opendataloader-pdf
opendataloader-pdf 是一款专为人工智能应用打造的开源 PDF 解析工具,旨在将各类 PDF 文件(包括数字版、扫描件及已标记文件)高效转化为机器可读的结构化数据。它主要解决了大语言模型(LLM)和检索增强生成(RAG) pipeline 中非结构化文档难以处理的问题,同时自动化了繁琐的 PDF 无障碍合规流程,大幅降低了手动修复文档的成本。
这款工具非常适合开发者、数据科学家及研究人员使用,尤其是那些需要构建高质量知识库或关注信息无障碍的专业人士。其核心亮点在于卓越的提取精度:在权威基准测试中整体准确率排名第一,不仅能精准识别复杂表格、数学公式和图表,还内置支持 80 多种语言的 OCR 功能以应对低质量扫描件。opendataloader-pdf 提供确定性本地模式与混合 AI 模式,可输出带有坐标信息的 JSON、Markdown 及 HTML,完美适配数据分块与来源溯源需求。此外,它还是首个端到端开源的自动标记工具,能直接将普通 PDF 转换为符合国际标准的 Tagged PDF,助力企业轻松满足全球无障碍法规要求。支持 Python、Node.js 和 Java 多种开发语言,集成简便且完全开源。
使用场景
某金融科技公司正构建基于大模型的智能投研系统,需要将数千份包含复杂表格和双栏排版的上市公司年报 PDF 转化为高质量的 RAG(检索增强生成)数据。
没有 opendataloader-pdf 时
- 数据结构混乱:传统解析器无法识别多栏排版逻辑,导致跨栏文字顺序错乱,LLM 生成的摘要经常张冠李戴。
- 关键信息丢失:财报中的无边框表格和数学公式被还原为纯文本,行列关系彻底断裂,模型无法进行准确的数据分析。
- 人工成本高昂:处理扫描版旧文档需单独配置 OCR 流程,且后期需人工花费数小时校对和修复格式错误。
- 溯源困难:缺乏元素级的坐标定位数据,当模型回答出错时,开发人员无法快速回溯到原始 PDF 的具体位置进行验证。
使用 opendataloader-pdf 后
- 阅读顺序精准:利用 XY-Cut++ 算法自动识别双栏与复杂布局,输出的 Markdown 段落逻辑清晰,直接提升 RAG 检索命中率。
- 复杂元素结构化:混合模式(Hybrid Mode)完美还原无边框表格结构与 LaTeX 公式,甚至能为图表生成 AI 描述,确保数据完整性。
- 流程自动化闭环:内置支持 80+ 语言的 OCR 功能,一行代码即可处理低质量扫描件,将单页处理时间压缩至 0.015 秒。
- 精确溯源引用:输出的 JSON 包含每个元素的边界框(Bounding Boxes),让系统能精准高亮原文依据,大幅增强回答的可信度。
opendataloader-pdf 通过业界领先的解析精度和端到端的自动化能力,将非结构化 PDF 瞬间转化为大模型可直接理解的高质量数据资产。
运行环境要求
- 未说明 (支持 Python/Node.js/Java 跨平台环境)
非必需 (GPU required: No)
未说明
快速开始
OpenDataLoader PDF
面向 AI 的 PDF 解析器。自动化 PDF 无障碍功能。开源。
![]()



![]()

🔍 用于 AI 数据提取的 PDF 解析器 — 从任何 PDF 中提取 Markdown、JSON(带边界框)和 HTML。基准测试排名第一(总体 0.907)。具有确定性的本地模式以及适用于复杂页面的混合 AI 模式。
- 准确度如何? — 基准测试排名第一:总体准确率为 0.907,表格准确率为 0.928,测试对象涵盖 200 个真实场景中的多栏文档和科技论文。提供确定性的本地模式以及适用于复杂页面的混合 AI 模式(基准测试)
- 扫描版 PDF 和 OCR 呢? — 支持。混合模式内置 OCR 功能(支持 80 多种语言)。即使在 300 DPI 及以上分辨率下,也能处理质量较差的扫描件(混合模式)
- 表格、公式、图片、图表呢? — 支持。复杂的无边框表格、LaTeX 公式以及由 AI 生成的图片/图表描述均可通过混合模式实现(混合模式)
- 如何将其用于 RAG? — 使用
pip install opendataloader-pdf,只需三行代码即可完成转换。输出结构化的 Markdown 以供分块处理,带有边界框的 JSON 用于来源引用,以及 HTML。支持 LangChain 集成。提供 Python、Node.js 和 Java SDK(快速入门 | LangChain 集成)
♿ PDF 无障碍自动化 — 同样的布局分析引擎也可用于自动标记。首个开源工具,可端到端生成 Tagged PDF(预计于 2026 年第二季度推出)。
- 问题是什么? — 目前全球范围内均已强制执行无障碍法规。手动修复 PDF 每份需花费 50 至 200 美元,且无法规模化(法规)
- 免费部分是什么? — 布局分析 + 自动标记(2026 年第二季度,Apache 2.0 许可证)。输入未标记的 PDF,输出 Tagged PDF。无需依赖专有 SDK(自动标记预览)
- PDF/UA 合规呢? — 将 Tagged PDF 转换为 PDF/UA-1 或 PDF/UA-2 属于企业级附加功能。自动标记生成 Tagged PDF;PDF/UA 导出则是最后一步(流程)
- 为何值得信赖? — 本项目与 Dual Lab(veraPDF 的开发者)合作开发,基于 PDF 协会 的规范、最佳实践指南以及 PDF 社区 的专业知识。自动标记遵循 Well-Tagged PDF 规范,并通过 veraPDF 验证(合作)
30 秒快速入门
所需条件: Java 11+ 和 Python 3.10+(Node.js | Java 亦可用)
在开始之前,请运行
java -version。若未找到,请从 Adoptium 安装 JDK 11+。
pip install -U opendataloader-pdf
import opendataloader_pdf
# 批量处理所有文件只需一次调用 — 每次调用 convert() 都会启动一个 JVM 进程,因此重复调用效率较低
opendataloader_pdf.convert(
input_path=["file1.pdf", "file2.pdf", "folder/"],
output_dir="output/",
format="markdown,json"
)

带注释的 PDF 输出 — 每个元素(标题、段落、表格、图片)均被检测到,并附有边界框及语义类型。
本工具能解决哪些问题?
