VectorizedMultiAgentSimulator
VectorizedMultiAgentSimulator(简称 VMAS)是一款专为多智能体强化学习(MARL)设计的高效仿真平台。它旨在解决传统仿真器在训练大规模智能体时速度慢、扩展性差以及难以与深度学习框架无缝集成的痛点,让研究人员能够快速验证算法并复现复杂场景。
这款工具非常适合从事机器人协同控制、人工智能算法研究的研究人员,以及希望快速搭建多智能体训练环境的开发者。VMAS 的核心亮点在于其完全基于 PyTorch 构建的向量化 2D 物理引擎。这意味着它不仅支持可微分模拟,还能利用 GPU 加速,轻松实现成千上万个环境并行运行,极大提升了训练效率。此外,VMAS 提供了丰富的预设挑战场景,支持自定义传感器(如激光雷达)、智能体间通信及复杂的物理交互(如弹性碰撞和关节连接)。其接口兼容 OpenAI Gym、Gymnasium 及 TorchRL 等主流框架,并可与 BenchMARL 库配合使用,让用户能够开箱即用,专注于算法创新而非底层环境搭建。
使用场景
某机器人实验室的研究团队正在开发一套多无人机协同避障与编队控制算法,需要在大规模并行环境中验证强化学习策略的泛化能力。
没有 VectorizedMultiAgentSimulator 时
- 训练效率极低:传统模拟器只能串行运行少量环境,收集一次有效训练数据需要数小时,导致算法迭代周期长达数周。
- 物理引擎不可微:底层物理计算不支持梯度回传,研究人员无法利用基于梯度的优化方法,限制了高级控制策略的探索。
- 场景定制困难:每增加一种新的传感器(如激光雷达)或修改碰撞逻辑,都需要重写大量底层代码,开发门槛高且易出错。
- 框架兼容性差:模拟器接口与主流强化学习库(如 TorchRL、RLlib)不匹配,团队需花费大量时间编写适配层而非核心算法。
使用 VectorizedMultiAgentSimulator 后
- 万级环境并行:借助 PyTorch 向量化特性,单张 GPU 可同时运行上万个并行环境,数据采集速度提升数百倍,训练周期从数周缩短至数小时。
- 端到端可微分:内置的可微分 2D 物理引擎支持直接反向传播,团队成功实现了更精细的基于梯度的策略优化,显著提升了控制精度。
- 模块化快速扩展:通过简单的模块化接口,研究人员在几行代码内就添加了自定义 Lidar 传感器和弹性碰撞规则,新场景验证变得轻而易举。
- 无缝生态集成:原生兼容 Gymnasium 和 BenchMARL 等标准接口,团队直接调用现成的 MARL 算法库进行训练,实现了“开箱即用”。
VectorizedMultiAgentSimulator 通过向量化加速与可微分物理引擎,将多智能体强化学习的研发效率从“手工小作坊”带入了“工业化量产”时代。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- 支持 CPU 和 CUDA GPU(通过 device='cuda' 参数启用),利用 PyTorch 进行向量化加速,具体显存和 CUDA 版本取决于安装的 PyTorch 版本
未说明(取决于并行环境数量 num_envs 和场景复杂度)
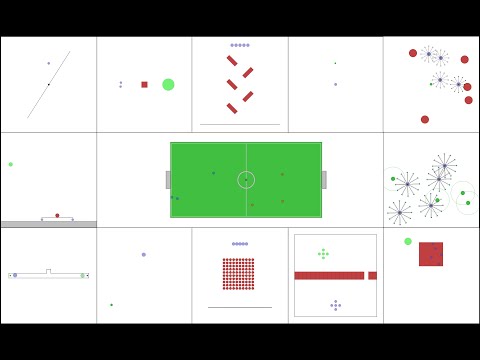
快速开始
向量化多智能体模拟器 (VMAS)


![]()


![]()
![]()
![]()
![]()
[!NOTE]
我们发布了BenchMARL,这是一个基准测试库,您可以在其中使用TorchRL训练VMAS任务! 请查看如何轻松使用它。
欢迎来到VMAS!
本仓库包含向量化多智能体模拟器(VMAS)的代码。
VMAS是一个向量化可微分模拟器,专为高效的多智能体强化学习基准测试而设计。 它由一个完全可微的PyTorch编写的向量化2D物理引擎和一组具有挑战性的多机器人场景组成。 场景的创建简单且模块化,以鼓励贡献。 VMAS可以模拟不同形状的智能体和地标,并支持旋转、弹性碰撞、关节以及自定义重力。 为了简化仿真,智能体采用了全向运动模型。还提供了诸如激光雷达之类的自定义传感器,且该模拟器支持智能体间的通信。 通过PyTorch中的向量化功能,VMAS能够批量执行仿真,在加速硬件上无缝扩展至数万个并行环境。 VMAS拥有与OpenAI Gym、Gymnasium、RLlib、torchrl及其多智能体强化学习训练库:BenchMARL兼容的接口, 从而实现与多种强化学习算法的开箱即用集成。 其实现灵感来源于OpenAI的MPE。 除了VMAS自带的场景外,我们还移植并将其余所有MPE场景进行了向量化处理。
论文
该arXiv论文可在此处找到。
如果您在研究中使用了VMAS,请引用它:
@article{bettini2022vmas,
title = {VMAS: A Vectorized Multi-Agent Simulator for Collective Robot Learning},
author = {Bettini, Matteo and Kortvelesy, Ryan and Blumenkamp, Jan and Prorok, Amanda},
year = {2022},
journal={The 16th International Symposium on Distributed Autonomous Robotic Systems},
publisher={Springer}
}
视频
观看VMAS的演示视频,展示其结构、场景和实验。


目录
使用方法
笔记本
 使用 VMAS 环境。
这是一个简单的笔记本,你可以运行它来创建、逐步执行并渲染 VMAS 中的任何场景。它复现了
使用 VMAS 环境。
