deepcompressor
DeepCompressor 是一款由麻省理工学院韩松实验室开发的开源模型压缩工具箱,专为大型语言模型(LLM)和扩散模型(Diffusion Models)打造。随着 AI 模型规模不断增大,其在部署时往往面临显存占用高、推理延迟大等挑战,DeepCompressor 正是为了解决这一痛点,帮助开发者在几乎不损失精度的前提下,大幅降低模型的资源消耗并提升运行速度。
该工具主要面向 AI 研究人员、算法工程师及系统开发者,提供了基于 PyTorch 的灵活后训练量化方案。它支持多种高精度的低比特量化格式(如 INT4、FP4 等),涵盖了仅权重量化、权重 - 激活联合量化以及针对 LLM 特有的 KV 缓存量化等多种策略。
DeepCompressor 的技术亮点在于集成了多项前沿研究成果,例如专为扩散模型设计的 SVDQuant 算法,能通过低秩分量有效处理 4 比特量化中的异常值问题;以及面向大语言模型的 QoQ 算法与 QServe 推理系统,实现了高效的 W4A8KV4 混合精度量化。此外,它还提供了与 TinyChat、Nunchaku 等推理引擎的集成示例,让用户能轻松将压缩后的模型部署到实际应用中,是进行模型轻量化探索与落地的得力助手。
使用场景
一家初创 AIGC 公司试图在消费级显卡上部署最新的文生图扩散模型,以提供低成本的实时图像生成服务。
没有 deepcompressor 时
- 显存爆满无法运行:原始扩散模型参数量巨大,在单张 RTX 4090 上加载时直接超出 24GB 显存上限,导致服务根本无法启动。
- 推理延迟过高:即使勉强在多卡环境下运行,生成一张图片需要数秒甚至更久,完全无法满足用户“实时预览”的交互需求。
- 量化精度严重损失:尝试使用传统量化方法将模型压缩至 4bit 时,由于缺乏对异常值的有效处理,生成的图像出现严重噪点、色彩失真或结构崩坏。
- 部署成本高昂:为了维持服务可用性,被迫租用昂贵的企业级 A100 集群,导致运营成本远超预算,商业模式难以跑通。
使用 deepcompressor 后
- 单卡轻松部署:利用 deepcompressor 集成的 SVDQuant 算法,成功将模型权重和激活值同时量化为 4bit(W4A4),显存占用降低 75%,单张消费级显卡即可流畅运行。
- 推理速度显著提升:配合 Nunchaku 推理系统,量化后的模型推理延迟大幅降低,实现了接近实时的图像生成体验,用户等待时间从秒级降至毫秒级。
- 生成质量几乎无损:deepcompressor 通过低秩分量吸收异常值的独特机制,即使在激进的 4bit 量化下,生成图像的清晰度、细节和色彩还原度仍与原始浮点模型几乎一致。
- 硬件成本大幅缩减:不再依赖昂贵的高端集群,仅用普通游戏显卡即可构建高性能推理节点,使整体基础设施成本下降了 80% 以上。
deepcompressor 通过极致的 4bit 量化技术,打破了扩散模型在消费级硬件上的部署瓶颈,让高质量 AIGC 应用真正实现了低成本落地。
运行环境要求
- Linux
需要 NVIDIA GPU(文中提及 RTX 4090, A100, L40S),显存需求视模型而定(文中提及在 16GB 显存上运行 12B 模型),需支持 CUDA(具体版本未说明,通常需配合 PyTorch 版本)
未说明
快速开始

面向大型语言模型和扩散模型的模型压缩工具箱

最新动态
- [2025年2月] 🎉 QServe 已被 MLSys 2025 接收!
- [2025年1月] 🎉 SVDQuant 已被 ICLR 2025(Spotlight)接收!
- [2024年12月] 🎉 QServe 已集成到 NVIDIA TensorRT-LLM 中!
- [2024年11月] 🔥 我们的最新 W4A4 扩散模型量化工作 SVDQuant 算法及 Nunchaku 系统已公开发布!请查看我们的 论文!
- [2024年5月] 🔥 我们的最新 W4A8KV4 LLM 量化工作 QoQ 算法及 QServe 系统已公开发布!QoQ 是 quattuor-octō-quattuor 的缩写,意为拉丁语中的 4-8-4。请查看我们的 论文!