| 问题 | 解决方案 | 状态 |
|---|---|---|
| 解析过程中 PDF 结构丢失 — 阅读顺序错误、表格损坏、缺少元素坐标 | 确定性的本地模式可将 PDF 转换为带边界框的 Markdown/JSON,并采用 XY-Cut++ 阅读顺序 | 已发布 |
| 复杂表格、扫描版 PDF、公式、图表 需要 AI 级别的理解 | 混合模式会将复杂页面路由至 AI 后端(基准测试排名第一) | 已发布 |
| PDF 无障碍合规 — EAA、ADA、第 508 条款已被强制执行。手动修复每份文档需花费 50–200 美元 | 自动标记:布局分析 → Tagged PDF(免费,2026 年第二季度)。与 PDF 协会合作开发,并通过 veraPDF 验证。PDF/UA 导出(企业级附加功能) | 自动标记:2026 年第二季度 |
功能矩阵
| 功能 | 支持情况 | 等级 |
|---|---|---|
| 数据提取 | ||
| 提取具有正确阅读顺序的文本 | 是 | 免费 |
| 为每个元素提供边界框 | 是 | 免费 |
| 表格提取(简单边框) | 是 | 免费 |
| 表格提取(复杂/无边框) | 是 | 免费(混合模式) |
| 标题层级检测 | 是 | 免费 |
| 列表检测(编号、项目符号、嵌套列表) | 是 | 免费 |
| 带坐标信息的图像提取 | 是 | 免费 |
| AI图表/图像描述 | 是 | 免费(混合模式) |
| 扫描PDF的OCR | 是 | 免费(混合模式) |
| 公式提取(LaTeX) | 是 | 免费(混合模式) |
| 标签化PDF结构提取 | 是 | 免费 |
| AI安全(提示注入过滤) | 是 | 免费 |
| 页眉/页脚/水印过滤 | 是 | 免费 |
| 可访问性 | ||
| 自动标签→为未标记PDF生成标签化PDF | 预计2026年第二季度推出 | 免费(Apache 2.0) |
| PDF/UA-1、PDF/UA-2导出 | 💼 可用 | 企业版 |
| 可访问性工作室(可视化编辑器) | 💼 可用 | 企业版 |
| 限制 | ||
| 处理Word/Excel/PPT文件 | 否 | — |
