YOLOv5-Lite
YOLOv5-Lite 是一款专为边缘设备打造的超轻量级目标检测模型,由经典的 YOLOv5 演进而来。它主要解决了传统检测模型在树莓派、手机等算力受限设备上运行缓慢、内存占用过高以及难以部署的痛点。通过引入 ShuffleNetV2 骨干网络、优化检测头结构以及移除复杂的 Focus 层,YOLOv5-Lite 在大幅降低计算量(Flops)和参数量的同时,依然保持了出色的检测精度。
该工具特别适合嵌入式开发者、物联网工程师以及在移动端进行 AI 落地的研究人员使用。其核心技术亮点在于极致的轻量化与广泛的框架兼容性:最小模型经 int8 量化后体积仅约 900KB,却能在树莓派 4B 上实现每秒 15 帧的实时推理速度。此外,YOLOv5-Lite 原生支持 NCNN、MNN、TNN、OpenVINO 等多种主流推理框架,提供了从 PyTorch 训练到多平台部署的完整解决方案,让高性能目标检测算法能轻松运行在各种低功耗硬件上。
使用场景
某农业初创团队需要在树莓派 4B 上部署一套实时害虫监测系统,用于田间边缘计算设备自动识别并统计虫害数量。
没有 YOLOv5-Lite 时
- 硬件性能瓶颈:标准版 YOLOv5s 在树莓派 4B 上推理耗时高达 371ms,帧率不足 3 FPS,画面严重卡顿,无法捕捉快速飞行的昆虫。
- 存储资源受限:模型文件体积超过 14MB,对于闪存空间有限的嵌入式设备而言占用过高,难以同时容纳操作系统与其他业务逻辑。
- 部署复杂度大:原模型包含 Focus 层等复杂算子,在 ARM 架构下进行量化(Int8)时精度损失严重,导致漏检率飙升,难以落地。
- 功耗与发热问题:低效的推理过程迫使 CPU 长期高负荷运转,导致设备发热严重且电池续航急剧缩短,不适合野外长时间工作。
使用 YOLOv5-Lite 后
- 实时流畅检测:YOLOv5-Lite 经过结构重优化(如引入 Shuffle Channel),在树莓派 4B 上轻松达到 15+ FPS,实现了对害虫运动的丝滑追踪。
- 极致轻量存储:模型大小压缩至 1.7MB(FP16)甚至 900KB+(Int8),仅为原版的十分之一,极大释放了嵌入式设备的存储空间。
- 无损量化部署:通过移除切片操作等改进,YOLOv5-Lite 在 Int8 量化下仍保持高精度(mAP@0.5 达 35.1%),完美平衡了速度与准确率。
- 低功耗运行:更少的参数量和计算量(Flops)显著降低了 CPU 负载,设备发热减少,支持太阳能供电下的全天候稳定运行。
YOLOv5-Lite 通过将重型模型“瘦身”为嵌入式友好的轻量级方案,成功让低成本硬件具备了工业级的实时视觉感知能力。
运行环境要求
- Linux
- Windows
- Android
- 非必需
- 支持 NVIDIA GPU (如 RTX 2080Ti) 配合 Torch/TensorRT
- 支持 ARM NPU/GPU (如 AXera-Pi, Snapdragon) 配合 NCNN/MNN/Tengine/AXPI
- 也支持纯 CPU (x86/ARM) 运行 OpenVINO/ONNXRuntime
未说明 (模型参数量极小,最小模型仅 0.78M 参数,适合树莓派等低内存设备)

快速开始
YOLOv5-Lite:更轻量、更快、更易部署 
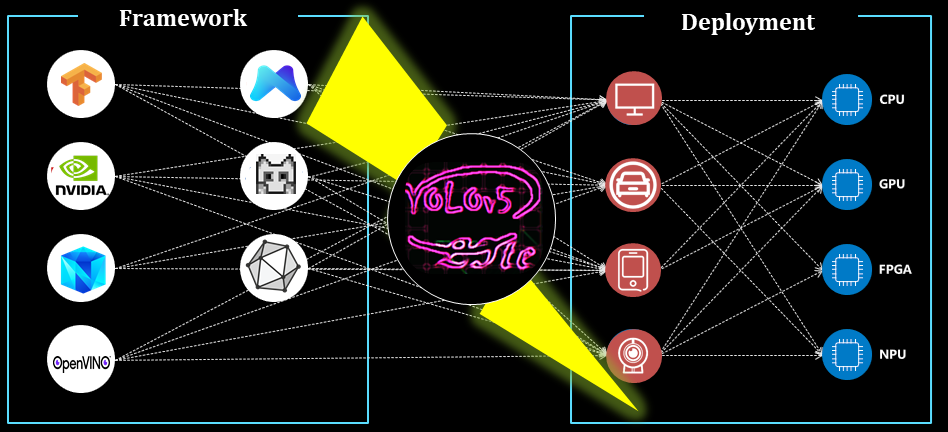
我们在 YOLOv5 上进行了一系列消融实验,使其更加轻量化(FLOPs 更小、内存占用更低、参数量更少)且速度更快(引入通道混洗操作,并对 YOLOv5 的检测头进行通道裁剪)。在树莓派 4B 上,使用 320×320 分辨率的输入时,该模型能够达到至少 10+ FPS 的推理速度;同时,通过移除 Focus 层和四次切片操作,并将模型量化精度控制在可接受范围内,进一步简化了部署流程。

消融实验结果对比