核心功能
DeepCompressor 是一个基于 PyTorch 的开源模型压缩工具箱,适用于大型语言模型和扩散模型。目前,DeepCompressor 支持使用任何 8 位以内的整数和浮点数据类型进行伪量化,例如 INT8、INT4 和 FP4_E2M1。以下是实现以下算法的示例。
- 大型语言模型的后训练量化:
- 仅权重量化
- 权重-激活量化
- 权重-激活及 KV 缓存量化
- 扩散模型的后训练量化:
- 权重-激活量化
DeepCompressor 还包含与其他推理库集成的示例。
安装
从源码安装
- 克隆本仓库并进入 deepcompressor 文件夹
git clone https://github.com/mit-han-lab/deepcompressor
cd deepcompressor
- 安装软件包
conda env create -f environment.yml
poetry install
亮点
SVDQuant:通过低秩组件吸收异常值,实现4位扩散模型量化
[官网][论文][Nunchaku 推理系统]
扩散模型在生成高质量图像方面表现出色。然而,随着模型规模的增大,它们对内存的需求显著增加,延迟也随之上升,这给部署带来了巨大挑战。在本工作中,我们旨在通过将扩散模型的权重和激活量化的4位来加速模型推理。在如此激进的量化级别下,权重和激活都变得非常敏感,传统的针对大型语言模型的后训练量化方法(如平滑化)已不足以应对。为克服这一局限性,我们提出了SVDQuant,一种全新的4位量化范式。与通过在权重和激活之间重新分配异常值的平滑化方法不同,我们的方法利用低秩分支来吸收这些异常值。我们首先通过将异常值从激活转移到权重来集中处理它们,然后使用高精度的低秩分支,借助奇异值分解(SVD)来处理权重中的异常值。这一过程有效缓解了两侧的量化压力。然而,如果简单地独立运行低秩分支,由于激活数据的额外移动,会带来显著的开销,从而抵消量化带来的加速效果。为此,我们协同设计了一款推理引擎Nunchaku,它将低秩分支的核与低比特分支的核融合在一起,以减少冗余的内存访问。此外,该引擎还能无缝支持现成的低秩适配器(LoRA),无需重新量化。我们在SDXL、PixArt-∑和FLUX.1上的大量实验验证了SVDQuant在保持图像质量方面的有效性。我们使120亿参数的FLUX.1模型的内存占用减少了3.5倍,在配备16GB显存的4090 GPU的笔记本电脑上,相比仅量化权重的4位基线实现了3.0倍的加速,为在个人电脑上实现更交互式的应用铺平了道路。


质量评估
以下是对MJHQ-30K数据集中的5000个样本进行的质量和相似性评估。IR代表ImageReward分数。我们的4位结果优于其他4位基线,能够有效保留16位模型的视觉质量。
| 模型 | 精度 | 方法 | FID ($\downarrow$) | IR ($\uparrow$) | LPIPS ($\downarrow$) | PSNR( $\uparrow$) |
|---|---|---|---|---|---|---|
| FLUX.1-dev (50步) | BF16 | -- | 20.3 | 0.953 | -- | -- |
| W4A16 | NF4 | 20.6 | 0.910 | 0.272 | 19.5 | |
| INT W4A4 | 20.2 | 0.908 | 0.322 | 18.5 | ||
