LMDrive
LMDrive 是一个基于大语言模型(LLM)的端到端自动驾驶框架,旨在实现闭环自主驾驶。它不仅能处理多视角传感器数据来感知动态环境,还能理解自然语言指令,让车辆像人类一样“听懂”导航要求并做出相应驾驶决策。
传统自动驾驶系统往往难以灵活应对复杂的长尾场景或遵循模糊的人类指令。LMDrive 通过引入大语言模型的强大推理能力,解决了这一痛点,将视觉感知与语言理解深度融合,使车辆能够在开放环境中进行更智能、更具解释性的规划与控制。
这款工具主要适合自动驾驶领域的研究人员和开发者使用。如果你正在探索多模态融合、具身智能或语言引导的机器人控制,LMDrive 提供了完整的代码库、预训练模型以及基于 CARLA 仿真器构建的数据集,便于复现论文成果或开展二次开发。
其核心技术亮点在于“闭环”与“语言引导”。不同于仅做单次预测的开环系统,LMDrive 能根据执行结果不断调整策略;同时,它利用大模型作为决策中枢,实现了从传感器输入到控制输出的端到端训练,为下一代可交互、可解释的智能驾驶系统提供了新的研究范式。
使用场景
某自动驾驶研发团队正在复杂城市路口测试车辆对突发指令的响应能力,要求车辆能理解“在前方施工区域减速并绕行”这类自然语言命令。
没有 LMDrive 时
- 指令解析僵化:传统系统依赖预定义代码规则,无法理解“施工区域”、“绕行”等非结构化自然语言,必须人工编写特定脚本。
- 感知决策割裂:视觉传感器识别到的障碍物数据与决策模块分离,导致车辆看到路障后无法立即结合语音指令调整路径。
- 闭环响应滞后:从接收指令到执行动作需经过多个独立模块转换,延迟高,难以应对动态变化的交通流。
- 场景泛化性差:遇到训练数据未覆盖的罕见路况(如临时改道),系统往往直接报错或停止运行。
使用 LMDrive 后
- 自然语言直连控制:LMDrive 利用大语言模型直接理解“施工区域绕行”指令,无需中间代码翻译,瞬间转化为驾驶策略。
- 多模态端到端融合:系统将多视角摄像头数据与语言指令在模型内部深度融合,边看路边理解意图,实时规划避让轨迹。
- 低延迟闭环执行:基于端到端架构,感知到执行的链路极短,车辆能流畅地完成减速、变道等连续动作。
- 强泛化适应能力:凭借大模型的推理能力,即使面对从未见过的临时路障组合,也能依据常识做出合理驾驶判断。
LMDrive 通过语言大模型重构了自动驾驶的感知决策闭环,让车辆真正具备了像人类司机一样“听懂话、看懂路、灵活开”的核心能力。
运行环境要求
- Linux
- 必需 NVIDIA GPU
- README 中启动 CARLA 服务器的命令使用了 CUDA_VISIBLE_DEVICES,且建议安装 flash-attn,隐含需要支持 CUDA 的 NVIDIA 显卡
- 具体显存大小未说明(取决于所选 LLM 基座模型,如 7B 模型通常建议 16GB+)
未说明

快速开始
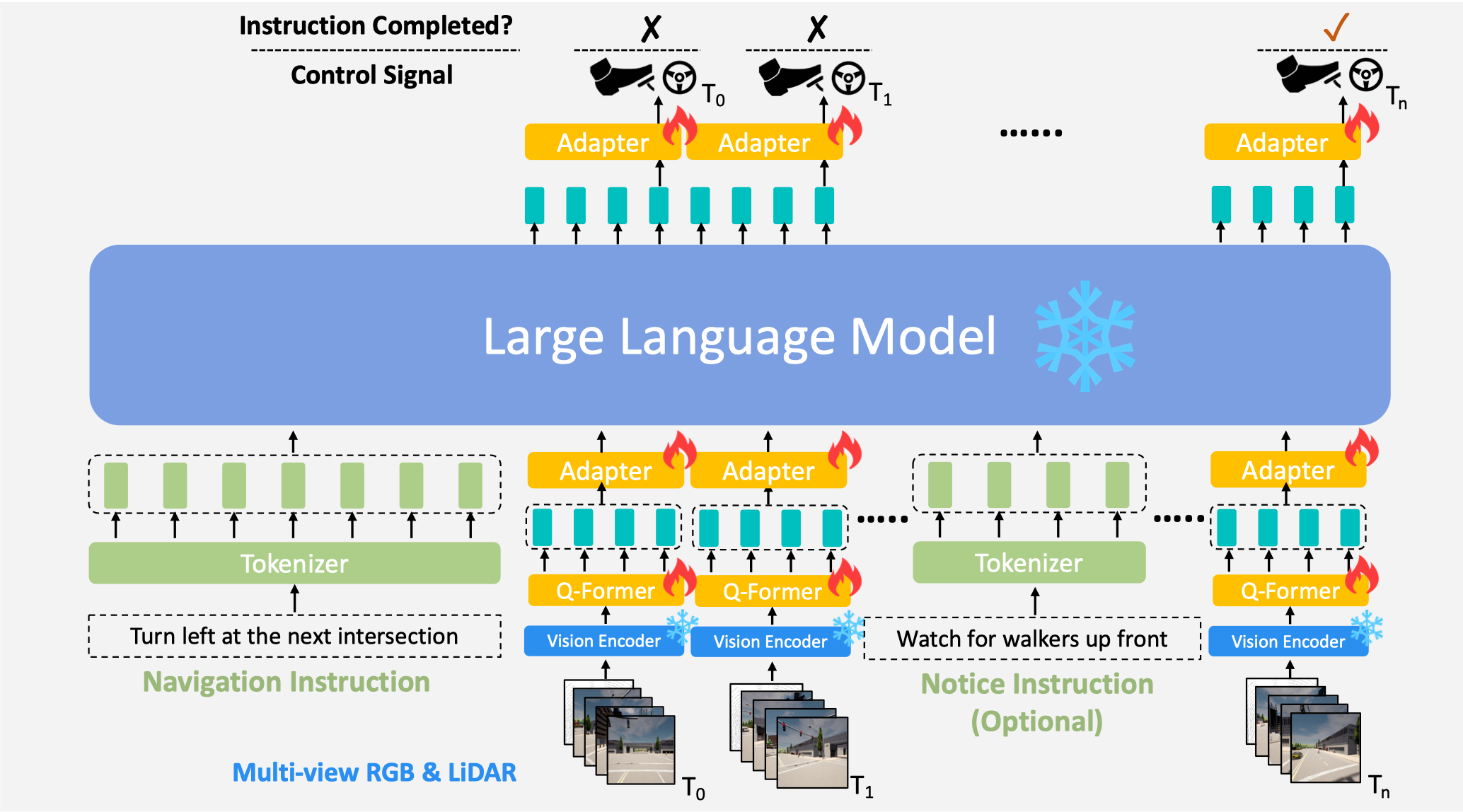
