xai_resources
xai_resources 是一个专注于可解释人工智能(XAI)领域的优质资源聚合库。它系统性地整理了学术论文、专业书籍、软件工具、新闻报道及学位论文等多类资料,旨在解决 XAI 领域知识分散、难以快速定位高质量参考文献的痛点。
面对 AI 模型日益复杂的“黑箱”特性,如何让决策过程透明化并满足临床或金融等实际场景的需求,是当前技术落地的关键挑战。xai_resources 通过精选如多模态医疗影像评估、基于实际应用的后验解释方法对比等前沿研究,帮助用户深入理解不同解释算法的优劣与适用边界。例如,库中收录的研究揭示了现有热力图在多模态数据中的局限性,以及 LIME、SHAP 等工具在真实欺诈检测任务中对人类决策的实际影响。
这份资源特别适合 AI 研究人员、算法开发者以及需要向利益相关者展示模型逻辑的产品设计师使用。无论是希望跟进最新学术动态,还是寻找经过验证的工具来优化系统透明度,xai_resources 都能提供坚实的理论与实证支持,助力构建更可信、更易理解的人工智能系统。
使用场景
某医疗 AI 团队正在开发一款多模态医学影像辅助诊断系统,急需向临床医生解释模型为何做出特定癌症预测以通过伦理审查。
没有 xai_resources 时
- 团队在海量文献中盲目搜索,难以找到针对“多模态影像”这一特定场景的可解释性评估指标,导致选用的热力图无法区分不同成像通道的临床意义。
- 直接套用通用的 LIME 或 SHAP 算法,未察觉这些方法在真实欺诈检测或医疗决策中可能反而降低人类专家的判断准确率,存在误导医生的风险。
- 缺乏系统的评估框架,无法回答监管机构关于“算法是否满足临床优先级需求”的质询,项目上线审批被迫搁置。
- 开发人员花费数周时间整理零散的论文和工具列表,严重拖慢了从模型训练到临床验证的迭代进度。
使用 xai_resources 后
- 团队迅速定位到《Evaluating Explainable AI on a Multi-Modal Medical Imaging Task》等关键论文,直接采用文中提出的 MSFI 指标,精准评估并优化了模型对特定影像模态的特征提取能力。
- 参考《How can I choose an explainer?》中的实证研究结论,团队避免了盲目部署通用解释器,转而设计符合医生实际决策习惯的人机协作流程,提升了最终诊断准确率。
- 利用资源库中分类清晰的软件工具和评估方法论,快速构建了符合临床要求的解释性报告,顺利通过了医院伦理委员会的严格审查。
- 借助汇总好的书籍、预印本及案例文章,团队将调研时间从数周缩短至几天,将更多精力投入到核心算法的临床适配与优化中。
xai_resources 通过提供经过筛选的权威资源与实证依据,帮助开发者避开理论陷阱,让可解释性 AI 真正服务于高风险领域的落地决策。
运行环境要求
未说明
未说明
快速开始
与可解释人工智能(XAI)相关的有趣资源
论文
2021年
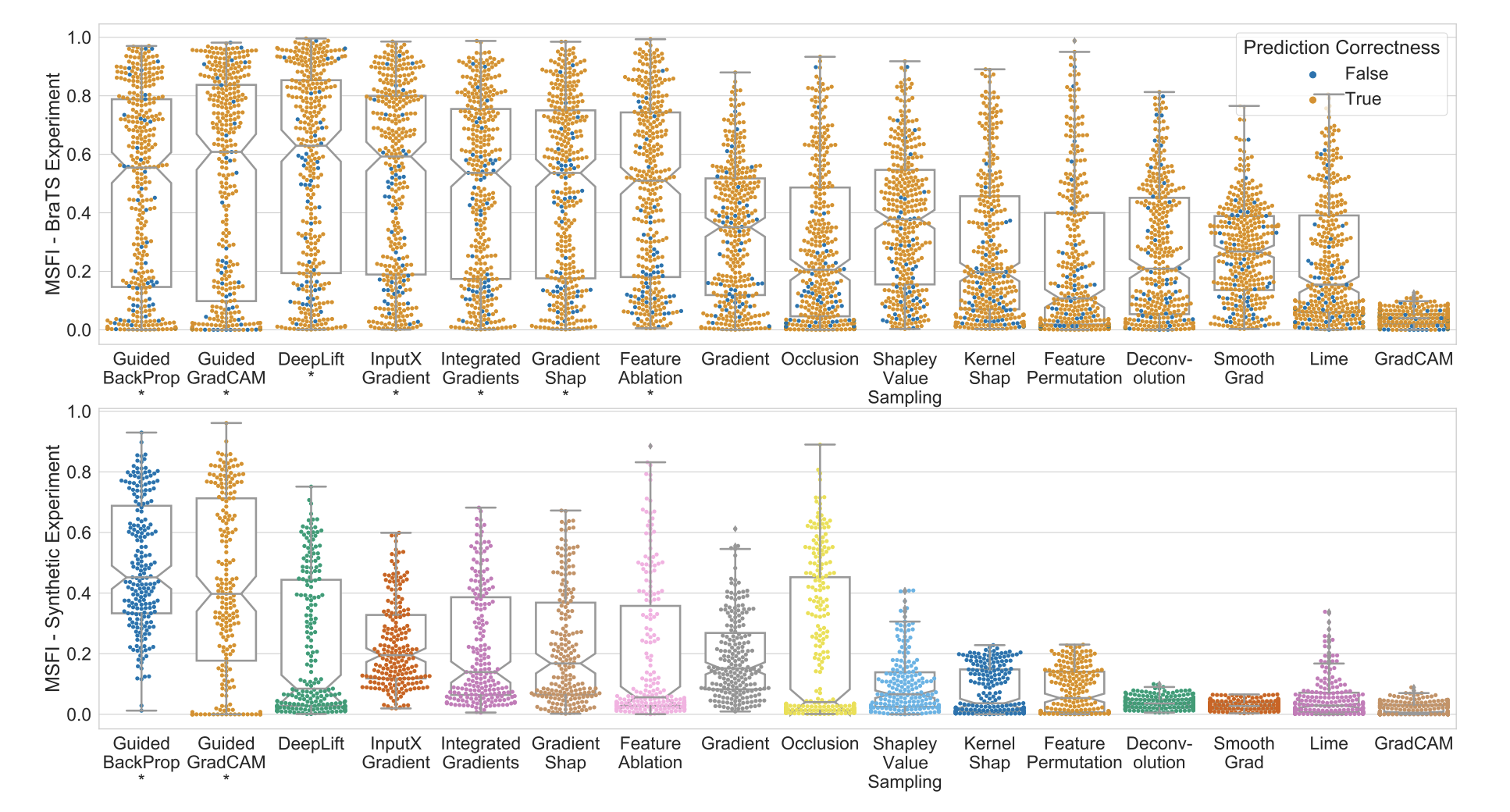
- 在多模态医学影像任务上评估可解释人工智能:现有算法能否满足临床需求?。魏娜·金、李晓晓、加桑·哈马尔内。能够向临床终端用户解释预测结果,是充分利用人工智能(AI)模型进行临床决策支持的必要条件。对于医学影像而言,特征归因图或热图是最常见的解释形式,它会突出显示对AI模型预测至关重要的特征。然而,目前尚不清楚热图在解释多模态医学影像决策方面的表现如何——在这种情况下,每种模态/通道都承载着同一生物医学现象的不同临床意义。理解这些依赖于模态的特征对于临床用户解读AI决策至关重要。为了解决这一具有重要临床意义但技术上却被忽视的问题,我们提出了模态特异性特征重要性(MSFI)指标。该指标编码了关于模态优先级和模态特异性特征定位的临床要求。我们基于MSFI、其他非模态特异性的指标以及临床医生用户研究,对16种常用的XAI算法进行了以临床需求为导向的系统性评估。结果表明,大多数现有的XAI算法无法充分突出模态特异性的重要特征来满足临床需求。评估结果和MSFI指标可以指导XAI算法的设计和选择,以满足临床医生对多模态解释的要求。
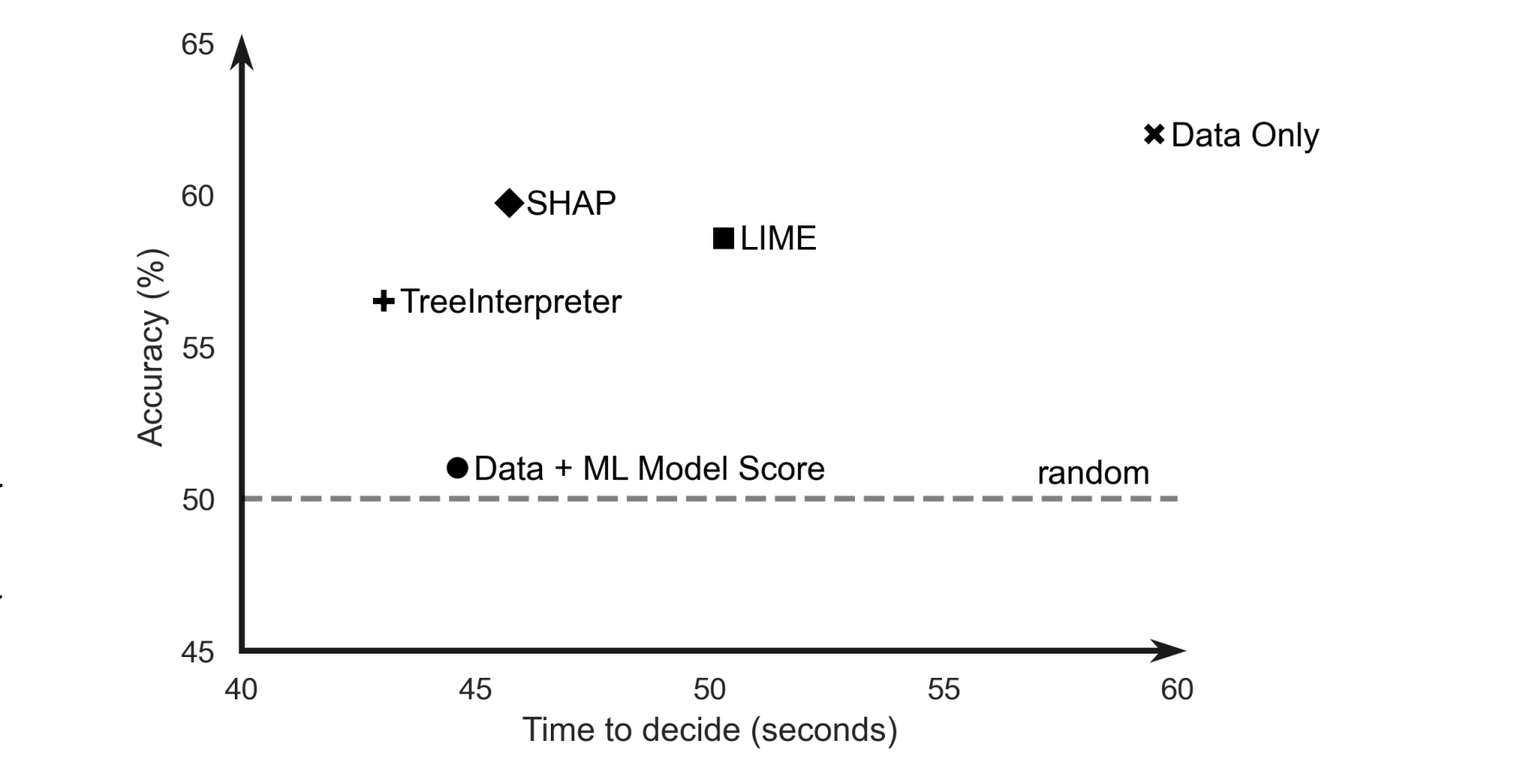
- 我该如何选择解释器?基于应用的后验解释评估。近年来,许多研究工作提出了新的可解释人工智能(XAI)方法,旨在生成具有特定属性或期望特征的模型解释,例如保真度、鲁棒性或人类可解释性。然而,这些解释很少根据其对决策任务的实际影响进行评估。如果没有这样的评估,所选择的解释可能会实际上损害ML模型与最终用户组成的整体系统的性能。本研究旨在通过提出XAI测试这一面向应用的评估方法来填补这一空白,该方法专门用于隔离向最终用户提供不同程度信息的影响。我们按照XAI测试的方法,对三种流行的后验解释方法——LIME、SHAP和TreeInterpreter——在一项真实的欺诈检测任务中进行了评估,使用真实数据、已部署的ML模型以及欺诈分析师。实验过程中,我们逐步增加了提供给欺诈分析师的信息,分为三个阶段:仅数据,即仅有交易数据,不访问模型分数或解释;数据+ML模型分数;以及数据+ML模型分数+解释。通过强有力的统计分析,我们表明,总体而言,这些流行的解释器的效果并不理想。结论要点包括:i) 仅提供数据时,在所有测试变体中,决策准确率最高且决策时间最长;ii) 所有解释器都能提高“数据+ML模型分数”变体的准确率,但与“仅数据”相比,准确率仍然较低;iii) LIME最受用户青睐,这可能是因为其在不同案例之间的解释差异性显著较低。
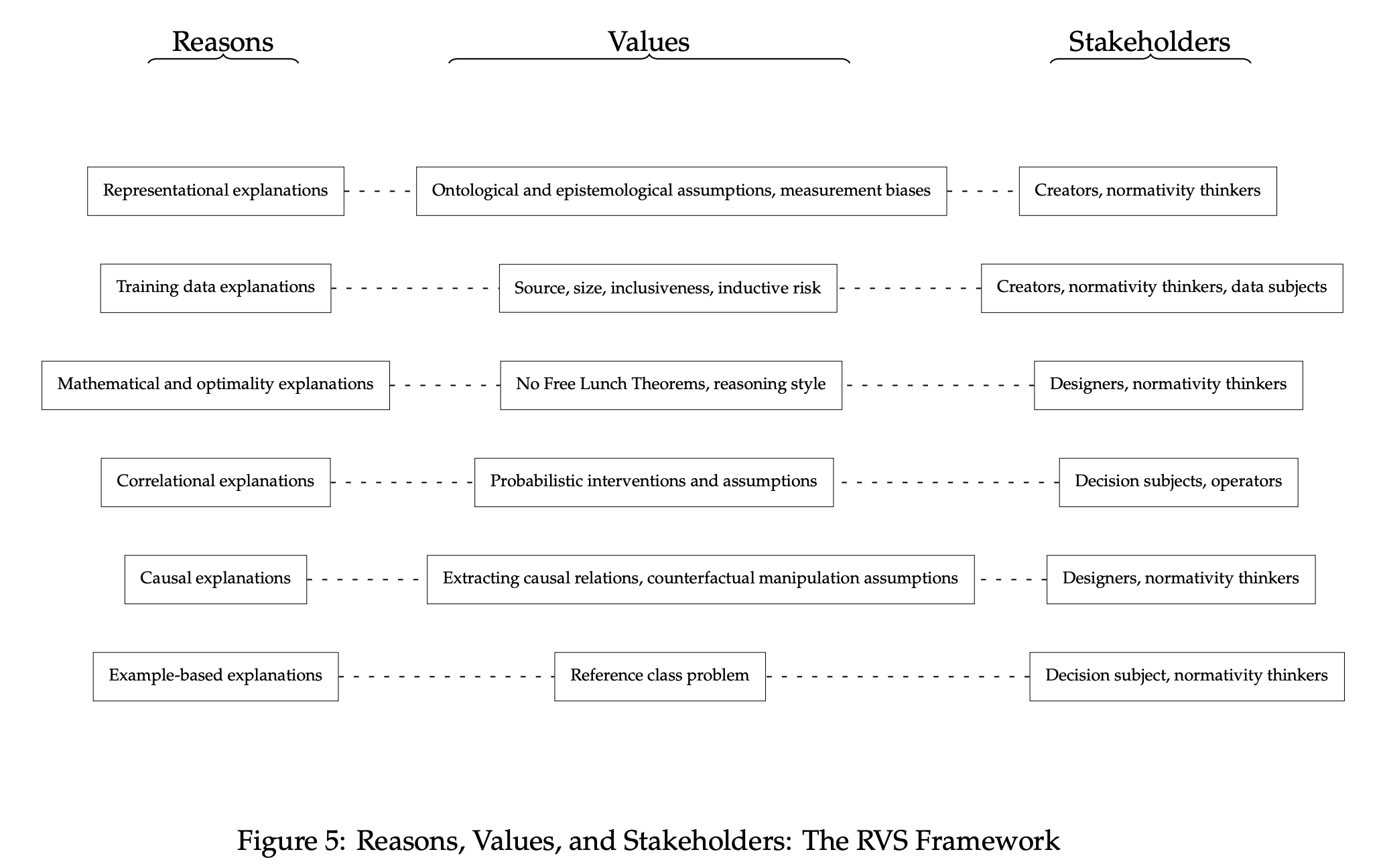
- 理由、价值、利益相关者:可解释人工智能的哲学框架。在福利分配和刑事司法等重大决策中使用不透明的人工智能系统所带来的社会和伦理影响,已经在计算机科学家、伦理学家、社会科学家、政策制定者和最终用户等多个利益相关者之间引发了热烈的讨论。然而,由于缺乏共同的语言或一个多维框架来恰当地连接这场辩论的技术、认识论和规范性方面,讨论几乎无法达到应有的成效。本文借鉴了关于解释的本质和价值的哲学文献,提出了一种多方面的框架,通过识别与人工智能预测最相关的解释类型、承认社会和伦理价值在评估这些解释中的相关性和重要性,以及展示这些解释对于采用多样化方法改进真实算法生态系统设计的重要性,从而为当前的辩论带来了更多的概念精确性。因此,所提出的哲学框架为建立人工智能系统的技术和伦理层面之间的相关性奠定了基础。
- 人工智能信任的正式化:人类对AI信任的前提、原因和目标。 信任是人与AI互动的核心组成部分,因为“不正确”的信任水平可能导致技术的误用、滥用或弃用。那么,究竟什么是AI中的信任本质呢?信任的认知机制有哪些前提和目标?我们又该如何促进这些前提和目标,或者评估它们是否在特定的互动中得到满足呢?本研究旨在回答这些问题。我们讨论了一个受人际信任(即社会学家定义的人与人之间的信任)启发但并不完全相同的信任模型。该模型基于两个关键属性:用户的脆弱性;以及预测AI模型决策影响的能力。我们引入了“契约式信任”的正式化概念,即用户与AI模型之间的信任是基于某种隐含或显式的契约将被遵守的信任;同时还引入了“可信度”的正式化概念(这与社会学中的“可信度”概念有所区别),并由此引出了“合理信任”和“不合理信任”的概念。我们指出,合理信任的可能原因包括内在推理和外在行为,并讨论了如何设计可信的AI、如何评估信任是否已经显现以及这种信任是否合理。最后,我们利用我们的正式化框架阐明了信任与XAI之间的联系。
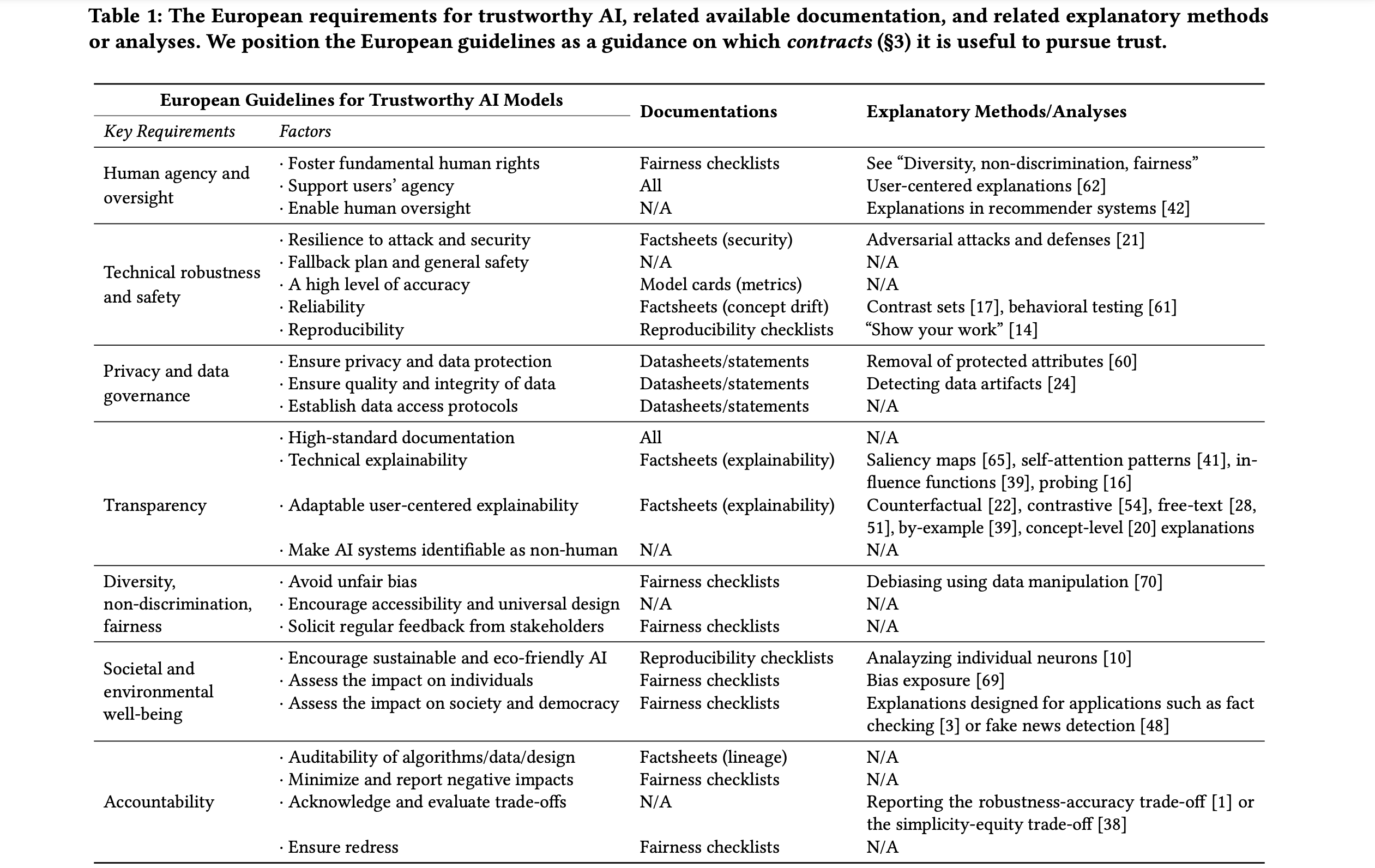
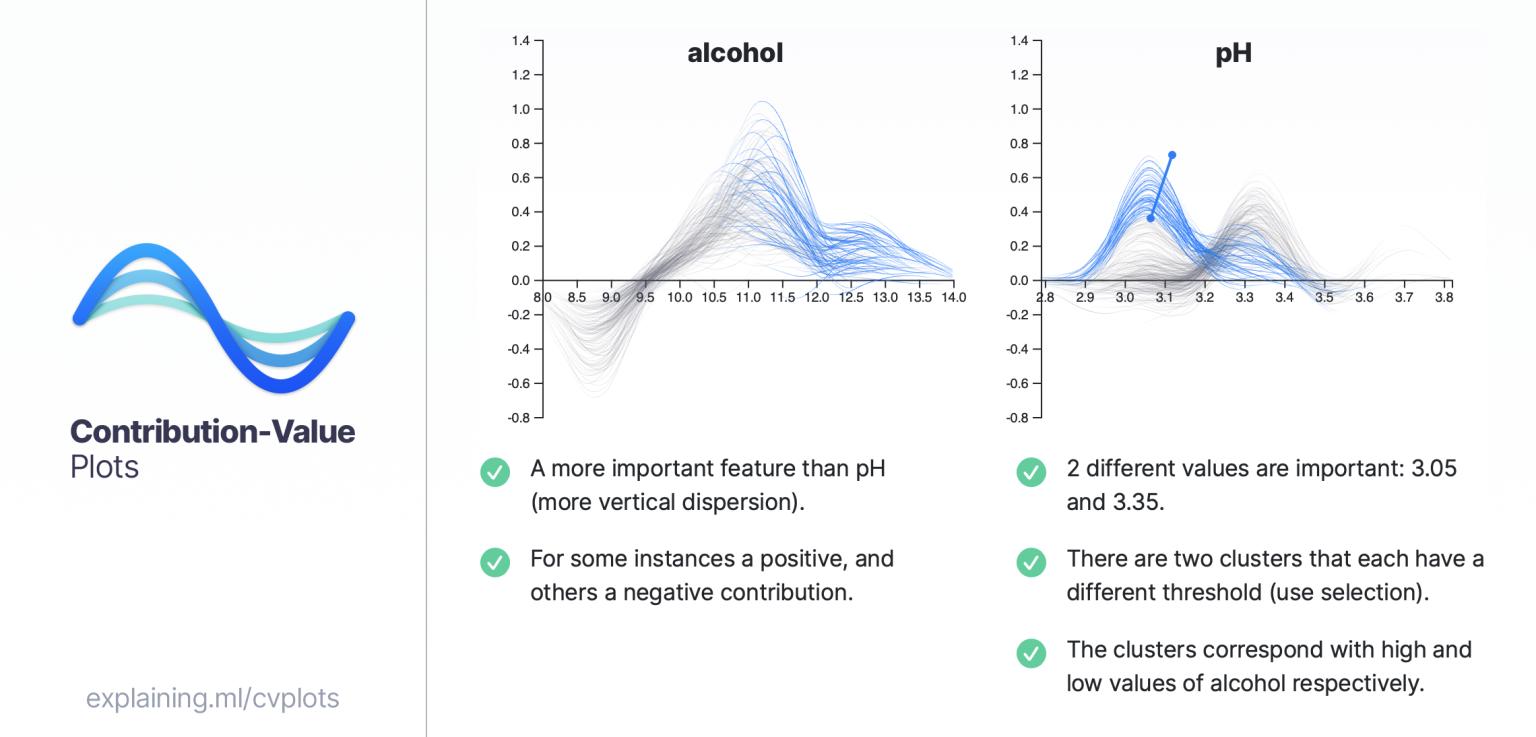
- 机器学习理解中贡献值图的比较评估 可解释人工智能领域旨在帮助专家理解复杂的机器学习模型。其中一种关键方法是展示某个特征对模型预测的影响,从而协助专家验证和确认模型的预测结果。然而,这一领域仍面临诸多挑战。例如,由于可解释性的主观性,诸如“特征贡献”之类的概念至今尚未有明确的定义。不同的技术往往基于不同的假设,这可能导致不一致甚至相互矛盾的观点。在本研究中,我们提出了一种新颖的方法——局部与全局贡献值图,用于可视化特征对预测的影响及其与特征取值之间的关系。我们讨论了设计决策,并展示了一个示例性的视觉分析实现,该实现为理解模型提供了新的洞见。通过用户研究,我们发现这些可视化工具能够提高解释的准确性和可信度,同时缩短获取洞察所需的时间,从而有效辅助模型解释。[网站]
2020年
- 用于基准测试机器学习方法的性能-可解释性框架:应用于多变量时间序列分类器;凯文·福韦尔、维罗妮克·马松、埃莉莎·弗龙东;我们的研究旨在提出一种新的性能-可解释性分析框架,以评估和基准测试机器学习方法。该框架详细定义了一组特性,用以具体化对现有机器学习方法的性能与可解释性评估。为了说明该框架的应用,我们将其用于基准测试当前最先进的多变量时间序列分类器。
EXPLAN:利用自适应邻域生成解释黑盒分类器;佩曼·拉苏利和英姬·齐赫·于;在基于扰动的解释方法中,如何定义具有代表性的局部区域是一个亟待解决的问题,它直接影响解释的忠实性和合理性。为此,我们提出了一种稳健且直观的方法——利用自适应邻域生成来解释黑盒分类器(EXPLAN)。EXPLAN是一种模块化的算法,包括密集数据生成、代表性数据选择、数据平衡以及基于规则的可解释模型构建。该方法会综合考虑从黑盒决策函数中提取的邻近信息以及数据本身的结构,从而为待解释的实例创建一个具有代表性的邻域。作为一种局部的、模型无关的解释方法,EXPLAN以逻辑规则的形式生成解释,这些规则高度可解释,非常适合用于定性分析模型的行为。我们探讨了忠实性与可解释性之间的权衡,并通过与当前最先进的解释方法LIME、LORE和Anchor的全面对比,展示了所提算法的性能。在真实数据集上进行的实验表明,我们的方法在解释的忠实性、精确性和稳定性方面均取得了扎实的实证结果。[论文] [GitHub]
GRACE:生成简洁而富有信息量的对比样本以解释神经网络模型的预测;泰·勒、王苏航、李东元;尽管近年来针对图像和文本数据的可解释人工智能/机器学习领域取得了显著进展,但目前大多数解决方案并不适用于解释那些数据集为表格形式、特征以高维向量化格式呈现的神经网络模型的预测。为缓解这一局限性,我们借鉴了两个重要理念——即来自因果关系的“干预式解释”和来自哲学的“解释具有对比性”——并提出了一种名为GRACE的新方案,以更好地解释针对表格型数据集的神经网络模型预测。具体而言,给定模型预测标签为X时,GRACE会通过干预生成一个经过最小修改的对比样本,使其被分类为Y,并附带直观的文字说明,回答“为何是X而非Y?”这一问题。我们使用十一组不同规模和领域的公开数据集进行了全面实验(例如,特征数量范围从5到216),并在忠实性、简洁性、信息增益和影响力等多个指标上将GRACE与竞争基线进行了比较。用户研究表明,我们生成的解释不仅更加直观易懂,还能使最终用户在获得解释后做出的决策准确性比使用Lime时提高多达60%。
ExplainExplore:机器学习解释的可视化探索;丹尼斯·科拉里斯、杰克·J·范威克;机器学习模型通常表现出复杂的行为,难以理解。近年来,可解释人工智能领域的研究已经开发出一些有前景的技术,可以通过特征贡献向量来解释此类模型的内部运作。这些向量在多种应用场景中都非常有用。然而,这一过程中涉及大量参数,而由于评估可解释性的主观性,很难确定最佳设置。为此,我们推出了ExplainExplore:一个交互式的解释系统,用于探索符合数据科学家主观偏好的解释方式。我们借助数据科学家的专业知识,找到最优的参数设置和实例扰动方案,并促进数据科学家与领域专家就模型及其解释展开讨论。我们以一个真实数据集为例,展示了该方法在机器学习解释的探索与调优方面的有效性。[网站]
- FACE:可行且可操作的反事实解释;拉斐尔·波亚季、卡茨珀·索科尔、劳尔·桑托斯-罗德里格斯、蒂耶尔·德·比、彼得·弗拉赫;反事实解释领域的研究通常聚焦于“最接近可能世界”原则,即寻找能够导致期望结果的最小改动。然而,在本文中,我们指出尽管这一方法在直觉上颇具吸引力,但它存在当前文献尚未解决的缺陷。首先,由现有最先进系统生成的反事实示例并不一定代表底层数据分布,因此可能会提出难以实现的目标(例如,一位因严重残疾而未能通过人寿保险申请的人,可能会被建议多参加体育锻炼)。其次,这些反事实可能并未基于主体当前状态与建议状态之间的“可行路径”,从而使得可操作的补救措施变得不可行(如,技能较低且未能获得抵押贷款的申请人可能会被告知要将收入翻倍,但在不先提升自身技能的情况下,这显然难以实现)。
可解释性信息表:一种系统评估可解释性方法的框架;卡茨珀·索科尔、彼得·弗拉赫;机器学习中的解释形式多种多样,但关于其理想属性的共识尚未形成。在本文中,我们提出了一套分类体系和描述符,可用于从功能、运行、可用性、安全性和验证五个关键维度对可解释性系统进行系统化刻画与评估。为了设计出全面且具有代表性的分类体系及相应描述符,我们调研了可解释人工智能领域的相关文献,提取了其他研究者在其工作中明确提出或隐含使用的标准与要求。该调研涵盖了介绍新型可解释性算法的论文,以了解指导其开发的标准以及这些算法的评估方式;同时也包括从计算机科学和社会科学视角提出此类标准的文献。这一创新框架能够系统地比较和对比不同的可解释性方法,不仅有助于更好地理解它们的能力,还能识别其理论特性与实际实现之间的差异。我们进一步将该框架具体化为可解释性信息表,使研究人员和从业者都能快速把握特定可解释性方法的优势与局限。
一种解释无法满足所有需求:交互式解释在提升机器学习透明度方面的潜力;卡茨珀·索科尔、彼得·弗拉赫;随着基于机器学习算法的预测系统在工业界日益普及,对其透明性的需求也愈发迫切。每当黑箱算法的预测影响到人类事务时,就必须审视这些算法的内部运作机制,并向相关利益方——包括系统工程师、系统操作人员以及案件当事人——解释其决策依据。尽管目前已有多种可解释性和可说明性方法可供选择,但尚无一种万能方案能够同时满足各方的不同期望与相互冲突的目标。本文旨在应对这一挑战,以对比式解释这一最先进的可解释机器学习方法为例,探讨交互式机器学习在提升黑箱系统透明度方面的潜力。具体而言,我们展示了如何通过交互调整条件语句来个性化反事实解释,并借助后续的“如果……会怎样?”问题进一步挖掘额外的解释信息。

- FAT取证工具包:用于算法公平性、问责制和透明度的Python工具箱;卡茨珀·索科尔、劳尔·桑托斯-罗德里格斯、彼得·弗拉赫;鉴于机器学习算法可能带来的潜在危害,预测系统的公平性、问责制和透明度显得尤为重要。近期文献曾建议对这些方面进行自愿性自我报告——例如针对数据集的数据说明书——但其覆盖范围往往仅限于机器学习流程中的某一环节,且制作过程需要大量人工投入。为打破这一僵局,确保高质量、公平、透明且可靠的机器学习系统,我们开发了一个开源工具箱,能够自动、客观地检测并报告这些系统在公平性、问责制和透明度方面的特定指标,供其工程师和用户参考。本文详细介绍了该Python工具箱的设计、适用范围及使用示例。该工具箱可对机器学习过程的各个环节——数据及其特征、模型和预测——的公平性、问责制和透明度进行检测。
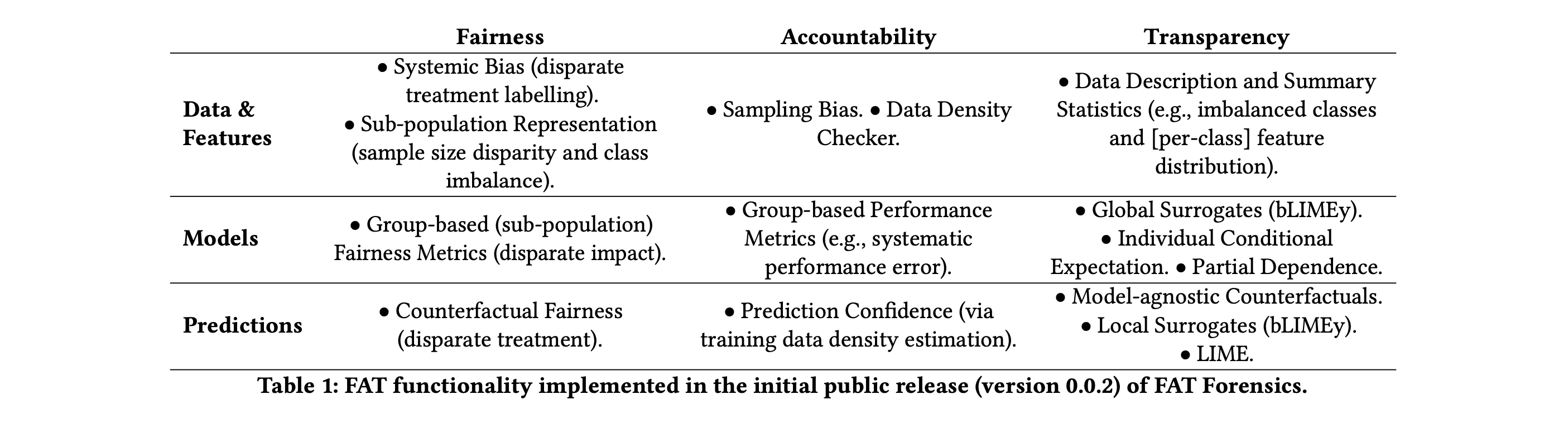
- 自适应可解释神经网络(AxNNs);陈杰、乔尔·沃恩、维贾扬·奈尔、阿古斯·苏吉安托;尽管机器学习技术已在多个领域取得成功应用,但模型的黑箱特性却给结果的解释与说明带来了挑战。为此,我们提出了一种名为自适应可解释神经网络(AxNNs)的新框架,旨在同时实现优异的预测性能与模型的可解释性。在预测性能方面,我们采用两阶段流程,构建由广义加性模型网络和加性指数模型组成的结构化神经网络(通过可解释神经网络实现),可使用提升集成或堆叠集成的方法完成。而在可解释性方面,我们展示了如何将AxNN的输出分解为主效应和高阶交互效应。
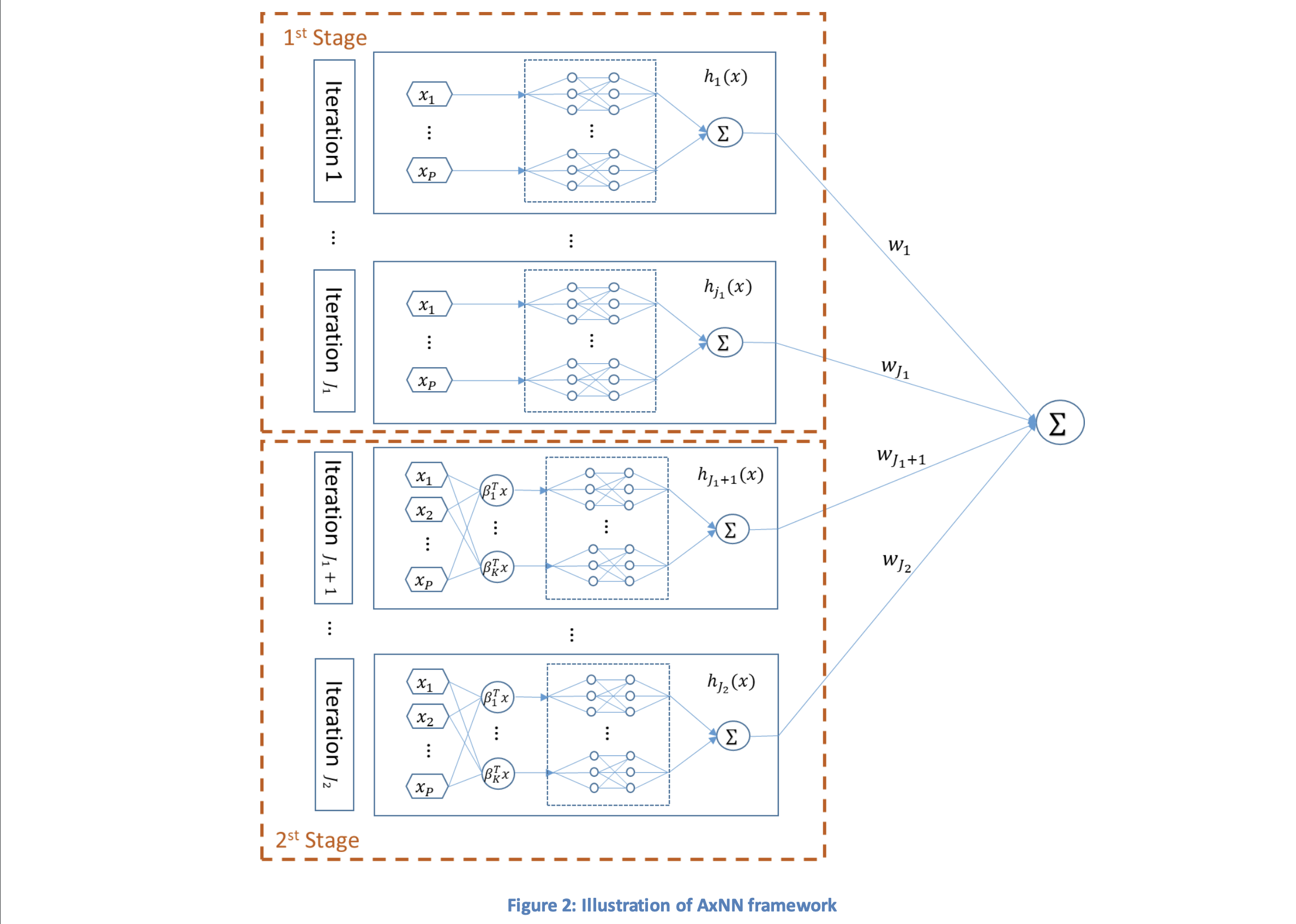
- 嵌入模型中的信息泄露;宋 Congzheng、Ananth Raghunathan;我们证明,嵌入除了编码通用语义外,通常还会生成一个泄露输入数据敏感信息的向量。我们开发了三类攻击方法,以系统性地研究嵌入可能泄露的信息。首先,嵌入向量可以被逆向还原,从而部分恢复部分输入数据。其次,嵌入可能会揭示输入中固有的、与当前语义任务无关的敏感属性。第三,对于不常出现的训练数据样本,嵌入模型会泄露一定程度的成员身份信息。我们在文本领域的多种最先进嵌入模型上广泛评估了这些攻击方法。此外,我们还提出并评估了一些防御措施,这些措施能够在对模型效用影响较小的情况下,在一定程度上防止信息泄露。
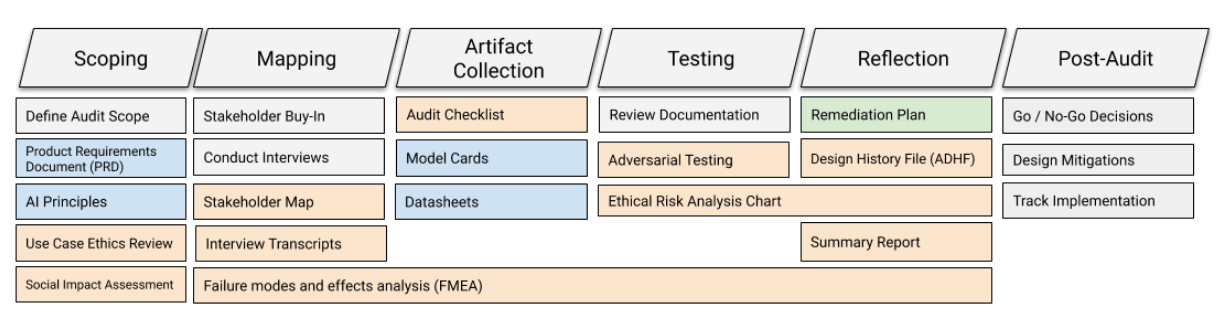
- 弥合人工智能问责鸿沟:定义端到端的内部算法审计框架;Inioluwa Deborah Raji 等人。人们对人工智能系统社会影响日益增长的担忧,催生了一波学术和新闻报道,其中部署的系统由算法部署组织外部的调查人员进行危害性审计。然而,从业者在系统部署前识别其潜在危害仍然面临挑战,而一旦系统上线,新出现的问题往往难以甚至无法追溯到其根源。在本文中,我们提出了一种端到端支持人工智能系统开发的算法审计框架,可在组织内部开发生命周期的各个阶段应用。审计的每个阶段都会产生一组文档,这些文档共同构成一份整体审计报告,该报告基于组织的价值观或原则来评估整个过程中所做决策的合理性。
- 解释解释器:LIME 的首次理论分析;Damien Garreau、Ulrike von Luxburg;机器学习越来越多地被应用于敏感领域,有时甚至取代人类参与关键决策过程。因此,这些算法的可解释性变得尤为迫切。目前广受欢迎的可解释性算法之一是 LIME(局部可解释的模型无关解释)。在本文中,我们首次对 LIME 进行了理论分析。当待解释函数为线性时,我们推导出了可解释模型系数的闭式表达式。好消息是,这些系数与待解释函数的梯度成正比:LIME 确实能够发现有意义的特征。然而,我们的分析也表明,参数选择不当可能导致 LIME 错过重要特征。
