BambooAI
BambooAI 是一款基于大语言模型(LLM)的开源 Python 库,旨在让数据分析变得像日常对话一样简单。它允许用户直接使用自然语言提问,自动完成从数据理解、代码生成、执行分析到可视化呈现的全过程,无需用户具备深厚的编程背景。
这一工具有效解决了传统数据分析中代码门槛高、探索效率低的问题。无论是处理本地 CSV 文件,还是通过 API 获取外部实时数据,BambooAI 都能灵活应对。它特别适合数据分析师、业务人员以及希望快速验证想法的研究者使用,同时也为开发者提供了强大的自动化辅助能力。
BambooAI 的技术亮点在于其智能的“自愈”机制,当生成的代码出错时能自动修正并重新运行;同时支持规划代理(Planning Agent)以拆解复杂任务,并结合向量数据库构建长期记忆,从而在多轮对话中保持上下文连贯。此外,它还集成了网络搜索功能,可补充外部知识以增强分析深度。通过简洁的 Web 界面或 Jupyter Notebook,BambooAI 让数据洞察变得更加直观和高效。
使用场景
某电商公司的数据分析师需要在周五下班前,快速从包含百万行订单记录的本地 CSV 文件中找出“上季度复购率下降的原因”,并生成可视化报告向管理层汇报。
没有 BambooAI 时
- 代码编写耗时:分析师需手动编写大量 Pandas 代码进行数据清洗、分组聚合及关联分析,耗时数小时且容易出错。
- 技能门槛限制:若遇到复杂的统计建模或异常值处理,非资深分析师往往需要暂停工作去查阅文档或求助同事。
- 迭代效率低下:当管理层提出“换个维度看”或“排除特定地区”等新问题时,必须重新修改代码并重新运行整个脚本。
- 可视化繁琐:将分析结果转化为直观的图表需要额外编写 Matplotlib 或 Plotly 代码,调整样式进一步拉长了交付时间。
使用 BambooAI 后
- 自然语言交互:分析师直接用中文提问“分析上季度复购率下降原因”,BambooAI 自动理解意图并生成执行代码。
- 智能代码生成与自愈:BambooAI 自动生成包含数据清洗、复杂聚合及建模的 Python 代码,若运行报错还能自我修正,无需人工干预。
- 敏捷多轮探索:面对“排除华东地区再算一次”的新指令,只需在对话中补充条件,BambooAI 即刻基于上下文更新分析结果。
- 一键可视化输出:BambooAI 直接根据数据特征推荐并绘制专业的交互式图表(如 Plotly),瞬间完成从数据到洞察的闭环。
BambooAI 将原本需要数小时的数据挖掘与编码工作压缩至分钟级,让业务人员能专注于决策而非代码调试。
运行环境要求
- 未说明
未说明
未说明

快速开始
BambooAI

BambooAI 是一个开源库,利用大型语言模型(LLMs)实现基于自然语言的数据分析。它既可以处理本地数据集,也能从外部来源和 API 获取数据。
目录
- 概述
- 功能
- 演示视频
- 安装
- 快速入门
- 工作原理
- 配置
- 辅助数据集
- DataFrame 本体论(语义记忆)
- 向量数据库(情景记忆)
- 使用示例
- Web 应用程序设置
- 模型支持
- 环境变量
- 日志记录
- 性能对比
- 贡献
概述
BambooAI 是一款实验性工具,通过允许用户以自然语言对话的方式与数据交互,使数据分析更加易于访问。它的设计目标是:
- 处理关于数据集的自然语言查询
- 生成并执行用于分析和可视化的 Python 代码
- 帮助用户在无需大量编程知识的情况下获得洞察
- 增强各层次数据分析师的能力
- 简化数据分析流程
功能
- 数据分析的自然语言界面
- 支持 Web UI 和 Jupyter Notebook
- 支持本地和外部数据集
- 集成互联网搜索和外部 API
- 流式过程中提供用户反馈
- 可选的复杂任务规划代理
- 集成自定义本体论
- 为数据分析和可视化生成代码
- 自我修复/错误纠正
- 自定义代码编辑和代码执行
- 通过向量数据库集成知识库
- 工作流保存和后续跟进
- 上下文相关及多模态查询
演示视频
机器学习示例(Jupyter Notebook)
演示如何创建一个预测泰坦尼克号乘客生存情况的机器学习模型:
https://github.com/user-attachments/assets/59ef810c-80d8-4ef1-8edf-82ba64178b85
体育数据分析(Web UI)
各种体育数据分析查询示例:
https://github.com/user-attachments/assets/7b9c9cd6-56e3-46ee-a6c6-c32324a0c5ef
安装
pip install bambooai
或者克隆仓库并安装依赖项:
git clone https://github.com/pgalko/BambooAI.git
pip install -r requirements.txt
快速入门
在 Google Colab 中尝试一个基本示例:![]()
基本示例
安装 BambooAI:
pip install bambooai配置环境:
cp .env.example .env # 编辑 .env 文件以适应您的设置配置代理/模型:
cp LLM_CONFIG_sample.json LLM_CONFIG.json # 根据您希望使用的代理、模型和参数组合编辑 LLM_CONFIG.json 文件运行:
import pandas as pd from bambooai import BambooAI import plotly.io as pio pio.renderers.default = 'jupyterlab' df = pd.read_csv('titanic.csv') bamboo = BambooAI(df=df, planning=True, vector_db=False, search_tool=True) bamboo.pd_agent_converse()
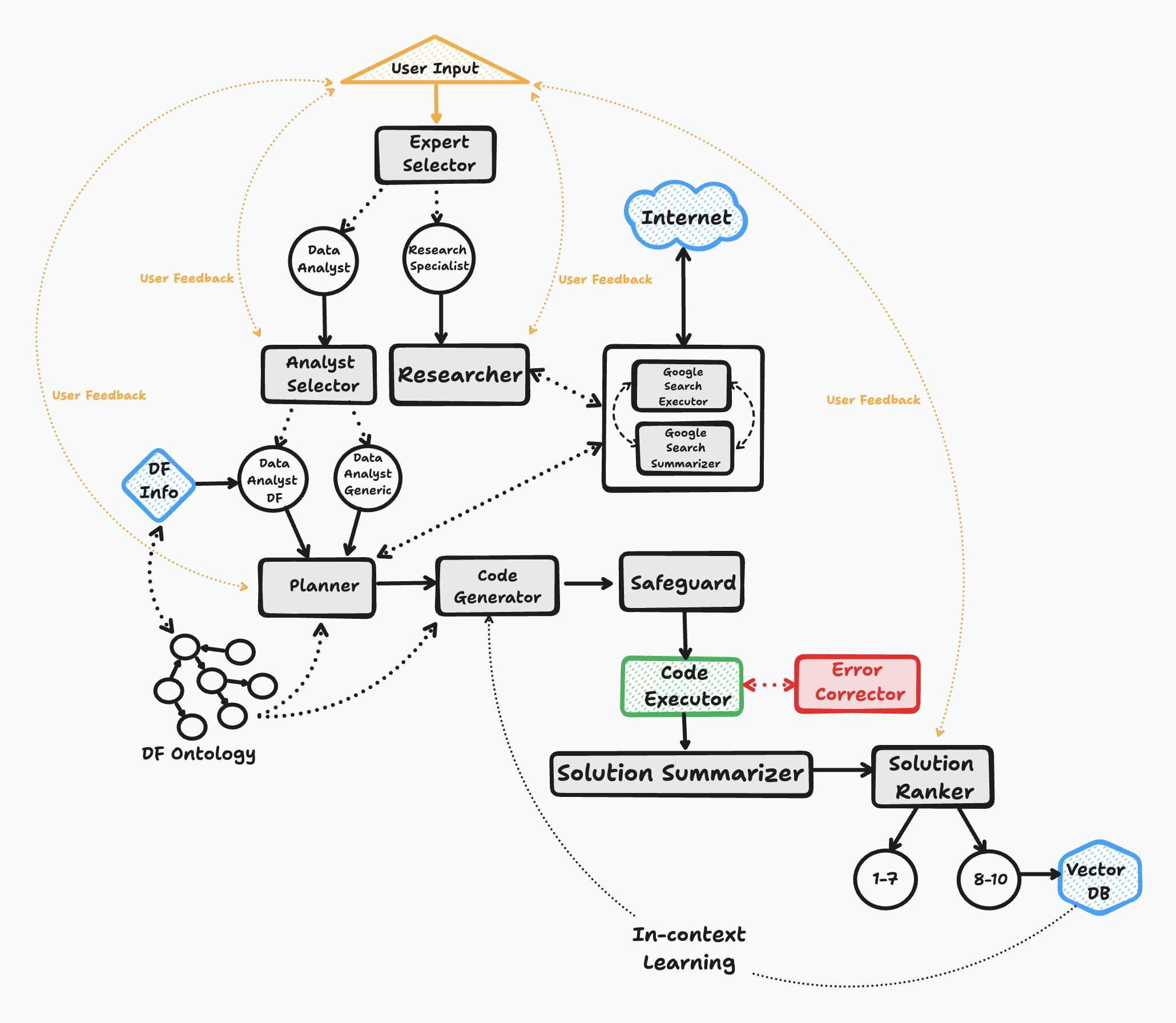
工作原理
BambooAI 的运行过程分为六个关键步骤:
初始化
- 以用户问题或提示开始
- 在退出之前持续进行对话循环
任务路由
- 使用 LLM 对问题进行分类
- 路由到适当的处理器(文本响应或代码生成)
用户反馈
- 如果指令模糊或不明确,模型会暂停并请求用户反馈
- 如果在求解过程中遇到任何歧义,模型会暂停并提供几个选项供选择
动态提示构建
- 评估数据需求
- 请求反馈或使用工具以获取更多上下文
- 制定分析计划
- 执行语义搜索以查找类似问题
- 使用选定的 LLM 生成代码
调试与执行
- 执行生成的代码
- 使用 LLM 进行错误纠正
- 重试直至成功或达到限制
结果与知识库
- 对答案进行质量排序
- 将高质量解决方案存储在向量数据库中
- 展示格式化后的结果或可视化内容
流程图
配置
参数
BambooAI 接受以下初始化参数:
bamboo = BambooAI(
df=None, # 用于分析的 DataFrame
auxiliary_datasets=None, # 辅助数据集路径列表
max_conversations=4, # 保留在内存中的对话对数量
search_tool=False, # 启用互联网搜索功能
planning=False, # 为复杂任务启用规划代理
webui=False, # 作为 Web 应用程序运行
vector_db=False, # 启用向量数据库以存储知识
df_ontology=False, # 使用自定义 DataFrame 本体
exploratory=True, # 启用专家选择来处理查询
custom_prompt_file=None # 允许使用自定义或修改后的提示模板
)
参数详细说明:
df(pd.DataFrame, 可选)- 用于分析的输入 DataFrame
- 如果未提供,BambooAI 将尝试从互联网或辅助数据集中获取数据
auxiliary_datasets(list, 默认 None)- 辅助数据集的路径列表
- 这些数据集将在需要时被纳入解决方案,并在代码执行时加载
- 它们用于补充主 DataFrame
max_conversations(int, 默认 4)- 在上下文中保持的用户与助手对话对数量
- 影响上下文窗口大小和 token 使用量
search_tool(bool, 默认 False)- 启用互联网搜索功能
- 启用时需要提供相应的 API 密钥
planning(bool, 默认 False)- 为复杂任务启用规划代理
- 将任务分解为可管理的步骤
- 提高复杂查询的解决方案质量
webui(bool, 默认 False)- 将 BambooAI 作为 Web 应用程序运行
- 使用 Flask API 提供 Web 界面
vector_db(bool, 默认 False)- 启用向量数据库以存储知识和进行语义搜索
- 存储高质量的解决方案供未来参考
- 需要 Pinecone 的 API 密钥
- 支持两种嵌入模型:
text-embedding-3-small(OpenAI)和all-MiniLM-L6-v2(HF)
df_ontology(str, 默认 None)- 使用自定义 DataFrame 本体以提升理解能力
- 需要 OWL 本体文件,格式为
