分割任意对象
[arXiv] [paper] [code] [blog]2023/03|VideoMAE V2| VideoMAE V2:通过双重掩码扩展视频掩码自编码器 - [Paper] [Code]2023/03|Grounding DINO|Liu et al.
Grounding DINO:将 DINO 与接地预训练结合用于开放集目标检测
[arXiv] [paper] [code]2022/03|VideoMAE| VideoMAE:掩码自编码器是自监督视频预训练中高效的数据学习者 - [Paper] [Code]2021/12|Stable Diffusion|Rombach et al., CVPR 2022
使用潜在扩散模型进行高分辨率图像合成
[arXiv] [paper] [code] [stable diffusion ]
]2021/09|LaMa| 具有傅里叶卷积的分辨率鲁棒性大范围遮罩修复 - [Paper] [Code]2021/03|Swin|Liu et al., ICCV 2021
Swin Transformer:使用移位窗口的分层视觉 Transformer
[arXiv] [paper] [code]2020/10|ViT|Dosovitskiy et al., ICLR 2021
一张图胜过 16x16 个词:大规模图像识别中的 Transformer
[arXiv] [paper] [Implementation]
2.3 多模态基础模型
MFMs
2024/01|LLaVA-1.6|Liu et al.
LLaVA-1.6:改进了推理能力、OCR 和世界知识
[代码] [博客]2024/01|MouSi|Fan et al.
MouSi:多视觉专家视觉-语言模型
[arXiv] [论文] [代码]2023/12|InternVL|Chen et al.
InternVL:扩展视觉基础模型并对其对齐,以应对通用的视觉-语言任务
[arXiv] [论文] [代码]2023/12|Gemini| Gemini:一个高度强大的多模态模型家族 - [论文] [项目]2023/10|LLaVA-1.5|Liu et al.
通过视觉指令微调改进基准模型
[arXiv] [论文] [代码] [项目]2023/08|Qwen-VL| Qwen-VL:一种多功能的视觉-语言模型,用于理解、定位、文本阅读等 - [论文] [代码]2023/05|InstructBLIP| InstructBLIP:通过指令微调迈向通用型视觉-语言模型 - [论文] [代码]2023/05|Caption Anything| Caption Anything:具有多样化多模态控制的交互式图像描述 - [论文] [代码]2023/05|SAMText| 视频文本检测的可扩展掩码标注 - [论文] [代码]2023/04|Text2Seg| Text2Seg:通过文本引导的视觉基础模型进行遥感图像语义分割 - [论文]2023/04|MiniGPT-4| MiniGPT-4:利用先进的大型语言模型增强视觉-语言理解能力 -2023/04|CLIP Surgery| CLIP 手术:在开放词汇任务中提升可解释性 - [论文] [代码]2023/03|UniDiffuser| 一个 Transformer 适用于大规模多模态扩散中的所有分布 -2023/01|GALIP| GALIP:用于文本到图像合成的生成对抗 CLIP - [论文] [代码]2023/01|BLIP-2| BLIP-2:使用冻结的图像编码器和大型语言模型进行语言-图像预训练的自举 - [论文] [代码]2022/12|Img2Prompt| 从图像到文本提示:使用冻结的大语言模型进行零样本 VQA -2022/05|CoCa| CoCa:对比式标题生成器是图像-文本的基础模型 - [论文]2022/01|BLIP| BLIP:为统一的视觉-语言理解和生成而进行的语言-图像预训练自举 - [论文] [代码]2021/09|CoOp| 学习如何为视觉-语言模型设计提示 - [论文] [代码]2021/02|CLIP| 从自然语言监督中学习可迁移的视觉模型 - [论文] [代码] [博客]
2.4 推理应用
推理应用
2022/06|Minerva| 使用语言模型解决定量推理问题 - [论文] [博客]2022/06|BIG-bench| 超越模仿游戏:量化并外推语言模型的能力 - [论文] [代码]2022/05|Zero-shot-CoT| 大型语言模型是零样本推理者 - [论文] [代码]2022/03|STaR| STaR:通过推理来启动推理 - [论文] [代码]2021/07|MWP-BERT| MWP-BERT:用于数学文字题求解的数值增强预训练 - [论文] [代码]2017/05|AQUA-RAT| 基于推理生成的程序归纳:学习解决并解释代数文字题 - [论文] [代码]
3 推理任务
推理任务
目录 - 3
推理任务(目录)
3.1 常识推理
常识推理
2023/12| Gemini在推理中的应用:揭示多模态大型语言模型中的常识 - [论文] [代码]2023/05|LLM-MCTS| 大型语言模型作为大规模任务规划的常识知识 - [论文] [代码] [项目]2022/11|DANCE| 通过知识图谱谜题提升视觉-语言模型中的常识 - [论文] [代码] [项目]2022/10|CoCoGen| 代码语言模型是少数样本常识学习者 - [论文] [代码]2021/10| 对大型语言模型中常识知识的系统性研究 - [论文]2021/05| 超越简单的微调:改进面向社会常识的预训练模型 - [论文]
3.1.1 常识问答(QA)
2019/06|CoS-E| 解释你自己!利用语言模型进行常识推理 - [论文] [代码]2018/11|CQA| 常识QA:一项针对常识知识的问答挑战 - [论文] [代码] [项目]2016/12|ConceptNet| ConceptNet 5.5:一个开放的多语言通用知识图谱 - [论文] [项目]
3.1.2 物理常识推理
2025/05|PhyX| PhyX:你的模型具备物理推理所需的“智慧”吗? - [论文] [代码] [项目]2023/10|NEWTON| NEWTON:大型语言模型是否具备物理推理能力? - [论文] [代码] [项目]2022/03|PACS| PACS:用于物理视听常识推理的数据集 - [论文] [代码]2021/10|VRDP| 通过从视频和语言中学习可微分物理模型实现动态视觉推理 - [论文] [代码]2020/05|ESPRIT| ESPRIT:解释物理推理任务的解决方案 - [论文] [代码]2019/11|PIQA| PIQA:自然语言中的物理常识推理 - [论文] [项目]
3.1.3 空间常识推理
2024/01|SpatialVLM|Chen et al.
