LightZero
LightZero 是一个轻量级、高效且易于理解的开源算法工具包,旨在将蒙特卡洛树搜索(MCTS)与深度强化学习(RL)无缝结合。它主要解决了在通用序列决策场景中,缺乏统一基准来评估和比较不同 MCTS 算法性能的问题。以往像 AlphaZero 或 MuZero 这样的顶尖算法虽在游戏领域表现卓越,但其实现复杂且难以直接迁移到新场景,而 LightZero 通过提供标准化的接口和丰富的环境支持,大幅降低了研究与复现的门槛。
这款工具特别适合人工智能领域的研究人员、算法开发者以及希望深入理解决策智能的学生使用。无论是想要快速验证新想法的学者,还是致力于构建通用决策系统的工程师,都能从中受益。LightZero 的独特亮点在于其“统一基准”的设计理念,不仅支持多种经典游戏环境,还具备高度的模块化特性,允许用户灵活替换模型组件或调整搜索策略。此外,作为 NeurIPS 2023 的焦点论文成果,它持续吸纳了如 UniZero、ReZero 等前沿研究的进展,确保用户能接触到最新的算法优化方案,是探索高效世界模型与多任务规划的理想起点。
使用场景
某自动驾驶初创公司的算法团队正在研发城市路况下的智能决策系统,需要在复杂多变的交通环境中实现安全且高效的路径规划。
没有 LightZero 时
- 基准缺失导致重复造轮子:团队需手动复现 AlphaZero 或 MuZero 等经典算法作为基线,耗费数周时间搭建环境且难以保证还原度,严重拖慢研发进度。
- 场景适配成本高昂:面对从棋盘游戏到连续控制(如车辆驾驶)的不同场景,原有框架缺乏统一接口,每次迁移新任务都需重写大量底层代码。
- 性能评估标准不一:由于缺乏标准化的评测流程,不同算法版本间的对比实验变量众多,难以客观判断模型改进是否真正有效。
- 资源消耗难以控制:自行集成的 MCTS 与深度学习模块往往耦合紧密且未优化,导致训练过程显存占用过高,无法在有限算力下进行大规模实验。
使用 LightZero 后
- 开箱即用的统一基准:直接调用 LightZero 内置的标准化 MCTS 基准套件,几分钟内即可建立可靠的对比基线,将算法验证周期从数周缩短至数天。
- 通用接口加速任务迁移:利用其统一的序列决策接口,团队无需修改核心逻辑即可将算法从仿真环境快速迁移至真实的车辆控制任务中。
- 公平高效的性能对标:基于官方提供的标准化评测流程,团队能精准量化策略提升效果,迅速定位模型瓶颈并进行针对性优化。
- 轻量架构降低算力门槛:得益于 LightZero 轻量化且高效的设计,相同硬件配置下的训练吞吐量显著提升,使得大规模并行实验成为可能。
LightZero 通过提供统一、轻量且高效的 MCTS 基准框架,彻底解决了通用序列决策场景中算法复现难、迁移成本高及评估标准混乱的核心痛点。
运行环境要求
- 未说明
未说明(项目提及使用混合异构计算编程优化 MCTS,且基于 PyTorch,通常建议配备 NVIDIA GPU 以加速训练,但 README 未明确具体型号或显存要求)
未说明
快速开始
LightZero






![]()
![]()
![]()








更新于 2026年3月11日 LightZero-v0.2.0
LightZero 是一个轻量级、高效且易于理解的开源算法工具包,结合了蒙特卡洛树搜索(MCTS)和深度强化学习(RL)。
English | 简体中文(Simplified Chinese) | Documentation | LightZero Paper | UniZero Paper | ReZero Paper | 🔥ScaleZero Paper
新闻
- [2026.02] 🔥 ScaleZero 论文已被 ICLR 2026 接受为会议论文:《一个模型适用于所有任务:在多任务规划中利用高效的世界模型》(https://arxiv.org/abs/2509.07945)。
- [2025.08] ReZero 论文已被 CoRL 2025 RemembeRL 研讨会接受。
- [2025.06] UniZero 论文已被 Transactions on Machine Learning Research (TMLR 2025) 接受。
- [2023.09] LightZero 论文已被 NeurIPS 2023 数据集与基准赛道接受为 Spotlight Presentation。
- [2023.04] LightZero v0.0.1 正式发布。
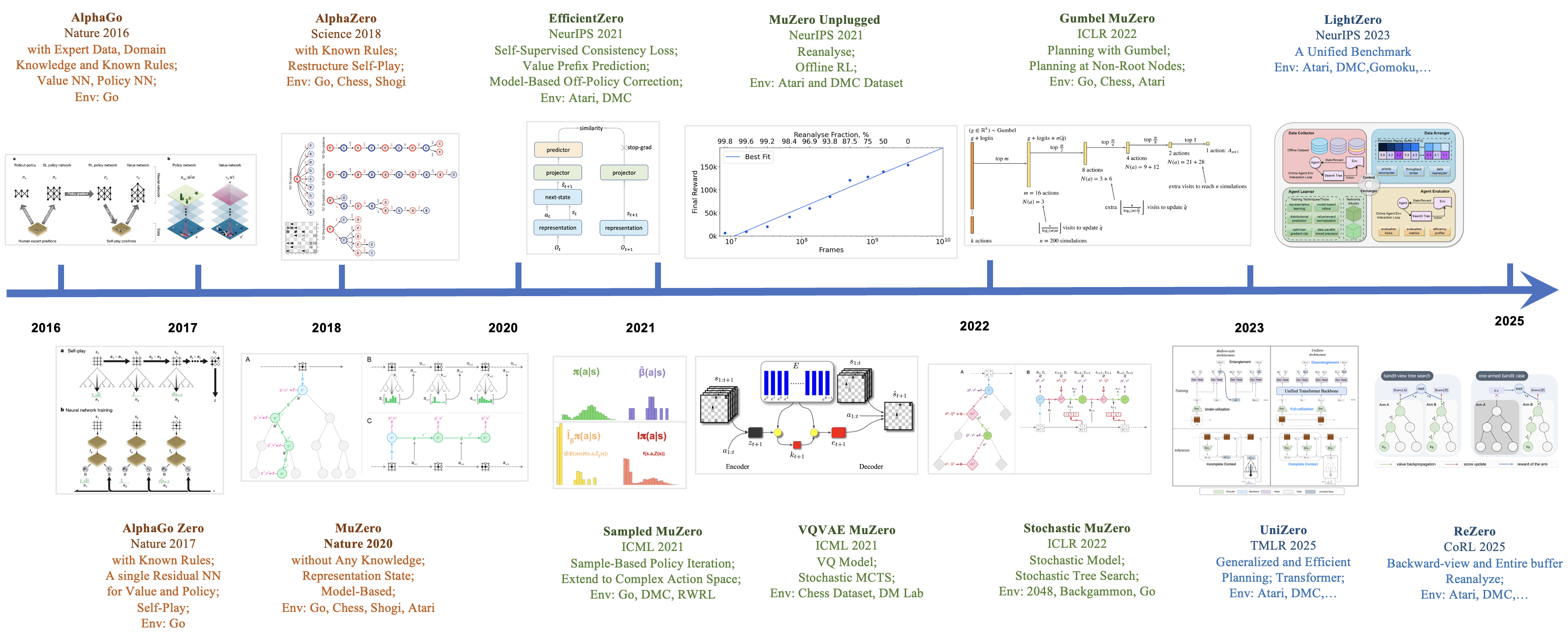
🔍 背景
以 AlphaZero 和 MuZero 为代表的蒙特卡洛树搜索与深度强化学习的结合,在围棋、Atari 游戏等多种游戏中取得了前所未有的性能水平。这一先进方法也在蛋白质结构预测和矩阵乘法算法搜索等科学领域取得了显著进展。以下是蒙特卡洛树搜索算法系列的历史演进概述:
🎨 概述
LightZero 是一个基于 PyTorch 的开源算法工具包,结合了蒙特卡洛树搜索(MCTS)和强化学习(RL)。它支持一系列基于 MCTS 的 RL 算法及应用,具有以下几大优势:
- 轻量级。
- 高效。
- 易于理解。
LightZero 的目标是 推动 MCTS+RL 算法家族的标准化,以加速相关研究与应用。所有实现算法在统一框架下的性能比较见 基准测试。
大纲
💥 功能特性
轻量级: LightZero 集成了多种 MCTS 算法家族,能够在轻量级框架中解决具有不同属性的决策问题。LightZero 已实现的算法和环境列表请参见 此处。
高效性: LightZero 采用混合异构计算编程,以提升 MCTS 算法中最耗时部分的计算效率。
易理解: LightZero 为所有集成的算法提供了详细的文档和算法框架图,帮助用户理解算法的核心,并比较同一种范式下不同算法之间的异同。此外,LightZero 还提供了算法代码实现的函数调用图和网络结构图,便于用户定位关键代码。所有文档均可在 这里找到。
🧩 框架结构

上图展示了 LightZero 的框架流程。下面我们简要介绍三个核心模块:
模型:
Model 用于定义网络结构,包括用于初始化网络结构的 __init__ 函数以及用于计算网络前向传播的 forward 函数。
策略:
Policy 定义了网络更新及与环境交互的方式,包含三个过程:学习过程、收集过程和评估过程。
MCTS:
MCTS 定义了蒙特卡洛搜索树的结构及其与策略模块的交互方式。MCTS 的实现使用 Python 和 C++ 两种语言,分别由 ptree 和 ctree 实现。
关于 LightZero 的文件结构,请参阅 lightzero_file_structure。
{kind=link}
🎁 集成的算法
LightZero 是一个基于 PyTorch 的 MCTS 算法库(有时结合 Cython 和 C++),其中包括:
目前 LightZero 支持的环境和算法如下表所示:
| 环境/算法 | AlphaZero | MuZero | 采样 MuZero | EfficientZero | 采样 EfficientZero | Gumbel MuZero | 随机 MuZero | UniZero | 采样 UniZero | ReZero |
|---|---|---|---|---|---|---|---|---|---|---|
| 井字棋 | ✔ | ✔ | 🔒 | 🔒 | 🔒 | ✔ | 🔒 | ✔ | 🔒 | 🔒 |
| 五子棋 | ✔ | ✔ | 🔒 | 🔒 | 🔒 | ✔ | 🔒 | ✔ | 🔒 | ✔ |
| 四子连珠 | ✔ | ✔ | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 | ✔ | 🔒 | ✔ |
| 2048 | --- | ✔ | 🔒 | 🔒 | 🔒 | 🔒 | ✔ | ✔ | 🔒 | 🔒 |
| 国际象棋 | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 |
| 围棋 | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 |
| 倒立摆 | --- | ✔ | 🔒 | ✔ | ✔ | ✔ | ✔ | ✔ | 🔒 | ✔ |
| 单摆 | --- | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 🔒 | ✔ | 🔒 |
| 登月飞船 | --- | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 🔒 |
| 双足行走者 | --- | ✔ | ✔ | ✔ | ✔ | ✔ | 🔒 | 🔒 | ✔ | 🔒 |
| Atar i游戏 | --- | ✔ | 🔒 | ✔ | ✔ | ✔ | ✔ | ✔ | 🔒 | ✔ |
| DeepMind 控制 | --- | --- | ✔ | --- | ✔ | 🔒 | 🔒 | 🔒 | ✔ | 🔒 |
| MuJoCo | --- | ✔ | 🔒 | ✔ | ✔ | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 |
| MiniGrid | --- | ✔ | 🔒 | ✔ | ✔ | 🔒 | 🔒 | ✔ | 🔒 | 🔒 |
| Bsuite | --- | ✔ | 🔒 | ✔ | ✔ | 🔒 | 🔒 | ✔ | 🔒 | 🔒 |
| 记忆任务 | --- | ✔ | 🔒 | ✔ | ✔ | 🔒 | 🔒 | ✔ | 🔒 | 🔒 |
| 三球相加(台球) | --- | 🔒 | 🔒 | 🔒 | ✔ | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 |
| MetaDrive | --- | 🔒 | 🔒 | 🔒 | ✔ | 🔒 | 🔒 | 🔒 | 🔒 | 🔒 |
(1): “✔” 表示该项目已完成并经过充分测试。
(2): “🔒” 表示该项目处于待处理状态(开发中)。
(3): “---” 表示该算法不支持此环境。
⚙️ 安装说明
您可以通过以下命令从 GitHub 源代码安装最新版本的 LightZero 开发版:
git clone https://github.com/opendilab/LightZero.git
cd LightZero
pip3 install -e .