2019年
- bLIMEy:超越 LIME 的代理预测解释?;Kacper Sokol、Alexander Hepburn、Raul Santos-Rodriguez、Peter Flach。黑箱机器学习预测的代理解释器在可解释人工智能领域具有至关重要的地位,因为它们可以应用于任何类型的数据(图像、文本和表格数据),且与具体模型无关,属于事后解释方法。然而,局部可解释的模型无关解释(LIME)算法常常被误认为是代理解释器这一更广泛框架的代表,这可能导致人们误以为它是解决代理可解释性的唯一方案。在本文中,我们通过提出一种构建自定义局部黑箱模型预测代理解释器的原则性算法框架——包括 LIME 本身——鼓励社区“自己动手构建 LIME”(bLIMEy)。为此,我们展示了如何将代理解释器家族分解为算法上独立且可互操作的模块,并以 LIME 为例,探讨了这些组件选择对最终解释器功能特性的影响。
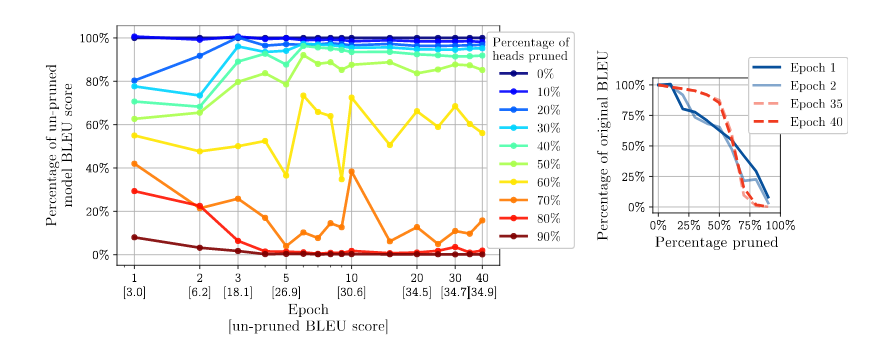
- 十六个注意力头真的比一个更好吗?;Paul Michel、Omer Levy、Graham Neubig。注意力机制是一种强大而普遍存在的技术,它允许神经网络在做出预测时通过对信息加权平均来聚焦于特定的关键信息。尤其是多头注意力机制,已成为许多最新 NLP 模型的核心驱动力,例如基于 Transformer 的机器翻译模型和 BERT。在本文中,我们发现了一个令人惊讶的现象:即使模型在训练时使用了多个注意力头,但在实际测试时,很大一部分注意力头都可以被移除,而不会显著影响性能。事实上,某些层甚至可以简化为单个注意力头。我们进一步研究了用于剪枝模型的贪心算法,以及由此可能带来的速度、内存效率和准确率提升。
- 揭秘 BERT 的黑暗秘密;Olga Kovaleva、Alexey Romanov、Anna Rogers、Anna Rumshisky。基于 BERT 的架构目前在许多 NLP 任务中表现出最先进的性能,但关于其成功背后的精确机制却知之甚少。在本工作中,我们专注于对自注意力机制的解读,这是 BERT 的基础组成部分之一。我们利用 GLUE 数据集的部分任务和一组精心设计的关注特征,提出了一套方法论,并对 BERT 各个注意力头所编码的信息进行了定性和定量分析。我们的研究结果表明,不同注意力头之间存在有限的一组重复出现的注意力模式,这暗示了模型的整体过度参数化。尽管不同的注意力头持续使用相同的注意力模式,它们对不同任务的性能影响却各不相同。我们发现,手动禁用某些注意力头反而能使微调后的 BERT 模型性能得到提升。
- 人工智能中的解释:来自社会科学的洞见;蒂姆·米勒。近年来,随着研究人员和从业者致力于使算法更加易于理解,可解释人工智能领域迎来了新的发展热潮。这一领域的许多研究都集中在向人类观察者明确解释决策或行为上,而认为从人类彼此之间的解释方式中汲取灵感,可以为人工智能的解释提供有益的起点,这一点并不令人争议。然而,也必须承认,目前大多数可解释人工智能的研究仅仅依赖于研究者对“良好”解释的直觉判断。事实上,在哲学、心理学和认知科学中,已有大量且极具价值的研究探讨了人们如何定义、生成、选择、评估并呈现解释,并指出人们在解释过程中会受到特定认知偏差和社会期望的影响。本文主张,可解释人工智能领域应当建立在这些既有研究的基础上,并综述了来自哲学、认知心理学/认知科学以及社会心理学的相关文献,这些文献正是围绕上述主题展开的。

- AnchorViz:促进交互式机器学习中的语义数据探索与概念发现;Jina Suh 等人。在构建交互式机器学习(iML)分类器时,人类关于目标类别的知识可以成为强有力的参考,从而使分类器对未见过的样本更具鲁棒性。主要挑战在于找到那些能够帮助发现或细化当前分类器尚无对应特征的概念的未标注样本(即分类器存在特征盲区)。然而,要求人类列出详尽的样本清单并不现实,尤其是对于难以回忆的稀有概念而言更是如此。本文介绍了一种名为 AnchorViz 的交互式可视化工具,它通过人类主导的语义数据探索,促进对预测错误及此前未见概念的发现。
随机化消融特征重要性;卢克·梅里克。假设有模型 f,可根据输入特征向量 x=x1,x2,…,xM 预测目标 y。我们希望衡量每个特征对于模型做出准确预测能力的重要性。为此,我们考察当将每个特征从模型中隐藏或消融时,某种用于衡量预测优劣的指标(我们称之为“损失”)平均会发生怎样的变化。所谓消融特征,即用另一个可能的值随机替换该特征的原始值。通过对多个数据点及多种可能的替换进行平均,我们可以量化某一特征对模型预测准确性的影响程度。此外,我们还提出了统计上的不确定性度量,以说明我们基于有限的数据集和有限次消融实验所测得的特征重要性,究竟在多大程度上接近其理论上的真实值。
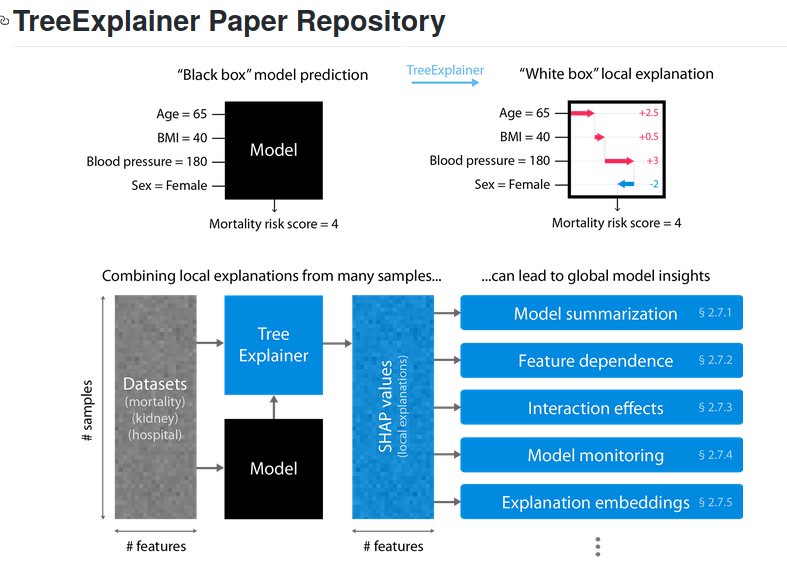
树模型的可解释人工智能:从局部解释到全局理解;斯科特·M·伦德伯格、加布里埃尔·埃里昂、休·陈、亚历克斯·德格雷夫、乔丹·M·普鲁特金、巴拉·奈尔、罗尼特·卡茨、乔纳森·希梅尔法布、尼莎·班萨尔、苏-因·李。基于树的机器学习模型,如随机森林、决策树和梯度提升树,是当今实践中最为流行的非线性预测模型,但对其预测结果的解释却一直关注较少。在此,我们通过三项主要贡献显著提升了树模型的可解释性:1) 首个基于博弈论的多项式时间最优解释算法;2) 一种直接衡量局部特征交互效应的新类型解释;3) 一套结合每条预测的局部解释来理解全局模型结构的新工具。我们将这些工具应用于三个医学机器学习问题,证明通过整合大量高质量的局部解释,既能够展现全局结构,又能保持对原始模型的忠实性。借助这些工具,我们得以:i) 在美国普通人群中识别出高风险但低频的非线性死亡危险因素;ii) 突出具有共同风险特征的不同人群子群;iii) 发现慢性肾脏病风险因素之间的非线性交互作用;iv) 监控医院中部署的机器学习模型,从而确定哪些特征正在随时间推移降低模型性能。鉴于基于树的机器学习模型的广泛应用,这些对其可解释性的改进将在广泛的领域产生深远影响。GitHub
- 一种解释并不适用于所有情况:人工智能可解释性技术工具包与分类体系;Vijay Arya、Rachel K. E. Bellamy、Pin-Yu Chen、Amit Dhurandhar、Michael Hind、Samuel C. Hoffman、Stephanie Houde、Q. Vera Liao、Ronny Luss、Aleksandra Mojsilović、Sami Mourad、Pablo Pedemonte、Ramya Raghavendra、John Richards、Prasanna Sattigeri、Karthikeyan Shanmugam、Moninder Singh、Kush R. Varshney、Dennis Wei、Yunfeng Zhang; 随着人工智能和机器学习算法在社会中的应用日益广泛,来自各方利益相关者的呼声也愈发高涨——要求这些算法能够对其输出结果作出解释。与此同时,这些利益相关者,无论是受影响的普通民众、政府监管机构、领域专家,还是系统开发者,对于解释的需求各不相同。为应对这些需求,我们推出了 AI Explainability 360(此网址),这是一个开源软件工具包,内含八种多样且处于前沿的可解释性方法以及两种评估指标。同样重要的是,我们提供了一个分类体系,以帮助需要解释的主体在解释方法的广阔领域中找到方向——不仅包括工具包中的方法,也涵盖更广泛的可解释性文献。针对数据科学家及其他工具包用户,我们设计了一套可扩展的软件架构,将各种方法按照其在 AI 模型构建流程中的位置进行组织。此外,我们还探讨了如何通过简化算法、推出更易懂的版本、编写教程以及开发交互式网页演示等方式,使研究成果更加贴近解释的受众,并向不同群体及应用领域介绍人工智能的可解释性。综上所述,我们的工具包与分类体系有助于识别当前尚需补充的可解释性方法空白,并为未来新方法的引入提供平台。 GitHub;演示
LIRME:局部可解释的排序模型解释;Manisha Verma、Debasis Ganguly;信息检索(IR)模型通常会采用复杂的词权重变化来计算查询-文档对的综合相似度得分。如果将 IR 模型视为黑箱,则很难理解或解释为何某些文档会在特定查询下被检索到前列。局部解释模型已成为理解分类模型单个预测的一种流行方式。然而,目前尚无系统性的研究来探索如何解释 IR 模型,而这正是本文的核心贡献。我们探讨了三种采样方法来训练解释模型,并提出了两种指标用于评估针对 IR 模型生成的解释。实验结果揭示了一些有趣的发现:一是样本多样性对训练局部解释模型至关重要;二是模型的稳定性与其用于解释该模型的参数数量呈反比关系。
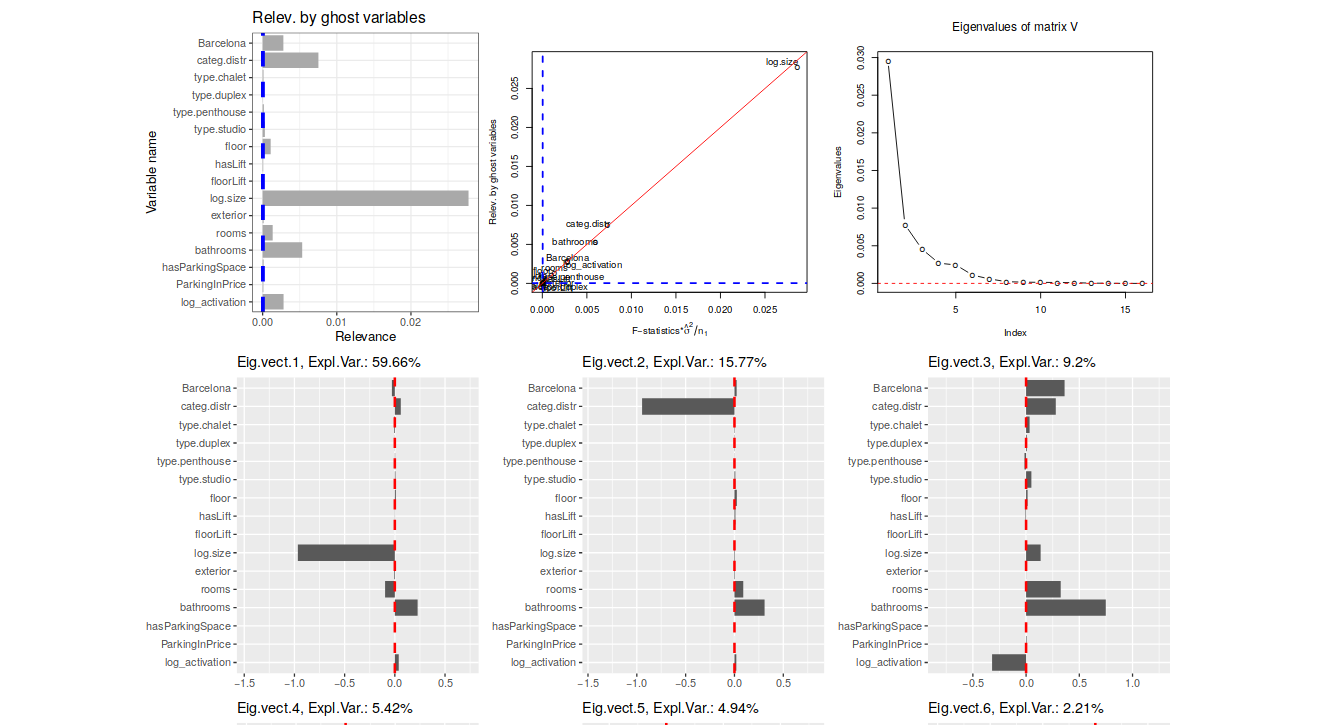
借助“幽灵变量”理解复杂预测模型;Pedro Delicado、Daniel Peña;一种为复杂预测模型中的每个解释变量分配相关性度量的方法。我们假设已有一个训练集用于拟合模型,以及一个测试集用于检验模型的泛化性能。首先,通过比较包含所有变量的模型与仅用“幽灵变量”替代目标变量的另一模型在测试集上的预测结果,计算出每个变量的单独相关性。其次,利用由各个变量单独效应向量构成的相关性矩阵的特征值,检查变量之间的联合效应。研究表明,在线性或加性等简单模型中,所提出的度量与变量的标准显著性度量相关;而在神经网络模型(以及其他算法类预测模型)中,该方法能够提供其他常规方法难以获得的关于变量联合与单独效应的信息。
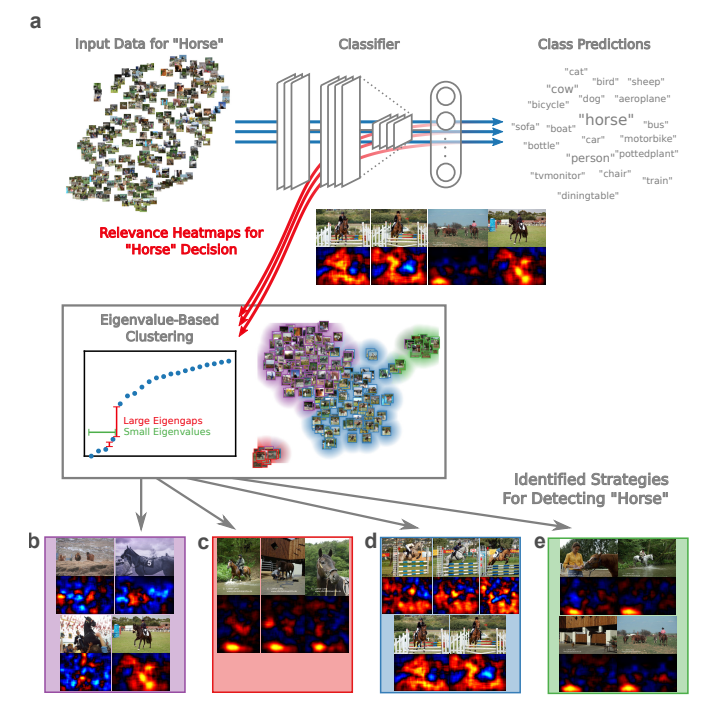
- 揭秘“聪明汉斯”式预测器并评估机器究竟学到了什么;Sebastian Lapuschkin、Stephan Wäldchen、Alexander Binder、Grégoire Montavon、Wojciech Samek、Klaus-Robert Müller;当前的学习型机器已经成功解决了许多高难度的实际问题,达到了极高的准确率,并展现出看似智能的行为。在此,我们运用最新的解释先进学习机器决策的技术,分析了来自计算机视觉和街机游戏领域的多项任务。这展示了从天真短视到深谋远虑、从简单直接到策略周密等多种问题解决行为模式。我们观察到,标准的性能评估指标往往无法区分这些多样的问题解决行为。此外,我们提出了一种半自动化的光谱相关性分析方法,能够切实有效地刻画和验证非线性学习机器的行为。这有助于评估所学习的模型是否确实能可靠地解决其设计初衷所针对的问题。同时,我们的工作旨在为当前关于机器智能的热烈讨论增添一份审慎的声音,并承诺以更为细致入微的方式评估和评判近期取得的一些成功成果。
- 预测解释中的特征影响力;Mohammad Bataineh;全球各地的企业都在积极采用复杂的机器学习(ML)技术,构建先进的预测模型,以优化运营和服务,并辅助决策。尽管这些 ML 技术功能强大,在多个行业中都取得了显著成效,但许多行业普遍反馈的一个问题是:这些技术往往过于“黑箱”,缺乏对特定预测概率是如何得出的细节说明。本文提出了一种创新算法,通过按各特征对模型预测的贡献程度排列清单,从而弥补这一不足。这种名为“预测解释中的特征影响力”(FIPE)的新算法,结合了单个特征的变化及其相互关联,计算出每个特征对预测的影响。FIPE 的真正优势在于其高效的计算能力,无论使用何种基础 ML 技术,都能快速给出特征影响力的结果。
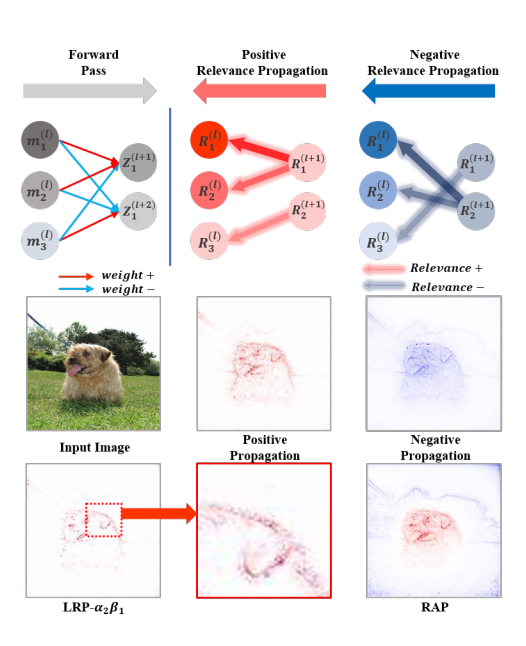
- 相对归因传播:解读深度神经网络中各单元的相对贡献;Nam Woo-Jeoung、Shir Gur、Choi Jaesik、Wolf Lior、Lee Seong-Whan;随着深度神经网络(DNN)在多个领域展现出超越人类的表现,人们对理解DNN复杂内部机制的兴趣日益浓厚。本文提出了一种名为相对归因传播(RAP)的方法,该方法从层间相对影响的角度出发,将DNN的输出预测分解为相关(正向)和不相关(负向)归因两部分。每个神经元的相关性根据其贡献程度被划分为正向与负向,并同时遵循守恒原则。通过考虑神经元按相对优先级分配的相关性,RAP能够为每个神经元赋予一个与输出相关的双极重要性评分——从高度相关到高度不相关。因此,我们的方法相比传统解释方法,能够以更加清晰、细致的可视化方式呈现分离后的归因结果,从而更好地解释DNN的行为。为了验证RAP传播的归因是否准确反映了每种含义,我们采用了以下评估指标:(i) 外部-内部相关性比例,(ii) 分割mIOU,以及(iii) 区域扰动。在所有实验和指标中,我们的方法均显著优于现有文献。
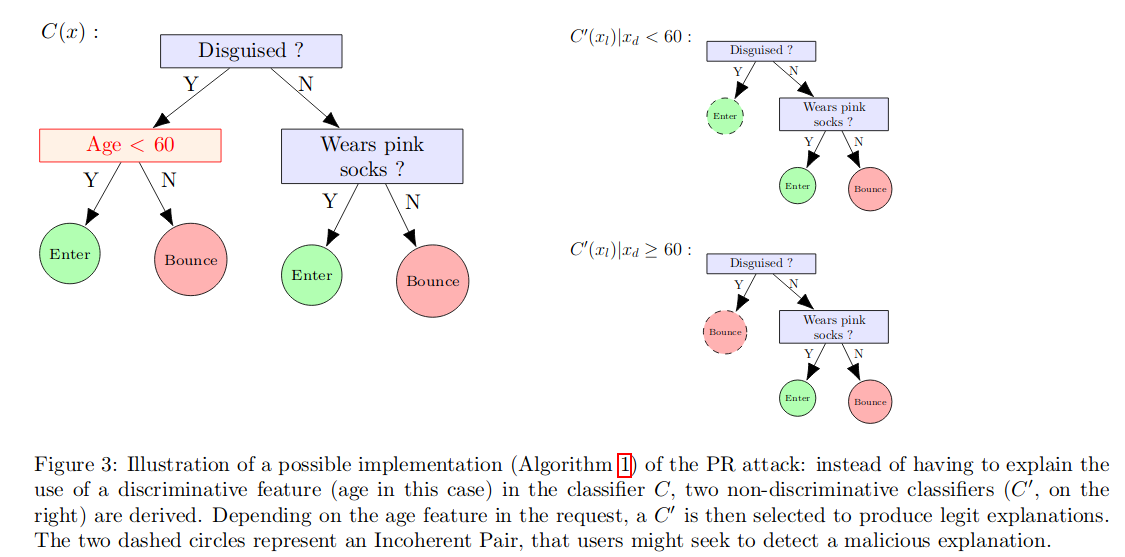
- 守门人问题:远程可解释性的挑战;Le Merrer Erwan、Tredan Gilles;可解释性的概念旨在满足社会对机器学习决策透明度的需求。其核心思想很简单:就像人类一样,算法也应当能够解释其决策背后的逻辑,以便对其公平性进行评估。然而,尽管这种思路在本地场景下颇具前景(例如在训练过程中调试模型时对其进行解释),但我们认为,这一逻辑无法简单地迁移到远程场景中——即由服务提供商训练好的模型仅能通过API访问的情况。这恰恰构成了从社会视角来看最需要透明度的应用场景,因而显得尤为棘手。通过类比于夜店守门员(可能在拒绝顾客入场时给出不实的解释),我们证明了提供解释并不能阻止远程服务就其决策的真实原因撒谎。更具体地说,我们通过构造一种针对解释的攻击,证明了对于单一解释而言,远程可解释性是不可能实现的;该攻击会向查询用户隐藏具有歧视性的特征。我们还提供了这一攻击的具体实现示例。随后,我们进一步指出,在实际应用中,观察者利用多份解释来寻找不一致之处从而发现此类攻击的概率非常低。这从根本上削弱了远程可解释性这一概念本身。
- 通过影响力函数理解黑盒预测;Koh Pang Wei、Liang Percy;我们如何解释黑盒模型的预测呢?在本文中,我们使用来自稳健统计学的经典技术——影响力函数——沿着学习算法的路径追溯至训练数据,从而识别出对特定预测贡献最大的训练样本点。为了将影响力函数扩展到现代机器学习环境中,我们开发了一种简单高效的实现方案,仅需梯度和Hessian向量乘积的oracle访问权限即可。我们证明,即使在理论失效的非凸、不可微分模型上,对影响力函数的近似计算仍能提供有价值的信息。在线性模型和卷积神经网络中,我们展示了影响力函数在多种用途上的价值:理解模型行为、调试模型、检测数据集错误,甚至用于创建视觉上难以区分的训练集投毒攻击。

- 迈向XAI:构建解释流程体系;El-Assady Mennatallah等;可解释的人工智能描述了一种揭示操作逻辑传播过程的方法,这些操作将给定输入转化为特定输出。在本文中,我们基于教育学、故事讲述、论证、编程、信任建立和游戏化六个研究领域的相关因素,探讨了解释流程的设计空间。我们提出了一种概念模型,用以描述解释流程的基本构成模块,其中包括对解释与验证阶段、路径、媒介和策略的全面概述。此外,我们还强调了研究有效可解释机器学习方法的重要性,并讨论了当前开放的研究挑战与机遇。
- 迈向自动化机器学习:AutoML方法与工具的评估与比较;Truong Anh、Walters Austin、Goodsitt Jeremy、Hines Keegan、Bruss C. Bayan、Farivar Reza;近年来,机器学习(ML)在工业领域的应用迅速增长,相关兴趣也持续升温。因此,ML工程师在整个行业中需求旺盛,但如何提升ML工程师的工作效率仍然是一个根本性挑战。自动化机器学习(AutoML)应运而生,旨在节省ML流水线中重复性任务的时间与精力,例如数据预处理、特征工程、模型选择、超参数优化以及预测结果分析等。在本文中,我们调研了当前用于自动化这些任务的AutoML工具现状,针对多个数据集和不同数据子集进行了多项评估,以考察其性能,并比较它们在不同测试案例下的优缺点。
- 可理解的医疗模型:预测肺炎风险与医院30天再入院; Rich Caruana 等;在机器学习中,常常需要在准确性和可理解性之间做出权衡。更精确的模型,如提升树、随机森林和神经网络,通常难以理解;而更易理解的模型,如逻辑回归、朴素贝叶斯和单棵决策树,则往往准确度显著较低。这种权衡有时会限制那些应用于医疗等关键任务中的模型的准确性,因为在这些领域中,能够理解、验证、修改并信任所学模型至关重要。我们展示了两个案例研究,其中高性能的具有两两交互作用的广义加性模型(GA2Ms)被应用于真实的医疗问题,生成了兼具先进准确度与可理解性的模型。在肺炎风险预测案例中,该可理解模型揭示了数据中一些令人惊讶的模式,而这些模式此前曾阻碍复杂的学习模型在此领域的部署。然而,由于该模型既可理解又模块化,这些模式得以被识别并移除。在30天医院再入院案例中,我们证明了相同的方法可以扩展到包含数十万患者和数千个特征的大规模数据集上,同时保持可理解性,并提供与最佳(不可理解)机器学习方法相当的准确度。
机器学习模型中R²的夏普利分解; Nickalus Redell;本文介绍了一种旨在帮助机器学习从业者快速总结并传达任何黑盒机器学习预测模型中各特征总体重要性的指标。我们提出的这一指标基于经典统计学中熟悉的R²的夏普利值方差分解,是一种不依赖于具体模型的特征重要性评估方法,能够公平地将模型解释的数据变异比例分配给每个特征。该指标具有若干理想特性,包括取值范围限定在0到1之间,且各特征层面的方差分解之和等于整个模型的R²。我们的实现已在R语言的shapFlex包中提供。
数据夏普利:机器学习中数据的公平估值; Amirata Ghorbani, James Zou;随着数据成为推动技术和经济增长的动力,如何量化数据在算法预测与决策中的价值成为一个根本性挑战。例如,在医疗和消费市场中,有人建议应就个人所产生的数据给予补偿,但何为公平的个体数据估值仍不甚明确。在本工作中,我们针对监督式机器学习场景下数据估值的问题,提出了一套原则性的框架。给定一个基于n个数据点训练而成的预测模型,我们提出使用“数据夏普利”作为衡量每个训练数据对模型性能贡献大小的指标。数据夏普利值独特地满足了公平数据估值的若干自然属性。我们开发了蒙特卡洛方法和基于梯度的方法,以高效估算复杂学习算法(包括神经网络)在大型数据集上训练时的各数据夏普利值。除了具备公平性之外,我们在生物医学、图像及合成数据上的大量实验还表明,数据夏普利还有其他多项优势:1) 与流行的留一法或杠杆率相比,它更能揭示哪些数据对于特定学习任务更为重要;2) 夏普利值较低的数据能有效捕捉异常值和数据污染;3) 夏普利值较高的数据则提示应采集何种新数据来进一步提升模型性能。