LMDrive: 基于大型语言模型的闭环端到端自动驾驶
一个端到端、闭环、基于语言的自动驾驶框架,通过多模态多视角传感器数据和自然语言指令与动态环境交互。
[项目页面] [论文] [数据集(Hugging Face)] [模型库]
[数据集(OpenXlab)] [模型库(OpenXLab)]
![]()
![]()
![]()
新闻
[02/27]LMDrive 被 CVPR 2024 接收 🎉🎉🎉[01/25]我们将模型上传至 OpenXLab[01/23]我们在 智东西 进行了演讲[01/20]我们将数据集上传至 OpenXLab[12/21]我们发布了项目官网 这里
邵浩、胡宇轩、王乐天、史蒂文·L·瓦斯兰德、刘宇、李宏升。
本仓库包含论文 LMDrive: 基于大型语言模型的闭环端到端自动驾驶 的代码。这项工作提出了一种新颖的、由语言引导的、端到端、闭环的自动驾驶框架。
演示视频
目录
设置
我们的项目基于三个部分构建:(1) 视觉编码器(对应仓库:timm);(2) 视觉大语言模型(对应仓库:LAVIS);(3) 数据采集、智能体控制器(对应仓库:InterFuser、Leaderboard、ScenarioRunner)。
安装 Anaconda
wget https://repo.anaconda.com/archive/Anaconda3-2020.11-Linux-x86_64.sh
bash Anaconda3-2020.11-Linux-x86_64.sh
source ~/.bashrc
克隆仓库并搭建环境
git clone https://github.com/opendilab/LMDrive.git
cd LMDrive
conda create -n lmdrive python=3.8
conda activate lmdrive
cd vision_encoder
pip3 install -r requirements.txt
python setup.py develop # 如果你之前已经安装过 timm,请先卸载
cd ../LAVIS
pip3 install -r requirements.txt
python setup.py develop # 如果你之前已经安装过 LAVIS,请先卸载
pip install flash-attn --no-build-isolation # 可选
下载并设置 CARLA 0.9.10.1
chmod +x setup_carla.sh
./setup_carla.sh
pip install carla
如果你在使用 Carla 时遇到问题,请先参考 Carla Issues 和 InterFuser Issues。
LMDrive 权重
如果你有兴趣在模型库中添加其他内容,请提交一个问题 :)