| 是否需要GPU | 否 | — |
提取基准测试
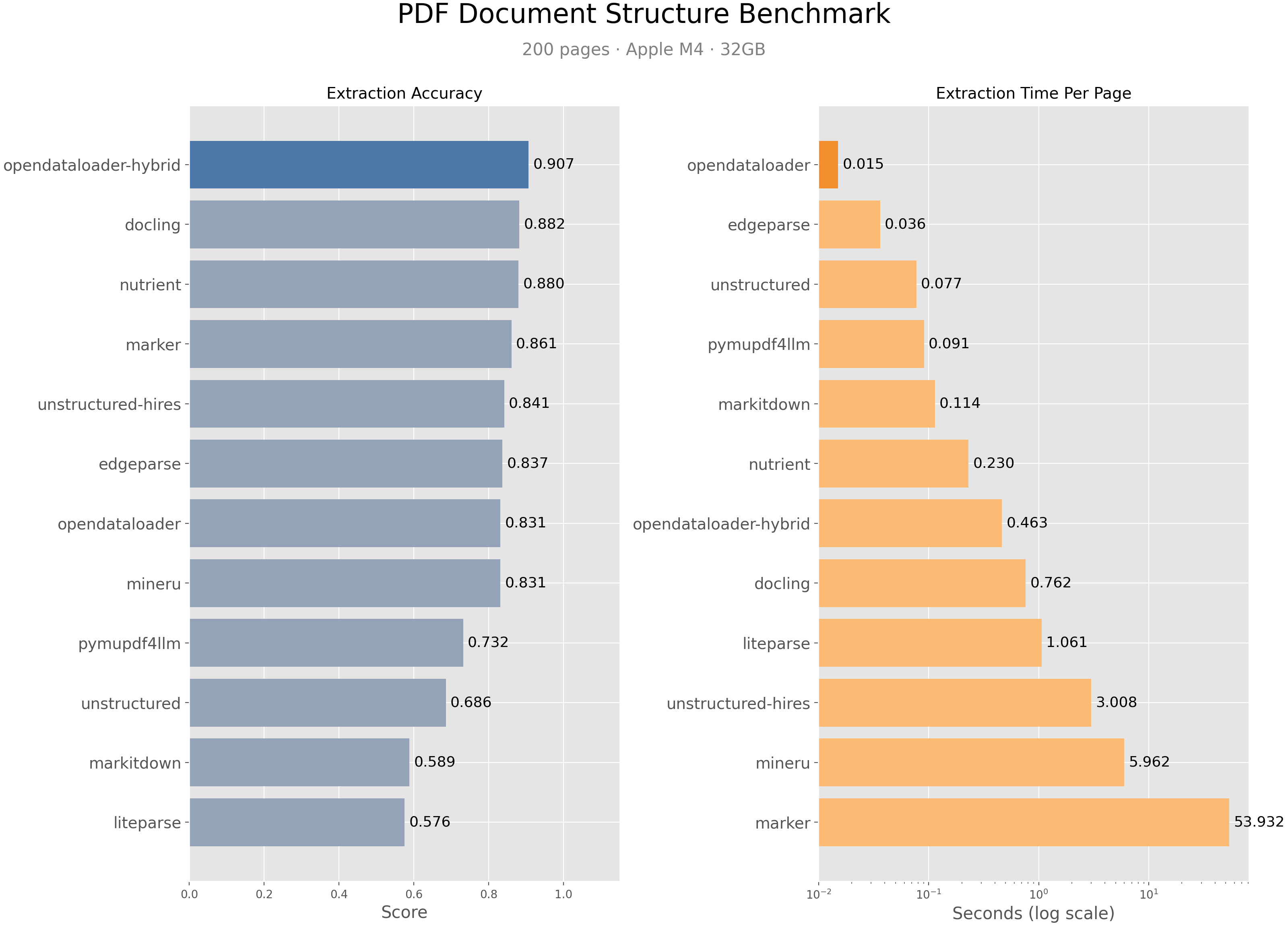
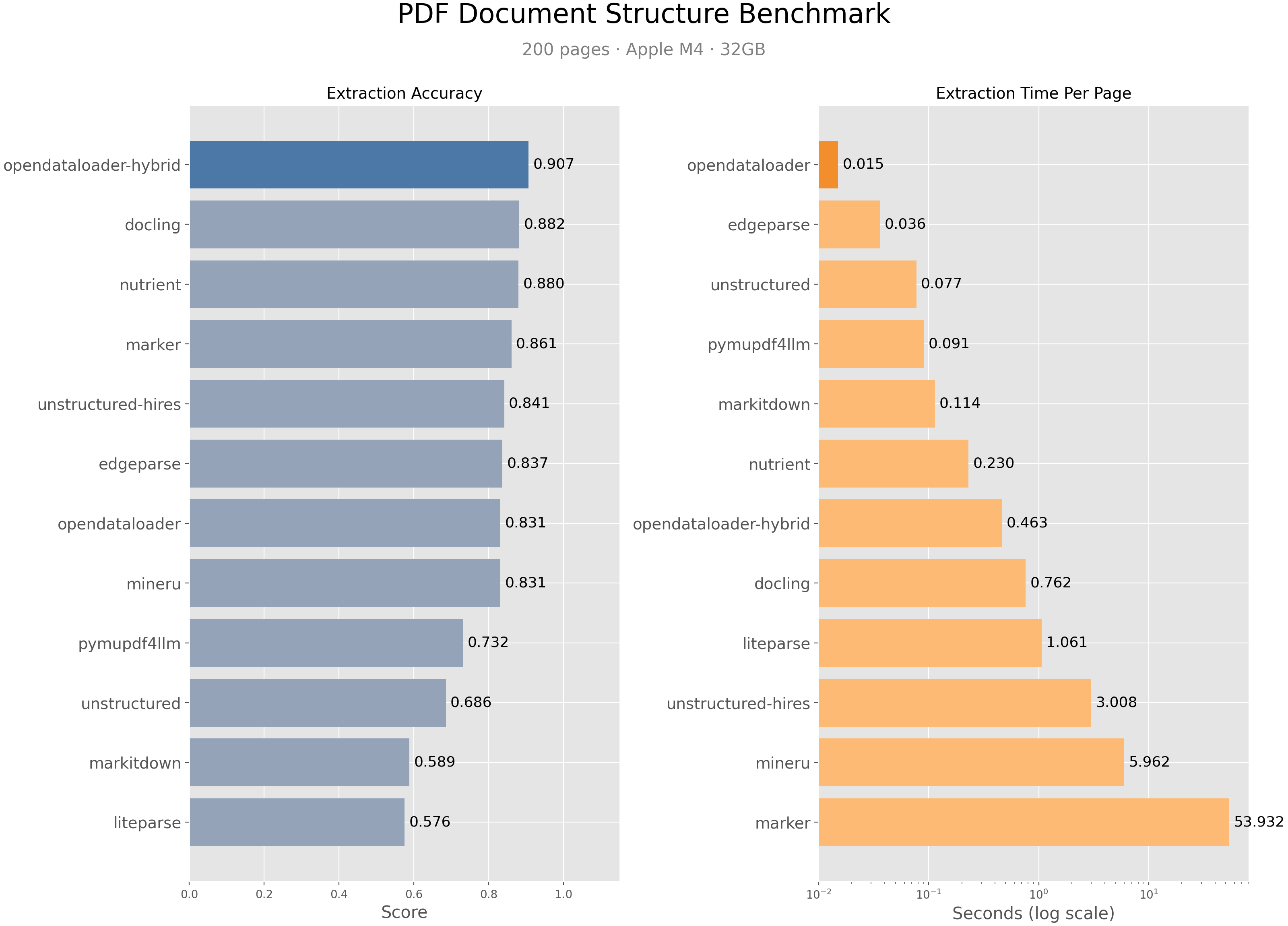
opendataloader-pdf [混合模式]在阅读顺序、表格和标题提取准确度方面综合排名第一(0.907分)。
| 引擎 | 综合得分 | 阅读顺序 | 表格 | 标题 | 速度(秒/页) |
|---|---|---|---|---|---|
| opendataloader [混合模式] | 0.907 | 0.934 | 0.928 | 0.821 | 0.463 |
| docling | 0.882 | 0.898 | 0.887 | 0.824 | 0.762 |
| nutrient | 0.880 | 0.924 | 0.662 | 0.811 | 0.230 |
| marker | 0.861 | 0.890 | 0.808 | 0.796 | 53.932 |
| unstructured [hi_res] | 0.841 | 0.904 | 0.588 | 0.749 | 3.008 |
| edgeparse | 0.837 | 0.894 | 0.717 | 0.706 | 0.036 |
| opendataloader | 0.831 | 0.902 | 0.489 | 0.739 | 0.015 |
| mineru | 0.831 | 0.857 | 0.873 | 0.743 | 5.962 |
| pymupdf4llm | 0.732 | 0.885 | 0.401 | 0.412 | 0.091 |
| unstructured | 0.686 | 0.882 | 0.000 | 0.388 | 0.077 |
| markitdown | 0.589 | 0.844 | 0.273 | 0.000 | 0.114 |
| liteparse | 0.576 | 0.866 | 0.000 | 0.000 | 1.061 |
分数已归一化至[0, 1]。准确度越高越好;速度越低越好。加粗表示最佳。完整基准测试详情
我应该使用哪种模式?