SpatialVLM:赋予视觉-语言模型空间推理能力
[arXiv] [论文] [项目]2022/03| 文本中未提及的事物:从视觉信号中探索空间常识 - [论文] [代码]2021/06|PROST| PROST:通过时空对物体进行物理推理 - [论文] [代码]2019/02|GQA| GQA:一个新的用于现实世界视觉推理和组合式问答的数据集 - [论文] [项目]
3.1.x 基准、数据集和指标
2023/06|CConS| 用反常识情境探测物理推理 -2023/05|SummEdits| LLMs作为事实推理者:来自现有基准及其他方面的洞见 - [论文] [代码]2021/03|RAINBOW| UNICORN在RAINBOW上:一种基于新型多任务基准的通用常识推理模型 -2020/11|ProtoQA| ProtoQA:一个用于原型式常识推理的问答数据集 - [论文]2020/10|DrFact| 可微分的开放式常识推理2019/11|CommonGen| CommonGen:一项针对生成式常识推理的受限文本生成挑战2019/08|Cosmos QA| Cosmos QA:带有上下文常识推理的机器阅读理解2019/08|αNLI| 溯因式常识推理 -2019/08|PHYRE| PHYRE:一个新的物理推理基准 -2019/07|WinoGrande| WinoGrande:大规模的对抗性维诺格拉德模式挑战 -2019/05|MathQA| MathQA:借助基于运算的形式化方法实现可解释的数学应用题求解 -2019/05|HellaSwag| HellaSwag:机器真的能帮你完成句子吗? -2019/04|Social IQa| SocialIQA:关于社会互动的常识推理 - [论文]2018/08|SWAG| SWAG:一个大规模的对抗性数据集,用于 grounded常识推理 -2002/07|BLEU| BLEU:一种自动评估机器翻译的方法 - [论文]
3.2 数学推理
数学推理
2023/10|MathVista| MathVista: 利用GPT-4V、Bard及其他多模态大模型评估视觉情境下的数学推理能力 - [论文] [代码] [项目主页] |Lu等人,ICLR 20242022/11| 知识理论中的分词 - [论文]2022/06|MultiHiertt| MultiHiertt:面向多层级表格与文本数据的数值推理2021/04|MultiModalQA| MultiModalQA:跨文本、表格和图像的复杂问答任务2017/05| 通过生成理由进行程序归纳:学习解决并解释代数应用题2014/04| 神经网络中的深度学习:综述 - [论文]2004| 维特根斯坦论逻辑与数学哲学 - [论文]1989|CLP| 连接主义学习算法 - [论文]
3.2.1 算术推理
2022/09|PromptPG| 基于策略梯度的动态提示学习用于半结构化数学推理2022/01| 思维链提示能够激发大型语言模型的推理能力 -2021/03|SVAMP| NLP模型真的能解决简单的数学应用题吗? - [论文] [代码]2021/03|MATH| 利用MATH数据集衡量数学问题解决能力 -2016/08| 计算机在解决数学应用题方面表现如何?大规模数据集构建与评估 - [论文]2015/09| 使用二次规划学习解决代数应用题 - [论文]2014/06|Alg514| 学习自动解决代数应用题 - [论文]
3.2.2 几何推理
2024/01|AlphaGeometry| 在无需人类示范的情况下解决奥林匹克几何问题 - [论文] [代码] [博客] |Trinh等人,Nature2022/12|UniGeo/Geoformer| UniGeo:通过重写数学表达式统一几何逻辑推理2021/05|GeoQA/NGS| GeoQA:迈向多模态数值推理的几何问答基准2021/05|Geometry3K/Inter-GPS| Inter-GPS:利用形式语言和符号推理实现可解释的几何问题求解2015/09|GeoS| 解决几何问题:结合文本与图形的解读 - [论文]
3.2.3 定理证明
2020/10|Prover| LEGO-Prover:具有不断增长库的神经定理证明系统 -2023/09|Lyra| Lyra:在自动化定理证明中协调双重校正2023/06|DT-Solver| DT-Solver:基于证明级价值函数引导的动态树采样自动化定理证明 - [论文]2023/05| 分解谜题:基于子目标的演示学习用于形式定理证明2023/03|Magnushammer| Magnushammer:一种基于Transformer的假设选择方法2022/10|DSP| 草稿、草图与证明:以非正式证明指导形式定理证明者 -2022/05| 通过优化搜索策略来学习寻找证明与定理:以循环不变式合成为例2022/05| 利用大型语言模型进行自动形式化 - [论文]2022/05|HTPS| 超树证明搜索用于神经定理证明2022/05|Thor| Thor:运用“锤子”整合语言模型与自动化定理证明器 -2022/02| 形式数学语句课程学习 -2021/07|Lean 4| Lean 4定理证明器与编程语言 -2021/02|TacticZero| TacticZero:利用深度强化学习从零开始学习证明定理 -2021/02|PACT| 与语言模型协同训练证明工件以用于定理证明 -2020/09|GPT-f| 用于自动化定理证明的生成式语言建模 -2019/07| 关键系统中硬件组件的形式验证 - [论文]2019/06|Metamath| 一种用于数学证明的计算机语言 - [论文]2019/05|CoqGym| 通过与证明助手交互学习证明定理2018/12|AlphaZero| 一种通用的强化学习算法,可通过自我对弈掌握国际象棋、将棋和围棋 - [论文]2018/04|TacticToe| TacticToe: 通过战术学习进行证明2015/08|Lean| Lean 定理证明器(系统说明) - [论文]2010/07| 使用 Sledgehammer 的三年经验:自动与交互式定理证明器之间的实用桥梁 - [论文]2010/04| 英特尔的形式化方法——概述 - [幻灯片]2005/07| 将仿真与形式验证相结合用于集成电路设计验证 - [论文]2003| 从证明助手提取一个经过形式化验证且完全可执行的编译器 - [论文]1996|Coq| Coq 证明助手参考手册 - [项目]1994|Isabelle| Isabelle:一种通用的定理证明器 - [论文]
3.2.4 科学推理
2023/07|SciBench| SciBench:评估大型语言模型的大学水平科学问题解决能力 -2022/09|ScienceQA| 学会解释:基于思维链的多模态推理在科学问答中的应用2022/03|ScienceWorld| ScienceWorld:你的智能体比五年级学生更聪明吗?2012| 儿童学习与认知的前沿课题 - [书籍]
3.2.x 基准、数据集和指标
2024/01|MathBench
MathBench:一个全面的多级别难度数学评估数据集