| ID | 模型 | 输入尺寸 | FLOPs | 参数量 | 大小(MB) | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|---|---|---|
| 001 | yolo-fastest | 320×320 | 0.25G | 0.35M | 1.4 | 24.4 | - |
| 002 | YOLOv5-Liteeours | 320×320 | 0.73G | 0.78M | 1.7 | 35.1 | - |
| 003 | NanoDet-m | 320×320 | 0.72G | 0.95M | 1.8 | - | 20.6 |
| 004 | yolo-fastest-xl | 320×320 | 0.72G | 0.92M | 3.5 | 34.3 | - |
| 005 | YOLOXNano | 416×416 | 1.08G | 0.91M | 7.3(fp32) | - | 25.8 |
| 006 | yolov3-tiny | 416×416 | 6.96G | 6.06M | 23.0 | 33.1 | 16.6 |
| 007 | yolov4-tiny | 416×416 | 5.62G | 8.86M | 33.7 | 40.2 | 21.7 |
| 008 | YOLOv5-Litesours | 416×416 | 1.66G | 1.64M | 3.4 | 42.0 | 25.2 |
| 009 | YOLOv5-Litecours | 512×512 | 5.92G | 4.57M | 9.2 | 50.9 | 32.5 |
| 010 | NanoDet-EfficientLite2 | 512×512 | 7.12G | 4.71M | 18.3 | - | 32.6 |
| 011 | YOLOv5s(6.0) | 640×640 | 16.5G | 7.23M | 14.0 | 56.0 | 37.2 |
| 012 | YOLOv5-Litegours | 640×640 | 15.6G | 5.39M | 10.9 | 57.6 | 39.1 |
更多详情请参阅 Wiki:https://github.com/ppogg/YOLOv5-Lite/wiki/Test-the-map-of-models-about-coco
不同平台上的性能对比
| 设备 | 计算后端 | 系统 | 输入分辨率 | 框架 | v5lite-e | v5lite-s | v5lite-c | v5lite-g | YOLOv5s |
|---|---|---|---|---|---|---|---|---|---|
| Intel | @i5-10210U | Windows(x86) | 640×640 | OpenVINO | - | - | 46ms | - | 131ms |
| NVIDIA | @RTX 2080Ti | Linux(x86) | 640×640 | PyTorch | - | - | - | 15ms | 14ms |
| Redmi K30 | @Snapdragon 730G | Android(armv8) | 320×320 | NCNN | 27ms | 38ms | - | - | 163ms |
| Xiaomi 10 | @Snapdragon 865 | Android(armv8) | 320×320 | NCNN | 10ms | 14ms | - | - | 163ms |
| 树莓派 4B | @ARM Cortex-A72 | Linux(arm64) | 320×320 | NCNN | - | 84ms | - | - | 371ms |
| 树莓派 4B | @ARM Cortex-A72 | Linux(arm64) | 320×320 | MNN | - | 71ms | - | - | 356ms |