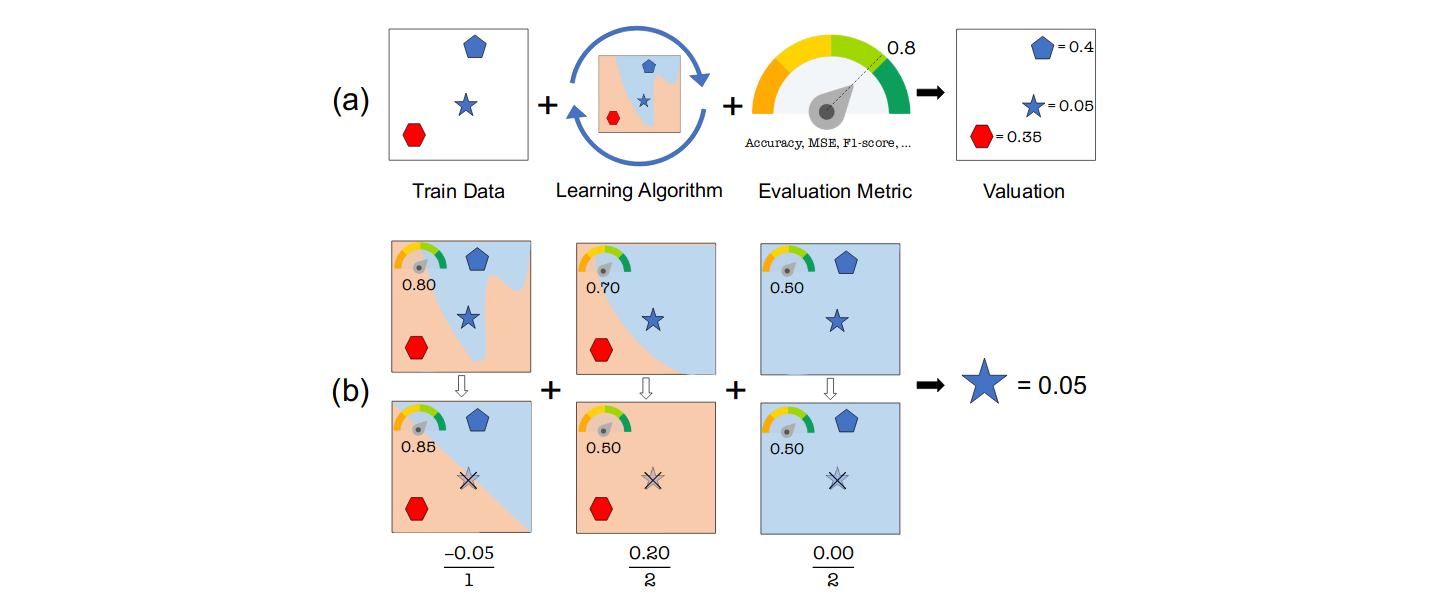
- 针对共依变量的偏依赖分层分析方法; Terence Parr, James Wilson;模型可解释性对机器学习从业者至关重要,而解释的关键组成部分之一就是刻画响应变量与模型中任意一组特征之间的偏依赖关系。目前最常用的两种偏依赖评估策略都存在诸多严重缺陷。第一种策略是通过线性回归模型的系数来描述当某一解释变量发生单位变化时,在其他变量保持不变的情况下,响应变量会如何变化。然而,线性回归并不适用于高维(p>n)数据集,且往往不足以捕捉解释变量与响应变量之间的复杂关系。第二种策略则是使用偏依赖图(PD)和个体条件期望图(ICE),但这两种方法在处理共依变量的常见情形时会产生偏差,而且它们依赖于用户提供的拟合模型。若用户提供的模型因系统性偏差或过拟合而选择不当,则PD/ICE图几乎无法提供任何有用的信息。为解决这些问题,我们提出了一种名为StratPD的新方法,该方法不依赖于用户提供的拟合模型,在存在共依变量的情况下仍能给出准确结果,并且适用于高维场景。其核心思想是利用决策树将数据集划分为若干组,每组内的观测值除目标变量外均相似,因此某组内响应变量的变化很可能是由目标变量引起的。我们将StratPD应用于一系列模拟和案例研究中,证实该方法速度快、可靠且稳健,相较于现有先进技术具有明显优势。
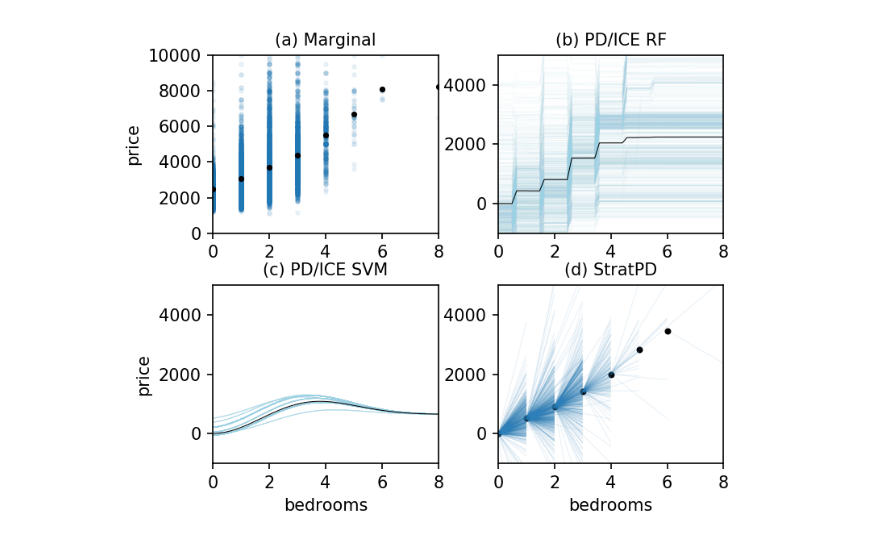
- DLIME:一种用于计算机辅助诊断系统的确定性局部可解释模型无关解释方法;Muhammad Rehman Zafar、Naimul Mefraz Khan;尽管LIME及类似局部算法因其简单性而广受欢迎,但其随机扰动和特征选择方式会导致生成的解释“不稳定”,即对于同一预测,可能会产生不同的解释。这一问题极为关键,可能阻碍LIME在计算机辅助诊断(CAD)系统中的部署,因为在该领域,稳定性是赢得医疗专业人员信任的重中之重。本文提出了一种LIME的确定性版本。我们未采用随机扰动,而是利用凝聚层次聚类(HC)对训练数据进行分组,并使用K近邻算法(KNN)来选择待解释新实例的相关簇。找到相关簇后,会在该簇上训练线性模型以生成解释。针对三个不同医学数据集的实验结果表明,确定性局部可解释模型无关解释(DLIME)具有显著优势,我们通过计算多次生成解释之间的Jaccard相似度,定量评估了DLIME相较于LIME的稳定性。
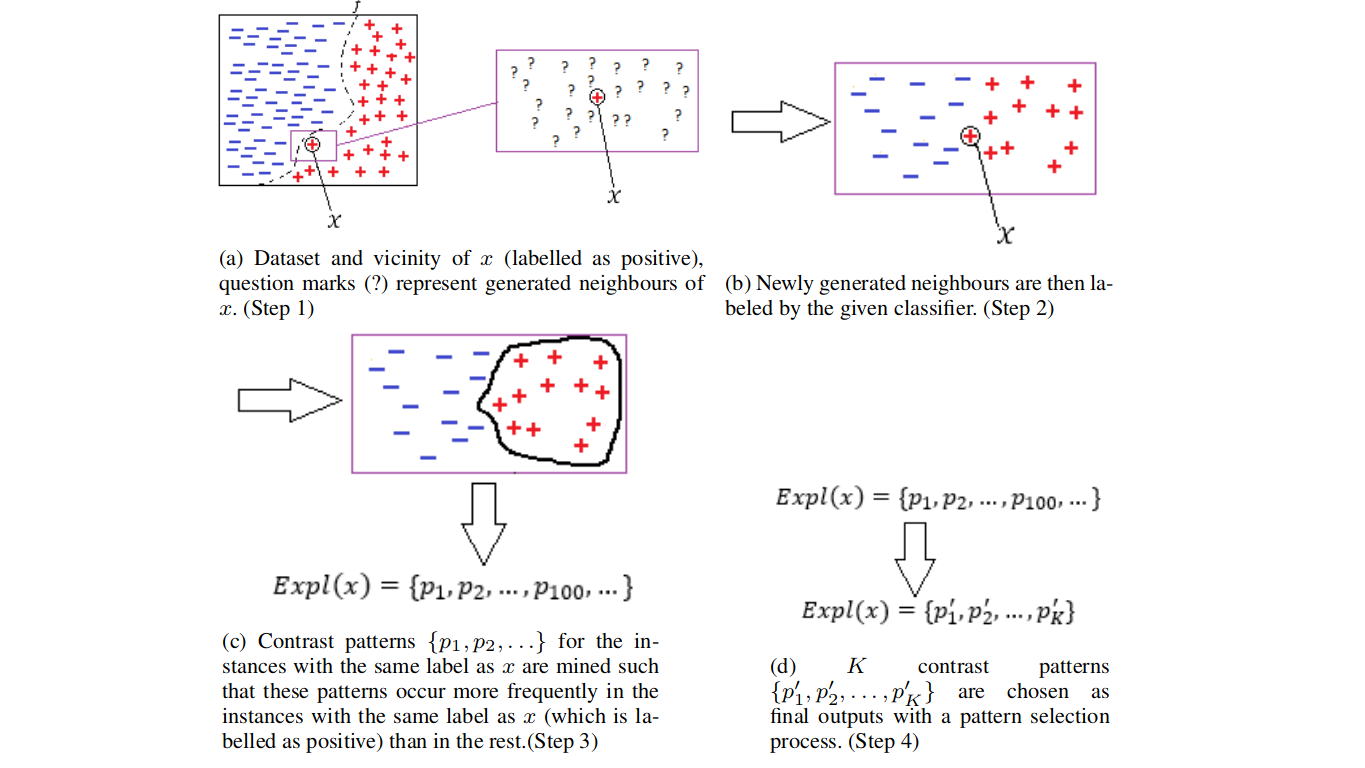
- 利用模式解释个体预测;Yunzhe Jia、James Bailey、Kotagiri Ramamohanarao、Christopher Leckie、Xingjun Ma;用户需要理解分类器的预测,尤其是在基于这些预测做出的决策可能带来严重后果时。对某一预测的解释能够揭示分类器作出该预测的原因,从而帮助用户更自信地接受或拒绝该预测。本文提出了一种名为模式辅助局部解释(PALEX)的解释方法,旨在为任意分类器提供实例级别的解释。PALEX以分类器、测试实例以及总结分类器训练数据的频繁模式集作为输入,输出分类器认为对该实例预测至关重要的支持证据。为了研究分类器在测试实例附近的行为,PALEX将训练数据中的频繁模式集作为额外输入,用以指导在测试实例附近生成新的合成样本。此外,PALEX还利用对比模式来识别测试实例附近的局部判别性特征。PALEX在存在多种解释的情境下尤为有效。
- 公平胜过哗众取宠:男人之于医生,正如女人之于医生;Malvina Nissim、Rik van Noord、Rob van der Goot;诸如“男人之于国王,正如女人之于X”之类的类比常被用来展示词嵌入的强大能力。然而,它们同时也揭示了人类偏见如何强烈地编码在基于自然语言构建的向量空间中。当我们发现“女王”是“男人之于国王,正如女人之于X”这一类比的答案时,往往会感到惊叹;但也有论文报告称,发现了深植人类偏见的类比,例如“男人之于计算机程序员,正如女人之于家庭主妇”,这类例子则令人担忧和愤怒。在本工作中,我们表明,嵌入空间常常未能得到公平对待,而且往往是无意之中。通过一系列简单的实验,我们指出了先前研究中存在的实际与理论问题,并证明了一些最广泛使用的有偏类比实际上并不符合数据支持。
由原型引导的可解释反事实解释;Arnaud Van Looveren、Janis Klaise;我们提出了一种快速且模型无关的方法,利用类别原型来寻找分类器预测的可解释反事实解释。我们证明,无论是通过编码器还是通过特定于类别的k-d树获得的类别原型,都能显著加快反事实实例的搜索速度,并生成更具可解释性的解释。我们引入了两个新颖的指标,用于定量评估实例层面的局部可解释性。借助这两个指标,我们分别在图像和表格型数据集——MNIST和威斯康星州乳腺癌(诊断)数据集——上展示了我们方法的有效性。
利用归因先验学习可解释模型;Gabriel Erion、Joseph D. Janizek、Pascal Sturmfels、Scott Lundberg、Su-In Lee;深度学习中有两个重要议题都涉及将人类因素融入建模过程:模型先验通过约束模型参数,将人类信息传递给模型;而模型归因则通过解释模型行为,将信息从模型传递给人类。我们提出将这两者结合,引入归因先验的概念,使人类能够借助归因这一通用语言,在训练过程中对模型行为施加先验期望。我们开发了一种可微分的公理化特征归因方法——期望梯度,并展示了如何在训练过程中直接对这些归因进行正则化。我们通过实证展示了归因先验的广泛应用:1) 在图像数据上,2) 在基因表达数据上,3) 在医疗健康数据集上。
可解释机器学习负责任且以人为本的使用指南;Patrick Hall;可解释机器学习(ML)已被应用于众多开源和专有软件包中,同时也是商业预测建模的重要组成部分。然而,可解释ML也可能被滥用,尤其可能被用作对有害黑盒模型的虚假保护措施,例如“漂绿”行为,或用于模型窃取等恶意目的。本文讨论了相关定义、示例及指导原则,旨在推动一种整体性和以人为本的机器学习方法,其中包括可解释(即白盒)模型,以及解释、调试和差异影响分析等技术。
概念树:用于更易解释的代理决策树的变量高层次表示;Xavier Renard、Nicolas Woloszko、Jonathan Aigrain、Marcin Detyniecki;在高维表格型数据集上训练的黑箱预测器的可解释代理模型,在存在相关变量的情况下,往往难以生成易于理解的解释。为此,我们提出了一种模型无关的可解释代理模型,能够提供黑箱分类器的全局和局部解释。我们引入了“概念”的概念,即由领域专家定义或利用相关系数自动发现的直观变量分组。这些概念被嵌入到代理决策树中,以提升其可解释性。
- 机器学习的奥秘:你在数据分析中若早知这十点,将会更加高效;Cynthia Rudin、David Carlson;尽管机器学习已在各组织中得到广泛应用,但仍有一些关键原则常常被忽视。具体而言:1)监督学习至少有四大类方法:逻辑建模方法、线性组合方法、基于案例的推理方法以及迭代归纳方法。2)对于许多应用领域,几乎所有机器学习方法的表现都相差无几(当然也有一些例外)。深度学习作为计算机视觉问题的主流技术,并未在大多数其他问题上保持优势——这背后自有其原因。3)神经网络训练难度大,且在训练过程中经常会出现一些奇怪的现象。4)如果不使用可解释模型,就可能犯下严重错误。5)解释本身也可能具有误导性,不可盲目信任。6)即使对于深度神经网络,也几乎总能找到既准确又可解释的模型。7)诸如决策能力或鲁棒性等特殊属性必须在设计时就加以构建,而不能自然形成。8)因果推断与预测不同(相关性并不等于因果关系)。9)深度神经网络架构看似复杂,其中确实存在一定的规律,但并非总是如此。10)人工智能无所不能只是一种误解。
- 关于模型脆弱性和安全性的建议;Patrick Hall;应采用公平且私密的模型、白帽与取证式的模型调试方法,以及常识性的防护措施,以保护机器学习模型免受恶意攻击。
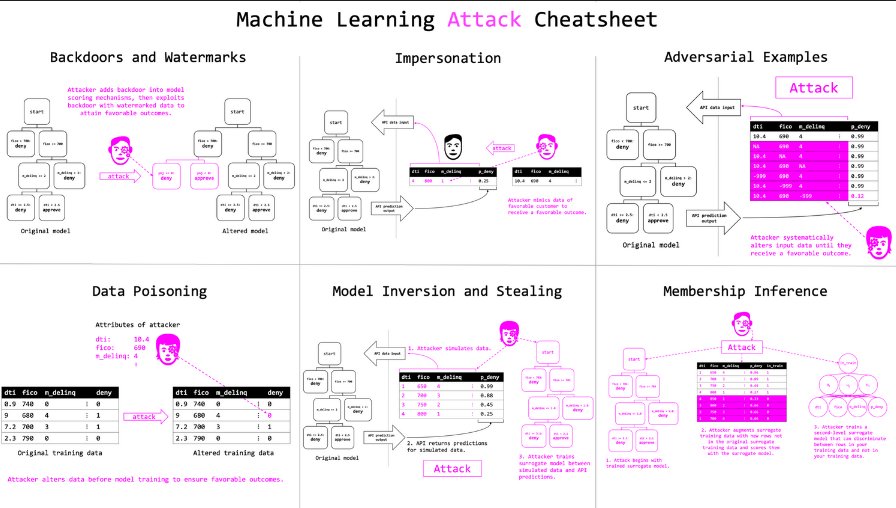
- 关于可解释机器学习的误解及更具人文关怀的机器学习;Patrick Hall;由于社区和商业领域的强烈需求,可解释机器学习(ML)方法已被广泛应用于流行的开源软件和商业软件中。然而,作为一名在过去三年中一直参与可解释ML软件开发的人,我发现目前关于这一主题的许多文献既令人困惑,又与我个人的实践经验相去甚远。本文旨在通过论点、建议和参考文献,澄清一些常见的可解释机器学习误解。
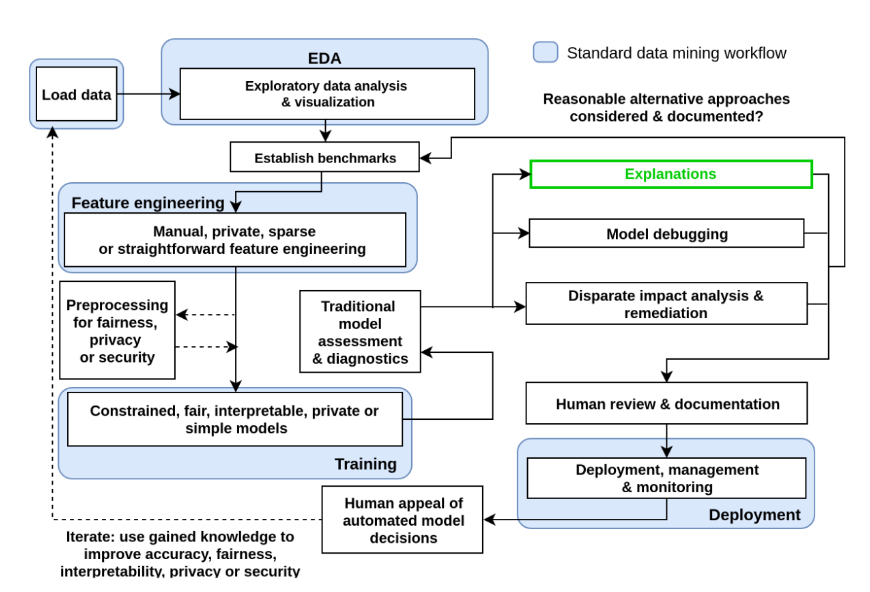
- 用于模型报告的模型卡片;Margaret Mitchell、Simone Wu、Andrew Zaldivar、Parker Barnes、Lucy Vasserman、Ben Hutchinson、Elena Spitzer、Inioluwa Deborah Raji、Timnit Gebru;经过训练的机器学习模型正越来越多地被用于执法、医疗、教育和就业等领域中具有重大影响的任务。为了明确机器学习模型的预期用途,并尽量避免将其应用于不适宜的场景,我们建议在发布模型时附带一份详细说明其性能特征的文档。本文提出了一种名为“模型卡片”的框架,以促进透明的模型报告。模型卡片是随训练好的机器学习模型附带的简短文件,其中提供了在多种条件下的基准评估结果,例如针对不同文化、人口统计或表型群体(如种族、地理位置、性别、菲茨帕特里克皮肤类型)以及交叉群体(如年龄与种族、性别与菲茨帕特里克皮肤类型)的相关评估。此外,模型卡片还会披露模型的预期使用场景、性能评估的具体流程以及其他相关信息。虽然我们的重点主要放在计算机视觉和自然语言处理领域中以人为本的机器学习模型上,但该框架同样适用于任何经过训练的机器学习模型。为巩固这一理念,我们为两款监督学习模型提供了示例卡片:一款用于检测图像中的微笑面孔,另一款用于识别文本中的有毒评论。我们提议将模型卡片作为推动机器学习及相关AI技术负责任地普及化的重要一步,从而提高人们对AI技术实际效果的透明度。我们希望这项工作能够鼓励那些发布训练好的机器学习模型的机构,在每次发布时都附上类似的详细评估数据及其他相关文档。

基于树的方法中特征重要性的无偏估计;Zhengze Zhou、Giles Hooker;我们提出了一种改进方法,用于校正随机森林及其他基于树的方法中基于分裂增益的特征重要性度量。已有研究表明,这类方法倾向于高估具有更多潜在分裂点的特征的重要性。我们证明,通过合理地利用在留出数据上计算的分裂增益,可以纠正这一偏差,从而得到更可靠的汇总结果和筛选工具。
请停止打乱特征:解释与替代方案;Giles Hooker、Lucas Mentch;本文反对使用“打乱并预测”(PaP)方法来解释黑箱模型。诸如随机森林中的特征重要性度量、部分依赖图以及个体条件期望图等方法之所以广受欢迎,是因为它们能够提供与具体模型无关的度量,仅依赖于预先训练好的模型输出。然而,大量研究发现,这些工具可能会产生极具误导性的诊断结果,尤其是在特征之间存在强相关性时。与其简单地重复已有文献中关于这些问题的论述,我们在此尝试对观察到的现象进行解释。具体而言,我们认为,在保留数据中打破特征间的依赖关系,会过度强调特征空间中的稀疏区域,迫使原始模型外推出现极少或没有数据的区域。我们通过若干已知真实情况的场景对此进行了探讨,并支持了先前文献中的观点:即使对真实模型应用打乱方法也不会出现类似现象,但PaP指标在特征重要性和部分依赖图中仍倾向于过度强调相关特征。作为替代方案,我们建议采用其他已被证明在不同场景中有效的直接方法,例如显式移除特征、条件打乱或模型蒸馏技术。
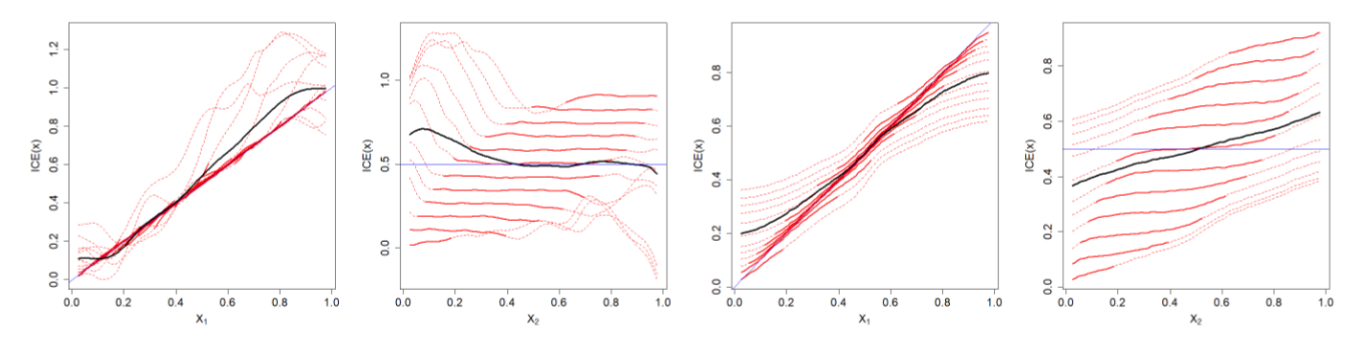
为什么你应该信任我的解释?理解LIME预测中的不确定性;Hui Fen (Sarah) Tan、Kuangyan Song、Madeilene Udell、Yiming Sun、Yujia Zhang;用于解释机器学习黑箱模型的方法能够提高结果的透明度,进而帮助人们深入了解算法的可靠性和公平性。然而,这些解释本身可能包含显著的不确定性,从而削弱人们对结果的信任,并引发对模型可靠性的担忧。以“局部可解释的模型无关解释”(LIME)方法为例,我们展示了两种不确定性来源:其采样过程中的随机性,以及不同输入数据点之间解释质量的差异。即使在训练和测试准确率都很高的模型中,这种不确定性依然存在。我们分别将LIME应用于合成数据、20 Newsgroup文本分类数据集以及COMPAS再犯风险评分数据集,以佐证我们的论点。
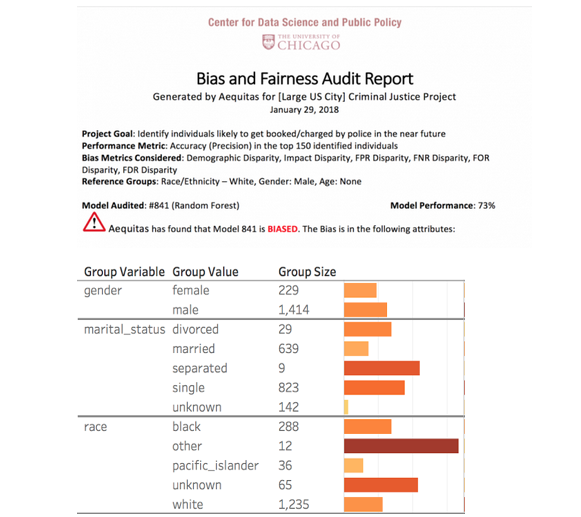
Aequitas:偏见与公平性审计工具包;Pedro Saleiro、Benedict Kuester、Loren Hinkson、Jesse London、Abby Stevens、Ari Anisfeld、Kit T. Rodolfa、Rayid Ghani;近期的研究引发了人们对当前人工智能系统中潜在无意偏见的担忧,这些偏见可能基于种族、性别或宗教等特征,对个人造成不公平的影响。尽管近年来提出了许多偏见度量和公平性定义,但对于应采用哪种度量或定义尚未达成共识,且可用于实际操作的资源也极为有限。因此,尽管人们的意识有所提高,但在开发和部署人工智能系统时进行偏见与公平性审计仍未成为标准做法。我们推出了Aequitas开源工具包,它是一个直观易用的机器学习工作流补充工具,使用户能够无缝地针对多个群体子集,测试模型在多种偏见和公平性指标上的表现。Aequitas有助于数据科学家、机器学习研究人员和政策制定者做出更加知情和公平的决策,以指导算法决策系统的开发和部署。
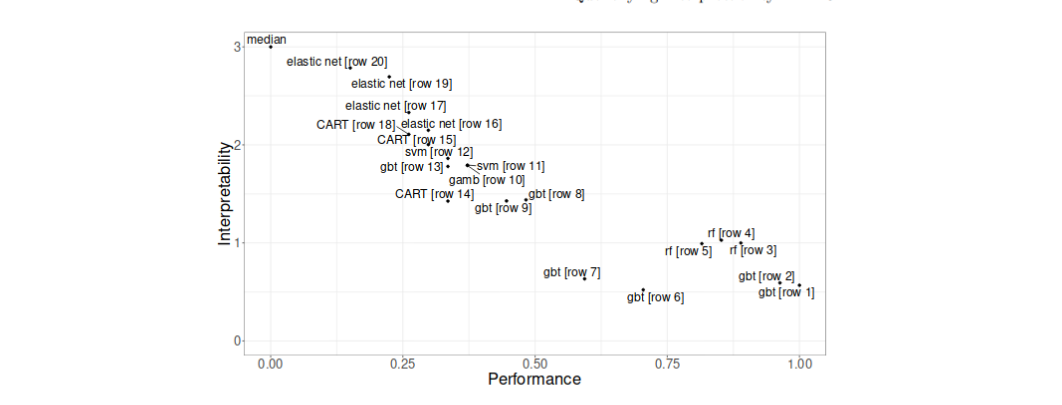
- 特征重要性云:探索一组优秀模型中特征重要性的方法;Jiayun Dong、Cynthia Rudin;特征重要性在科学研究中占据核心地位,涵盖社会科学与因果推断、医疗健康等领域。然而,目前的特征重要性概念往往与特定的预测模型紧密相关。这存在问题:如果存在多个性能良好的预测模型,而某个特征只对其中一部分重要,对另一部分则不重要,那么仅凭单一表现良好的模型,我们便无法判断该特征是否始终对预测结果至关重要。因此,我们希望不再依赖单个预测模型的特征重要性,而是探索所有近似精度相当的预测模型中特征的重要性。本文提出了“特征重要性云”的概念,它将每个特征映射到其在所有优秀预测模型中的重要性。我们探讨了特征重要性云的性质,并将其与统计学的其他领域建立了联系。此外,我们还引入了“特征重要性图”,作为特征重要性云在二维空间中的投影,以便于可视化展示。
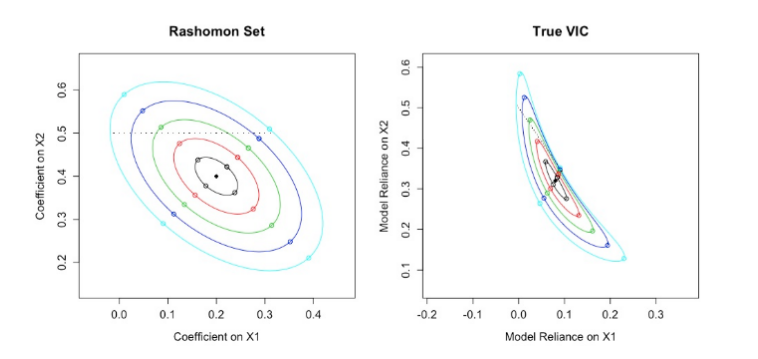
- 一项系统综述表明,对于临床预测模型而言,机器学习并不比逻辑回归更具性能优势;Evangelia Christodoulou、Jie Ma、Gary Collins、Ewout Steyerberg、Jan Yerbakela、Ben Van Calster;研究目的:本研究旨在比较文献中用于临床预测建模的逻辑回归(LR)与机器学习(ML)的性能。研究设计与设置:我们对Medline数据库进行了检索(2016年1月至2017年8月),并提取了针对二分类结局的逻辑回归模型与机器学习模型之间的比较结果。研究结果:在927项研究中,我们纳入了71项。样本量的中位数为1,250(范围72–3,994,872),平均每个模型包含19个预测变量(范围5–563),每个多重共线性变量对应8个事件(范围0.3–6,697)。最常见的机器学习方法包括分类树、随机森林、人工神经网络和支持向量机。在48项(68%)研究中,我们观察到验证程序存在潜在偏倚。64项(90%)研究使用受试者工作特征曲线下面积(AUC)来评估区分能力。而在56项(79%)研究中并未考虑校准问题。我们共识别出282组逻辑回归模型与机器学习模型的比较(AUC范围0.52–0.99)。对于145组低偏倚风险的比较,逻辑回归与机器学习之间logit(AUC)的差异为0.00(95%置信区间,−0.18至0.18)。而对于137组高偏倚风险的比较,机器学习的logit(AUC)则高出0.34(0.20–0.47)。结论:我们未发现机器学习优于逻辑回归的证据。在比较不同建模算法的研究中,仍需改进方法学与报告规范。
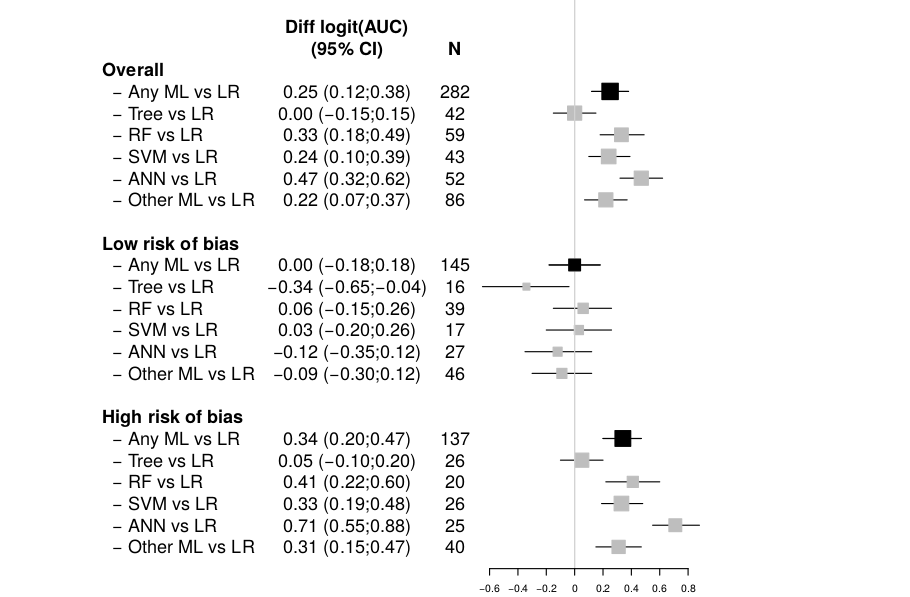
- iBreakDown:非可加性预测模型的解释不确定性;Alicja Gosiewska、Przemyslaw Biecek;可解释人工智能(XAI)近年来备受关注。解释性被视为解决人们对模型预测缺乏信任的一种途径。诸如LIME、SHAP或Break Down等模型无关工具,承诺为任何复杂的机器学习模型提供实例级别的可解释性。然而,这些解释究竟有多可靠?我们能否依赖于针对非可加性模型的可加性解释呢?在本文中,我们探讨了在存在交互作用时模型解释器的行为。我们定义了两种不确定性来源:模型层面的不确定性以及解释层面的不确定性。我们证明,引入交互作用可以降低解释层面的不确定性。同时,我们提出了一种新的方法——iBreakDown,该方法能够生成包含局部交互效应的非可加性解释。
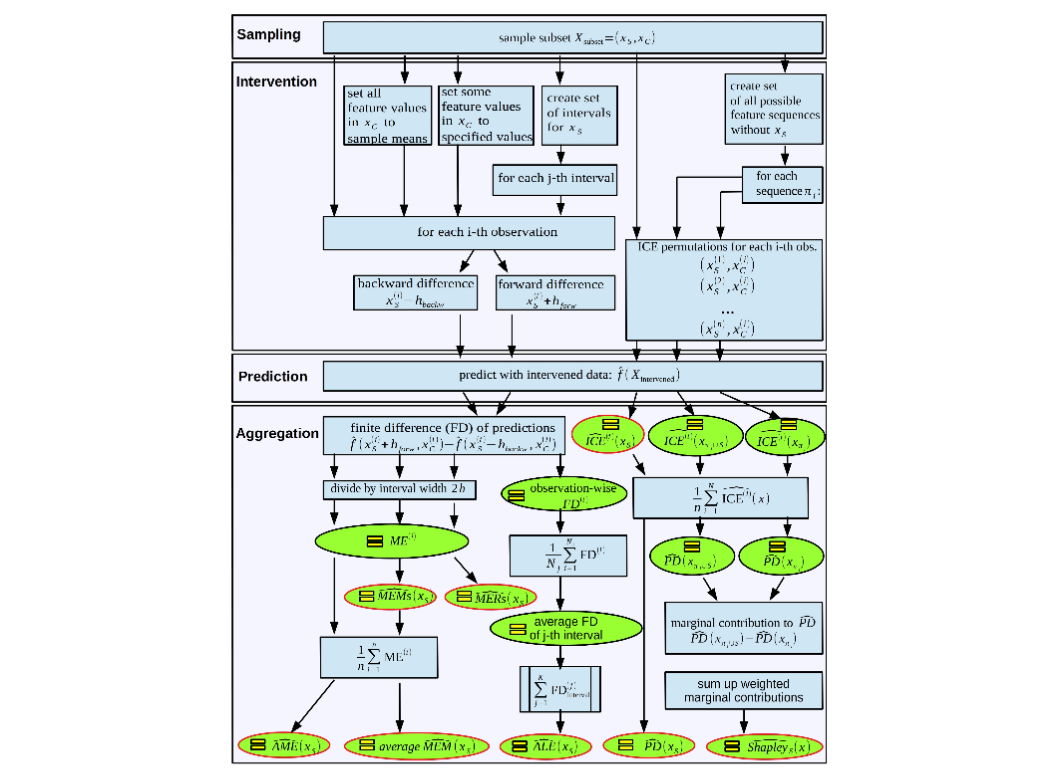