[代码]2023/08|Math23K-F/MAWPS-F/FOMAS| 通过掌握常识公式知识引导数学推理 - [论文]2023/07|ARB| ARB:面向大型语言模型的高级推理基准 -2023/05|SwiftSage| SwiftSage:一种具有快慢思维的生成式智能体,适用于复杂交互任务 -2023/05|TheoremQA| TheoremQA:一个以定理为导向的问答数据集 -2022/10|MGSM| 语言模型是多语言的思维链推理者 - [论文] [代码]2021/10|GSM8K| 训练验证器解决数学文字题 - [论文] [代码] [博客]2021/10|IconQA| IconQA:一个新的抽象图表理解和视觉语言推理基准 -2021/09|FinQA| FinQA:一个关于金融数据的数值推理数据集 -2021/08|MBPP/MathQA-Python| 使用大型语言模型进行程序合成2021/08|HiTab/EA| HiTab:一个用于问答和自然语言生成的层次化表格数据集2021/07|HumanEval/Codex| 评估基于代码训练的大型语言模型 -2021/06|ASDiv/CLD| 一个多样化的语料库,用于评估和开发英语数学文字题求解器 -2021/06|AIT-QA| AIT-QA:一个关于航空业复杂表格的问答数据集 -2021/05|APPS| 用 APPS 衡量编码挑战能力 -2021/05|TAT-QA| TAT-QA:一个关于金融领域表格与文本混合内容的问答基准2021/03|SVAMP| NLP 模型真的能解决简单的数学文字题吗? -2021/01|TSQA/MAP/MRR| TSQA:基于表格场景的问答2020/10|HMWP| 语义对齐的通用树状结构数学文字题求解器 -2020/04|HybridQA| HybridQA:一个关于表格和文本数据的多跳问答数据集2019/03|DROP| DROP:一个需要对段落进行离散推理的阅读理解基准 -2019|NaturalQuestions| 自然问题:一个用于问答研究的基准 - [论文]2018/09|HotpotQA| HotpotQA:一个用于多样化、可解释的多跳问答的数据集 -2018/09|Spider| Spider:一个大规模的人工标注数据集,用于复杂且跨领域的语义解析和文本到 SQL 任务 -2018/03|ComplexWebQuestions| 网络作为解答复杂问题的知识库 -2017/12|MetaQA| 基于知识图谱的变分推理用于问答 -2017/09|GEOS++| 从教科书到知识:以教科书中的公理化知识为例,用于解决几何问题 - [论文]2017/09|Math23k| 深度神经网络求解数学文字题 - [论文]2017/08|WikiSQL/Seq2SQL| Seq2SQL:利用强化学习从自然语言生成结构化查询 -2017/08| 从教科书中的自然语言演示中学习如何解决几何问题 - [论文]2017/05|TriviaQA| TriviaQA:用于阅读理解的大规模远距离监督挑战数据集 -2017/05|GeoShader| 阴影区域几何问题解法的综合 - [论文]2016/09|DRAW-1K| 标注推导过程:代数文字题的新评估策略与数据集 -2016/08|WebQSP| 语义解析标注在知识库问答中的价值 - [论文]2016/06|SQuAD| SQuAD:超过10万个用于机器阅读理解的问题 -2016/06|WikiMovies| 用于直接阅读文档的键值记忆网络 -2016/06|MAWPS| MAWPS:数学文字题库 - [论文]2015/09|Dolphin1878| 通过语义解析与推理自动求解数字文字题 - [论文]2015/08|WikiTableQA| 半结构化表格上的组合语义解析 -2015|SingleEQ| 将代数文字题解析为方程 - [论文]2015|DRAW| DRAW:一套具有挑战性且多样化的代数文字题集 - [论文]2014/10|Verb395| 通过动词分类学习解决算术文字题 - [论文]2013/10|WebQuestions| 基于问题—答案对的Freebase语义解析 - [论文]2013/08|Free917| 通过模式匹配和词汇扩展进行大规模语义解析 - [论文]2002/04|NMI| 聚类集成——一种结合多个划分的知识重用框架 - [论文]1990|ATIS| ATIS口语语言系统试点语料库 - [论文]
3.3 逻辑推理
逻辑推理
2024/12|FLDx2| 通过原则性的合成逻辑语料库增强大语言模型的推理能力 -2023/11|FLD| 基于形式逻辑的合成语料库学习演绎推理 -2023/10|LogiGLUE| 迈向 LogiGLUE:关于分析语言模型逻辑推理能力的简要综述与基准测试 -2023/05|LogicLLM| LogicLLM:探索用于大语言模型的自监督逻辑增强训练 -2023/05|Logic-LM| Logic-LM:利用符号求解器赋能大语言模型实现忠实的逻辑推理 -2023/03|LEAP| 显式规划有助于语言模型进行逻辑推理 -2023/03| 通用人工智能的火花:GPT-4 的早期实验 -2022/10|Entailer| Entailer:以忠实且真实的推理链回答问题 -2022/06|NeSyL| 面向认知任务的弱监督神经符号学习 - [论文]2022/05|NeuPSL| NeuPSL:神经概率软逻辑 -2022/05|NLProofS| 通过验证者引导的搜索生成自然语言证明 -2022/05|Least-to-Most Prompting| 由浅入深提示法使大语言模型具备复杂推理能力 -2022/05|SI| 选择—推理:利用大语言模型实现可解释的逻辑推理 -2022/05|MERIt| MERIt:元路径引导的对比学习用于逻辑推理 -2022/03| 自我一致性提升语言模型的思维链推理能力 -2021/11|NSPS| 神经符号程序搜索在自动驾驶决策模块设计中的应用 - [论文]2021/09|DeepProbLog| DeepProbLog 中的神经概率逻辑编程 - [论文]2021/08|GABL| 基于基础知识库的溯因学习 - [论文]2021/05|LReasoner| 基于逻辑的上下文扩展与数据增强用于文本的逻辑推理 -2020/02|RuleTakers| Transformer 作为语言上的软推理器 -2019/12|NMN-Drop| 用于文本推理的神经模块网络 -2019/04|NS-CL| 神经符号概念学习者:从自然监督中理解场景、词语和句子 -2012| 逻辑推理与学习 - [论文]
3.3.1 命题逻辑
2022/09| 通过神经 Transformer 语言模型进行命题推理 - [论文]
3.3.2 谓词逻辑
2021/06|ILP| 归纳逻辑编程三十周年 - [论文]2011| 统计关系学习 - [论文]
3.3.x 基准、数据集和指标
2022/10|PrOntoQA| 语言模型是贪婪的推理者:对思维链的系统性形式化分析 -2022/09|FOLIO| FOLIO:使用一阶逻辑进行自然语言推理 -2022/06|BIG-bench| 超越模仿游戏:量化并外推语言模型的能力 - [论文] [代码]2021/04|AR-LSAT| AR-LSAT:探究文本的分析推理能力 - [论文] [代码]2020/12|ProofWriterProofWriter:在自然语言上生成蕴含、证明和溯因陈述 -
3.4 因果推理
因果推理
2023/08| 因果鹦鹉:大型语言模型可能谈论因果关系,但并不具备真正的因果能力2023/07| 利用语言模型作为不完美专家进行因果发现 -2023/06| 从查询工具到因果架构师:利用大型语言模型从数据中进行高级因果发现 -2023/06|Corr2Cause| 大型语言模型能否从相关性中推断出因果关系? -2023/05|Code-LLMs| IF的魔力:探究代码类大型语言模型的因果推理能力 -2023/04| 利用大型语言模型理解因果关系:可行性与机遇 -2023/04| 因果推理与大型语言模型:开启因果关系研究的新前沿 -2023/03| 大型语言模型能否构建因果图? -2023/01| ChatGPT在神经性疼痛诊断背景下的因果发现性能 -2022/09| 探查因果事实的相关性:大型语言模型与因果关系 - [论文]2022/07| 大型语言模型能否区分原因与结果? - [论文]2021/08| 学习因果图的忠实表示 - [论文]2021/05|InferBERT| InferBERT:一种基于Transformer的因果推断框架,用于增强药物警戒 - [论文]2021/02| 迈向因果表征学习 -2020/05|CausaLM| CausaLM:通过反事实语言模型解释因果模型 -2019/06| 用于评估因果发现算法的神经性疼痛诊断模拟器 -2017| 因果推断要素:基础与学习算法 - [书籍]2016| 实际因果关系 - [书籍]2013| 因果推理 - [论文]
