libpostal
libpostal 是一个专为全球街道地址解析与标准化设计的开源 C 语言库。它致力于让计算机能够像人类一样,理解并处理世界各地不同语言、不同格式的地址字符串。
在日常应用中,地址数据往往充满挑战:各国书写习惯差异巨大,缩写、俚语和本地惯例层出不穷,导致传统搜索引擎难以准确索引或匹配。libpostal 正是为了解决这一痛点而生。它能将用户输入的自由格式地址(如“北京市朝阳区建国路 88 号”或"1600 Amphitheatre Pkwy, Mountain View, CA")自动拆解并转换为干净、统一的标准化形式,极大提升了机器比对和地理编码的准确性。
这款工具特别适合开发者、数据工程师及地理空间研究人员使用。无论是构建地图搜索、物流配送系统,还是清洗大规模位置数据,libpostal 都能作为强大的预处理组件,让应用在国际范围内表现得更智能、更一致。
其核心技术亮点在于结合了统计自然语言处理(NLP)与 OpenStreetMap 等开放地理数据。不同于依赖固定规则的传统方案,libpostal 通过机器学习模型自动学习全球地址模式,无需手动维护繁琐的规则库,即可灵活适应从巴西到日本等上百个国家的复杂地址结构。
使用场景
一家跨国即时配送平台在整合全球骑手与商家数据时,面临海量非标准化地址导致的派单失败难题。
没有 libpostal 时
- 解析错误率高:面对"北京市朝阳区建国路 88 号"或"123 Main St, Apt 4B, NY"等混合了缩写、大小写不一的自由文本,传统正则规则难以准确拆分街道、门牌和单元号,导致系统无法识别具体位置。
- 多语言支持匮乏:业务拓展至日本、德国或俄罗斯时,因缺乏针对当地语言习惯(如日语地址从大到小、德语街道后缀变体)的解析能力,新市场的地址数据几乎无法自动化处理。
- 数据去重困难:同一地点因用户输入习惯不同(如"St."与"Street"、"Rd"与"Road")被记录为多条差异巨大的数据,造成地图上的重复标记和运力浪费。
- 地理编码成本高:直接将脏数据发送给收费的地理编码 API,不仅因格式不规范导致大量请求失败,还因无效调用产生了高昂的账单。
使用 libpostal 后
- 结构化解析精准:libpostal 利用统计自然语言处理技术,能自动将混乱的地址文本清洗并拆分为标准的“道路名”、“门牌号”、“城市”等字段,无论输入多么随意都能输出机器可读的统一格式。
- 全球语言无缝覆盖:内置对全球数十种语言和开放地理数据的支持,无需为每个新国家编写特定规则,即可完美处理从中文到阿拉伯语的各种地址 conventions。
- 标准化实现去重:通过将不同写法的地址归一化为标准形式(例如统一将"Blvd."转换为"Boulevard"),系统能轻松识别并合并重复记录,显著提升地图数据的准确性。
- 提升下游效率:作为地理编码的前置预处理步骤,libpostal 大幅提高了后续定位服务的成功率,减少了无效 API 调用,使整体派单系统的响应速度更快且成本更低。
libpostal 通过将全球复杂的自由文本地址转化为标准化的机器语言,成为跨国物流与地图应用实现高效、低成本全球扩张的核心基础设施。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明

快速开始
libpostal:国际街道地址自然语言处理
![]()

![]()
![]()
libpostal 是一个使用统计自然语言处理和开放数据来解析/规范化全球各地街道地址的 C 语言库。该项目的目标是在任何地方、用任何语言理解基于位置的字符串。如需更全面地了解 libpostal 背后的研究,请务必阅读以下介绍性博文(篇幅较长):
- 原文:OpenStreetMap 上的统计自然语言处理
- 1.0 版发布后的后续文章:OpenStreetMap 上的统计自然语言处理:第二部分
🇧🇷 🇫🇮 🇳🇬 :jp: 🇽🇰 🇧🇩 🇵🇱 🇻🇳 🇧🇪 🇲🇦 🇺🇦 🇯🇲 :ru: 🇮🇳 🇱🇻 🇧🇴 :de: 🇸🇳 🇦🇲 :kr: 🇳🇴 🇲🇽 🇨🇿 🇹🇷 :es: 🇸🇸 🇪🇪 🇧🇭 🇳🇱 :cn: 🇵🇹 🇵🇷 :gb: 🇵🇸
地址及其所代表的位置对于任何涉及地图的应用都至关重要(地点搜索、交通、按需/配送服务、签到、评论等)。然而,即使是最简单的地址也充满了本地惯例、缩写和上下文信息,这使得它们难以通过传统的全文搜索引擎进行有效索引和查询。该库可以帮助将人类使用的自由格式地址转换为适合机器比较和全文索引的规范形式。尽管 libpostal 本身并不是一个完整的地理编码器,但它可以用作预处理步骤,使任何地理编码应用在国际范围内更加智能、简单和一致。