这是一个简单的笔记本,你可以运行它来创建、逐步执行并渲染 VMAS 中的任何场景。它复现了 examples文件夹中的use_vmas_env.py脚本。- 创建 VMAS 场景并在 BenchMARL 中进行训练。 我们将创建一个场景,其中多个具有不同形态的机器人需要在避开彼此(以及障碍物)的同时导航到各自的目标,并使用 MAPPO 和 MLP/GNN 策略对其进行训练。
- 在 BenchMARL 中训练 VMAS(推荐)。 在这个笔记本中,我们展示了如何在 TorchRL 的 MARL 训练库 BenchMARL 中使用 VMAS。
- 在 TorchRL 中训练 VMAS。 在这个笔记本中,可在 TorchRL 文档中找到,我们展示了如何在 TorchRL 中使用任何 VMAS 场景。它将引导你完成使用 MAPPO/IPPO 训练智能体所需的完整流程。
- 在 TorchRL 中训练竞争性 VMAS MPE。 在这个笔记本中,可在 TorchRL 文档中找到,我们展示了如何使用 MADDPG/IDDPG 解决竞争性多智能体强化学习 (MARL) 问题。
- 在 RLlib 中训练 VMAS。 在这个笔记本中,我们展示了如何在 RLlib 中使用任何 VMAS 场景。它复现了
examples文件夹中的rllib.py脚本。
安装
要安装模拟器,你可以使用 pip 获取最新版本:
pip install vmas
如果你想安装当前的 master 版本(比最新版本更新),可以这样做:
git clone https://github.com/proroklab/VectorizedMultiAgentSimulator.git
cd VectorizedMultiAgentSimulator
pip install -e .
默认情况下,vmas 只包含核心依赖项。若要安装更多依赖项以支持使用 Gymnasium 包装器、RLLib 包装器进行训练、渲染和测试,你可以安装以下可选依赖项:
# 安装 gymnasium 以使用 gymnasium 包装器
pip install vmas[gymnasium]
# 安装 rllib 以使用 rllib 包装器
pip install vmas[rllib]
# 安装渲染依赖项
pip install vmas[render]
# 安装测试依赖项
pip install vmas[test]
# 安装所有依赖项
pip install vmas[all]
你还可以安装以下训练库:
pip install benchmarl # 用于在 BenchMARL 中训练
pip install torchrl # 用于在 TorchRL 中训练
pip install "ray[rllib]"==2.1.0 # 用于在 RLlib 中训练。我们支持 "ray[rllib]<=2.2,>=1.13" 版本
运行
要使用模拟器,只需通过将您想要的场景名称(来自 scenarios 文件夹)传递给 make_env 函数来创建环境。
函数参数在文档中已详细说明。该函数会返回一个具有 VMAS 接口的环境对象:
以下是一个示例:
env = vmas.make_env(
scenario="waterfall", # 可以是场景名称或 BaseScenario 类
num_envs=32,
device="cpu", # 或者使用 "cuda" 表示 GPU
continuous_actions=True,
wrapper=None, # 可选值:None、"rllib"、"gym"、"gymnasium"、"gymnasium_vec"
max_steps=None, # 定义时间步长上限。None 表示无上限。
seed=None, # 环境的随机种子
dict_spaces=False, # 默认使用元组空间,每个元素对应一个智能体。
# 如果 dict_spaces=True,则空间会变为字典形式,键为智能体名称。
grad_enabled=False, # 如果启用梯度计算,模拟器将具备可微性,输出到输入之间可以传播梯度。
terminated_truncated=False, # 如果启用此选项,模拟器将在 `done()`、`step()` 和 `get_from_scenario()` 函数中分别返回 `terminated` 和 `truncated` 标志,而不是单一的 `done` 标志。
**kwargs # 您希望传递给场景初始化的其他参数
)
您可以在 examples 目录下的 use_vmas_env.py 中找到另一个可运行的示例。
当 terminated_truncated 标志设置为 True 时,模拟器会在 done()、step() 和 get_from_scenario() 函数中分别返回 terminated 和 truncated 标志,而不是单一的 done 标志。
这在您需要区分环境结束是因为回合已经结束,还是因为达到了最大回合长度/时间步长上限时非常有用。
有关此功能的更多详细信息,请参阅 Gymnasium 文档。
RLlib
要了解如何在 RLlib 中使用 VMAS,请查看 examples/rllib.py 脚本。
您还可以在 HetGPPO 仓库中找到更多关于 VMAS 多智能体训练的示例。
TorchRL
VMAS 很好地支持 TorchRL 及其多智能体强化学习训练库 BenchMARL。
请参阅此 笔记本,了解在 BenchMARL 中使用 VMAS 是何等简单。
我们提供了一个 笔记本,它将引导您完成一个完整的多智能体强化学习流程,使用 MAPPO/IPPO 在 TorchRL 中训练 VMAS 场景。