| AXera-Pi | Cortex A7@CPU 3.6TOPs @NPU |
Linux(arm64) | 640×640 | axpi | - | - | - | 22ms | 22ms |
树莓派 4B 上实现 15 FPS 的教程:
https://zhuanlan.zhihu.com/p/672633849
- 以上为四线程测试基准
- 树莓派 4B 启用 bf16 优化,需使用 Raspberry Pi 64 位操作系统
QQ交流群:993965802
入群暗号:剪枝 或 蒸馏 或 量化 或 低秩分解(任选其一即可)
·模型动物园·
@v5lite-e:
| 模型 | 大小 | 骨干网络 | 头部 | 框架 | 适用场景 |
|---|---|---|---|---|---|
| v5Lite-e.pt | 1.7m | shufflenetv2(旷视科技) | v5Litee-head | Pytorch | Arm-cpu |
| v5Lite-e.bin v5Lite-e.param |
1.7m | shufflenetv2 | v5Litee-head | ncnn | Arm-cpu |
| v5Lite-e-int8.bin v5Lite-e-int8.param |
0.9m | shufflenetv2 | v5Litee-head | ncnn | Arm-cpu |
| v5Lite-e-fp32.mnn | 3.0m | shufflenetv2 | v5Litee-head | mnn | Arm-cpu |
| v5Lite-e-fp32.tnnmodel v5Lite-e-fp32.tnnproto |
2.9m | shufflenetv2 | v5Litee-head | tnn | arm-cpu |
| v5Lite-e-320.onnx | 3.1m | shufflenetv2 | v5Litee-head | onnxruntime | x86-cpu |
@v5lite-s:
| 模型 | 大小 | 骨干网络 | 头部 | 框架 | 适用场景 |
|---|---|---|---|---|---|
| v5Lite-s.pt | 3.4m | shufflenetv2(旷视科技) | v5Lites-head | Pytorch | Arm-cpu |
| v5Lite-s.bin v5Lite-s.param |
3.3m | shufflenetv2 | v5Lites-head | ncnn | Arm-cpu |
| v5Lite-s-int8.bin v5Lite-s-int8.param |
1.7m | shufflenetv2 | v5Lites-head | ncnn | Arm-cpu |
| v5Lite-s.mnn | 3.3m | shufflenetv2 | v5Lites-head | mnn | Arm-cpu |
| v5Lite-s-int4.mnn | 987k | shufflenetv2 | v5Lites-head | mnn | Arm-cpu |
| v5Lite-s-fp16.bin v5Lite-s-fp16.xml |
3.4m | shufflenetv2 | v5Lites-head | openvivo | x86-cpu |
| v5Lite-s-fp32.bin v5Lite-s-fp32.xml |
6.8m | shufflenetv2 | v5Lites-head | openvivo | x86-cpu |
| v5Lite-s-fp16.tflite | 3.3m | shufflenetv2 | v5Lites-head | tflite | arm-cpu |