3.4.1 反事实推理
2023/07| 推理还是背诵?通过反事实任务探索语言模型的能力与局限性 -2023/05| 反事实推理:测试语言模型对假设情景的理解 -2007| 理性的想象:人们如何创造现实的替代方案 - [论文]1986| 规范理论:将现实与其替代方案进行比较 - [论文]
3.4.x 基准、数据集和指标
2021/12|CRASS| CRASS:一个用于测试大型语言模型反事实推理能力的新数据集和基准 -2021/08|Arctic sea ice| 北极海冰与大气相互作用中数据驱动的因果发现方法的基准测试 - [论文]2014/12|CauseEffectPairs| 利用观测数据区分原因与结果:方法与基准 -
3.5 视觉推理
视觉推理
2025/02|VPT| 在多模态大语言模型中引入视觉感知标记 - [论文] - [代码] - [模型] - [数据集]2022/11|G-VUE| 感知、定位、推理与行动:通用视觉表征的基准测试 -2021/03|VLGrammar| VLGrammar:视觉与语言的接地语法归纳 -2020/12| 基于学习到的对象嵌入的注意力机制可实现复杂的视觉推理 -
3.5.1 3D 推理
2023/08|PointLLM| PointLLM:赋能大语言模型理解点云 -2023/08|3D-VisTA| 3D-VisTA:用于3D视觉与文本对齐的预训练Transformer -2023/07|3D-LLM| 3D-LLM:将3D世界注入大语言模型 -2022/10|SQA3D| SQA3D:3D场景中的情境问答 -
3.5.x 基准、数据集和指标
2025/04|VisuLogic| VisuLogic:评估多模态大语言模型中视觉推理能力的基准测试 -2021/12|PTR| PTR:基于部件的概念、关系及物理推理的基准测试 -2019/05|OK-VQA| OK-VQA:需要外部知识的视觉问答基准测试 -2016/12|CLEVR| CLEVR:用于组合语言和基础视觉推理的诊断性数据集 -
3.6 音频推理
音频推理
2023/11|M2UGen| M2UGen:利用大语言模型的力量进行多模态音乐理解和生成 - [论文] [代码]2023/08|MU-LLaMA| 音乐理解LLaMA:通过问答和字幕生成推进文本到音乐的创作 - [论文] [代码]2022/05| 自监督语音表示学习:综述 -
3.6.1 语音
2022/03|SUPERB-SG| SUPERB-SG:增强版语音处理通用性能基准,适用于语义和生成能力 -2022/02|Data2Vec| data2vec:一种用于语音、视觉和语言的自监督学习通用框架 -2021/10|WavLM| WavLM:面向全栈语音处理的大规模自监督预训练 -2021/06|HuBERT| HuBERT:通过掩码预测隐藏单元进行自监督语音表示学习 -2021/05|SUPERB| SUPERB:语音处理通用性能基准 -2020/10|Speech SIMCLR| Speech SIMCLR:结合对比和重建目标的自监督语音表示学习 -2020/06|Wav2Vec 2.0| wav2vec 2.0:语音表示自监督学习的框架 -2020/05|Conformer| Conformer:用于语音识别的卷积增强型Transformer -2019/10|Mockingjay| Mockingjay:使用深度双向Transformer编码器进行无监督语音表示学习 -2019/04|APC| 一种用于语音表示学习的无监督自回归模型 -2018/07|CPC| 通过对比预测编码进行表示学习 -2018/04|Speech-Transformer| Speech-Transformer:一种用于语音识别的无循环序列到序列模型 - [论文]2017/11|VQ-VAE| 神经离散表示学习 -2017/08| 通过师生学习进行大规模领域适应 -
3.6.x 基准、数据集和指标
2022/03|SUPERB-SG| SUPERB-SG:增强版语音处理通用性能基准,适用于语义和生成能力 -2021/11|VoxPopuli/XLS-R| XLS-R:大规模自监督跨语言语音表示学习 -2021/05|SUPERB| SUPERB:语音处理通用性能基准 -2020/12|Multilingual LibriSpeech| MLS:用于语音研究的大规模多语言数据集 -2020/05|Didi Dictation/Didi Callcenter| 关于基于Transformer的语音识别中无监督预训练的进一步研究 -2019/12|Libri-Light| Libri-Light:用于有限或无监督ASR的基准 -2019/12|Common Voice| Common Voice:一个大规模多语言语音语料库 -
3.7 多模态推理
多模态推理
2023/12| GPT-4V的挑战者?Gemini在视觉专长中的早期探索 - [论文] [项目]
3.7.1 对齐
2023/01|BLIP-2| BLIP-2:利用冻结图像编码器和大型语言模型进行语言-图像预训练的自举方法 - [论文] [代码]
3.7.2 生成
2023/06|Kosmos-2| Kosmos-2:将多模态大型语言模型与现实世界联系起来 -2023/05|BiomedGPT| BiomedGPT:一种用于视觉、语言和多模态任务的统一且通用的生物医学生成式预训练Transformer -2023/03|Visual ChatGPT| Visual ChatGPT:与视觉基础模型对话、绘图和编辑 -2023/02|Kosmos-1| 语言并非一切:将感知与语言模型对齐 -2022/07|Midjourney- [项目]2022/04|Flamingo| Flamingo:用于少样本学习的视觉语言模型 -2021/12|MAGMA| MAGMA——通过基于适配器的微调增强生成模型的多模态能力 -
3.7.3 多模态理解
2023/09|Q-Bench| Q-Bench:面向低级视觉的通用基础模型基准测试 - [论文] [代码]2023/05|DetGPT| DetGPT:通过推理检测所需内容 -2023/03|Vicuna| Vicuna:一款开源聊天机器人,以90%*的ChatGPT质量令人印象深刻 - [博客] [代码]2022/12|DePlot| DePlot:通过图表到表格的转换实现一次性的视觉语言推理 -2022/12|MatCha| MatCha:通过数学推理和图表反渲染增强视觉语言预训练 -
3.7.x 基准、数据集和度量
2023/06|LVLM-eHub| LVLM-eHub:大型视觉-语言模型的综合评估基准 -2023/06|LAMM| LAMM:语言辅助的多模态指令微调数据集、框架和基准 -2023/05|AttackVLM| 关于评估大型视觉-语言模型对抗鲁棒性的研究 -2023/05|POPE| 评估大型视觉-语言模型中的对象幻觉现象 -2023/05|MultimodalOCR| 关于大型多模态模型中OCR隐藏奥秘的研究 -2022/10|ObjMLM| 看似合理未必忠实:探测视觉-语言预训练中的对象幻觉现象2022/06|RAVEN/ARC| 在概念抽象基准上评估理解能力的研究 -2021/06|LARC| 向人类和机器传达自然程序的研究 -2014/11|CIDEr/PASCAL-50S/ABSTRACT-50S| CIDEr:基于共识的图像描述评估方法 -
3.8 代理推理
代理推理
2024/01|AutoRT|Ahn et al.