请注意,LightZero 目前仅支持在 Linux 和 macOS 平台上进行编译。我们正在积极努力将支持扩展到 Windows 平台。在此过渡期间,您的耐心等待将不胜感激。
使用 Docker 安装
我们还提供了一个 Dockerfile,用于搭建运行 LightZero 库所需的所有依赖环境。该 Docker 镜像是基于 Ubuntu 20.04 构建的,并安装了 Python 3.8 以及其他必要的工具和库。 以下是使用我们的 Dockerfile 构建 Docker 镜像、从该镜像运行容器,并在容器内执行 LightZero 代码的方法。
- 下载 Dockerfile:Dockerfile 位于 LightZero 仓库的根目录下。请将此文件下载到本地机器。
- 准备构建上下文:在本地机器上创建一个空目录,将 Dockerfile 移动到该目录中,并进入该目录。这一步有助于避免在构建过程中向 Docker 守护进程发送不必要的文件。
mkdir lightzero-docker mv Dockerfile lightzero-docker/ cd lightzero-docker/ - 构建 Docker 镜像:使用以下命令构建 Docker 镜像。此命令应在包含 Dockerfile 的目录内执行。
docker build -t ubuntu-py38-lz:latest -f ./Dockerfile . - 从镜像运行容器:使用以下命令以交互模式并带有 Bash shell 启动容器。
docker run -dit --rm ubuntu-py38-lz:latest /bin/bash - 在容器内执行 LightZero 代码:进入容器后,可以使用以下命令运行示例 Python 脚本:
python ./LightZero/zoo/classic_control/cartpole/config/cartpole_muzero_config.py
🚀 快速入门
训练一个 MuZero 智能体来玩 CartPole:
cd LightZero
python3 -u zoo/classic_control/cartpole/config/cartpole_muzero_config.py
训练一个 MuZero 智能体来玩 Pong:
cd LightZero
python3 -u zoo/atari/config/atari_muzero_segment_config.py
训练一个 MuZero 智能体来玩 TicTacToe:
cd LightZero
python3 -u zoo/board_games/tictactoe/config/tictactoe_muzero_bot_mode_config.py
训练一个 UniZero 智能体来玩 Pong:
cd LightZero
python3 -u zoo/atari/config/atari_unizero_segment_config.py
📚 文档
LightZero 的文档可以在这里找到:LightZero 文档。其中包含了教程和 API 参考。
对于希望自定义环境和算法的用户,我们提供了相关指南:
如果您有任何问题,请随时联系我们获取支持。
📊 基准测试
点击展开
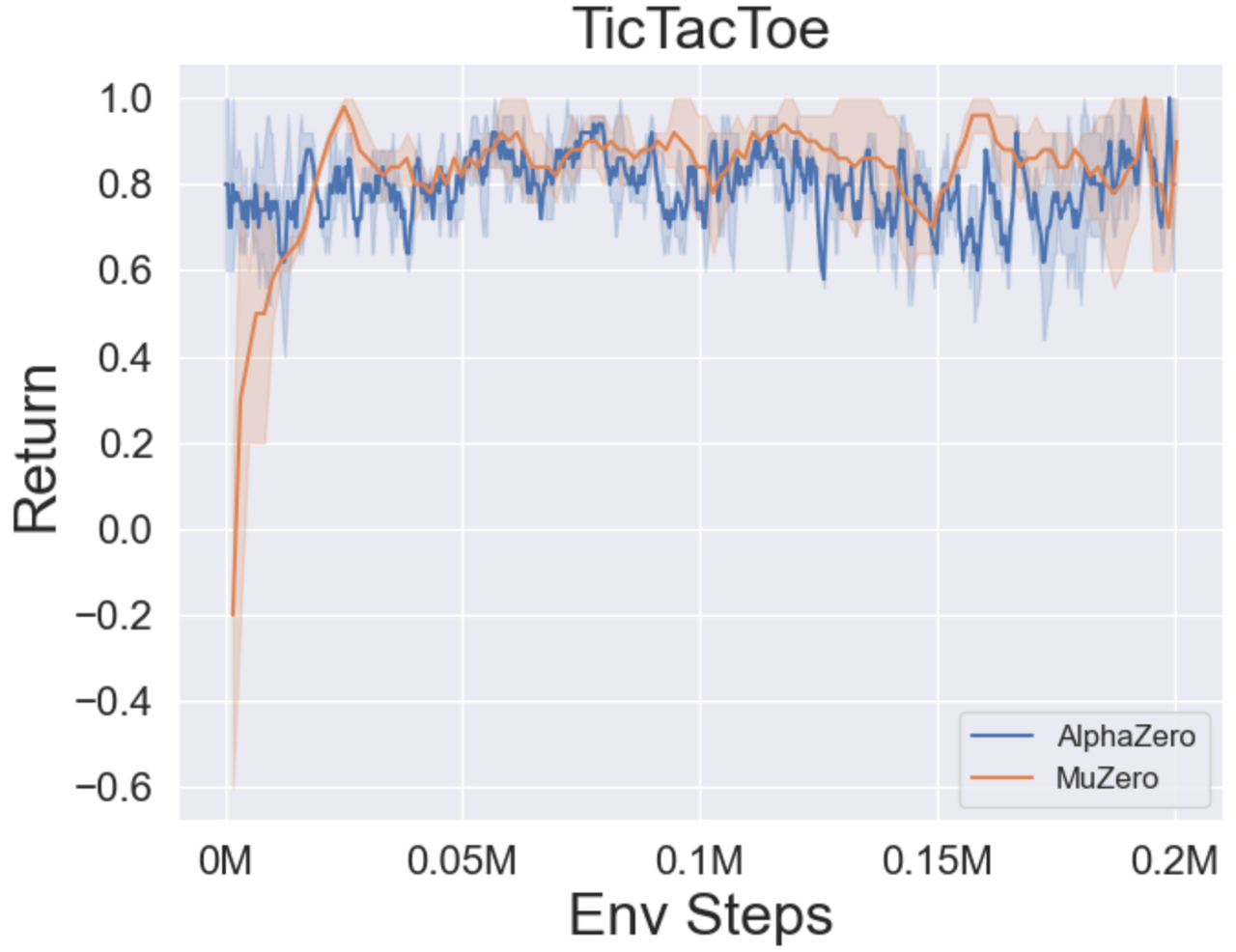
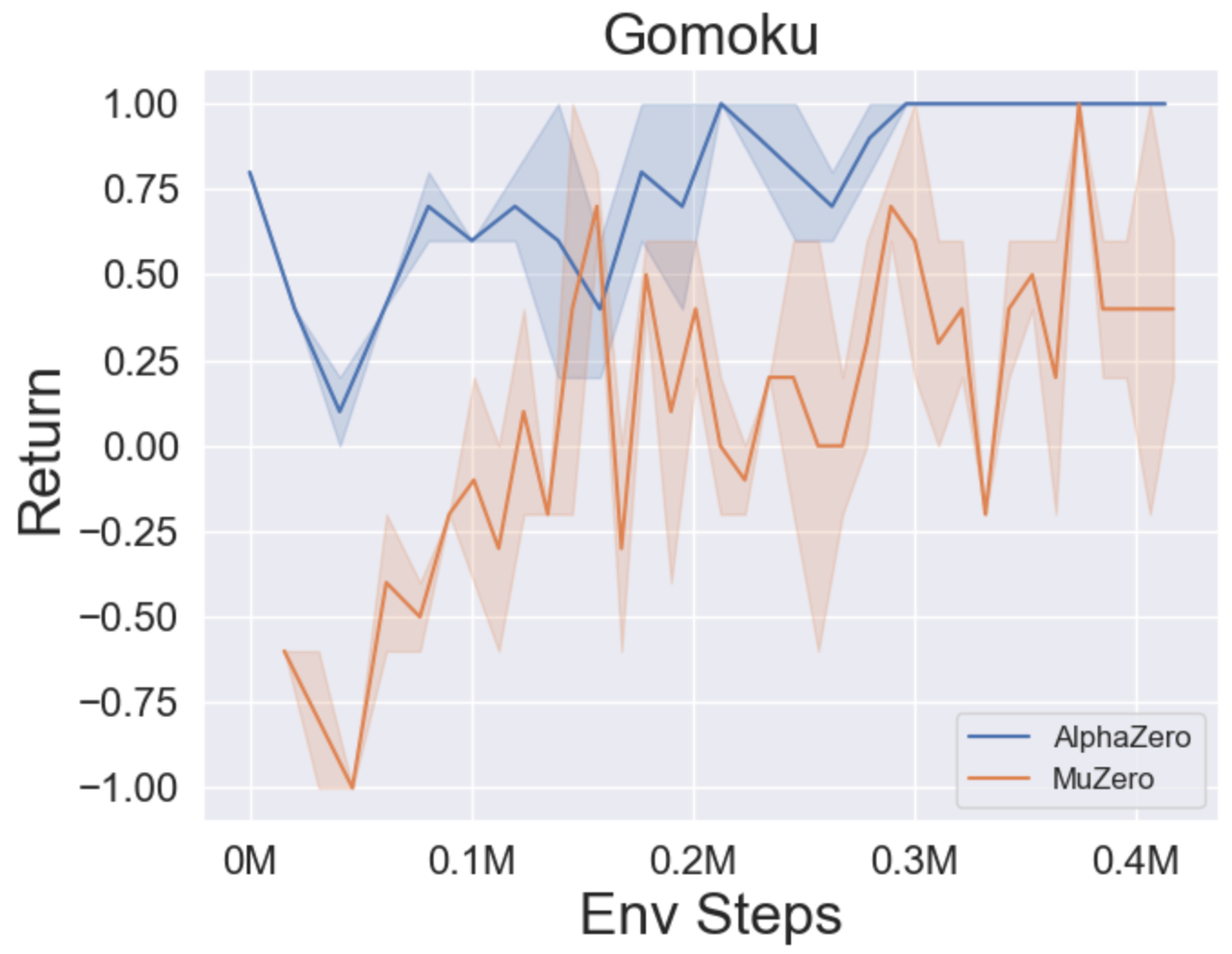
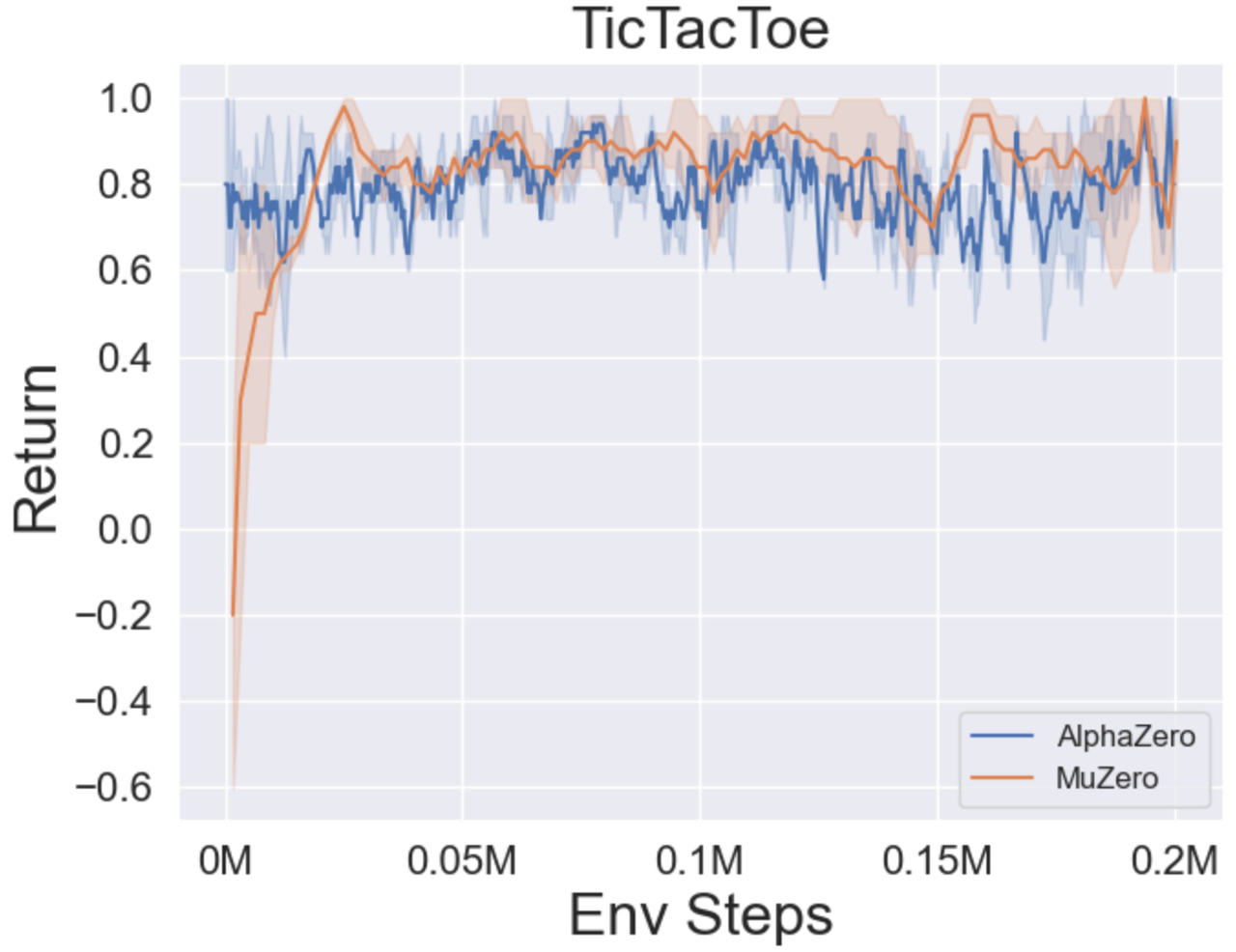
- 以下是 MuZero、带 SSL 的 MuZero、EfficientZero 和 采样 EfficientZero 在 [Atari] 游戏中的三个离散动作空间环境上的基准测试结果:Pong、Q*bert、Ms. Pac-Man。
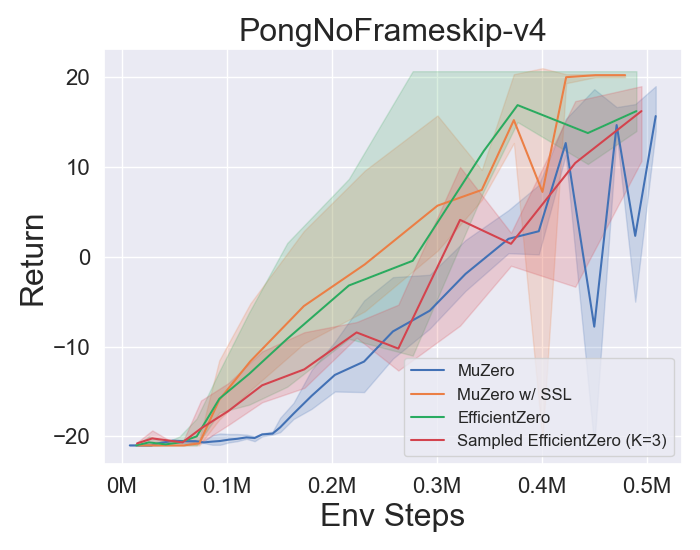
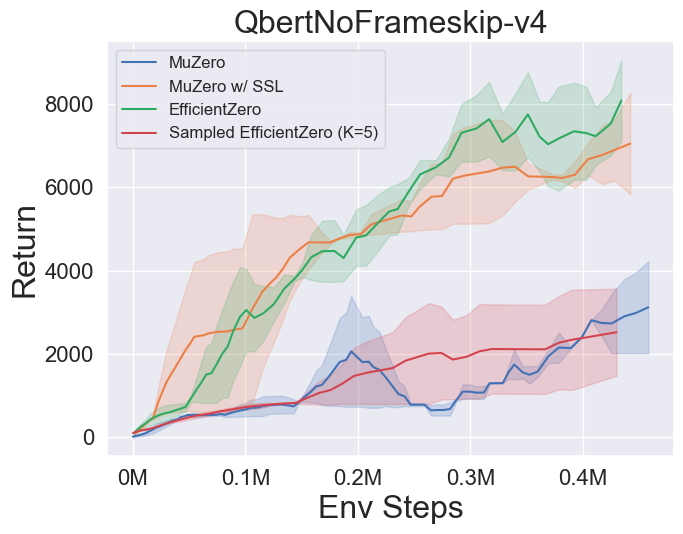
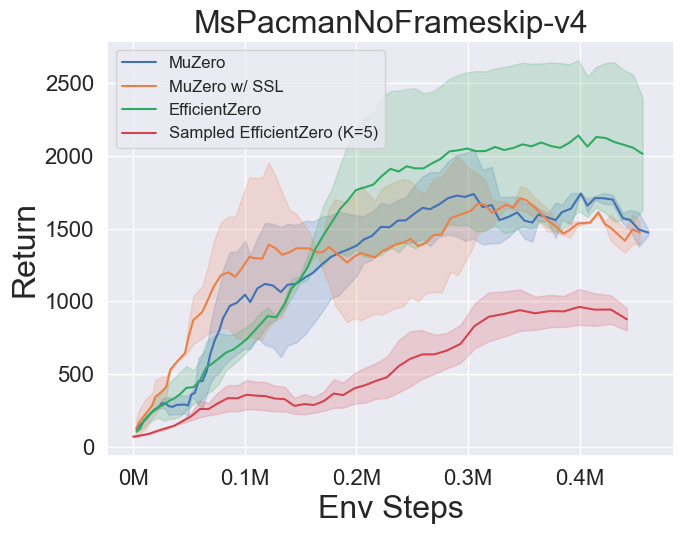
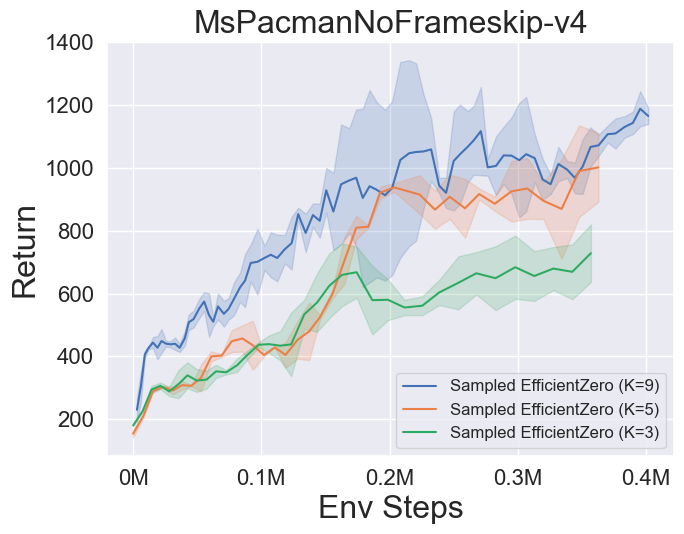
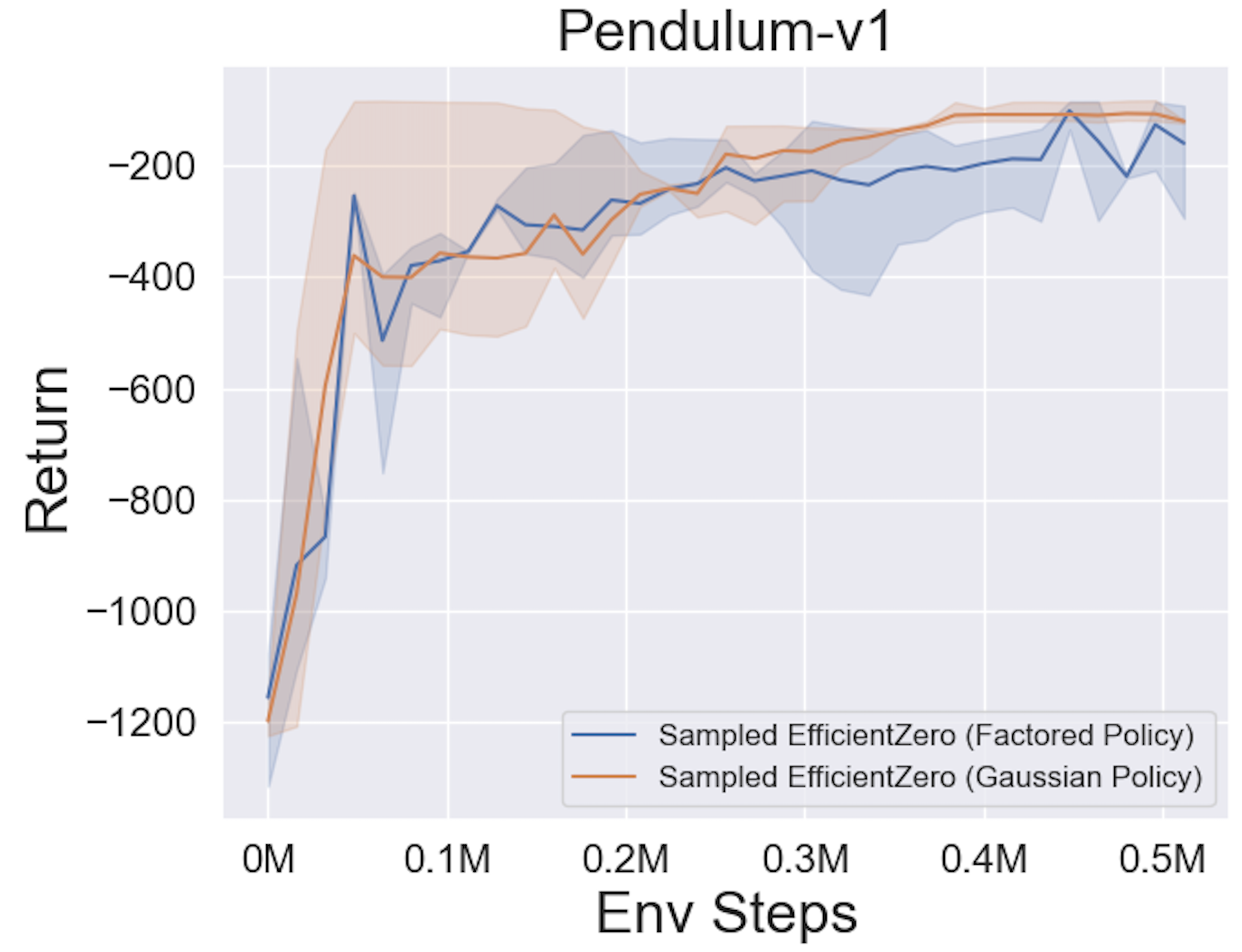
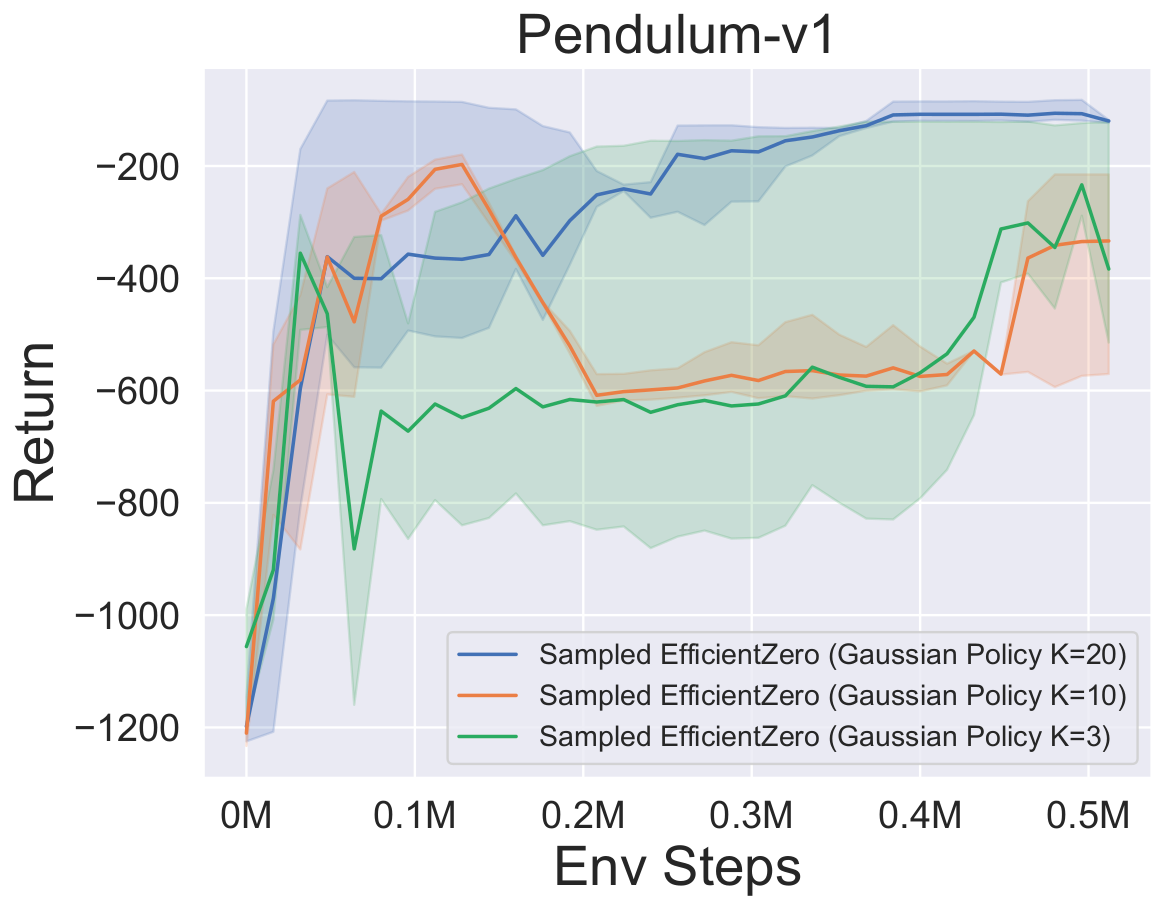
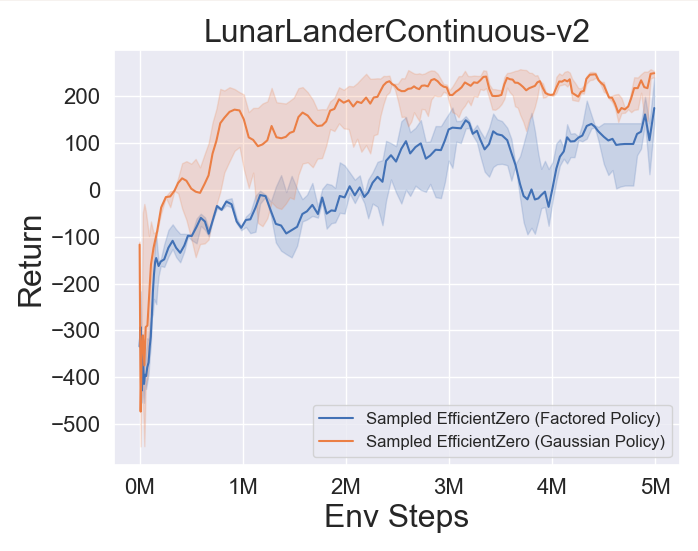
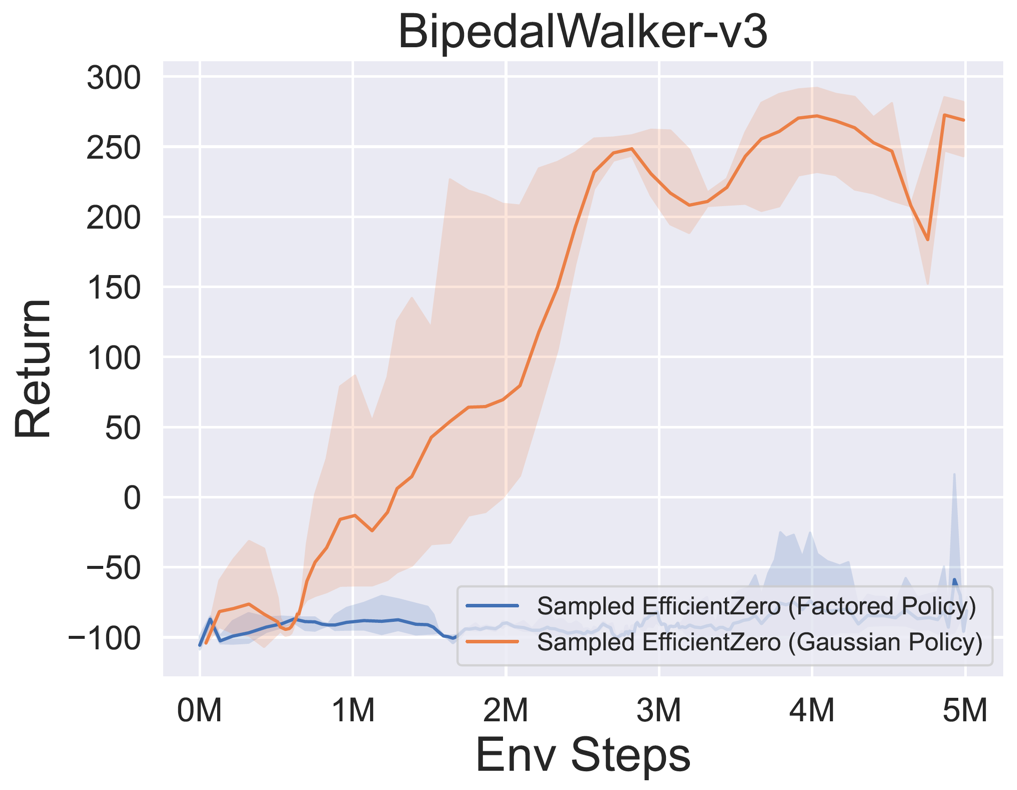
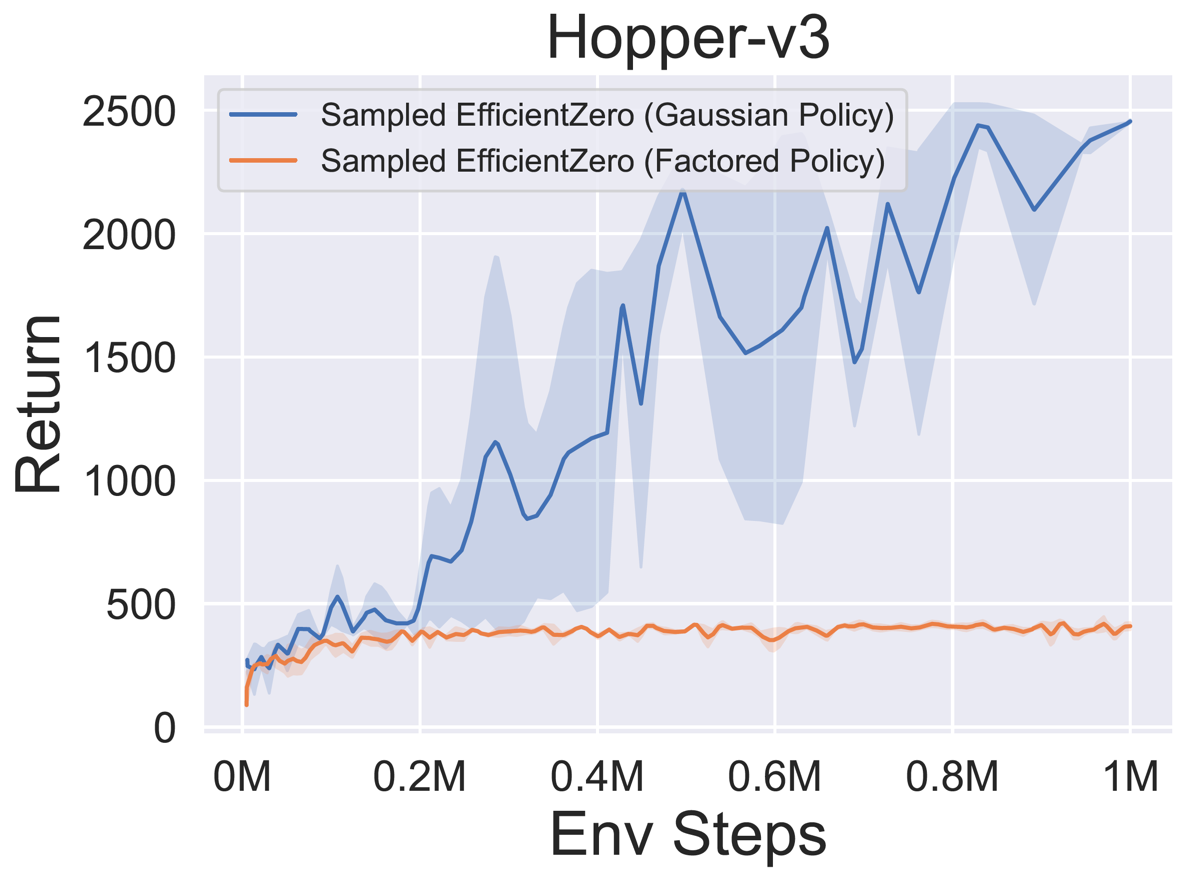
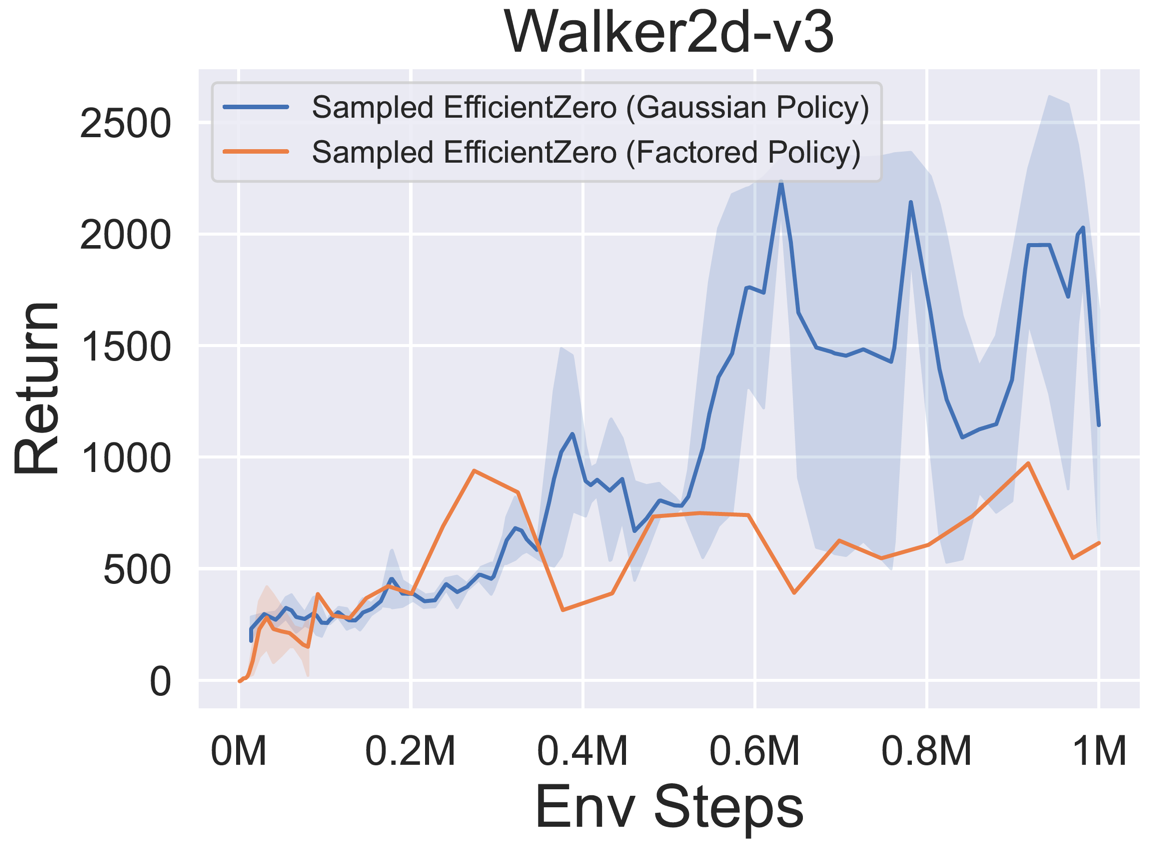