| v5Lite-s-fp32.tflite | 6.7m | shufflenetv2 | v5Lites-head | tflite | arm-cpu |
| v5Lite-s-int8.tflite | 1.8m | shufflenetv2 | v5Lites-head | tflite | arm-cpu |
| v5Lite-s-416.onnx | 6.4m | shufflenetv2 | v5Lites-head | onnxruntime | x86-cpu |
@v5lite-c:
| 模型 | 大小 | 骨干网络 | 头部 | 框架 | 适用场景 |
|---|---|---|---|---|---|
| v5Lite-c.pt | 9m | PPLcnet(百度) | v5s-head | Pytorch | x86-cpu / x86-vpu |
| v5Lite-c.bin v5Lite-c.xml |
8.7m | PPLcnet | v5s-head | openvivo | x86-cpu / x86-vpu |
| v5Lite-c-512.onnx | 18m | PPLcnet | v5s-head | onnxruntime | x86-cpu |
@v5lite-g:
| 模型 | 大小 | 骨干网络 | 头部 | 框架 | 适用场景 |
|---|---|---|---|---|---|
| v5Lite-g.pt | 10.9m | Repvgg(清华大学) | v5Liteg-head | Pytorch | x86-gpu / arm-gpu / arm-npu |
| v5Lite-g-int8.engine | 8.5m | Repvgg-yolov5 | v5Liteg-head | Tensorrt | x86-gpu / arm-gpu / arm-npu |
| v5lite-g-int8.tmfile | 8.7m | Repvgg-yolov5 | v5Liteg-head | Tengine | arm-npu |
| v5Lite-g-640.onnx | 21m | Repvgg-yolov5 | yolov5-head | onnxruntime | x86-cpu |
| v5Lite-g-640.joint | 7.1m | Repvgg-yolov5 | yolov5-head | axpi | arm-npu |
下载链接:
v5lite-e.pt: | 百度网盘 | Google Drive ||──────
ncnn-fp16: | 百度网盘 | Google Drive |
|──────ncnn-int8: | 百度网盘 | Google Drive |
|──────mnn-e_bf16: | Google Drive |
|──────mnn-d_bf16: | Google Drive|
└──────onnx-fp32: | 百度网盘 | Google Drive |
v5lite-s.pt: | 百度网盘 | Google Drive ||──────
ncnn-fp16: | 百度网盘 | Google Drive |
|──────ncnn-int8: | 百度网盘 | Google Drive |
└──────tengine-fp32: | 百度网盘 | Google Drive |
v5lite-c.pt: 百度网盘 | Google Drive |└──────
openvino-fp16: | 百度网盘 | Google Drive |
v5lite-g.pt: | 百度网盘 | Google Drive |└──────
axpi-int8: Google Drive |
百度网盘密码: pogg
v5lite-s 模型:TFLite Float32、Float16、INT8、动态范围量化、ONNX、TFJS、TensorRT、OpenVINO IR FP32/FP16、Myriad Inference Engin Blob、CoreML