| INT W4A4 | SVDQuant | 19.9 | 0.935 | 0.223 | 21.0 | |
| NVFP4 | 20.3 | 0.961 | 0.345 | 16.3 | ||
| NVFP4 | SVDQuant | 20.3 | 0.945 | 0.205 | 21.5 | |
| FLUX.1-schnell (4步) | BF16 | -- | 19.2 | 0.938 | -- | -- |
| W4A16 | NF4 | 18.9 | 0.943 | 0.257 | 18.2 | |
| INT W4A4 | 18.1 | 0.962 | 0.345 | 16.3 | ||
| INT W4A4 | SVDQuant | 18.3 | 0.951 | 0.257 | 18.3 | |
| NVFP4 | 19.0 | 0.952 | 0.276 | 17.6 | ||
| NVFP4 | SVDQuant | 18.9 | 0.966 | 0.228 | 19.0 | |
| SANA-1.6b (20步) | BF16 | -- | 20.6 | 0.952 | -- | -- |
| INT W4A4 | 20.5 | 0.894 | 0.339 | 15.3 | ||
| INT W4A4 | SVDQuant | 19.3 | 0.935 | 0.220 | 17.8 | |
| NVFP4 | 19.7 | 0.929 | 0.236 | 17.4 | ||
| NVFP4 | SVDQuant | 20.2 | 0.941 | 0.176 | 19.0 | |
| PixArt-Sigma (20步) | FP16 | -- | 16.6 | 0.944 | -- | -- |
| INT W4A8 | ViDiT-Q | 37.3 | 0.573 | 0.611 | 12.0 | |
| INT W4A4 | SVDQuant | 19.2 | 0.878 | 0.323 | 17.6 | |
| NVFP4 | 31.8 | 0.660 | 0.517 | 14.8 | ||
| NVFP4 | SVDQuant | 16.6 | 0.940 | 0.271 | 18.5 |
QServe:W4A8KV4量化,用于高效的大语言模型服务
[官网][论文][QoQ算法代码][QServe GPU系统]
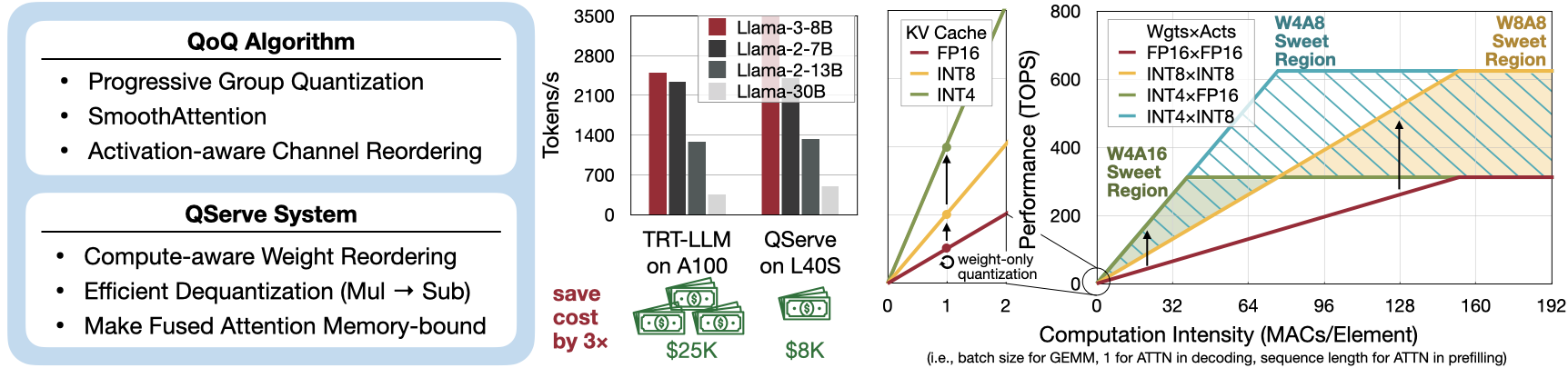
量化可以加速大型语言模型(LLM)的推理过程。除了INT8量化之外,研究界也在积极探索更低精度的量化方法,例如INT4。然而,目前最先进的INT4量化技术仅能加速低批次、端侧的LLM推理,在大规模批次、云端部署的LLM服务中却无法带来性能提升。我们发现了一个关键问题:现有的INT4量化方法在GPU上对权重或部分和进行反量化时,会引入显著的运行时开销(20%–90%)。为了解决这一挑战,我们提出了QoQ,一种W4A8KV4量化算法,即权重采用4位、激活采用8位、KV缓存采用4位。QoQ源自拉丁语“quattuor-octo-quattuor”,意为4-8-4。QoQ由QServe推理库实现,并通过实测验证了其加速效果。驱动QServe的核心洞察是:GPU上的LLM服务效率主要受低吞吐量CUDA核心上的操作所影响。基于这一洞察,我们在QoQ算法中引入了渐进式量化,能够在W4A8 GEMM中大幅降低反量化开销。此外,我们还开发了SmoothAttention,以有效缓解4位KV量化带来的精度损失。在QServe系统中,我们采用了计算感知的权重重排,并充分利用寄存器级并行性来减少反量化延迟。同时,我们将注意力机制的内存访问部分融合化,从而充分发挥KV4量化带来的性能优势。最终,与TensorRT-LLM相比,QServe使Llama-3-8B在A100上的最大可实现服务吞吐量提升了1.2倍,在L40S上提升了1.4倍;而Qwen1.5-72B在A100上的吞吐量提升了2.4倍,在L40S上提升了3.5倍。