- 以下是 采样 EfficientZero 使用
Factored/Gaussian策略表示在三个经典连续动作空间游戏上的基准测试结果:摆锤-v1、月球着陆器连续-v2、双足行走者-v3,以及两个 MuJoCo 连续动作空间游戏:跳鼠-v3、Walker2d-v3。
“Factored Policy” 表示智能体学习一个输出分类分布的策略网络。经过手动离散化后,这五个环境的动作空间维度分别为 11、49 (7^2)、256 (4^4)、64 (4^3) 和 4096 (4^6)。另一方面,“Gaussian Policy” 指的是智能体学习一个直接输出高斯分布参数(均值 μ 和标准差 σ)的策略网络。
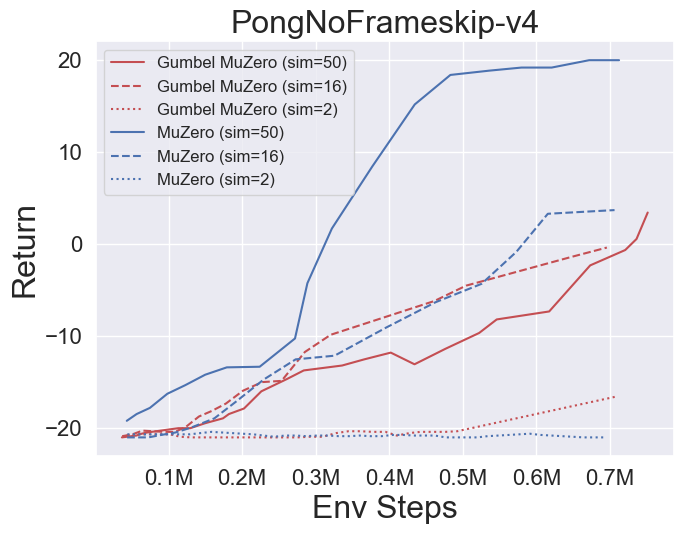
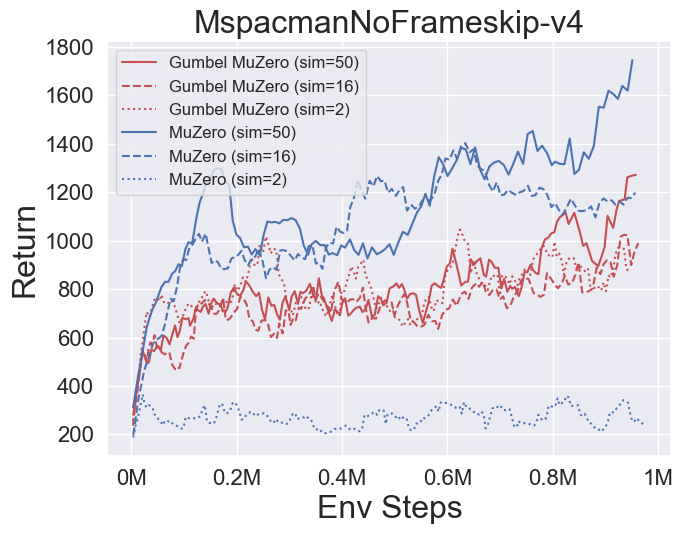
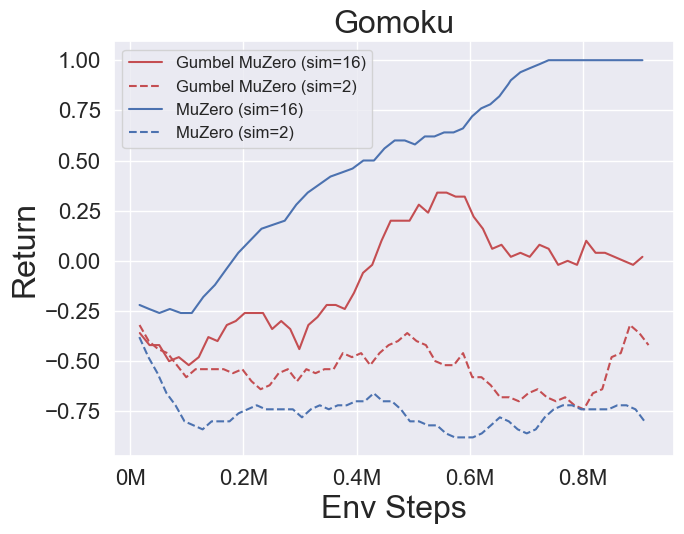
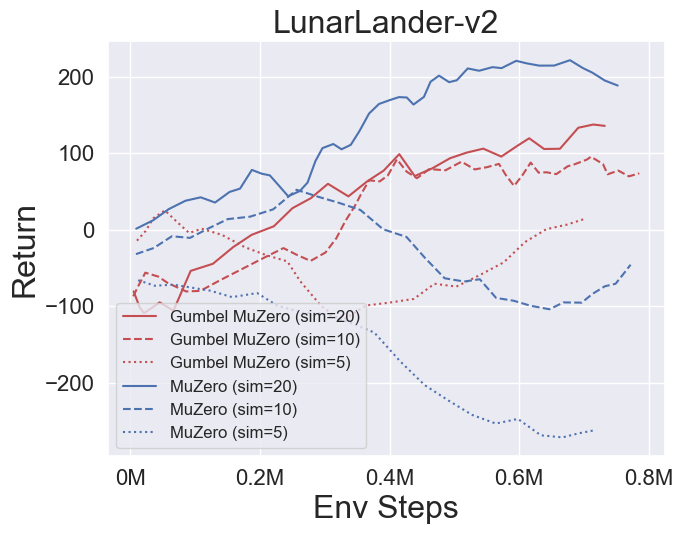
- 以下是 GumbelMuZero 和 MuZero(在不同模拟成本下)在四个环境上的基准测试结果:PongNoFrameskip-v4、Ms. Pac-Man NoFrameskip-v4、五子棋、月球着陆器连续-v2。
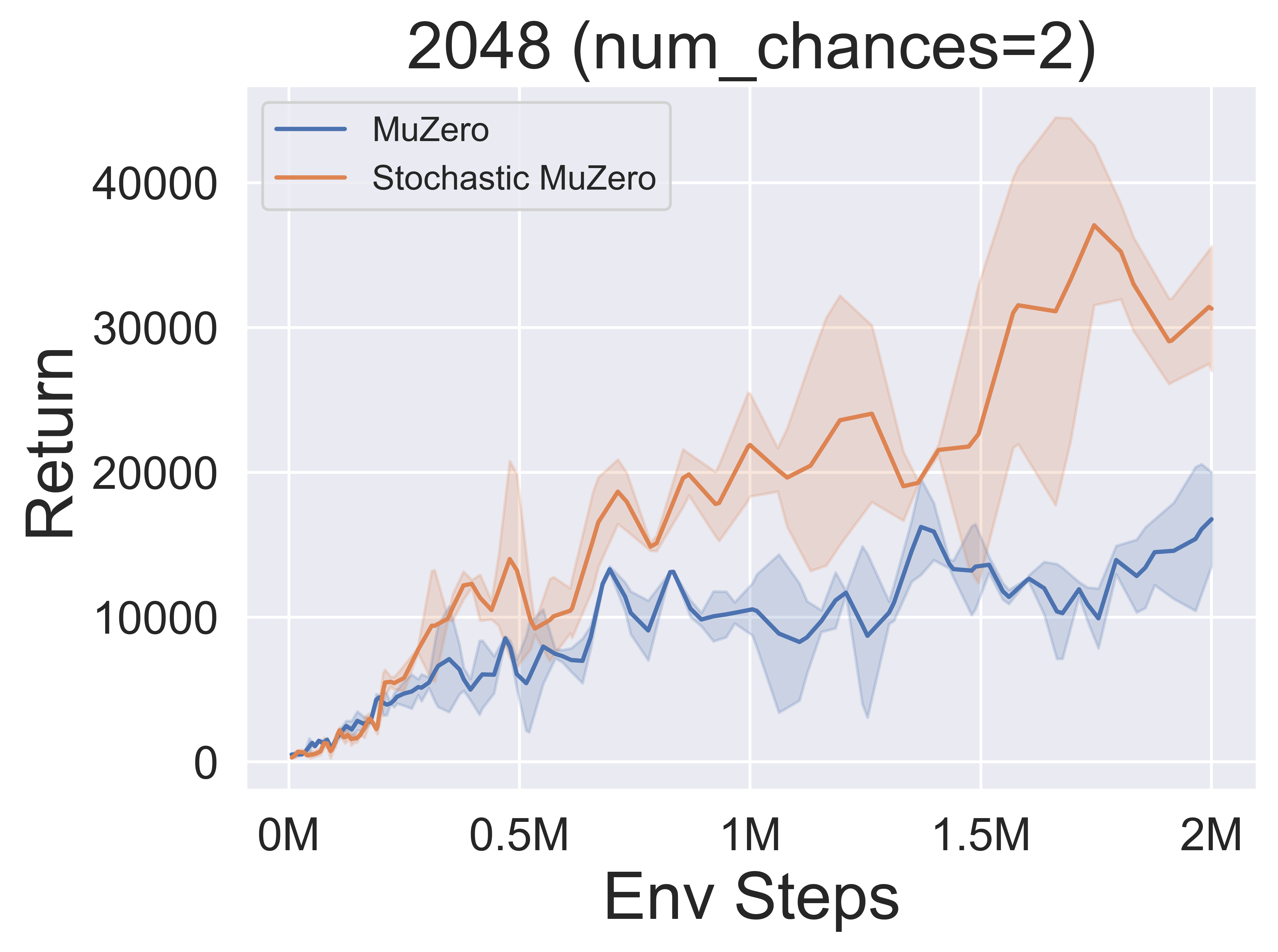
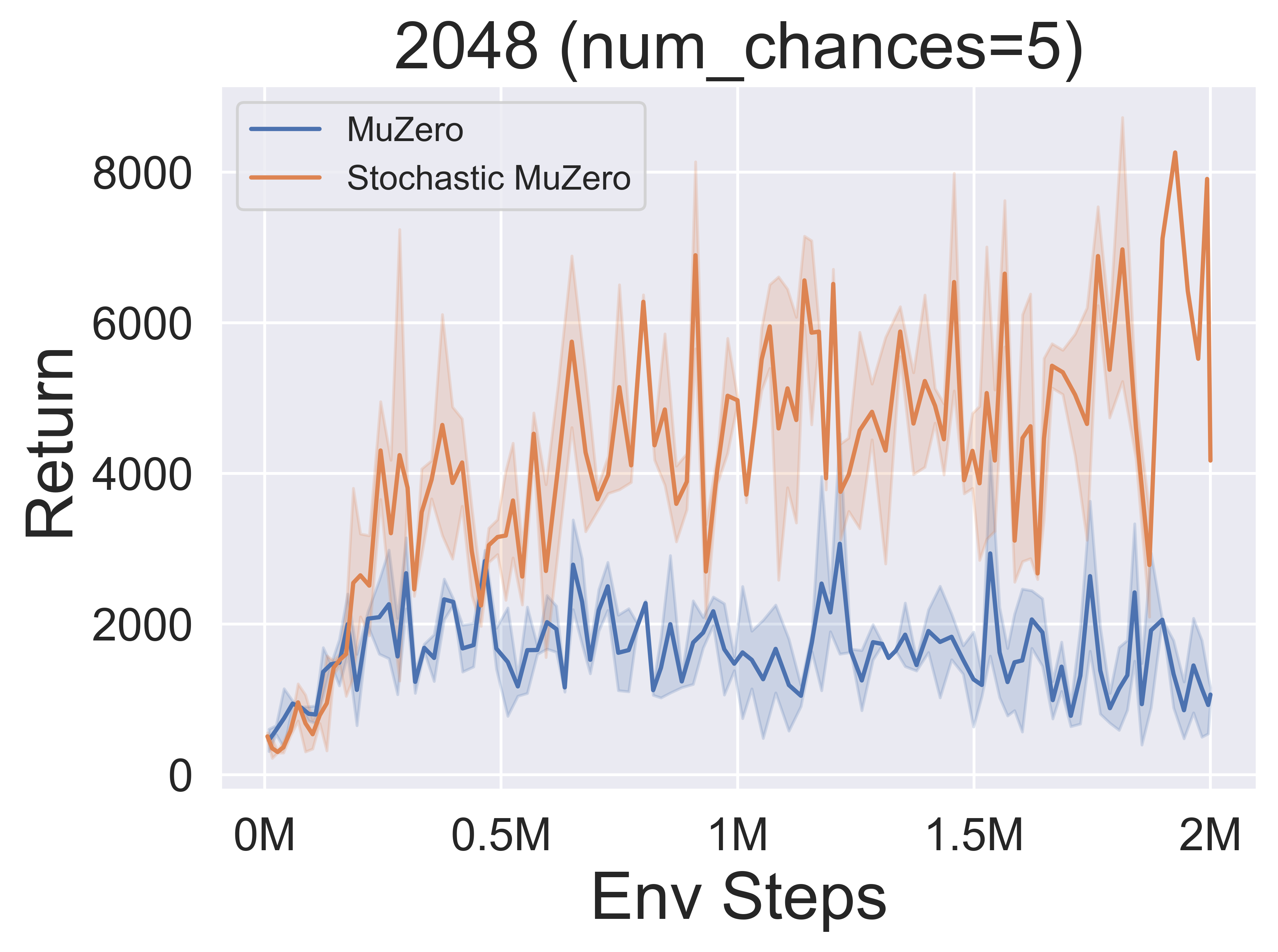
- 以下是 StochasticMuZero 和 MuZero 在 2048 环境 上,面对不同随机性水平(num_chances=2 和 5)时的基准测试结果。
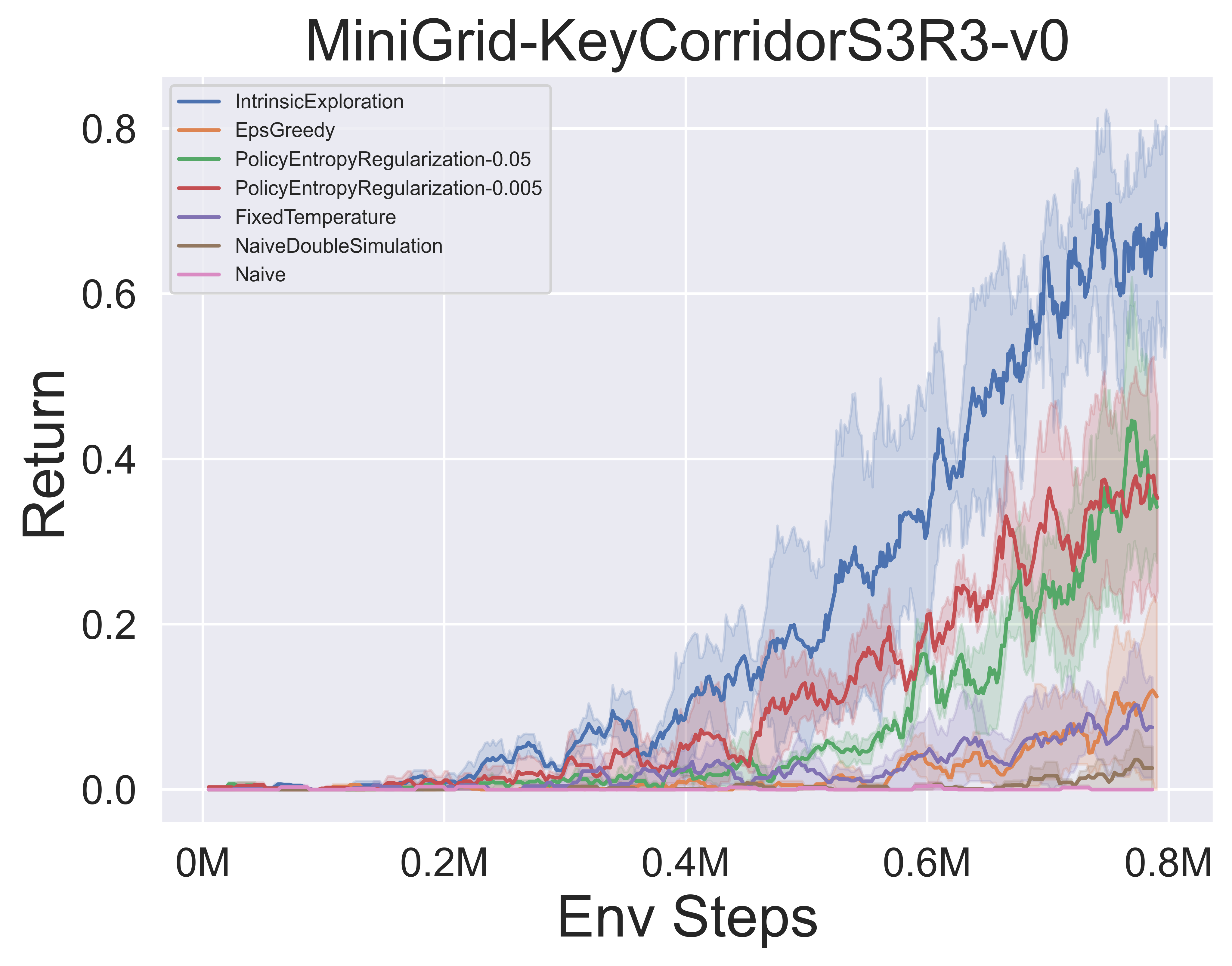
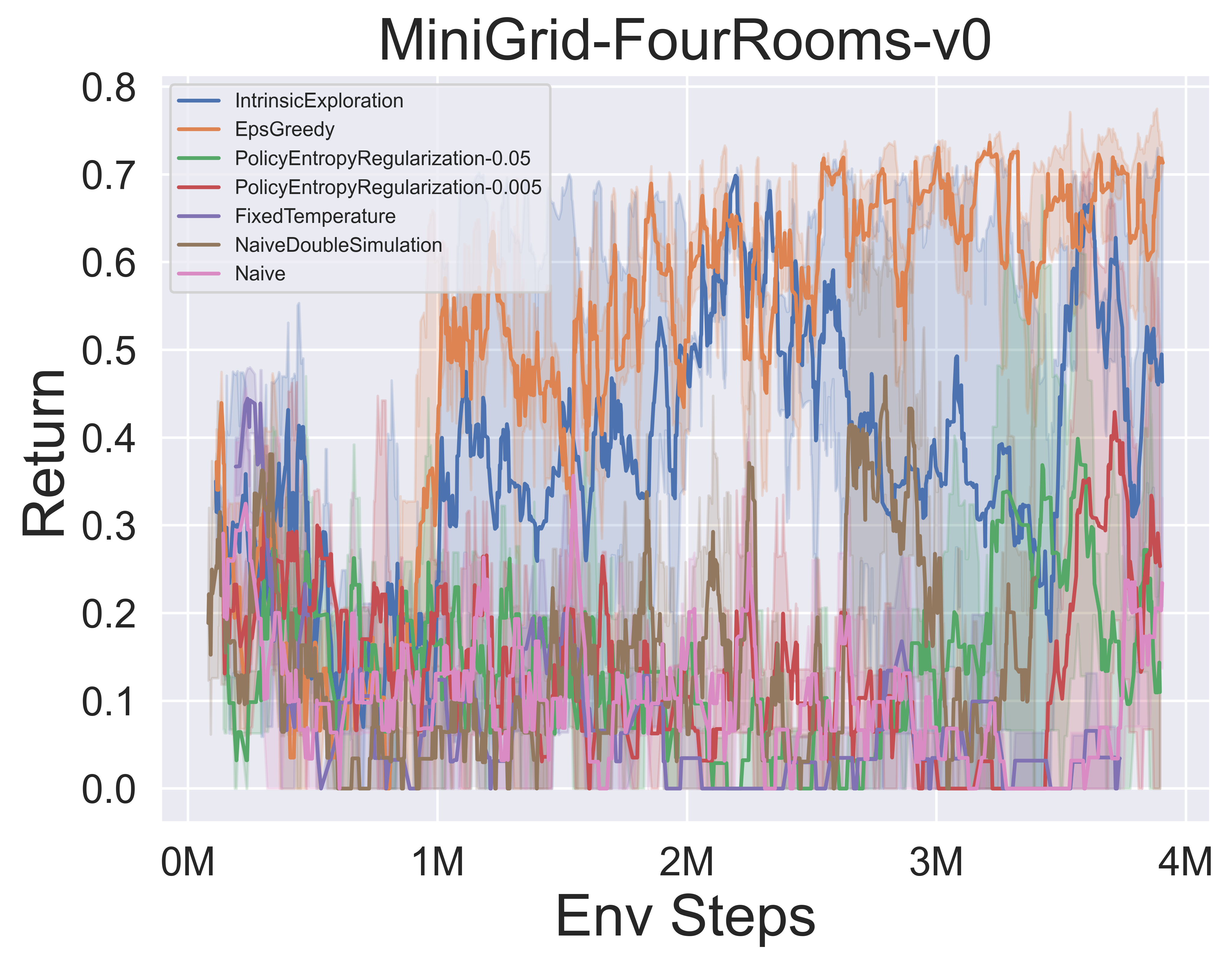
- 以下是 带 SSL 的 MuZero 在 MiniGrid 环境 中,采用多种 MCTS 探索机制时的基准测试结果。
📝 Awesome-MCTS 笔记
论文笔记
以下是上述算法的详细论文笔记(中文):
点击收起
你也可以参考相关的知乎专栏(中文):MCTS+RL前沿理论与应用深度解析。
算法概览
以下是上述算法的MCTS原理示意图概览:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Awesome-MCTS论文
这里收集了关于蒙特卡洛树搜索的研究论文。 本节将持续更新,以追踪MCTS的前沿进展。
经典与基础论文
点击展开
LightZero实现系列
- 2018年《科学》杂志 AlphaZero:通过自我对弈掌握国际象棋、将棋和围棋的通用强化学习算法
- 2019年 MuZero:通过规划与学习模型掌握雅达利游戏、围棋、国际象棋和将棋
- 2021年 EfficientZero:在数据有限的情况下掌握雅达利游戏
- 2021年 Sampled MuZero:在复杂动作空间中进行学习与规划
- 2022年 Stochastic MuZero:利用学习模型在随机环境中进行规划
- 2022年 Gumbel MuZero:通过Gumbel规划改进策略
- 2024年 UniZero:基于可扩展潜在世界模型的通用高效规划
AlphaGo系列
- 2015年《自然》杂志 AlphaGo:利用深度神经网络和树搜索掌握围棋
- 2017年《自然》杂志 AlphaGo Zero:无需人类知识即可掌握围棋
- 2019年 ELF OpenGo:对AlphaZero的分析与开源重实现
- 2023年 Student of Games:一种适用于完全信息和不完全信息游戏的统一学习算法
MuZero系列
MCTS分析
MCTS应用
最新研究与新兴应用
点击展开
ICML
- STAIR: 通过内省推理提升安全对齐 2025
- 张一驰、张思远、黄耀、夏泽宇、方正伟、杨晓、段然杰、闫东、董银鹏、朱俊
- 关键词:大语言模型、安全对齐、推理
- 实验环境:StrongReject、XsTest、WildChat、Do-Not-Answer、GSM8k、AlpacaEval 2.0、BIG-bench HHH、SimpleQA、InfoFlow、AdvGLUE
- rStar-Math: 小型大语言模型通过自我进化式深度思考掌握数学推理 2025
- 关鑫宇、李琳娜·张、刘一飞、尚宁、孙佑然、朱毅、杨帆、杨茂
- 关键词:大语言模型、推理、自我进化
- 实验环境:GSM8K、MATH、AIME 2024、AMC 2023、奥林匹克基准测试、大学数学、高考(2023年中国高考)
- 基于最优传输的不确定性传播蒙特卡洛树搜索 2025