.ttl。该参数接受 TTL 文件的路径。 - 能显著提高解决方案的质量
exploratory(bool, 默认 True)- 启用专家选择机制来处理查询
- 在研究专家和数据分析员角色之间进行选择
custom_prompt_file(str, 默认 None)- 允许用户提供自定义的提示模板
- 需要提供包含模板的 YAML 文件路径
代理与模型配置
BambooAI 采用多代理系统,不同的专业代理负责数据分析过程中的特定环节。每个代理可以根据其具体需求配置不同的大语言模型及参数。
配置结构
LLM 配置存储在 LLM_CONFIG.json 文件中。以下是完整的配置结构:
{
"agent_configs": [
{"agent": "专家选择器", "details": {"model": "gpt-4.1", "provider":"openai","max_tokens": 2000, "temperature": 0}},
{"agent": "分析师选择器", "details": {"model": "claude-3-7-sonnet-20250219", "provider":"anthropic","max_tokens": 2000, "temperature": 0}},
{"agent": "理论家", "details": {"model": "gemini-2.5-pro-preview-03-25", "provider":"gemini","max_tokens": 4000, "temperature": 0}},
{"agent": "数据框检查器", "details": {"model": "gemini-2.0-flash", "provider":"gemini","max_tokens": 8000, "temperature": 0}},
{"agent": "规划者", "details": {"model": "gemini-2.5-pro-preview-03-25", "provider":"gemini","max_tokens": 8000, "temperature": 0}},
{"agent": "代码生成器", "details": {"model": "claude-3-5-sonnet-20241022", "provider":"anthropic","max_tokens": 8000, "temperature": 0}},
{"agent": "错误修正器", "details": {"model": "claude-3-5-sonnet-20241022", "provider":"anthropic","max_tokens": 8000, "temperature": 0}},
{"agent": "评审员", "details": {"model": "gemini-2.5-pro-preview-03-25", "provider":"gemini","max_tokens": 8000, "temperature": 0}},
{"agent": "解决方案总结器", "details": {"model": "gemini-2.5-flash-preview-04-17", "provider":"gemini","max_tokens": 4000, "temperature": 0}},
{"agent": "谷歌搜索执行器", "details": {"model": "gemini-2.5-flash-preview-04-17", "provider":"gemini","max_tokens": 4000, "temperature": 0}},
{"agent": "谷歌搜索总结器", "details": {"model": "gemini-2.5-flash-preview-04-17", "provider":"gemini","max_tokens": 4000, "temperature": 0}}
],
"model_properties": {
"gpt-4o": {"capability":"base","multimodal":"true", "templ_formating":"text", "prompt_tokens": 0.0025, "completion_tokens": 0.010},
"gpt-4.1": {"capability":"base","multimodal":"true", "templ_formating":"text", "prompt_tokens": 0.002, "completion_tokens": 0.008},