- 采样、干预、预测、聚合:一种通用的模型无关解释框架;Christian A. Scholbeck、Christoph Molnar、Christian Heumann、Bernd Bischl、Giuseppe Casalicchio;非线性机器学习模型往往以牺牲可解释性为代价,换取卓越的预测性能。然而,如今的模型无关解释技术使我们能够估算任意预测模型中各特征的影响及重要性。不同的表述方式和术语使得这些方法的理解及其相互关系变得复杂。目前尚缺乏对这些方法的统一视角。我们提出了SIPA(采样、干预、预测、聚合)这一通用的工作流程框架,用于模型无关的解释技术,并展示了如何将几种主流的特征效应分析方法嵌入到该框架中。此外,我们正式引入了“边际效应”这一概念,用以描述黑箱模型中的特征效应。进一步地,我们将该框架扩展至特征重要性的计算,指出基于方差和基于性能的重要性度量均建立在相同的工作步骤之上。这一通用框架可作为开展机器学习中模型无关解释工作的指导方针。
- 通过功能分解量化任意机器学习模型的可解释性;Christoph Molnar、Giuseppe Casalicchio、Bernd Bischl;为了获得可解释的机器学习模型,人们通常会选择从一开始就构建可解释的模型——例如浅层决策树、规则列表或稀疏广义线性模型——或者采用事后解释方法——如部分依赖图或ALE图。然而,这两种方法各有其缺点。前者可能过于保守地限制假设空间,从而导致次优解;而后者在面对复杂模型尤其是涉及特征交互作用时,则可能产生过于冗长或误导性的结果。为此,我们建议通过量化机器学习模型的复杂性与可解释性之间的权衡,明确预测能力与可解释性之间的折衷。基于功能分解,我们提出了三个衡量指标:使用的特征数量、交互作用强度以及主效应的复杂程度。我们证明,对那些在这三项指标上都尽可能低的模型进行事后解释,会更加可靠且简洁。此外,我们还展示了一种多目标优化方法的应用,在该方法中同时考虑模型的预测能力和可解释性。
- 仅用一个像素即可攻破深度神经网络的攻击方法;Jiawei Su、Danilo Vasconcellos Vargas、Sakurai Kouichi;近期研究表明,只需在输入向量中加入相对较小的扰动,就能轻易改变深度神经网络(DNN)的输出。在本文中,我们分析了一种极端受限场景下的攻击方式,即仅能修改图像中的一个像素。为此,我们提出了一种基于差分进化的新型单像素对抗性扰动生成方法。该方法所需对抗信息较少(属于黑盒攻击),并且由于差分进化本身的特性,能够欺骗更多类型的网络。实验结果显示,在CIFAR-10测试数据集中,68.36%的自然图像以及在ImageNet(ILSVRC 2012)验证集中的41.22%图像,仅通过修改一个像素便能被分别以73.22%和5.52%的置信度引导至至少一个目标类别。因此,所提出的攻击方法从极端受限的角度重新审视了对抗性机器学习,揭示了当前的深度神经网络同样容易受到此类低维度攻击的影响。此外,我们还说明了差分进化(或更广泛地说,进化计算)在对抗性机器学习领域的重要应用:即开发能够高效生成低成本对抗性攻击的工具,用于评估神经网络的鲁棒性。

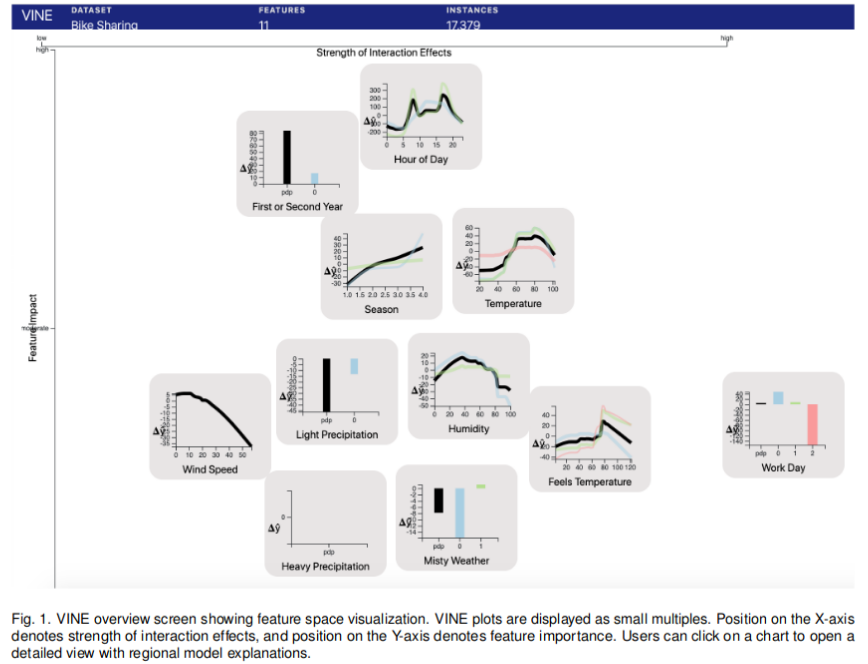
- VINE:在黑盒模型中可视化统计交互作用;马修·布里顿;随着机器学习的日益普及,对预测模型的可解释性说明的需求变得十分迫切。先前的研究已经开发出有效的方法来可视化全局模型行为,并生成局部(特定实例)的解释。然而,针对区域级解释——即在复杂模型中相似实例群体的行为方式——以及相关的统计特征交互作用可视化问题,相关工作相对较少。由于缺乏满足这些分析需求的工具,阻碍了关键任务型、透明且符合社会目标的模型的开发。我们提出了VINE(Visual INteraction Effects,交互效应可视化),这是一种新颖的算法,用于提取并可视化黑盒模型中的统计交互效应。同时,我们还提出了一种新的评估指标,用于可解释机器学习领域的可视化效果。
- 机器学习算法的临床应用:超越黑盒;大卫·沃森等;机器学习算法有望从根本上提升我们诊断和治疗疾病的能力;出于道德、法律和科学层面的考虑,医生和患者必须能够理解并解释这些模型的预测结果;通过与包括患者、数据科学家和政策制定者在内的相关利益方紧密合作,可以实现可扩展、可定制且符合伦理的解决方案。
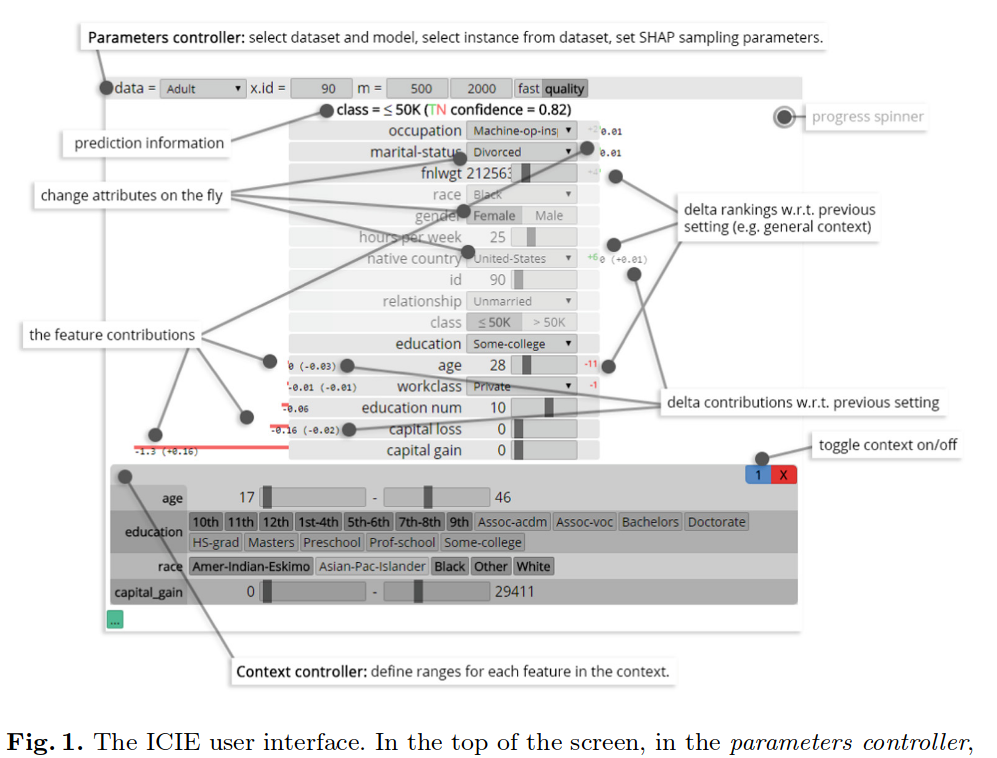
- ICIE 1.0:一种用于交互式上下文交互解释的新工具;西蒙·B·范德宗等;随着有关隐私和知情权的新法律法规的出台,对自动化决策的解释愈发重要。如今,机器学习模型被广泛应用于银行和保险等领域,以帮助专业人士识别可疑交易、审批贷款和信用卡申请。使用此类系统的公司必须能够提供其决策背后的依据;单纯依赖训练好的模型是远远不够的。目前已有多种方法可以洞察模型及其决策过程,但它们往往只擅长展示全局或局部行为。全局行为通常过于复杂而难以直观呈现或理解,因此只能采用近似的方式;而局部行为的可视化则容易产生误导,因为很难准确定义“局部”究竟指什么(例如,我们的方法无法判断某个特征值的改变难度,哪些是灵活可变的,哪些则是固定不变的)。为此,我们提出了ICIE框架(交互式上下文交互解释),使用户能够在不同情境下查看单个实例的解释。我们将看到,同一案例在不同情境下的解释会有所不同,从而揭示出不同的特征交互模式。
人机系统中的解释:文献元分析、关键思想与出版物概要以及可解释人工智能的参考文献;谢恩·T·穆勒、罗伯特·R·霍夫曼、威廉·克兰西、阿比盖尔·埃姆雷、加里·克莱因;这是一篇综合性综述,围绕“什么样的解释才是好的解释”这一问题展开讨论,并以人工智能系统为参照。相关文献浩如烟海,因此本综述必然具有选择性。尽管如此,报告中仍涵盖了大多数关键概念和议题。报告梳理了计算机科学领域在构建能够解释与教学的系统(如智能辅导系统和专家系统)方面的历史进程。同时,报告阐述了现代人工智能中的可解释性问题与挑战,并简要介绍了主流的解释心理学理论。其中一些文章因其与XAI的高度相关性而尤为突出,其研究方法、结果及核心观点均被重点呈现。
解释的解释:机器学习可解释性的概述;莱拉尼·H·吉尔平、大卫·鲍、本·Z·袁、阿耶莎·巴杰瓦、迈克尔·斯佩克特、拉拉娜·卡加尔;近年来,解释性人工智能(XAI)领域的研究呈现出蓬勃发展的态势。该研究方向致力于解决一个重要问题:复杂的机器和算法往往难以揭示其行为与思维过程。XAI通过提高用户与系统内部各环节的透明度,能够在一定程度上对决策作出解释。这些解释对于确保算法公平性、识别训练数据中的潜在偏差或问题,以及保证算法按预期运行至关重要。然而,目前由这些系统生成的解释既缺乏标准化,也未得到系统的评估。为了制定最佳实践并明确尚未解决的挑战,我们提出了可解释性的定义,并说明如何利用这一概念对现有文献进行分类。此外,我们还探讨了当前针对解释方法,尤其是深度神经网络的解释方法为何存在不足之处。
SAFE ML:基于代理模型的特征提取用于模型学习;艾丽西亚·戈谢夫斯卡、亚历山德拉·加切克、皮奥特尔·卢邦、普热米斯瓦夫·别切克;复杂的黑盒预测模型可能具有较高的准确性,但其不透明性会导致信任缺失、稳定性不足以及对概念漂移的敏感等问题。另一方面,可解释模型则需要投入大量精力进行特征工程,耗时较长。那么,我们能否在无需耗费大量时间进行特征工程的情况下,训练出既可解释又准确的模型呢?本文提出了一种方法,即利用弹性黑盒作为代理模型,从而构建更为简单、透明度更高,同时保持准确性和可解释性的白盒模型。新模型基于借助代理模型提取或学习到的新特征而构建。我们展示了该方法在模型层面解释中的应用,并探讨了其向实例层面解释扩展的可能性。此外,文中还提供了一个Python实现示例,并在多个表格型数据集上对该方法进行了基准测试。
注意力并非解释;萨尔塔克·贾因、拜伦·C·华莱士;注意力机制已在神经网络自然语言处理模型中得到广泛应用。除了提升预测性能外,它们还常被宣传为能够提供透明度:配备注意力机制的模型会输出对输入单元的关注分布,而这往往被(至少是隐性地)视为传达了各输入的重要性权重。然而,注意力权重与模型输出之间究竟存在何种关系尚不明确。在本研究中,我们针对多种NLP任务开展了广泛的实验,旨在评估注意力权重在多大程度上能够为预测提供有意义的“解释”。结果表明,它们在很大程度上并不能做到这一点。例如,学习到的注意力权重通常与基于梯度的特征重要性度量无关,而且即使关注分布截然不同,也可能产生相同的预测结果。我们的研究发现,标准的注意力模块并不能提供有意义的解释,也不应被视为能够做到这一点。
高效搜索多样且一致的反事实解释;克里斯·拉塞尔;本文提出了一种基于混合整数规划的反事实解释新搜索算法。我们关注的是复杂数据,其中变量可以取连续范围内的任意值,或属于一组离散状态。我们提出了一组新颖的约束条件,称为“混合多面体”,并展示了如何将其与整数规划求解器结合使用,以高效地找到一致的反事实解释——即那些能够可靠地映射回原始数据结构,同时避免暴力枚举的解决方案。此外,我们还探讨了多样化解释的问题,并说明如何在我们的框架内生成此类解释。
机器学习研究中的七个误区;奥斯卡·张、霍德·利普森;随着深度学习在医学影像等高风险应用中日益普及,我们必须谨慎对待对神经网络所作决策的解读。例如,虽然让卷积神经网络将核磁共振图像上的一个斑点识别为恶性肿瘤是一件好事,但如果这一结论建立在脆弱的解释方法之上,则不应轻信。
迈向加权特征归因的聚合;乌芒·巴特、普拉迪普·拉维库马尔、若泽·M·F·莫拉;当前用于解释机器学习模型的方法主要分为两类:先决事件影响法和数值归因法。前者利用训练样本描述某个训练点对测试点的影响程度,而后者则试图为与特定预测最相关的特征赋予数值意义。在本工作中,我们讨论了一种名为AVA的算法——先决事件价值聚合法——它将这两种解释方法融合在一起,形成一种新的特征归因方式,不仅能够获取局部解释,还能捕捉模型所学习到的全局模式。
人类对解释的可理解性评估;艾萨克·拉格、艾米莉·陈、杰弗里·何、梅纳卡·纳拉亚南、彬·金、萨姆·格什曼、菲娜莱·多希-维莱兹;究竟怎样的解释才真正符合人类的理解习惯,这一问题至今仍缺乏清晰的认识。本研究通过三项用户在使用机器学习系统时可能执行的具体任务——模拟响应、验证建议响应,以及判断建议响应的正确性是否会因输入变化而改变——来深化我们对解释可理解性的理解。通过精心设计的人体实验,我们确定了可用于优化机器学习系统可解释性的正则化参数。研究结果表明,复杂性的类型至关重要:认知块(新定义的概念)对解释效果的影响大于变量重复,且这一趋势在不同任务和领域中均保持一致。这提示我们,解释系统或许存在一些共通的设计原则。
可解释的机器学习:定义、方法与应用;W·詹姆斯·默多卡、钱丹·辛格、卡尔·昆比埃拉、雷扎·阿巴西-阿斯、宾·宇;机器学习模型在学习复杂模式并据此对未观测数据进行预测方面取得了巨大成功。除了利用模型进行预测之外,如何解释模型所学到的内容也日益受到关注。然而,这种关注度的提升却引发了关于可解释性概念的诸多困惑。特别是,人们尚不清楚各种提出的解释方法之间有何关联,以及可以用哪些共同的概念来对其进行评估。
学习最优且公平的决策树以实现非歧视性决策;西纳·阿加伊、穆罕默德·贾瓦德·阿齐齐、菲比·瓦亚诺斯;近年来,基于数据驱动的自动化决策系统在多个领域取得了巨大成功(例如用于产品推荐或指导娱乐内容的制作)。近来,这类算法越来越多地被用于辅助涉及社会敏感性的决策(如决定录取哪些学生进入学位课程,或为公共住房分配优先顺序)。然而,这些自动化工具可能会导致歧视性决策,即根据个体所属的群体或少数族裔身份对其区别对待,从而造成差别待遇或差别影响,进而违背道德与伦理规范。这种情况可能发生在训练数据本身存在偏见时(例如,某一特定群体的成员历来遭受歧视)。但也可能出现在训练数据无偏见的情况下,如果系统错误对不同群体或少数族裔成员造成的影响不同(例如,黑人的误分类率高于白人)。在本文中,我们统一了分类与回归任务中不公平的定义。随后,我们提出了一种多功能的混合整数优化框架,用于学习最优且公平的决策树及其变体,以根据具体情况防止差别待遇和/或差别影响。这相当于为设计公平且可解释的政策提供了一个灵活的方案,适用于各类社会敏感决策。我们进行了大量的计算实验,结果表明,我们的框架能够改进该领域的现有技术水平(通常依赖启发式方法),从而在不降低整体准确性的前提下实现非歧视性决策。
通过对比反向传播理解CNN的个体决策;Jindong Gu、Yinchong Yang、Volker Tresp;为了更好地理解深度卷积神经网络的个体决策,已经提出了许多基于反向传播的方法,如DeConvNets、普通梯度可视化和引导反向传播等。然而,这些方法生成的显著性图被证明缺乏判别性。最近,层级相关性传播(LRP)方法被提出用于解释整流器神经网络的分类决策。在本工作中,我们评估了所生成解释的判别能力,并分析了LRP的理论基础——深度泰勒分解。实验和分析表明,LRP生成的解释并不具备类别判别性。在此基础上,我们提出了对比层级相关性传播(CLRP),该方法能够生成实例特异、类别判别且像素级别的解释。在实验中,我们利用CLRP来解释决策过程,并理解个体分类决策中不同神经元之间的差异。此外,我们还通过“指向游戏”和消融研究对解释进行了定量评估。定性和定量评估均显示,CLRP生成的解释优于LRP。代码已公开。
2018年
通过类别对比的反事实陈述进行机器学习预测的对话式解释;Kacper Sokol、Peter Flach;机器学习模型已广泛渗透到我们的日常生活中,它们决定了影响教育、就业和司法系统等重要事务的决策。许多此类预测系统属于受商业秘密保护的商业产品,因此其决策过程不透明。为此,在我们的研究中,我们关注机器学习模型预测的可解释性和说明性问题。我们的工作大量借鉴了社会科学领域的人类解释研究:通过对话提供的对比式和示例式解释。这种以用户为中心的设计,面向普通大众而非领域专家,应用于机器学习时,能够让被解释者根据自身需求主导解释过程,而不是被动接受预设模板。
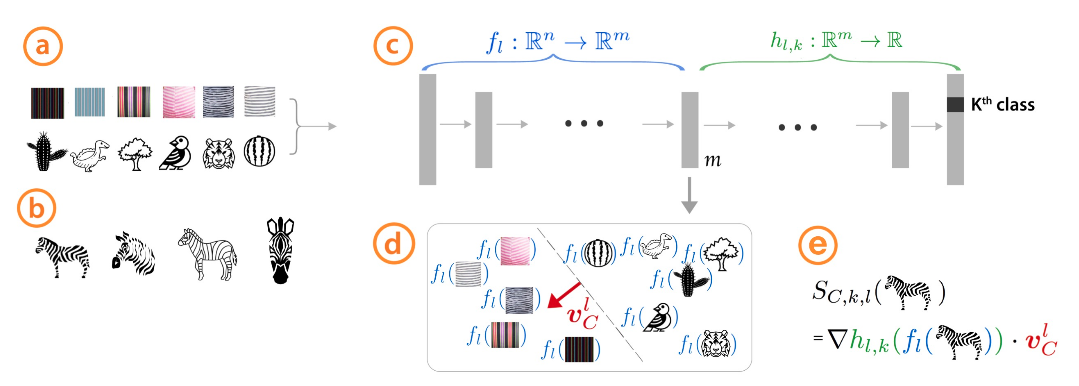
超越特征归因的可解释性:使用概念激活向量进行量化测试(TCAV);Been Kim、Martin Wattenberg、Justin Gilmer、Carrie Cai、James Wexler、Fernanda Viegas、Rory Sayres;由于深度学习模型规模庞大、结构复杂且内部状态往往不透明,对其解释一直是一项挑战。此外,许多系统(如图像分类器)是基于低层次特征而非高层次概念进行操作的。为应对这些挑战,我们引入了概念激活向量(CAV),它能够用人类友好的概念来解释神经网络的内部状态。核心思想是将神经网络的高维内部状态视为一种辅助工具,而非障碍。我们展示了如何将CAV作为“使用CAV进行测试”(TCAV)技术的一部分,利用方向导数来量化用户定义的概念对分类结果的重要性——例如,“斑马”的预测对条纹存在的敏感程度。以图像分类领域为试验平台,我们描述了如何利用CAV探索假设并为标准图像分类网络以及医疗应用提供洞见。TowardsDataScience。
机器决策与人类后果;牛津大学出版社即将出版的《算法监管》一书中已获接受发表的一章草稿;Teresa Scantamburlo、Andrew Charlesworth、Nello Cristianini;此处的讨论主要聚焦于刑事司法系统中的执法决策案例,但也借鉴了其他用于控制机会获取的算法中的类似情形,以解释机器学习的工作原理及其导致现代智能算法或“分类器”作出决策的方式。文中考察了分类器性能的关键方面,包括分类器的学习方式、其基于相关性而非因果关系运作的事实,以及机器学习中“偏差”一词与日常用法的不同含义。随后,以现实世界中的一个典型“分类器”——伤害评估风险工具(HART)为例,通过识别其技术特征——分类方法、训练数据与测试数据、特征与标签、验证及性能指标——展开分析。接着,参照HART,从四个规范性基准出发进行考量:(a) 预测准确性 (b) 公平与法律面前的平等 (c) 透明度与问责制 (d) 信息隐私与言论自由,以此展示其技术特征所具有的重要规范性维度,这些维度直接决定了该系统在多大程度上可以被视为现有人类决策者的可行且合法的支持,甚至替代方案。
争议规则——发现分类器之间存在异常分歧的区域;Oren Zeev-Ben-Mordehai、Wouter Duivesteijn、Mykola Pechenizkiy;寻找不同分类器之间存在更高争议的区域,对于特定领域及其模型而言具有重要的洞察意义。这类评估既可以证伪某些假设,也可以强化部分假设,甚至揭示此前未知的现象。本文描述了一种基于异常模型挖掘框架的算法,能够支持此类研究。我们探索了多个公开数据集,并展示了该方法在分类任务中的实用性。在论文中,我们分享了几项关于这些已被广泛研究的数据集的有趣观察,其中一些是广为人知的知识,另一些则据我们所知此前未曾报道过。
机器学习中的超参数窃取;王炳辉、戈登·尼尔;超参数在机器学习中至关重要,因为不同的超参数设置往往会导致模型性能出现显著差异。由于其商业价值以及训练者用于学习这些超参数的专有算法的保密性,超参数可能被视为机密信息。在本工作中,我们提出了针对训练者所学习超参数的窃取攻击,并将其称为“超参数窃取攻击”。我们的攻击适用于多种流行的机器学习算法,如岭回归、逻辑回归、支持向量机和神经网络。我们从理论和实验两方面评估了这些攻击的有效性。例如,我们在亚马逊机器学习平台上对这些攻击进行了评估。结果表明,我们的攻击能够准确地窃取超参数。此外,我们也研究了相应的防御措施。研究结果强调,对于某些机器学习算法而言,亟需开发新的防御机制来抵御此类超参数窃取攻击。
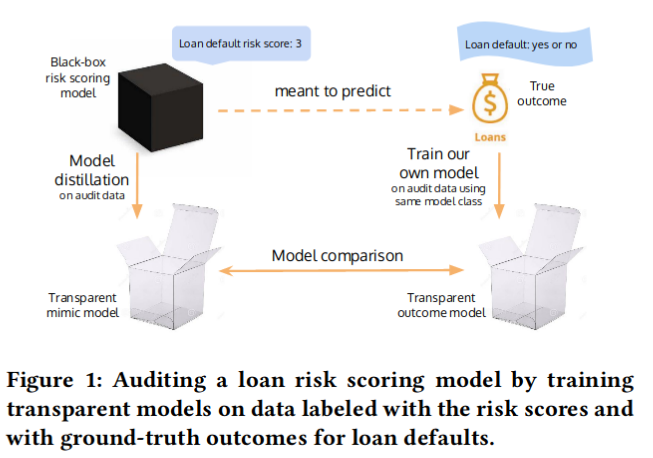
蒸馏与比较:利用透明模型蒸馏审计黑盒模型;黑盒风险评分模型广泛存在于我们的生活中,但通常属于专有或不透明的系统。我们提出了一种名为“蒸馏与比较”的模型蒸馏与对比方法,用于审计这类模型。为了深入了解黑盒模型,我们将它们视为教师,训练透明的学生模型以模仿黑盒模型所分配的风险评分。随后,我们将通过蒸馏训练得到的学生模型与另一款基于真实标签数据训练的未蒸馏透明模型进行比较,并利用两者之间的差异来洞察黑盒模型的特性。该方法无需探测黑盒模型的API即可在实际场景中应用。我们在四个公开数据集上展示了这一方法:COMPAS、Stop-and-Frisk、芝加哥警察局数据集以及Lending Club数据集。此外,我们还提出了一项统计检验方法,用于判断某个数据集是否缺失了训练黑盒模型时使用的关键特征。我们的检验结果显示,ProPublica的数据很可能缺少COMPAS模型训练过程中使用的关键特征。