| 您的文档 | 模式 | 安装 | 服务器命令 | 客户端命令 |
|---|---|---|---|---|
| 标准数字PDF | 快速(默认) | pip install opendataloader-pdf |
无需额外操作 | opendataloader-pdf file1.pdf file2.pdf folder/ |
| 复杂或嵌套表格 | 混合模式 | pip install "opendataloader-pdf[hybrid]" |
opendataloader-pdf-hybrid --port 5002 |
opendataloader-pdf --hybrid docling-fast file1.pdf file2.pdf folder/ |
| 扫描或基于图像的PDF | 混合模式+OCR | pip install "opendataloader-pdf[hybrid]" |
opendataloader-pdf-hybrid --port 5002 --force-ocr |
opendataloader-pdf --hybrid docling-fast file1.pdf file2.pdf folder/ |
| 非英语扫描PDF | 混合模式+OCR | pip install "opendataloader-pdf[hybrid]" |
opendataloader-pdf-hybrid --port 5002 --force-ocr --ocr-lang "ko,en" |
opendataloader-pdf --hybrid docling-fast file1.pdf file2.pdf folder/ |
| 数学公式 | 混合模式+公式 | pip install "opendataloader-pdf[hybrid]" |
opendataloader-pdf-hybrid --enrich-formula |
opendataloader-pdf --hybrid docling-fast --hybrid-mode full file1.pdf file2.pdf folder/ |
| 需要描述的图表 | 混合模式+图片 | pip install "opendataloader-pdf[hybrid]" |
opendataloader-pdf-hybrid --enrich-picture-description |
opendataloader-pdf --hybrid docling-fast --hybrid-mode full file1.pdf file2.pdf folder/ |
| 未标记且需提升可访问性的PDF | 自动标签→生成标签化PDF | 预计2026年第二季度推出 | — | — |
快速入门
Python
pip install -U opendataloader-pdf
import opendataloader_pdf
# 批量处理所有文件只需一次调用——每次convert()都会启动一个JVM进程,因此重复调用会很慢
opendataloader_pdf.convert(
input_path=["file1.pdf", "file2.pdf", "folder/"],
output_dir="output/",
format="markdown,json"
)
Node.js
npm install @opendataloader/pdf
import { convert } from '@opendataloader/pdf';
await convert(['file1.pdf', 'file2.pdf', 'folder/'], {
outputDir: 'output/',
format: 'markdown,json'
});
Java
<dependency>
<groupId>org.opendataloader</groupId>
<artifactId>opendataloader-pdf-core</artifactId>
</dependency>
Python快速入门 | Node.js快速入门 | Java快速入门
混合模式:复杂PDF提取准确度第一
混合模式结合了快速的本地Java处理与AI后端。简单页面保留在本地处理(0.02秒);复杂页面则路由到AI以实现超过90%的表格提取准确度。
pip install -U "opendataloader-pdf[hybrid]"
终端1——启动后端服务器:
opendataloader-pdf-hybrid --port 5002
终端2——处理PDF文件:
# 批量处理所有文件只需一次调用——每次调用都会启动一个JVM进程,因此重复调用会很慢
opendataloader-pdf --hybrid docling-fast file1.pdf file2.pdf folder/
Python:
# 批量处理所有文件只需一次调用——每次convert()都会启动一个JVM进程,因此重复调用会很慢
opendataloader_pdf.convert(
input_path=["file1.pdf", "file2.pdf", "folder/"],
output_dir="output/",
hybrid="docling-fast"
)
扫描PDF的OCR
对于没有可选文本的基于图像的PDF,请使用--force-ocr选项启动后端:
opendataloader-pdf-hybrid --port 5002 --force-ocr
对于非英语文档,需指定语言:
opendataloader-pdf-hybrid --port 5002 --force-ocr --ocr-lang "ko,en"
支持的语言包括:英语、韩语、日语、简体中文、繁体中文、德语、法语、阿拉伯语等。
公式提取(LaTeX)
从科学PDF中提取数学公式并以LaTeX格式输出:
# 服务器端启用公式增强功能
opendataloader-pdf-hybrid --enrich-formula
# 一次性批量处理所有文件 — 每次调用都会启动一个 JVM 进程,因此重复调用会很慢
opendataloader-pdf --hybrid docling-fast --hybrid-mode full file1.pdf file2.pdf folder/
输出为 JSON 格式:
{
"type": "formula",
"page number": 1,
"bounding box": [226.2, 144.7, 377.1, 168.7],
"content": "\\frac{f(x+h) - f(x)}{h}"
}
注意:公式和图片描述增强功能需要在客户端使用
--hybrid-mode full。
图表与图片描述
为图表和图片生成 AI 描述 — 对 RAG 搜索和辅助性替代文本非常有用:
# 服务器端
opendataloader-pdf-hybrid --enrich-picture-description
# 一次性批量处理所有文件 — 每次调用都会启动一个 JVM 进程,因此重复调用会很慢
opendataloader-pdf --hybrid docling-fast --hybrid-mode full file1.pdf file2.pdf folder/
输出为 JSON 格式:
{
"type": "picture",
"page number": 1,
"bounding box": [72.0, 400.0, 540.0, 650.0],
"description": "一个条形图,显示从 2016 年到 2030 年各地区的废弃物产生情况……"
}
使用 SmolVLM(256M),这是一种轻量级视觉模型。可通过
--picture-description-prompt支持自定义提示。
Hancom 数据加载器集成 — 即将推出
通过 Hancom 数据加载器 实现企业级 AI 文档分析 — 客户可基于其领域特定文档训练自定义模型。支持 30 多种元素类型(表格、图表、公式、标题、脚注等),基于 VLM 的图像/图表理解,复杂表格提取(合并单元格、嵌套表格),针对扫描文档的 SLA 保障 OCR,以及原生 HWP/HWPX 支持。支持 PDF、DOCX、XLSX、PPTX、HWP、PNG、JPG 等格式。在线演示
输出格式
| 格式 | 使用场景 |
|---|---|
| JSON | 带有边界框和语义类型的结构化数据 |
| Markdown | 用于 LLM 上下文和 RAG 分块的纯文本 |
| HTML | 带样式的网页展示 |
| 带标注的 PDF | 可视化调试 — 查看检测到的结构(示例) |
| 文本 | 纯文本提取 |
组合格式:format="json,markdown"
JSON 输出示例
{
"type": "heading",
"id": 42,
"level": "Title",
"page number": 1,
"bounding box": [72.0, 700.0, 540.0, 730.0],
"heading level": 1,
"font": "Helvetica-Bold",
"font size": 24.0,
"text color": "[0.0]",
"content": "引言"
}
| 字段 | 描述 |
|---|---|
type |
元素类型:标题、段落、表格、列表、图片、标题、公式 |
id |
用于交叉引用的唯一标识符 |
page number |
以 1 为起始的页码参考 |
bounding box |
[left, bottom, right, top],单位为 PDF 点(72pt = 1 英寸) |
heading level |
标题深度(1+) |
content |
提取的文本 |
高级功能
标记 PDF 支持
当 PDF 包含结构标记时,OpenDataLoader 会提取作者原本设计的 精确布局 — 不需猜测或启发式方法。标题、列表、表格和阅读顺序都将保留自源文件。
# 一次性批量处理所有文件 — 每次 convert() 调用都会启动一个 JVM 进程,因此重复调用会很慢
opendataloader_pdf.convert(
input_path=["file1.pdf", "file2.pdf", "folder/"],
output_dir="output/",
use_struct_tree=True # 使用原生 PDF 结构标记
)
大多数 PDF 解析器完全忽略结构标记。了解更多
AI 安全:提示注入防护
PDF 文件可能包含隐藏的提示注入攻击。OpenDataLoader 会自动过滤:
- 隐藏文本(透明字体、零尺寸字体)
- 页面外内容
- 可疑的不可见图层