🇷🇴 🇬🇭 🇦🇺 🇲🇾 🇭🇷 🇭🇹 :us: 🇿🇦 🇷🇸 🇨🇱 :it: 🇰🇪 🇨🇭 🇨🇺 🇸🇰 🇦🇴 🇩🇰 🇹🇿 🇦🇱 🇨🇴 🇮🇱 🇬🇹 :fr: 🇵🇭 🇦🇹 🇱🇨 🇮🇸 🇮🇩 🇦🇪 🇸🇰 🇹🇳 🇰🇭 🇦🇷 🇭🇰
核心库采用纯 C 语言编写。官方支持 Python、Ruby、Go、Java、PHP 和 NodeJS 的语言绑定,并且也很容易为其他语言编写绑定。
赞助商
如果贵公司正在使用 libpostal,请考虑让贵组织赞助该项目。理解人类在提及地点时的意图远未解决,而赞助有助于我们探索地理空间自然语言处理的新领域。作为赞助商,贵公司的 logo 将 prominently 显示在 GitHub 仓库页面上,并附带指向贵公司网站的链接。赞助信息
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
支持者
个人用户也可以通过每月捐款来支持开源地理自然语言处理研究:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
安装(Mac/Linux)
在安装之前,请确保您已满足以下先决条件:
在 Ubuntu/Debian 上
sudo apt-get install -y curl build-essential autoconf automake libtool pkg-config
在 CentOS/RHEL 上
sudo yum install curl autoconf automake libtool pkgconfig
在 macOS 上
通过 MacPorts 用一条命令安装:
port install libpostal
或者使用 Homebrew:
brew install libpostal
要从源代码编译 C 库:
如果您使用的是 M1 Mac,请在 ./configure 命令中添加 --disable-sse2。这会导致性能下降,但构建过程仍能成功完成。
git clone https://github.com/openvenues/libpostal
cd libpostal
# 如果是首次安装,则跳过此步骤
make distclean
./bootstrap.sh
# 省略 --datadir 标志以将数据安装到当前目录
./configure --datadir=[...某个有几 GB 空间且存在或可创建/修改 "libpostal" 目录的路径...]
make -j4
# 对于 Intel/AMD 处理器和默认模型
./configure --datadir=[...某个有几 GB 空间且存在或可创建/修改 "libpostal" 目录的路径...]
# 对于 Apple / ARM CPU 和默认模型
./configure --datadir=[...某个有几 GB 空间且存在或可创建/修改 "libpostal" 目录的路径...] --disable-sse2
# 对于改进的 Senzing 模型:
./configure --datadir=[...某个有几 GB 空间且存在或可创建/修改 "libpostal" 目录的路径...] MODEL=senzing
make -j8
sudo make install
# 在 Linux 上,最好运行
sudo ldconfig
libpostal 支持 pkg-config,因此您可以使用 pkg-config 打印出链接您的程序所需的标志:
pkg-config --cflags libpostal # 打印编译器标志
pkg-config --libs libpostal # 打印链接器标志
pkg-config --cflags --libs libpostal # 同时打印两者
例如,如果您编写了一个名为 app.c 的程序,可以这样编译它:
gcc app.c `pkg-config --cflags --libs libpostal`
安装(Windows)
MSys2/MinGW
对于 Windows,目前的构建流程需要 MSys2 和 MinGW。这些工具可以从 http://msys2.org 下载。请按照 MSys2 官网上的说明进行安装。
请确保 MSYS2 已更新到最新版本,运行以下命令:
pacman -Syu
安装以下依赖项:
pacman -S autoconf automake curl git make libtool gcc mingw-w64-x86_64-gcc
然后构建 C 库:
git clone https://github.com/openvenues/libpostal
cd libpostal
cp -rf windows/* ./
./bootstrap.sh
./configure --datadir=[...某个有几GB空间的目录...]
