CleanS2S
CleanS2S 是一个仅需单个文件即可运行的高质量、流式语音对语音(Speech-to-Speech)交互智能体原型。它旨在模拟类似 GPT-4o 的自然对话体验,让用户能直接感受语言用户界面(LUI)的魅力,并帮助研究者快速验证语音交互流水线的潜力。
传统语音交互系统往往架构复杂、配置繁琐且难以实时响应。CleanS2S 通过极简的单文件设计解决了这一痛点,将自动语音识别(ASR)、大语言模型(LLM)和语音合成(TTS)完整集成,无需复杂的环境配置即可启动。其核心技术亮点在于实现了真正的全双工实时流式交互:基于 WebSocket 和多线程机制,用户不仅可以与智能体像真人一样自然对话,还能在智能体播报过程中随时打断并插入新指令,系统会立即响应。
这款工具非常适合希望快速探索 S2S 技术的研究人员、想要低成本验证新想法的开发者,以及需要参考实现来构建自定义语音应用的技术团队。由于代码结构清晰且易于修改,用户也可以轻松替换其中的大模型组件或添加新功能。无论是用于学术实验还是原型开发,CleanS2S 都提供了一个干净、高效且功能强大的起点。
使用场景
一位独立开发者希望快速构建一个能像真人一样实时对话、支持随时打断的语音助手原型,用于验证新的交互理念。
没有 CleanS2S 时
- 工程搭建繁琐:需要分别集成 ASR、LLM 和 TTS 多个模块,配置复杂的依赖环境和项目文件结构,耗时数天才能跑通基础流程。
- 交互体验割裂:传统方案多为“说完再转、转完再答”的半双工模式,用户必须等待对方完全说完才能回应,无法实现自然的人机对话节奏。
- 难以支持打断:若想在模型播报时通过语音插话打断,需自行设计复杂的音频流中断逻辑和多线程队列管理,开发门槛极高。
- 迭代验证缓慢:每更换一个底层大模型或调整流水线逻辑,都涉及大量代码重构,严重阻碍了新想法的快速验证。
使用 CleanS2S 后
- 单文件即刻启动:所有核心逻辑封装在单一文件中,无需纠结依赖配置,开发者下载即可运行,几分钟内建立起完整的流式语音链路。
- 拟人化实时流交互:基于 WebSocket 的全双工架构,让声音与文字数据实时流转,用户可与 CleanS2S 进行如 GPT-4o 般流畅的“边说边听”对话。
- 原生支持智能打断:内置 VAD(语音活动检测)与中断机制,用户在助手播报时随时开口,CleanS2S 能立即停止当前输出并响应新指令。
- 灵活定制易扩展:代码结构清晰透明,开发者可轻松替换喜欢的 LLM 模型或添加新功能组件,极大加速了从原型到产品的探索过程。
CleanS2S 通过极简的单文件架构与强大的全双工流式能力,让开发者能以最低成本瞬间拥有高保真的类人语音交互原型。
运行环境要求
- Linux
- 未明确说明具体型号,但运行 FunASR (paraformer-zh) 和 CosyVoice-300M 通常需要 NVIDIA GPU
- 建议使用支持 CUDA 的显卡以确保实时流式处理性能
未说明(建议 16GB+ 以承载多个语音模型及 LLM 上下文)

快速开始
CleanS2S
英语 | 简体中文
CleanS2S 是一款语音到语音(S2S)原型代理,以单文件实现方式提供高质量、流式交互。该设计简洁明了,旨在打造类似 GPT-4o 风格的中文交互式原型代理。本项目希望让用户直接体验语言用户界面(LUI)的强大功能,并帮助研究人员快速探索和验证 S2S 流水线的潜力。
新增【主观行动判断】功能(详见 backend/README.zh.md),增强了代理在对话中主动发起行动的能力。
以下是 CleanS2S 的一些实时对话演示:
注意:请先打开视频的静音。
|
投资话题1 |
投资话题2 |
心情话题 |
高考志愿话题 |