您可以在 TorchRL 仓库的 这里 找到 示例脚本,演示如何利用 VMAS 封装运行 MAPPO-IPPO-MADDPG-QMIX-VDN。
输入与输出空间
VMAS 使用 gym 空间来定义输入和输出空间。 默认情况下,动作和观测空间是元组形式:
spaces.Tuple(
[agent_space for agent in agents]
)
在创建环境时,通过将 dict_spaces 设置为 True,可以将元组转换为字典形式:
spaces.Dict(
{agent.name: agent_space for agent in agents}
)
输出空间
如果 dict_spaces=False,环境返回的观测、信息和奖励将是一个列表,每个元素对应某个智能体的值。
如果 dict_spaces=True,环境返回的观测、信息和奖励将是一个字典,其中每个键是智能体名称,对应的值则是该智能体的相应数值。
无论采用哪种结构,每个智能体的 观测 都可能是(取决于场景的具体实现):
- 形状为
[num_envs, observation_size]的张量,其中observation_size是该智能体的观测维度。
def observation(self, agent: Agent):
return torch.cat([agent.state.pos, agent.state.vel], dim=-1)
- 或者由多个此类张量组成的字典。
def observation(self, agent: Agent):
return {
"pos": agent.state.pos,
"nested": {"vel": agent.state.vel},
}
每个智能体的 奖励 都是一个形状为 [num_envs] 的张量。
每个智能体的 信息 则是一个字典,其中每个条目都包含一个键(表示信息名称)和一个形状为 [num_envs, info_size] 的张量,info_size 是该智能体相关信息的维度。
done 是一个形状为 [num_envs] 的张量。
输入动作空间
VMAS 中的每个智能体都需要提供一个形状为 [num_envs, action_size] 的动作张量,其中 num_envs 是向量化环境的数量,action_size 是该智能体的动作维度。
智能体的动作可以通过两种方式传递给 env.step():
- 一个长度等于智能体数量的 列表,形式为
[tensor_action_agent_0, ..., tensor_action_agent_n]; - 一个长度等于智能体数量的 字典,形式为
{agent_0.name: tensor_action_agent_0, ..., agent_n.name: tensor_action_agent_n}。
用户可以在这两种格式之间自由切换,甚至在执行过程中更改格式,VMAS 始终会进行所有必要的合法性检查。无论选择元组空间还是字典空间,这两种格式都能正常工作。
模拟器特性
- 向量化:VMAS 的向量化功能可以并行推进任意数量的环境。这显著减少了在多智能体强化学习中收集训练轨迹所需的时间。
- 简单:虽然存在复杂的向量化物理引擎(例如 Brax),但在处理多个智能体时,它们的扩展效率并不高。这违背了向量化所追求的计算速度目标。VMAS 使用一个用 PyTorch 编写的简单自定义 2D 动力学引擎,以提供快速的仿真。
- 通用性:VMAS 的核心设计使其能够用于实现 2D 空间中的通用高层次多机器人问题。它既支持对抗性场景,也支持合作性场景。我们选择了全向点机器人仿真,以便专注于高层次的通用问题,而不通过 MARL 学习低层次的自定义机器人控制。
- 可扩展性:VMAS 不仅仅是一个包含一组环境的模拟器,它还是一种框架,可用于创建新的多智能体场景,并以整个 MARL 社区都能使用的方式呈现这些场景。为此,我们将任务创建过程模块化,并引入了交互式渲染功能来调试场景。您可以在几分钟内定义自己的场景。请参阅本文档中的专门章节。
- 兼容性:VMAS 提供了针对 RLlib、torchrl、OpenAI Gym 和 Gymnasium 的封装接口。RLlib 和 torchrl 已经实现了大量的强化学习算法。
请注意,这种封装接口的效率低于未封装版本。封装示例请参见
make_env的主函数。 - 经过测试:我们的场景附带测试,会在每个场景上运行一个定制的启发式算法。
- 实体形状:我们的实体(智能体和地标)可以具有不同的可定制形状(球体、盒子、线段等)。 所有这些形状都支持弹性碰撞。
- 比物理引擎更快:我们的模拟器极其轻量,仅使用张量运算。它非常适合大规模运行包含多智能体碰撞和交互的 MARL 训练。
- 可定制性:在创建您自己的新场景时,世界、智能体和地标都可以高度定制。例如:阻力、摩擦力、重力、仿真时间步长、不可微分的通信、智能体传感器(如激光雷达)以及质量等。
- 不可微分的通信:场景可能要求智能体执行离散或连续的通信动作。
- 重力:VMAS 支持可定制的重力。
- 传感器:我们的模拟器实现了光线投射功能,可用于模拟多种基于距离的传感器,并将其添加到智能体上。目前我们支持激光雷达。有关可用传感器的信息,请参阅
sensors脚本。 - 关节:我们的模拟器支持关节。关节是一种约束,用于将两个实体保持在指定的距离。用户可以指定两个物体上的锚定点、距离(包括 0)、关节的厚度、是否允许在任一锚点旋转,以及是否希望关节参与碰撞。请查看瀑布场景,了解如何使用关节。有关示例,请参阅
waterfall和joint_passage场景。 - 智能体动作:智能体的物理动作是用于全向运动的 2D 力。智能体的旋转也可以通过扭矩动作来控制(在创建智能体时设置