make -j4
make install
注意:设置 datadir 时,C: 盘应输入为 /c。libpostal 的构建脚本会在路径末尾自动添加 libpostal,因此在 Windows 上 /c 将变为 C:\libpostal\。
编译后的 .dll 文件将位于 src/.libs/ 目录下,文件名为 libpostal-1.dll。
如果你需要一个 .lib 导入库来链接到你的应用程序,可以使用 Visual Studio 的 lib.exe 工具和 libpostal.def 定义文件生成:
lib.exe /def:libpostal.def /out:libpostal.lib /machine:x64
使用替代数据模型进行安装
libpostal 提供了一个替代数据模型,由 Senzing 公司创建,用于改进对美国、英国和新加坡地址的解析,并优化美国农村路线地址的处理。要启用此模型,在安装时的配置命令中添加 MODEL=senzing:
./configure --datadir=[...某个有几GB空间的目录...] MODEL=senzing
该模型的数据来源于 OpenAddress、OpenStreetMap 以及 Senzing 根据客户反馈生成的数据(约几百条记录),总计来自超过 230 个国家、100 多种语言的约 12 亿条记录。虽然 OpenStreetMap 和 OpenAddress 的数据质量较高,但并不完美,因此通过过滤掉格式错误的地址、纠正分类错误的地址标记以及移除不属于地址的标记等方式对数据集进行了修正。
Senzing 还创建了一个包含来自 89 个国家 12,950 条地址的数据集,用于测试和验证其模型的质量。该数据集主要基于 OSM 中的随机地址,每个国家至少包含 50 条地址。此外,Senzing 支持团队和客户提供的难以解析的地址,以及从 libpostal GitHub 页面收集的地址也被加入到该数据集中。使用此测试集,Senzing 模型的解析准确率比默认模型高出 4.3%。
该模型的大小约为 2.2GB,而默认模型为 1.8GB,因此如果存储空间有限,请务必考虑这一点。
有关此数据模型的更多信息,请访问:https://github.com/Senzing/libpostal-data
如果您在此模型的解析、安装或其他方面遇到任何问题,请在 https://github.com/Senzing/libpostal-data 上提交问题报告。
解析示例
libpostal 的国际地址解析器采用机器学习技术(条件随机场),并基于地球上所有有人居住国家的超过 10 亿条地址进行训练。我们以 OpenStreetMap 和 OpenAddresses 作为结构化地址的来源,并结合 OpenCage 地址格式模板(位于 https://github.com/OpenCageData/address-formatting)构建训练数据,同时补充包含多边形信息,并生成公寓号、楼层号和邮政信箱等建筑物内部组件。此外,我们还会引入缩写、随机删除某些组件等方法,以使解析器能够更好地应对现实世界中混乱无序的输入。
这些解析示例取自与 libpostal 一起编译的交互式 address_parser 程序,当你运行 make 命令时会生成该程序。请注意,解析器可以处理带逗号或不带逗号的情况,以及各种大小写和组件排列组合(例如,仅输入城市或仅输入城市/邮编)。
该解析器在保留数据上的准确率非常高,目前完整解析的正确率达到 99.45%,即每解析 100 条地址,就有 99 条地址的所有标记都能被正确识别。
使用方法(解析器)
以下是使用 Python 绑定调用解析器 API 的示例:
from postal.parser import parse_address
parse_address('The Book Club 100-106 Leonard St Shoreditch London EC2A 4RH, United Kingdom')
以下是使用 C API 的示例:
#include <stdio.h>
#include <stdlib.h>
#include <libpostal/libpostal.h>
int main(int argc, char **argv) {
// 初始化(只需在程序开始时调用一次)
if (!libpostal_setup() || !libpostal_setup_parser()) {
exit(EXIT_FAILURE);
}
libpostal_address_parser_options_t options = libpostal_get_address_parser_default_options();
libpostal_address_parser_response_t *parsed = libpostal_parse_address("781 Franklin Ave Crown Heights Brooklyn NYC NY 11216 USA", options);