| 版本 | 大小 | 检查点 | 视觉编码器 | LLM 基础 | DS (LangAuto) | DS (LangAuto-short) |
|---|---|---|---|---|---|---|
| LMDrive-1.0 (LLaVA-v1.5-7B) | 7B | LMDrive-llava-v1.5-7b-v1.0 | R50 | LLaVA-v1.5-7B | 36.2 | 50.6 |
| LMDrive-1.0 (Vicuna-v1.5-7B) | 7B | LMDrive-vicuna-v1.5-7b-v1.0 | R50 | Vicuna-v1.5-7B | 33.5 | 45.3 |
| LMDrive-1.0 (LLaMA-7B) | 7B | LMDrive-llama-7b-v1.0 | R50 | LLaMA-7B | 31.3 | 42.8 |
DS 表示驾驶评分
数据集
我们旨在开发一种智能驾驶代理,该代理能够根据三种输入源生成驾驶动作:1) 传感器数据(多视角摄像头和 LiDAR),使代理能够生成既了解当前场景又符合场景要求的动作;2) 导航指令(例如变道、转弯),使代理能够按照自然语言指令(来自人类或导航软件)进行驾驶;以及 3) 人工提示指令,使代理能够与人类互动,并适应人类的建议和偏好(例如关注对抗性事件、处理长尾事件等)。
我们提供了一个包含约 6.4 万个数据片段的数据集,每个片段包括一条导航指令、若干条提示指令、一系列多模态多视角传感器数据以及控制信号。每个片段的时长从 2 秒到 20 秒不等。我们论文中使用的数据集可在此下载 这里。如果你想创建自己的数据集,请按照我们下面列出的步骤操作。
概述
数据是使用 CARLA 0.9.10.1 中 leaderboard/data 路径下的路线和场景文件,在 8 个 CARLA 城镇中,通过 leaderboard/team_code/auto_pilot.py 生成的。数据集以高频率(约 10Hz)采集。
在下载我们的数据集或自行采集数据后,需要按照以下方式系统地组织数据。DATASET_ROOT 是您存储数据集的根目录。
├── $DATASET_ROOT
│ └── dataset_index.txt # 用于视觉编码器预训练
│ └── navigation_instruction_list.txt # 用于指令微调
│ └── notice_instruction_list.json # 用于指令微调
│ └── routes_town06_long_w7_11_28_18_28_35 # 数据文件夹
│ └── routes_town01_short_w2_11_16_08_27_10
│ └── routes_town02_short_w2_11_16_22_55_25
│ └── routes_town01_short_w2_11_16_11_44_08
├── rgb_full
├── lidar
└── ...