agent.action.u_rot_range即可启用)。智能体还可以配备连续或离散的通信动作。 - 动作预处理:通过实现场景的
process_action函数,您可以在动作传递给模拟器之前对其进行修改。这在controllers(我们提供了不同类型的控制器供使用)和dynamics(我们提供了自定义的机器人动力学模型)中都有应用。 - 控制器:控制器是可以附加到神经网络策略上的组件,也可以完全替代该策略。我们提供了一个
VelocityController,它可以将输入动作视为速度(而不是默认的 VMAS 输入力)。这个 PID 控制器接收速度值,并输出作为输入力传递给模拟器。有关示例,请参阅vel_control调试场景。 - 动力学模型:VMAS 默认模拟全向动力学模型。在创建智能体时可以选择自定义动力学模型。目前实现的模型包括用于差速驱动机器人的
DiffDriveDynamics、用于运动学自行车模型的KinematicBicycleDynamics以及用于四旋翼无人机的动力学模型Drone。有关示例,请参阅diff_drive、kinematic_bicycle和drone调试场景。 - 可微分性:在创建环境时设置
grad_enabled=True,模拟器将变为可微分的,从而允许梯度在其任何函数中流动。
创建新场景
要创建新场景,只需在 scenario.py 中扩展 BaseScenario 类即可。
您至少需要实现 make_world、reset_world_at、observation 和 reward。此外,您还可以选择实现 done、info、process_action 和 extra_render。
您还可以通过修改 make_world 函数中的继承属性来调整视图大小、缩放比例,并启用背景网格渲染。
具体操作方法,请阅读 scenario.py 中 BaseScenario 的文档,并参考已实现的场景。
交互式游玩场景
您可以交互式地体验场景!只需运行其脚本即可!
使用 interactive_rendering.py 脚本中的 render_interactively 函数即可。相关数值会实时显示在屏幕上。
使用方向键移动智能体,按 TAB 键切换智能体。按下 R 键可重置环境。
如果您有多个智能体,可以使用 W、A、S、D 键控制另一个智能体,并按 LSHIFT 键切换第二个智能体。为此,只需设置 control_two_agents=True 即可。如果智能体还具备旋转动作,您可以使用 M、N 键控制第一个智能体,使用 Q、E 键控制第二个智能体(例如在 diff_drive 场景中)。
屏幕上会显示由方向键控制的智能体的相关数据,包括:名称、当前观测、当前奖励、累计奖励以及环境是否结束的标志。
以下是其界面概览:
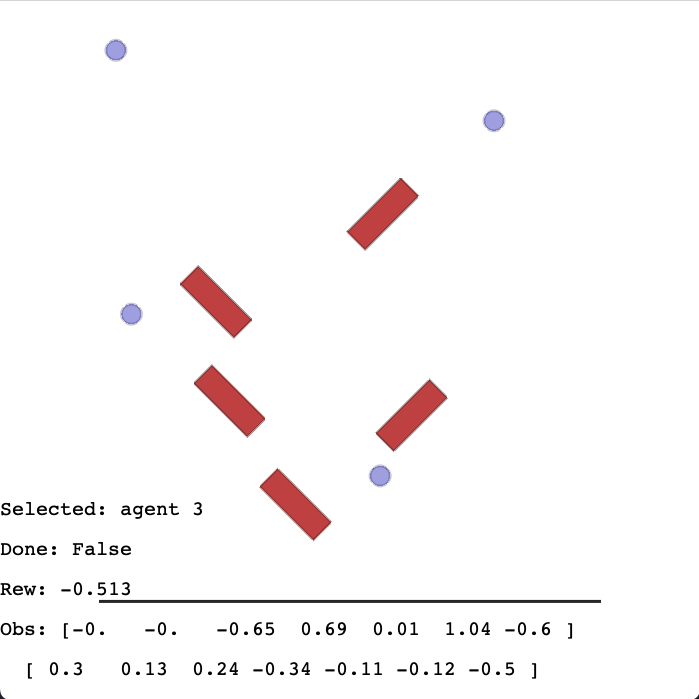
渲染
要渲染环境,只需调用 render 或 try_render_at 函数(具体取决于环境的包装方式)。
示例:
env.render(
mode="rgb_array", # "rgb_array" 返回图像,"human" 在显示窗口中渲染
agent_index_focus=4, # 如果为 None,则相机保持所有智能体在视野内;否则将相机聚焦到特定智能体
index=0, # 要渲染的批处理环境的索引
visualize_when_rgb: bool = False, # 当 mode=="rgb_array" 时,同时运行人类可读的可视化
)
你还可以通过修改场景 make_world 函数中的这些继承属性来调整查看器大小、缩放比例,并启用背景网格渲染。
| 动画 | 智能体聚焦 |
|---|---|
 |
当 agent_index_focus=None 时,相机保持所有智能体在视野内 |
 |
当 agent_index_focus=0 时,相机跟随智能体 0 |
 |
当 agent_index_focus=4 时,相机跟随智能体 4 |
渲染下的绘图函数
可以通过向 render 函数提供一个函数 f,在智能体的渲染画面下方绘制函数图形。
env.render(
plot_position_function=f
)
该函数接受一个形状为 (n_points, 2) 的 NumPy 数组,表示一组用于评估并绘制函数 f 的 x, y 值。f 可以输出形状为 (n_points, 1) 的数组,作为颜色映射进行绘制;也可以输出形状为 (n_points, 4) 的数组,作为 RGBA 值进行绘制。
更多信息请参阅 sampling.py 场景。
在服务器机器上渲染
在没有显示设备的机器上进行渲染时,请使用 mode="rgb_array"。请确保已安装 OpenGL 和 Pyglet。若要使用 GPU 进行无头渲染,可以安装 EGL 库。
如果没有 EGL,需要创建一个虚拟屏幕。可以在脚本运行前执行以下命令:
export DISPLAY=':99.0'
Xvfb :99 -screen 0 1400x900x24 > /dev/null 2>&1 &
或者采用另一种方式:
xvfb-run -s \"-screen 0 1400x900x24\" python <your_script.py>
创建虚拟屏幕需要先安装 Xvfb。
环境列表
VMAS
辍学  |
足球  |
交通  |
轮子  |
平衡  |
反向  |
让行 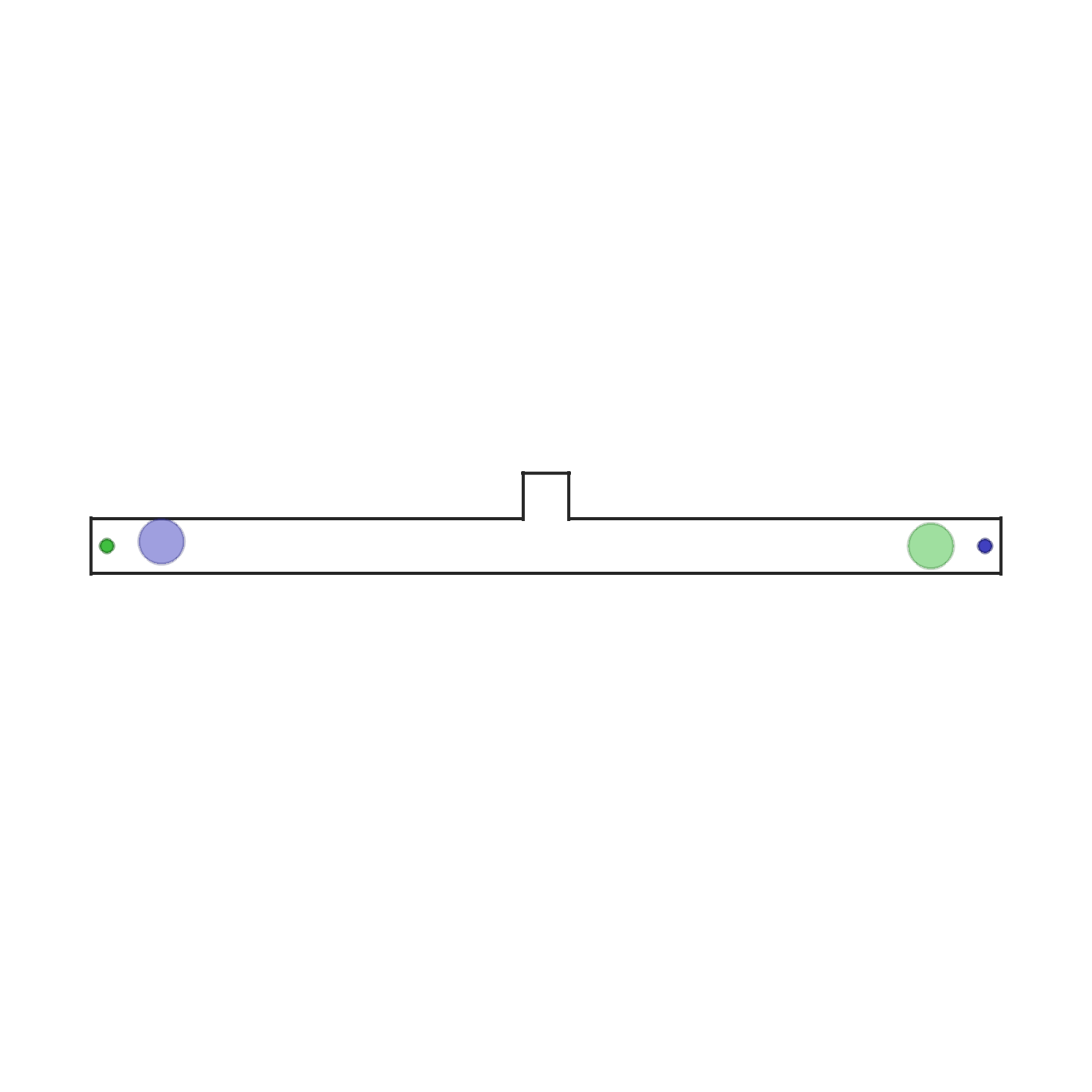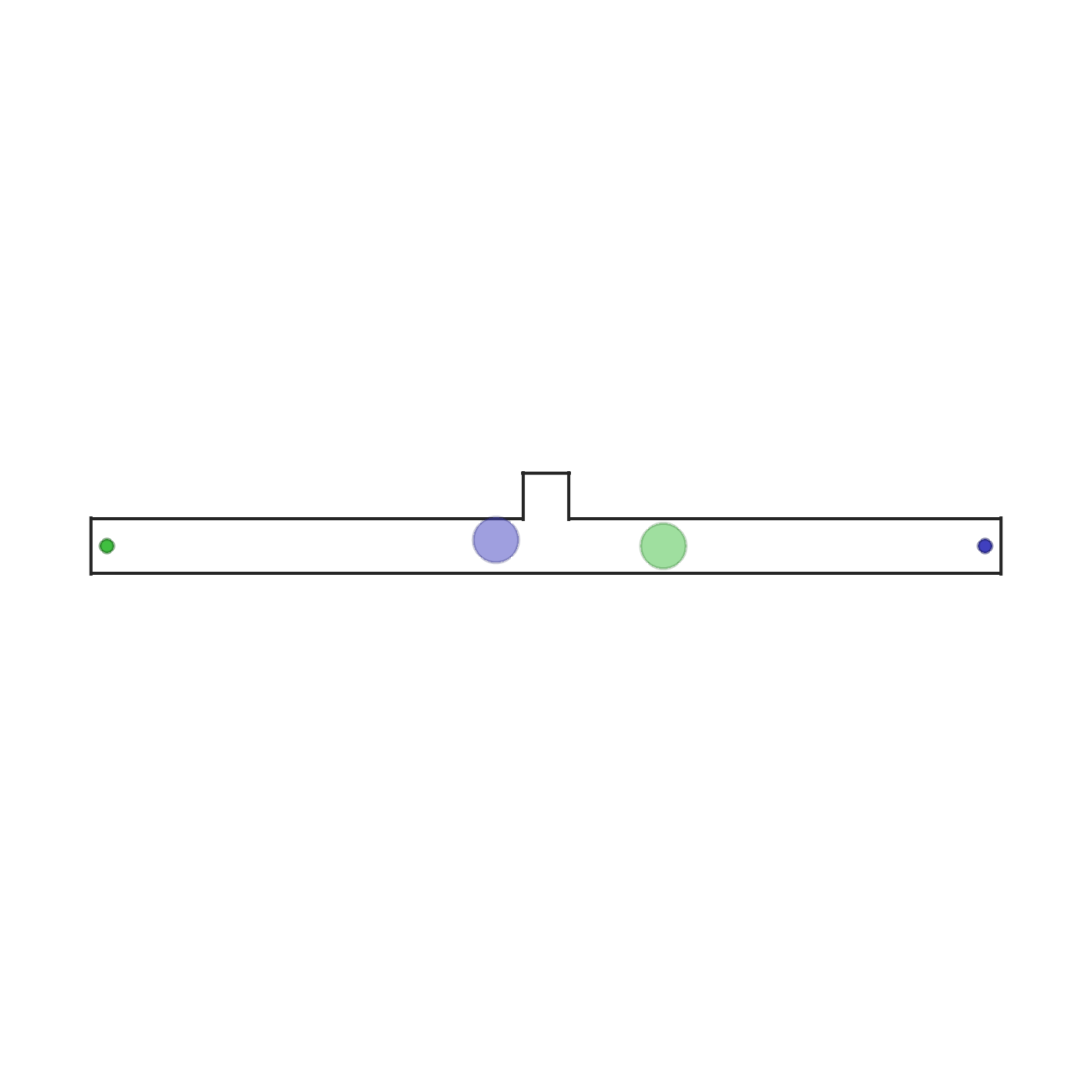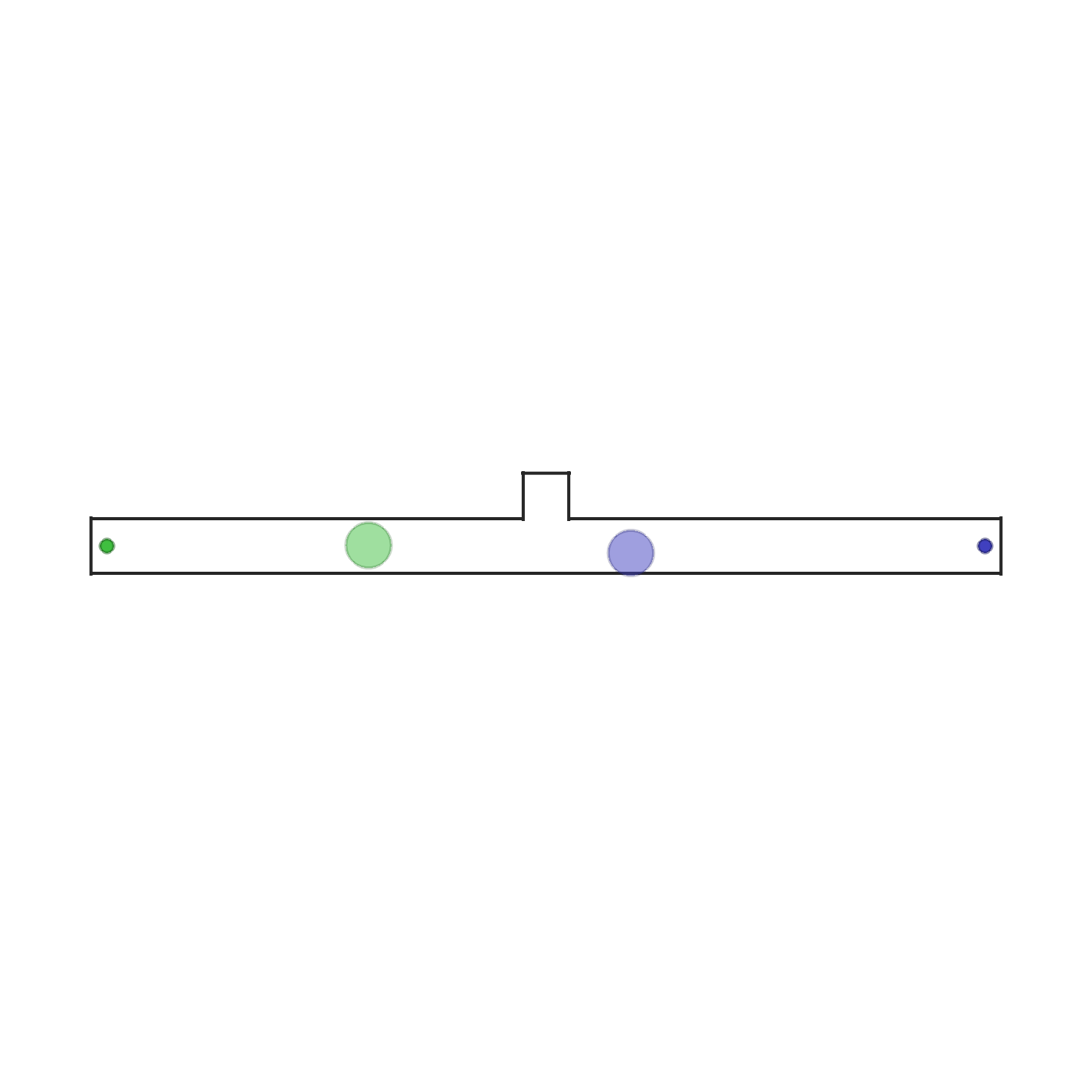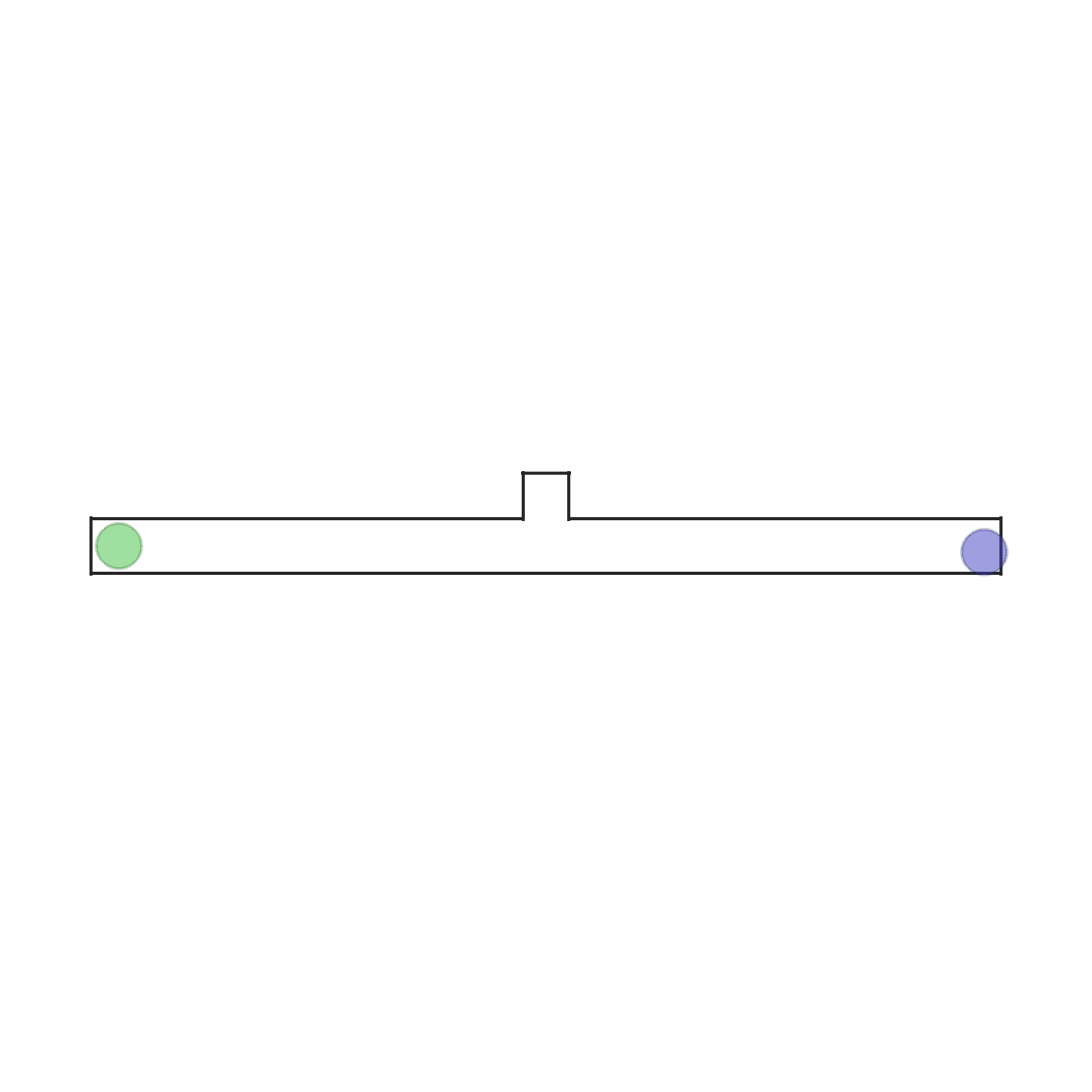 |