"gpt-4o-mini": {"capability":"base", "multimodal":"true","templ_formating":"text", "prompt_tokens": 0.00015, "completion_tokens": 0.0006},
"gpt-4.1-mini": {"capability":"base", "multimodal":"true","templ_formating":"text", "prompt_tokens": 0.0004, "completion_tokens": 0.0016},
"o1-mini": {"capability":"reasoning", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.003, "completion_tokens": 0.012},
"o3-mini": {"capability":"reasoning", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.0011, "completion_tokens": 0.0044},
"o1": {"capability":"reasoning", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.015, "completion_tokens": 0.06},
"gemini-2.0-flash": {"capability":"base", "multimodal":"true","templ_formating":"text", "prompt_tokens": 0.0001, "completion_tokens": 0.0004},
"gemini-2.5-flash-preview-04-17": {"capability":"reasoning", "multimodal":"true","templ_formating":"text", "prompt_tokens": 0.00015, "completion_tokens": 0.0035},
"gemini-2.0-flash-thinking-exp-01-21": {"capability":"reasoning", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.0, "completion_tokens": 0.0},
"gemini-2.5-pro-exp-03-25": {"capability":"reasoning", "multimodal":"true","templ_formating":"text", "prompt_tokens": 0.0, "completion_tokens": 0.0},
"gemini-2.5-pro-preview-03-25": {"capability":"reasoning", "multimodal":"true","templ_formating":"text", "prompt_tokens": 0.00125, "completion_tokens": 0.01},
"claude-3-5-haiku-20241022": {"capability":"base", "multimodal":"true","templ_formating":"xml", "prompt_tokens": 0.0008, "completion_tokens": 0.004},
"claude-3-5-sonnet-20241022": {"capability":"base", "multimodal":"true","templ_formating":"xml", "prompt_tokens": 0.003, "completion_tokens": 0.015},
"claude-3-7-sonnet-20250219": {"capability":"base", "multimodal":"true","templ_formating":"xml", "prompt_tokens": 0.003, "completion_tokens": 0.015},
"open-mixtral-8x7b": {"capability":"base", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.0007, "completion_tokens": 0.0007},