- DIVE:支持集成式数据探索工作流的混合交互系统;胡凯文等;从数据中生成知识正变得越来越重要。这一数据探索过程包含多个环节:数据导入、可视化、统计分析和故事讲述。尽管这些任务相辅相成,但分析师通常会在不同的工具中分别执行它们。此外,由于这些工具依赖于手动查询语句的编写,其学习曲线往往较为陡峭。在此,我们描述了DIVE系统的设计与实现——这是一个将最先进的数据探索功能整合到单一工具中的Web平台。DIVE采用一种混合交互模式,将推荐机制与点选式的手动指定相结合,并提供一套统一的视觉语言,以衔接数据探索流程的不同阶段。在一项针对67名专业数据科学家的受控用户研究中,我们发现,与使用Excel的用户相比,DIVE用户在完成预定义的数据可视化和分析任务时,不仅效率更高,而且速度更快。

从噪声数据中学习解释规则;理查德·埃文斯、爱德华·格雷芬斯特特;人工神经网络是强大的函数逼近器,能够对各类有监督和无监督问题的解进行建模。随着网络规模和表达能力的增加,模型的方差也随之增大,从而导致几乎普遍存在的过拟合问题。尽管可以通过多种模型正则化方法来缓解这一问题,但常见的解决办法仍然是获取大量训练数据——而这些数据并不总是容易获得——以充分近似我们希望测试的领域中的数据分布。相比之下,诸如归纳逻辑编程之类的逻辑编程方法提供了一种极高的数据效率流程,使模型能够在符号域上进行推理。然而,这些方法无法处理神经网络可应用的多样化领域:它们对输入中的噪声或标签错误缺乏鲁棒性,更重要的是,无法应用于数据具有歧义性的非符号域,例如直接操作原始像素。在本文中,我们提出了一种可微归纳逻辑框架,它不仅能够解决传统ILP系统擅长的任务,还表现出ILP无法应对的训练数据噪声和误差下的鲁棒性。
通过展开潜在结构实现可解释的R-CNN;吴天富、李西来、宋曦、孙伟、董亮和李博;本文提出了一种在目标检测中学习定性可解释模型的方法,使用流行的两阶段基于区域的卷积神经网络检测系统(即R-CNN)。R-CNN由区域建议网络和RoI(感兴趣区域)预测网络组成。所谓可解释模型,我们关注的是弱监督提取式理由生成,即在不使用任何关于部件配置的监督信息的情况下,自动且同时地在检测过程中展开对象实例的潜在判别性部件配置。我们利用一种自顶向下、分层且组合式的语法模型,该模型嵌入在一个有向无环与或图(AOG)中,以探索并展开RoI的潜在部件配置空间。我们提出用AOG解析算子替代R-CNN中广泛使用的RoIPooling算子,因此所提方法适用于许多最先进的基于卷积神经网络的检测系统。
公平信贷需要可解释模型以实现负责任的推荐;陈嘉豪;金融服务行业在信用决策中面临着由合规性和伦理考量引发的独特可解释性和公平性挑战。这些挑战使得在业务决策过程中使用机器学习和人工智能方法变得复杂。
ICIE 1.0:用于交互式上下文交互解释的新工具;西蒙·B·范德宗、沃特·杜伊夫斯泰因、维尔纳·范伊彭堡、扬·费尔德辛克、米科拉·佩切尼茨基;随着有关隐私和知情权的新法律的出台,对自动化决策的解释变得日益重要。如今,机器学习模型被用于协助银行和保险等领域的专家识别可疑交易、审批贷款和信用卡申请。使用此类系统的公司必须能够提供其决策背后的依据;仅仅依赖于训练好的模型是不够的。目前已有多种方法可以提供对模型及其决策的洞察,但这些方法往往要么擅长展示全局行为,要么擅长展示局部行为。全局行为通常过于复杂而难以可视化或理解,因此只能展示近似结果;而局部行为的可视化又常常具有误导性,因为很难界定“局部”究竟意味着什么(即我们的方法并不知道某个特征值可以多容易地被改变,哪些是灵活的,哪些是固定的)。我们引入了ICIE框架(交互式上下文交互解释),使用户能够在不同情境下查看单个实例的解释。我们会发现,同一案例在不同情境下的解释会有所不同,揭示出不同的特征交互作用。
公平机器学习的延迟效应;莉迪娅·T·刘、萨拉·迪恩、埃丝特·罗尔夫、马克斯·辛乔维茨、莫里茨·哈特;机器学习中的公平性研究主要集中在静态分类场景中,而较少关注决策如何随时间推移改变底层人群。传统观点认为,公平性标准有助于其所保护群体的长期福祉。我们研究静态公平性标准与福祉的时间指标之间的相互作用,例如某一变量的长期改善、停滞和下降。我们证明,即使在单步反馈模型中,常见的公平性标准通常并不能促进长期改善,反而可能在原本不受约束的目标不会造成伤害的情况下带来损害。我们全面刻画了三种标准公平性准则的延迟效应,并对比了它们在不同情况下表现出的质性差异。此外,我们还发现,一种自然的测量误差会扩大公平性标准表现良好的范围。我们的研究结果强调了在评估公平性标准时测量和时间建模的重要性,指出了诸多新的挑战和权衡。
构建可理解智能的挑战;丹尼尔·S·韦尔德、加甘·班萨尔;由于人工智能(AI)软件采用深度前瞻搜索和大型神经网络的随机优化等技术来拟合海量数据集,其行为往往非常复杂,难以被人理解。然而,各组织却在许多关键任务环境中部署AI算法。为了信任这些算法的行为,我们必须使AI变得可理解,要么使用本身可解释的模型,要么开发新的方法,通过局部近似、词汇对齐和交互式解释来解释和控制那些原本极其复杂的决策。本文认为可理解性至关重要,综述了近年来构建此类系统的研究进展,并指出了未来研究的关键方向。
具有全局一致解释的信用风险可解释模型;陈超凡、林康成、辛西娅·鲁丁、亚伦·沙波什尼克、王思佳、王彤;我们针对公平艾萨克公司(FICO)提出的公开挑战——提供一个信用风险评估的可解释模型——提出了一种解决方案。我们没有简单地呈现一个黑盒模型后再加以解释,而是提供了一个与其它神经网络同样准确的全局可解释模型。“两层加法风险模型”可以分解为多个子尺度,第二层中的每个节点都代表一个有意义的子尺度,且所有的非线性部分都是透明的。我们提供了三种比全局模型更简单但与其保持一致的解释方式。其中一种解释方法涉及求解最小集合覆盖问题,以找到高支持度的全局一致解释。我们还展示了一款新的在线可视化工具,供用户探索全局模型及其解释。
通过拓扑层次分解评估HELOC申请人风险表现;凯尔·布朗、德里克·多兰、瑞安·克莱默、布拉德·雷诺兹;金融行业的严格监管要求所有基于机器学习的决策都必须加以解释。这限制了诸如神经网络等强大有监督技术的应用。在本研究中,我们提出了一种名为拓扑层次分解(THD)的新无监督及半监督技术。该过程将数据集逐步分解为越来越小的组别,每组与一个单纯复形相关联,该复形近似表示数据集的底层拓扑结构。我们将THD应用于FICO机器学习挑战数据集,该数据集包含匿名化的房屋净值贷款申请,并使用MAPPER算法构建单纯复形。我们识别出无法偿还贷款的不同人群,并说明如何利用单纯复形中特征值的分布来解释批准或拒绝贷款的决定,具体做法是从数据集上的两个THD中提取说明性解释。
从黑箱到白箱:基于核机器的可解释学习;张浩、中台真司、福水健二;我们提出了一种基于核机器的可解释学习新方法。在许多实际学习任务中,核机器已被成功应用。然而,普遍的看法是,由于其固有的黑箱性质,核机器难以被人理解。这限制了核机器在对模型可解释性要求极高的领域的应用。在本文中,我们提出构建可解释的核机器。具体而言,我们设计了一种基于随机傅里叶特征(RFF)的新型核函数以提高可扩展性,并开发了一种两阶段学习流程:在第一阶段,我们将成对特征显式映射到由所设计核产生的高维空间,并学习一个稠密的线性模型;在第二阶段,从第一阶段提取可解释的数据表示,并学习一个稀疏的线性模型。最后,我们使用基准数据集评估了我们的方法,并通过可视化展示了其在可解释性方面的优势。
从软分类器到硬决策:我们能有多公平?;兰·卡内蒂、阿洛尼·科恩、尼山特·迪卡拉、戈文德·拉姆纳拉扬、萨拉·谢弗勒、亚当·史密斯;我们研究通过后处理校准分数来实现各种公平属性的可行性,并表明允许后处理器推迟某些决策,可以使最终决策满足更多的公平条件。具体来说,我们证明:1. 并不存在一种通用的方法,可以通过后处理使校准分类器在受保护群体之间实现相等的阳性预测值或阴性预测值(PPV或NPV)。对于某些“良好”的校准分类器,当后处理器在不同受保护群体间使用不同阈值时,PPV或NPV可以被均等化……2. 当允许后处理在某些决策上推迟执行(即通过将部分示例转交给另一个流程来避免做出决策)时,对于未推迟的决策,最终得到的分类器可以在受保护群体之间实现PPV、NPV、假阳性率(FPR)和假阴性率(FNR)的均等化。这暗示了一种部分规避丘尔德乔娃和克莱因伯格等人提出的不可能性结果的方式,这些结果禁止同时均等化所有这些指标。我们还介绍了不同的推迟策略,并展示了它们如何影响整个系统的公平性。我们使用2016年的COMPAS数据集评估了我们的后处理技术。
黑箱模型解释方法综述;里卡多·圭多蒂、安娜·蒙雷亚莱、萨尔瓦托雷·鲁吉耶里、弗朗科·图里尼、福斯卡·詹诺蒂、迪诺·佩德雷斯基;近年来,许多精确的决策支持系统被构建为黑箱,即隐藏其内部逻辑的系统。这种缺乏解释既是一个实际问题,也是一个伦理问题。文献中报告了许多旨在克服这一关键弱点的方法,有时甚至是以牺牲准确性为代价来换取可解释性。黑箱决策系统可应用的领域多种多样,而每种方法通常都是为了解决特定问题而开发的,因此它明确或隐含地界定了自己对可解释性和解释的定义。本文旨在根据解释的概念和黑箱系统的类型,对文献中讨论的主要问题进行分类。给定一个问题定义、黑箱类型和期望的解释,这篇综述应帮助研究人员找到对其工作更有用的方案。所提出的开放黑箱模型方法分类也有助于将众多研究中的开放性问题置于更清晰的视角之下。
深度k近邻:迈向自信、可解释且鲁棒的深度学习;尼古拉斯·帕佩罗特、帕特里克·麦克丹尼尔;在本工作中,我们利用深度学习的结构,开发新的基于学习的推理和决策策略,以实现鲁棒性和可解释性等理想特性。我们迈出了第一步,提出了深度k近邻(DkNN)。这种混合分类器将k近邻算法与深度神经网络每一层所学习到的数据表示相结合:测试输入会根据其在这些表示中的距离,与相邻的训练样本进行比较。我们发现,这些相邻样本的标签可以为模型训练流形之外的输入提供置信度估计,包括对抗样本等恶意输入——从而为超出模型理解范围的输入提供保护。这是因为可以通过最近邻来估计预测在训练数据中是否缺乏支持,即非一致性程度。同时,这些邻居也为预测提供了人类可解释的说明。
RISE:用于黑箱模型解释的随机输入采样;维塔利·佩秋克、阿比尔·达斯、凯特·萨恩科;深度神经网络越来越多地被用于自动化数据分析和决策制定,然而其决策过程在很大程度上仍不明确,也难以向最终用户解释。在本文中,我们针对以图像为输入、输出类别概率的深度神经网络的可解释AI问题提出了解决方案。我们提出了一种名为RISE的方法,该方法可以生成一张重要性地图,指示每个像素对模型预测的重要性。与使用梯度或其他内部网络状态来估计像素重要性的白箱方法不同,RISE适用于黑箱模型。它通过用随机遮蔽的输入图像版本探测模型,并获取相应的输出,以经验方式估计重要性。我们还将我们的方法与最先进的重要性提取方法进行了比较,既使用自动删除/插入指标,也使用基于人工标注对象片段的指向指标。在多个基准数据集上的大量实验表明,我们的方法在性能上与白箱方法相当或超越之。
可视化黑箱模型的特征重要性;朱塞佩·卡萨利奇奥、克里斯托夫·莫尔纳尔和贝恩德·比施;基于一种近期的模型无关全局特征重要性方法,我们引入了针对单个观测的局部特征重要性度量,并提出了两种可视化工具:部分重要性(PI)和个体条件重要性(ICI)图,它们分别展示了特征变化如何平均影响模型性能,以及对单个观测的影响。我们提出的方法与部分依赖(PD)和个体条件期望(ICE)图相关,但它们展示的是预期的(条件性)特征重要性,而非预期的(条件性)预测。此外,我们还表明,将各个观测的ICI曲线取平均即可得到PI曲线,而将PI曲线按所考虑特征的分布积分,则可得到全局特征重要性。
通过模型提取解释黑箱模型;奥斯伯特·巴斯塔尼、卡罗琳·金、汉萨·巴斯塔尼;随着机器学习越来越多地用于支持重大决策,可解释性变得愈发重要。我们提议以一棵近似原模型的决策树形式,为复杂的黑箱模型构建全局解释——只要这棵决策树是良好的近似,它就能反映黑箱模型所做的计算。我们设计了一种新颖的决策树解释提取算法,该算法会主动采样新的训练点,以避免过拟合。我们以一棵用于预测糖尿病风险的随机森林和一个用于控制倒立摆的已学习控制器为例,评估了我们的算法。与多个基线相比,我们的决策树不仅精度显著更高,而且在用户研究中也被认为同样或更加可解释。最后,我们描述了由我们的解释所提供的若干见解,其中包括一项经医生验证的因果关系问题。
基于游戏的深度神经网络近似验证,附带可证明的保证;吴敏、马修·维克1、阮文杰、黄晓伟、玛尔塔·克维亚特科夫斯卡;尽管深度神经网络的准确度有所提高,但对抗样本的发现引发了严重的安全担忧。在本文中,我们研究了两种点态鲁棒性的变体:最大安全半径问题,即对于给定的输入样本,计算其与对抗样本之间的最小距离;以及特征鲁棒性问题,旨在量化单个特征对对抗扰动的抵抗能力。我们证明,在假设利普希茨连续性的前提下,这两个问题都可以通过离散化输入空间来进行有限优化近似,且这种近似具有可证明的保证,即误差是有界的。随后,我们指出,由此产生的优化问题可以简化为两人轮流进行的游戏,其中一方选择特征,另一方在选定的特征范围内扰动图像。虽然第二方的目标是尽量缩短与对抗样本的距离,但根据优化目标的不同,第一方可能是合作的,也可能是竞争的。我们采用随时可用的方法来解决这些游戏,即通过单调改进游戏的上下界来近似其价值。我们使用蒙特卡洛树搜索算法来计算这两场游戏的上界,而可接受A*算法和Alpha-Beta剪枝算法则分别用于计算最大安全半径和特征鲁棒性游戏的下界。在计算最大安全半径问题的上界时,我们的工具在与现有对抗样本生成算法的竞争中表现出优异性能。此外,我们还展示了如何将我们的框架应用于评估自动驾驶汽车中交通标志识别等安全关键应用中的神经网络点态鲁棒性。
所有模型都是错的,但许多是有用的:利用模型类别依赖性计算黑箱、专有或误设预测模型的变量重要性;亚伦·费舍尔、辛西娅·鲁丁、弗朗切斯卡·多米尼奇;变量重要性(VI)工具描述了协变量对预测模型准确度的贡献程度。然而,对于一个表现良好的模型(例如线性模型f(x) = x T β,其中系数向量β固定)来说重要的变量,对于另一个模型可能并不重要。在本文中,我们提出使用模型类别依赖性(MCR)作为预先指定类别中所有表现良好模型的VI值范围。因此,MCR通过考虑到许多预测模型(可能具有不同的参数形式)都能很好地拟合数据这一事实,提供了更为全面的关于重要性的描述。
请停止为高风险决策解释黑箱模型;辛西娅·鲁丁;当前社会上存在许多用于高风险决策的黑箱模型。与其一开始就创建可解释的模型,不如不断尝试解释黑箱模型的做法,很可能会延续不良实践,甚至可能对社会造成灾难性危害。正确的出路在于设计本身就可解释的模型。
公平机器学习的最新进展:从道德哲学和立法到公平分类器;埃利亚斯·鲍曼、约瑟夫·伦贝格;随着许多决策,例如是否发放贷款,不再由人类而是由机器学习算法做出,机器学习正日益渗透到我们的生活中。然而,这些决策往往存在不公平现象,会基于种族或性别等受保护特征歧视特定群体。随着近期《通用数据保护条例》(GDPR)的生效,人们对这类问题的认识显著提高。鉴于计算机科学家对人们生活的影响日益深远,采取行动以发现并防止歧视行为显得尤为必要。本文旨在介绍歧视的概念、应对歧视的法律基础,以及检测和预防机器学习算法出现此类行为的策略。
人工智能中的解释性研究;布伦特·米特尔施塔特、克里斯·拉塞尔、桑德拉·瓦赫特;近年来,关于机器学习和人工智能可解释性的研究主要集中在构建能够近似真实决策标准的简化模型上。这些模型对于培训专业人员理解复杂系统将如何作出决策,尤其是系统可能出现哪些故障,具有重要的教学价值。然而,在评估任何此类模型时,都应牢记乔治·博克斯的名言:“所有模型都是错的,但有些模型是有用的。”我们着重探讨这些模型与哲学和社会学中“解释”概念之间的区别。这些模型可以被视为一种用于生成解释的“自助工具包”,使从业者无需外部协助即可直接回答“如果……会怎样”的问题,或生成对比性解释。尽管这一能力颇具价值,但将这些模型作为解释提供却显得过于复杂,而其他形式的解释可能并不具备同样的权衡取舍。我们比较了关于何为有效解释的不同理论流派,并建议机器学习领域可以从更广阔的视角来审视这一问题。
人类在获得解释与机器学习模型预测情况下的判断:以欺骗检测为例;维维安·赖、陈浩·谭;在涉及伦理和法律问题的关键任务中,如累犯风险预测、医学诊断以及打击虚假新闻等,人类始终是最终决策者。尽管机器学习模型在这些任务中有时能取得令人瞩目的表现,但这些任务并不适合完全自动化。为了充分发挥机器学习改善人类决策的潜力,有必要了解机器学习模型的辅助如何影响人类的表现与自主性。在本文中,我们以欺骗检测作为实验平台,探讨如何利用机器学习模型提供的解释和预测来提升人类表现,同时保持人类的自主性。我们提出了一个介于完全人类自主与完全自动化之间的连续谱,并沿该谱设计了不同层次的机器辅助方案,逐步增加机器预测的影响力。研究发现,仅提供解释而不展示预测标签时,人类在最终任务中的表现并无统计学上的显著提升。相比之下,展示预测标签可大幅提高人类表现(相对提升超过20%),而明确提示机器表现出色则能进一步提升效果。有趣的是,当同时展示预测标签和机器预测的解释时,其准确率与直接声明机器表现出色的效果相当。我们的研究结果揭示了人类表现与自主性之间的权衡,并表明机器预测的解释可以在一定程度上缓解这一矛盾。
机器学习解释的艺术与科学;帕特里克·霍尔;介绍了超越传统用于评估机器学习模型的误差度量和图表的解释方法。其中一些方法属于行业常用工具,另一些则基于长期积累的理论体系严谨推导而来。这些方法包括决策树代理模型、个体条件期望图(ICE)、局部可解释的模型无关解释(LIME)、部分依赖图以及沙普利值解释等,它们在适用范围、忠实度及应用场景等方面各有差异。除了对这些方法的详细描述外,本文还结合实际案例和深入的软件示例,给出了相应的使用建议。