- 段端光、帕斯卡尔·施滕格、卢卡斯·施奈德、乔尼·帕亚里宁、卡洛·德埃拉莫、奥达尔里克-安布里姆·迈亚尔
- 关键词:蒙特卡洛树搜索、不确定性下的规划
- 实验环境:FrozenLake、NChain、RiverSwim、SixArms、Taxi、Rocksample、Pocman、Tag、LaserTag
- 利用树搜索对推理上下文进行重排序使大型视觉-语言模型更强大 2025
- 杨琪、张成浩、范鲁斌、丁坤、叶洁平、项世明
- 关键词:大型视觉语言模型、多模态检索增强生成、上下文学习、蒙特卡洛树搜索
- 实验环境:ScienceQA、MMMU、MathV、VizWiz、VSR-MC
- 通过语言模型实现内外部规划来精通棋类游戏 2025
- 约翰·舒尔茨、雅库布·阿达梅克、马泰伊·尤苏普、马克·兰科特、迈克尔·凯瑟斯、萨拉·佩林、丹尼尔·亨尼斯、杰里米·沙尔、坎纳达·A·刘易斯、阿尼安·鲁奥斯、汤姆·扎哈维、彼得·韦利奇科维奇、劳雷尔·普林斯、萨廷德·辛格、埃里克·马尔米、内纳德·托马塞夫
- 关键词:搜索、规划、语言模型、游戏、国际象棋
- 实验环境:国际象棋、Chess960、四子连珠、六角棋
- 语言模型作为隐式树搜索 2025
- 陈子良、赖兆荣、杨宇峰、方亮达、杨振福、林亮
- 关键词:无强化学习偏好优化;基于大语言模型的蒙特卡洛树搜索;大语言模型对齐;大语言模型推理
- 实验环境:Anthropic HH、GSM8K、MATH、Game24
- 无需过程标签即可获得过程奖励 2025
- 袁立凡、李文迪、陈华宇、崔甘渠、丁宁、张凯燕、周博文、刘志远、彭浩
- 关键词:过程奖励模型
- 实验环境:MATH
- 基于大语言模型的自动启发式设计中的全面探索蒙特卡洛树搜索 2025
- 郑智、谢卓亮、王振坤、布莱恩·胡伊
- 关键词:自动启发式设计、组合优化、大语言模型、神经组合优化、蒙特卡洛树搜索
- 实验环境:TSP、背包问题、CVRP、多背包问题、装箱问题、容许集问题、贝叶斯优化
- 提升虚拟智能体学习与推理能力:具有基准测试的分步、多维度且通用型奖励模型 2025
- 苗炳辰、吴洋、高明赫、于启凡、卜文东、张文桥、李云飞、唐思亮、蔡宗盛、李俊诚
- 关键词:虚拟智能体;数字智能体;奖励模型
- 实验环境:WebArena、VisualWebArena、Android World、OSWorld
- 通过蒙特卡洛规划实现在线稳健强化学习 2025
- 段端光、基尚·帕纳甘蒂、布拉欣·德里斯、亚当·维尔曼
- 关键词:蒙特卡洛树搜索、分布鲁棒强化学习、在线强化学习
- 实验环境:赌徒问题、冰湖、美式期权定价
- 信任区域扭曲策略改进 2025
- 乔瑞·A·德弗里斯、何金科、亚尼夫·奥伦、马蒂斯·T·J·斯潘
- 关键词:强化学习;序列蒙特卡洛;蒙特卡洛树搜索;规划;基于模型;策略改进
- 实验环境:Brax、Jumanji
- KBQA-o1: 基于蒙特卡洛树搜索的代理式知识库问答 2025
- 罗浩然、E海红、郭义凯、林其卡、吴小宝、穆新宇、刘文豪、宋美娜、朱一凡、刘安团
- 关键词:知识库问答、大语言模型、LLM代理、蒙特卡洛树搜索
- 实验环境:GrailQA、WebQSP、GraphQ
- 蒙特卡洛树扩散用于系统2规划 2025
- 尹在植、赵贤书、白斗镇、约书亚·本吉奥、安成镇
- 关键词:扩散模型、MCTS、系统2规划、轨迹优化
- 实验环境:2D迷宫、厨房、积木堆叠
- 代码
- 基于最优传输的不确定性传播蒙特卡洛树搜索 2025
- 段端光、帕斯卡尔·施滕格、卢卡斯·施奈德、乔尼·帕亚里宁、卡洛·德埃拉莫、奥达尔里克-安布里姆·迈亚尔
- 关键词:最优传输、Wasserstein距离、不确定性传播、MCTS
- 实验环境:FrozenLake、NChain、RiverSwim、SixArms、Taxi、Rocksample
- 通过蒙特卡洛规划实现在线稳健强化学习 2025
- 段端光、基尚·帕纳甘蒂、布拉欣·德里斯、亚当·维尔曼
- 关键词:稳健RL、MCTS、分布鲁棒优化、模拟到现实
- 实验环境:赌徒问题、冰湖、美式期权定价
- 代码
- 随机连续蒙特卡洛树搜索中的幂平均估计 2025
- 段端光
- 关键词:连续MCTS、多项式探索、随机环境、幂平均
- 实验环境:连续Cartpole、倒立摆
- 语言代理树搜索统一了语言模型中的推理、行动和规划 2024
- 周安迪、严凯、米哈尔·什拉彭托赫-罗斯曼、王浩瀚、王宇雄
- 关键词:语言模型、决策、蒙特卡洛树搜索、推理、行动、规划
- 实验环境:HumanEval、WebShop、交互式问答、编程、数学
- 通过层次化对手建模和规划实现在混合动机环境中的高效适应 2024
- 黄一哲、刘安吉、孔凡奇、杨耀东、朱松春、冯雪