"mistral-small-latest": {"capability":"base", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.001, "completion_tokens": 0.003},
"codestral-latest": {"capability":"base", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.001, "completion_tokens": 0.003},
"open-mixtral-8x22b": {"capability":"base", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.002, "completion_tokens": 0.006},
"mistral-large-2407": {"capability":"base", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.003, "completion_tokens": 0.009},
"deepseek-chat": {"capability":"base", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.00014, "completion_tokens": 0.00028},
"deepseek-reasoner": {"capability":"reasoning", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.00055, "completion_tokens": 0.00219},
"/mnt/c/Users/pgalk/vllm/models/DeepSeek-R1-Distill-Qwen-14B": {"capability":"reasoning", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.00, "completion_tokens": 0.00},
"deepseek-r1-distill-llama-70b": {"capability":"reasoning", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.00, "completion_tokens": 0.00},
"deepseek-r1:32b": {"capability":"reasoning", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.00, "completion_tokens": 0.00},
"deepseek-ai/deepseek-r1": {"capability":"reasoning", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.00, "completion_tokens": 0.00},
"MiniMax-M2.7": {"capability":"base", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.001, "completion_tokens": 0.005},
"MiniMax-M2.7-highspeed": {"capability":"base", "multimodal":"false","templ_formating":"text", "prompt_tokens": 0.001, "completion_tokens": 0.005}
}
}
LLM_CONFIG.json 配置文件需要位于 BambooAI 工作目录中,例如 /Users/palogalko/AI_Experiments/Bamboo_AI/web_app/LLM_CONFIG.json,且所有指定模型的 API 密钥都需要存在于同样位于工作目录中的 .env 文件中。
根据我们在 2025 年 4 月 22 日使用体育和绩效数据集进行的测试结果,上述代理/模型组合是性能最佳的。我强烈建议您尝试不同的设置,以找到最适合您特定用例的组合。
代理角色
- 专家选择器:确定处理查询的最佳专家类型
- 分析师选择器:选择具体的分析方法
- 理论家:提供理论背景和方法论
- 数据框检查器:分析并理解数据结构。(需要本体文件)
- 规划者:创建逐步的分析计划