可解释性是为谁而设?一种基于角色的可解释性机器学习系统分析模型;理查德·汤姆塞特、戴夫·布雷内斯、丹·哈本、阿伦·普里斯、苏普里约·查克拉博蒂;我们不应仅仅询问系统是否可解释,而应关注它对谁而言是可解释的。为此,我们提出了一种模型,旨在通过识别主体在机器学习系统中可能扮演的不同角色来帮助解答这一问题。我们通过多种场景展示了该模型的应用,探讨了主体角色对其目标的影响,以及这对定义可解释性的意义。最后,我们还就该模型如何为可解释性研究人员、系统开发者以及负责审计机器学习系统的监管机构提供帮助提出了建议。
通过允许提问来解释模型;康成珉、朴基泰、张在赫、秋在国;问题本身蕴含着提问者的信息,即其所不了解的内容。在本文中,我们提出了一种新方法,允许学习型智能体在生成最终输出的过程中,主动询问自己认为难以预测的部分。通过分析其提问的时机和内容,我们可以使模型更加透明且易于理解。首先,我们将这一想法扩展为一套通用的深度神经网络框架——我们称之为“提问网络”。针对色彩化这一典型的“一对多”任务,我们提出了专门的架构和训练流程,因为在这种任务中,通过提问有助于更准确地完成工作。研究结果表明,该模型能够学会提出有意义的问题,优先询问难点,并比基准模型更高效地利用所提供的提示信息。我们得出结论:所提出的提问框架能够让学习型智能体暴露自身的薄弱环节,这为开发可解释且具有交互性的模型开辟了一个充满前景的新方向。
对比性解释:基于结构模型的方法;蒂姆·米勒;……哲学和社会科学研究表明,解释具有对比性:也就是说,当人们询问某个事件的原因时,他们(有时是隐含地)实际上是在寻求相对于某个对比情境的解释,即“为什么是P而不是Q?”在本文中,我们扩展了结构因果模型方法,定义了两种互补的对比性解释概念,并将其应用于两个经典的AI问题:分类和规划。
面向设计师的可解释AI:一种以人为本的混合式协同创作视角;朱继晨、安东尼奥斯·利亚皮斯、塞巴斯蒂安·里西、拉斐尔·比达拉、迈克尔·扬布拉德;在这篇愿景论文中,我们提出了一种新的研究领域——面向设计师的可解释AI(XAID),尤其针对游戏设计师。通过聚焦特定用户群体的需求与任务,我们提出了一种以人为本的方法,旨在借助XAID技术帮助游戏设计师与AI/ML系统共同创作。我们通过三个用例展示了初步的XAID框架,这些用例既需要理解AI技术的本质特性,也需要洞察用户需求,并在此基础上识别出关键的开放性挑战。
教育中的AI需要可解释的机器学习:来自开放学习者建模的经验教训;克里斯蒂娜·科纳蒂、卡斯卡·波赖斯卡-蓬斯塔、马诺利斯·马夫里基斯;底层AI表示的可解释性是开放学习者建模(OLM)——智能辅导系统(ITS)研究的一个分支——的核心价值所在。OLM提供了工具,能够“打开”学习者认知与情感的AI模型,从而支持人类的学习与教学。——用例
欺诈检测中的实例级解释:一个案例研究;丹尼斯·科拉里斯、利奥·M·芬克、雅克·J·范·维克;欺诈检测是一个复杂的问题,预测建模可以为其提供帮助。然而,对预测结果的验证却颇具挑战:对于单个保险单,模型仅会给出一个预测分数。我们展示了一个案例研究,探讨了不同的实例级模型解释技术如何协助欺诈检测团队开展工作。为此,我们设计了两款新颖的仪表盘,结合了多种最先进的解释技术。
论可解释性方法的鲁棒性;大卫·阿尔瓦雷斯-梅利斯、汤米·S·雅各卡;我们认为,解释的鲁棒性——即相似的输入应产生相似的解释——是可解释性的关键要求之一。我们引入了用于量化鲁棒性的指标,并证明当前的方法在这些指标下表现不佳。最后,我们提出了在现有可解释性方法上强化鲁棒性的途径。
基于局部对照树的对比性解释;贾斯珀·范德瓦、马塞尔·罗贝尔、尤里安·范迪格伦、马蒂厄·布林克胡伊斯、马克·尼林克斯;近年来,可解释机器学习(iML)和可解释AI(XAI)领域的进展主要基于特征在分类任务中的重要性来构建解释。然而,在高维特征空间中,如果不限制重要特征的集合,这种方法可能会变得不可行。我们建议利用人类倾向于提出“为什么是这个输出(事实)而不是那个输出(对照)?”这类问题的心理倾向,将特征数量缩减到那些在所提对比中起主要作用的特征。我们提出的方法使用本地训练的一对多决策树,以识别出使树将数据点分类为对照而非事实的互斥规则集。
评估特征重要性估计;萨拉·胡克、杜米特鲁·埃尔汉、彼得-扬·金德曼斯、彬·金;估计某一特征对模型预测的影响是一项挑战。我们引入ROAR——移除并重新训练——这一基准测试,用于评估深度神经网络中估计输入特征重要性的可解释性方法的准确性。我们根据每种估计方法认为最重要的特征,移除一部分输入特征,并测量重新训练后模型准确率的变化。
知识库嵌入模型的解释:一种教学法方法;阿瑟·科隆比尼·古斯芒、阿尔瓦罗·恩里克·柴姆·科雷亚、格劳伯·德·博纳、法比奥·加利亚尔迪·科兹曼;嵌入模型在知识库补全任务中达到了最先进的精度,但其预测却以难以解释而闻名。在本文中,我们借鉴神经网络文献中的“教学法方法”,通过从嵌入模型中提取加权霍恩规则来实现对其的解释。我们展示了教学法方法如何适应知识库的大规模关系特性,并通过实验说明了其优势与局限性。
流形:一种与模型无关的机器学习模型解释与诊断框架;张佳伟、王洋、皮耶罗·莫利诺、李乐志和戴维·S·埃伯特;介绍了流形——一种用于在检查(假设)、解释(推理)和优化(验证)过程中对模型进行可视化探索的工具。支持多模型比较。这是一种面向机器学习模型开发的可视化探索方法。
通过有意义扰动实现黑盒模型的可解释性解释;露丝·C·冯、安德烈娅·韦达尔迪;(摘自摘要)一种通用框架,可用于为任何黑盒算法学习不同类型的解释。该框架能够找到图像中对分类器决策贡献最大的部分……该方法与模型无关且可测试,因为它基于明确且可解释的图像扰动。
多分类场景下的可解释性更为困难:多分类加法模型的公理化可解释性;张学周、莎拉·谭、保罗·科赫、尹娄、乌尔苏拉·查耶夫斯卡、里奇·卡鲁阿纳;(……)随后,我们开发了一种后处理技术(API),该技术能够保证将预训练的加法模型转换为满足可解释性公理的形式,同时不牺牲准确性。该技术不仅适用于使用我们的算法训练的模型,也适用于任何多分类加法模型。我们在一个包含12个类别的婴儿死亡率数据集上演示了该API。(……)最初针对广义加法模型(GAMs)。
大数据中的统计天堂与悖论;孟晓犁;(...) 天堂得失?数据质量与数量的权衡。(“我应该更信任回复率为60%的1%抽样调查,还是覆盖了80%人口的非概率数据集?”);数据质量 × 数据数量 × 问题难度;
深度学习中的解释方法:用户、价值、关切与挑战;加布里埃尔·拉斯、马塞尔·范·赫尔文、皮姆·哈塞拉格尔;可解释AI相关问题涉及四个要素:用户、法律法规、解释本身以及算法。总体而言,很明显,关于输入对输出影响的各个方面都可以给出(可视化)解释……未来很可能会出现一类新的解释方法,它们结合规则提取、归因分析和内在解释等技术,以简单易懂的人类语言回答具体问题。此外,显而易见的是,当前的解释方法主要面向专家用户,因为解读结果需要对深度神经网络的工作原理有深入了解。据我们所知,目前尚不存在专为普通用户设计的解释方法,例如直观的解释界面。
TED:教会AI解释其决策;诺埃尔·C·F·科德拉等人;由于人工智能系统在提升决策效率、规模、一致性、公平性和准确性方面的潜力,其应用正日益广泛。然而,许多此类系统的工作机制不透明,因此社会对这些系统提供决策解释的需求也不断增长。传统的解决思路是试图揭示或挖掘机器学习模型的内部运作机制,期望由此产生的解释能够被用户理解。与此不同,本文提出了一种全新的方法,即“教人解释决策”(TED)框架——一个简单实用的体系,能够生成符合用户认知模型的有意义解释。
算法与人类决策中的透明度:是否存在双重标准?;约翰·泽里利、阿里斯泰尔·诺特、詹姆斯·麦克劳林、科林·加瓦根;我们对算法决策工具不透明性的担忧持怀疑态度。尽管透明度和可解释性确实是算法治理中值得追求的重要目标,但我们担心自动化决策正被要求达到一种不切实际的高标准,这或许源于人们对人类决策者所能达到的透明度水平存在过高估计。在本文中,我们回顾了大量证据,表明许多人类决策同样存在透明度问题,并指出AI在这些方面并未显著优于或劣于人类;同时认为,某些关于可解释AI的监管提案可能将标准定得过高,甚至超出必要范围,反而不利于实际应用。实践理性的要求决定了行动的理由应以实践理性所能接受的程度来阐述。那些支持或替代实践推理的决策工具,不应被期待达到更高的标准。我们将这一要求置于丹尼尔·丹内特的“意向立场”理论框架下,认为既然人类行为的合理性通常以意向立场式的解释来表达,那么算法决策的合理性也应采取相同的形式。实际上,这意味着在算法决策的解释中,应优先选择与意向立场式解释相类似的类型,而非那些试图深入剖析决策工具内部结构的解释。
机器学习中增强公平性的干预措施比较研究;索雷尔·A·弗里德勒、卡洛斯·谢伊德格、苏雷什·文卡塔苏布拉马尼安、索南·乔杜里、埃文·P·汉密尔顿、德里克·罗斯;计算机越来越多地被用于做出对人们生活产生重大影响的决策。然而,这些预测往往会对不同的人口子群体造成不成比例的影响。因此,公平性问题近年来备受关注,学术界也涌现出了许多旨在提升公平性的分类器和预测模型。本文旨在探讨以下问题:这些不同的技术在本质上如何相互比较?造成差异的原因又是什么?具体而言,我们希望引起人们对这类公平性干预措施中诸多未受足够重视方面的关注。为此,我们介绍了一个自行开发的公开基准测试平台,该平台允许我们在多种公平性指标及大量现有数据集上比较不同的算法。研究发现,尽管不同算法倾向于偏好特定形式的公平性保障,但这些指标之间却高度相关。此外,我们还发现,保持公平性的算法对数据集构成的变化较为敏感(我们的基准测试通过调整训练集与测试集的比例来模拟这种变化),这表明公平性干预措施的实际稳健性可能比先前预期的要差。
三思而后行:通过预测性模拟评估离散选择模型;蒂莫西·布拉思韦特;图形化模型检验:通常,离散选择模型的研究者会不断开发更为复杂的模型和估计方法。然而,相较于模型开发和估计技术取得的显著进步,模型检验技术却相对滞后。许多选择模型研究者仅采用一些粗略的方法来评估已估计模型对现实的拟合程度。这些方法往往仅限于检查参数符号、模型弹性以及系数之间的比例关系。在本文中,我通过引入基于预测性模拟图形展示的模型检验程序,大幅扩展了离散选择模型研究者的评估工具箱。
基于示例和特征重要性的黑盒机器学习模型解释; Ajaya Adhikari, D.M.J Tax, Riccardo Satta, Matthias Fath; 随着机器学习模型精度的提高,它们往往变得更加复杂,难以被人类理解。这些模型的“黑箱”特性阻碍了其在实际应用中的推广,尤其是在医疗保健或国防等高风险领域,失败的后果可能极为严重。为机器学习模型或预测提供可理解且有用的解释,能够增强用户的信任。基于示例的推理——即利用以往处理类似任务的经验来做出决策——是一种广为人知的问题解决与论证策略。本文提出了一种新的解释提取方法LEAFAGE,用于任何黑盒机器学习模型的预测。该解释包括训练集中相似示例的可视化以及各特征的重要性。此外,这些解释具有对比性,旨在考虑用户的期望。LEAFAGE从对底层黑盒模型的忠实度和对用户的实用性两个方面进行了评估。结果表明,在具有非线性决策边界的机器学习模型上,LEAFAGE在忠实度方面总体优于当前最先进的方法LIME。研究还进行了一项用户研究,重点比较基于示例的解释与基于特征重要性的解释之间的差异。结果显示,就感知到的透明度、信息充分性、能力感和信心而言,基于示例的解释显著优于基于特征重要性的解释。出乎意料的是,当测试参与者获得的知识时,发现他们通过查看基于特征重要性的解释后,对黑盒模型的理解反而比完全没有解释时更少。参与者认为基于特征重要性的解释模糊不清,且难以推广到其他实例。
2017年
可解释人工智能:警惕疯人院里的病人掌权——或者:我如何学会不再担忧并爱上社会与行为科学; Tim Miller, Piers Howe, Liz Sonenberg; 在其经典著作《疯人院里的病人正在掌权:为什么高科技产品让我们抓狂,以及如何恢复理智》[2004,Sams印第安纳波利斯,美国]中,Alan Cooper认为,软件经常从用户角度设计不佳的一个主要原因在于,程序设计师而非交互设计师主导了设计决策。因此,程序员往往为自己设计软件,而不是为目标用户服务,他将这一现象称为“疯人院里的病人掌权”。本文指出,可解释人工智能也面临类似的命运。尽管可解释人工智能的重新兴起是积极的,但本文认为,大多数人工智能研究人员实际上是在为自己构建解释性工具,而非为最终用户服务。然而,如果研究人员和从业者能够理解、采纳、实施并改进哲学、心理学和认知科学等领域丰富而有价值的理论成果,并且在评估这些模型时更多地关注人本身而非技术本身,那么可解释人工智能才更有可能取得成功。通过对相关文献的初步梳理,我们证明了将更多来自社会与行为科学的研究成果融入可解释人工智能具有广阔的空间,并列举了一些与可解释人工智能相关的关键研究成果。
用于在R中交互式诊断随机森林分类器的交互式图形; Natalia da Silva, Dianne Cook, Eun-Kyung Lee; 本文描述了如何组织数据并构建图表,以交互方式探索随机森林分类模型。随机森林分类器是集成学习的一种,由对多棵决策树进行自助采样并组合其结果而成。通过自助采样和整合多棵树的结果,会产生大量诊断指标,结合交互式图形,可以深入洞察高维空间中的类别结构。本文探讨了多个方面,用以评估模型复杂性、各子模型的贡献、变量重要性和降维,以及与单个观测相关的预测不确定性。这些思路被应用于随机森林算法和投影寻踪森林,但也同样适用于其他采用自助采样的集成模型。

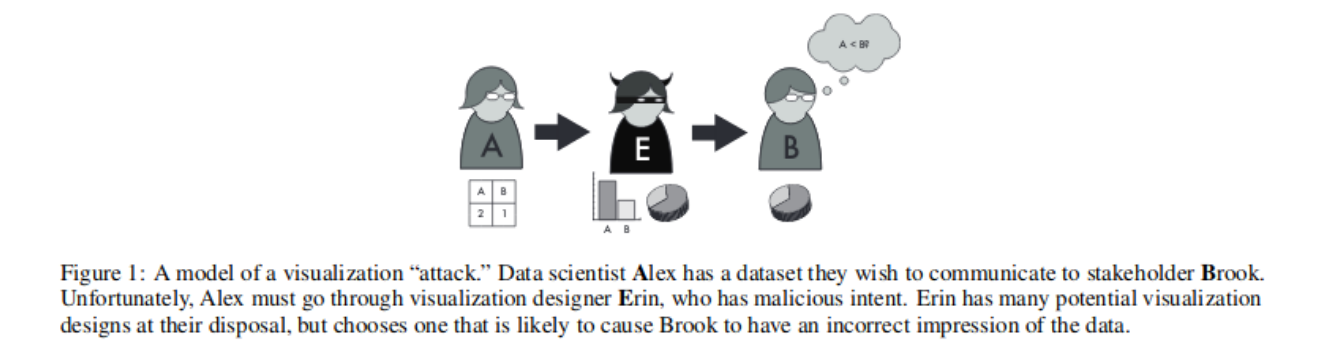
- 黑帽可视化; Michael Correll, Jeffrey Heer; 人们会以各种方式撒谎、误导或胡说八道。作为沟通形式之一,可视化也不例外。然而,我们用来描述人们如何利用可视化手段进行误导的语言却相对匮乏。例如,人们可能会“用可视化撒谎”或使用“欺骗性可视化”。在本文中,我们借鉴计算机安全领域的术语,扩展了不道德者(黑帽)为不良目的操纵可视化的方式。除了可视化文献中已有详细讨论的欺骗形式外,我们还重点关注那些忠实于原始数据的可视化(因此在常规的可视化语境下可能并不被视为欺骗),但仍然会对数据的感知产生负面影响。我们鼓励设计师从防御性和全面性的角度思考其视觉设计可能导致的数据误读问题。
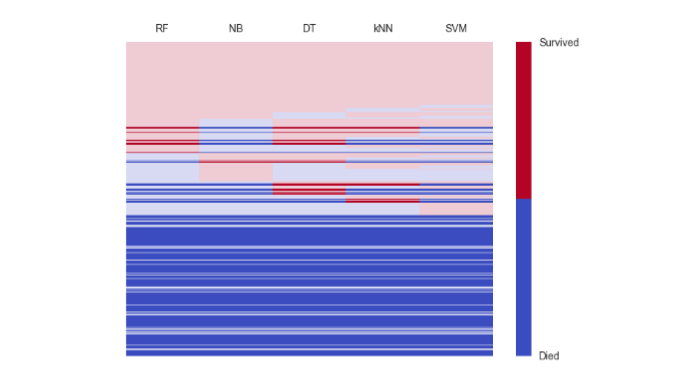
- 基于实例级解释的二分类器可视化诊断工作流;Josua Krause、Aritra Dasgupta、Jordan Swartz、Yindalon Aphinyanaphongs、Enrico Bertini;人机协作的数据分析应用要求机器学习模型具有更高的透明度,以便专家理解并信任其决策。为此,我们提出了一种可视分析工作流,帮助数据科学家和领域专家探索、诊断并理解二分类器的决策过程。该方法利用“实例级解释”——即用于解释单个样本的局部特征重要性度量——构建一系列可视化表示,引导用户进行深入调查。该工作流主要包含三种可视化表示及相应步骤:一种基于聚合统计,用于观察数据在正确与错误决策之间的分布情况;一种基于解释,用于理解哪些特征被用来做出这些决策;另一种则基于原始数据,以挖掘导致所观察到模式的潜在根本原因。
- 公平森林:通过正则化树结构构建最小化模型偏差的随机森林;Edward Raff、Jared Sylvester、Steven Mills;近年来,机器学习算法输出中可能存在的不公平性问题,不仅在学术界,也在更广泛的社会层面引起了关注。令人惊讶的是,此前尚未有研究致力于开发用于构建公平决策树或公平随机森林的树结构生成算法。这类方法因其兼具可解释性、非线性建模能力以及易用性而广受欢迎。本文首次提出了公平决策树的构建技术。实验表明,“公平森林”既保留了树模型的优势,又在“群体公平”和“个体公平”两个维度上,同时实现了比其他方法更高的准确性和公平性。此外,我们还引入了新的公平性度量指标,能够处理多类别和连续型特征以及回归问题,而不仅仅是二元特征和标签。最后,我们提出了一种更为稳健的算法评估流程,该流程会综合考虑整个数据集,而非仅针对某一特定受保护属性。
- 迈向可解释机器学习的严谨科学;Finale Doshi-Velez 和 Been Kim;在这种情况下,一个常见的应对策略是采用可解释性标准:如果系统能够解释其推理过程,我们便可以验证该推理是否符合这些辅助性标准。然而,目前对于什么是机器学习中的可解释性以及如何对其进行基准测试式评估,仍缺乏共识。在很大程度上,现有的评估方法都依赖于一种“一目了然”的主观判断。我们是否应该对这种缺乏严谨性的现状感到担忧?多目标权衡:目标不一致:伦理:安全:科学理解:
- 注意力驱动的解释:为决策提供依据并指向证据;Dong Huk Park 等;由于在各类视觉任务中表现出色,深度模型已成为视觉决策问题的事实标准。我们提出了两个大规模数据集,其中包含针对不同活动分类决策(ACT-X)以及问答任务(VQA-X)的视觉和文本双重解释性标注。
- SPINE:稀疏可解释的神经网络词嵌入;Anant Subramanian、Danish Pruthi、Harsh Jhamtani、Taylor Berg-Kirkpatrick、Eduard Hovy;缺乏解释的预测其实际价值有限。神经网络模型的成功很大程度上归功于它们能够学习丰富、稠密且富有表现力的表征。然而,尽管这些表征能够捕捉数据背后的复杂性和潜在趋势,却远未达到可解释的程度。为此,我们提出了一种新颖的去噪k稀疏自编码器变体,能够从现有最先进的GloVe和word2vec等词嵌入基础上,生成高效且可解释的分布式词表示。通过大规模的人工评估,我们发现所生成的词嵌入相比原始的GloVe和word2vec嵌入,可解释性显著提升。此外,在一系列下游基准任务中,我们的词嵌入也优于现有的主流词嵌入。
- 利用模型解释检测数据流中的概念漂移;Jaka Demšar、Zoran Bosnic;解释工具的一个有趣应用场景——类似PDP的解释器可用于识别概念漂移。