- 关键词:多智能体强化学习、层次化对手建模、蒙特卡洛树搜索、少量样本适应、混合动机环境
- 实验环境:多智能体决策场景、自我对弈、混合动机互动
- 加速贝叶斯优化中的前瞻:只需多级蒙特卡洛即可 2024
- 杨尚达、维塔利·赞金、马克西米利安·巴兰达特、斯特凡·舍雷尔、凯文·托马斯·卡尔伯格、尼尔·沃尔顿、科迪·J·H·劳
- 关键词:贝叶斯优化、多级蒙特卡洛、嵌套期望、采集函数
- 实验环境:基准示例
- 基于树状蒙特卡洛的加速推测采样 2024
- 胡正勉、黄恒
- 关键词:推测采样、大语言模型、树状蒙特卡洛、推理加速
- 实验环境:未指定
- 通过状态占用正则化在蒙特卡洛树搜索中实现可证明高效的长 horizon 探索 2024
- 利亚姆·施拉姆、阿卜杜斯拉姆·布拉里亚斯
- 关键词:探索、状态占用、长 horizon 规划、体积-MCTS
- 实验环境:机器人导航、2D迷宫
- 代码
- 通过蒙特卡洛树搜索实现可扩展的安全策略改进 2023
- 阿尔贝托·卡斯特利尼、费德里科·比安奇、爱德华多·佐尔齐、蒂亚戈·D·西芒、亚历山德罗·法里内利、马蒂斯·T·J·斯潘
- 关键词:使用基于MCTS的策略在线进行安全策略改进、带有基准引导的安全策略改进
- 实验环境:Gridworld和SysAdmin
- 通过路径一致性实现AlphaZero的高效学习 2022
- 赵登伟、涂士奎、徐磊
- 关键词:有限数量的自我对弈、路径一致性(PC)最优性
- 实验环境:围棋、奥赛罗、五子棋
- 可视化MuZero模型 2021
- 乔瑞·A·德弗里斯、肯·S·沃斯奎尔、托马斯·M·莫兰德、阿斯克·普拉特
- 关键词:可视化价值等效动力学模型、动作轨迹发散、两种正则化技术
- 实验环境:CartPole和MountainCar。
- 蒙特卡洛树搜索中的凸正则化 2021
- 段端光、卡洛·德埃拉莫、扬·彼得斯、乔尼·帕亚里宁
- 关键词:熵正则化备份算子、遗憾分析、Tsallis熵
- 实验环境:合成树、Atari
- 信息粒子滤波树:一种适用于连续域上基于信念奖励的POMDP的在线算法 2020
- 约翰内斯·费舍尔、厄默·萨欣·塔斯
- 关键词:连续POMDP、粒子滤波树、基于信息的奖励塑造、信息收集。
- 实验环境:POMDPs.jl框架
- 代码
- Retro*: 使用神经引导的A*搜索学习逆向合成规划 2020
- 陈炳宏、李承涛、戴汉军、宋乐
- 关键词:化学逆向合成规划、基于神经网络的类似A*的算法、ANDOR树
- 实验环境:USPTO数据集
- 代码
ICLR
- OptionZero: 带有学习选项的规划 2025
- 黄柏伟、彭沛纯、洪贵、吴季荣
- 关键词:选项、半马尔可夫决策过程、MuZero、MCTS、规划、强化学习
- 实验环境:26款Atari游戏
- 使用大语言模型为文字冒险游戏进行蒙特卡洛规划 2025
- 史子京、方萌、陈玲
- 关键词:大语言模型、蒙特卡洛树搜索、文字冒险游戏
- 实验环境:Jericho基准测试
- 认识论蒙特卡洛树搜索 2025
- 亚尼夫·奥伦、维利亚姆·瓦多奇、马蒂斯·T·J·斯潘、温德林·博默
- 关键词:基于模型、认识论不确定性、探索、规划、alphazero、muzero
- 实验环境:SUBLEQ(汇编语言)、深海
- 利用蒙特卡洛树搜索和事后反馈增强软件智能体 2025
- 安东尼斯·安东尼阿德斯、阿尔伯特·厄尔瓦尔、张克勋、谢宇熙、阿尼鲁德·戈亚尔、威廉·杨·王
- 关键词:智能体、LLM、SWE智能体、SWE基准测试、搜索、规划、推理、自我改进、开放性
- 实验环境:SWE基准测试
- 认识论蒙特卡洛树搜索 2025
- 温德林·博默、沈郑、段浩然、毛成志、罗萨里奥·斯卡利塞
- 关键词:MCTS、认识论不确定性、探索、稀疏奖励、基于模型的强化学习
- 实验环境:深海、SUBLEQ(汇编语言)
- DeepSeek-Prover-V1.5: 利用证明助手反馈进行强化学习和蒙特卡洛树搜索 2025
- DeepSeek Prover团队
- 关键词:自动化定理证明、LLM、MCTS、来自证明助手反馈的强化学习(RLPAF)、RMaxTS
- 实验环境:Lean 4、miniF2F、ProofNet
- 代码
- 面向离线基于模型的强化学习的贝叶斯自适应蒙特卡洛树搜索 2025
- 卢卡斯·牛·詹森等人
- 关键词:离线RL、基于模型的RL、贝叶斯自适应MDP、不确定性传播
- 实验环境:D4RL
- 决策时间规划的更新等价框架 2024
- 塞缪尔·索科塔、加布里埃莱·法里纳、大卫·J·吴、胡恒源、凯文·A·王、J·齐科·科尔特、诺姆·布朗
- 关键词:不完全信息游戏、搜索、决策时间规划、更新等价
- 实验环境:Hanabi、3x3突发黑暗六角棋和幽灵井字棋