https://github.com/PINTO0309/PINTO_model_zoo/tree/main/180_YOLOv5-Lite
感谢 PINTO0309:https://github.com/PINTO0309/PINTO_model_zoo/tree/main/180_YOLOv5-Lite
使用方法
安装
需要 Python>=3.6.0,并安装所有 requirements.txt 中的依赖项,包括 PyTorch>=1.7:
$ git clone https://github.com/ppogg/YOLOv5-Lite
$ cd YOLOv5-Lite
$ pip install -r requirements.txt
使用 detect.py 进行推理
detect.py 可以对多种输入源进行推理,会自动从
最新的 YOLOv5-Lite 发布版本 下载模型,并将结果保存到 runs/detect。
$ python detect.py --source 0 # 网络摄像头
file.jpg # 图片
file.mp4 # 视频
path/ # 目录
path/*.jpg # 全局匹配
'https://youtu.be/NUsoVlDFqZg' # YouTube
'rtsp://example.com/media.mp4' # RTSP、RTMP、HTTP 流
训练
$ python train.py --data coco.yaml --cfg v5lite-e.yaml --weights v5lite-e.pt --batch-size 128
v5lite-s.yaml v5lite-s.pt 128
v5lite-c.yaml v5lite-c.pt 96
v5lite-g.yaml v5lite-g.pt 64
如果您使用多 GPU,速度会提升数倍:
$ python -m torch.distributed.launch --nproc_per_node 2 train.py
数据集
训练集和测试集的分布(路径中包含 xx.jpg)
train: ../coco/images/train2017/
val: ../coco/images/val2017/
├── images # xx.jpg 示例
│ ├── train2017
│ │ ├── 000001.jpg
│ │ ├── 000002.jpg
│ │ └── 000003.jpg
│ └── val2017
│ ├── 100001.jpg
│ ├── 100002.jpg
│ └── 100003.jpg
└── labels # xx.txt 示例
├── train2017
│ ├── 000001.txt
│ ├── 000002.txt
│ └── 000003.txt
└── val2017
├── 100001.txt
├── 100002.txt
└── 100003.txt
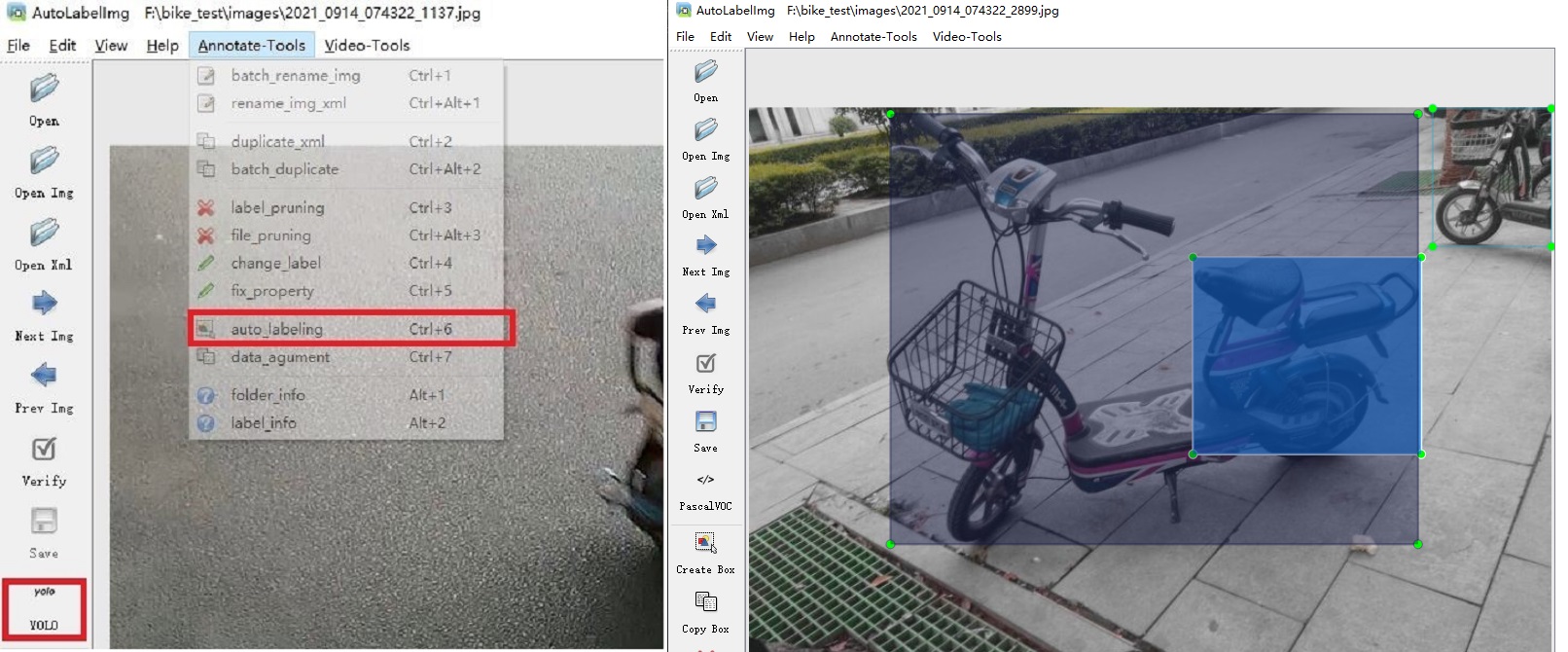
Auto LabelImg
链接:https://github.com/ppogg/AutoLabelImg
您可以使用基于 LabelImg 的 YOLOv5-5.0 和 YOLOv5-Lite 进行自动标注,biubiubiu 🚀 🚀 🚀
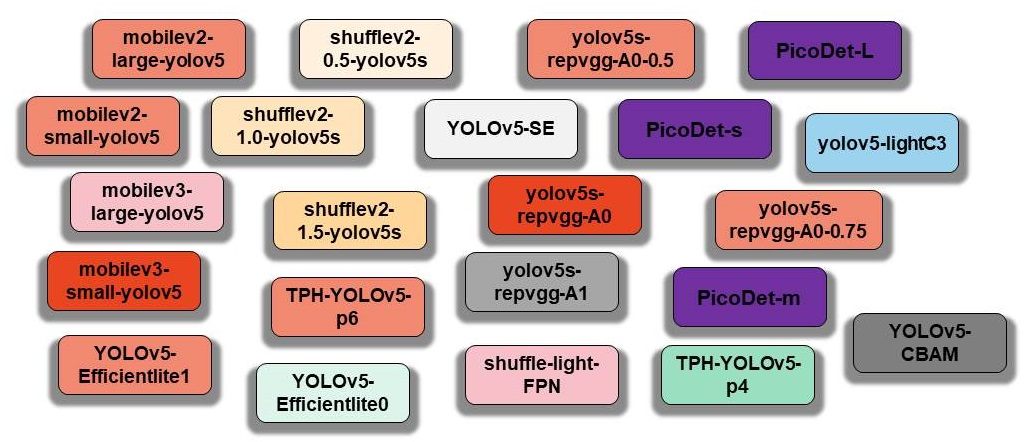
模型库
这里整理并存储了 YOLOv5 的原始组件以及 YOLOv5-Lite 的复现组件,位于 模型库:
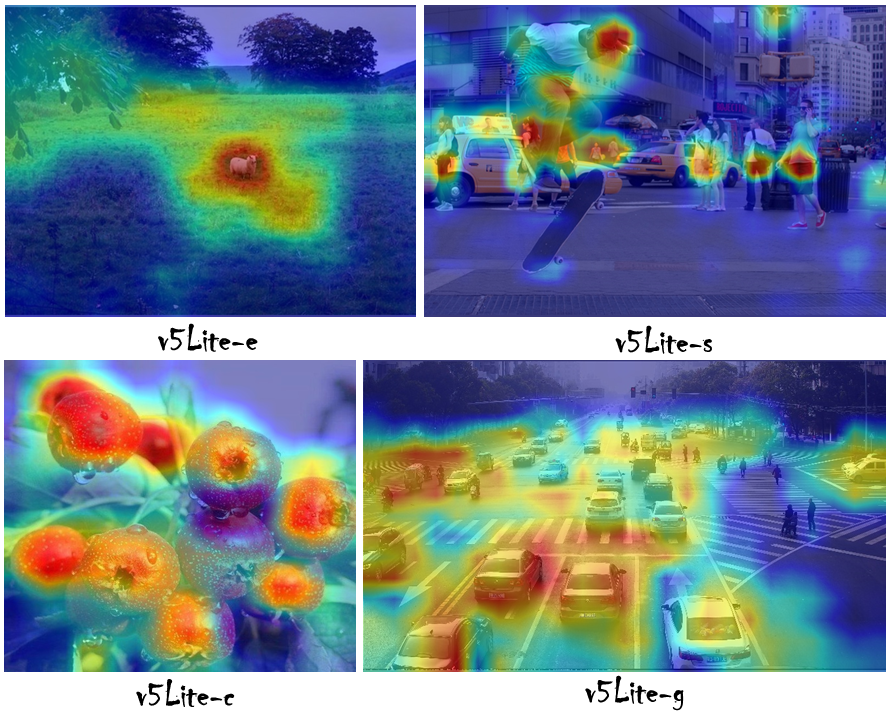
热力图分析
$ python main.py --type all
正在更新...
部署方式
ncnn 适用于 arm-cpu