若要对敏感数据进行脱敏处理(如电子邮件、URL、电话号码 → 替换为占位符),请显式启用:
# 一次性批量处理所有文件 — 每次调用都会启动一个 JVM 进程,因此重复调用会很慢
opendataloader-pdf file1.pdf file2.pdf folder/ --sanitize
LangChain 集成
pip install -U langchain-opendataloader-pdf
from langchain_opendataloader_pdf import OpenDataLoaderPDFLoader
loader = OpenDataLoaderPDFLoader(
file_path=["file1.pdf", "file2.pdf", "folder/"],
format="text"
)
documents = loader.load()
LangChain 文档 | GitHub | PyPI
高级选项
# 一次性批量处理所有文件 — 每次 convert() 调用都会启动一个 JVM 进程,因此重复调用会很慢
opendataloader_pdf.convert(
input_path=["file1.pdf", "file2.pdf", "folder/"],
output_dir="output/",
format="json,markdown,pdf",
image_output="embedded", // "off"、"embedded"(Base64)或 "external"(默认)
image_format="jpeg", // "png" 或 "jpeg"
use_struct_tree=True, // 使用原生 PDF 结构
)
PDF 无障碍访问与 PDF/UA 转换
问题:数百万现有 PDF 文件缺乏结构标记,无法满足无障碍法规(EAA、ADA/第 508 条、韩国数字包容法)。手动修复每份文档的成本为 50–200 美元,且难以规模化。
OpenDataLoader 的解决方案:与 PDF Association 和 Dual Lab(veraPDF 的开发者,行业标准的开源 PDF/A 和 PDF/UA 验证工具)合作开发。自动标记遵循 Well-Tagged PDF 规范,并通过 veraPDF 进行程序化验证 — 自动检查 PDF 无障碍标准,而非人工审核。目前尚无任何开源工具能够端到端生成标记 PDF — 大多数依赖专有 SDK 完成标记写入步骤。而 OpenDataLoader 则在 Apache 2.0 许可下实现了全流程。(合作详情)
| 法规 | 截止日期 | 要求 |
|---|---|---|
| 欧洲无障碍法案 (EAA) | 2025 年 6 月 28 日 | 欧盟范围内可访问的数字产品 |
| ADA 与第 508 条 | 已生效 | 美国联邦机构和公共场所 |
| 数字包容法 | 已生效 | 韩国数字服务的可访问性 |
標準與驗證
| 方面 | 詳細 |
|---|---|
| 規範 | PDF協會的良好標記的PDF |
| 驗證 | veraPDF — 行業標準的開源PDF/A及PDF/UA驗證工具 |
| 合作 | PDF協會 + Dual Lab(veraPDF開發者)共同開發標記與驗證功能 |
| 許可證 | 自動標記 → 標記PDF:Apache 2.0(免費)。PDF/UA匯出:企業版 |
可訪問性流程
| 步驟 | 功能 | 狀態 | 等級 |
|---|---|---|---|
| 1. 審計 | 讀取現有PDF標記,檢測未標記的PDF | 已推出 | 免費 |
| 2. 自動標記 → 標記PDF | 為未標記的PDF生成結構標記 | 2026年第二季即將推出 | 免費(Apache 2.0) |
| 3. 匯出PDF/UA | 轉換為符合PDF/UA-1或PDF/UA-2標準的檔案 | 💼 可用 | 企業版 |
| 4. 視覺編輯 | 可訪問性工作室 — 審查並修復標記 | 💼 可用 | 企業版 |
💼 企業版功能 可根據需求提供。請聯絡我們 (聯繫我們) 開始使用。
自動標記預覽(2026年第二季即將推出)
# API形狀預覽 — 2026年第二季可用
opendataloader_pdf.convert(
input_path=["file1.pdf", "file2.pdf", "folder/"],
output_dir="output/",
auto_tag=True # 為未標記的PDF生成結構標記
)
端到端合規工作流程
現有PDF(未標記)
│
▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 1. 審計 │───>│ 2. 自動標記 │───>│ 3. 匯出 │───>│ 4. 工作室 │
│ (檢查標記) │ │ (→ 標記PDF) │ │ (PDF/UA) │ │ (視覺編輯器) │
└─────────────────┘ └─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │ │
▼ ▼ ▼ ▼
use_struct_tree auto_tag PDF/UA匯出 可訪問性工作室
(現已可用) (2026年第二季,Apache 2.0) (企業版) (企業版)
路線圖
| 功能 | 時程 | 等級 |
|---|---|---|