- 通过规划实现高效的多智能体强化学习 2024
- 刘启涵、叶嘉宁、马晓腾、杨俊、梁斌、张崇杰
- 关键词:多智能体强化学习、规划、多智能体MCTS
- 实验环境:SMAC、LunarLander、MuJoCo和Google Research Football
- PromptAgent: 带有大语言模型的战略规划实现专家级提示优化 2024
- 杨竹天等人
- 关键词:提示优化、战略规划、MCTS、LLM代理
- 实验环境:BIG-Bench Hard(BBH)、MMLU、HellaSwag
- 代码
- 通过观看纯视频以有限数据成为熟练玩家 2023
- 叶伟睿、张云生、皮特·阿贝尔、高阳
- 关键词:从无动作视频中预训练、基于向量量化的目标前向-反向循环一致性(FICC)、预训练阶段、微调阶段
- 实验环境:Atari
- 基于策略的自我竞争解决规划问题 2023
- 乔纳森·皮尔奈、奎林·格特尔、雅各布·布尔格、多米尼克·格哈德·格林姆
- 关键词:自我竞争、通过针对过去可能策略的规划找到强轨迹
- 实验环境:旅行商问题和作业车间调度问题
- 通过探险者-导航者框架解释时序图模型 2023
- 夏文文、赖敏才、单彩华、张瑶、戴新楠、李翔、李东升
- 关键词:时序GNN解释器、利用MCTS寻找事件子集的探险者、学习事件之间相关性的导航者,从而减少搜索空间
- 实验环境:维基百科和Reddit、合成数据集
- SpeedyZero: 以有限数据和时间掌握Atari 2023
- 梅一轩、高佳轩、叶伟睿、刘绍怀、高阳、吴毅
- 关键词:分布式RL系统、优先刷新、剪切LARS
- 实验环境:Atari
- 使用学习模型进行高效的离线策略优化 2023
- 刘子晨、李思怡、李伟孙、颜水成、徐仲文
- 关键词:正则化一步基于模型的算法用于离线RL
- 实验环境:Atari、BSuite
- 代码
- 利用适应性树搜索实现任意翻译目标 2022
- 王凌、沃伊切赫·斯托科维茨、多梅尼克·多纳托、克里斯·戴尔、余磊、洛朗·萨特朗、奥斯汀·马修斯
- 关键词:适应性树搜索、翻译模型、自回归模型
- 实验环境:WMT2020的中文–英语和普什图语–英语任务、WMT2014的德语–英语任务
- 组合优化树搜索中的深度学习有何问题 2022
- 马克西米利安·博特尔、奥托·基西格、马丁·塔拉兹、萨雷尔·科恩、卡伦·赛德尔、托比亚斯·弗里德里希
- 关键词:组合优化、用于NP-hard最大独立集问题的开源基准测试套件、对流行的引导式树搜索算法的深入分析、将树搜索实现与其他求解器进行比较
- 实验环境:NP-hard的最大独立集
- 代码
- 带有语言行动价值估计的蒙特卡洛规划与学习 2021
- 张英洙、徐世钦、李钟民、金基雄
- 关键词:蒙特卡洛树搜索结合语言驱动的探索、本地乐观的语言价值估计
- 实验环境:互动小说(IF)游戏
- 应用于分子设计的实际大规模并行蒙特卡洛树搜索 2021
- 杨秀峰、塔努杰·克·阿萨瓦特、吉崎和纪
- 关键词:大规模并行蒙特卡洛树搜索、分子设计、哈希驱动的并行搜索
- 实验环境:辛醇-水分配系数(logP)受合成可及性(SA)和高额环罚分的影响
- 观察未被观测的事物:一种简单的方法来并行化蒙特卡洛树搜索 2020
- 刘安吉、陈建树、俞明泽、翟宇、周雪雯、刘继
- 关键词:并行蒙特卡洛树搜索、高效地将树分割成子树、比较每个处理器的观测比例
- 实验环境:JOY-CITY游戏的速度提升和性能对比、Atari游戏的平均回合回报
- 代码
- 通过神经探索-开发树学习高维规划 2020
- 陈炳宏、戴博、林秦杰、叶国、刘汉、宋乐
- 关键词:元路径规划算法、利用一种新颖的神经架构,可以从问题结构中学习有希望的搜索方向
- 实验环境:一个具有2自由度点机器人、一个3自由度棍形机器人和一个5自由度蛇形机器人的2D工作空间
NeurIPS
- 面向目标的信息获取的反馈感知MCTS 2025
- 哈曼普里特·乔普拉、奇拉格·沙阿
- 关键词:对话式AI、目标导向的信息获取、MCTS、LLM
- 实验环境:20个问题、GuessWhat?、MutualFriends
- MCTS-Transfer: 基于蒙特卡洛树搜索的空间转移用于黑箱优化 2024
- 王淑宽、薛科、宋乐、黄晓彬、钱超
- 关键词:黑箱优化、迁移学习、MCTS、搜索空间转移
- 实验环境:合成函数(Ackley等)、Design-Bench、超参数优化
- 代码
- 推测式蒙特卡洛树搜索 2024
- 朴勇宇、大卫·吴、凯林·佩尔林、吉米·魏、托马斯·安东尼、朱利安·施里特维瑟、安俊焕
- 关键词:效率、推测执行、并行性、AlphaZero
- 实验环境:围棋(9x9、19x19)
- 利用大语言模型引导的蒙特卡洛树搜索生成代码世界模型 2024