for (size_t i = 0; i < parsed->num_components; i++) {
printf("%s: %s\n", parsed->labels[i], parsed->components[i]);
}
// 释放解析结果
libpostal_address_parser_response_destroy(parsed);
// 清理(只需在程序结束时调用一次)
libpostal_teardown();
libpostal_teardown_parser();
}
解析标签
地址解析器理论上可以使用训练数据中定义的任何字符串标签,但目前定义的标签主要基于 OpenCage 地址格式库 中的字段,此外 libpostal 还添加了一些用于处理特定模式的标签:
- house: 场馆名称,例如“布鲁克林音乐学院”,以及建筑物名称,例如“帝国大厦”
- category: 用于类别查询,如“餐馆”等。
- near: 类似“在……内”、“靠近……”等短语,通常跟在类别短语之后,帮助解析类似“布鲁克林的餐馆”这样的查询。
- house_number: 一般指建筑物的外部(面向街道)门牌号。在某些国家,这可能是一个包含公寓号或街区号的复合、带连字符的号码,但为了简化起见,libpostal 仍将其称为 house_number。
- road: 街道名称
- unit: 公寓、单元、办公室、地块或其他次要单位标识符
- level: 表示楼层的表达方式,例如“3楼”、“地面层”等。
- staircase: 编号或字母标记的楼梯
- entrance: 编号或字母标记的入口
- po_box: 邮政信箱:通常出现在非实体地址中(仅用于邮寄)
- postcode: 用于邮件分拣的邮政编码
- suburb: 通常是非官方的社区名称,如“哈莱姆”、“南布朗克斯”或“皇冠高地”
- city_district: 这些通常是城市内的区或行政区,具有某种官方用途,例如“布鲁克林”、“哈克尼”或“布拉迪斯拉发四区”
- city: 任何人类聚居地,包括城市、城镇、村庄、小村落、地方等。
- island: 有名称的岛屿,例如“茂宜岛”
- state_district: 通常是第二级行政分区或县。
- state: 第一级行政分区。英国的苏格兰、北爱尔兰、威尔士和英格兰也被归类为“state”(OSM、GeoPlanet 等采用的惯例)。
- country_region: 国家内部的非正式划分,不具有任何政治地位
- country: 主权国家及其附属领土,任何拥有 ISO-3166 代码 的实体。
- world_region: 目前仅用于在国家名称后附加“西印度群岛”,这是英语加勒比地区常用的一种模式,例如“牙买加,西印度群岛”。
规范化示例
expand_address API 将杂乱无章的真实世界地址转换为适合搜索索引、哈希等操作的规范化等效形式。
以下是使用 Python 绑定的交互式示例:
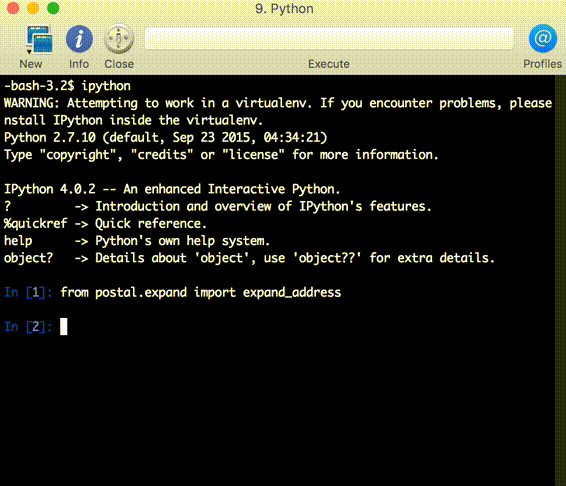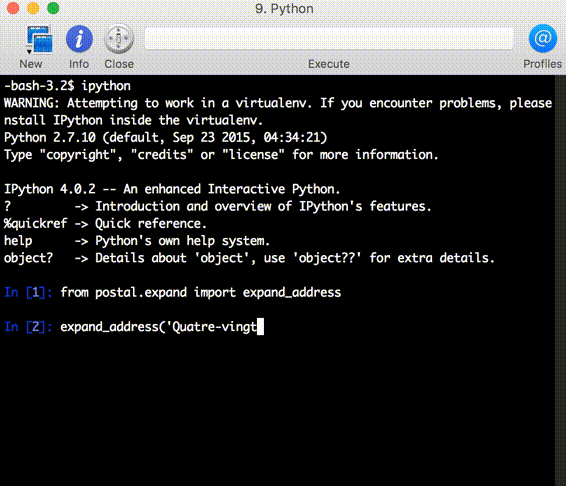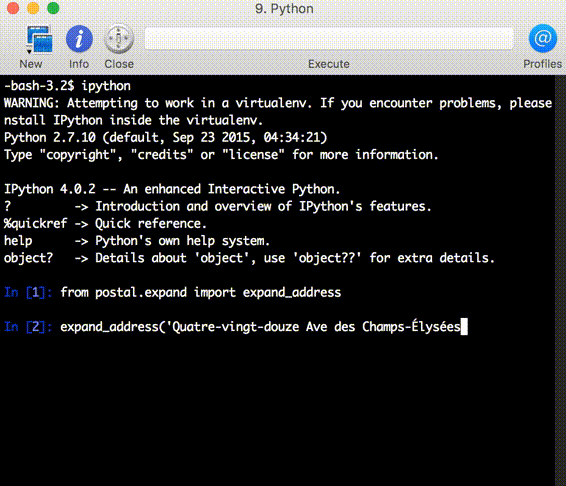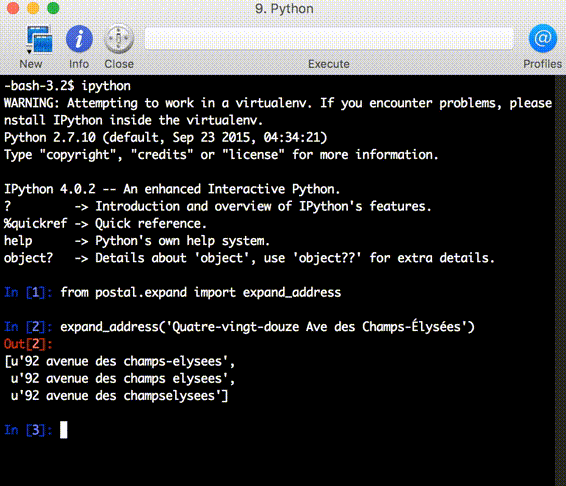
libpostal 包含一个基于 OSM 训练的语言分类器,用于检测给定地址中使用的语言,以便应用适当的规范化规则。所需的唯一输入就是原始地址字符串。以下是一些不同语言中较为复杂的规范化示例。
| 输入 | 输出(libpostal 中可能有多个) |
|---|---|
| One-hundred twenty E 96th St | 120 east 96th street |
| C/ Ocho, P.I. 4 | calle 8 polígono industrial 4 |
| V XX Settembre, 20 | via 20 settembre 20 |
| Quatre vingt douze R. de l'Église | 92 rue de l eglise |
| ул Каретный Ряд, д 4, строение 7 | улица каретныи ряд дом 4 строение 7 |
| ул Каретный Ряд, д 4, строение 7 | ulitsa karetnyy ryad dom 4 stroyeniye 7 |
| Marktstraße 14 | markt strasse 14 |
目前,libpostal 支持 60 多种语言 的此类规范化,并且您可以添加更多(无需编写任何 C 代码)。
如需进一步阅读及一些奇特的地址边缘案例,请参阅: 程序员对地址的误解。
用法(规范化)
以下是使用 Python 绑定的示例,以简洁明了为主(大多数高级语言绑定也类似):