navigation_instruction_list.txt 和 notice_instruction_list.json 可以通过我们的数据解析脚本生成 脚本。
您收集的数据集中每个子文件夹应按如下结构组织:
- routes_town(town_id)_{tiny,short,long}_w(weather_id)_timestamp:对应不同的城镇和路线文件
- routes_X:包含单条路线的数据
- rgb_full:分辨率为 400x1200 的多视角大图,可拆分为四张图像(左、中、右、后)
- lidar:.npy 格式的 3D 点云数据。仅包含 1/20 秒内采集的 LiDAR 点,覆盖 180 度水平视野。若需 360 度视野,则需与 lidar_odd 数据合并。
- lidar_odd:.npy 格式的 3D 点云数据。
- birdview:俯视分割图像,LAV 和 LBC 曾使用此类数据进行训练。
- topdown:类似于 birdview,但由向下拍摄的摄像头捕捉。
- 3d_bbs:不同目标的 3D 包围盒。
- affordances:各类可供性信息。
- actors_data:包含周围车辆及交通信号灯的位置、速度等元数据。
- measurements:包含自车位置、速度、未来航点等元数据。
- measurements_full:将 measurements 和 actors_data 合并。
- measurements_all.json:将 measurements_full 中的文件合并为一个单独的文件。
$DATASET_ROOT 目录下必须包含名为 dataset_index.txt 的文件,该文件可通过我们的数据预处理脚本生成 脚本。文件应按以下格式列出训练和评估数据:
<relative_route_path_dir> <num_data_frames_in_this_dir>
routes_town06_long_w7_11_28_18_28_35/ 1062
routes_town01_short_w2_11_16_08_27_10/ 1785
routes_town01_short_w2_11_16_09_55_05/ 918
routes_town02_short_w2_11_16_22_55_25/ 134
routes_town01_short_w2_11_16_11_44_08/ 569
其中 <relative_route_path_dir> 应为相对于 $DATASET_ROOT 的相对路径。训练代码会将 $DATASET_ROOT 和 <relative_route_path_dir> 拼接起来,形成加载数据的完整路径。例如,1062 表示 routes_town06_long_w7_11_28_18_28_35/rgb_full 或 routes_town06_long_w7_11_28_18_28_35/lidar 等目录中的帧数。
数据生成
使用多个 CARLA 服务器生成数据
除了数据集外,我们还提供了所有用于生成数据的脚本,并可根据不同 CARLA 版本的需求进行修改。数据集由基于规则的专家智能体在不同天气和城镇中采集。
启动 CARLA 服务器
# 启动 4 个 CARLA 服务器:IP [localhost],端口 [2000, 2002, 2004, 2006]。您可以根据实际情况调整 CARLA 服务器的数量,更多的服务器可以采集更多数据。如果您使用 N 个服务器采集数据,则意味着您在每条路线上采集了 N 次数据,每次的天气和交通场景都是随机的。
cd carla
CUDA_VISIBLE_DEVICES=0 ./CarlaUE4.sh --world-port=2000 -opengl &
CUDA_VISIBLE_DEVICES=1 ./CarlaUE4.sh --world-port=2002 -opengl &
CUDA_VISIBLE_DEVICES=2 ./CarlaUE4.sh --world-port=2004 -opengl &
CUDA_VISIBLE_DEVICES=3 ./CarlaUE4.sh --world-port=2006 -opengl &
Docker 设置说明请参见 此处。拉取 CARLA 0.9.10.1 的 Docker 镜像:docker pull carlasim/carla:0.9.10.1。
Docker 18:
docker run -it --rm -p 2000-2002:2000-2002 --runtime=nvidia -e NVIDIA_VISIBLE_DEVICES=0 carlasim/carla:0.9.10.1 ./CarlaUE4.sh --world-port=2000 -opengl
Docker 19:
docker run -it --rm --net=host --gpus '"device=0"' carlasim/carla:0.9.10.1 ./CarlaUE4.sh --world-port=2000 -opengl
如果 Docker 容器无法正常启动,请添加环境变量 -e SDL_AUDIODRIVER=dsp。
运行自动驾驶程序
批量采集数据的脚本生成。
cd dataset
python init_dir.py
cd ..
cd data_collection
# 您可以修改 auto_agent.yaml 中的 FPS、航点分布强度等参数...
# 如果未使用 4 个服务器,则需要使用以下 Python 脚本来调整:
python generate_bashs.py
python generate_batch_collect.py
cd ..