- 尼古拉·戴内塞、马泰奥·梅勒、明图·阿拉库亚拉、佩卡·马尔蒂宁
- 关键词:代码生成、世界模型、MCTS、基于模型的规划
- 实验环境:CWMB(代码世界模型基准测试)、Crafter
- ReST-MCTS*: LLM通过过程奖励引导的树搜索进行自我训练 2024
- 张丹、周思宁、胡子牛、岳一松、董宇晓、唐杰
- 关键词:LLM自我训练、过程奖励、推理、CoT
- 实验环境:GSM8K、MATH
- 代码
- LightZero: 用于一般顺序决策场景中蒙特卡洛树搜索的统一基准 2023
- 牛雅哲、浦元、杨振杰、李雪艳、周彤、任继远、胡帅、李鸿胜、刘宇
- 关键词:首个用于在一般顺序决策场景中部署MCTS/MuZero的统一基准
- 实验环境:ClassicControl、Box2D、Atari、MuJoCo、GoBigger、MiniGrid、井字棋、四子连珠、五子棋、2048等
- 大语言模型作为常识知识用于大规模任务规划 2023
- 赵子睿、李伟孙、大卫·许
- 关键词:世界模型(LLM)和由LLM诱导的策略可以结合在MCTS中,以扩大任务规划规模
- 实验环境:乘法运算、旅行规划、物品重新排列
- 带有玻尔兹曼探索的蒙特卡洛树搜索 2023
- 迈克尔·画家、穆罕默德·拜乌米、尼克·霍斯、布鲁诺·拉塞尔达
- 关键词:带有MCTS的玻尔兹曼探索、最大化熵目标的最佳行动不一定对应于原始目标的最佳行动、两种改进算法
- 实验环境:冰湖环境、航海问题、围棋
- 广义加权路径一致性以掌握Atari游戏 2023
- 赵登伟、涂士奎、徐磊
- 关键词:广义加权路径一致性、一种加权机制
- 实验环境:Atari
- 通过概率树状态抽象加速蒙特卡洛树搜索 2023
- 傅阳青、孙明、聂步清、高悦
- 关键词:概率树状态抽象、传递性和聚合误差界限
- 实验环境:Atari、CartPole、LunarLander、五子棋
- 明智地利用思考时间:利用虚拟扩展加速MCTS 2022
- 叶伟睿、皮特·阿贝尔、高阳
- 关键词:计算与性能之间的权衡、虚拟扩展、灵活地分配思考时间
- 实验环境:Atari、9x9围棋
- 为样本高效的模仿学习进行规划 2022
- 尹兆恒、叶伟睿、陈启峰、高阳
- 关键词:行为克隆、对抗性模仿学习(AIL)、基于MCTS的RL
- 实验环境:DeepMind Control Suite
- 代码
- 超越任务表现的评估:分析Hex中AlphaZero的概念 2022
- 查尔斯·洛弗林、杰西卡·佐萨·福德、乔治·科尼达里斯、艾莉·帕夫利克、迈克尔·L·利特曼
- 关键词:AlphaZero的内部表征、模型探测和行为测试、这些概念如何在网络中被捕获
- 实验环境:Hex
- 类似AlphaZero的智能体是否能抵御对抗性扰动? 2022
- 兰力成、张欢、吴季荣、蔡孟瑜、吴一臣、4位侯居正
- 关键词:对抗性状态、首次针对围棋AI的攻击
- 实验环境:围棋
- 用于黑箱优化的蒙特卡洛树下降 2022
- 翟耀光、高思存
- 关键词:黑箱优化、如何进一步整合基于样本的下降以加快优化速度
- 实验环境:非线性优化的合成函数、MuJoCo运动环境中的强化学习问题以及神经架构搜索(NAS)中的优化问题
- 基于蒙特卡洛树搜索的高维贝叶斯优化变量选择 2022
- 宋乐∗、薛科∗、黄晓彬、钱超
- 关键词:通过MCTS确定低维子空间,在该子空间中使用任何贝叶斯优化算法进行优化
- 实验环境:NAS-bench问题和MuJoCo运动
- 带有迭代细化状态抽象的蒙特卡洛树搜索 2021
- 塞缪尔·索科塔、迦勒·霍、扎欣·艾哈迈德、J·齐科·科尔特
- 关键词:随机环境、渐进式扩张、抽象细化
- 实验环境:二十一点、陷阱、五乘五围棋
- 侦察盲棋中的深度综合蒙特卡洛规划 2021
- 格雷戈里·克拉克
- 关键词:不完全信息、使用无权重粒子滤波器的状态信念、一种新型的随机信息状态抽象
- 实验环境:侦察盲棋
- POLY-HOOT: 在连续空间MDP中进行蒙特卡洛规划,并附带非渐近分析 2020
- 茂伟超、张凯庆、谢巧敏、塔米尔·巴萨尔
- 关键词:连续状态-动作空间、分层乐观优化
- 实验环境:CartPole、倒立摆、摇摆起、月球着陆器
- 利用蒙特卡洛树搜索学习黑箱优化的搜索空间划分 2020
- 王琳楠、罗德里戈·丰塞卡、田元东
- 关键词:通过少量样本学习搜索空间的划分、非线性决策边界以及学习局部模型以挑选出优秀的候选者
- 实验环境:MuJoCo运动任务、小型基准测试
- 混搭:一种乐观的树搜索方法,用于从混合分布中学习模型 2020
- 马修·法夫、拉贾特·森、卡尔提凯扬·桑穆甘、康斯坦丁·卡拉马尼斯、桑杰·沙科泰