from postal.expand import expand_address
expansions = expand_address('Quatre-vingt-douze Ave des Champs-Élysées')
assert '92 avenue des champs-elysees' in set(expansions)
C API 的等效代码虽然多几行,但仍然相当简单:
#include <stdio.h>
#include <stdlib.h>
#include <libpostal/libpostal.h>
int main(int argc, char **argv) {
// 设置(只需在程序开始时调用一次)
if (!libpostal_setup() || !libpostal_setup_language_classifier()) {
exit(EXIT_FAILURE);
}
size_t num_expansions;
libpostal_normalize_options_t options = libpostal_get_default_options();
char **expansions = libpostal_expand_address("Quatre-vingt-douze Ave des Champs-Élysées", options, &num_expansions);
for (size_t i = 0; i < num_expansions; i++) {
printf("%s\n", expansions[i]);
}
// 释放扩张结果
libpostal_expansion_array_destroy(expansions, num_expansions);
// 清理(只需在程序结束时调用一次)
libpostal_teardown();
libpostal_teardown_language_classifier();
}
命令行用法(expand)
构建 libpostal 后:
cd src/
./libpostal "Quatre vingt douze Ave des Champs-Élysées"
如果您有一个每行包含一个地址的文本文件或流,命令行界面也支持从标准输入读取:
cat some_file | ./libpostal --json
命令行用法(parser)
构建 libpostal 后:
cd src/
./address_parser
address_parser 是一个交互式 shell。您只需输入地址,libpostal 就会解析它们并打印结果。
绑定
Libpostal 专为高级语言设计。如果您没有找到自己偏好的语言绑定,或者您正在开发一种语言绑定,请告知我们!
官方支持的语言绑定
- Python: pypostal
- Ruby: ruby_postal
- Go: gopostal
- Java/JVM: jpostal
- PHP: php-postal
- NodeJS: node-postal
- R: poster
非官方语言绑定
- Java: javacpp-presets-libpostal
- LuaJIT: lua-resty-postal
- Perl: Geo::libpostal
- Elixir: Expostal
- Haskell: haskell-postal
- Rust: rust-postal
- Rust: rustpostal
非官方数据库扩展
- PostgreSQL: pgsql-postal
非官方服务器
- Libpostal REST Go 服务器(需要约4GB内存)并具备基本安全功能:postal_server
- Libpostal REST Go Docker 镜像:libpostal-rest-docker
- Libpostal REST FastAPI Docker 镜像:libpostal-fastapi
- Libpostal ZeroMQ Docker 镜像:libpostal-zeromq
测试
libpostal 使用 greatest 进行自动化测试。要运行测试,可以使用以下命令:
make check
即使你的 C 语言基础较弱或完全不熟悉,添加 测试用例 也非常简单,我们非常欢迎贡献。我们的测试主要采用功能测试,即通过对比字符串输入与输出来验证结果。
此外,libpostal 还会定期在来自 OSM(干净数据)以及生产级地理编码器的匿名查询(相对复杂的数据)中进行大规模压力测试。在此过程中,我们会使用 valgrind 工具检查内存泄漏及其他潜在错误。
数据文件
libpostal 需要从 S3 下载一些数据文件。这些基础文件是用于地址展开操作所需数据结构的磁盘存储表示。对于地址解析部分,由于模型训练可能需要数天时间,我们会在 S3 上发布经过完整训练的模型,并随着 OSM、OpenAddresses 等数据源新增地址时自动更新该模型。语言分类器模型也同样如此。