- 代码生成器:编写用于分析的Python代码
- 错误纠正器:调试并修复代码问题
- 评审员:评估解决方案的质量,并相应地调整计划
- 解决方案总结器:创建简洁的结果摘要
- 谷歌搜索执行器:优化并执行搜索查询
- 谷歌搜索总结器:综合搜索结果
配置字段
agent_configs:智能体配置agent:智能体类型details:model:模型标识符provider:服务提供商(openai、anthropic、gemini等)max_tokens:完成时的最大令牌数temperature:创造力参数(0-1)
model_properties:模型属性capability:基础模型或推理模型multimodal:多模态或仅文本templ_formating:提示格式化。XML或文本prompt_tokens:输入成本(1K)completion_tokens:输出成本(1K)
如果在agent_configs中为某个智能体指定了模型,请确保该模型已在model_properties中定义。
示例替代配置
- 使用Ollama:
{
"agent": "Planner",
"details": {
"model": "llama3:70b",
"provider": "ollama",
"max_tokens": 2000,
"temperature": 0
}
}
- 使用VLLM:
{
"agent": "Code Generator",
"details": {
"model": "/path/to/model/DeepSeek-R1-Distill-14B",
"provider": "vllm",
"max_tokens": 2000,
"temperature": 0
}
}
- 使用MiniMax:
{
"agent": "Code Generator",
"details": {
"model": "MiniMax-M2.7",
"provider": "minimax",
"max_tokens": 8000,
"temperature": 0.1
}
}
辅助数据集
BambooAI支持同时处理多个数据集,从而实现更全面和更具上下文的分析。辅助数据集功能使您能够在主要数据集之外引用和整合其他数据源。
当您提出可能受益于辅助数据的问题时,BambooAI会:
- 分析哪些数据集包含相关信息
- 只加载必要的数据集
- 根据需要进行数据连接或交叉引用
- 生成并执行能够正确处理多数据集操作的代码
使用方法
from bambooai import BambooAI
import pandas as pd
# 加载主数据集
main_df = pd.read_csv('main_data.csv')
# 指定辅助数据集路径
auxiliary_paths = [
'path/to/supporting_data1.csv',
'path/to/supporting_data2.parquet',
'path/to/reference_data.csv'
]
# 初始化带有辅助数据集的BambooAI
bamboo = BambooAI(
df=main_df,
auxiliary_datasets=auxiliary_paths,
)
数据框本体(语义记忆)
BambooAI支持自定义本体,以将智能体置于感兴趣的特定领域中。
使用方法
from bambooai import BambooAI
import pandas as pd
# 使用本体文件路径初始化
bamboo = BambooAI(
df=your_dataframe,
df_ontology="path/to/ontology.ttl"
)
它的作用
本体文件使用RDF/OWL表示法定义您的数据结构,包括:
- 对象属性(关系)
- 数据属性(属性)
- 类(数据类型)
- 个体(具体实例)
这有助于BambooAI理解复杂的数据关系,并生成更准确的代码。
向量数据库(情景记忆)
BambooAI支持与向量数据库的集成。其主要目的是允许存储和检索成功的分析结果,从而使系统能够随着时间的推移不断进化和学习。
使用方法
from bambooai import BambooAI
import pandas as pd
# 使用本体文件路径初始化
bamboo = BambooAI(
df=your_dataframe,
vector_db=True
)
支持Pinecone和Qdrant两种向量数据库。通过环境变量配置您选择的数据库:
对于Pinecone:
需要一个Pinecone账户(免费),并将API密钥存储在.env文件中:
VECTOR_DB_TYPE=pinecone
PINECONE_API_KEY=<YOUR API KEY HERE>
PINECONE_CLOUD=aws
PINECONE_REGION=us-east-1
对于Qdrant:
可以使用本地Qdrant实例或Qdrant云服务。在.env文件中配置:
VECTOR_DB_TYPE=qdrant
QDRANT_URL=http://localhost:6333 # 用于本地Qdrant
QDRANT_API_KEY=<YOUR API KEY HERE> # 本地可选,云端必填
它的作用
成功完成分析后,用户可以对解决方案进行排名并存储。
- 排名较高的解决方案(>6)将使用所选模型进行向量化,并连同解决方案元数据一起存储到配置的向量数据库中(Pinecone或Qdrant)。
- 元数据包括:
- 数据模型
- 计划
- 编写的代码
- 排名
- 当有新任务到来时,系统会查询向量索引,检索出相似度高于阈值(0.8)的最接近匹配项。
- 存储的解决方案将作为后续类似任务的参考,指导相关智能体完成求解过程。
使用示例
交互模式(Jupyter Notebook或CLI)
import pandas as pd
from bambooai import BambooAI
import plotly.io as pio
pio.renderers.default = 'jupyterlab'
df = pd.read_csv('training_activity_data.csv')
aux_data = [
'path/to/wellness_data.csv',
'path/to/nutrition_data.parquet',
]
bamboo = BambooAI(df=df, search_tool=True, planning=True)
bamboo.pd_agent_converse()
单次查询模式(Jupyter Notebook或CLI)
bamboo.pd_agent_converse("计算心率列的30%、50%、75%和90%分位数")
Web应用程序设置
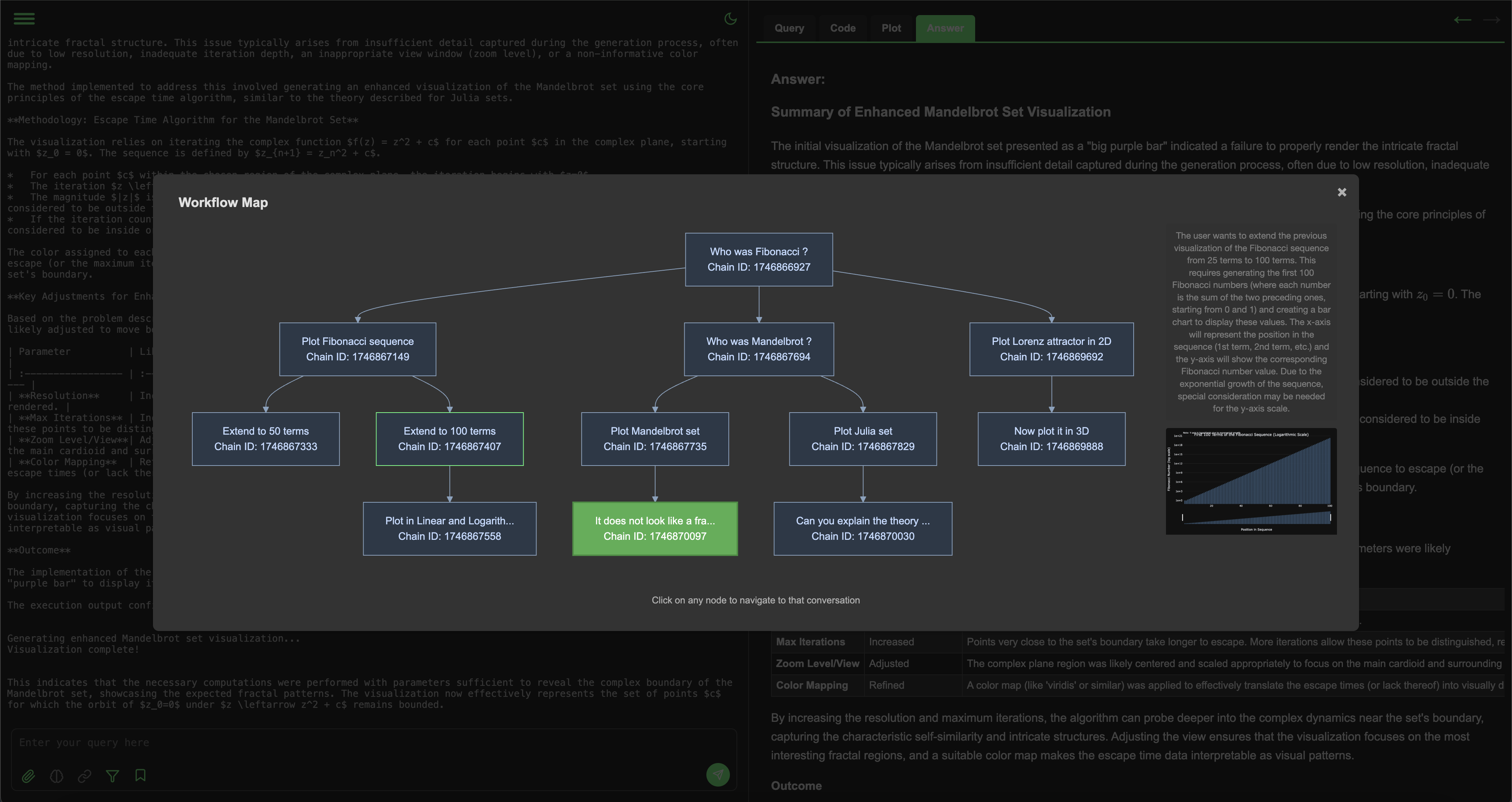
Web UI截图(交互式工作流图):
选项 1:使用 Docker(推荐)
BambooAI 可以通过 Docker 轻松部署,Docker 提供了一致的运行环境,不受您的操作系统或本地配置的影响。
有关详细的 Docker 设置和使用说明,请参阅我们的 Docker 设置 Wiki。
使用 Docker 的方法具有以下优势:
- 无需在本地管理 Python 依赖项
- 在不同机器上保持一致的运行环境
- 通过挂载卷轻松进行配置
- 支持基于仓库和独立部署
- 沙箱式代码执行,提升安全性
先决条件:
- 已在您的系统上安装 Docker
- 已在您的系统上安装 Docker Compose
选项 2:使用 pip 包
安装 BambooAI:
pip install bambooai从仓库下载 web_app 文件夹
配置环境:
cp .env.example <web_app路径>/.env # 编辑 .env 文件以设置您的参数配置 LLM 代理、模型和参数:
cp LLM_CONFIG_sample.json <web_app路径>/LLM_CONFIG.json- 编辑 web_app 目录下的
web_app/LLM_CONFIG.json - 为每个代理配置所需的模型:
{ "agent_configs": [ { "agent": "代码生成器", "details": { "model": "您首选的模型", "provider": "提供商名称", "max_tokens": 4000, "temperature": 0 } } ] }- 如果未提供配置,程序将无法运行,并会显示错误信息。
- 编辑 web_app 目录下的
运行应用程序:
cd <web_app路径> python app.py
选项 3:使用完整仓库
克隆仓库:
git clone https://github.com/pgalko/BambooAI.git cd BambooAI安装依赖项:
pip install -r requirements.txt配置环境:
cp .env.example web_app/.env # 编辑 .env 文件以设置您的参数配置 LLM 代理、模型和参数:
cp LLM_CONFIG_sample.json web_app/LLM_CONFIG.json- 编辑 web_app 目录下的