通道 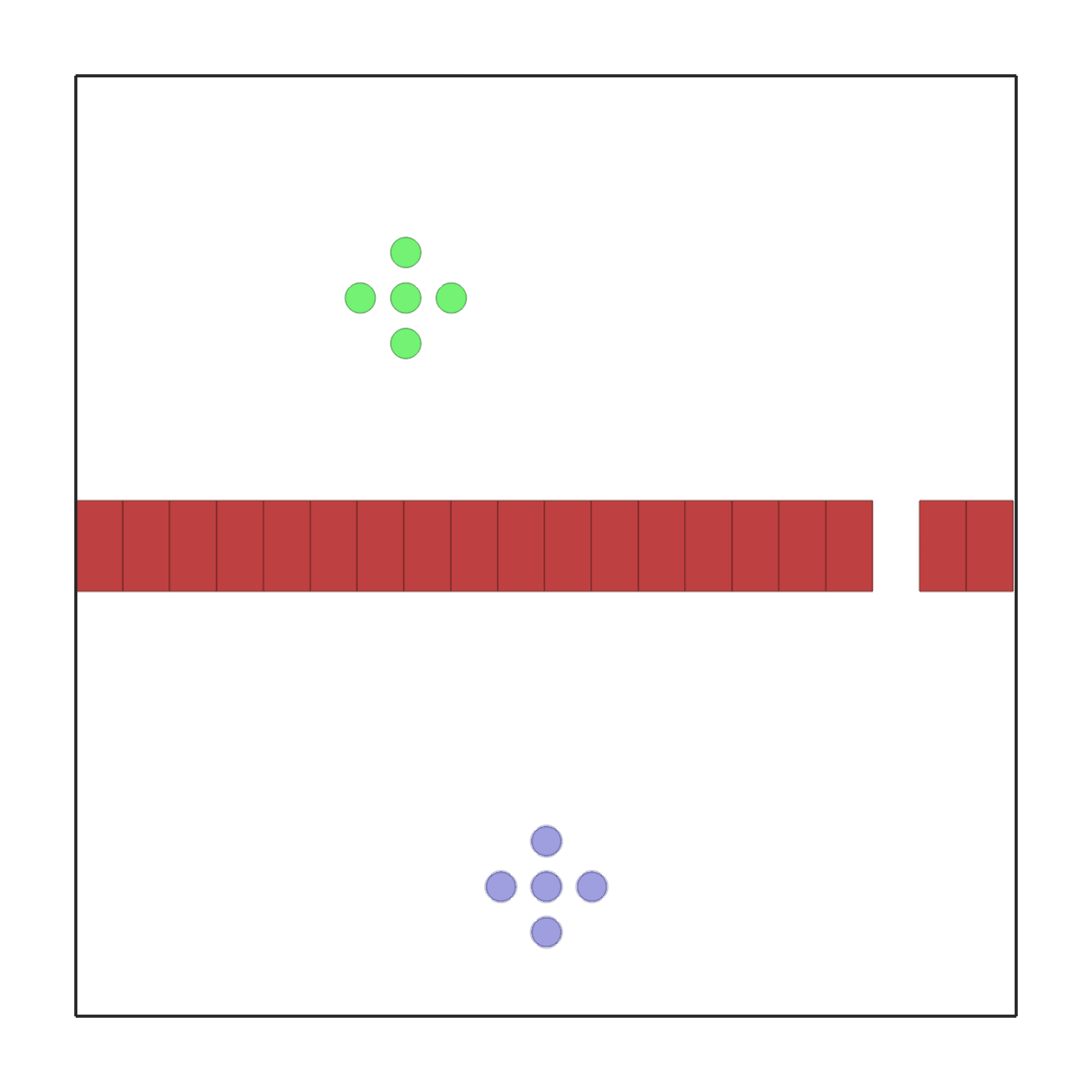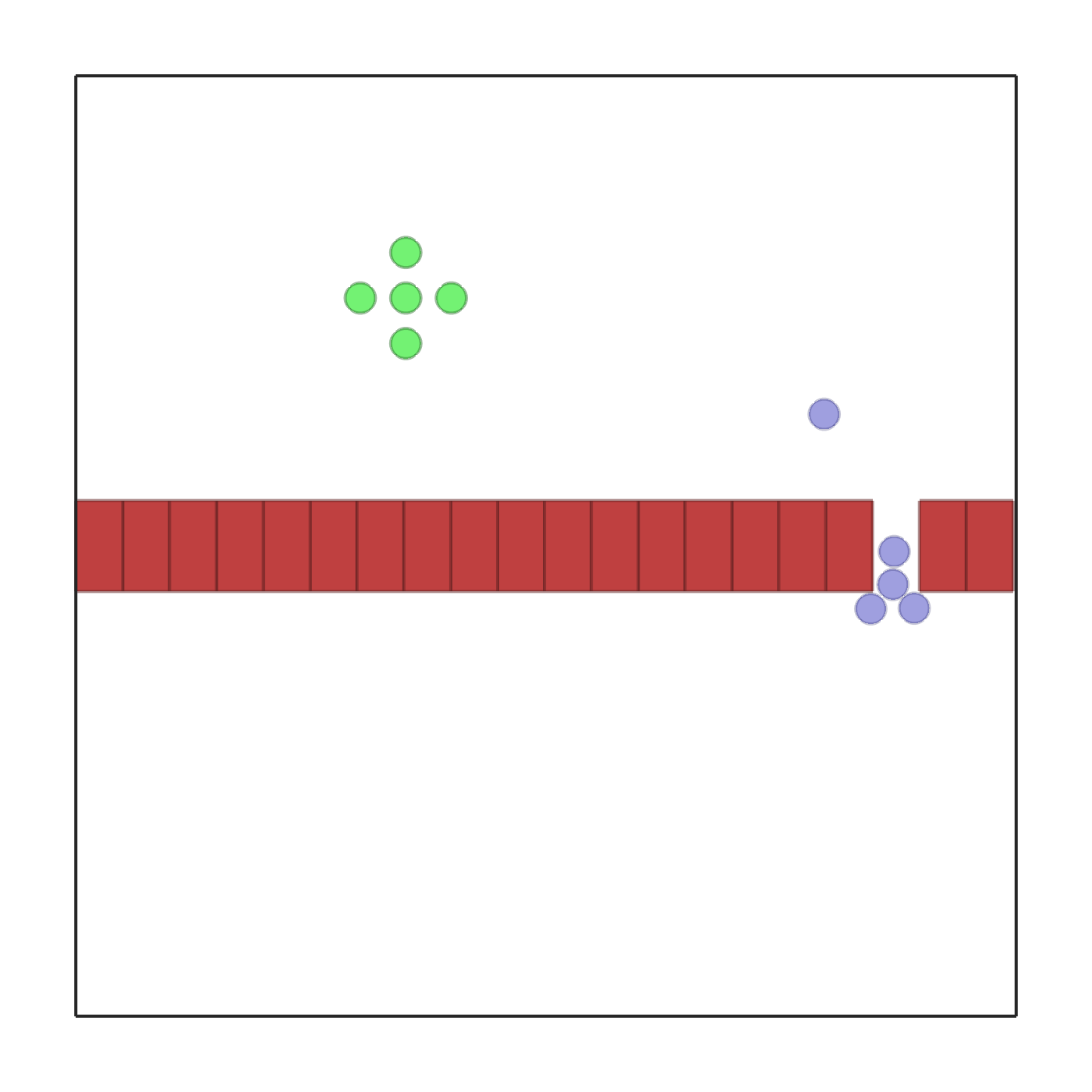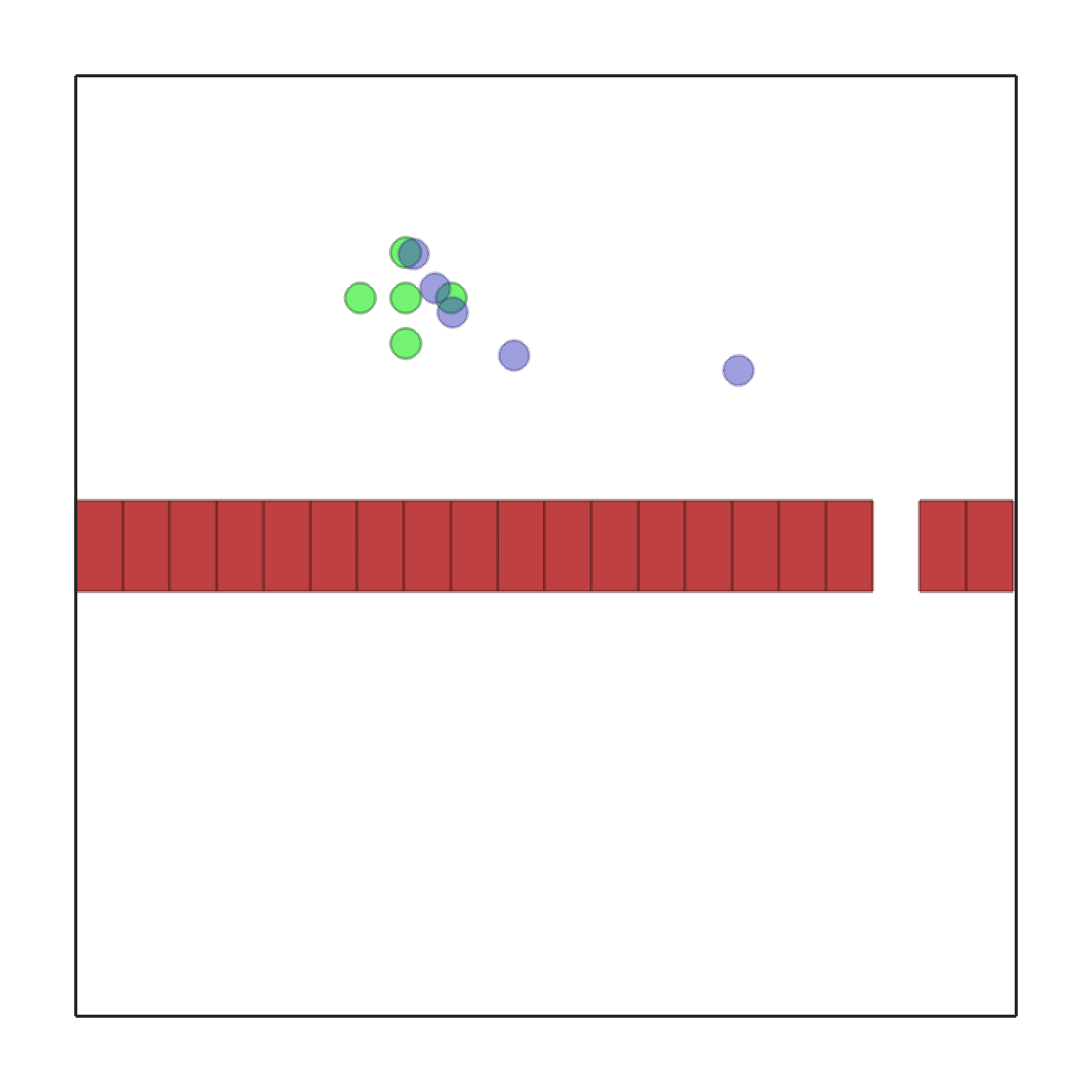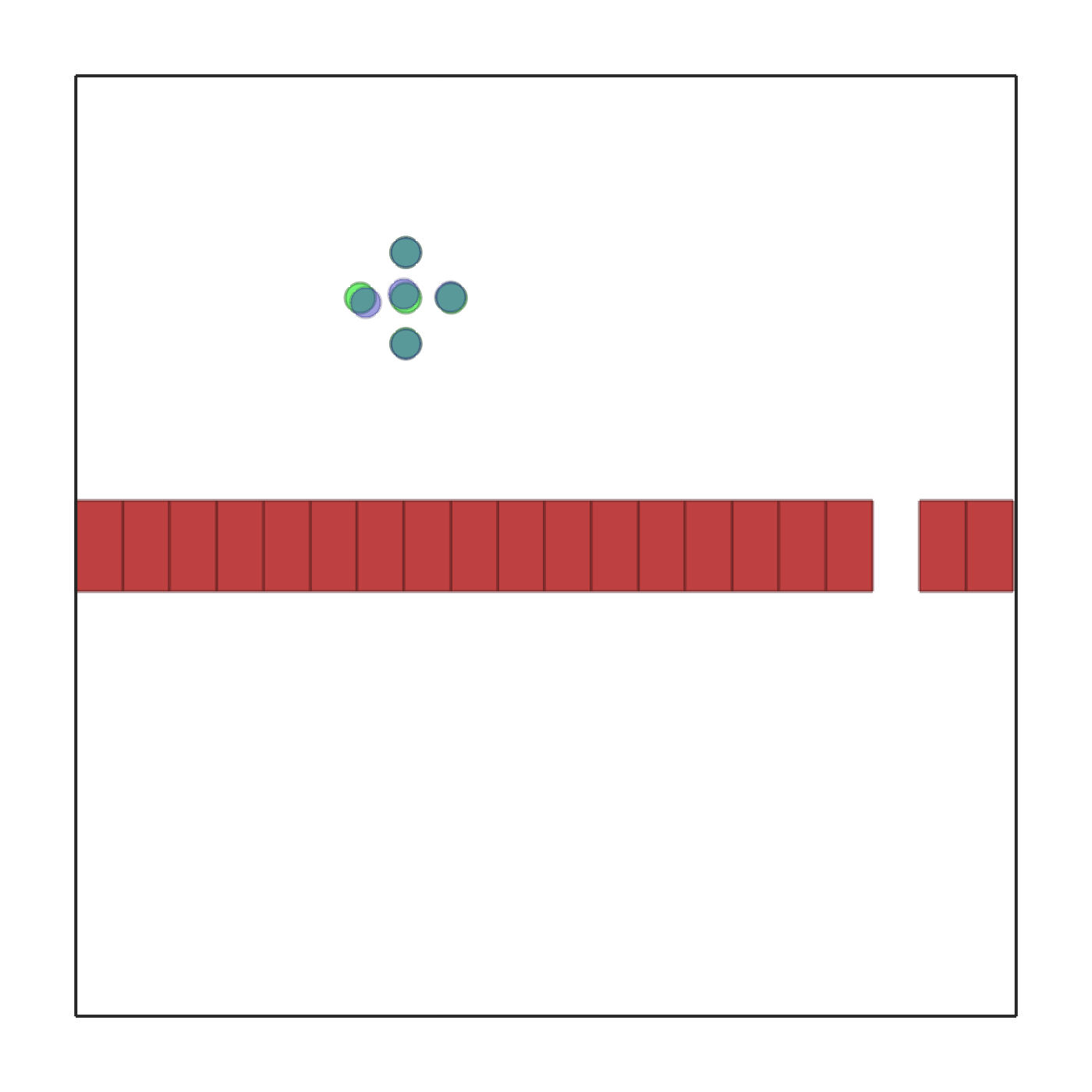 |
分散  |
联合通道大小 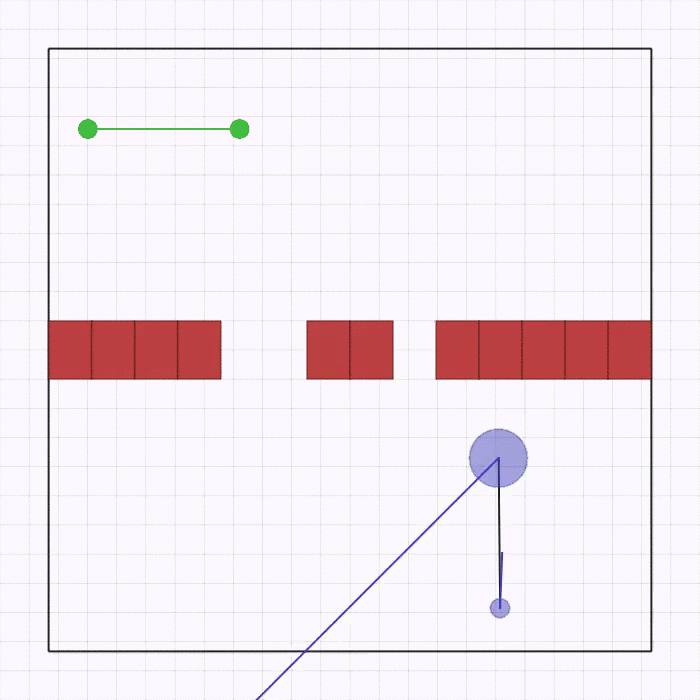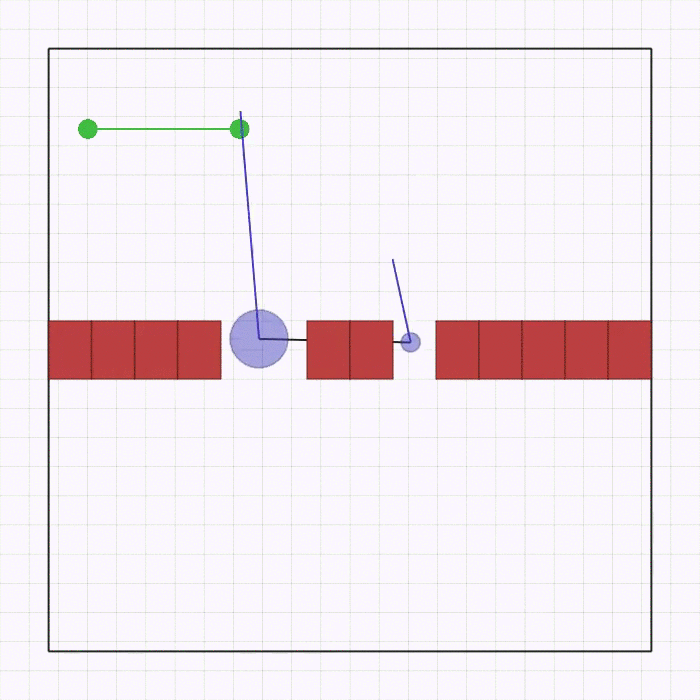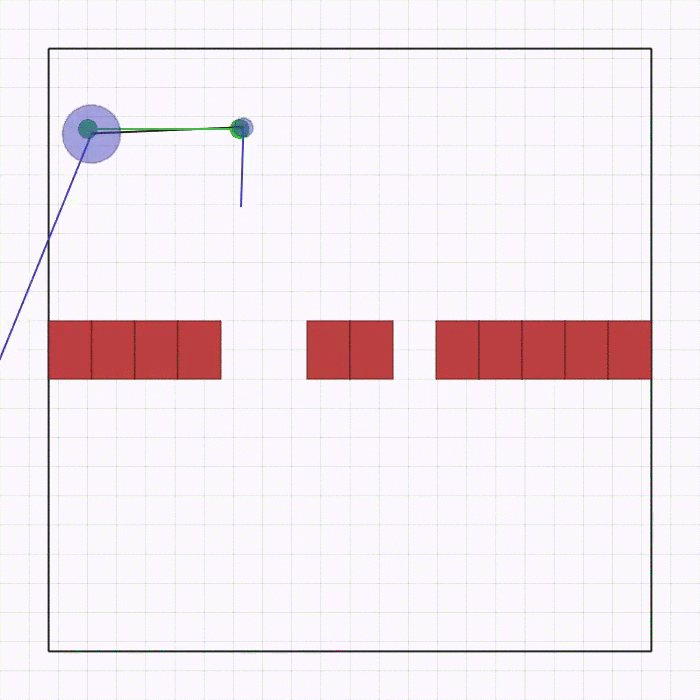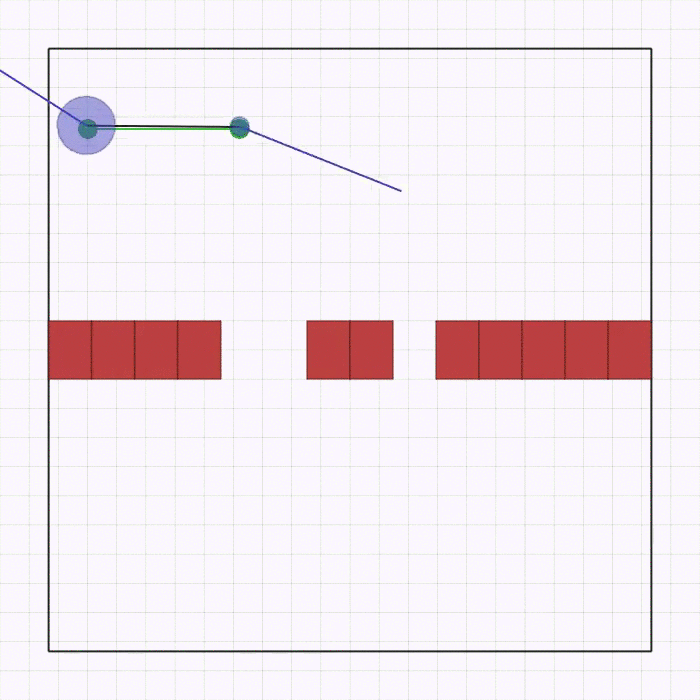 |
flocking  |
发现  |
联合通道 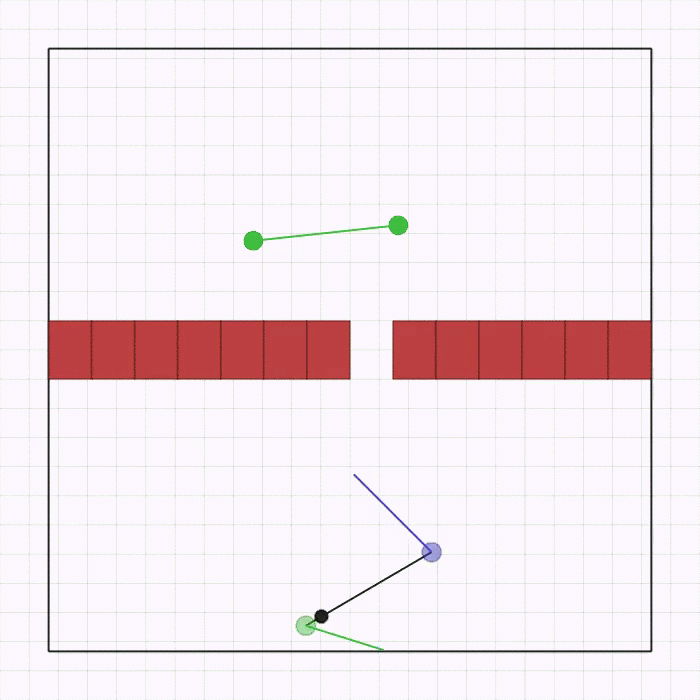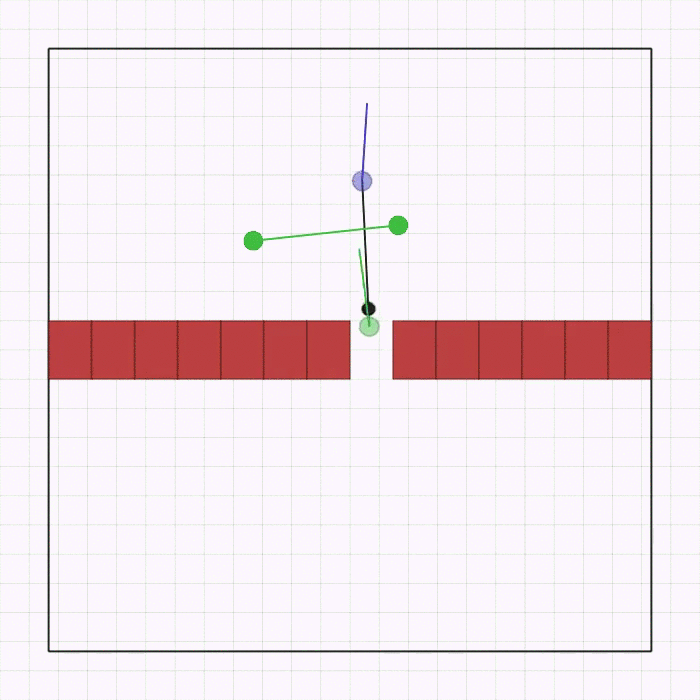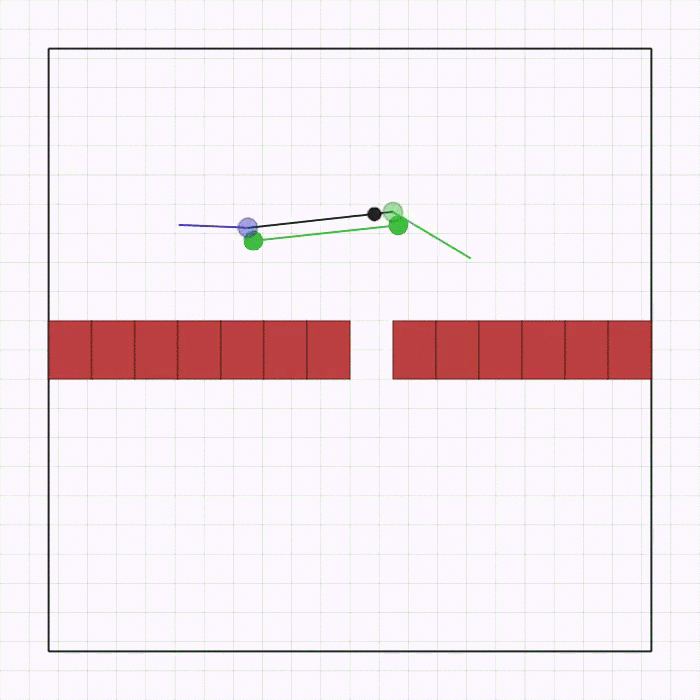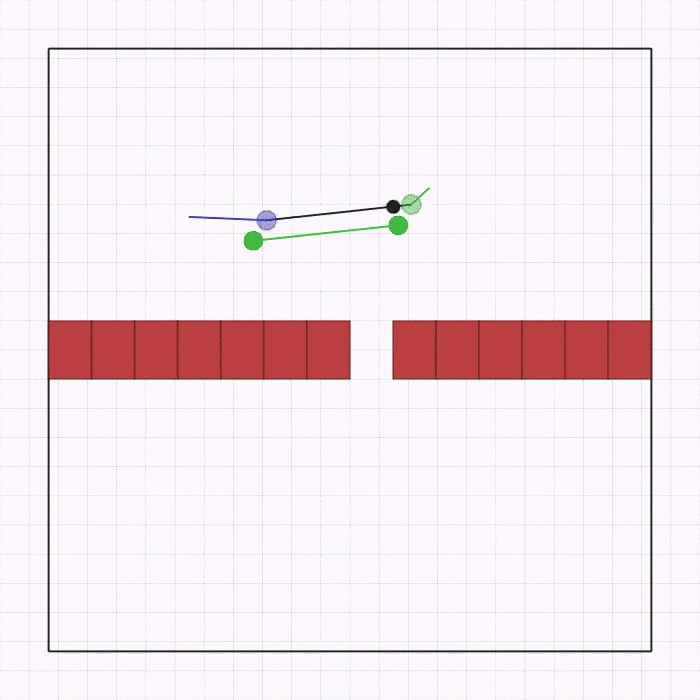 |
球类通道 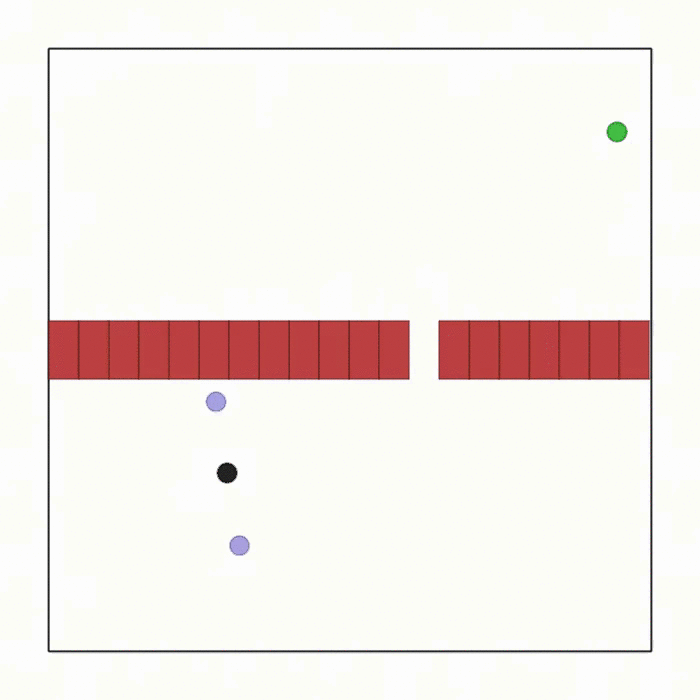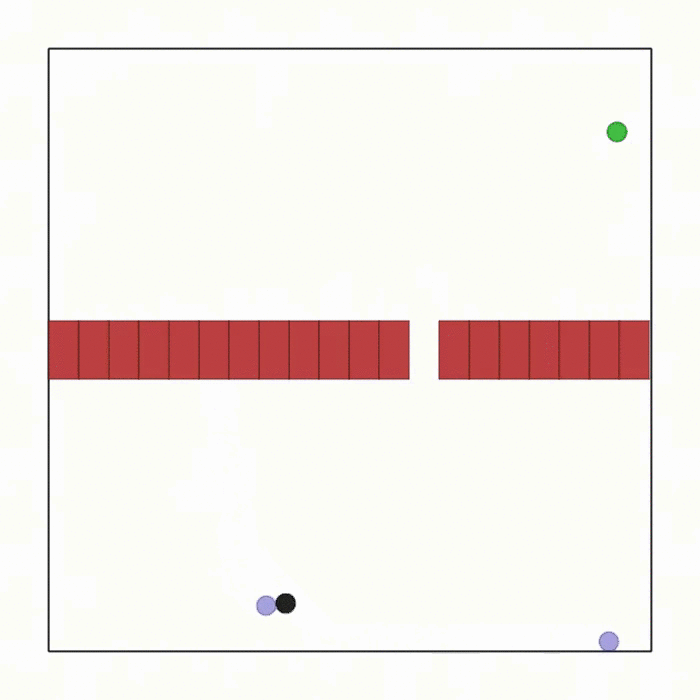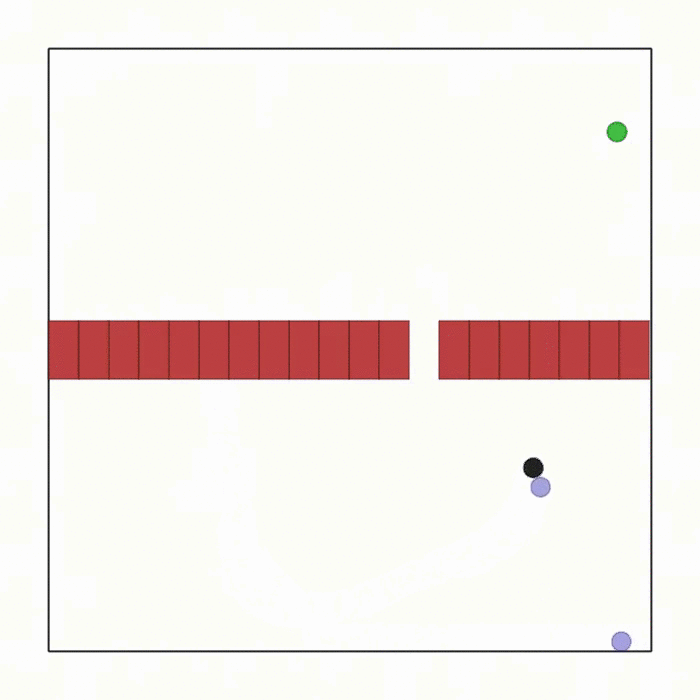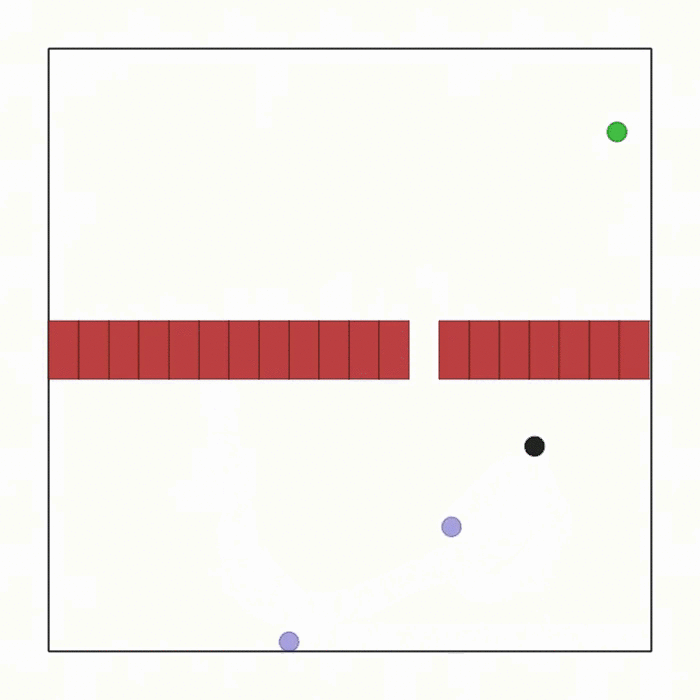 |
球的轨迹 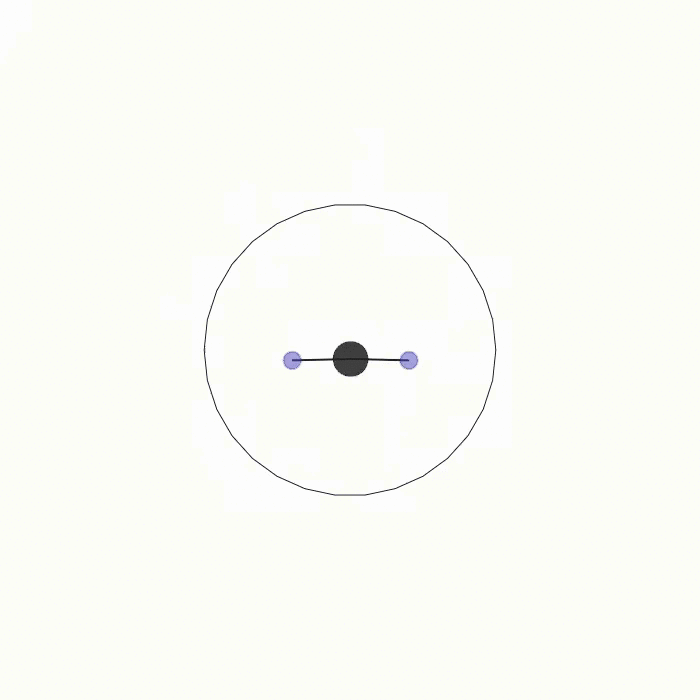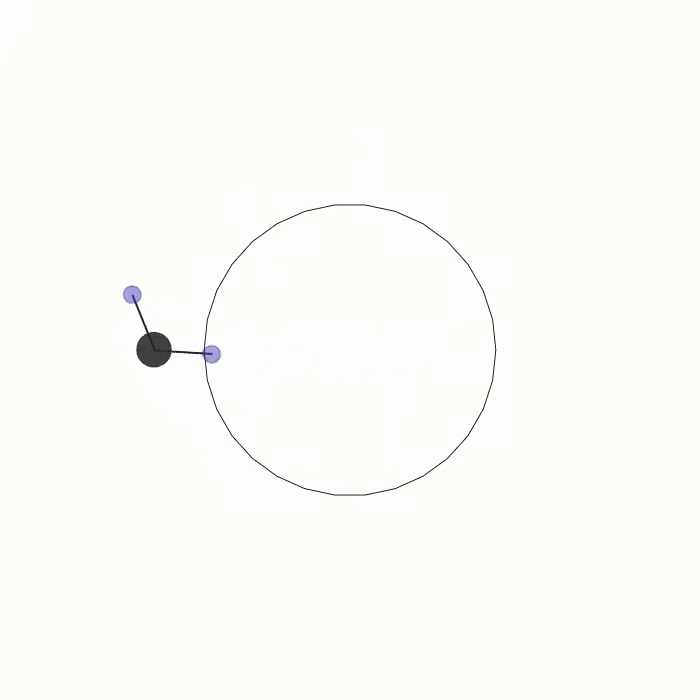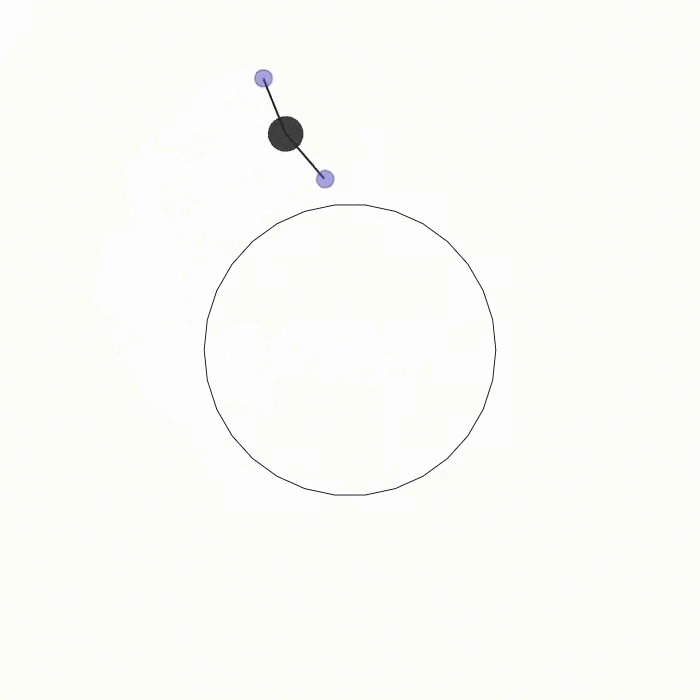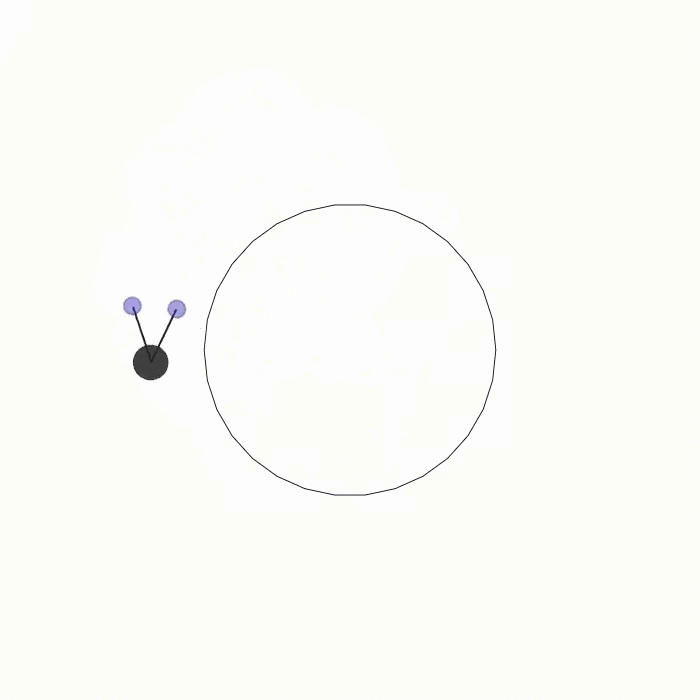 |
嗡嗡线  |
多重让行  |
导航  |
采样 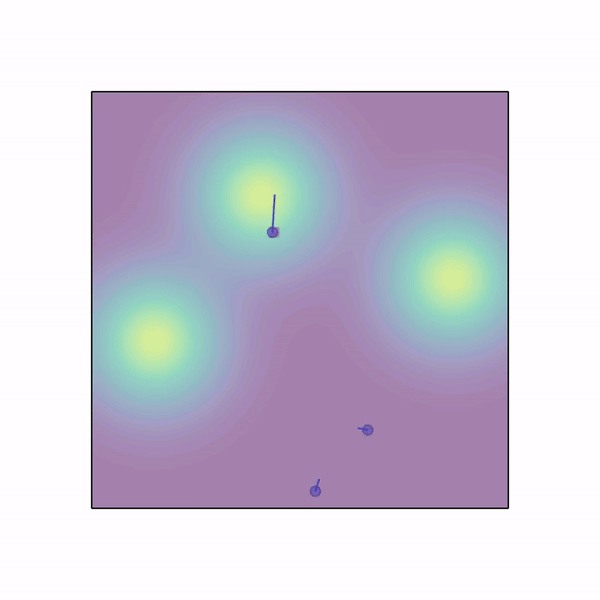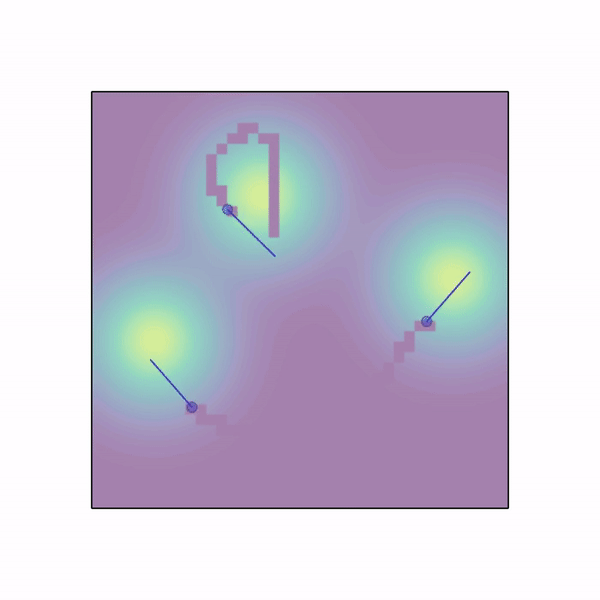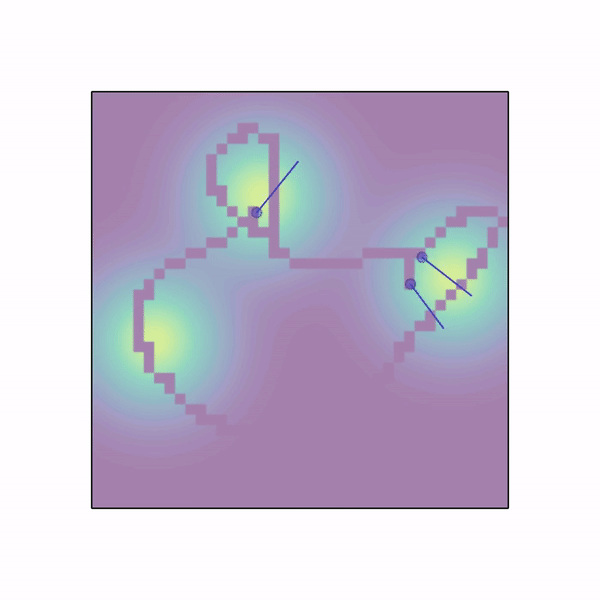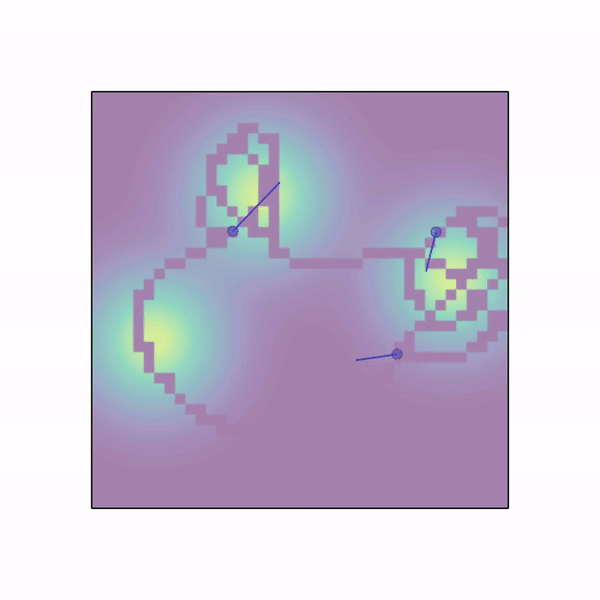 |
风力flocking  |
道路交通  |
主要场景
| 环境名称 | 描述 | 动图 |
|---|---|---|
dropout.py |
在此场景中,n_agents 个智能体和一个目标会随机生成在 -1 到 1 之间的位置。智能体之间以及与目标之间不能发生碰撞。奖励由所有智能体共享。当至少有一个智能体到达目标时,团队将获得 1 分的奖励。同时,团队还会根据每个智能体动作大小的总和受到惩罚,以此来鼓励智能体尽量减少移动。能量奖励的影响可以通过设置 energy_coeff 来调整。默认系数为 0.02,这意味着对于单个智能体来说,始终值得去到达目标。最优策略是让离目标最近的智能体独自前往目标,从而尽可能节省能量。每个智能体能够观察到自己的位置、速度、相对于目标的位置,以及是否已有人到达目标的标志。当有智能体到达目标时,环境结束。解决该环境需要智能体之间的通信。 |
|
dispersion.py |
在此场景中,会生成 n_agents 个智能体和若干目标。所有智能体初始位于 [0,0],而目标则随机分布在 -1 到 1 之间。智能体之间及与目标之间均不能发生碰撞。智能体的任务是各自到达不同的目标。当某个目标被成功到达时,如果 share_reward 为真,则整个团队获得 1 分的奖励;否则,同一时间步内到达该目标的所有智能体平分这 1 分。若 penalise_by_time 为真,每一步每个智能体会额外获得 -0.01 的奖励。最优策略是智能体分散开来,各自负责一个不同的目标。这需要高度的协调与行为多样性。每个智能体可以观察到自身的位子和速度,以及每个目标的相对位置和是否已被其他智能体到达的标志。当所有目标都被到达时,环境结束。 |
|
transport.py |
在此场景中,n_agents 个智能体、n_packages 个包裹(默认为 1)以及一个目标会随机生成在 -1 到 1 之间的位置。包裹是具有 package_mass 质量(默认为智能体质量的 50 倍)和指定尺寸的方块。任务是让智能体将所有包裹推送到目标位置。当所有包裹都与目标重叠时,场景结束。每个智能体获得的奖励与其推动包裹靠近目标的距离变化成正比。也就是说,向目标方向推动包裹会得到正奖励,而将其推开则会得到负奖励。一旦包裹与目标重叠,它会变成绿色,不再对奖励做出贡献。每个智能体可以观察到自己的位置、速度、相对于包裹的位置、包裹的速度、包裹与目标之间的相对位置,以及每个包裹是否已到达目标的标志。默认情况下,包裹非常重,单个智能体几乎无法推动它们。因此,智能体需要协作共同推动包裹,才能更快地完成任务。 |
|
reverse_transport.py |
此场景与 transport.py 完全相同,唯一的区别是所有智能体都被困在一个包裹内部。其余部分完全一致。 |
|
give_way.py |
在此场景中,两个智能体和两个目标被放置在一个狭窄的走廊里。每个智能体需要到达与其颜色对应的目标。由于两个智能体分别站在对方目标的前方,因此他们必须交换位置才能各自到达目标。走廊中间有一个不对称的开口,仅能容纳一个智能体通过。因此,最优策略是其中一个智能体主动让路给另一个智能体。这需要智能体表现出异质的行为。每个智能体可以观察到自己的位置、速度以及相对于目标的相对位置。当两个智能体都到达各自的目标时,场景结束。 | |