在执行 make 命令时,数据文件会自动下载。若需检查并下载最新数据文件,可以运行 make,或者执行以下命令:
libpostal_data download all $YOUR_DATA_DIR/libpostal
其中 $YOUR_DATA_DIR 应替换为您在安装时通过 configure 指定的路径。
语言词典
libpostal 包含多个针对不同语言的词典,这些词典会影响地址展开、语言分类及解析器的行为。如需浏览这些词典或贡献您所在语言的缩写和短语,请参阅 resources/dictionaries 目录。
训练数据
在机器学习领域,大量高质量的训练数据往往是取得良好效果的关键。许多开源机器学习项目要么只公开模型代码(只有谷歌才能复现结果),要么直接提供预训练好的模型,而训练的具体条件则对外保密。
libpostal 则有所不同,它基于对所有人开放的公开数据进行训练,因此我们不仅公开了完整的训练流程(本仓库中的 geodata 包),还将最终的训练数据上传至 Internet Archive,解压后容量超过 100GB。
训练数据按创建日期分别存储于 archive.org 上。此外,在本仓库的主目录下还有一个名为 current_parser_training_set 的文件,记录着最新训练集的创建日期。为了始终指向最新的数据,您可以使用类似以下的命令:latest=$(cat current_parser_training_set),然后将该变量用于指定日期。
解析器训练集
所有文件均可在 https://archive.org/download/libpostal-parser-training-data-YYYYMMDD/$FILE 找到,格式为 gzip 压缩的制表符分隔值(TSV)文件,内容形式如下:language\tcountry\taddress。
- formatted_addresses_tagged.random.tsv.gz(ODBL):OSM 中的地址数据。公寓、邮政信箱、类别等信息主要添加到这些示例中。
- formatted_places_tagged.random.tsv.gz(ODBL):OSM 中的所有地名(包括以点表示的城市等),均已反向地理编码至其上级行政区,若点或多边形上标注有邮政编码,则一并包含在内。每个地点都有最低限度的代表性,人口较多的地方则会分配更多样本。
- formatted_ways_tagged.random.tsv.gz(ODBL):OSM 中的所有街道(具有 highway=* 属性的道路,满足若干条件),均已反向地理编码至其上级行政区。
- geoplanet_formatted_addresses_tagged.random.tsv.gz(CC-BY):Yahoo GeoPlanet 中的所有邮政编码及其对应的上级行政区。GeoPlanet 的行政区信息已被清理并映射到 libpostal 的标签体系。
- openaddresses_formatted_addresses_tagged.random.tsv.gz(多种许可,多数为 CC-BY):来自 OpenAddresses 的大部分地址数据,这些数据直接来源于政府机构。
- uk_openaddresses_formatted_addresses_tagged.random.tsv.gz(CC-BY):来自 OpenAddresses UK 的地址数据。
如果解析器在处理某类特定地址时表现不佳,最好的办法是使用 grep 或 awk 工具浏览训练数据,尝试找出是否存在未被捕捉到的地址模式或风格。
功能特性
缩写展开:例如将“rd”扩展为“road”,几乎适用于任何语言。libpostal 支持超过 50 种语言,且易于添加新语言或扩充现有词典。支持非空格分隔的语言(如中文),也支持日耳曼语系中道路类型直接附加在地址末尾的情况;同时允许选择是否保留空格分隔,从而实现 Rosenstraße 和 Rosen Straße 的等价性。
国际地址解析:采用 条件随机场 技术,可将“123 Main Street New York New York”解析为 {"house_number": 123, "road": "Main Street", "city": "New York", "state": "New York"}。该解析器适用于多种国家和语言,而不仅限于美国英语环境。模型基于超过 10 亿条地址及相关字符串进行训练,使用 OpenCage 地址格式化库 中的模板,为全球各有人居住的国家构建格式化、带标签的训练样本。为使训练数据尽可能接近真实的混乱地理编码输入,还进行了多种 归一化处理。