大纲
特性
📜 单文件实现
一种代理流水线的所有细节都被整合进一个独立的文件中。无需额外配置依赖或理解复杂的项目结构,因此对于希望快速了解 S2S 流水线并在此基础上直接验证新想法的人来说,这是一个极佳的参考实现。所有流水线组件都易于修改和扩展,用户可以迅速更换自己喜欢的模型(如 LLM)、添加新组件或自定义流水线。
🎮 实时流式交互界面
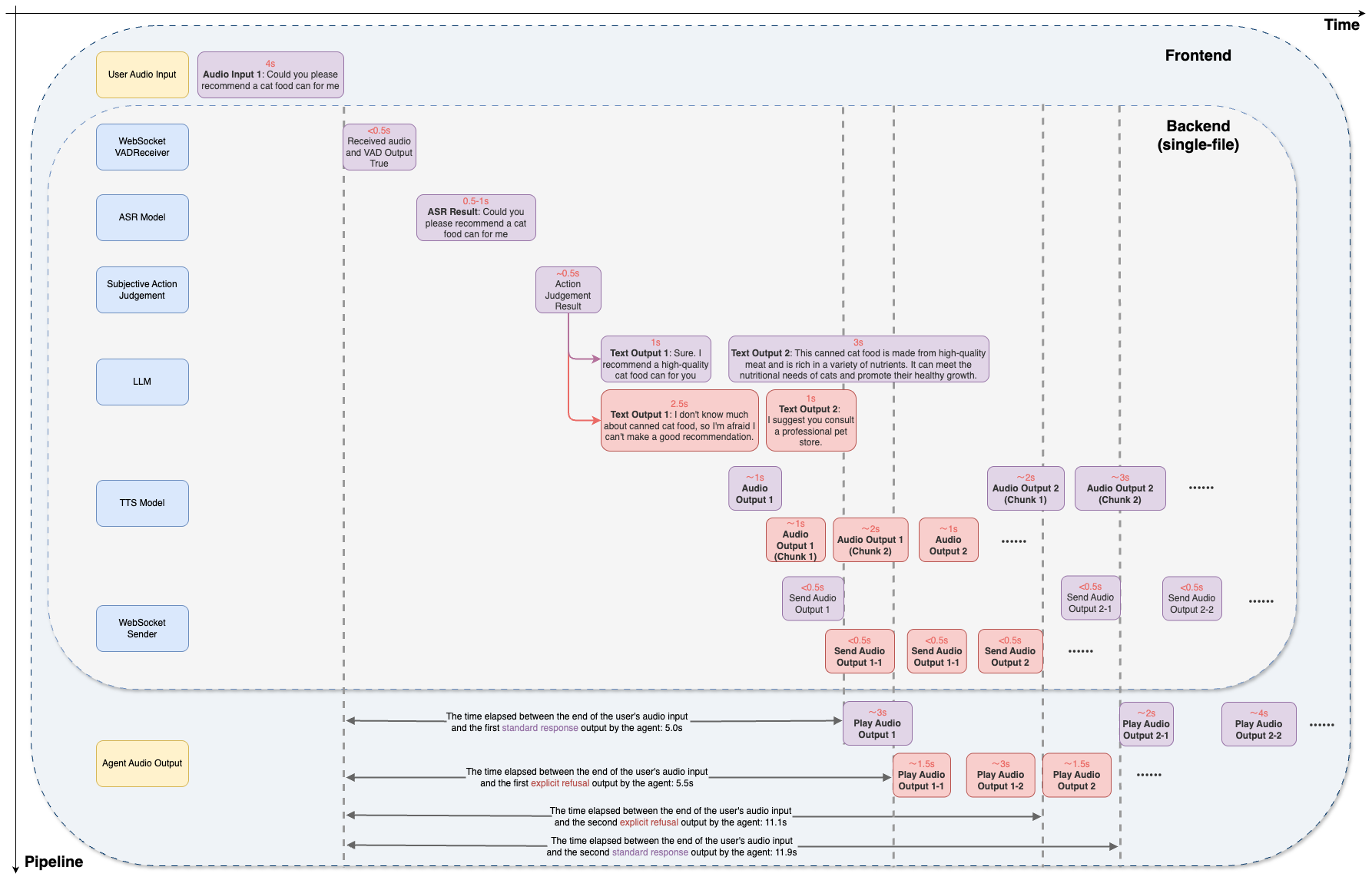
整个 S2S 流水线主要由 ASR(自动语音识别,即语音转文本)、LLM(大型语言模型)和 TTS(文本转语音)组成,同时包含两个 WebSocket 组件:接收器(内置 VAD)和发送器。该流水线专为实时流式交互设计,使用户能够像与真人对话一样与代理进行实时互动。所有音频和文本信息均通过 WebSocket 流式传输。
为此,我们采用了多线程和队列机制来确保流式处理的顺畅运行,避免阻塞问题。所有组件均为异步非阻塞设计,从输入队列获取数据并将其处理结果放入输出队列。
🧫 全双工交互与打断功能
基于 WebSockets 提供的强大机制,该流水线支持全双工交互,即用户可以在与代理交谈的同时进行发言和聆听。此外,流水线还支持打断功能——用户可在对话中的任何时刻通过新的语音输入打断代理,代理会立即停止当前处理任务,转而根据之前的对话内容及打断信息继续处理新输入。
值得一提的是,我们发现聊天机器人中常见的“助手式”和“轮次式”响应方式是阻碍人机对话自然流畅的主要原因之一。为此,我们为代理增加了更多有趣的策略,以提升对话的互动性和吸引力。
🌍 配备网络搜索和RAG功能
该流程进一步通过集成网络搜索能力和检索增强生成(RAG)模型而得到增强。 这些功能使智能体不仅能够实时处理并响应用户输入,还能访问并整合来自网络的外部信息到其回复中。 这为回答用户提出的各种实际问题提供了扩展性和灵活性。
- WebSearchHelper类负责根据用户查询进行在线搜索,或收集与对话相关的额外信息。这使得智能体能够引用最新或外部数据,从而提升其回复的丰富性和准确性。
- RAG类实现了检索增强生成方法,首先从数据库中检索相关信息,然后利用这些信息生成回复。这一两步流程确保了智能体的回答建立在相关、真实的数据基础上,从而实现更加知情且符合上下文的交互。
输出示例
注意:由于我们的计算资源限制,最大输出标记数被限制在一个较小的规模。
| 案例 |
语言模型处理器 |
RAG语言模型助手 |
|---|---|---|
| 1 | 芭比波朗虫草粉底液产品口播文案\n\n大家好,我是你们的美妆达人小美,今天我要向大家介绍一款我最近发现的宝藏产品——芭比波朗虫草粉底液。首先,让我们来看看这款粉底液的 产品特性。它采用三重持色科技,能够均匀分散,贴肤不结块,让你的妆容持久不暗沉。同时,它还拥有面霜级的质地,特别适合干性肌肤使用,能够提供长时间的滋润和保湿效果,使肌肤在上妆的同时得到滋养。其次,>让我们来看看这款粉底液是如何满足用户需求的。它含有37种护肤精粹,包括冬虫夏草与人参提取物,这些成分能够激发肌肤能量,提供抗老效果,同时积雪草与圣保罗草有助于紧致肌肤。此外,它还含有透明质酸与稻米>提取物,确保了粉底液的高保湿效果,使用后肌肤不会感到干燥紧绷。 | 天啊,我太恨芭比布朗了,为什么这么晚才让我知道还有这么好用的产品!芭比布朗,你不营销你的虫草粉底液你糊涂啊!\n\n你知道吗。我之前用的那些粉底液,不是卡粉就>是脱妆,冬天用还特别干,简直让人抓狂。直到我遇到了芭比波朗的虫草粉底液,我的天,简直是干皮救星!它的质地就像面霜一样,滋润得不得了,上妆后皮肤感觉水润润的,完全没有紧绷感。而且,它的粉质超级细腻>,用三重持色科技,上妆后均匀分散,贴肤不结块,简直就是自然无瑕的代名词。更别提 |