wheel.py |
在此场景中,n_agents 个智能体随机生成在 -1 到 1 之间的位置。一条长度为 line_length、质量为 line_mass 的杆状物被放置在场景中央,其一端固定在原点,可以自由旋转。智能体的目标是使杆的绝对角速度达到 desired_velocity。因此,仅仅让智能体在杆的两端施力是不够的,他们需要协同合作,以精确控制并不超过目标角速度。每个智能体可以观察到自己的位置、速度、杆当前角度(模 π)、当前角速度与目标角速度之间的绝对差,以及相对于杆两端的位置。奖励由所有智能体共享,其数值等于当前角速度与目标角速度之间的绝对差。 |
|
balance.py |
在此场景中,n_agents 个智能体均匀分布在线条下方,线上放置着一个质量为 package_mass 的球形包裹。团队和线条会在环境底部的随机 X 位置生成。环境中存在竖直方向的重力。如果 random_package_pos_on_line 为真(默认),包裹在线上的相对 X 位置则是随机的。环境的上半部分会生成一个目标。智能体的任务是将包裹运送到目标处。每个智能体获得的奖励与其推动包裹靠近目标的距离变化成正比。换句话说,越接近目标,奖励越高;反之则越低。如果包裹或线条掉落到地面,团队将受到 -10 的惩罚。每个智能体可以观察到自己的位置、速度、相对于包裹和线条的位置、包裹与目标之间的相对位置、包裹和线条的速度、线条的角速度以及线条旋转的角度(模 π)。当包裹或线条掉落,或者包裹触碰到目标时,场景结束。 |
|
football.py |
在此场景中,一支由 n_blue_agents 组成的蓝队与一支由 n_red_agents 组成的红队进行足球比赛。布尔参数 ai_blue_agents 和 ai_red_agents 决定每支球队是由玩家输入控制,还是由预设的 AI 控制。因此,足球既可以被视为合作任务,也可以被视为竞争任务。场景中的奖励可以根据 dense_reward_ratio 进行调整:值为 0 表示完全稀疏的奖励系统(进球得 1 分,失球得 -1 分);值为 1 则表示完全密集的奖励系统(基于双方“进攻价值”的差异,该值考虑了球与目标的距离,以及是否存在畅通的带球或射门路线)。每个智能体可以观察到自己的位置、速度、相对于球的位置以及相对于球的速度。当一方球队进球时,比赛结束。 |
|
discovery.py |
在此场景中,n_agents 名智能体需要协调合作,在避免碰撞的同时尽快覆盖 n_targets 个目标。当每个目标都有 agents_per_target 名智能体接近到至少 covering_range 的距离时,该目标即被视为被覆盖。目标被覆盖后,参与的智能体将获得奖励,而目标会重新出现在一个新的随机位置。如果智能体之间发生碰撞,将会受到惩罚。每个智能体可以观察到自己的位置、速度,以及使用 LIDAR 测量到其他智能体和目标的距离。场景将在固定的时间步数后结束。 |
|
flocking.py |
在此场景中,n_agents 名智能体需要围绕一个目标进行群集飞行,同时保持彼此间的紧密联系并最大化速度,且不得与其他智能体或 n_obstacles 个障碍物发生碰撞。智能体因相互碰撞或与障碍物碰撞而受到惩罚,同时因提高速度和缩小群集范围(增强凝聚力)而获得奖励。每个智能体可以观察到自己的位置、速度,以及使用 LIDAR 测量到其他智能体的距离。场景将在固定的时间步数后结束。 |
|
passage.py |
在此场景中,5 个机器人以编队形式随机生成在环境的底部区域。同样数量的目标也随机生成在环境的顶部区域。每个机器人需要到达与其对应的目标。环境中部有一堵墙,上面开有 n_passages 个通道。每个通道一次只能通过一个机器人。每个智能体获得的奖励与其与目标之间的距离变化成正比。也就是说,越靠近目标,奖励越高;反之则越低。如果设置了 shared_reward,这些奖励将由所有智能体共享。如果机器人之间发生碰撞,涉及的每个机器人将受到 -10 的惩罚。每个智能体可以观察到自己的位置、速度、相对于目标的位置,以及相对于每个通道中心的位置。当所有机器人到达各自的目标时,场景结束。 |
|
joint_passage_size.py |
在这里,两个不同大小的机器人(蓝色圆圈)通过两个转动关节连接成一个联动装置,需要穿过一个通道,同时保持联动装置与通道平行,并最终到达另一侧的目标位置(绿色圆圈)。通道由一大一小两个缝隙组成,它们以随机顺序和位置出现在墙上,但两者之间的距离始终保持不变。团队以随机顺序和位置生成在通道的下侧,联动装置始终垂直于通道。目标则水平放置在通道的另一侧的随机位置。每个机器人可以观察自己的速度、相对于每个缝隙的位置,以及相对于目标中心的位置。机器人会收到一种特殊的全局奖励,引导他们安全穿过通道而不与通道发生碰撞。 | |
joint_passage.py |
此场景与 joint_passage_size.py 相同,唯一的区别在于机器人现在物理上完全相同,但联动装置的质量分布不均匀(黑色圆圈)。通道是一个单独的缝隙,随机出现在墙上。智能体需要穿过这个通道,同时保持联动装置垂直于墙壁,并避免碰撞。团队和目标分别以随机的位置、顺序和旋转角度生成在通道的两侧。 |
|
ball_passage.py |
此场景与 joint_passage.py 相同,只是这次智能体之间没有联动装置,而是需要推动一个球穿过通道。奖励只与球相关,并经过特殊设计以引导球顺利通过通道。 |
|
ball_trajectory.py |
此场景与 circle_trajectory.py 类似,唯一的区别在于轨迹奖励现在依赖于一个球体对象。两名智能体需要将球沿着圆形轨迹推动。如果设置 joints=True,智能体将通过联动装置与球相连。 |