语言分类:多项逻辑回归模型,使用 FTRL-Proximal 方法进行训练以引入稀疏性,训练数据涵盖 OpenStreetMap 中的所有道路、addr:* 标签、地名及格式化地址。标签通过点在多边形内测试获得,分别针对 OSM 国家以及各国和一级行政区的官方或地区语言。例如,在西班牙,西班牙语是默认语言,但在加泰罗尼亚、加利西亚、巴斯克地区等不同区域,各自的地方语言才是默认语言。当地方语言非默认语言时(如威尔士语、布列塔尼语、奥克西坦语),会采用基于词典的消歧方法。这些词典还用于缩写规范短语,比如“Calle” => “C/”,这一处理同时应用于语言分类器和地址解析器的训练集。
数字表达式解析(“twenty first” => 21st,“quatre-vingt-douze” => 92,同样基于 CLDR 提供的数据),支持超过 30 种语言。能够处理包含复合表达式的语言,例如 milleottocento => 1800。还可选择对罗马数字进行标准化处理,无论语言如何(IX => 9),这在许多君主、教皇等的名称中常见。
快速、准确的分词/词法分析:速度超过每秒 100 万个词元,遵循 TR-29 规范进行 UTF-8 分词,并以字符为单位对东亚语言进行分词,而非按空格分隔。
UTF-8 规范化:可选将 UTF-8 转换为 NFD 规范形式,去除重音符号(如 à => a)和/或进行拉丁—ASCII 转写。
音译:例如 улица => ulica 或 ulitsa。使用所有 CLDR 转换规则——与 ICU 使用的源数据完全相同——但 libpostal 并不需要引入整个 ICU 库(以免与系统版本冲突)。注意:部分语言,尤其是希伯来语、阿拉伯语和泰语,可能不包含元音,因此其音译结果往往难以与人工音译一致。未来或许可以为这些语言开发统计型音译工具。
文字脚本检测:识别给定字符串所使用的文字脚本(可能包含多种脚本,例如香港或澳门的自由格式地址可能在同一地址中同时使用汉字和拉丁字母)。在音译过程中,我们可以针对特定 Unicode 脚本应用所有适用的音译规则(例如,希腊文可以分别用希腊—拉丁、希腊—拉丁—BGN 和希腊—拉丁—UNGEGN 等方式进行音译)。
非目标
- 验证某个位置是否为有效地址
- 将地址实际地理编码为经纬度坐标(这需要数据库和搜索索引)
- 从自由文本中提取地址
存在意义
libpostal 最初是作为 OpenVenues 项目的一部分而创建的,旨在解决场所重复数据清理的问题。在 OpenVenues 中,我们拥有一个由数百万个地点组成的数据库,这些地点来源于来自 Common Crawl 的数 TB 网页数据。由于 Common Crawl 每月发布一次,即使合并两次抓取的结果也会产生大量重复数据。
去重是一个研究较为充分的领域,对于网页、学术论文等文本文档,已有相当不错的近似相似度算法,例如 MinHash。
然而,对于实体地址而言,由于经常使用诸如 Road == Rd、California == CA 或 New York City == NYC 等约定俗成的缩写,情况就变得复杂一些。即便使用像 MinHash 这样适用于近似匹配且等同于两个集合 Jaccard 相似度的方法,我们也只能处理非常短的文本,而且通常情况下,两个含义相同的地址——一个缩写、另一个完整表述——在 n 元组集合的重叠程度上并不会十分接近。而在非拉丁文字系统中,比如一条俄语地址及其音译版本,即使是指向同一地点的两条地址,也可能连一个字符都对不上。
举个例子,以下是两种书写方式不同的曼哈顿街道地址,它们在语法和详略程度上各有差异,但实际上指代的是同一个地点:
- 30 W 26th St Fl #7
- 30 West Twenty-sixth Street Floor Number 7
显然,在字符串比较层面,“30 W 26th St Fl #7”并不等于“30 West Twenty-sixth Street Floor Number 7”,但人类却能理解这两条地址指的是同一处物理位置。
libpostal 的目标是生成规范化后的地理字符串,并将其解析为各个组成部分,从而更有效地判断两条地址的实际匹配程度,以便在服务器端自动做出去重决策。
那么它不是地理编码工具吗?
如果上述描述听起来很像地理编码,那确实如此。只不过在 OpenVenues 的场景下,我们需要在没有用户界面、也没有用户通过自动补全下拉菜单选择正确地址的情况下完成地理编码。借助诸如 OpenAddresses 或 OpenStreetMap 等原始地址数据库(或两者兼备),libpostal 可以用于实现地址去重以及在 MapReduce 或流处理等环境中进行服务器端批量地理编码。
现在,与其尝试通过庞大的同义词文件、脚本、自定义分析器、分词器等方式,将地址特有的约定嵌入到 Elasticsearch 等传统文档搜索引擎中,不如让地理编码按照以下步骤进行:
- 将数据库中的地址输入 libpostal 的 expand_address 函数;
- 将规范化后的字符串存储在您喜爱的搜索引擎、数据库、哈希表等中;
- 对用户的查询或新导入的数据运行 libpostal 处理,并使用这些字符串在现有数据库中进行搜索。
通过这种方式,libpostal 可以在与数据集大小无关的时间复杂度内完成模糊地址匹配。
为何选择 C 语言?