| 2 | MAC无暇粉底液二代\n\n## 产品特性\n\nMAC无暇粉底液二代是一款专为油皮星姐妹打造的粉底液。它具有以下特点:\n\n- 持久控油:能够24小时持妆,即使到了晚上也能保持妆容>不花。- 全新科技:采用PRO流体黑科技,使得粉底液能够均匀覆盖肤色,同时保持轻薄服帖。- 不脱妆:妆效持久,不卡粉、不斑驳、不拔干,适合长时间保持完美妆容。- 控油成分:含有糖海带精粹,有助于控油,使油 性皮肤能够全天保持雾面效果。- 高遮瑕力:能够有效遮盖痘痘、痘坑和毛孔,提供高遮瑕效果,即使近距离观察也不怕。- 养肤成分:含有80%的养肤精粹,成分温和,有助于抵抗外界刺激,同时长效平衡水油。- 专为亚洲肌肤定制:提供三大明星色号,适合亚洲人的肤色,更容易找到匹配自己肤色的粉底液。## 用户需求对接\n\n油皮星姐妹常常苦恼于粉底液经常脱妆,容易氧化,假白等问题。而MAC无暇粉底液二代正是为了解决这些问>题而生。它能够持久控油,不脱妆,不卡粉,不斑驳,不拔干,适合爱夜生活的晚8人们。同时,它还能够遮盖痘痘、痘坑和毛孔,提供高遮瑕效果,让油皮姐妹们在任何场合都能保持完美妆容。 | 嘿,油皮姐妹们,是不是常常为脱妆、氧化、假白这些问题烦恼。别担心,MAC无暇粉底液二代来拯救你们啦!这款粉底液简直就是油皮的救星,24小时持妆,晚8点出门也不怕>花妆,整夜都能保持无暇状态。全新PRO流体黑科技,让你的肤色匀净,轻薄服帖,妆效持久不卡粉、不斑驳、不拔干。更厉害的是,它含有糖海带精粹,一抹就能控油,大油皮全天都能保持雾面效果。痘痘、痘坑、毛孔统 统不在话下,高遮瑕力让你不怕怼脸看。而且,80%的养肤精粹 |
开始使用
后端(服务器)
安装
## 克隆仓库
git clone https://github.com/opendilab/CleanS2S.git
cd CleanS2S/backend
pip install -r requirements.txt
下载模型
你需要下载4个必要的模型(3个ASR + 1个TTS),可以从以下链接下载,并将其放置在你自己的合适目录中。
- ASR: paraformer-zh, ct-punc, fsmn-vad
- TTS: CosyVoice-300M
对于LLM,默认使用LLM API,你也可以按照下面的说明自定义你本地的LLM模型(如DeepSeek-V2.5、Qwen2.5等)。
删除
--enable_llm_api和--lm_model_url参数,并将--lm_model_name参数修改为你本地LLM模型的路径(例如:--lm_model_name /home/users/deepseek-v2.5)。
你还需要准备一个参考音频目录,其中包含用于韵律和音色迁移的参考音频。我们在这个仓库中提供了一个示例参考音频目录。 如果你想要使用自己的参考音频,需要保持与示例参考音频目录相同的格式。音频长度应在10~20秒之间,且发音清晰。
运行服务器
以下是使用默认设置运行服务器的示例:
export LLM_API_KEY=<your-deepseek-api-key>
python3 -u s2s_server_pipeline.py \
--recv_host 0.0.0.0 \
--send_host 0.0.0.0 \
--stt_model_name <your-asr-path> \
--enable_llm_api \
--lm_model_name "deepseek-chat" \
--lm_model_url "https://api.deepseek.com" \
--tts_model_name <your-tts-path> \