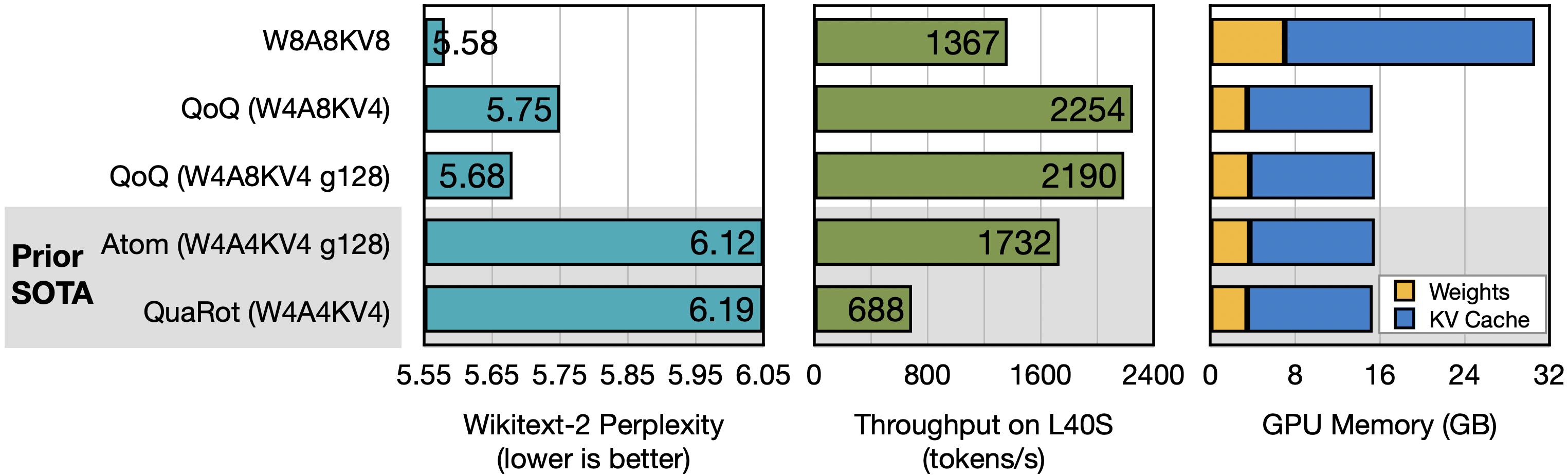
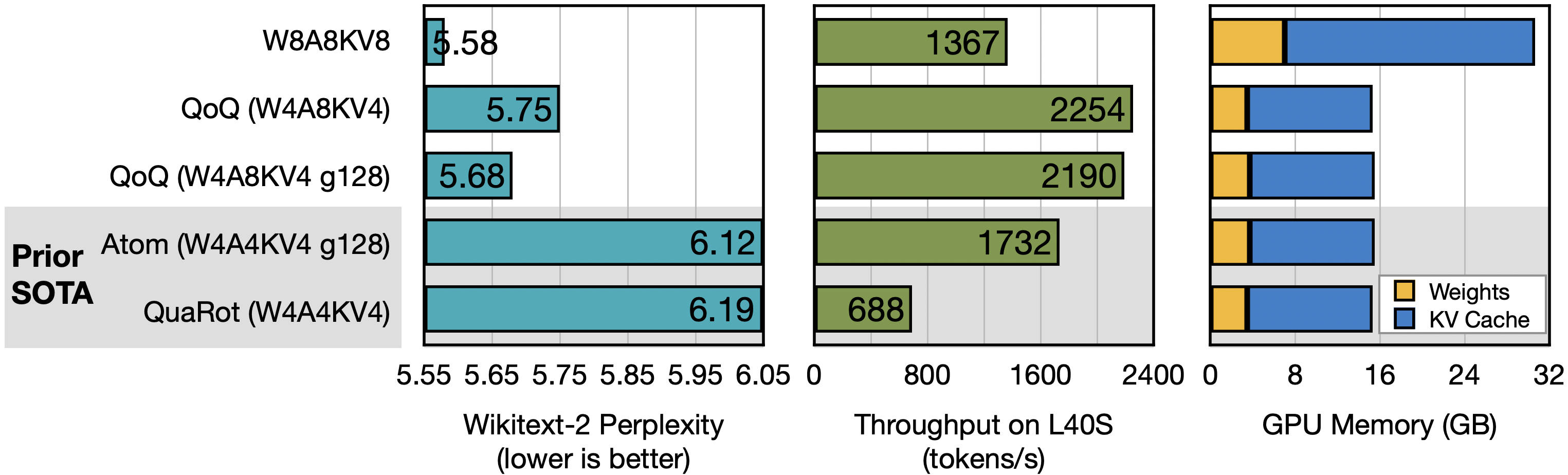
困惑度评估
以下是序列长度为2048时的WikiText2困惑度评估结果,数值越低越好。
| 方法 | 精度 | Llama-3.1 70B | Llama-3.1 8B | Llama-3 70B | Llama-3 8B | Llama-2 7B | Llama-2 13B | Llama-2 70B | Llama 7B | Llama 13B | Llama 30B | Mistral 7B | Yi 34B |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FP16 | 2.81 | 6.24 | 2.85 | 6.14 | 5.47 | 4.88 | 3.32 | 5.68 | 5.09 | 4.10 | 5.25 | 4.60 | |
| SmoothQuant | W8A8 | 3.23 | 6.38 | 3.14 | 6.28 | 5.54 | 4.95 | 3.36 | 5.73 | 5.13 | 4.23 | 5.29 | 4.69 |
| GPTQ-R | W4A16 g128 | 3.46 | 6.64 | 3.42 | 6.56 | 5.63 | 4.99 | 3.43 | 5.83 | 5.20 | 4.22 | 5.39 | 4.68 |
| AWQ | W4A16 g128 | 3.22 | 6.60 | 3.20 | 6.54 | 5.60 | 4.97 | 3.41 | 5.78 | 5.19 | 4.21 | 5.37 | 4.67 |
| QuaRot | W4A4 | 5.97 | 8.32 | 6.75 | 8.33 | 6.19 | 5.45 | 3.83 | 6.34 | 5.58 | 4.64 | 5.77 | - |
| SpinQuant | W4A4 | 4.80 | 7.42 | 6.27 | 7.37 | 5.96 | 5.24 | 3.71 | 6.14 | 5.39 | 4.56 | - | - |
| Atom | W4A4 g128 | - | - | 4.33 | 7.78 | 6.12 | 5.31 | 3.73 | 6.25 | 5.52 | 4.61 | 5.76 | 4.97 |
| QoQ | W4A8KV4 | 3.68 | 6.87 | 3.65 | 6.81 | 5.75 | 5.11 | 3.50 | 5.92 | 5.27 | 4.31 | 5.44 | 4.73 |
| QoQ | W4A8KV4 g128 | 3.51 | 6.77 | 3.50 | 6.70 | 5.67 | 5.06 | 3.46 | 5.88 | 5.23 | 4.27 | 5.41 | 4.73 |
* SmoothQuant采用逐张量静态KV缓存量化进行评估。