运行您需要采集的城镇和路线类型的批量执行脚本。
bash data_collection/batch_run/run_route_routes_town01_long.sh
bash data_collection/batch_run/run_route_routes_town01_short.sh
...
bash data_collection/batch_run/run_route_routes_town07_tiny.sh
...
bash data_collection/batch_run/run_route_routes_town10_tiny.sh
注意: 我们的脚本在采集数据时会随机选择天气条件。
使用单个 CARLA 服务器生成数据
使用单个 CARLA 服务器,运行自动驾驶程序开始数据生成。
carla/CarlaUE4.sh --world-port=2000 -opengl
./leaderboard/scripts/run_evaluation.sh
用于数据生成的专家智能体定义在 leaderboard/team_code/auto_pilot.py 中。需要设置的不同变量在 leaderboard/scripts/run_evaluation.sh 中指定。
数据预处理
我们在 tools/data_preprocessing 中提供了一些用于预处理采集数据的 Python 脚本,其中部分为可选步骤。请按照以下顺序执行:
python get_list_file.py $DATASET_ROOT:生成 dataset_list.txt。python batch_merge_data.py $DATASET_ROOT:将分散的多个数据文件合并为一个文件,以减少训练时的 IO 时间。[可选]python batch_rm_rgb_data.py $DATASET_ROOT:在将数据合并到新文件后,删除冗余文件。[可选]python batch_stat_blocked_data.py $DATASET_ROOT:查找自车长时间被阻挡的帧。移除这些帧可以改善数据分布并减小整体数据量。python batch_rm_blocked_data.py $DATASET_ROOT:删除被阻挡的帧。python batch_recollect_data.py $DATASET_ROOT:由于我们已移除部分帧,需要重新整理数据,以确保帧 ID 连续。python batch_merge_measurements.py $DATASET_ROOT:将单个路线文件夹中所有帧的测量文件合并,以减少 IO 时间。
数据解析
在完成数据采集和预处理后,我们需要使用 tools/data_parsing 中的一些 Python 脚本来解析导航指令和提示指令数据。
解析导航指令的脚本:
python3 parse_instruction.py $DATSET_ROOT
解析后的导航片段将保存在数据集根目录下的 $DATSET_ROOT/navigation_instruction_list.txt 中。
解析提示指令的脚本:
python3 parse_notice.py $DATSET_ROOT
解析后的提示片段将保存在 $DATSET_ROOT/notice_instruction_list.txt 中。
解析误导性指令的脚本:
python3 parse_misleading.py $DATSET_ROOT
解析后的误导性片段将保存在 $DATSET_ROOT/misleading_data.txt 中。
训练
LMDrive 的训练分为两个阶段:1) 视觉编码器预训练阶段,用于从传感器输入中生成视觉 token;2) 指令微调阶段,用于对齐指令/视觉信息与控制信号。
LMDrive 使用 8 张 80GB 显存的 A100 GPU 进行训练(第一阶段也可在 32GB 显存的 GPU 上进行)。若使用较少的 GPU,可在保持比例不变的情况下降低 batch-size 和 learning-rate。
如果您未自行采集数据,请从论文中使用的 CARLA 模拟器中收集的多模态指令数据集下载数据,链接如下:Hugging Face 或 OpenXLab。您也可以仅下载部分数据来验证我们的框架或您的改进。
视觉编码器预训练
在 8 张 A100(80G)上,视觉编码器的预训练大约需要 2~3 天。训练完成后,您可以在 output/ 目录下找到视觉编码器的检查点。
cd vision_encoder
bash scripts/train.sh
需要注意的几个选项:
GPU_NUM:您希望使用的 GPU 数量,默认为 8。DATASET_ROOT:存储数据集的根目录。--model:视觉模型的结构。您可以选择 memfuser_baseline_e1d3_r26,它用 ResNet26 替代了 ResNet50。此外,您还可以在visual_encoder/timm/models/memfuser.py中创建新的模型变体。--train-towns/train-weathers:用于筛选训练数据集的过滤条件。同样地,也有对应的val-towns/val-weathers选项来筛选验证数据集。