| 自動標記 → 標記PDF — 從未標記的PDF生成標記PDF | 2026年第二季 | 免費 |
| Hancom資料加載器 — 企業級AI文檔分析、客戶自定義模型、基於VLM的圖表/影像理解、生產級OCR | 2026年第二至第三季 | 計劃中 |
| 結構驗證 — 驗證PDF標記樹 | 2026年第二季 | 計劃中 |
常見問題
對於RAG來說,最好的PDF解析器是什麼?
對於RAG管道,你需要一個能保留文檔結構、維持正確閱讀順序,並提供元素坐標以供引用的解析器。OpenDataLoader正是為此設計——它輸出帶有邊界框的結構化JSON,能處理多欄佈局並採用XY-Cut++技術,且可在本地運行而無需GPU。在混合模式下,它在基準測試中總體排名第一(0.907)。
最佳的開源PDF解析器是什麼?
OpenDataLoader PDF是唯一結合以下特點的開源解析器:基於規則的確定性提取(無需GPU)、每個元素的邊界框、XY-Cut++閱讀順序、內建AI安全過濾器、原生標記PDF支持,以及用於複雜文檔的混合AI模式。它在整體準確率上排名第一(0.907),同時可在CPU上本地運行。
如何從PDF中提取表格以供LLM使用?
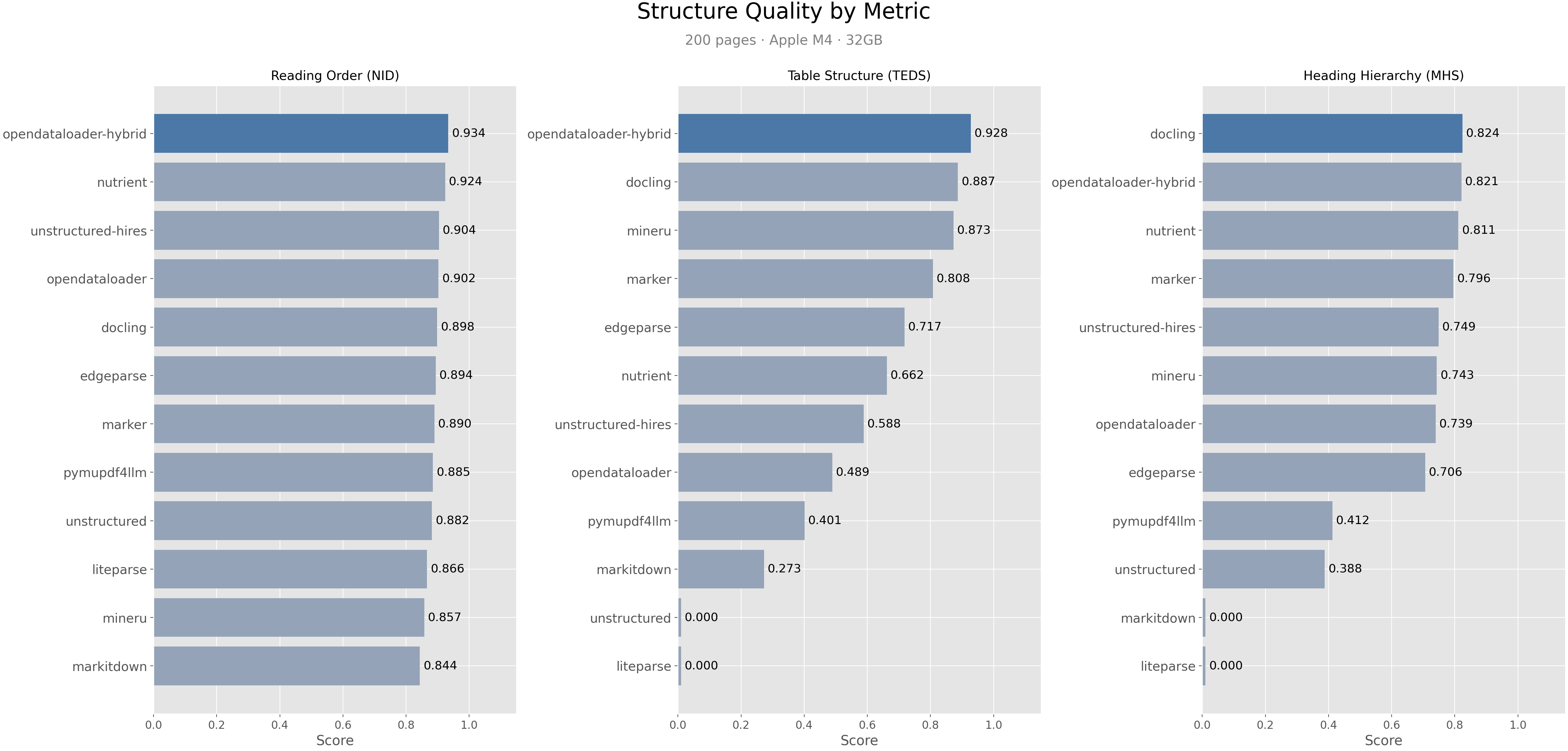
OpenDataLoader通過邊界分析和文本聚類來檢測表格,並保持行/列結構。對於複雜表格,啟用混合模式可將準確率提升超過90%(TEDS分數從0.489提高到0.928):
# 批量處理所有文件一次調用 — 每次convert()都會啟動一個JVM進程,因此重複調用會很慢
opendataloader_pdf.convert(
input_path=["file1.pdf", "file2.pdf", "folder/"],
output_dir="output/",
format="json",
hybrid="docling-fast" # 用於複雜表格
)
它與docling、marker或pymupdf4llm相比如何?
OpenDataLoader [混合]模式在閱讀順序、表格和標題準確性方面總體排名第一(0.907)。主要差異如下:docling(0.882)表現強勁,但缺乏邊界框和AI安全過濾器;marker(0.861)需要GPU,且速度慢1000倍(53.932秒/頁);pymupdf4llm(0.732)速度快,但表格(0.401)和標題(0.412)準確性較差。OpenDataLoader是唯一一款結合確定性本地提取、每個元素的邊界框,以及內建提示注入防護的解析器。詳見完整基準測試。
我可以在不將數據傳送到雲端的情況下使用它嗎?
可以。OpenDataLoader完全在本地運行。無需API調用,也無數據傳輸——您的文檔永遠不會離開您的環境。混合模式的後端也在您自己的機器上運行。非常適合法律、醫療保健和金融文檔。
它是否支援掃描PDF的OCR?
是的,通過混合模式實現。安裝時使用pip install "opendataloader-pdf[hybrid]",啟動後端時加上--force-ocr,然後照常處理即可。支援多種語言,包括韓語、日語、中文、阿拉伯語等,可通過--ocr-lang指定。
它適用於韓語、日語或中文文檔嗎?
是的。對於數字PDF,文本提取可直接使用。對於掃描PDF,請使用混合模式並搭配--force-ocr --ocr-lang "ko,en"(或ja、ch_sim、ch_tra)。即將推出的Hancom資料加載器整合——企業級AI文檔分析,內建生產級OCR,並根據您的特定文檔類型和工作流程優化客戶自定義模型。
它的速度如何?
本地模式在CPU上每秒可處理60頁以上(0.02秒/頁)。混合模式每秒可處理2頁以上(0.46秒/頁),對複雜文檔的準確性顯著更高。無需GPU。已在Apple M4上進行了基準測試。完整基準測試詳情。透過多進程批量處理,在8核心以上的機器上,吞吐量可超過每秒100頁。
它能否處理多欄佈局?
是的。OpenDataLoader使用XY-Cut++閱讀順序分析技術,可正確地排列跨多欄頁面、側欄及混合佈局中的文字順序。這在本地模式和混合模式下均有效,無需任何配置。
什么是混合模式?
混合模式将快速的本地 Java 处理与 AI 后端相结合。简单的页面会在本地处理(0.02 秒/页);而复杂页面(表格、扫描内容、公式、图表)则会自动路由到 AI 后端,以获得更高的准确性。后端在您的本地机器上运行——无需云端支持。请参阅我应该使用哪种模式?和混合模式指南。
它能与 LangChain 配合使用吗?
是的。安装 langchain-opendataloader-pdf 即可实现官方的 LangChain 文档加载器集成。详情请参阅 LangChain 文档。
如何为 RAG 切分 PDF?
OpenDataLoader 输出保留标题、表格和列表的结构化 Markdown——这是语义切分的理想输入。JSON 输出中的每个元素都包含 type、heading level 和 page number,因此您可以按章节或页边界进行分割。对于大多数 RAG 流水线:使用 format="markdown" 解析以获取文本块,或者在需要元素级控制时使用 format="json"。配合 LangChain 的 RecursiveCharacterTextSplitter 或您自己的基于标题的切分器,可以获得最佳效果。
如何在 RAG 回答中引用 PDF 来源?