mnn 适用于 arm-cpu
openvino 适用于 x86-cpu 或 x86-vpu
tensorrt(C++) 适用于 arm-gpu、arm-npu 或 x86-gpu
tensorrt(Python) 适用于 arm-gpu、arm-npu 或 x86-gpu
Android 适用于 arm-cpu
Android_demo
这是一台 Redmi 手机,处理器为 Snapdragon 730G,使用 yolov5-lite 进行检测。性能如下:
链接:https://github.com/ppogg/YOLOv5-Lite/tree/master/android_demo/ncnn-android-v5lite
Android_v5Lite-s:https://drive.google.com/file/d/1CtohY68N2B9XYuqFLiTp-Nd2kuFWgAUR/view?usp=sharing
Android_v5Lite-g:https://drive.google.com/file/d/1FnvkWxxP_aZwhi000xjIuhJ_OhqOUJcj/view?usp=sharing
新 Android 应用:[链接] https://pan.baidu.com/s/1PRhW4fI1jq8VboPyishcIQ [关键词] pogg

更详细的说明
模型详细链接:
YOLOv5-Lite S/E 模型是什么: 知乎链接(中文):https://zhuanlan.zhihu.com/p/400545131
YOLOv5-Lite C 模型是什么: 知乎链接(中文):https://zhuanlan.zhihu.com/p/420737659
YOLOv5-Lite G 模型是什么: 知乎链接(中文):https://zhuanlan.zhihu.com/p/410874403
如何使用 fp16 或 int8 在 ncnn 上部署: CSDN 链接(中文):https://blog.csdn.net/weixin_45829462/article/details/119787840
如何使用 fp16 或 int8 在 mnn 上部署: 知乎链接(中文):https://zhuanlan.zhihu.com/p/672633849
如何在 onnxruntime 上部署: 知乎链接(中文):https://zhuanlan.zhihu.com/p/476533259(旧版本)
如何在 tensorrt 上部署: 知乎链接(中文):https://zhuanlan.zhihu.com/p/478630138
如何在 tensorrt 上优化: 知乎链接(中文):https://zhuanlan.zhihu.com/p/463074494
参考文献
https://github.com/ultralytics/yolov5
https://github.com/megvii-model/ShuffleNet-Series
https://github.com/Tencent/ncnn
引用 YOLOv5-Lite
如果您在研究中使用 YOLOv5-Lite,请引用我们的工作并给个 star ⭐:
@misc{yolov5lite2021,
title = {YOLOv5-Lite: 轻量级、更快且更易部署},
author = {Xiangrong Chen 和 Ziman Gong},
doi = {10.5281/zenodo.5241425}
year={2021}
}
版本历史
v1.52023/12/27v1.42022/03/05v1.32021/10/14v1.22021/10/14v1.12021/08/25v1.02021/08/24常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器