AutoRT:用于大规模机器人代理编排的具身基础模型
[arXiv] [论文] [项目]2023/11|OpenFlamingo| 视觉-语言基础模型作为有效的机器人模仿者 -2023/07|RT-2| RT-2:视觉-语言-动作模型将网络知识迁移到机器人控制中 -2023/05|RAP| 用语言模型进行推理就是用世界模型进行规划 -2023/03|PaLM-E|Driess et al., ICML 2023
PaLM-E:一款具身多模态语言模型
[arXiv] [论文] [项目]2022/12|RT-1| RT-1:用于大规模真实世界控制的机器人Transformer2022/10| 通过潜在语言进行技能归纳与规划 -2022/05|Gato| 一种通用型智能体 -2022/04|SMs| 苏格拉底模型:用语言组合零样本多模态推理 -2022/02| 用于交互式决策的预训练语言模型 -2022/01|语言-规划者| 语言模型作为零样本规划者:为具身智能体提取可操作的知识 -2021/11| 价值函数空间:以技能为中心的状态抽象,用于长期推理 -2020/09| 无需视觉的视觉接地规划:语言模型从高层次指令中推断出详细计划 -2016/01|AlphaGo| 通过深度神经网络和树搜索掌握围棋 - [论文]2014/05| 理性中的手势:具身视角 - [论文]
3.8.1 内省式推理
2022/11|PAL| PAL:程序辅助语言模型 -2022/09|ProgPrompt| ProgPrompt:利用大型语言模型生成情境化的机器人任务计划 -2022/09|代码即策略| 代码即策略:用于具身控制的语言模型程序 -2022/04|SayCan| 像我能做的那样做,而不是像我说的那样做:将语言与机器人可用性相结合 -2012| 内省学习与推理 - [论文]
3.8.2 外省式推理
2023/06|Statler| Statler:用于具身推理的状态保持语言模型 -2023/02|规划者-执行者-报告者| 与语言模型协作进行具身推理 -2023/02|Toolformer| Toolformer:语言模型可以自我教授如何使用工具 -2022/12|LLM-Planner| LLM-Planner:利用大型语言模型为具身智能体进行少样本接地规划 -2022/10|ReAct| ReAct:在语言模型中协同推理与行动 -2022/10|Self-Ask| 衡量并缩小语言模型中的组合性差距 -2022/07|内心独白| 内心独白:通过语言模型规划实现具身推理 -
3.8.3 多智能体推理
2023/07|联邦LLM| 联邦大型语言模型:立场文件 -2023/07| 基于自适应大型语言模型(LLM)的多智能体系统 -2023/07|Co-LLM-Agents| 利用大型语言模型模块化构建合作型具身智能体 -2023/05| 通过多智能体辩论提升语言模型的事实性和推理能力 -2017/02|FIoT| FIoT:一种基于物联网的自适应、自组织应用的代理框架 - [论文]2004| IBM 自动计算工具包实用指南 - [书籍]
3.8.4 驾驶推理
2023/12|DriveLM| DriveLM:基于图的视觉问答进行驾驶 - [论文] [代码]2023/12|LiDAR-LLM| LiDAR-LLM:探索大型语言模型在3D LiDAR理解方面的潜力 - [论文] [项目]2023/12|DriveMLM| DriveMLM:将多模态大型语言模型与自动驾驶的行为规划状态对齐 - [论文] [代码]2023/12|LMDrive| LMDrive:利用大型语言模型实现闭环端到端驾驶 - [论文] [代码]2023/10| 穿越概念僵局:解开自动驾驶中的可解释性瓶颈 -2023/10| 视觉语言模型在自动驾驶和智能交通系统中的应用 -2023/10|DriveGPT4| DriveGPT4:通过大型语言模型实现可解释的端到端自动驾驶 -2023/09|MotionLM| MotionLM:将多智能体运动预测视为语言建模 -2023/06| 端到端自动驾驶:挑战与前沿 -2023/04| 基于图的驾驶场景拓扑推理 -2022/09| 深入探讨鸟瞰感知的难点:综述、评估与解决方案 -2021/11| 人工智能:科学研究的强大范式 - [论文]
3.8.x 基准、数据集和指标
2023/12|DriveLM| DriveLM:基于图的视觉问答进行驾驶 - [论文] [代码]2023/09|NuPrompt/PromptTrack| 自动驾驶的语言提示 -2023/07|LCTGen| 语言条件下的交通流生成2023/05|NuScenes-QA| NuScenes-QA:自动驾驶场景的多模态视觉问答基准 -2022/06|BEHAVIOR-1K| BEHAVIOR-1K:包含1,000项日常活动和真实模拟的具身AI基准 -2021/08|iGibson| iGibson 2.0:以物体为中心的仿真,用于机器人学习日常家务任务 -2021/06|Habitat 2.0| Habitat 2.0:训练家庭助手重新布置其栖息地z -2020/04|RoboTHOR| RoboTHOR:一个开放的仿真到现实的具身AI平台 -2019/11|HAD| 为自动驾驶车辆提供人车交互建议的接地 -2019/04|Habitat| Habitat:用于具身AI研究的平台 -2018/08|Gibson| Gibson环境:具身智能体的真实世界感知 -2018/06|VirtualHome| VirtualHome: 通过程序模拟家庭活动 -
3.9 其他任务与应用
其他任务与应用
3.9.1 心理理论 (ToM)
2023/02|ToM| 大型语言模型中可能自发出现心理理论 -
3.9.2 大型语言模型在天气预报中的应用
3.9.3 抽象推理
2023/05| 大型语言模型并非强大的抽象推理者 -
3.9.4 可废止推理
2023/06|BoardgameQA| BoardgameQA:一个包含矛盾信息的自然语言推理数据集 -2021/10|CURIOUS| 想一想!通过先建模问题场景来提升可废止推理能力 -2020/11|Defeasible NLI/δ-NLI| 像怀疑论者一样思考:自然语言中的可废止推理 - [论文]2020/04|KACC| KACC:一个用于知识抽象、具体化和补全的多任务基准 -2009/01| 可废止推理的递归语义 - [论文]
3.9.5 医学推理
2024/01|CheXagent/CheXinstruct/CheXbench|Chen 等人
CheXagent:迈向胸部X光片解读的基础模型
[arXiv] [论文] [代码] [项目页面] [Hugging Face]2024/01|EchoGPT|Chao 等人
EchoGPT:用于超声心动图报告摘要的大语言模型
[medRxiv] [论文]2023/10|GPT4V-医学报告|Yan 等人
面向医疗应用的多模态ChatGPT:GPT-4V的实验研究
[arXiv] [论文] [代码]2023/10|VisionFM|Qiu 等人
VisionFM:一种通用眼科人工智能的多模态多任务视觉基础模型
[arXiv] [论文]2023/09|Yang 等人
LMMs 的曙光:使用 GPT-4V(ision) 的初步探索
[arXiv] [论文]2023/09|RETFound|Zhou 等人,Nature
一种用于从视网膜图像中进行泛化疾病检测的基础模型
[论文] [代码]2023/08|ELIXR|Xu 等人
ELIXR:通过对齐大语言模型和放射影像编码器,迈向通用X射线人工智能系统
[arXiv] [论文]2023/07|Med-Flamingo|Moor 等人
Med-Flamingo:一种多模态医学小样本学习模型
[arXiv] [论文] [代码]2023/06|Endo-FM|Wang et al., MICCAI 2023
基于大规模自监督预训练的内窥镜视频分析基础模型
[arXiv] [paper] [code]2023/06|XrayGPT|Thawkar et al.
XrayGPT:利用医学视觉-语言模型进行胸部X光片摘要生成
- [arXiv] [paper] [code]2023/06|LLaVA-Med|Li et al., NeurIPS 2023
LLaVA-Med:一天内训练一个用于生物医学的大规模语言-视觉助手
[arXiv] [paper] [code]2023/05|HuatuoGPT|Zhang et al., Findings of EMNLP 2023
HuatuoGPT:朝着驯服语言模型成为医生的目标迈进
[arXiv] [paper] [code]2023/05|Med-PaLM 2|Singhal et al.