- 使用ExplainPrediction解释预测模型介绍了两种用于局部和全局解释的方法EXPLAIN和IME(R包)。
- 为医疗领域构建可解释人工智能系统需要什么?;Andreas Holzinger、Chris Biemann、Constantinos Pattichis、Douglas Kell。本文概述了我们在相对较新的可解释人工智能领域的一些研究方向,并特别关注其在医学领域的应用,因为医学是一个非常特殊的领域。这主要是由于医疗专业人员通常需要处理分散、异构且复杂的数据源。本文聚焦于三大类数据:影像、组学数据和文本。我们认为,可解释人工智能的研究总体上有助于推动人工智能和机器学习在医疗领域的应用,尤其是能够提升透明度和信任度。然而,人工智能和机器学习技术的整体效能,往往受限于算法无法向人类专家解释其结果这一缺陷——而这正是医疗领域面临的一大挑战。
2016年
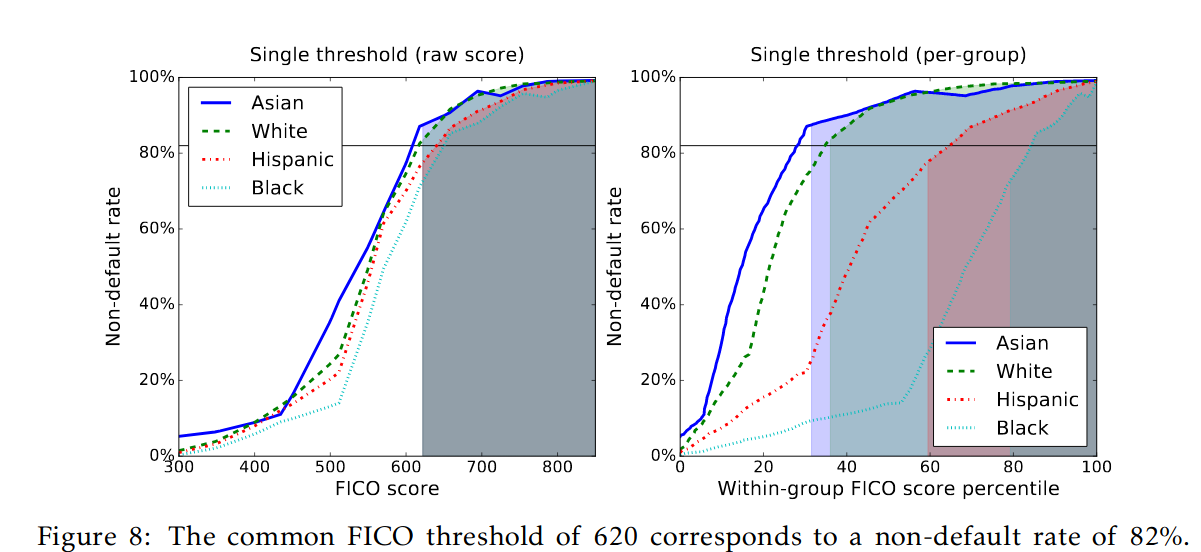
监督学习中的机会均等;莫里茨·哈特、埃里克·普赖斯、内森·斯雷布罗;我们提出了一种在监督学习中针对特定敏感属性进行歧视的判定标准,其目标是基于可用特征预测某个目标变量。假设我们已知预测器、目标变量以及个体所属受保护群体的相关数据,我们展示了如何对任意已学习的预测器进行最优调整,以消除按照我们的定义所界定的歧视。此外,我们的框架通过将低分类准确率的成本从弱势群体转移到决策者身上来改善激励机制,而决策者则可以通过提高分类准确性来应对这一变化。 与其它研究一致,我们的概念是“无感知”的:它仅依赖于预测器、目标变量和受保护属性的联合统计分布,而不涉及对单个特征的解释。我们研究了基于此类无感知度量来定义和识别偏见的内在局限性,并阐明了不同无感知测试能够推断出什么、又不能推断出什么。 我们以FICO信用评分为例说明了这一概念。
与预测交互:黑箱机器学习模型的可视化检查;约书亚·克劳斯、亚当·佩雷尔、肯尼·吴;介绍了Prospector——一款用于预测模型可视化探索的工具。其中包含一些有趣且新颖的想法,例如部分依赖条形图。Prospector可以比较多个模型,并同时展示局部和全局的解释。
模型可解释性的迷思;扎卡里·C·利普顿;监督学习模型具有非凡的预测能力。但你真的能信任你的模型吗?它在实际部署中会表现良好吗?它还能告诉你关于世界的哪些信息呢?我们希望模型不仅性能优异,而且具备可解释性。然而,可解释性的任务似乎缺乏明确的定义。(…) 首先,我们考察了人们对可解释性感兴趣的各种动机,发现这些动机多种多样,有时甚至相互矛盾。接着,我们探讨了被认为能够赋予模型可解释性的特性及技术,指出面向人类的透明性和事后解释是两种相互竞争的概念。在整个过程中,我们讨论了不同概念的可行性和合理性,并质疑一种常见的说法——即线性模型是可解释的,而深度神经网络则不是。
是什么让分类树易于理解?;罗克·皮尔塔韦尔、米特雅·卢什特雷克、马蒂亚日·甘姆斯、桑达·马丁契奇-伊普希奇;分类树因其易懂性而在实际应用中备受青睐。然而,关于影响其可理解性和可用性的参数的研究却十分匮乏。本文系统地研究了树结构参数(叶子数量、分支因子、树深度)以及可视化特性如何影响分类树的可理解性。此外,我们还分析了问题深度(回答有关分类树的问题时所需访问的最深叶子的深度)的影响,结果表明这是最重要的参数,尽管它通常被忽视。分析基于精心设计的问卷调查所得的实证数据,该问卷包含98个问题,由69名受访者作答。论文评估了几种树的可理解性指标,并提出了两个新指标(叶子深度加权总和以及从根到叶子路径上分支因子的加权总和),这些指标得到了调查结果的支持。新可理解性指标的主要优势在于,它们不仅考虑了树的结构,还结合了树的语义信息。
2015年
- 基于残差的预测曲线——评估预测模型性能的可视化工具;朱塞佩·卡萨利基奥、伯恩德·比施尔、安妮-洛尔·布勒斯泰克斯、马蒂亚斯·施密德;RBP(基于残差的预测)曲线同时反映了预测模型的校准程度和区分能力。此外,该曲线还可方便地用于进行有效的性能检验和指标比较。RBP曲线已在R包RBPcurve中实现。
- 基于规则与贝叶斯分析的可解释分类器:构建更好的脑卒中预测模型;本杰明·莱瑟姆、辛西娅·鲁丁、泰勒·H·麦科米克、大卫·马迪根;我们的目标是构建不仅准确,而且对人类专家可解释的预测模型。我们的模型是决策列表,由一系列“如果…那么…”语句组成(例如,“如果血压高,则发生脑卒中”),这些语句将高维的多变量特征空间离散化为一系列简单且易于理解的决策陈述。我们引入了一种名为贝叶斯规则列表的生成模型,该模型给出了可能的决策列表的后验分布,并采用了一种新颖的先验结构来鼓励稀疏性。
2009年
- 如何解释个体分类决策,大卫·贝伦斯、蒂蒙·施罗特、斯特凡·哈梅林、川边元章、卡佳·汉森、克劳斯-罗伯特·穆勒;(摘自摘要)目前唯一能够提供此类解释的方法是决策树。……一种模型无关的方法,引入了“解释向量”,用以总结模型决策随输入变化的陡峭程度。
2005年
- 隐性知识的暴政:人工智能告诉我们关于知识表示的什么;库尔特·D·芬斯特马赫;波兰尼的隐性知识概念揭示了一个观点:“我们所知道的往往多于我们所能言说的。”许多知识管理领域的研究者都曾利用隐性知识的概念,将无法正式表述的知识(隐性知识)与能够被正式表述的知识(显性知识)区分开来。我则认为,知识管理研究者对隐性知识的过度推崇,由于两个重要原因,阻碍了潜在的富有成效的工作。首先,无法将知识明确表达出来并不意味着该知识就无法被正式表示;其次,即使承认人们头脑中的隐性知识无法被形式化,也不能排除计算机系统通过其他表示方式完成相同任务的可能性。通过对人工智能相关工作的回顾,我将论证,为了研究和构建知识管理系统,我们需要一个更为丰富的认知与知识表示模型。
2004年
- 在黑盒函数中发现加性结构,贾尔斯·胡克
图书
2020年
- 人工智能的鲁棒性与可解释性;哈蒙·罗南、容克莱维茨·亨里克、桑切斯·伊格纳西奥著;从技术解决方案到政策解决方案;JRC技术报告;由欧盟委员会的科学与知识服务机构——联合研究中心(JRC)发布的技术报告。

2019年
- 预测模型:探索、解释与调试;普热米斯瓦夫·别切克、托马什·布尔齐科夫斯基著。如今,预测建模的瓶颈并不在于数据不足、计算能力匮乏、算法不够完善或模型不够灵活,而在于缺乏用于模型验证、模型探索以及解释模型决策的工具。因此,在本书中,我们介绍了一系列可用于此目的的方法。

- 可解释的人工智能:深度学习的解读、解释与可视化;萨梅克、蒙塔冯、韦达尔迪、汉森、穆勒—克劳斯等著。能够自主做出决策并执行任务的“智能”系统的开发,可能会带来更快、更一致的决策。然而,人工智能技术更广泛普及的一个限制因素,是将人类控制权和监督权交予“智能”机器所带来的固有风险。对于涉及关键基础设施、影响人类福祉或健康的敏感任务而言,必须严格限制不当、不稳健且不安全的决策和行动的可能性。在部署人工智能系统之前,我们迫切需要对其行为进行验证,从而确保其在真实环境中部署后仍能按预期运行。为实现这一目标,人们一直在探索让人类能够验证人工智能决策结构与其自身基于事实的知识之间是否一致的方法。可解释的人工智能(XAI)作为人工智能的一个子领域,专注于以系统化且易于理解的方式向人类揭示复杂的人工智能模型。
本书包含的22章,及时呈现了近年来提出的可解释人工智能及相关技术的算法、理论和应用,反映了该领域的当前讨论,并指明了未来的发展方向。全书共分为六部分:迈向人工智能透明度;人工智能系统的解释方法;解释人工智能系统的决策;评估可解释性和解释结果;可解释人工智能的应用;以及可解释人工智能的软件工具。
2018年
- 使用H2O Driverless AI进行机器学习可解释性分析;帕特里克·霍尔、纳夫迪普·吉尔、梅根·库尔卡、温·范著;
- 机器学习可解释性导论;纳夫迪普·吉尔、帕特里克·霍尔著;书中包含大量优秀图表,对模型可解释性的常用技术进行了高层次概述。
- 可解释的机器学习;克里斯托夫·莫尔纳尔著;介绍了最流行的方法(LIME、PDP、SHAP等)以及关于可解释性的更为宏观的概览。
工具
2019年
- ExplainX;ExplainX 是一个快速、轻量且可扩展的可解释人工智能框架,旨在帮助数据科学家仅用一行代码就能向业务相关方解释任何黑盒模型。该库由纽约大学 VIDA 实验室的人工智能研究人员维护。详细的文档也可在此网站上找到。
- EthicalML / xai;XAI 是一个以 AI 可解释性为核心设计的机器学习库。它包含多种工具,可用于对数据和模型进行分析与评估。XAI 库由伦理人工智能与机器学习研究所维护,并基于“负责任机器学习的八项原则”开发而成。您可以在 https://ethicalml.github.io/xai/index.html 找到相关文档。
- Aequitas:偏见与公平审计工具包;近期的研究引发了人们对当前使用的 AI 系统中潜在无意偏见的担忧,这些偏见可能基于种族、性别或宗教等特征而对个人造成不公平的影响。尽管近年来提出了许多偏见度量指标和公平性定义,但尚未就应采用哪种指标或定义达成共识,且可用于实际操作的资源也十分有限。Aequitas 能够帮助数据科学家、机器学习研究人员以及政策制定者在开发和部署算法决策系统时做出知情且公平的决策。
tf-explain;tf-explain 将可解释性方法实现为 TensorFlow 2.0 的回调函数,从而简化神经网络的理解过程。详情请参阅介绍 tf-explain:TensorFlow 2.0 的可解释性工具。
由伦理人工智能与机器学习研究所维护的 XAI 库;XAI 是一个以 AI 可解释性为核心设计的机器学习库。它包含多种工具,可用于对数据和模型进行分析与评估。该库由伦理人工智能与机器学习研究所维护,并基于负责任机器学习的八项原则开发而成。
微软的 InterpretML;微软推出的一款与机器学习模型可解释性相关的 Python 库。
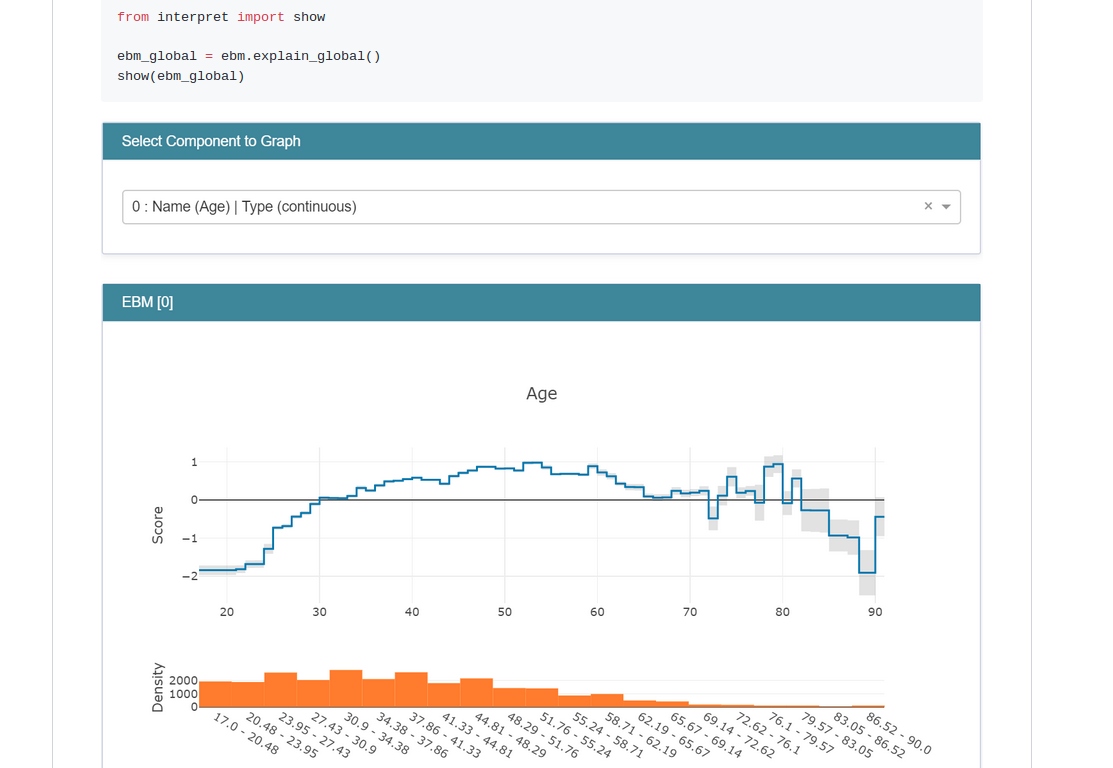
sklearn_explain;模型解释能够帮助理解各个预测变量对个体评分构成的影响。
heatmapping.org;该网页旨在汇集弗劳恩霍夫 HHI 研究所、柏林工业大学和新加坡科技与设计大学联合项目所产生的出版物及软件,致力于开发新的方法来理解最先进机器学习模型的非线性预测。机器学习模型,尤其是深度神经网络(DNN),具有极强的预测能力,但在许多情况下却难以被人类理解。解释非线性分类器对于建立对预测结果的信任、识别潜在的数据选择偏差或伪影至关重要。该项目特别研究如何将预测分解为各个输入变量的贡献,以便将这种分解结果(即解释)以与输入数据相同的方式可视化。
iNNvestigate 神经网络!;由 heatmapping.org 的作者创建的一个工具箱,旨在更好地理解神经网络。它包含了显著图、反卷积网络、引导反向传播、平滑梯度、集成梯度、LRP、PatternNet 和归因等多种方法的实现。该库提供了一个通用接口和开箱即用的实现方案,适用于多种分析方法。

ggeffects;丹尼尔·吕德克;用于计算统计模型的边际效应,并将结果以整洁的数据框形式返回。这些数据框可以直接与 ggplot2 包配合使用。边际效应可以针对多种不同的模型进行计算。交互项、样条曲线和多项式项同样受到支持。主要函数包括 ggpredict()、ggemmeans() 和 ggeffect()。此外,还有一个通用的 plot() 方法,可用于借助 ggplot2 绘制结果。
对比 LRP——一篇论文《通过对比反向传播理解 CNN 的个体决策》(https://arxiv.org/pdf/1812.02100.pdf)的 PyTorch 实现。该代码生成 CLRP 显著图,用于解释 VGG16 模型中的单个分类结果。
相对归因传播——一种新的 DNN 输出预测分解方法,它根据各层之间的相对影响,将归因分为相关(正向)和无关(负向)两部分。该方法的详细描述发表在论文 https://arxiv.org/pdf/1904.00605.pdf 中。
2018年
- KDD 2018:医疗AI中的可解释模型;该教程由KenSci公司的三位专家主讲,其中包括一位数据科学家和一位临床医生。会议的核心观点是,在机器学习的医疗应用中,可解释性尤为重要,因为决策的影响范围广、错误代价高,且涉及公平性和合规性要求。教程详细介绍了可解释性的多个方面,并探讨了可用于解释模型预测结果的技术。
- MAGMIL:面向可解释机器学习的模型无关方法;欧盟将于2018年5月25日起生效的新《通用数据保护条例》将对机器学习算法的常规使用产生潜在影响,它限制了可能“显著影响”用户的自动化个人决策(即基于用户级特征进行决策的算法)。该法律还将有效确立“知情权”,允许用户要求对其作出的算法决策提供解释。鉴于这些对机器学习系统使用的严格规范,我们正致力于提高模型的可解释性。在努力深入理解机器学习模型决策的同时,从机器学习系统中提取解释信息——也称为模型无关的可解释性方法——相比特定于模型的可解释性方法,在灵活性上具有一定的优势。
- 用于探究神经网络预测的工具箱!;Maximilian Alber;近年来,神经网络在目标检测、语音识别等诸多领域不断刷新技术前沿。然而,尽管取得了成功,神经网络通常仍被视为黑箱,其内部工作机制尚未完全阐明,预测依据也并不清晰。为了更好地理解神经网络,研究者们提出了多种方法,如显著性图、反卷积网络、引导反向传播、平滑梯度、积分梯度、LRP、PatternNet及归因分析等。由于缺乏统一的参考实现,对比这些方法的工作量极大。该库通过提供通用接口和开箱即用的实现,解决了这一问题,旨在简化神经网络预测的分析过程!
- 黑盒审计、认证与消除差异性影响;该仓库包含梯度特征审计(GFA)的示例实现,旨在使其能够推广到大多数数据集。有关修复流程的更多信息,请参阅我们的论文《认证与消除差异性影响》。关于完整的审计流程,请参阅我们的论文《针对间接影响的黑盒模型审计》。
- Skater:用于模型解释的Python库;Skater是一个统一的框架,旨在为各种类型的模型提供解释能力,帮助构建适用于实际应用场景的可解释机器学习系统(我们正在积极努力实现对所有类型模型的忠实可解释性)。它是一个开源的Python库,设计用于揭示黑箱模型的内在结构,无论是在全局层面(基于完整数据集的推断)还是局部层面(针对单个预测的推断)。
- Weight Watcher;Charles Martin;Weight Watcher用于分析深度神经网络(DNN)权重矩阵中的厚尾分布。该工具无需测试集,即可预测一系列DNN模型(如VGG11、VGG13等)或整个ResNet系列模型的泛化准确率趋势。其原理基于近期关于DNN中重尾自正则化的研究成果。
- 对抗鲁棒性工具箱 - ART;这是一个专门用于对抗性机器学习的库,旨在快速构建和分析针对机器学习模型的攻击与防御方法。对抗鲁棒性工具箱提供了许多最先进的分类器攻击与防御方法的实现。
- 模型描述器;一个生成HTML报告的Python脚本,用于总结预测模型的信息,交互性强且内容丰富。
- AI公平性360;由IBM开发的Python库,用于帮助检测和消除机器学习模型中的偏差。相关介绍
- What-If工具:无代码的机器学习模型探查工具;这是谷歌开发的一款交互式What-If场景工具,属于TensorBoard的一部分。
2017年
- 分类特征的影响编码;想象一下,你正在处理一个包含美国所有邮政编码的数据集。这个数据集几乎有4万个唯一的类别。如果你打算进行预测建模,该如何处理这类数据呢?独热编码并不能带来任何有用的结果,因为它会为你的数据集增加4万个稀疏变量。而直接丢弃这些数据又可能浪费掉宝贵的信息,因此也不太合适。在这篇文章中,我将探讨如何使用一种称为“影响编码”的策略来处理高基数的分类变量。为了说明这一点,我使用了一个二手车销售的数据集。这个问题特别适合演示,因为其中包含多个具有大量水平的分类特征。让我们开始吧。
- FairTest;FairTest使开发者或审计机构能够发现并测试算法输出与由受保护特征标识的特定用户子群体之间是否存在不合理的关联。
- Explanation Explorer;这是一个用Python实现的可视化工具,用于通过实例级解释(局部解释器)对二元分类器进行视觉诊断。
- ggeffects;从模型输出创建适用于ggplot的边际效应整洁数据框。ggeffects包的目标与broom包类似:将“不整洁”的输入转换为整洁的数据框,尤其便于后续与ggplot结合使用。然而,ggeffects并不返回模型摘要;相反,该包会计算统计模型在均值处的边际效应或平均边际效应,并以整洁的数据框形式(更准确地说,是tibbles格式)返回结果。
文章
2019年
- AI黑箱恐怖故事——当透明度比以往任何时候都更加重要时;可以说,2019年数据科学领域最大的争论之一就是对AI可解释性的需求。解释机器学习模型的能力正逐渐成为企业决策中接受统计模型的关键因素。企业利益相关者要求透明地了解这些算法是如何以及为何做出特定预测的。对机器学习中任何潜在偏见的清晰理解,始终处于数据科学团队需求的最前沿。因此,大数据生态系统中的许多顶级供应商都在推出新工具,试图破解打开AI“黑箱”这一难题。
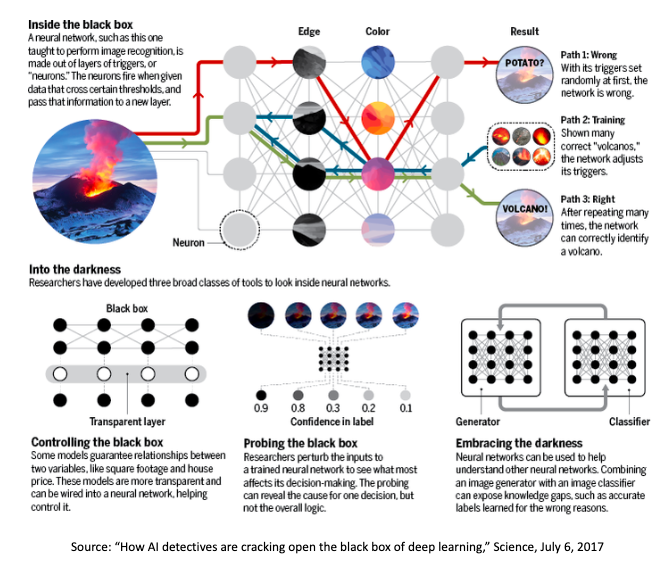
人工智能面临“可重复性”危机;几年前,麦吉尔大学的计算机科学教授乔埃尔·派诺正在帮助她的学生设计一种新的算法,但他们的工作陷入僵局。她的实验室研究强化学习,这是一种人工智能技术,常被用来让虚拟角色(如“半猎豹”和“蚂蚁”等)在虚拟世界中自主学习运动方式。这是构建自主机器人和自动驾驶汽车的基础。派诺的学生希望改进另一个实验室的系统,但首先他们需要重新构建该系统,然而由于某种未知原因,他们的设计始终无法达到预期效果。直到有一天,学生们尝试了一些并未出现在另一家实验室论文中的“创造性操作”。
模型解释器与新闻发言人——直接优化机器学习的信任度可能有害;如果黑箱模型解释器旨在优化人类对机器学习模型的信任,那么我们为什么不能期待黑箱模型解释器会像一位不诚实的政府新闻发言人一样行事呢?