效率基准测试
在L40S和A100 GPU上服务Llama-3-8B和Qwen1.5-72B等大型语言模型时,QServe表现出卓越的性能,相较于行业领先的解决方案TensorRT-LLM,Llama-3-8B的吞吐量提升了1.2–1.4倍,而Qwen1.5-72B的吞吐量则提升了2.4–3.5倍。
更多关于基准测试设置的信息,请参阅QServe GPU推理系统。
| L40S (48G) | Llama-3-8B | Llama-2-7B | Mistral-7B | Llama-2-13B | Llama-30B | Yi-34B | Llama-2-70B | Qwen-1.5-72B |
|---|---|---|---|---|---|---|---|---|
| TRT-LLM-FP16 | 1326 | 444 | 1566 | 92 | OOM | OOM | OOM | OOM |
| TRT-LLM-W4A16 | 1431 | 681 | 1457 | 368 | 148 | 313 | 119 | 17 |
| TRT-LLM-W8A8 | 2634 | 1271 | 2569 | 440 | 123 | 364 | OOM | OOM |
| Atom-W4A4 | -- | 2120 | -- | -- | -- | -- | -- | -- |
| QuaRot-W4A4 | -- | 805 | -- | 413 | 133 | -- | -- | 15 |
| QServe-W4A8KV4 | 3656 | 2394 | 3774 | 1327 | 504 | 869 | 286 | 59 |
| 吞吐量提升* | 1.39倍 | 1.13倍 | 1.47倍 | 3.02倍 | 3.41倍 | 2.39倍 | 2.40倍 | 3.47倍 |
| A100 (80G) | Llama-3-8B | Llama-2-7B | Mistral-7B | Llama-2-13B | Llama-30B | Yi-34B | Llama-2-70B | Qwen-1.5-72B |
|---|---|---|---|---|---|---|---|---|
| TRT-LLM-FP16 | 2503 | 1549 | 2371 | 488 | 80 | 145 | OOM | OOM |
| TRT-LLM-W4A16 | 2370 | 1549 | 2403 | 871 | 352 | 569 | 358 | 143 |
| TRT-LLM-W8A8 | 2396 | 2334 | 2427 | 1277 | 361 | 649 | 235 | 53 |
| Atom-W4A4 | -- | 1160 | -- | -- | -- | -- | -- | -- |
| QuaRot-W4A4 | -- | 1370 | -- | 289 | 267 | -- | -- | 68 |
| QServe-W4A8KV4 | 3005 | 2908 | 2970 | 1741 | 749 | 803 | 419 | 340 |
| 吞吐量提升* | 1.20倍 | 1.25倍 | 1.22倍 | 1.36倍 | 2.07倍 | 1.23倍 | 1.17倍 | 2.38倍 |
QServe 与基线系统在绝对标记生成吞吐量方面的对比(单位:标记/秒。“--”表示不支持)。所有实验均在相同的设备内存预算下进行。QServe 的吞吐量提升是相对于各列中最佳基线计算得出的。