迈向使用大型语言模型实现专家级医学问答
[arXiv] [paper]2022/12|Med-PaLM/MultiMedQA/HealthSearchQA|Singhal et al., Nature
大型语言模型编码临床知识
[arXiv] [paper]

3.9.6 生物信息学推理
2023/07|Prot2Text| Prot2Text:利用GNN和Transformer进行多模态蛋白质功能生成 -2023/07|Uni-RNA| Uni-RNA:通用预训练模型革新RNA研究 -2023/07|RFdiffusion| 利用RFdiffusion从头设计蛋白质结构和功能 - [Paper]2023/06|HyenaDNA| HyenaDNA:以单核苷酸分辨率进行长距离基因组序列建模 -2023/06|DrugGPT| DrugGPT:一种基于GPT的策略,用于设计针对特定蛋白质的潜在配体 -2023/04|GeneGPT| GeneGPT:通过领域工具增强大型语言模型,以更好地获取生物医学信息 -2023/04| 制药公司正在定制ChatGPT:以下是具体做法 - [News]2023/01|ProGen| 大型语言模型可生成跨不同家族的功能性蛋白质序列 - [Paper]2022/06|ProGen2| ProGen2:探索蛋白质语言模型的边界 -2021/07|AlphaFold| 使用AlphaFold实现高精度的蛋白质结构预测 - [Paper]
3.9.7 长链推理
2022/12|Fine-tune-CoT| 大型语言模型是推理教师 -2021/09|PlaTe| PlaTe:在程序性任务中利用Transformer进行视觉接地规划 -
4 推理技术
推理技术
目录 - 4
4.1 预训练
预训练
4.1.1 数据
a. 数据 - 文本
2023/07|peS2o| peS2o(在 S2ORC 上高效预训练)数据集 - [代码]2023/05|ROOTS/BLOOM| BigScience ROOTS 语料库:一个 1.6TB 的多语言复合数据集 -2023/04|RedPajama| RedPajama:用于训练大型语言模型的开放数据集 - [代码]2020/12|The Pile| The Pile:用于语言建模的 800GB 多样化文本数据集 -2020/04|Reddit| 构建开放域聊天机器人的配方 -2020/04|CLUE| CLUE:中文语言理解评估基准 -2019/10|C4| 探索统一文本到文本变换器迁移学习的极限 -2013/10|Gutenberg| 单词搭配网络的复杂性:初步结构分析
b. 数据 - 图像
2023/06|I2E/MOFI| MOFI:从带有噪声实体标注的图像中学习图像表示 -2022/01|SWAG重新审视弱监督视觉感知模型的预训练 -2021/04|ImageNet-21K| 面向大众的 ImageNet-21K 预训练 -2017/07|JFT| 重新审视深度学习时代数据的不合理有效性 -2014/09|ImageNet| ImageNet 大规模视觉识别挑战赛 -
c. 数据 - 多模态
2023/09|Point-Bind| Point-Bind & Point-LLM:将点云与多模态对齐,用于 3D 理解、生成和指令遵循 -2023/05|ImageBind| ImageBind:一个嵌入空间绑定一切 -2023/04|DataComp| DataComp:寻找下一代多模态数据集 -2022/10|LAION-5B| LAION-5B:用于训练下一代图文模型的开放大规模数据集 -2022/08|Shutterstock| 质量而非数量:关于数据集设计与 CLIP 鲁棒性的相互作用 -2022/08|COYO-700M| COYO-700M:图文配对数据集 - [代码]2022/04|M3W| Flamingo:用于少样本学习的视觉语言模型 -2021/11|RedCaps| RedCaps:由人民创建、为人民服务的网络精选图文数据 -2021/11|LAION-400M| LAION-400M:经过 CLIP 过滤的 4 亿图文配对的开放数据集 -2021/03|WIT| WIT:基于维基百科的多模态多语言机器学习图文数据集 -2011/12|Im2Text/SBU| Im2Text:使用 100 万张带说明的照片描述图像 -
4.1.2 网络架构
2023/04| 仅解码器还是编码器-解码器?将语言模型解释为正则化的编码器-解码器 -
a. 编码器-解码器
2019/10|BART| BART:用于自然语言生成、翻译和理解的去噪序列到序列预训练 -2019/10|T5| 探索统一文本到文本变换器迁移学习的极限 -2018/10|BERT| BERT: 用于语言理解的深度双向 Transformer 预训练 - [论文] [代码] [博客]2017/06|Transformer| 注意力就是一切 -
b. 仅解码器
2023/07|Llama 2| Llama 2:开放的基础及微调聊天模型 - [论文] [代码] [博客]2023/02|LLaMA| LLaMA:开放且高效的通用语言模型 - [论文] [代码] [博客]2022/11|BLOOM| BLOOM:一个拥有 1760 亿参数的开源多语言语言模型 -2022/10|GLM| GLM-130B:一个开放的双语预训练模型 -2022/05|OPT| OPT:开放的预训练 Transformer 语言模型 -2021/12|Gopher| 扩展语言模型:训练 Gopher 的方法、分析与见解 -2021/05|GPT-3| 语言模型是少样本学习者 - [论文] [代码]2019/02|GPT-2| 语言模型是无监督的多任务学习者 - [论文]2018/06|GPT-1| 通过生成式预训练提升语言理解能力 - [论文]
c. CLIP 变体
2023/05|LaCLIP| 通过语言重写改进 CLIP 训练 -2023/04|DetCLIPv2| DetCLIPv2:基于词—区域对齐的可扩展开放词汇目标检测预训练 -2022/12|FLIP| 通过掩码扩展语言—图像预训练 -2022/09|DetCLIP| DetCLIP:面向开放世界检测的字典增强型视觉—概念并行预训练 -2022/04|K-LITE| K-LITE:利用外部知识学习可迁移的视觉模型 -2021/11|FILIP| FILIP:细粒度交互式语言—图像预训练 -2021/02|CLIP| 从自然语言监督中学习可迁移的视觉模型 - [论文] [代码] [博客]
d. 其他
2023/09|StreamingLLM| 具有注意力汇流的高效流式语言模型 -2023/07|RetNet| Retentive Network:大型语言模型的 Transformer 继任者 -2023/07| | LongNet:将 Transformer 扩展至 10 亿标记 -2023/05|RWKV| RWKV:为 Transformer 时代重新发明 RNN -2023/02|Hyena| Hyena 层次结构:迈向更大的卷积语言模型 -2022/12|H3| 饥饿的河马:迈向使用状态空间模型的语言建模 -2022/06|GSS| 通过门控状态空间实现长距离语言建模 -2022/03|DSS| 对角线状态空间与结构化状态空间同样有效 -2021/10|S4| 利用结构化状态空间高效建模长序列 -
4.2 微调
微调
4.2.1 数据