指令微调
在 8 张 A100(80G)上,指令微调大约需要 2~3 天。训练完成后,您可以在 lavis/output/ 目录下找到适配器和 qformer 的检查点。
cd LAVIS
bash run.sh 8 lavis/projects/lmdrive/notice_llava15_visual_encoder_r50_seq40.yaml # 8 表示 GPU 数量
config.yaml 中需要注意的几个选项:
preception_model:视觉编码器的模型架构。preception_model_ckpt:视觉编码器的检查点路径。llm_model:LLM(Vicuna/LLaVA)的检查点路径。use_notice_prompt:训练时是否使用提示指令数据。split_section_num_for_visual_encoder:视觉特征前向编码过程中,帧被分割成的段数。数值越高越节省显存,且必须是token_max_length的因数。- 数据集:
storage:存储数据集的根目录。towns/weathers:用于训练和评估的数据筛选条件。token_max_length:最大帧数,超过此值的帧会被截断。sample_interval:采样间隔。
评估
启动 CARLA 服务器(如上所述)并运行所需的智能体。充分的路线和场景文件位于 leaderboard/data 中,所需变量需在 leaderboard/scripts/run_evaluation.sh 中设置。
需要在 leaderboard/team_code/lmdrive_config.py 中更新以下选项:
preception_model:视觉编码器的模型架构。preception_model_ckpt:视觉编码器的检查点路径(在视觉编码器预训练阶段获得)。llm_model:LLM(LLaMA/Vicuna/LLaVA)的检查点路径。lmdrive_ckpt:LMDrive 的检查点路径(在指令微调阶段获得)。
更新 leaderboard/scripts/run_evaluation.sh,加入以下代码以评估模型在 Town05 Long Benchmark 上的表现:
export CARLA_ROOT=/path/to/carla/root
export TEAM_AGENT=leaderboard/team_code/lmdrive_agent.py
export TEAM_CONFIG=leaderboard/team_code/lmdrive_config.py
export CHECKPOINT_ENDPOINT=results/lmdrive_result.json
export SCENARIOS=leaderboard/data/official/all_towns_traffic_scenarios_public.json
export ROUTES=leaderboard/data/LangAuto/long.xml
CUDA_VISIBLE_DEVICES=0 ./leaderboard/scripts/run_evaluation.sh
在此处,将 long.json 和 long.xml 替换为 short.json 和 short.xml,即可评估智能体在 LangAuto-Short 基准上的表现。
对于 LangAuto-Tiny 基准的评估,将 long.json 和 long.xml 替换为 tiny.json 和 tiny.xml:
export SCENARIOS=leaderboard/data/LangAuto/tiny.json
export ROUTES=leaderboard/data/LangAuto/tiny.xml
LangAuto-Notice
在 lmdriver_config.py 中将 agent_use_notice 设置为 True。
引用
如果您认为我们的仓库、数据集或论文有用,请按以下格式引用:
@misc{shao2023lmdrive,
title={LMDrive: Closed-Loop End-to-End Driving with Large Language Models},
author={Hao Shao and Yuxuan Hu and Letian Wang and Steven L. Waslander and Yu Liu and Hongsheng Li},
year={2023},
eprint={2312.07488},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
致谢
本实现基于多个仓库中的代码。
许可证
本仓库中的所有代码均采用 Apache License 2.0 许可证。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。