破解黑箱:Python中可解释机器学习模型的重要入门指南;安基特·乔杜里;可解释的机器学习是每位数据科学家都应了解的关键概念;那么,如何构建可解释的机器学习模型呢?本文将提供一个框架,并且我们还将使用Python编写这些可解释的机器学习模型。
我,黑箱:可解释的人工智能与人类 deliberative 过程的局限;在战场上使用人工智能(AI)的伦理问题上,关于理解机器内部运作的重要性已被广泛讨论。致命性自主武器政府专家组会议的代表们仍在不断提出这一议题。法律和科学学者对此表达了大量担忧。一位评论员总结道:“为了让人类决策者能够在涉及 AI 的道德相关决策中保持自主性,他们需要清晰地洞察 AI 黑箱,理解数据、其来源以及算法逻辑。”
教授人工智能、伦理、法律与政策;Asher Wilk;网络空间以及利用人工智能(AI)开发智能系统,为计算机专业人士、数据科学家、监管机构和政策制定者带来了新的挑战。例如,自动驾驶汽车引发了全新的技术、伦理、法律和政策问题。本文提出了一门名为“计算机、伦理、法律与公共政策”的课程,并给出了相应的课程大纲。文章探讨了构建和使用软件及人工智能时所涉及的伦理、法律和公共政策问题,同时阐述了与 AI 系统相关的伦理原则和价值观。
可解释人工智能简介及其必要性;Patrick Ferris;今年我有幸参加了知识发现与数据挖掘(KDD)大会。在众多报告中,有两个研究方向尤为引人关注:一是如何为图结构找到有意义的表示形式,以输入到神经网络中。DeepMind 的 Oriol Vinyals 介绍了他们的消息传递神经网络。另一个方向,也是本文的重点,就是可解释的人工智能模型。随着我们开发出更多创新的神经网络应用,关于“它们是如何工作的?”这一问题变得愈发重要。
AI 黑箱解释难题;从高层次来看,我们将这一问题归纳为两种不同的模式:设计驱动型解释(XbD),即给定一组用于训练的决策记录数据集,如何开发一个兼具决策功能及其解释的机器学习模型;黑箱解释(BBX),即给定由黑箱决策模型生成的决策记录,如何为其重建解释。
VOZIQ 推出“Agent Connect”,一款可解释的人工智能产品,助力大规模客户留存计划;美国弗吉尼亚州雷斯顿,2019 年 4 月 3 日 /EINPresswire.com/——VOZIQ 是一家基于云的企业级应用解决方案提供商,旨在帮助实现经常性收入的企业开展大规模预测性客户留存计划。该公司宣布推出其全新的可解释人工智能(XAI)产品“Agent Connect”,以提升企业最关键资源——客户留存专员——的主动式留存能力。“Agent Connect”是 VOZIQ 最新推出的下一代可解释人工智能产品,它能够整合多种留存风险信号,结合客户表达与推断的需求、情感倾向、流失驱动因素及行为模式,从而从数百万次客户互动中直接挖掘出导致客户流失的关键信息,并将这些洞察转化为易于执行的、具有指导性的预测性客户健康状况分析。
降低机器学习和人工智能的风险;机器学习和人工智能有望通过利用海量数据构建模型,从而改善决策、定制服务并加强风险管理,进而彻底改变银行业。据麦肯锡全球研究院估计,这将在银行业创造超过 2500 亿美元的价值。然而,这一趋势也存在潜在风险:机器学习模型会放大某些模型风险因素。尽管许多银行,尤其是那些位于监管要求严格的司法管辖区的银行,已经建立了验证框架和实践来评估并缓解传统模型的相关风险,但这些措施往往不足以应对机器学习模型带来的风险。鉴于此,许多银行正采取谨慎态度,仅将机器学习模型应用于低风险场景,如数字营销。考虑到可能面临的财务、声誉和监管风险,这种谨慎做法完全可以理解。例如,银行可能会因违反反歧视法律而面临巨额罚款——正是这一担忧促使一家银行禁止其人力资源部门使用机器学习简历筛选工具。不过,更好的方法——也是银行若想充分受益于机器学习模型所必须采取的唯一可持续方式——是加强模型风险管理。
可解释的人工智能应帮助我们避免第三次“AI 冬季”;去年在整个欧洲生效的《通用数据保护条例》(GDPR)确实提高了消费者和企业的个人数据意识。然而,过度纠正数据收集行为可能会对关键的人工智能发展产生负面影响,这一风险不容忽视。这不仅是数据科学家面临的问题,同样也影响着那些利用 AI 解决方案提升竞争力的企业。潜在的负面影响不仅会波及实施 AI 的企业,还可能导致消费者错失 AI 为其依赖的产品和服务所带来的益处。
可解释的人工智能:从预测到理解;仅仅做出预测是不够的。有时,我们需要获得深入的理解。仅仅建立了一个模型,并不意味着我们就真正了解它的运作机制。在传统的机器学习中,算法会输出预测结果,但在某些情况下,这并不足以解决问题。George Cevora 博士解释了为什么 AI 的黑箱模式并不总是适用,以及如何从预测转向理解。
为什么可解释的人工智能(XAI)是营销和电子商务的未来;“新一代机器学习系统将具备解释其推理过程、描述其优缺点以及传达对其未来行为方式理解的能力。”——DARPA 负责人 David Gunning。随着机器学习在商业和内容领域个性化客户体验中的作用日益增强,最有力的机会之一就是开发能够让营销人员通过可操作的洞察最大化每一分营销预算投入的系统。然而,AI 在商业中用于提供可操作性洞察的同时,也带来了一个挑战:营销人员如何才能了解并信任 AI 系统作出行动建议背后的逻辑?由于 AI 借助极其复杂的流程做出决策,其决策过程往往对终端用户而言不透明。
可解释的 AI 或者我如何学会不再担心并信任 AI 构建稳健且无偏见的 AI 应用程序的技术;Ajay Thampi;仅在过去五年里,AI 研究人员就在图像识别、自然语言理解以及棋类游戏等领域取得了重大突破!随着企业开始考虑将关键决策权交予 AI,尤其是在医疗和金融等行业,人们对复杂机器学习模型缺乏理解的问题显得尤为突出。这种理解不足可能导致模型传播偏见,我们在刑事司法、政治、零售、面部识别和语言理解等领域都已目睹了不少此类案例。
探寻可解释的人工智能;如今,如果一位初创企业家想要弄清银行为何拒绝了他的贷款申请,或者如果一位年轻毕业生想知道她心仪的大型企业为何没有邀请她参加面试,他们将无法得知这些决定背后的原因。因为银行和企业都使用了人工智能(AI)算法来决定贷款或求职申请的结果。实际上,这意味着如果你的贷款申请被拒,或者你的简历未获采纳,你将不会收到任何解释。这种情况令人尴尬,也使得 AI 技术常常只能提供需要人类进一步验证的解决方案。
可解释的人工智能与规则的复兴;人工智能(AI)常被称为“预测机器”。总体而言,这项技术非常擅长生成自动化预测。然而,如果你想在受监管的行业中使用人工智能,最好能够解释机器是如何预测欺诈行为、犯罪嫌疑人、不良信用风险或适合参与药物试验的候选人的。国际律师事务所泰勒·韦辛希望利用 AI 作为分诊工具,帮助其客户评估其可能受到《现代奴隶法》或《反海外腐败法》等法规约束的程度。这些客户通常在全球范围内拥有供应商或进行并购,因此需要系统的尽职调查来确定哪些地方需要更深入的审查。供应链尤其复杂,特别是当其中包含数百家小型供应商时。关于规则引擎即将消亡的传言被大大夸大了。
用更智能的机器学习打击歧视;这里我们讨论的是“阈值分类器”,它是某些机器学习系统中与歧视问题密切相关的一部分。阈值分类器本质上是一种二元决策机制,将事物归入某一类别或另一类别。我们探讨了这些分类器的工作原理、可能存在的不公平之处,以及如何将不公平的分类器改进为更加公平的形式。以贷款审批为例,银行可能会根据一个自动计算出的单一数值(如信用评分)决定是否批准贷款。
更精准的偏好预测:可调谐且可解释的推荐系统;Amber Roberts;广告推荐应当让每位消费者都能理解,但能否在不牺牲准确性的前提下提高其可解释性呢?
机器学习正在引发科学危机;Kevin McCaney;机器学习技术的广泛应用正导致越来越多的研究成果无法被其他研究人员重复验证。
人工智能与伦理;Jonathan Shaw;2018 年 3 月,晚上 10 点左右,Elaine Herzberg 正在亚利桑那州坦佩市的一条街道上推行自行车,却被一辆自动驾驶汽车撞倒并身亡。尽管当时车内有驾驶员,但完全掌控车辆的是一个自主系统——人工智能。这起事件以及其他涉及人与 AI 技术交互的事故,都引发了诸多伦理和准法律问题。该系统的程序员在防止其产品夺走人类生命方面负有哪些道德义务?而 Herzberg 的死又该由谁来负责?是坐在驾驶座上的人?还是测试车辆性能的公司?抑或是 AI 系统的设计者,甚至是其车载传感器设备的制造商?
构建值得信赖的人机合作关系;无论是体育、商业还是军事团队,高效协作的关键要素之一就是信任,而信任的基础部分在于团队成员对彼此履行职责能力的相互理解。在组建人类与自主系统组成的高效团队时,人类需要及时、准确地了解其机器伙伴的能力、经验和可靠性,才能在动态环境中对其产生信任感。目前,当天气或光照等条件变化导致机器能力波动时,自主系统尚无法提供实时反馈。机器自身对其能力缺乏认知,也无法将其传达给人类伙伴,这降低了信任度并削弱了团队效能。
增强分析与可解释的人工智能将如何在 2019 年及以后引发颠覆性变革;Kamalika Some;人工智能(AI)是一项价值 15 万亿美元的变革性机遇,吸引了所有科技用户、领导者和意见领袖的关注。然而,随着 AI 技术的日益成熟,算法“黑箱”在决策过程中占据了主导地位。为了确保最终结果的可信度和利益相关者的信任,并充分利用这一机遇,我们必须了解算法得出其推荐或决策的依据,而这正是可解释的人工智能(XAI)的基本前提。
为什么“可解释的人工智能”是打击金融犯罪的下一个前沿;Chad Hetherington;金融机构(FIs)必须在管理合规预算的同时,不偏离其核心职能和质量控制目标。为此,许多机构开始采用 AI 和机器学习等创新技术,自动化耗时且重复性强的数据收集和警报筛选工作,从而释放时间紧张的分析师,使其能够专注于更明智、更精确的决策过程。
机器学习的可解释性:你知道你的模型在做什么吗?;Marcel Spitzer;随着 GDPR 的实施,欧盟范围内现已出台有关自动化个人决策和画像的法规(第 22 条,又称“解释权”),要求企业向个人提供处理相关信息,允许其请求干预,甚至定期检查以确保系统按预期运行。
构建可解释的机器学习模型;Thomas Wood;有时作为数据科学家,我们会遇到需要构建一种不应是黑箱的机器学习模型的情况,这种模型应当做出人类可以理解的透明决策。这可能与我们的科研直觉相悖,因为我们往往倾向于构建尽可能精确的模型。
AI 不是 IT;Silvie Spreeuwenberg;XAI 提供了一种介于两者之间的解决方案。它仍然是窄义 AI,但以一种能够与环境形成反馈回路的方式使用。这种反馈回路可能涉及人工干预。我们可以明确窄义 AI 解决方案的适用范围。当任务需要更多知识时,我们可以调整方案;反之,当任务超出 AI 解决方案的范围时,我们也会得到有意义的提示。
用于保释和量刑判决的计算机程序被指存在针对黑人的偏见。但实际上情况并不那么明确。;今年夏天,一场激烈的辩论围绕着全国各法院用来辅助保释和量刑判决的工具展开。这场争议触及了我们社会面临的一些重大刑事司法问题。而这一切的核心就在于一个算法。
AAAS:机器学习“引发科学危机”;数千名科学家使用的机器学习技术在分析数据时会产生误导性甚至完全错误的结果。休斯敦莱斯大学的 Genevera Allen 博士表示,这类系统的使用增加正在导致“科学危机”。她警告科学家们,如果不改进自己的技术,他们将会浪费时间和金钱。
自动机器学习已失效;维护和理解复杂模型所带来的负担
查尔斯河分析公司开发工具,帮助 AI 与人类有效沟通;智能系统解决方案开发商查尔斯河分析公司,在美国国防高级研究计划局(DARPA)的可解释人工智能(XAI)项目框架下,提出了因果模型解释学习(CAMEL)方法。CAMEL 工具的目标是帮助人工智能与其人类队友进行有效沟通。
DARPA 创建可解释的人工智能的努力内幕;在 DARPA 许多令人振奋的项目中,可解释的人工智能(XAI)是一项始于 2016 年的倡议,旨在解决深度学习和神经网络领域的主要挑战之一——而这一子集的人工智能正日益在各个不同行业中占据重要地位。
波士顿大学研究人员开发框架,以提升 AI 的公平性;近年来的经验表明,AI 算法可能会表现出性别和种族偏见,这引发了人们对其在关键领域的应用的担忧,比如决定谁的贷款获批、谁有资格获得工作、谁可以获释、谁将继续服刑。波士顿大学科学家的新研究表明,评估 AI 算法的公平性有多么困难,并试图建立一个框架来检测和缓解自动化决策中的问题行为。这篇题为“从软分类器到硬决策:我们能有多公平?”的研究论文将于本周在计算机协会关于公平、问责制和透明度(ACM FAT*)的会议上发表。
2018年
理解可解释人工智能;(摘自《在高度监管行业整合人工智能的基础技术手册》)长期以来,公众对人工智能的看法往往与末日景象联系在一起:人工智能就是“天网”,我们应该对其感到恐惧。这种恐惧情绪在人们对优步自动驾驶汽车悲剧的反应中可见一斑。尽管每年因人为因素导致的交通事故死亡人数高达数万,但只要涉及人工智能的事故哪怕只有一起,就会引发强烈的社会关注。然而,这种恐惧掩盖了一个关于现代世界技术基础设施的重要事实:人工智能早已深度融入我们的生活。这并不是说我们无需对日益依赖人工智能技术保持警惕。“黑箱”问题正是这种担忧的一个合理理由。
人类可解释机器学习的重要性;本文是我关于“可解释人工智能(XAI)”系列文章的第一篇。过去十年间,由机器学习和深度学习驱动的人工智能领域经历了翻天覆地的变化。从最初纯粹的学术研究领域,如今已广泛应用于零售、科技、医疗、科学等多个行业。进入21世纪后,数据科学和机器学习的核心目标已不再是单纯为发表论文而进行实验室实验,而是致力于解决现实世界中的复杂问题、自动化繁琐任务,从而让生活更加便捷美好。尽管如此,常用的机器学习、统计或深度学习模型工具箱却变化不大。虽然诸如胶囊网络等新模型不断涌现,但这些新技术真正被行业采纳通常需要数年时间。因此,在实际应用中,数据科学和机器学习更注重“落地”而非理论探讨,如何将这些模型有效应用于正确的数据以解决复杂的现实问题,显得尤为重要。
优步开源自动驾驶车辆可视化系统;通过开源其自动驾驶可视化系统,优步希望为工程师开发自动驾驶车辆时提供一套标准化的可视化工具。
企业级人工智能的圣杯——可解释人工智能(XAI);Saurabh Kaushik;除了应对上述场景外,XAI还能带来更深层次的商业价值,例如:提升AI模型性能,因为解释有助于 pinpoint 数据和特征行为中的问题;促进更明智、果断的决策,因为解释提供了额外的信息和信心,使决策者能够采取恰当行动;增强掌控感,作为AI系统的拥有者,可以清晰了解影响系统行为的关键因素及边界;提升安全感,因为每项决策都可以经过安全准则的检验,并在违反时发出警报;赢得利益相关者的信任,他们能够全面理解每一项决策背后的逻辑;监控伦理问题及由训练数据偏差引发的违规行为;更好地满足组织内部审计及其他用途下的问责制要求;更有效地遵守监管规定(如GDPR),其中“知情权”已成为系统的基本要求。
人工智能并非一项技术;Kathleen Walch;制造智能机器既是人工智能的目标,也是理解如何使机器具备智能这一根本科学的核心所在。人工智能代表了我们期望达到的结果,而在此过程中取得的一系列进展,例如自动驾驶汽车、图像识别技术以及自然语言处理与生成等,都是通往通用人工智能(AGI)道路上的重要步骤。
可解释性的构建模块;Chris Olah …;通常,可解释性技术会被单独研究。我们则探索当这些技术组合使用时所产生的强大交互作用,以及由此形成的丰富组合空间结构。
为什么机器学习的可解释性至关重要;尽管机器学习(ML)已经存在数十年,但似乎在过去一年里,围绕它的新闻报道(尤其是在主流媒体中)更多地聚焦于可解释性问题——包括信任、机器学习“黑箱”以及公平性和伦理等议题。毫无疑问,如果这一话题越来越受到关注,那一定是因为它很重要。但究竟为何重要?又对哪些人而言重要呢?
IBM与哈佛大学联合开发工具,解决人工智能翻译中的“黑箱”问题;seq2seq可视工具;IBM和哈佛大学的研究人员共同开发了一款新的调试工具来解决这一问题。该工具上周在柏林举行的IEEE视觉分析科学与技术大会上亮相,它能够让深度学习应用的开发者直观地观察到人工智能在将一段文字从一种语言翻译成另一种语言时的决策过程。
机器学习解释器的五大流派;Michał Łopuszyński;PyData Berlin 2018闪电演讲
警惕随机森林特征重要性的默认设置;Terence Parr、Kerem Turgutlu、Christopher Csiszar 和 Jeremy Howard;简而言之:scikit-learn 随机森林的特征重要性算法以及 R 语言中随机森林的默认特征重要性计算方法都存在偏差。若要在 Python 中获得可靠结果,应使用置换重要性指标,该指标在此处及我们的 rfpimp 包中均有提供(可通过 pip 安装)。对于 R 语言,则应在随机森林构造函数中设置 importance=T,随后在 R 的 importance() 函数中指定 type=1。此外,只有当模型采用合适的超参数进行训练时,所得到的特征重要性评估才具有可靠性。
可解释人工智能与机器学习的应用案例;非常详尽地列举了可解释人工智能的潜在应用场景,例如:检测能源窃取行为——不同类型的窃电行为需要调查人员采取不同的应对措施;信用评分——《公平信用报告法》(FCRA)是一项联邦法律,旨在规范信用报告机构的行为,并要求其确保所收集和发布的消费者信用信息真实、准确;视频威胁检测——将某人标记为威胁可能引发严重的法律后果;
人工智能伦理:数据科学家的视角;QuantumBlack
可解释AI与解释AI;Ahmad Haj Mosa;一些观点将XAI工具与《思考,快与慢》中的理念联系起来。
监管黑箱医疗;数据驱动现代医学。而我们用于分析这些数据的工具正变得越来越强大。随着健康数据的不断积累,基于这些数据的复杂算法能够推动医疗创新、改善诊疗流程并提高效率。然而,这些算法的质量参差不齐。有些准确且强大,而另一些则可能充满错误或建立在有缺陷的科学基础上。当一个不透明的算法为糖尿病患者推荐胰岛素剂量时,我们如何确定该剂量是正确的呢?患者、医疗服务提供者和保险公司都面临着识别高质量算法的巨大困难——他们既缺乏专业知识,也难以获取相关专有信息。那么,我们应如何确保医疗算法的安全性和有效性?
优秀AI模型的三个标志;Troy Hiltbrand;直到最近,AI项目的成功与否仅以公司收益来衡量,但一种新兴的行业趋势提出了另一个目标——可解释的人工智能(XAI)。向XAI发展的动因来自消费者(乃至整个社会)对理解AI决策过程的需求增加。例如,欧洲的《通用数据保护条例》(GDPR)等法规,进一步提升了在使用AI进行自动化决策时的问责性要求,尤其是在偏见可能对个人造成不利影响的情况下。
人工智能领域正迅速取得新进展;然而,随着AI应用的日益广泛,具备可解释性的模型的重要性也将不断提升。简而言之,如果系统负责做出决策,那么在流程中就必须展示这一决策——即说明决策是什么、如何得出的,以及如今更为关键的——为什么AI会做出这样的选择。
为何我们需要审计算法;James Guszcza, Iyad Rahwan, Will Bible, Manuel Cebrian, Vic Katyal;算法决策和人工智能(AI)蕴含巨大潜力,有望成为经济领域的重磅突破,但我们担心炒作使得许多人忽视了将算法引入商业和社会所面临的严重问题。事实上,我们看到许多人陷入了微软的Kate Crawford所称的“数据原教旨主义”——即认为海量数据集本身就是可靠客观真理的宝库,只要我们能用机器学习工具将其挖掘出来即可。然而,这种看法过于简单化,现在已十分清楚,若不加以约束,嵌入数字和社交技术中的AI算法可能会固化社会偏见、加速谣言和虚假信息的传播、放大舆论回音壁效应、劫持我们的注意力,甚至损害我们的心理健康。
让机器思维走出黑箱;Anne McGovern;可适应可解释机器学习项目正在重新设计机器学习模型,以便人类能够理解计算机的思考过程。
可解释AI无法兑现承诺。原因如下;Cassie Kozyrkov;可解释性:你确实能理解它,但它效果并不好。性能:你并不理解它,但它却非常有效。为何不能两者兼得呢?
我们需要一个算法版的FDA;Hannah Fry;我们是否需要培养一种全新的直觉,来理解如何与算法互动?当你说最好的算法是在每个环节都考虑到人的因素时,具体指的是什么?最危险的算法又是什么?
可解释AI、交互性与人机交互; Erik Stolterman Bergqvist;开发能够在技术层面上以人类易于理解的方式解释其内部运作的AI系统。从法律角度探讨XAI。可解释AI出于实际需求而必要,也可以从更哲学的角度切入,提出关于人类要求系统解释自身行为是否合理等更广泛的问题。
为何你的企业必须拥抱可解释AI,才能在热潮中脱颖而出并理解AI的业务逻辑;Maria Terekhova;如果AI要真正具备可应用于商业的能力,只有当我们能够清晰地设计其背后的业务逻辑时才有可能实现。这意味着深谙业务逻辑的企业领导者必须处于AI设计和管理流程的核心位置。
可解释AI:问责的边界;Yaroslav Kuflinski;人们究竟能在多大程度上信任AI的建议呢?提升人工智能伦理的应用程度
2017年
- 被软件程序的秘密算法送进监狱;Adam Liptak,《纽约时报》;Loomis先生案件中的报告是由Northpointe公司销售的一款名为Compas的产品生成的。报告包含一系列条形图,用于评估Loomis先生再次犯罪的风险。检察官在庭审中告诉法官,Compas报告表明“暴力风险高、累犯风险高、审前风险高”。法官同意这一观点,并告知Loomis先生:“根据Compas评估,您被认定为对社会构成高度威胁的人。”
- AI可能复活种族歧视性住房政策 以及为何我们需要透明度来阻止它——“我们无法调查Compas算法的事实本身就是一个问题”
2016年
- 我们如何分析COMPAS累犯预测算法;ProPublica调查报告。黑人被告往往被预测具有比实际情况更高的累犯风险。我们的分析发现,在两年内未再次犯罪的黑人被告中,被错误归类为高风险的概率几乎是白人被告的两倍(45%对比23%)。该分析还表明,即使在控制了既往犯罪记录、未来累犯可能性、年龄和性别等因素后,黑人被告被分配到高风险评分的可能性仍比白人被告高出45%。
学位论文
2018年
2016年
- 机器学习中的不确定性与标签噪声;贝努瓦·弗雷奈;这篇论文探讨了机器学习面临的三大挑战:高维数据、标签噪声以及计算资源有限的问题。
音频
2018年
- 解释可解释的人工智能;在本次网络研讨会上,我们将与帕特里克·霍尔和汤姆·阿利夫围绕可解释人工智能的业务需求及其对任何组织可能带来的价值展开小组讨论。
- 与理查德·泽梅尔探讨机器学习中的公平性问题;今天,我们将继续探索“AI之信任”这一主题,采访多伦多大学计算机科学系教授兼Vector研究所研究主任理查德·泽梅尔。
- 与大卫·施皮格尔哈尔特探讨如何使算法值得信赖;在本系列NeurIPS专题的第二期节目中,我们邀请到了剑桥大学温顿风险与证据传播中心主任、英国皇家统计学会会长大卫·施皮格尔哈尔特。
研讨会
2018年
- 第二届可解释人工智能研讨会;戴维·W·阿哈、特雷弗·达雷尔、帕特里克·多赫蒂和丹尼尔·马加泽尼;
- 可解释的人工智能;里卡多·巴埃萨-耶茨;2018年大数据大会
- 信任与可解释性:人与AI之间的关系;托马斯·博兰德;衡量AI应用成功与否的标准,在于其为人类生活创造的价值。从这个角度来看,AI系统的设计应当帮助人们更好地理解这些系统、参与其使用并建立信任。如今,AI技术已广泛渗透到我们的生活中。随着它逐渐成为社会的核心力量,该领域正从单纯构建智能系统,转向打造具备人类感知且值得信赖的智能系统。
- 21种公平性定义及其政治内涵;本教程有两个目标。一是解释各种技术性定义,同时明确其中所蕴含的价值观。这将有助于政策制定者及其他相关人士更深入地理解关于公平性标准的争论真正涉及的内容(例如个体公平与群体公平、统计均等与误差率平等之间的区别)。此外,也能让计算机科学家认识到,定义的多样化应被积极看待,而非回避;而一味追求单一的“正确”定义并无意义,因为技术考量无法解决道德层面的争议。
- 2018年ICML机器学习中人类可解释性研讨会论文集(WHI 2018)
2017年
- NIPS 2017机器学习公平性教程;索隆·巴罗卡斯、莫里茨·哈特
- 可解释性与AI安全;维多利亚·克拉科夫娜;长期AI安全、可靠地向高级AI系统传达人类偏好与价值观、为与这些偏好一致的AI系统设置激励机制
- 调试机器学习;米哈尔·沃普什任斯基;模型内省 只有非常简单的模型(如线性模型、基础决策树)才能回答“为什么”的问题有时,即使这样的简单模型无法达到顶级性能,将其应用于你的数据集仍然具有启发性你可以通过引入更高级的(非线性变换的)特征来提升简单模型的表现
其他
- 安德烈·沙拉波夫关于可解释人工智能、算法公平性等方面的全部内容 https://github.com/andreysharapov/xaience
- FAT ML 机器学习中的公平、问责与透明度
- 华盛顿大学交互式数据实验室 IDL
- CS 294:机器学习中的公平性 Fairness Berkeley
- 谷歌的机器学习公平性指南
- 米哈尔·沃普什任斯基的优秀可解释机器学习资源库
- 可解释的人工智能:拓展人工智能的边界
- 谷歌 - 可解释的人工智能 —— 用于部署可解释且包容性机器学习模型的工具和框架。
- 谷歌可解释性白皮书
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器