2023/09|MetaMath| MetaMath: 自举式生成大型语言模型的数学问题 -2023/09|MAmmoTH| MAmmoTH: 通过混合指令微调构建数学通才模型 -2023/08|WizardMath| WizardMath: 基于强化进化指令提升大型语言模型的数学推理能力 -2023/08|RFT| 大型语言模型学习数学推理的规模关系 -2023/05|PRM800K/ `` | 让我们逐步验证 -2023/05|Distilling Step-by-Step| 逐步提炼!用更少的训练数据和更小的模型规模超越更大的语言模型 -2023/01| 将小型语言模型专门化用于多步推理 -2022/12|Fine-tune-CoT| 大型语言模型是推理教师 -2022/12| 教导小型语言模型进行推理 -2022/10| 大型语言模型可以自我改进 -2022/10| 大型语言模型的解释使小型推理者表现更好 -
4.2.2 参数高效微调
a. Adapter微调
2023/03|LLaMA-Adapter| LLaMA-Adapter: 使用零初始化注意力机制高效微调语言模型 -2022/05|AdaMix| AdaMix: 用于参数高效模型微调的混合适配器 -2021/10| 迈向参数高效迁移学习的统一视角 -2021/06|Compacter| Compacter: 高效的低秩超复数适配器层 -2020/04|MAD-X| MAD-X: 基于适配器的多任务跨语言迁移框架 -2019/02|Adapter| NLP中的参数高效迁移学习 -
b. 低秩适应
2023/09|LongLoRA/LongAlpaca-12k|Chen et al., ICLR 2024
LongLoRA: 长上下文大型语言模型的高效微调
[arXiv] [论文] [代码]2023/05|QLoRA| QLoRA: 量化LLM的高效微调 -2023/03|AdaLoRA| 参数高效微调中的自适应预算分配 -2022/12|KronA| KronA: 使用克罗内克适配器进行参数高效微调 -2022/10|DyLoRA| 使用动态无搜索低秩适应对预训练模型进行参数高效微调 -2021/06|LoRA| LoRA: 大型语言模型的低秩适应 -
c. 提示词微调
2021/10|P-Tuning v2| P-Tuning v2: 提示词微调在不同规模和任务中可与微调相媲美 -2021/04|Prompt Tuning| 规模的力量:参数高效提示词微调 -2021/04|OptiPrompt| 事实探针是[MASK]:学习还是学会回忆 -2021/03|P-Tuning| GPT也懂得 -2021/01|Prefix-Tuning| 前缀微调:优化连续提示以进行生成 -
d. 部分参数微调
2023/04|DiffFit| DiffFit: 通过简单的参数高效微调解锁大型扩散模型的迁移性 -2022/10|SSF| 缩放与平移你的特征:高效模型微调的新基准 -2021/09|Child-Tuning| 在大型语言模型中培养孩子:迈向有效且通用的微调 -2021/06|BitFit| BitFit: 适用于基于Transformer的掩码语言模型的简单参数高效微调 -
e. 多模态混合适应
2023/10|LLaVA-1.5| 通过视觉指令微调改进基准 -2023/05|MMA/LaVIN| 廉价快速:大型语言模型的高效视觉-语言指令微调 -2023/04|LLaMA-Adapter V2| LLaMA-Adapter V2: 参数高效的视觉指令模型 -2023/04|LLaVA| 视觉指令微调 -2023/02|RepAdapter| 通过结构重参数化实现高效视觉适应 -
4.3 对齐训练
对齐训练
4.3.1 数据
a. 数据 - 人类
2023/06|Dolly| 免费Dolly:推出全球首个真正开放的指令微调大模型 - [代码]2023/04|LongForm| LongForm:通过语料库提取优化长文本生成的指令微调 -2023/04|COIG| 中文开放指令通用模型:初步发布 -2023/04|OpenAssistant Conversations| OpenAssistant Conversations——民主化大型语言模型对齐 -2023/01|Flan 2022| The Flan Collection:设计用于有效指令微调的数据与方法 -2022/11|xP3| 通过多任务微调实现跨语言泛化 -2022/04|Super-NaturalInstructions| Super-NaturalInstructions:通过1600多个NLP任务的声明式指令实现泛化 -2021/11|ExT5| ExT5:迈向迁移学习的极端多任务扩展 -2021/10|MetaICL| MetaICL:在上下文中学习如何学习 -2021/10|P3| 多任务提示训练实现零样本任务泛化 -2021/04|CrossFit| CrossFit:NLP中跨任务泛化的少样本学习挑战 -2021/04|NATURAL INSTRUCTIONS| 通过自然语言众包指令实现跨任务泛化 -2020/05|UnifiedQA| UnifiedQA:用单一问答系统跨越格式界限 -
b. 数据 - 合成
2023/08|指令反译| 通过指令反译进行自我对齐 -2023/05|Dynosaur| Dynosaur:一种用于指令微调数据整理的动态增长范式 -2023/05|UltraChat| 通过扩展高质量指令对话提升聊天语言模型性能 -2023/05|CoT Collection| The CoT Collection:通过思维链微调改善语言模型的零样本和少样本学习 -2023/05|CoEdIT| CoEdIT:通过特定任务指令微调进行文本编辑 -2023/04|LaMini-LM| LaMini-LM:从大规模指令中蒸馏出的多样化模型群 -2023/04|GPT-4-LLM| 使用GPT-4进行指令微调 -2023/04|Koala| Koala:一款用于学术研究的对话模型 - [博客]2023/03|Alpaca| Alpaca:一款强大且可复现的指令遵循模型 - [博客]2023/03|GPT4All| GPT4All:利用从GPT-3.5-Turbo蒸馏的大规模数据训练助理型聊天机器人 - [代码]2022/12|OPT-IML/OPT-IML Bench| OPT-IML:从泛化角度扩展语言模型指令元学习 -2022/12|Self-Instruct| Self-Instruct:用自动生成的指令对齐语言模型 -2022/12|Unnatural Instructions| 不自然指令:几乎无需人工即可微调语言模型 -
4.3.2 训练流程
a. 在线人类偏好训练
2023/06|APA| 利用优势诱导策略对齐微调语言模型 -2023/04|RAFT| RAFT:奖励排序微调用于生成式基础模型对齐 -2022/03|InstructGPT/RLHF| 通过人类反馈训练语言模型遵循指令 -
b. 离线人类偏好训练
2023/06|PRO| 为人类对齐优化偏好排序 -2023/05|DPO| 直接偏好优化:你的语言模型其实是一个奖励模型 -2023/04|RRHF| RRHF:无需泪水,仅凭响应排序就能让语言模型与人类反馈保持一致 -2022/09|SLiC| 校准序列似然性可改善条件语言生成 -
4.4 混合专家模型(MoE)
混合专家模型
2024/01|MoE-LLaVA|Lin et al.