--ref_dir <ref-audio-path> \
--enable_interruption
ℹ️ 支持自定义LLM:这里我们默认使用 deepseek-chat 作为LLM API,你也可以根据 OpenAI 接口更换为其他LLM API。(修改
--lm_model_name和--lm_model_url,并设置你自己的API密钥)
ℹ️ 支持 MiniMax:MiniMax 提供兼容 OpenAI 的 API,并支持长上下文模型。设置
MINIMAX_API_KEY(或LLM_API_KEY)后,可以使用以下示例:export MINIMAX_API_KEY=<your-minimax-api-key> python3 -u s2s_server_pipeline.py \ --recv_host 0.0.0.0 \ --send_host 0.0.0.0 \ --stt_model_name <your-asr-path> \ --enable_llm_api \ --lm_model_name "MiniMax-M2.7" \ --lm_model_url "https://api.minimax.io/v1" \ --tts_model_name <your-tts-path> \ --ref_dir <ref-audio-path> \ --enable_interruption支持的模型:
MiniMax-M2.7(204K上下文)、MiniMax-M2.7-highspeed(204K上下文,速度更快)。
ℹ️ 支持其他自定义:你可以参考后端管道文件(如
s2s_server_pipeline.py)中由argparse库实现的参数列表,根据自己的需求进行自定义。所有参数都在其帮助属性中进行了详细说明,易于理解。
运行带有Web搜索+RAG的服务器
首先,你需要安装 Websearch 和 RAG 所需的依赖项。
pip install -r backend/requirements-rag.txt
其次,选择一个嵌入模型,用于将 Websearch 结果嵌入到 RAG 中。 例如以下嵌入模型:
git lfs install
git clone https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
然后,在 s2s_server_pipeline_rag.py 中为 Websearch 和 RAG 模块提供令牌,我们使用 Serper 作为 Websearch 工具,使用 Deepseek 作为 RAG。
export LLM_API_KEY=''
export SERPER_API_KEY=''
最后,将运行服务器示例代码中的 s2s_server_pipeline.py 替换为 s2s_server_pipeline_rag.py,并添加一个参数 --embedding_model_name。
以下是使用默认设置运行带有 Webseach+RAG 的服务器的示例:
python3 -u s2s_server_pipeline_rag.py \
--recv_host 0.0.0.0 \
--send_host 0.0.0.0 \
--stt_model_name <your-asr-path> \
--enable_llm_api \
--lm_model_name "deepseek-chat" \
--lm_model_url "https://api.deepseek.com" \
--tts_model_name <your-tts-path> \
--embedding_model_name <embedding-model-path> \