- 关键词:协变量偏移问题、Mix&Match将随机梯度下降(SGD)与乐观树搜索和模型再利用相结合(用来自不同混合分布的样本逐步完善部分训练好的模型)
- 代码
其他会议或期刊
- 学会停止:动态模拟蒙特卡洛树搜索 AAAI 2021。
- 关于蒙特卡洛树搜索和强化学习 《人工智能研究杂志》2017年。
- 通过学习蒙特卡洛树搜索的动作实现样本高效的神经架构搜索 IEEE模式分析与机器智能事务 2022年。
💬 反馈与贡献
在 Github 上 提交问题
打开或参与我们的 讨论论坛
在 LightZero 的 Discord 服务器 中讨论
联系我们的邮箱 (opendilab@pjlab.org.cn)
我们非常感谢所有关于改进 LightZero 的反馈和贡献,无论是算法还是系统设计方面。
🌏 引用
@article{niu2024lightzero,
title={LightZero: A Unified Benchmark for Monte Carlo Tree Search in General Sequential Decision Scenarios},
author={Niu, Yazhe and Pu, Yuan and Yang, Zhenjie and Li, Xueyan and Zhou, Tong and Ren, Jiyuan and Hu, Shuai and Li, Hongsheng and Liu, Yu},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}
@article{puunizero,
title={UniZero: Generalized and Efficient Planning with Scalable Latent World Models},
author={Pu, Yuan and Niu, Yazhe and Yang, Zhenjie and Ren, Jiyuan and Li, Hongsheng and Liu, Yu},
journal={Transactions on Machine Learning Research}
}
@article{xuan2024rezero,
title={ReZero: Boosting MCTS-based Algorithms by Backward-view and Entire-buffer Reanalyze},
author={Xuan, Chunyu and Niu, Yazhe and Pu, Yuan and Hu, Shuai and Liu, Yu and Yang, Jing},
journal={arXiv preprint arXiv:2404.16364},
year={2024}
}
@article{pu2025one,
title={One Model for All Tasks: Leveraging Efficient World Models in Multi-Task Planning},
author={Pu, Yuan and Niu, Yazhe and Tang, Jia and Xiong, Junyu and Hu, Shuai and Li, Hongsheng},
journal={arXiv preprint arXiv:2509.07945},
year={2025}
}
💓 致谢
本项目部分基于 GitHub 仓库中的以下开创性工作开发而成。我们对这些基础资源表示由衷的感谢:
- https://github.com/opendilab/DI-engine
- https://github.com/deepmind/mctx
- https://github.com/YeWR/EfficientZero
- https://github.com/werner-duvaud/muzero-general
我们还要特别感谢以下贡献者 @PaParaZz1、@karroyan、@nighood、 @jayyoung0802、@timothijoe、@TuTuHuss、@HarryXuancy、@puyuan1996、@HansBug,感谢他们对本算法库的宝贵贡献和支持。
感谢所有为本项目做出贡献的人:

🏷️ 许可证
本仓库中的所有代码均采用 Apache License 2.0 许可证。
(返回顶部)
版本历史
v0.2.02025/04/09v0.1.02024/07/12v0.0.52024/04/16v0.0.42024/02/21v0.0.32023/12/07v0.0.22023/09/21v0.0.12023/04/14常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器