参考文献
如果您认为 deepcompressor 对您的研究有用或相关,请引用我们的论文:
@article{lin2024qserve,
title={QServe: W4A8KV4 量化与系统协同设计,用于高效的大模型推理},
author={Lin*, Yujun 和 Tang*, Haotian 和 Yang*, Shang 和 Zhang, Zhekai 和 Xiao, Guangxuan 和 Gan, Chuang 和 Han, Song},
journal={arXiv 预印本 arXiv:2405.04532},
year={2024}
}
@article{
li2024svdquant,
title={SVDQuant:通过低秩成分吸收异常值,实现 4 位扩散模型量化},
author={Li*, Muyang 和 Lin*, Yujun 和 Zhang*, Zhekai 和 Cai, Tianle 和 Li, Xiuyu 和 Guo, Junxian 和 Xie, Enze 和 Meng, Chenlin 和 Zhu, Jun-Yan 和 Han, Song},
journal={arXiv 预印本 arXiv:2411.05007},
year={2024}
}
相关项目
以下项目与 QServe 密切相关。我们团队为高效大模型开发了从应用、算法、系统到硬件的全栈支持,获得了 9000 多颗 GitHub 星标 和 超过 100 万次 Hugging Face 社区下载。
也欢迎您访问 MIT HAN 实验室,了解更多关于 高效生成式 AI 的精彩项目!
[系统] [QServe:用于高效 LLM 推理的 W4A8KV4 量化] (https://github.com/mit-han-lab/qserve)
[系统] [TinyChat:基于 AWQ 的高效轻量级聊天机器人] (https://github.com/mit-han-lab/llm-awq/tree/main/tinychat)
[应用] [VILA:视觉-语言模型的预训练研究] (https://github.com/Efficient-Large-Model/VILA)
[算法] [AWQ:面向 LLM 压缩与加速的激活感知权重量化] (https://github.com/mit-han-lab/llm-awq)
[算法] [SmoothQuant:针对大型语言模型的高精度高效后训练量化] (https://github.com/mit-han-lab/smoothquant)
[算法] [DistriFusion:高分辨率扩散模型的分布式并行推理] (https://github.com/mit-han-lab/distrifuser)
[硬件] [SpAtten:基于级联标记与头剪枝的高效稀疏注意力架构] (https://arxiv.org/abs/2012.09852)
致谢
DeepCompressor 灵感来源于众多开源库,包括但不限于 [GPTQ] (https://arxiv.org/abs/2210.17323)、[QuaRot] (https://arxiv.org/abs/2404.00456) 和 [Atom] (https://arxiv.org/abs/2310.19102)。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。