JSON 输出中的每个元素都包含一个边界框(以 PDF 点表示的 [left, bottom, right, top])和页码。当您的 RAG 流水线返回答案时,可以将来源块映射回其边界框,以高亮显示原始 PDF 中的确切位置。这样就能实现“点击即溯源”的用户体验——用户可以看到答案来自哪一段落、表格或图表。目前没有其他开源解析器默认为每个元素提供边界框。
如何将 PDF 转换为 LLM 可用的 Markdown?
import opendataloader_pdf
# 批量处理所有文件只需一次调用——每次调用都会启动一个 JVM 进程,因此重复调用会很慢
opendataloader_pdf.convert(
input_path=["file1.pdf", "file2.pdf", "folder/"],
output_dir="output/",
format="markdown"
)
OpenDataLoader 在 Markdown 输出中保留了标题层级、表格结构和阅读顺序。对于包含无边框表格或扫描页面的复杂文档,请使用混合模式(hybrid="docling-fast"),以获得更高的准确性。输出结果足够干净,可以直接输入到 LLM 的上下文窗口或 RAG 切分流水线中。
是否有自动化的 PDF 无障碍修复工具?
是的。OpenDataLoader 是首个端到端自动化 PDF 无障碍修复的开源工具。该工具与 PDF Association 和 Dual Lab(veraPDF 开发者)合作开发,自动标记功能遵循 Well-Tagged PDF 规范,并通过 veraPDF 进行程序化验证。布局分析引擎能够检测文档结构(标题、表格、列表、阅读顺序),并自动生成无障碍标签。自动标记功能将于 2026 年第二季度推出,在 Apache 2.0 许可下免费提供,不依赖任何专有 SDK。对于需要完全符合 PDF/UA 标准的组织,企业版附加组件提供了 PDF/UA 导出和可视化标签编辑器功能。这将取代通常每份文档成本达 50–200+ 美元的手动修复流程。
这真的是首个开源的 PDF 自动标记工具吗?
是的。现有的工具要么依赖专有 SDK 来写入结构标签,要么只输出非 PDF 格式(例如,Docling 输出 Markdown/JSON,但无法生成 Tagged PDF),或者需要人工干预。OpenDataLoader 是首个在完全开源许可(Apache 2.0)下完成布局分析→标签生成→Tagged PDF 输出的工具,且没有任何专有依赖。自动标记功能遵循 PDF Association 的 Well-Tagged PDF 规范,并通过行业参考级的开源 PDF/A 和 PDF/UA 验证工具 veraPDF 进行验证。
如何将现有 PDF 转换为 PDF/UA?
OpenDataLoader 提供了一个端到端的流程:先审计现有 PDF 是否包含标签(use_struct_tree=True),然后自动将未标记的 PDF 转换为 Tagged PDF(2026 年第二季度,Apache 2.0 许可下免费提供),最后导出为 PDF/UA-1 或 PDF/UA-2(企业版附加组件)。自动标记功能遵循 PDF Association 的 Well-Tagged PDF 规范,并通过 veraPDF 进行验证。自动标记生成的是 Tagged PDF;PDF/UA 导出则是最后一步。如需企业级集成,请联系我们。
如何使我的 PDF 符合 EAA 合规要求?
《欧洲无障碍法案》要求数字产品在 2025 年 6 月 28 日前达到无障碍标准。OpenDataLoader 支持完整的修复流程:审计→自动标记→Tagged PDF→PDF/UA 导出。自动标记功能遵循 PDF Association 的 Well-Tagged PDF 规范,并通过 veraPDF 进行验证,确保输出符合标准。自动标记至 Tagged PDF 的功能将于 2026 年第二季度以 Apache 2.0 许可开源。PDF/UA 导出和无障碍工作室是企业版附加组件。请参阅我们的无障碍合规指南。
OpenDataLoader PDF 是免费的吗?
核心库采用 Apache 2.0 开源许可——可供商业用途免费使用。这包括所有提取功能(文本、表格、图片、OCR、公式、图表,通过混合模式实现)、AI 安全过滤器、Tagged PDF 支持以及自动标记至 Tagged PDF(2026 年第二季度)。我们致力于保持核心无障碍修复流程(布局分析→自动标记→Tagged PDF)的免费和开源特性。企业版附加组件(PDF/UA 导出、无障碍工作室)适用于需要端到端法规合规的组织。
为什么许可证从 MPL 2.0 更改为 Apache 2.0 ?
MPL 2.0 要求文件级别的 copyleft,这往往会在企业采用前触发法律审查。而 Apache 2.0 则完全宽松——没有 copyleft 义务,更容易集成到商业项目中。如果您正在使用 2.0 版本之前的版本,它仍然受 MPL 2.0 许可约束,您可以继续使用。升级到 2.0 及以上版本意味着您的项目将遵循 Apache 2.0 许可条款,该条款更为宽松——您无需承担额外义务,也无需采取任何行动。
文档
贡献
我们欢迎贡献!请参阅 CONTRIBUTING.md 获取相关指南。
许可证
注意: 2.0 版本之前的版本采用 Mozilla 公共许可证 2.0 许可。
觉得有用吗? 请给项目点个星,帮助更多人发现 OpenDataLoader。
版本历史
v2.2.12026/04/03v2.2.02026/03/27v2.1.12026/03/26v2.0.22026/03/18v2.0.12026/03/18v2.0.02026/03/11v1.12.02026/03/06v1.11.32026/03/04v1.11.22026/02/26v1.11.12026/02/26v1.11.02026/02/26v1.10.12026/02/05v1.10.02026/02/04v1.9.12026/01/22v1.9.02026/01/22v1.8.22026/01/20v1.8.12026/01/20v1.8.02026/01/20v1.7.22026/01/19v1.7.12026/01/08常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器