MoE-LLaVA:用于大型视觉-语言模型的混合专家模型
[arXiv] [paper] [code]2023/06| 通过多任务异构训练实现高效通用模块化视觉模型 -2023/03|MixedAE| 用于自监督视觉表征学习的混合自动编码器 -2022/12|Mod-Squad| Mod-Squad:将混合专家设计为模块化的多任务学习者 -2022/04|MoEBERT| MoEBERT:通过重要性引导的适应从BERT到混合专家模型 -2021/12|GLaM| GLaM:利用混合专家模型高效扩展语言模型 -2021/07|WideNet| 与其加深网络,不如拓宽网络 -2021/01|Switch Transformers| Switch Transformers:通过简单高效的稀疏性扩展至万亿参数模型 -2020/06|GShard| GShard:利用条件计算和自动分片扩展巨型模型 -2017/01|稀疏门控混合专家模型| 超大规模神经网络:稀疏门控混合专家层 -1991/03| 自适应局部专家混合模型 - [Paper]
4.5 上下文学习
上下文学习
2022/10|FLAN-T5| 扩展指令微调的语言模型 -2021/05|GPT-3| 语言模型是少样本学习者 - [Paper] [Code]
4.5.1 示范样例选择
a. 先验知识方法
2022/12| 多样化的示范样例提升上下文组合泛化能力 -2022/11| 互补解释促进有效的上下文学习 -2022/10|Auto-CoT| 大型语言模型中的自动思维链提示 -2022/10|Complex CoT| 基于复杂度的多步推理提示 -2022/10|EmpGPT-3| GPT-3能否生成共情对话?一种新颖的上下文样例选择方法及共情对话生成的自动评估指标 - [Paper]2022/09| 选择性标注使语言模型成为更好的少样本学习者 -2021/01| 什么样的上下文样例对GPT-3有效? -
b. 检索方法
2023/10|DQ-LoRe| DQ-LoRe:低秩近似重排的双重查询用于上下文学习 -2023/07|LLM-R| 学习检索大型语言模型的上下文样例 -2023/05|Dr.ICL| Dr.ICL:演示检索式上下文学习 -2023/02|LENS| 寻找上下文学习的支持样例 -2023/02|CEIL| 用于上下文学习的组合示例 -2021/12| 学习检索上下文学习的提示 -
4.5.2 思维链
a. 零样本思维链
2023/09|LoT| 通过逻辑增强大型语言模型中的零样本思维链推理 - [Paper] [Code]2023/05|Plan-and-Solve| 计划与解决提示:改善大型语言模型的零样本思维链推理 -2022/05|Zero-shot-CoT| 大型语言模型是零样本推理者 - [Paper] [Code]
b. 少样本思维链
2023/07|SoT| 思维骨架:大型语言模型可以进行并行解码 -2023/05|代码提示| 代码提示:一种用于大型语言模型复杂推理的神经符号方法 -2023/05|GoT| 超越思维链,大型语言模型中的有效图思维链推理 -2023/05|ToT| 思维之树:使用大型语言模型进行深思熟虑的问题解决 -2023/03|MathPrompter| MathPrompter:利用大型语言模型进行数学推理 -2022/11|PoT| 思维程序提示:将计算与推理分离以处理数值推理任务 -2022/11|PAL| PAL:程序辅助语言模型 -2022/10|Auto-CoT| 大型语言模型中的自动思维链提示 -2022/10|Complex CoT| 基于复杂度的多步推理提示 -2022/05|由简入繁提示法| 由简入繁提示法赋能大型语言模型进行复杂推理 -2022/01| 思维链提示法激发大型语言模型的推理能力 -
c. 多路径聚合
2023/05|RAP| 利用语言模型进行推理即是在用世界模型进行规划 -2023/05| 基于大型语言模型的自动模型选择用于推理 -2023/05|AdaptiveConsistency| 让我们逐步采样:面向高效推理与编码的自适应一致性方法 -2023/05|ToT| 思维之树:利用大型语言模型进行审慎的问题解决 -2023/05|ToT| 大型语言模型引导的思维之树 -2023/05| 自我评估引导的束搜索用于推理 -2022/10|Complex CoT| 基于复杂度的提示方法用于多步推理 -2022/06|DIVERSE| 通过步骤感知验证器使大型语言模型成为更好的推理者 -2022/03| 自我一致性提升语言模型中的思维链推理 -
4.5.3 多轮提示法
a. 学习型精炼器
2023/02|LLM-Augmenter| 核对事实并再试一次:借助外部知识和自动化反馈改进大型语言模型 -2022/10|Self-Correction| 通过学习自我修正来生成序列 -2022/08|PEER| PEER:一种协作式语言模型 -2022/04|R3| 阅读、修订、重复:人机协作迭代文本修订系统演示 -2021/10|CURIOUS| 好好想想!通过先建模问题场景来改进可废止推理 -2020/05|DrRepair| 基于图的自监督程序修复,利用诊断反馈 -
b. 提示型精炼器
2023/06|InterCode| InterCode:标准化并基准化带有执行反馈的交互式编程 -2023/06| 自我修复是代码生成的万能药吗? -2023/05| 通过多智能体辩论提升语言模型的事实性和推理能力 -2023/05|CRITIC| CRITIC:大型语言模型可通过工具交互式批评实现自我修正 -2023/05|GPT-Bargaining| 通过自我博弈及从AI反馈中进行上下文学习来改进语言模型谈判 -2023/05|Self-Edit| Self-Edit:面向代码生成的故障感知代码编辑器 -2023/04|PHP| 渐进式提示法提升大型语言模型的推理能力 -2023/04|Self-collaboration| 通过ChatGPT实现自我协作式代码生成 -2023/04|Self-Debugging| 教导大型语言模型进行自我调试 -2023/04|REFINER| REFINER:针对中间表示的推理反馈 -2023/03|Self-Refine| Self-Refine:基于自我反馈的迭代精炼 -
4.6 自主代理
自主代理
2023/10|规划标记| 利用规划标记引导语言模型推理 -2023/09|AutoAgents| AutoAgents:一个用于自动生成代理的框架 -2023/06|AssistGPT| AssistGPT:一款能够规划、执行、检查和学习的通用多模态助手 -2023/05|SwiftSage| SwiftSage:一种具有快慢思维的生成式代理,适用于复杂的交互任务 -2023/05|MultiTool-CoT| MultiTool-CoT:GPT-3 可以在思维链提示下使用多种外部工具 -2023/05|Voyager| Voyager:一个基于大型语言模型的开放式具身代理 -2023/05|ChatCoT| ChatCoT:基于聊天的大规模语言模型上的工具增强型思维链推理 -2023/05|CREATOR| CREATOR:为解耦大型语言模型的抽象与具体推理而创建工具 -2023/05|TRICE| 通过执行反馈使语言模型成为更好的工具学习者 -2023/05|ToolkenGPT| ToolkenGPT:通过工具嵌入将大量工具增强到冻结的语言模型中 -2023/04|Chameleon| Chameleon:利用大型语言模型实现即插即用的组合式推理 -2023/04|OpenAGI| OpenAGI:当LLM遇到领域专家时 -2023/03|CAMEL| CAMEL:用于探索大型语言模型社会“心智”的交流型代理 -2023/03|HuggingGPT| HuggingGPT:利用ChatGPT及其在Hugging Face中的伙伴解决AI任务 -2023/03|Reflexion| Reflexion:具备言语强化学习的语言代理 -2023/03|ART| ART:面向大型语言模型的自动多步推理与工具使用 -2023/03|Auto-GPT| Auto-GPT:一项自主GPT-4实验 - [代码]2023/02|Toolformer| Toolformer:语言模型可以自我教授如何使用工具 -2022/11|VISPROG| 视觉编程:无需训练即可进行组合式视觉推理 -2022/10|ReAct| ReAct:在语言模型中协同推理与行动 -
版本历史
v1.0.02023/12/08相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备