web_app/LLM_CONFIG.json - 为每个代理配置所需的模型:
{ "agent_configs": [ { "agent": "代码生成器", "details": { "model": "您首选的模型", "provider": "提供商名称", "max_tokens": 4000, "temperature": 0 } } ] }- 如果未提供配置,程序将无法运行,并会显示错误信息。
- 编辑 web_app 目录下的
运行应用程序:
cd web_app python app.py
访问 Web 界面:http://localhost:5000(如果使用 Docker,则为 5001)。
模型支持
基于 API 的模型
- OpenAI
- Google(Gemini)
- Anthropic
- Groq
- Mistral
- DeepSeek
- OpenRouter
- MiniMax
本地模型
- Ollama(所有模型)
- VLLM(所有模型)
- 各种本地模型
环境变量
.env 文件中需要的变量:
模型 API 密钥。请指定您想要使用且拥有访问权限的模型的 API 密钥。
<厂商名称>_API_KEY:选定提供商的 API 密钥GEMINI_API_KEY:如果您想使用原生 Gemini 网络搜索工具(Grounding),则需要设置此密钥。您也可以选择使用 Selenium,但其速度较慢且集成度较低。
搜索和向量数据库 API 密钥(可选)
PINECONE_API_KEY:用于向量数据库的可选密钥SERPER_API_KEY:用于 Selenium 搜索的必需密钥。
远程 API 端点(可选)
REMOTE_OLLAMA:远程 Ollama 服务器的可选 URLREMOTE_VLLM:远程 VLLM 服务器的可选 URL。
应用程序配置
FLASK_SECRET:用于对 WebApp 的会话 Cookie 进行签名WEB_SEARCH_MODE:'google_ai' 表示使用 Gemini 原生搜索工具,'selenium' 表示使用 Selenium Web 驱动程序SELENIUM_WEBDRIVER_PATH:Selenium Web 驱动程序的路径。如果您使用 'selenium' 搜索模式,则必须设置此路径。EXECUTION_MODE:'local' 表示在本地运行代码执行器,'api' 表示在远程服务器或容器上运行代码执行器。EXECUTOR_API_BASE_URL:远程代码执行器 API 的 URL。如果您使用 'api' 执行模式,则需要设置此参数,例如 http://192.168.1.201:5000。
日志记录
每次运行/线程的日志都存储在 logs/bambooai_run_log.json 中。当新线程开始时,该文件会被覆盖。
汇总日志存储在 logs/bambooai_consolidated_log.json 中,文件大小限制为 5MB,最多保留 3 个文件。日志信息包括:
- 链 ID
- LLM 调用详情(代理、时间戳、模型、提示、响应)
- 令牌使用情况和费用
- 性能指标
- 每个模型的统计摘要
性能对比
有关详细评估报告,请参阅:客观评估报告
贡献
欢迎通过拉取请求贡献代码。请注重代码的可读性和简洁性。
该项目已被 Cognition Labs 的 DeepWiki 索引,为开发者提供:
- AI 生成的全面文档
- 交互式代码探索
- 上下文感知开发指导
- 项目工作流可视化
访问项目的完整交互式文档: DeepWiki pgalko/BambooAI
注意事项
- 支持多种模型提供商和本地执行
- 代码执行需谨慎
- 请监控令牌使用情况
- 开发仍在进行中
联系方式
待办事项
- 计划进行未来改进
版本历史
v0.4.262025/10/31v0.4.252025/08/10v0.4.242025/07/07v0.4.222025/06/25v0.4.212025/06/18v0.4.202025/06/16v0.4.192025/06/140.4.182025/06/13v0.4.172025/06/10v0.4.152025/06/07v0.4.132025/06/06v0.4.122025/06/03v0.4.112025/06/02v0.4.092025/06/01v0.4.082025/06/01v0.4.072025/05/28v0.4.062025/05/24v0.4.052025/05/170.4.042025/05/11v0.4.032025/05/09常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。