|
buzz_wire.py |
两个智能体通过联动装置与一个质量相连,需要在一个直线型走廊中玩“嗡嗡线游戏”(Buzz Wire game)。注意不要触碰边界,否则游戏立即结束! | |
multi_give_way.py |
此场景是 give_way.py 的扩展版本,其中四名智能体需要通过互相让路来各自到达目标。 |
|
navigation.py |
随机生成的智能体需要导航到各自的目标。可以开启碰撞检测功能,智能体也可以使用 LIDAR 来避免相互碰撞。奖励可以选择共享或个体奖励。除了位置、速度和 LIDAR 数据外,每个智能体还可以选择只观察自己与目标之间的相对距离,或者观察自己与所有目标之间的相对距离(在这种情况下,需要智能体表现出异质性才能解决问题)。此外,该场景还允许多个智能体共享同一个目标。 | |
sampling.py |
n_agents 个智能体随机生成在一个具有高斯分布密度函数的工作空间中,该密度函数由 n_gaussians 个模式组成。智能体需要在这个场中移动并收集样本。整个区域被划分为网格,一旦智能体访问某个格子,就会采集该格子的样本,且样本不会重复出现,采集到的样本将作为奖励分配给整个团队(或仅分配给该智能体,如果 shared_rew=False)。智能体可以使用 LIDAR 来感知彼此。除了 LIDAR、位置和速度观测之外,每个智能体还能观察到周围 3x3 格子内的样本数值。 |
|
wind_flocking.py |
两名智能体需要以指定的距离向北方向进行群集飞行。他们将根据与参考方向的一致性以及自身速度向量的对齐程度获得奖励。场景中存在从北向南吹来的风。这两名智能体在物理特性上存在差异:较小的智能体具有一定的空气动力学特性,可以为较大的智能体遮挡风力,从而优化群集效果。因此,解决这一任务的最佳方案是智能体之间进行异质性的风阻协作。更多信息请参阅 SND 论文。 | |
road_traffic.py |
此场景提供了一个用于联网自动驾驶车辆(CAVs)的 MARL 基准测试,使用来自网络物理移动实验室(CPM Lab)的高清地图,该实验室是一个面向 CAVs 的开源测试平台。地图包含一个八车道交叉路口和一个环形高速公路,设有多个汇入和驶出匝道,能够模拟多种复杂的交通状况。预先定义了四十条环形参考路径,支持无限时长的仿真运行。您可以初始化最多 100 个智能体,但默认数量为 20。训练过程中如果发生碰撞,场景会重新初始化所有智能体,随机分配新的参考路径、初始位置和速度。这种设置旨在模拟真实驾驶环境中的不可预测性。此外,观测设计注重提升样本效率和泛化能力(即智能体对未见场景的适应能力)。同时,实现了自车视角和鸟瞰视角两种观测方式,并支持部分可观测的马尔可夫决策过程建模。更多信息请参阅 这篇论文。 | |
调试场景
| 环境名称 | 描述 | 动图 |
|---|---|---|
waterfall.py |
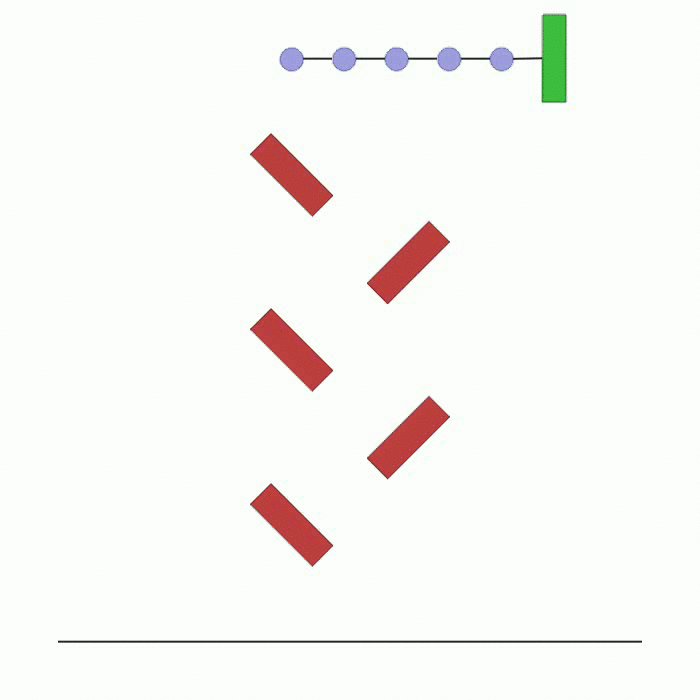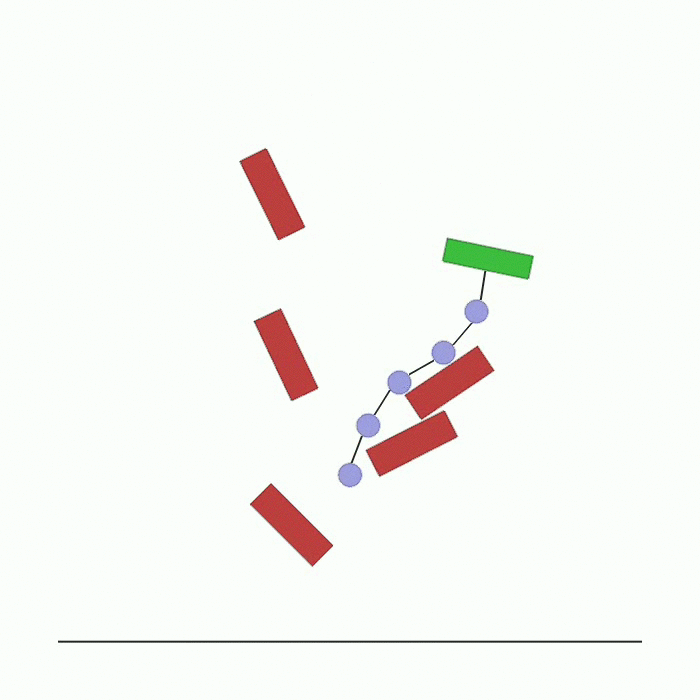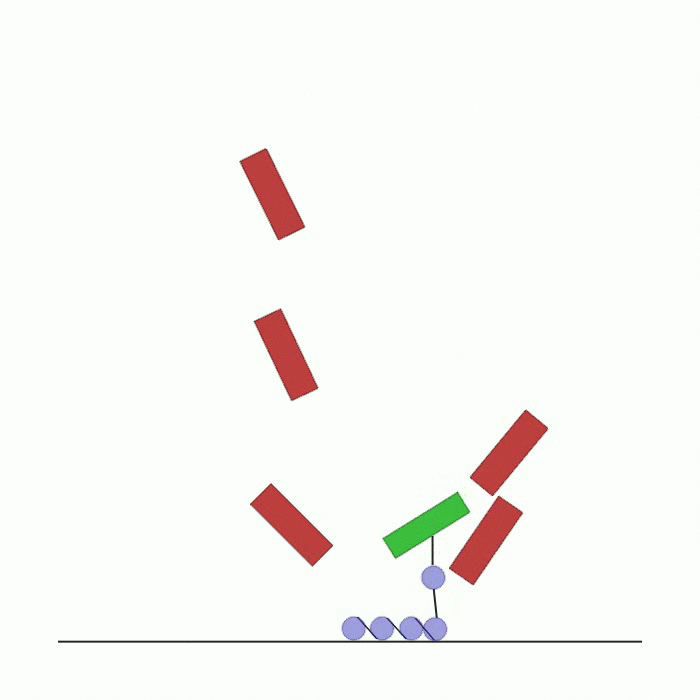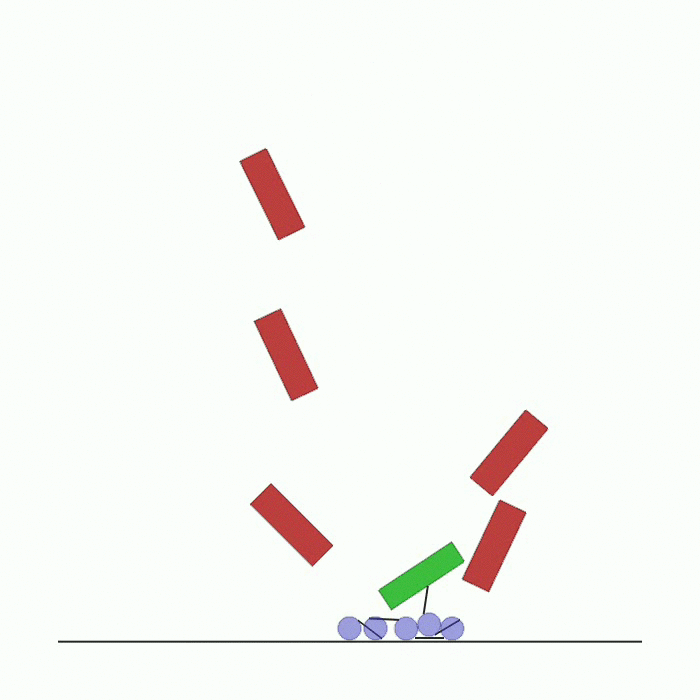
在环境顶部生成 n_agents 个智能体。它们之间通过可碰撞的连杆相互连接,最后一个智能体连接着一个方块。每个智能体的奖励取决于其与底部黑线中心的距离。智能体需要到达这条线,在此过程中可能会相互碰撞以及与环境中的方块发生碰撞。 |
 |
asym_joint.py |
两个智能体通过一个质量不对称的连杆相连。智能体的奖励是将连杆摆放到垂直位置,同时尽量减少团队的能量消耗。 |  |
vel_control.py |
示例场景:三个智能体分别具有不同加速度约束的速度控制器。 |  |
goal.py |
在工作空间中随机生成一个带有速度控制器的智能体。它的奖励是移动到一个随机初始化的目标位置,同时尽量减少能量消耗。该智能体可以观察自己的速度以及相对于目标的位置。 |  |
het_mass.py |
在工作空间中随机生成两个质量不同的智能体。它们的奖励是最大化团队的最大速度,同时最小化团队的能量消耗。最优策略要求重的智能体静止不动,而轻的智能体以最大速度运动。 |  |
line_trajectory.py |
一个智能体被奖励沿着直线轨迹运动。 |  |
circle_trajectory.py |
一个智能体被奖励以 desired_radius 为半径做圆周运动。 |
 |
diff_drive.py |
diff_drive 动力学模型约束的示例。两个智能体都具有可交互控制的旋转动作。第一个智能体采用差速驱动动力学,第二个智能体则采用标准的 V-MAS 全向动力学。 |
 |
kinematic_bicycle.py |
kinematic_bicycle 动力学模型约束的示例。两个智能体都具有可交互控制的旋转动作。第一个智能体采用自行车运动学模型动力学,第二个智能体则采用标准的 V-MAS 全向动力学。 |
 |
drone.py |
drone 动力学模型的示例。 |
 |
MPE
| 代码中的环境名称(论文中名称) | 是否有通信? | 是否竞争性? | 备注 |
|---|---|---|---|
simple.py |
否 | 否 | 单智能体观察地标位置,奖励基于其与地标之间的距离。这不是多智能体环境——用于策略调试。 |
simple_adversary.py(物理欺骗) |