--ref_dir <ref-audio-path> \
--enable_interruption
前端(客户端)
我们建议使用 Docker镜像 来安装和运行客户端。具体步骤如下:
## 运行基础 Docker 镜像
docker run -it -p 3001:3001 amazonlinux:2023.2.20231011.0 sh
## 安装必要的软件包
dnf install vim git nodejs -y
npm install -g pnpm
git clone https://github.com/opendilab/CleanS2S.git
cd CleanS2S/frontend_nextjs
pnpm install
在 frontend_nextjs 目录下准备好合适的 .env.local 文件,可以参考 .env.example 文件来设置必要的环境变量。
## 运行客户端
pnpm dev --port 3001
然后你可以在浏览器中访问客户端页面 http://localhost:3001(推荐使用Chrome浏览器)。
附注:如果你想在本地运行客户端,需要先安装 node.js 和 pnpm,然后使用 pnpm 安装必要的软件包并运行客户端。
路线图
- 语音转换管道(ASR + TTS)(即 backend/vc_server_pipeline.py)
- WebUI优化(支持更多样化的交互和功能)
- 推理速度优化
- 后端多用户支持
- 对话中的长期记忆和主动意图机制
- 非文本交互机制,如表情包
- 更多提示词和RAG策略(serper + jina + LightRAG)
- 实际场景中的实用声纹检测机制
- 更多示例和评估工具
- 自定义示例角色
- 更有趣的交互和更具挑战性的机制
- e2e s2s模型训练和部署
支持与参与
我们非常感谢所有的反馈和贡献。欢迎随时提问,也欢迎在Github Issues和PR中提出讨论。
致谢
- 我们感谢 speech-to-speech 首次开源英语语音到语音的流水线。
- 我们感谢 funasr 和 CosyVoice 开源高质量的中文 ASR/TTS 模型。
- 我们感谢 HumeAI 开源了一系列前端组件。
引用 CleanS2S
@misc{lu2025cleans2s
title={CleanS2S: 用于主动式语音到语音交互的单文件框架},
author={Yudong Lu and Yazhe Niu and Shuai Hu and Haolin Wang},
year={2025},
eprint={2506.01268},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2506.01268},
}
许可证
CleanS2S 代码库根据 Apache 2.0 许可证发布。
重要的第三方许可证声明:
本项目使用了 jinaai/jina-embeddings-v3 模型,该模型单独依据 知识共享署名-非商业性使用4.0国际许可协议(CC BY-NC 4.0) 授权。
Jina Embeddings 模型的主要限制:
- ✅ 允许:非商业用途及修改
- ❌ 禁止:将该模型用于商业用途
- 📝 要求:必须注明 Jina AI 的贡献
在使用本项目时,您必须:
- 同时遵守两种许可证的要求
- 确保对 Jina Embeddings 模型的任何使用均符合 CC BY-NC 4.0 的条款
- 不得再授权或以商业方式分发 Jina 模型
完整条款请参阅:
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器