libpostal 使用 C 语言编写主要有三个原因(按重要性排序):
可移植性/普适性:libpostal 面向的是人们日常使用的高级编程语言,如 Python、Go、Ruby、NodeJS 等。C 语言的优势在于几乎任何编程语言都可以与之绑定,且 C 编译器无处不在。因此,您可以选择自己喜欢的语言编写绑定代码,直接在应用程序中使用 libpostal,而无需搭建独立的服务器。我们支持 Mac 和 Linux 系统(Windows 不是优先考虑对象,但欢迎接受补丁提交),并采用标准的 autotools 构建流程以及字节序无关的数据文件格式。Python 绑定代码则作为本仓库的一部分维护,因为它们是构建训练数据所必需的。
内存效率:libpostal 专为 MapReduce 环境设计,在该环境中,根据机器配置,每个进程的可用内存可能受限于 < 1GB。为了尽可能降低内存占用,libpostal 大量使用连续数组、基于连续数组的前缀树(Trie)、布隆过滤器以及压缩稀疏矩阵等数据结构。即使在仅训练了单个国家或少数几个国家模型的情况下,也可以在移动设备上运行 libpostal。
性能:性能之所以排在最后是有原因的。libpostal 的大部分优化都集中在内存使用上,而非单纯追求速度。尽管如此,考虑到其处理的工作量,libpostal 的速度仍然相当快。在我们测试过的平台上,单线程/单进程每秒可处理 1–3 万个地址(这意味着只需略超过一小时即可处理完 OSM 全球数据集中的所有地址)。您可以使用简单的基准测试程序,在自己的环境中和不同类型的输入上进行测试。在 MapReduce 环境中,单核性能并不那么重要,因为所有任务都是并行执行的;但在 Mapzen 的一些流式数据导入应用中,仍需要在进程中高效运行。
C 语言编码规范
libpostal 使用现代且易读的 C99 语言编写,并遵循以下编码规范:
- 尽可能以 C 语言实现面向对象风格;
- 几乎不使用基于指针的数据结构,全程使用数组;
- 采用动态字符数组(受 sds 启发)来更安全地处理字符串;
- 将几乎所有 malloc 操作限制在 name_new 函数中,而所有释放操作则集中于 name_destroy 函数;
- 对哈希表等简单数据结构采用高效的现有实现;
- 尽可能使用通用容器(通过 klib 库);
- 数据结构尽可能利用稀疏性特点;
- 对大多数字符串词典采用高效的双数组 Trie 实现;
- 尽可能实现跨平台兼容,尤其是针对类 Unix 系统。
预处理(Python)
libpostal 仓库中的 geodata Python 包包含用于预处理各类地理数据集并构建 C 模型训练数据的完整流程。对于大多数用户而言,此包并非必需;但对于希望生成新型地址或改进 libpostal 训练数据的用户来说,这里正是所需之处。
地址解析器准确率
在保留的测试数据上(即模型从未见过的已标注解析结果),地址解析器的完整解析准确率达到 99.45%。
对于命名实体识别等任务,通常更适合使用 F1 分数或其他变体,主要是因为存在类别偏差问题(大多数词语并非实体,如果系统简单地将每个标记都预测为非实体,其准确率反而会很高)。然而,地址解析并不属于这种情况。每个标记都有明确的标签,且训练数据中每种类别都有数百万个示例,因此准确率是一种更为清晰、简单且直观的性能衡量标准。
在此,我们采用完整解析准确率,即只有当解析器正确识别出地址中的每一个标记时,才会在分子中计为“1 分”。这种度量方式比单纯检查每个标记是否正确更为合理。
改进地址解析器
尽管当前的解析器对大多数标准地址表现良好,但仍有一定改进空间,尤其是在确保所使用的训练数据尽可能贴近真实环境中的地址方面。进一步提升地址解析器性能主要有两种途径(按难度排序):
- 向 OSM 贡献地址数据。凡是带有 addr:housenumber 标签的地址,下次训练解析器时都会自动纳入其中。
- 如果地址解析器对某个特定国家、语言或地址格式表现不佳,很可能是在创建训练数据时遗漏或错误标注了一些名称变体或地点。有时只需更新 https://github.com/OpenCageData/address-formatting 中的地址格式定义即可解决问题;而在许多其他情况下,只需在创建训练数据时进行一些相对简单的调整,就能确保模型被训练成能够处理您的具体用例,而无需您手动录入任何数据。如果您发现明显的地址解析错误模式,请直接在 GitHub 上提交问题。
贡献
欢迎提交 bug 报告、问题和拉取请求。请在提交问题、bug 报告或拉取请求之前阅读 贡献指南。
问题提交地址:https://github.com/openvenues/libpostal/issues。
致谢
特别感谢 @BenK10 完成了最初的 Windows 构建工作,以及 @AeroXuk 将其无缝集成到项目中,并搭建了 Appveyor 构建系统。
许可证
本软件以开源形式发布,遵循 MIT 许可证 的条款。
版本历史
v1.12018/05/09v1.0.02017/04/07v0.3.42017/02/09v0.3.32017/01/09v0.3.22016/12/20v0.3.12016/08/29v0.32016/05/26常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。