否 | 是 | 1个敌对智能体(红色),N个良性智能体(绿色),N个地标(通常N=2)。所有智能体都能观察地标和其他智能体的位置。其中一个地标是“目标地标”(绿色)。良性智能体的奖励基于其中任意一个接近目标地标的程度,但如果敌对智能体靠近目标地标,则会受到惩罚。敌对智能体的奖励基于其与目标地标的距离,但它并不知道哪个地标是目标地标。因此,良性智能体需要学会“分散”并覆盖所有地标,以迷惑敌对智能体。 |
simple_crypto.py(隐秘通信) |
是 | 是 | 两个良性智能体(alice和bob),一个敌对智能体(eve)。alice必须通过公共信道向bob发送一条秘密消息。alice和bob的奖励基于bob成功还原消息的程度,但如果eve也能还原消息,则会受到惩罚。alice和bob拥有一把在每轮开始时随机生成的密钥,他们必须学会利用这把密钥来加密消息。 |
simple_push.py(保持距离) |
否 | 是 | 1个智能体、1个敌对智能体、1个地标。智能体的奖励基于其与地标的距离。敌对智能体则会在靠近地标且智能体远离地标时获得奖励。因此,敌对智能体会学习将智能体推离地标。 |
simple_reference.py |
是 | 否 | 2个智能体,3个不同颜色的地标。每个智能体都想到达自己专属的目标地标,而这个目标地标只有另一方智能体才知道。奖励是集体性的。因此,智能体需要学会相互沟通对方的目标,并导航到各自的地标。这与simple_speaker_listener场景相同,即两个智能体既是说话者又是倾听者。 |
simple_speaker_listener.py(合作性通信) |
是 | 否 | 与simple_reference相同,区别在于:一个智能体是“说话者”(灰色),不移动,负责观察另一智能体的目标;另一个智能体是“倾听者”(不能说话,但必须导航到正确的目标地标)。 |
simple_spread.py(合作性导航) |
否 | 否 | N个智能体,N个地标。智能体的奖励基于任意一个智能体与每个地标之间的距离。如果智能体之间发生碰撞,则会受到惩罚。因此,智能体需要学会在避免碰撞的同时覆盖所有地标。 |
simple_tag.py(捕食者-猎物) |
否 | 是 | 捕食者-猎物环境。良性智能体(绿色)速度较快,希望避免被敌对智能体(红色)击中。敌对智能体速度较慢,希望击中良性智能体。障碍物(大黑圆圈)会阻挡路径。 |
simple_world_comm.py |
是 | 是 | 论文中附带视频中展示的环境。与simple_tag相同,区别在于:(1) 存在食物(小蓝球),良性智能体靠近食物时会获得奖励;(2) 现在有“森林”,可以将智能体隐藏起来,使其从外部无法被看到;(3) 存在一名“领导者敌对智能体”,它可以始终看到所有智能体,并能与其他敌对智能体通信,以协调追捕行动。 |
我们使用 VMAS 的论文
- VMAS 支持
balance、transport、give_way、wheel等任务的训练。 - HetGPPO 支持
het_mass、give_way、joint_passage、joint_passage_size等任务的训练。 - SND 支持
navigation、joint_passage、joint_passage_size、wind等任务的训练。 - TorchRL 支持
navigation、sampling、balance等任务的训练。 - BenchMARL 支持
navigation、sampling、balance等任务的训练。 - 剑桥 RoboMaster 支持
navigation任务的训练。 - DiversityControl (DiCo) 支持
navigation、sampling、dispersion、simple_tag等任务的训练。
待办事项
待办事项现已列在 这里。
- 提升测试效率并添加新测试
- 实现 2D 无人机动力学
- 允许任意数量的动作
- 提高 VMAS 性能
- 在 torchrl 中支持字典型观测
- 将 TextLine 使能为场景中可用的 Geom
- 编写关于如何将 torch rl 与 vmas 结合使用的笔记本
- 允许字典型观测空间和多维观测
- 讨论动作预处理和速度控制器
- 来自联合项目的全新环境及其描述
- 讨论导航 / 多目标问题
- 链接实验视频
- 添加 LiDAR 章节
- 实现 LiDAR
- 重写所有 MPE 场景
- simple
- simple_adversary
- simple_crypto
- simple_push
- simple_reference
- simple_speaker_listener
- simple_spread
- simple_tag
- simple_world_comm
版本历史
VMAS-1.5.22025/11/101.5.12025/09/301.5.02025/02/021.4.32024/09/211.4.22024/07/101.4.12024/05/20VMAS-1.4.02024/02/07VMAS-1.3.42024/01/19VMAS-1.3.32023/12/19VMAS-1.3.02023/12/02VMAS-1.2.132023/11/02VMAS-1.2.122023/09/20VMAS-1.2.112023/05/24VMAS-1.2.102023/05/10VMAS-1.2.92023/04/06VMAS-1.2.82023/03/20VMAS-1.2.72023/03/20VMAS-1.2.62023/01/20VMAS-1.2.52023/01/19VMAS-1.2.42023/01/18常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。